Hadoop入门学习笔记
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
这里写目录标题
- 一、VMware准备Linux虚拟机
- 1.1. VMware安装Linux虚拟机
- 1.1.1. 修改虚拟机子网IP和网关
- 1.1.2. 安装Linux虚拟机
- 1.2. VMware克隆三台Linux虚拟机
- 1.3. 为三台虚拟机配置固定IP
- 1.4. 配置免密登录
- 1.5. JDK环境部署
- 1.6. 防火墙、SELinux、时间同步配置
- 1.6.1. 关闭防火墙
- 1.6.2. 关闭SELinux
- 1.6.3. 配置时间同步
- 1.7. 使用VMware快照功能保存当前已配置好的初始环境
- 二、在虚拟机里部署HDFS集群
- 2.1. 部署node1虚拟机
- 2.2. 部署node2和node3虚拟机
- 2.3. 初始化并启动Hadoop集群(格式化文件系统)
- 2.4. 快照部署好的集群
- 2.5. 部署过程中可能会遇到的问题
- 2.5. Hadoop HDFS集群启停脚本
- 三、使用HDFS文件系统
- 3.1. 使用命令操作HDFS文件系统
- 3.1.1. HDFS文件系统基本信息
- 3.1.2. HDFS文件系统的2套命令体系
- 3.1.3. 创建文件夹
- 3.1.4. 查看指定目录下的内容
- 3.1.5. 上传文件到HDFS指定目录下
- 3.1.6. 查看HDFS中文件的内容
- 3.1.7. 从HDFS下载文件到本地
- 3.1.8. 复制HDFS文件(在HDFS系统内复制)
- 3.1.9. 追加数据到HDFS文件中
- 3.1.10. 移动或重命名HDFS文件(在HDFS系统内移动)
- 3.1.11. 删除HDFS文件
- 3.1.12. 其他HDFS命令
- 3.2. HDFS Web浏览
- 3.3. HDFS系统权限
- 3.3.1. 修改HDFS文件权限
- 3.3.2. 修改HDFS文件所属用户和组
一、VMware准备Linux虚拟机
1.1. VMware安装Linux虚拟机
VMware虚拟机安装程序下载地址(需要自己想办法激活):https://download3.vmware.com/software/WKST-1750-WIN/VMware-workstation-full-17.5.0-22583795.exe
CentOS操作系统镜像下载地址:https://vault.centos.org/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso
1.1.1. 修改虚拟机子网IP和网关
下载后,先安装VMware虚拟机,安装成功后,需改虚拟机网络配置。
1、在“编辑”-“虚拟网络编辑器”中修改NAT8网卡的子网IP地址;
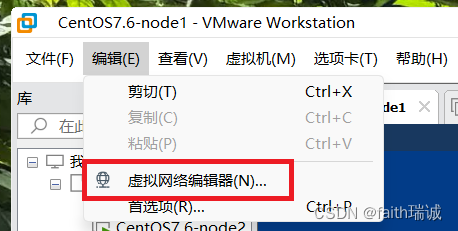
2、进入编辑器后,选择“VMnet8”网卡,然后点击右下角的“更改设置”按钮;
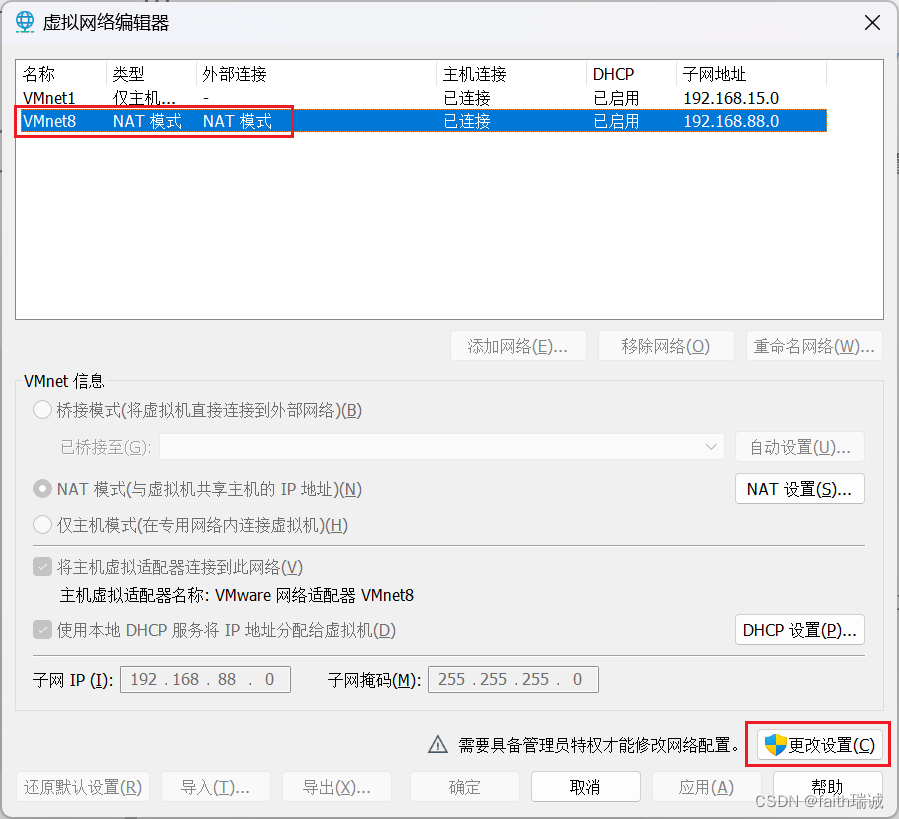
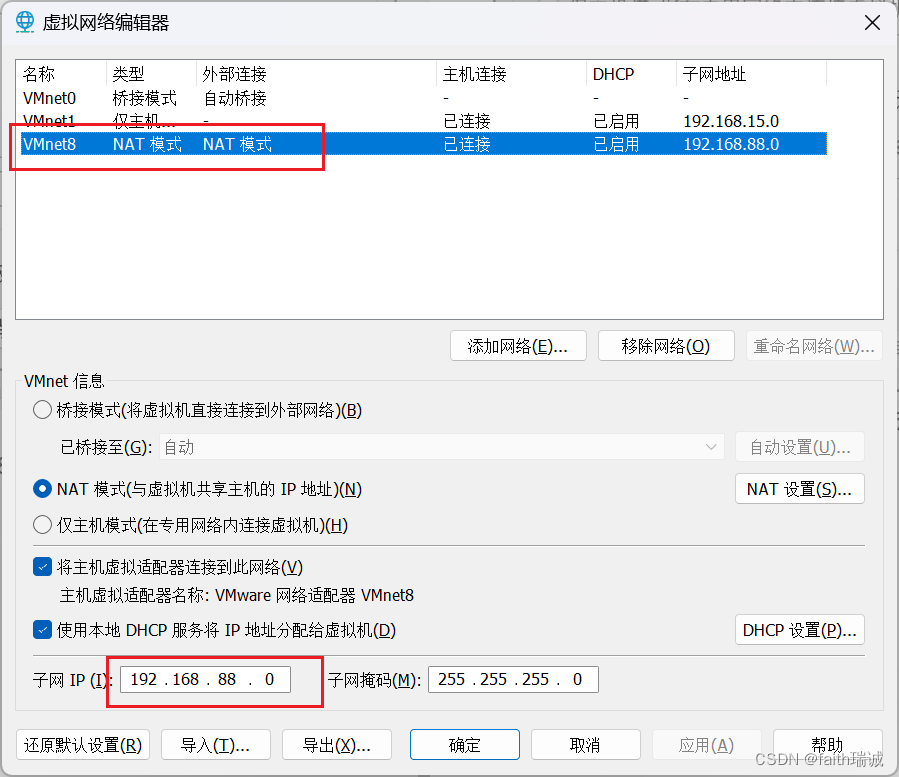
3、获取管理员权限后,选择“VMnet8”网卡,将其子网IP修改为“192.168.88.0”;
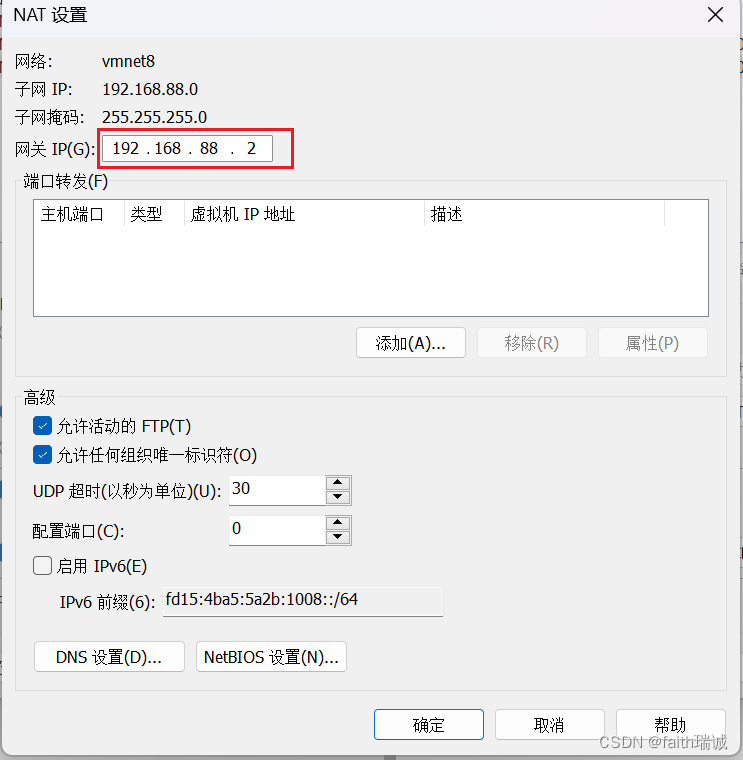
4、点击“NAT设置”按钮,在NAT设置界面,将网关IP修改为“192.168.88.2”,并保存上述设置。
1.1.2. 安装Linux虚拟机
1、通过VMware菜单中的“文件”-“新建虚拟机”创建一个新的虚拟机;
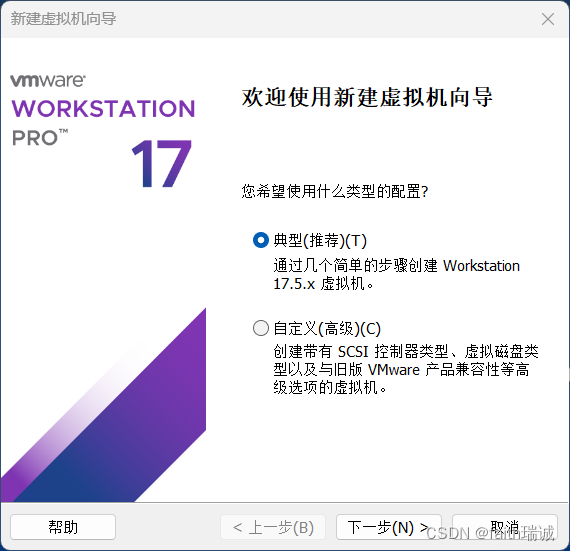
2、选择前面下载的CentOS操作系统镜像;
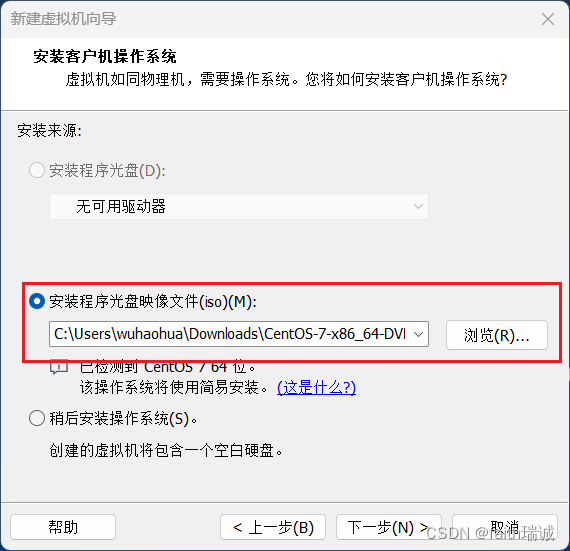
3、输入Linux系统用户名和密码(该密码也是root的密码);
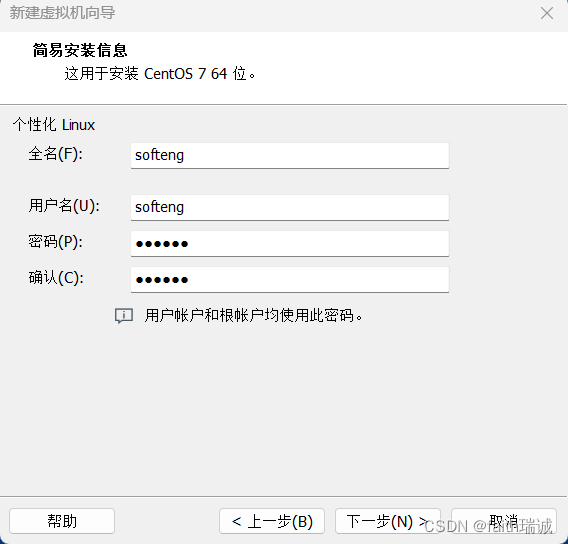
4、填写虚拟机名称和虚拟机的存放位置;
5、之后一直下一步、完成,然后虚拟机开始自己安装,直至安装完成,此过程视个人电脑和网络情况可能需要半小时左右,中间不用任何操作,待系统安装完毕后,虚拟机会自动重启,看到如下界面,代表安装成功。
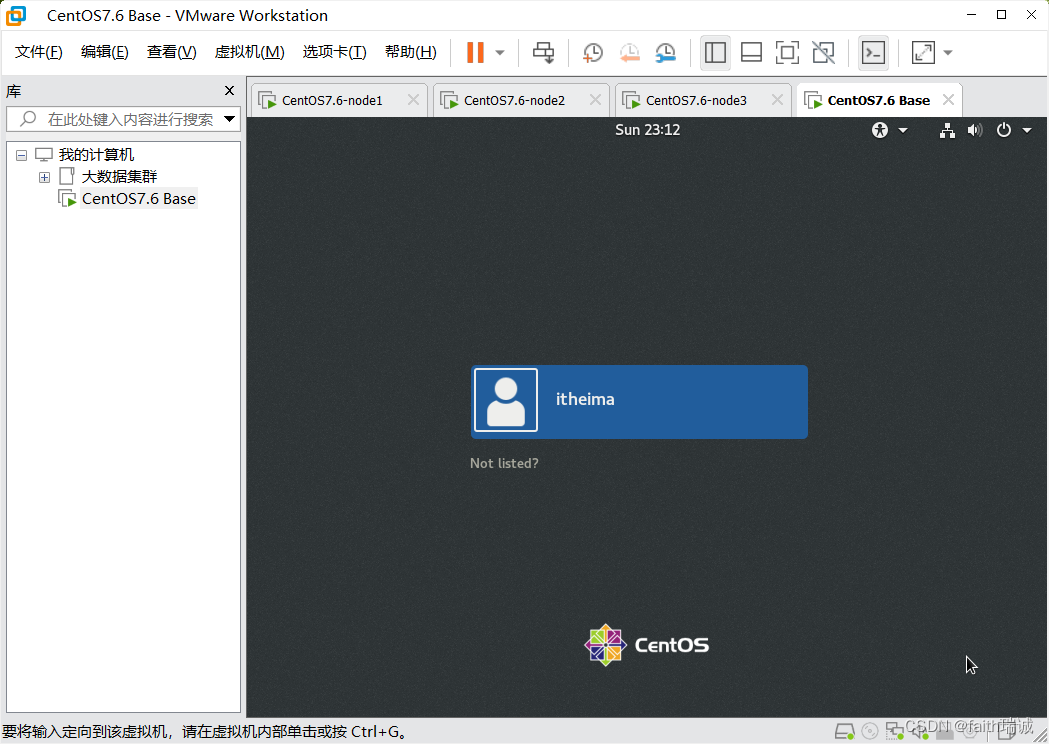
1.2. VMware克隆三台Linux虚拟机
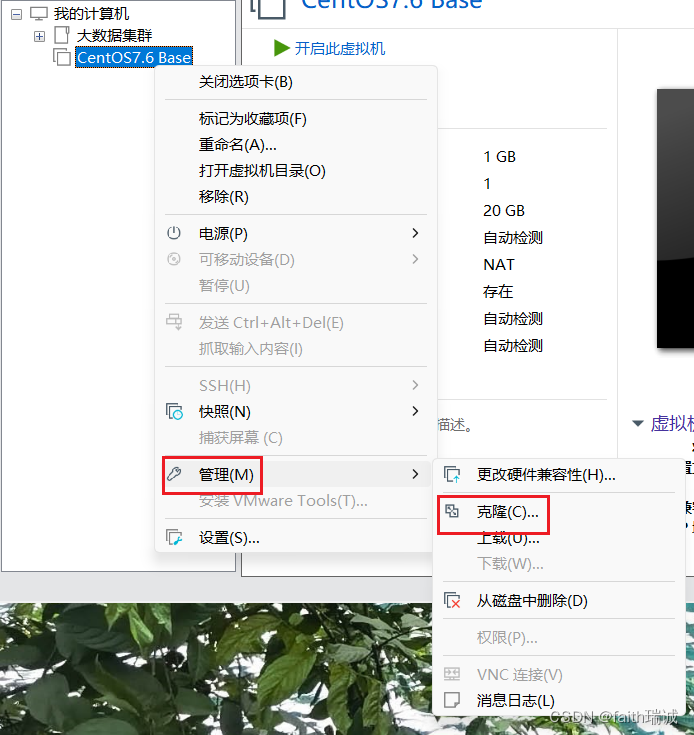
1、将前面安装好的虚拟机关机,然后在VMware左侧的菜单中,鼠标右键刚才安装好的虚拟机,选择“管理”-“克隆”;
2、然后点击下一页按钮,直到“克隆方法”界面;

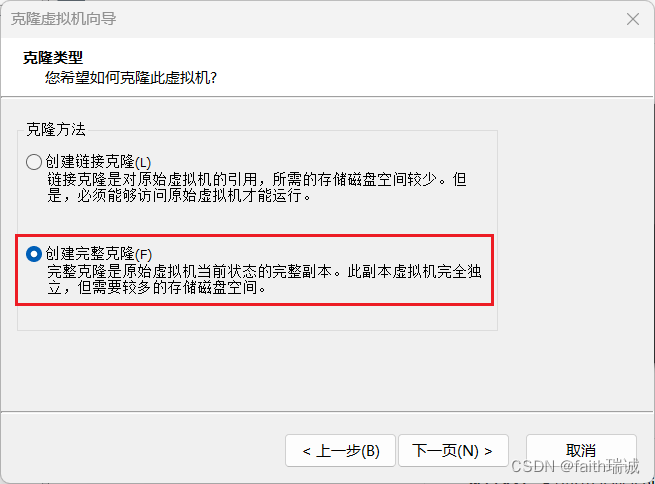
3、在克隆方法界面选择“创建完整克隆”,然后继续下一页;
4、重命名虚拟机名称为node1,选择克隆出来的虚拟机存放的路径,然后点击“完成”按钮,VMware就会克隆出一个一摸一样的虚拟机,此过程很快,一般3~5秒的样子;
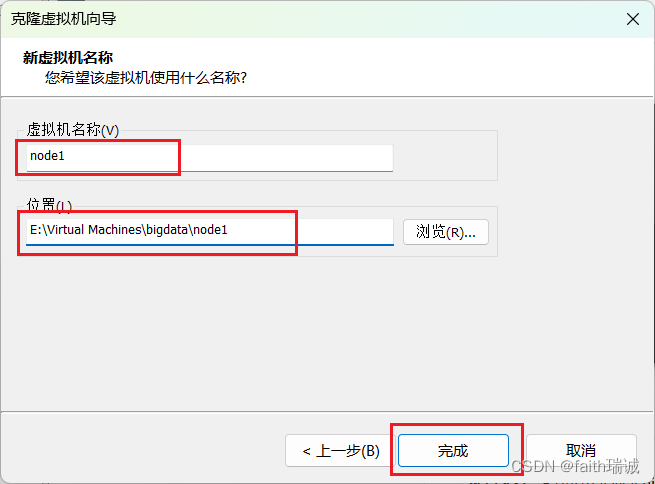
5、依照上述方法,再克隆出node2和node3,总共3台虚拟机出来;
6、此时先别启动这3台虚拟机,先对3台虚拟机的内存大小进行调整,分别将node1调整到4GB,node2和node3调整成2GB;
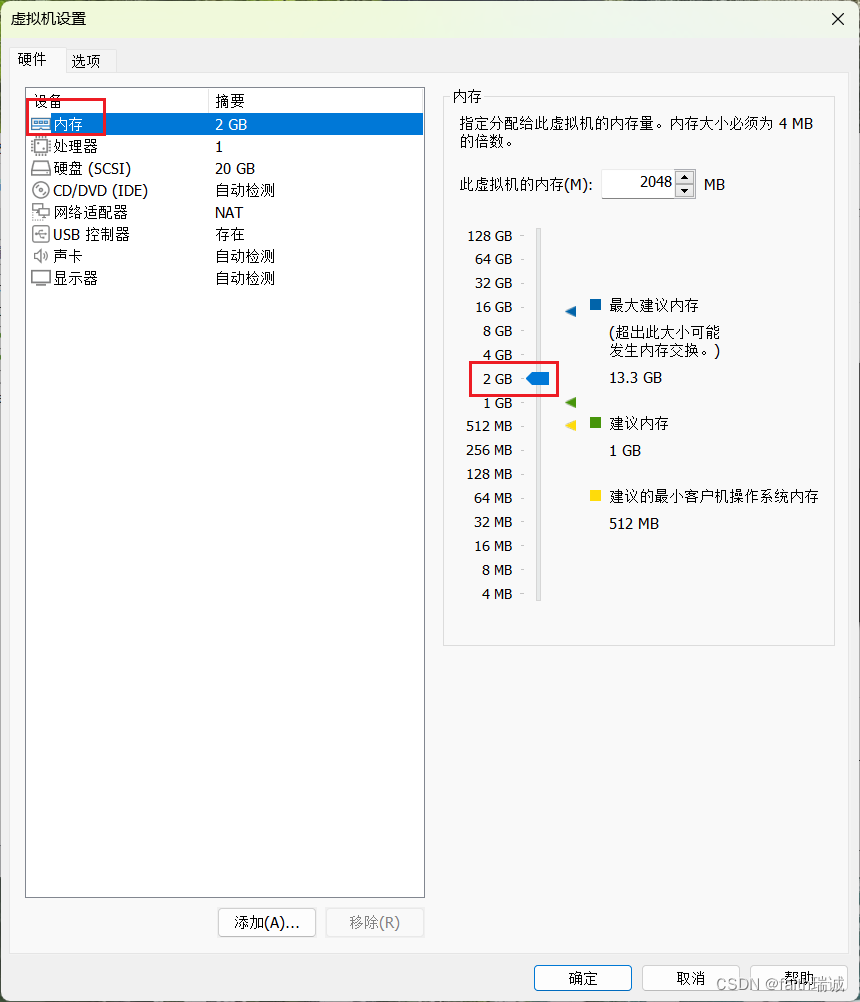 7、内存调整完毕后,分别将node1、2、3开机,在开机时,VMware会弹窗提示“无法连接虚拟设备 ide1:0…”,直接点“否”即可,至此,虚拟机克隆完毕,后续我们使用的也是这3台虚拟机。
7、内存调整完毕后,分别将node1、2、3开机,在开机时,VMware会弹窗提示“无法连接虚拟设备 ide1:0…”,直接点“否”即可,至此,虚拟机克隆完毕,后续我们使用的也是这3台虚拟机。
1.3. 为三台虚拟机配置固定IP
1、三台虚拟机分别启动后,在虚拟机中打开命令行,修改主机名,输入如下命令:
# 切换成root用户
[itheima@locahost ~]$ su -
# 修改当前虚拟机的主机名,这里只演示node1,node2和node3命令相同,只是最后的参数需要修改成node2和node3
[root@locahost ~]# hostnamectl set-hostname node1
2、上述命令执行完毕后,关闭命令行,并重新打开命令行,此时可以看到命令行内的主机名已经变成了node1、node2和node3
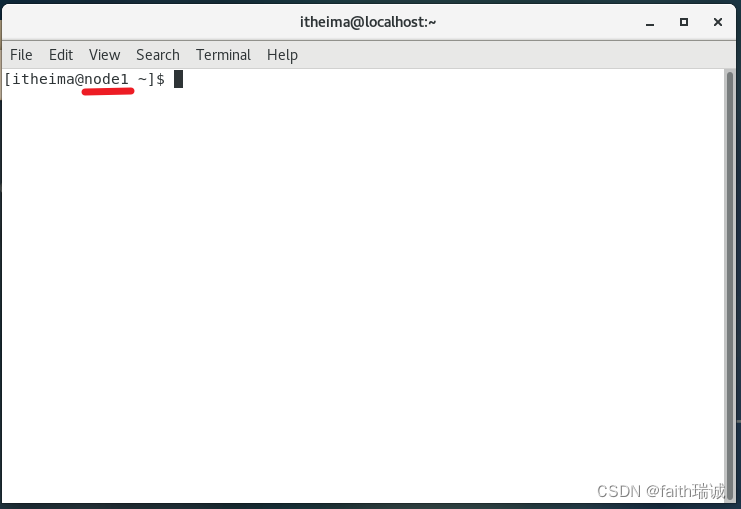
3、在命令行里切换到root用户,并执行如下命令:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
4、打开ifcfg-ens33文件后,将其中BOOTPROTO配置项的值修改为static,然后再在文件末尾追加如下内容:
IPADDR="192.168.88.101"
NETMASK="255.255.255.0"
GATEWAY="192.168.88.2"
DNS1="192.168.88.2"
其中,在node1虚拟机中,IPADDR的值为192.168.88.101,node2虚拟机的IPADDR的值为192.168.88.102,node3虚拟机的IPADDR的值为192.168.88.103;
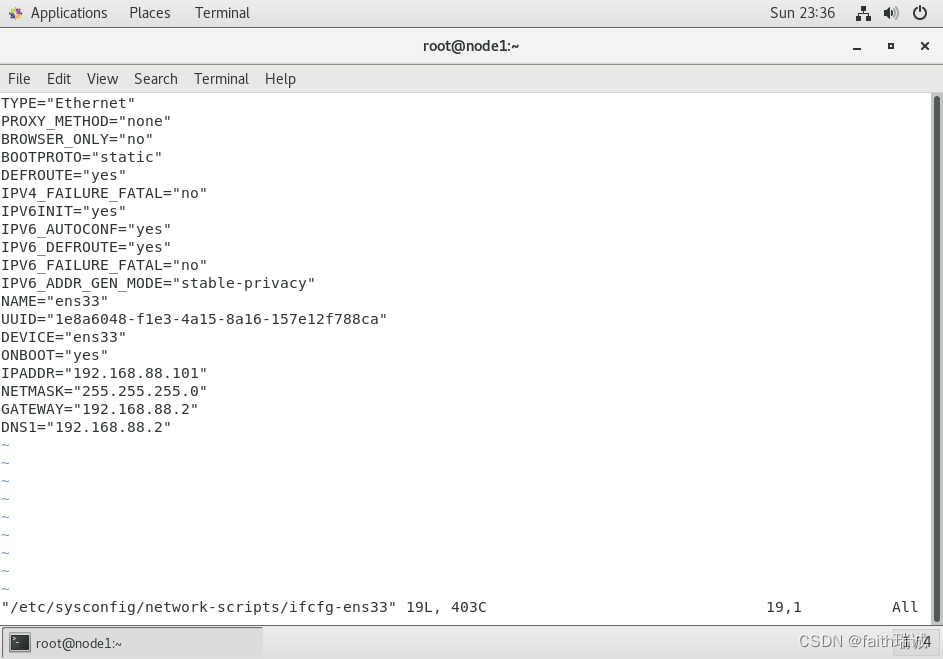
5、修改网网卡配置后,在命令行中重启网卡,执行如下命令:
systemctl restart network
然后可以使用ifconfig命令查看及其的IP地址,查看上述修改是否成功。
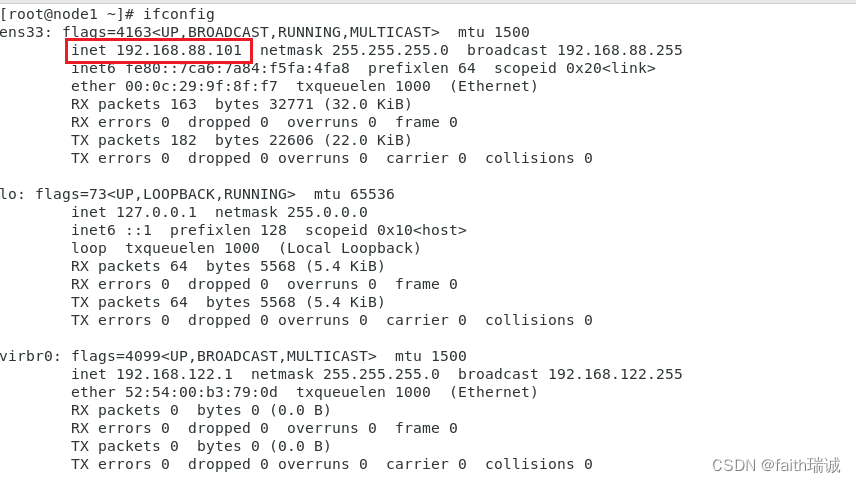
1.4. 配置免密登录
1、修改Windows系统(本机,非虚拟机)的hosts文件(目录为C:\Windows\System32\drivers\etc\),将如下内容追加在hosts文件末尾并保存
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
2、使用本机的ssh工具连接三台虚拟机(node1、node2、node3),后续所有的命令通过ssh工具操作;
3、分别修改三台虚拟机的hosts文件,此处以node1为例,在命令行中输入
vim /etc/hosts
在hosts文件中追加如下内容:
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
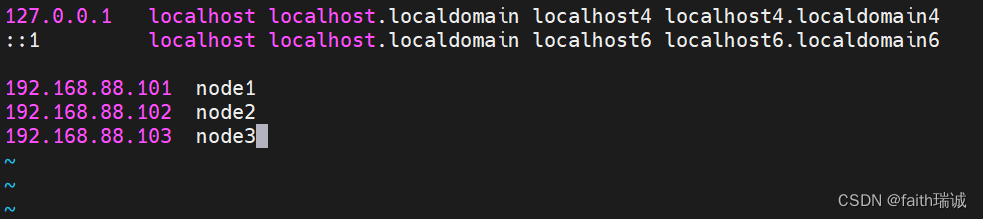
保存并退出,然后同样的步骤修改node2和node3的hosts文件。
4、在三台虚拟机上分别执行ssh-keygen -t rsa -b 4096命令,然后一路回车到底,给三台虚拟机分别生成好自己的密钥;
5、在三台虚拟机上都执行如下命令,完成免密登录的授权操作:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
执行命令过程中,有配置项需要确认输入yes,然后,还需要输入root密码;
6、可以在node1虚拟机通过命令ssh node2查看是否已经配置好了node1到node2的免密登录,同理,可以在node2验证到另两台服务器的免密登录;
7、至此,我们配置好了三台虚拟机root用户之间的免密登录,接下来,我们还需要配置三台虚拟机之间hadoop用户的免密登录;
8、使用useradd hadoop和passwd hadoop命令分别在三台虚拟机上创建hadoop用户;
9、在三台虚拟机上使用su - hadoop命令切换成hadoop用户,然后使用签名用过的ssh-keygen -t rsa -b 4096命令生成hadoop用户的ssh密钥;
10、然后再在三台虚拟机上执行如下命令,实现hadoop用户之间的免密登录:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
具体操作和上面配置root用户的免密登录时一样。至此,免密登录配置完成。
1.5. JDK环境部署
1、目前还是使用jdk 1.8版本,下载页面:https://www.oracle.com/cn/java/technologies/downloads/,打开页面一直往下划,划到JDK 1.8的部分,下载x64 Compressed Archive版本;
2、下载后,在虚拟机里面切换成root用户,然后将刚才下载好的jdk压缩包上传到root目录下,执行如下命令:
mkdir -p /export/server
# 解压刚才上传的jdk压缩包到/export/server目录
tar -zxvf jdk-8u391-linux-x64.tar.gz -C /export/server/
# 创建软连接
ln -s /export/server/jdk1.8.0_391/ /export/server/jdk
3、配置环境变量,使用命令vim /etc/profile打开环境变量配置文件,然后在文件末尾追加如下内容:
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
然后使用source /etc/profile命令使环境变量生效;
4、将操作系统自带的jdk替换成我们刚才安装的jdk:
# 删除系统自带的java程序
rm -f /usr/bin/java
# 软连接我们自己安装的java程序
ln -s /export/server/jdk/bin/java /usr/bin/java
此时,jdk配置完成,可以使用java -version和javac -version命令校验系统所使用的java是否已经是我们自己安装的JDK。
5、使用scp命令,将已解压的jdk文件夹复制到node2和node3
# 复制到node2
scp -r /export/server/jdk1.8.0_391/ node2:`pwd`/
# 复制到node3
scp -r /export/server/jdk1.8.0_391/ node3:`pwd`/
6、然后参考上面的流程,创建软连接、配置环境变量、移除系统自带的java,完成node2和node3的配置。
1.6. 防火墙、SELinux、时间同步配置
1.6.1. 关闭防火墙
在三台虚拟机上分别执行如下命令:
# 关闭防火墙
systemctl stop firewalld.service
# 关闭防火墙的开机自启
systemctl disable firewalld.service
1.6.2. 关闭SELinux
使用vim /etc/sysconfig/selinux打开selinux的配置文件,将其中的SELINUX=enforcing修改为SELINUX=disabled,然后保存退出,并重启虚拟机(可通过reboot命令)即可。
1.6.3. 配置时间同步
在三台虚拟机上分别依次执行以下步骤
1、安装ntp软件
yum install -y ntp
2、更新时区
# 删除系统的默认时区信息
rm -f /etc/localtime
# 设置虚拟机的时区为中国上海时区
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3、同步时间
# 使用阿里云的ntp服务校准本机时间
ntpdate -u ntp.aliyun.com
4、开启ntp服务并设置开机自启
# 启动NTP服务
systemctl start ntpd.service
# 设置NTP服务开机自启动
systemctl enable ntpd.service
1.7. 使用VMware快照功能保存当前已配置好的初始环境
1、将三台虚拟机全部关机;
2、在VMware中,在左侧虚拟机上右键,选择“快照”-“拍摄快照”,填写快照名称和备注,创建虚拟机快照;
node2和node3重复上述步骤,完成快照拍摄
二、在虚拟机里部署HDFS集群
下载Hadoop:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
本次演示部署结构如下图所示:
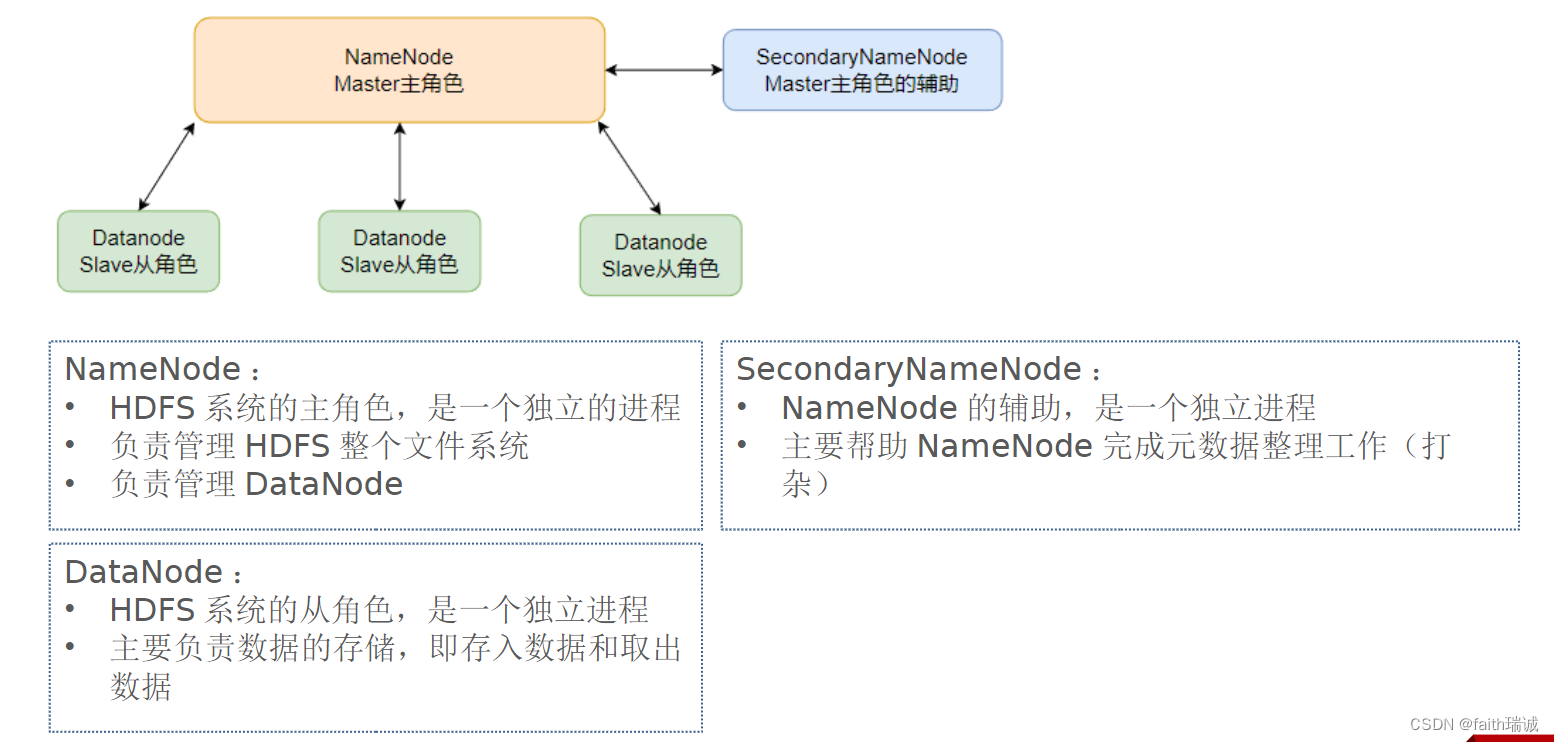
本次部署服务清单如下表所示:
| 节点 | 部署的服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNameNode |
| node2 | DataNode |
| node3 | DataNode |
2.1. 部署node1虚拟机
1、将下载好的Hadoop压缩包上传至node1虚拟机的root目录;
2、将Hadoop压缩包解压至/export/server目录下
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server/
3、创建hadoop目录的软链接
# 切换工作目录
cd /export/server/
# 创建软连接
ln -s /export/server/hadoop-3.3.4/ hadoop
4、hadoop目录结构如下

| 目录 | 存放内容 |
|---|---|
| bin | 存放Hadoop的各类程序(命令) |
| etc | 存放Hadoop的配置文件 |
| include | 存放Hadopp用到的C语言的头文件 |
| lib | 存放Linux系统的动态链接库(.so文件) |
| libexec | 存放配置Hadoop系统的脚本文件(.sh和.cmd文件) |
| licenses_binary | 存放许可证文件 |
| sbin | 管理员程序(super bin) |
| share | 存放二进制源码(jar包) |
5、配置workers文件
cd etc/hadoop/
vim workers
将workers文件原有的内容删掉,改为
node1
node2
node3
保存即可;
6、配置hadoop-env.sh文件,使用vim hadoop-env.sh打开,修改以下配置:
# 指明JDK安装目录
export JAVA_HOME=/export/server/jdk
# 指明HADOOP安装目录
export HADOOP_HOME=/export/server/hadoop
# 指明HADOOP配置文件的目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#指明HADOOP运行日志文件的目录
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
7、配置core-site.xml文件,使用vim core-site.xml打开文件,修改以下配置:
<configuration><property><!--HDFS 文件系统的网络通讯路径--><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><!--io 操作文件缓冲区大小--><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
8、配置hdfs-site.xml文件,修改以下配置:
<configuration><property><!--hdfs 文件系统,默认创建的文件权限设置--><name>dfs.datanode.data.dir.perm</name><!-- 700权限即rwx------ --><value>700</value></property><property><!--NameNode 元数据的存储位置--><name>dfs.namenode.name.dir</name><!-- 在 node1 节点的 /data/nn 目录下 --><value>/data/nn</value></property><property><!--NameNode 允许哪几个节点的 DataNode 连接(即允许加入集群)--><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property><property><!--hdfs 默认块大小--><name>dfs.blocksize</name><!--268435456即256MB--><value>268435456</value></property><property><!--namenode 处理的并发线程数--><name>dfs.namenode.handler.count</name><value>100</value></property><property><!--从节点 DataNode 的数据存储目录,即数据存放在node1、node2、node3三台机器中的路径--><name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>
9、根据上一步的配置项,在node1节点创建/data/nn和/data/dn目录,在node2和node3节点创建/data/dn目录;
10、将已配置好的hadoop程序从node1分发到node2和node3:
# 切换工作目录
cd /export/server/
# 将node1的hadoop-3.3.4/目录复制到node2的同样的位置
scp -r hadoop-3.3.4/ node2:`pwd`/
# 将node1的hadoop-3.3.4/目录复制到node3的同样的位置
scp -r hadoop-3.3.4/ node3:`pwd`/
11、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
12、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.2. 部署node2和node3虚拟机
本小节内容如无特殊说明,均需在node2和node3虚拟机分别执行!
1、为hadoop创建软链接,命令都是一样的,如下所示:
cd /export/server/
ln -s /export/server/hadoop-3.3.4/ hadoop
2、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
3、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.3. 初始化并启动Hadoop集群(格式化文件系统)
1、在node1虚拟机上执行以下命令:
# 切换为hadoop用户
su - hadoop
# 格式化namenode
hadoop namenode -format
2、启动集群,在node1虚拟机上执行以下命令:
# 一键启动整个集群,包括namenode、secondarynamenode和所有的datanode
start-dfs.sh
# 查看当前系统中正在运行的Java进程,可以看到每台虚拟机上hadoop的运行情况
jps
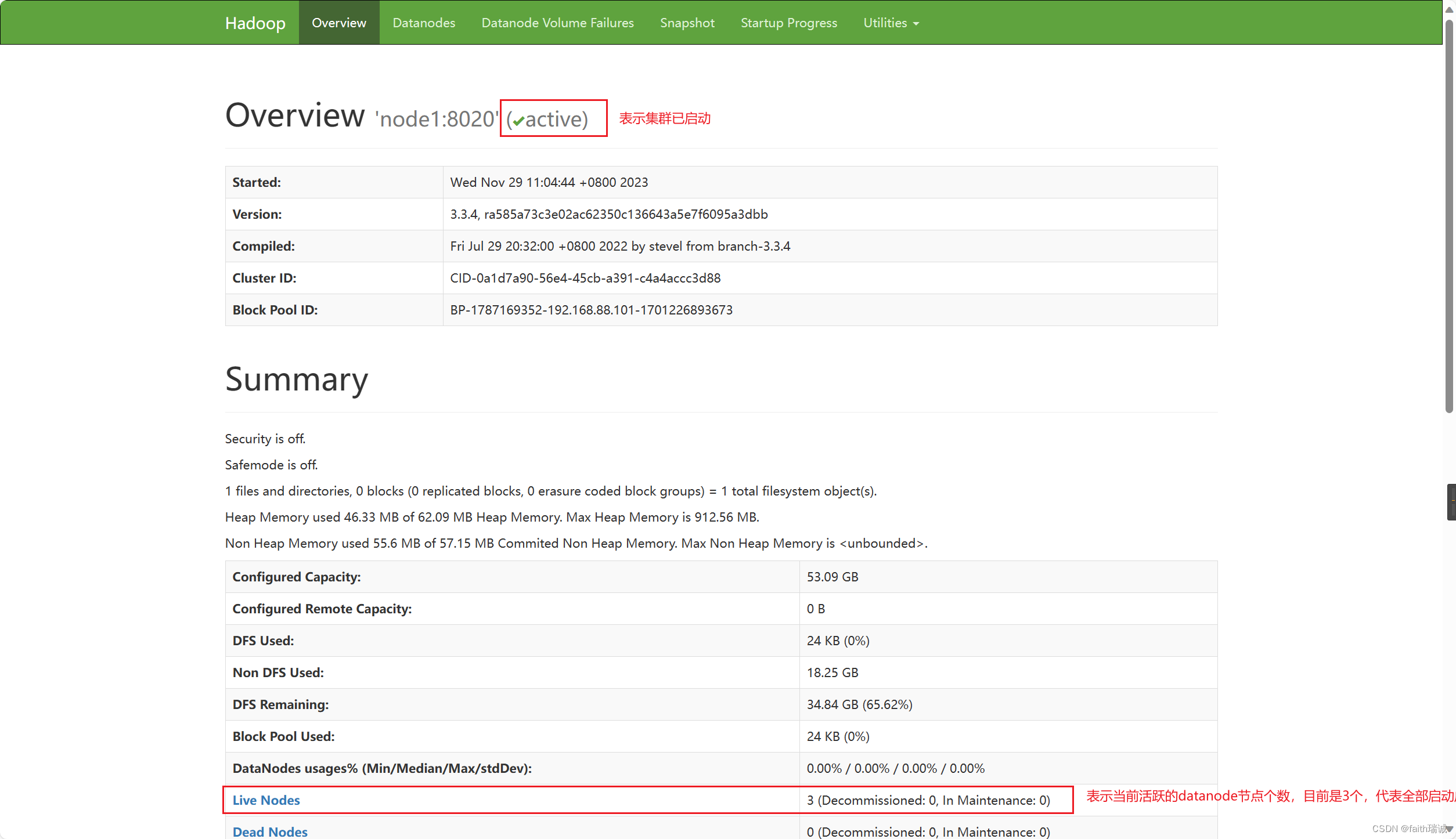
3、执行上述步骤之后,我们可以在我们自己的电脑(非虚拟机)上查看 HDFS WEBUI(即HADOOP管理页面),可以通过访问namenode所在服务器的9870端口查看,在本案例中因为namenode处于node1虚拟机上,所以可以访问http://node1:9870/打开。PS:因为之前我们已经配置了本机的hosts文件,所以这里可以使用node1访问,其实这个地址对应的就是http://192.168.88.101:9870/。
4、如果看到以下界面,代表Hadoop集群启动成功了。
2.4. 快照部署好的集群
为了保存刚部署好的集群,在后续如果出现无法解决的问题,不至于重新部署一遍,使用虚拟机快照的方式进行备份。
1、一键关闭集群,在node1虚拟机执行以下命令:
# 切换为hadoop用户
su - hadoop
# 一键关闭整个集群
stop-dfs.sh
关闭完成后,可以在node1、node2、node3虚拟机中使用jps命令查看相应Java进程是否已消失。
2、关闭三台虚拟机;
3、在VMware中,分别在三台虚拟机上右键,“快照”-“拍摄快照”功能创建快照。
2.5. 部署过程中可能会遇到的问题
- 在以Hadoop用户身份执行
start-dfs.sh命令时,提示Permission denied。此时需要检查三台虚拟机上相关路径(/data、/export/server及其子路径)上hadoop用户是否具有读、写、执行的权限。 - 在执行
start-dfs.sh命令后,使用jps命令可以查看已启动的服务,若发现有服务未启动成功的,可以查看/export/server/hadoop/logs目录下的日志文件,若在日志文件中看到类似于无权限、不可访问等报错信息,同样需要检查对应机器的相关路径权限。 - 执行
hadoop namenode -format、start-dfs.sh、stop-dfs.sh等Hadoop相关命令时,若提示command not found,则代表着环境变量没配置好,需要检查三台机器的/etc/profile文件的内容(需要使用source命令使环境变量生效)以及hadoop的软连接是否正确。 - 执行
start-dfs.sh命令后,node1的相关进程启动成功,但node2和node3没有启动的,需要检查workers文件的配置是否有node2和node3。 - 若在日志文件中看到WstxEOFException或Unexpected EOF等信息,大概率是xml配置文件有问题,需要仔细检查core-site.xml和hdfs-site.xml文件里面的内容(少了某个字母或字符、写错了某个字母或字符),尤其是符号。
综上,常见出错点总结为:
- 权限未正确配置;
- 配置文件错误;
- 未格式化
2.5. Hadoop HDFS集群启停脚本
注意:在使用以下命令前,一定要确保当前是hadoop用户,否则将报错或没有效果!!!
-
Hadoop HDFS 组件内置了HDFS集群的一键启停脚本。
-
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行流程:- 在执行此脚本的机器上,启动SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,启动NameNode; - 读取
workers内容,确定DataNode所在机器,启动全部DataNode。
-
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行流程:- 在执行此脚本的机器上,关闭SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,关闭NameNode; - 读取
workers内容,确认DataNode所在机器,关闭全部NameNode。
-
-
除了一键启停外,也可以单独控制某个进程的启停。
-
$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode) -
$HADOOP_HOME/sbin/hdfs,此程序也可以单独控制所在机器的进程启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
-
三、使用HDFS文件系统
3.1. 使用命令操作HDFS文件系统
3.1.1. HDFS文件系统基本信息
- HDFS和Linux系统一样,均是以
/作为根目录的组织形式; - 如何区分HDFS和Linux文件系统:
- Linux文件系统以
file://作为协议头,HDFS文件系统以hdfs://namenode:port作为协议头; - 例如,有路径
/usr/local/hello.txt,在Linux文件系统中表示为file:///usr/local/hello.txt,在HDFS文件系统中表示为hdfs://node1:8020/usr/local/hello.txt; - 但一般情况下,协议头是可以省略的,使用Linux命令时,会自动识别为
file://协议头,使用HDFS命令时,会自动识别为hdfs://namenode:port协议头; - 但如果需要再使用HDFS命令操作Linux文件时,需要明确使用
file://协议头。
- Linux文件系统以
3.1.2. HDFS文件系统的2套命令体系
老版本
用法:hadoop fs [generic options]
新版本
用法:hdfs dfs [generic options]
两套命令用法完全一致,效果完全一样,但某些特殊命令需要选择hadoop或hdfs命令。
3.1.3. 创建文件夹
用法:
hadoop fs -mkdir [-p] <path> ...
hdfs dfs -mkdir [-p] <path> ...
path为待创建的目录
-p 选项意思与Linux的mkdir -p一样,自动逐层创建对应的目录。
例如:
hadoop fs -mkdir -p file:///home/hadoop/test 在Linux系统下创建/home/hadoop/test文件夹;
hadoop fs -mkdir -p hdfs://node1:8020/itheima/bigdata 在HDFS中创建/itheima/bigdata文件夹;
hdfs dfs -mkdir -p /home/hadoop/itcast 在HDFS中创建/home/hadoop/itcast文件夹;
3.1.4. 查看指定目录下的内容
用法:
hadoop fs -ls [-h] [-R] [<path> ...]
hdfs dfs -ls [-h] [-R] [<path> ...]
path为指定的目录路径
-h 人性化显示size
-R 递归查看指定目录及其子目录。
例如:
hdfs dfs -ls / 查看HDFS 根目录下的内容
hadoop fs -ls / 查看HDFS 根目录下的内容,与上面等效
hdfs dfs -ls -R / 递归查看HDFS根目录下的内容
hdfs dfs -ls file:/// 查看当前这台Linux机器根目录下的内容
hdfs dfs -ls -h / 查看HDFS根目录下的内容,当文件大小大于1k之后,其大小会有单位,便于人的阅读;
3.1.5. 上传文件到HDFS指定目录下
用法:
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
-f 当目标文件已存在时,覆盖目标文件
-p 保留访问和修改时间,所有权和权限
localsrc 要上传的本地(Linux系统)文件的路径
dst 要保存在HDFS中的具体路径。
例如:
hadoop fs -put file:///home/hadoop/test.txt hdfs://node1:8020/ 将本地/home/hadoop/下的test.txt文件上传到HDFS的根目录下的完整写法;
hdfs dfs -put test2.txt / 将本地当前目录下的test2.txt文件上传到HDFS的根目录下;
hdfs dfs -put -f test2.txt / 将本地目录下的test2.txt文件上传到HDFS的根目录下,并强制覆盖原有的test2.txt文件;
3.1.6. 查看HDFS中文件的内容
用法:
hadoop fs -cat <src> ...
hdfs dfs -cat <src> ...
读取大文件时,可以使用管道符配合more
hadoop fs -cat <src> | more
hdfs dfs -cat <src> | more
例如:
hadoop fs -cat /test.txt 查看HDFS根目录下test.txt文件的内容
hdfs dfs -cat /test2.txt | more 查看HDFS根目录下的test2.txt文件的内容,可以翻页,适用于查看大文件
3.1.7. 从HDFS下载文件到本地
用法:
hadoop fs -get [-f] [-p] <src> ... <localdst>
hdfs dfs -get [-f] [-p] <src> ... <localdst>
-f 当目标文件已存在时,覆盖目标文件
-p 保留访问和修改时间,所有权和权限
src 要下载的HDFS文件路径
localdst 要保存在本地Linux系统中的路径。
例如:
hadoop fs -get /test.txt . 将HDFS根目录下的test.txt文件下载到本地Linux系统的当前目录下;
hadoop fs -get -f /test.txt . 将HDFS根目录下的test.txt文件下载到本地Linux系统的当前目录下,若本地已存在test.txt,则强制覆盖;
hdfs dfs -get /test2.txt . 将HDFS根目录下的test2.txt文件下载到本地的当前目录下;
3.1.8. 复制HDFS文件(在HDFS系统内复制)
用法:
hadoop fs -cp [-f] <src> ... <dst>
hdfs dfs -cp [-f] <src> ... <dst>
-f 若目标文件存在,则强制覆盖目标文件
src HDFS文件系统中被复制的文件路径
dst 要复制到的HDFS文件系统目标路径
例如:
hadoop fs -cp /test.txt /home/ 将HDFS根目录下的test.txt文件复制到HDFS文件系统/home/目录下
hadoop fs -cp /test.txt /home/abc.txt 将HDFS根目录下的test.txt文件复制到HDFS文件系统/home/目录下,并将其改名为abc.txt
3.1.9. 追加数据到HDFS文件中
用法:
hadoop fs -appendToFile <localsrc> ... <dst>
hdfs dfs -appendToFile <localsrc> ... <dst>
localsrc Linux系统的本地文件路径,要追加的内容放在这个文件里
dst HDFS文件系统中被追加的文件,如果文件不存在则创建该文件
在HDFS系统中想要修改文件,仅有两种方式:删除 或 追加
例如:
hadoop fs -appendToFile append.txt /test.txt 将Linux本地当前目录下的append.txt文件中的内容追加到HDFS系统根目录下test.txt文件中去
3.1.10. 移动或重命名HDFS文件(在HDFS系统内移动)
用法:
hadoop fs -mv <src> ... <dst>
hdfs dfs -mv <src> ... <dst>
src HDFS文件系统中的源文件
dst HDFS文件系统中的目标位置
例如:
hadoop fs -mv /test.txt /itheima 将HDFS系统根目录下的test.txt文件移动到HDFS系统/itheima/目录里
hdfs dfs -mv /test2.txt /itheima/abc.txt 将HDFS系统根目录下的test2.txt文件移动到HDFS系统/itheima/目录里,并将其改名为abc.txt
3.1.11. 删除HDFS文件
用法:
hadoop fs -rm [-r] [-skipTrash] URI [URI ...]
hdfs dfs -rm [-r] [-skipTrash] URI [URI ...]
-r 删除文件夹时需要此参数,删除文件时不用
-skipTrash 跳过回收站,直接删除(彻底删除)
回收站功能默认是关闭的,如果需要开启,需要修改core-site.xml配置文件。
例如:
hadoop fs -rm -r /home 删除HDFS系统中的/home文件夹
hdfs dfs -rm /itheima/test.txt 删除HDFS系统中/itheima目录下的test.txt文件
配置开启Hadoop的回收站
修改core-site.xml配置文件vim /export/server/hadoop/etc/hadoop/core-site.xml:
<property><!--回收站保留的时间,1440的单位是分钟,代表着1天,超过这个时间之后,删除的文件就彻底删除了--><name>fs.trash.interval</name><value>1440</value>
</property><property><!--指垃圾回收的检查间隔,应该是小于或者等于fs.trash.interval,120分钟即每2小时检查一次,检查时发现如果有文件的删除时间大于上面的1440,就从回收站里面删掉,也就是彻底删除了--><name>fs.trash.checkpoint.interval</name><value>120</value>
</property>
无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。即如果只是在node1节点配置了,那只有在node1节点执行删除命令才有用,在其他节点执行是没用的!!!
回收站默认位置在:/user/用户名(hadoop)/.Trash
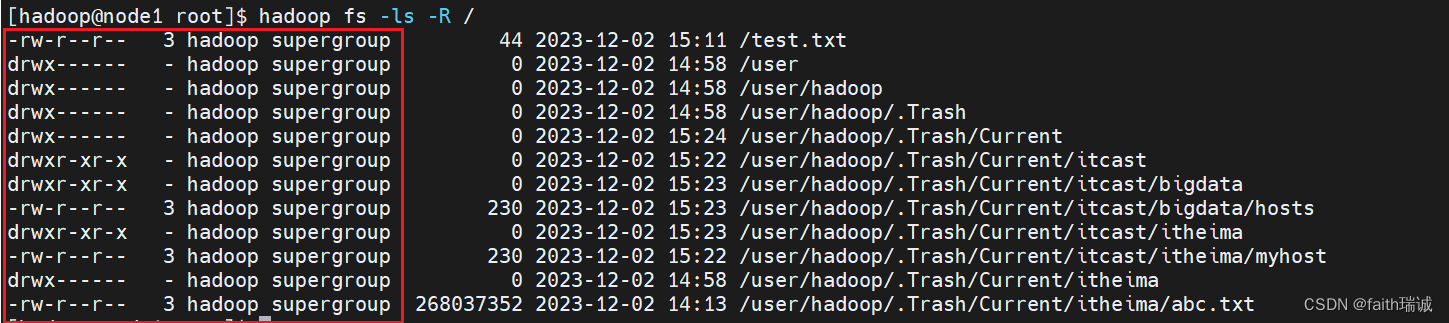
删除HDFS系统内的文件hadoop fs -rm /itheima/abc.txt会看到有如下提示
[hadoop@node1 ~]$ hadoop fs -rm /itheima/abc.txt
2023-12-02 14:58:06,322 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/itheima/abc.txt' to trash at: hdfs://node1:8020/user/hadoop/.Trash/Current/itheima/abc.txt
可以看到,虽然输入的是rm命令,但实际上HDFS系统会将要删除的文件移动到hdfs://node1:8020/user/hadoop/.Trash/Current/目录下。
此时,可以使用 hadoop fs -ls -R /命令查看,当开启回收站后,HDFS系统会在根目录下默认创建/user/当前用户/Current的目录(当前用户为hadoop)

当然,也可以通过参数-skipTrash实现彻底删除,不让被删除的文件进入回收站
hadoop fs -rm -r -skipTrash /itheima 彻底删除(不进入回收站)HDFS根目录下的itheima文件夹,此命令执行效果如下:
[hadoop@node1 ~]$ hadoop fs -rm -r -skipTrash /itheima
Deleted /itheima
可以看到,和不开回收站时,执行rm命令的效果一样。
3.1.12. 其他HDFS命令
官方文档:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html

3.2. HDFS Web浏览
除了上述的命令方式外,还可以通过HDFS NameNode节点的Web页面操作文件系统,入口在http://node1:9870/中

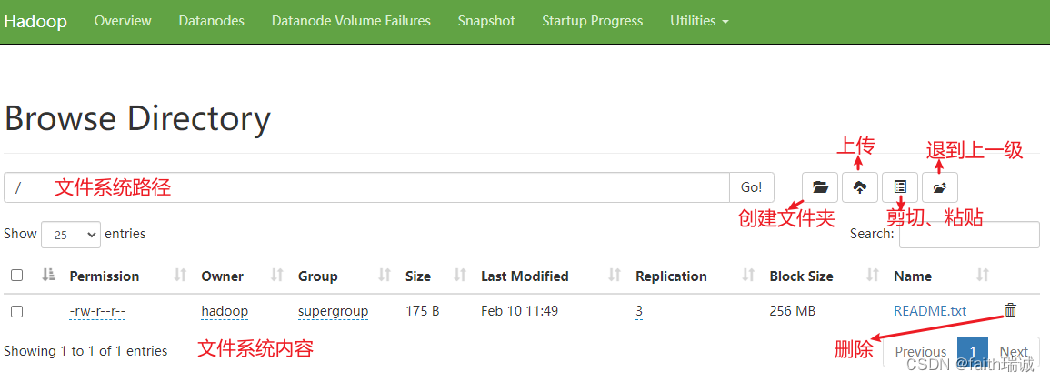
在Web页面中可以查看,但是没法操作文件,因为HDFS系统的权限是给hadoop用户的,但是Web页面默认情况下其实是个匿名用户(dr.who)

当然,也可以让Web页面拥有权限,需要修改core-site.xml配置文件,增加如下配置:
<property><name>hadoop.http.staticuser.user</name><value>hadoop</value>
</property>
将Web页面的权限设置成hadoop用户。
但是,不推荐这样做:
- HDFS WEBUI,只读权限挺好的,简单浏览即可
- 如果给与高权限,会有很大的安全问题,造成数据泄露或丢失
3.3. HDFS系统权限
HDFS系统有自己独立的权限体系,但其权限类型与Linux一致,都是按照读(r)、写(w)、可执行(x)进行授权,权限分为三组,从左到右依次是所有者的权限、所有组的权限、其他用户权限。通过hadoop fs -ls或hdfs dfs -ls命令可以查看到HDFS系统内各文件和文件夹的权限。
但与Linux不同的是,在Linux系统中超级用户是root,但在HDFS系统中,超级用户是启动namenode的用户(本示例中就是hadoop用户),如果在HDFS系统中的文件时遇到Permission denied等权限不足的报错提醒时,首先要检查的就是当前用户是否为启动namenode的用户。
3.3.1. 修改HDFS文件权限
用法:
hadoop fs -chmod [-R] 777 <path>
hdfs dfs -chmod [-R] 777 <path>
例如:
hadoop fs -chmod 777 /test3.txt 将HDFS根目录下的test3.txt文件的权限修改成所有人可读、可写、可执行
[hadoop@node1 ~]$ hadoop fs -chmod 777 /test3.txt
[hadoop@node1 ~]$ hdfs dfs -ls /test3.txt
-rwxrwxrwx 3 hadoop supergroup 268037352 2023-12-05 10:48 /test3.txt
3.3.2. 修改HDFS文件所属用户和组
用法:
hadoop fs -chown [-R] hadoop:supergroup <path>
hdfs dfs -chown [-R] hadoop:supergroup <path>
例如:
hadoop fs -chown root:supergroup /test.txt 将HDFS根目录下的test.txt文件的所有者修改为root用户,所有组为supergroup。
[hadoop@node1 ~]$ hadoop fs -chown root:supergroup /test.txt
[hadoop@node1 ~]$ hdfs dfs -ls /test.txt
-rw-r--r-- 3 root supergroup 44 2023-12-02 15:11 /test.txt
相关文章:
Hadoop入门学习笔记
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 这里写目录标题 一、VMware准备Linux虚拟机1.1. VMware安装Linux虚拟机1.1.1. 修改虚拟机子网IP和网关1.1.2. 安装…...
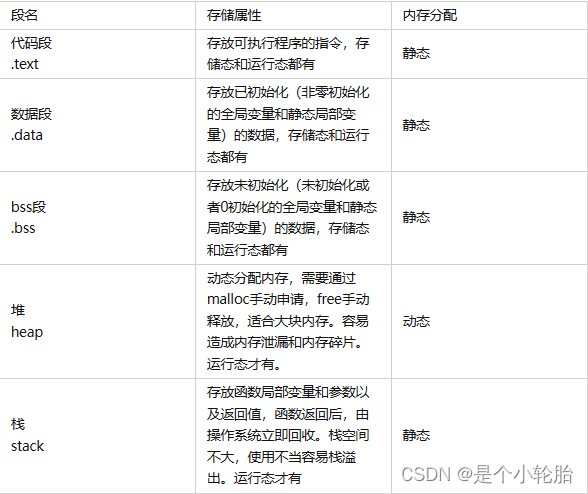
堆栈,BSS,DATA,TEXT
一、目标文件 首先目标文件的构成,Linux下就是.o 文件 编译器编译源码后生成的文件叫目标文件(Object File)。 目标文件和可执行文件一般采用同一种格式,这种存储格式为 ELF。 目前文件的内容至少有编译后的机器指令代码和数据&a…...

Java八股文面试全套真题【含答案】-JSON篇
什么是JSON? 答案:JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,基于JavaScript的对象字面量表示法,用于在不同语言和平台之间传输数据。JSON的数据结构是怎样的? 答案…...

数据库管理-第119期 记一次迁移和性能优化(202301130)
数据库管理-第119期 记一次迁移和性能优化(202301130) 1 迁移 之前因为DV组件没有迁移成功的那个PDB,后来想着在目标端安装DV组件迁移,结果目标端装不上,而且开了SR也没看出个所以然来。只能换一个方向,尝…...
【云原生-K8s】镜像漏洞安全扫描工具Trivy部署及使用
基础介绍基础描述Trivy特点 部署在线下载百度网盘下载安装 使用扫描nginx镜像扫描结果解析json格式输出 总结 基础介绍 基础描述 Trivy是一个开源的容器镜像漏洞扫描器,可以扫描常见的操作系统和应用程序依赖项的漏洞。它可以与Docker和Kubernetes集成,…...
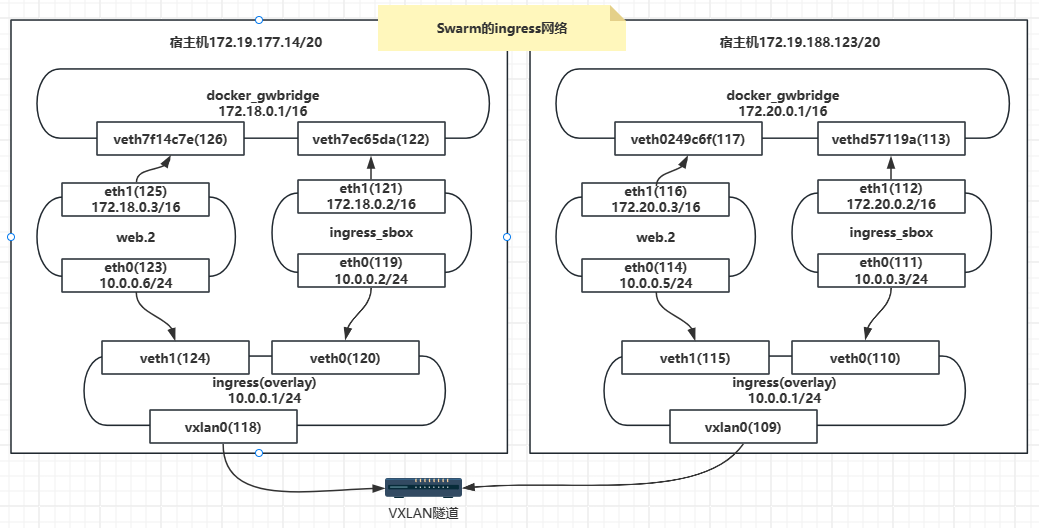
【Docker】Swarm的ingress网络
Docker Swarm Ingress网络是Docker集群中的一种网络模式,它允许在Swarm集群中运行的服务通过一个公共的入口点进行访问。Ingress网络将外部流量路由到Swarm集群中的适当服务,并提供负载均衡和服务发现功能。 在Docker Swarm中,Ingress网络使…...

gcc安全特性之FORTIFY_SOURCE
GCC 4.0引入了FORTIFY_SOURCE特性,旨在加强程序的安全性,特别是对于字符串和内存操作函数的使用。下面是对FORTIFY_SOURCE机制的深入分析: 1. 功能 FORTIFY_SOURCE旨在检测和防止缓冲区溢出,格式化字符串漏洞以及其他与内存操作…...

【JUC】二十、volatile变量的特点与使用场景
文章目录 1、volatile可见性案例2、线程工作内存与主内存之间的原子操作3、volatile变量不具有原子性案例4、无原子性的原因分析:i5、volatile变量小总结6、重排序7、volatile变量禁重排的案例8、日常使用场景9、总结 volatile变量的特点: 可见性禁重排无…...
)
软件工程期末复习(2)
学习资料 设计模式与软件体系结构【期末全整理答案】_软件设计模式与体系结构期末考试题_鸽子不二的博客-CSDN博客 软件设计与体系结构(第二版)部分习题_软件设计与体系结构第二版课后答案-CSDN博客 软件体系结构试题库试题和答案 - 豆丁网Docin 软件设计与体系结构复习 - CN…...
[vue3] 使用 vite 创建vue3项目的详细流程
一、vite介绍 Vite(法语意为 “快速的”,发音 /vit/,发音同 “veet”) 是一种新型前端构建工具,能够显著提升前端开发体验(热更新、打包构建速度更快)。 二、使用vite构建项目 【学习指南】学习新技能最…...
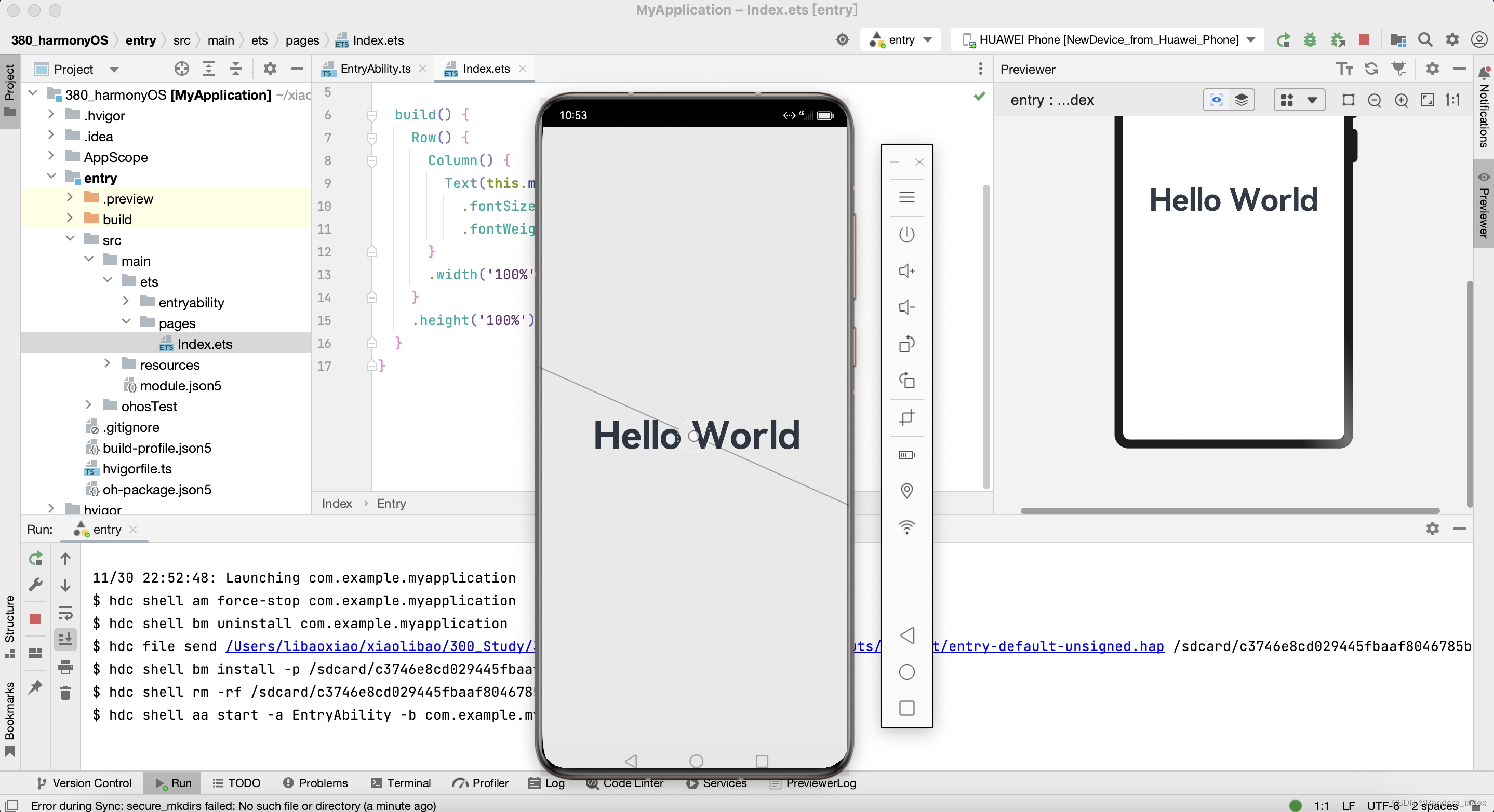
#HarmonyOS:软件安装window和mac预览Hello World
Window软件地址 https://developer.harmonyos.com/cn/develop/deveco-studio#download 安装的建议 这个界面这样选,其他界面全部按照默认路径往下走!!! 等待安装… 安装环境错误处理 一般就是本地node配置异常导致ÿ…...

nginx 一键切换停机维护页面 —— 筑梦之路
背景说明 进行停机维护或者系统升级等操作,会影响到用户使用,如果停机维护期间用户未看到停机维护的通知,仍去访问系统,会提示默认不太友好的访问错误界面 ,这时如果在维护的时候直接展示停机公告的具体信息࿰…...

Python作业答疑
1. 旋转字符串 1.1 问题描述 给定一个字符串(以字符数组的形式)和一个偏移量,根据偏移量原地从左向右旋转字符串。 1.2 问题示例 输入str"abcdefg",offset3,输出"efgabcd"。 输入str"ab…...

计算机网络实用工具之Hydra
简介 Hydra 是一个并行登录破解程序,支持多种协议进行攻击。它非常快速且灵活,并且很容易添加新模块。 该工具使研究人员和安全顾问能够展示远程未经授权访问系统是多么容易。 目前该工具支持以下协议: Asterisk, AFP, Cisco AAA, Cisco au…...
AUTOSAR 入门
前言 AUTOSAR是什么Vector DaVinci 工具功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants 创建一个自定义列表如何创建一个注脚注释也是必…...
新版IDEA中,module模块无法被识别,类全部变成咖啡杯无法被识
新版IDEA中,module模块无法被识别,类全部变成咖啡杯无法被识 如下图: 解决方法:java的Directory文件没有被设置为根目录,解决方法如下: 这是方法之一,还有很多的原因 可能的原因: …...

vue.js el-table 动态单元格列合并
一、业务需求: 一个展示列表,表格中有一部分列是根据后端接口动态展示,对于不同类型的数据展示效果不一样。如果接口返回数据是’类型1‘的,则正常展示,如果是’类型2‘的数据,则合并当前数据的动态表格。…...

word模板导出word文件
前期准备工作word模板 右键字段如果无编辑域 ctrlF9 一下,然后再右键 wps 直接 ctrlF9 会变成编辑域 pom.xml所需依赖 <dependencies> <!--word 依赖--> <dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId…...

debianubuntu的nvidia驱动升级
背景 给出的机器的驱动版本不符合要求,使用自定义的驱动版本。 前置 如果使用nvidia官方的.run安装的驱动包,可以使用系统自带的nvidia-uninstall命令卸载比较方便,不建议使用apt pruge nvidia-*命令删除。会带来其他的问题。 卸载完成之…...
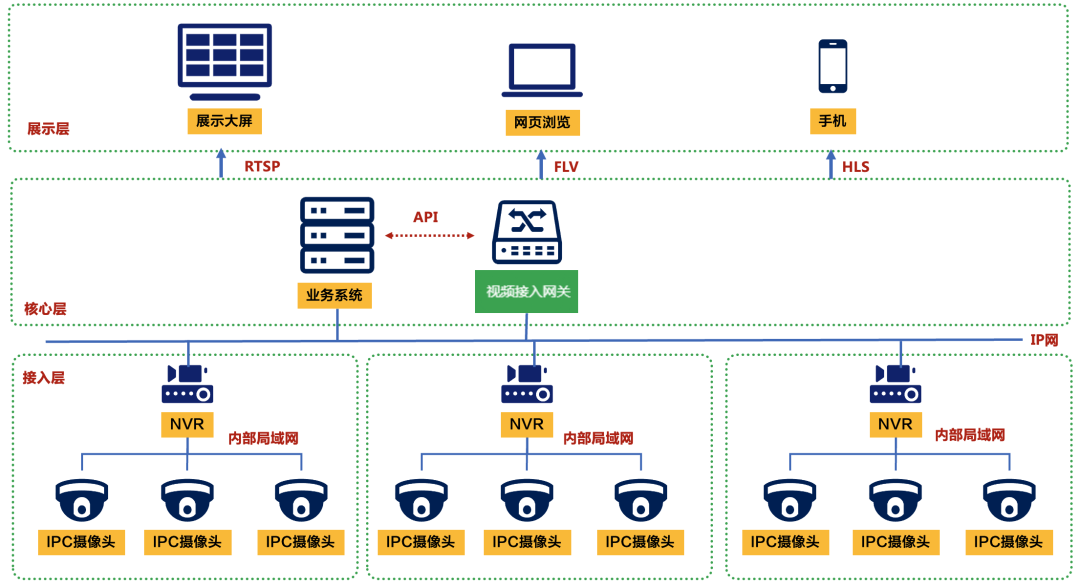
【开源视频联动物联网平台】视频接入网关的用法
视频接入网关是一种功能强大的视频网关设备,能够解决各种视频接入、视频输出、视频转码和视频融合等问题。它可以在应急指挥、智慧融合等项目中发挥重要作用,与各种系统进行对接,解决视频能力跨系统集成的难题。 很多视频接入网关在接入协议…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...