物流实时数仓ODS层——Mysql到Kafka
目录
1.采集流程
2.项目架构
3.resources目录下的log4j.properties文件
4.依赖
5.ODS层——OdsApp
6.环境入口类——CreateEnvUtil
7.kafka工具类——KafkaUtil
8.启动集群项目
这一层要从Mysql读取数据,分为事实数据和维度数据,将不同类型的数据进行不同的ETL处理,发送到kakfa中。
代码
1.采集流程

2.项目架构
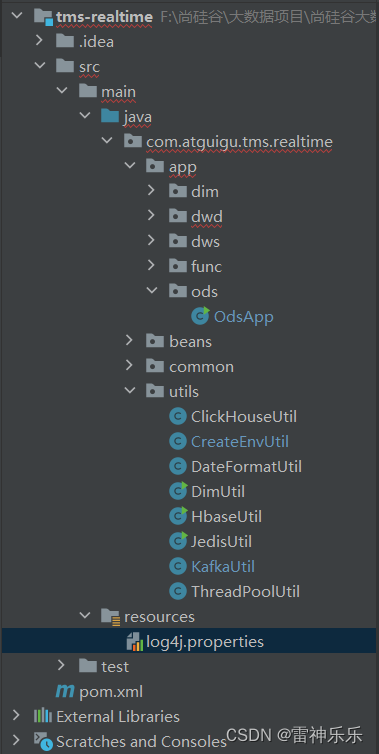
3.resources目录下的log4j.properties文件
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n4.依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu.tms.realtime</groupId><artifactId>tms-realtime</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><java.version>1.8</java.version><flink.version>1.17.0</flink.version><hadoop.version>3.3.4</hadoop.version><flink-cdc.version>2.3.0</flink-cdc.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.68</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-reload4j</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version><scope>provided</scope></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-loader</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.11</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-auth</artifactId><version>${hadoop.version}</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-reload4j</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.20</version></dependency><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.3.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency><dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.3.2</version><exclusions><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId></exclusion></exclusions></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude><exclude>org.apache.hadoop:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><!-- 打包时不复制META-INF下的签名文件,避免报非法签名文件的SecurityExceptions异常--><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><!-- The service transformer is needed to merge META-INF/services files --><!-- connector和format依赖的工厂类打包时会相互覆盖,需要使用ServicesResourceTransformer解决--><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/></transformers></configuration></execution></executions></plugin></plugins></build></project>5.ODS层——OdsApp
package com.atguigu.tms.realtime.app.ods;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.tms.realtime.utils.CreateEnvUtil;
import com.atguigu.tms.realtime.utils.KafkaUtil;
import com.esotericsoftware.minlog.Log;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;/*** ODS数据的采集*/
public class OdsApp {public static void main(String[] args) throws Exception {// TODO 1.获取流处理环境并指定检查点StreamExecutionEnvironment env = CreateEnvUtil.getStreamEnv(args);env.setParallelism(4);// TODO 2.使用FlinkCDC从Mysql中读取数据-事实数据-保存到kafkaString dwdOption = "dwd";String dwdServerId = "6030";String dwdSourceName = "ods_app_dwd_source";mysqlToKafka(dwdOption, dwdServerId, dwdSourceName, env, args);// TODO 3.使用FlinkCDC从Mysql中读取数据-维度数据-保存到kafkaString realtimeOption = "realtime_dim";String realtimeServerId = "6040";String realtimeSourceName = "ods_app_realtimeDim_source";mysqlToKafka(realtimeOption, realtimeServerId, realtimeSourceName, env, args);env.execute();}public static void mysqlToKafka(String option, String serverId, String sourceName, StreamExecutionEnvironment env, String[] args) {// TODO 1.使用FlinkCDC从Mysql中读取数据MySqlSource<String> mysqlSource = CreateEnvUtil.getMysqlSource(option, serverId, args);SingleOutputStreamOperator<String> strDS = env.fromSource(mysqlSource, WatermarkStrategy.noWatermarks(), sourceName).setParallelism(1)// 并行度设置为1的原因是防止乱序.uid(option + sourceName);// TODO 2.简单的ETLSingleOutputStreamOperator<String> processDS = strDS.process(new ProcessFunction<String, String>() {@Overridepublic void processElement(String jsonStr, ProcessFunction<String, String>.Context ctx, Collector<String> out) throws Exception {try {// 将json字符串转为json对象JSONObject jsonObj = JSON.parseObject(jsonStr);// after属性不为空,并且不是删除if (jsonObj.getJSONObject("after") != null && !"d".equals(jsonObj.getString("op"))) {// 为了防止歧义,将ts_ms字段改为tsLong tsMs = jsonObj.getLong("ts_ms");jsonObj.put("ts", tsMs);jsonObj.remove("ts_ms");// 移除原来的ts_ms字段// 符合条件以后,向下传递之前先将json对象转为json字符串out.collect(jsonObj.toJSONString());}} catch (Exception e) {e.printStackTrace();Log.error("从Flink-CDC得到的数据不是一个标准的json格式");}}}).setParallelism(1);// 防止乱序// TODO 3.按照主键进行分许,避免出现乱序,主键就是after下的id字段KeyedStream<String, String> keyedDS = processDS.keyBy(new KeySelector<String, String>() {@Overridepublic String getKey(String jsonStr) throws Exception {// 获取当前的key// 流中的字符串转为json对象JSONObject jsonObj = JSON.parseObject(jsonStr);return jsonObj.getJSONObject("after").getString("id");}});// TODO 4.将数据写到kafka主题中keyedDS.sinkTo(KafkaUtil.getKafkaSink("tms_ods", sourceName + "_transPre", args)).uid(option + "_ods_app_sink");}
}6.环境入口类——CreateEnvUtil
package com.atguigu.tms.realtime.utils;import com.esotericsoftware.minlog.Log;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.source.MySqlSourceBuilder;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.hadoop.yarn.webapp.hamlet2.Hamlet;
import org.apache.kafka.connect.json.DecimalFormat;
import org.apache.kafka.connect.json.JsonConverterConfig;import java.util.HashMap;/*** 获取执行环境* flinkCDC读取mysqlSource的原因是将自己伪装成从机*/
public class CreateEnvUtil {//获取流处理环境public static StreamExecutionEnvironment getStreamEnv(String[] args) {//TODO 1.基本环境准备//1.1 指定流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//TODO 2.检查点相关的设置//2.1 开启检查点env.enableCheckpointing(60000L, CheckpointingMode.EXACTLY_ONCE);//2.2 设置检查点的超时时间env.getCheckpointConfig().setCheckpointTimeout(120000L);//2.3 设置job取消之后 检查点是否保留env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//2.4 设置两个检查点之间的最小时间间隔env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000L);//2.5 设置重启策略env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.days(1), Time.seconds(3)));//2.6 设置状态后端env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/tms/ck");//2.7 设置操作hdfs的用户//获取命令行参数ParameterTool parameterTool = ParameterTool.fromArgs(args);String hdfsUserName = parameterTool.get("hadoop-user-name", "atguigu");System.setProperty("HADOOP_USER_NAME", hdfsUserName);return env;}//获取MySqlSourcepublic static MySqlSource<String> getMysqlSource(String option, String serverId, String[] args) {ParameterTool parameterTool = ParameterTool.fromArgs(args);String mysqlHostname = parameterTool.get("mysql-hostname", "hadoop102");int mysqlPort = Integer.valueOf(parameterTool.get("mysql-port", "3306"));String mysqlUsername = parameterTool.get("mysql-username", "root");String mysqlPasswd = parameterTool.get("mysql-passwd", "root");option = parameterTool.get("start-up-options", option);// serverId是对服务器节点进行标记serverId = parameterTool.get("server-id", serverId);// 创建配置信息 Map 集合,将 Decimal 数据类型的解析格式配置 k-v 置于其中HashMap config = new HashMap<>();config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());// 将前述 Map 集合中的配置信息传递给 JSON 解析 Schema,该 Schema 将用于 MysqlSource 的初始化JsonDebeziumDeserializationSchema jsonDebeziumDeserializationSchema =new JsonDebeziumDeserializationSchema(false, config);MySqlSourceBuilder<String> builder = MySqlSource.<String>builder().hostname(mysqlHostname).port(mysqlPort).username(mysqlUsername).password(mysqlPasswd).deserializer(jsonDebeziumDeserializationSchema);// 读取的数据可能是维度或事实,需要通过标记来区分,从而对不同类型的数据进不同的处理switch (option) {// 读取事实数据case "dwd":String[] dwdTables = new String[]{"tms.order_info","tms.order_cargo","tms.transport_task","tms.order_org_bound"};// 只读取这4个事实表return builder.databaseList("tms").tableList(dwdTables).startupOptions(StartupOptions.latest())// 表示从mysql的binlog最新位置读取最新的数据.serverId(serverId).build();// 读取维度数据case "realtime_dim":String[] realtimeDimTables = new String[]{"tms.user_info","tms.user_address","tms.base_complex","tms.base_dic","tms.base_region_info","tms.base_organ","tms.express_courier","tms.express_courier_complex","tms.employee_info","tms.line_base_shift","tms.line_base_info","tms.truck_driver","tms.truck_info","tms.truck_model","tms.truck_team"};// 读取维度数据表15张return builder.databaseList("tms").tableList(realtimeDimTables).startupOptions(StartupOptions.initial())// 表示在第一次启动时对监控的数据库表执行初始快照,并继续读取最新的binlog。.serverId(serverId).build();case "config_dim":return builder.databaseList("tms_config").tableList("tms_config.tms_config_dim").startupOptions(StartupOptions.initial()).serverId(serverId).build();}Log.error("不支持的操作类型!");return null;}
}7.kafka工具类——KafkaUtil
package com.atguigu.tms.realtime.utils;import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import org.apache.kafka.clients.producer.ProducerConfig;import java.io.IOException;/*** 操作Kafka的工具类*/
public class KafkaUtil {private static final String KAFKA_SERVER = "hadoop102:9092,hadoop103:9092,hadoop104:9092";// 获取kafkaSink的方法 事务id的前缀public static KafkaSink<String> getKafkaSink(String topic, String transIdPrefix, String[] args) {// 使用args参数的原因是为了从外部获取参数。在Java中,args是一个命令行参数数组,当你在命令行中运行Java程序时,你可以通过在命令行中输入参数来传递数据给程序。// 将命令行参数对象封装为 ParameterTool 类对象ParameterTool parameterTool = ParameterTool.fromArgs(args);// 提取命令行传入的 key 为 topic 的配置信息,并将默认值指定为方法参数 topic// 当命令行没有指定 topic 时,会采用默认值topic = parameterTool.get("topic", topic);// 如果命令行没有指定主题名称且默认值为 null 则抛出异常if (topic == null) {throw new IllegalArgumentException("主题名不可为空:命令行传参为空且没有默认值!");}// 获取命令行传入的 key 为 bootstrap-servers 的配置信息,并指定默认值String bootstrapServers = parameterTool.get("bootstrap-severs", KAFKA_SERVER);// 获取命令行传入的 key 为 transaction-timeout 的配置信息,并指定默认值String transactionTimeout = parameterTool.get("transaction-timeout", 15 * 60 * 1000 + "");KafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers(bootstrapServers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix(transIdPrefix).setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, transactionTimeout).build();return kafkaSink;}// 使用这个就只需要传入topic和args即可public static KafkaSink<String> getKafkaSink(String topic, String[] args) {return getKafkaSink(topic, topic + "_trans", args);}
}8.启动集群项目
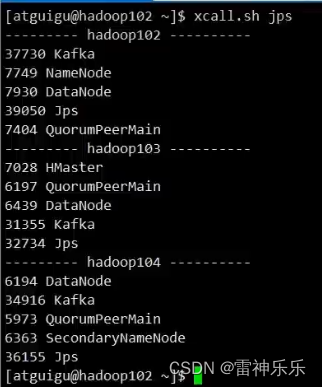
开启消费者,然后启动java项目即可
相关文章:
物流实时数仓ODS层——Mysql到Kafka
目录 1.采集流程 2.项目架构 3.resources目录下的log4j.properties文件 4.依赖 5.ODS层——OdsApp 6.环境入口类——CreateEnvUtil 7.kafka工具类——KafkaUtil 8.启动集群项目 这一层要从Mysql读取数据,分为事实数据和维度数据,将不同类型的数据…...

奇迹mu 架设过程中可能会出现的问题及解决办法
通常我们在架设奇迹的时候,可能会遇见这种问题那种问题,很多用户都不知道该如何解决,今天我们就来系统的说明一下一些常见的问题,帮助遇见这些问题的用户理清一个架设的思路,更清楚的判断问题出在哪里,该如…...
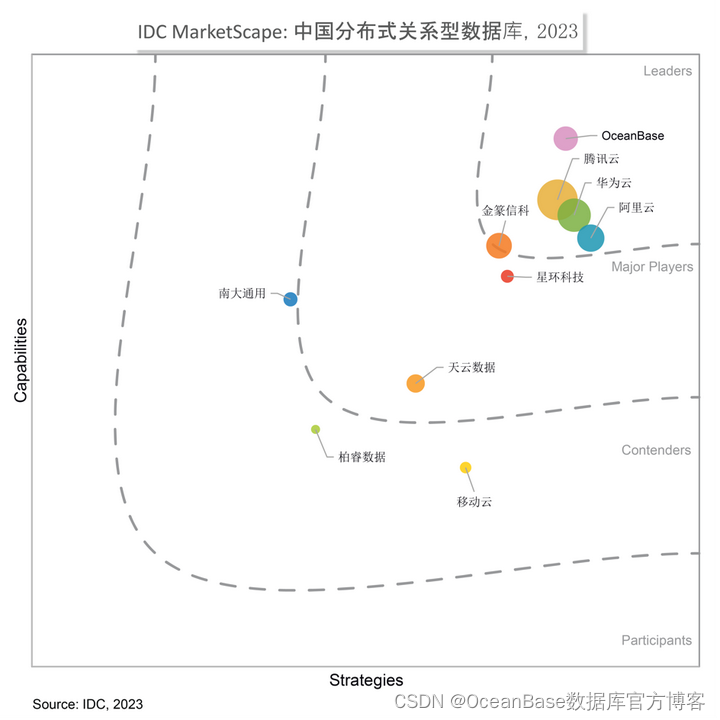
IDC MarketScape2023年分布式数据库报告:OceanBase位列“领导者”类别,产品能力突出
12 月 1 日,全球领先的IT市场研究和咨询公司 IDC 发布《IDC MarketScape:中国分布式关系型数据库2023年厂商评估》(Document number:# CHC50734323)。报告认为,头部厂商的优势正在扩大,OceanBase 位列“领导者”类别。…...

Docker创建mqtt容器mosquitto
#1.创建映射到主机的配置文件/bwss/agent/docker/mosquitto_public/config/mosquitto.conf 内容为: listener 51883 0.0.0.0 # 0.0.0.0 allow_anonymous false persistence false persistence_location /mosquitto/data password_file /mosquitto/config/passwd …...
运维知识点-SQLServer/mssql
SQLServer/mssql Microsoft structed query language常见注入提权 技术点:0x00 打点前提 0x01 上线CS0x02 提权0x03 转场msf0x04 抓取Hash0x05 清理痕迹 Microsoft structed query language 常见注入 基于联合查询注入 order by 判断列数(对应数据类型…...

Reactor实战,创建一个简单的单线程Reactor(理解了就相当于理解了多线程的Reactor)
单线程Reactor package org.example.utils.echo.single;import java.io.IOException; import java.net.InetSocketAddress; import java.nio.channels.*; import java.util.Iterator; import java.util.Set;public class EchoServerReactor implements Runnable{Selector sele…...
)
NoSQL大数据存储技术测试题(参考答案)
目录 1.绪论 2.NoSQL数据库的基本原理 4.HBase的基本原理与使用 5.HBase高级原理 7.MongoDB 8.其他NoSQL数据库 1.绪论 总分: 14.0 10分 单项选择题 4分 判断题 教师评语: 一 单项选择题(10分) 1、NoSQL一词表示的含义是()。…...

Python查看文件列表
os.listdir 是 Python 的一个内置函数,用于列出指定目录中的所有文件和子目录。它接受一个字符串参数,即要列出内容的目录的路径。 列出当前工作目录中的所有文件和子目录 files_and_dirs os.listdir() print(files_and_dirs) 列出指定目录中的所…...
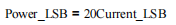
INA219电流感应芯片_程序代码
详细跳转借鉴链接INA219例程此处进行总结 简单介绍一下 INA219: 1、 输入脚电压可以从 0V~26V,INA219 采用 3.3V/5V 供电. 2、 能够检测电流,电压和功率,INA219 内置基准器和乘法器使之能够直接以 A 为单位 读出电流值。 3、 16 位可编程地…...

FlinkSql-Temporal Joins-Lookup Join
说明 在 Flink SQL 中,Temporal Joins 是一种常见的数据关联操作,特别适用于处理包含时间维度的数据。Lookup Join 是 Temporal Joins 的一种类型,它允许将流数据与维表数据进行关联。使用场景如下: 实时维度关联: 当…...
STM32之定时器
目录 1、定时器介绍 1.定时器工作原理 2.定时器的分类 3.通用定时器主要功能介绍 4.定时器计数模式 5.定时器时钟源 6.定时器溢出时间计算公式 2、定时器中断的实验 codeMX的配置 代码编写 1.使用到的HAL库函数 1.中断回调函数需要我们重写 2. 在中断模式下启动TIM…...
Canvas鼠标画线
鼠标按下开始画线,鼠标移动根据鼠标的轨迹去画,鼠标抬起停止画线 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0">…...
Docker 安装部署 Sentinel Dashboard
1、下载 jar 包 官方 jar 包下载地址:https://github.com/alibaba/Sentinel/releases 或者点击 链接 直接跳转到下载页 进入链接下载你需要的版本 下载完毕(我这里统一放在一个sentinel目录内) 2、编写 Dockerfile 文件(这里我不…...

第21章网络通信
Internet 提供了大量有用的信息,很少有人能在接触过Internet后拒绝它的诱惑。计算机网络实现了多台计算机间的互联,使得它们彼此之间能够进行数据交流。网络应用程序就是在已连接的不同计算机上运行的程序,这些程序借助于网络协议,…...
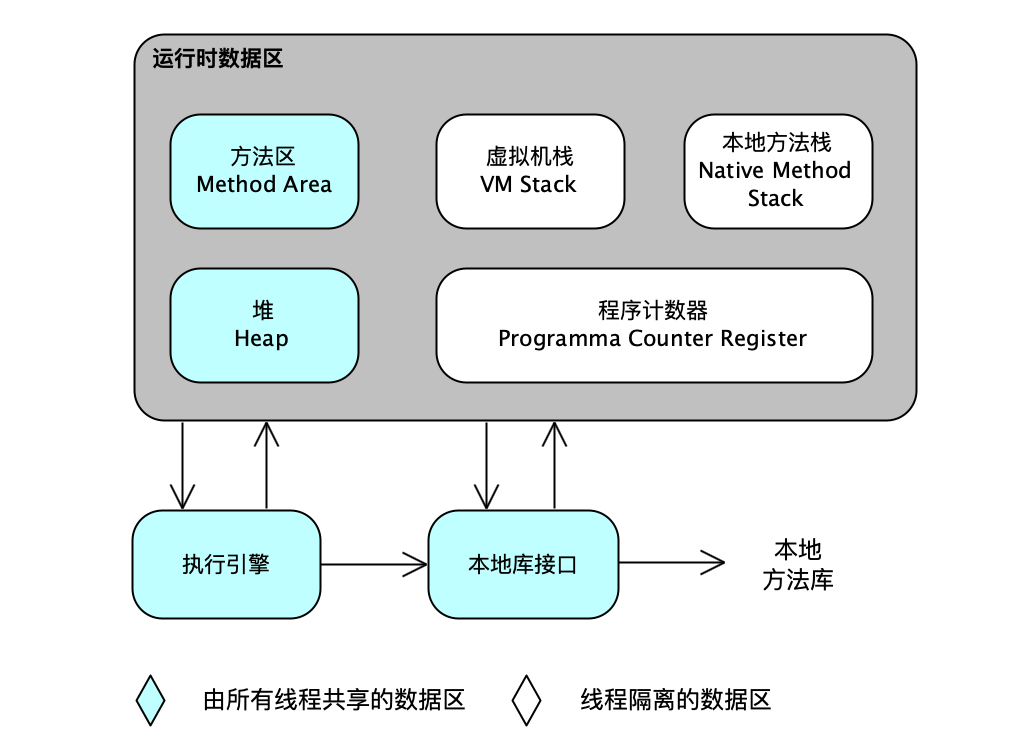
一、运行时数据区域
根据 《Java 虚拟机规范》的规定,Java 虚拟机所管理的内存将会包括以下截个运行时数据区域,如图所示。 1、程序计数器 程序计数器是一块较小的内存空间,它可以看做是当前线程所执行的字节码的行号指示器。在 Java 虚拟机的概念模型里&#x…...

OCR原理解析
目录 1.概述 2.应用场景 3.发展历史 4.基于传统算法的OCR技术原理 4.1 图像预处理 4.1.1 灰度化 4.1.2 二值化 4.1.3 去噪 4.1.4 倾斜检测与校正 4.1.4.2 轮廓矫正 4.1.5 透视矫正 4.2 版面分析 4.2.1 连通域检测文本 4.2.2 MSER检测文本 4.3 字符切割 4.3.1 连…...
使用com组件编辑word
一个普通的窗体应用,6个button using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; u…...
系统安装docker)
国产Euler(欧拉)系统安装docker
国产的真™难用呀 生态又差还不开源 血泪经验 解压Docker安装包。 tar zxf docker-19.03.10.tgz 将解压后目录中的文件移动到“/usr/bin”下。 cp docker/* /usr/bin配置docker.service文件。 编辑docker.service文件。 vim /usr/lib/systemd/system/docker.service添加以…...
Linux 进程控制
文章目录 进程创建进程终止进程结果wait函数waitpid函数status参数 进程替换进程替换原理进程替换函数 补充/拓展 进程创建 fork函数 #include <unistd.h>pid_t fork(void);函数返回值: 在父进程中,fork函数返回子进程的进程ID(PID&…...

[ Linux Audio 篇 ] 音频开发入门基础知识
在短视频兴起的背景下,音视频开发越来越受到重视。接下来将为大家介绍音频开发者入门知识,帮助读者快速了解这个领域。 轻柔的音乐、程序员有节奏感的键盘声、嗡嗡的发动机、刺耳的手提钻……这些声音是如何产生的呢?又是如何传到我们耳中的…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...

Sklearn 机器学习 缺失值处理 获取填充失值的统计值
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 使用 Scikit-learn 处理缺失值并提取填充统计信息的完整指南 在机器学习项目中,数据清…...