C++11(下)
可变参数模板
C++11的新特性可变参数模板能够创建可以接受可变参数的函数模板和类模板.
相比C++98/03, 类模版和函数模版中只能含固定数量的模版参数, 可变模版参数无疑是一个巨大的改进, 然而由于可变模版参数比较抽象, 使用起来需要一定的技巧, 所以这块还是比较晦涩的.掌握一些基础的可变参数模板特性就暂时够用了.
我们之前就接触过函数的可变参数, 比如说c语言的printf函数和scanf函数,这两个就是经典的可变参数函数, c语言printf的底层是指针数组实现的, 把参数存到那个数组里, 然后遇到可变参数就是去解析那个数组里的内容.


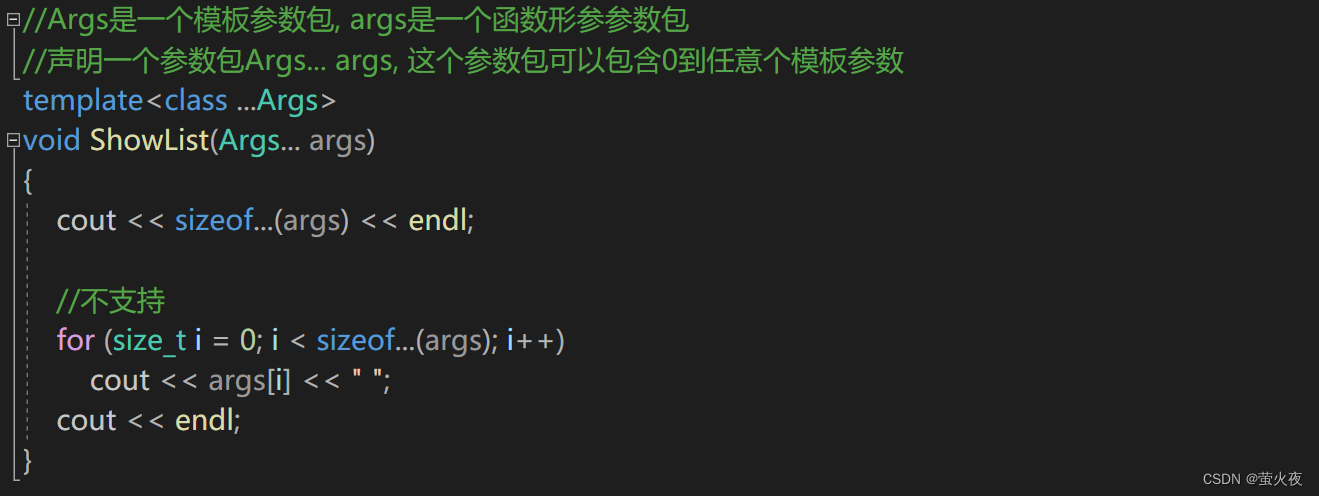
//Args是一个模板参数包, args是一个函数形参参数包
//声明一个参数包Args... args, 这个参数包可以包含0到任意个模板参数
template<class ...Args>
void ShowList(Args... args)
{}int main()
{ShowList(1);ShowList(1, 2);ShowList(1, 2, 3);ShowList(1, 2.2, "x", 3);return 0;
}模板参数包里面是类型, 函数参数包里面是变量
如果要计算参数包的大小, 需要用sizeof..., 这个用法是固定的:
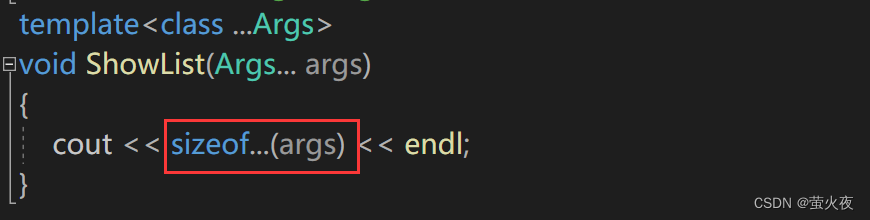

如果想要解析参数包的内容, 首先可能会想到数组式地访问, 但是不支持这样访问:
想要访问模板参数包的内容有两种方法, 第一种递归函数方式展开参数包:
void _ShowList()
{cout << endl;
}//编译时的递归推演
//第一个模板参数依次解析获取参数值
template<class T, class ...Args>
void _ShowList(const T& val, Args... args)
{cout << val << " ";_ShowList(args...);
}template<class ...Args>
void ShowList(Args... args)
{//cout << sizeof...(args) << endl;_ShowList(args...);
}int main()
{ShowList(1);ShowList(1, 2);ShowList(1, 2, 3);ShowList(1, 2.2, "x", 3);return 0;
} 
以1,2,3为例, 第一次先将参数包传递给_ShowList, _ShowListval先接收第一个参数, 然后其他的参数就会全部都给参数包args, 那么对应在上面的代码就是1传递给val, 2和3就会传递给args, 然后递归调用ShowList继续传递参数包, 重复场面的步骤第一个参数val接收2, 参数包则接收剩下的参数3. 如果剩余的参数为空的话就会匹配空类型的参数(最上面的_ShowList), 最终结束了递归.
第二种逗号表达式展开参数包:
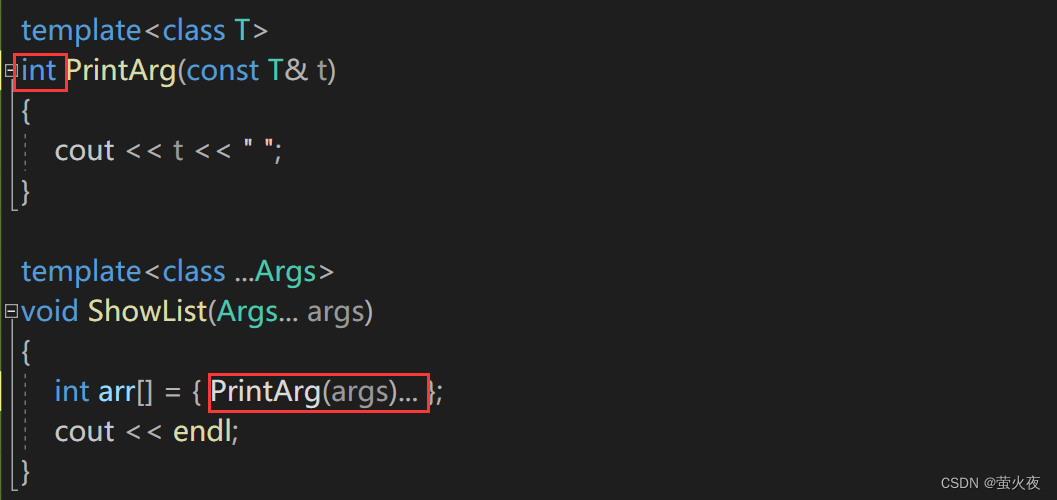
这种展开参数包的方式, 不需要通过递归终止函数, 是直接在函数体中展开的, printarg
不是一个递归终止函数, 只是一个处理参数包中每一个参数的函数.这用到了C++11的另外一个特性——初始化列表, 通过初始化列表来初始化一个变长数组, {(printarg(args), 0)...}将会展开成((printarg(arg1),0),(printarg(arg2),0), (printarg(arg3),0), etc... ), 最终会创建一个元素值都为0的数组int arr[sizeof...(Args)].
由于是逗号表达式, 在创建数组的过程中会先执行逗号表达式前面的部分printarg(args)
打印出参数, 也就是说在构造int数组的过程中就将参数包展开了, 这个数组的目的纯粹是为了在数组构造的过程展开参数包.
数组里面添加了三个点, 这个就表示数组在推断的时候需要把这个参数包进行展开, 展开的空间为多大, 这个数组的大小就是多大:
template<class T>
void PrintArg(const T& t)
{cout << t << " ";
}template<class ...Args>
void ShowList(Args... args)
{int arr[] = { (PrintArg(args),0)... };cout << endl;
}int main()
{ShowList(1);ShowList(1, 2);ShowList(1, 2, 3);ShowList(1, 2.2, "x", 3);return 0;
} 
上面的写法其实也用不到逗号表达式, 直接这样写也可以:
emplace
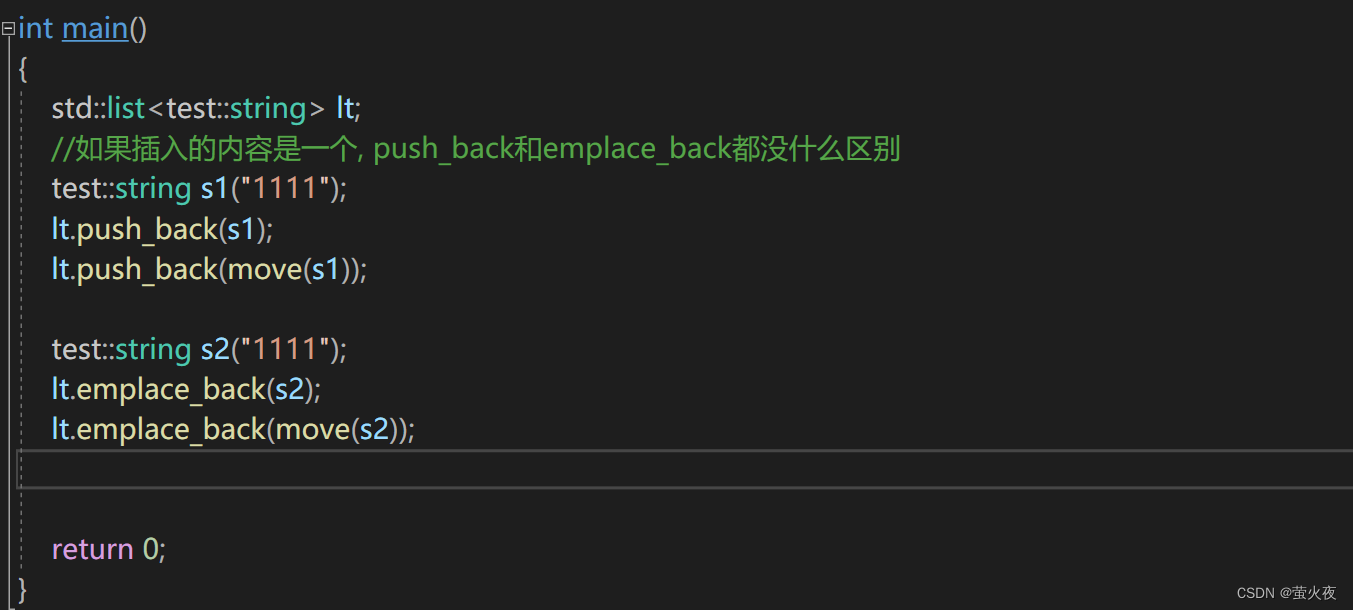
在之前的使用过程中对于容器我们一般传递的都是左值, 但是在c++11中我们发现容器不仅可以传递左值还可以传递右值, 并且传递右值的效率会比单独传递左值的效率高很多, 但是不管你是传递左值还是传递右值之前学习的插入方式一次都只能传递一个值, 而emplace版本的插入函数它可以一次传递0~N个参数, 我们来看看list容器的emplace版本的push_back函数:

template <class... Args>
void emplace_back (Args&&... args);这里的可变参数包里的类型是 Args&&, 结合之前学过的, 模板里的&&就是万能引用, 也就是说这个参数包里的参数都可以是万能引用.
那么相对insert和emplace系列接口的优势在哪里呢?
首先插入的参数是一个的话, 两者其实没有什么区别:

这样写会有一些区别, 但只是形式上有一些区别, 实际也没什么区别:
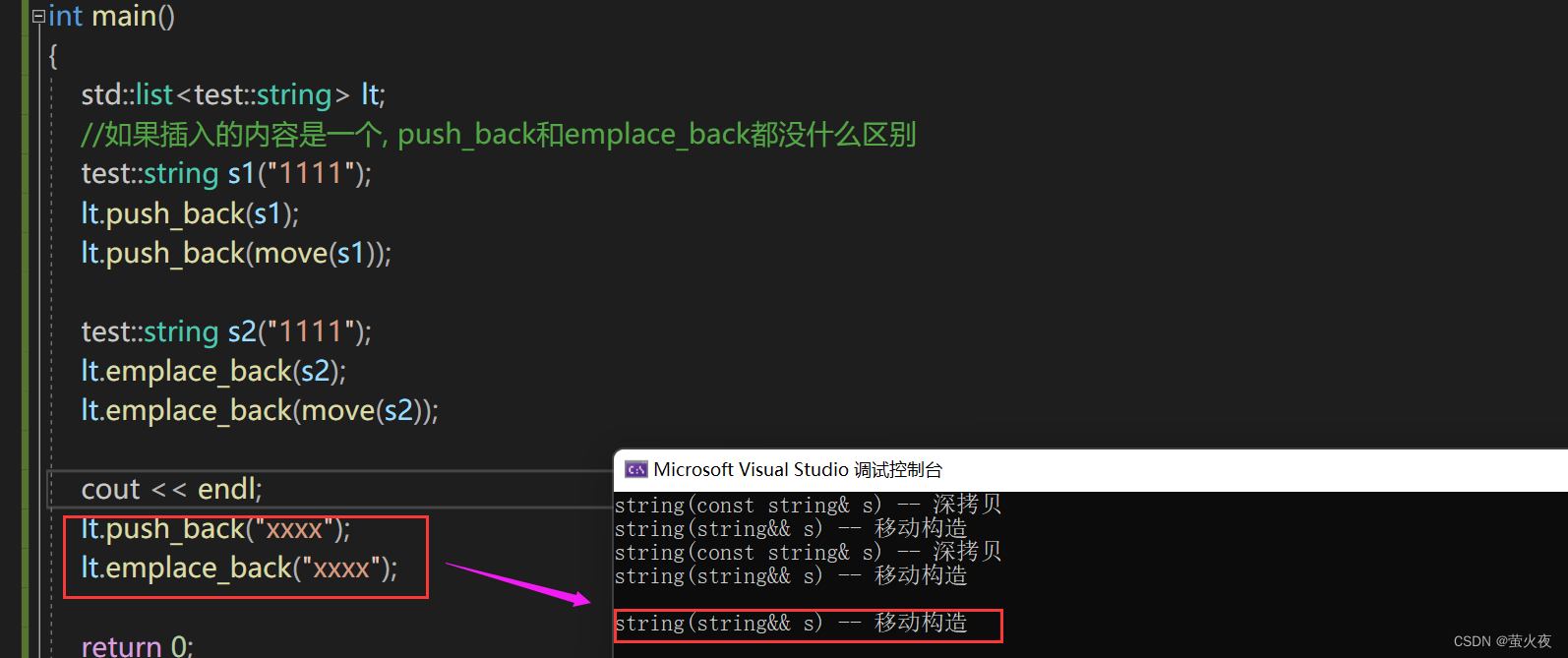
可以发现这里只有一个移动构造, 而明确地说是这是push_back的移动构造, 现在把string的构造函数也打印出来, 就可以解释原因:
再次运行:

可以发现push_back是构造+移动构造, 而emplace_back是直接构造.
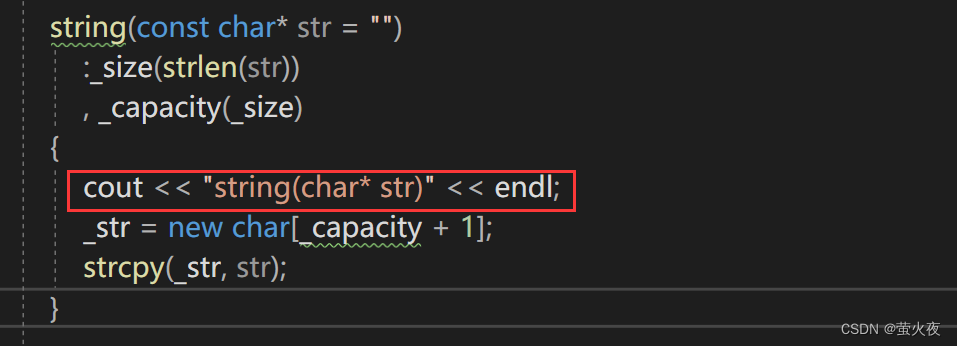
对于前两种情况不会出现这种问题原因是, push_back的value_type可以明确确定val的类型就是test::string, 而emplace_back只有一个参数也是test::string类型的, 所以也可以比较明确地推断出参数是test::string类型的.

而这种情况就不一样了:

因为push_back里的value_type是test::string, push_back是直接隐式类型转换, 传给万能引用就继续移动构造了, 而emplace_back拿着参数包去推类型, 此时只能推断出它是const char*类型的, 并不知道list结点里实际是什么类型, 所以就带着这个参数包一直向下传递, 一直传到list的结点要构建它的data的时候直接用调用构造.
再举一个例子, 如果push_back的话参数需要传一个pair因为value_type是写死的,需要传一个pair过去, 而emplace_back直接传两个参数进去, 让它直接去构造就可以了, 这里用string的构造间接表示pair的构造.
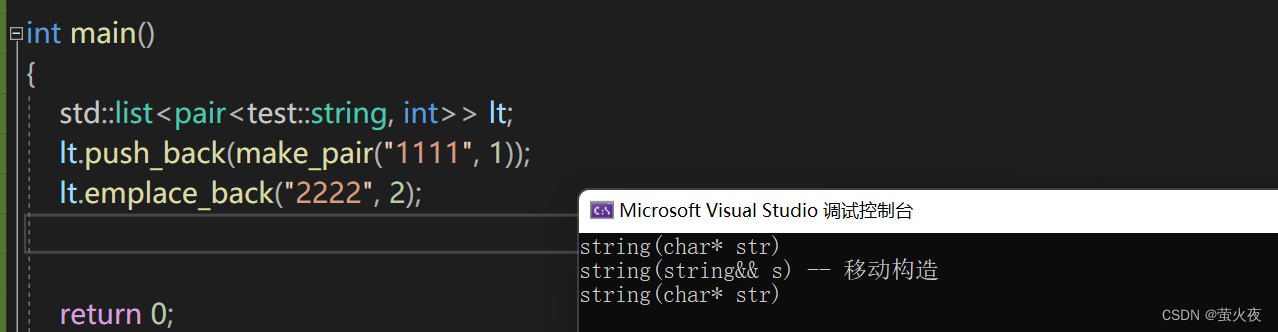
所以多参数时, emplace_back可以一个一个传参, 因为emplace_back的形参是可变参数包, 直接把参数包不断往下传, 直接构造到结点的val中.
所以回归最开始的话题, 插入的参数是一个的话, push_back和emplace_back其实没有什么区别不管是传参方式还是底层效率, 因为移动构造的成本也很低, 可以说emplace_back是略微高效一点.
而多参数时效率其实也没什么区别, 但是emplace_back传参的方式更多了一点, 它不仅可以传左值和右值,还可以把参数一个个分开传:
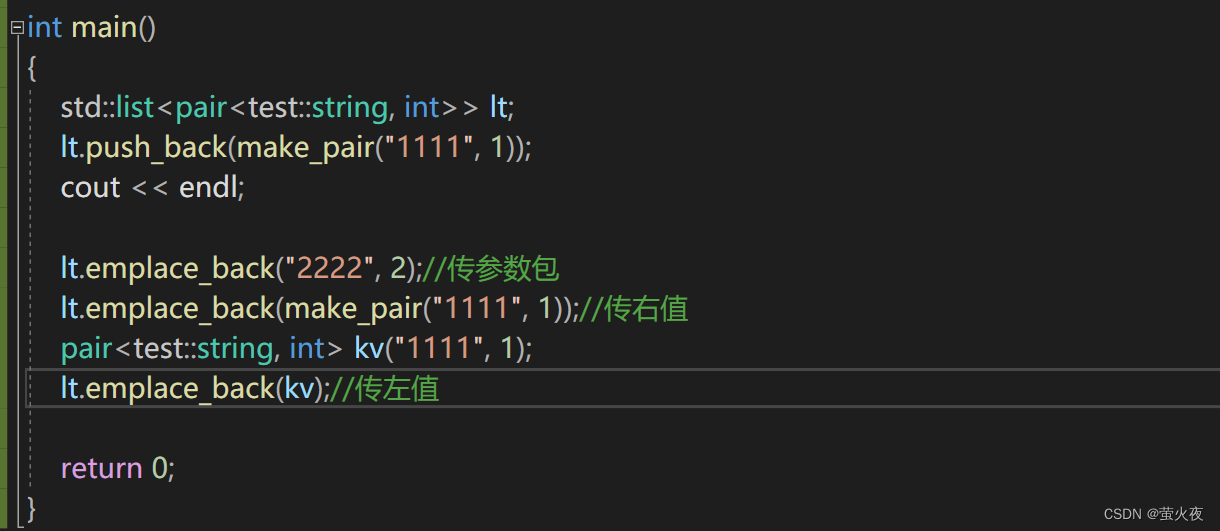

可以再用自己的链表试一试:
int main()
{test::list<pair<test::string, int>> lt;cout << endl;lt.push_back(make_pair("1111", 1));lt.emplace_back("2222", 2);return 0;
}先实现一个emplace_back:
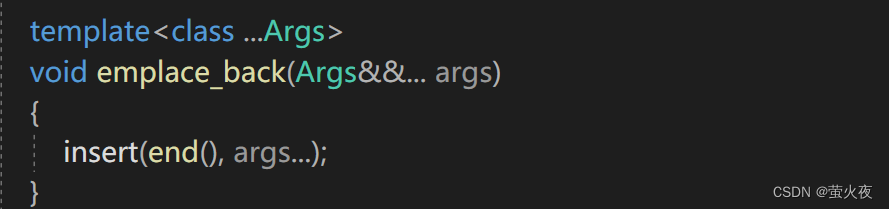
emplace_back要复用insert(实际上应该去复用emplace, push_back复用insert, emplace_back应该复用emplace, 这里就先这样写), 需要把函数参数包传给insert, 所以insert也要实现一个可变参数包版的:

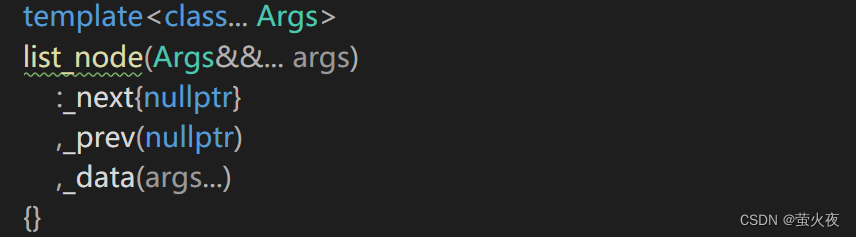
insert里创建结点要用到new需要把参数包向下传, 所以node的构造函数也要实现一个可变参数包版的:
运行:
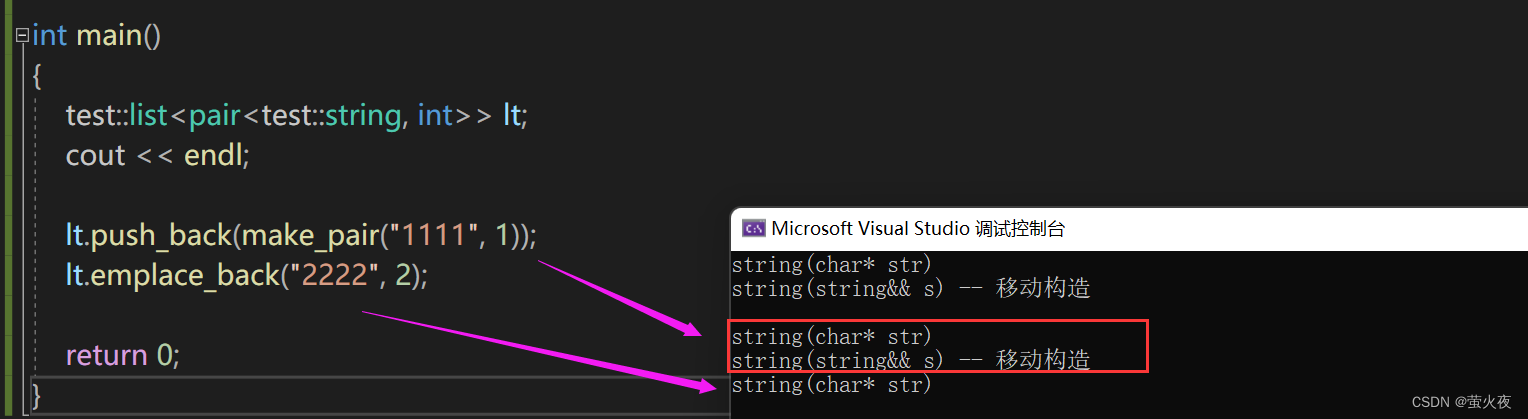
结果整体上符合预期, push_back就正常调用构造+移动构造, emplace_back直接构造, 但是前面多出来两行构造+拷贝构造, 因为我们是new出来一个头结点, 头结点初始化需要调用构造, 而C++库里用的是内存池, 内存池只管开空间, 需要初始化的时候用定位new即可.

所以参数包其实有的时候不用去解析, 最终是一层一层往下传, 可变参数包直接被使用了.
总结:
总体而言emplace的效率并没有比push_back高多少, 但是有一种场景提升比较明显, 对于浅拷贝而且是对象很大的类有效果, 因为浅拷贝push_back不存在移动构造(不存在资源转换), 就是构造+拷贝构造, 而emplace是直接构造, 直接构造肯定比构造+拷贝构造效率高, 所以emplace对于深拷贝的类效果不是很明显, 因为移动构造的成本就是转移资源, 成本很低; 对于浅拷贝的类有一定的提升.
lambda表达式
为什么会有lambda表达式
c语言中有函数指针, 它可以让我们传入函数作为参数, 但是函数指针在一些比较复杂的情况时会变得很难理解. 为了解决这个问题, C++就提出来了仿函数, 它可以大大的提高函数指针的可读性, 比如常用的sort函数:
在C++98中, 如果想要对一个数据集合中的元素进行排序, 可以使用std::sort方法:
#include <algorithm>
#include <functional>
int main()
{int array[] = { 4,1,8,5,3,7,0,9,2,6 };// 默认按照小于比较,排出来结果是升序std::sort(array, array + sizeof(array) / sizeof(array[0]));// 如果需要降序,需要改变元素的比较规则std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());return 0;
}如果待排序元素为自定义类型, 需要用户定义排序时的比较规则:
#include <algorithm>
struct Goods
{string _name; // 名字double _price;// 价格int _evaluate;// 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}};struct ComparePriceLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._price < gr._price;}
};struct ComparePriceGreater
{bool operator()(const Goods& gl, const Goods& gr){return gl._price > gr._price;}
};ostream& operator<<(ostream& out, const Goods& g)
{out << g._name << " "<< "评价" << g._evaluate << " " << "价格" << g._price << endl;return out;
}int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };sort(v.begin(), v.end(), ComparePriceLess());for (auto e : v)cout << e;cout << "---------------------------" << endl;sort(v.begin(), v.end(), ComparePriceGreater());for (auto e : v)cout << e;}
可以得到我们预期排序的结果.
但随着C++语法的发展, 人们开始觉得上面的写法太复杂了, 每次为了实现一个algorithm算法, 都要重新去写一个类, 如果每次比较的逻辑不一样, 还要去实现多个类, 特别是相同类的命名, 这些都给编程者带来了极大的不便, 因此, 在C++11语法中出现了Lambda表达式.
lambda表达式语法
lambda表达式书写格式:
[capture-list] (parameters) mutable -> return-type { statement }
lambda表达式各部分说明
[capture-list]: 捕捉列表, 该列表总是出现在lambda函数的开始位置, 编译器根据[]来判断接下来的代码是否为lambda函数, 捕捉列表能够捕捉上下文中的变量供lambda函数使用.
(parameters): 参数列表, 与普通函数的参数列表一致, 如果不需要参数传递, 则可以连同()一起省略.
mutable: 默认情况下, lambda函数总是一个const函数, mutable可以取消其常量性, 使用该修饰符时, 参数列表不可省略(即使参数为空).->returntype: 返回值类型, 用追踪返回类型形式声明函数的返回值类型, 没有返回值时此部分可省略, 返回值类型明确情况下, 也可省略, 由编译器对返回类型进行推导.
{statement}: 函数体, 在该函数体内, 除了可以使用其参数外, 还可以使用所有捕获到的变量.
注意:
在lambda函数定义中, 参数列表和返回值类型都是可选部分, 而捕捉列表和函数体可以为空,但不能省略, 因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情.
举几个例子:
int main()
{// 最简单的lambda表达式, 该lambda表达式没有任何意义[] {};// 省略参数列表和返回值类型,返回值类型由编译器推导为intint a = 3, b = 4;[=] {return a + 3; };// 省略了返回值类型,无返回值类型auto fun1 = [&](int c) {b = a + c; };fun1(10);cout << a << " " << b << endl;//3 13// 各部分都很完善的lambda函数auto fun2 = [=, &b](int c)->int {return b += a + c; };cout << fun2(10) << endl;// 复制捕捉xint x = 10;auto add_x = [x](int a) mutable { x *= 2; return a + x; };cout << add_x(10) << endl;return 0;
}使用lambda表达式之后之前按照Goods的价格排序的代码就变成下面这个样子:
#include <algorithm>
#include <functional>
struct Goods
{string _name; // 名字double _price;// 价格int _evaluate;// 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}};ostream& operator<<(ostream& out, const Goods& g)
{out << g._name << " "<< "评价" << g._evaluate << " " << "价格" << g._price << endl;return out;
}int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };sort(v.begin(), v.end(), [](const Goods& g1, Goods g2) ->bool {return g1._price < g2._price; });for (auto e : v)cout << e;cout << "---------------------------" << endl;sort(v.begin(), v.end(), [](const Goods& g1, Goods g2) ->bool {return g1._price < g2._price; });for (auto e : v)cout << e;
}sort的第三个参数传lambda表达式即可:


这里可能存在一个疑问, lambda表达式为什么可以直接传递使用呢?
这里的lambda表达式实际上是一个对象, 上面的直接传递就是创建了一个匿名函数对象,将这个匿名对象进行传递.
sort的第三个参数是一个可调用对象的模板, 只要传过去的参数是一个(可进行比较的)可调用对象即可, 所以传函数指针, 仿函数, lambda表达式都可以.

如果我想接收这个lambda表达式返回的匿名对象呢?
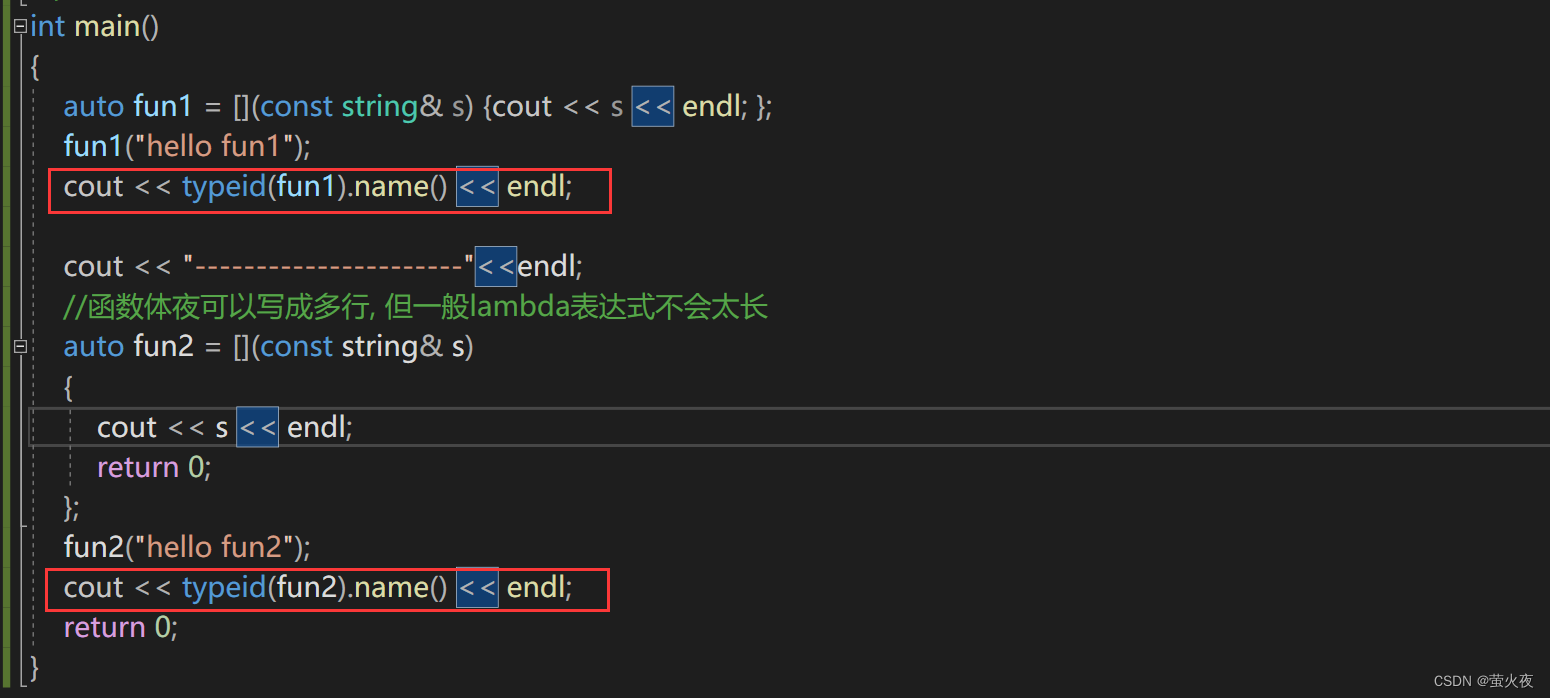
可以用auto接收, 不用管返回值的类型, auto会自动推导:
int main()
{auto fun1 = [](const string& s) {cout << s << endl; };fun1("hello fun1");//函数体夜可以写成多行, 但一般lambda表达式不会太长auto fun2 = [](const string& s){cout << s << endl; return 0; };fun2("hello fun2");return 0;
}
捕获列表说明
捕捉列表描述了上下文中那些数据可以被lambda使用, 以及使用的方式传值还是传引用.
捕捉值:
[var]: 表示值传递方式捕捉变量var.
[=]: 表示值传递方式捕获所有父作用域中的变量(包括this).捕捉引用:
[&var]: 表示引用传递捕捉变量var.
[&]: 表示引用传递捕捉所有父作用域中的变量(包括this).捕捉this:
[this]: 表示值传递方式捕捉当前的this指针.
这是一个简单的交换两个值的lambda函数:
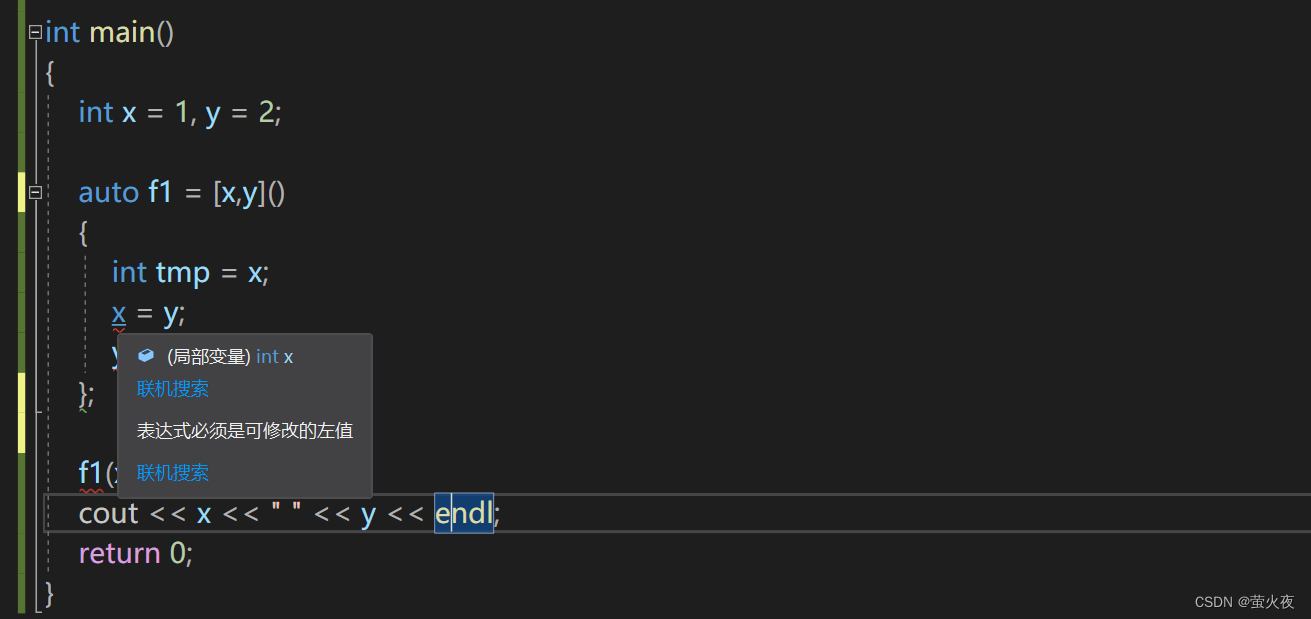
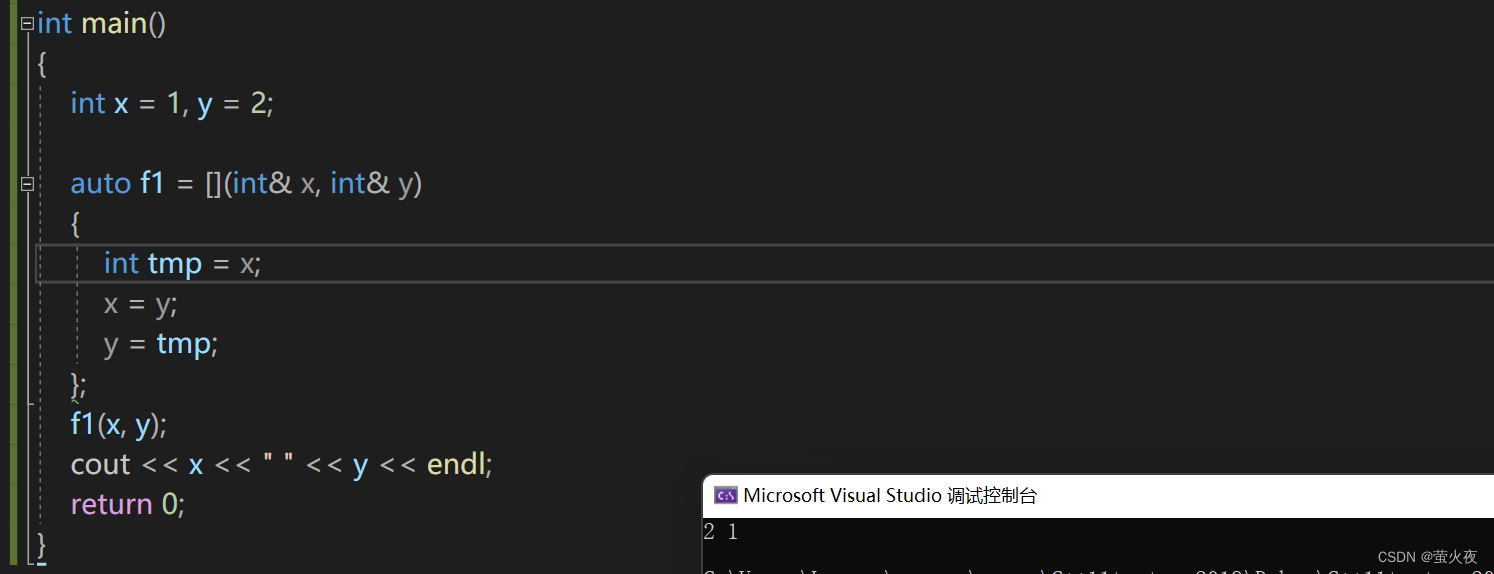 现在如果我只想对main函数里的x和y进行交换呢? 可以用捕获列表进行捕获:
现在如果我只想对main函数里的x和y进行交换呢? 可以用捕获列表进行捕获:
int main()
{int x = 1, y = 2;auto f1 = [x,y](){int tmp = x;x = y;y = tmp;};f1();cout << x << " " << y << endl;return 0;
}
但是捕捉的值并不能进行修改, 为什么呢?
捕获的值其实就相当于底层仿函数类中的成员变量, 而lambda不加mutable默认是const修饰的, 其实是底层的operator()是const修饰的, const修饰this指针就不能对类的成员变量进行修改, 所以加一个mutable即可:
int main()
{int x = 1, y = 2;auto f1 = [x,y]()mutable{int tmp = x;x = y;y = tmp;};f1();cout << x << " " << y << endl;return 0;
} 
但是结果并不是预期的值交换, 因为这里是传值捕获, 要想修改父作用域内捕获的变量, 需要传引用捕获:

因为这里父作用域只有两个变量, 所以也可以直接输入一个&, 引用传递捕捉所有父作用域中的变量.
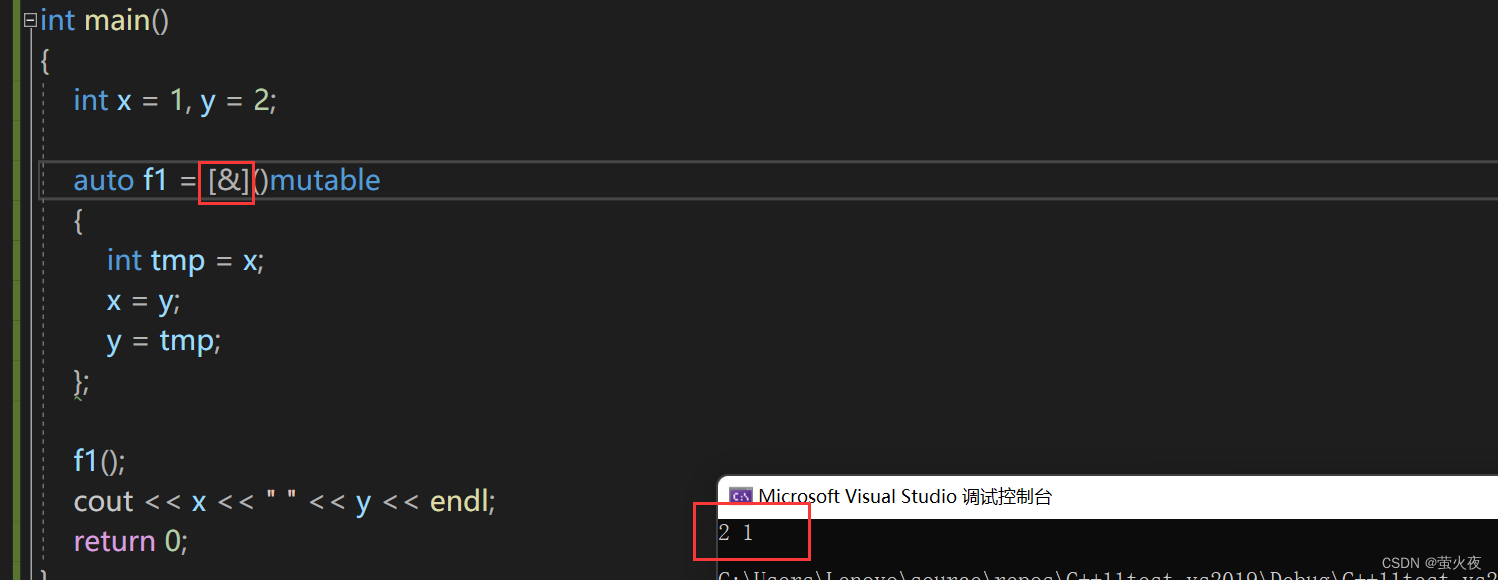
以引用方式捕捉就可以理解为仿函数中的两个成员变量是引用, 引用分别用x和y初始化.
那传引用捕捉这里的mutable可以去掉吗? 按照上面的理解是不能去掉的, 但是实际可以去掉.

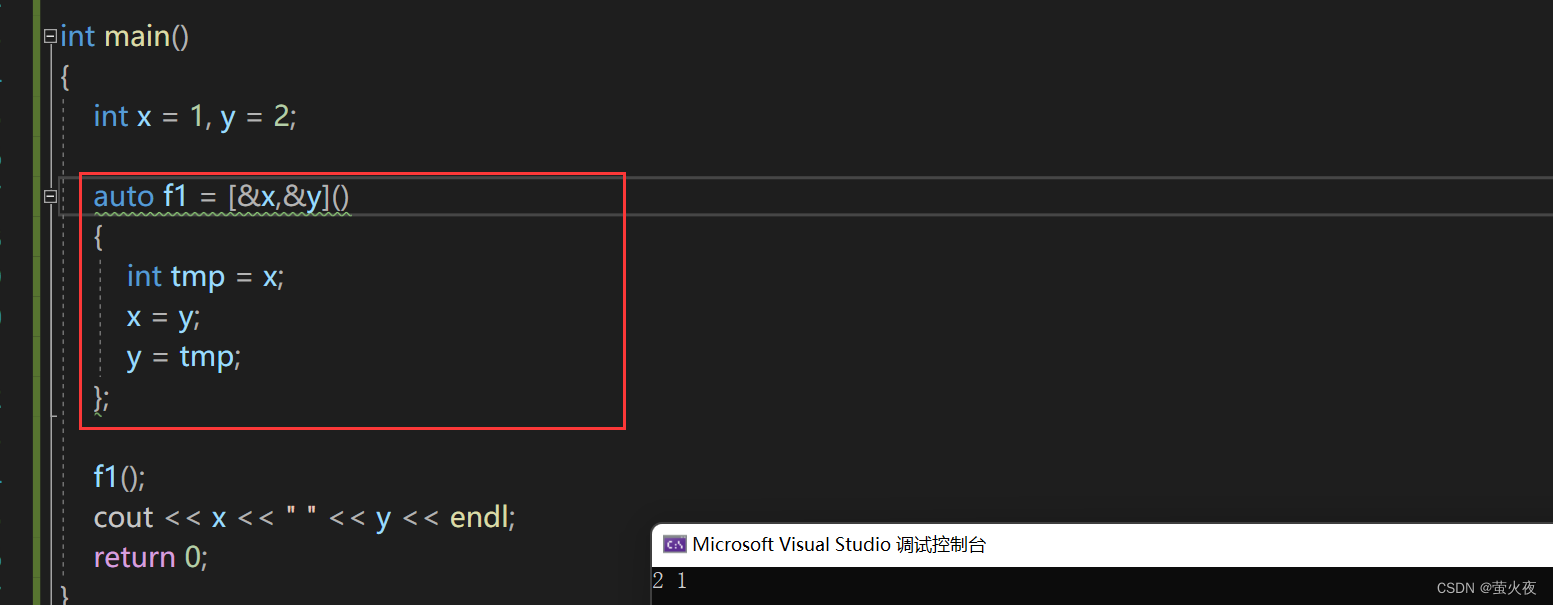
所以其实这里的mutable更多的针对传值捕捉的变量, 不希望修改传值捕捉的变量, 但传引用捕捉其实就是为了修改, 又上mutable感觉就有些重复, 所以const只是一个形象的说法, 可以理解为mutable是专门为了处理传值捕捉. 如果是传值捕捉和引用捕捉混合想要修改传值捕捉的变量还是要加mutable.
最开始的捕获说明部分有提到捕捉this, 捕捉this是什么?
class AA
{
public:void func(){auto f1 = [this](){cout << a1 << endl;cout << a2 << endl;};f1();}
private:int a1 = 1;int a2 = 1;
};int main()
{AA a;a.func();return 0;
}
直接用赋值符号捕捉也会默认捕捉this, 因为this实际也在父作用域中.
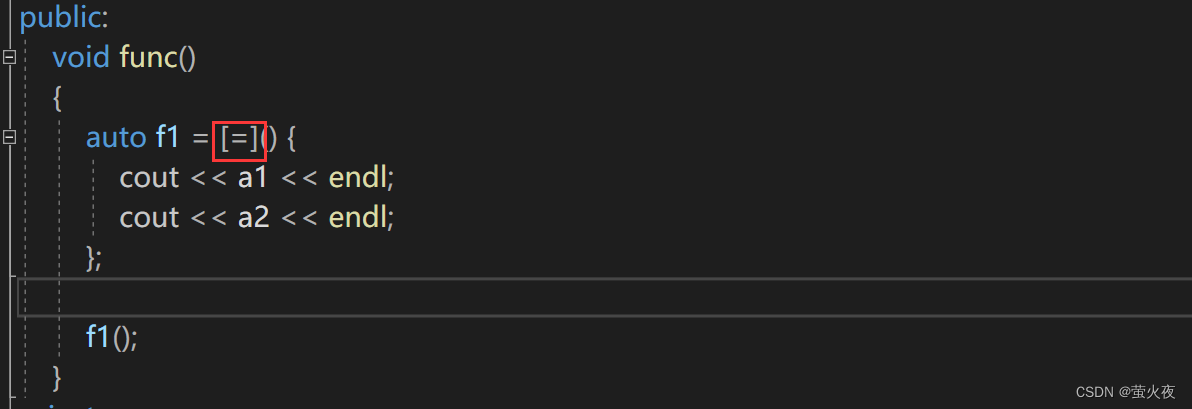 如果直接捕捉a1和a2呢? 可以看到报错了, 因为a1和a2并不在父作用域中, 而且还没有捕捉this指针, 也无法访问a1和a2, 因为类内访问成员变量默认都是通过this访问.
如果直接捕捉a1和a2呢? 可以看到报错了, 因为a1和a2并不在父作用域中, 而且还没有捕捉this指针, 也无法访问a1和a2, 因为类内访问成员变量默认都是通过this访问.
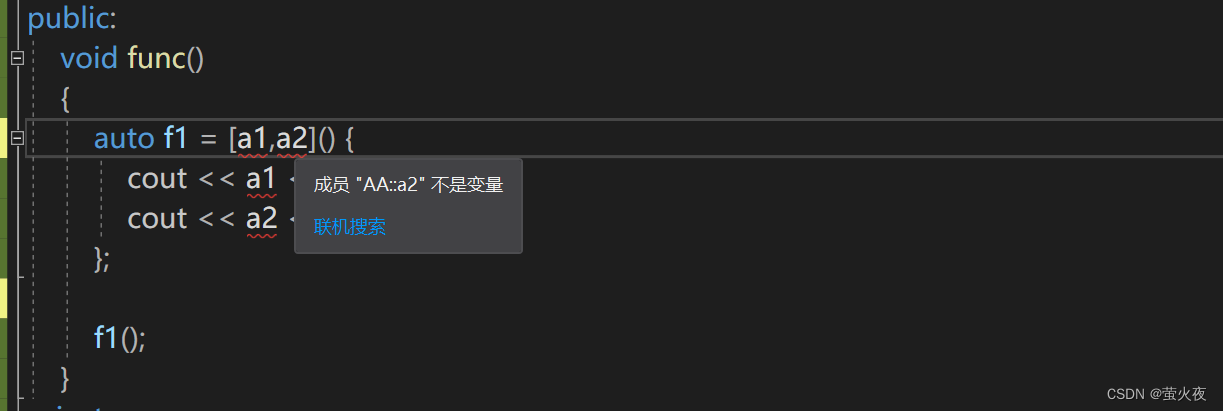

注意:
a. 父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成, 并以逗号分割. 比如:[=, &a, &b]: 以引用传递的方式捕捉变量a和b, 值传递方式捕捉其他所有变量
[&, a,this]: 值传递方式捕捉变量a和this, 引用方式捕捉其他变量.
c. 捕捉列表不允许变量重复传递, 否则就会导致编译错误. 比如:[=, a]:=已经以值传递方式捕捉了所有变量, 捕捉a重复.
d. 在块作用域以外的lambda函数捕捉列表必须为空.
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量, 捕捉任何非此作用域或者非局部变量都会导致编译报错.
f. lambda表达式之间不能相互赋值.
void (*PF)();
int main()
{auto f1 = [] {cout << "hello world" << endl; };auto f2 = [] {cout << "hello world" << endl; };//f1 = f2; // 编译失败--->提示找不到operator=()// 允许使用一个lambda表达式拷贝构造一个新的副本auto f3(f2);f3();// 可以将lambda表达式赋值给相同类型的函数指针PF = f2;PF();return 0;
}函数对象与lambda表达式
可以把lambda表达式的返回值类型打印出来看一看:

可以看到lambda的类型还是一个类, 它的具体名称是lambda+UUID, UUID叫作通用唯一识别码, 它的作用是让元素都能有唯一的辨识信息. 每个lambda都要生成一个的仿函数, 不同的仿函数对应的类型都应该不一样.小科普:通用唯一标识码UUID的介绍及使用 - 知乎 (zhihu.com)
从使用方式上来看, 函数对象与lambda表达式完全一样.
class Rate
{
public:Rate(double rate) : _rate(rate){}double operator()(double money, int year){return money * _rate * year;}
private:double _rate;
};int main()
{// 函数对象double rate = 0.49;Rate r1(rate);r1(10000, 2);// lambdaauto r2 = [=](double monty, int year)->double {return monty * rate * year;};r2(10000, 2);return 0;
}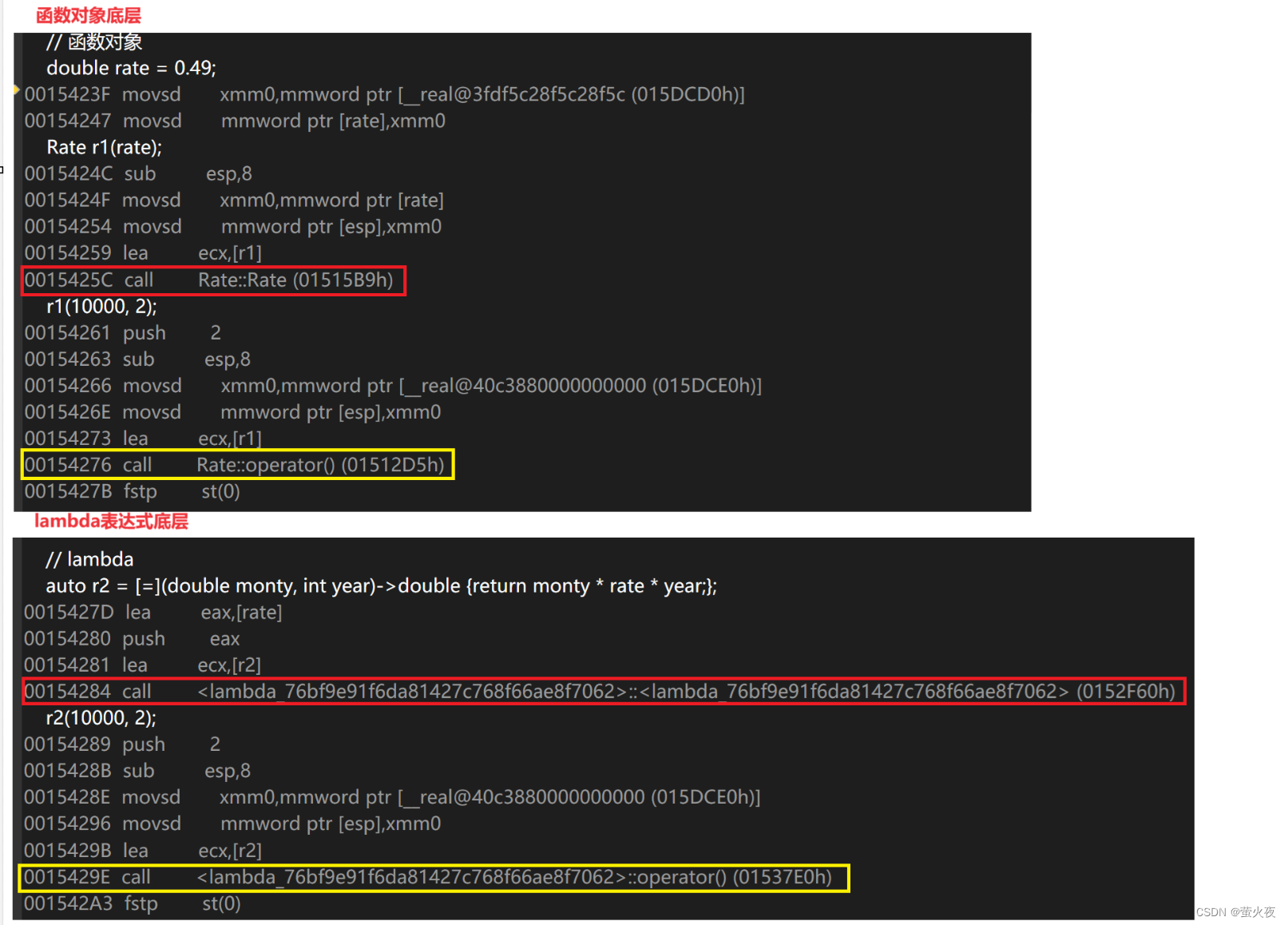
lambda真正到编译阶段就没有所谓的"lambda", 实际在底层编译器对于lambda表达式的处理方式, 完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式, 编译器会自动生成一个类, 在该类中重载了operator(), 说明lambda的底层其实还是仿函数, lambda传入的那些形参, 返回值, 函数体最终是传给了operator().
包装器
function包装器
function包装器, 也叫作适配器. C++中的function本质是一个类模板, 也是一个包装器.
那么我们来看看, 我们为什么需要function呢?
ret = func(x);上面func可能是什么呢, func可能是函数名?函数指针? 函数对象(仿函数对象)? lamber表达式对象? 这几个可调用对象其实各有自己的缺陷:
函数指针的缺点是类型写起来太复杂, 仿函数的缺点是用起来比较"重", 需要在外部定义一个类才能实现, 哪怕是简单的功能也要重新写一个类, 于是就有了lambda, 但是lambda它的类型完全是随机的, 虽然decltype可以取类型, 但是它的类型相对我们来说还是匿名的. 为了统一, 就出现了function包装器.

模板参数说明:
Ret: 被调用函数的返回类型
Args…: 被调用函数的形参
先分别用函数,仿函数,lambda表达式实现交换:
//函数
void Swap_func(int& r1, int& r2)
{int tmp = r1;r1 = r2;r2 = tmp;
}//仿函数
struct Swap
{void operator()(int& r1, int& r2){int tmp = r1;r1 = r2;r2 = tmp;}
};int main()
{//lambda表达式auto Swaplambda = [](int& r1, int& r2) {int tmp = r1;r1 = r2;r2 = tmp;};
}然后再用包装器分别对它们进行包装:
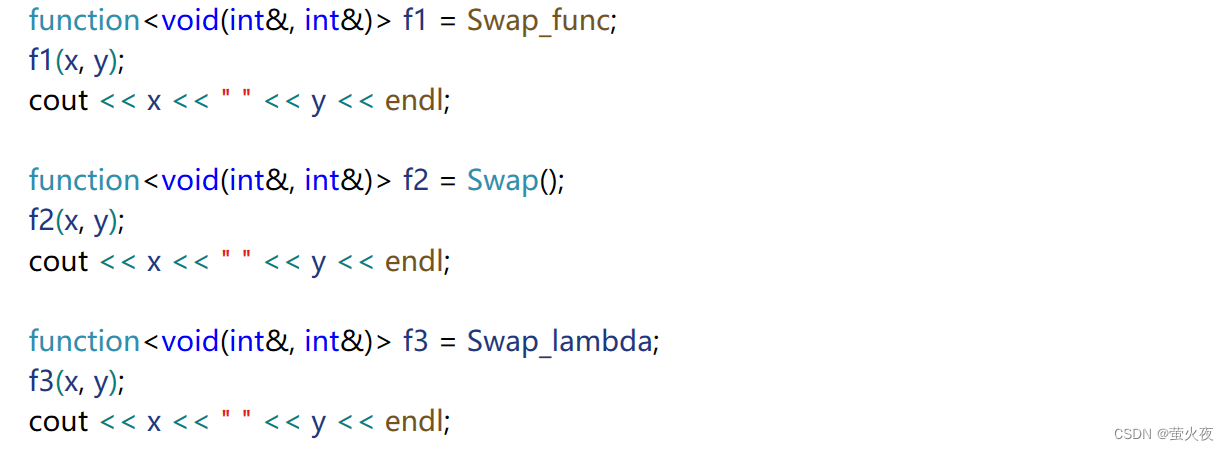

在此基础上就可以让function包装器与map的配合使用:
std::function和std::map可以很好地配合使用, 以实现基于字符串的事件处理程序或回调函数的映射. 具体来说, 可以将不同的字符串映射到不同的std::function对象上, 然后根据字符串查找相应的函数并调用它.
假设需要实现一个简单的命令行工具, 用户可以输入不同的命令, 然后程序会执行相应的操作, 可以使用std::map将不同的命令字符串映射到相应的std::function对象上, 然后在用户输入命令时查找相应的函数并调用它.

除此之外, 函数指针, 函数对象(仿函数对象), lamber表达式, 这些都是可调用的类型, 如此丰富的类型, 可能会导致模板的效率低下!
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}// 函数名
double f(double i)
{return i / 2;
}// 函数对象
struct Functor
{double operator()(double d){return d / 3;}
};int main()
{
// 函数名cout << useF(f, 11.11) << endl << endl;// 函数对象cout << useF(Functor(), 11.11) << endl << endl;// lamber表达式cout << useF([](double d)->double { return d / 4; }, 11.11) << endl << endl;return 0;
}我们知道static修饰的变量是存放在静态区的它不会随着函数的结束生命周期就终止, 所以我们每次调用函数的时候都可以看到它的值在不断的累加并且地址也是一样的.
但是如果模板实例化出来多个函数呢? 由于静态变量是在函数第一次运行的时候进行创建, 而如果模板实例化出来多个函数, 所以每个函数的静态成员变量地址就是不一样的:
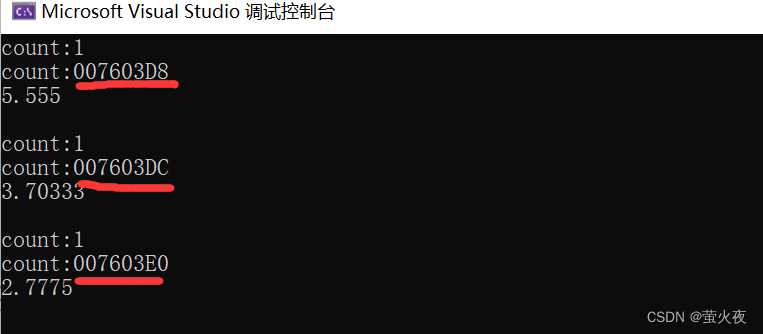
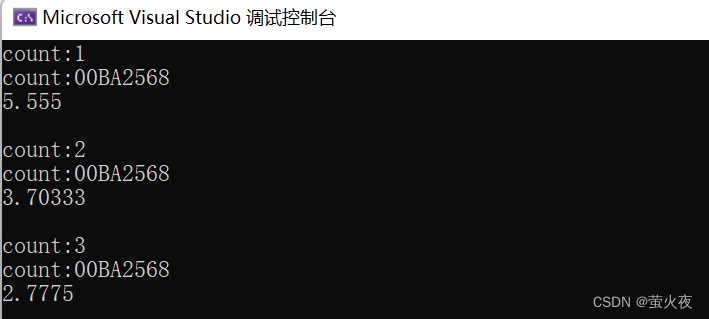
可以看到这里传递三个不同的对象过去, 并且函数模板也实例化出来了三个不同的函数对象, 但是这就有点浪费, 我们用包装器就可以将这三个类型的对象合成一个类型, 这样模板就只需要实例化出一个函数, 节省了很多资源.
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}// 函数名
double f(double i)
{return i / 2;
}// 函数对象
struct Functor
{double operator()(double d){return d / 3;}
};int main()
{
// 函数名function<double(double x)> f1 = f;cout << useF(f1, 11.11) << endl<<endl;// 函数对象function<double(double x)> f2 = Functor();cout << useF(f2, 11.11) << endl << endl;// lamber表达式function<double(double x)> f3 = [](double d)->double { return d / 4; };cout << useF(f3, 11.11) << endl << endl;return 0;
}
除此之外, 包装器还可以包装一些类的成员函数, 但是注意, 在包装类中函数的时候需要指定作用域, 并且如果包装的是非静态成员函数得在作用域的前面加上&, 如果是静态成员函数则加不加均可, 比如:
class Plus
{
public:static int plusi(int a, int b){return a + b;}double plusd(double a, double b){return a + b;}
};int main()
{// 成员函数取地址, 比较特殊, 要加一个类域和&//静态成员函数加不加&均可function<int(int, int)> f1 = Plus::plusi; function<int(int, int)> f1 =& Plus::plusi;cout << f1(1, 2) << endl;//非静态成员函数需要加&function<double(double, double)> f2 = &Plus::plusd;Plus ps;cout << f2(1.1, 2.2) << endl;return 0;
}但是这里依然编译不通过, 通过报错信息可以看到这里类型不匹配, 模板参数少了一个Plus*类型的参数:

类的成员函数还有一个默认的this指针需要传, 加上之后编译通过:

也可以这样:
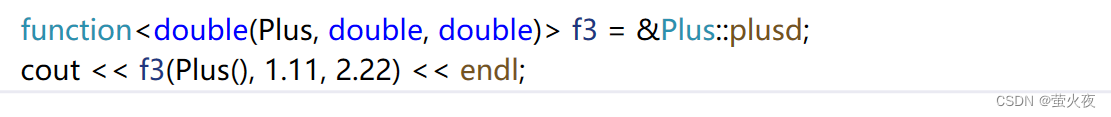

可以理解成传对象的指针就用对象的指针去调用函数指针, 传对象就用对象去调用函数指针.
第二种写法也更简洁, 不需要定义一个对象再取地址.
能不能每次不传这个第一个参数?
第一种方法我们可以创建一个该类型的对象, 然后通过lambda表达式来捕捉这个对象, 最后调用里面的函数来实现同样的功能, 那么这里的代码就如下:
int main()
{Plus plus;function<int(int, int)> f = [&plus](double x, double y)->double {return plus.plusd(x, y); };cout<<f(1.1, 2.2)<<endl;return 0;
}
第二种方法可以用bind
bind
std::bind函数定义在头文件中, 是一个函数模板, 它就像一个函数包装器(适配器), 接受一个可
调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表.
// 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);fn表示调用的对象, Args表示的就是调用对象的参数列表.
一般而言, bind有两个用途:
1.我们用它可以把一个原本接收N个参数的函数fn, 通过绑定一些参数, 返回一个接收M个参数的新函数(M一般小于N, M也可以大于N, 但这么做没什么意义).
2. 使用std::bind函数还可以实现参数顺序调整等操作.
可以将bind函数看作是一个通用的函数适配器, 它接受一个可调用对象, 生成一个新的可调用对
象来“适应”原对象的参数列表.
调用bind的一般形式: auto newCallable = bind(callable, arg_list);
其中, newCallable本身是一个可调用对象, arg_list是一个逗号分隔的参数列表, 对应给定的
callable的参数. 当我们调用newCallable时, newCallable会调用callable, 并传给它arg_list中
的参数.
arg_list中的参数可能包含形如_n的名字, 其中n是一个整数, 这些参数是“占位符”, 表示
newCallable的参数, 它们占据了传递给newCallable的参数的“位置”. 数值n表示生成的可调用对
象中参数的位置:_1为newCallable的第一个参数, _2为第二个参数, 以此类推.
int Sub(int a, int b)
{return a - b;
}int main()
{function<int(int, int)> f1 = Sub;cout << f1(10, 5) << endl;// 调整参数顺序, 第一个参数和第二个参数位置互换function<int(int, int)> f2 = bind(Sub, placeholders::_2, placeholders::_1);cout << f2(10, 5) << endl;// 调整参数个数,有些参数可以bind时写死function<int(int)> f3 = bind(Sub, 20, placeholders::_1);cout << f3(5) << endl;return 0;
}bind一般和function结合在一起进行使用, 后面的bind我们知道第一个参数表示的是需要绑定的函数对象, 那后面的placeholders::_1和placeholders::_2又代表的是什么意思呢?

可以看到placeholders是一个命名空间, 上面的bind表示的就是第二个位置传递给第一个参数, 第一个位置则传递给第二个参数.

之前的plus类可以试着把第一个参数绑定, 这样每次调用就不需要传一个对象了:

可以查看一下绑定之后的f3的类型:
int Sub(int a, int b)
{return a - b;
}int main()
{// 调整参数个数,有些参数可以bind时写死function<int(int)> f3 = bind(Sub, 20, placeholders::_1);cout <<"第一个参数绑定为20后: " << f3(5) << endl;cout << typeid(f3).name() << endl;return 0;
}
可以看到还是一个function的类型.
如果用auto接受bind的返回值:
int Sub(int a, int b)
{return a - b;
}int main()
{// 调整参数个数,有些参数可以bind时写死/*function<int(int)> f3 = bind(Sub, 20, placeholders::_1);*/auto f3 = bind(Sub, 20, placeholders::_1);cout <<"第一个参数绑定为20后: " << f3(5) << endl;cout << typeid(f3).name() << endl;return 0;
}
变成了bind对应的类型.
如果有多个参数能不能只绑定中间的参数呢?
void func(int a, int b, int c)
{cout << a << endl;cout << b << endl;cout << c << endl;
}int main()
{function<void(int, int)> f1 = bind(func, placeholders::_1, 100, placeholders::_2);f1(1, 3);return 0;
}
可以, 所以这里_1代表第一个实参, _2代表第二个实参, 这里原来func的第二个参数绑定了, 下一个参数不是_3, 而应该是_2, 对应着是绑定调用的时候的实参顺序.
相关文章:
C++11(下)
可变参数模板 C11的新特性可变参数模板能够创建可以接受可变参数的函数模板和类模板. 相比C98/03, 类模版和函数模版中只能含固定数量的模版参数, 可变模版参数无疑是一个巨大的改进, 然而由于可变模版参数比较抽象, 使用起来需要一定的技巧, 所以这块还是比较晦涩的.掌握一些基…...

深度学习与逻辑回归模型的融合--TensorFlow多元分类的高级应用
手写数字识别 文章目录 手写数字识别1、线性回归VS逻辑回归Sigmoid函数 2、逻辑回归的基本模型-神经网络模型3、多元分类基本模型4、TensorFlow实战解决手写数字识别问题准备数据集数据集划分 特征数据归一化归一化方法归一化场景 标签数据独热编码One-Hot编码构建模型损失函数…...

水库大坝安全监测参数与设备
智慧水利中,水库大坝的安全监测必不可少。做好水库大坝的安全监测,是确保水库大坝结构安全和预防灾害的重要手段。对于预防灾害、保护人民生命财产安全、优化工程管理、改进工程设计、保护环境资源和提高公众信任等方面有着重要的意义。 水利水库大坝安全…...

要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 22 章:情感分析提示
要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 22 章:情感分析提示 情感分析是一种可以让模型确定一段文字的情感基调或态度的技术,比如它是正面的、负面的还是中性的。 要在 ChatGPT 中使用情感分析提示,应向模型提…...

数据清洗、特征工程和数据可视化、数据挖掘与建模的主要内容
1.4 数据清洗、特征工程和数据可视化、数据挖掘与建模的内容 视频为《Python数据科学应用从入门到精通》张甜 杨维忠 清华大学出版社一书的随书赠送视频讲解1.4节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。内容涵盖数据科学…...

C++ STL容器与常用库函数
STL是提高C编写效率的一个利器 STL容器: 一、#include <vector> 英文翻译:vector :向量 vector是变长数组(动态变化),支持随机访问,不支持在任意位置O(1)插入。为了保证效率,元素的增删一般应该在末尾…...

Nmap脚本简介
什么是Nmap脚本 Nmap脚本是一种由Nmap扫描器使用的脚本语言,用于扫描目标网络中的主机、端口、服务等信息,并提供一系列自动化的测试和攻击功能。从渗透测试工程师的角度来看,Nmap脚本是一种非常有用的工具,能够帮助渗透测试工程师…...
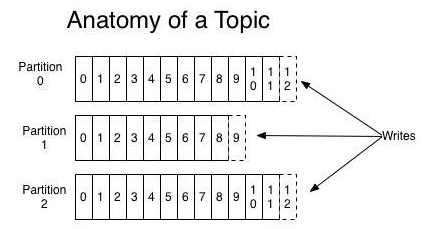
Kafka -- 初识
目录 kafka是什么 Topic Partition Broker Cousumer CousumerGroup Offset reblance broker 消息存储 Isr kafka是什么 Kafka 是一个分布式的消息引擎,能够发布和订阅消息流(类似于消息队列) 以容错的、持久的方式存储消息流 多分区…...

玩转Sass:掌握数据类型!
当我们在进行前端开发的时候,有时候需要使用一些不同的数据类型来处理样式,Sass 提供的这些数据类型可以帮助我们更高效地进行样式开发,本篇文章将为您详细介绍 Sass 中的数据类型。 布尔类型 在 Sass 中,布尔数据类型可以表示逻…...

Django + Matplotlib:实现数据分析显示与下载为PDF或SVG
写作背景 首先,数据分析在当前的信息时代中扮演着重要的角色。随着数据量的增加和复杂性的提高,人们对于数据分析的需求也越来越高。 其次,笔者也确确实实曾经接到过一个这样的开发需求,甲方是一个医疗方面的科研团队࿰…...

【Rust】第一节:安装
1 说明 一些学习记录 环境:MacOS 2 步骤 1、执行curl --proto https --tlsv1.2 https://sh.rustup.rs -sSf | sh 2、看到打印 info: downloading installerWelcome to Rust!... ...This path will then be added to your PATH environment variable by modifyin…...
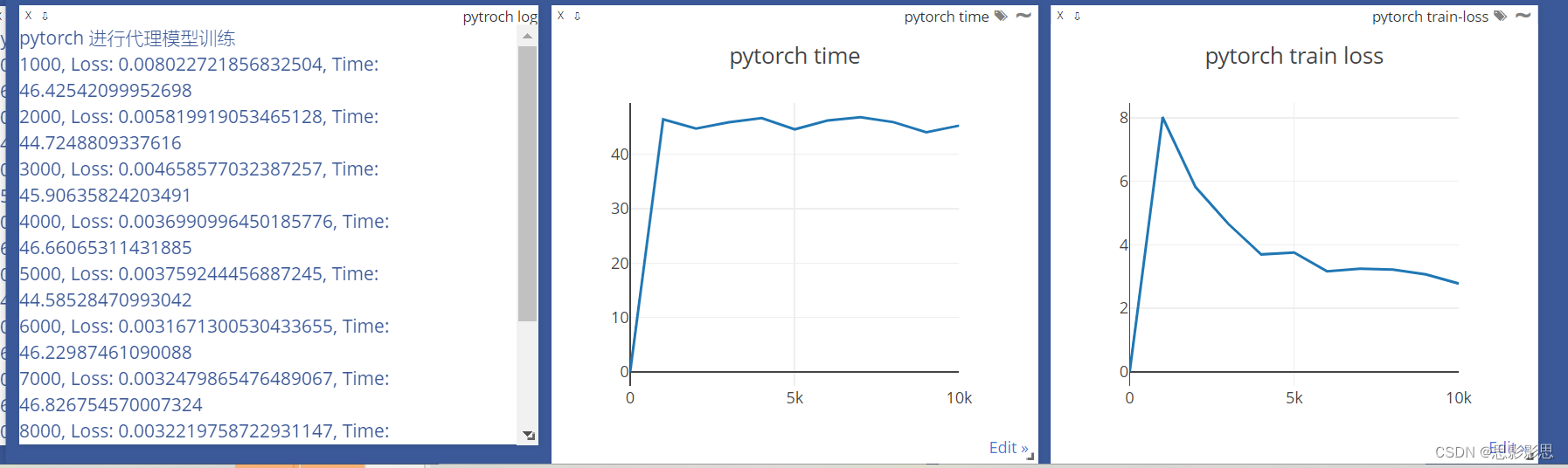
12-07 周四 Pytorch 使用Visdom 进行可视化
简介 在完成了龙良曲的Pytroch视频课程之后,楼主对于pytroch有了进一步的理解,比如,比之前更加深刻的了解了BP神经网络的反向传播算法,梯度、损失、优化器这些名词更加熟悉。这个博客简要介绍一下在使用Pytorch进行数据可视化的一…...

基于微信小程序的智慧校园导航系统研究
点我下载完整版 基于微信小程序的智慧校园导航系统研究 Research on Smart Campus Navigation System based on WeChat mini program 目录 目录 2 摘要 3 关键词 4 第一章 研究背景与意义 4 1.1 校园导航系统研究的背景 4 1.2 微信小程序在校园导航系统中的应用 5 1.3 研究的目…...

VUE3给table的head添加popover筛选、时间去除时分秒、字符串替换某字符
1. VUE3给table的head添加popover筛选 <el-tableref"processTableRef"class"process-table"row-key"secuId":data"pagingData"style"width: 100%"highlight-current-row:height"stockListHeight":default-exp…...

19、XSS——HTTP协议安全
文章目录 一、Weak Session IDs(弱会话IDs)二、HTTP协议存在的安全问题三、HTTPS协议3.1 HTTP和HTTPS的区别3.2 SSL协议组成 一、Weak Session IDs(弱会话IDs) 当用户登录后,在服务器就会创建一个会话(Session),叫做会话控制&…...

深圳锐杰金融:用金融力量守护社区健康
深圳市锐杰金融投资有限公司,作为中国经济特区的中流砥柱,近年来以其杰出的金融成绩和坚定的社会责任立场引人注目。然而,这并非一个寻常的金融机构。锐杰金融正在用自己的方式诠释企业责任和慈善精神,通过一系列独特的慈善项目&a…...

python对py文件加密
参考文献: 【编程技巧】py文件批量编译,py批量转pyd,PyCharm设置py转pyd功能_py文件编译pyd-CSDN博客 【Python小技巧】加密又提速,把.py文件编译为.pyd文件(类似dll函数库),你值得拥有&#x…...
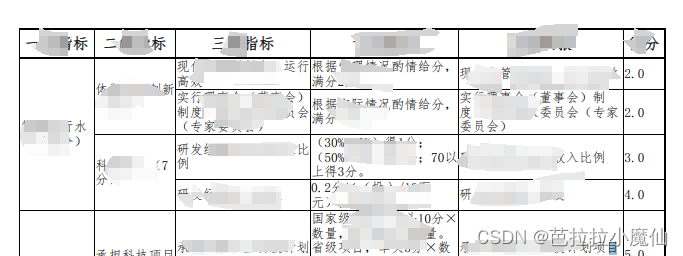
Thymeleaf生成pdf表格合并单元格描边不显示
生成pdf后左侧第一列的右描边不显示,但是html显示正常 显示异常时描边的写法 cellpadding“0” cellspacing“0” ,td,th描边 .self-table{border:1px solid #000;border-collapse: collapse;width:100%}.self-table th{font-size:12px;border:1px sol…...
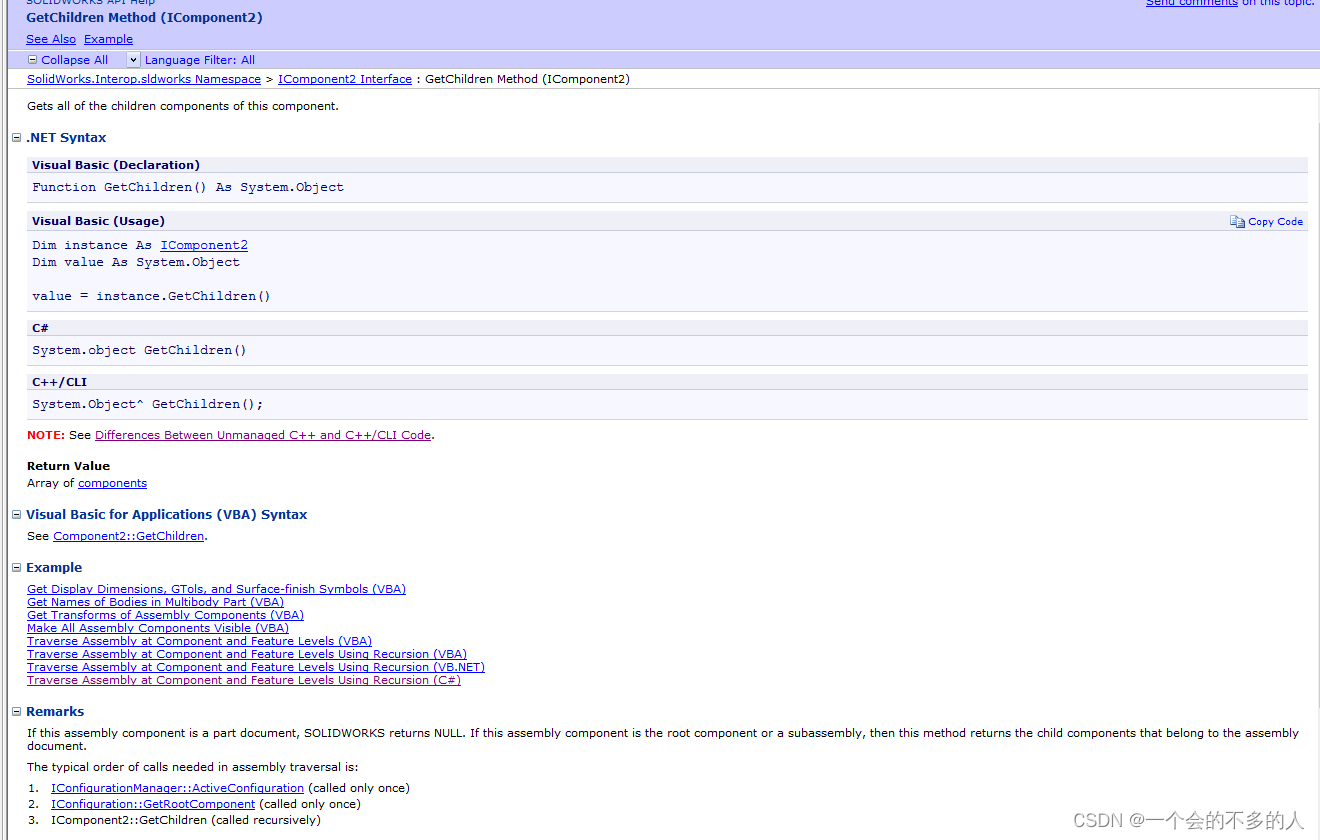
C# Solidworks二次开发:三种获取SW设计结构树的方法-第二讲
今天这篇文章是接上一篇文章的,主要讲述的是获取SW设计结构树节点的第二种方法。 这个方法获取节点的逻辑是先获取最顶层节点,然后再通过获取顶层节点的子节点一层一层的把所有节点都找出来,也就是需要递归。想要用这个方法就要了解下面几个…...
分布式搜索引擎03
1.数据聚合 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如: 什么品牌的手机最受欢迎? 这些手机的平均价格、最高价格、最低价格? 这些手机每月的销售情况如何? 实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近…...

RAG实战解析:如何通过检索增强生成提升知识密集型NLP任务性能
1. RAG技术为什么能改变知识密集型NLP任务格局 第一次听说RAG(Retrieval-Augmented Generation)这个概念时,我正被一个开放域问答项目折磨得焦头烂额。当时我们用纯BART模型生成的答案总是出现事实性错误,比如把"特斯拉创始人…...

Go语言中的工具链:从go build到go generate
Go语言中的工具链:从go build到go generate 前言 作为一个在小厂挣扎的Go后端老兵,我对工具链的理解就一句话:能自动化的绝不手动。 想当年在大厂时,工具链那叫一个完善,从代码编译到部署上线,全程自动化。…...

基于uniapp的SUPOIN PDA激光扫码广播监听功能实现与优化
1. 为什么选择SUPOIN PDA激光扫码方案 在工业级移动应用中,扫码功能可以说是刚需中的刚需。我做过不少仓库管理、物流配送的项目,深刻体会到扫码速度差个0.5秒,工人一天下来就能多处理上百件货物。SUPOIN PDA设备自带的激光扫码模块…...

别再只盯着YOLOv5了!聊聊FPN、PANet这些‘特征融合’老将如何帮你搞定小目标检测
小目标检测实战:FPN与PANet如何突破YOLO系列的性能瓶颈 在工业质检项目中,我们团队曾遇到一个典型问题:使用YOLOv5s模型检测电路板元件时,虽然大尺寸的电容电阻识别准确率超过95%,但0402封装的微型贴片元件(…...

在macOS上利用PyInstaller为Windows生成exe文件的3种实用方法
1. 为什么macOS不能直接生成Windows的exe文件? 很多刚开始接触Python打包的开发者都会遇到一个头疼的问题:明明在macOS上写好的脚本,用PyInstaller打包后却不能在Windows电脑上运行。这其实和PyInstaller的工作原理有关——它需要访问目标平…...

AI 模型推理性能瓶颈与优化方向
AI模型推理性能瓶颈与优化方向 随着AI技术在各行业的广泛应用,模型推理性能成为影响落地效果的关键因素。无论是实时交互场景还是大规模数据处理,推理效率直接决定了用户体验和成本控制。受限于计算资源、算法复杂度及硬件适配性等因素,AI模…...

3分钟上手!FrankMocap让普通摄像头变身专业动捕设备
3分钟上手!FrankMocap让普通摄像头变身专业动捕设备 【免费下载链接】frankmocap A Strong and Easy-to-use Single View 3D HandBody Pose Estimator 项目地址: https://gitcode.com/gh_mirrors/fr/frankmocap 在数字内容创作与交互设计领域,3D动…...

DAMOYOLO-S与数据库联动:检测结果实时入库与查询
DAMOYOLO-S与数据库联动:检测结果实时入库与查询 你有没有想过,当AI模型在摄像头前“看到”一个人、一辆车时,这些信息除了在屏幕上显示一下,还能做什么?如果这些“看见”的瞬间——谁、在哪儿、什么时候、有多确定—…...
)
用Python和C语言两种解法,搞定ZZULIOJ 1091‘爬楼梯’问题(附多实例测试详解)
用Python和C语言两种解法,搞定ZZULIOJ 1091‘爬楼梯’问题(附多实例测试详解) 当你第一次看到这个题目时,可能会觉得它只是一个简单的递归问题。但深入思考后会发现,这实际上是动态规划的经典案例——斐波那契数列的变…...

本地部署 LookScanned:轻松将 PDF 转为逼真扫描件,结合内网穿透实现远程访问
前言 本文主要介绍了 LookScanned 这款工具的部署与使用方法。LookScanned 可将普通电子 PDF 转换为高度逼真的纸质扫描件效果,全程本地处理保障隐私,操作简单且无需打印扫描的物理步骤。 文中详细讲解了在极空间通过 Docker 部署 LookScanned 的流程&…...