C++ STL容器与常用库函数
STL是提高C++编写效率的一个利器
STL容器:
一、#include <vector>
英文翻译:vector :向量
vector是变长数组(动态变化),支持随机访问,不支持在任意位置O(1)插入。为了保证效率,元素的增删一般应该在末尾进行。
声明
#include<vector> 头文件
vector<int>a; 相当于一个长度动态变化的int数组
vector<int>b[233]; 相当于第一维长233,第二位长度动态变化的int数组
struct rec{…};
vector<rec>c; 自定义的结构体类型也可以保存在vector中
size/empty
size函数返回vector的实际长度(包含的元素个数),empty函数返回一个bool类型,表明vector是否为空。二者的时间复杂度都是O(1)。
所有的STL容器都支持这两个方法,含义也相同。
clear
clear函数把vector清空。
front/back
front函数返回vector的第一个元素,等价于*a.begin() 和 a[0]。
back函数返回vector的最后一个元素,等价于*==a.end() 和 a[a.size() – 1]。
push_back() 和pop_back()
a.push_back(x) 把元素x插入到vector a的尾部。
b.pop_back()删除vector a的最后一个元素。
#include<iostream>
#include<vector>
using namespace std;int main()
{vector<int> a; //相当于一个长度动态变化的int数组vector<int> b[233]; //相当于第一维长233,第二位长度动态变化的int数组a.size(); //函数返回vector的实际长度(包含的元素个数)a.empty(); //函数返回一个bool类型,表明vector是否为空。a.clear(); //clear函数把vector清空struct rec{int a;double b;};vector<rec> c; //自定义的结构体类型也可以保存在vector中vector<int> d({1,2,3});cout<<d.front()<<" "<<d[0]<<" "<<endl;cout<<d.back()<<" "<<d[d.size()-1]<<" "<<endl;d.push_back(4);for(auto x:d)cout<<x<<" ";//把元素x插入到vector a的尾部。cout<<endl;d.pop_back();for(auto x:d)cout<<x<<" ";//删除vector a的最后一个元素。cout<<endl;return 0;
}二、#include <queue>
英文翻译:queue :队列
头文件queue主要包括循环队列(先进先出)
queue和优先队列priority_queue两个容器。
声明
queue<int>q;//队列
structrec{…}; queue<rec> q; //结构体rec中必须定义小于号
priority_queue<int>q; // 大根堆
priority_queue<int,vector<int>, greater<int> q; //小根堆
priority_queue<pair<int,int>>q; //小根堆
循环队列 queue
push从队尾插入
pop从队头弹出
front返回队头元素
back返回队尾元素
优先队列 priority_queue(堆)
**默认为大根堆
push把元素插入堆
pop删除堆顶元素
top 查询堆顶元素(最大值)
#include<iostream>
#include<queue>
using namespace std;int main()
{queue<int> q;//队列queue<double> q1;struct rec{int a,b;bool operator< (const rec& t)const{return a<t.a;}}; queue<rec> q2; //结构体rec中必须定义小于号priority_queue<int> q3; // 大根堆priority_queue<int, vector<int>, greater<int>>q4; // 小根堆priority_queue<pair<int, int>>q5;queue<int> s;//队列s.push(1); //从队尾插入s.pop(); //从队头弹出s.front(); //返回队头元素s.back(); //返回队尾元素priority_queue<int> s1;s1.push(1); //把元素插入堆s1.pop(); //删除堆顶元素s1.top(); //查询堆顶元素(最大值)s1.push(-x); //按小根堆插入return 0;
}三、#include <stack>
英文翻译:stack :堆栈
头文件stack包含栈。声明和前面的容器类似。
push 向栈顶插入
pop 弹出栈顶元素
#include<iostream>
#include<stack>
using namespace std;int main()
{stack<int>stk;stk.push(1);//向栈顶插入元素stk.pop(); //弹出栈顶元素stk.top(); //查询栈顶元素(最大值)return 0;
}四、#include <deque>
双端队列deque是一个支持在两端高效插入或删除元素的连续线性存储空间。它就像是vector和queue的结合。与vector相比,deque在头部增删元素仅需要O(1)的时间;与queue相比,deque像数组一样支持随机访问。
[] 随机访问
front/back 队头/队尾元素
push_back 从队尾入队
push_front 从队头入队
pop_back 从队尾出队
pop_front 从队头出队
clear 清空队列
#include<iostream>
#include<deque>
using namespace std;int main()
{deque<int>a;a[0]; //随机访问a.front(); a.back();//队头/队尾元素a.push_back(1); //从队尾入队a.push_front(2); //从队头入队a.pop_back(); //从队尾出队a.pop_front(); //从队头出队a.clear(); //清空队列return 0;
}五、#include <set>
英文翻译: set :集
头文件set主要包括set和multiset两个容器,分别是“有序集合”和“有序多重集合”,即前者的元素不能重复,而后者可以包含若干个相等的元素。set和multiset的内部实现是一棵红黑树,它们支持的函数基本相同。
声明
set<int> s;
struct rec{…}; set<rec> s; //结构体rec中必须定义小于号
multiset<double> s;
size/empty/clear
与vector类似
insert
s.insert(x)把一个元素x插入到集合s中,时间复杂度为O(logn)。
在set中,若元素已存在,则不会重复插入该元素,对集合的状态无影响。
find
s.find(x) 在集合s中查找等于x的元素,并返回指向该元素的迭代器。
若不存在,则返回s.end()。时间复杂度为O(logn)。
lower_bound/upper_bound
这两个函数的用法与find类似,但查找的条件略有不同,时间复杂度为 O(logn)。
s.lower_bound(x) 查找大于等于x的元素中最小的一个,并返回指向该元素的迭代器。
s.upper_bound(x) 查找大于x的元素中最小的一个,并返回指向该元素的迭代器。
count
s.count(x)返回集合s中等于x的元素个数,时间复杂度为 O(k +logn),其中k为元素x的个数。
#include<iostream>
#include<set>
using namespace std;int main()
{set<int>a;//元素不能重复multiset<int>b;//元素可以重复int x;a.insert(x);//把一个元素x插入到集合x中if(a.find(x)==a.end())//判断x是否存在于x中a.lower_bound(x);//查找大于等于x的元素中最小的一个a.upper_bound(x);//查找大于x的元素中最小的一个b.count(x);//返回集合b中等于x的元素个数return 0;
}六、#include <map>
#include<unordered_map>
英文翻译: map:地图
map容器是一个键值对key-value的映射,其内部实现是一棵以key为关键码的红黑树。Map的key和value可以是任意类型,其中key必须定义小于号运算符。
声明
map<key_type,value_type> name;
例如:
map<long,long, bool> vis;
map<string,int> hash;
map<pair<int,int>, vector<int>> test;
size/empty/clear/begin/end
均与set类似。
Insert/erase
与set类似,但其参数均是pair<key_type, value_type>。
find
h.find(x)在变量名为h的map中查找key为x的二元组。
[]操作符
h[key]返回key映射的value的引用,时间复杂度为O(logn)。
[]操作符是map最吸引人的地方。我们可以很方便地通过h[key]来得到key对应的value,还可以对h[key]进行赋值操作,改变key对应的value。
#include<iostream>
#include<map>
#include<vector>
using namespace std;int main()
{//相当于数组map<int,int>a;a[10000]=8;cout<<a[10000]<<endl;//和数组的区别(可以随便定义数组类型,包括下标)map<string,int>b;b["zyq"]=9;cout<<b["zyq"]<<endl;map<string,vector<int>>c;c["zyq"]=vector<int>({1,2,3,4,5,6});cout<<c["zyq"][2]<<endl;c.insert({"b",{10}});cout<<(c.find("b")==c.end())<<endl;//输出0为存在,输出1为不存在return 0;
}map和unordered_map的区别
一.头文件不同,分别是:
#include<map>
#include<unordered_map>
二.其实现不同
map:其实现是使用了红黑树
unordered_map:其实现使用的是哈希表
三.特点
map:
1.元素有序,并且具有自动排序的功能(因为红黑树具有自动排序的功能)
2.元素按照二叉搜索树存储的,也就是说,其左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值,使用中序遍历可将键值按照从小到大遍历出来
3.空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
4.适用情况:对顺序有要求的情况下,如排序等
unordered_map:
-
元素无序。
-
查找速度非常的快。
-
哈希表的建立比较耗费时间
-
适用情况:对于查找问题
-
对于unordered_map或者unordered_set容器,其遍历顺序与创建该容器时输入元素的顺序是不一定一致的,遍历是按照哈希表从前往后依次遍历的
七、#include<string>
1.size/empty/clear/begin/end
string均可以用
2.substr();
返回字符串长度
#include<bits/stdc++.h>using namespace std;int main()
{string a="abnd";a+="hdush";//a="abndhdush"a+='z';//a="abndhdushz"//从第1个(起始点在0)位置开始,输出3个字符cout<<a.substr(1,3);//bndcout<<endl;//输出从4开始的整个子串cout<<a.substr(4);//hdushzreturn 0;
}八、位运算
& 与
| 或
~ 非
^ 异或
>> 右移
<< 左移
常用操作:
-
求x的第k位数字 x >> k & 1
-
lowbit(x) = x & -x,返回x的最后一位1
九、总结:
vector, 变长数组,倍增的思想size() 返回元素个数empty() 返回是否为空clear() 清空front()/back()push_back()/pop_back()begin()/end()[]支持比较运算,按字典序pair<int, int>first, 第一个元素second, 第二个元素支持比较运算,以first为第一关键字,以second为第二关键字(字典序)string,字符串size()/length() 返回字符串长度empty()clear()substr(起始下标,(子串长度)) 返回子串c_str() 返回字符串所在字符数组的起始地址queue, 队列size()empty()push() 向队尾插入一个元素front() 返回队头元素back() 返回队尾元素pop() 弹出队头元素priority_queue, 优先队列,默认是大根堆size()empty()push() 插入一个元素top() 返回堆顶元素pop() 弹出堆顶元素定义成小根堆的方式:priority_queue<int, vector<int>, greater<int>> q;也可以使用push(-x) 变成一个小根堆stack, 栈size()empty()push() 向栈顶插入一个元素top() 返回栈顶元素pop() 弹出栈顶元素deque, 双端队列size()empty()clear()front()/back()push_back()/pop_back()push_front()/pop_front()begin()/end()[]set, map, multiset, multimap, 基于平衡二叉树(红黑树),动态维护有序序列size()empty()clear()begin()/end()++, -- 返回前驱和后继,时间复杂度 O(logn)set/multisetinsert() 插入一个数find() 查找一个数count() 返回某一个数的个数erase()(1) 输入是一个数x,删除所有x O(k + logn)(2) 输入一个迭代器,删除这个迭代器lower_bound()/upper_bound()lower_bound(x) 返回大于等于x的最小的数的迭代器upper_bound(x) 返回大于x的最小的数的迭代器map/multimapinsert() 插入的数是一个pairerase() 输入的参数是pair或者迭代器find()[] 注意multimap不支持此操作。 时间复杂度是 O(logn)lower_bound()/upper_bound()unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表和上面类似,增删改查的时间复杂度是 O(1)不支持 lower_bound()/upper_bound(), 迭代器的++,--bitset, 圧位bitset<10000> s;~, &, |, ^>>, <<==, !=[]count() 返回有多少个1any() 判断是否至少有一个1none() 判断是否全为0set() 把所有位置成1set(k, v) 将第k位变成vreset() 把所有位变成0flip() 等价于~flip(k) 把第k位取反
常用库函数
C++帮我们实现好了很多有用的函数,我们要避免重复造轮子
#include<algorithm>算法库
reverse 翻转(十星重要度)
翻转一个vector:
reverse(a.begin(), a.end());
翻转一个数组,元素存放在下标1~n:
reverse(a + 1, a + 1 + n);
cout<<"*****vector翻转*******"<<endl;vector<int> a({1,2,3,4,5});reverse(a.begin(),a.end());for(int x:a)cout<<x<<" ";cout<<endl;cout<<"*****数组翻转**********"<<endl;int b[]={1,2,3,4,5};reverse(b,b+5);for(int y:b)cout<<y<<" ";cout<<endl;
unique 去重
返回去重之后的尾迭代器(或指针),仍然为前闭后开,即这个迭代器是去重之后末尾元素的下一个位置。该函数常用于离散化,利用迭代器(或指针)的减法,可计算出去重后的元素个数。
把一个vector去重:
int m = unique(a.begin(), a.end()) – a.begin();
把一个数组去重,元素存放在下标1~n:
int m = unique(a + 1, a + 1 + n) – (a + 1);
cout<<"*****vector去重**********"<<endl;vector<int> a1({1,1,2,2,3,3,4,5,8,8,8,8,8,8});int n=unique(a1.begin(),a1.end())-a1.begin();cout<<"去掉重复数剩余:"<<n<<endl;for(int i=0;i<n;i++)cout<<a1[i]<<" ";cout<<endl;cout<<"*****数组去重**********"<<endl;int b1[]={1,1,2,2,3,3,4,5,8,8,8,8,8,8};int m=unique(b1,b1+14)-b1;cout<<"去掉重复数剩余:"<<m<<endl;for(int i=0;i<m;i++)cout<<b1[i]<<" ";cout<<endl;
random_shuffle 随机打乱
用法与reverse相同
cout<<"*****生成随机数*********"<<endl;vector<int> c({1,1,2,8,5,8});srand((time(0)));//需要生成随机数random_shuffle(c.begin(),c.end());for(int q:c)cout<<q<<" ";cout<<endl;
sort(十星重要度)
对两个迭代器(或指针)指定的部分进行快速排序。可以在第三个参数传入定义大小比较的函数,或者重载“小于号”运算符。
把一个int数组(元素存放在下标1~n)从大到小排序,传入比较函数:
int a[MAX_SIZE];
bool cmp(int a, int b) {return a > b; }
sort(a + 1, a + 1 + n, cmp);
把自定义的结构体vector排序,重载“小于号”运算符:
方法一:
struct rec{ int id, x, y; }
vector<rec> a;
bool operator <(const rec &a, const rec &b) {
return a.x < b.x ||a.x == b.x && a.y < b.y;
}
sort(a.begin(), a.end());
方法二:(推荐)
struct rep
{
int x,y;
}r[5];
//结构体的比较函数
bool cmp1(rep a,rep b) //自己决定如何排序
{
return a.x<a.y;//这里决定sort排序是升序还是降序
}
//定义的结构体
struct rep
{int x,y;
}r[5];
//结构体的比较函数
bool cmp1(rep a,rep b) //自己决定如何排序
{return a.x<a.y;//这里决定sort排序是升序还是降序
}//数组的比较函数
bool cmp(int a,int b) //自己决定如何排序
{return a>b;//这里决定sort排序是升序还是降序
}
cout<<"*****随机数排序*********"<<endl;sort(c.begin(),c.end(),cmp);for(int q1:c)cout<<q1<<" ";cout<<endl;cout<<"*****结构体排序*********"<<endl;for(int i=0;i<5;i++){r[i].x=-i;r[i].y=i;}cout<<"排序前结构体"<<endl;for(int i=0;i<5;i++)printf("(%d,%d) ",r[i].x,r[i].y);cout<<endl;sort(r,r+5,cmp1);cout<<"排序后结构体"<<endl;for(int i=0;i<5;i++)printf("(%d,%d) ",r[i].x,r[i].y);
lower_bound/upper_bound 二分
lower_bound 的第三个参数传入一个元素x,在两个迭代器(指针)指定的部分上执行二分查找,返回指向第一个大于等于x的元素的位置的迭代器(指针)。
upper_bound 的用法和lower_bound大致相同,唯一的区别是查找第一个大于x的元素。当然,两个迭代器(指针)指定的部分应该是提前排好序的。
在有序int数组(元素存放在下标1~n)中查找大于等于x的最小整数的下标:
int I = lower_bound(a + 1, a + 1 + n,. x) – a;
在有序vector<int> 中查找小于等于x的最大整数(假设一定存在):
int y = *--upper_bound(a.begin(), a.end(), x);
cout<<"********二分查找*********"<<endl;cout<<"大于等于x的最小整数:"<<endl;int x[]={1,2,3,4,5,6,9,10};int* p=lower_bound(x,x+7,6);cout<<"查找到的值为:"<<*p<<endl;int l=*p=lower_bound(x,x+7,10)-x;cout<<"大于等于x的最小整数下标:"<<l<<endl<<endl;cout<<"小于等于x的最大整数"<<endl;int* q=upper_bound(x,x+7,4);cout<<"查找到的值为:"<<*q<<endl;int t=*p=upper_bound(x,x+7,4)-x;cout<<"小于等于x的最大整数下标:"<<t<<endl;
全部代码段
#include<iostream>
#include<algorithm>
#include<vector>
#include<ctime>
#include<cstdio>using namespace std;struct rep
{int x,y;
}r[5];
//结构体的比较函数
bool cmp1(rep a,rep b) //自己决定如何排序
{return a.x<a.y;//这里决定sort排序是升序还是降序
}//数组的比较函数
bool cmp(int a,int b) //自己决定如何排序
{return a>b;//这里决定sort排序是升序还是降序
}int main()
{cout<<"*****vector翻转*******"<<endl;vector<int> a({1,2,3,4,5});reverse(a.begin(),a.end());for(int x:a)cout<<x<<" ";cout<<endl;cout<<"*****数组翻转**********"<<endl;int b[]={1,2,3,4,5};reverse(b,b+5);for(int y:b)cout<<y<<" ";cout<<endl;cout<<"*****vector去重**********"<<endl;vector<int> a1({1,1,2,2,3,3,4,5,8,8,8,8,8,8});int n=unique(a1.begin(),a1.end())-a1.begin();cout<<"去掉重复数剩余:"<<n<<endl;for(int i=0;i<n;i++)cout<<a1[i]<<" ";cout<<endl;cout<<"*****数组去重**********"<<endl;int b1[]={1,1,2,2,3,3,4,5,8,8,8,8,8,8};int m=unique(b1,b1+14)-b1;cout<<"去掉重复数剩余:"<<m<<endl;for(int i=0;i<m;i++)cout<<b1[i]<<" ";cout<<endl;cout<<"*****生成随机数*********"<<endl;vector<int> c({1,1,2,8,5,8});srand((time(0)));//需要生成随机数random_shuffle(c.begin(),c.end());for(int q:c)cout<<q<<" ";cout<<endl;cout<<"*****随机数排序*********"<<endl;sort(c.begin(),c.end(),cmp);for(int q1:c)cout<<q1<<" ";cout<<endl;cout<<"*****结构体排序*********"<<endl;for(int i=0;i<5;i++){r[i].x=-i;r[i].y=i;}cout<<"排序前结构体"<<endl;for(int i=0;i<5;i++)printf("(%d,%d) ",r[i].x,r[i].y);cout<<endl;sort(r,r+5,cmp1);cout<<"排序后结构体"<<endl;for(int i=0;i<5;i++)printf("(%d,%d) ",r[i].x,r[i].y);cout<<endl;cout<<"********二分查找*********"<<endl;cout<<"大于等于x的最小整数:"<<endl;int x[]={1,2,3,4,5,6,9,10};int* p=lower_bound(x,x+7,6);cout<<"查找到的值为:"<<*p<<endl;int l=*p=lower_bound(x,x+7,10)-x;cout<<"大于等于x的最小整数下标:"<<l<<endl<<endl;cout<<"小于等于x的最大整数"<<endl;int* q=upper_bound(x,x+7,4);cout<<"查找到的值为:"<<*q<<endl;int t=*p=upper_bound(x,x+7,4)-x;cout<<"小于等于x的最大整数下标:"<<t<<endl;return 0;
}
相关文章:
C++ STL容器与常用库函数
STL是提高C编写效率的一个利器 STL容器: 一、#include <vector> 英文翻译:vector :向量 vector是变长数组(动态变化),支持随机访问,不支持在任意位置O(1)插入。为了保证效率,元素的增删一般应该在末尾…...

Nmap脚本简介
什么是Nmap脚本 Nmap脚本是一种由Nmap扫描器使用的脚本语言,用于扫描目标网络中的主机、端口、服务等信息,并提供一系列自动化的测试和攻击功能。从渗透测试工程师的角度来看,Nmap脚本是一种非常有用的工具,能够帮助渗透测试工程师…...
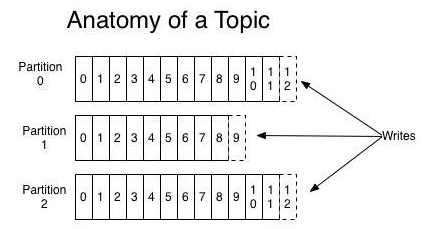
Kafka -- 初识
目录 kafka是什么 Topic Partition Broker Cousumer CousumerGroup Offset reblance broker 消息存储 Isr kafka是什么 Kafka 是一个分布式的消息引擎,能够发布和订阅消息流(类似于消息队列) 以容错的、持久的方式存储消息流 多分区…...

玩转Sass:掌握数据类型!
当我们在进行前端开发的时候,有时候需要使用一些不同的数据类型来处理样式,Sass 提供的这些数据类型可以帮助我们更高效地进行样式开发,本篇文章将为您详细介绍 Sass 中的数据类型。 布尔类型 在 Sass 中,布尔数据类型可以表示逻…...

Django + Matplotlib:实现数据分析显示与下载为PDF或SVG
写作背景 首先,数据分析在当前的信息时代中扮演着重要的角色。随着数据量的增加和复杂性的提高,人们对于数据分析的需求也越来越高。 其次,笔者也确确实实曾经接到过一个这样的开发需求,甲方是一个医疗方面的科研团队࿰…...

【Rust】第一节:安装
1 说明 一些学习记录 环境:MacOS 2 步骤 1、执行curl --proto https --tlsv1.2 https://sh.rustup.rs -sSf | sh 2、看到打印 info: downloading installerWelcome to Rust!... ...This path will then be added to your PATH environment variable by modifyin…...
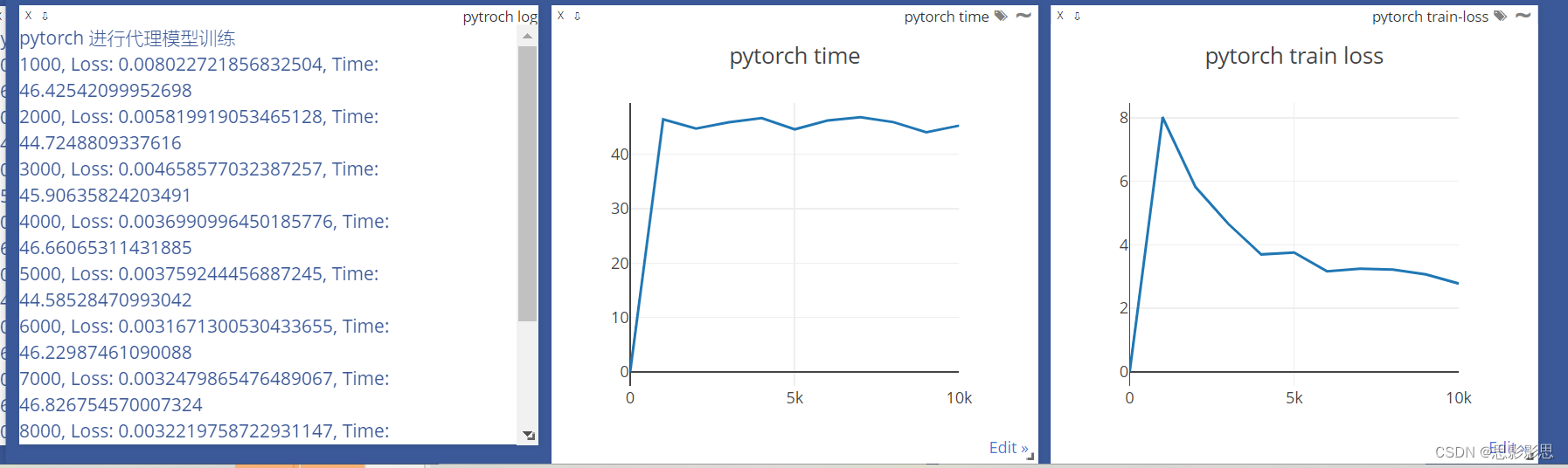
12-07 周四 Pytorch 使用Visdom 进行可视化
简介 在完成了龙良曲的Pytroch视频课程之后,楼主对于pytroch有了进一步的理解,比如,比之前更加深刻的了解了BP神经网络的反向传播算法,梯度、损失、优化器这些名词更加熟悉。这个博客简要介绍一下在使用Pytorch进行数据可视化的一…...

基于微信小程序的智慧校园导航系统研究
点我下载完整版 基于微信小程序的智慧校园导航系统研究 Research on Smart Campus Navigation System based on WeChat mini program 目录 目录 2 摘要 3 关键词 4 第一章 研究背景与意义 4 1.1 校园导航系统研究的背景 4 1.2 微信小程序在校园导航系统中的应用 5 1.3 研究的目…...

VUE3给table的head添加popover筛选、时间去除时分秒、字符串替换某字符
1. VUE3给table的head添加popover筛选 <el-tableref"processTableRef"class"process-table"row-key"secuId":data"pagingData"style"width: 100%"highlight-current-row:height"stockListHeight":default-exp…...

19、XSS——HTTP协议安全
文章目录 一、Weak Session IDs(弱会话IDs)二、HTTP协议存在的安全问题三、HTTPS协议3.1 HTTP和HTTPS的区别3.2 SSL协议组成 一、Weak Session IDs(弱会话IDs) 当用户登录后,在服务器就会创建一个会话(Session),叫做会话控制&…...

深圳锐杰金融:用金融力量守护社区健康
深圳市锐杰金融投资有限公司,作为中国经济特区的中流砥柱,近年来以其杰出的金融成绩和坚定的社会责任立场引人注目。然而,这并非一个寻常的金融机构。锐杰金融正在用自己的方式诠释企业责任和慈善精神,通过一系列独特的慈善项目&a…...

python对py文件加密
参考文献: 【编程技巧】py文件批量编译,py批量转pyd,PyCharm设置py转pyd功能_py文件编译pyd-CSDN博客 【Python小技巧】加密又提速,把.py文件编译为.pyd文件(类似dll函数库),你值得拥有&#x…...
Thymeleaf生成pdf表格合并单元格描边不显示
生成pdf后左侧第一列的右描边不显示,但是html显示正常 显示异常时描边的写法 cellpadding“0” cellspacing“0” ,td,th描边 .self-table{border:1px solid #000;border-collapse: collapse;width:100%}.self-table th{font-size:12px;border:1px sol…...
C# Solidworks二次开发:三种获取SW设计结构树的方法-第二讲
今天这篇文章是接上一篇文章的,主要讲述的是获取SW设计结构树节点的第二种方法。 这个方法获取节点的逻辑是先获取最顶层节点,然后再通过获取顶层节点的子节点一层一层的把所有节点都找出来,也就是需要递归。想要用这个方法就要了解下面几个…...
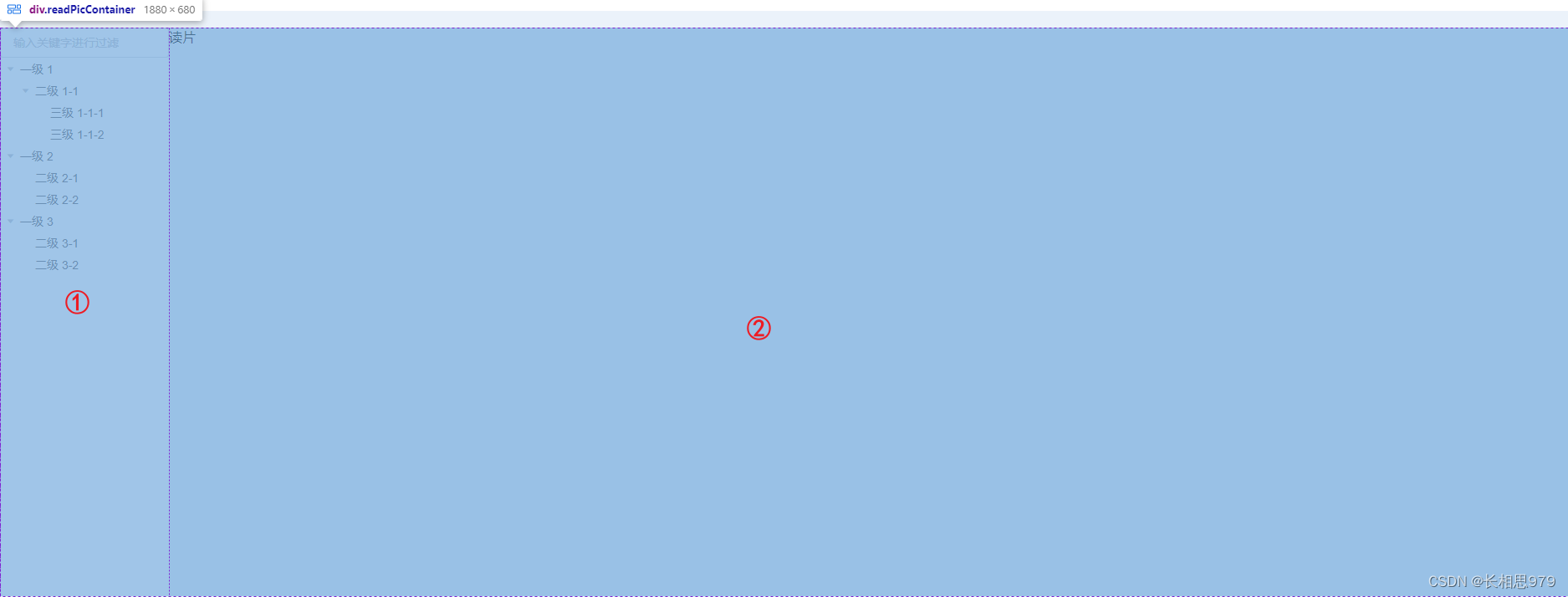
分布式搜索引擎03
1.数据聚合 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如: 什么品牌的手机最受欢迎? 这些手机的平均价格、最高价格、最低价格? 这些手机每月的销售情况如何? 实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近…...
flex布局的flex为1到底是什么
参考博客:flex:1什么意思_公孙元二的博客-CSDN博客 flex:1即为flex-grow:1,经常用作自适应布局,将父容器的display:flex,侧边栏大小固定后,将内容区flex:1,内…...

class050 双指针技巧与相关题目【算法】
class050 双指针技巧与相关题目【算法】 算法讲解050【必备】双指针技巧与相关题目 code1 922. 按奇偶排序数组 II // 按奇偶排序数组II // 给定一个非负整数数组 nums。nums 中一半整数是奇数 ,一半整数是偶数 // 对数组进行排序,以便当 nums[i] 为…...

计算机操作系统4
1.什么是进程同步 2.什么是进程互斥 3.进程互斥的实现方法(软件) 4.进程互斥的实现方法(硬件) 5.遵循原则 6.总结: 线程是一个基本的cpu执行单元,也是程序执行流的最小单位。 调度算法:先来先服务FCFS、短作业优先、高响应比优先、时间片…...

【ASP.NET CORE】EntityFrameworkCore 数据迁移
如果数据库中已经有数据结构,可以使用Scaffold-DbContext来同步model,-connection是字符串,-outputdir 是输入文件夹名称,举例的脚本使用的是sqlserver数据库 通用 Scaffold-DbContext -Connection "DatabaseAddress;Data …...

说说React jsx转换成真实DOM的过程?
在React中,JSX(JavaScript XML)是一种语法糖,用于描述用户界面的结构和组件关系。当你编写React组件并包含JS JSX解析:React中的JSX代码首先会被解析成JavaScript对象。这个过程通常是通过Babel等工具进行的࿰…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...