机器学习实战:预测波士顿房价
前言:Hello大家好,我是Dream。 今天来学习一下机器学习中一个非常经典的案例:预测波士顿房价,在此过程中也会补充很多重要的知识点,欢迎大家一起前来探讨学习~
一、导入数据
在这个项目中,我们利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并对模型的性能和预测能力进行测试。此项目的数据集来自UCI机器学习知识库。波士顿房屋这些数据于1978年开始统计,共506个数据点,涵盖了麻省波士顿不同郊区房屋14种特征的信息。
通过该数据训练后的好的模型可以被用来对房屋做特定预测—尤其是对房屋的价值。对于房地产经纪等人的日常工作来说,这样的预测模型被证明非常有价值。
本项目对原始数据集做了以下处理:
- 有16个
'MEDV'值为50.0的数据点被移除。 这很可能是由于这些数据点包含遗失或看不到的值。 - 有1个数据点的
'RM'值为8.78. 这是一个异常值,已经被移除。 - 对于本项目,房屋的
'RM','LSTAT','PTRATIO'以及'MEDV'特征是必要的,其余不相关特征已经被移除。 'MEDV'特征的值已经过必要的数学转换,可以反映35年来市场的通货膨胀效应。
import numpy as np
import pandas as pd
from sklearn.model_selection import ShuffleSplit
import visuals as vs
%matplotlib inline# Load the Boston housing dataset
data = pd.read_csv('housing.csv')
prices = data['MEDV']
features = data.drop('MEDV', axis = 1)
data.head(5)
二、分析数据
在项目的第一个部分,会对波士顿房地产数据进行初步的观察,通过对数据的探索来熟悉数据可以让你更好地理解和解释你的结果。
由于这个项目的最终目标是建立一个预测房屋价值的模型,我们需要将数据集分为特征(features)和目标变量(target variable)。
- 特征
'RM','LSTAT',和'PTRATIO',给我们提供了每个数据点的数量相关的信息。 - 目标变量:
'MEDV',是我们希望预测的变量。
他们分别被存在 features 和 prices 两个变量名中。
基础统计运算
- 计算
prices中的'MEDV'的最小值、最大值、均值、中值和标准差; - 将运算结果储存在相应的变量中。
# TODO: Minimum price of the data
minimum_price = np.min(prices)# TODO: Maximum price of the data
maximum_price = np.max(prices)# TODO: Mean price of the data
mean_price =np.mean(prices)# TODO: Median price of the data
median_price = np.median(prices)# TODO: Standard deviation of prices of the data
std_price = np.std(prices)# Show the calculated statistics
print("Statistics for Boston housing dataset:\n")
print("Minimum price: ${:.2f}".format(minimum_price))
print("Maximum price: ${:.2f}".format(maximum_price))
print("Mean price: ${:.2f}".format(mean_price))
print("Median price ${:.2f}".format(median_price))
print("Standard deviation of prices: ${:.2f}".format(std_price))
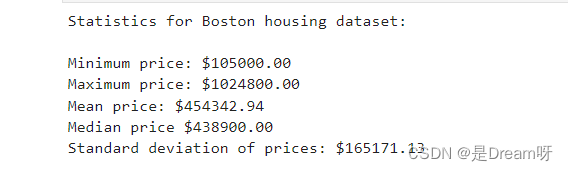
特征观察
如前文所述,本项目中我们关注的是其中三个值:'RM'、'LSTAT' 和'PTRATIO',对每一个数据点:
'RM'是该地区中每个房屋的平均房间数量;'LSTAT'是指该地区有多少百分比的业主属于是低收入阶层(有工作但收入微薄);'PTRATIO'是该地区的中学和小学里,学生和老师的数目比(学生/老师)。
凭直觉,上述三个特征中对每一个来说,你认为增大该特征的数值,'MEDV'的值会是增大还是减小呢?
‘1’: ‘RM’ 是该地区中每个房屋的平均房间数量:
- ‘回答:’ 'RM’增加,意味着房子的总面积会增加,所以价值会更高。
‘2’: ‘LSTAT’ 是指该地区有多少百分比的业主属于是低收入阶层(有工作但收入微薄);_
- ‘回答:’ 'LSTAT’占比增加,低收入阶层增加,可支配消费能力就会不多,房屋的价值不会更高。
‘3’: ‘PTRATIO’ 是该地区的中学和小学里,学生和老师的数目比(学生/老师)
- ‘回答:’ 'PTRATIO’增加,说明学生/老师数目比增加,优质教育程度下降,政府配额不足,学位房优势不明显,价值会下降。
三、 建立模型
定义衡量标准
如果不能对模型的训练和测试的表现进行量化地评估,我们就很难衡量模型的好坏。通常我们会定义一些衡量标准,这些标准可以通过对某些误差或者拟合程度的计算来得到。我们通过运算[决定系数] R 2 R^2 R2 来量化模型的表现。模型的决定系数是回归分析中十分常用的统计信息,经常被当作衡量模型预测能力好坏的标准。
R 2 R^2 R2 的数值范围从0至1,表示目标变量的预测值和实际值之间的相关程度平方的百分比。一个模型的 R 2 R^2 R2 值为0还不如直接用平均值来预测效果好;而一个 R 2 R^2 R2 值为1的模型则可以对目标变量进行完美的预测。从0至1之间的数值,则表示该模型中目标变量中有百分之多少能够用特征来解释。模型也可能出现负值的 R 2 R^2 R2,这种情况下模型所做预测有时会比直接计算目标变量的平均值差很多。
在下方代码的 performance_metric 函数中,我们实现:
- 使用
sklearn.metrics中的r2_score来计算y_true和y_predict的 R 2 R^2 R2 值,作为对其表现的评判。 - 将他们的表现评分储存到
score变量中。
# TODO: Import 'r2_score'
from sklearn.metrics import r2_score
def performance_metric(y_true, y_predict):score= r2_score(y_true,y_predict)# Return the scorereturn score
拟合程度
假设一个数据集有五个数据且一个模型做出下列目标变量的预测:
| 真实数值 | 预测数值 |
|---|---|
| 3.0 | 2.5 |
| -0.5 | 0.0 |
| 2.0 | 2.1 |
| 7.0 | 7.8 |
| 4.2 | 5.3 |
| 你觉得这个模型已成功地描述了目标变量的变化吗?如果成功,请解释为什么,如果没有,也请给出原因。 |
提示1:运行下方的代码,使用 performance_metric 函数来计算 y_true 和 y_predict 的决定系数。
提示2: R 2 R^2 R2 分数是指可以从自变量中预测的因变量的方差比例。 换一种说法:
- R 2 R^2 R2 为0意味着因变量不能从自变量预测。
- R 2 R^2 R2 为1意味着可以从自变量预测因变量。
- R 2 R^2 R2 在0到1之间表示因变量可预测的程度。
- R 2 R^2 R2 为0.40意味着 Y 中40%的方差可以从 X 预测。
# Calculate the performance of this model
score = performance_metric([3, -0.5, 2, 7, 4.2], [2.5, 0.0, 2.1, 7.8, 5.3])
print("Model has a coefficient of determination, R^2, of {:.3f}.".format(score))
Model has a coefficient of determination, R^2, of 0.923.
R^2=0.923,决定系数接近1,说明已经成功的描述了目标变量的变化.
数据分割与重排
接下来,我们需要把波士顿房屋数据集分成训练和测试两个子集。通常在这个过程中,数据也会被重排列,以消除数据集中由于顺序而产生的偏差。
- 使用
sklearn.model_selection中的train_test_split, 将features和prices的数据都分成用于训练的数据子集和用于测试的数据子集。- 分割比例为:80%的数据用于训练,20%用于测试;
- 选定一个数值以设定
train_test_split中的random_state,这会确保结果的一致性;
- 将分割后的训练集与测试集分配给
X_train,X_test,y_train和y_test。
# TODO: Import 'train_test_split'
from sklearn.model_selection import train_test_split# X_train:训练输入数据
# X_test:测试输入数据
# y_train:训练标签
# y_test:测试标签X = np.array(features)
Y = np.array(prices)# TODO: Shuffle and split the data into training and testing subsets
X_train, X_test, y_train, y_test =train_test_split(X, Y, test_size = 0.2,random_state=30)# Success
print("Training and testing split was successful.")
训练及测试
测试数据集通过未知数据来验证算法效果。如果没有数据来对模型进行测试,无法验证未知数据对结果预测。
四、分析模型的表现
在项目的第四步,我们来看一下不同参数下,模型在训练集和验证集上的表现。这里,我们专注于一个特定的算法(带剪枝的决策树,但这并不是这个项目的重点),和这个算法的一个参数 'max_depth'。用全部训练集训练,选择不同'max_depth' 参数,观察这一参数的变化如何影响模型的表现。画出模型的表现来对于分析过程十分有益。
学习曲线
下方区域内的代码会输出四幅图像,它们是一个决策树模型在不同最大深度下的表现。每一条曲线都直观得显示了随着训练数据量的增加,模型学习曲线的在训练集评分和验证集评分的变化,评分使用决定系数 R 2 R^2 R2。曲线的阴影区域代表的是该曲线的不确定性(用标准差衡量)。
vs.ModelLearning(features, prices)
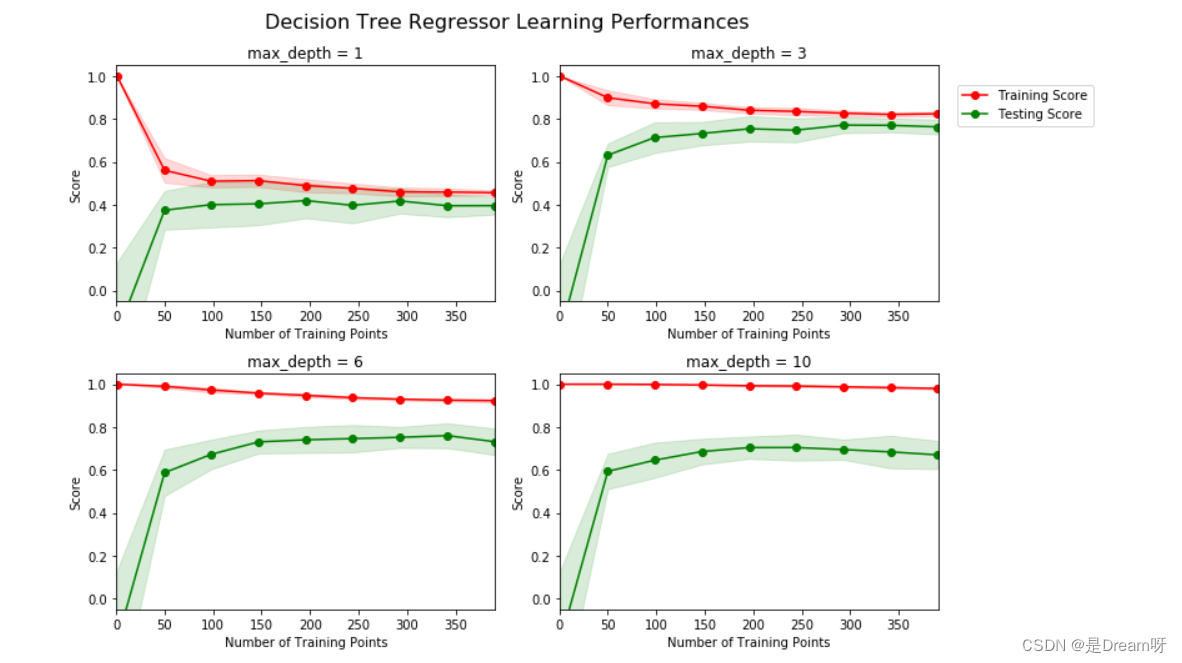
max-depth = 1 ;当训练数据从0到50增加时,训练集曲线的评分急速下降,验证集曲线的评分急速增加,随着数据量大于50再往上增加,训练集评分逐渐缓慢0.5附近收敛,验证集评分逐渐缓慢向0.4左右收敛,分数大于100以后,训练集评分和验证集评分基本趋向稳定。如果再有更多的训练数据,也不会有效提升模型的表现。
复杂度曲线
下列代码内的区域会输出一幅图像,它展示了一个已经经过训练和验证的决策树模型在不同最大深度条件下的表现。这个图形将包含两条曲线,一个是训练集的变化,一个是验证集的变化。跟学习曲线相似,阴影区域代表该曲线的不确定性,模型训练和测试部分的评分都用的 performance_metric 函数。
vs.ModelComplexity(X_train, y_train)
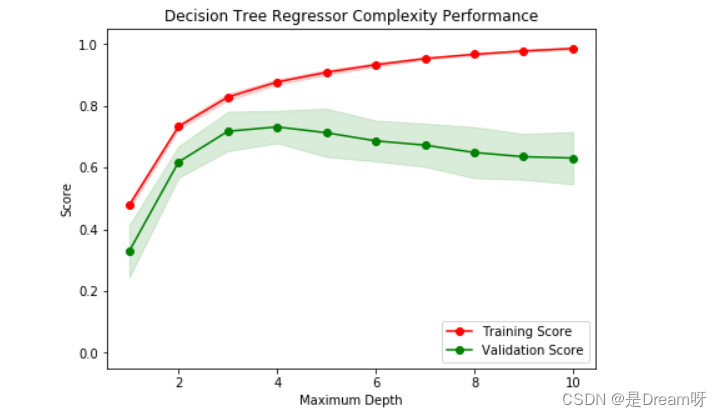
1:当模型以最大深度 1训练时,模型的预测是出现很大的偏差还是出现了很大的方差?
- ** 回答:** 欠拟合,出现大的偏差
2:当模型以最大深度10训练时,情形又如何呢?
- ** 回答:** 过拟合,出现大的方差
3:图形中的哪些特征能够支持你的结论?
- ** 回答:** 当深度=1时训练集评分和验证集评分比较低。深度=10时,训练集评分和验证集评分误差越来越大。
五、评估模型的表现
我们使用 fit_model 中的优化模型去预测客户特征集:
网格搜索法
1: 什么是网格搜索法?
- 回答: 通过各种训练数据训练一堆模型,然后通过交叉验证数据挑选最佳模型。
2:如何用它来优化模型?
- **回答:**例如决策树算法,通过不同深度的1,2,3,4的训练数据模型,通过交叉验证数据算出F1得分最高的,即最优化参数模型。
K折交叉验证法:
1:什么是K折交叉验证法
- 回答: 数据被按一定比例分成了训练集和测试集,在K折交叉验证中训练集又被分成了K份,每一份作为验证集。并进行K份训练和验证,最后求出平均分数,以此来得出最优参数和最优模型。
2:GridSearchCV 是如何结合交叉验证来完成对最佳参数组合的选择的?
- 回答: 可以通过输入参数,给出最优化的结果和参数
3:GridSearchCV 中的’cv_results_'属性能告诉我们什么?
- 回答: 通过修改 fit_model(X_train, y_train) 函数的返回值 print(pd.DataFrame(reg.cv_results_)) 可以看到显示的是每次训练模型的结果集
4:网格搜索为什么要使用K折交叉验证?K折交叉验证能够避免什么问题?
- 回答: 为了更好地拟合和预测,得出最优参数和最优模型。K折交叉验证通过将训练集分成K份,每一份依次作为验证集,并进行K次训练和验证,最后求出平均分数,这样可以减少模型表现得评分误差,从而更准确地找到最优参数
拟合模型
我们使用决策树算法训练一个模型。为了得出的是一个最优模型,我们需要使用网格搜索法训练模型,以找到最佳的 'max_depth' 参数。我们把'max_depth' 参数理解为决策树算法在做出预测前,允许其对数据提出问题的数量。决策树是监督学习算法中的一种。
ShuffleSplit 在 Scikit-Learn 版本0.17和0.18中有不同的参数。对于下面代码单元格中的 fit_model 函数:
- 定义
'regressor'变量: 使用sklearn.tree中的DecisionTreeRegressor创建一个决策树的回归函数; - 定义
'params'变量: 为'max_depth'参数创造一个字典,它的值是从1至10的数组; - 定义
'scoring_fnc'变量: 使用sklearn.metrics中的make_scorer创建一个评分函数。将‘performance_metric’作为参数传至这个函数中; - 定义
'grid'变量: 使用sklearn.model_selection中的GridSearchCV创建一个网格搜索对象;将变量'regressor','params','scoring_fnc'和'cross_validator'作为参数传至这个对象构造函数中;
# TODO: Import 'make_scorer', 'DecisionTreeRegressor', and 'GridSearchCV'
from sklearn.metrics import make_scorer
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCVdef fit_model(X, y):cv_sets = ShuffleSplit(n_splits=10, test_size=0.20, random_state=0)regressor = DecisionTreeRegressor(random_state=0)params = {"max_depth":list(range(1,11))}scoring_fnc = make_scorer(performance_metric)grid = GridSearchCV(regressor,params,scoring=scoring_fnc,cv=cv_sets)grid = grid.fit(X, y)return grid
六、做出预测
当我们用数据训练出一个模型,它现在就可用于对新的数据进行预测。在决策树回归函数中,模型已经学会对新输入的数据提问,并返回对目标变量的预测值。我们可以用这个预测来获取数据未知目标变量的信息,这些数据必须是不包含在训练数据之内的。
# Fit the training data to the model using grid search
reg = fit_model(X_train, y_train)# clf.cv_results_ 是选择参数的日志信息
#print(pd.DataFrame(reg.cv_results_))
# Produce the value for 'max_depth'
print("Parameter 'max_depth' is {} for the optimal model.".format(reg.best_estimator_.get_params()['max_depth']))
最优模型的最大深度是 max_depth = 4
预测销售价格
假如我们是一个在波士顿地区的房屋经纪人,并期待使用此模型以帮助你的客户评估他们想出售的房屋。你已经从你的三个客户收集到以下的资讯:
| 特征 | 客戶 1 | 客戶 2 | 客戶 3 |
|---|---|---|---|
| 房屋内房间总数 | 5 间房间 | 4 间房间 | 8 间房间 |
| 社区贫困指数(%被认为是贫困阶层) | 17% | 32% | 3% |
| 邻近学校的学生-老师比例 | 15:1 | 22:1 | 12:1 |
- 你会建议每位客户的房屋销售的价格为多少?
- 从房屋特征的数值判断,这样的价格合理吗?为什么?
运行下列的代码区域,使用你优化的模型来为每位客户的房屋价值做出预测。
# Produce a matrix for client data
client_data = [[5, 17, 15], # Client 1[4, 32, 22], # Client 2[8, 3, 12]] # Client 3# Show predictions
for i, price in enumerate(reg.predict(client_data)):print("Predicted selling price for Client {}'s home: ${:,.2f}".format(i+1, price))
Predicted selling price for Client 1’s home: $409,752.00
Predicted selling price for Client 2’s home: $220,886.84
Predicted selling price for Client 3’s home: $937,650.00
1: 你会建议每位客户的房屋销售的价格为多少?
回答:
-
客户1建议价格:$409,752.00 理由是:5间房 社区贫困指数为17%不到1/5 学生:老师比例15:1,教育环境中等偏上,房屋宜居性良好,综上价格合理。
-
客户2建议价格:$220,886.84 理由是:4间房 社区贫困指数将近1/3,学生:老师比例22:1,教育环境很一般。房屋购买吸引力不是很好,所以价值低合理
-
客户3建议价格:$937,650.00 理由是:8间房 社区贫困指数只有3%属于富人区,老师比例12:1教育环境优,综上该房屋属于上游配套,房间较高合理。
2: 从房屋特征的数值判断,这样的价格合理吗?为什么?
回答: 客户1、客户2、客户2的预测数据分别为:$409,752.00 、$220,886.84、 $937960;房间越多价值越高,邻近学校的学生-老师比例越低价值越高,社区贫困 指数(%)占比越低价值越高,这三个房屋特征数据预测数来的数据我认为是比较合理的,从价值来看几个特征衡量价值影响权重分别为:社区贫困指数 (高端生活区)> 邻近学校的学生-老师比例 (教育资源)> 房屋内房间总数
刚刚预测了三个客户的房子的售价。在这个练习中,我们用最优模型在整个测试数据上进行预测, 并计算相对于目标变量的决定系数 R 2 R^2 R2 的值。
# TODO Calculate the r2 score between 'y_true' and 'y_predict'
predicted = reg.predict(X_test)
r2 = performance_metric(y_test,predicted)print("Optimal model has R^2 score {:,.2f} on test data".format(r2))
Optimal model has R^2 score 0.80 on test data
R^2=0.8,说明符合变量的变化的结果.
模型健壮性
一个最优的模型不一定是一个健壮模型。有的时候模型会过于复杂或者过于简单,以致于难以泛化新增添的数据;有的时候模型采用的学习算法并不适用于特定的数据结构;有的时候样本本身可能有太多噪点或样本过少,使得模型无法准确地预测目标变量。这些情况下我们会说模型是欠拟合的。模型是否足够健壮来保证预测的一致性?
vs.PredictTrials(features, prices, fit_model, client_data)
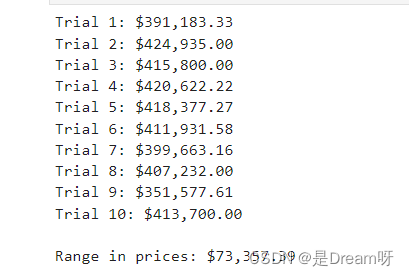
10次训练结果除了第9次,其他基本在训练结果数值比较稳定,说明模型相对健壮
1:1978年所采集的数据,在已考虑通货膨胀的前提下,在今天是否仍然适用?
**回答:**不适用,数据太旧,无法体现现在的价值。
2: 数据中呈现的特征是否足够描述一个房屋?
回答: 不足,还有很多影响房屋价格的特征:房屋的新旧程度、楼层的高低、建筑结构等等。
3: 在波士顿这样的大都市采集的数据,能否应用在其它乡镇地区?
回答: 不适合
4:你觉得仅仅凭房屋所在社区的环境来判断房屋价值合理吗?
回答: 不合理,社区环境房屋价值的一部分,还应考虑地理位置、城市经济因素、交通因素、教育发达程度、已经房屋本身的一些其他特征等诸多因素。
文末推荐与福利

《Python从入门到精通(微课精编版)》免费包邮送出3本!
内容介绍:
《Python从入门到精通(微课精编版)》使用通俗易懂的语言、丰富的案例,详细介绍了Python语言的编程知识和应用技巧。全书共24章,内容包括Python开发环境、变量和数据类型、表达式、程序结构、序列、字典和集合、字符串、正则表达式、函数、类、模块、异常处理和程序调试、进程和线程、文件操作、数据库操作、图形界面编程、网络编程、Web编程、网络爬虫、数据处理等,还详细介绍了多个综合实战项目。其中,第24章为扩展项目在线开发,是一章纯线上内容。全书结构完整,知识点与示例相结合,并配有案例实战,可操作性强,示例源代码大都给出详细注释,读者可轻松学习,快速上手。本书采用O2O教学模式,线下与线上协同,以纸质内容为基础,同时拓展更多超值的线上内容,读者使用手机微信扫一扫即可快速阅读,拓展知识,开阔视野,获取超额实战体验。

抽奖方式: 评论区随机抽取3位小伙伴免费送出!
参与方式: 关注博主、点赞、收藏、评论区评论“人生苦短,我用Python!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
活动截止时间: 2023-12-12 20:00:00
当当购买链接: https://product.dangdang.com/29484801.html
京东购买链接: https://item.jd.com/13524355.html
😄😄😄名单公布方式: 下期活动开始将在评论区和私信一并公布,中奖者请三天内私信提供收货信息😄😄😄

相关文章:
机器学习实战:预测波士顿房价
前言: Hello大家好,我是Dream。 今天来学习一下机器学习中一个非常经典的案例:预测波士顿房价,在此过程中也会补充很多重要的知识点,欢迎大家一起前来探讨学习~ 一、导入数据 在这个项目中,我们利用马萨诸…...
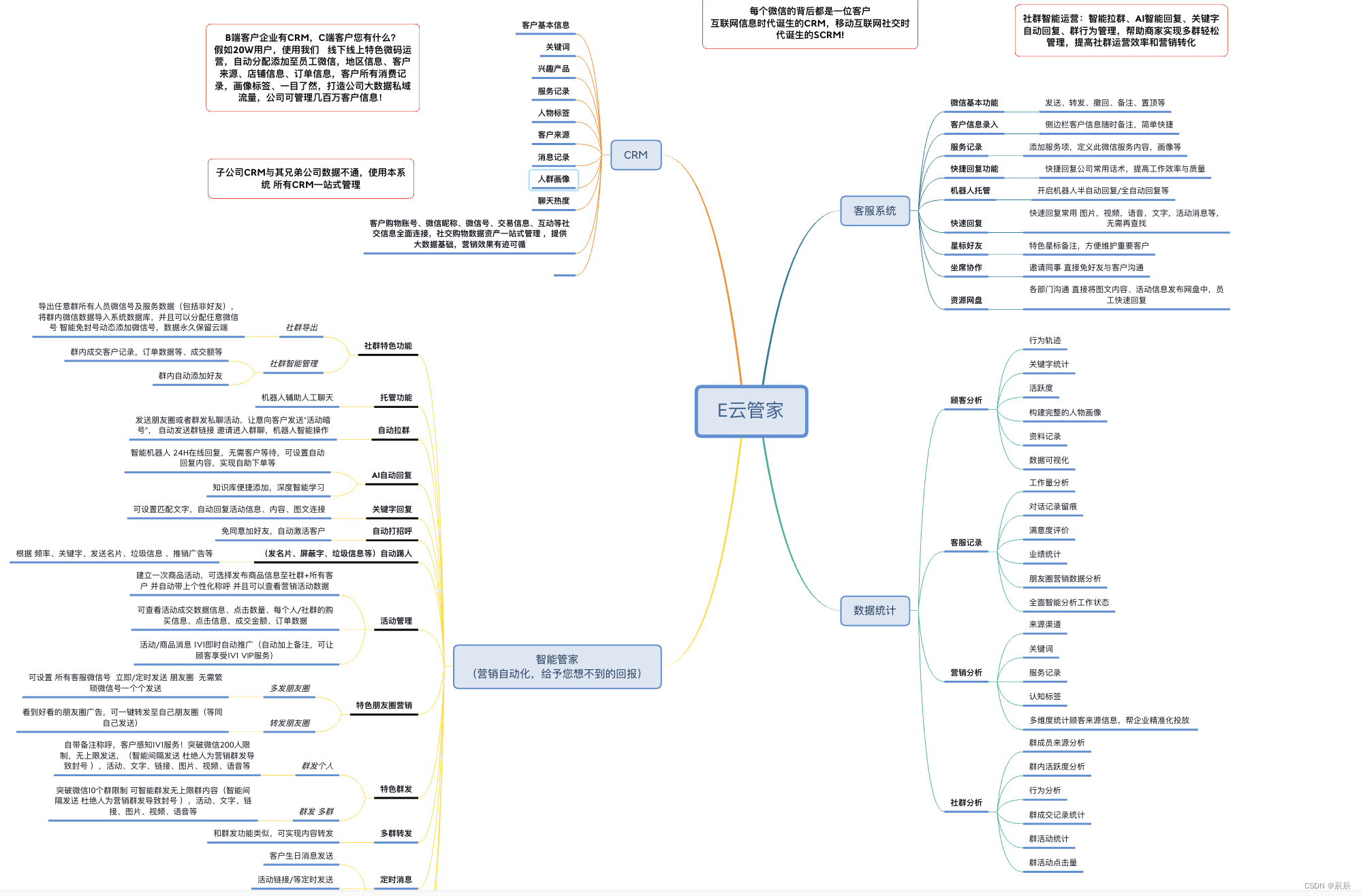
基于个微机器人的开发
简要描述: 下载消息中的动图 请求URL: http://域名/getMsgEmoji 请求方式: POST 请求头Headers: Content-Type:application/jsonAuthorization:login接口返回 参数: 参数名必选类型说明…...

程序员学习方法
https://www.zhihu.com/question/24187324 https://www.zhihu.com/question/505750740 windows系统: 如何业余开展 Windows 系统的学习? - 知乎 wifi工作原理: WiFi的工作原理是什么? - 知乎 发...

VUE+THREE.JS 点击模型相机缓入查看模型相关信息
点击模型相机缓入查看模型相关信息 1.引入2.初始化CSS3DRenderer3.animate 加入一直执行渲染4.点击事件4.1 初始化renderer时加入监听事件4.2 触发点击事件 5. 关键代码分析5.1 移除模型5.2 创建模型上方的弹框5.3 相机缓入动画5.4 动画执行 1.引入 引入模型所要呈现的3DSprite…...
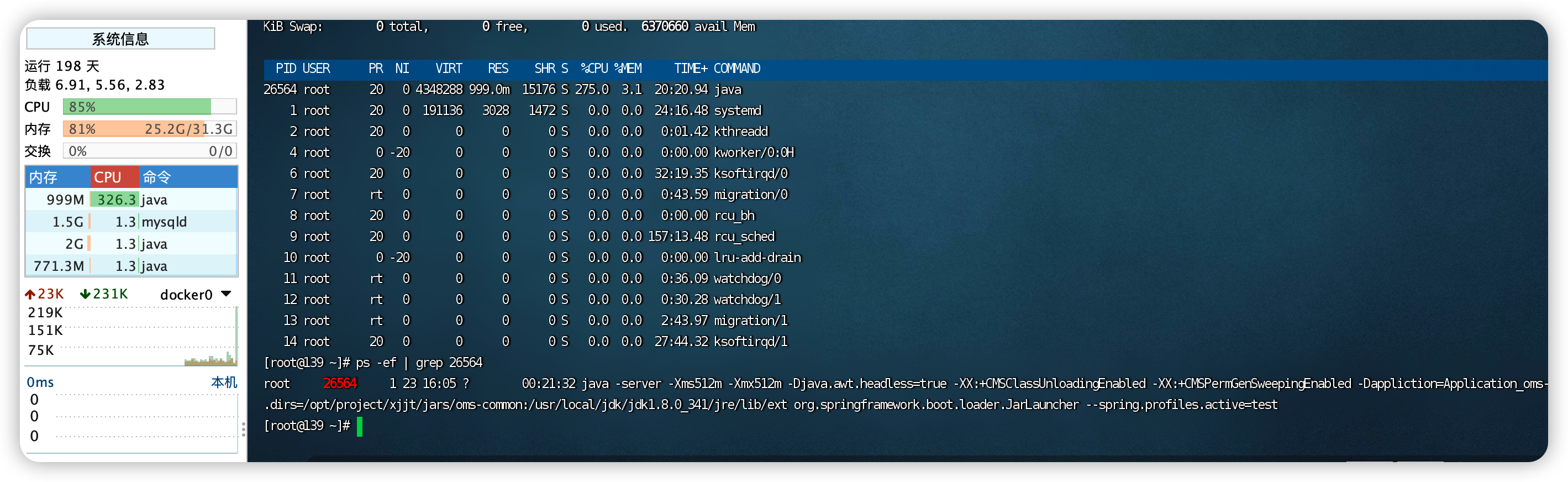
cpu 300% 爆满 内存占用不高 排查
top查询 cpu最高的PID ps -ef | grep PID 查看具体哪一个jar服务 jstack -l PID > ./jstack.log 下载/打印进程的线程栈信息 可以加信息简单分析 或进一步 查看堆内存使用情况 jmap -heap Java进程id jstack.log 信息示例 Full thread dump Java HotSpot(TM) 64-Bit Se…...
Halcon 简单的ORC 字体识别
文章目录 仿射变化识别 仿射变化 将图片进行矫正处理 dev_close_window() read_image(Image,C:/Users/Augustine/Desktop/halcon/image.png) *获取图片的大小 get_image_size(Image, Width, Height) *仿射运算获取图片的角度对图片进行矫正 *选中图片的区域 gen_rectangle1 (Re…...
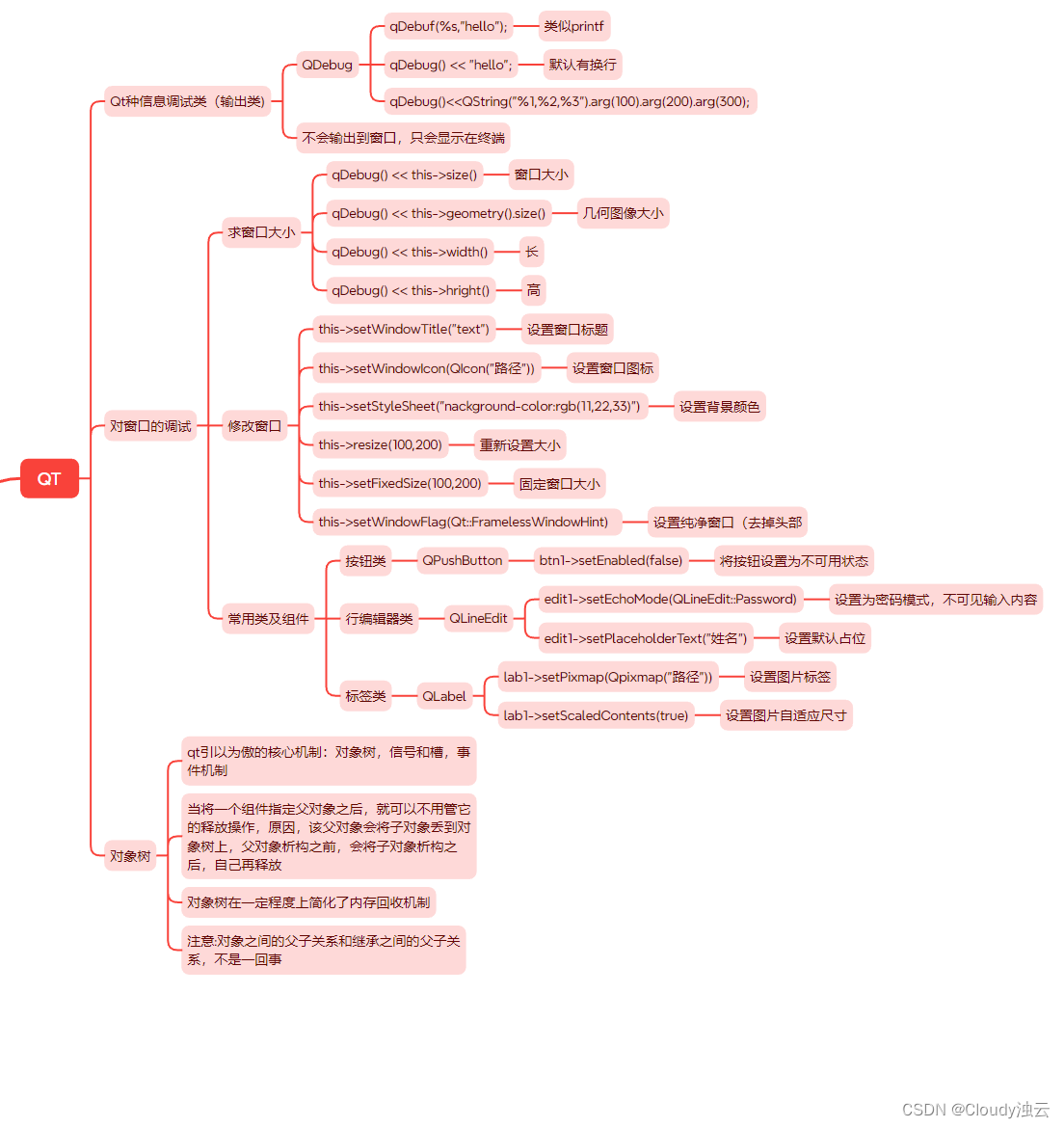
12月7日作业
使用QT模仿一个登陆界面(模仿育碧Ubisoft登录界面) #include "myqq.h"MyQQ::MyQQ(QWidget *parent): QMainWindow(parent) {this->resize(880,550); //设置窗口大小this->setFixedSize(880,550); //固定窗口大小this->setStyleShee…...
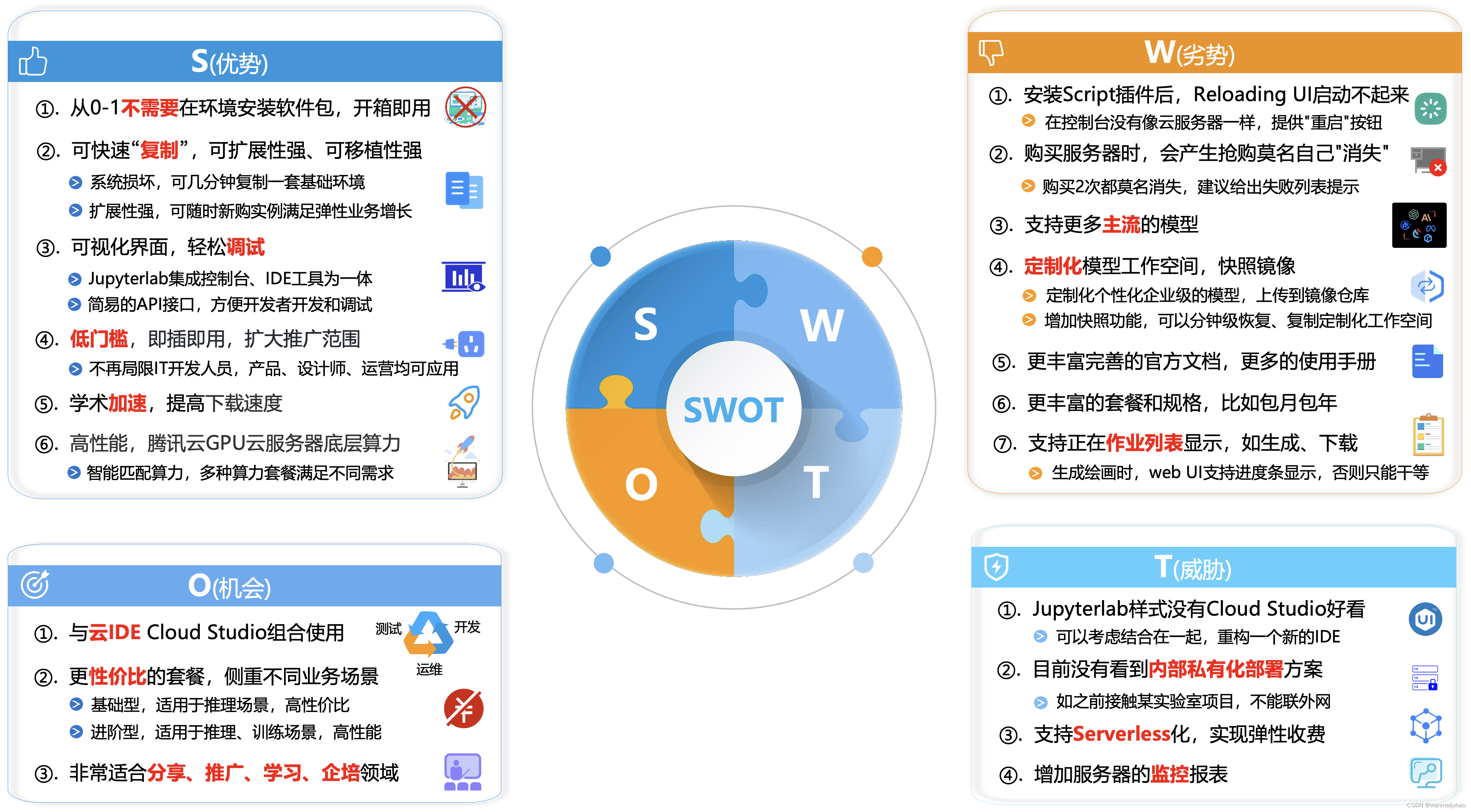
【腾讯云HAI域探密】- AIGC应用助力企业降本增效之路
一、前言: 近年来,随着深度学习、大数据、人工智能、AI等技术领域的不断发展,机器学习是目前最火热的人工智能分支之一,是使用大量数据训练计算机程序,以实现智能决策、语音识别、图像处理等任务。 作者也是经过了以上…...
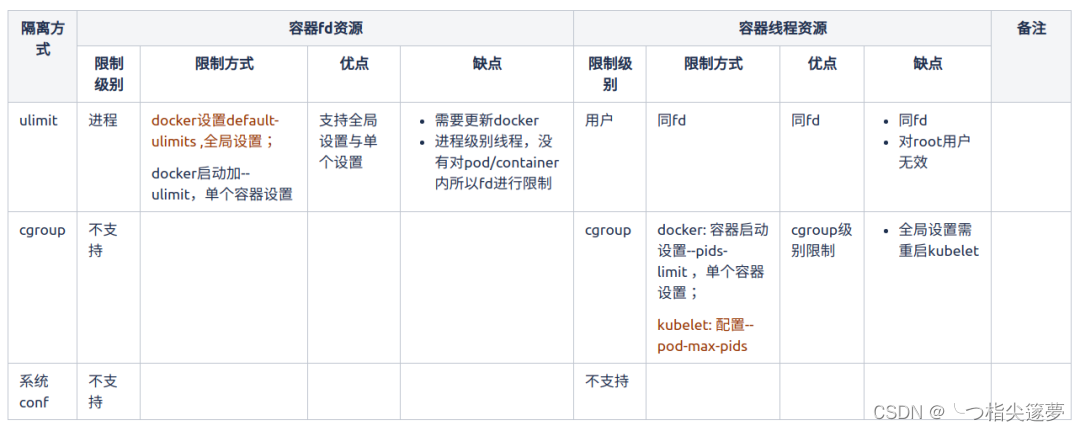
云原生之深入解析如何限制Kubernetes集群中文件描述符与线程数量
一、背景 linux 中为了防止进程恶意使用资源,系统使用 ulimit 来限制进程的资源使用情况(包括文件描述符,线程数,内存大小等)。同样地在容器化场景中,需要限制其系统资源的使用量。ulimit: docker 默认支持…...

Django的Auth模块
Auth模块 我们在创建好一个Django项目后执行数据库迁移命令会自动生成很多表 其中有auth_user等表 Django在启动之后就可以直接访问admin路由,需要输入用户名和密码,数据参考的就是auth_user表,并且必须是管理员才能进入 依赖于a…...
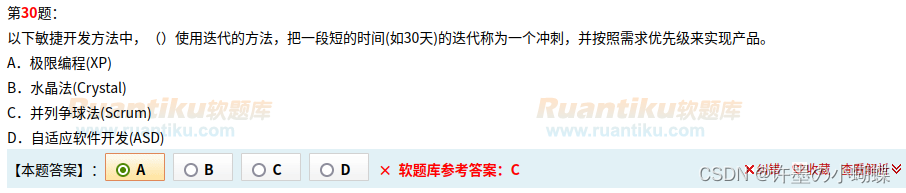
敏捷开发方法
理解: 极限编程(XP):敏捷开发的典型方法之一,是一种轻量级(敏捷)、高效,低风险、柔性、可预测的、科学的软件开发方法,它由价值观、原则、实践和行为4个部分组成。其中4大…...

vue 前端实现login页登陆 验证码
实现效果 // template <el-form :model"loginForm" :rules"fieldRules" ref"loginForm" label-position"left" label-width"0px" class"login-container"><span class"tool-bar"></sp…...
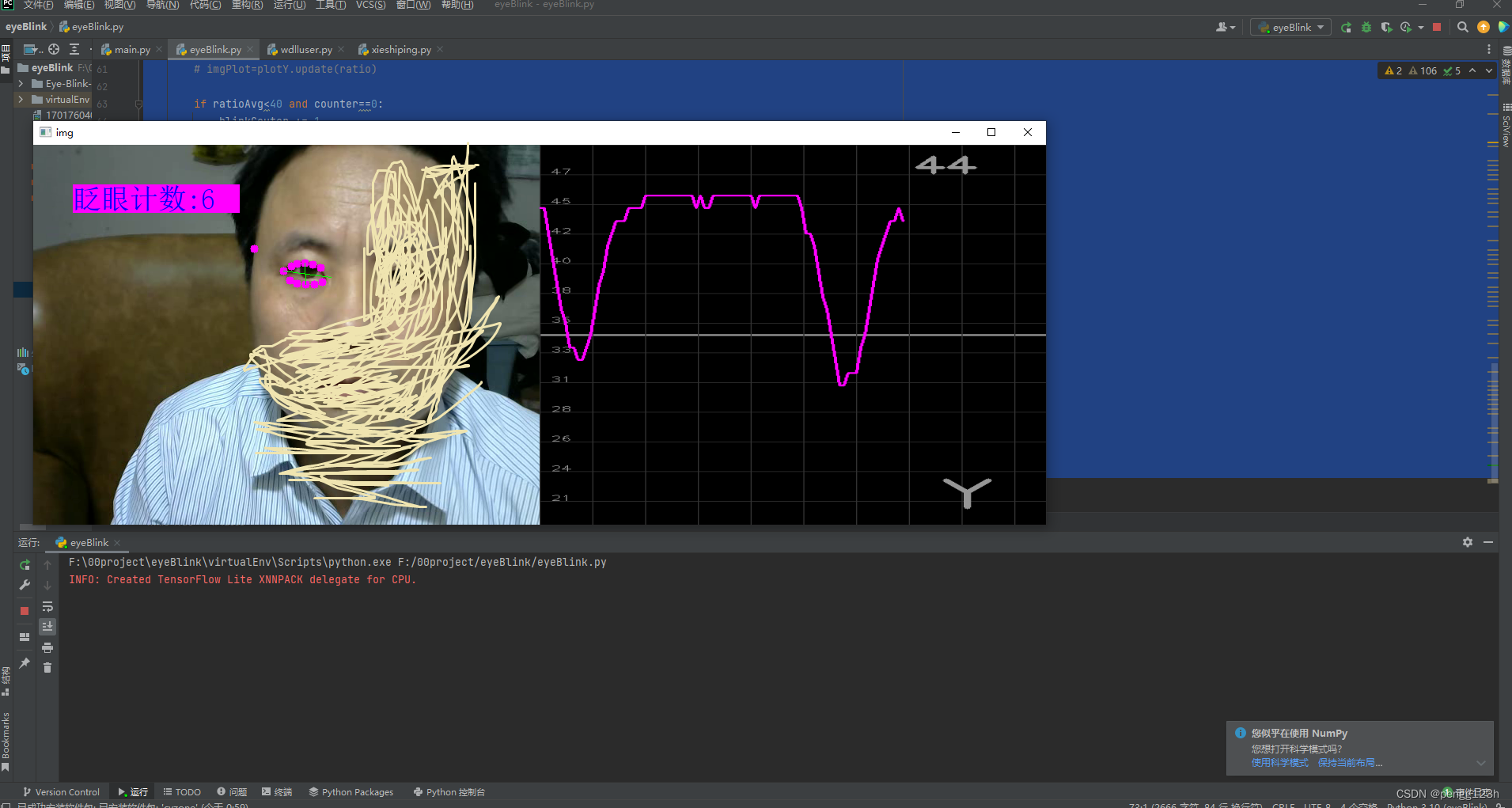
python 涉及opencv mediapipe知识,眨眼计数 供初学者参考
基本思路 我们知道正面侦测到人脸时,任意一只眼睛水平方向上的两个特征点构成水平距离,上下两个特征点构成垂直距离 当头像靠近或者远离摄像头时,垂直距离与水平距离的比值基本恒定 根据这一思路 当闭眼时 垂直距离变小 比值固定小于某一个…...
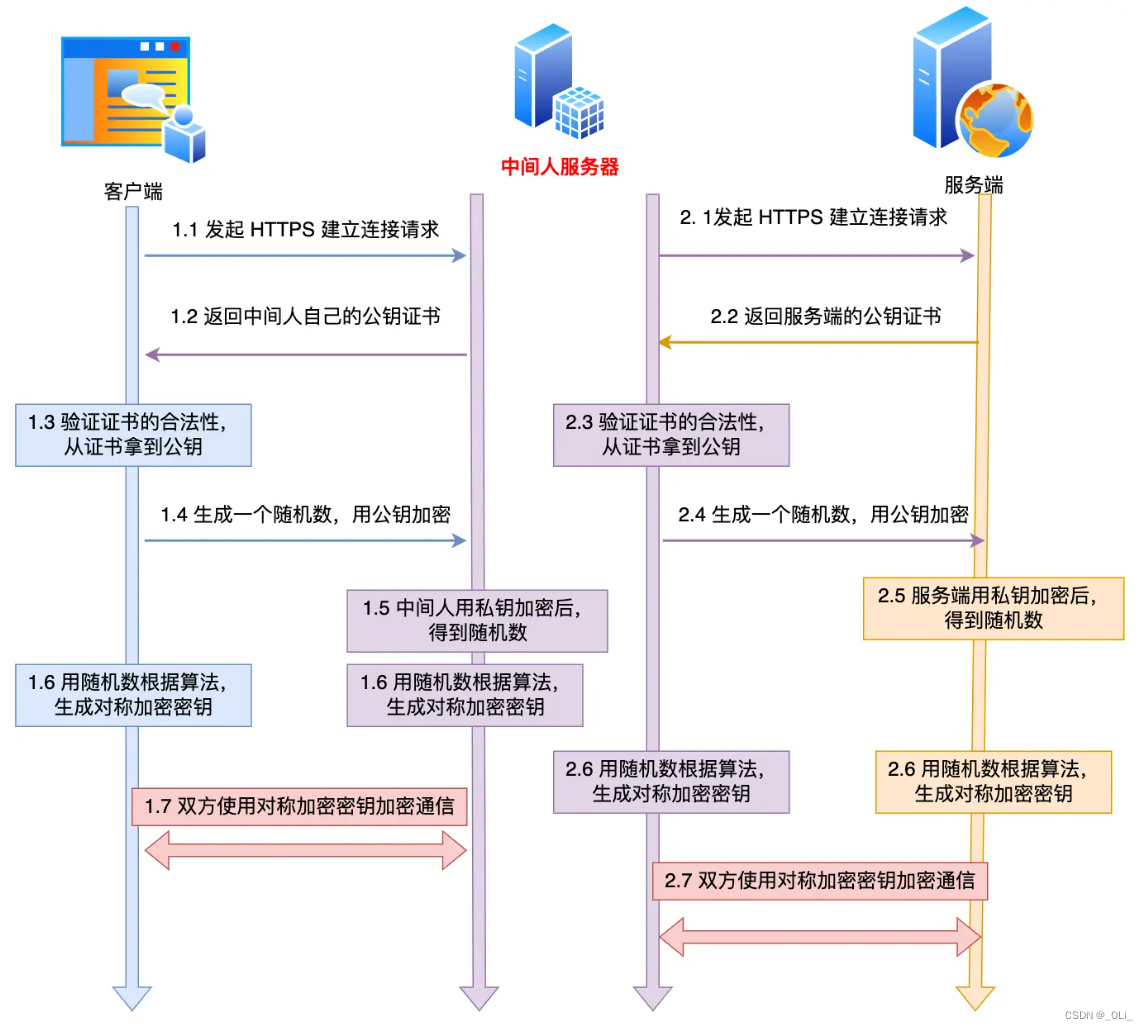
HTTP 和 HTTPS的区别
一、HTTP 1.明文传输,不安全 2.默认端口号:80 3.TCP三次握手即可 二、HTTPS 1.加密传输,更安全(在HTTP层与TCP层之间加上了SSL/TTL安全协议) SSL和TTL是在不同时期的两种叫法,含义相同。 2.默认端口号:443 3.TCP三…...

从零开始训练一个ChatGPT大模型(低资源,1B3)
macrogpt-prertrain 大模型全量预训练(1b3), 多卡deepspeed/单卡adafactor 源码地址:https://github.com/yongzhuo/MacroGPT-Pretrain.git 踩坑 1. 数据类型fp16不太行, 很容易就Nan了, 最好是fp32, tf32, 2. 单卡如果显存不够, 可以用优化器adafactor, 3. 如果…...

从文字到使用,一文读懂Kafka服务使用
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

什么是https加密协议?
前言: HTTPS(全称:Hypertext Transfer Protocol Secure) 是一个安全通信通道,它基于HTTP开发用于在客户计算机和服务器之间交换信息。它使用安全套接字层(SSL)进行信息交换,简单来说它是HTTP的安全版&…...
0012Java程序设计-ssm医院预约挂号及排队叫号系统
文章目录 **摘** **要**目 录系统实现5.2后端功能模块5.2.1管理员功能模块5.2.2医生功能模块 开发环境 摘 要 网络的广泛应用给生活带来了十分的便利。所以把医院预约挂号及排队叫号管理与现在网络相结合,利用java技术建设医院预约挂号及排队叫号系统,实…...
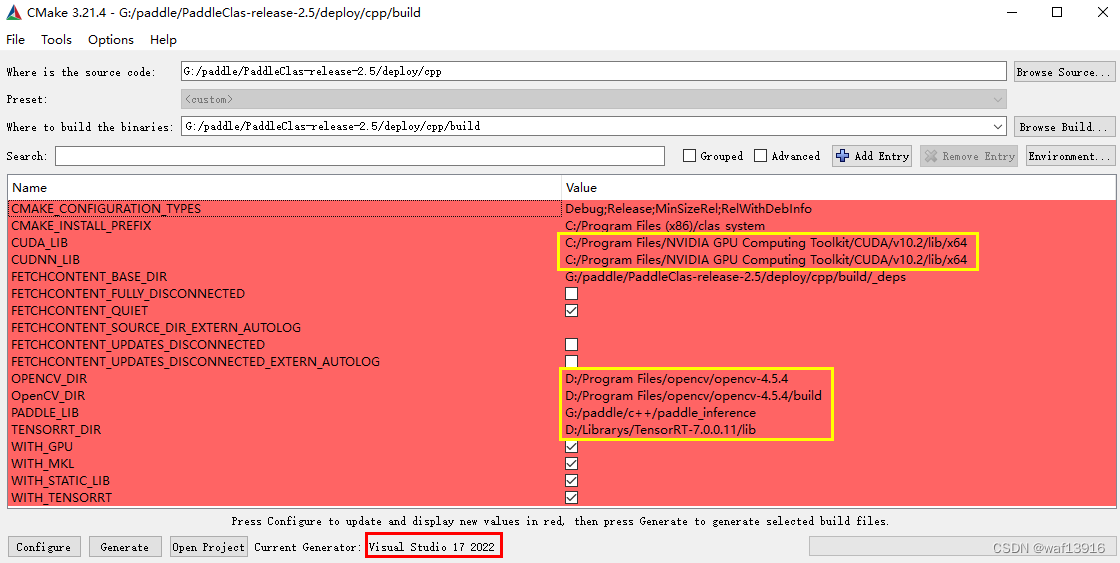
PaddleClas学习3——使用PPLCNet模型对车辆朝向进行识别(c++)
使用PPLCNet模型对车辆朝向进行识别 1 准备环境2 准备模型2.1 模型导出2.2 修改配置文件3 编译3.1 使用CMake生成项目文件3.2 编译3.3 执行3.4 添加后处理程序3.4.1 postprocess.h3.4.2 postprocess.cpp3.4.3 在cls.h中添加函数声明3.4.4 在cls.cpp中添加函数定义3.4.5 在main.…...
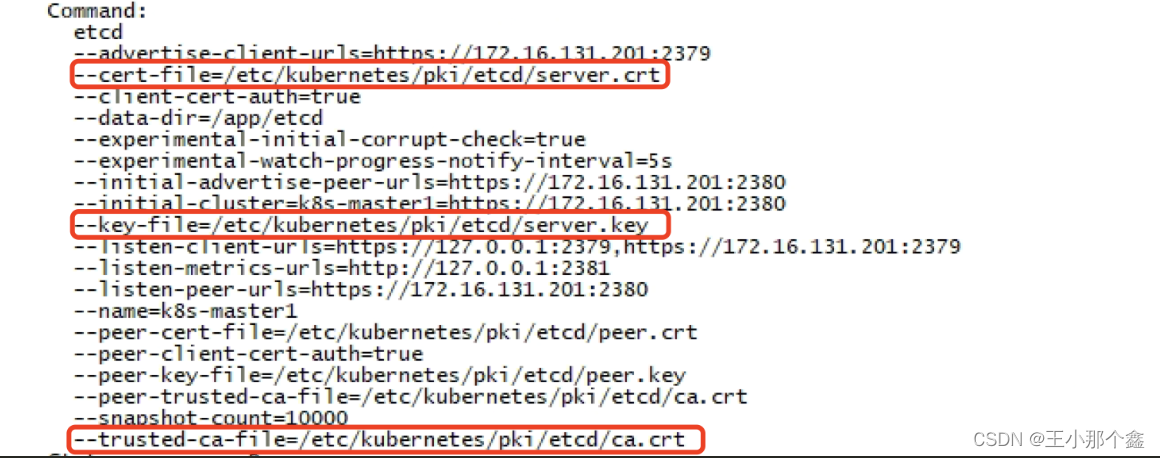
学习记录---kubernetes中备份和恢复etcd
一、简介 ETCD是kubernetes的重要组成部分,它主要用于存储kubernetes的所有元数据,我们在kubernetes中的所有资源(node、pod、deployment、service等),如果该组件出现问题,则可能会导致kubernetes无法使用、资源丢失等情况。因此…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...