scrapy介绍,并创建第一个项目
一、scrapy简介
- scrapy的概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
- Scrapy 使用了Twisted异步网络框架,可以加快我们的下载速度。
-
- Scrapy文档地址:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
- 工作流程
-
传统的爬虫流程
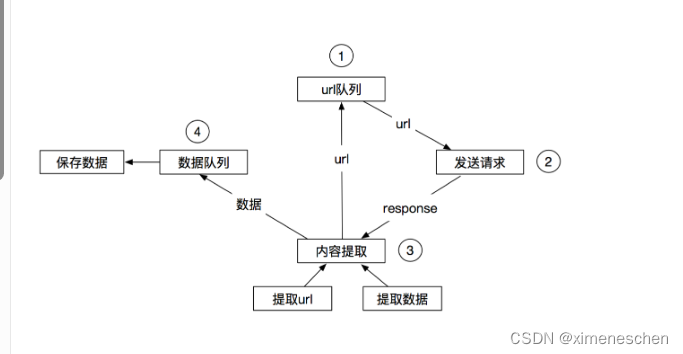
-
scrapy的流程
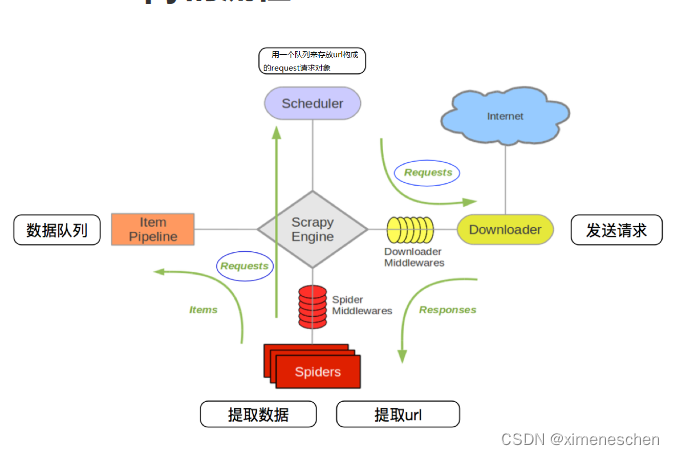
- 描述
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
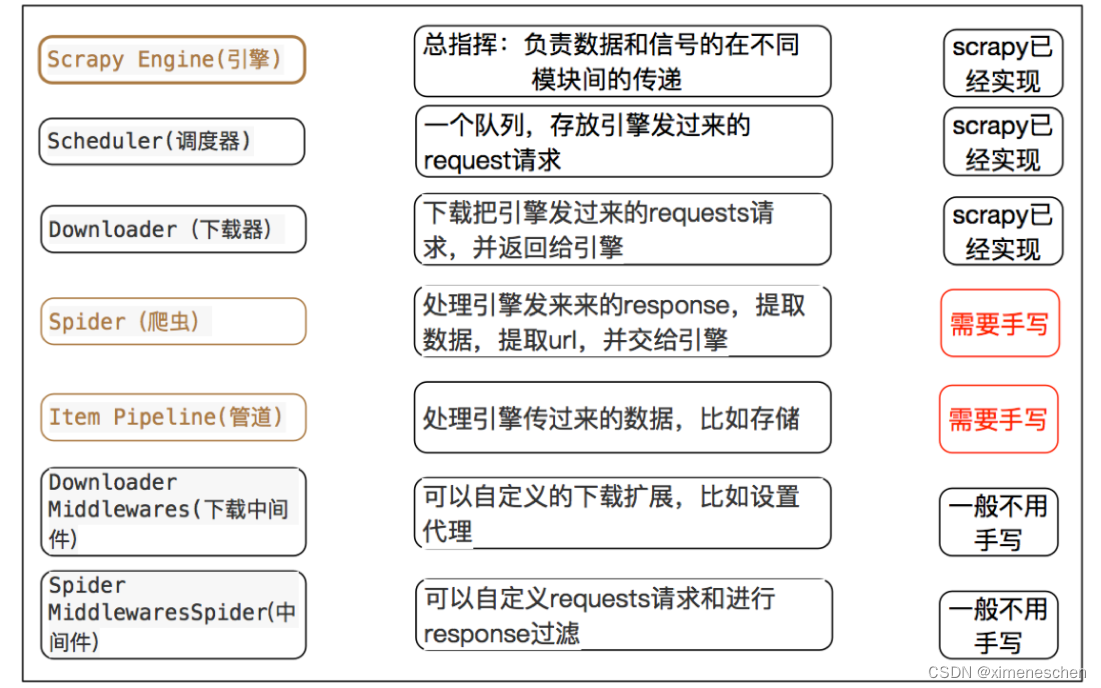
二、关于中间件
- 爬虫中间件(Spider Middleware)
作用: 爬虫中间件主要负责处理从引擎发送到爬虫的请求和从爬虫返回到引擎的响应。这些中间件在请求发送给爬虫之前或响应返回给引擎之前可以对它们进行处理。
- 功能:
- 修改请求或响应。
- 在请求被发送到爬虫之前进行预处理。
- 在响应返回给引擎之前进行后处理。
- 过滤或修改爬虫产生的请求和响应。
- 常见的爬虫中间件:
- HttpErrorMiddleware: 处理 HTTP 错误。
- OffsiteMiddleware: 过滤掉不在指定域名内的请求。
- RefererMiddleware: 添加请求的 Referer 头。
- UserAgentMiddleware: 添加请求的
- User-Agent 头。
- DepthMiddleware: 限制爬取深度。
- 下载中间件(Downloader Middleware)
-
作用: 下载中间件
主要负责处理引擎发送到下载器的请求和从下载器返回到引擎的响应。这些中间件在请求发送给下载器之前或响应返回给引擎之前可以对它们进行处理。 -
功能:
- 修改请求或响应。
- 在请求被发送到下载器之前进行预处理。
- 在响应返回给引擎之前进行后处理。
- 对请求进行代理、设置代理认证等。
- 常见的下载中间件:
HttpProxyMiddleware: 处理 HTTP 代理。- UserAgentMiddleware: 添加请求的 User-Agent头。
- RetryMiddleware: 处理请求重试。
- HttpCompressionMiddleware: 处理 HTTP 压缩。
- CookiesMiddleware: 管理请求的 Cookies。
三、scrapy的三个内置对象
- scrapy.Item:
-
作用: scrapy.Item 是一个简单的容器对象,
用于封装存储爬取到的数据。每个 scrapy.Item 对象都代表了网站上的一个特定数据项。 -
使用: 在 Scrapy 爬虫中,你可以定义一个继承自 scrapy.Item 的类,
定义这个类的属性来表示要提取的字段。这样,当你从页面中提取数据时,可以将提取到的数据存储在 scrapy.Item 对象中。 -
示例:
import scrapyclass MyItem(scrapy.Item):title = scrapy.Field()url = scrapy.Field()
- scrapy.Request:
-
作用: scrapy.Request 对象
用于指示 Scrapy 下载某个URL,并在下载完成后返回一个 scrapy.Response 对象。 -
使用: 在爬虫中,
你可以创建 scrapy.Request 对象,指定要访问的URL、回调函数、请求方法、请求头等信息,然后通过调用这个对象,将请求添加到爬虫的调度队列中。 -
示例:
import scrapy
class MySpider(scrapy.Spider):name = 'myspider'def start_requests(self):urls = ['http://example.com/page1', 'http://example.com/page2']for url in urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):# 处理响应的逻辑pass
- scrapy.Response:
-
作用: scrapy.Response 对象表示从服务器接收到的响应,它包含了网页的内容以及一些有关响应的元数据。
-
使用: 在爬虫的回调函数中,你
将接收到的响应作为参数,通过对 scrapy.Response 对象的操作,提取数据或者进一步跟踪其他URL。 -
示例:
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'def start_requests(self):urls = ['http://example.com/page1']for url in urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):# 使用 response.xpath 或 response.css 提取数据title = response.xpath('//h1/text()').get()
这三个内置对象是构建 Scrapy 爬虫时非常重要的组件。scrapy.Item 用于封装爬取到的数据,scrapy.Request 用于定义要爬取的URL和请求参数,scrapy.Response 用于处理从服务器返回的响应。通过巧妙地使用这些对象,你可以有效地构建和组织你的爬虫逻辑。
四、scrapy的入门使用
- 安装
pip/pip3 install scrapy
- scrapy项目开发流程
- 创建项目:
scrapy startproject mySpider
- 创建一个爬虫:
1.进入刚才的项目路径
2.执行生成命令:scrapy genspider <爬虫名字> <允许爬取的域名>
例如:scrapy genspider baidui baidu.com
3.执行后就会在myspider/spider下,生成一个baidu.py,这就是我们的爬虫文件
- 提取数据:
根据网站结构在spider中(即baidu.py文件)实现数据采集相关内容- 保存数据:
使用pipeline进行数据后续处理和保存
- 定义一个管道类
- 重写管道类的process_item方法
- process_item方法处理完item之后必须返回给引擎
- 在setting文件中启用管道

管道文件
import jsonclass ItcastPipeline():# 爬虫文件中提取数据的方法每yield一次item,就会运行一次# 该方法为固定名称函数def process_item(self, item, spider):print(item)return item
配置文件
#值越小越先运行
ITEM_PIPELINES = {'myspider.pipelines.ItcastPipeline': 400
}
- 运行爬虫项目
scrapy crawl baidu
相关文章:

scrapy介绍,并创建第一个项目
一、scrapy简介 scrapy的概念 Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。 Scrapy 使用了Twisted异步网络框架,可以加快我们的下载速度。 Scrapy文档地址:http://scrapy-chs.readthedocs.io/z…...
 - 胜利与失败)
Rust语言项目实战(九 - 完结) - 胜利与失败
回顾 在前面的章节中,我们已经实现了这个游戏中大部分的模块和功能,我们可以指挥我们的战机左右移动,并发射子弹;我们还创造了一堆的侵略者,从屏幕上方缓缓降落,试图到达屏幕的底部。 本章中,我们将对游戏的输赢作出最后的裁决,到底是我们的保卫者英勇无敌,还是侵略…...
【Linux系统编程】项目自动化构建工具make/Makefile
介绍: make和Makefile是用于编译和构建C/C程序的工具和文件。Makefile是一个文本文件,其中包含了编译和构建程序所需的规则和指令。它告诉make工具如何根据源代码文件生成可执行文件,里面保存的是依赖关系和依赖方法。make是一个命令行工具&a…...

harmony开发之Text组件的使用
TextInput、TextArea是输入框组件,通常用于响应用户的输入操作,比如评论区的输入、聊天框的输入、表格的输入等,也可以结合其它组件构建功能页面,例如登录注册页面。 图片来源黑马程序员 Text组件的使用: 文本显示组…...

using meta-SQL 使用元SQL 六
%Table Syntax %Table(recname) Description Use the %Table construct to return the SQL table name for the record specified with recname. 使用%Table构造返回使用recname指定的记录的SQL表名。 This construct can be used to specify temporary tables for runn…...

如何将浮点数点左边的数每三位添加一个逗号,如 12000000.11 转化为『12,000,000.11』
// 方法二 function format1(number) {return Intl.NumberFormat().format(number); } // 方法三 function format2(number) {return number.toLocaleString("en"); }...

朴素贝叶斯 贝叶斯方法
朴素贝叶斯 贝叶斯方法 背景知识 贝叶斯分类:贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。先验概率:根据以往经验和分析得到的概率。我们用 P ( Y ) P(Y) P(Y)来代表在没有训练数据前假设…...
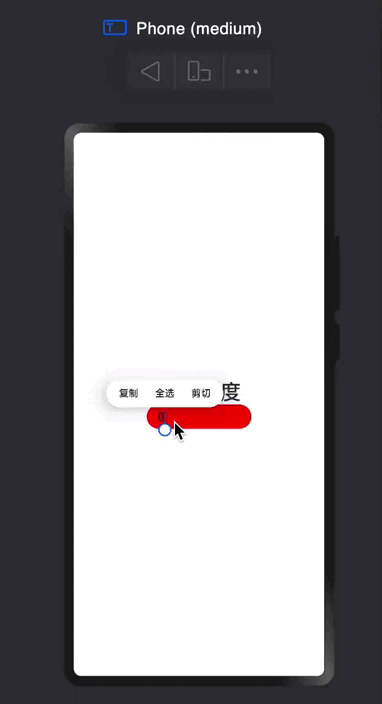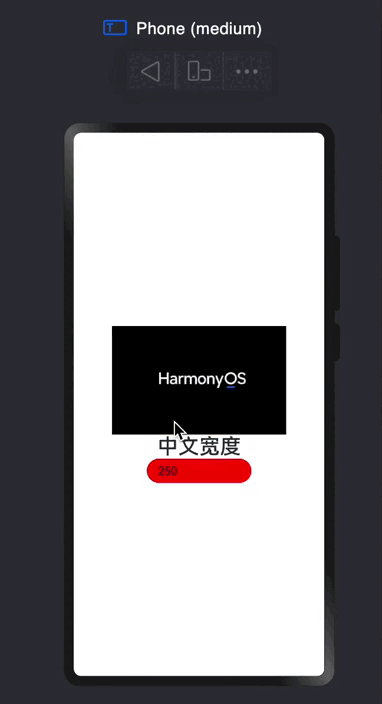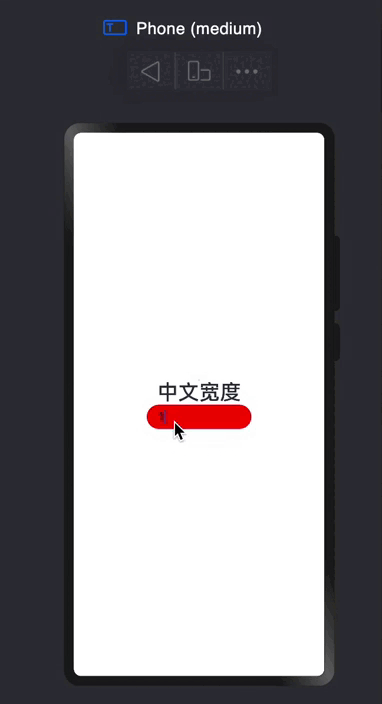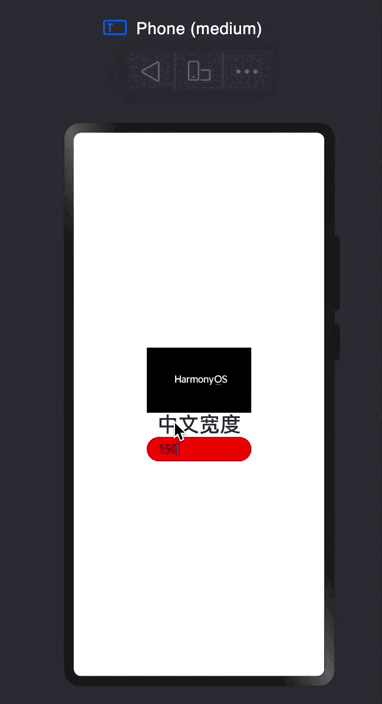
探索鸿蒙 TextInput组件
TextInput 根据组件名字,可以得知他是一个文本输出框。 声明代码👇 TextInput({placeholder?:ResourceStr,text?:ResourceStr}); placeholder: 就是提示文本,跟网页开发中的placeholder一样的 text:输入框当前的文本内容 特殊属…...
)
CNN,DNN,RNN,GAN,RL+图像处理常规算法(未完待续)
好的,让我们先介绍一些常见的神经网络模型,然后再讨论图像处理的常规算法。 神经网络模型: 1. CNN(卷积神经网络) 原理: CNN主要用于处理图像数据。它包含卷积层、池化层和全连接层。卷积层通过卷积操作…...
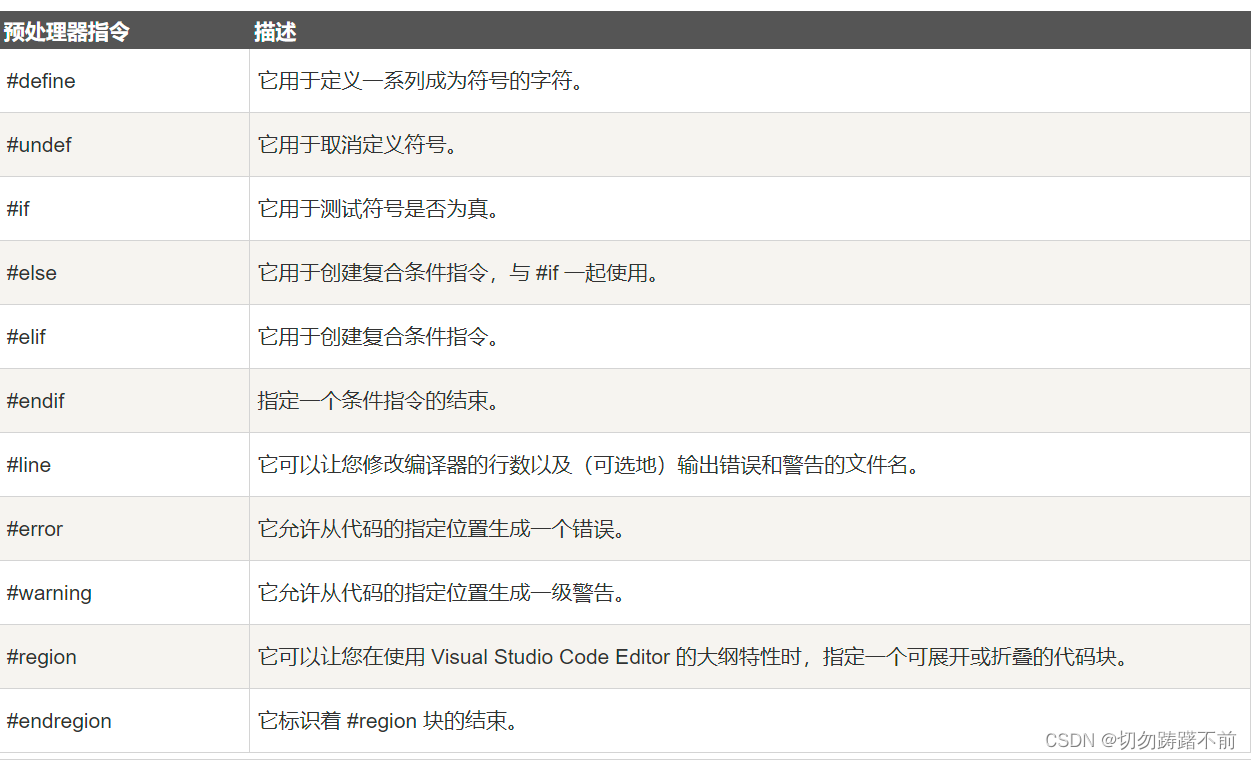
C# 语法笔记
1.ref、out:参数传递的两种方式 ref:引用传递 using System; namespace CalculatorApplication {class NumberManipulator{public void swap(ref int x, ref int y){int temp;temp x; /* 保存 x 的值 */x y; /* 把 y 赋值给 x */y temp; /* 把 t…...
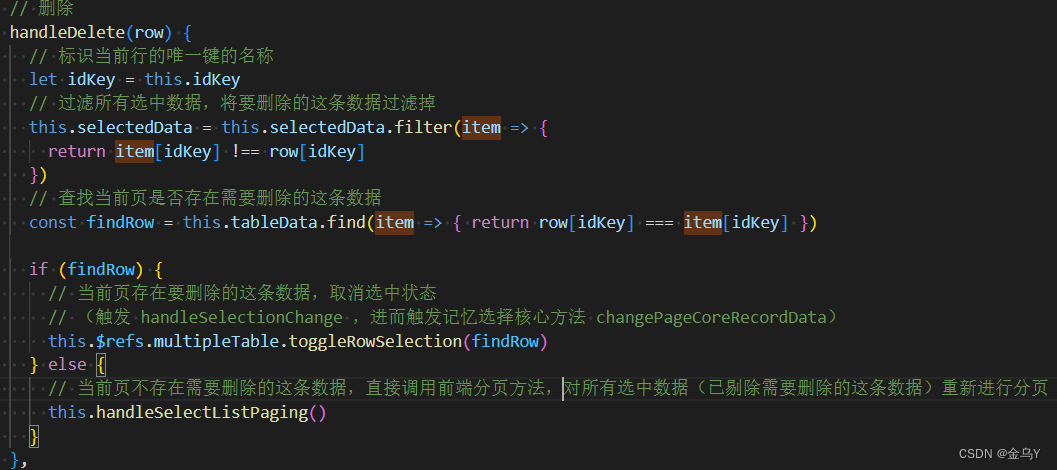
el-table 表格多选(后端接口搜索分页)实现已选中的记忆功能。实现表格数据和已选数据(前端分页)动态同步更新。
实现效果:(可拉代码下来看:vue-demo: vueDemo) 左侧表格为点击查询调用接口查询出来的数据,右侧表格为左侧表格所有选择的数据,由前端实现分页。 两个el-table勾选数据联动更新 实现逻辑: el-…...

Vue3自定义Hooks定义
在Vue3中,自定义Hooks的定义是通过创建一个函数来共享逻辑或状态,以便在多个组件之间重复使用。Vue3中的自定义Hooks与React中的自定义Hooks非常相似,但有一些细微的差别。 要定义一个自定义Hook,可以按照以下步骤进行操作&#x…...

为什么Java程序员需要掌握多线程?揭秘并发编程的奥秘
为什么Java程序员需要掌握多线程?揭秘并发编程的奥秘 个人简介前言多线程对于Java的意义📌1.提高程序性能:📌2 提高用户体验:📌3支持并发处理:📌4 资源共享和同步:&#…...
)
数组实现循环队列(新增一个空间)
目录 一、前言 1.如何实现循环? 2.如何判断队列为空? 3.如何判断队列为满? 二、循环队列的结构定义 三、循环队列的创建及其初始化 四、入队 五、出队 六、取队头元素 七、取队尾元素 八、判空 九、判满 十、销毁队列 一、前言 …...

Mysql 索引概念回顾
一、什么是索引 在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据…...

基于SpringBoot+Vue学生成绩管理系统前后端分离(源码+数据库)
一、项目简介 本项目是一套基于SpringBootVue学生成绩管理系统,主要针对计算机相关专业的正在做bishe的学生和需要项目实战练习的Java学习者。 包含:项目源码、数据库脚本等,该项目可以直接作为bishe使用。 项目都经过严格调试,确…...

Hadoop集群破坏试验可靠性验证
集群环境说明: 准备5台服务器,hadoop1、hadoop2、hadoop3、hadoop4、hadoop5; 分别部署5个节点的zookeeper集群、hadoop集群、hbase集群 本次对于Hadoop集群测试主要分为五个方面: 手动进行datanode节点删除:&#…...

Notepad++ 安装TextFx插件失败
据说TextFx插件是Notepad常用插件之一;有很多格式化代码的功能;下面安装一下; 插件管理里面看一下,没有这个TextFx; 根据资料,先安装NppExec; 然后下一个5.9老版本的Notepad,如下图…...
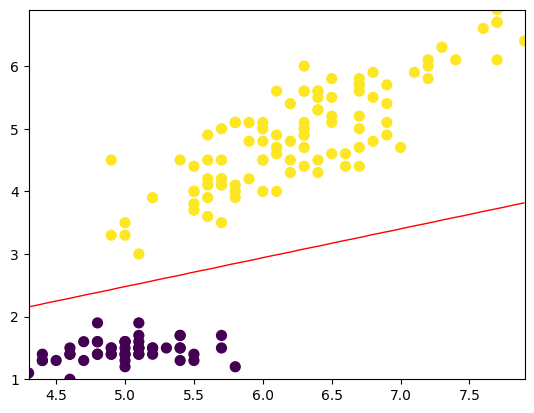
探究Logistic回归:用数学解释分类问题
文章目录 前言回归和分类Logistic回归线性回归Sigmoid函数把回归变成分类Logistic回归算法的数学推导Sigmoid函数与其他激活函数的比较 Logistic回归实例1. 数据预处理2. 模型定义3. 训练模型4. 结果可视化 结语 前言 当谈论当论及机器学习中的回归和分类问题时,很…...

杨辉三角
打印n行杨辉三角,n<10。 输入格式: 直接输入一个小于10的正整数n。 输出格式: 输出n行杨辉三角,每个数据输出占4列。 输入样例: 5输出样例: 11 11 2 11 3 3 11 4 6 4 1代码长度限制 16 KB 时间限制 400 ms 内存限制 6…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...

CppCon 2015 学习:Reactive Stream Processing in Industrial IoT using DDS and Rx
“Reactive Stream Processing in Industrial IoT using DDS and Rx” 是指在工业物联网(IIoT)场景中,结合 DDS(Data Distribution Service) 和 Rx(Reactive Extensions) 技术,实现 …...