NLP项目实战01之电影评论分类
介绍:
欢迎来到本篇文章!在这里,我们将探讨一个常见而重要的自然语言处理任务——文本分类。具体而言,我们将关注情感分析任务,即通过分析电影评论的情感来判断评论是正面的、负面的。
展示:
训练展示如下:
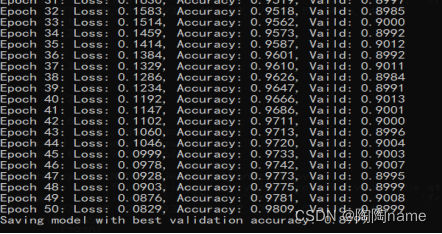
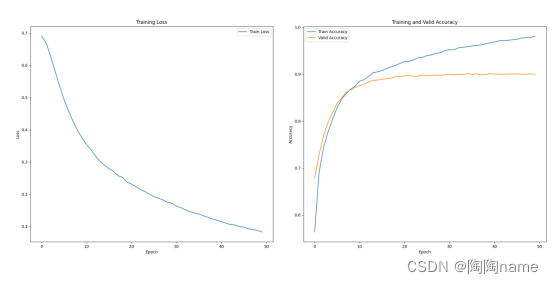
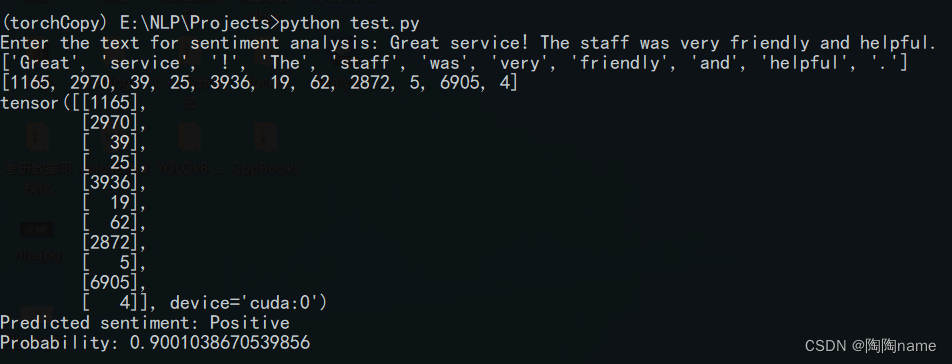
实际使用如下:
实现方式:
选择PyTorch作为深度学习框架,使用电影评论IMDB数据集,并结合torchtext对数据进行预处理。
环境:
Windows+Anaconda
重要库版本信息
torch==1.8.2+cu102
torchaudio==0.8.2
torchdata==0.7.1
torchtext==0.9.2
torchvision==0.9.2+cu102
实现思路:
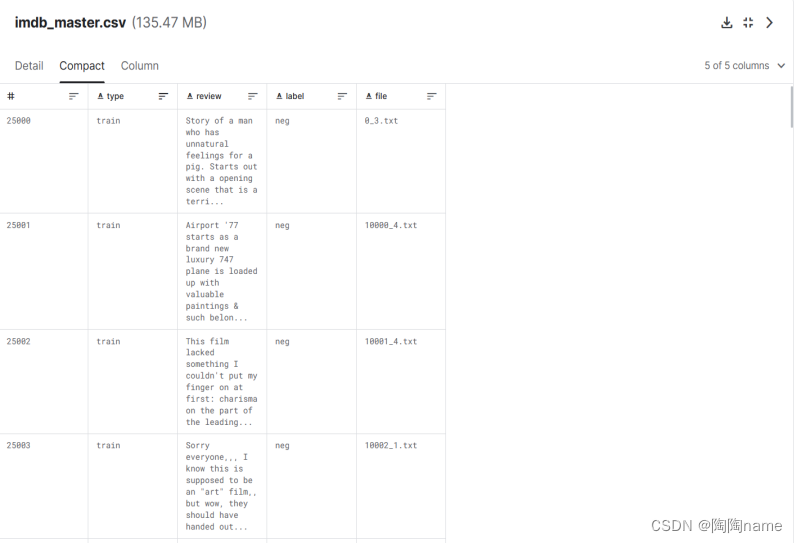
1、数据集
本次使用的是IMDB数据集,IMDB是一个含有50000条关于电影评论的数据集
数据如下:
2、数据加载与预处理
使用torchtext加载IMDB数据集,并对数据集进行划分
具体划分如下:
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm')
LABEL = data.LabelField(dtype=torch.float)
# Load the IMDB dataset
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
创建一个 Field 对象,用于处理文本数据。同时使用spacy分词器对文本进行分词,由于IMDB是英文的,所以使用en_core_web_sm语言模型。
创建一个 LabelField 对象,用于处理标签数据。设置dtype 参数为 torch.float,表示标签的数据类型为浮点型。
使用 datasets.IMDB.splits 方法加载 IMDB 数据集,并将文本字段 TEXT 和标签字段 LABEL 传递给该方法。返回的 train_data 和 test_data 包含了 IMDB 数据集的训练和测试部分。
下面是train_data的输出

3、构建词汇表与加载预训练词向量
TEXT.build_vocab(train_data,max_size=25000,vectors="glove.6B.100d",unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
train_data:表示使用train_data中数据构建词汇表
max_size:限制词汇表的大小为 25000
vectors=“glove.6B.100d”:表示使用预训练的 GloVe 词向量,其中 “glove.6B.100d” 指的是包含 100 维向量的 6B 版 GloVe。
unk_init=torch.Tensor.normal_ :表示指定未知单词(UNK)的初始化方式,这里使用正态分布进行初始化。
LABEL.build_vocab(train_data):表示对标签进行类似的操作,构建标签的词汇表
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits( (train_data, valid_data, test_data), batch_size=BATCH_SIZE, device=device)
使用data.BucketIterator.splits 来创建数据加载器,包括训练、验证和测试集的迭代器。这将确保你能够方便地以批量的形式获取数据进行训练和评估。
4、定义神经网络
这里的网络定义比较简单,主要采用在词嵌入层(embedding)后接一个全连接层的方式完成对文本数据的分类。
具体如下:
class NetWork(nn.Module):def __init__(self,vocab_size,embedding_dim,output_dim,pad_idx):super(NetWork,self).__init__()self.embedding = nn.Embedding(vocab_size,embedding_dim,padding_idx=pad_idx)self.fc = nn.Linear(embedding_dim,output_dim)self.dropout = nn.Dropout(0.5)self.relu = nn.ReLU()def forward(self,x):embedded = self.embedding(x)embedded = embedded.permute(1,0,2) pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)pooled = self.relu(pooled)pooled = self.dropout(pooled)output = self.fc(pooled)return output
5、模型初始化
vocab_size = len(TEXT.vocab)
embedding_dim = 100
output = 1
pad_idx = TEXT.vocab.stoi[TEXT.pad_token]
model = NetWork(vocab_size,embedding_dim,output,pad_idx)
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
定义模型的超参数,包括词汇表大小(vocab_size)、词向量维度(embedding_dim)、输出维度(output,在这个任务中是1,因为是二元分类,所以使用1),以及 PAD 标记的索引(pad_idx)
之后需要将预训练的词向量加载到嵌入层的权重中。TEXT.vocab.vectors 包含了词汇表中每个单词的预训练词向量,然后通过 copy_ 方法将这些词向量复制到模型的嵌入层权重中对网络进行初始化。这样做确保了模型的初始化状态良好。
6、训练模型
total_loss = 0train_acc = 0
model.train()
for batch in train_iterator:optimizer.zero_grad()preds = model(batch.text).squeeze(1)loss = criterion(preds,batch.label)total_loss += loss.item()batch_acc = (torch.round(torch.sigmoid(preds)) == batch.label).sum().item()train_acc += batch_accloss.backward()optimizer.step()average_loss = total_loss / len(train_iterator)train_acc /= len(train_iterator.dataset)
optimizer.zero_grad():表示将模型参数的梯度清零,以准备接收新的梯度。
preds = model(batch.text).squeeze(1):表示一次前向传播的过程,由于model输出的是torch.tensor(batch_size,1)所以使用squeeze(1)给其中的1维度数据去除,以匹配标签张量的形状
criterion(preds,batch.label):定义的损失函数 criterion 计算预测值 preds 与真实标签 batch.label 之间的损失
(torch.round(torch.sigmoid(preds)) == batch.label).sum().item():
通过比较模型的预测值与真实标签,计算当前批次的准确率,并将其累加到 train_acc 中
后面的就是进行反向传播更新参数,还有就是计算loss和train_acc的值了
7、模型评估:
model.eval()valid_loss = 0valid_acc = 0best_valid_acc = 0with torch.no_grad():for batch in valid_iterator:preds = model(batch.text).squeeze(1)loss = criterion(preds,batch.label)valid_loss += loss.item()batch_acc = ((torch.round(torch.sigmoid(preds)) == batch.label).sum().item())valid_acc += batch_acc
和训练模型的类似,这里就不解释了
8、保存模型
这里一共使用了两种保存模型的方式:
torch.save(model, "model.pth")
torch.save(model.state_dict(),"model.pth")
第一种方式叫做模型的全量保存
第二种方式叫做模型的参数保存
全量保存是保存了整个模型,包括模型的结构、参数、优化器状态等信息
参数量保存是保存了模型的参数(state_dict),不包括模型的结构
9、测试模型
测试模型的基本思路:
加载训练保存的模型、对待推理的文本进行预处理、将文本数据加载给模型进行推理
加载模型:
saved_model_path = "model.pth"
saved_model = torch.load(saved_model_path)
输入文本:
input_text = “Great service! The staff was very friendly and helpful.”
文本进行处理:
tokenizer = get_tokenizer("spacy", language="en_core_web_sm")
tokenized_text = tokenizer(input_text)
indexed_text = [TEXT.vocab.stoi[token] for token in tokenized_text]
tensor_text = torch.LongTensor(indexed_text).unsqueeze(1).to(device)
模型推理:
saved_model.eval()
with torch.no_grad():output = saved_model(tensor_text).squeeze(1)prediction = torch.round(torch.sigmoid(output)).item()probability = torch.sigmoid(output).item()
由于笔者能力有限,所以在描述的过程中难免会有不准确的地方,还请多多包含!
更多NLP和CV文章以及完整代码请到"陶陶name"获取。
相关文章:
NLP项目实战01之电影评论分类
介绍: 欢迎来到本篇文章!在这里,我们将探讨一个常见而重要的自然语言处理任务——文本分类。具体而言,我们将关注情感分析任务,即通过分析电影评论的情感来判断评论是正面的、负面的。 展示: 训练展示如下…...

一款可无限扩展的软件定时器开源框架项目代码
摘自链接 时间片轮询架构如何稳定高效实现,取代传统的标志位判断方式,更优雅更方便地管理程序的时间触发操作。 可以在STM32单片机上运行。...

GRE与顺丰圆通快递盒子
1. DNS污染 随想: 在输入一串网址后,会发生如下变化如果你在系统中配置了 Hosts 文件,那么电脑会先查询 Hosts 文件如果 Hosts 里面没有这个别名,就通过域名服务器查询域名服务器回应了,那么你的电脑就可以根据域名服…...
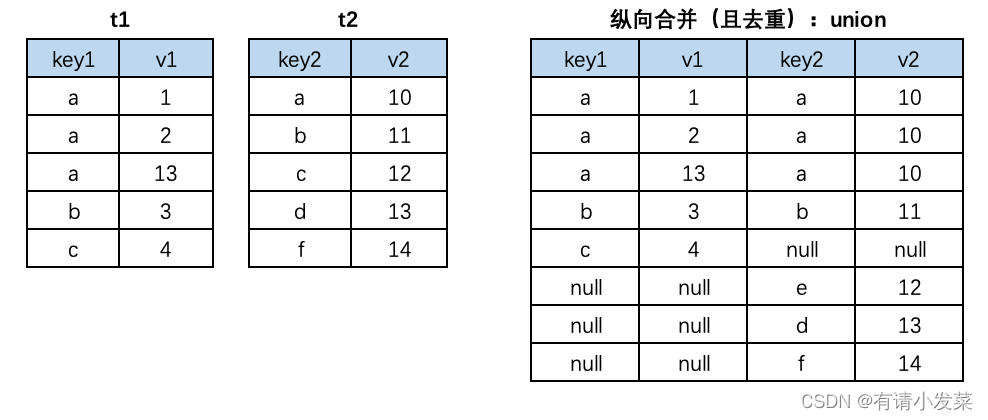
12.Mysql 多表数据横向合并和纵向合并
Mysql 函数参考和扩展:Mysql 常用函数和基础查询、 Mysql 官网 Mysql 语法执行顺序如下,一定要清楚!!!运算符相关,可前往 Mysql 基础语法和执行顺序扩展。 (8) select (9) distinct (11)<columns_name…...

线性回归与逻辑回归:深入解析机器学习的基石模型
目录 一、线性回归 二、逻辑回归 逻辑回归算法和 KNN 算法的区别 分类算法评价维度...

电脑待机怎么设置?让你的电脑更加节能
在日常使用电脑的过程中,合理设置待机模式是一项省电且环保的好习惯。然而,许多用户对于如何设置电脑待机感到困扰。那么电脑待机怎么设置呢?本文将深入探讨三种常用的电脑待机设置方法,通过详细的步骤,帮助用户更好地…...
数据库对象介绍与实践:视图、函数、存储过程、触发器和物化视图
文章目录 一、视图(View)1、概念2、基本操作1)创建视图2)修改视图3)删除视图4)使用视图 3、使用场景4、实践 二、函数(Function)1、概念2、基本操作1)创建函数2ÿ…...

arm平台编译so文件回顾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、几个点二、回顾过程 1.上来就执行Makefile2.编译第三方开源库.a文件 2.1 build.sh脚本2.2 Makefile3.最终编译三、其它知识点总结 前言 提示:这…...
【数据结构】顺序表的定义和运算
目录 1.初始化 2.插入 3.删除 4.查找 5.修改 6.长度 7.遍历 8.完整代码 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 &…...
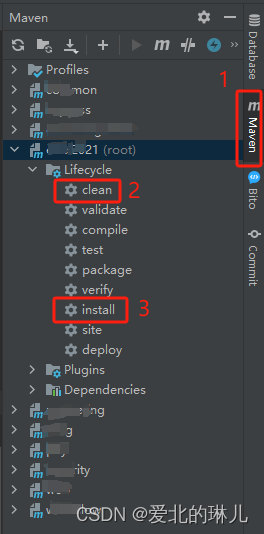
idea使用maven的package打包时提示“找不到符号”或“找不到包”
介绍:由于我们的项目是多模块开发项目,在打包时有些模块内容更新导致其他模块在引用该模块时不能正确引入。 情况一:找不到符号 情况一:找不到包 错误代码部分展示: Failure to find com.xxx.xxxx:xxx:pom:0.5 in …...

MetricBeat监控MySQL
目录 一、安装部署 二、开启mysql监控模块 三、编辑mysql配置文件 四、启动Metricbeat 五、查看监控图表 一、安装部署 metriceat的安装部署参考章节: Metricbeat安装使用,这里不再赘述。 二、开启mysql监控模块 进入metricbeat安装目录 ./metricb…...
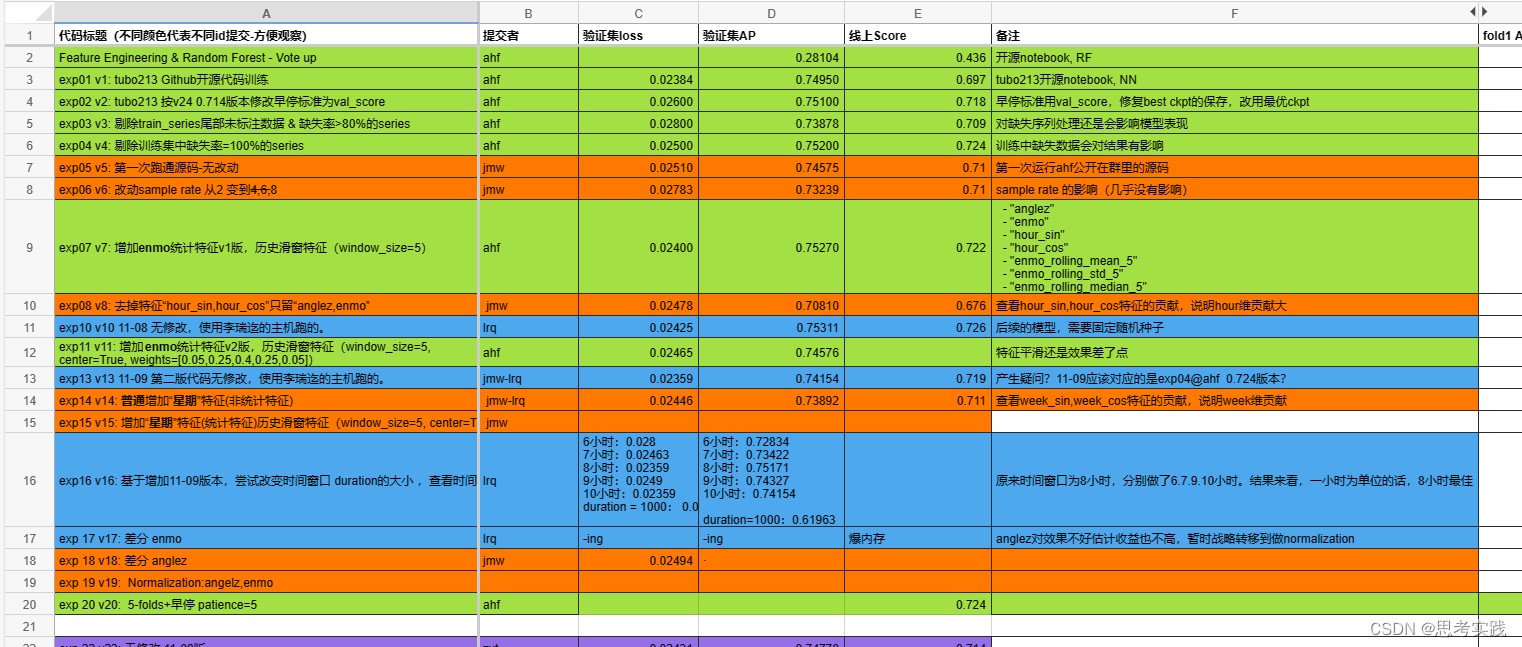
Child Mind Institute - Detect Sleep States(2023年第一次Kaggle拿到了银牌总结)
感谢 感谢艾兄(大佬带队)、rich师弟(师弟通过这次比赛机械转码成功、耐心学习)、张同学(也很有耐心的在学习),感谢开源方案(开源就是银牌),在此基础上一个月…...

Esxi7Esxi8设置VMFSL虚拟闪存的大小
Esxi7Esxi8设置VMFSL虚拟闪存的大小 ESXi7,8 默认安装会分配一个 VMFSL(VMFS-L)(Local VMFS)很大空间(120G), 感觉很浪费, 实际给 8G 就可以了, 最少 6G , 经实验,给2G没法安装 . Esxi7是虚拟闪存的 修改的方法是: 在安装时修改 设置 autoPartitionOSDataSize8192 在cdromBoo…...
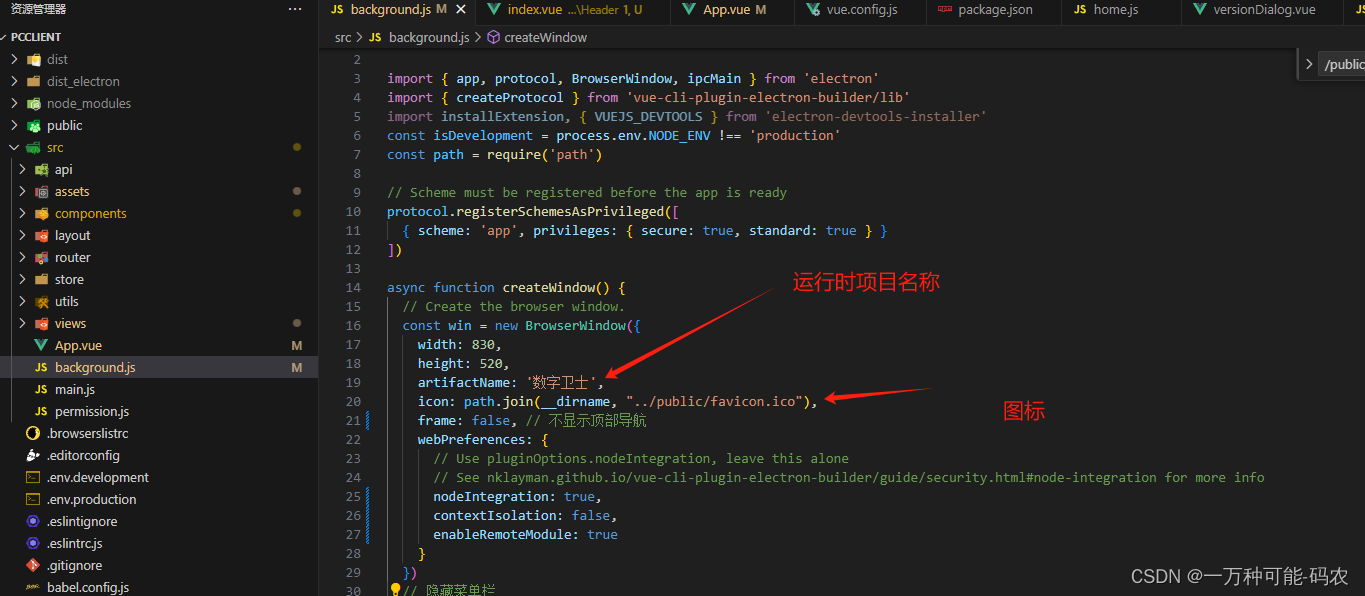
vue2+electron桌面端一体机应用
vue2+electron项目 前言:公司有一个项目需要用Vue转成exe,首先我使用vue-cli脚手架搭建vue2项目,然后安装electron 安装electron 这一步骤可以省略,安装electron-builder时会自动安装electron npm i electron 安装electron-builder vue add electron-builder 项目中多出…...

目标检测——OverFeat算法解读
论文:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 作者:Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun 链接:https://arxiv.org/abs/1312.6229 文章…...

vue获取主机id和IP地址
获取主机id和IP地址 在vue.config.js const os require(“os”); function getNetworkIp() { let needHost “”; // 打开的host try { // 获得网络接口列表 let network os.networkInterfaces(); for (let dev in network) { let iface network[dev]; for (let i 0; i …...
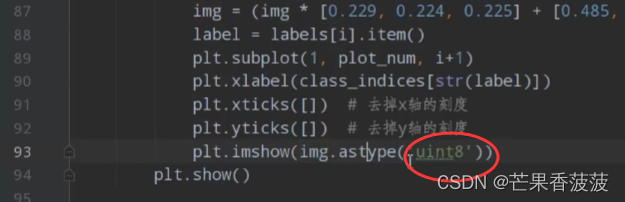
在pytorch中自定义dataset读取数据
这篇是我对哔哩哔哩up主 霹雳吧啦Wz 的视频的文字版学习笔记 感谢他对知识的分享 有关我们数据读取预训练 以及如何将它打包成一个一个batch输入我们的网络的 首先我们来看一下之前我们在讲resnet网络时所使用的源码 我们去使用了官方实现的image folder去读取我们的图像数据 然…...

ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
1.关于稀疏卷积的解释:https://zhuanlan.zhihu.com/p/382365889 2. 答案: 在深度学习领域,尤其是计算机视觉任务中,遮蔽图像建模(Masked Image Modeling, MIM)是一种自监督学习策略,其基本思想…...

Java后端的登录、注册接口是怎么实现的
目录 Java后端的登录、注册接口是怎么实现的 Java后端的登录接口是怎么实现的 Java后端的注册接口怎么实现? 如何防止SQL注入攻击? Java后端的登录、注册接口是怎么实现的 Java后端的登录接口是怎么实现的 Java后端的登录接口的实现方式有很多种&a…...

TCP Keepalive 和 HTTP Keep-Aliv
HTTP的Keep-Alive 在http1.0的版本中,它是基于请求-应答模型和TCP协议的,也就是在建立TCP连接后,客户端发送一次请求并且接收到响应后,就会立马断开TCP连接,称为HTTP短连接,这种方式比较耗费时间以及浪费资…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...
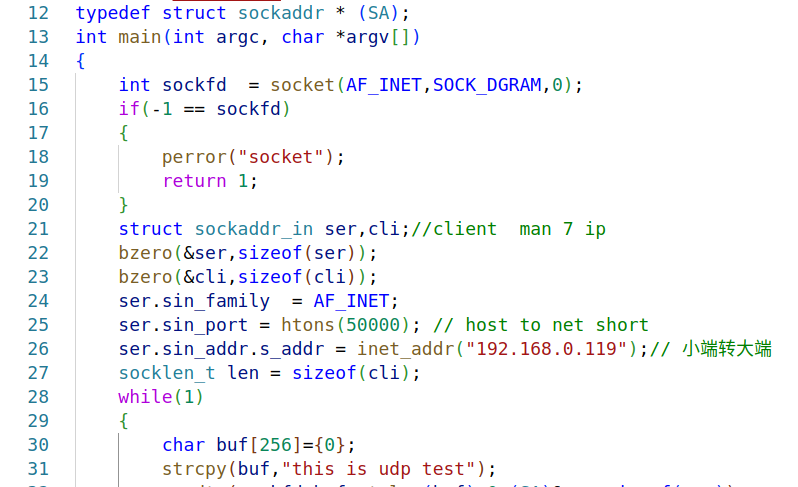
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...