【文件上传系列】No.1 大文件分片、进度图展示(原生前端 + Node 后端 Koa)
分片(500MB)进度效果展示
效果展示,一个分片是 500MB 的
分片(10MB)进度效果展示
大文件分片上传效果展示
前端
思路
前端的思路:将大文件切分成多个小文件,然后并发给后端。
页面构建
先在页面上写几个组件用来获取文件。
<body><input type="file" id="file" /><button id="uploadButton">点击上传</button>
</body>
功能函数:生成切片
切分文件的核心函数是 slice,没错,就是这么的神奇啊
我们把切好的 chunk 放到数组里,等待下一步的包装处理
/*** 默认切片大小 10 MB*/
const SIZE = 10 * 1024 * 1024;/*** 功能:生成切片*/
function handleCreateChunk(file, size = SIZE) {const fileChunkList = [];progressData = [];let cur = 0;while (cur < file.size) {fileChunkList.push({file: file.slice(cur, cur + size),});cur += size;}return fileChunkList;
}
功能函数:请求逻辑
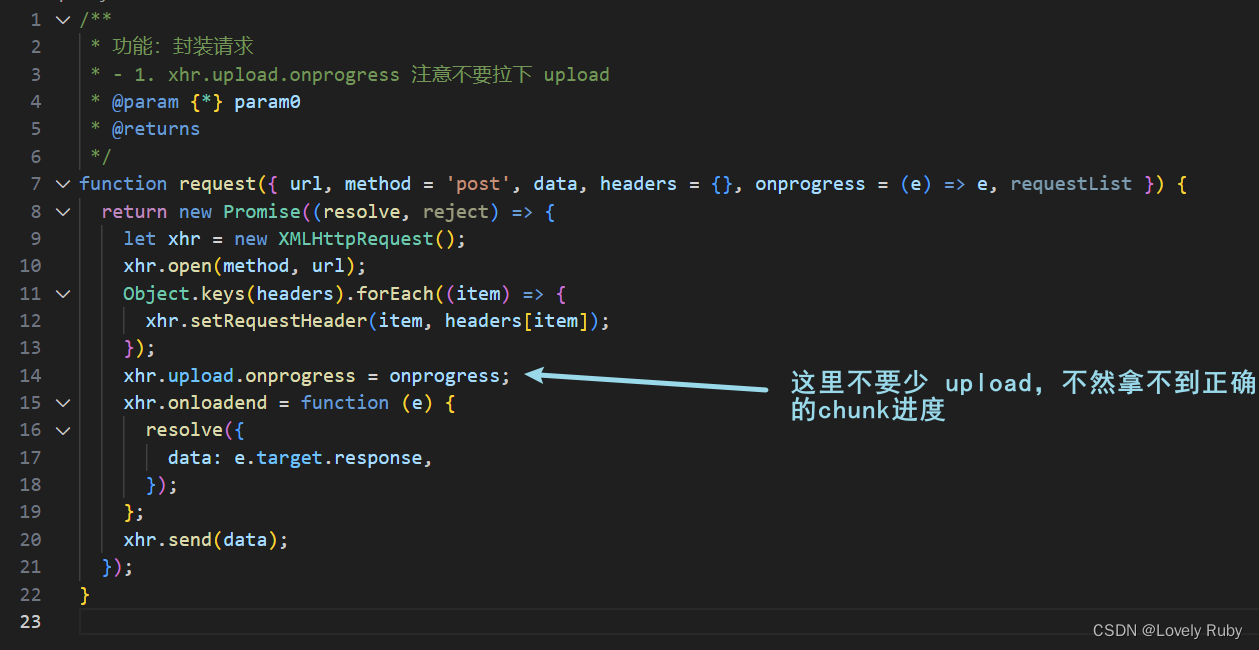
在这里简单封装一下 XMLHttpRequest
/*** 功能:封装请求* @param {*} param0* @returns*/
function request({ url, method = 'post', data, header = {}, requestList }) {return new Promise((resolve, reject) => {let xhr = new XMLHttpRequest();xhr.open(method, url);Object.keys(header).forEach((item) => {xhr.setRequestHeader(item, header[item]);});xhr.onloadend = function (e) {resolve({data: e.target.response,});};xhr.send(data);});
}
功能函数:上传切片
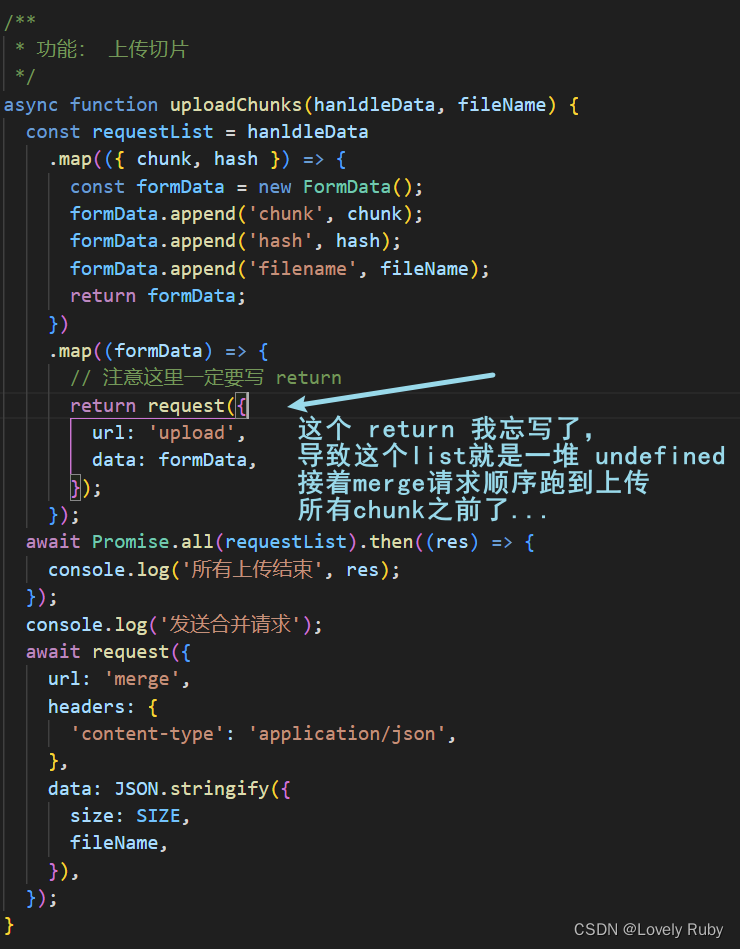
/*** 功能: 上传切片* 包装好 FormData 之后通过 Promise.all() 并发所有切片*/
async function uploadChunks(hanldleData, fileName) {const requestList = hanldleData.map(({ chunk, hash }) => {const formData = new FormData();formData.append('chunk', chunk);formData.append('hash', hash);formData.append('filename', fileName);return formData;}).map((formData) => {request({// url: 'http://localhost:3001/upload',url: 'upload',data: formData,});});await Promise.all(requestList);
}/*** 功能:触发上传
*/
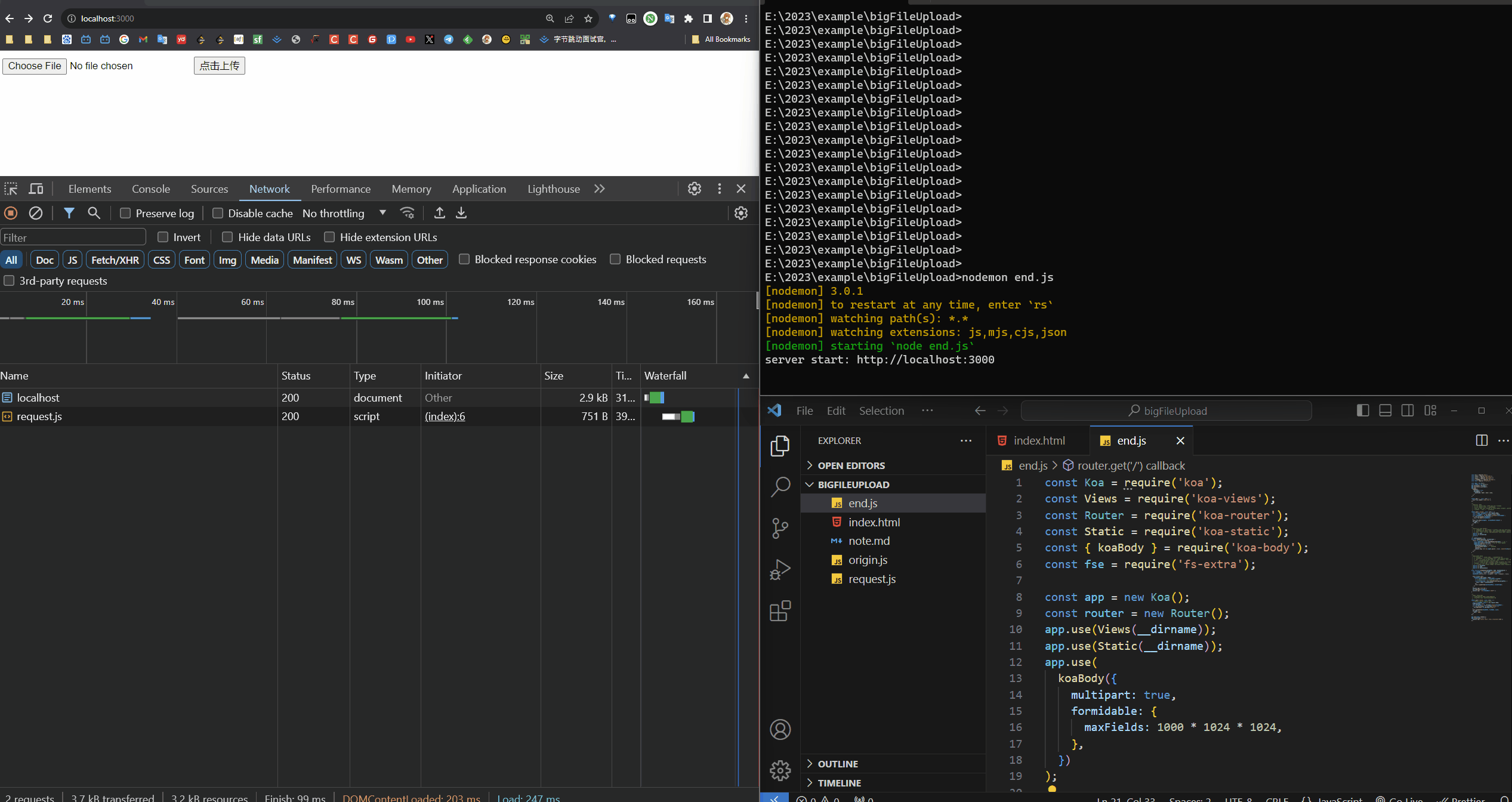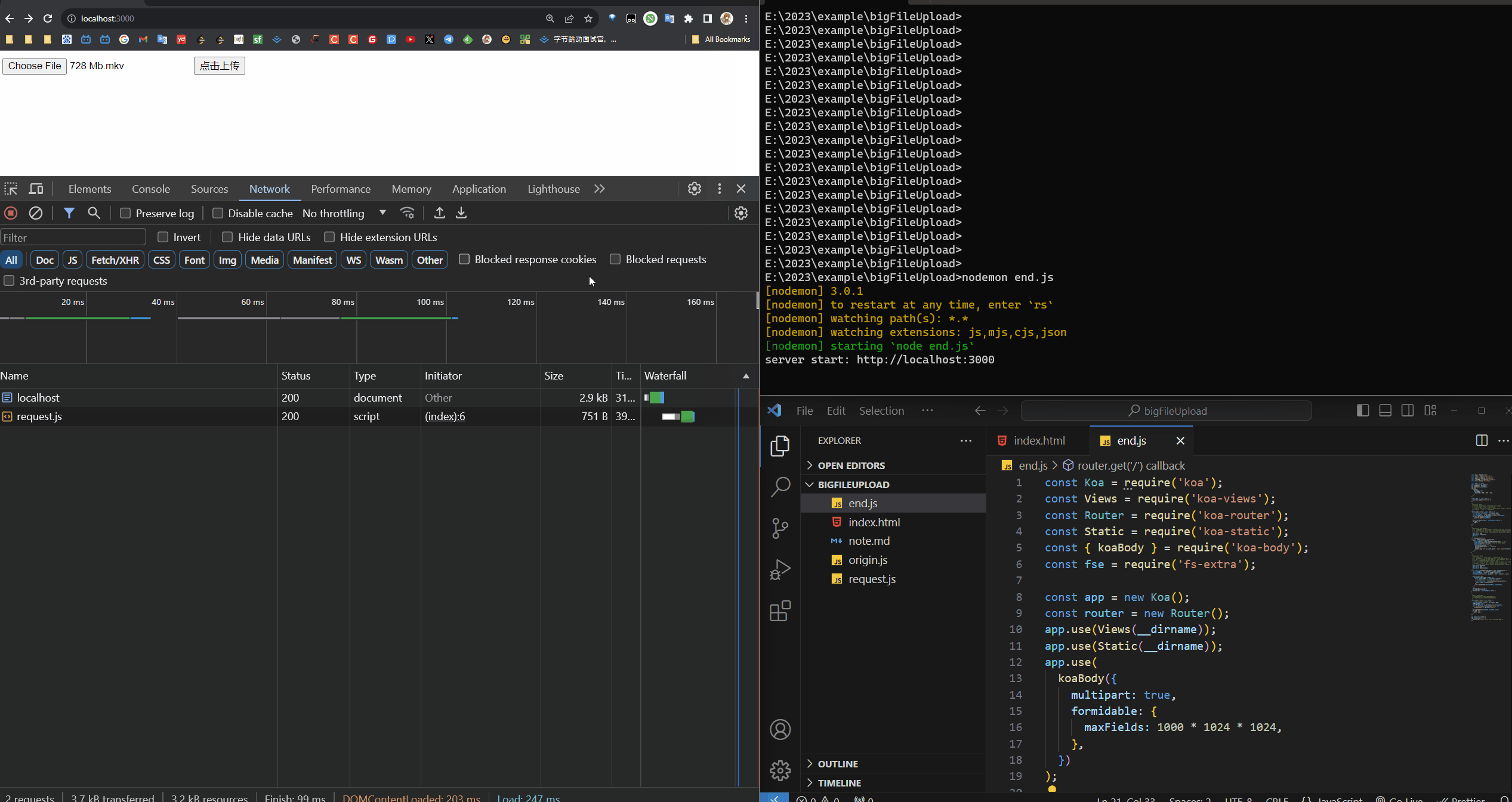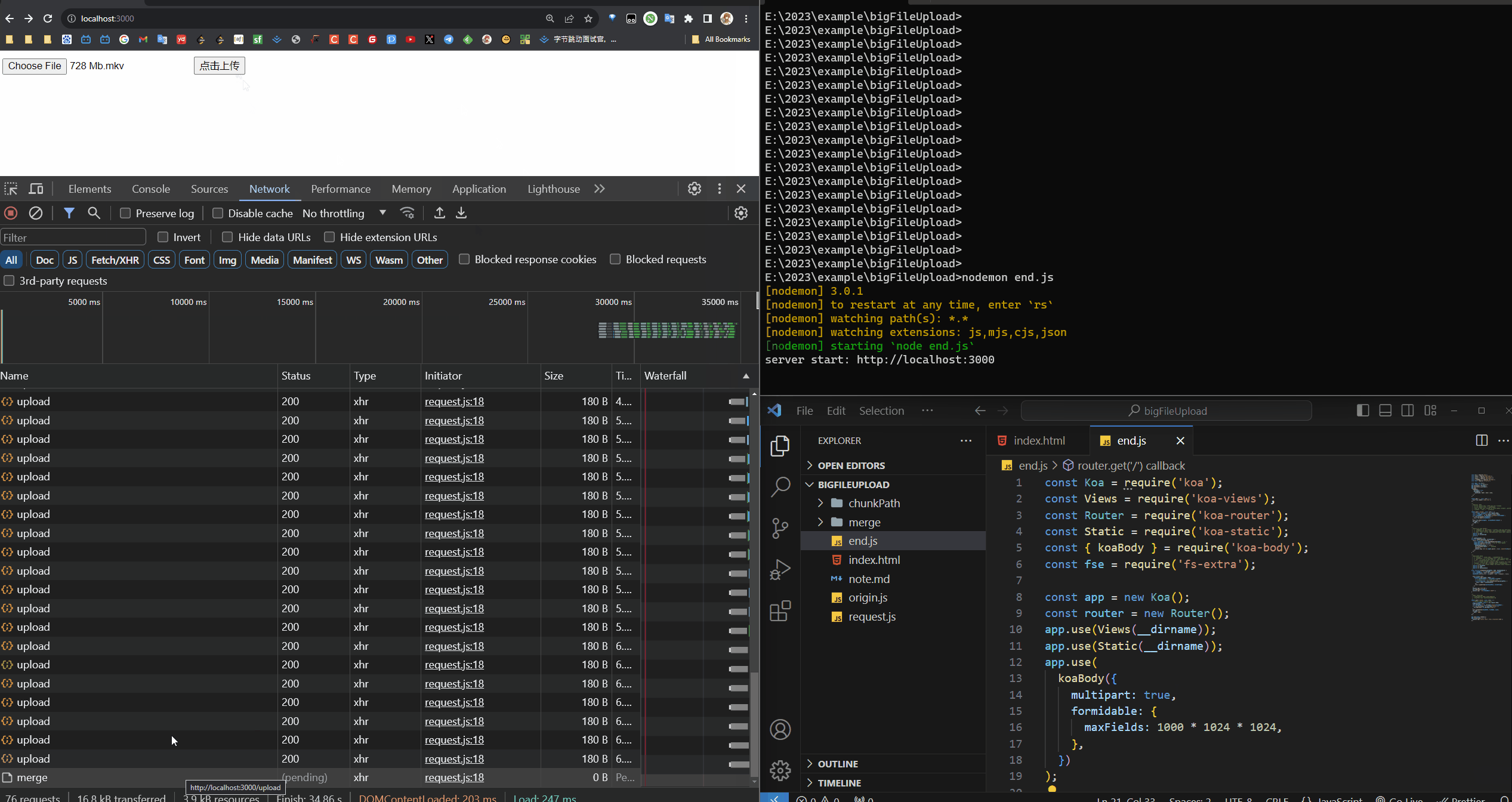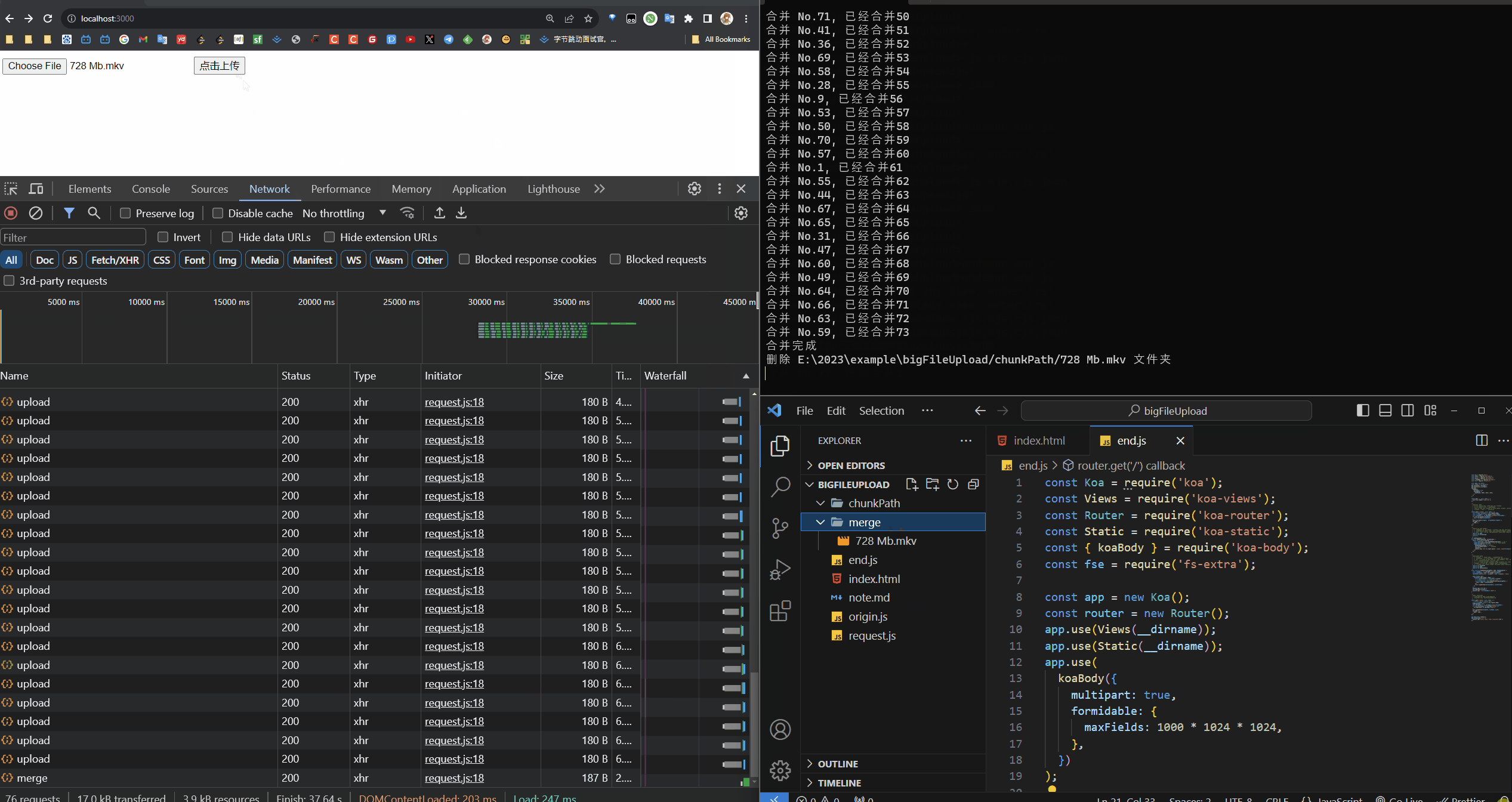
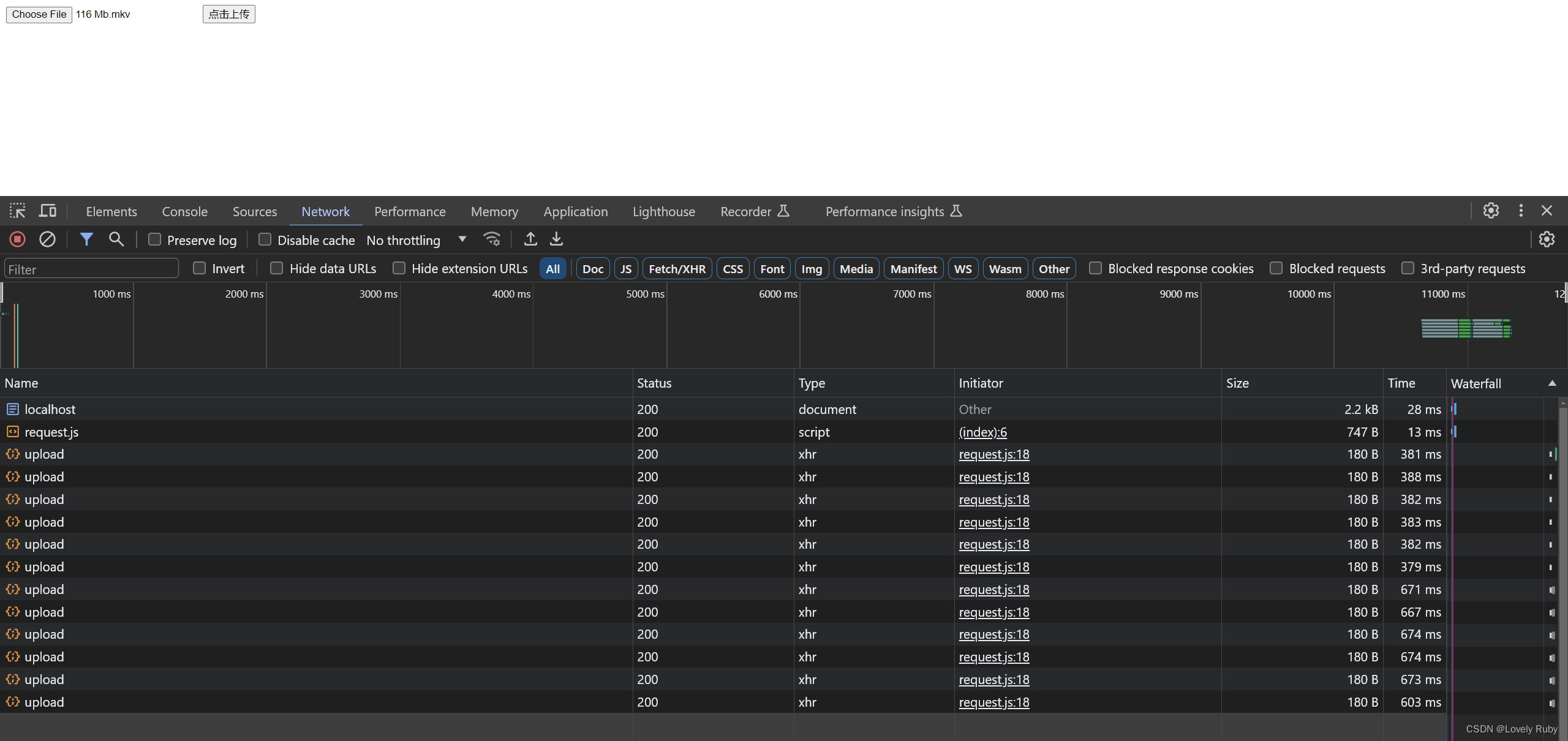
document.getElementById('uploadButton').onclick = async function () {// 切片const file = document.getElementById('file').files[0];console.log(file);const fileName = file.name;const fileChunkList = handleCreateChunk(file);// 包装const hanldleData = fileChunkList.map(({ file }, index) => {return {chunk: file,hash: `${fileName}_${index}`,};});await uploadChunks(hanldleData, fileName);
};
可以在请求中看到有很多个请求并发的上传
优化:进度条的生成
自己简单撸了几个 cube 进度条
<style>#uploadCube {margin-top: 10px;/* width: 520px; */overflow: hidden;}.cube {width: 50px;height: 50px;background-color: #fff;float: left;border: 1px solid #000;.progress {height: 100%;line-height: 50px;text-align: center;}.uploading {background-color: #409eff;}.success {background-color: #51f400;}.error {background-color: #ff9090;}}
</style>
<body><input type="file" id="file" /><button id="uploadButton">点击上传</button><div id="uploadCube"></div>
</body>
/*** 功能:生成页面进度的 HTML*/
function handleUpdateHTML(progressData) {let uploadCube = document.querySelector('#uploadCube');let html = '';progressData.forEach((item) => {const { presentage } = item;let className = '';if (presentage < 100) {className = 'progress uploading';} else if (presentage == 100) {className = 'progress success';}html += ` <div class="cube"><div class="${className}" style="width: ${presentage}%">${presentage}%</div></div>`;});uploadCube.innerHTML = html;
}/*** 功能:处理每个 chunk 的 xhr.upload.onprogress,拿到各个 chunk 的上传进度* - 1. 同时通过 handleUpdateHTML 更新进度页面* - 2. progressData 用来记录各个 chunk 的进度*/
let progressData = [];
function handleCreateOnProgress(data) {return (e) => {data.presentage = ((e.loaded / e.total) * 100).toFixed(2);console.log(JSON.stringify(progressData));handleUpdateHTML(progressData);};
}
后端 (Koa)
后端的思路是:
- 把 Node 暂存的
chunk文件转移到我想处理的地方(也可以直接处理,看你的)- 创建写入流,把各个
chunk合并,前端会给你每个 chunk 的大小,还有hash值来定位每个chunk的位置
获取 chunk 切片文件
先把上传的接口写好
const Koa = require('koa');
const Views = require('koa-views');
const Router = require('koa-router');
const Static = require('koa-static');
const { koaBody } = require('koa-body');
const fs = require('fs');
const fse = require('fs-extra');const app = new Koa();
const router = new Router();
app.use(Views(__dirname));
app.use(Static(__dirname));
app.use(koaBody({multipart: true,formidable: {maxFields: 1000 * 1024 * 1024,},})
);router.get('/', async (ctx) => {await ctx.render('index.html');
});/*** 功能:上传接口* - 从 ctx.request.body 中获取 hash 以及 filename* - 从 ctx.request.files 中拿到分片数据* - 然后再把 node 帮我们临时存放的 chunk 文件的 filepath 拿到,之后移动到我们想要存放的路径下* - filepath 和 hash 是一一对应的关系*/
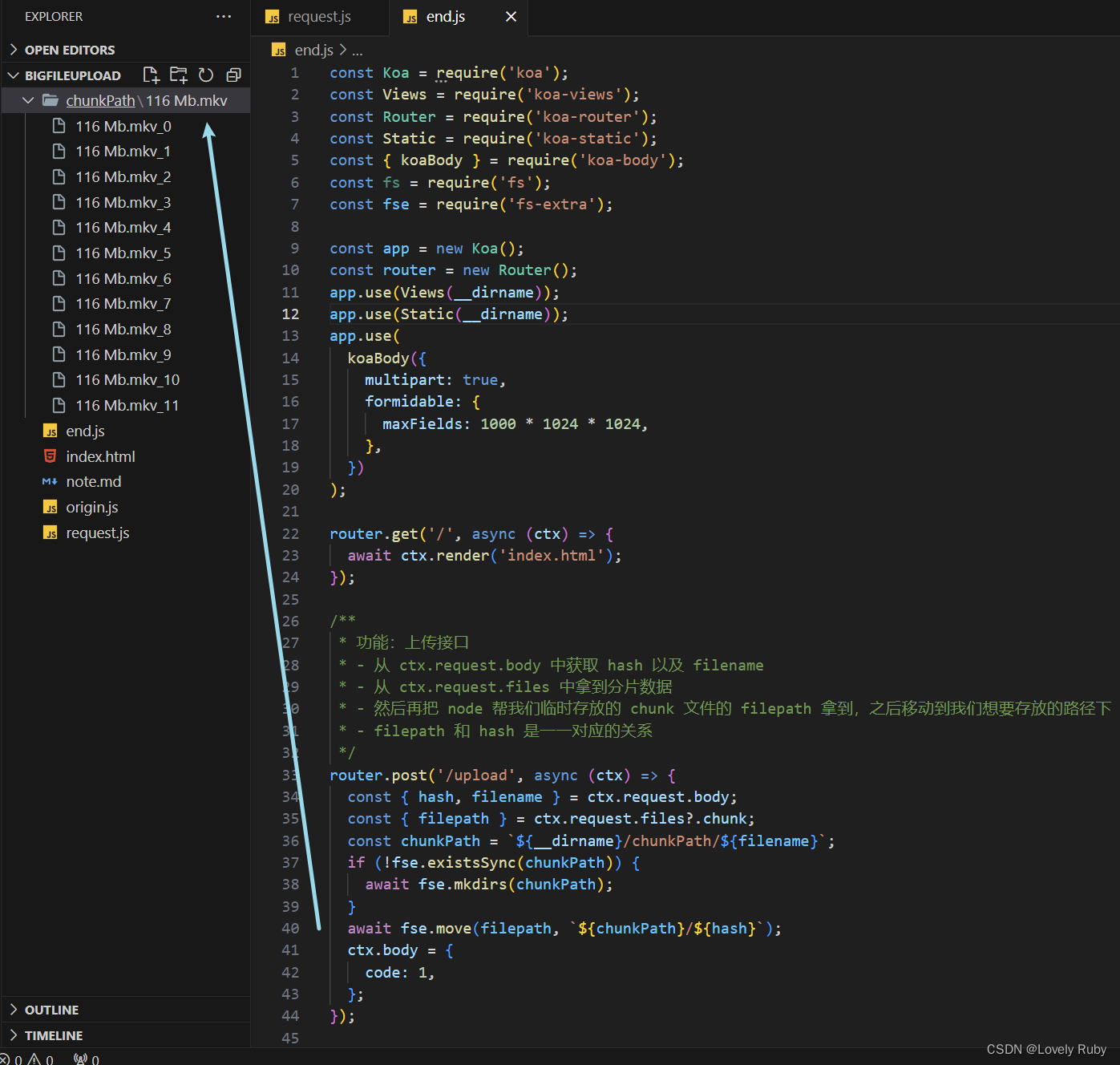
router.post('/upload', async (ctx) => {const { hash, filename } = ctx.request.body;const { filepath } = ctx.request.files?.chunk;const chunkPath = `${__dirname}/chunkPath/${filename}`;if (!fse.existsSync(chunkPath)) {await fse.mkdirs(chunkPath);}await fse.move(filepath, `${chunkPath}/${hash}`);ctx.body = {code: 1,};
});app.use(router.routes());
app.listen(3000, () => {console.log(`server start: http://localhost:3000`);
});
写完这些就可以拿到 chunk
合并接口
先写一个接口,用来拿到 hash、文件名
/*** 功能: merge 接口* - hasMergeChunk 变量是上面用来记录的* - mergePath 定义一下合并后的文件的路径*/
router.post('/merge', async (ctx) => {// console.log(ctx.request.body);const { fileName, size } = ctx.request.body;hasMergeChunk = {};const mergePath = `${__dirname}/merge/${fileName}`;if (!fse.existsSync(`${__dirname}/merge`)) {fse.mkdirSync(`${__dirname}/merge`);}await mergeChunk(mergePath, fileName, size);ctx.body = {data: '成功',};
});
合并分片的功能函数
然后开始合并
/*** 功能:合并 Chunk* - 1. chunkDir: 是 chunks 文件们所在的文件夹的路径* - 2. chunkPaths: 是个 Array,数组中包含所有的 chunk 的 path* - 3. 因为 每个 chunk 的 path 命名是通过 hash 组成的,所以我们先排序一下,* - 算是为 createWriteStream 中的 start 做准备* - 4. 为每个 chunk 的 path 创建写入流,写到 mergePath 这个路径下。因为已经* - 排序了,所以 start 就是每个文件的 index * eachChunkSize* @param {*} mergePath* @param {*} name* @param {*} eachChunkSize*/
async function mergeChunk(mergePath, name, eachChunkSize) {const chunkDir = `${__dirname}/chunkPath/${name}`;const chunkPaths = await fse.readdir(chunkDir);chunkPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);await Promise.all(chunkPaths.map((chunk, index) => {const eachChunkPath = `${chunkDir}/${chunk}`;const writeStream = fse.createWriteStream(mergePath, {start: index * eachChunkSize,});return pipeStream(eachChunkPath, writeStream);}));console.log('合并完成');fse.rmdirSync(chunkDir);console.log(`删除 ${chunkDir} 文件夹`);
}
接着就是写入流
/*** 功能:创建 pipe 写文件流* - 1. [首先了解一下什么是输入输出流](https://www.jmjc.tech/less/111)* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。* - 3. 可以检测输出流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。* @param {*} path* @param {*} writeStream* @returns*/
let hasMergeChunk = {};
function pipeStream(path, writeStream) {return new Promise((resolve) => {const readStream = fse.createReadStream(path); // 输出流readStream.pipe(writeStream); // 输出通过管道流向输入readStream.on('end', () => {hasMergeChunk[path] = 'finish';fse.unlinkSync(path); // 删除此文件resolve();console.log(`合并 No.${path.split('_')[1]}, 已经合并${Object.keys(hasMergeChunk).length}`);});});
}
至此一个基本的逻辑上传就做好了!
后端 (Node 原生)
想了想还是有必要用原生写一下 ,复习一下。
基础:搭建简单的服务
先写一个基本的服务框架
const http = require('http');
const server = http.createServer();
server.on('request', async (req, res) => {res.setHeader('Access-Control-Allow-Origin', '*');res.setHeader('Access-Control-Allow-Headers', '*');if (req.method === 'OPTION') {res.status = 200;res.end();return;}res.end('hello node');
});
const POST = 3000;
server.listen(POST, null, null, () => {console.log(`server start: http://localhost:${POST}`);
});
基础:资源返回
添加页面的返回,以及资源的返回
const http = require('http');
const server = http.createServer();
const url = require('url');
const fs = require('fs');
const path = require('path');
const MIME = require('./mime.json');
server.on('request', async (req, res) => {res.setHeader('Access-Control-Allow-Origin', '*');res.setHeader('Access-Control-Allow-Headers', '*');res.setHeader('content-type', 'text/html;charset=utf-8');if (req.method === 'OPTION') {res.status = 200;res.end();return;}let { pathname } = url.parse(req.url); // 解析一下 url,因为 req.url 可能会带一些参数// console.log('req.url:>>', req.url);// console.log('url.parse(req.url):>>', url.parse(req.url));console.log(`进入${pathname}`);switch (pathname) {case '/':case '/index': {let rs = fs.createReadStream('./index.html');rs.pipe(res);break;}case '/favicon.ico': {res.end('我没有哦');break;}default: {let ext = path.extname(pathname);res.setHeader('Content-Type', MIME[ext]); // 通过请求的资源后缀名,来返回对应的 Content-type 的类型let rs = fs.createReadStream(`.${pathname}`);rs.pipe(res);}}
});
const POST = 3000;
server.listen(POST, null, null, () => {console.log(`server start: http://localhost:${POST}`);
});
MIME.json 在这个文章的最底下, 或者可以自己找个更全的。
功能:上传接口
接着写上传的接口,这里参考大圣老师的代码,写一个类来收集方法。
类定义如下,新建一个文件 controller.js:
/*** module.exports 方法用于在服务器端导出模块,并以 CommonJS 格式提供。* - 参考:https://www.delftstack.com/zh/howto/node.js/create-and-export-classes/*/
const multiparty = require('multiparty');
const fse = require('fs-extra');
class Controller {constructor(dirPath) {this.chunkPath = dirPath;}/*** multiparty 使用方法:https://www.npmjs.com/package/multiparty* - chunkFileDirPath 为关于文件 chunks 的文件夹路径,每个大文件根据文件名生成相关的文件夹* - 注意回调函数里的 this* @param {*} url* @param {*} path*/async handleUpload(req, res) {const _this = this;const form = new multiparty.Form();form.parse(req, async function (err, fields, files) {if (err) {console.log(err);return;}const [chunk] = files.chunk;const [hash] = fields.hash;const [filename] = fields.filename;const chunkFileDirPath = `${_this.chunkPath}/${filename}`;if (!fse.existsSync(chunkFileDirPath)) {await fse.mkdirs(chunkFileDirPath);}await fse.move(chunk?.path, `${chunkFileDirPath}/${hash}`);res.end('收到文件 chunks');});}
}
module.exports = Controller;然后在主服务里引入这个类,再上传接口这里调用一下类方法。
// ...
const Controller = require('./controller');
const UPLOAD_DIR = `${__dirname}/chunkPath`; // chunks 上传的文件夹
const controller = new Controller(UPLOAD_DIR);
// ...
case '/upload': {await controller.handleUpload(req, res);break;
}
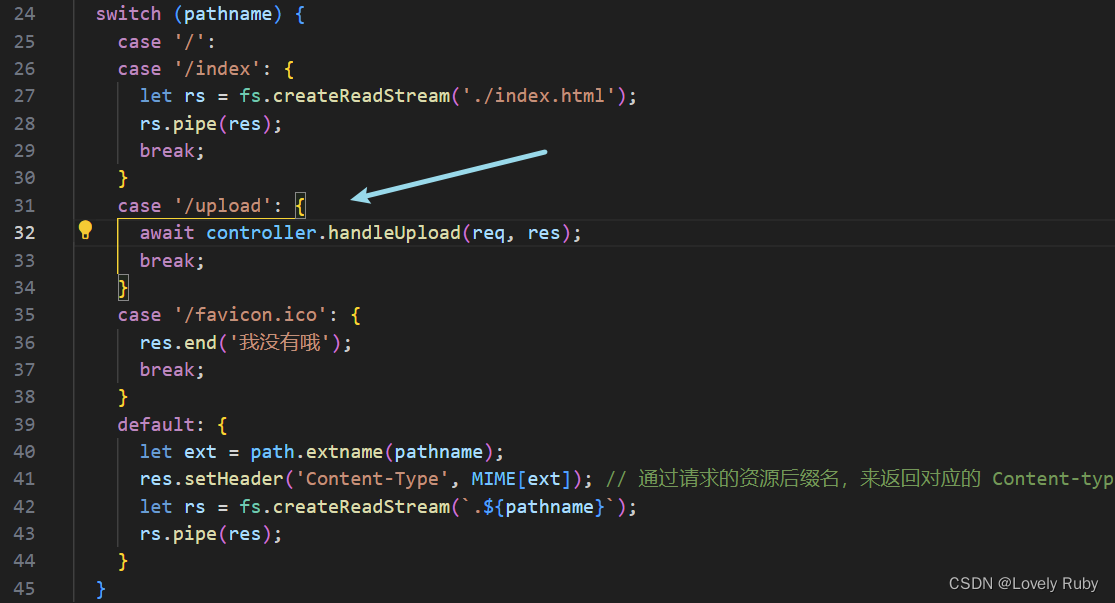
功能:写合并接口
合并的逻辑跟 Koa 几乎没什么差别,只不过我都把方法封装到类里了。
首先写路由
case '/merge': {await controller.handleMerge(req, res);break;
}
然后在类中定义合并的方法
/*** 功能:合并* - 1. handlePostData 用来处理 POST 传递的数据,具体怎么处理的请查看方法* - 2. 把各个文件的 path 先想清楚要存到哪儿,建议自己写一写。* - 我是把所有的 chunks 都放到大目录 chunkPath 中,* - 然后在用文件名新建文件夹,再把chunks放到子文件夹中。* @param {*} req* @param {*} res*/
async handleMerge(req, res) {const postData = await handlePostData(req);const { fileName, size: eachChunkSize } = postData;const mergePath = `${__dirname}/merge`;const mergeFilePath = `${__dirname}/merge/${fileName}`;if (!fse.existsSync(mergePath)) {fse.mkdirSync(mergePath);}const mergeOptions = { chunksPath: this.chunksPath, mergeFilePath, fileName, eachChunkSize };await handleMergeChunks(mergeOptions);console.log('Success Merge');res.end(JSON.stringify({code: 1,message: 'success merge',}));
}
这里的 POST 请求需要处理一下
/*** 功能:处理 POST 请求* - 与 GET 数据相比,POST 数据量大,需要分段。* - 通过 req.on('data', function(data) {}) 监听* - 当有一段数据到达的时候执行回调,回调函数参数 data 为每段达到的数据。* - 当数据全部到达时会触发 req.on('end', function() {}) 里面的回调函数。* - 可以通过 JSON.parse(str) 解析成我们想要的 POST 请求数据格式。* - 参考资料:https://juejin.cn/post/7142700338414518286#heading-2* @param {*} req* @returns*/
function handlePostData(req) {return new Promise((resolve, reject) => {let allData = '';let i = 0;req.on('data', function (chunkData) {// console.log(`第 ${++i} 次收到数据`);allData += chunkData;});req.on('end', function () {const POST_MESSAGE = JSON.parse(allData);resolve(POST_MESSAGE);});});
}
然后就是合并 chunks,具体的注释我都放到代码里了
/*** 功能:合并 chunks* - 1. 首先根据 fileChunksDir 拿到所有 chunks 的文件名* - 2. 然后拼接成 fileAllChunksPaths <Array> 数组,然后一一创建可写流* - 3. fileAllChunksPaths 注意这里需要排序一下,不然就是乱的,这也是我们创建可写流 srart 位置的基础* - 4. 然后这里通过 pipeStream 函数用 Promise 包装了一下可读流,代码需要慢慢读去理解。* - 5. 我们这里的 可写流们,是根据 chunks 的不同,定义好写入的文件 path,* - 以及每个块儿写的开始位置和写入大小,每个可写流都是不一样的!* - 6. hasMergeChunk 初始化一下数据* @param {*} param0*/
async function handleMergeChunks({ chunksPath, mergeFilePath, fileName, eachChunkSize }) {hasMergeChunk = {};const fileChunksDir = `${chunksPath}/${fileName}`;const fileAllChunksPaths = await fse.readdir(fileChunksDir);console.log(fileAllChunksPaths);fileAllChunksPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);const promiseArray = fileAllChunksPaths.map((chunk, index, array) => {const eachChunkPath = `${fileChunksDir}/${chunk}`;const writeStream = fse.createWriteStream(mergeFilePath, {start: index * eachChunkSize,});return pipeStream(eachChunkPath, writeStream, array.length);});await Promise.all(promiseArray);
}
把创建写文件流功能也拆分出来。不了解流的概念的话,首先了解一下什么是输入可读流。
/*** 功能:创建 pipe 写文件流* - 1. [首先了解一下什么是输入可读流](https://www.jmjc.tech/less/111)* - 方便记忆:可读流 通过 管道 流入 可写流。 可读流 =======> 可写流* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。* - 3. 可以检测可读流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。* @param {*} path* @param {*} writeStream* @returns*/
let hasMergeChunk = {};
function pipeStream(path, writeStream, length) {return new Promise((resolve) => {const readStream = fse.createReadStream(path);readStream.pipe(writeStream);readStream.on('end', function () {hasMergeChunk[path] = 'finished';fse.unlinkSync(path);resolve();console.log(`doing: No.${path.split('_')[1]} progress: [ ${Object.keys(hasMergeChunk).length} / ${length} ]`);});});
}
结语
真的只是收藏不点赞嘛…
上传还有合并这两大功能基本上也就完成啦!觉得有用的话,请点个赞吧~谢谢吴彦祖们!!!

参考文章
- 字节跳动面试官:请你实现一个大文件上传和断点续传
- 字节跳动面试官,我也实现了大文件上传和断点续传
Q & A
Q: 发送片段之后的合并可能出现错误
这个情况分析了一下是前端的锅啊,前端的 await Promise.all() 并不能保证后端的文件流都写完了。
Q: 进度条直接从 0 到了 100
我发现我的请求写错了
完整代码
前端
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><title>Document</title><script src="request.js"></script><style>#uploadCube {margin-top: 10px;/* width: 520px; */overflow: hidden;}.cube {width: 50px;height: 50px;background-color: #fff;float: left;border: 1px solid #000;.progress {height: 100%;line-height: 50px;text-align: center;}.uploading {background-color: #409eff;}.success {background-color: #51f400;}.error {background-color: #ff9090;}}</style></head><body><input type="file" id="file" /><button id="uploadButton">点击上传</button><!-- <button id="mergeButton">点击合并</button> --><div id="uploadCube"></div></body><script>/*** 默认切片大小*/const SIZE = 10 * 1024 * 1024;/*** 功能:生成切片*/function handleCreateChunk(file, size = SIZE) {const fileChunkList = [];progressData = [];let cur = 0;while (cur < file.size) {fileChunkList.push({file: file.slice(cur, cur + size),});progressData.push({ presentage: 0 });cur += size;}return fileChunkList;}/*** 功能:生成页面进度的 HTML*/function handleUpdateHTML(progressData) {let uploadCube = document.querySelector('#uploadCube');let html = '';progressData.forEach((item) => {const { presentage } = item;let className = '';if (presentage < 100) {className = 'progress uploading';} else if (presentage == 100) {className = 'progress success';}html += ` <div class="cube"><div class="${className}" style="width: ${presentage}%">${presentage}%</div></div>`;});uploadCube.innerHTML = html;}/*** 功能:处理每个 chunk 的 xhr.upload.onprogress,拿到各个 chunk 的上传进度* - 1. 同时通过 handleUpdateHTML 更新进度页面* - 2. progressData 用来记录各个 chunk 的进度*/let progressData = [];function handleCreateOnProgress(data) {return (e) => {data.presentage = ((e.loaded / e.total) * 100).toFixed(2);console.log(JSON.stringify(progressData));handleUpdateHTML(progressData);};}/*** 功能: 上传切片* - 注意 map 里别忘了写 return*/async function uploadChunks(hanldleData, fileName) {const requestList = hanldleData.map(({ chunk, hash, index }) => {const formData = new FormData();formData.append('chunk', chunk);formData.append('hash', hash);formData.append('filename', fileName);return { formData, index };}).map(({ formData, index }) => {return request({url: 'upload',data: formData,onprogress: handleCreateOnProgress(progressData[index]),});});await Promise.all(requestList).then((res) => {console.log('所有上传结束', res);});console.log('发送合并请求');await request({url: 'merge',headers: {'content-type': 'application/json',},data: JSON.stringify({size: SIZE,fileName,}),});}document.getElementById('uploadButton').onclick = async function () {// 切片const file = document.getElementById('file').files[0];const fileName = file.name;const fileChunkList = handleCreateChunk(file);// 包装const hanldleData = fileChunkList.map(({ file }, index) => {return {chunk: file,hash: `${fileName}_${index}`,index,};});await uploadChunks(hanldleData, fileName);};</script>
</html>后端 Koa
const Koa = require('koa');
const Views = require('koa-views');
const Router = require('koa-router');
const Static = require('koa-static');
const { koaBody } = require('koa-body');
const fse = require('fs-extra');const app = new Koa();
const router = new Router();
app.use(Views(__dirname));
app.use(Static(__dirname));
app.use(koaBody({multipart: true,formidable: {maxFileSize: 1000 * 1024 * 1024,},})
);router.get('/', async (ctx) => {await ctx.render('index.html');
});/*** 功能:上传接口* - 从 ctx.request.body 中获取 hash 以及 filename* - 从 ctx.request.files 中拿到分片数据* - 然后再把 node 帮我们临时存放的 chunk 文件的 filepath 拿到,之后移动到我们想要存放的路径下* - filepath 和 hash 是一一对应的关系*/
router.post('/upload', async (ctx) => {const { hash, filename } = ctx.request.body;const { filepath } = ctx.request.files?.chunk;const chunkPath = `${__dirname}/chunkPath/${filename}`;if (!fse.existsSync(chunkPath)) {await fse.mkdirs(chunkPath);}await fse.move(filepath, `${chunkPath}/${hash}`);ctx.body = {code: 1,};
});/*** 功能:创建 pipe 写文件流* - 1. [首先了解一下什么是输入可读流](https://www.jmjc.tech/less/111)* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。* - 3. 可以检测可读流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。* @param {*} path* @param {*} writeStream* @returns*/
let hasMergeChunk = {};
function pipeStream(path, writeStream) {return new Promise((resolve) => {const readStream = fse.createReadStream(path); // 可读流readStream.pipe(writeStream); // 可读流通过管道流向可写流readStream.on('end', () => {hasMergeChunk[path] = 'finish';fse.unlinkSync(path); // 删除此文件resolve();console.log(`合并 No.${path.split('_')[1]}, 已经合并${Object.keys(hasMergeChunk).length}`);});});
}/*** 功能:合并 Chunk* - 1. chunkDir: 是 chunks 文件们所在的文件夹的路径* - 2. chunkPaths: 是个 Array,数组中包含所有的 chunk 的 path* - 3. 因为 每个 chunk 的 path 命名是通过 hash 组成的,所以我们先排序一下,* - 算是为 createWriteStream 中的 start 做准备* - 4. 为每个 chunk 的 path 创建写入流,写到 mergePath 这个路径下。因为已经* - 排序了,所以 start 就是每个文件的 index * eachChunkSize* - 5. 每个写入流都用 Promise 包装了一下,然后用 await Promise.all() 等待处理完* @param {*} mergePath* @param {*} name* @param {*} eachChunkSize*/
async function mergeChunk(mergePath, name, eachChunkSize) {const chunkDir = `${__dirname}/chunkPath/${name}`;const chunkPaths = await fse.readdir(chunkDir);chunkPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);await Promise.all(chunkPaths.map((chunk, index) => {const eachChunkPath = `${chunkDir}/${chunk}`;// 创建输入流,并为每个 chunk 定好位置const writeStream = fse.createWriteStream(mergePath, {start: index * eachChunkSize,});return pipeStream(eachChunkPath, writeStream);}));console.log('合并完成');fse.rmdirSync(chunkDir);console.log(`删除 ${chunkDir} 文件夹`);
}/*** 功能: merge 接口* - hasMergeChunk 变量是上面用来记录的* - mergePath 定义一下合并后的文件的路径*/
router.post('/merge', async (ctx) => {// console.log(ctx.request.body);const { fileName, size } = ctx.request.body;hasMergeChunk = {};const mergePath = `${__dirname}/merge/${fileName}`;if (!fse.existsSync(`${__dirname}/merge`)) {fse.mkdirSync(`${__dirname}/merge`);}await mergeChunk(mergePath, fileName, size);ctx.body = {data: '成功',};
});app.use(router.routes());
app.listen(3000, () => {console.log(`server start: http://localhost:3000`);
});
request.js 的封装
/*** 功能:封装请求* - 1. xhr.upload.onprogress 注意不要拉下 upload* @param {*} param0* @returns*/
function request({ url, method = 'post', data, headers = {}, onprogress = (e) => e, requestList }) {return new Promise((resolve, reject) => {let xhr = new XMLHttpRequest();xhr.open(method, url);Object.keys(headers).forEach((item) => {xhr.setRequestHeader(item, headers[item]);});xhr.upload.onprogress = onprogress;xhr.onloadend = function (e) {resolve({data: e.target.response,});};xhr.send(data);});
}
后端原生
主服务
const http = require('http');
const server = http.createServer();
const url = require('url');
const fs = require('fs');
const path = require('path');
const MIME = require('./mime.json');const Controller = require('./controller');
const UPLOAD_DIR = `${__dirname}/chunkPath`; // chunks 上传的文件夹
const controller = new Controller(UPLOAD_DIR);server.on('request', async (req, res) => {res.setHeader('Access-Control-Allow-Origin', '*');res.setHeader('Access-Control-Allow-Headers', '*');res.setHeader('content-type', 'text/html;charset=utf-8');if (req.method === 'OPTION') {res.status = 200;res.end();return;}let { pathname } = url.parse(req.url); // 解析一下 url,因为 req.url 可能会带一些参数// console.log('req.url:>>', req.url); console.log('url.parse(req.url):>>', url.parse(req.url));console.log(`进入${pathname}`);switch (pathname) {case '/':case '/index': {let rs = fs.createReadStream('./index.html');rs.pipe(res);break;}case '/upload': {await controller.handleUpload(req, res);break;}case '/merge': {await controller.handleMerge(req, res);break;}case '/favicon.ico': {res.end('我没有哦');break;}default: {let ext = path.extname(pathname);res.setHeader('Content-Type', MIME[ext]); // 通过请求的资源后缀名,来返回对应的 Content-type 的类型let rs = fs.createReadStream(`.${pathname}`);rs.pipe(res);}}
});
const POST = 3000;
server.listen(POST, null, null, () => {console.log(`server start: http://localhost:${POST}`);
});
类
/*** module.expothis.chunksPathrts 方法用于在服务器端导出模块,并以 CommonJS 格式提供。* - 参考:https://www.delftstack.com/zh/howto/node.js/create-and-export-classes/*/
const multiparty = require('multiparty');
const fse = require('fs-extra');
const { handlePostData, handleMergeChunks } = require('./tools');
class Controller {constructor(dirPath) {this.chunksPath = dirPath;}/*** 功能:合并* - 1. handlePostData 用来处理 POST 传递的数据,具体怎么处理的请查看方法* - 2. 把各个文件的 path 先想清楚要存到哪儿,建议自己写一写。* - 我是把所有的 chunks 都放到大目录 chunkPath 中,* - 然后在用文件名新建文件夹,再把chunks放到子文件夹中。* @param {*} req* @param {*} res*/async handleMerge(req, res) {const postData = await handlePostData(req);const { fileName, size: eachChunkSize } = postData;const mergePath = `${__dirname}/merge`;const mergeFilePath = `${__dirname}/merge/${fileName}`;if (!fse.existsSync(mergePath)) {fse.mkdirSync(mergePath);}const mergeOptions = { chunksPath: this.chunksPath, mergeFilePath, fileName, eachChunkSize };await handleMergeChunks(mergeOptions);console.log('Success Merge');res.end(JSON.stringify({code: 1,message: 'success merge',}));}/*** multiparty 使用方法:https://www.npmjs.com/package/multiparty* - chunkFileDirPath 为关于文件 chunks 的文件夹路径,每个大文件根据文件名生成相关的文件夹* - 注意回调函数里的 this* @param {*} url* @param {*} path*/async handleUpload(req, res) {const _this = this;const form = new multiparty.Form();form.parse(req, async function (err, fields, files) {if (err) {console.log(err);return;}const [chunk] = files.chunk;const [hash] = fields.hash;const [filename] = fields.filename;const chunkFileDirPath = `${_this.chunksPath}/${filename}`;if (!fse.existsSync(chunkFileDirPath)) {await fse.mkdirs(chunkFileDirPath);}await fse.move(chunk?.path, `${chunkFileDirPath}/${hash}`);res.end('收到文件 chunks');});}
}
module.exports = Controller;
工具函数
/*** 学习:__dirname 就是跟文件一起的,不会因为引用关系而恒定*/
// console.log(__dirname);
const fse = require('fs-extra');
/*** 功能:处理 POST 请求* - 与 GET 数据相比,POST 数据量大,需要分段。* - 通过 req.on('data', function(data) {}) 监听* - 当有一段数据到达的时候执行回调,回调函数参数 data 为每段达到的数据。* - 当数据全部到达时会触发 req.on('end', function() {}) 里面的回调函数。* - 可以通过 JSON.parse(str) 解析成我们想要的 POST 请求数据格式。* - 参考资料:https://juejin.cn/post/7142700338414518286#heading-2* @param {*} req* @returns*/
function handlePostData(req) {return new Promise((resolve, reject) => {let allData = '';let i = 0;req.on('data', function (chunkData) {// console.log(`第 ${++i} 次收到数据`);allData += chunkData;});req.on('end', function () {const POST_MESSAGE = JSON.parse(allData);resolve(POST_MESSAGE);});});
}/*** 功能:创建 pipe 写文件流* - 1. [首先了解一下什么是输入可读流](https://www.jmjc.tech/less/111)* - 方便记忆:可读流 通过 管道 流入 可写流。 可读流 =======> 可写流* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。* - 3. 可以检测可读流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。* @param {*} path* @param {*} writeStream* @returns*/
let hasMergeChunk = {};
function pipeStream(path, writeStream, length) {return new Promise((resolve) => {const readStream = fse.createReadStream(path);readStream.pipe(writeStream);readStream.on('end', function () {hasMergeChunk[path] = 'finished';fse.unlinkSync(path);resolve();const merging = path.split('_')[1];const merged = Object.keys(hasMergeChunk).length;console.log(`merging: No.${padS(merging)}. progress: [ ${padS(merged)} / ${padS(length)} ]`);});});
}/*** 功能:合并 chunks* - 1. 首先根据 fileChunksDir 拿到所有 chunks 的文件名* - 2. 然后拼接成 fileAllChunksPaths <Array> 数组,然后一一创建可写流* - 3. fileAllChunksPaths 注意这里需要排序一下,不然就是乱的,这也是我们创建可写流 srart 位置的基础* - 4. 然后这里通过 pipeStream 函数用 Promise 包装了一下可读流,代码需要慢慢读去理解。* - 5. 我们这里的 可写流们,是根据 chunks 的不同,定义好写入的文件 path,* - 以及每个块儿写的开始位置和写入大小,每个可写流都是不一样的!* -* @param {*} param0*/
async function handleMergeChunks({ chunksPath, mergeFilePath, fileName, eachChunkSize }) {hasMergeChunk = {};const fileChunksDir = `${chunksPath}/${fileName}`;const fileAllChunksPaths = await fse.readdir(fileChunksDir);console.log(fileAllChunksPaths);fileAllChunksPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);const promiseArray = fileAllChunksPaths.map((chunk, index, array) => {const eachChunkPath = `${fileChunksDir}/${chunk}`;const writeStream = fse.createWriteStream(mergeFilePath, {start: index * eachChunkSize,});return pipeStream(eachChunkPath, writeStream, array.length);});await Promise.all(promiseArray);
}module.exports = {handlePostData,handleMergeChunks,
};相关文章:
【文件上传系列】No.1 大文件分片、进度图展示(原生前端 + Node 后端 Koa)
分片(500MB)进度效果展示 效果展示,一个分片是 500MB 的 分片(10MB)进度效果展示 大文件分片上传效果展示 前端 思路 前端的思路:将大文件切分成多个小文件,然后并发给后端。 页面构建 先在页…...
性能测试 —— Jmeter分布式测试的注意事项和常见问题
Jmeter是一款开源的性能测试工具,使用Jmeter进行分布式测试时,也需要注意一些细节和问题,否则可能会影响测试结果的准确性和可靠性。 Jmeter分布式测试时需要特别注意的几个方面 1. 参数化文件的位置和内容 如果使用csv文件进行参数化&#x…...

“SRP模型+”多技术融合在生态环境脆弱性评价模型构建、时空格局演变分析与RSEI 指数的生态质量评价及拓展应用
近年来,国内外学者在生态系统的敏感性、适应能力和潜在影响等方面开展了大量的生态脆弱性研究,他们普遍将生态脆弱性概念与农牧交错带、喀斯特地区、黄土高原区、流域、城市等相结合,评价不同类型研究区的生态脆弱特征,其研究内容…...
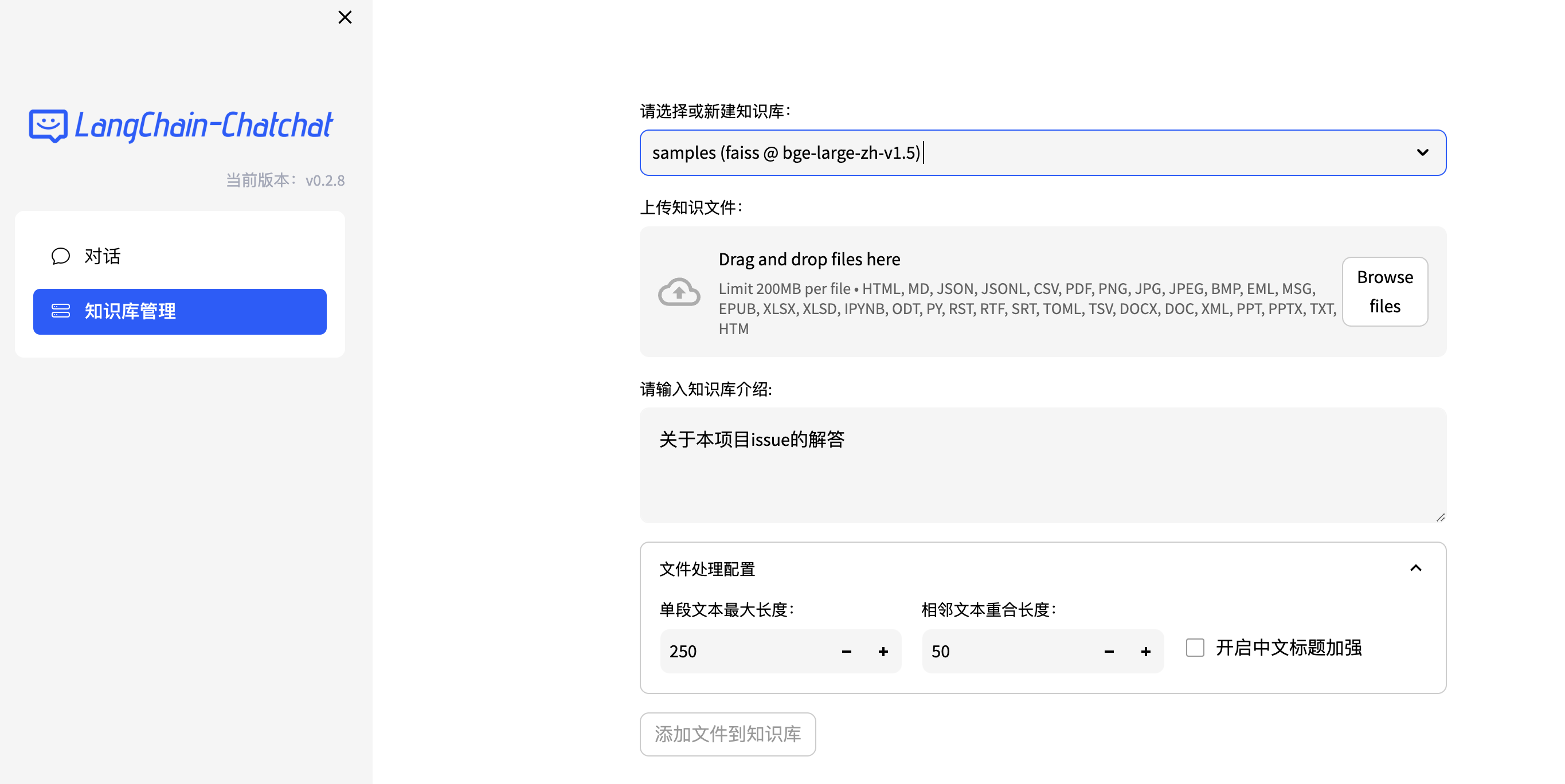
总结|哪些平台有大模型知识库的Web API服务
截止2023/12/6 笔者个人的调研,有三家有大模型知识库的web api服务: 平台类型文档数量文档上传并解析的结构api情况返回页码文心一言插件版多文档有问答api,文档上传是通过网页进行上传有,而且是具体的chunk id,需要设…...
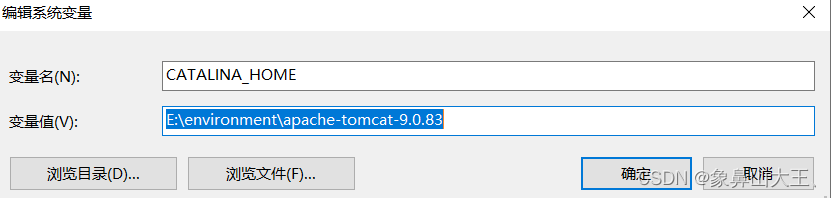
TOMCAT9安装
1、官网下载 2、解压到任意盘符,注意路径不要有中文 3、环境变量 path 下 配置 %CATALINA_HOME%\bin 4、找到tomcat9/bin, 点击 start.bat启动 tomcat...
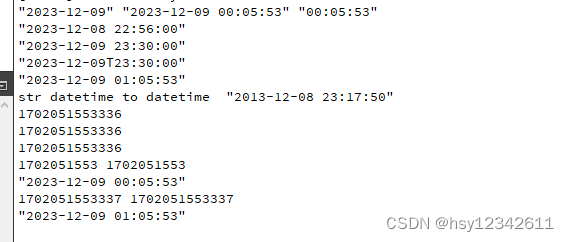
QT中时间时区处理总结
最近项目中要做跨国设备时间校正功能,用到了时区时间,在此做一下记录。 目录 1.常见时区名 2.测试代码 3.运行效果 1.常见时区名 "Pacific/Midway": "中途岛 (UTC-11:00)", …...

OpenAtom OpenHarmony三方库创建发布及安全隐私检测
OpenAtom OpenHarmony 三方库(以下简称“三方库”或“包”),是经过验证可在 OpenHarmony 系统上可重复使用的软件组件,可帮助开发者快速开发 OpenHarmony 应用。三方库根据其开发语言分为 2 种,一种是使用 JavaScript …...
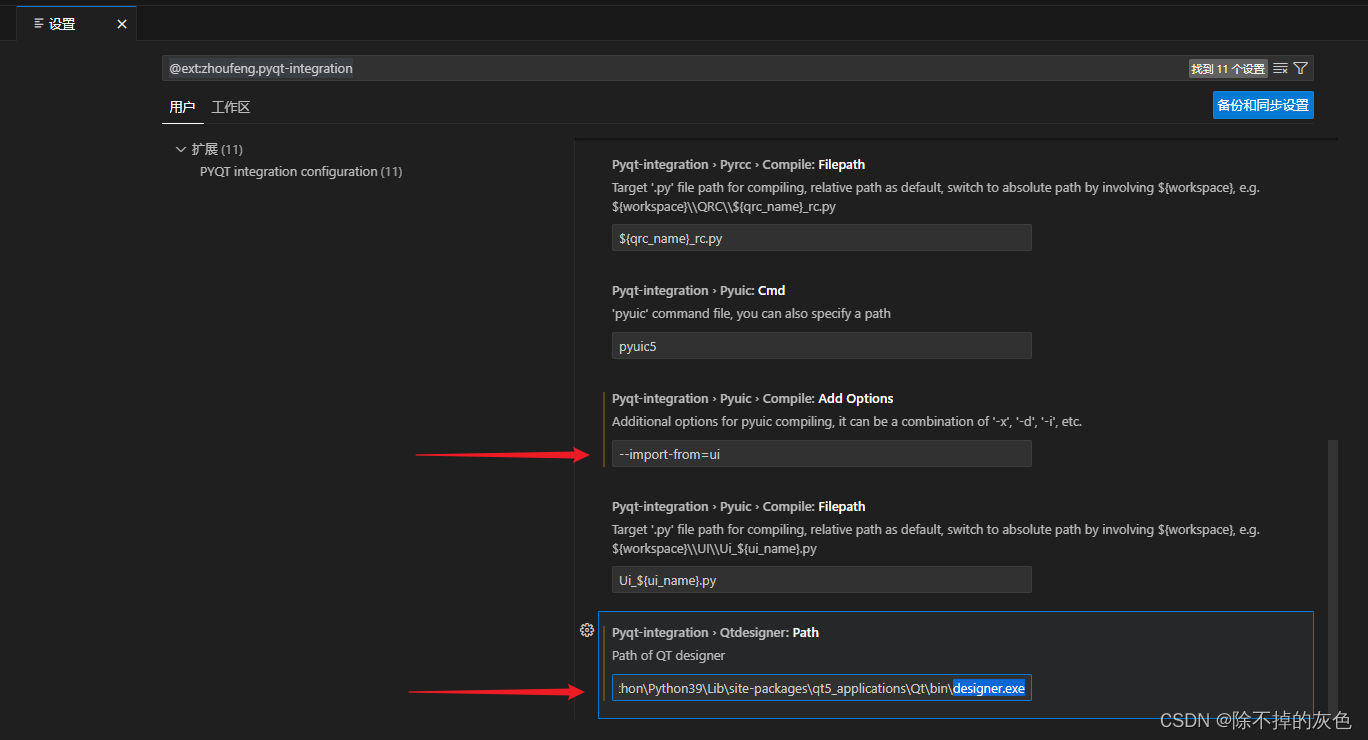
【1】一文读懂PyQt简介和环境搭建
目录 1. PyQt简介 1.1. Qt 1.2. PyQt 1.3. 关于PyQt和PySide 2. 通过pip安装PyQt5 3. 无法运行处理 4. VSCode配置PYQT插件 PyQt官网:Riverbank Computing | Introduction 1. PyQt简介 PyQt是一套Python的GUI开发框架,即图形用户界面开发框架。 Python中经常使用的GU…...
windows install git
refer: https://developers.weixin.qq.com/miniprogram/dev/devtools/wechatvcs.html https://blog.csdn.net/weixin_40228200/article/details/128451324 在使用小程序的时候,需要初始化项目,需要注册Git账号 1.在本地确认cmd没有安装Git,进入Git官网…...

【华为数据之道学习笔记】3-7 报告数据治理
报告数据是指对数据进行处理加工后,用作业务决策依据的数据。它用于支持报告和报表的生成。 用于报告和报表的数据可以分为如下几种。 用于报表项数据生成的事实表、指标数据、维度。 用于报表项统计和计算的统计函数、趋势函数及报告规则。 用于报表和报告展示的…...

SpringDataRedis 操作 Redis,并指定数据序列化器
文章目录 1. SpringDataRedis 概述2. 快速入门2.1 导入pom坐标2.2 配置文件2.3 测试代码2.4 数据序列化器2.5 StringRedisTemplate2.6 总结 1. SpringDataRedis 概述 SpringData 是Spring 中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模…...

useradd 在Linux原生应用开发过程中的简单应用
useradd命令是用于在Linux系统中创建新用户的命令。它可以创建一个新用户,并设置该用户的属性、家目录、默认shell等。useradd命令实际上是一个包装了一系列系统调用的高级命令。 在Linux系统中,用户信息存储在/etc/passwd文件中。当执行useradd命令时&…...

Linux 删除文件名乱码的文件
现象: 处理: 1.>ls -li 获取文件对应的ID号 2.把删除指定文件(ID号 )执行: find ./ -inum 268648910 -exec rm {} \;...

【测试人生】数据同步和迁移的变更注意事项
数据同步或者迁移操作也算是线上数据变更的一种类型。由于涉及的数据量非常大,一旦发生故障,会直接影响线上业务,并且较难止损。从变更风险管控的角度考虑,数据同步或迁移操作也需要走合理的发布窗口,并且在操作前也需…...
快手视频如何去掉水印?三个简单好用视频去水印方法
快手视频如何去掉水印?尽管新兴的短视频平台如春笋般涌现,吸引了众多观众在业余时间浏览和分享视频,快手作为当下主流短视频之一,许多自媒体创作者也常常会下载一些热门的视频素材进行二次编辑。然而,他们都可能会面临…...

【Linux】stat命令使用
stat命令 stat命令用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细。 著者 由Michael Meskes撰写。 stat命令 -Linux手册页 语法 stat [文件或目录] 命令选项及作用 执行令 : stat --help 执行命令结果 参数 -L、 --dereference 跟…...

【JavaEE】多线程(3) -- 线程等待 wait 和 notify
目录 1. wait()⽅法 2. notify()⽅法 3. notifyAll()⽅法 4. wait 和 sleep 的对⽐(⾯试题) 由于线程之间是抢占式执⾏的, 因此线程之间执⾏的先后顺序难以预知. 但是实际开发中有时候我们希望合理的协调多个线程之间的执⾏先后顺序. 完成这个协调⼯…...
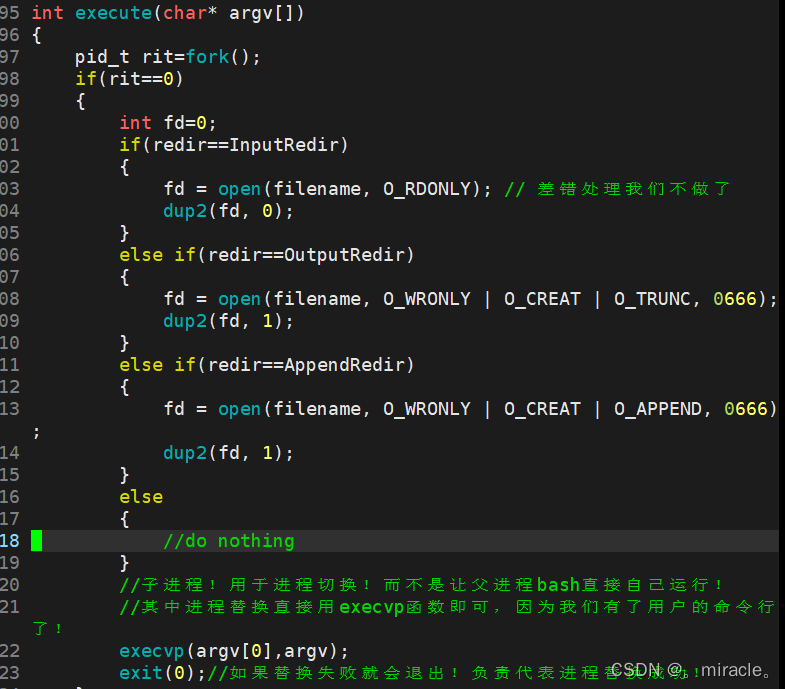
自行编写一个简单的shell!
本文旨在编写一个简单的shell外壳程序!功能类似于shell的一些基本操作!虽然不能全部实现shell的一些功能!但是通过此文章,自己写一个简单的shell程序也是不成问题!并且通过此文章,可以让读者对linux中一些环…...

mvn site 命令
概述 在Maven中,site指的是一个特定的阶段,其目的是生成项目相关的站点文档。这些站点文档可以为项目的开发者、用户、以及其他利益相关者提供有关项目的详细信息。 Maven的站点文档通常包括以下内容: 项目信息:这部分提供了关于…...
<JavaEE> 经典设计模式之 -- 定时器
目录 一、定时器的概念 二、Java 标准库中的定时器 三、实现自己的定时器 一、定时器的概念 什么是定时器?定时器是软件开发中的一个常用且重要组件,作用是在达到设定时间后,执行指定的代码。 二、Java 标准库中的定时器 1)T…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...