2023.12面试题汇总小结
文章目录
- Java字节码都包括哪些内容
- Java双亲委派机制如何打破
- Java Memory Model是什么
- synchronized的锁优化是什么
- CountDownLatch、CyclicBarrier、Semaphore有啥区别,什么场景下使用
- MySQL MVCC原理
- MySQL RR隔离级别,会出现幻读吗
- MySQL的RR隔离级别下,当前读是什么意思
- MySQL的undolog、redolog、binlog作用
- MySQL的Redo Log,是InnoDB独有的吗?
- MySQL如果要恢复到一个月前的数据,如何操作恢复
- MySQL的聚簇索引和非聚簇索引是什么
- Redis的bigkey问题,该如何解决
- MySQL和Redis数据一致性问题,该如何保证
- Redis ZSET的底层实现
- 用Redis如何实现滑动窗口
- kafka消息丢失和可靠性如何保障
- kafka的选举机制
- kafka如何保证消息的顺序消费
- 分布式一致性算法有哪些
- kafka的分区同步原理
- zookeeper脑裂问题如何解决
- ES的查询过程
- ES的倒排索引是什么
- 微服务的限流和熔断,熔断后如何恢复
Java字节码都包括哪些内容
Java字节码是Java源代码编译后生成的中间代码,它包括以下内容:
- 常量池(Constant Pool):存储字节码中使用的符号引用、字面量和其他常量。
- 类信息(Class Information):包括类的修饰符、父类、接口、字段和方法等信息。
- 字段(Field):描述类中定义的字段的访问修饰符、名称和类型等信息。
- 方法(Method):描述类中定义的方法的访问修饰符、名称、参数列表、返回类型和方法体等信息。
- 接口表(Interface Table):包含实现的接口的符号引用。
- 属性(Attribute):用于存储字节码中的其他元数据,例如注解、调试信息和行号表等。
Java字节码是一种平台中立的中间表示,它可以在Java虚拟机上运行,通过字节码解释器将其转换为机器码执行。这种中间表示使得Java程序可以在不同的平台上运行,实现了"一次编写,到处运行"的特性。
Java双亲委派机制如何打破
Java双亲委派机制是Java类加载器的一种工作机制,它通过层级结构的方式来加载和管理Java类。按照双亲委派机制,当一个类加载器收到类加载请求时,它首先会将该请求委派给其父类加载器,只有当父类加载器无法加载该类时,才会由子类加载器尝试加载。
在一些特殊情况下,我们可能需要打破Java双亲委派机制。以下是一些常见的方法:
- 自定义类加载器:通过自定义类加载器,可以重写loadClass()方法,自行控制类的加载流程。可以在自定义类加载器中实现特定的加载逻辑,例如从指定位置加载类文件。
- 线程上下文类加载器:Java提供了线程上下文类加载器(Thread Context Class Loader),可以通过设置线程的上下文类加载器来改变类加载器的委派顺序。可以使用Thread.currentThread().setContextClassLoader()方法来设置线程的上下文类加载器。
- 使用类加载器的defineClass()方法:通过反射调用类加载器的defineClass()方法,可以手动加载类,并打破双亲委派机制。这种方式需要自行处理类的字节码,并将字节码转换为Class对象。
需要注意的是,打破双亲委派机制可能引入一些潜在的问题和风险,因此在使用时需要谨慎考虑,并确保了解其潜在影响。
Java Memory Model是什么
Java Memory Model(JMM)是Java虚拟机(JVM)中关于多线程并发访问主存(共享变量)的规范。它定义了线程如何与主存进行交互,以及线程间如何实现可见性、有序性和原子性。
JMM确保多线程程序在不同的计算机体系结构和操作系统上都能正确地执行。它定义了一组规则和规范,确保线程之间的操作按照一定的顺序进行,并且对其他线程是可见的。
JMM中的一些重要概念包括:
- 主内存(Main Memory):主存是线程共享的内存区域,包含所有的共享变量。
- 工作内存(Working Memory):每个线程都有自己的工作内存,它是线程私有的,用于存储线程的局部变量和对共享变量的副本。
- 内存间的交互操作:线程通过特定的操作将工作内存中的数据与主存中的数据进行交互,包括读取、写入和刷新操作。
- happens-before关系:happens-before是JMM中的一个重要概念,用于定义操作之间的顺序关系,保证线程间的可见性和有序性。
通过JMM的规范,Java程序员可以编写正确且可靠的多线程程序,避免出现竞态条件、死锁和其他并发问题。在实际开发中,了解JMM的特性和规则对于编写高效且正确的多线程代码非常重要。
synchronized的锁优化是什么
synchronized是Java中的关键字,用于实现线程之间的同步和互斥。在使用synchronized时,JVM会自动为每个被synchronized修饰的方法或代码块分配一把锁(也称为监视器)。这把锁用于确保同一时间只有一个线程可以执行被锁定的代码,从而保证线程安全。
然而,synchronized的性能开销较高,因为它涉及到线程的上下文切换和互斥操作。为了提高synchronized的性能,JVM引入了一些锁优化技术,包括:
- 自旋锁(Spin Lock):在获取锁之前,线程会先尝试自旋一段时间,而不是立即进入阻塞状态。这样可以减少线程切换的开销。如果在自旋期间锁被其他线程释放,则当前线程可以立即获取锁,避免了线程阻塞。
- 锁消除(Lock Elimination):JVM在编译时对代码进行静态分析,判断某些锁不会被竞争,从而可以将它们消除掉。这样可以减少锁的使用,提高代码的执行效率。
- 锁粗化(Lock Coarsening):当连续的代码块都需要加锁时,JVM会将这些代码块合并成一个大的代码块,只需要加锁一次,减少了锁的获取和释放次数。
- 适应性自旋(Adaptive Spinning):JVM会根据在过去的执行中,同一段代码的锁竞争情况来调整自旋等待的时间。如果该代码段经常会出现锁竞争,则自旋等待的时间会减少,避免浪费CPU资源。
这些锁优化技术在不同的JVM实现中可能会有所差异,但它们的目标都是提高synchronized的性能,减少线程的阻塞和唤醒操作,从而提高多线程程序的执行效率。
CountDownLatch、CyclicBarrier、Semaphore有啥区别,什么场景下使用
CountDownLatch、CyclicBarrier和Semaphore都是Java中用于多线程编程的同步工具类,但它们在功能和使用场景上有一些区别。
- CountDownLatch(倒计时门栓):
CountDownLatch用于一个或多个线程等待一组操作完成后再继续执行。它通过一个计数器来实现,计数器的初始值可以设定,每当一个操作完成时,计数器的值减一,当计数器的值变为0时,所有等待线程被唤醒。CountDownLatch通常用于一个线程等待多个线程完成某项操作,然后再继续执行。 - CyclicBarrier(循环屏障):
CyclicBarrier也用于多个线程之间的等待,但它的功能稍微复杂一些。CyclicBarrier设定一个等待的线程数,当所有线程都达到屏障点时,所有线程才能继续执行。与CountDownLatch不同的是,CyclicBarrier可以重复使用,当所有线程都达到屏障点后,屏障会自动重置,线程可以继续使用。 - Semaphore(信号量):
Semaphore用于控制同时访问某个资源的线程数量。它通过维护一定数量的许可证来实现,每当一个线程访问资源时,它需要获取一个许可证,当许可证用尽时,其他线程需要等待,直到有线程释放许可证。Semaphore常用于限制同时访问某个资源的线程数量,或者控制同时执行某个操作的线程数量。
使用场景:
- CountDownLatch适用于一个线程等待多个线程完成某个操作,常用于主线程等待其他线程完成初始化工作。
- CyclicBarrier适用于多个线程互相等待,然后同时开始执行某个操作,常用于分布式系统中的并行计算。
- Semaphore适用于限制同时访问某个资源的线程数量,常用于数据库连接池、线程池等资源的管理。
需要根据具体的需求和场景来选择适合的同步工具类。
MySQL MVCC原理
MySQL的MVCC(Multi-Version Concurrency Control)是一种并发控制机制,用于解决读写冲突的问题,实现并发事务的隔离性。
MVCC的原理如下:
- 每行数据都有一个隐藏的版本号(或者称为事务ID),用于标识数据的版本。
- 在事务开始时,MySQL会为该事务分配一个唯一的事务ID。
- 当读取数据时,MySQL会根据事务ID判断当前事务可见的数据版本。只有版本号早于当前事务ID的数据才对当前事务可见。
- 在写操作(插入、更新、删除)执行时,MySQL会为新的数据版本生成一个新的事务ID,并将旧的版本标记为不可见。
- 当其他事务读取数据时,如果该数据的版本号晚于当前事务ID,则表示该数据对当前事务不可见。
MVCC的优点:
- 读写并发性能高:不同事务可以并发地读取不同版本的数据,避免了对同一数据的读写冲突。
- 读操作不加锁:在读操作中,不需要加任何锁,避免了读锁的开销。
- 数据一致性:每个事务只能看到在事务开始时已经存在的数据版本,保证了每个事务的数据一致性。
MVCC的缺点:
- 存储空间开销:为每行数据维护版本号会增加存储空间开销。
- 清理过程:删除不可见的旧版本数据需要执行清理过程,会增加系统负载。
总结:MySQL的MVCC通过给每行数据添加版本号,实现了读写并发的隔离性,提高了数据库的并发性能和数据一致性。但也需要注意存储空间开销和清理过程可能带来的性能影响。
MySQL RR隔离级别,会出现幻读吗
在MySQL中,RR(Repeatable Read)隔离级别下,是不会出现幻读的。幻读是指在事务执行过程中,某个事务重新读取数据时,发现有新的数据插入,导致前后两次读取的数据不一致。
在RR隔离级别下,事务会通过使用多版本并发控制(MVCC)机制来避免幻读的问题。MVCC会为每行数据维护一个版本号,读取操作只会读取已经提交的数据,而不会读取未提交的数据。当事务开始时,会记录下读取的版本号,保证后续读取操作都是基于这个版本号进行的,这样就可以避免幻读的问题。
需要注意的是,在RR隔离级别下,仍然可能出现其他的并发问题,比如更新丢失和写倾斜等。因此,在选择隔离级别时,需要根据具体的业务场景和并发需求来进行权衡。
MySQL的RR隔离级别下,当前读是什么意思
在MySQL的RR(Repeatable Read)隔离级别下,当前读(Current Read)是指在事务中读取数据时,会读取已经提交的最新版本的数据,并且会对读取的数据加锁,防止其他事务对该数据进行修改。
在RR隔离级别下,当前读涉及到两种类型的锁:共享锁(Shared Lock)和排他锁(Exclusive Lock)。当一个事务进行当前读时,会对读取的数据加上共享锁,其他事务也可以读取该数据,但不能对其进行修改。而如果一个事务对数据进行当前读并且需要修改数据,就会对该数据加上排他锁,其他事务无法读取和修改该数据,直到当前事务释放该锁。
当前读保证了事务读取数据的一致性,即读取的是已经提交的最新版本的数据,并且通过加锁来避免其他事务对数据进行修改。然而,需要注意的是,当前读在并发环境下可能会导致锁竞争和性能问题,因此在使用当前读时需要考虑好锁的粒度和并发控制策略,以避免潜在的性能问题。
MySQL的undolog、redolog、binlog作用
在MySQL中,undolog、redolog和binlog是三种不同的日志文件,它们各自具有不同的作用和功能。
- Undolog(回滚日志):
-
- 作用:记录事务的操作,用于回滚(撤销)事务所做的修改。
- 存储位置:在InnoDB存储引擎中,undolog以文件的形式存储在磁盘上。
- 使用方式:在事务执行期间,对数据进行修改时,会先将修改的操作记录到undolog中,以便在事务回滚时可以撤销这些操作,保证数据的一致性。
- Redolog(重做日志):
-
- 作用:记录事务的操作,用于事务的持久性和恢复。
- 存储位置:在InnoDB存储引擎中,redolog以循环写的方式存储在磁盘上。
- 使用方式:在事务执行期间,对数据进行修改时,会先将修改的操作记录到redolog中,以确保即使在数据库崩溃的情况下,也能够通过重做日志来恢复事务,保证数据的持久性。
- Binlog(二进制日志):
-
- 作用:记录数据库的所有DDL(数据定义语言)和DML(数据操作语言)语句,用于数据备份、恢复、复制和主从同步。
- 存储位置:在MySQL服务器中,binlog以文件的形式存储在磁盘上。
- 使用方式:在执行DDL和DML语句时,会将这些语句记录到binlog中。通过解析binlog文件,可以恢复数据到指定的时间点,进行数据备份和恢复,或者用于主从复制,实现数据库的高可用性和数据一致性。
总结:undolog主要用于事务的回滚,redolog用于事务的持久性和恢复,binlog用于数据备份、恢复、复制和主从同步。它们各自在MySQL中扮演着重要的角色,确保数据的一致性、可靠性和可用性。
MySQL的Redo Log,是InnoDB独有的吗?
是的,Redo Log是InnoDB存储引擎独有的特性。Redo Log是InnoDB用于保证事务的持久性和恢复能力的重要组成部分。当事务提交时,InnoDB会将事务的修改操作记录到Redo Log中,然后再将数据写入磁盘。这样即使在数据库崩溃时,通过Redo Log的重做操作,可以将数据恢复到最新提交的状态。
Redo Log的存在可以保证数据库的持久性,即使在发生崩溃或故障的情况下,数据不会丢失。当数据库重新启动时,通过重做Redo Log中记录的操作,可以将数据回滚到最新提交的状态。
需要注意的是,MySQL还有另外一种日志文件叫做Undo Log,用于实现事务的回滚操作。Undo Log和Redo Log是配合使用的,它们共同确保了InnoDB存储引擎的事务安全性和数据一致性。
MySQL如果要恢复到一个月前的数据,如何操作恢复
要将MySQL恢复到一个月前的数据,通常需要使用备份和恢复的方式进行操作。以下是一般的恢复步骤:
- 确保你有一个在一个月前的MySQL数据库备份。如果没有备份,恢复到一个月前的数据将是非常困难的。
- 停止MySQL服务,确保数据库处于关闭状态。
- 备份当前的数据文件和日志文件,以防止后续操作中的意外情况。
- 将一个月前的备份文件恢复到MySQL数据文件的目录中。这将覆盖当前的数据文件。
- 启动MySQL服务,它将加载恢复的数据文件。
- 检查数据库是否恢复到了一个月前的状态。进行一些测试操作,确保数据的正确性。
需要注意的是,这个恢复过程会覆盖当前的数据,因此在操作之前一定要确保备份的完整性和准确性。此外,如果你使用的是InnoDB引擎,还需要考虑Redo Log和Undo Log的问题,以确保数据的完整性和一致性。如果不确定如何操作,建议咨询专业的数据库管理员或MySQL技术支持人员。
MySQL的聚簇索引和非聚簇索引是什么
在MySQL中,聚簇索引(Clustered Index)和非聚簇索引(Non-Clustered Index)是两种不同的索引结构。
- 聚簇索引(Clustered Index):
-
- 聚簇索引是将数据按照索引的顺序直接存储在磁盘上,因此数据的物理存储顺序和聚簇索引的顺序是一致的。
- 一个表只能有一个聚簇索引,一般是通过将主键设置为聚簇索引来实现。
- 聚簇索引的优势是能够提高数据的读取性能,因为相关数据存储在一起,减少了磁盘I/O操作,适用于范围查询和顺序访问。
- 聚簇索引的缺点是当更新聚簇索引列的数据时,可能会导致数据的移动和页面的分裂,对性能有一定影响。
- 非聚簇索引(Non-Clustered Index):
-
- 非聚簇索引是将索引的键值和指向实际数据的指针存储在一起,而实际数据则按照主键的顺序存储在磁盘上。
- 一个表可以有多个非聚簇索引,可以根据查询需求创建多个非聚簇索引。
- 非聚簇索引的优势是可以快速定位到所需数据的位置,适用于等值查询和部分范围查询。
- 非聚簇索引的缺点是查询需要先通过索引找到指针,再通过指针找到实际数据,增加了一次磁盘I/O操作。
综上所述,聚簇索引和非聚簇索引在数据存储和访问方式上有所不同,适用于不同的查询操作。在使用时,需要根据具体的业务需求和查询模式选择适合的索引类型。
Redis的bigkey问题,该如何解决
Redis的Bigkey问题是指在Redis中存储了大量数据的键,这些键可能会导致性能下降和内存占用过高的问题。解决Bigkey问题的方法如下:
- 分割大的键:如果一个键存储了大量数据,可以考虑将其拆分为多个小键。例如,将一个包含大量元素的列表拆分为多个小列表,或将一个包含大量字段的哈希拆分为多个小哈希。
- 使用分片机制:将大key拆分为多个小key并分布在不同的Redis节点上,通过分片机制来处理。这样可以减轻单个节点的负载,提高整体性能。
- 使用分布式缓存:将大key存储在分布式缓存中,如Redis Cluster或Memcached。这样可以将数据分布在多个节点上,提高并发读写能力。
- 定期清理过期数据:通过设置适当的过期时间,定期清理不再使用的大key,以释放内存空间。
- 使用Redis的数据结构:根据具体业务需求,选择合适的数据结构来存储数据。例如,使用Redis的Sorted Set来存储有序的大key,或使用Redis的Bitmap来存储大量的布尔类型数据。
- 使用Redis的持久化机制:将大key存储在磁盘上,而不是内存中,以减少内存占用。可以使用Redis的RDB快照或AOF持久化机制来实现。
总而言之,解决Redis的Bigkey问题需要根据具体场景和业务需求来选择合适的方法,以提高性能和减少内存占用。
MySQL和Redis数据一致性问题,该如何保证
在MySQL和Redis之间保持数据一致性是一个常见的挑战,因为它们是不同的数据存储系统,具有不同的特性和机制。以下是一些方法来保证MySQL和Redis之间的数据一致性:
- 双写:在写入MySQL之前,先写入Redis。这样可以确保Redis中的数据与MySQL中的数据保持一致。但是,这种方法会增加写入操作的延迟,并且如果Redis写入失败,可能会导致数据不一致。
- 异步同步:使用消息队列或事件驱动机制,将MySQL中的更改操作异步地发送到Redis。这样可以降低写操作的延迟,并且即使Redis写入失败,也不会影响主要的业务逻辑。但是,这种方法可能会导致MySQL和Redis之间存在一定的数据延迟。
- 定期同步:定期将MySQL中的数据同步到Redis。可以使用定时任务或触发器来实现。这种方法可以确保数据的一致性,但可能会增加系统的负载和网络流量。
- 利用MySQL的Binlog:通过解析MySQL的Binlog日志,将更改操作同步到Redis。这种方法可以实现实时的数据同步,并且不会对主要的业务逻辑产生太大的影响。但是,需要编写复杂的代码来解析Binlog日志,并且对系统性能有一定的影响。
无论选择哪种方法,都需要注意以下几点来确保数据一致性:
- 错误处理:在数据同步过程中,如果出现错误,需要有相应的错误处理机制,确保数据的一致性和完整性。
- 监控和报警:需要监控数据同步过程中的异常情况,并及时报警,以便快速发现和解决问题。
- 数据验证:定期验证MySQL和Redis中的数据是否一致,可以通过比较特定的数据集或使用工具来实现。
综上所述,保证MySQL和Redis之间的数据一致性是一个复杂的问题,需要根据具体的业务需求和系统架构选择合适的方法,并进行适当的监控和验证。
Redis ZSET的底层实现
Redis中的有序集合(Sorted Set)使用跳跃表(Skip List)和哈希表(Hash Table)两种数据结构来实现。
跳跃表是一种有序链表的数据结构,可以在 O(log N) 的时间复杂度内进行插入、删除和查找操作。它通过在每个节点中维护多个指向其他节点的指针,从而在查找时可以跳过部分节点,提高查找效率。
在Redis中,跳跃表用于实现有序集合中的成员和分值的有序排列。每个跳跃表节点包含一个成员和分值,以及指向下一个节点的指针数组。
除了跳跃表,Redis还使用哈希表来存储有序集合的成员和对应的分值。哈希表的键是有序集合的成员,值是成员对应的分值。
通过同时使用跳跃表和哈希表,Redis可以在 O(log N) 的时间复杂度内进行有序集合的插入、删除和查找操作,并且可以根据分值范围进行范围查找。
需要注意的是,Redis的有序集合中的成员必须是唯一的,但分值可以重复。在有序集合中,成员是唯一的主要是通过哈希表来实现的。
用Redis如何实现滑动窗口
在Redis中,可以使用有序集合和过期时间来实现滑动窗口。
滑动窗口是一种时间窗口,可以用来限制某个操作在一定时间内的频率。例如,我们可以使用滑动窗口来限制某个用户在一分钟内的请求次数。
以下是使用Redis实现滑动窗口的一种方法:
- 为每个时间窗口创建一个有序集合,集合的成员是请求的时间戳,分值是时间戳对应的权重。
- 每次有请求进来时,先将当前时间戳加入到当前时间窗口的有序集合中。
- 使用Redis的命令ZREMRANGEBYSCORE,删除当前时间窗口之前的所有时间戳,以保持时间窗口内只有最近一段时间的请求记录。
- 使用Redis的命令ZCOUNT,统计当前时间窗口内的时间戳数量,即为当前时间窗口内的请求次数。
下面是一个示例的Python代码,演示如何使用Redis实现滑动窗口:
import time
import redis# 连接到Redis
r = redis.Redis(host='localhost', port=6379, db=0)# 定义时间窗口的长度和频率限制
window_size = 60 # 时间窗口长度,单位为秒
rate_limit = 100 # 频率限制,每分钟最多100次请求def check_rate_limit(user_id):current_time = int(time.time())window_start_time = current_time - window_size # 当前时间窗口的起始时间# 将当前时间戳加入到有序集合中r.zadd(user_id, {current_time: current_time})# 删除当前时间窗口之前的所有时间戳r.zremrangebyscore(user_id, 0, window_start_time)# 统计当前时间窗口内的时间戳数量count = r.zcount(user_id, window_start_time, current_time)# 判断请求次数是否超过限制if count > rate_limit:return Falseelse:return True# 测试
user_id = 'user_123'
for i in range(120):if check_rate_limit(user_id):print(f"第{i+1}次请求通过频率限制")else:print(f"第{i+1}次请求超过频率限制")time.sleep(1)
在上面的代码中,我们使用Redis的有序集合来存储每个用户的请求记录,其中键为用户ID,成员为时间戳,分值也是时间戳。然后使用ZREMRANGEBYSCORE命令删除过期的时间戳,使用ZCOUNT命令统计当前时间窗口内的时间戳数量,即为当前时间窗口内的请求次数。最后,根据请求次数是否超过限制来判断是否通过频率限制。
请注意,以上代码只是一个示例,实际情况下可能需要根据具体需求进行适当的调整和优化。
kafka消息丢失和可靠性如何保障
Kafka通过多个机制来保障消息的可靠性和避免消息丢失:
- 内部副本机制(Replication):Kafka使用分布式的发布-订阅模型,将消息分发到多个分区,并在不同的Broker上保存多个副本。每个分区的消息会被复制到多个Broker上的副本中,确保即使某个Broker出现故障,仍然能够从其他副本中获取消息。
- ISR机制(In-Sync Replicas):Kafka中的每个分区都有一个ISR(In-Sync Replicas)集合,这个集合中的副本与Leader副本保持同步。只有ISR中的副本才能参与消息的读写,确保消息的可靠性。如果某个副本与Leader副本的同步延迟过大或者无法同步,那么就会被从ISR中剔除。
- 消息持久化:Kafka将消息写入磁盘,以确保即使在Broker故障时,消息也不会丢失。Kafka的持久化机制可以通过配置参数来进行调整,可以设置消息在磁盘上的持久化策略和时机。
- Producer确认机制:Kafka的Producer在发送消息后,可以选择等待Broker的确认。通过配置参数,可以设置消息发送的可靠性级别,包括不等待确认、等待Leader副本确认、等待ISR中的副本确认等。
- Consumer偏移量管理:Kafka的Consumer会跟踪每个分区的偏移量(offset),确保消费者可以从上次消费的位置继续消费消息,避免消息的重复消费或丢失。
综上所述,Kafka通过副本机制、ISR机制、持久化、确认机制和偏移量管理等多个机制来保障消息的可靠性和避免消息丢失。但是在极端情况下(例如所有副本都无法同步),仍然存在消息丢失的可能性,因此在实际应用中,需要综合考虑业务需求和可靠性要求来选择适当的配置和机制。
kafka的选举机制
Kafka使用了一种称为"Controller"的特殊角色来实现选举机制,确保集群中的各个Broker之间能够动态地选出一个新的Controller。
选举过程如下:
- 当集群启动时,其中一个Broker会自动成为Controller并担任该角色。
- Controller会定期(默认为每秒钟一次)向集群中的其他Broker发送心跳信号,以了解其他Broker的状态。
- 如果Controller发现某个Broker在一段时间内没有发送心跳信号,就会将该Broker标记为失效。
- 当失效的Broker被标记后,Controller会开始一个选举过程。
- 在选举过程中,Controller会向集群中的其他Broker发送选举请求,要求它们参与选举。
- 参与选举的Broker会通过比较自己与其他Broker的ID来确定自己的优先级。
- 最终,选举出的优先级最高的Broker将成为新的Controller,并开始担任该角色。
通过选举机制,Kafka能够在原Controller失效时,动态地选举出一个新的Controller来管理集群的状态和分配任务。这种机制确保了Kafka集群的高可用性和容错性。
https://cloud.tencent.com/developer/article/1852157
kafka如何保证消息的顺序消费
Kafka通过分区(partition)和分区内的偏移量(offset)来保证消息的顺序消费。
首先,Kafka将消息划分为多个分区,每个分区都有一个唯一的标识符。每个分区内的消息按照写入的顺序进行排序,保证了分区内的消息是有序的。在消费者消费消息时,可以指定消费的分区。
其次,每个分区内的消息都有一个偏移量,表示消息在分区内的顺序位置。消费者可以通过指定偏移量来消费消息,这样就可以按照指定的顺序来消费。
Kafka使用了消费者组(consumer group)的概念来实现消息的并行消费。每个消费者组内的消费者可以同时消费不同的分区,但是同一个分区只能由同一个消费者组内的一个消费者进行消费。这样就保证了同一个分区的消息只能被一个消费者消费,从而保证了消息的顺序性。
需要注意的是,如果消息的发送和消费都是异步的,那么在消息传递的过程中可能会存在一些延迟,导致消息的顺序性受到影响。为了提高消息的顺序性,可以将发送和消费操作设置为同步的方式,或者使用带有回调函数的异步方式来处理消息。
分布式一致性算法有哪些
有几种常见的分布式一致性算法,包括:
- Paxos算法:Paxos是一种经典的分布式一致性算法,用于解决分布式系统中的一致性问题。它通过选举一个领导者来处理请求,并使用多个阶段的投票和提案来达成一致。
- Raft算法:Raft是一种简化的分布式一致性算法,相较于Paxos更易于理解和实现。它通过选举领导者、日志复制和心跳机制来实现一致性。
- ZAB协议:ZAB(ZooKeeper Atomic Broadcast)协议是ZooKeeper分布式协调服务中使用的一致性协议。它基于原子广播的方式实现分布式系统的一致性。
- 2PC和3PC协议:2PC(Two-Phase Commit)和3PC(Three-Phase Commit)是两种常见的分布式事务协议。它们通过协调器和参与者之间的消息交互来确保分布式事务的一致性。
- Gossip协议:Gossip协议是一种基于消息传播的分布式一致性协议,它通过节点之间的随机通信来达成一致性。每个节点将自身状态以及其他节点的状态进行交换和传播,最终达到一致的状态。
这些算法各有特点,适用于不同的场景和需求。选择适合的分布式一致性算法需要考虑系统的性能、可靠性和复杂性等因素。
kafka的分区同步原理
Kafka的分区同步原理是基于副本复制的机制来实现的。每个主题(topic)的分区都可以配置多个副本(replica),其中一个副本被选举为领导者(leader),其他副本称为追随者(follower)。
当生产者发送消息到某个分区时,消息首先会被写入领导者副本的日志中。一旦消息被写入领导者副本的日志,领导者将会向所有追随者副本发送同步请求。追随者副本收到同步请求后,会将消息复制到自己的日志中,并向领导者发送确认消息。一旦领导者接收到足够多(根据配置的最小副本数)的追随者的确认消息,就会向生产者发送确认消息,表示消息已经成功写入到多个副本中。
对于消费者而言,消费者从分区的领导者副本中读取消息。当消费者消费完消息后,消费者会向领导者发送确认消息。领导者收到确认消息后,会记录消费的偏移量,并向消费者发送确认消息。这样就保证了消费者消费的消息和偏移量的可靠性。
当领导者副本发生故障时,Kafka会从剩余的追随者副本中选举新的领导者。选举过程中,Kafka使用了ZooKeeper来协调和管理副本的状态。一旦新的领导者选举完成,消费者会重新从新的领导者副本中读取消息,并继续消费。
通过这种分区同步的机制,Kafka实现了高可用性和数据冗余,保证了消息的持久性和可靠性。
zookeeper脑裂问题如何解决
要解决Zookeeper脑裂问题,可以考虑以下几个方面的解决方案:
- 配置合理的选举超时时间:选举超时时间是指在一个节点没有收到来自Leader心跳的时间后,它会发起一次选举。如果选举超时时间设置得太短,会导致网络短暂波动或延迟引起的选举,进而增加脑裂的概率。因此,可以适当增加选举超时时间,避免频繁的选举。
- 使用奇数个节点:在Zookeeper集群中,使用奇数个节点可以增加集群的容错性。因为奇数个节点中,只有多数派的节点才能进行Leader选举,这样可以避免出现多个Leader的情况,减少脑裂的发生。
- 配置合理的网络拓扑结构:将Zookeeper节点分布在不同的机架、数据中心或云区域中,可以减少网络分区的发生。这样,即使发生网络分区,也能保证大多数节点仍然能够互相通信。
- 使用专用硬件设备:使用专用的硬件设备,如专用网络交换机,可以提高网络的可靠性和稳定性,减少网络故障引起的脑裂问题。
- 使用多种选举算法:Zookeeper支持多种选举算法,如FastLeaderElection和LeaderElection等。根据实际情况选择合适的选举算法,可以提高集群的容错性和选举的稳定性。
除了上述方案,还可以使用一些辅助工具和技术来监控和管理Zookeeper集群,及时发现和解决脑裂问题。例如,使用监控工具来实时监测集群的状态和节点的健康状况,使用自动化运维工具来管理和维护集群的配置和状态等。
总之,解决Zookeeper脑裂问题需要综合考虑选举超时时间、节点数量、网络拓扑结构、硬件设备和选举算法等因素,并采取相应的措施来保证集群的一致性和可用性。
ES的查询过程
ES(Elasticsearch)的查询过程可以简单分为以下几个步骤:
- 客户端发送查询请求:客户端发送查询请求到ES集群中的任意一个节点,请求中包含了查询的条件、过滤条件、排序规则等。
- 路由和分片:ES集群中的节点会根据索引的路由规则,将查询请求路由到对应的分片上。每个分片都是独立的,包含了部分索引数据和相关的倒排索引。
- 查询分片数据:分片接收到查询请求后,会根据查询条件和分片上的倒排索引进行查询,并返回满足条件的文档列表。
- 结果合并和排序:如果查询请求需要返回多个分片的结果,那么这些分片的查询结果会被合并,并根据排序规则进行排序。
- 返回查询结果:最后,ES将查询结果返回给客户端,客户端可以根据结果进行进一步的处理和展示。
需要注意的是,ES是一个分布式搜索引擎,它将索引数据分片存储在多个节点上,并且通过分布式的方式进行查询和计算。这使得ES能够处理大规模的数据和高并发的查询请求。同时,ES还提供了丰富的查询DSL和聚合功能,可以满足各种复杂的查询需求。
ES的倒排索引是什么
倒排索引(Inverted Index)是Elasticsearch中一种用于快速定位文档的索引结构。它与传统的正排索引(Forward Index)不同,正排索引是根据文档ID来查找相关的词项,而倒排索引则是根据词项来查找相关的文档。
倒排索引的基本原理是将文档中的每个词项都映射到包含该词项的文档列表上。具体而言,倒排索引由两部分组成:
- 词项表(Term Dictionary):存储了所有出现过的词项及其在倒排索引中的位置。
- 倒排列表(Inverted List):每个词项对应一个倒排列表,列表中存储了包含该词项的文档ID及其在文档中的位置信息。
通过倒排索引,可以快速地根据查询的词项定位到包含该词项的文档,而无需遍历所有的文档。这样可以大幅提高查询的效率,尤其是在大规模文档和复杂查询条件下。
此外,倒排索引还支持词项的权重计算、分片存储和分布式查询等特性,使得Elasticsearch能够高效地处理全文搜索和相关性排序等功能。倒排索引是ES的核心之一,也是其高性能和强大搜索能力的基础。
微服务的限流和熔断,熔断后如何恢复
微服务的限流和熔断是在分布式系统中常用的保护机制,用于提高系统的稳定性和可用性。
限流是指限制系统的请求流量,防止系统因为过多的请求而崩溃或过载。常见的限流策略包括固定窗口、滑动窗口和令牌桶等算法。通过限制请求的数量或速率,可以控制系统的负载,保证系统能够正常处理请求。
熔断是指当某个服务或接口出现故障或响应时间过长时,及时中断对该服务的请求,避免造成更多的资源浪费或系统崩溃。熔断器会监控服务的状态,当达到一定的故障阈值时,会触发熔断操作,将请求快速失败,而不是等待超时。
熔断后的恢复可以通过以下几种方式来实现:
- 半开状态恢复:当熔断器开启一段时间后,会进入半开状态,允许部分请求通过,用于测试服务是否已经恢复正常。如果这些请求成功返回,熔断器会将状态切换为关闭状态,继续接收请求;如果请求失败,熔断器会继续保持开启状态。
- 定时恢复:在熔断器开启后的一段时间后,定时检查服务的状态,如果服务已经恢复正常,则将熔断器关闭,继续接收请求;否则继续保持开启状态。
- 手动恢复:当发现服务已经修复,可以手动关闭熔断器,恢复对该服务的正常请求。
总之,根据具体的业务需求和系统状态,可以选择不同的方式来恢复熔断后的服务。重要的是要及时监控和修复故障,确保系统的可用性和稳定性。
相关文章:

2023.12面试题汇总小结
文章目录 Java字节码都包括哪些内容Java双亲委派机制如何打破Java Memory Model是什么synchronized的锁优化是什么CountDownLatch、CyclicBarrier、Semaphore有啥区别,什么场景下使用MySQL MVCC原理MySQL RR隔离级别,会出现幻读吗MySQL的RR隔离级别下&am…...
Linux权限命令详解
Linux权限命令详解 文章目录 Linux权限命令详解一、什么是权限?二、权限的本质三、Linux中的用户四、linux中文件的权限4.1 文件访问者的分类(人)4.2 文件类型和访问权限(事物属性) 五、快速掌握修改权限的做法【第一种…...
)
【Android】Glide的简单使用(下)
文章目录 缓存设置内存缓存硬盘缓存自定义磁盘缓存行为图片请求优先级缩略图旋转图片Glide的回调:TargetsBaseTargetTarget注意事项设置具体尺寸的Target 调试及Debug获取异常信息 配置第三方网络库自定义缓存 缓存设置 GlideApp .with(context).load(gifUrl).asGif().error(…...
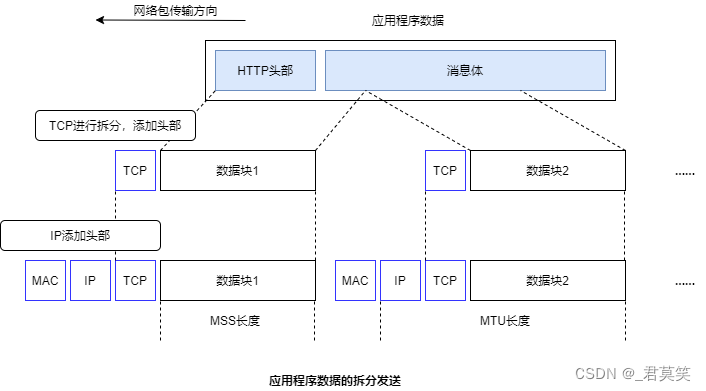
TCP对数据的拆分
应用程序的数据一般都比较大,因此TCP会按照网络包的大小对数据进行拆分。 当发送缓冲区中的数据超过MSS的长度,数据会被以MSS长度为单位进行拆分,拆分出来的数据块被放进单独的网路包中。 根据发送缓冲区中的数据拆分情况,当判断…...

面试问题--计算机网络:二层转发、三层转发与osi模型
计算机网络:二层转发、三层转发与OSI模型 1. 二层转发和三层转发 1.1 二层转发(Data Link Layer) 在计算机网络中,二层转发是通过数据链路层(Data Link Layer)实现的。以下是关于二层转发的一些关键信息…...
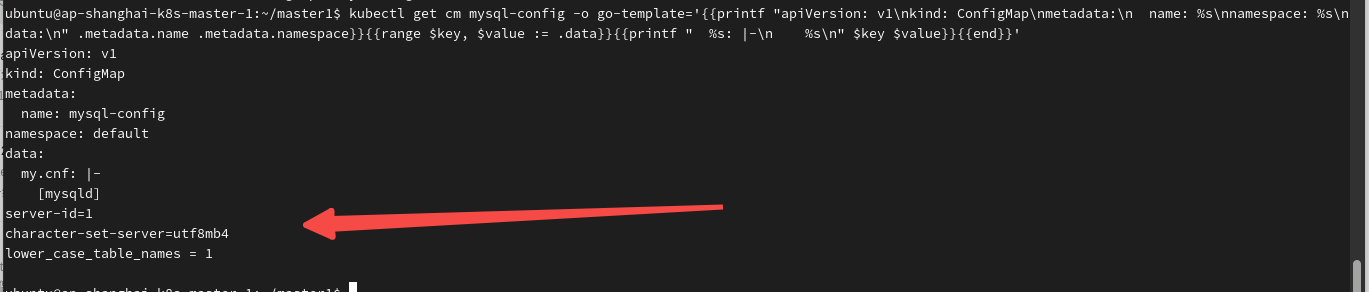
kubectl获取ConfigMap导出YAML时如何忽略某些字段
前言: 当我们在使用Kubernetes时,常常需要通过kubectl命令行工具来管理资源。有时我们也想将某个资源的配置导出为YAML文件,这样做有助于版本控制和资源的迁移。然而,默认情况下,使用kubectl get命令导出资源配置会包…...
复制粘贴——QT实现原理
复制粘贴——QT实现原理 QT 剪贴板相关类 QClipboard 对外通用的剪贴板类,一般通过QGuiApplication::clipboard() 来获取对应的剪贴板实例。 // qtbase/src/gui/kernel/qclipboard.h class Q_GUI_EXPORT QClipboard : public QObject {Q_OBJECT private:explici…...
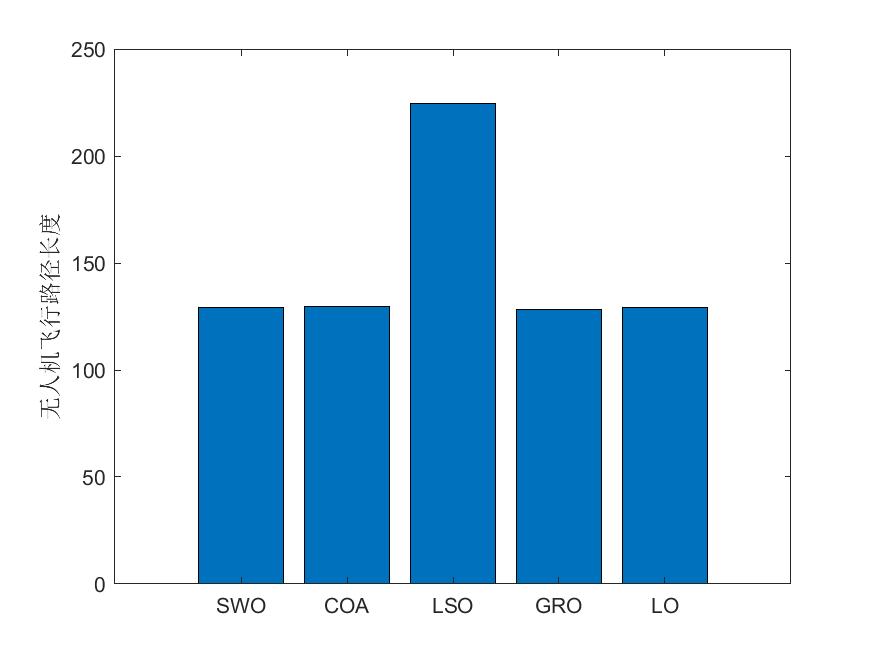
(一)五种最新算法(SWO、COA、LSO、GRO、LO)求解无人机路径规划MATLAB
一、五种算法(SWO、COA、LSO、GRO、LO)简介 1、蜘蛛蜂优化算法SWO 蜘蛛蜂优化算法(Spider wasp optimizer,SWO)由Mohamed Abdel-Basset等人于2023年提出,该算法模型雌性蜘蛛蜂的狩猎、筑巢和交配行为&…...

LED透镜粘接UV胶是一种特殊的UV固化胶,用于固定和粘合LED透镜。
LED透镜粘接UV胶是一种特殊的UV固化胶,用于固定和粘合LED透镜。 它具有以下特点: 1. 高透明度:LED透镜粘接UV胶具有高透明度,可以确保光线的透过性,不影响LED的亮度和效果。 2. 快速固化:经过UV紫外线照射…...
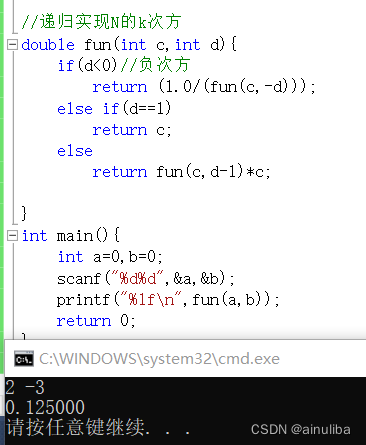
C语言 题目
1.写一个函数算一个数的二进制(补码)表示中有几个1 #include<stdio.h>//统计二进制数中有几个1 //如13:1101 //需要考虑负数情况 如-1 结果应该是32// n 1101 //n-1 1100 //n 1100 //n-1 1011 //n 1000 //n-1 0111 //n 0000 //看n的变化 int funca(int c){int co…...

CDN 内容分发网络
CDN常见问题 什么是 CDN ? CDN 全称是 Content Delivery Network/Content Distribution Network,翻译过的意思是 内容分发网络 。 我们可以将内容分发网络拆开来看: 内容:指的是静态资源比如图片、视频、文档、JS、CSS、HTML。…...
Android : Xui- RecyclerView+BannerLayout 轮播图简单应用
实例图: 1.引用XUI http://t.csdnimg.cn/Wb4KR 2.创建显示图片布局 banner_item.xml <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app"…...
Java网络通信-第21章
Java网络通信-第21章 1.网络程序设计基础 网络程序设计基础涵盖了许多方面,包括网络协议、Web开发、数据库连接、安全性等。 1.1局域网与互联网 局域网(LAN)与互联网(Internet)是两个不同的概念,它们分…...

Leetcode 345. Reverse Vowels of a String
Problem Given a string s, reverse only all the vowels in the string and return it. The vowels are ‘a’, ‘e’, ‘i’, ‘o’, and ‘u’, and they can appear in both lower and upper cases, more than once. Algorithm Collect all the vowels and reverse the…...

[linux] 用命令行wget下载google drive的大文件
使用wget命令下载Google drive上的文件_ubuntu上wget下载谷歌云盘文件-CSDN博客 如何用命令行下载Google Drive上的共享文件?-腾讯云开发者社区-腾讯云 举例:https://drive.google.com/drive/folders/1vKj3VvJEKgS_o-uOSmz3I0-GomECpql3 1、在网页上&…...
Docker Network(网络)——8
目录: Docker 为什么需要网络管理Docker 网络架构简介 CNMLibnetwork驱动常见网络类型 bridge 网络host 网络container 网络none 网络overlay 网络docker 网络管理命令 docker network createdocker network inspectdocker network connectdocker network disconne…...

网页设计--第6次课后作业
试用Vue相关指令完成对以下json数据的显示。显示效果如下: 其中:gender1 显示为女,gender2显示为男。价格超过30元,显示“有点小贵”。价格少于等于30元,则显示“价格亲民”。 data: {books: [{"id": "…...

R语言学习
Part1阶段1:入门基础 1安装R和RStudio: 下载并安装R:https://cran.r-project.org/ 下载并安装RStudio:https://www.rstudio.com/products/rstudio/download/ 2Hello World: 学习如何在R中输出"Hello, World!"…...
基于Unity3D 低多边形地形模型纹理贴图
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 当谈到游戏角色的3D模型风格时,有几种不同的风格…...
vue预览pdf,放大缩小拖动,dialog拖动,父页面滚动
公共组件部分代码 main.js import draggable from /directive/drag/index Vue.use(draggable) pdf组件部分代码...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...