MySQL系列(一):索引篇
为什么是B+树?
我们推导下,首先看下用哈希表做索引,是否可以满足需求。如果我们用哈希建了索引,那么对于如下这种SQL,通过哈希,可以快速检索出数据:
select * from t_user_info where id=1;
但是这里有个问题,哈希会存在碰撞的问题,当然解决碰撞的办法也很多,可以用链地址法,不过如果碰撞特别厉害,那性能也会下降的厉害,不管咋说,这种场景还是可以解决的。但是如果又来了一个其他需求,比如:
select * from t_user_info where id>10;
这是一个范围查询,如果使用哈希算法作为索引,这种情况就很难办,我们可能需要遍历一遍所有的数据,然后做排序,最后得到结果,这显然是不能接受的。因此,这种情况,用哈希是不适合做为InnoDB的索引的。
对于范围查询,我们怎么优化了,很容易就想到了“二叉查找树”,二叉查找树的左边节点都是小于根节点的,右边节点都是大于根节点的,这样不仅单点查询不会很慢,此外可以加快范围查询效率。
一般的情况下,二叉查询树都是没问题的,但是了,极端情况,比如对于数据库的自增ID, 这时候二叉查找树就会退化为线性链表查询,查询性能将急剧下降,那显然不能接受。
之所以会出现上面的情况,主要就是因为二叉查找树不平衡导致的。那我们可以换用平衡二叉树AVL,插入新数据后AVL会自动的旋转保持平衡。这样就避免了极端情况下的低效查找问题。对于单点查找和范围查询效率都不错。
那么,是否AVL就适合做MYSQL的底层索引数据结构了?这里还要考虑一个问题,那就是存储和磁盘IO开销的问题,如果使用的是AVL树,我们每一个树节点只存储了一个数据,我们一次磁盘IO只能取出来一个节点上的数据加载到内存里,那么一次查询将会发生多次磁盘IO,而一般磁盘IO是比较耗时的,我们需要尽可能的减少磁盘IO的次数。
那么有没有既是平衡的树,又可以减少磁盘IO访问的数据结构存在了,有的,那么就是B树和B+树了。InnoDB用的是B+树,这里为何要选用B+树了?主要原因是:
- 磁盘IO消耗。B+树的非叶子节点中不保存数据,B树中非叶子节点会保存数据,通常一个节点大小会设置为磁盘页大小,这样B+树每个节点可放更多的key,B树则更少。这样就造成了,B树的高度会比B+树更高,从而会产生更多的磁盘IO消耗。
- 查找效率。B+树叶子节点构成链表,更利用范围查找和排序,而B树进行范围查找和排序则要对树进行递归遍历。
索引查询原理
我们将查询分为聚簇索引场景,以及非聚簇索引场景,来分别说明其查询原理。
本节内容参考了:从数据页的角度看 B+ 树 ,有兴趣可以去看看作者原文,感谢作者辛苦画的图,比较生动形象。
聚簇索引
InnoDB 里的 B+ 树中的每个节点都是一个数据页,结构示意图如下:
我们看看 B+ 树如何实现快速查找主键为 6 的记录,以上图为例子:
从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6,在[1, 7)范围之间,所以到页 30 中查找更详细的目录项;
在非叶子节点(页30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5,所以就到叶子节点(页16)查找记录;
接着,在叶子节点(页16)中,通过槽查找记录时,使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为 6 的记录。
可以看到,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
非聚簇索引
注意,上面是主键查询,也就是“聚簇索引”查询,如果是“二级索引”查询,也就是非聚簇索引查询,查询会有一些不同。二级索引的叶子节点存放的是主键值,不是实际数据,二级索引的 B+ 树如下图,数据部分为主键值:
因此,如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中获得数据行,这个过程就叫作「回表」,也就是说要查两个 B+ 树才能查到数据。不过,当查询的数据是主键值时,因为只在二级索引就能查询到,不用再去聚簇索引查,这个过程就叫作「索引覆盖」,也就是只需要查一个 B+ 树就能找到数据。
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
Page Directory
注意,B+树索引本身并不能找到具体的一条记录,能找到的只是该记录所在的页。数据库把页载入内存后,再通过Page Directory再进行二分查找。只不过二分查找的时间复杂度很低,同时在内存中的查找很快,因此通常忽略这部分查找所用的时间。
这里,看看InnoDB 是如何给记录创建页目录的。Page Directory与记录的关系如下图:
页目录创建的过程如下:
将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
索引如何选择
如何一个表拥有多个索引,那么数据库最终会选择哪个索引了?这里就涉及到索引选择问题,一般数据库会计算不同根据不同索引的查询开销,那一个开销最小,那么就选择这个索引。
那么查询开销如何计算了?开销一般包括:IO开销,CPU开销,以及网络开销。其中网络开销我们一般忽略不计,那么主要考虑IO开销以及CPU开销,这里IO开销一般占大头。所以数据库会重点参考索引扫描行数。如果扫描行数越多,那么代价越大。
这里行数怎么得出了,难道是每次都去实时查吗?并不是的,数据库可以通过抽样获取,比如随机抽取几页,然后统一一下分布,然后根据分布乘以总页数,那么就得到了数据的一个大致的基数,这样就可以通过这个基数来判断IO开销了。
那么,数据库是否会存在选错索引的情况了?是存在的,这里主要有两种情况:1)表增删十分频繁,导致扫描行数预估的统计信息不准确,可能会选择错误的索引。解决该类问题的方法是强制触发统计信息的更新,即analyze table。这个操作只是触发重新采样更新统计信息,因此用户不用担心这个操作会影响DML操作;2)有时候扫描的行太多,再加上回表等操作,优化器认为,还不如不走这个索引,此时也会出现不符合预期的情况。
对于没有使用预期的索引,我们应该怎么做了?可以使用force index强制使用索引。其外,如果有按扰且无用的索引存在,那么可以删除这个干扰的索引。
索引页的结构
首先看下InnoDBd的逻辑存储结构,如下图所示:
TableSpace可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。InnoDB存储引擎有一个共享的空间ibdata1,即所有的数据都存放在这个空间内,如果用户启用了参数innodb_file_per_table,则每张表一个单独的表空间。表空间由各种Segement组成,常见Segment比如数据段、索引段、回滚段等。
Segement由一个个Extent组成。Extent是由连续的Page组成的空间。Page是InnoDB磁盘管理的最小单位,下面着重了解下Page。这片博客中的图比较形象:从MySQL InnoDB物理文件格式深入理解索引 ,有兴趣可以看看这篇文章,写的比较深刻。
更详细的Page结构字段描述如下图所示:
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:
感谢网上提供的各种资源,尤其是这些图,感谢感谢!
估算索引记录数
既然上面我们已经了解了Page的结构,那不如我们顺势一起估算下,在某个特定的场景下,比如每行数据1K大小,B+树索引的情况。
本节内容来自:为什么大家说mysql数据库单表最大两千万?依据是啥? ,有兴趣可以去看看原文,作者写的非常不错,我摘录一下。
B+树的最末级叶子结点里放了record数据。而非叶子结点里则放了用来加速查询的索引数据。也就是说同样一个16k的页,非叶子节点里每一条数据都指向一个新的页,而新的页有两种可能。
如果是末级叶子节点的话,那么里面放的就是一行行record数据。
如果是非叶子节点,那么就会循环继续指向新的数据页。
假设:
非叶子结点内指向其他内存页的指针数量为x
叶子节点内能容纳的record数量为y
B+树的层数为z
那这棵B+树放的行数据总量等于 (x ^ (z-1)) * y。
X怎么算
非叶子节点里主要放索引查询相关的数据,放的是主键和指向页号。
主键假设是bigint(8Byte),而页号在源码里叫FIL_PAGE_OFFSET(4Byte),那么非叶子节点里的一条数据是12Byte左右。
整个数据页16k, 页头页尾那部分数据全加起来大概128Byte,加上页目录毛估占1k吧。那剩下的15k除以12Byte,等于1280,也就是可以指向x=1280页。
我们常说的二叉树指的是一个结点可以发散出两个新的结点。m叉树一个节点能指向m个新的结点。这个指向新节点的操作就叫扇出(fanout) 。
而上面的B+树,它能指向1280个新的节点,恐怖如斯,可以说扇出非常高了。
Y怎么算
叶子节点和非叶子节点的数据结构是一样的,所以也假设剩下15kb可以发挥。
叶子节点里放的是真正的行数据。假设一条行数据1kb,所以一页里能放y=15行。
行总数计算
回到 (x ^ (z-1)) * y 这个公式。
已知x=1280,y=15。
假设B+树是两层,那z=2。则是(1280 ^ (2-1)) * 15 ≈ 2w
假设B+树是三层,那z=3。则是(1280 ^ (3-1)) * 15 ≈ 2.5kw
这个2.5kw,就是我们常说的单表建议最大行数2kw的由来。 毕竟再加一层,数据就大得有点离谱了。三层数据页对应最多三次磁盘IO,也比较合理。
索引失效场景
前面对于原理以及索引存储结构,以及记录数估算等进行了了解。本节探讨一下索引失效的问题,毕竟也是我们经常遇到的,一起避避坑。
假如有如下一张用户表,我们一起看一下那些场景会出现索引失效的情况:
CREATE TABLE `person` (`id` int unsigned NOT NULL AUTO_INCREMENT,`name` varchar(127) NOT NULL COMMENT '姓名',`age` int DEFAULT 0 COMMENT '年龄',`salary` int DEFAULT 0 COMMENT '工资',`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`),UNIQUE KEY `uniq_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='人员信息';
对索引使用左或者左右模糊匹配
场景描述
当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx% 这两种方式都会造成索引失效。比如如下SQL:
select * from person where name like '%李'
explain结果如下:

失效原因
因为索引 B+ 树是按照「索引值」有序排列存储的,只能根据前缀进行比较。
如果使用 name like ‘%李’ 方式来查询,因为查询的结果可能是「小李、大李、老李」等之类的,所以不知道从哪个索引值开始比较,于是就只能通过全表扫描的方式来查询。
对索引使用函数
场景描述
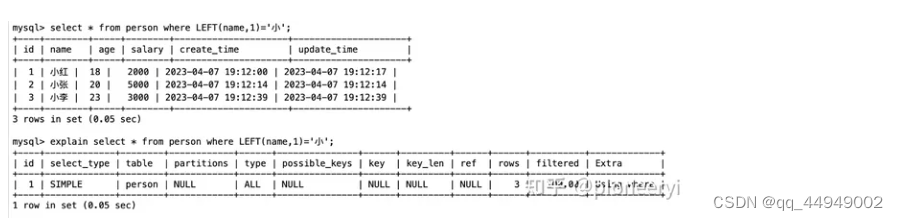
失效原因
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。注意,也不一定完全放弃这个索引,可能对比开销后,还是会用这个索引,不过是全索引扫描。
特别说明
Mysql从8.0.13版本后,开始支持函数索引,我开始以为是直接使用函数即可,然后发现并未走索引,如下所示:

仔细看了下官方文档,是这样的:
MySQL 8.0.13 and higher supports functional key parts that index
expression values rather than column or column prefix values. Use of
functional key parts enables indexing of values not stored directly in
the table. Examples:
CREATE TABLE t1 (col1 INT, col2 INT, INDEXfunc_index ((ABS(col1)))); ALTER TABLE t1 ADD INDEXfun_index(ABS(col1));
看明白了没,是需要显式的创建一个相应的索引才可以的,不过想想也合理,如果用户不创建,那么就需要默认给所有的函数创建出索引,这样代价未免太大。函数还可以穷举,表达式则是完全没办法穷举的,所以这样也合理。我们单独建立一个函数索引试试:

可以看到,这次就走了新增加的函数索引。
对索引隐式类型转换
场景描述
失效原因
这是因为,上述查询,MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。因此对于上述查询,相当于:
select * from person where cast(name as int)=123;
通过场景2,我们知道了,当对索引使用了函数时,索引会失效,因此这个查询,索引会失效。
特别说明
这里需要注意,如果隐式转换发生在索引值,而非索引字段时,那么索引不会失效,比如我们对age创建索引,然后进行如下查询:

可以看到,上述查询,索引并没有失效。因为上述转换是发生在值上的,SQL相当于如下这样:
select * from person where age=cast(‘123’ as int);
这个查询,不会导致索引失效。
多索引进行表达式计算
场景说明
失效原因
表达式失效的原因同函数的类似,都是:
对索引字段做表达式计算,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
特别说明
Mysql8.0.13版本后,除了提供函数索引,还提供了表达式索引,比如我们对上述表达式计算加一个索引,如下所示:
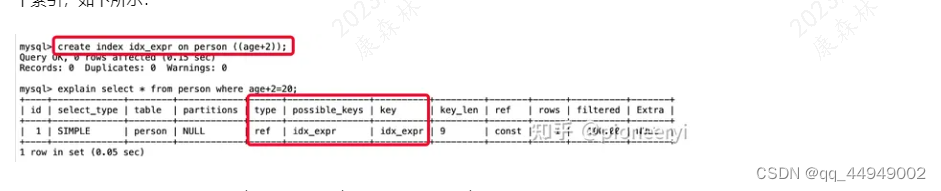
可以看到,当增加了表达式计算索引后,上述查询就可以成功走索引了。
Where子句中的OR
场景描述

失效原因
这是因为 OR 的含义就是两个只要满足一个即可,因此只有一个条件列是索引列是没有意义的,只要有条件列不是索引列,就会进行全表扫描。
联合索引非最左匹配
场景描述
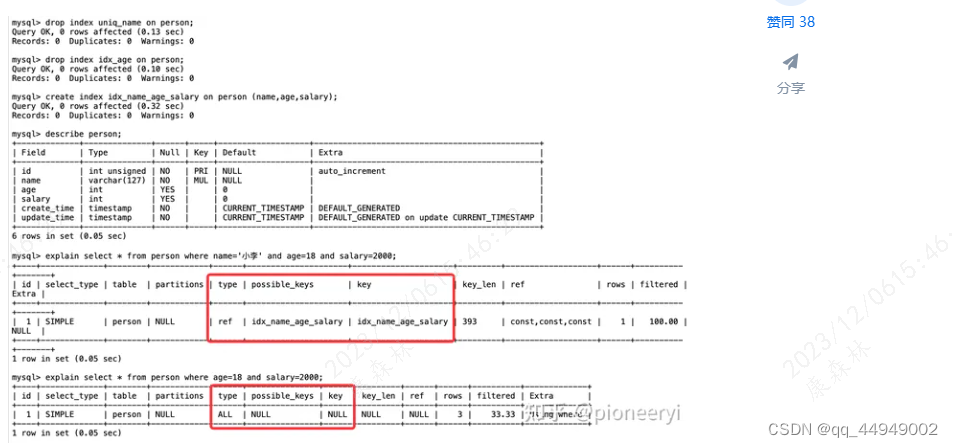
失效原因
原因是,在联合索引的情况下,数据是按照索引字段顺序逐个排序的,第二个是第一个排好序的基础上排的,以此类推。
联合索引中有范围查
场景描述
当前联合索引中,前面的字段存在范围查时,后面的字段就会失效,相当于没有联合的效果,如下所示:
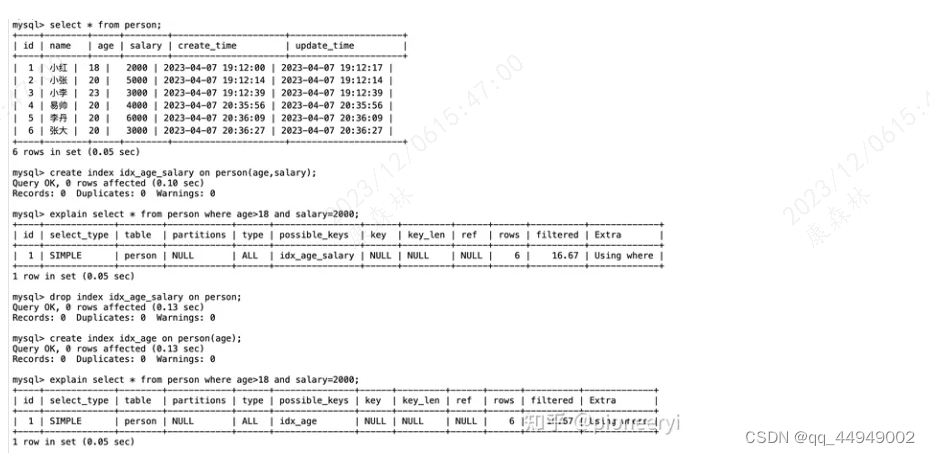
对于这种场景,联合索引age和salary和单个索引age没有区别,因为联合索引中的后一个字段已经失效了。
失效原因
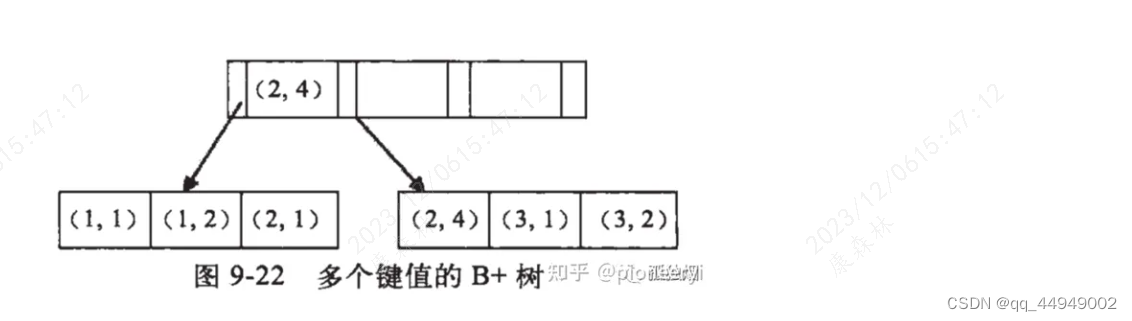
如上面这个图,当我们使用范围查询时,比如查询大于等于2的记录,记录为:(2,1)、(2,4)、(3,1)、(3,2),可以看到后一个字段的值(1、4、1、2)是无序的,因此没有起到索引的效果。
索引不等于比较
场景描述
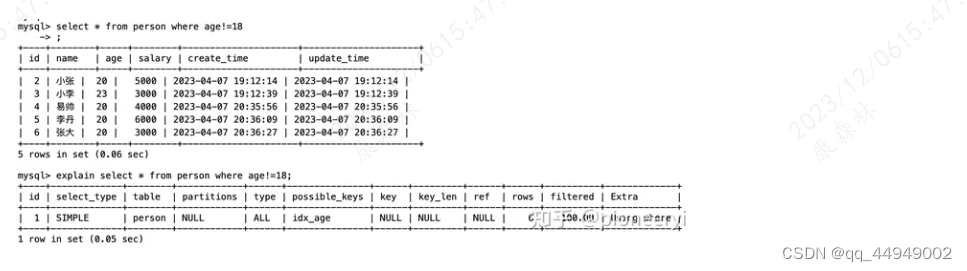
对于<>、IS NOT NULL、NOT EXISTS都属于类似的情况。
失效原因
不等于几乎要读取非聚簇索引上的所有数据,然后再去回表,这样可能反而没有直接去全表扫描快了,因此不如直接全表扫描。
特别说明
如果使用索引查询索引字段,那么还是会用索引的,如下所示:
此外,如果用主键进行不等于查询时,也会走主键索引,如下所示:
后记
再次感谢网上各个大佬的文章和图片资源,推荐大家都去读读本文参考的原文。
参考文档
B+Tree index structures in InnoDB
从数据页的角度看 B+ 树
从MySQL InnoDB物理文件格式深入理解索引
为什么大家说mysql数据库单表最大两千万?依据是啥?
相关文章:
MySQL系列(一):索引篇
为什么是B树? 我们推导下,首先看下用哈希表做索引,是否可以满足需求。如果我们用哈希建了索引,那么对于如下这种SQL,通过哈希,可以快速检索出数据: select * from t_user_info where id1;但是这…...
Flink Flink数据写入Kafka
一、环境准备 官网地址 flink官方集成了通用的 Kafka 连接器,使用时需要根据生产环境的版本引入相应的依赖 <properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.6</flink.version&g…...

《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 Affective Computing 2021
《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 前言简介模型结构实验结果总结前言 今天为大家带来的是《Emotion-Regularized Conditional Variational Autoencoder for Emotional Response Generation》 出版:IEEE Transactions on Affective Computing 时间…...

Pytorch CIFAR10图像分类 Swin Transformer篇
Pytorch CIFAR10图像分类 Swin Transformer篇 文章目录 Pytorch CIFAR10图像分类 Swin Transformer篇4. 定义网络(Swin Transformer)Swin Transformer整体架构Patch MergingW-MSASW-MSARelative position biasSwin Transformer 网络结构Patch EmbeddingP…...
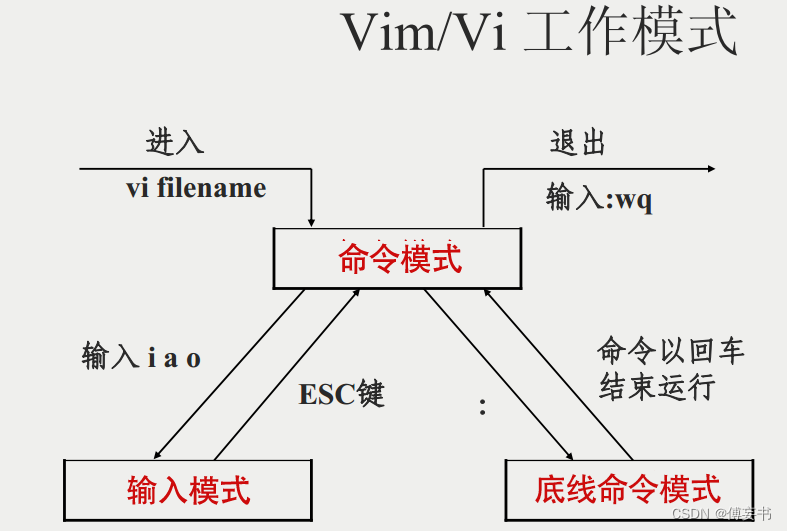
【vim】常用操作
用的时候看看,记太多也没用,下面都是最常用的,更多去查文档vim指令集。 以下均为正常模式下面操作,正在编辑的,先etc一下. 1/拷贝当前行 yy,5yy为拷贝包含当前行往下五行 2/p将拷贝的东西粘贴到当前行下…...

oracle、误操作删除数据库 数据恢复。
–查询 执行 delete 的语句 ,拿到删除的时间 FIRST_LOAD_TIME ,删除行数可参考 ROWS_PROCESSED select t.FIRST_LOAD_TIME,t.ROWS_PROCESSED,t.* from v$sql t where t.sql_text like %delete from trade% ;select *from trade as of timestamp to_time…...
【Angular开发】Angular在2023年之前不是很好
做一个简单介绍,年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师酒馆】…...
 但是 3.0.8-1ubuntu1.2 正要被安装)
记录 | 报错:libssl-dev : 依赖: libssl3 (= 3.0.8-1ubuntu1.1) 但是 3.0.8-1ubuntu1.2 正要被安装
ubuntu 上安装 libssl-dev 失败的报错解决 报错: 下列软件包有未满足的依赖关系: libssl-dev : 依赖: libssl3 ( 3.0.8-1ubuntu1.1) 但是 3.0.8-1ubuntu1.2 正要被安装 E: 无法修正错误,因为您要求某些软件包保持现状,就是它们破…...

MySQL联合查询、最左匹配、范围查询导致失效
服务器版本 客户端:navicat premium16.0.11 联合索引 假设有如下表 联合索引就是同时把多列设成索引,如(empno,ename)在查询的时候就会先按照empno进行查询,再按照ename进行查询其中empno是全局有序,ename是局部有…...

部署zabbix
源码下载地址: Download Zabbix sources nginx: download 防火墙和selinux都需要关闭 1、部署监控服务器 1)安装LNMP环境 Zabbix监控管理控制台需要通过Web页面展示出来,并且还需要使用MySQL来存储数据,因此需要先为Zabbix准备基础…...

服务器感染了.locked、.locked1勒索病毒,如何确保数据文件完整恢复?
尊敬的读者: locked、.locked1勒索病毒的威胁如影随形,深刻影响着数字世界的安全。本文将深入揭示locked、.locked1的狡猾特征,为您提供实用的数据恢复方法,并分享一系列特别定制的预防措施,旨在使您的数字生活摆脱勒…...
【Linux系统化学习】命令行参数 | 环境变量的再次理解
个人主页点击直达:小白不是程序媛 Linux专栏:Linux系统化学习 代码仓库:Gitee 目录 mian函数传参获取环境变量 手动添加环境变量 导出环境变量 environ获取环境变量 本地变量和环境变量的区别 Linux的命令分类 常规命令 内建命令 …...
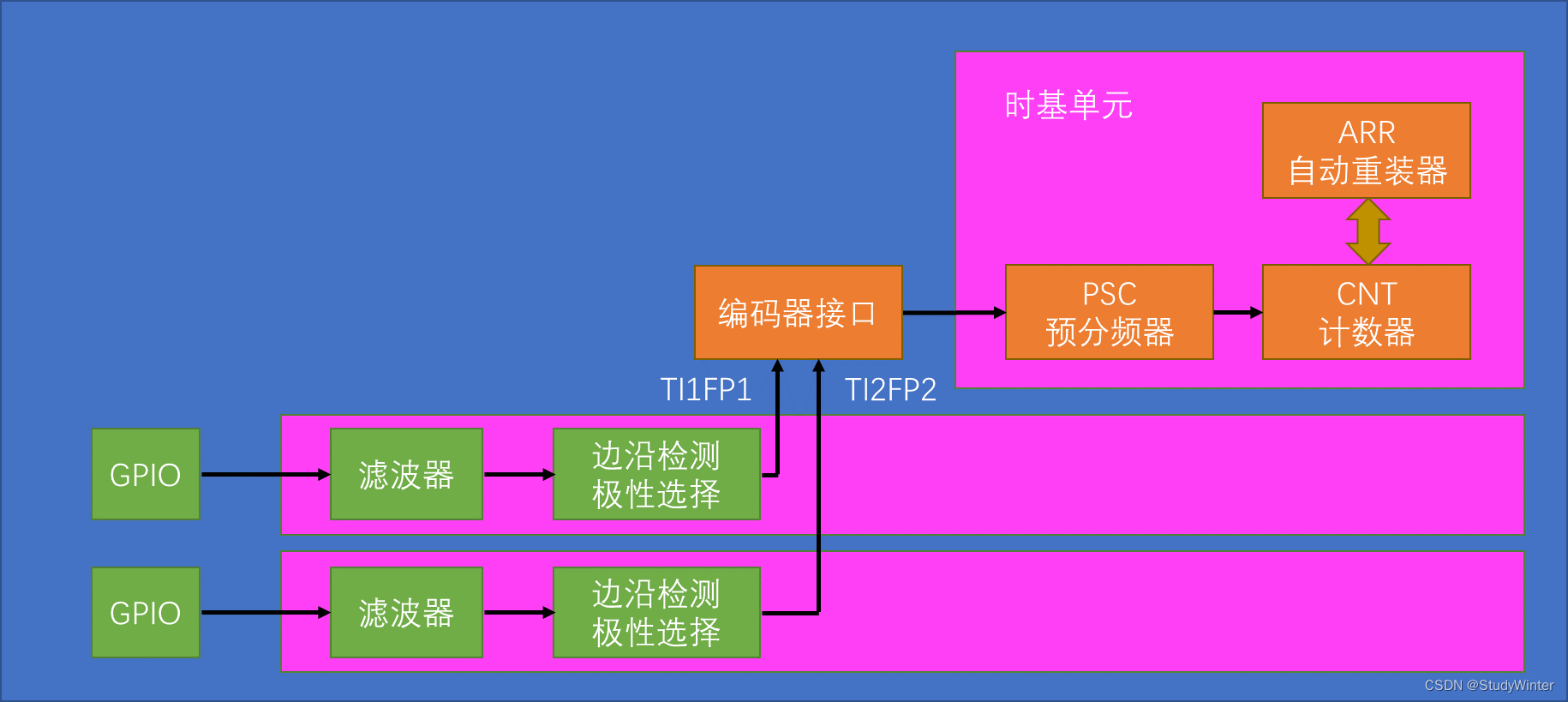
【STM32】TIM定时器编码器
1 编码器接口简介 Encoder Interface 编码器接口 编码器接口可接收增量(正交)编码器的信号,根据编码器旋转产生的正交信号脉冲,自动控制CNT自增或自减,从而指示编码器的位置、旋转方向和旋转速度 接收正交信号&#…...

力扣44题通配符匹配题解
44. 通配符匹配 - 力扣(LeetCode) 给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字符。* 可以匹配任意字符序列(包括空字符序列)。 …...
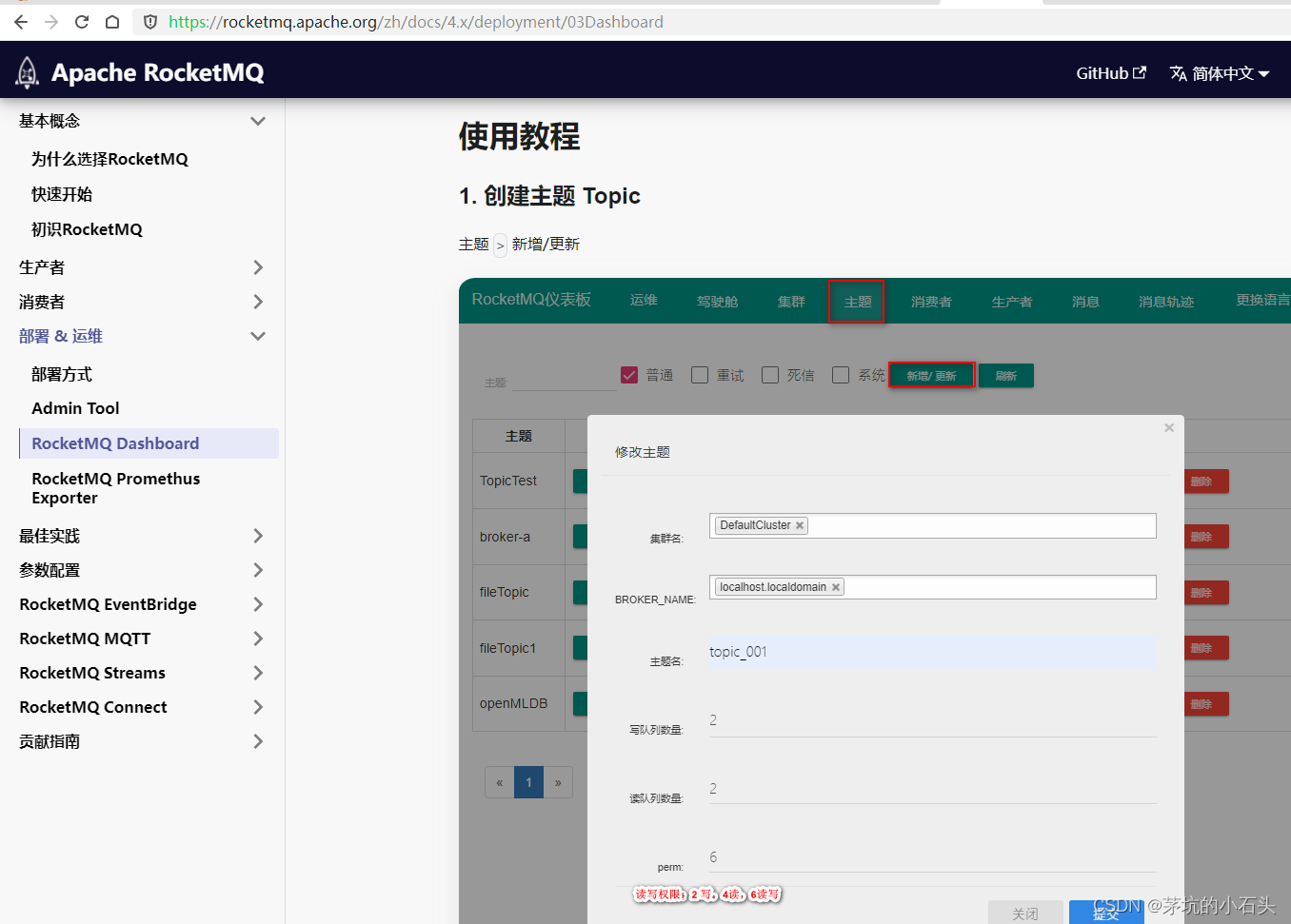
windows系统安装RocketMQ_dashboard
1.下载源码 按照官网说明下载源码 官网 官网文档 2.源码安装 2.1.① 编译rocketmq-dashboard 注释掉报错的maven插件frontend-maven-plugin、maven-antrun-plugin mvn clean package -Dmaven.test.skiptrue2.2.② 运行rocketmq-dashboard java -jar target/rocketmq-…...

ATECLOUD电源自动测试系统打破传统 助力新能源汽车电源测试
随着新能源汽车市场的逐步扩大,技术不断完善提升,新能源汽车测试变得越来越复杂,测试要求也越来越严格。作为新能源汽车的关键部件之一,电源为各个器件和整个电路提供稳定的电源,满足需求,确保新能源汽车的…...

如何教会小白使用淘宝API接口获取商品数据
随着互联网的普及,越来越多的人开始接触网络购物,而淘宝作为中国最大的电商平台之一,成为了众多消费者首选的购物平台。然而,对于一些小白用户来说,如何通过淘宝API接口获取商品数据可能是一个难题。本文将详细介绍如何…...
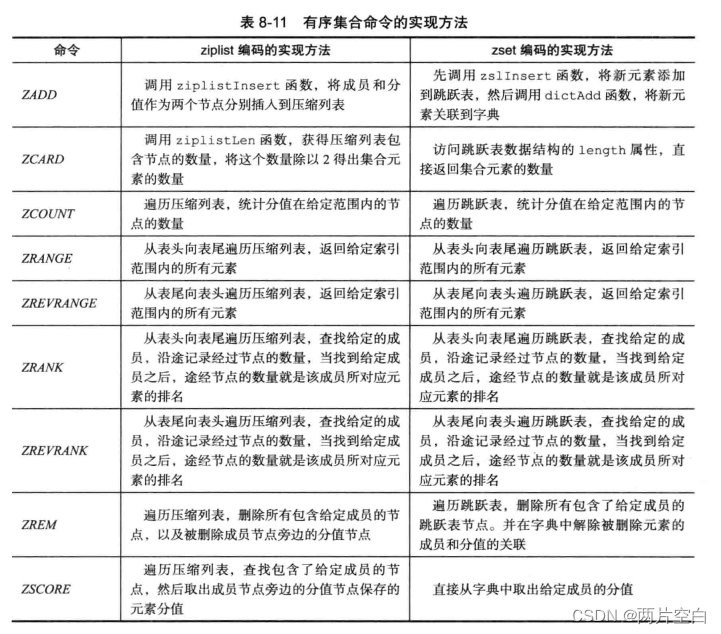
Redis有序集合对象
一.编码 有序集合的编码可以是ziplist或者skiplist。 ziplist编码的有序集合对象使用压缩列表作为底层实现,每一个集合元素使用紧挨在一起的两个压缩列表节点来保存。第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。 127.0.0.…...

【C++数据结构 | 字符串速通】10分钟秒杀字符串相关操作 | 字符串的增删改查 | 字符串与数组相互转换
字符串 by.Qin3Yu 文中所有代码默认已使用std命名空间且已导入部分头文件: #include <iostream> #include <string> using namespace std;概念速览 字符串是一种非常好理解的数据类型,它用于存储和操作文本数据。字符串可以包含任意字符…...
运动重定向:C-3PO
C-3PO: Cyclic-Three-Phase Optimization for Human-Robot Motion Retargeting based on Reinforcement Learning解析 摘要1. 简介2. 相关工作2.1 运动重定向(Motion Retargeting)2.2 强化学习(Reinforcement Learning) 3. 预备知…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...