基于Solr的全文检索系统的实现与应用
文章目录
- 一、概念
- 1、什么是Solr
- 2、与Lucene的比较区别
- 1)Lucene
- 2)Solr
- 二、Solr的安装与配置
- 1、Solr的下载
- 2、Solr的文件夹结构
- 3、运行环境
- 4、Solr整合tomcat
- 1)Solr Home与SolrCore
- 2)整合步骤
- 5、Solr管理后台
- 1)Dashboard
- 2)Logging
- 3)Cloud
- 4)Core Admin
- 5) java properties
- 6)Tread Dump
- 7)Core selector
- 8)Analysis
- 9)Dataimport
- 10)Document
- 11)Query
- 6、配置中文分析器
- 1)Schema.xml
- 1. FieldType域类型定义
- 2. Field定义
- 3. uniqueKey
- 4. copyField复制域
- 5. dynamicField(动态字段)
- 2)安装使用IKAnalyzer中文分词器
- 三、Solr管理索引库(不推荐)
- 1、添加/更新文档
- 2、批量导入数据
- 3、删除文档
- 4、查询文档
- 四、使用SolrJ管理索引库
- 1、什么是solrJ
- 2、创建Java工程,导入jar包
- 3、添加文档
- 4、删除文档
- 5、修改文档
- 6、查询文档
- 五、案例实现
- 1、创建一个web工程导入jar包
- 2、配置xml文件
- 3、导入jsp页面和css
- 4、具体代码实现
一、概念
1、什么是Solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
2、与Lucene的比较区别
1)Lucene
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
2)Solr
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
二、Solr的安装与配置
1、Solr的下载
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3,根据Solr的运行环境,Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
Solr使用指南可参考:https://wiki.apache.org/solr/FrontPage。
2、Solr的文件夹结构
将solr-4.10.3.zip解压后,目录如下:

- bin:solr的运行脚本
- contrib:solr的一些贡献软件/插件,用于增强solr的功能。
- dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
- docs:solr的API文档
- example:solr工程的例子目录:
example/solr:该目录是一个包含了默认配置信息的Solr的Core目录。
example/multicore:该目录包含了在Solr的multicore中设置的多个Core目录。
example/webapps: 该目录中包括一个solr.war,该war可作为solr的运行实例工程。 - licenses:solr相关的一些许可信息
3、运行环境
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器,环境如下:
- Solr:Solr4.10.3
- Jdk:jdk1.8.0_72
- Tomcat:apache-tomcat-7.0.53
4、Solr整合tomcat
1)Solr Home与SolrCore
创建一个Solr home目录,SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
example\solr是一个solr home目录结构,如下:

上图中“collection1”是一个SolrCore(Solr实例)目录 ,目录内容如下所示:

说明:
collection1:是一个Solr运行实例SolrCore,SolrCore名称不固定,一个solr运行实例对外单独提供索引和搜索接口。
solrHome中可以创建多个solr运行实例SolrCore。
一个solr的运行实例对应一个索引目录
conf是SolrCore的配置文件目录 。
data目录存放索引文件需要创建
2)整合步骤
- 第一步:安装tomcat。
- 第二步:把solr的war包复制到tomcat 的webapp目录下。
- 第三步:solr.war解压。
- 第四步:把\solr-4.10.3\example\lib\ext目录下的所有的jar包添加到solr工程中的WEB-INF\lib。
- 第五步:配置solrHome和solrCore。
1)创建一个solrhome(存放solr所有配置文件的一个文件夹)。
2)把\solr-4.10.3\example\solr文件夹复制到solrhome文件夹中,文件夹名字没规定是这个,是为了便于理解。 - 第六步:告诉solr服务器配置文件也就是solrHome的位置。修改solr工程中的web.xml。
Solr/home名称必须是固定的。

- 第七步:启动tomcat
- 第八步:访问http://localhost:8090/solr/
5、Solr管理后台
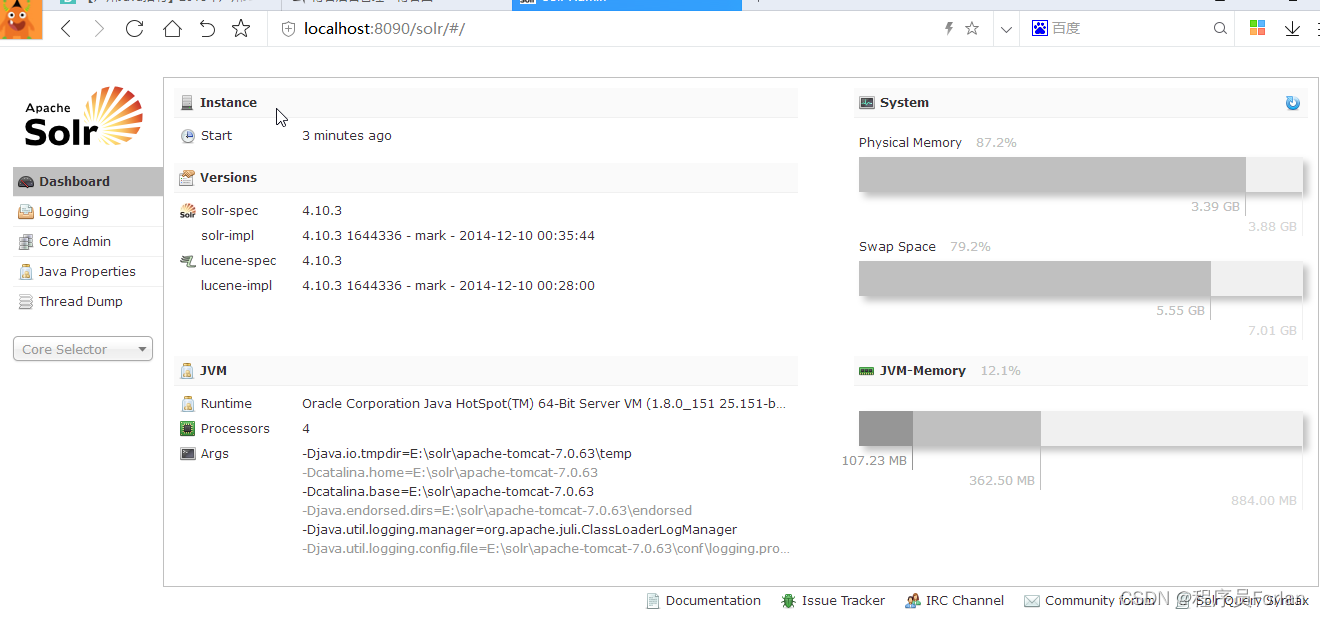
1)Dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
2)Logging
Solr运行日志信息
3)Cloud
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单。
4)Core Admin
Solr Core的管理界面。Solr Core 是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。
添加solrcore:
- 第一步:复制collection1改名为collection2
- 第二步:修改core.properties。name=collection2
- 第三步:重启tomcat
5) java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
6)Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
7)Core selector
选择一个SolrCore进行详细操作,如下:
8)Analysis

通过此界面可以测试索引分析器和搜索分析器的执行情况。
9)Dataimport
可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
10)Document
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
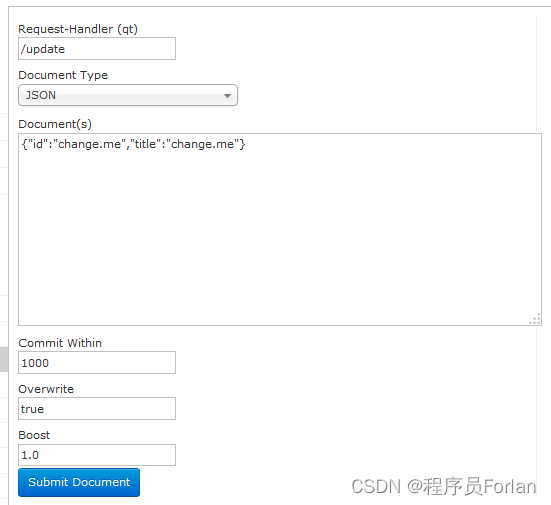
/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
11)Query

通过/select执行搜索索引,必须指定“q”查询条件方可搜索。
6、配置中文分析器
1)Schema.xml
schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
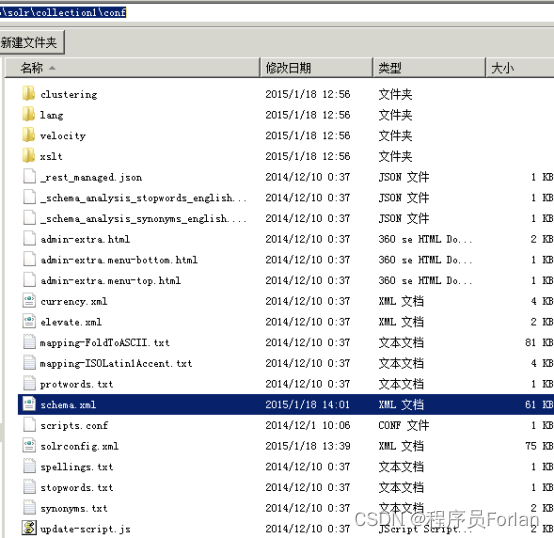
1. FieldType域类型定义
“text_general”是Solr默认提供的FieldType,通过它说明FieldType定义的内容:
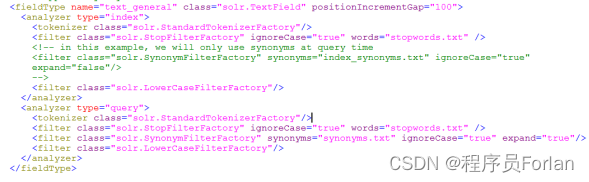
FieldType子结点包括:name,class,positionIncrementGap等一些参数:
- name:是这个FieldType的名称
- class:是Solr提供的包solr.TextField,solr.TextField 允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
- positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤
- 索引分析器:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,solr.LowerCaseFilterFactory小写过滤器。
- 搜索分析器:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。
2. Field定义
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性,如下:
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="features" type="text_general" indexed="true" stored="true" multiValued="true"/>
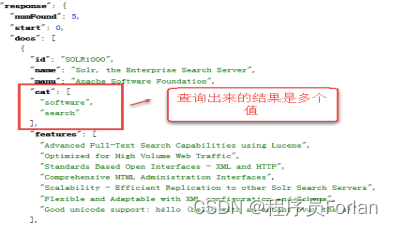
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组:
3. uniqueKey
Solr中默认定义唯一主键key为id域,如下:
Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束
4. copyField复制域
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索,比如,输入关键字搜索title标题内容content,定义title、content、text的域:

根据关键字只搜索text域的内容就相当于搜索title和content,将title和content复制到text中,如下:

5. dynamicField(动态字段)
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
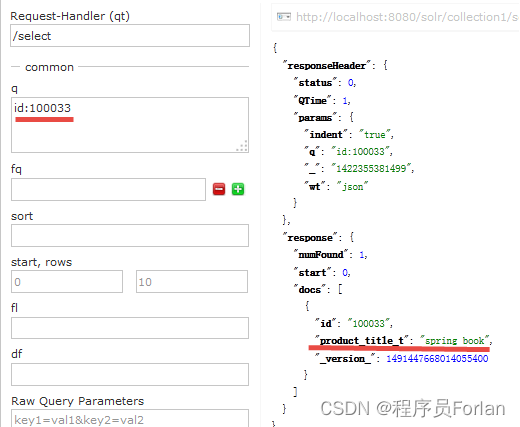
a、自定义Field名为:product_title_t,“product_title_t”和scheam.xml中的dynamicField规则匹配成功,如下:“product_title_t”是以“_t”结尾。

b、创建索引

c、搜索索引
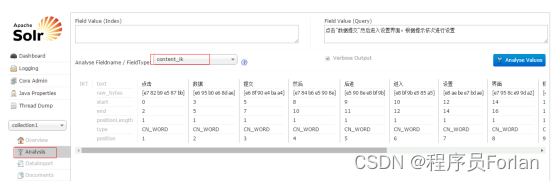
2)安装使用IKAnalyzer中文分词器
- 第一步:把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下。
- 第二步:复制IKAnalyzer的配置文件和自定义词典和停用词词典到solr的classpath(在web-inf中自建的)下。
- 第三步:在schema.xml中添加一个自定义的fieldType,使用中文分析器。
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField"><analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
- 第四步:定义field,指定field的type属性为text_ik
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
- 第五步:重启tomcat
测试效果:
三、Solr管理索引库(不推荐)
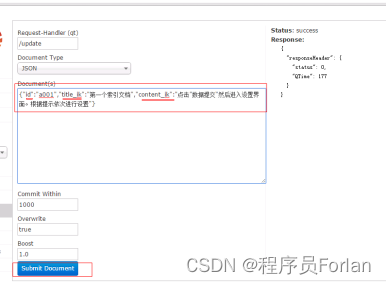
1、添加/更新文档
添加或更新单个文档
2、批量导入数据
使用dataimport插件批量导入数据。
- 第一步:把dataimport插件依赖的jar包以及mysql的数据库驱动包
添加到solrhome\collection1\lib中


- 第二步:配置solrhome\collection1\conf路径下的solrconfig.xml文件,添加一个requestHandler。
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler"><lst name="defaults"><str name="config">data-config.xml</str></lst></requestHandler>
- 第三步:创建一个data-config.xml,保存到collection1\conf\目录下
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/lucene" user="root" password="123"/>
<document> <entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products "><field column="pid" name="id"/> <field column="name" name="product_name"/> <field column="catalog_name" name="product_catalog_name"/> <field column="price" name="product_price"/> <field column="description" name="product_description"/> <field column="picture" name="product_picture"/> </entity>
</document>
</dataConfig>
- 第四步:这里还没有lucene数据库,创建一个,然后导入sql文件。
- 第五步:data-config.xml里面的字段还没映射,配置schema.xml
<!--product--><field name="product_name" type="text_ik" indexed="true" stored="true"/><field name="product_price" type="float" indexed="true" stored="true"/><field name="product_description" type="text_ik" indexed="true" stored="false" /><field name="product_picture" type="string" indexed="false" stored="true" /><field name="product_catalog_name" type="string" indexed="true" stored="true" /><field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/><copyField source="product_name" dest="product_keywords"/><copyField source="product_description" dest="product_keywords"/>
- 第六步:重启tomcat
- 第七步:点击“execute”按钮导入数据
导入数据前会先清空索引库,然后再导入。
3、删除文档
1) 删除制定ID的索引
<delete>
<id>8</id>
</delete>
<commit/>
2) 删除查询到的索引数据
<delete>
<query>product_catalog_name:幽默杂货</query>
</delete>
3) 删除所有索引数据
<delete>
<query>*:*</query>
</delete>
4、查询文档
通过/select搜索索引,Solr制定一些参数完成不同需求的搜索:
1.q - 查询字符串,必须的,如果查询所有使用,例如:
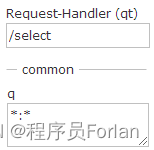
2.fq-(filter query)过虑查询,作用:在q查询符合结果中同时是fq查询符合的,例如:

过滤查询价格从1到20的记录。
也可以在“q”查询条件中使用product_price:[1 TO 20],例如:

也可以使用“*”表示无限,例如:
- 20以上:product_price:[20 TO *]
- 20以下:product_price:[* TO 20]
3.sort - 排序,格式:sort=+<desc|asc>[,+<desc|asc>]… 。示例:

4.start - 分页显示使用,开始记录下标,从0开始
5.rows - 指定返回结果最多有多少条记录,配合start来实现分页

显示前10条
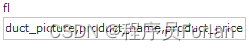
6.fl - 指定返回那些字段内容,用逗号或空格分隔多个。
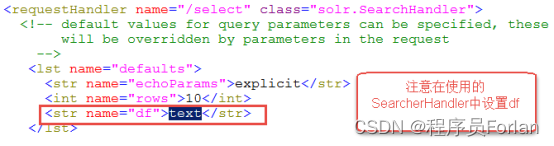
7.df-指定一个搜索Field

也可以在SolrCore目录 中conf/solrconfig.xml文件中指定默认搜索Field,指定后就可以直接在“q”查询条件中输入关键字。
8.wt - (writer type)指定输出格式,可以有 xml, json, php, phps, 后面 solr 1.3增加的,要用通知我们,因为默认没有打开。
9.hl 是否高亮 ,设置高亮Field,设置格式前缀和后缀。

四、使用SolrJ管理索引库
1、什么是solrJ
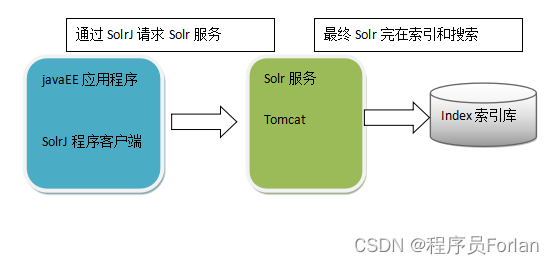
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图:
2、创建Java工程,导入jar包
依赖的jar包
新建一个java文件:SolrManager,方便后续操作
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test;public class SolrManager {}
3、添加文档
@Test
public void testadd() throws Exception{String baseURL="http://localhost:8090/solr";SolrServer solrServer=new HttpSolrServer(baseURL);SolrInputDocument doc = new SolrInputDocument();doc.setField("id", "123");doc.setField("name", "林格");//添加solrServer.add(doc);solrServer.commit();
}4、删除文档
根据id删除
//删除文档,根据id删除
@Test
public void deleteDocumentByid() throws Exception {//创建连接SolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr");//根据id删除文档solrServer.deleteById("123");//提交修改solrServer.commit();
}
根据查询删除
//根据查询条件删除文档
@Test
public void deleteDocumentByQuery() throws Exception {//创建连接SolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr");//根据查询条件删除文档solrServer.deleteByQuery("*:*");//提交修改solrServer.commit();
}
5、修改文档
在solrJ中修改没有update方法,只有add方法,我们只需要添加一条新的文档,和被修改的文档id一致就可以修改了。本质上就是先删除后添加。
6、查询文档
//简单查询
@Test
public void queryIndex() throws Exception{//创建连接SolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr");//创建一个query对象SolrQuery query = new SolrQuery();//设置查询条件query.setQuery("*:*");//执行查询QueryResponse queryResponse = solrServer.query(query);//得到查询结果SolrDocumentList solrDocumentList= queryResponse.getResults();//查询到的商品数量System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());for (SolrDocument solrDocument : solrDocumentList) {System.out.println(solrDocument.get("id"));System.out.println(solrDocument.get("product_name"));System.out.println(solrDocument.get("product_price"));System.out.println(solrDocument.get("product_catalog_name"));System.out.println(solrDocument.get("product_picture"));}
}复杂查询,其中包含查询、过滤、分页、排序、高亮显示等处理。
//复杂查询
@Test
public void queryIndex2() throws Exception{//创建连接SolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr");//创建一个query对象SolrQuery query = new SolrQuery();//设置查询条件query.setQuery("台灯");//过滤条件query.set("fq","product_catalog_name:雅致灯饰");//排序query.addSort("product_price",ORDER.desc);//分页query.setStart(0);query.setRows(10);//指定返回那些字段内容query.setFields("id","product_name","product_price","product_catalog_name","product_picture");//指定一个搜索Fieldquery.set("df", "product_name");//高亮显示query.setHighlight(true);//高亮显示的域query.addHighlightField("product_name");//高亮显示的前缀query.setHighlightSimplePre("<em>");//高亮显示的后缀query.setHighlightSimplePost("</em>");//执行查询QueryResponse queryResponse = solrServer.query(query);//得到查询结果SolrDocumentList solrDocumentList= queryResponse.getResults();//查询到的商品数量System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound()); for (SolrDocument solrDocument : solrDocumentList) {System.out.println(solrDocument.get("id"));//取高亮显示String productName = "";Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();List<String> list = highlighting.get(solrDocument.get("id")).get("product_name");//判断是否有高亮内容if (null != list) {productName = list.get(0);} else {productName = (String) solrDocument.get("product_name");}System.out.println(solrDocument.get("productName"));System.out.println(solrDocument.get("product_price"));System.out.println(solrDocument.get("product_catalog_name"));System.out.println(solrDocument.get("product_picture"));}}
五、案例实现
原型分析
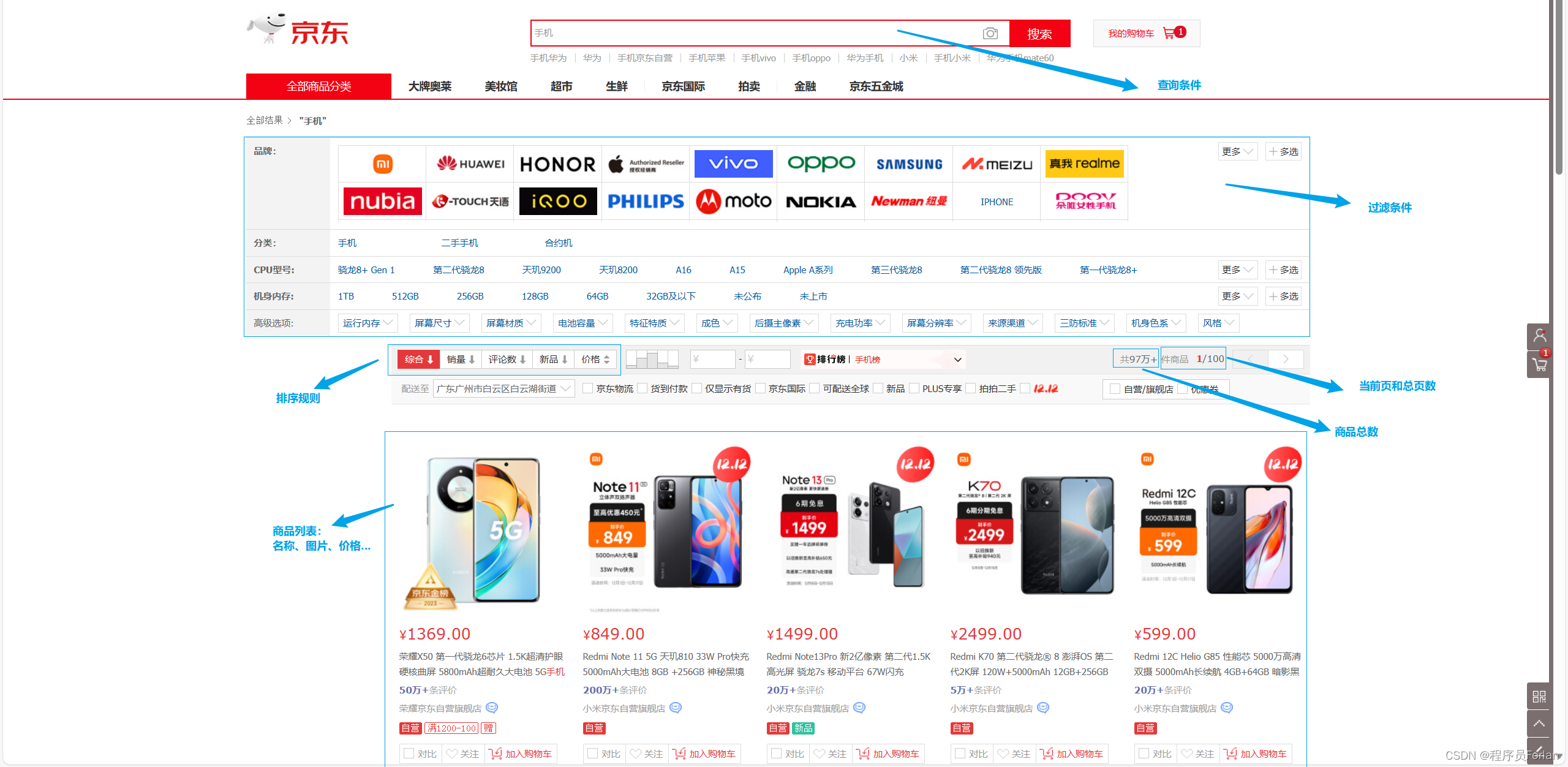
系统架构
具体工程搭建实现如下:
1、创建一个web工程导入jar包
springmvc的相关jar包+solrJ的jar包+Example\lib\ext下的jar包
2、配置xml文件
配置web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" id="WebApp_ID" version="2.5"><display-name>jd</display-name><welcome-file-list><welcome-file>index.html</welcome-file><welcome-file>index.htm</welcome-file><welcome-file>index.jsp</welcome-file><welcome-file>default.html</welcome-file><welcome-file>default.htm</welcome-file><welcome-file>default.jsp</welcome-file></welcome-file-list><!-- 前端控制器 --><servlet><servlet-name>jd</servlet-name><servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class><init-param><param-name>contextConfigLocation</param-name><param-value>classpath:springmvc.xml</param-value></init-param></servlet><servlet-mapping><servlet-name>jd</servlet-name><url-pattern>*.action</url-pattern></servlet-mapping><!-- 解决post乱码问题 --><filter><filter-name>CharacterEncodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class><init-param><param-name>encoding</param-name><param-value>utf-8</param-value></init-param></filter><filter-mapping><filter-name>CharacterEncodingFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping>
</web-app>
配置springmvc.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"xmlns:context="http://www.springframework.org/schema/context"xmlns:mvc="http://www.springframework.org/schema/mvc"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsdhttp://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-4.0.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd"><context:component-scan base-package="com.it.jd"/><!-- 配置注解驱动,如果配置此标签可以不用配置处理器映射器和适配器 --><mvc:annotation-driven/><!-- 配置视图解析器 --><bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"><property name="prefix" value="/WEB-INF/jsp/"/><property name="suffix" value=".jsp"/></bean><!-- SolrServer的配置 --><bean id="httpSolrServer" class="org.apache.solr.client.solrj.impl.HttpSolrServer"><constructor-arg index="0" value="http://localhost:8090/solr"/></bean>
</beans>
3、导入jsp页面和css
4、具体代码实现
pojo代码
package com.it.jd.pojo;public class ProductModel {// 商品编号private String pid;// 商品名称private String name;// 商品分类名称private String catalog_name;// 价格private float price;// 商品描述private String description;
// 图片名称private String picture;
public String getPid() { return pid; } public void setPid(String pid) { this.pid = pid; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getCatalog_name() { return catalog_name; } public void setCatalog_name(String catalog_name) { this.catalog_name = catalog_name; } public float getPrice() { return price; } public void setPrice(float price) { this.price = price; } public String getDescription() { return description; } public void setDescription(String description) { this.description = description; } public String getPicture() { return picture; } public void setPicture(String picture) { this.picture = picture; } }
Dao代码
package com.it.jd.dao;import java.util.ArrayList;
import java.util.List;
import java.util.Map;import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;import com.it.jd.pojo.ProductModel;@Repository
public class jdDaoImpl implements jdDao {@Autowiredprivate SolrServer solrServer;@Overridepublic List<ProductModel> selectProductModelListByQuery(String queryString, String catalog_name, String price,String sort) throws Exception {//创建一个query对象SolrQuery query = new SolrQuery();//设置查询条件query.setQuery(queryString);//过滤条件if(catalog_name!=null&&!"".equals(catalog_name))query.set("fq","product_catalog_name:"+catalog_name);if(null != price && !"".equals(price)){//0-9 50-*String[] p = price.split("-");query.set("fq", "product_price:[" + p[0] + " TO " + p[1] + "]");}//排序if("1".equals(sort))query.addSort("product_price",ORDER.desc);elsequery.addSort("product_price",ORDER.asc);//分页query.setStart(0);query.setRows(10);//指定返回那些字段内容query.set("fl","id","product_name","product_price","product_picture");//指定一个搜索Fieldquery.set("df", "product_name");//高亮显示query.setHighlight(true);//高亮显示的域query.addHighlightField("product_name");//高亮显示的前缀query.setHighlightSimplePre("<span style='color:red'>");//高亮显示的后缀query.setHighlightSimplePost("</span>");//执行查询QueryResponse queryResponse = solrServer.query(query);//得到查询结果SolrDocumentList solrDocumentList= queryResponse.getResults();//查询到的商品数量//System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound()); Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();List<ProductModel> productModels = new ArrayList<ProductModel>();for (SolrDocument doc : solrDocumentList) {ProductModel pm=new ProductModel();pm.setPid((String) doc.get("id"));pm.setPrice((Float) doc.get("product_price"));pm.setPicture((String) doc.get("product_picture"));Map<String, List<String>> map = highlighting.get((String) doc.get("id"));List<String> list = map.get("product_name");pm.setName(list.get(0));productModels.add(pm);}return productModels;}}
Service代码
package com.it.jd.service;import java.util.List;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import com.it.jd.dao.jdDao;
import com.it.jd.pojo.ProductModel;@Service
public class jdServiceImpl implements jdService {@Autowiredprivate jdDao dao;@Overridepublic List<ProductModel> selectProductModelListByQuery(String queryString, String catalog_name, String price,String sort) throws Exception {return dao.selectProductModelListByQuery(queryString, catalog_name, price, sort);}}
Controller代码
package com.it.jd.controller;import java.util.List;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;import com.it.jd.pojo.ProductModel;
import com.it.jd.service.jdService;@Controller
public class jdController {@Autowiredprivate jdService jdService;@RequestMapping("list.action")public String list(String queryString,String catalog_name,String price,String sort,Model model) throws Exception{List<ProductModel> productModels = jdService.selectProductModelListByQuery(queryString, catalog_name, price, sort);model.addAttribute("productModels", productModels);model.addAttribute("queryString", queryString);model.addAttribute("catalog_name", catalog_name);model.addAttribute("price", price);model.addAttribute("sort", sort);return "product_list";}
}
相关文章:
基于Solr的全文检索系统的实现与应用
文章目录 一、概念1、什么是Solr2、与Lucene的比较区别1)Lucene2)Solr 二、Solr的安装与配置1、Solr的下载2、Solr的文件夹结构3、运行环境4、Solr整合tomcat1)Solr Home与SolrCore2)整合步骤 5、Solr管理后台1)Dashbo…...
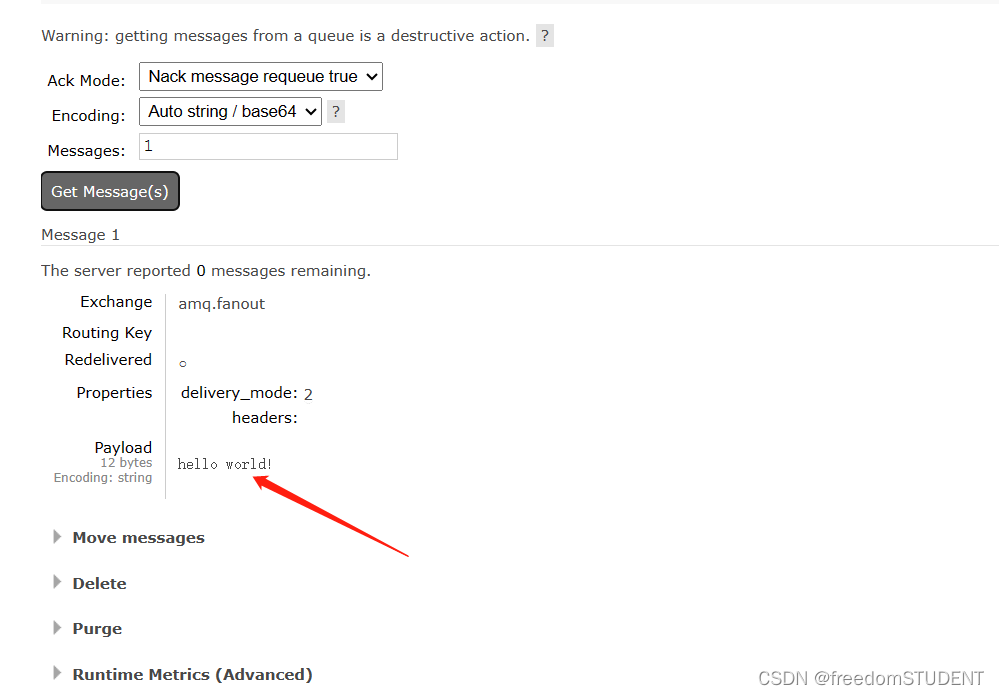
【rabbitMQ】rabbitMQ控制台模拟收发消息
目录 1.新建队列 2.交换机绑定队列 3.查看消息是否到达队列 总结: 1.新建队列 2.交换机绑定队列 点击amq.fonout 3.查看消息是否到达队列 总结: 生产者(publisher)发送消息,先到达交换机,再到队列&…...

Java NIO, IO 整理
NIO: IO多路复用: 参考: Redis(六)单线程I/O多路复用模型浅析_单线程多路复用-CSDN博客 Java NIO 详解_java nio详解_开发菜鸡的博客-CSDN博客 Java Socket 之 NIO - 掘金 答应我,这次搞懂 I/O 多路复用!_小林coding的博客-CS…...
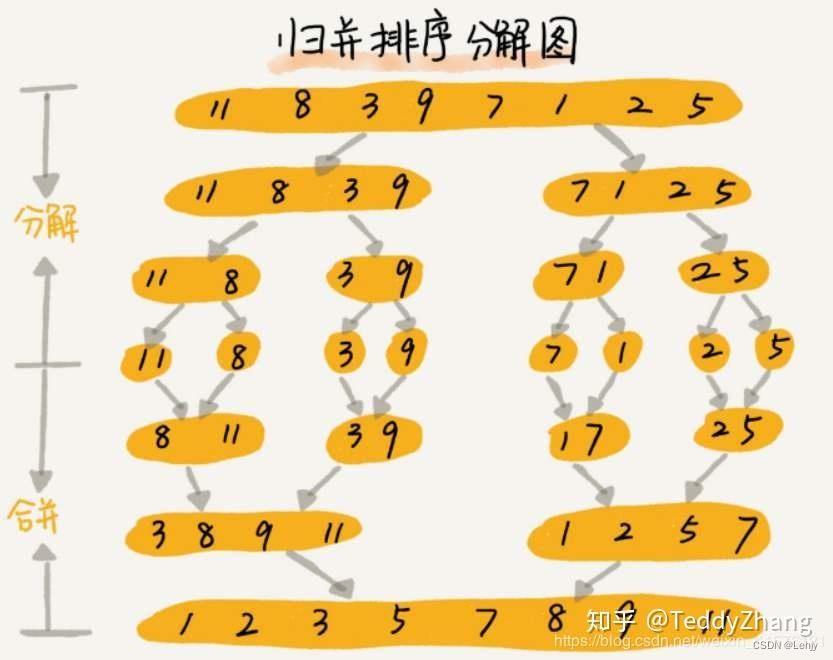
【数据结构】——排序篇(下)
前言:前面我们的排序已经详细的讲解了一系列的方法,那么我们现在久之后一个归并排序了,所以我们现在就来讲解一下归并排序。 归并排序: 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法…...

C++ 模拟实现vector
目录 一、定义 二、模拟实现 1、无参初始化 2、size&capacity 3、reserve 4、push_back 5、迭代器 6、empty 7、pop_back 8、operator[ ] 9、resize 10、insert 迭代器失效问题 11、erase 12、带参初始化 13、迭代器初始化 14、析构函数 完整版代码 一、…...
基于hadoop下的spark安装
目录 简介 安装准备 spark安装 配置文件配置 简介 Spark主要⽤于⼤数据的并⾏计算,⽽Hadoop在企业主要⽤于⼤数据的存储(⽐如HDFS、Hive和HBase 等),以及资源调度(Yarn)。但是也有很多公司也在使⽤MR2进…...
)
面试经典150题(10-13)
leetcode 150道题 计划花两个月时候刷完,今天(第四天)完成了4道(10-13)150: 10. (45. 跳跃游戏 II)题目描述: 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[…...
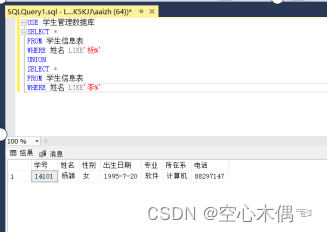
Sql server数据库数据查询
请查询学生信息表的所有记录。 答:查询所需的代码如下: USE 学生管理数据库 GO SELECT * FROM 学生信息表 执行结果如下: 查询学生的学号、姓名和性别。 答:查询所需的代码如下: USE 学生管理数据库 GO SELE…...

前端开发tips
前端开发tips 关于package.json里面,尖角号(^)和波浪线(~)的区别 在package.json里面,我们可以使用尖角号(^)和波浪线(~)来表示不同的包版本。这些符号通常被…...
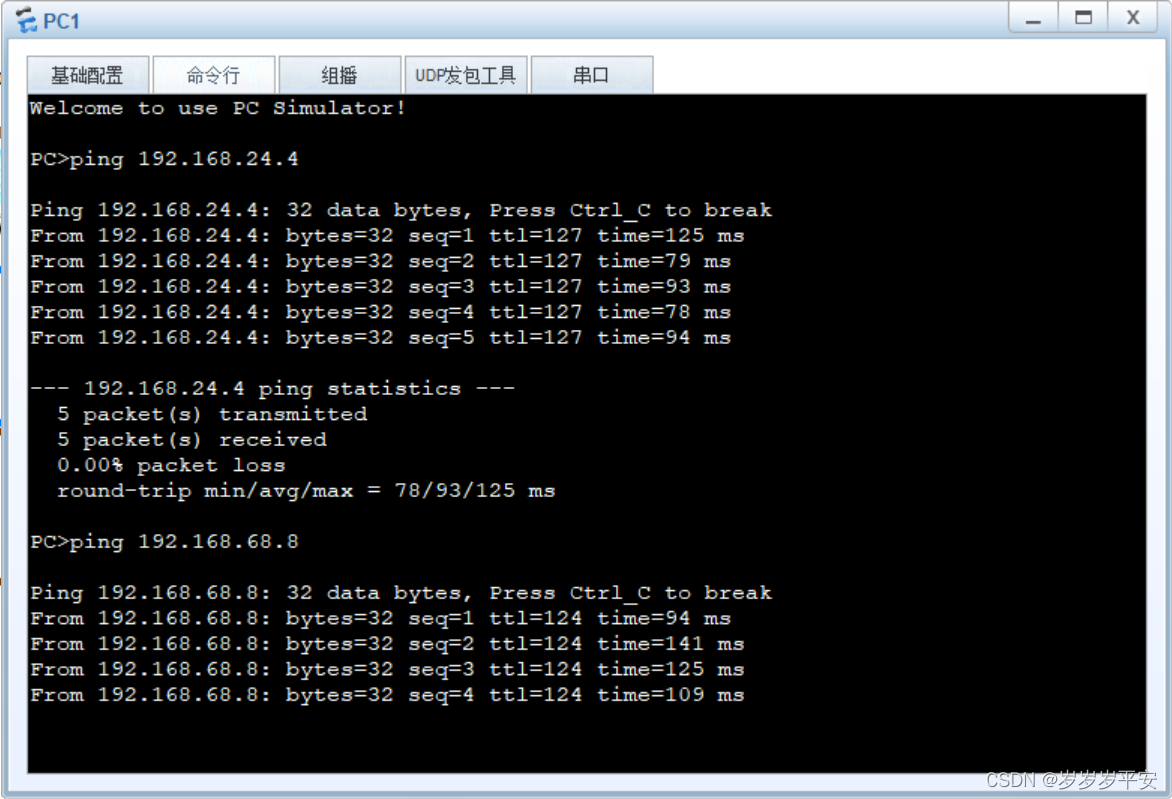
实现跨VLAN通信、以及RIP路由协议的配置
一、如下图片: 1. 按照拓扑图所示,将8台计算机分别配置到相应的VLAN中。(20分) 2. 配置实现同一VLAN中的计算机可以通信。(22分) 3. 配置实现PC1,PC2,PC3,PC4可以互相通信,PC5,PC6,PC7,PC8可以互…...
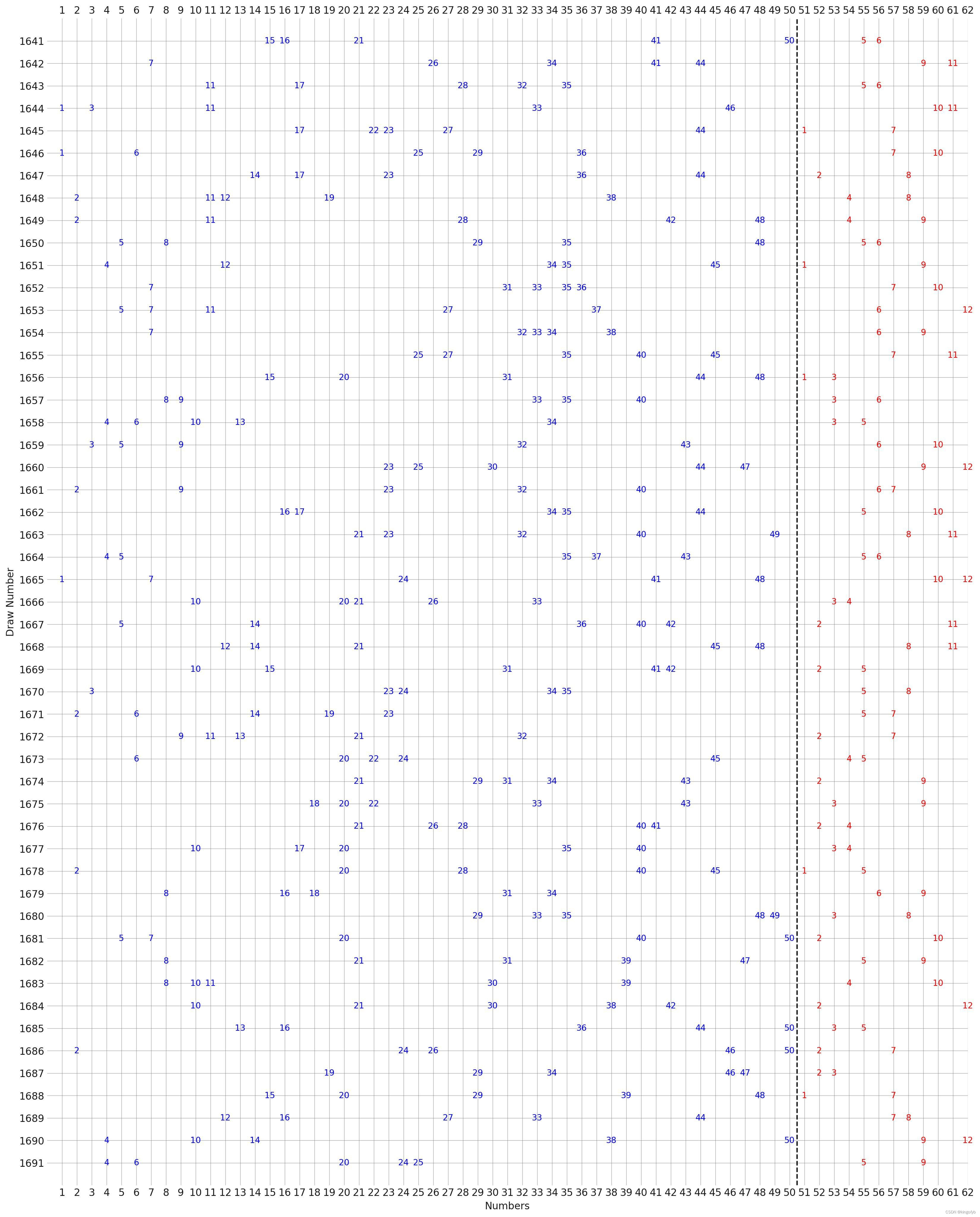
使用python绘制现有彩票记录走势图
在数据分析和可视化的领域中,彩票走势图是一个经典的例子,它可以展示彩票数字随时间的出现频率和趋势。这里使用英国使用EuroMillions彩票的历史数据作为示例,使用Python和Matplotlib库来创建一个简单的走势图。可以在以下网站搜索.csv文件。…...
-升级k8s集群)
Kubernetes实战(十)-升级k8s集群
1 Kubernetes(k8s) 集群升级过程 Kubernetes 使用 kubeadm 工具来管理集群组件的升级。在集群节点层面,升级 Kubernetes(k8s)集群的过程可以分为以下几个步骤: 1)检查当前环境和配置是否满足升级要求。 2)升级master主节点&…...
点击el-tree小三角后去除点击后的高亮背景样式,el-tree样式修改
<div class"videoTree" v-loading"loadingTree" element-loading-text"加载中..." element-loading-spinner"el-icon-loading" element-loading-background"rgba(0, 0, 0, 0.8)" > <el-tree :default-expand-all&q…...
【电子取证篇】汽车取证数据提取与汽车取证实例浅析(附标准下载)
【电子取证篇】汽车取证数据提取与汽车取证实例浅析(附标准下载) 关键词:汽车取证,车速鉴定、声像资料鉴定、汽车EDR提取分析 汽车EDR一般记录车辆碰撞前后的数秒(5s左右)相关数据,包括车辆速…...

系列学习前端之第 3 章:一文精通 css
全套学习 HTMLCSSJavaScript 代码和笔记请下载网盘的资料: 链接: 百度网盘 请输入提取码 提取码: 6666 一、CSS基础 1. CSS简介 CSS 的全称为:层叠样式表 ( Cascading Style Sheets ) 。 CSS 也是一种标记语言,用于给 HTML 结构设…...

基于JavaWeb+SSM+Vue马拉松报名系统微信小程序的设计和实现
基于JavaWebSSMVue马拉松报名系统微信小程序的设计和实现 源码获取入口Lun文目录前言主要技术系统设计功能截图订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码获取入口 Lun文目录 1系统概述 1 1.1 研究背景 1 1.2研究目的 1 1.3系统设计思想 1 2相关技术 2 2.…...
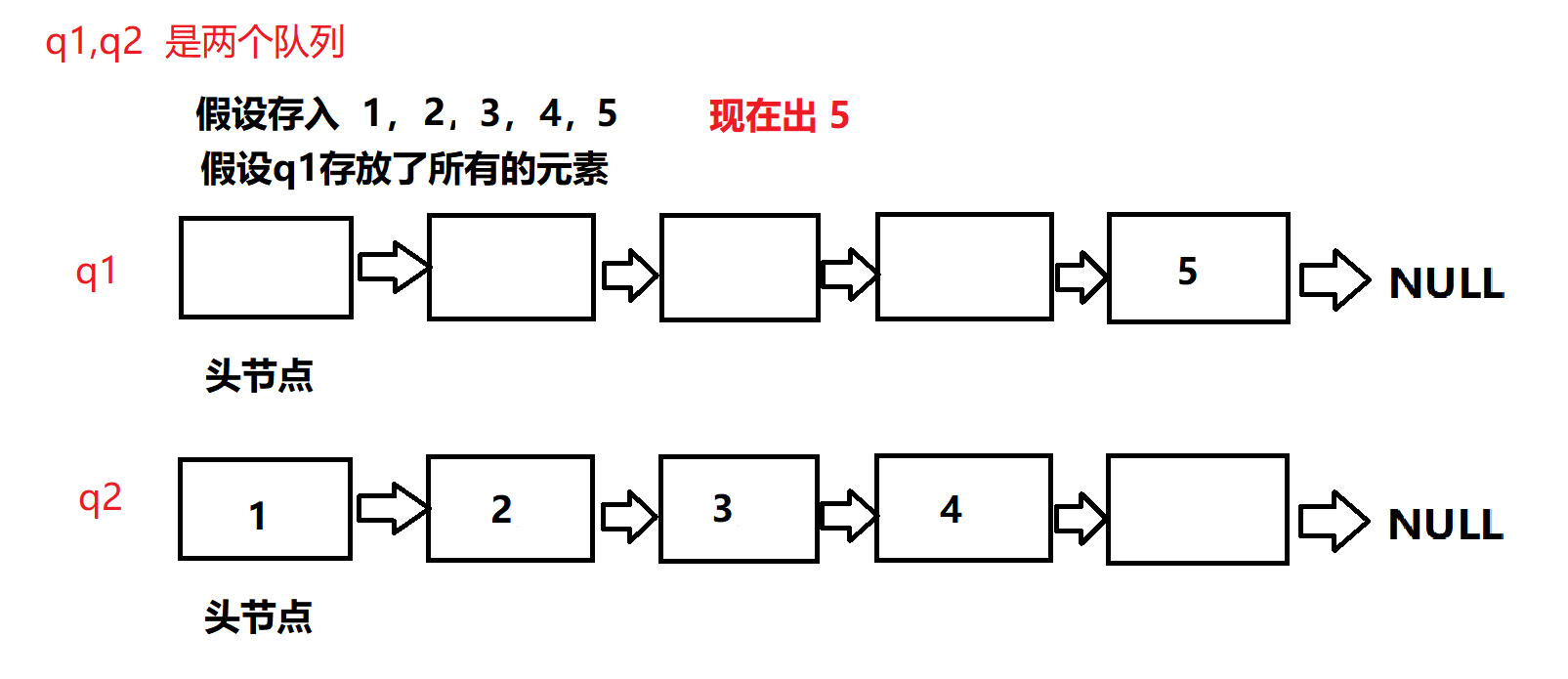
leetcode 255.用队列实现栈
255.用队列实现栈 不出意外大概率这几天都会更新 leetcode,如果没有做新的题,大概就会把 leetcode 之前写过的题整理(单链表的题目居多一点)出来写成博客 今天讲的题蛮容易出错的(注意传参啊,最好把队列的…...
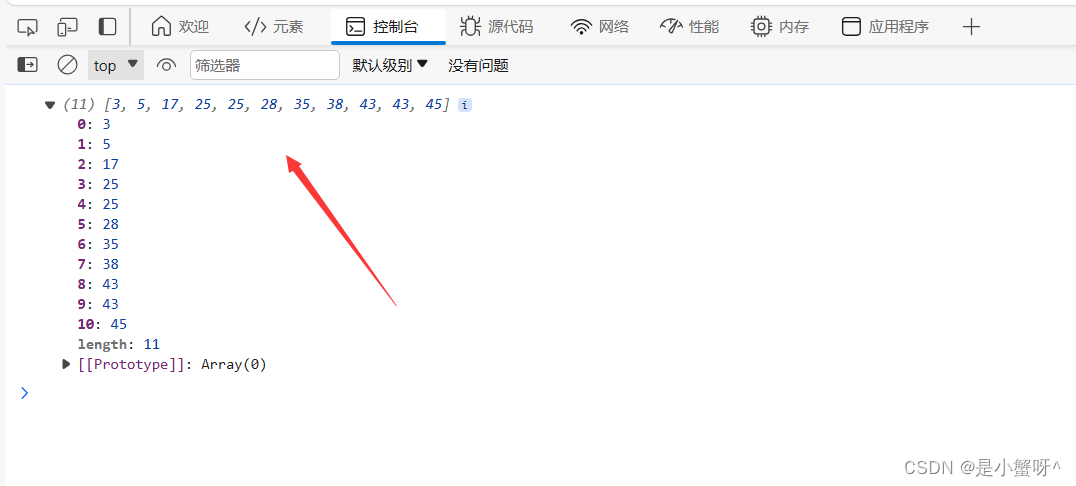
排序算法---选择排序
1.实现流程: 1. 把第一个没有排序过的元素设置为最小值; 2. 遍历每个没有排序过的元素; 3. 如果元素 < 现在的最小值; 4. 将此元素设置成为新的最小值; 5. 将最小值和第一个没有排序过的位置交换 选择排序执行流程…...

物联网IC
物联网IC 电子元器件百科 文章目录 物联网IC前言一、物联网IC是什么二、物联网IC的类别三、物联网IC的应用实例四、物联网IC的作用原理总结前言 物联网IC的功能和特性可以根据不同的物联网应用需求来选择和配置,以满足物联网设备在连接、通信、感知和控制方面的需求。 一、物…...

2022年第十一届数学建模国际赛小美赛A题翼龙如何飞行解题全过程文档及程序
2022年第十一届数学建模国际赛小美赛 A题 翼龙如何飞行 原题再现: 翼龙是翼龙目中一个已灭绝的飞行爬行动物分支。它们存在于中生代的大部分时期:从三叠纪晚期到白垩纪末期。翼龙是已知最早进化出动力飞行的脊椎动物。它们的翅膀是由皮肤、肌肉和其他组…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...