MapReduce
1. MapReduce是什么?请简要说明它的工作原理。
MapReduce是一种编程模型,主要用于处理大规模数据集的并行运算,特别是非结构化数据。这个模型的核心思想是将大数据处理任务分解为两个主要步骤:Map和Reduce。用户只需实现map()和reduce()两个函数,即可实现分布式计算。
在Map阶段,接受输入数据并将其分解成一系列的键值对。这些键值对会被传送到对应的Reduce任务中进行处理。而在Reduce阶段,将由Map阶段传递过来的键值对进行处理,最终生成一个最终的结果。
此外,MapReduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。其核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。因此,MapReduce可以以一种可靠的、具有容错能力的方式并行地处理上TB级别的海量数据集,主要用于搜索领域,解决海量数据的计算问题。
2. MapReduce有哪些主要组件?请简要介绍它们的作用。
MapReduce主要包括以下四个核心组件:Mapper、Reducer、Driver和Job。
- Mapper模块:负责处理输入的数据,具体的业务逻辑在map()方法中完成。Mapper将输入数据解析成键值对,输出的数据也是KV格式。
- Reducer模块:其主要任务是处理Mapper程序输出的KV数据,具体的业务逻辑在reduce()方法中进行。Reducer会对具有相同key的值进行合并处理,并输出最终结果。
- Driver模块:主要负责将用户编写的程序提交到Yarn(Yet Another Resource Negotiator)进行调度运行,提交的程序是一个封装了运行参数的job对象。
- Job模块:表示整个MapReduce作业,它由一系列的Map任务和Reduce任务组成,这些任务并行执行,共同完成大规模数据集的处理。
举个简单的例子,假设我们需要统计一份日志文件中每个单词出现的次数。在这个场景下,Mapper的任务就是读取每一行日志文件,将每行文本拆分为一个个单词,并将每个单词作为key,出现次数作为value输出;而Reducer则需要接收所有Mapper输出的key-value对,对于相同的key,将其对应的所有value值进行累加,从而得到每个单词的总出现次数。
3. 请解释MapReduce的Shuffle阶段。它为什么重要?
在MapReduce中,Shuffle阶段是一个核心流程,它负责将Mapper阶段处理的数据传递给Reduce在MapReduce中,Shuffle阶段是一个核心流程,它负责将Mapper阶段处理的数据传递给Reducer阶段。这一阶段涵盖了数据分区、排序、局部聚合、缓存、拉取和再合并等关键步骤。
首先,数据分区是将输出的键值对按照特定的规则分发到不同的Reduce任务中。例如,如果我们只需要找出一个数据集的最大值,那么每个Mapper都只需输出自己所知道的最大值及其位置,这样就可以显著减少数据传输量。
其次,排序是为了保证相同key的数据能够发送到同一个Reduce任务中进行处理。这样,Reduce任务可以对具有相同key的值进行合并处理,从而得到每个单词的总出现次数。
接着,局部聚合是为了在网络节点间对数据进行整理。在这个过程中,Mapper会生成大量的键值对,这些键值对需要在网络节点间进行传输。通过局部聚合,可以减少数据传输的数量。
然后,缓存和拉取是为了在数据传输过程中提高效率。在这个过程中,Mapper端会将数据暂时存储在内存中,而Reducer会从Mapper端拉取需要的数据进行处理。
最后,再合并是为了将同一key的所有value进行汇总。这样,Reducer就可以对这些value进行求和或其他操作,得出最终的结果。
因此,Shuffle阶段对于MapReduce作业的执行至关重要,它直接影响到数据处理的效率和准确性。
4. 请解释MapReduce的Combiner函数。它有什么作用?如何实现?
Combiner函数是MapReduce中的一个优化步骤,其主要目标是在Map阶段结束后进行局部聚合操作,以减少数据的传输量。Combiner函数的运行逻辑如下:
- 输入:Combiner接收到的输入数据与Mapper输出的数据格式相同,都是键值对。
- 处理:对具有相同key的值进行合并处理。
- 输出:Combiner的输出是经过合并处理后的键值对。
Combiner函数的使用场景通常是当Mapper的输出数据量过大,网络传输和磁盘I/O压力较大时。通过使用Combiner函数,可以在Map阶段结束后就进行部分数据的合并和压缩,从而减少Shuffle阶段的数据传输量和计算压力。
5. 请解释MapReduce的Partitioner类。它有什么作用?如何实现?
Partitioner类在MapReduce编程模型中起着关键的作用,其主要任务是对Mapper阶段的输出数据Partitioner类在MapReduce编程模型中起着关键的作用,其主要任务是对Mapper阶段的输出数据进行分区,确定每个键值对被分发到哪个Reduce任务中去处理。这样,具有相同key的数据会被发送到同一个Reduce任务中进行处理,从而极大地增加了数据处理的效率。
具体来说,Partitioner类的工作方式类似于哈希函数。首先,它获取键的哈希值,然后使用这个哈希值对Reduce任务数求模,以此确定每个键值对将被分发到哪个Reduce任务。默认情况下,MapReduce作业只有一个Reduce任务,因此Partitioner只需将数据均匀地分发到这一个Reduce任务上。
如果需要自定义分区逻辑,可以通过继承Partitioner类并重写getPartition方法来实现。例如,根据数字把文件分为两部分的需求,可以定义一个Partitioner类,使得数字大于15的数据归为一类,小于等于15的数据分为另一类。注意,自定义分区的数量需要和Reduce任务的数量保持一致。
6. MapReduce如何处理数据排序?请说明WritableComparable接口的作用。
在MapReduce中,数据排序是通过Sort阶段来实现的。在这个阶段,MapReduce框架会将所有具有相同key的数据发送到同一个Reduce任务中进行处理。为了确保相同的key被发送到同一个Reducer,MapReduce需要对数据进行排序。
WritableComparable接口是Hadoop中的一个基本接口,它定义了可写和可比较两个方法。任何实现了这个接口的类都可以被序列化和反序列化,并且可以进行比较。在MapReduce中,键值对的key通常需要实现WritableComparable接口,以便在排序阶段正确地将具有相同key的数据发送到同一个Reduce任务中进行处理。
例如,如果我们想要统计一个文本文件中每个单词出现的次数,那么单词就可以作为key,而出现次数可以作为value。在这种情况下,我们需要自定义一个类来表示单词及其出现次数,并让这个类实现WritableComparable接口。这样,MapReduce就可以正确地将具有相同单词的数据发送到同一个Reduce任务中进行处理,从而实现数据的排序。
7. 请解释MapReduce中的InputFormat和OutputFormat类。它们的作用分别是什么?
在MapReduce中,InputFormat和OutputFormat是两个关键的接口。它们分别负责数据输入和输出的处理。
InputFormat的主要职责是读取数据。当运行MapReduce程序时,输入的文件格式可以是多种多样的,例如基于行的日志文件、二进制文件、数据库表等。为了处理这些不同类型的数据,MapReduce通过InputFormat来实现数据的读取。InputFormat有许多子类可供选择,包括TextInputFormat(用于读取普通文本,这是MR框架默认的读取实现类型)、KeyValueTextInputFormat(用于读取一行文本数据,按照指定分隔符将数据封装为键值对类型)、NLineInputFormat(用于按照行数划分数据)以及CombineTextInputFormat(用于合并小文件,以避免启动过多的MapTask任务)。用户也可以根据需要自定义InputFormat。
相对于InputFormat的数据处理输入,OutputFormat则主要关注结果数据的输出。在Reducer执行完reduce()方法后,Reducer会通过OutputFormat将处理结果输出到外部环境。在Hadoop中,默认使用的OutputFormat是TextOutputFormat,它会将reduce()方法的处理结果按行输出到文件中。OutputFormat是所有MapReduce输出程序的基类,任何实现了MapReduce输出功能的程序都必须实现OutputFormat接口。此外,OutputFormat有多种官方自带的实现类,包括NullOutputFormat、FileOutputFormat、MapFileOutputFormat等,用户可以根据需要选择合适的OutputFormat类。例如,TextOutputFormat是默认的字符串输出格式,它会使用tab作为key和value之间的分隔符;而SequenceFileOutputFormat则会将key和value以sequencefile格式输出。
8. 请解释MapReduce中的Counter类。它有什么作用?如何使用?
在MapReduce中,Counter类是一个用于记录作业执行过程中某些感兴趣的变量的工具。这些变量可以包括作业的执行进度和状态,以及一些自定义的变量。例如,你可能会使用一个Counter来跟踪作业已经处理了多少个键值对,或者已经消耗了多少数据输入。
Hadoop内置了计数器功能,它可以帮助用户理解程序的运行情况,辅助用户诊断故障。此外,MapReduce还提供了许多默认的Counter,以帮助用户观察MapReduce job运行期间的各种细节数据。
要使用Counter类,你需要首先创建一个Counter对象,然后使用其inc()方法来增加计数器的值,或使用dec()方法来减少计数器的值。例如:
import org.apache.hadoop.mapreduce.Counter;public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Counter wordCount = new Counter();public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String[] words = value.toString().split("\\s+");for (String word : words) {wordCount.increment(word);}}
}
在这个例子中,我们创建了一个名为wordCount的Counter对象,并在map()函数中使用它来统计每个单词出现的次数。
9. 请解释MapReduce中的IdentityMapper和IdentityReducer类。它们有什么作用?
在MapReduce编程模型中,IdentityMapper和IdentityReducer是两种默认的组件。它们的主要作用是将输入的数据不做任何处理,直接原封不动地输出。
具体来说,IdentityMapper是Map阶段的默认处理类,它不对输入数据进行任何处理,而是将输入的键值对直接传递到下一个阶段。这意味着,如果你没有为你的MapReduce任务定义自定义的Mapper类,Hadoop将自动使用IdentityMapper作为默认的Mapper。
同理,IdentityReducer是Reduce阶段的默认处理类。它也不对输入数据做任何处理,直接将输入的键值对传递给Reduce函数进行处理并输出。如果用户没有提供自定义的Reducer类,Hadoop将自动使用IdentityReducer作为默认的Reducer。
因此,IdentityMapper和IdentityReducer可以被视为一种“空操作”的处理类,用于确保MapReduce作业至少能够正常运行。
10. 如何在MapReduce中处理小文件问题?请提供一种解决方案。
在MapReduce中,小文件问题是一个常见的问题。当输入数据被分割成很多小文件时,每个Mapper任务处理的数据量就会很小,这会导致大量的Map任务和Reduce任务,从而增加了作业的运行时间和资源消耗。
一种解决小文件问题的常见方法是使用Combiner函数。Combiner函数可以在Map阶段结束后对具有相同key的数据进行局部聚合,减少数据的传输量。这样,即使有大量小文件,也可以大大减少网络传输和磁盘I/O压力。
例如,假设我们有一个包含单词及其出现次数的文件,我们想要统计每个单词出现的次数。如果文件中有很多小文件,我们可以使用Combiner函数来合并具有相同单词的键值对,然后只发送一个包含所有相同单词的键值对到Reduce阶段。
具体来说,首先我们需要定义一个实现了WritableComparable接口的Combine类:
public class WordCountCombiner extends WritableComparable<Text, IntWritable> {private Text word = new Text();private IntWritable count = new IntWritable();public void set(Text word, IntWritable count) {this.word.set(word);this.count.set(count);}public Text getWord() { return word; }public IntWritable getCount() { return count; }@Overridepublic void write(DataOutput out) throws IOException {word.write(out);count.write(out);}@Overridepublic void readFields(DataInput in) throws IOException {word.readFields(in);count.readFields(in);}@Overridepublic int compareTo(WritableComparable<Text, IntWritable> o) {return word.compareTo(o.get());}
}
然后,在Mapper类中重写setup()方法,将Combiner类作为参数传递给Context对象:
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private WordCountCombiner combiner = new WordCountCombiner();@Overrideprotected void setup(Context context) throws IOException, InterruptedException {super.setup(context);context.setCombinerClass(WordCountCombiner.class);}
}
最后,在Reducer类中处理Combiner输出的数据:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}
}
11. 请解释MapReduce的ChainMapper和ChainReducer类。它们有什么作用?如何使用?
ChainMapper和ChainReducer是MapReduce编程中的两种特殊类,它们主要用于ChainMapper和ChainReducer是MapReduce编程中的两种特殊类,它们主要用于处理线性链式的Mapper任务。在Map或Reduce阶段中,如果存在多个Mapper,这些Mapper就可以像Linux管道一样,将前一个Mapper的输出结果直接重定向到下一个Mapper的输入,形成一个流水线。
具体来说,ChainMapper允许使用多个Map子类作为一个Map任务。这些map子类的执行与liunx的管道命令十分相似,第一个map的输出会成为第二个map的输入,第二个map的输出也会变成第三个map的输入,以此类推,直到最后一个map的输出会变成整个mapTask的输出。
同时,ChainReducer则用于设置Reducer并添加后处理的Mapper。整个Job中只能有一个Reducer,而在Reducer前面可以有一个或者多个Mapper,后面的链式Mapper数量可以为0。通过使用ChainReducer的addMapper()方法,你可以方便地添加额外的Mapper到作业中。
例如,假设我们有一个需要进行多步处理的大数据集。首先,我们可以通过一系列的Mapper进行数据预处理;然后是核心的MapReduce任务;最后可能还需要一些其他的Mapper进行后处理。在这种情况下,我们就可以利用ChainMapper来链接这些预处理的Map任务,而利用ChainReducer来设置Reducer并添加后处理的Mapper。这样设计的优点是提高了生成效率。
12. 请解释MapReduce中的JobClient和JobTracker类。它们各自的作用是什么?
在MapReduce编程模型中,JobClient和JobTracker分别扮演着重要的角色。
JobClient是客户端类,其主要功能是提交作业并包含一些与作业相关的配置信息,例如设置作业的输入输出路径、Mapper和Reducer类以及输入输出的数据类型等。当客户端提交作业后,它会将一些必要的文件上传到HDFS(如作业的jar包等),并将路径信息提交给JobTracker。此外,用户还可以通过JobClient查看作业的运行状态。
而JobTracker则是整个集群的全局管理者,其主要职责包括作业管理、状态监控和任务调度等。具体来说,当JobClient将作业提交后,JobTracker会创建每一个任务(包括MapTask和ReduceTask),并将它们发送到各个TaskTracker上去执行。同时,它还需要监控这些任务的执行状态,并在任务失败时进行恢复操作。
以一个实际的例子来说明,假设我们有一个需要进行大数据分析的任务。首先,我们需要编写一个MapReduce程序,并通过JobClient将这个程序以及相关的配置信息提交到Hadoop集群上。然后,JobTracker会在集群中分配资源并创建任务,这些任务会被发送到各个节点上的TaskTracker去执行。最后,我们可以使用JobClient来查看作业的运行状态,以便及时了解任务是否执行成功。
13. 请解释MapReduce中的TaskTracker类。它的作用是什么?如何与JobTracker通信?
在MapReduce编程模型中,TaskTracker是一个关键的组件,它扮演着JobTracker和Task之间的桥梁。一方面,TaskTracker会接收并执行来自JobTracker的各种命令,包括运行任务、提交任务、杀死任务等。另一方面,它会周期性地将本节点上各种信息通过心跳机制汇报给JobTracker。这些信息主要包括两部分:机器级别信息(如节点健康情况、资源使用情况等)和任务级别信息(如任务执行进度、任务运行状态等)。
具体来说,当JobTracker接收到用户提交的MapReduce作业后,会将这个作业分解为多个任务,并将这些任务分配给各个TaskTracker去执行。每个TaskTracker在接收到任务后,会开始执行具体的任务,并将任务的执行进度和状态等信息通过心跳汇报给JobTracker。如果某个任务因为某种原因失败,JobTracker会根据TaskTracker上报的状态信息来重新分配任务或者重新启动失败的任务。
以一个实际的文本处理任务为例,假设我们需要统计一个大文本集中每个单词出现的次数。首先,用户需要编写一个MapReduce程序,并在其中定义如何进行单词计数的逻辑。然后,用户通过JobClient将这个程序提交到Hadoop集群中执行。在这个过程中,JobTracker负责整个作业的协调和管理,而TaskTracker则负责执行具体的任务。
14. 请解释MapReduce中的ResourceManager和NodeManager类。它们各自的作用是什么?
在MapReduce框架中,ResourceManager和NodeManager是两个关键的组件。ResourceManager主要负责整个集群的资源管理和任务调度。具体来说,它接收来自各个节点(NodeManager)的资源汇报信息,并根据这些信息按照一定的策略分配给各个应用程序。资源分配的单位被称为“容器”(Container),这是一个动态的资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。除此之外,ResourceManager还负责处理客户端请求,启动或监控ApplicationMaster,以及监控NodeManager。
而NodeManager则是每个节点上的资源和任务管理器。其主要功能是对本节点上的资源进行管理和监控,并向ResourceManager汇报本节点的资源使用情况和各个Container的运行状态。同时,NodeManager还负责启动和监控在本节点上运行的任务。
以一个实际的大数据处理任务为例,假设我们需要对一个大数据集进行处理并获取结果。首先,用户需要编写一个MapReduce程序,并在其中定义数据处理的逻辑。然后,用户通过提交作业将这个程序提交到Hadoop集群中执行。在这个过程中,ResourceManager负责整个集群中所有资源的统一管理和分配,而NodeManager则负责执行具体的任务。
15. 请解释MapReduce中的作业提交过程。请说明YARN的作用。
在MapReduce模型中,作业提交过程主要包括以下几个步骤:首先,用户编写好MapReduce程序并配置相关参数;然后,使用客户端将这个程序和配置信息提交到Hadoop集群上。如果提交到本地工作环境,只需要提交切片信息和xml配置文件;如果提交到Yarn工作环境,还需要提交jar包。
一旦作业提交成功,ResourceManager会为该作业分配资源并启动任务。具体来说,ResourceManager会根据作业的需求和集群中的资源状况,划分出多个“资源容器”(Container),每个Container内包含一定数量的CPU、内存等计算资源。然后,ResourceManager将这些Container分配给各个NodeManager去执行具体的任务。
在这个过程中,YARN(Yet Another Resource Negotiator)分布式资源管理系统扮演了重要的角色。作为Hadoop的资源管理系统,YARN主要由ResourceManager和NodeManager两个组件构成。其中,ResourceManager是主节点,负责管理整个集群的资源以及调度任务;而NodeManager则是从节点,每个NodeManager都包含了一定的计算资源,并且负责启动和监控在其上运行的任务。通过这样的设计,YARN能够有效地协调和管理集群中的资源,保证MapReduce作业的顺利执行。
16. 请解释MapReduce中的计数器(Counter)和布隆过滤器(Bloom Filter)。它们各自的作用是什么?如何实现?
在MapReduce编程模型中,计数器(Counter)和布隆过滤器(Bloom Filter)是两种常用的数据结构工具。
计数器主要用于统计MapReduce作业中的各种键值对的数量。例如,如果我们想要统计一个文本数据集中每个单词出现的次数,就可以使用计数器来实现。计数器会跟踪并更新作业中的键值对数量,并在作业完成后将结果返回给客户端。
而布隆过滤器则是一种空间效率极高的概率型数据结构,它的主要功能是判断一个元素是否存在于集合中。布隆过滤器可以快速地判断出一个元素是否可能在集合中,但可能会产生假阳性的结果。换句话说,布隆过滤器可能会错误地认为某个元素存在于集合中,也可能会错误地认为某个元素不存在于集合中。因此,布隆过滤器通常用于大规模数据集的过滤操作,比如垃圾邮件过滤、恶意网址检测等。
具体到MapReduce作业中,这两种工具的使用场景非常广泛。以舆情分析为例,我们可以利用计数器来统计某个话题下的所有舆情数据,然后通过布隆过滤器来过滤掉无关的或者恶意的信息。
17. 请解释MapReduce中的本地化计算(Local Computation)。它有什么优点?如何实现?
在MapReduce中,本地化计算(Local Computation)是一种优化策略,其基本思想在MapReduce中,本地化计算(Local Computation)是一种优化策略,其基本思想是将计算任务移动到数据所在的节点上执行,而不是把数据移动到计算节点上。这样做的主要原因是,移动大量数据往往需要消耗大量的网络资源和时间,而将计算任务移至数据所在的位置执行可以显著减少这部分开销,从而提高整体的系统吞吐量。
具体来说,Hadoop集群中的数据集通常会被切割成多个块,并将这些块分布在不同的节点上。在进行MapReduce计算时,可以通过配置任务调度器,使得每个map task处理的数据均位于同一台机器上,即数据的存储位置和计算位置尽可能保持一致。这样,就大大减少了数据在网络中的传输,降低了网络延迟,提高了处理效率。
实现本地化计算的一种常见做法是使用Hadoop的任务调度器,通过设置任务调度器的优先级,使得相同数据的map task尽可能地分配到同一台机器上运行。此外,还可以结合数据本地性优化算法,如First-Fit、Best-Fit等,进一步优化任务调度的策略,以实现更高效的本地化计算。
18. 请解释MapReduce中的Combiner优化和分组排序(Grouping and Sorting)优化。它们各自的作用是什么?如何实现?
在MapReduce编程模型中,Combiner优化和分组排序(Grouping and Sorting)优化是两种重要的优化策略。
Combiner是一种优化组件,它在Map阶段进行数据的部分聚合,以减少需要传输到Reduce阶段的数据量。Combiner的主要作用是合并重复的key值,并减少网络拷贝量,从而降低网络开销。例如,在WordCount的案例里,对于像 (a,1)、 (a,1)、 (a,1)这种完全一样的数据,启用Combiner进行一个简单的聚合,即转换成 (a,3)这样的数据。这样做的好处很明显,就是大大减少了输入到Reduce的数据量,从而减少了reduce处理的资源压力。Combiner的使用场景有两个地方:第一个场景,是mapper每次溢写到磁盘的时候,每当溢写的时候就可以进行Combiner操作。每个分区内部就开始简单合并。
分组排序(Grouping and Sorting)优化则是在Reduce端进行的。在进行分组之前,数据会先根据key进行排序,然后才开始分组;进行分组的时候,只会比较相邻的元素。如果排序规则和分组规则不统一,是无法正确分组的。这种优化策略可以有效地提高Reduce阶段的处理效率。
19. 请解释MapReduce中的数据压缩(Data Compression)。它有什么优点?如何实现?
在MapReduce编程模型中,数据压缩是一种关键的优化策略。其主要优点包括减少磁盘IO和磁盘存储空间。通过这种方式,可以有效地提高网络带宽和磁盘空间的利用效率,特别是在处理大规模数据时,能够显著降低I/O操作、网络数据传输以及Shuffle和Merge的时间开销。
实现数据压缩的方式有多种,Hadoop提供了多种压缩编码方式如Gzip和Bzip2等。在选择压缩方式时,需要综合考虑压缩/解压缩速度、压缩率(即压缩后的数据大小)、以及压缩后的数据是否支持切片等因素。例如,Gzip压缩算法的压缩率较高,但其不支持Split操作,且压缩/解压速度一般;而Bzip2压缩算法虽然解压速度较慢,但其支持Split操作,并且具有较高的压缩率。
然而,需要注意的是,数据压缩也会带来一些负面影响,主要体现在增加了CPU的开销。因此,在选择是否进行数据压缩时,还需要根据任务类型进行权衡。例如,对于运算密集型的任务,由于CPU的占用本就较多,如果再采取压缩可能会进一步降低CPU性能,从而影响整体效率。
20. 请解释MapReduce中的数据分片(Data Sharding)。它有什么作用?如何实现?
MapReduce中的数据分片(Data Sharding)是一种数据处理策略,主要目的是MapReduce中的数据分片(Data Sharding)是一种数据处理策略,主要目的是将大规模数据集切分为多个较小的数据块,以便并行处理。在MapReduce作业提交时,会预先对将要分析的原始数据进行划分处理,形成一个个等长的逻辑数据对象,称之为输入分片(inputSplit),简称“分片”。之后,MapReduce为每一个分片构建一个单独的MapTask,并由该任务来运行用户自定义的map方法。
数据分片的主要作用可以归纳为以下几点:首先,通过分片,大规模数据集可以被分解成多个较小的数据块,进而提高了处理效率;其次,数据分片可以实现数据的并行处理,充分利用集群资源,提高处理速度;最后,对于超大数据集,数据分片还可以实现数据的分布式存储和处理。
在实际的处理过程中,如何进行数据分片通常取决于具体的业务需求和数据特性。例如,可以按照时间、地域、用户ID等方式进行数据分片。此外,还需要考虑到数据的均衡性问题,尽可能保证每个分片数据量的大小和处理复杂度相近,以避免出现数据倾斜的问题。
相关文章:

MapReduce
1. MapReduce是什么?请简要说明它的工作原理。 MapReduce是一种编程模型,主要用于处理大规模数据集的并行运算,特别是非结构化数据。这个模型的核心思想是将大数据处理任务分解为两个主要步骤:Map和Reduce。用户只需实现map()和r…...

Spring Boot 快速入门
Spring Boot 快速入门 什么是Spring Boot Spring Boot是一个用于简化Spring应用开发的框架,它基于Spring框架,提供了自动配置、快速开发等特性,使得开发者可以更加便捷地构建独立的、生产级别的Spring应用。 开始使用Spring Boot 步骤一&a…...

什么是神经网络的非线性
大家好啊,我是董董灿。 最近在写《计算机视觉入门与调优》(右键,在新窗口中打开链接)的小册,其中一部分说到激活函数的时候,谈到了神经网络的非线性问题。 今天就一起来看看,为什么神经网络需…...
——浅谈用户体验测试的主要功能)
前端知识(十四)——浅谈用户体验测试的主要功能
用户体验(User Experience,简称UX)在现代软件和产品开发中变得愈发重要。为了确保产品能够满足用户期望,提高用户满意度,用户体验测试成为不可或缺的环节。本文将详细探讨用户体验测试的主要功能,以及它在产品开发过程中的重要性 …...

解决前端跨域问题,后端解决方法
Spring CloudVue前后端分离项目报错:Network Error;net::ERR_FAILED(请求跨越)-CSDN博客记录自用...

【网络奇缘系列】计算机网络|数据通信方式|数据传输方式
🌈个人主页: Aileen_0v0🔥系列专栏: 一见倾心,再见倾城 --- 计算机网络~💫个人格言:"没有罗马,那就自己创造罗马~" 这篇文章是关于计算机网络中数据通信的基础知识点, 从模型,术语再到数据通信方式&#…...

数组 注意事项
1.一维数组的初始化 int a[5]{1,2,3,4,5}; 合法 int a[5]{1,2,3}; 合法 int a[]{1,2,3,4,5}; 合法,后面决定前面的大小 int a[5]{1,2,3,4,5,6}; 不合法! 2.一维数组的定义 int a[5] 合法 int a[11] 合法 int a[1/24] 合法 int x5,a[x…...

day11 滑动窗口中的最大值
class MyQueue { //单调队列(从大到小)public:deque<int> que; // 使用deque来实现单调队列// 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。// 同时pop之前判断队列当前是否为空。void…...
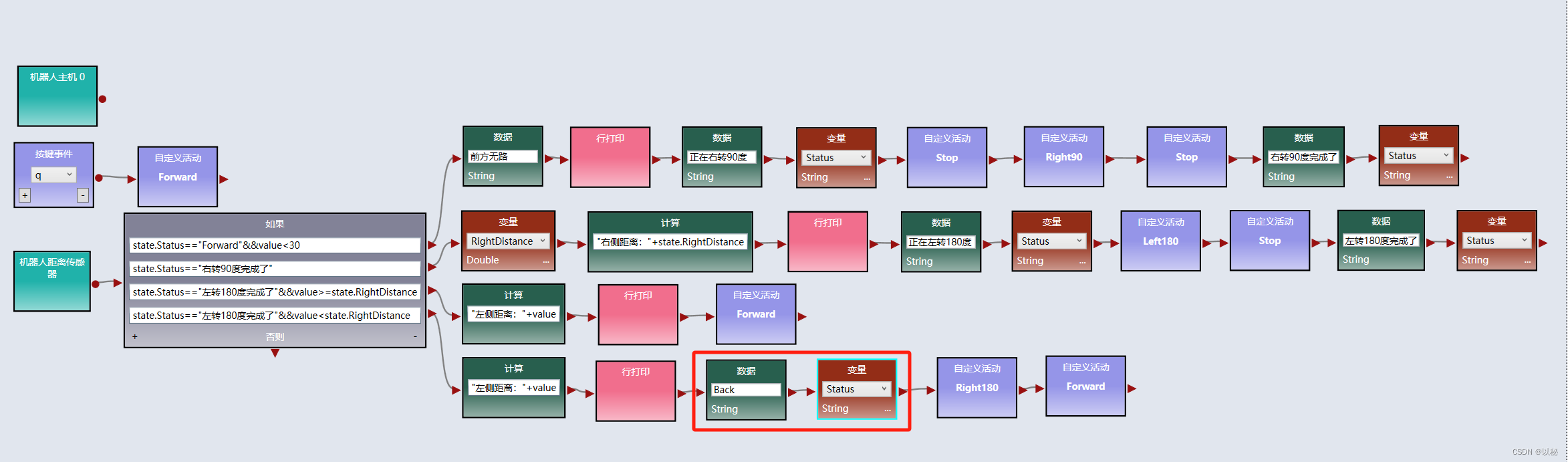
viple模拟器使用(五):Web 2D模拟器中实现两距离局部最优迷宫算法
关于两距离局部最优迷宫算法的原理本文不再赘述,详情请参考:viple模拟器使用(四),归纳总结为: 前方有路,则直行; 前方无路,则右转90度,标记右转完成ÿ…...
)
每日一道算法题 3(2023-12-11)
题目描述: VLAN是一种对局域网设备进行逻辑划分的技术,为了标识不同的VLAN,引入VLAN ID(1-4094之间的整数)的概念。 定义一个VLAN ID的资源池(下称VLAN资源池),资源池中连续的VLAN用开始VLAN-结束VLAN表示,不连续的用单…...
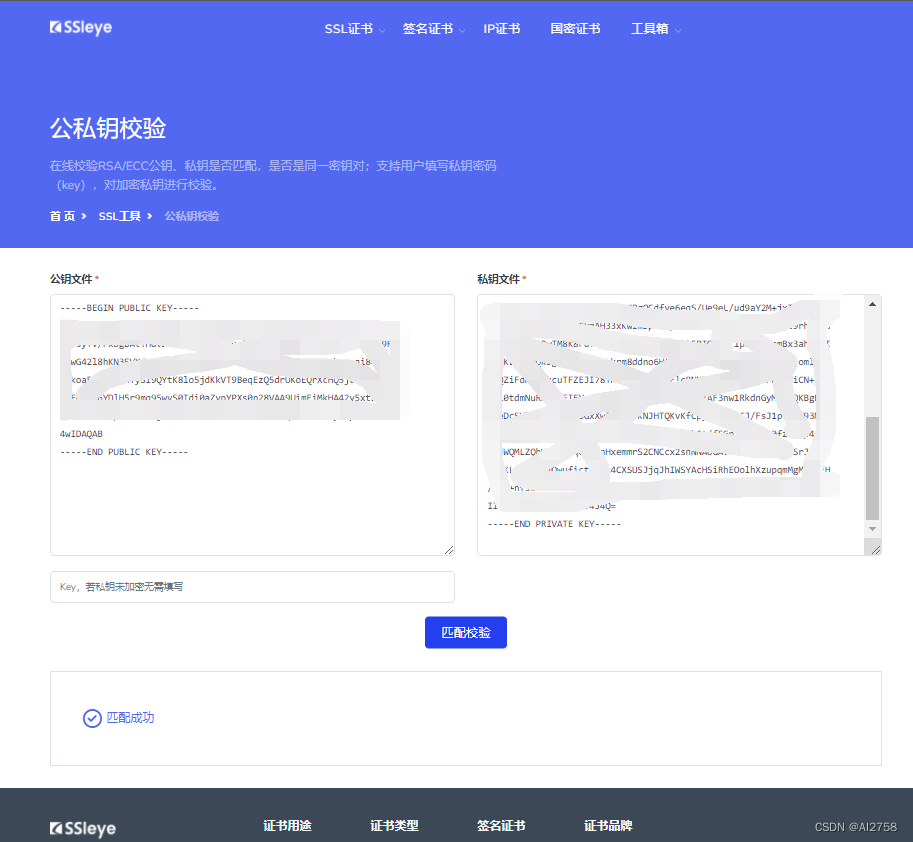
【Android】查看keystore的公钥和私钥
前言: 查看前准备好.keystore文件,安装并配置openssl、keytool。文件路径中不要有中文。 一、查看keystore的公钥: 1.从keystore中获取MD5证书 keytool -list -v -keystore gamekeyold.keystore 2.导出公钥文件 keytool -export -alias …...

ChatGPT的常识
什么是ChatGPT? ChatGPT是一个基于GPT模型的聊天机器人,GPT即“Generative Pre-training Transformer”,是一种预训练的语言模型。ChatGPT使用GPT-2和GPT-3两种模型来生成自然语言响应,从而与人类进行真实的对话。 ChatGPT的设计…...

Spring Boot中的事务是如何实现的?懂吗?
SpringBoot中的事务管理,用得好,能确保数据的一致性和完整性;用得不好,可能会给性能带来不小的影响哦。 基本使用 在SpringBoot中,事务的使用非常简洁。首先,得感谢Spring框架提供的Transactional注解&am…...

应用安全:JAVA反序列化漏洞之殇
应用安全:JAVA反序列化漏洞之殇 概述 序列化是让Java对象脱离Java运行环境的一种手段,可以有效的实现多平台之间的通信、对象持久化存储。Java 序列化是指把 Java 对象转换为字节序列的过程便于保存在内存、文件、数据库中,ObjectOutputStream类的 wri…...
)
基于以太坊的智能合约开发Solidity(函数继承篇)
参考教程:【实战篇】1、函数重载_哔哩哔哩_bilibili 1、函数重载: pragma solidity ^0.5.17;contract overLoadTest {//不带参数function test() public{}//带一个参数function test(address account) public{}//参数类型不同,虽然uint160可…...

【论文极速读】LVM,视觉大模型的GPT时刻?
【论文极速读】LVM,视觉大模型的GPT时刻? FesianXu 20231210 at Baidu Search Team 前言 这一周,LVM在arxiv上刚挂出不久,就被众多自媒体宣传为『视觉大模型的GPT时刻』,笔者抱着强烈的好奇心,在繁忙工作之…...

TS基础语法
前言: 因为在写前端的时候,发现很多UI组件的语法都已经开始使用TS语法,不学习TS根本看不到懂,所以简单的学一下TS语法。为了看UI组件的简单代码,不至于一脸懵。 一、安装node 对于windows来讲,node版本高…...

【基于NLP的微博情感分析:从数据爬取到情感洞察】
基于NLP的微博情感分析:从数据爬取到情感洞察 背景数据集技术选型功能实现创新点 今天我将分享一个基于NLP的微博情感分析项目,通过Python技术、NLP模型和Flask框架,对微博数据进行清洗、分词、可视化,并利用NLP和贝叶斯进行情感分…...

Ubuntu 18.04使用Qemu和GDB搭建运行内核的环境
安装busybox 参考博客: 使用GDBQEMU调试Linux内核环境搭建 一文教你如何使用GDBQemu调试Linux内核 ubuntu22.04搭建qemu环境测试内核 交叉编译busybox 编译busybox出现Library m is needed, can’t exclude it (yet)的解释 S3C2440 制作最新busybox文件系统 https:…...

GEE——利用Landsat系列数据集进行1984-2023EVI指数趋势分析
简介: 利用Landsat系列数据集进行1984-2023EVI指数趋势分析其主要目的是进行长时序的分析,这里我们选用EVI指数,然后进行了4个月的分析,查看其最后的线性趋势以及分布状况。 EVI指数: EVI指数(Enhanced Vegetation Index,增强型植被指数)是一种反映植被生长状态的遥…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...
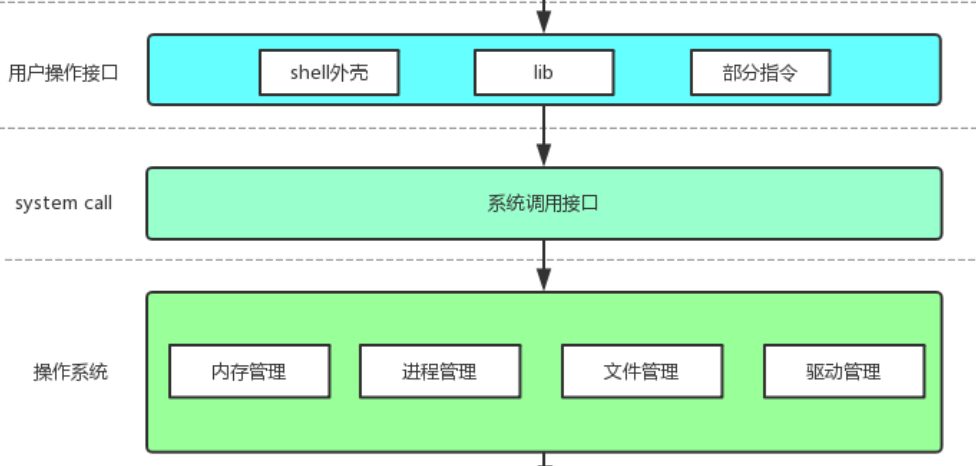
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

【深尚想】TPS54618CQRTERQ1汽车级同步降压转换器电源芯片全面解析
1. 元器件定义与技术特点 TPS54618CQRTERQ1 是德州仪器(TI)推出的一款 汽车级同步降压转换器(DC-DC开关稳压器),属于高性能电源管理芯片。核心特性包括: 输入电压范围:2.95V–6V,输…...