·神经网络
目录
- 11神经网络demo1
- 12神经网络demo2
- 13神经网络demo3
- 20tensorflow2.0 安装教程,所有安装工具(神经网络)
- 21神经网络-线性回归- demo1
- 22神经网络-线性回归- demo2
- 28神经网络-多层感知- demo1
- 目录
11神经网络demo1
package com.example.xxx;
import java.util.Vector;class Data
{Vector<Double> x = new Vector<Double>(); //输入数据Vector<Double> y = new Vector<Double>(); //输出数据
};class BPNN {final int LAYER = 3; //三层神经网络final int NUM = 10; //每层的最多节点数float A = (float) 30.0;float B = (float) 10.0; //A和B是S型函数的参数int ITERS = 1000; //最大训练次数float ETA_W = (float) 0.0035; //权值调整率float ETA_B = (float) 0.001; //阀值调整率float ERROR = (float) 0.002; //单个样本允许的误差float ACCU = (float) 0.005; //每次迭代允许的误差int in_num; //输入层节点数int ou_num; //输出层节点数int hd_num; //隐含层节点数Double[][][] w =new Double[LAYER][NUM][NUM]; //BP网络的权值Double[][] b = new Double[LAYER][NUM]; //BP网络节点的阀值Double[][] x= new Double[LAYER][NUM]; //每个神经元的值经S型函数转化后的输出值,输入层就为原值Double[][] d= new Double[LAYER][NUM]; //记录delta学习规则中delta的值Vector<Data> data;//获取训练所有样本数据void GetData(Vector<Data> _data) {data = _data;}//开始进行训练void Train() {System.out.printf("Begin to train BP NetWork!\n");GetNums();InitNetWork();int num = data.size();for(int iter = 0; iter <= ITERS; iter++) {for(int cnt = 0; cnt < num; cnt++) {//第一层输入节点赋值for(int i = 0; i < in_num; i++)x[0][i] = data.get(cnt).x.get(i);while(true){ForwardTransfer();if(GetError(cnt) < ERROR) //如果误差比较小,则针对单个样本跳出循环break;ReverseTransfer(cnt);}}System.out.printf("This is the %d th trainning NetWork !\n", iter);Double accu = GetAccu();System.out.printf("All Samples Accuracy is " + accu);if(accu < ACCU) break;}System.out.printf("The BP NetWork train End!\n");}//根据训练好的网络来预测输出值Vector<Double> ForeCast(Vector<Double> data) {int n = data.size();assert(n == in_num);for(int i = 0; i < in_num; i++)x[0][i] = data.get(i);ForwardTransfer();Vector<Double> v = new Vector<Double>();for(int i = 0; i < ou_num; i++)v.add(x[2][i]);return v;}//获取网络节点数void GetNums() {in_num = data.get(0).x.size(); //获取输入层节点数ou_num = data.get(0).y.size(); //获取输出层节点数hd_num = (int)Math.sqrt((in_num + ou_num) * 1.0) + 5; //获取隐含层节点数if(hd_num > NUM) hd_num = NUM; //隐含层数目不能超过最大设置}//初始化网络void InitNetWork() {for(int i = 0; i < LAYER; i++){for(int j = 0; j < NUM; j++){for(int k = 0; k < NUM; k++){w[i][j][k] = 0.0;}}}for(int i = 0; i < LAYER; i++){for(int j = 0; j < NUM; j++){b[i][j] = 0.0;}}}//工作信号正向传递子过程void ForwardTransfer() {//计算隐含层各个节点的输出值for(int j = 0; j < hd_num; j++) {Double t = 0.0;for(int i = 0; i < in_num; i++)t += w[1][i][j] * x[0][i];t += b[1][j];x[1][j] = Sigmoid(t);}//计算输出层各节点的输出值for(int j = 0; j < ou_num; j++) {Double t = (double) 0;for(int i = 0; i < hd_num; i++)t += w[2][i][j] * x[1][i];t += b[2][j];x[2][j] = Sigmoid(t);}}//计算单个样本的误差double GetError(int cnt) {Double ans = (double) 0;for(int i = 0; i < ou_num; i++)ans += 0.5 * (x[2][i] - data.get(cnt).y.get(i)) * (x[2][i] - data.get(cnt).y.get(i));return ans;}//误差信号反向传递子过程void ReverseTransfer(int cnt) {CalcDelta(cnt);UpdateNetWork();}//计算所有样本的精度double GetAccu() {Double ans = (double) 0;int num = data.size();for(int i = 0; i < num; i++) {int m = data.get(i).x.size();for(int j = 0; j < m; j++)x[0][j] = data.get(i).x.get(j);ForwardTransfer();int n = data.get(i).y.size();for(int j = 0; j < n; j++)ans += 0.5 * (x[2][j] - data.get(i).y.get(j)) * (x[2][j] - data.get(i).y.get(j));}return ans / num;}//计算调整量void CalcDelta(int cnt) {//计算输出层的delta值for(int i = 0; i < ou_num; i++)d[2][i] = (x[2][i] - data.get(cnt).y.get(i)) * x[2][i] * (A - x[2][i]) / (A * B);//计算隐含层的delta值for(int i = 0; i < hd_num; i++) {Double t = (double) 0;for(int j = 0; j < ou_num; j++)t += w[2][i][j] * d[2][j];d[1][i] = t * x[1][i] * (A - x[1][i]) / (A * B);}}//根据计算出的调整量对BP网络进行调整void UpdateNetWork() {//隐含层和输出层之间权值和阀值调整for(int i = 0; i < hd_num; i++) {for(int j = 0; j < ou_num; j++)w[2][i][j] -= ETA_W * d[2][j] * x[1][i];}for(int i = 0; i < ou_num; i++)b[2][i] -= ETA_B * d[2][i];//输入层和隐含层之间权值和阀值调整for(int i = 0; i < in_num; i++) {for(int j = 0; j < hd_num; j++)w[1][i][j] -= ETA_W * d[1][j] * x[0][i];}for(int i = 0; i < hd_num; i++)b[1][i] -= ETA_B * d[1][i];}//计算Sigmoid函数的值Double Sigmoid(double x) {return A / (1 + Math.exp(-x / B));}}package com.example.xxx;import java.io.IOException;
import java.util.Vector;public class xxx2 {}class BPNeuralNetworks {static Double[][] sample={{0.0,0.0,0.0,0.0},{5.0,1.0,4.0,19.020},{5.0,3.0,3.0,14.150},{5.0,5.0,2.0,14.360},{5.0,3.0,3.0,14.150},{5.0,3.0,2.0,15.390},{5.0,3.0,2.0,15.390},{5.0,5.0,1.0,19.680},{5.0,1.0,2.0,21.060},{5.0,3.0,3.0,14.150},{5.0,5.0,4.0,12.680},{5.0,5.0,2.0,14.360},{5.0,1.0,3.0,19.610},{5.0,3.0,4.0,13.650},{5.0,5.0,5.0,12.430},{5.0,1.0,4.0,19.020},{5.0,1.0,4.0,19.020},{5.0,3.0,5.0,13.390},{5.0,5.0,4.0,12.680},{5.0,1.0,3.0,19.610},{5.0,3.0,2.0,15.390},{1.0,3.0,1.0,11.110},{1.0,5.0,2.0,6.521},{1.0,1.0,3.0,10.190},{1.0,3.0,4.0,6.043},{1.0,5.0,5.0,5.242},{1.0,5.0,3.0,5.724},{1.0,1.0,4.0,9.766},{1.0,3.0,5.0,5.870},{1.0,5.0,4.0,5.406},{1.0,1.0,3.0,10.190},{1.0,1.0,5.0,9.545},{1.0,3.0,4.0,6.043},{1.0,5.0,3.0,5.724},{1.0,1.0,2.0,11.250},{1.0,3.0,1.0,11.110},{1.0,3.0,3.0,6.380},{1.0,5.0,2.0,6.521},{1.0,1.0,1.0,16.000},{1.0,3.0,2.0,7.219},{1.0,5.0,3.0,5.724}};public static void main( String[] args ) throws IOException{Vector<Data> data = new Vector<Data>();System.out.println("===>"+sample.length);for(int i = 0; i < sample.length; i++){Data t = new Data();for(int j = 0; j < 3; j++)t.x.add(sample[i][j]);t.y.add(sample[i][3]);data.add(t);}BPNN bp = new BPNN();bp.GetData(data);bp.Train();while(true){Vector<Double> in = new Vector<Double>();for(int i = 0; i < 3; i++){Double v = 0.0;in.add(v);}Vector<Double> ou;ou = bp.ForeCast(in);System.out.println("===> "+ou.get(0));}}}
···················································································································································································
12神经网络demo2
package com.example.xxx;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class xxxx {
}class Neuron {/*** 神经元值*/public double value;/*** 神经元输出值*/public double o;public Neuron () {init ();}public Neuron (double v) {init (v);}public Neuron (double v, double o) {this.value = v;this.o = o;}public void init () {this.value = 0;this.o = 0;}public void init (double v) {this.value = v;this.o = 0;}public void init (double v, double o) {this.value = v;this.o = o;}/*** sigmod激活函数*/public void sigmod () {this.o = 1.0 / ( 1.0 + Math.exp(-1.0 * this.value));}public String toString () {return "(" + value + " " + o + ")";}
}class RandomUtil {public static final int RAND_SEED = 2016;public static Random rand = new Random (RAND_SEED);public static double nextDouble () {return rand.nextDouble();}public static double nextDouble (double a, double b) {if (a > b) {double tmp = a;a = b;b = tmp;}return rand.nextDouble() * (b - a) + a;}
}class NeuronNet {/*** 神经网络*/public List<List<Neuron>> neurons;/*** 网络权重, weight[i][j][k] = 第i层和第i+1层之间, j神经元和k神经元的权重, i = 0 ... layer-1*/public double [][][] weight;/*** 下一层网络残差, deta[i][j] = 第i层, 第j神经元的残差, i = 1 ... layer-1*/public double [][] deta;/*** 网络层数(包括输入与输出层)*/public int layer;/*** 学习率*/public static final double RATE = 0.1;/*** 误差停止阈值*/public static final double STOP = 0.0001;/*** 迭代次数阈值*/public static final int NUMBER_ROUND = 5000000;public NeuronNet () {}public NeuronNet (int [] lens) {init (lens);}public void init (int [] lens) {layer = lens.length;neurons = new ArrayList<List<Neuron>>();for (int i = 0; i < layer; ++ i) {List<Neuron> list = new ArrayList<Neuron> ();for (int j = 0; j < lens[i]; ++ j) {list.add(new Neuron ());}neurons.add(list);}weight = new double [layer-1][][];for (int i = 0; i < layer-1; ++ i) {weight[i] = new double [lens[i]][];for (int j = 0; j < lens[i]; ++ j) {weight[i][j] = new double [lens[i+1]];for (int k = 0; k < lens[i+1]; ++ k) {weight[i][j][k] = RandomUtil.nextDouble(0, 0.1);}}}deta = new double [layer][];for (int i = 0; i < layer; ++ i) {deta[i] = new double [lens[i]];for (int j = 0; j < lens[i]; ++ j) deta[i][j] = 0;}}/*** 前向传播* @param features* @return*/public boolean forward (double [] features) {// c = layer indexfor (int c = 0; c < layer; ++ c) {if (c == 0) {// 初始化输入层List<Neuron> inputLayer = neurons.get(c);if (inputLayer.size() != features.length) {System.err.println("[error] Feature length != input layer neuron number");return false;}for (int i = 0; i < inputLayer.size(); ++ i) {Neuron neuron = inputLayer.get(i);neuron.init(features[i], features[i]);}} else {// 前向传播:从c-1层传播到c层List<Neuron> vList = neurons.get(c);List<Neuron> uList = neurons.get(c-1);for (int i = 0; i < vList.size(); ++ i) {Neuron v = vList.get(i);v.value = 0;for (int j = 0; j < uList.size(); ++ j) {Neuron u = uList.get(j);v.value += u.o * weight[c-1][j][i];}v.sigmod();}}}return true;}/*** 求误差函数* @param labels 期望输出层向量* @return*/public double getError (double [] labels) {if (labels.length != neurons.get(layer-1).size()) {System.err.println("[error] label length != output layer neuron number");return -1;}double e = 0;for (int i = 0; i < labels.length; ++ i) {double o = neurons.get(layer-1).get(i).o;e += (labels[i] - o) * (labels[i] - o);}return e / 2;}/*** 获取输出层向量* @return*/public double[] getOutput () {double [] output = new double [neurons.get(layer-1).size()];for (int i = output.length-1; i >= 0 ; -- i)output [i] = neurons.get(layer-1).get(i).o;return output;}/*** 反向传播* @param labels* @return*/public boolean backward (double [] labels) {if (labels.length != neurons.get(layer-1).size()) {System.err.println("[error] label length != output layer neuron number");return false;}// 初始化output层(layer-1)残差for (int j = neurons.get(layer-1).size()-1; j >= 0 ; -- j) {double o = neurons.get(layer-1).get(j).o;// 求导公式deta[layer-1][j] = -1 * (labels[j] - o) * o * (1 - o);// 更新倒数第二层和最后一层之间的权重for (int i = neurons.get(layer-2).size()-1; i >= 0; -- i) {weight[layer-2][i][j] -= RATE * deta[layer-1][j] * neurons.get(layer-2).get(i).o;}}//A层(layer=L)和B层(layer=L+1)间权重调整,用到了C层(layer=L+2)for (int l = layer-3; l >= 0; -- l) {// 遍历B层for (int j = neurons.get(l+1).size()-1; j >= 0; -- j) {// B层J神经元残差deta[l+1][j] = 0;// 遍历C层, 求残差和for (int k = neurons.get(l+2).size()-1; k >= 0; -- k) {// C层残差通过权重weight传递过来deta[l+1][j] += deta[l+2][k] * weight[l+1][j][k];}double o = neurons.get(l+1).get(j).o;deta[l+1][j] *= o * (1 - o);// 遍历A层for (int i = neurons.get(l).size()-1; i >= 0; -- i) {// A层i神经元和B层j神经元权重weight[l][i][j] -= RATE * deta[l+1][j] * neurons.get(l).get(i).o;}}}return true;}public void train (double [][] features, double [][] labels) {SGD (features, labels);}public void SGD (double [][] features, double [][] labels) {int num = 0;double error = 1;while ((num ++) <= NUMBER_ROUND && error > STOP) {for (int i = 0; i < features.length; ++ i) {boolean flag = forward (features[i]);if (!flag) {return;}error = this.getError(labels[i]);if (error == -1) {return;}if (error <= STOP)break;flag = backward (labels[i]);if (!flag) {return;}}System.out.println("[Info] Times = " + num + ", error = " + error);}}public double [] predict (double [] feature) {forward (feature);return this.getOutput();}
}class Main {public static void main(String[] args) {// 三层神经网络,每层神经元个数分别是3,5,8NeuronNet bpnn = new NeuronNet (new int [] {3, 5, 8});// 数据说明,求二进制X[i]的十进制表示Y[i]double[][] X = {{0,0,0},{0,0,1},{0,1,0},{0,1,1},{1,0,0},{1,0,1},{1,1,0},{1,1,1}};double [][] Y = {{1, 0, 0, 0, 0, 0, 0, 0},{0, 1, 0, 0, 0, 0, 0, 0},{0, 0, 1, 0, 0, 0, 0, 0},{0, 0, 0, 1, 0, 0, 0, 0},{0, 0, 0, 0, 1, 0, 0, 0},{0, 0, 0, 0, 0, 1, 0, 0},{0, 0, 0, 0, 0, 0, 1, 0},{0, 0, 0, 0, 0, 0, 0, 1}};bpnn.train(X, Y);for (int i = 0; i < 8; ++ i) {double [] output = bpnn.predict(X[i]);double max = -1;int pos = -1;// 求最接近的神经元for (int j = 0; j < output.length; ++ j) {if (max < output[j]) {max = output[j];pos = j;}}System.out.print (X[i][0]);for (int j = 1; j < X[i].length; ++ j) {System.out.print (", " + X[i][j]);}System.out.println(" = " + pos);}}
}
···················································································································································································
13神经网络demo3
package com.example.xxx;import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;public class xxxx {}class Main {private static String path = "./src/data.txt"; //deta数据在最下面private static ArrayList<ArrayList<String>> data = new ArrayList<ArrayList<String>>();public static void main(String[] args) {readData(path);//对缺失值进行处理,但文件data.txt不处理,可能对缺失值进行另一种方法处理 //山鸢尾,变色鸢尾, 和维吉尼亚鸢尾, 分类3种花 (包括决策树、贝叶斯分类方法、BP神经网络和SVM)dealWithData();System.out.println("对数据进行朴素贝叶斯分类:");Bayesian bayesian = new Bayesian("6.4","2.7","5.3","1.8",data);bayesian.calculate_Bayesian();Bayesian bayesian1 = new Bayesian("4.5","2.3", "1.3", "0.3",data);bayesian1.calculate_Bayesian();Bayesian bayesian2 = new Bayesian("5.5","2.6","4.4","1.2",data);bayesian2.calculate_Bayesian();Bayesian bayesian3 = new Bayesian("5.1","2.5","3.0","1.1",data);bayesian3.calculate_Bayesian();Bayesian bayesian4 = new Bayesian("6.7","3.0","5.0","1.7",data);bayesian4.calculate_Bayesian();//show();}/*** -1代表缺失值,通过计算属性的平均值作为缺失值的填补值。*/private static void dealWithData() {double sum1 = 0.0, sum2 = 0.0, sum3 = 0.0, sum4 = 0.0;double value1, value2, value3, value4;int len1 = data.size(),len2 = data.size(),len3 = data.size(),len4 = data.size();for (int i=0; i<data.size(); i++){if (!data.get(i).get(0).equals("-1")){sum1 += Double.parseDouble(data.get(i).get(0));len1--;}if (!data.get(i).get(1).equals("-1")){sum2 += Double.parseDouble(data.get(i).get(1));len2--;}if (!data.get(i).get(2).equals("-1")){sum3 += Double.parseDouble(data.get(i).get(2));len3--;}if (!data.get(i).get(3).equals("-1")){sum4 += Double.parseDouble(data.get(i).get(3));len4--;}}value1 = sum1/(len1*1.0);value2 = sum2/(len2*1.0);value3 = sum3/(len3*1.0);value4 = sum4/(len4 *1.0);for (int j=0; j<data.size(); j++){if (data.get(j).get(0).equals("-1")){data.get(j).set(0,Double.toString(value1));}if (data.get(j).get(1).equals("-1")){data.get(j).set(1,Double.toString(value2));}if (data.get(j).get(2).equals("-1")){data.get(j).set(2,Double.toString(value3));}if (data.get(j).get(3).equals("-1")){data.get(j).set(3,Double.toString(value4));}}}/*** 导入数据到data* @param path* @return*/public static ArrayList<ArrayList<String>> readData(String path){ArrayList<String> d = null;ArrayList<ArrayList<String>> t = new ArrayList<ArrayList<String>>();try {InputStreamReader isr = new InputStreamReader(new FileInputStream(new File(path)));BufferedReader br = new BufferedReader(isr);String str = null;while((str = br.readLine()) != null){d = new ArrayList<String>();String[] str1 = str.split(",");for(int i = 0; i < str1.length ; i++) {d.add(str1[i]);}t.add(d);}data = t;br.close();isr.close();} catch (Exception e) {e.printStackTrace();System.out.println("读取文件内容出错!");}return t;}/*** 遍历data*/public static void show(){for(int i=0;i<data.size();i++){System.out.println(data.get(i));}}}class Bayesian {private String calyx_len;private String calyx_wid;private String petal_len;private String petal_wid;private ArrayList<ArrayList<String>> data;public Bayesian(String calyx_len, String calyx_wid, String petal_len, String petal_wid, ArrayList<ArrayList<String>> data){this.calyx_len = calyx_len;this.calyx_wid = calyx_wid;this.petal_len = petal_len;this.petal_wid = petal_wid;this.data = data;}/*** 贝叶斯运算部分*/public void calculate_Bayesian(){//获取P(Iris-setosa|Iris-versicolor|Iris-virginica)的分子————————————P(x|y)的分母int setosa = getNums("Iris-setosa");int versicolor = getNums("Iris-versicolor");int virginica = getNums("Iris-virginica");/*** 对数据进行划分等级,取整数位为分级标准* 花萼长度以4.x,5.x,6.x,7.x为等级* 花萼宽度以2.x,3.x,4.x* 花瓣长度以1.x,3.x,4.x,5.x,6.x* 花瓣宽度以0.x,1.x,2.x*///获取P(x|y)的分子,0代表花萼长度,1代表花萼宽度,2代表花瓣长度,3代表花瓣宽度int calyx_len_setosa = getNums(0,calyx_len,"Iris-setosa");int calyx_wid_setosa = getNums(1,calyx_wid,"Iris-setosa");int petal_len_setosa = getNums(2,petal_len,"Iris-setosa");int petal_wid_setosa = getNums(3,petal_wid,"Iris-setosa");int calyx_len_versicolor = getNums(0,calyx_len,"Iris-versicolor");int calyx_wid_versicolor = getNums(1,calyx_wid,"Iris-versicolor");int petal_len_versicolor = getNums(2,petal_len,"Iris-versicolor");int petal_wid_versicolor = getNums(3,petal_wid,"Iris-versicolor");int calyx_len_virginica = getNums(0,calyx_len,"Iris-virginica");int calyx_wid_virginica = getNums(1,calyx_wid,"Iris-virginica");int petal_len_virginica = getNums(2,petal_len,"Iris-virginica");int petal_wid_virginica = getNums(3,petal_wid,"Iris-virginica");//计算概率Iris_setosa,Iris_versicolor,Iris_virginicadouble setosa_probability = (setosa/(data.size()*1.0))*(calyx_len_setosa/(setosa*1.0))*(calyx_wid_setosa/(setosa*1.0))*(petal_len_setosa/(setosa*1.0))*(petal_wid_setosa/(setosa*1.0));double versicolor_probability = (versicolor/(data.size()*1.0))*(calyx_len_versicolor/(versicolor*1.0))*(calyx_wid_versicolor/(versicolor*1.0))*(petal_len_versicolor/(versicolor*1.0))*(petal_wid_versicolor/(versicolor*1.0));double virginica_probability = (virginica/(data.size()*1.0))*(calyx_len_virginica/(virginica*1.0))*(calyx_wid_virginica/(virginica*1.0))*(petal_len_virginica/(virginica*1.0))*(petal_wid_virginica/(virginica*1.0));//比较概率得出结论if(setosa_probability > versicolor_probability && setosa_probability > virginica_probability){System.out.println("<"+calyx_len+","+calyx_wid+","+petal_len+","+petal_wid+","+"> ---> Iris-setosa");}if(versicolor_probability > setosa_probability && versicolor_probability > virginica_probability){System.out.println("<"+calyx_len+","+calyx_wid+","+petal_len+","+petal_wid+","+"> ---> Iris-versicolor");}if(virginica_probability > setosa_probability && virginica_probability > versicolor_probability){System.out.println("<"+calyx_len+","+calyx_wid+","+petal_len+","+petal_wid+","+"> ---> Iris-virginica");}}private int getNums(String str) {int num = 0;for(int i=0;i<data.size();i++){if(data.get(i).get(4).equals(str)){num++;}}return num;}private int getNums(int id, String str1, String str2){int num = 0;for(int i=0;i<data.size();i++){if(data.get(i).get(4).equals(str2)){if(data.get(i).get(id).charAt(0) == str1.charAt(0)){num++;}}}return num;}
}// 5.1,3.5,1.4,0.2,Iris-setosa// -1,3.0,1.4,0.2,Iris-setosa// 4.7,3.2,1.3,0.2,Iris-setosa// 4.6,3.1,-1,0.2,Iris-setosa// 5.0,3.6,1.4,0.2,Iris-setosa// 5.5,2.3,4.0,1.3,Iris-versicolor// 6.5,2.8,4.6,1.5,Iris-versicolor// -1,2.8,4.5,1.3,Iris-versicolor// 6.3,3.3,4.7,1.6,Iris-versicolor// 7.1,3.0,5.9,2.1,Iris-virginica// -1,2.9,5.6,1.8,Iris-virginica// 6.5,3.0,5.8,2.2,Iris-virginica// 4.9,2.4,3.3,1.0,Iris-versicolor// 5.6,3.0,4.5,1.5,Iris-versicolor// 5.8,2.7,4.1,1.0,Iris-versicolor// 6.3,3.3,-1,2.5,Iris-virginica// 5.8,2.7,5.1,1.9,Iris-virginica// 7.6,3.0,6.6,2.1,Iris-virginica// 4.9,2.5,4.5,1.7,Iris-virginica// 7.3,2.9,6.3,1.8,Iris-virginica// 5.7,2.5,-1,2.0,Iris-virginica// 5.8,2.8,5.1,2.4,Iris-virginica// 6.6,2.9,4.6,1.3,Iris-versicolor// 5.2,2.7,3.9,1.4,Iris-versicolor// 5.4,3.9,1.7,0.4,Iris-setosa// 4.6,3.4,1.4,0.3,Iris-setosa// 5.0,3.4,1.5,0.2,Iris-setosa// 4.4,2.9,1.4,-1,Iris-setosa// 4.9,3.1,1.5,0.1,Iris-setosa// 5.4,3.7,1.5,0.2,Iris-setosa// 4.8,-1,1.6,0.2,Iris-setosa// 4.8,3.0,1.4,0.1,Iris-setosa// 4.3,3.0,1.1,0.1,Iris-setosa// 5.8,4.0,1.2,0.2,Iris-setosa// 6.1,2.9,4.7,1.4,Iris-versicolor// 5.6,2.9,3.6,1.3,Iris-versicolor// 6.7,3.1,4.4,1.4,Iris-versicolor// 6.4,3.2,5.3,2.3,Iris-virginica// 6.5,3.0,5.5,1.8,Iris-virginica// 5.7,4.4,1.5,0.4,Iris-setosa// 5.4,3.9,1.3,0.4,Iris-setosa// 5.1,3.5,1.4,0.3,Iris-setosa// 5.7,3.8,1.7,0.3,Iris-setosa// 5.1,3.8,-1,0.3,Iris-setosa// 5.4,3.4,1.7,0.2,Iris-setosa// 5.1,3.7,1.5,0.4,Iris-setosa// 6.7,2.5,5.8,-1,Iris-virginica// 7.2,3.6,6.1,2.5,Iris-virginica// 6.5,3.2,5.1,2.0,Iris-virginica// 6.8,3.0,5.5,2.1,Iris-virginica// 4.6,3.6,1.0,0.2,Iris-setosa// 5.1,3.3,1.7,0.5,Iris-setosa// -1,3.4,1.9,0.2,Iris-setosa// 5.0,3.0,1.6,0.2,Iris-setosa// 7.0,3.2,4.7,1.4,Iris-versicolor// 6.4,3.2,4.5,1.5,Iris-versicolor// 6.9,3.1,4.9,1.5,Iris-versicolor// 5.0,2.0,3.5,1.0,Iris-versicolor// 5.9,-1,4.2,1.5,Iris-versicolor// 6.0,2.2,4.0,1.0,Iris-versicolor// 7.7,3.8,6.7,2.2,Iris-virginica// 7.7,2.6,6.9,2.3,Iris-virginica// 6.0,2.2,5.0,-1,Iris-virginica// 6.9,3.2,5.7,2.3,Iris-virginica
···················································································································································································
20tensorflow2.0 安装教程,所有安装工具(神经网络)
安装:常用的工具 jupyter notebook
pip install tensorflow-cpu==2.3.0 -i https://pypi.douban.com/simple/
pip install seaborn -i https://pypi.douban.com/simple/
pip install matplotlib notebook -i https://pypi.douban.com/simple/pip install sklearn -i https://pypi.douban.com/simple/
pip install xgboost -i https://pypi.douban.com/simple/环境要求:
64位操作系统
ubuntu 16.04 或以上
windows 7 或以上
masOS 10.12.6 或以上
raspbian 9.0 或以上
python 3.5-3.7 ****版本升级,用更高版本***
搭建开发环境:
使用:miniconda 搭建环境
官网:https://docs.conda.io/en/latest/miniconda.html#windows-installers它包括了:
1,conda包管理工具
2,python
windows用户需要安装VC
官网:http://support.microsoft.com/zh-cn/help/2977003/the-latest-supported-visual-c-downloads
安装完成 miniconda + VC 环境安装就完毕。 安装完毕 需要重启电脑。 (下一步即可)
安装包在qq群里,也可以去官网下载,网站如上。

进入命令行查看版本如下
打开命令行窗口: Anaconda Prompt (tensorflow2.0)
输入查看命令: pip -V

安装tensorflow2…3.0版本
安装命令:(如下图) *版本升级,用更高版本
pip install tensorflow-cpu==2.3.0 -i https://pypi.douban.com/simple/

输入命令开始安装: (如下图)

安装完成 进行查看:
命令:如下
python
import tensorflow as tf
print(tf.__version__)
exit()
pip install matplotlib notebook -i https://pypi.douban.com/simple/

安装完成后 (matplotlib notebook)
进入notebook
jupyter notebook

→ 进入notebook → 弹窗如下 (自动弹窗)

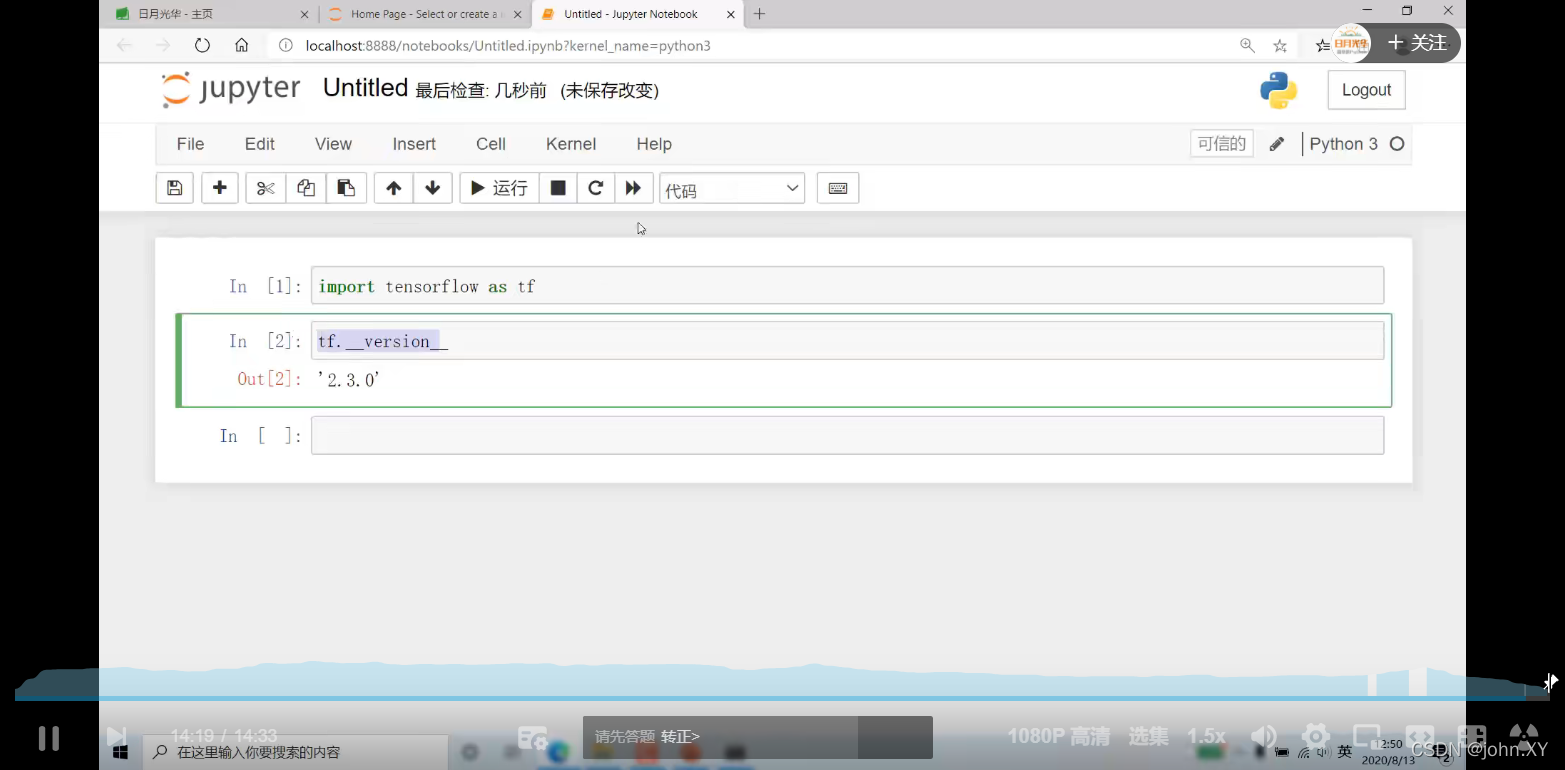
导入tensorflow 查看版本
import tensorflow as tf
tf.version
···················································································································································································
21神经网络-线性回归- demo1
// Incomel.csv 为文件名 ./dataset/ 为路径
//进入
jupyter notebook
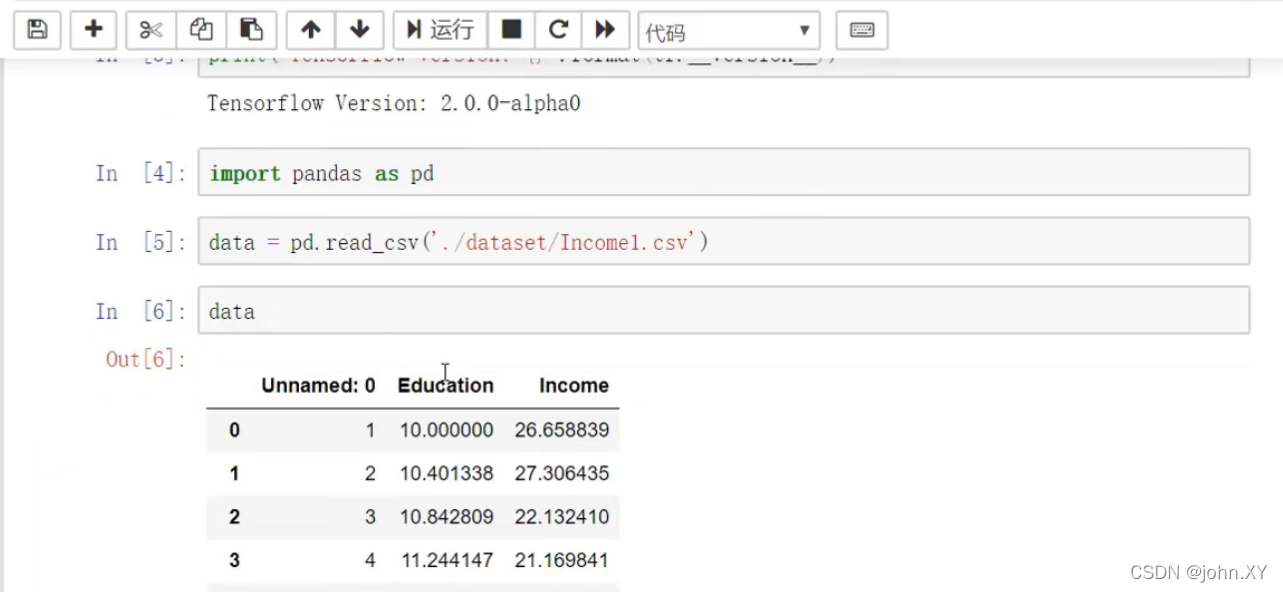
import pandas as pd
data = pd.read_csv('./dataset/Incomel.csv')
data
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(data.Education,data.Income)
解释:
import pandas as pd 引入 → pandas
import matplotlib.pyplot as plt 为绘图工具 → 引入
%matplotlib inline 显示出来
plt.scatter(data.Education,data.Income) 绘制的文件的列名
Education,Income 为文件的列名
单变量线性回归算法方程式: f(x) = ax + b
下图为:引入文件
下图为:引入绘图工具

下图为:绘制的效果

···················································································································································································
22神经网络-线性回归- demo2
打开命令行窗口: Anaconda Prompt (tensorflow2.0)
进入notebook: jupyter notebook
1
import pathlibimport matplotlib.pyplot as plt
import pandas as pd
import seaborn as snsimport tensorflow as tffrom tensorflow import keras
from tensorflow.keras import layersprint(tf.__version__)
2 下载数据
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
3 使用 pandas 导入数据集。
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight','Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,na_values = "?", comment='\t',sep=" ", skipinitialspace=True)dataset = raw_dataset.copy()
dataset.tail()
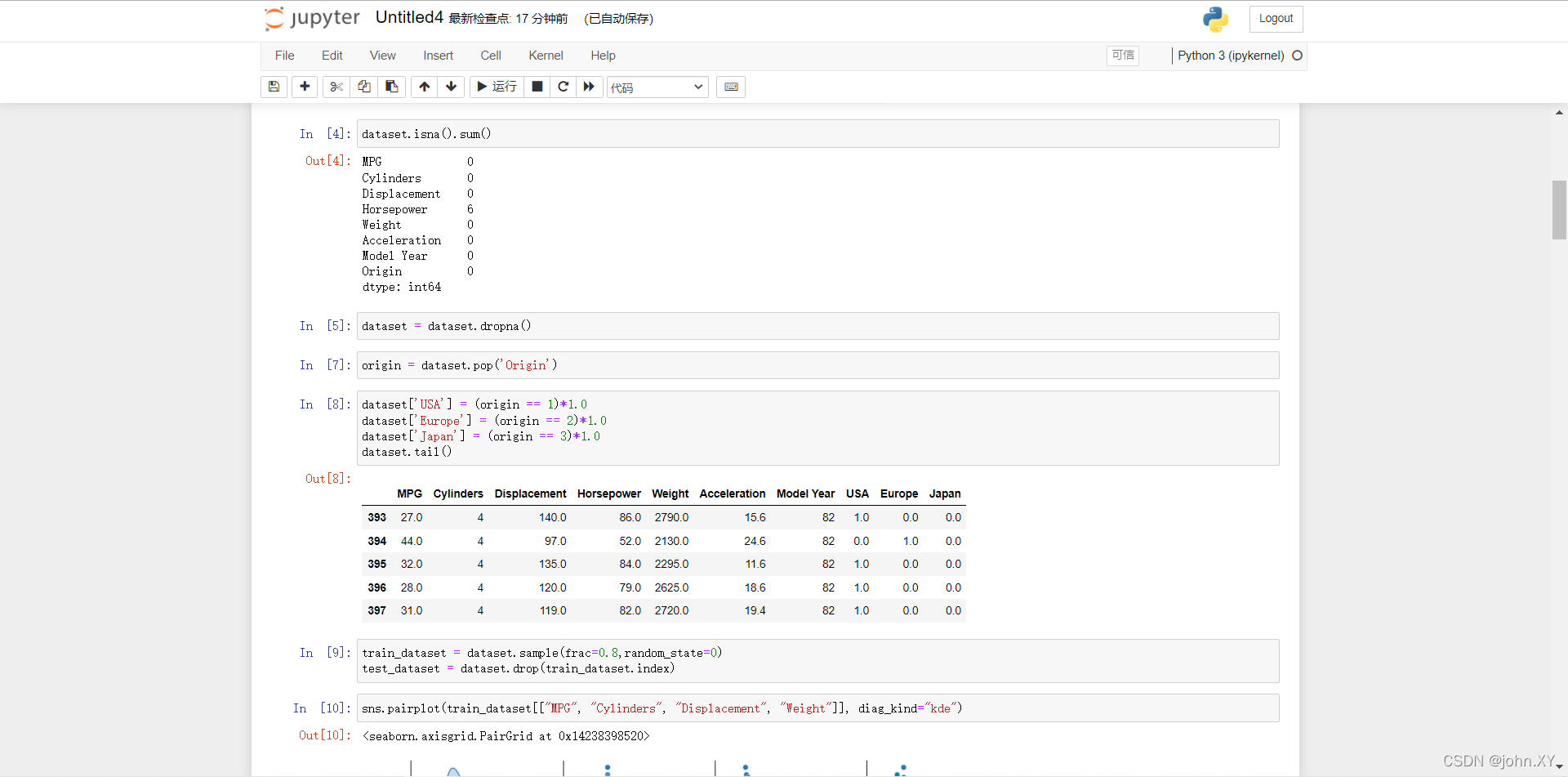
4 数据清洗,数据集中包括一些未知值。
dataset.isna().sum()
5 为了保证这个初始示例的简单性,删除这些行。
dataset = dataset.dropna()
7 (5 → 7) “Origin” 列实际上代表分类,而不仅仅是一个数字。所以把它转换为独热码 (one-hot)
origin = dataset.pop('Origin')
8
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail()
9 拆分训练数据集和测试数据集,现在需要将数据集拆分为一个训练数据集和一个测试数据集,我们最后将使用测试数据集对模型进行评估。
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
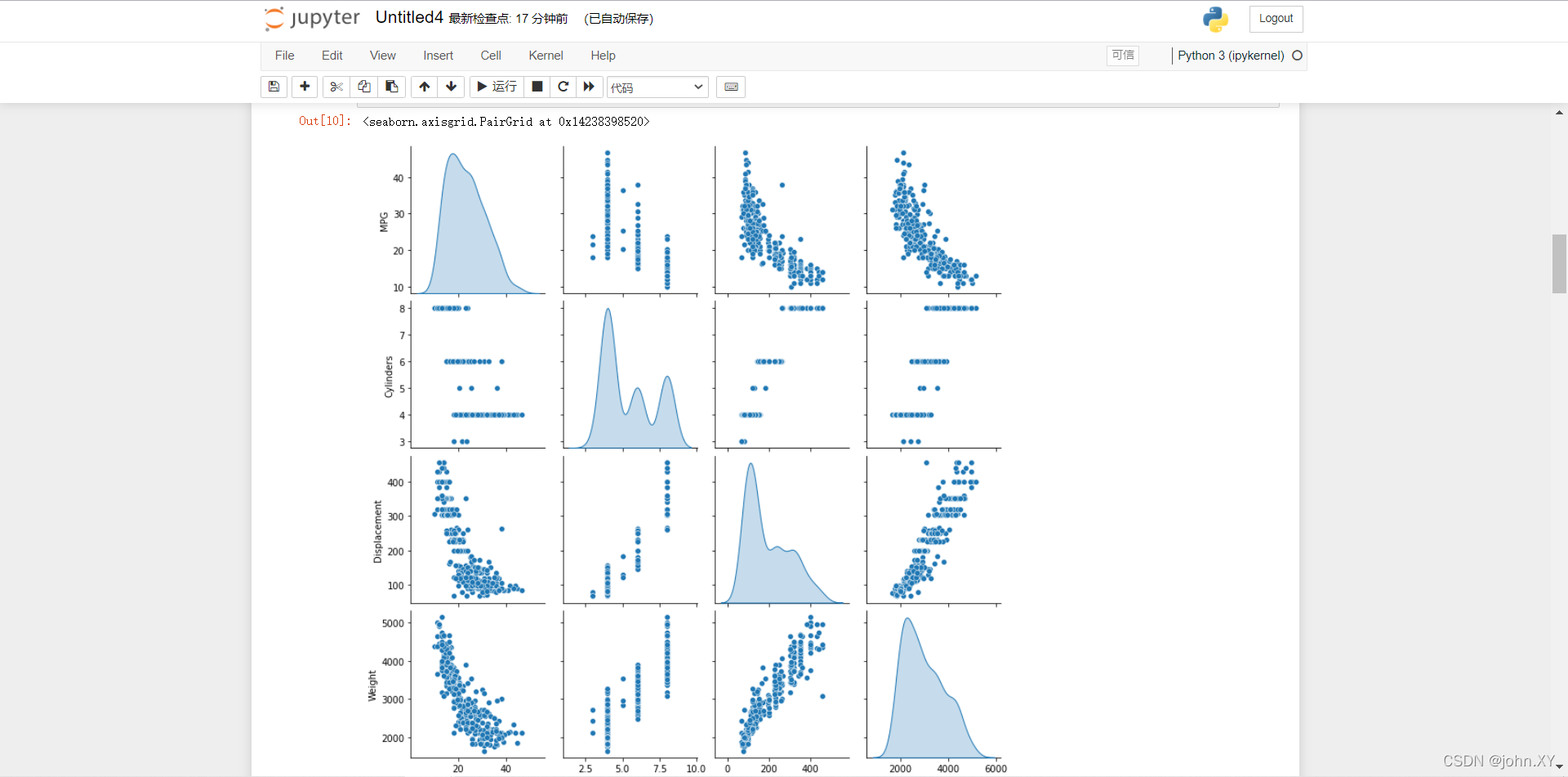
10 快速查看训练集中几对列的联合分布。
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
11 查看总体的数据统计。
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
25 (11 → 25) 从标签中分离特征,将特征值从目标值或者"标签"中分离。 这个标签是你使用训练模型进行预测的值。
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
26 数据规范化,将测试数据集放入到与已经训练过的模型相同的分布中。
def norm(x):return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
27 构建模型,这里,我们将会使用一个“顺序”模型,其中包含两个紧密相连的隐藏层,以及返回单个、连续值得输出层。模型的构建步骤包含于一个名叫 ‘build_model’ 的函数中,稍后我们将会创建第二个模型。 两个密集连接的隐藏层。
def build_model():model = keras.Sequential([layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),layers.Dense(64, activation='relu'),layers.Dense(1)])optimizer = tf.keras.optimizers.RMSprop(0.001)model.compile(loss='mse',optimizer=optimizer,metrics=['mae', 'mse'])return model
28
model = build_model()
下面代码:输出打印(可有可无)
model.summary()
29 试用下这个模型。从训练数据中批量获取‘10’条例子并对这些例子调用 model.predict 。
example_batch = normed_train_data[:10]
example_result = model.predict(example_batch)
example_result
30 训练模型,对模型进行1000个周期的训练,并在 history 对象中记录训练和验证的准确性。
class PrintDot(keras.callbacks.Callback):def on_epoch_end(self, epoch, logs):if epoch % 100 == 0: print('')print('.', end='')EPOCHS = 1000history = model.fit(normed_train_data, train_labels,epochs=EPOCHS, validation_split = 0.2, verbose=0,callbacks=[PrintDot()])
31 使用 history 对象中存储的统计信息可视化模型的训练进度。
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
32
def plot_history(history):hist = pd.DataFrame(history.history)hist['epoch'] = history.epochplt.figure()plt.xlabel('Epoch')plt.ylabel('Mean Abs Error [MPG]')plt.plot(hist['epoch'], hist['mae'],label='Train Error')plt.plot(hist['epoch'], hist['val_mae'],label = 'Val Error')plt.ylim([0,5])plt.legend()plt.figure()plt.xlabel('Epoch')plt.ylabel('Mean Square Error [$MPG^2$]')plt.plot(hist['epoch'], hist['mse'],label='Train Error')plt.plot(hist['epoch'], hist['val_mse'],label = 'Val Error')plt.ylim([0,20])plt.legend()plt.show()plot_history(history)
33
model = build_model()# patience 值用来检查改进 epochs 的数量
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])plot_history(history)
34
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)print("Testing set Mean Abs Error: {:5.2f} MPG".format(mae))
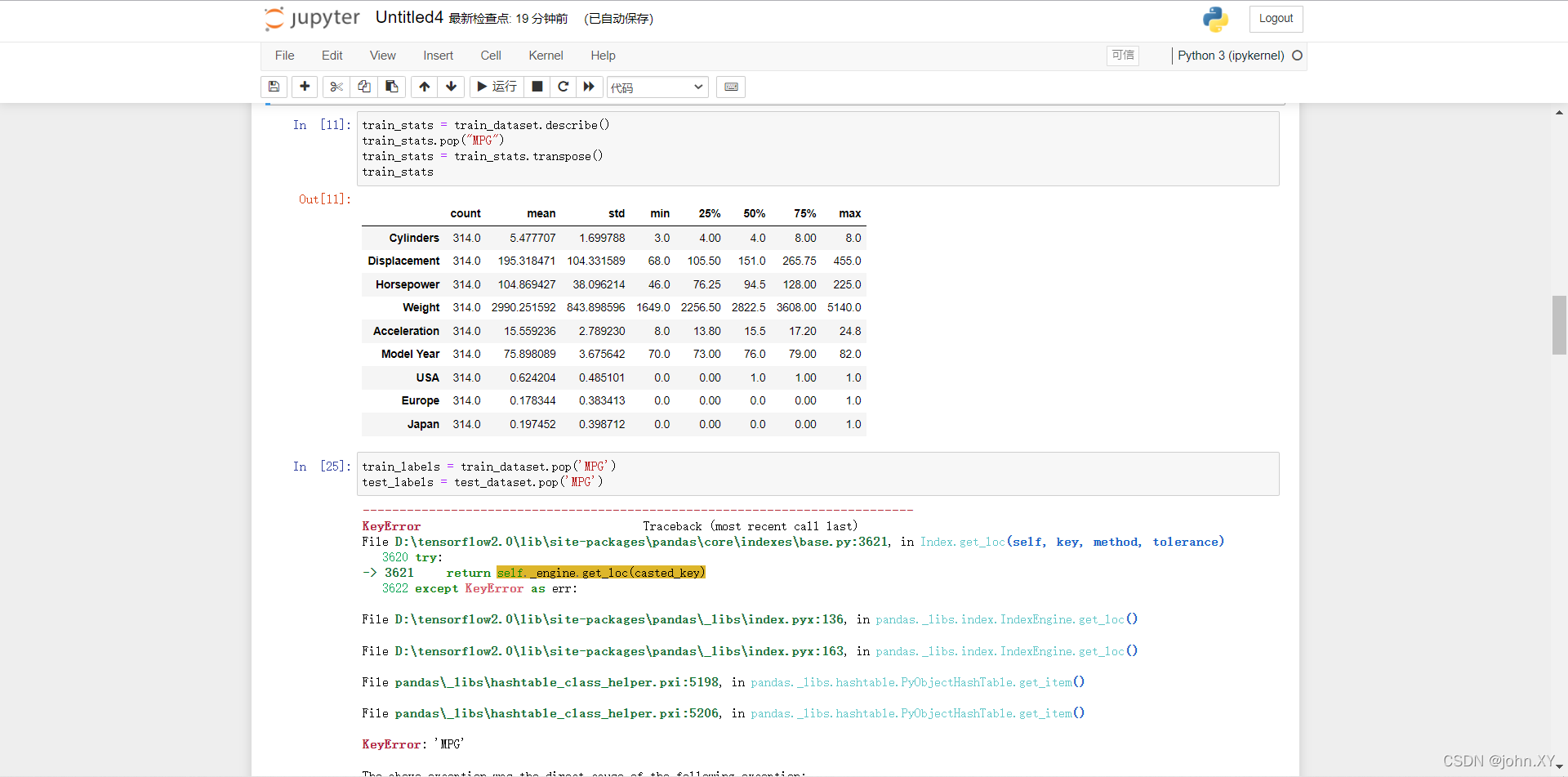
35 做预测,使用测试集中的数据预测 MPG 值。
test_predictions = model.predict(normed_test_data).flatten()plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
36 误差分布。
error = test_predictions - test_labels
plt.hist(error, bins = 25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")
完。如下图(亲测有效)








···················································································································································································
28神经网络-多层感知- demo1
打开命令行窗口: Anaconda Prompt (tensorflow2.0)
进入notebook: jupyter notebook
1
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
2
d = pd.read_csv('C:/Users/Zachary.sang/Desktop/test123.csv') #读取文件
print(d) #打印文件
3
plt.scatter(d.name,d.age) #输出线性关系
4
x = d.iloc[:,1:-1] # :, 代表所有行, 1 代表除去第一列,-1 代表除去最后一列 (name,age,t1,t2)
y = d.iloc[:,-1] # :,-1 取最后一列 (t3)
5
model = tf.keras.Sequential([tf.keras.layers.Dense(10, input_shape=(3,), activation='relu'),tf.keras.layers.Dense(1)])
# 10 隐含层10个单元可以是任意。 (50 , 100 都 行 )
#input_shape=(4,) 输入层的维度为4。( name age t1 t2 )
# activation='relu' 激活函数
#tf.keras.layers.Dense(1) 输出层 维度为1 。( t3 )
6
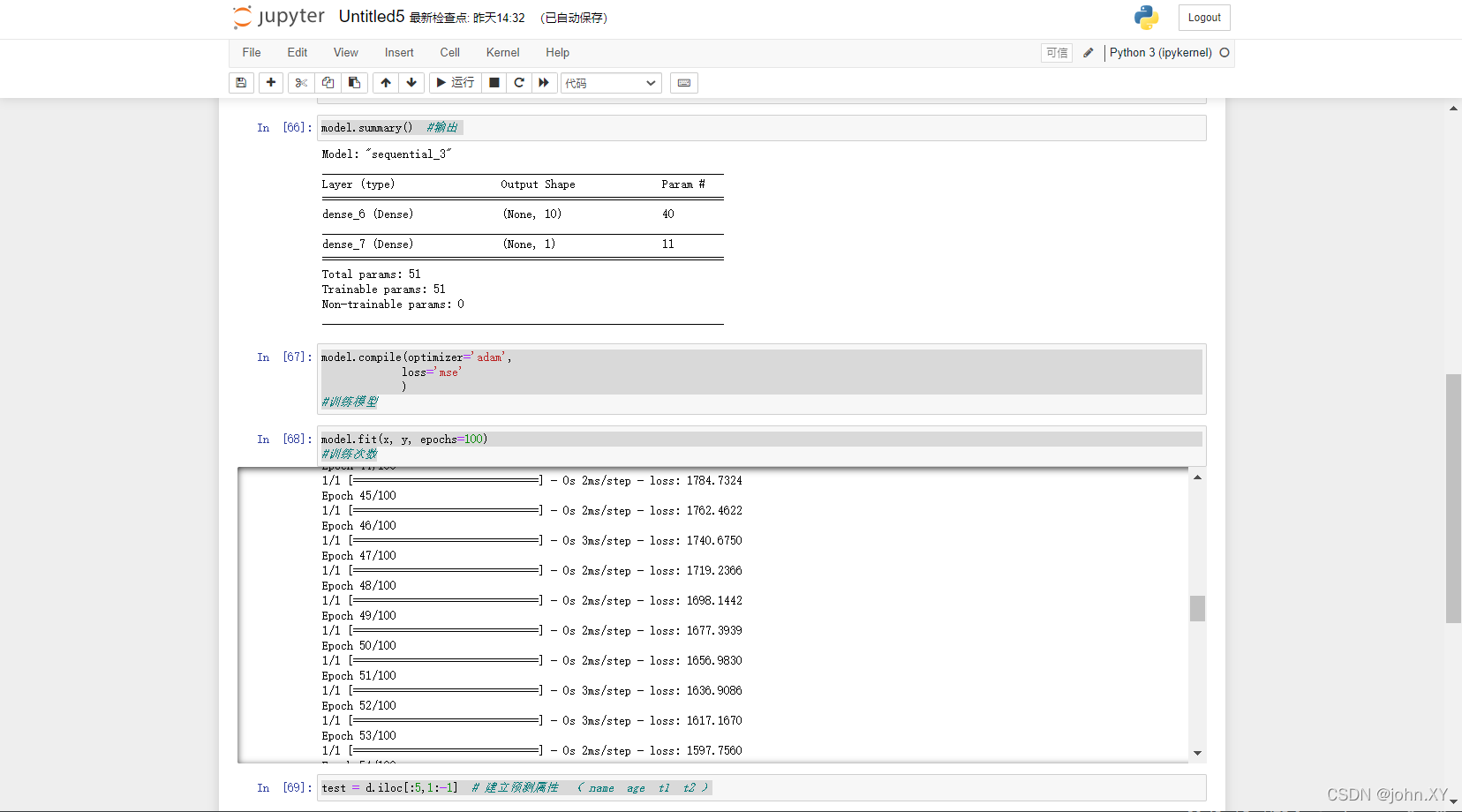
model.summary() #输出
7
model.compile(optimizer='adam',loss='mse')
#训练模型
8
model.fit(x, y, epochs=100)
#训练次数
9
test = d.iloc[:5,1:-1] # 建立预测属性 ( name age t1 t2 )
10
model.predict(test) # 用模型进行预测
11
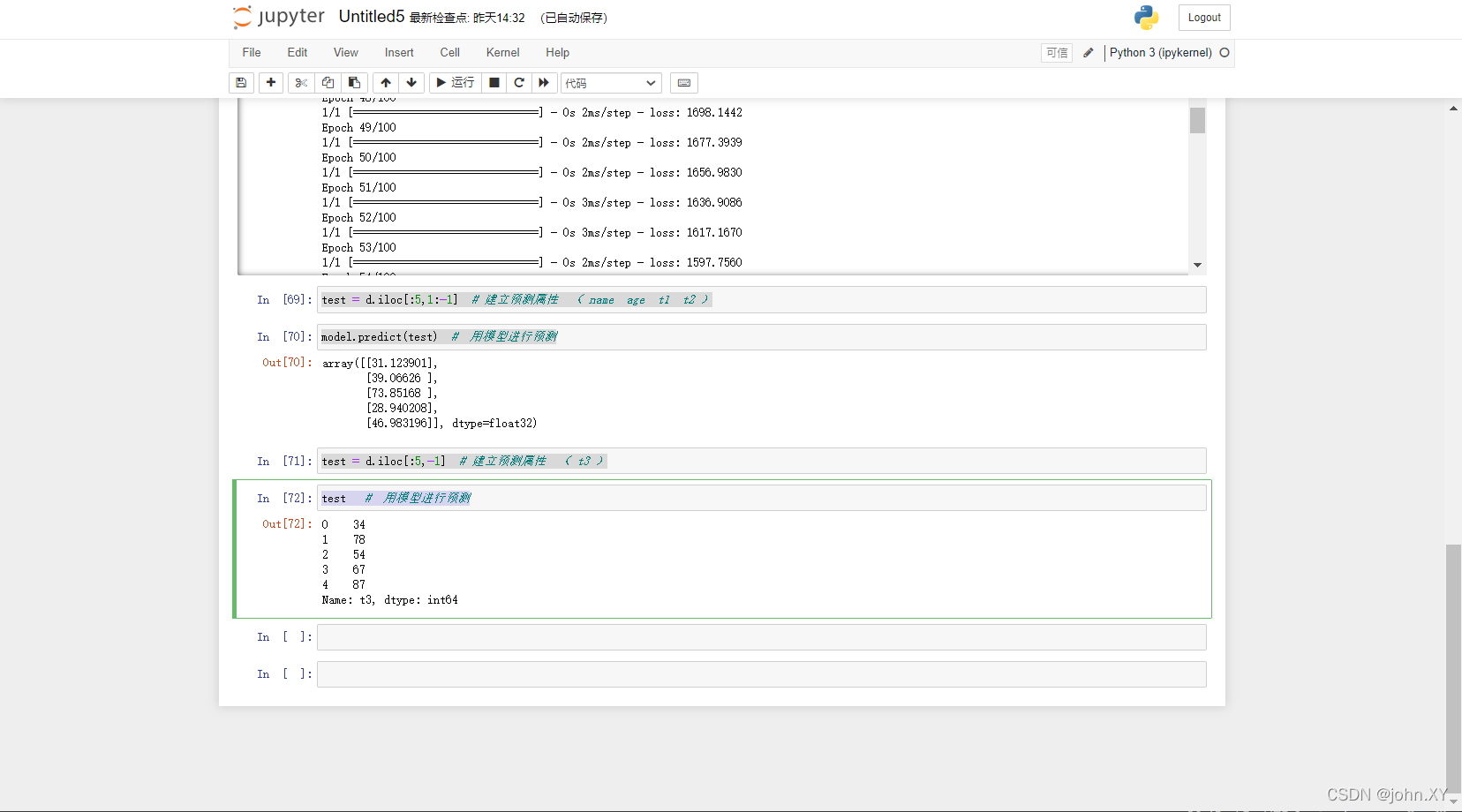
test = d.iloc[:5,-1] # 建立预测属性 ( t3 )
12
test # 用模型进行预测

···················································································································································································
目录
···················································································································································································
相关文章:
·神经网络
目录11神经网络demo112神经网络demo213神经网络demo320tensorflow2.0 安装教程,所有安装工具(神经网络)21神经网络-线性回归- demo122神经网络-线性回归- demo228神经网络-多层感知- demo1目录11神经网络demo1 package com.example.xxx; import java.ut…...

【Java 多线程学习】
多线程学习多线程1. 并行与并发2.进程和线程3. *****多线程的实现方式3.1 继承Thread类的方式进行实现3.2 实现Runnable接口方式进行实现3.3 利用Callable和Future接口方式实现3.4 设置获取线程名字4.获得线程对象5.线程休眠6.线程调度[线程的优先级]7.后台线程/守护线程多线程…...

【计算机考研408】快速排序的趟数问题 + PAT 甲级 7-2 The Second Run of Quicksort
前言 该题还未加入PAT甲级题库中,可以通过购买2022年秋季甲级考试进行答题,纯考研题改编 快速排序 常考的知识点 快速排序是基于分治法快速排序是所有内部排序算法中平均性能最优的排序算法快速排序是一种不稳定的排序算法快速排序算法中,…...
CSS-Grid(网格)布局
前言 之前HTML 页面的布局基本上都是通过 Flexbox 来实现的,能轻松的解决复杂的 Web 布局。 现在又出现了一个构建 HTML 最佳布局体系的新竞争者。就是强大的CSS Grid 布局。 grid和flex区别是什么?适用什么场景? Flexbox 是一维布局系统&am…...

软件测试4
一 form表单标签 1.form表单标签里面就是所有用户填写的表单数据; action“xxx.py”把表单数据提交给哪一个后台程序去处理 method“post” 传递数据时候的方式方法,post代表隐式提交数据、get明文传送数据 2.input标签的type类型 type“text” 普通的输…...

996的压力下,程序员还有时间做副业吗?
996怎么搞副业? 这个问题其实蛮奇怪的:996的压力下,怎么会还想着搞副业呢? 996还想搞副业的原因有哪些? 大家对于996应该都不陌生,总结就是一个字:忙。 996的工作性质就是加班,就…...

每日学术速递3.1
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CV 1.Directed Diffusion: Direct Control of Object Placement through Attention Guidance 标题:定向扩散:通过注意力引导直接控制物体放置 作者:…...
金融行业数据模型
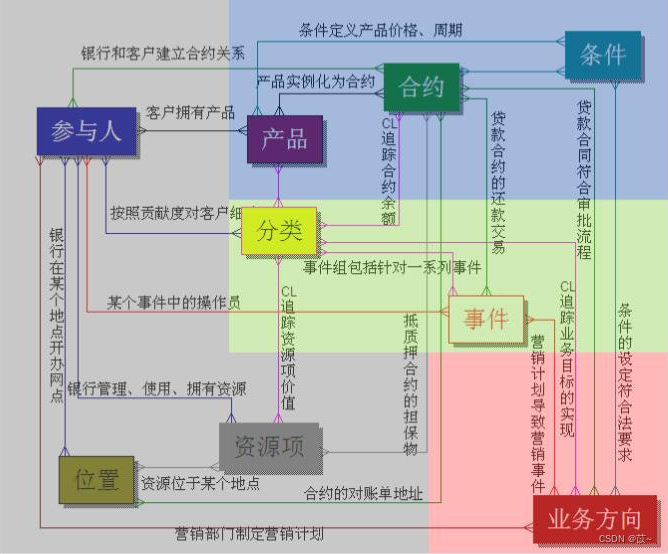
一、Teradata FS-LDM Teradata 公司基于金融业务发布的FS-LDM(Financial Servies Logical Data Model) 十大主题:当事人、产品、协议、事件、资产、财务、机构、地域、营销、渠道。 1、当事人(Party) 银行所服务的任…...

【面试题】2023前端vue面试题及答案
Vue3.0 为什么要用 proxy?在 Vue2 中, 0bject.defineProperty 会改变原始数据,而 Proxy 是创建对象的虚拟表示,并提供 set 、get 和 deleteProperty 等处理器,这些处理器可在访问或修改原始对象上的属性时进行拦截&…...
leetcode128. 最长连续序列)
(哈希查找)leetcode128. 最长连续序列
文章目录一、题目1、题目描述2、基础框架3、原题链接二、解题报告1、思路分析2、时间复杂度3、代码详解三、本题小知识一、题目 1、题目描述 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。…...

js中splice方法和slice方法
splice方法用来操作数组splice(startIndex,deleteNum,item1,....,)此操作会改变原数组。删除数组中元素参数解释:startIndex为起始index索引。deleteNum为从startIndex索引位置开始需要删除的个数。分三种情况:没有传第三个参数的情况下,dele…...

c++ argparse
需求 c程序传参数,像python中argparse一样方便。 方法1 用gflags 参考https://heroacool.blog.csdn.net/?typeblog git clone https://github.com/gflags/gflags cd gflags # 进入项目文件夹 cmake . # 使用 cmake 编译生成 Makefile 文件 make -j 24 # make 编…...

内大892复试真题16年
内大892复试真题16年 1. 输出三个数中较大数2. 求两个数最大公约数与最小公倍数3. 统计字符串中得字符个数4. 输出菱形5. 迭代法求平方根6. 处理字符串(逆序、进制转换)7. 寻找中位数8. 输入十进制输出n进制1. 输出三个数中较大数 问题 代码 #include <iostream>usin…...

面试题 05.02. 二进制数转字符串
二进制数转字符串。给定一个介于0和1之间的实数(如0.72),类型为double,打印它的二进制表达式。如果该数字无法精确地用32位以内的二进制表示,则打印“ERROR”。 示例1: 输入:0.625输出:"0…...

MySQL数据更新操作
文章目录前言添加数据插入数据删除数据修改数据前言 提示:这里可以添加本文要记录的大概内容: 数据更新有两种办法: 1:使用数据可视化工具操作 2:SQL语句 添加数据 前面的添加数据命令一次只能插入一条记录。如果想…...

C# 封装
修正bug之前总是要考虑是什么导致了这个bug,并花些时间了解发生了什么。增加打印输出行的语句可能是一个很有效的调试工具。增加语句来打印诊断信息时,要使用Debug.WriteLine。构造器是CLR第一次创建一个新对象实例时调用的方法。字符串插值会让字符串拼…...
每日学术速递3.2
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CV 1.Interactive Segmentation as Gaussian Process Classification(CVPR 2023) 标题:作为高斯过程分类的交互式分割 作者:Minghao Zhou, Hong Wang, Qian Zha…...

PCBA方案设计——LCD体重电子秤方案
体重秤,一种测量体重的电子秤,与最近很火的体脂秤来比来说,他是的功能能就有点单一了,只能测量体重,而体脂秤可以精准抓取测量体脂体重等一系列的数据,功能更为多样,但相比之下体重秤的功能简单…...

动态规划--背包问题
动态规划背包问题算法思路代码实现背包问题 假设你要去野营。你有一个容量为6磅的背包,需要决定该携带下面的哪些东西。其中每样东西都有相应的价值,价值越大意味着越重要: 水(重3磅,价值10) 书&…...

从0开始学python -45
Python3 正则表达式 -3 正则表达式对象 re.RegexObject re.compile() 返回 RegexObject 对象。 re.MatchObject group() 返回被 RE 匹配的字符串。 start() 返回匹配开始的位置end() 返回匹配结束的位置span() 返回一个元组包含匹配 (开始,结束) 的位置 正则表达式修饰符…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...