SpringDataJPA基础
简介
Spring Data为数据访问层提供了熟悉且一致的Spring编程模版,对于每种持久性存储,业务代码通常需要提供不同存储库提供对不同CURD持久化操作。Spring Data为这些持久性存储以及特定实现提供了通用的接口和模版。其目的是统一简化对不同类型持久性存储的访问。
JPA 全称为
Java Persistence API(2019年重新命名为Jakarta Persistence API),是SUN官方提供一种ORM规范、O:Object R:Rlational M: Mapping规范:
1、ORM映射元素数据:JPA支持
xml和注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此实体对象持久化到数据表中,如@Enity、@Table、@Id与@Column注解等2、JPA的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有事情,开发者从繁琐的JDBC和SQL代码中解脱出来
3、JPQL查询语句:通过面向对象而非面向数据库的查询语句数据,避免程序的SQL语句紧密耦合,如
from User where name = ?
Spring Data特性
1、模版制作:Spring Data提供了对不同数据库对应的模版,例如MongoTemplate、RedisTemplate、JDBCTemplate。模版提供存储特定CRUD操作,Spring Data JPA不提供模版,只是Spring Data JPA本身就是对JDBC API上的抽象。
2、对象/数据存储映射:可以通过xml文件或注解来映射数据之间的关系
代码示例:
@Entity
@Table(name = "User")
public class User {@Idprivate String id;@Column(name = "user_name")private String name;private Date lastLogin;@OneToManyprivate List<Role> roles;
}
3、对Respository支持:对持久层提供了基础的CRUD操作以及分页操作等
Hibernate入门案例
在项目目录下的resource创建一个hibernate.cfg.xml文件
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD//EN""http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration><session-factory><!--配置数据库连接信息--><property name="connection.url">jdbc:mysql://localhost:3306/spring_data_jpa</property><property name="hibernate.connection.username">root</property><property name="hibernate.connection.password">123456</property><property name="connection.driver_class">com.mysql.jdbc.Driver</property><!--选择数据库类型--><property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property><!--打印sql语句--><property name="hibernate.show_sql">true</property><!--格式化sql--><property name="hibernate.format_sql">true</property><!-- 表的生成策略,自动生成,默认不自动生成 --><property name="hbm2ddl.auto">update</property><!-- 映射实体类 --><mapping class="org.example.entity.Customer"/></session-factory>
</hibernate-configuration>
其中映射的实体类如下:
@Entity
@Data
@Table(name = "cst_customer")
public class Customer {/**** @Id 声明主键配置* @GeneratedValue 配置主键生成策略* @@Column 配置属性和字段映射关系* @author Tang* @date 2023/10/8 22:38:25*/@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "cust_id")private Long custId;@Column(name = "cust_name")private String custName;@Column(name = "cust_address")private String custAddress;
}
写入数据:
public class HibernateApp {public static void main(String[] args) {try (Session session = initSessionFactory().openSession()) {Transaction tx = session.beginTransaction();Customer customer = new Customer();customer.setCustName("张三");session.save(customer);tx.commit();} catch (Exception e) {System.out.println(e);}}public static SessionFactory initSessionFactory() {return new MetadataSources(new StandardServiceRegistryBuilder().configure("/hibernate.cfg.xml").build()).buildMetadata().buildSessionFactory();}
}
具体的CRUD操作详细见文档连接 文档
在项目跟目录下的resource创建META-INF目录,并在其中创建persistence.xml文件,其配置如下
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0"><!-- jpa持久化单元 --><persistence-unit name="springJpa" transaction-type="RESOURCE_LOCAL"><!-- jpa实现方式 --><provider>org.hibernate.ejb.HibernatePersistence</provider><!-- 配置需要进行ORM的POJO类 --><class>org.example.entity.Customer</class><properties><property name="javax.persistence.jdbc.user" value="root"/><property name="javax.persistence.jdbc.password" value="123456"/><property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/><property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/spring_data_jpa"/><property name="hibernate.show_sql" value="true"/><property name="hibernate.format_sql" value="true"/><property name="hibernate.hbm2ddl.auto" value="update"/><property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect"/></properties></persistence-unit>
</persistence>配置持久化单元并写入到数据库中
public static void main(String[] args) {EntityManager entityManager = init().createEntityManager();EntityTransaction tx = entityManager.getTransaction();tx.begin();// 持久化操作, 写入到mysql表中Customer customer = new Customer();customer.setCustName("hello jpa");entityManager.persist(customer);tx.commit();}public static EntityManagerFactory init() {// 配置jpa持久化单元名称return Persistence.createEntityManagerFactory("springJpa");
}
使用JPQL语句
JPQL代表Java持久化查询语言。它被用来创建针对实体的查询存储在关系数据库中。 JPQL是基于SQL语法的发展。但它不会直接影响到数据库。
JPQL可以检索使用SELECT子句中的数据,可以使用 UPDATE子句做批量UPDATE和DELETE子句。
使用JPQL语句进行更新
public static void main(String[] args) {EntityManager entityManager = init().createEntityManager();EntityTransaction tx = entityManager.getTransaction();tx.begin();// 这里的Customer是映射的实体类名称,其查询都是使用映射实体类的属性String jpql = "UPDATE Customer set custName=:custName where custId=:id";entityManager.createQuery(jpql).setParameter("custName", "tang").setParameter("id", 3L).executeUpdate();tx.commit();
}
也可以使用
sql语句来进行对数据库的操作,代码变更如下:
String sql = "UPDATE cst_customer set cust_name=:custName where cust_id=:id";
entityManager.createNativeQuery(sql).setParameter("custName", "tang").setParameter("id", 3L).executeUpdate();
其中的
cst_customer是表结构,cust_name和cust_id是表的字段名
JPA对象四种状态
临时状态:刚创建出来,没有与
entityManager发生关系,没有被持久化,不处于entityManager的对象中持久状态:与
entityManager发生关系,已经被持久化,可以把持久化状态当做实实在在的数据库记录删除状态:执行
remove方法,事务提交之前游离状态:游离状态就是提交到数据库后,事务
commit后实体的状态,因为事务已经提交了,此时实体属性你如何改变都不会同步到数据库中。

persist方法可以将实例转换为managed状态,在调用flush()方法或事务提交后,实例将被插入到数据库中
Spring Data JPA入门
Spring Data JPA是Spring提供的一套简化JPA开发的框架,按照约定好的规则进行方法命名来实现dao层接口,就可以在不写接口实现的前提下,实现对数据库的访问和操作。同时提供了很多除了CRUD在外的功能,如分页、排序、复杂查询等功能
引入maven依赖
<dependencies><!-- 统一管理Spring Data子项目的版本 --><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-bom</artifactId><version>2021.1.0</version><type>pom</type></dependency><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-jpa</artifactId><version>2.7.7</version></dependency><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-entitymanager</artifactId><version>5.6.15.Final</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.15</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId><version>5.1.10.RELEASE</version><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.10</version><scope>provided</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency>
</dependencies>
在resource文件夹下创建Spring.xml文件进行对JPA的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:jpa="http://www.springframework.org/schema/data/jpa" xmlns:tx="http://www.springframework.org/schema/tx"xsi:schemaLocation="http://www.springframework.org/schema/beanshttps://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/data/jpahttps://www.springframework.org/schema/data/jpa/spring-jpa.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd"><!-- 整合jpa 配置entityManagerFactory以及对应的事务 --><jpa:repositories base-package="org.example.repositories"entity-manager-factory-ref="entityManagerFactory"transaction-manager-ref="transactionManager"/><!-- 配置EntityManagerFactory的Bean --><bean name="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"><property name="jpaVendorAdapter"><bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"><property name="generateDdl" value="true"/><property name="showSql" value="true"/></bean></property><property name="packagesToScan" value="org.example.entity"/><property name="dataSource" ref="dataSource"/></bean><!-- 配置数据源 --><bean class="com.alibaba.druid.pool.DruidDataSource" name="dataSource"><property name="url" value="jdbc:mysql://localhost:3306/spring_data_jpa"/><property name="driverClassName" value="com.mysql.jdbc.Driver"/><property name="username" value="root"/><property name="password" value="123456"/></bean><!-- 配置说明式事务 --><bean class="org.springframework.orm.jpa.JpaTransactionManager" name="transactionManager"><property name="entityManagerFactory" ref="entityManagerFactory"/></bean><!-- 配置注解式事务 --><tx:annotation-driven transaction-manager="transactionManager"/>
</beans>其中Spring.xml文件的配置可以等同于如下配置类
@Configuration
@EnableJpaRepositories(basePackages = "org.example.repositories")
@EnableTransactionManagement
public class SpringDataJpaConfig {@Beanpublic DataSource dataSource() {DruidDataSource druidDataSource = new DruidDataSource();druidDataSource.setUsername("root");druidDataSource.setPassword("123456");druidDataSource.setDriverClassName("com.mysql.jdbc.Driver");druidDataSource.setUrl("jdbc:mysql://localhost:3306/spring_data_jpa");return druidDataSource;}@Beanpublic LocalContainerEntityManagerFactoryBean entityManagerFactory() {HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();vendorAdapter.setGenerateDdl(true);LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();factory.setJpaVendorAdapter(vendorAdapter);factory.setPackagesToScan("org.example.entity");factory.setDataSource(dataSource());return factory;}@Beanpublic PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {JpaTransactionManager txManager = new JpaTransactionManager();txManager.setEntityManagerFactory(entityManagerFactory);return txManager;}
}Spring data jpa 增删改查
// 使用配置类直接变更为@ContextConfiguration(classes = SpringDataJpaConfig.class)
@ContextConfiguration(locations = "/Spring.xml")
@RunWith(SpringJUnit4ClassRunner.class)
public class SpringDataJPATest {@AutowiredCustomerRepositories customerRepositories;@Testpublic void testQuery() {Optional<Customer> customer = customerRepositories.findById(1L);customer.ifPresent(System.out::println);}@Testpublic void testInsert() {Customer customer = new Customer();customer.setName("hello jpa test");customerRepositories.save(customer);}@Testpublic void testUpdate() {Customer customer = new Customer();customer.setId(3L);customer.setName("hello jpa test update");customerRepositories.save(customer);}@Testpublic void testDelete() {Customer customer = new Customer();customer.setId(3L);customerRepositories.delete(customer);}
}Spring Data Repositories
Spring Data Respositories的抽象目的是为了减少各种持久层存储实现数据访问层所需的样板代码。其中CrudRepository提供了简单的增删改查的操作。PagingAndSortingRepository在增删改查的基础上添加了分页排序的操作。
PagingAndSortingRepository演示代码
@Autowired
CustomerRepositories customerRepositories;
@Test
public void testPaging() {Page<Customer> all = customerRepositories.findAll(PageRequest.of(0, 2));System.out.println(all.getContent());
}
@Test
public void testSort() {// 通过对实体类的id属性进行降序排列Iterable<Customer> sorted = customerRepositories.findAll(Sort.sort(Customer.class).by(Customer::getId).descending());System.out.println(sorted);
}
如果需要多个字段进行排序,代码变更如下
Iterable<Customer> sorted = customerRepositories.findAll(Sort.sort(Customer.class).by(Customer::getId).descending().and(Sort.sort(Customer.class).by(Customer::getName)));
JPQL和SQL
Spring Data JPA提供了多种自定义操作,比如使用JPQL或者原始的SQL、规定的方法名称、Query by Examply、通过Specifications、通过Querydsl方式
使用JPQL进行查询
JPQL语法格式详细见 JPQL语法文档
在Repositories进行改造
public interface CustomerRepositories extends PagingAndSortingRepository<Customer, Long> {@Query("FROM Customer where name=?1")Customer findCustomerByName(String name);
}
也可以通过具名参数来进行JPQL语句的条件查询
public interface CustomerRepositories extends PagingAndSortingRepository<Customer, Long> {@Query("FROM Customer where name=:customerName")Customer findCustomerByName(@Param("customerName") String name);
}
执行增删改操作
在
Spring Data JPA中对增删改都需要加上事务,同时添加@Modifying注解通知Spring Data JPA执行增删改操作
public interface CustomerRepositories extends PagingAndSortingRepository<Customer, Long> {@Transactional@Modifying@Query("UPDATE Customer c set c.name=:custName where c.id=:id")int updateCustomer(@Param("custName") String custName, @Param("id") Long id);
}
其中
c.name和c.id都是实体类的属性名,如果是新增一定只能是在Hibernate下才能支持而且必须是INSERT INTO SELECT的方式来进行插入,其他方法不支持新增方法
使用原生SQL
public interface CustomerRepositories extends PagingAndSortingRepository<Customer, Long> {@Query(value = "SELECT * FROM cst_customer where cust_name=:custName", nativeQuery = true)List<Customer> findCustomerByName(@Param("custName") String name);
}
其中
cst_customer是数据库表名,cust_name是数据库表字段,当使用原生SQL时需要在@Query注解的nativeQuery设置为true
指定方法规则名称
支持查询的主题关键字(前缀)
决定方法的作用、只支持查询和删除的操作
| 关键字 | 描述 |
|---|---|
find...By、read..By、get...By、query...By、search..By、stream..By | 通用查询方法通常返回存储库类型、Collection或Streamable子类型或结果包装类,例如Page,GeoResults或任何其他特定与商店的结果包装类。可以作findBy..、findMyDomainTypeBy...或与其他关键字结合使用 |
exists..By | 存在投影。通常返回boolean结果 |
count..By | 计数投影返回数字结果 |
delete...By、remove...By | 删除查询方法返回无结果void或者删除计数 |
..First<number>...、...Top<number>.. | 将查询结果限制为第一个<number>结果。此关键字可以出现主题的find(和其他关键字)和之间的任何位置By |
...Distinct... | 使用不同查询仅返回唯一结果。查阅特定与商店的问题是否支持该功能。此关键字可以出现在主题find(和其他关键字)和之间任何位置By |
支持查询方法谓词关键字和修饰符
决定查询条件
| 关键词 | 样本 | JPQL片段 |
|---|---|---|
Distinct | findDistinctByLastnameAndFirstname | select distinct .. where x.lastname = ?1 and x.firstname = ?2 |
And | findByLastnameAndFirstname | .. where x.lastname = ?1 and x.firstname = ?2 |
Or | findByLastnameOrFirstname | ..where x.lastname = ?1 and x.firstname = ?2 |
Is、Equals | findByFirstname、findByFirstnameIs、findByFirstnameEquals | ..where x.firstname = ?1 |
Between | findByStartDateBetween | ...where x.startDate between ?1 and ?2 |
LessThan | findByAgeLessThan | ...where x.age < ?1 |
LessThanEqual | findByAgeLessThanEqual | ..where x.age >= ?1 |
GreaterThan | findByAgeGreaterThan | ..where x.age > ?1 |
GreaterThanEqual | findByAgeGreaterThanEqual | ..where x.age >= ?1 |
After | findByStarterDateAfter | ..where x.startDate > ?1 |
Before | findByStartDateBefore | ..where x.startDate < ?1 |
IsNull、Null | findByAge(Is)Null | ..where x.age is null |
IsNotNull、NotNull | findByAge(Is)NotNull | ..where x.age not null |
Like | findByFirstnameLike | ..where x.firstname like ?1 自己指定%位置 |
NotLike | findByFirstnameNotLike | ..where x.firstname not like ?1自己指定%位置 |
StartingWith | findByFirstnameStartingWith | ..where x.firstname like ?2(参数绑定了append%) |
EndingWith | findByFirstnameEndingWith | ..where x.firstname like ?1(参数绑定了prepended%) |
Containing | findByFirstnameContaining | ..where x.firstname like ?1(参数绑定包裹在%) |
OrderBy | findByAgeOrderByLastnameDesc | ..where x.age = ?1 order by x.lastname desc |
Not | findByLastnameNot | ..where x.lastname <> ?1 |
In | findByAgeIn(Collection<Age> ages) | ..where x.age in ?1 |
NotIn | findByAgeNotIn(Collection<Age> ages) | ..where x.age not in ?1 |
True | findByActiveTrue() | ..where x.active = true |
False | findByActiveFalse() | ..where x.active = false |
IgoreCase | findByFirstnameIgoreCase | ..where UPPER(x.firstname) = UPPER(?1) |
详细查阅官方文档官方文档
代码示例
public interface CustomerMethodNameRepositories extends PagingAndSortingRepository<Customer, Long> {List<Customer> findByName(String name);
}
其中的
name是实体类中Customer类中的name属性
删除操作
public interface CustomerMethodNameRepositories extends PagingAndSortingRepository<Customer, Long> {@Transient@Modifyingvoid deleteById(Long id);
}
需要使用
@Transient开启事务以及使用@Modifying告诉Spring Data JPA这是增删改操作
模糊查询
public interface CustomerMethodNameRepositories extends PagingAndSortingRepository<Customer, Long> {List<Customer> findByNameLike(String name);
}
调用方法是需要指定
%,如下
@ContextConfiguration(classes = SpringDataJpaConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class MethodNameTest {@Autowiredprivate CustomerMethodNameRepositories customerMethodNameRepositories;@Testpublic void queryLikeTest() {List<Customer> customers = customerMethodNameRepositories.findByNameLike("%test%");System.out.println(customers);}
}
动态条件查询
Query By Example
只支持查询,不支持嵌套或者分组的属性约束,如
firstname=?0或者firstname=?1 and lastname=?2,只支持字符串start/contains/ends/regex匹配和其他属性类型精确匹配。
详细查询官方文档 使用Ctrl + F 搜索by example
查询所有
public interface QueryByExampleRepositories extends PagingAndSortingRepository<Customer, Long>,QueryByExampleExecutor<Customer> {
}
接口需要继承
QueryByExampleExecutor,同时查询时需要通过Example.of()构建查询条件
@Test
public void queryTest() {// 查询条件,通过Example.of()构建查询条件Customer customer = new Customer();customer.setName("test");Iterable<Customer> all = queryByExampleRepositories.findAll(Example.of(customer));System.out.println(all);
}
构建条件匹配器
@Test
public void queryWhereRegexTest() {Customer customer = new Customer();customer.setName("张三");customer.setAddress("shanghai");// 忽略指定的属性Iterable<Customer> ignore = queryByExampleRepositories.findAll(Example.of(customer, ExampleMatcher .matching().withIgnorePaths("address")));System.out.println(ignore);
}
其中
address是实体类Customer类中的属性
Specifications查询方式
Query By Example的查询方式只支持字符串且无法对查询条件做出>、<和<>的限制,所以需要使用Specifications的查询方式来实现,但Specifications的查询方式不能使用分组、聚合函数。
public interface SpecificationsRepositories extends CrudRepository<Customer, Long>,JpaSpecificationExecutor<Customer> {
}
使用
Specifications的查询方式需要继承JpaSpecificationExecutor接口,如下案例查询address是BEIJIN且id在3,20,18的数据
@Test
public void queryTest() {Iterable<Customer> all = specificationsRepositories.findAll((Specification<Customer>)(root, query, criteriaBuilder) -> criteriaBuilder .and(criteriaBuilder.equal(root.get("id"), "BEIJIN"), criteriaBuilder.in(root.get("address")).value(3L).value(20L).value(18L)));all.forEach(System.out::println);
}
参数说明
(root, query, criteriaBuilder)中的root相当于from Customer可以获取查询的列,criteriaBuilder设置各种查询条件如<、>或者in等操作、query设置各种组合条件如order by、where等。
QueryDSL
QueryDSL是基于ORM框架或者SQL平台上的一个通用查询框架,借助QueryDSL可以在任何支持的ORM框架或者SQL平台上以通用的API方式构建查询。
引入依赖
<dependency><groupId>com.querydsl</groupId><artifactId>querydsl-jpa</artifactId><version>4.4.0</version>
</dependency>
安装插件
<build><plugins><plugin><groupId>com.mysema.maven</groupId><artifactId>apt-maven-plugin</artifactId><version>1.1.3</version><dependencies><dependency><groupId>com.querydsl</groupId><artifactId>querydsl-apt</artifactId><version>4.4.0</version></dependency></dependencies><executions><execution><phase>generate-sources</phase><goals><goal>process</goal></goals><configuration><outputDirectory>target/generated-sources/queris</outputDirectory><processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor><logOnlyOnError>true</logOnlyOnError></configuration></execution></executions></plugin></plugins>
</build>
导入依赖并安装好插件后使用
maven compile一下
将编译生成的QClass进行source


这样子就可以引用编译生成的QClass
查询案例
public interface QueryDSLRepositories extends QuerydslPredicateExecutor<Customer>, CrudRepository<Customer, Long> {
}
注意必须继承
QuerydslPredicateExecutor和CrudRepository或CrudRepository的子类
@ContextConfiguration(classes = SpringDataJpaConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class QueryDSLTest {@Autowiredprivate QueryDSLRepositories queryDSLRepositories;@Testpublic void queryTest() {QCustomer customer = QCustomer.customer;Iterable<Customer> all = queryDSLRepositories.findAll(customer.id.in(1L, 18L, 20L).and(customer.id.gt(5L)).and(customer.address.eq("BEIJIN")));all.forEach(System.out::println);}
}
相当于
sql语句SELECT * FROM customer WHERE id IN(1, 18, 20) AND id > 5 AND address = 'BEIJIN'
自定义列查询或者分组查询
@ContextConfiguration(classes = SpringDataJpaConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class QueryDSLTest {@PersistenceContext // 保证线程安全private EntityManager entityManager;@Testpublic void groupQueryTest() {JPAQueryFactory factory = new JPAQueryFactory(entityManager);QCustomer customer = QCustomer.customer;JPAQuery<Tuple> query = factory.select(customer.id, customer.name).from(customer).where(customer.id.eq(18L)).orderBy(customer.id.desc());List<Tuple> fetch = query.fetch();for (Tuple tuple : fetch) {System.out.println(tuple.get(customer.id));System.out.println(tuple.get(customer.name));}}
}
相当于
SQL语句SELECT id, name FROM customer WHERE id = 18 ORDER BY id DESC
多表关联
一对一
配置关联关系,实体类
Customer配置单向关联
@Data
@Entity
@Table(name = "cst_customer")
public class Customer {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "cust_id")private Long id;@Column(name = "cust_address")private String address;@Column(name = "cust_name")private String name;// 单向关联@OneToOne(cascade = CascadeType.PERSIST)@JoinColumn(name = "account_id")private Account account;
}
注解
@OneToOne的cascade参数说明:
CascadeType.PERSIST
级联持久化(保存)操作:持久保存拥有方实体时,也会持久保存该实体的所有相关数据。这个属性就是造成上面问题的关键。当你保存一天条数据时,所有的关联数据都会进行保存,无论数据库里面有没有,但有时候我们是需要这样的级联操作的。
CascadeType.REMOVE
级联删除操作:删除当前实体时,与它有映射关系的实体也会跟着被删除。
CascadeType.DETACH
级联脱管/游离操作:如果你要删除一个实体,但是它有外键无法删除,你就需要这个级联权限了。它会撤销所有相关的外键关联。
CascadeType.REFRESH
级联刷新操作:假设场景 有一个订单,订单里面关联了许多商品,这个订单可以被很多人操作,那么这个时候A对此订单和关联的商品进行了修改,与此同时,B也进行了相同的操作,但是B先一步比A保存了数据,那么当A保存数据的时候,就需要先刷新订单信息及关联的商品信息后,再将订单及商品保存。
CascadeType.MERGE
级联更新(合并)操作:当Student中的数据改变,会相应地更新Course中的数据。
CascadeType.ALL
清晰明确,拥有以上所有级联操作权限。
fetch参数说明:
fetch参数的作用类似于设计模式中的单例模式,默认为EAGER饿汉模式,可以设置为LAZY懒汉模式,当设置为LAZY的时候只有在使用到对应的实体类的时候就会加载执行查询
示例在
Customer类中对应的属性添加如下代码
@OneToOne(cascade = CascadeType.PERSIST,fetch = FetchType.LAZY)
@JoinColumn(name = "account_id")
private Account account;
查询案例
@Test
@Transactional(readOnly = true)
public void queryTest() {Optional<Customer> byId = repositories.findById(1L);System.out.println(byId.get());
}
需要添加
@Transactional注解开启事务,这是由于通过repositories接口来调用查询方法执行完后,session会立即关闭,一旦session关闭了就不能进行查询了,所以在fetch = FetchType.LAZY的情况下执行完repositories.findById(1L)后会关闭session导致在执行byId.get()调用查询会报错。而事务是在整个方法执行完后关闭session
实体类
Account配置如下
@Data
@Entity
@Table(name = "cst_account")
public class Account {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String username;private String password;
}
测试代码
public interface CustomerRepositories extends PagingAndSortingRepository<Customer, Long> {
}
@ContextConfiguration(classes = SpringDataJpaConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class OneToOneTest {@Autowiredprivate CustomerRepositories repositories;@Testpublic void saveTest() {Account account = new Account();account.setUsername("xushu");Customer customer = new Customer();customer.setName("徐庶");customer.setAccount(account);repositories.save(customer);}
}
如果出现
Field 'id' doesn't have a default value的错误,请检查对应的表的主键Id是否设置为自增
一对多
表设计如下

实体类
Message配置如下:
@Data
@Entity
@Table(name = "cst_message")
public class Message {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String info;public Message(String info) {this.info = info;}public Message() {}
}
必须需要拥有无参构造函数
实体类
Customer配置如下:
@Data
@Entity
@Table(name = "cst_customer")
public class Customer {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "cust_id")private Long id;@Column(name = "cust_address")private String address;@Column(name = "cust_name")private String name;@OneToMany(cascade = CascadeType.ALL)@JoinColumn(name = "customer_id")private List<Message> messages;
}
注意当查询一对多的数据表的时候,
Spring Data JPA默认使用的是懒加载,所以需要使用@Transactional开启事务来解决运行时出现no-session的错误
示例代码
@Test
@Transactional
public void testQuery() {Optional<Customer> byId = repositories.findById(7L);System.out.println(byId.get());
}
或者在实体类中的
Customer中添加@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)注解,解决出现no-session错误,如下:
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinColumn(name = "customer_id")
private List<Message> messages;
一对多删除操作注意事项
如果在
Customer实体类中@OneToMany的cascade = CascadeType.PERSIST这会只删除Customer表中的信息不会删除Message表中的信息
多对一
实例代码:
Message实体类中进行绑定
@Data
@Entity
@Table(name = "cst_message")
public class Message {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String info;@ManyToOne(cascade = CascadeType.PERSIST)@JoinColumn(name = "customer_id")private Customer customer;public Message(String info) {this.info = info;}public Message(Customer customer, String info) {this.customer = customer;this.info = info;}public Message() {}
}
使用注解
@ManyToOne(cascade = CascadeType.PERSIST)以及@JoinColumn(name = "customer_id")
多对多
多对多表的关系如下:

注意:在
cst_customer_role表中不需要任何主键
Customer类配置如下:
@Data
@Entity
@Table(name = "cst_customer")
public class Customer {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "cust_id")private Long id;@Column(name = "cust_address")private String address;@Column(name = "cust_name")private String name;@OneToMany(cascade = CascadeType.PERSIST, fetch = FetchType.LAZY)@JoinColumn(name = "customer_id")private List<Message> messages;public Customer(String name) {this.name = name;}public Customer() {}/*** 单向的多对多* 中间表需要通过@JoinTable来维护外键* name 指定中间表名称* joinColumn 设置本表的外键名称* inverseJoinColumns 关联表的外键名称*/@ManyToMany(cascade = CascadeType.PERSIST)@JoinTable(name = "cst_customer_role",joinColumns = {@JoinColumn(name = "cust_id")},inverseJoinColumns = {@JoinColumn(name = "role_id")})private List<Role> roles;@Overridepublic String toString() {return "Customer{" +"id=" + id +", address='" + address + '\'' +", name='" + name + '\'' +'}';}
}
Role类信息如下:
@Data
@Entity
@Table(name = "cst_role")
public class Role {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "role_id")private Long id;@Column(name = "role_name")private String name;public Role(String name) {this.name = name;}public Role() {}
}
实例代码
/***
* 如果保存的关联对象的数据,希望使用数据库已有的数据,
* 那么就需要从数据库中查询出来。否则会抛出异常
* 同事需要使用@Transactional来解决报错问题,
* 单元测试需要使用@Commit解决事务持久化问题
* @return void
* @author Tang
* @date 2023/12/6 23:25:17
*/
@Test
public void testSave() {Customer customer = new Customer();customer.setName("zhangshang");List<Role> roles = new ArrayList<Role>() {{add(new Role("超级管理员"));add(new Role("商品管理员"));}};customer.setRoles(roles);customerRepository.save(customer);
}
其中如果出现了
Field 'xxx_id' doesn't have a default value,是在数据库方没有设置主键自增所导致的
审计
为了数据库中的数据方便溯源所以经常需要在数据库中添加
创建人、修改人、修改时间、创建时间。由于经常频繁的操作所以Spring data jpa使用审计功能来解决这个问题,操作如下:
由于Spring Data JPA的审计功能需要依赖Spring AOP相关依赖,否则会抛出Could not configure Spring Data JPA auditing-feature because spring-aspects.jar is not on the classpath!异常
<dependency><groupId>org.springframework</groupId><artifactId>spring-aspects</artifactId><version>5.3.28</version>
</dependency>
在对应的实体类添加如下字段
// 创建人@CreatedByprivate String creator;// 修改人@LastModifiedByprivate String modifier;// 创建时间 @Temporal 注解指定时间类型@Temporal(TemporalType.TIMESTAMP)@CreatedDateprivate Date dateCreated = new Date();// 修改时间@Temporal(TemporalType.TIMESTAMP)@LastModifiedDateprivate Date dateModified = new Date();
同时在实体类上添加
@EntityListeners(AuditingEntityListener.class)用于监听审计监听对应的实体类
在配置类上配置如下Bean信息
/***
* 配置审计功能,AuditorAware中泛型的类型与
* 后端获取到的用户类型一直可以是String可以是User对象等
* @return org.springframework.data.domain.AuditorAware<java.lang.String>
* @author Tang
* @date 2023/12/7 23:19:17
*/
@Bean
public AuditorAware<String> auditorAware() {return () -> Optional.of("创建人");
}
使用
@EnableJpaAuditing开启审计功能
相关文章:
SpringDataJPA基础
简介 Spring Data为数据访问层提供了熟悉且一致的Spring编程模版,对于每种持久性存储,业务代码通常需要提供不同存储库提供对不同CURD持久化操作。Spring Data为这些持久性存储以及特定实现提供了通用的接口和模版。其目的是统一简化对不同类型持久性存储…...
程序员如何成为自由的独立开发者?
你是不是那个整天坐在电脑前敲代码的程序员朋友?作为程序员,你是否也曾思考过如何成为一名独立开发者?思考过究竟如何踏上这段充满挑战和创造的旅程? 现在这个数码时代,技术不断演进,越来越多的程序员朋友…...

Ant Design Vue(v1.7.8)a-table组件的插槽功能
本案例中,编写了一个名为stockAdd的vue(v2.5.17)自定义组件,使用a-table组件的插槽功能,创建了一个可编辑的数据表格: 表格用于添加采购的物品,点“新增物品”按键,表格添加一行&…...

笔记69:Conv1d 和 Conv2d 之间的区别
笔记地址:D:\work_file\(4)DeepLearning_Learning\03_个人笔记\4. Transformer 网络变体 a a a a a a a a a a a...
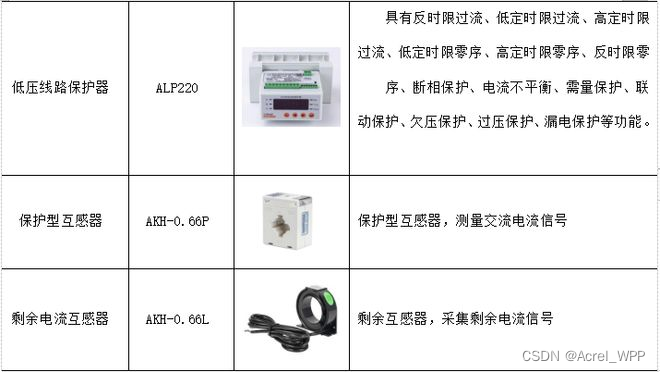
关于马达保护器 的选型 你知道吗
一、智能马达保护器的介绍 在有色冶炼中,根据工艺需求和客户需求,智能电动机保护器的主要应用模式有保护模式、端子控制模式、全通信模式和半通信模式。 4.1保护模式 在保护模式下,智能电动机保护器只利用其自身的保护功能和测量功能&#…...

springboot(ssm高校竞赛管理系统 在线竞赛平台 Java系统
springboot(ssm高校竞赛管理系统 在线竞赛平台 Java系统 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0) 数…...
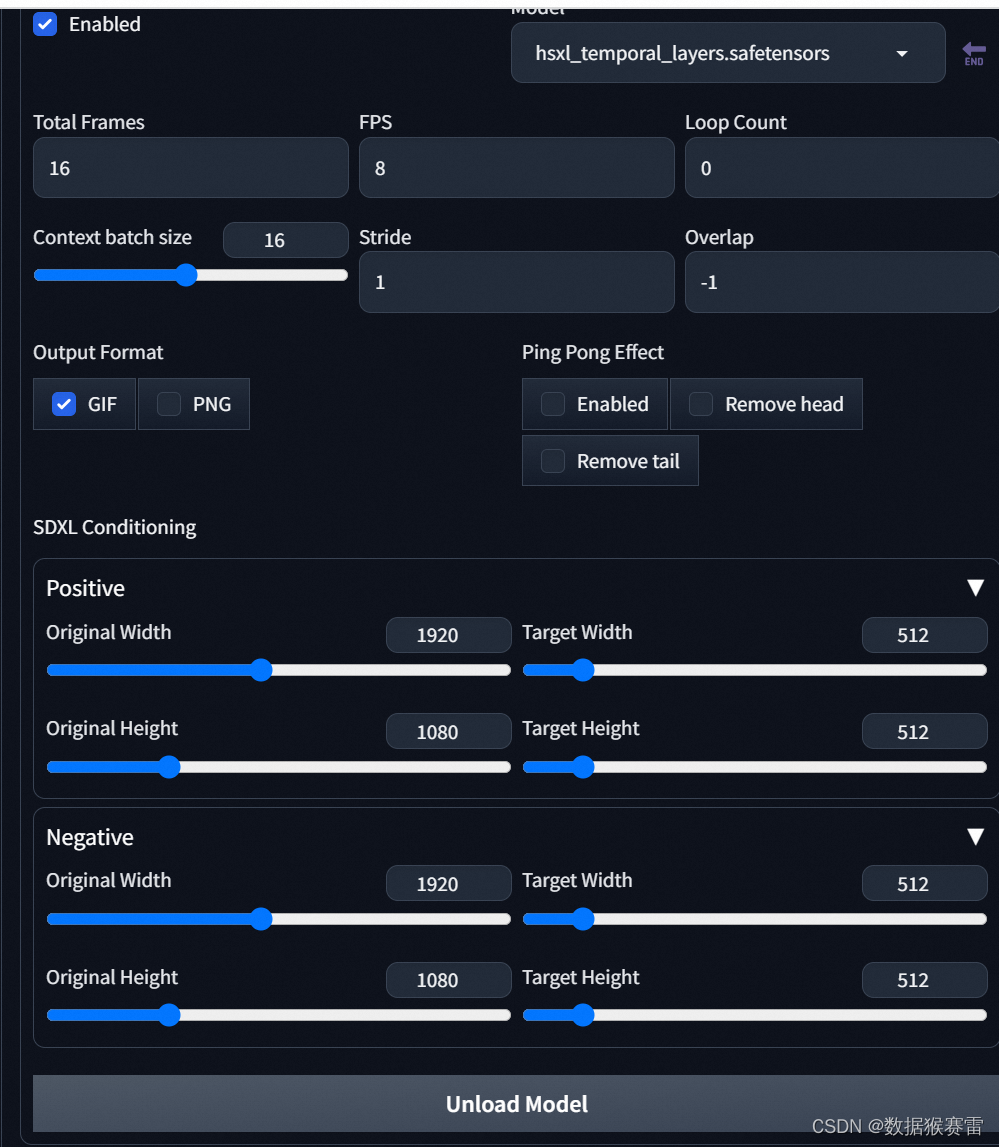
SDXL使用animateDiff和hotshot-xl进行文生视频
截至2023.12.8号,目前市面上有两款适用于SDXL的文生视频开源工具,分别是AnimateDiff和hotshot-xl。 一、工具下载链接 (1)AnimateDiff的webui版本的git链接: GitHub - continue-revolution/sd-webui-animatediff: A…...

【高数:3 无穷小与无穷大】
【高数:3 无穷小与无穷大】 1 无穷小与无穷大2 极限运算法则3 极限存在原则4 趋于无穷小的比较 参考书籍:毕文斌, 毛悦悦. Python漫游数学王国[M]. 北京:清华大学出版社,2022. 1 无穷小与无穷大 无穷大在sympy中用两个字母o表示无…...

C语言预读取技术 __builtin_prefetch
__builtin_prefetch 是一个编译器内置函数,用于在编译时向编译器发出指令,要求在执行期间预取内存数据。它通常用于提高程序的性能,特别是对于那些需要频繁访问内存的情况。 __builtin_prefetch 函数的语法如下:c __builtin_prefe…...
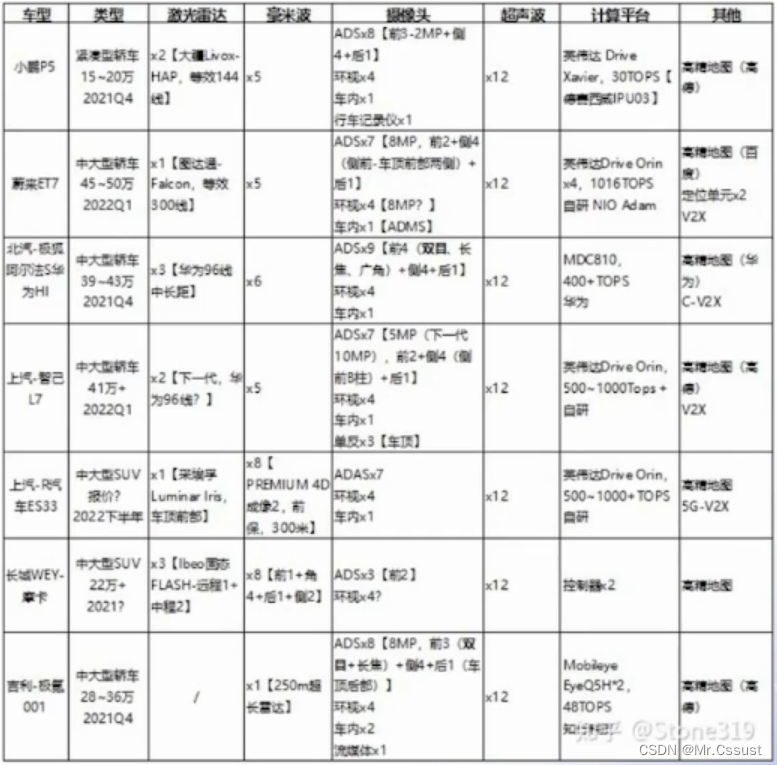
自动驾驶学习笔记(十三)——感知基础
#Apollo开发者# 学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往: 《自动驾驶新人之旅》免费课程—> 传送门 《Apollo Beta宣讲和线下沙龙》免费报名—>传送门 文章目录 前言 传感器 测距原理 坐标系 标定 同…...
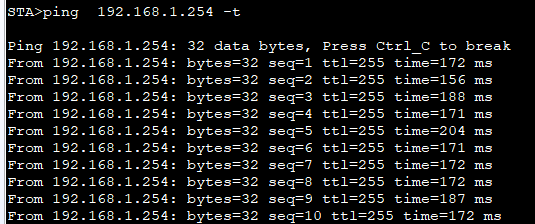
WLAN配置实验
本文记录了WLAN配置实践的过程,该操作在华为HCIA中属于相对较复杂的实验,记录过程备忘。这里不就WLAN原理解释,仅进行配置实践,可以作为学习原理时候的参考。本文使用华为ENSP进行仿真。实验拓扑图如下: 1.WLAN工作流程…...

java_web接收前端传的excel文件读取数据
#本次做一个将患者数据导入到某个模块的功能,前期集成的代码时不时出现异常,本次进行修改记录 //controller层/*** 导入患者数据*/RejectReplayRequestPostMapping("/importData")public Result<?> importData(HttpServletRequest req…...

在Vue开发中v-if指令和v-show指令的使用介绍和区别及使用场景
一、条件渲染 v-if v-if 指令用于条件性地渲染一块内容。这块内容只会在指令的表达式返回真值时才被渲染。 <h1 v-if"awesome">Vue is awesome!</h1>v-else 你也可以使用 v-else 为 v-if 添加一个“else 区块”。 <h1 v-if"awesome"&g…...

Power Query是啥
Power Query是一种用于数据获取、转换和整理的功能强大的工具,它是Microsoft Excel和Power BI中的一个组件。Power Query可以帮助用户从各种数据源中获取数据,并进行数据清洗、转换和整理,以便进一步分析和可视化。 使用Power Query…...

在k8s中部署nfs-client-provisioner
1、部署过程 1.1、环境依赖 在部署nfs-client-provisioner之前,需要先部署nfs服务。 因为,nfs-client-provisioner创建的pv都是要在nfs服务器中搭建的。 本示例中的nfs server的地址如下: [rootnode1 /]# showmount -e Export list for …...
23.12.10日总结
周总结 这周三的晚自习,学姐讲了一下git的合作开发,还有懒加载,防抖,节流 答辩的时候问了几个问题: 为什么在js中0.10.2!0.3? 在js中进行属性运算时,会出现0.10.20.300000000000000004js遵循IEEE754标…...
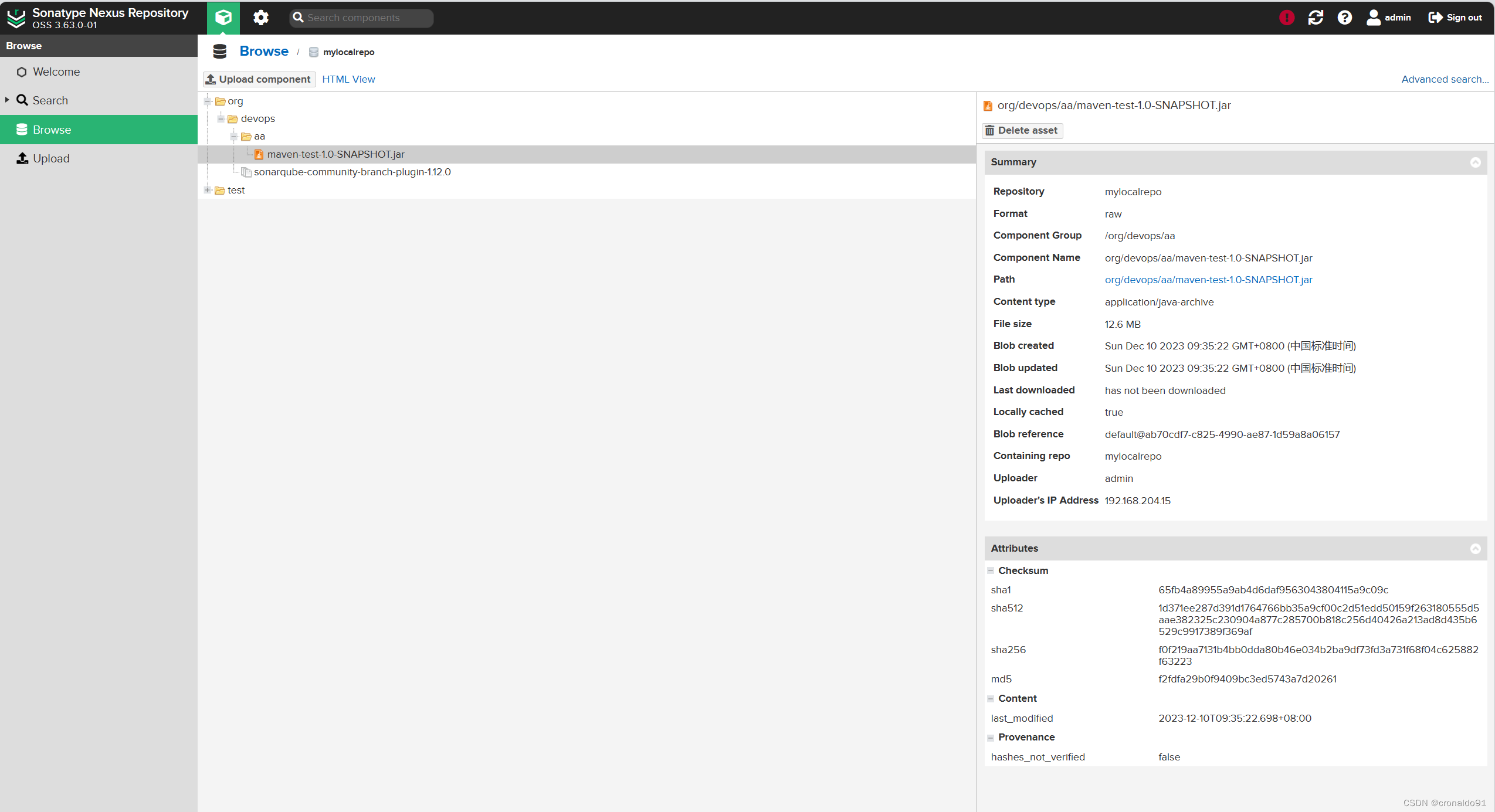
持续集成交付CICD:通过API方式上传Nexus制品
目录 一、实验 1.通过API方式上传Nexus制品 二、问题 1.如何通过API方式上传PNG图片 2.如何通过API方式上传tar.gz 与 ZIP文件 3.如何通过API方式上传Jar file文件 4.如何通过API方式上传制品(maven类型的制品)文件 5.如何下载制品 一、实验 1.通…...

Hadoop学习笔记(HDP)-Part.14 安装YARN+MR
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...
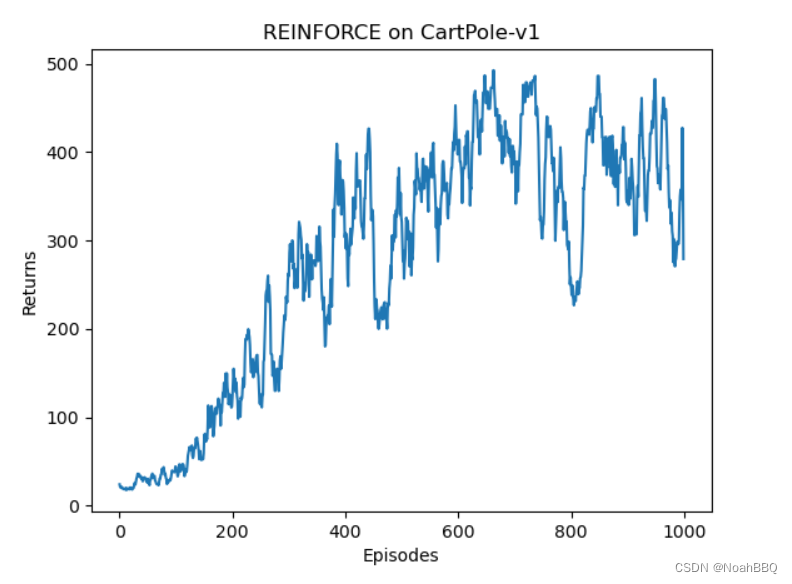
reinforce 跑 CartPole-v1
gym版本是0.26.1 CartPole-v1的详细信息,点链接里看就行了。 修改了下动手深度强化学习对应的代码。 然后这里 J ( θ ) J(\theta) J(θ)梯度上升更新的公式是用的不严谨的,这个和王树森书里讲的严谨公式有点区别。 代码 import gym import torch from …...
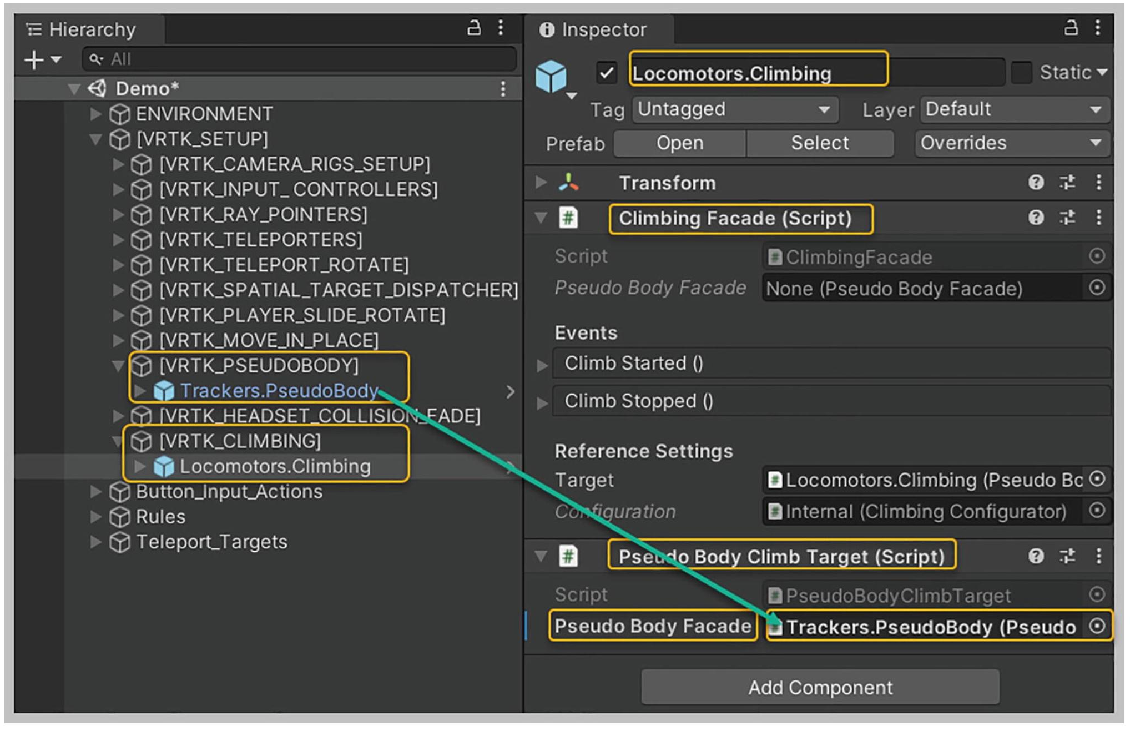
【VRTK】【VR开发】【Unity】13-攀爬
课程配套学习资源下载 https://download.csdn.net/download/weixin_41697242/88485426?spm=1001.2014.3001.5503 【概述】 VRTK提供两个预制件实现攀爬 Climbing Controller,用于控制Player的物理义体Climbable Interactable,用于设置可攀爬对象【设置Climbing Controller…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...