【数据结构(六)】排序算法介绍和算法的复杂度计算(1)
文章目录
- 1. 排序算法的介绍
- 1.1. 排序的分类
- 2. 算法的时间复杂度
- 2.1. 度量一个程序(算法)执行时间的两种方法
- 2.2. 时间频度
- 2.2.1. 忽略常数项
- 2.2.2. 忽略低次项
- 2.2.2. 忽略系数
- 2.3. 时间复杂度
- 2.4. 常见的时间复杂度
- 2.5. 平均时间复杂度和最坏时间复杂度
- 3. 算法的空间复杂度
1. 排序算法的介绍
排序也称排序算法(Sort Algorithm),排序是将一组数据,依指定的顺序进行排列的过程。
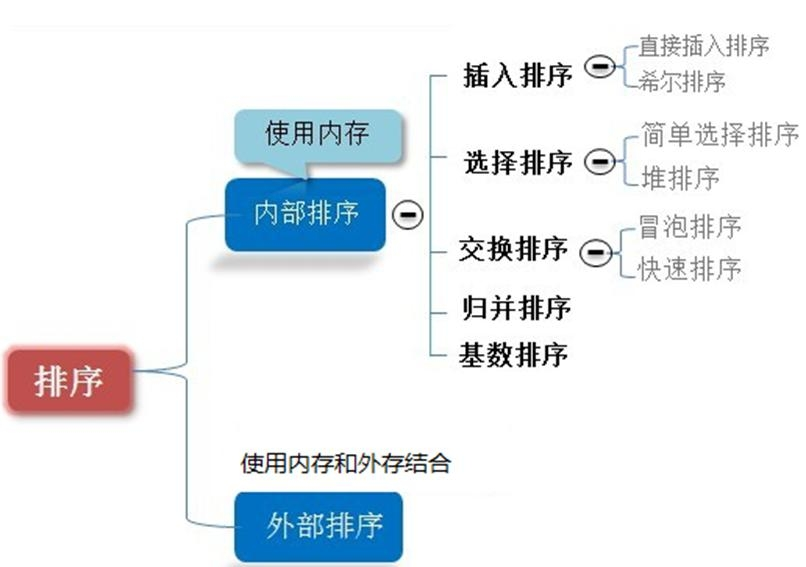
1.1. 排序的分类
- 内部排序:
指将需要处理的所有数据都加载到**内部存储器(内存)**中进行排序。 - 外部排序法:
数据量过大,无法全部加载到内存中,需要借助**外部存储(文件等)**进行排序。
常见的排序算法分类(见下图):
2. 算法的时间复杂度
2.1. 度量一个程序(算法)执行时间的两种方法
-
事后统计的方法
这种方法可行, 但是有两个问题:
一是要想对设计的算法的运行性能进行评测,需要实际运行该程序;
二是所得时间的统计量依赖于计算机的硬件、软件等环境因素, 这种方式,要在同一台计算机的相同状态下运行,才能比较那个算法速度更快。 -
事前估算的方法
通过分析某个算法的时间复杂度来判断哪个算法更优。
2.2. 时间频度
基本介绍:
时间频度:一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为 T ( n ) T(n) T(n)。
举例说明-基本案例
比如计算 1-100 所有数字之和, 可设计两种算法:

2.2.1. 忽略常数项
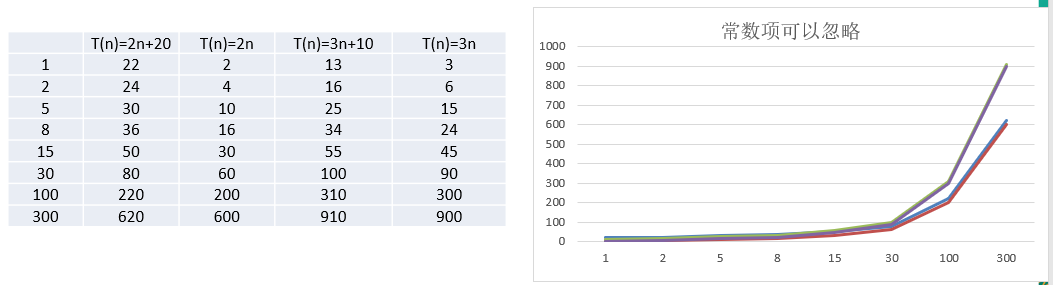
结论:
① 2 n + 20 2n+20 2n+20 和 2 n 2n 2n 随着 n n n 变大,执行曲线无限接近, 20 20 20 可以忽略
② 3 n + 10 3n+10 3n+10 和 3 n 3n 3n 随着 n n n 变大,执行曲线无限接近, 10 10 10 可以忽略
2.2.2. 忽略低次项
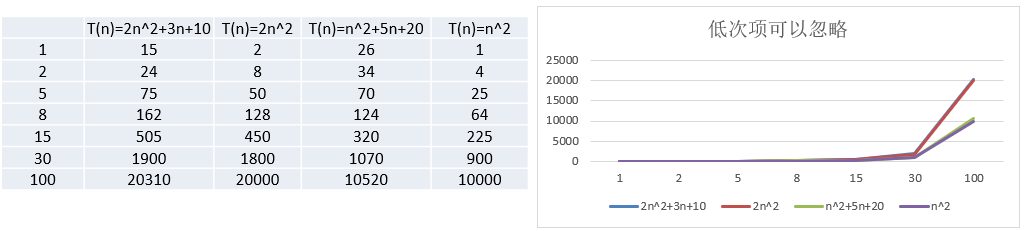
结论:
① 2 n 2 + 3 n + 10 2n^2+3n+10 2n2+3n+10 和 2 n 2 2n^2 2n2 ,随着 n n n 变大, 执行曲线无限接近, 可以忽略 3 n + 10 3n+10 3n+10
② n 2 + 5 n + 20 n^2+5n+20 n2+5n+20 和 n 2 n^2 n2 ,随着 n n n 变大,执行曲线无限接近, 可以忽略 5 n + 20 5n+20 5n+20
2.2.2. 忽略系数
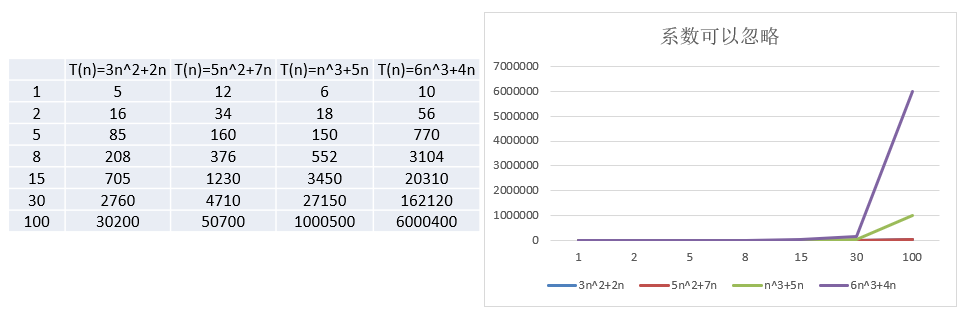
结论:
① 随着 n n n 值变大, 5 n 2 + 7 n 5n^2+7n 5n2+7n 和 3 n 2 + 2 n 3n^2 + 2n 3n2+2n ,执行曲线重合, 说明 这种情况下, 5 5 5 和 3 3 3 可以忽略。
② 而 n 3 + 5 n n^3+5n n3+5n 和 6 n 3 + 4 n 6n^3+4n 6n3+4n ,执行曲线分离,说明多少次方是关键
2.3. 时间复杂度
一般情况下,算法中的基本操作语句的重复执行次数是问题规模 n n n 的某个函数,用 T ( n ) T(n) T(n)表示,若有某个辅助函数 f ( n ) f(n) f(n),使得当 n n n 趋近于无穷大时, T ( n ) f ( n ) \frac {T(n)}{f(n)} f(n)T(n) 的极限值为不等于零的常数,则称 f ( n ) f(n) f(n)是 T ( n ) T(n) T(n)的同数量级函数。记作 T ( n ) = O ( f ( n ) ) \pmb{T(n)=O( f(n) )} T(n)=O(f(n)),称 O ( f ( n ) ) O( f(n) ) O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
T ( n ) T(n) T(n) 不同,但时间复杂度可能相同。 如: T ( n ) = n 2 + 7 n + 6 T(n)=n^2+7n+6 T(n)=n2+7n+6 与 T ( n ) = 3 n 2 + 2 n + 2 T(n)=3n^2+2n+2 T(n)=3n2+2n+2 它们的 T ( n ) T(n) T(n) 不同,但时间复杂度相同,都为 O ( n 2 ) \pmb{O(n²)} O(n2)。
计算时间复杂度的方法:
(以 T ( n ) = n 2 + 7 n + 6 T(n)=n^2+7n+6 T(n)=n2+7n+6 为例)
①用常数 1 1 1 代替运行时间中的所有加法常数。
T ( n ) = n 2 + 7 n + 6 T(n)=n^2+7n+6 T(n)=n2+7n+6
-->T ( n ) = n 2 + 7 n + 1 T(n)=n^2+7n+1 T(n)=n2+7n+1
②修改后的运行次数函数中,只保留最高阶项。
T ( n ) = n 2 + 7 n + 1 T(n)=n^2+7n+1 T(n)=n2+7n+1
-->T ( n ) = n 2 T(n) = n^2 T(n)=n2
③去除最高阶项的系数。
T ( n ) = n 2 T(n) = n^2 T(n)=n2
-->T ( n ) = n 2 T(n) = n^2 T(n)=n2-->O ( n 2 ) O(n^2) O(n2)
2.4. 常见的时间复杂度
- 常数阶 O ( 1 ) O(1) O(1)
- 对数阶 O ( l o g 2 n ) O(log_2n) O(log2n)(其中, l o g log log以2为底,也可以是以3、4、5……为底)
- 线性阶 O ( n ) O(n) O(n)
- 线性对数阶 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)(其中, l o g log log以2为底,也可以是以3、4、5……为底)
- 平方阶 O ( n 2 ) O(n^2) O(n2)
- 立方阶 O ( n 3 ) O(n^3) O(n3)
- k 次方阶 O ( n k ) O(n^k) O(nk)
- 指数阶 O ( 2 n ) O(2^n) O(2n)
常见的时间复杂度对应的图:
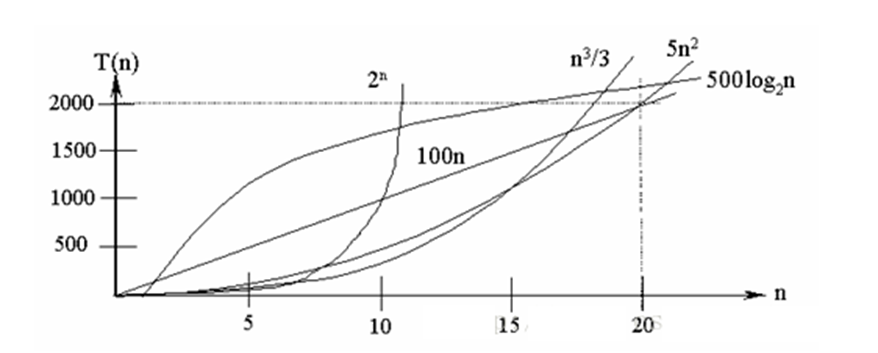
说明:
- 常见的算法时间复杂度由小到大依次为: O ( 1 ) Ο(1) O(1)< O ( l o g 2 n ) Ο(log_2n) O(log2n)< O ( n ) Ο(n) O(n)< O ( n l o g 2 n Ο(nlog_2n O(nlog2n)< O ( n 2 ) Ο(n^2) O(n2)< O ( n 3 ) Ο(n^3) O(n3)< O ( n k ) Ο(n^k) O(nk) < O ( 2 n ) Ο(2^n) O(2n) ,随着问题规模 n 的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
- 从图中可见,我们应该尽可能避免使用指数阶的算法。
① 常数阶 O ( 1 ) O(1) O(1)
无论代码执行了多少行,只要是没有循环等复杂结构,那这个代码的时间复杂度就都是 O ( 1 ) O(1) O(1)
int i = 1;
int j =2;
++i;
j++;
int m = i + j;
上述代码在执行的时候,它消耗的时候并不随着某个变量的增长而增长,那么无论这类代码有多长,即使有几万几十万行,都可以用O(1)来表示它的时间复杂度。
② 对数阶 O ( l o g 2 n ) O(log_2n) O(log2n)
int i =1;
while(i < n){i= i * 2;
}
说明:
在while循环里面,每次都将 i i i 乘以 2 2 2,乘完之后, i i i 距离 n n n 就越来越近了。假设循环 x x x 次之后, i i i 就大于 n n n 了,此时这个循环就退出了,也就是说 2 2 2 的 x x x 次方等于 n n n,那么 x = l o g 2 n x=log_2n x=log2n也就是说当循环 l o g 2 n log_2n log2n 次以后,这个代码就结束了。因此这个代码的时间复杂度为: O ( l o g 2 n ) O(log_2n) O(log2n) 。
O ( l o g 2 n ) O(log_2n) O(log2n) 中的2是根据代码变化的,若 i = i ∗ 3 i = i * 3 i=i∗3 ,则是 O ( l o g 3 n ) O(log_3n) O(log3n)。
如果 N = a x ( a > 0 , a ≠ 1 ) N= a^x(a > 0,a ≠1) N=ax(a>0,a=1),即 a a a 的 x x x 次方等于 N ( a > 0 , a ≠ 1 ) N(a>0,a≠1) N(a>0,a=1),那么数 x x x 叫做以 a a a 为底 N N N 的对数 ( l o g a r i t h m ) (logarithm) (logarithm),记作 x = l o g a N x = log_aN x=logaN 。其中, a a a 叫做对数的底数, N N N 叫做真数, x x x 叫做 “以 a a a 为底 N N N 的对数” 。
③ 线性阶 O ( n ) O(n) O(n)
for(i = 1; i <= n; ++i){j = i;j++;
}
说明:
这段代码,for循环 里面的代码会执行 n n n 遍,因此它消耗的时间是随着 n n n 的变化而变化的,因此这类代码都可以用 O ( n ) O(n) O(n) 来表示它的时间复杂度。 T ( n ) = n + 1 T(n)=n+1 T(n)=n+1 --> O ( n ) O(n) O(n)
④ 线性对数阶 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)
for(m = 1; m < n; m++){i = 1;while(i < n){i = i * 2;}
}
说明:
线性对数阶 O ( n l o g 2 N ) O(nlog_2N) O(nlog2N) 其实非常容易理解,将时间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n) 的代码循环 N N N 遍的话,那么它的时间复杂度就是 n ∗ O ( l o g 2 N ) n * O(log_2N) n∗O(log2N),也就是了 O ( n l o g 2 N ) O(nlog_2N) O(nlog2N)
⑤ 平方阶 O ( n 2 ) O(n^2) O(n2)
for(x = 1; x <= n; x++){for(i = 1; i <= n; i++){j = i;j++;}
}
说明:
平方阶 O ( n 2 ) O(n²) O(n2) 就更容易理解了,如果把 O ( n ) O(n) O(n) 的代码再嵌套循环一遍,它的时间复杂度就是 O ( n 2 ) O(n²) O(n2),这段代码其实就是嵌套了2层 n n n 循环,它的时间复杂度就是 O ( n ∗ n ) O(n*n) O(n∗n),即 O ( n 2 ) O(n²) O(n2) 如果将其中一层循环的 n n n 改成 m m m ,那它的时间复杂度就变成了 O ( m ∗ n ) O(m*n) O(m∗n)
⑥ 立方阶 O ( n 3 ) O(n^3) O(n3) 和 ⑦ k 次方阶 O ( n k ) O(n^k) O(nk)
说明: 参考上面的 O ( n 2 ) O(n²) O(n2) 去理解就好了, O ( n 3 ) O(n³) O(n3) 相当于3层 n n n 循环,其它的类似。
2.5. 平均时间复杂度和最坏时间复杂度
平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,该算法的运行时间。
最坏情况下的时间复杂度称最坏时间复杂度。一般讨论的时间复杂度均是最坏情况下的时间复杂度。这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的界限,这就保证了算法的运行时间不会比最坏情况更长。
平均时间复杂度和最坏时间复杂度是否一致,和算法有关(如下图所示)。
| 排序法 | 平均时间 | 最差情况 | 稳定度 | 额外空间 | 备注 |
|---|---|---|---|---|---|
| 冒泡 | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | 稳定 | O ( 1 ) O(1) O(1) | n n n小的情况较好 |
| 交换 | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | 不稳定 | O ( 1 ) O(1) O(1) | n n n小的情况较好 |
| 选择 | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | 不稳定 | O ( 1 ) O(1) O(1) | n n n小的情况较好 |
| 插入 | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | 稳定 | O ( 1 ) O(1) O(1) | 大部分已排序时较好 |
| 基数 | O ( l o g R B ) O(log_RB) O(logRB) | O ( l o g R B ) O(log_RB) O(logRB) | 稳定 | O ( n ) O(n) O(n) | B是真数(0~9) R是基数(个十百) |
| Shell | O ( n l o g n ) O(nlogn) O(nlogn) | O ( n s ) , 1 < s < 2 O(n^s) ,1<s<2 O(ns),1<s<2 | 不稳定 | O ( 1 ) O(1) O(1) | s是所选分组 |
| 快速 | O ( n l o g n ) O(nlogn) O(nlogn) | O ( n 2 ) O(n^2) O(n2) | 不稳定 | O ( n l o g n ) O(nlogn) O(nlogn) | n n n大的情况较好 |
| 归并 | O ( n l o g n ) O(nlogn) O(nlogn) | O ( n l o g n ) O(nlogn) O(nlogn) | 稳定 | O ( n ) O(n) O(n) | n n n大的情况较好 |
| 堆 | O ( n l o g n ) O(nlogn) O(nlogn) | O ( n l o g n ) O(nlogn) O(nlogn) | 不稳定 | O ( 1 ) O(1) O(1) | n n n大的情况较好 |
3. 算法的空间复杂度
类似于时间复杂度的讨论,一个算法的空间复杂度(Space Complexity)定义为该算法所耗费的存储空间,它也是问题规模 n n n 的函数。
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度。有的算法需要占用的临时工作单元数与解决问题的规模 n n n 有关,它随着 n n n 的增大而增大,当 n n n 较大时,将占用较多的存储单元,例如快速排序、归并排序、 基数排序就属于这种情况。
在做算法分析时,主要讨论的是时间复杂度。从用户使用体验上看,更看重的程序执行的速度。一些缓存产品(redis, memcache)和算法(基数排序)本质就是用空间换时间。
相关文章:
【数据结构(六)】排序算法介绍和算法的复杂度计算(1)
文章目录 1. 排序算法的介绍1.1. 排序的分类 2. 算法的时间复杂度2.1. 度量一个程序(算法)执行时间的两种方法2.2. 时间频度2.2.1. 忽略常数项2.2.2. 忽略低次项2.2.2. 忽略系数 2.3. 时间复杂度2.4. 常见的时间复杂度2.5. 平均时间复杂度和最坏时间复杂度 3. 算法的空间复杂度…...

带有 RaspiCam 的 Raspberry Pi 监控和延时摄影摄像机
一、说明 一段时间以来,我一直想构建一个运动激活且具有延时功能的树莓派相机,但从未真正找到我喜欢的案例。我在thingiverse上找到了这个适合树莓派和相机的好案例。它是为特定的鱼眼相机设计的,但从模型来看,我拥有的廉价中国鱼…...
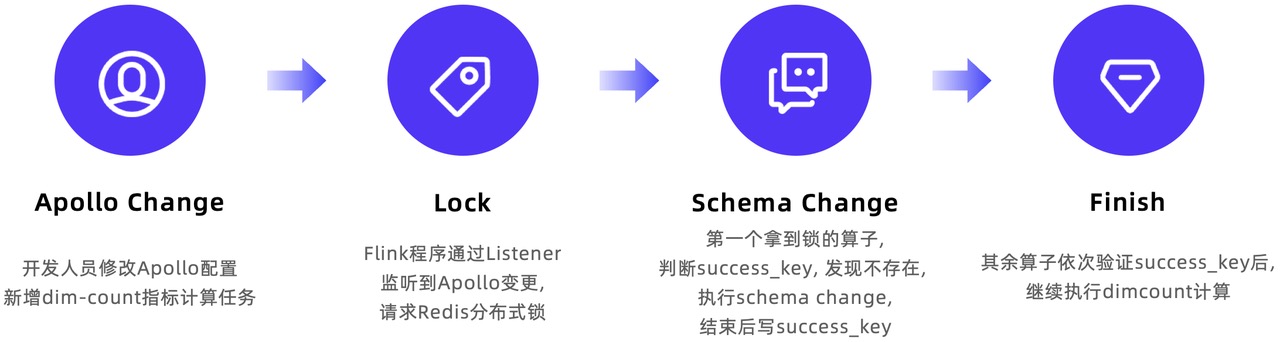
Apache Doris 在某工商信息商业查询平台的湖仓一体建设实践
作者|某工商信息商业查询平台 高级数据研发工程师 李昂 信息服务行业可以提供多样化、便捷、高效、安全的信息化服务,为个人及商业决策提供了重要支撑与参考。对于行业相关企业来说,数据收集、加工、分析能力的重要性不言而喻。以某工商信息…...

【尘缘送书第六期】2023年度学习:AIGC、AGI、GhatGPT、人工智能大模型实现必读书单
【文末送书】今天推荐几本AIGC、AGI、GhatGPT、人工智能大模型领域优质书籍。 目录 前言1 《ChatGPT 驱动软件开发》2 《ChatGPT原理与实战》3 《神经网络与深度学习》4 《AIGC重塑教育》5 《通用人工智能》6 文末送书 前言 2023年是人工智能大语言模型大爆发的一年࿰…...
我的 CSDN 三周年创作纪念日:2020-12-12
本人大叔一枚,自1992年接触电脑,持续了30年的业余电脑发烧爱好者,2022年CSDN博客之星Top58,阿里云社区“乘风者计划”专家博主。自某不知名财校毕业后进入国有大行工作至今,先后任职于某分行信息科技部、电子银行部、金…...

什么是css初始化
什么是css初始化 CSS初始化是指重设浏览器的样式。 因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异。 每次新开发网站或新网页时候通过初始化CSS样式的属性,为我们将用…...

谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!
文章目录 谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!前言重磅!Mixtral MoE 8x7B!!!Mixtral是啥模型介绍模型结构长啥样?表现如何?可…...

Linux升级nginx版本
处于漏洞修复目的服务器所用nginx是1.16.0版本扫出来存在安全隐患,需要我们升级到1.17.7以上。 一般nginx默认在 /usr/local/ 目录,这里我的nginx是自定义的路径安装在 /app/weblogic/nginx 。 1.查看生产环境nginx版本 cd /app/weblogic/nginx/sbin/…...
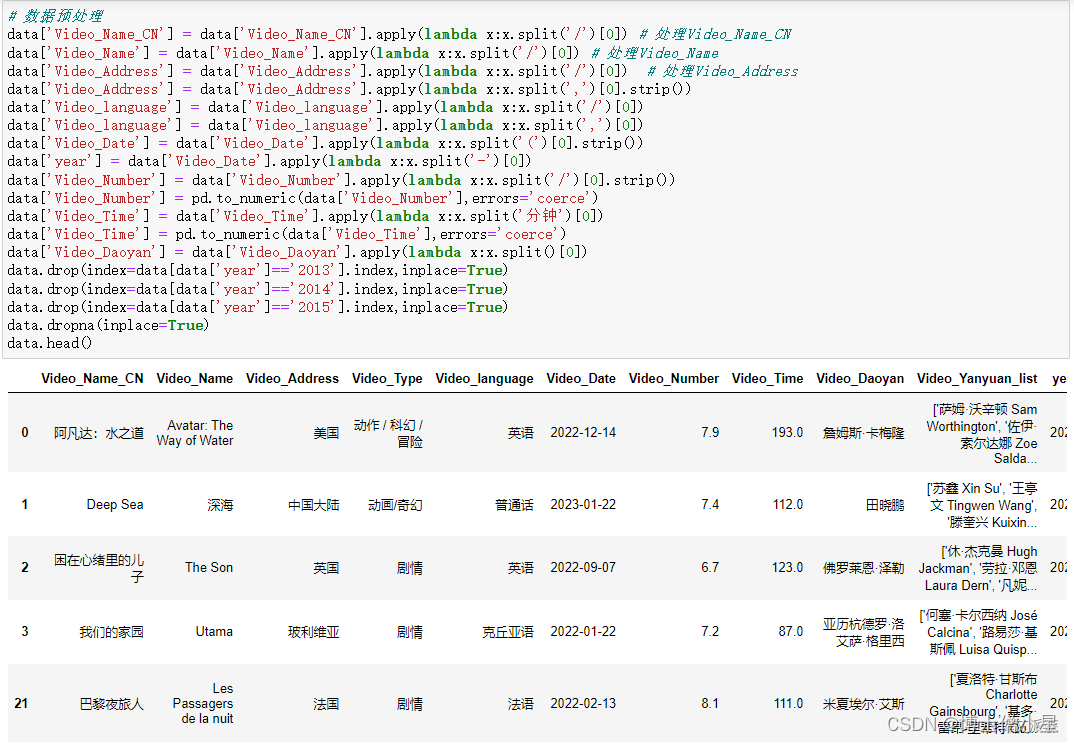
人工智能|网络爬虫——用Python爬取电影数据并可视化分析
一、获取数据 1.技术工具 IDE编辑器:vscode 发送请求:requests 解析工具:xpath def Get_Detail(Details_Url):Detail_Url Base_Url Details_UrlOne_Detail requests.get(urlDetail_Url, headersHeaders)One_Detail_Html One_Detail.cont…...

mac苹果笔记本电脑如何强力删除卸载app软件?
苹果电脑怎样删除app?不是把app移到废纸篓就行了吗,十分简单呢! 其实不然,因为在Mac电脑上,删除应用程序只是删除了应用程序的主要组件。大多数时候,系统会有一个相当长的目录,包含所有与应用程…...

net6中使用MongoDB
目录 一、MongoDB是什么? 二、使用步骤 1.安装驱动 2.设置连接字符串、配置类 3.建立实体类 4.服务层 5.在Program添加服务 6.在Controller注入服务 总结 一、MongoDB是什么? MongoDB 是一个开源的、可扩展的、跨平台的、面向文档的非关系型数据库&…...

vue中yarn install超时问题
囚笼中的网络固然可以稳定局势,不让猴子们得以随时醒悟!给你吃的你就好好吃,不要有其他的翻然醒悟的时刻。无论如何,愚蠢的活着也是一种幸福,听着那些耐心寻味的统计幸福指数,我们不由的幸福的一批。。 最…...

vue3 引入 markdown编辑器
参考文档 安装依赖 pnpm install mavon-editor // "mavon-editor": "3.0.1",markdown 编辑器 <mavon-editor></mavon-editor>新增文本 <mavon-editor ref"editorRef" v-model"articleModel.text" codeStyle"…...

算法----K 和数对的最大数目
题目 给你一个整数数组 nums 和一个整数 k 。 每一步操作中,你需要从数组中选出和为 k 的两个整数,并将它们移出数组。 返回你可以对数组执行的最大操作数。 示例 1: 输入:nums [1,2,3,4], k 5 输出:2 解释&…...
RocketMQ-源码架构
源码环境搭建 1、主要功能模块 RocketMQ官方Git仓库地址:GitHub - apache/rocketmq: Apache RocketMQ is a cloud native messaging and streaming platform, making it simple to build event-driven applications. RocketMQ的官方网站下载:下载 | R…...
14-1、IO流
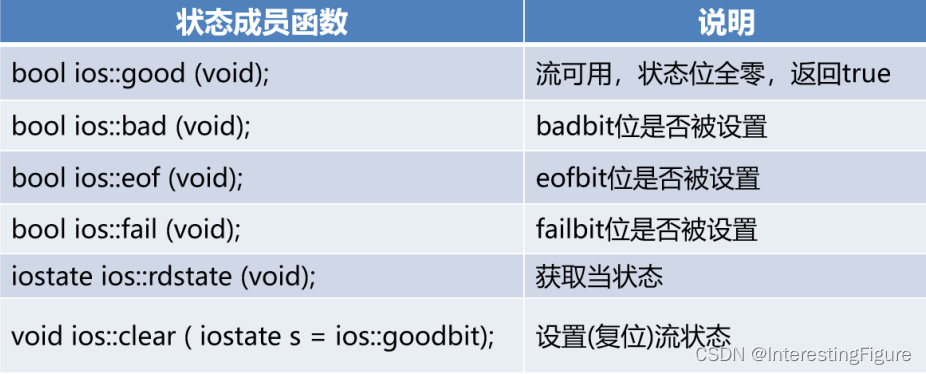
14-1、IO流 lO流打开和关闭lO流打开模式lO流对象的状态 非格式化IO二进制IO读取二进制数据获取读长度写入二进制数据 读写指针 和 随机访问设置读/写指针位置获取读/写指针位置 字符串流 lO流打开和关闭 通过构造函数打开I/O流 其中filename表示文件路径,mode表示打…...

每日一道算法题 1
借鉴文章:Java-敏感字段加密 - 哔哩哔哩 题目描述 给定一个由多个命令字组成的命令字符串; 1、字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号 2、命令字之间以一个或多个下划线_进行分割…...

【网络奇缘】- 计算机网络|深入学习物理层|网络安全
🌈个人主页: Aileen_0v0🔥系列专栏: 一见倾心,再见倾城 --- 计算机网络~💫个人格言:"没有罗马,那就自己创造罗马~" 回顾链接:http://t.csdnimg.cn/ZvPOS 这篇文章是关于深入学习原理参考模型-物理层的相关知识点&…...

❀expect命令运用于bash❀
目录 ❀expect命令运用于bash❀ expect使用原理 expet使用场景 常用的expect命令选项 Expect脚本的结尾 常用的expect命令选参数 Expect执行方式 单一分支语法 多分支模式语法第一种 多分支模式语法第二种 在shell 中嵌套expect Shell Here Document(内…...

2023年团体程序设计天梯赛——总决赛题
F-L1-1 最好的文档 有一位软件工程师说过一句很有道理的话:“Good code is its own best documentation.”(好代码本身就是最好的文档)。本题就请你直接在屏幕上输出这句话。 输入格式: 本题没有输入。 输出格式: 在一…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...