python自学之《21天学通Python》(18)——第21章 案例2 Python搞定大数据
“大数据(Big Data)”这个术语最早期的引用可追溯到apache org的开源项目Nutch。当时,大数据用来描述为更新网络搜索索引需要同时进行批量处理或分析的大量数据集。随着谷歌MapReduce和GoogleFileSystem (GFS)的发布,大数据不仅用来描述大量的数据,还涵盖了处理数据的速度。
随着云时代的来临,大数据也吸引了越来越多的关注。大数据分析相比于传统的数据仓库应用,具有数据量大、查询分析复杂等特点。
大数据通常用来形容一个公司创造的大量非结构化和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。
在开源领域,Hadoop的发展正如日中天。Hadoop旨在通过一个高度可扩展的分布式批量处理系统,对大型数据集进行扫描,以产生其结果。在Hadoop中可用2种方式来实现Map/Reduce:
(1)Java的方式,由于Hadoop本身是用Java来实现的,因此,这种方式最常见;
(2)HadoopStreaming方式,可通过SHELL/Python/ruby等各种支持标准输入/输出的语言实现。
21.1 案例背景
在Hadoop环境下编写Python程序,需要预先搭建好Hadoop开发环境,比较麻烦。为了演示Python在大数据处理方面的应用,本章的案例将不以Hadoop环境作基础,而是以处理某一个或多个大数据量的数据为基础,这也符合目前大部分用户的实际应用。根据本章案例,读者可编写程序处理自己工作中的大数据。
21.1.1 大数据处理方式概述
在Hadoop中,采用MapReduce编程模型来处理大数据,MapReduce编程模型用于大规模数据集(大于1TB)的并行运算。“Map(映射)”和“Reduce(规约)”的概念以及他们的主要思想,都是从函数式编程语言里借来的,此外,还有从矢量编程语言里借来的特性。这种方式极大地方便了编程人员在不深入了解分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(规约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
简单地说,在Hadoop中通过MapReduce编程模型处理大数据时,首先对大数据进行分割,划分为一定大小的数据,然后将分割的数据分交给Map函数进行处理。Map函数处理后将产生一组规模较小的数据。多个规模较小的数据再提交给Reduce函数进行处理,得到一个更小规模的数据或直接结果。
本章的案例将模仿这种MapReduce模型进行大数据处理,下面简单介绍本章需要处理的数据及最终要达到的目标。
21.1.2 处理日志文件
本章案例将处理apache服务器的日志文件access.log。
apache是一个非常流行的Web(网站)服务器,很多网站都在apache上发布。在网站的日常管理中,经常需要对apache网站的日志文件进行分析。通过对这些日志数据进行分析,可得到很多有用的信息。例如,可分析用户访问量最大的页面,知道用户最关注的商品。还可以分析出用户访问时段,了解网站在一天的哪个时间段访问者最多。还可以从访问者IP地址了解访问者的所在区域,了解哪个区域的用户更关注网站……
apache服务器的日志文件access.log是一个文本格式的文件,可以使用Windows的记事本打开。例如,如图21.1所示,就是打开该日志文件时所看到的内容。

从图中可看到,在日志文件中,每一条数据占用1行,每行又分为7个部分(用空格隔开),这7部分内容依次是:远程主机、空白(E-mail)、空白(登录名)、请求时间、方法+资源+协议、状态代码、发送字节数。



如果网站的日志文件比较小,可直接使用Windows的记事本(或其他文本文件编辑器)打开查看。但是,这个日志文件往往却很大,很多时候,这个文件大到无法用文本编辑器打开。
其实,提到大数据,可能首先想到的就是上亿条、几十亿条的数据。这在互联网应用中是非常普遍的,例如,若某一个电商网站每天有20万访问流量,每位访问者平均打开10个页面(每个页面平均产生8次请求),则一天将产生1600万条访问日志记录数据,一个月就有48000万条数据。每条日志数据约在50~70个字符,则每个月的日志文件大约在25~35G大小。
将问题规模缩小一下,即便是访问流量一般的网站,如果每天上千次的流量,每个月生成的日志文件也有几百M大小。
对于这么大的文本文件,想打开都很困难,更别说对其进行数据分析了。
21.1.3 要实现的案例目标
本章案例将演示用Python编写程序对apache日志文件access.log进行处理的过程。模似Hadoop的MapReduce编程模型,按以下流程对数据进行处理:
(1)首先对大的日志文件进行分割,根据处理计算机的配置设置一个分割大小的标准,将大的日志文件分割为n份。
(2)将分割出来的较小日志文件分别提交给Map函数进行处理,这时的Map函数可分布在多台计算机中。根据工作量,一个Map函数可处理多个小日志文件。处理结果保存为一个文本文件,作为Reduce函数的输入。
(3)将各Map函数处理的结果提交给Reduce函数进行处理,最终得到处理结果。

提示:按以上流程编写Python程序,在测试时可用一个较小的日志文件,最好将日志文件限制在100M以内进行测试,以减少程序处理的时间,提高开发测试效率。当测试通过之后,再用其处理大的日志。
21.2 分割日志文件
前面已经提到过,日志文件很大时,没办法将其直接打开,这时就可考虑将其分割为较小的文件。在分割文件时,需要考虑到处理数据的计算机的内存,如果分割的文件仍然较大,在处理时容易造成内存溢出。
在Python中,对于打开的文件,可以逐行读入数据。因此,分割文件的程序很简单,具体的程序如下所示。


在以上程序中,首先设置了每一个分割文件要保存数据的数量,并设置一个空的列表作为缓存,用来保存分割文件的数据。接着打开大的日志文件,逐行读入数据,再将其添加到缓存列表中,当达到分割文件保存数据的数量时,将缓存列表中的数据写入文件。然后,清空缓存列表,继续从大的日志文件中读入数据,重复前面的操作,保存到第2个文件中。这样不断重复,最终就可将大的日志文件分割成小的文件。
在命令行状态中执行FileSplit.py程序,将当前目录中的access.log文件分割成小文件,并保存到当前目录的下层access目录中。执行结果如图21.3所示,从图中输出的结果可看出,在将文件大小为27M的日志文件(约有25万条数据)按每个文件10万条数据进行分割,得到3个文件,并且从执行时间来看,在1秒钟之内就完成了3个文件的分割、保存操作。图21.4 分割得到的小文件

21.3 用Map函数处理小文件
得到分割的小文件之后,接下来就需要编写Map函数,对这些小文件进行处理。Map函数最后得到一个小的数据文件,可能经过处理,将11M大小的文件中的数据进行加工汇总得到一个大小为几百K的文件。再将这个结果文件交给Reduce进行处理,这样,就可减轻Reduce处理的压力了。
在编写Map函数之前,首先需要明确本次处理的目标是什么,即希望从数据中收集哪些信息。根据不同的目标,Map函数处理的结果将不同。
例如,若需要统计出网站中最受欢迎的页面(即打开次数最多的页面),则在Map函数中就需从每条日志中找出页面(日志的第5部分,包含“方法+资源+协议”,其中的“资源”就是页面地址),将页面提取出来进行统计。
需要注意的是,在一个Map函数中统计的结果不能作为依据。因此,在这一部分日志文件中可能A页面访问量最大,但在另一部分日志(可能由另一台计算机的Map函数在处理)中可能B页面的访问量最大。因此,在Map函数中,只能将各页面的访问量分类汇总起来,保存到一个文件中,交由Reduce函数进行最后的汇总。
下面的程序就可完成分类汇总页面访问量的工作。



在上面的程序中,Map函数打开分割后的小日志文件,然后定义了一个空的字典,用字典来保存不同页面的访问量(用页面链接地址作为字典的键,对应的值就是访问量)。
前面介绍过,日志文件中每一条数据可分为7部分,用空格来隔开,但是注意,这里最好不用split函数以空格对一条日志进行切分,因为可能日志某些字段内部也会出现空格。因此,最好的方式是使用正则表达式来提取页面地址。
得到页面地址后,接着就判断字典中是否已有此地址作为键,若有,则在该键的值上累加1,表示增加了一次访问。若没有该键,则新建一个键,并设置访问量为1。
当将(分割后的)小日志文件的每条数据都读入并处理之后,字典tempData中就保存了当前这一部分日志文件中所有页面的访问数据了。最后,对字典进行排序(也可不排序)后生成到一个列表中,再将列表保存到一个后缀为“_map.txt”的文件中,完成当前这一部分日志文件的处理,得到一个较小的结果文件。
执行以上程序,几秒钟时间就处理完成,在access目录中得到3个后缀为“_map.txt”的文件,如图21.5所示,从执行结果可看到,经过Map函数的处理,对分割后11M左右的文件进行处理后得到的结果文件大小为300K。

21.4 用Reduce函数归集数据
Reduce函数进行最后的归集处理,将Map函数运算的结果作为Reduce函数的输入,经过处理最后得到一个文件,这个文件就是针对大日志文件的处理结果,不再是一个部分结果了。
Reduce函数的处理流程也很简单,就是读入后缀为“_map.txt”的文件,进行数据的归并处理,最后输出一个结果文件。具体的程序如下。


以上程序中,在循环的外面定义了一个空的字典,用来归并所有的页面访问量数据。接着使用os.walk函数循环指定目录中的文件,找到后缀为“_map.txt”的文件进行处理。具体处理过程是:逐个将Map函数的输出文件(后缀为“_map.txt”)读入,并将数据装入字典。然后对字典进行排序并转换为列表,最后将列表输出到文件,即可得到一个后缀为“_reduce.txt”的文件,在这个文件中保存了日志中所有页面的访问量数据。如果只需要获取访问量前10(或前50)的页面,还可以只输出排序后前10条(或前50条)数据。
经过以上文件分割,Map、Reduce处理,即可将原来大小为27M的文件归集成只有几百K的一个文件,并得到需要的数据。
Reduce处理得到数据之后,就可以使用Excel或其他常用数据处理软件对数据进行分析、输出图表等操作了。当然,也可以在Python中继续编写程序来分析这些数据。
上面的操作是以页面访问量为统计目标进行的数据处理操作。如果有其他目标,就需要编写不同的Map和Reduce函数来进行处理。例如,若要统计网站每天不同时段的访问量,则在Map函数中可使用正则表达式提取日志中的访问时间段,并根据一定的规则进行数据统计。在Reduce函数中再根据Map函数的输出数据进行归并处理,即可得到要求的数据。
由于Python程序的开发效率很高,因此,开发Map、Reduce函数的效率非常快,当统计目标改变后,可以在几分钟就完成函数的修改,这是其他很多程序设计语言无法办到的。
21.5 小结
本章通过编写Python程序模仿了Hadoop处理大数据的过程。首先介绍了大数据处理的相关知识,接着编写了FileSplit函数对大数据文件进行分割,然后编写Map函数处理分割的小文件,将处理结果保存起来,最后编写Reduce函数对这些小文件进行处理,得到最终处理结果。通过本章案例,你可对大数据处理的流程有一个基本的了解。
相关文章:
python自学之《21天学通Python》(18)——第21章 案例2 Python搞定大数据
“大数据(Big Data)”这个术语最早期的引用可追溯到apache org的开源项目Nutch。当时,大数据用来描述为更新网络搜索索引需要同时进行批量处理或分析的大量数据集。随着谷歌MapReduce和GoogleFileSystem (GFS)的发布&a…...
面试问题【数据库】
数据库数据库的三范式是什么drop、delete、truncate 分别在什么场景之下使用char 和 varchar 的区别是什么数据库的乐观锁和悲观锁是什么SQL 约束有哪几种mysql 的内连接、左连接、右连接有什么区别MyIASM和Innodb两种引擎所使用的索引的数据结构是什么mysql 有关权限的表都有哪…...
Allegro如何输出钻孔表操作指导
Allegro如何输出钻孔表操作指导 用Allegro做PCB设计的时候,需要输出钻孔表格,用于生产加工,如下图 如何输出钻孔表,具体操作如下 点击Manufacture点击NC...

消息队列 面试题 整理
消息队列 为什么要使用消息队列? 异步解耦:关注的是通知而非处理。 流量削峰:将短时间内高并发的请求持久化,然后逐步处理,削平高峰期的请求。 日志收集: 事务最终一致性 系统间的消息通信方式ÿ…...

【Java】对象比较大小
在Java中经常会涉及到对象数组的排序问题,那么就涉及到对象之间的比较问题。Java实现对象排序的方式有两种: 自然排序:java.lang.Comparable定制排序:java.util.Comparator 规则:需要我们自定义根据对象的某个或某些属…...
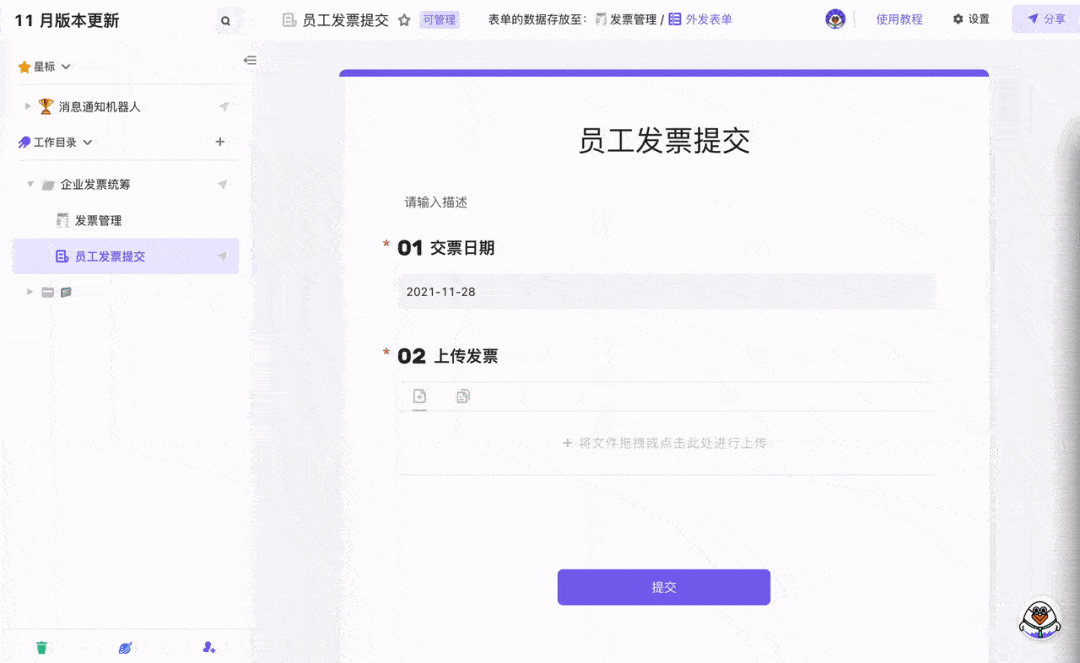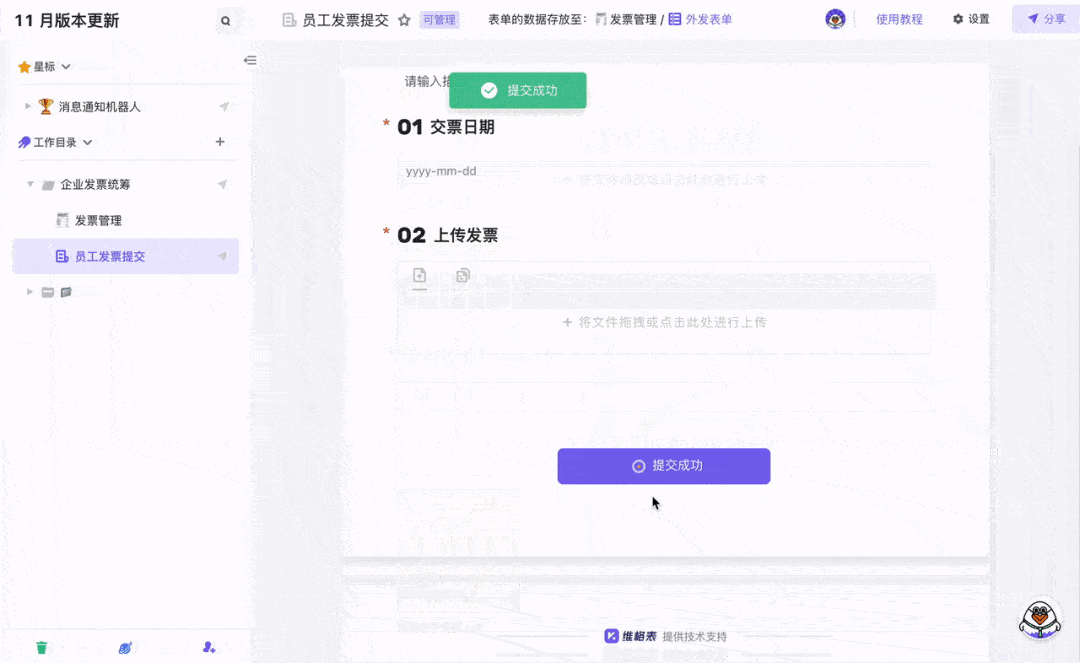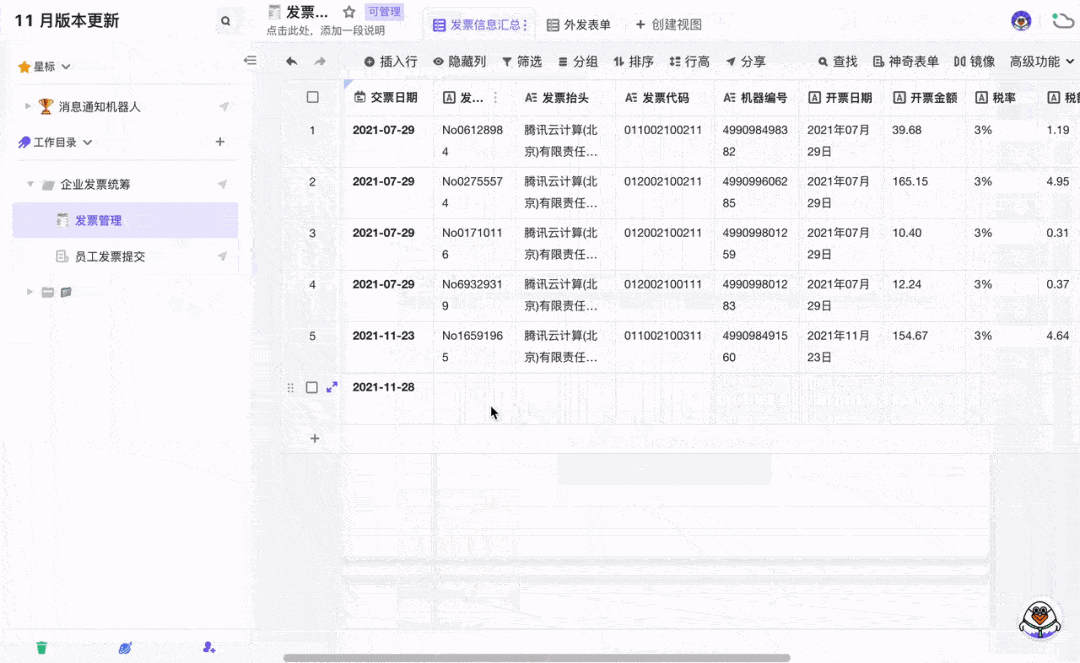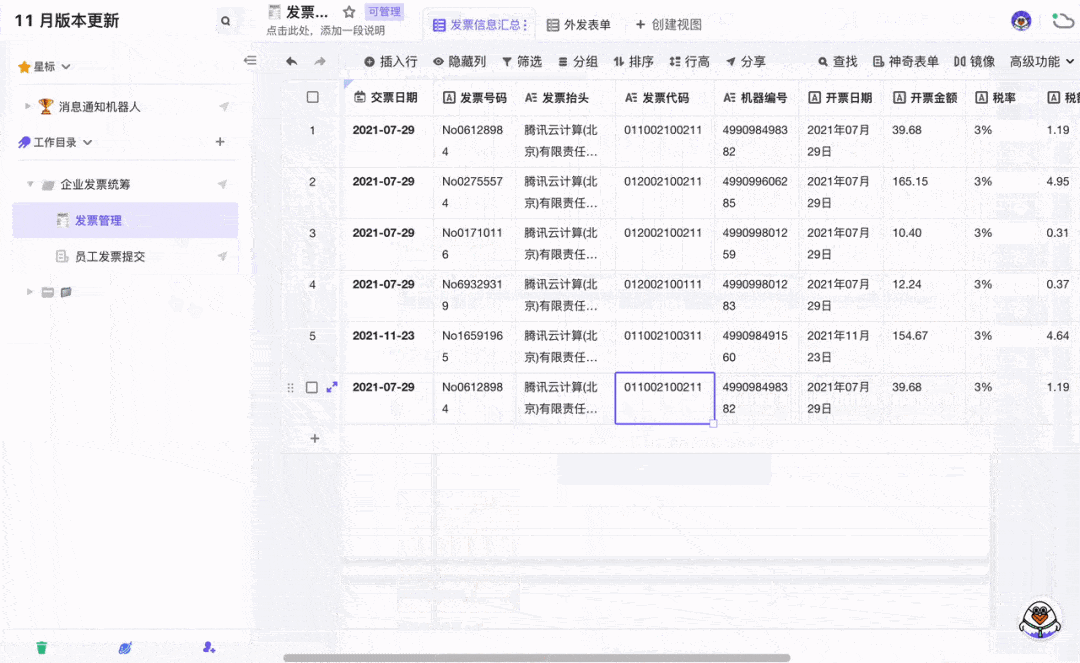
发票自动OCR识别并录入模板 3分钟免费配置
要问整个公司里和数据打交道最多的职能,非财务莫属了吧。除了每天要处理大量财务数据外,还有发票录入的工作让财务陷入“易燃易爆炸”的工作状态。发票报销看似简单,但发票的类型有很多种,每种发票需要录入的信息也有差别。再加上…...

Dubbo 配置说明
dubbo:scan:base-packages: com.ut.msdasw.services.appservice //这个会扫描该包下得全部接口protocol: //这个主要是配置传输的协议和端口,只是一个协议name: dubbo port: 30032registry: //这里是服务注册中心的地址address: spring-cloud://localhost consum…...

英飞凌TCxxx实战系列01_Alarm处理
目录 1.概述2. Alarm内部处理2.1关联的寄存器2.2 Alarm设置case3. SMU外部处理3.1 关联的寄存器4. WDT Alarm的特殊处理4.1 看门狗超时测试4.2 RecoveryTimer相关的Alarm1.概述 当MCU运行出现问题,如MCU温度过高、过低,看门狗超时等会触发一个Alarm,当SMU收到Alarm信号后,…...
飞桨全量支持业内AI科学计算工具——DeepXDE!
AI技术在跨学科融合创新方面扮演着日益重要的角色,特别是在Al for Science领域,AI技术的发展为跨学科、跨领域的融合创新带来了巨大的机会。AI已成为一个关键的研究工具,改变了基础科学的研究范式。依托AI技术开发的科学计算工具,…...

【c++基础】
C基础入门统一初始化输入输出输入输出符输入字符串const与指针c和c中const的区别const与指针的关系常变量与指针同类型指针赋值的兼容规则引用引用的特点const引用作为形参替换指针其他引用形式引用和指针的区别inline函数缺省参数函数重载判断函数重载的规则名字粉碎C编译时函…...

语音识别技术对比分析
文章目录一、语音识别产品对比二、百度语音识别产品1、套餐及价格:2、官网3、调研结果三、华为语音识别产品四、阿里云语音识别产品1、套餐及价格:2、官网地址3、调研结果五、科大讯飞语音识别产品1、套餐及价格:2、官网3、调研结果六、有道语…...

Idea git 回滚远程仓库版本
目标 回滚远程仓库到特定版本。 将【添加test03】版本回滚到【行为型模式】版本。 回滚前的效果图 步骤 ①复制需要回滚到的版本的版本号 ②右键项目,选择Git-Repository-Reset Head ③Reset Type选择Hard;To Commit填入步骤①复制的版本号ÿ…...

vscode C++配置
program:调试入口文件的地址cwd:程序启动调试的目录miDebuggerPath:调试器的路径launch.json// { // // Use IntelliSense to learn about possible attributes. // // Hover to view descriptions of existing attributes. // /…...

【微电网_储能】基于启发式状态机策略和线性程序策略优化方法的微电网中的储能研究【给定系统约束和定价的情况下】(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...

rk3288-android8-IR-mouse
IR问题: mouse按键使用不了 然后排查: 1.排查上报 ir_key6{ rockchip,usercode <0xbf00>;rockchip,key_table <0xff KEY_POWER>,<0xfe KEY_MUTE>, <0xfd KEY_1>, <0xfc KEY_2>, <0xfb KEY_3>, <0xfa KEY_4>, <0xf9 KEY_5>…...

2023-03-01干活小计
昨天组会,元气大伤,拖更直接。今天继续,三月加油! python魔术方法: __repr__:print()时候调用,注意函数返回值就是打印值。 __len__:len()时候调用 __call__:实例()时候调用 __getitem__:self[i]时候调…...
客户服务软件推荐榜:28款!
在这个竞争激烈的时代,做到服务对企业的存亡有着深刻的意义。改善客户服务,做好客户服务工作,是关键,因为客户服务团队代表着企业的形象,面孔,客户有可能 不大会记得企业的某个东西,但是他们将会…...

Spring注入和注解实现IOC
标题注入依赖注入的方式通过Set方法注入通过构造方法注入自动注入依赖注入的数据类型注入Bean对象注入基本数据类型和字符串注入List注入Set注入Map注入Properties注解实现IOCComponentRepository、Service、Controller注入 依赖注入的方式 在使用依赖注入时,如果…...
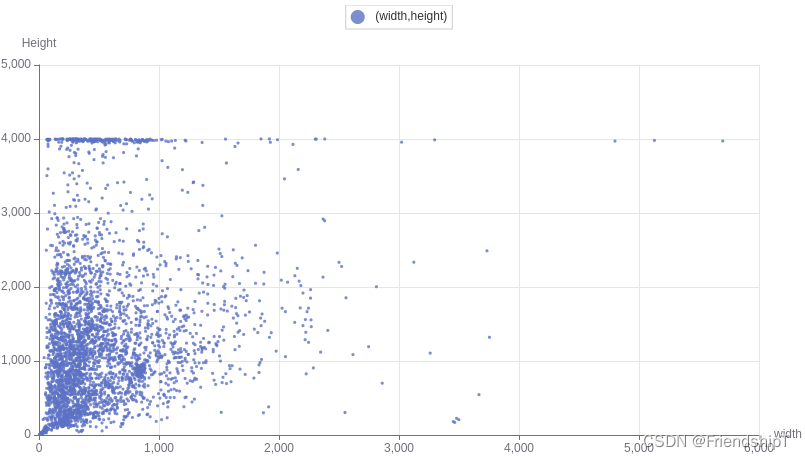
Python统计Labelme标注文件信息并绘制散点图
Python统计Labelme标注文件信息并绘制散点图前言前提条件相关介绍实验环境Python统计Labelme标注文件信息并绘制散点图前言 本文是个人使用Python处理文件的电子笔记,由于水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击…...
 客户案例——ET Innovations)
远程接入方案 OpenText Exceed TurboX(ETX) 客户案例——ET Innovations
远程接入方案 OpenText Exceed TurboX(ETX) 客户案例——ET Innovations ET Innovations GmbH 助力奥地利各地的医疗保健专业人员提升患者体验 医疗保健信息系统开发商利用 OpenText™ Exceed™ TurboX 将远程访问其软件的稳定性提高了 95% 公司:ET I…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...