Presto 在美图的实践
导读:本文的主题是Presto高性能引擎在美图的实践,首先将介绍美图在处理ad-hoc场景下为何选择Presto,其次我们如何通过外部组件对Presto高可用与稳定性的增强。然后介绍在美图业务中如何做到合理与高效的利用集群资源,最后如何利用Presto应用于部分离线计算场景中。使大家了解Presto引擎的优缺点,适合的使用场景,以及在美图的实践经验。
正在上传…重新上传取消
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
技术选型
Presto是一个Ad-Hoc的ROLAP解决方案。ROLAP的优缺点简单介绍如下:

ROLAP优点:
-
ROLAP适合非常灵活的查询。
-
ROLAP查询性能相对比较高。
-
ROLAP针对MPP架构支持实时数据的写入与实时分析。
-
Presto内置支持各种聚合的算子,如sum、count,擅长计算一些指标如PV、UV,适合多维度聚合查询。
ROLAP缺点:
-
所有计算和分析都是基于内存去完成的,对内存的需求比较大。
-
线上实际使用过程中发现,查询周期相对比较长时(如查一年、两年的数据),经常会遇到数据量会过大的问题,会线性影响查询性能。
-
对比MOLAP由于需要提前做一次预计算,Presto则存在一定的性能差距。
MOLAP的典型技术实现是Druid和Kylin。两者均通过做预计算,创建对应的cube,来实现一个性能上比较快的OLAP方案。但是,这是以牺牲业务灵活性为代价的。相比来说,Presto有更好的灵活性。
我们内部调研了三个Ad-Hoc的ROLAP技术组件选型,包括Hive on Spark,Impala和Presto。
Hive on Spark

Hive on Spark的优点,首先是在美图内部广泛使用,经受住了时间的考验。其次是使用上的灵活性,因为已经使用了很多年,相对比较熟悉,做过较多二次改造,包括源码增强和一些重点模块重构。
缺点也是显而易见的,Hive on Spark在查询一些相对比较大的任务,容易发生shuffle、OOM和数据倾斜等问题。其次,Hive on Spark和其他竞品如Impala和 Presto相比,查询速度很慢,明显无法满足在线查询的需求。
Impala
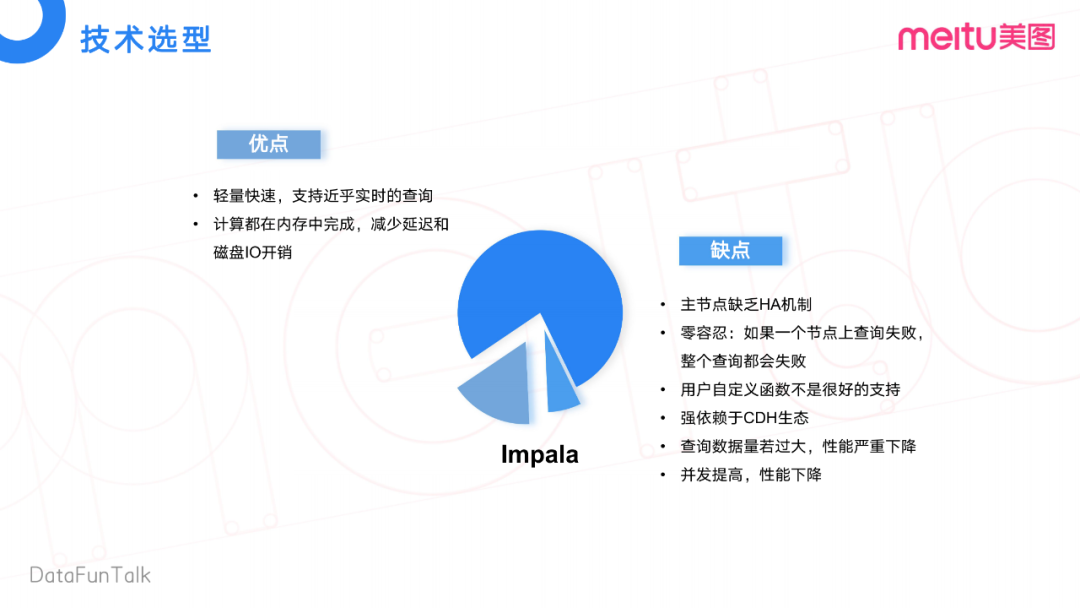
Impala的优点,首先是轻量快速,支持近实时的查询。其次,所有计算均在内存中完成,减少了计算延迟和磁盘IO开销。
但缺点也比较多,首先是主节点缺乏高可用的机制(HA机制)。其次是零容忍问题,即一个查询发送过来的话,如果其中一个节点查询失败,会导致整个查询都失败。再次,我们在使用过程中发现它对自定义函数支持的不是很好。另外,Impala强依赖于CDH的生态,跟我们现有架构不能很好的融合。我们现有架构使用了一些开源社区的组件。如果强依赖于CDH, 当我们要做版本升级、补丁升级或者代码重构后的升级时,存在过度依赖CDH而操作不友好的问题。最后,就是查询数据量过大的话,会发生比较严重的性能下降。此外,还有对于并发的支持,不是特别好。
Presto
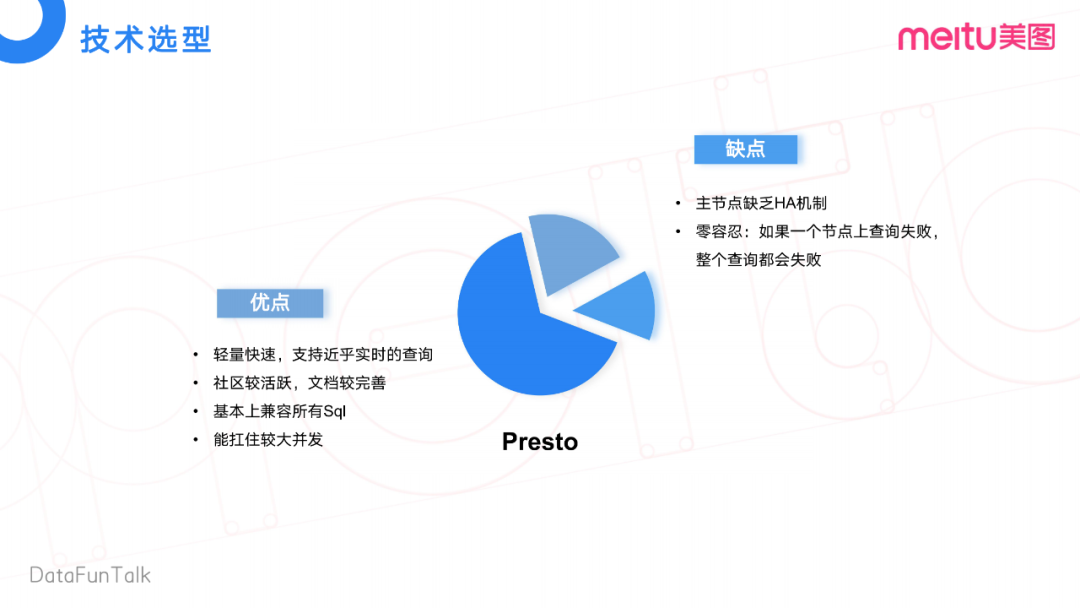
最后来看今天的主角Presto。Presto优点首先是轻量快速,支持近乎实时查询。其次,它的社区活跃度也比较高,文档也比较完善,基本可以兼容业务上所有的SQL,也能扛住比较大的并发。
当然Presto也有一些缺点,一是零容忍问题,如果一个失败,一个节点上的查询失败,会导致整个查询的失败。再就是主节点缺乏HA的机制。HA这个缺点,业界也有方案可以去完善。在下一个章节,会分享美图是如何完善HA机制的。

我们通过对比三个组件的一些特性,包括多表关联、单表查询和系统负载等,得到了一个打分。分数越高越适合我们的业务场景,优势越明显。表格中可以看到,Presto总计39分是最高的,最符合我们的业务场景。

同时我们也做了计算性能上的对比。Presto的性能最好,Impala略微差一些。可能比较细心的同学会发现,在Query 9里面,Impala的结果是空白的,这是因为Impala不兼容Query 9中的语法。这里面我们也对比了在美图内部用的比较多的Spark SQL,由于上篇文章没讲到Spark SQL,所以这里只做了一个性能的比较。基于这些维度考虑,我们最终选择了Presto。
Coordinator HA
单点问题
前面提到,Presto有一个比较致命的缺陷,就是缺乏主节点的HA高可用性。在这一章节中,看看我们如何去克服和完善这个组件。
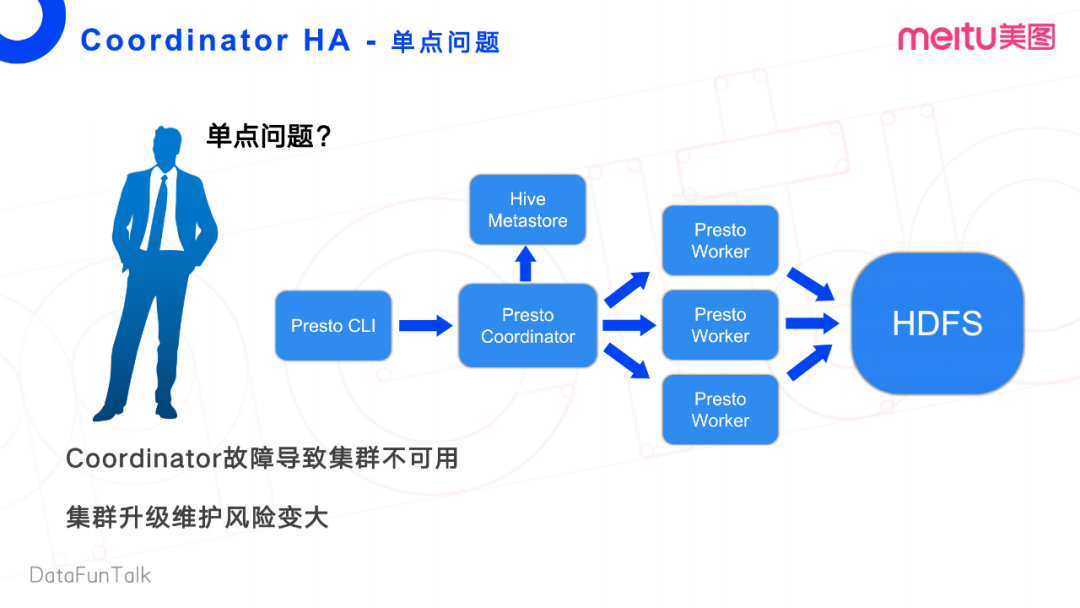
首先,我们看一看Presto的整体流程。Presto Client端发送一个查询请求给Presto的Coordinator, Coordinator先去Hive Metastore获取这个任务执行过程中所需的一些源数据信息,再将任务转发给它对应的Worker节点,然后Worker节点从文件系统里面去拉数据做计算。
这个流程中,显而易见致命的缺点是Coordinator的单节点。Coordinator故障会导致整个集群的不可用,会严重影响线上业务。此外,Coordinator对集群升级也带来比较大的风险。
方案
这里面整理了业界广泛使用的两个方案。
方案一:

方案一是多集群部署的方式,分为两个集群,分别为Presto集群一和Presto集群二。Client端在运行任务时,会按照一定的规则去选择某一个Presto集群,建立连接,创建任务。任务建立完成后,Client端将连接的Presto Coordinator会话信息保存起来,存储在DB里面。这样当Presto集群挂掉之后,当前会话会有一些任务失败,在连接到新的集群之后,可以做任务恢复。最后,每一次任务进行交互的时候,都直接访问当前获取连接的Presto集群即可。
这个方案本身没有问题,可以快速的搭建出一套容灾方案。但是其缺点也是显而易见的。其实只需要一套集群,但是做了过多的冗余,用了两套集群来完成在线查询的业务,在成本方面不能接受。当然基于这个方案,也可以在同一个机器上做混部,相当于一个机器多个Worker实例。但会存在管理难度比较大的问题,可能会涉及到Worker与Worker之间的资源抢占,终归不是最优的方案。
这里稍微点一下,这边Meta Store有三台机器,是为了实现高可用。Coordinator接收到任务,会去获取任务的一些源数据信息。此时通过三个Meta Store进行轮询选择。当一台Meta Store挂掉之后,还有两个实例可以用。这个方案一被pass掉了,因为不能接受它的冗余。
方案二:

接下来看方案二,Presto采取了一个主备的Coordinator单集群部署方式。这个是大规模集群比较常见的部署方式。
首先,在Presto集群上层部署一个KeepAlived的第三方服务。然后通过KeepAlived创建单独的虚拟IP(Virtual IP),指向对应的主备节点。这样,客户端通过虚拟IP访问集群,内部Worker也通过虚拟IP访问Coordinator节点。主节点故障时,KeepAlived通过内部的服务注册Discovery机制,注册到一台新的Coordinator上,这样对虚拟IP的访问会飘移至另外一台Coordinator,同样Worker节点也会访问另外一台Coordinator。
总结来说:如果Coordinator master发生了故障,可以业务无感知的切换到备用Coordinator上。这个方案可以解决我们Coordinator单点的问题,也不存在任何的资源浪费的问题。
实施步骤
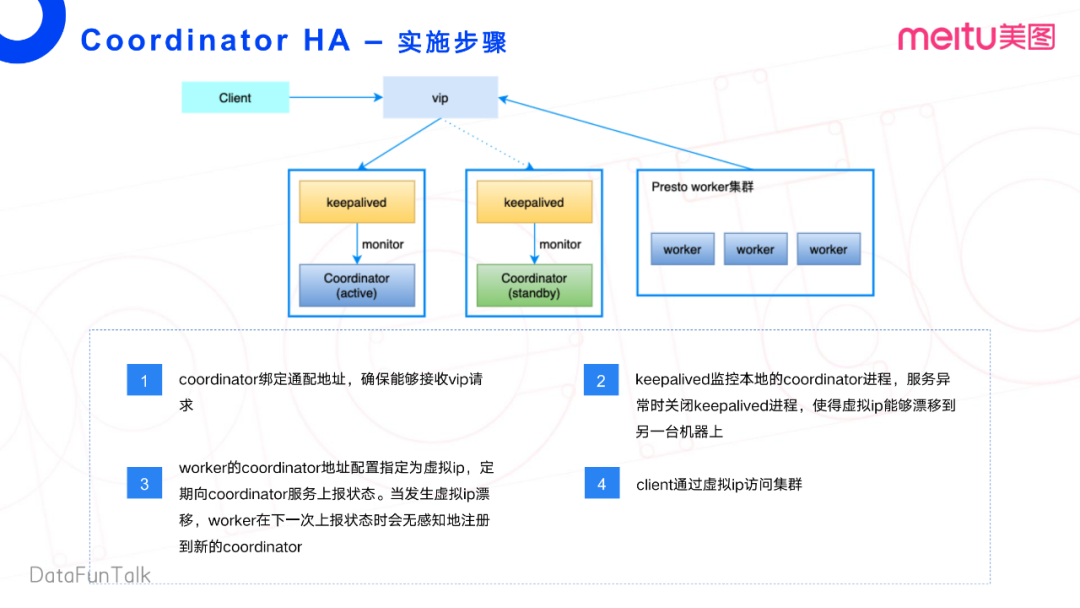
接下来我们再细细的看一下方案二的一个大致的实施步骤。第一,需要绑定一个通配地址,也就是类似0.0.0.0这么一个通配地址,确保能接受VIP的请求。如果是同网段,这样的IP也可以, 只要他的这个网络环境是互通的就可以了。
第二点就是使用KeepAlived去监控本地的Coordinator进程。当服务发生异常时,去关闭这个KeepAlived进程,使得这个VIP可以漂移到另外一台机器上。将Worker的Coordinator地址配置成对应的VIP,然后定期上报状态。其实再展开一点,Worker并不是向真正的Coordinator服务上报状态,而是向Discovery这个服务去上报状态。Discovery相当于是Coordinator的一个进程。当发生虚拟IP漂移的时候,Worker会在下一次上报状态的时候,无感知的去注册到新的Coordinator。Client可以继续通过VIP去访问集群。
可能会有点绕,大家只要记住,Coordinator和Worker都是通过这个VIP去进行关联与信息交互。在网上,这个方案也相对比较成熟,具体的代码和配置都可以找到。
跨集群调度
背景介绍
![]()

第三部分,我们来介绍一下美图内部跨集群调度的实现。这是基于我们的业务特性去做的一个优化。我们内部有两套集群,其中一个为离线集群,主要就是跑一些统计报表,离线查询之类的任务,另一个是Presto集群。他们存在一个资源错峰状态,离线集群业务高峰是在凌晨的0点到9点,会将资源利用率持续打满。Presto本身是一个在线查询的集群,基本上凌晨没人使用,0点到9点是它的一个业务低谷,资源利用率接近0%。这样存在一个资源错峰。我们想把Presto在业务低谷的这部分资源利用上。
可能大家会有个疑问,传统的集群部署基本上都是从自己的HDFS去拉取数据。如果资源要互通的话,就需要去访问各个集群上的文件,才能做下一步的计算。
架构演进
![]()
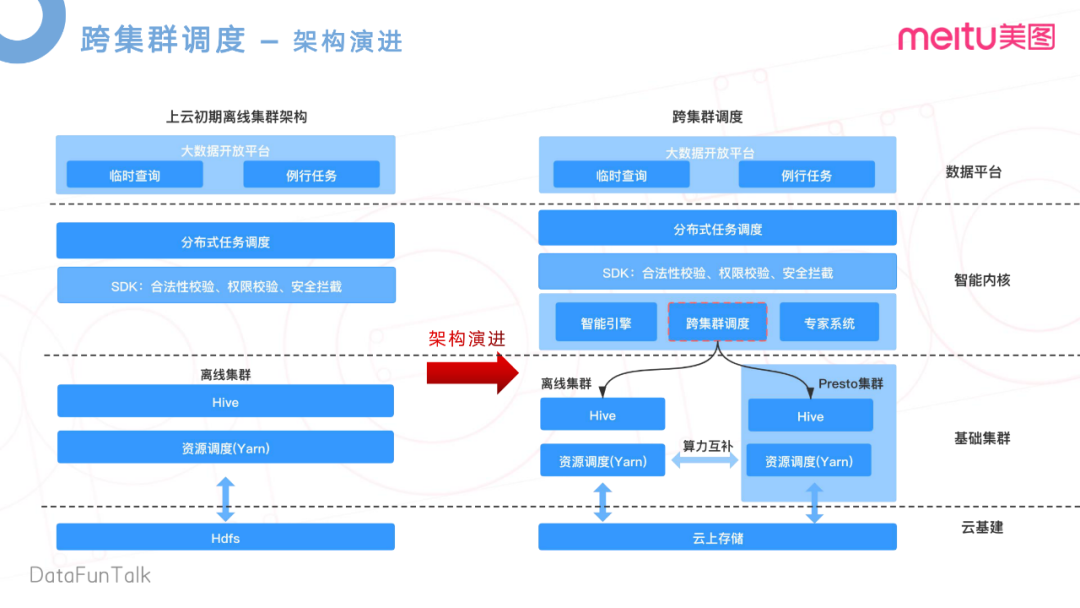
美图在去年完成了一个上云的操作,在云上使用了存算分离的架构,实现了数据的统一存储。这样的好处是打破了传统架构的数据孤岛的问题,离线集群和Presto集群可以无差别的访问云上的存储,即离线集群可以访问到Presto集群上的数据,Presto上的数据也可以访问到离线集群的数据。基于这两点,我们就提出了一个跨集群调度的概念,去减轻离线集群的高峰负载,提升Presto集群凌晨业务低谷资源使用率。
在上云初期,因为有数据孤岛,各自集群有各自的HDFS,数据没法互通。如图所示,这是上云初期架构示意图。在上层,是对应的大数据开放平台,做一些临时查询,和一些例行任务。在下一层,是自研的一个分布式调度系统,主要是做任务的一些日常调度。再下来,我们开发了一个检验层,做一些合法性的校验。任务合法性,是指这个任务所携带的参数和语法,是否合法等。在这里还做了统一的权限校验等数据安全的拦截。这些校验完成之后,才会转发给离线集群,通过Yarn去做资源调度,以及跟HDFS的交互。
转发策略
![]()

在实现跨区域调度之后,团队内部研发了一个智能内核。智能内核其实里面有三个比较核心的东西,一个是智能引擎,也就是和团队现在一起在做的事情。跨集群调度就是通过这个任务根据评估离线集群和Presto集群的一个业务集群负载,去转发到各自的集群,去分担各自的集群压力,或者说提升一个资源的利用率。这边也实现了一个算力互补的这么一个东西,当然最底层是通过我们的云基建,云上存储进行实现的。当然我们在评估这个转发,就是什么样的任务可以去转发到Presto上呢,我们也做了一些简单的转发策略,比如说转发量上,我们会根据Presto集群规模,去设置一些离线任务的转发率。
再就是转发的时间段,需要在指定的时间段内转发。因为业务低峰是0点到9点,那么在9点之后,分析师同学已经上班了,可以开始去做一些在线查询的一些操作。那不能影响他们的业务,所以我们需要规定一个转发时间段。还有一些任务的类型,需要判断历史任务的一些耗时,若耗时比较大的任务,就不适合做这个转发。
实施步骤
![]()

具体的实施步骤跟大家简单的看一下。
首先是Hive Server服务的搭建。在离线集群上,我们用了Hive on Spark。了解过Hive on Spark的同学呢,就知道他们其实是通过Hive Server进行任务接收的。我们在Presto集群内去搭建和部署自己的Yarn和Hive Server环境,主要是用于跨区域调度的任务、接受和执行等。再就是,因为Hive集群的这个任务要转发至Presto集群上运行,所以离线集群的配置也要和Presto集群做一些统一。
其次是用到的一些第三方包,还有一些补丁。在内部团队也做了比较多的代码重构。需要去将这些代码去Merge到Presto的集群上,做好补丁的统一,还有相关告警配置,队列资源计费统计。再就是一些服务开发,这个服务开发主要就是用于我们的专家系统,还有智能引擎的一些服务模块,最后就是灰度上线。
当前面的这些环境全部都做好之后,开始灰度,灰度覆盖率由小到大做任务的转发。可以看一下这个收益分析。离线集群的资源在夜间它的消耗降低了10%,因为集群间已经实现了算力互补,可以将离线集群的一部分机器去迁移至Presto集群上,那也相当于对Presto做一个扩容。这样Presto的集群性能也提高了19%。
展望未来
![]()

最后,我们对未来进行一个展望。在大数据场景下,根据任务属性的不同可以分为三类任务:大shuffle任务,中大型任务和小型任务。
-
大shuffle任务数据量非常大,查询级别在数百亿,还有比如说做多维度的cube构建,或者grouping set类似这样的操作,比较适合Hive on Spark运行。因为Hive on Spark是基于磁盘进行计算,稳定性相对高。
-
中大型任务的数据量相对比较大,SQL语句也比较复杂,比较适合Hive on Spark或者Spark SQL。在日常使用中,我们发现Spark on SQL的性能明显优于Hive on Spark。但是,对于在这部分中大型任务,团队内正在尝试使用Presto来解决时效性或者运行时间问题。
-
小型任务的数据量比较小,SQL也比较简单,非常适合Presto去做。Presto对小型任务也有比较好的性能表现。
用一句话来总结:对于中大型任务和小型任务,会将原来的Hive on Spark或者Spark SQL的运行方式,逐步切换到Presto上,来达到性能提升的目的。
![]()
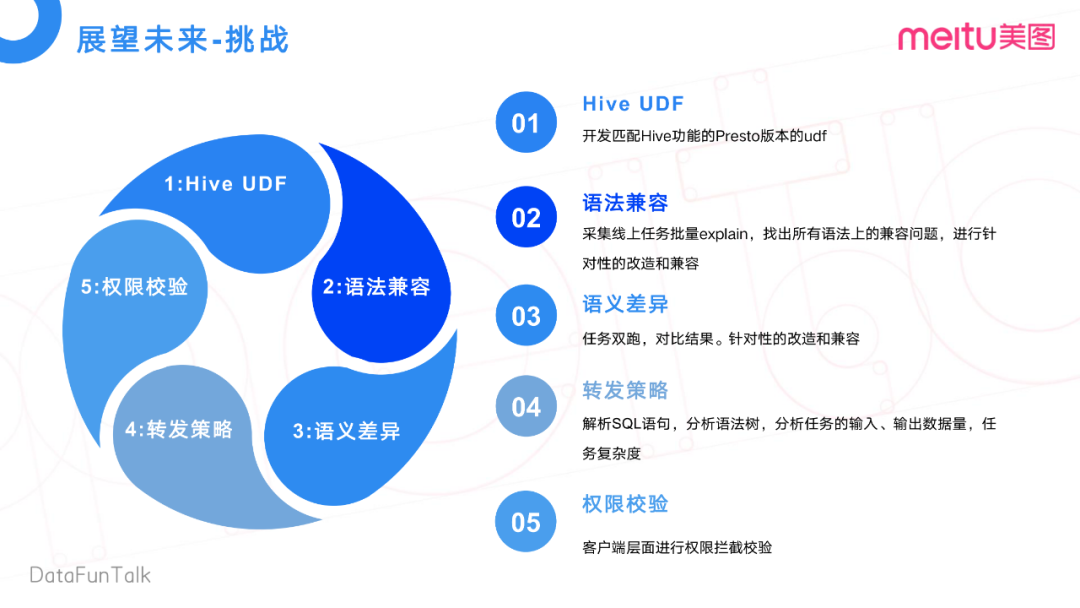
目前的架构也遇到了一些挑战:
-
比如,在离线统计Hive集群上,有些UDF有一些语法兼容的问题,还有一些语义差异。
-
比如某个任务,在离线集群上用了一个Hive UDF,在Presto上也要实现对应的UDF。现在这个完全是靠人力去开发对应的UDF。当然,后面也在想一些更好的方式,如何去快速的适配Hive上已有的UDF。
-
再就是一些语法上的兼容,比如说Hive语法在Presto上去跑,它不一定能兼容。那么我们会去采集线上所有的任务,去做一个提前的预编译,去找出语法上的一个兼容性问题,然后针对性的有选择的去做一些改造和兼容。为什么是有选择性呢?我们不一定会将线上所有任务都都扔到Presto上,只是有选择性把一些中小任务放Presto上执行。
-
还有就是语义的差异,我们会用Hive和Presto两个引擎执行,然后对比结果,针对性的做一些改造的兼容。再就是转发策略,什么样的任务能够转发到Presto上呢?我们会分析它的一个SQL语句,包括一些语法树的分析,还有任务的输入输出,任务复杂度的一些分析。
-
最后一点,是权限校验。我们会在客户端层做一个基于多引擎级别的统一权限校验。
问答环节
Q:是否考虑过使用Doris来对接Hive,性能相比Presto会快。
A:Doris暂时没有考虑,我们有在做ClickHouse。ClickHouse在我们内部慢慢做起来了之后,随着业务的接入,框架的相对比较成熟之后,也会考虑将ClickHouse接入到多引擎的这个架构里面。所以说Doris我们现在没有用。
Q:Presto在查询大数据性能和Hive on Mapreduce差的很多吗?可以对比一下吗?
A:Presto在查询中小型任务性能远远好于Hive on Mapreduce,但如果查询大任务的话就不一定了,因为Presto主要基于内存上的计算。在线上其实也发现,如果一个任务查询的时间周期比较长的话,拉取数据的量级也比较大,计算复杂度高。任务很可能会失败,甚至会拖垮整个集群。所以我们会在客户端做一定的拦截去保护,相当于一定的熔断机制,就不让这样的任务发到Presto集群内部。所以若一个非常大的查询的话,我还是比较建议将这样的任务去转发到Hive on MR或者说Hive on Spark这样的引擎上。中小型任务可以尝试在Presto引擎上执行。
Q:更进一步了解智能引擎是如何工作的?
A:智能引擎一个核心的概念,就是会对历史的一些做一些分析,得到任务画像系统。当任务下一次任务再运行后,会根据这个画像系统里面的存储的一些任务metric信息,去指定给我们下层的最适合的引擎,就是相当于最适合的任务交给最适合的引擎执行。例如我们有MapReduce,Hive on Spark, Spark SQL引擎还有包括说后面会继续引入的Presto,那么什么样的任务适合什么样的引擎执行,这正是智能引擎做的事。
分享嘉宾:
![]()

本博客文章除特别声明,全部都是原创!
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Presto 在美图的实践】(https://www.iteblog.com/archives/10015.html)喜欢 (1)
赏
分享 (0)
相关文章:
Presto 在美图的实践
导读:本文的主题是Presto高性能引擎在美图的实践,首先将介绍美图在处理ad-hoc场景下为何选择Presto,其次我们如何通过外部组件对Presto高可用与稳定性的增强。然后介绍在美图业务中如何做到合理与高效的利用集群资源,最后如何利用…...

Molecule:使用Jetpack Compose构建StateFlow流
Molecule:使用Jetpack Compose构建StateFlow流 看下面的jetpack compose片段: Composable fun MessageCard(message: Message) {Column {Text(text message.author)Text(text message.body)} }这段代码最有趣的部分是它实际上是reactive。其反应性为 通过Composa…...
计算机组成原理(2.2)--系统总线
目录 一、总线结构 1.单总线结构 1.1单总线结构框图 编辑1.2单总线性能下降的原因 2.多总线结构 2.1双总线结构 2.2三总线结构 2.3四总线结构 编辑 二、总线结构举例 1. 传统微型机总线结构 2. VL-BUS局部总线结构 3. PCI 总线结构 4. 多层 PCI 总线结构 …...

如何使用dlinject将一个代码库实时注入到Linux进程中
关于dlinject dlinject是一款针对Linux进程安全的注入测试工具,在该工具的帮助下,广大研究人员可以在不使用ptrace的情况下,轻松向正在运行的Linux进程中注入一个共享代码库(比如说任意代码)。之所以开发该工具&#…...
Docker安装Cassandra数据库,在SpringBoot中连接Cassandra
简介 Apache Cassandra是一个高度可扩展的高性能分布式数据库,旨在处理许多商用服务器上的大量数据,提供高可用性而没有单点故障。它是NoSQL数据库的一种。首先让我们了解一下NoSQL数据库的作用。 NoSQL 数据库 NoSQL数据库(有时称为“Not …...
)
Linux常用命令总结(建议收藏)
Linux常用命令总结(建议收藏) 这里收集了一些常用命令以便需要时查看,欢迎作补充。(这里的提到操作都默认以CentOS系统为基础) 文件管理 目录操作 切换目录 cd 查看目录 ls -l 列出文件详细信息 或者直接ll-a 列出当前目录下所有文件及…...

【Java】P1 基础知识与碎碎念
Java 基础知识 碎碎念安装 Intellij IDEAJDK 与 JREJava 运行过程Java 系统配置Java 运行过程Java的三大分类前言 本节内容主要围绕Java基础内容,从Java的安装到helloworld,什么是JDK与什么是JRE,系统环境配置,不深入Java代码知识…...
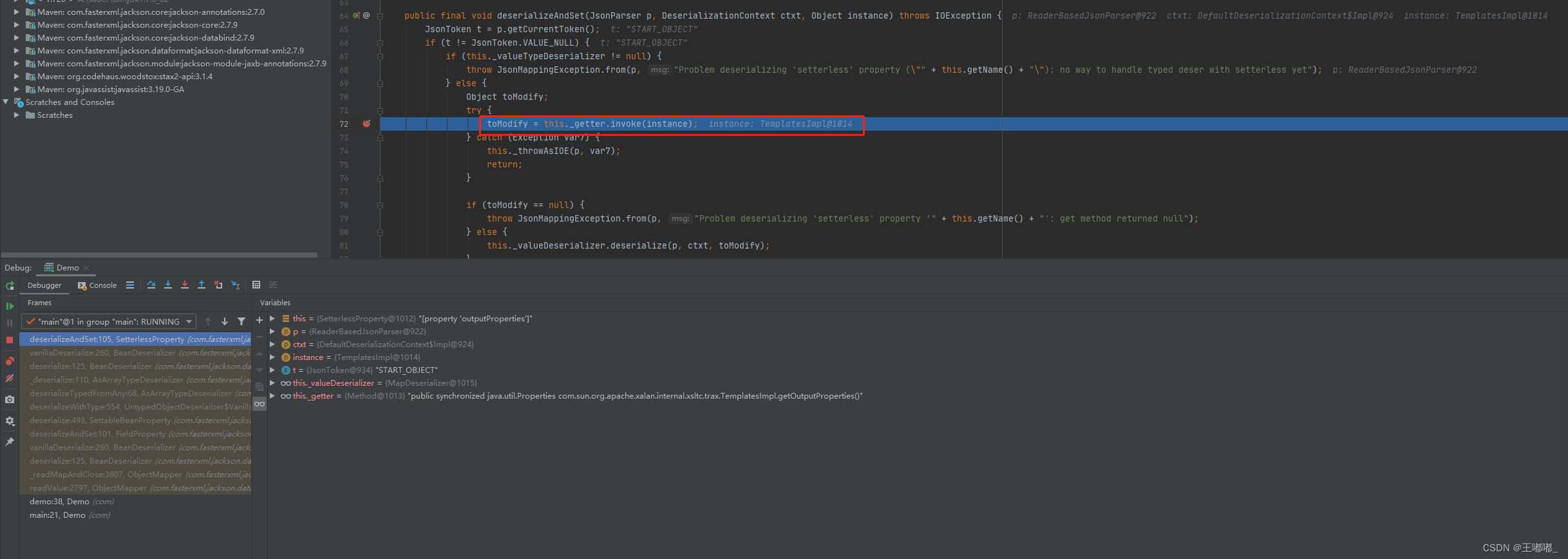
Jackson CVE-2017-7525 反序列化漏洞
0x00 前言 Jackson 相对应fastjson来说利用方面要求更加苛刻,默认情况下无法进行利用。 同样本次的调用链也可以参考fastjson内容:Java代码审计——Fastjson TemplatesImpl调用链 相关原理,可以参考:Jackson 反序列化漏洞原理 …...

【2023】DevOps、SRE、运维开发面试宝典之Kubernetes相关面试题
文章目录 1、Kubernetes集群的特点?2、Kubernetes集群各节点的组件有那些?分别有什么作用?3、简述Kubernetes集群的工作原理4、什么是Pod资源5、Label标签的作用?6、Deployment控制器与Statfulset控制器的区别?7、Pod拉取镜像的三种策略?8、简述Pod的生命周期9、Pod的生命…...
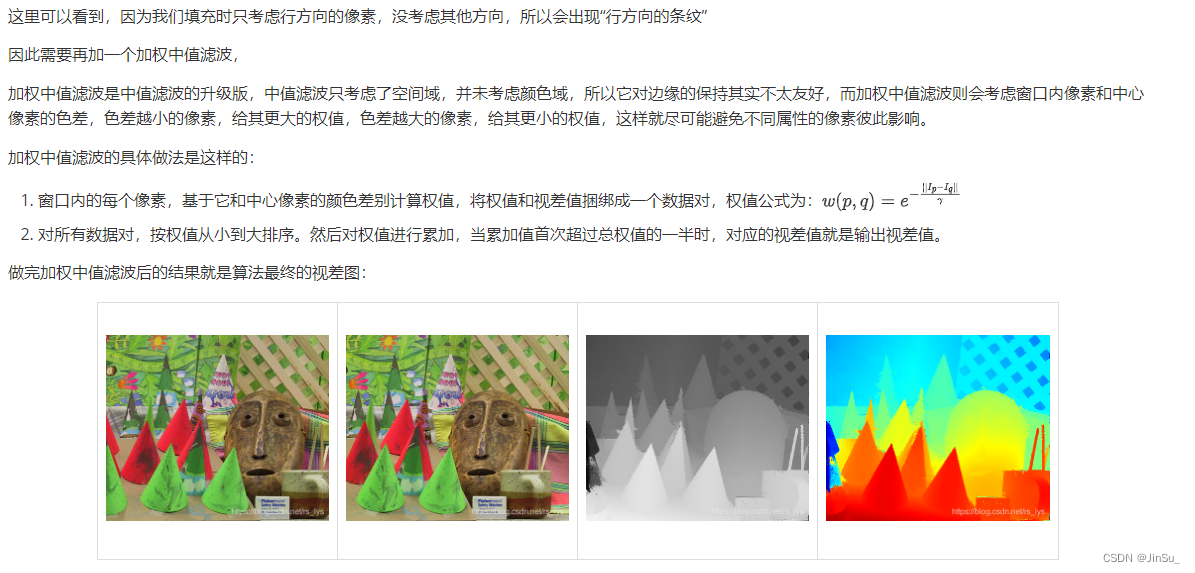
【算法】PatchMatch立体匹配算法_原理解析
目录 前言 原理解析 1.倾斜支持窗口(Slanted Support Windows) 什么是视差平面? 为什么视差和像素坐标点之间的关系可以解释为平面方程? 视差平面的通用参数方程和点加法向量方程 什么是倾斜支持窗口? 2.基于倾…...

【同步工具类:CyclicBarrier】
同步工具类:CyclicBarrier介绍源码分析CyclicBarrier 基于ReetrantLock Condition实现。构造函数await() 函数业务场景方案一:代码实现测试截图方案二代码实现测试打印总结介绍 官方介绍: 一种同步辅助工具,允许一组线程都等待对方到达共同的障碍点。CyclicBarrie…...

Android 12.0 Settings 去掉打开开发者模式和USB调试模式的广播
1.概述 在12.0的系统产品rom定制化开发中,在系统Settings的开发者模式中,打开开发者模式和usb调试模式都会发出开发者模式改变广播和usb调试模式改变广播, 项目开发功能需要要求去掉这两个广播以免影响其他功能,所以就要看哪里发出广播来屏蔽掉就可以了,这样就可以去掉开发…...

OSI七层网络模型和TCP/IP四层网络模型的异同
文章目录前言一、什么是OSI?二、什么是TCP/IP四层模型?三、OSI七层网络模型和TCP/IP四层网络模型的关系:四、 OSI七层和TCP/IP的区别:前言 本节系统总结: 一、什么是OSI?二、什么是TCP/IP四层模型…...

接口测试必备技能 - 加密和签名
1、什么是加密以及解密? 加密:在网络上传输的原始数据(明文)经过加密后形成(密文)传输,防止被窃取。 解密:将加密还原成原始数据 2、加密方式分类? 对称式加密…...

JVM虚拟机概述(1)
1.JVM概述 1.1为什么要学习JVM 通过学习JVM ( java Virtual Machine )可以帮助我们理解java程序运行的过程,了解虚拟机中各种机制的实现原理。为后期写出优质的代码做好准备,为向更高的层次提升打好基础。 1.2虚拟机 虚拟机的本质就是在windows中&…...

学习.NET MAUI Blazor(七)、实现一个真正的ChatGPT聊天应用
今天在新闻上看到一条消息,OpenAI已经开放了ChatGPT的接口,也就是GPT-3.5,对比原来的GPT-3,增加了gpt-3.5-turbo、gpt-3.5-turbo-0301两个模型。 gpt-3.5-turbo:使用最新的GPT-3.5模型,并针对聊天进行了优…...

Django框架学习
文章目录Django框架项目开发1. 创建项目2. 项目目录结构3. 视图函数(view)4. 路由配置url5. HTTP请求6. HTTP响应 - 状态吗7. GET方式传参8. POST传递参数模板Templates1. 通过 loader 获取模板,通过HttpResponse进行响应2. 使用 render() 直接加载并响应…...

JavaSE21-集合1-set
文章目录一、集合概念二、set集合1、set集合的特点2、HashSet2.1 特点2.2 创建对象2.3 常用方法2.4 遍历2.4.1 foreach遍历2.4.2 使用迭代器遍历2.4.3 转换为数组遍历一、集合概念 集合就是用于存储多个数据的容器。相对于具有相同功能的数组来说,集合的长度可变会…...
Web版和客户端哪种SQL工具更好?ChatGPT有话要说
2023年年初公司发布了一款Web版SQL工具,短期内就赢得了众多用户的喜爱和下载。不过,也有SQL用户在评论区中提出自己的观点,认为Web版工具都不可靠,甚至看见Web版工具就劝返… … 工具Web化逐渐成为一种趋势,比如&…...

从客户端的角度来看移动端IM即时通讯的消息可靠性和送达机制
如何确保IM 不丢消息是个相对复杂的话题,从客户端发送数据到服务器,再从服务器抵达目标客户端,最终在 UI 成功展示,其间涉及的环节很多,这里只取其中一环「接收端如何确保消息不丢失」来探讨,粗略聊下我接触…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...