LangChain学习二:提示-实战(下半部分)
文章目录
- 上一节内容:LangChain学习二:提示-实战(上半部分)
- 学习目标:提示词中的示例选择器和输出解释器
- 学习内容一:示例选择器
- 1.1 LangChain自定义示例选择器
- 1.2 实现自定义示例选择器
- 1.2.1实战:定义一个类继BaseExampleSelector并且承实现方法
- 1.2.2实战:使用示例选择器
- 1.3 实现基于长度的选择器
- 1.4 最大边际相关性示例选择器
- 1.5 gram重叠
- 1.5.1 创建示例集
- 1.5.2 选择示例
- 1.5.2.1 threshold=-1.0,示例排序、不排除任何示例
- 1.5.2.2 threshold=0.0,`排除`具有与输入无ngram重叠的示例
- 1.5.2.3 threshold大于0小于1意味着只有相似度大于 设置值的示例才会被选择
- 1.5.2.4 threshold大于1,不会选择任何
- 1.6 相似度
- 学习内容二:输出解析器
上一节内容:LangChain学习二:提示-实战(上半部分)
LangChain学习二:提示-实战(上半部分)
学习目标:提示词中的示例选择器和输出解释器
- 示例选择器:在写提示词的时候给与少量的示例在前面,在上一节的最后提到,这一节细化说一下
- 输出解释器:语言模型输出文本。但是很多时候,你可能想要获得比文本更结构化的信息。这就是输出解析器的作用。
学习内容一:示例选择器
1.1 LangChain自定义示例选择器
自定义示例选择器它的英文名叫做few shot examples:就像我们教小朋友一样,比如教小朋友分类水果,先给他演示一下水果怎么分类的,红色的放哪一个框框,白色的放哪一个框框,然后在给它一个新的水果,小朋友根据你教的示范,就会自己去分类了
具体在上一节的2.5有介绍
1.2 实现自定义示例选择器
具体步骤如下
- 定义一个类,继承BaseExampleSelector
- 实现add_example方法,它接受一个示例并将其添加到该ExampleSelector中。
- 实现select_examples方法,它接受输入变量(这些变量应为用户输入),并返回要在few-shot提示中使用的示例列表。
1.2.1实战:定义一个类继BaseExampleSelector并且承实现方法
from langchain.prompts.example_selector.base import BaseExampleSelector
from typing import Dict, List
import numpy as npclass CustomExampleSelector(BaseExampleSelector):def __init__(self, examples: List[Dict[str, str]]):self.examples = examplesdef add_example(self, example: Dict[str, str]) -> None:"""为密钥添加要存储的新示例。"""self.examples.append(example)def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:"""根据输入选择要使用的示例。 你可以在这里写你自己的算法,我这里就表示随机从examples里拿两个示例,replace表示不会重复"""return np.random.choice(self.examples, size=2, replace=False)1.2.2实战:使用示例选择器
examples = [{"foo": "1"},{"foo": "2"},{"foo": "3"}
]# 初始化示例选择器。
example_selector = CustomExampleSelector(examples)#选择示例
example_selector.select_examples({"foo": "foo"})
# -> array([{'foo': '2'}, {'foo': '3'}], dtype=object)# 将新示例添加到示例集
example_selector.add_example({"foo": "4"})
print(f"======查看现在有哪些示例\n{example_selector.examples}\n")
# -> [{'foo': '1'}, {'foo': '2'}, {'foo': '3'}, {'foo': '4'}]# 选择示例
llm_example=example_selector.select_examples({"foo": "foo"})
print(f"======选择示例\n{llm_example}\n")

因为这里选择写的是随机的,所以这里就是随机的找两条
1.3 实现基于长度的选择器
总长度是由max_length控制的,如果我们输入的长一些,就会少从examples 拿一些,输入短,则反之
from langchain import PromptTemplate, FewShotPromptTemplate# 首先,创建少数快照示例的列表。
from langchain.prompts import LengthBasedExampleSelectorexamples = [{"word": "开心", "antonym": "悲伤"},{"word": "高", "antonym": "低"},
]# 接下来,我们指定模板来格式化我们提供的示例。
# 为此,我们使用“PromptTemplate”类。
example_formatter_template = """
单词: {word}
反义词: {antonym}\n
"""
example_prompt = PromptTemplate(input_variables=["word", "antonym"],template=example_formatter_template,
)
#我们将使用' LengthBasedExampleSelector '来选择示例。
example_selector = LengthBasedExampleSelector(# 这些是可供选择的例子。examples=examples,#这是用于格式化示例的PromptTemplate。example_prompt=example_prompt,# 这是格式化示例的最大长度。# 长度由下面的get_text_length函数测量。max_length=25,
)
# 我们现在可以使用' example_selector '来创建' FewShotPromptTemplate '。
dynamic_prompt = FewShotPromptTemplate(# We provide an ExampleSelector instead of examples.example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个输入的反义词",suffix="单词: {input}\n反义词:",input_variables=["input"],example_separator="",
)# We can now generate a prompt using the `format` method.
print(dynamic_prompt.format(input="大"))
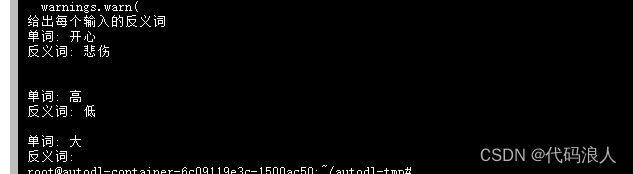
这个是上一节举的例子,当然上一节没有提到现在的示例添加新的示例方法
#您也可以将示例添加到示例选择器中。
new_example = {"word": "大", "antonym": "小"}
dynamic_prompt.example_selector.add_example(new_example)
print(dynamic_prompt.format(input="多"))
1.4 最大边际相关性示例选择器
这种示例选择器基于与输入之间的边际相关性来选择示例。它计算每个示例与输入之间的相关性,并选择具有最高相关性的示例作为回答。
这种方法适用于输入和示例之间有很强相关性的情况,例如问答系统中的问题和答案。
这里我们要借助一个类MaxMarginalRelevanceExampleSelector
MaxMarginalRelevanceExampleSelector:基于哪些示例与输入最相似以及优化多样性的组合选择示例。
这里我们用m3e-base作为向量化引擎
下载
from modelscope.hub.snapshot_download import snapshot_downloadlocal_dir_root = "/root/autodl-tmp/models_from_modelscope"
snapshot_download('Jerry0/m3e-base', cache_dir=local_dir_root)
from langchain.prompts.example_selector import MaxMarginalRelevanceExampleSelector
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
embeddings = HuggingFaceEmbeddings(
model_name = "/root/autodl-tmp/models_from_modelscope/Jerry0/m3e-base",
model_kwargs = {'device': 'cuda'})
example_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)#这是许多创建反义词的假装任务的例子。
examples = [{"input": "开心", "output": "悲伤"},{"input": "发呆", "output": "兴奋"},{"input": "高", "output": "底"},{"input": "精力充沛的", "output": "无精打采"},{"input": "晴天", "output": "雨天"},{"input": "天上", "output": "地下"},
]example_selector = MaxMarginalRelevanceExampleSelector.from_examples(#这是可供选择的示例列表。examples, #这是用于生成用于测量语义相似性的嵌入的嵌入类。embeddings, #这是VectorStore类,用于存储嵌入并进行相似性搜索。FAISS, #这是要生成的示例数。k=2
)
mmr_prompt = FewShotPromptTemplate(#我们提供了ExampleSelector而不是示例。example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个输入的反义词",suffix="Input: {adjective}\nOutput:", input_variables=["adjective"],
)# 输入是一种感觉,所以应该选择快乐/悲伤的例子作为第一个
print(mmr_prompt.format(adjective="快乐"))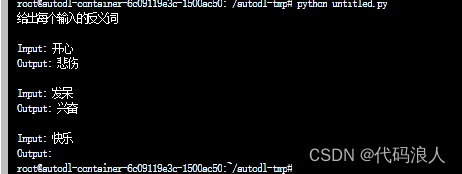
1.5 gram重叠
其实是对1.4的补充和优化
我们需要借助一个NGramOverlapExampleSelector的类,然后根据ngram重叠得分选择和排序示例.
该得分表示示例与输入的相似程度
ngram重叠得分是一个介于0.0和1.0之间的浮点数。
-
选择器允许设置阈值得分。 ngram重叠得分小于或等于阈值的示例将被排除。默认情况下,阈值设置为
-1.0,因此不会排除任何示例,只会对它们进行重新排序。 -
将阈值设置为0.0将
排除具有与输入无ngram重叠的示例
1.5.1 创建示例集
pip install nltk
from langchain.prompts import PromptTemplate
from langchain.prompts.example_selector.ngram_overlap import NGramOverlapExampleSelector
from langchain.prompts import FewShotPromptTemplate, PromptTemplate# 创建模板
example_prompt = PromptTemplate(input_variables=["input", "output"],template="输入: {input}\n输出: {output}",
)
#示例集合:这些是虚构翻译任务的例子:英语转化为葡萄牙语examples = [{"input": "See Spot run.", "output": "Ver correr a Spot."},{"input": "My dog barks.", "output": "Mi perro ladra."},{"input": "Spot can run.", "output": "Spot puede correr."},
]1.5.2 选择示例
1.5.2.1 threshold=-1.0,示例排序、不排除任何示例
example_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)
example_selector = NGramOverlapExampleSelector(# 以下是可供选择的示例。examples=examples, # 这是用于格式化示例的PromptTemplate。example_prompt=example_prompt, # 这是选择器停止的阈值。# 默认情况下,它设置为-1.0。threshold=-1.0,#对于负阈值:#Selector按ngram重叠分数对示例进行排序,不排除任何示例。#对于大于1.0的阈值:#选择器排除所有示例,并返回一个空列表。#对于等于0.0的阈值:#Selector根据ngram重叠分数对示例进行排序,#并且排除与输入没有ngram重叠的那些。
)
dynamic_prompt = FewShotPromptTemplate(# We provide an ExampleSelector instead of examples.example_selector=example_selector,example_prompt=example_prompt,prefix="提供每个Input的西班牙语翻译",suffix="Input: {sentence}\nOutput:", input_variables=["sentence"],
)#一个与“Spot can run”有较大ngram重叠的示例输入
#与“我的狗叫”没有重叠
print(dynamic_prompt.format(sentence="Spot can run fast."))

让我们添加示例,再来一次
new_example = {"input": "Spot plays fetch.", "output": "Spot juega a buscar."}example_selector.add_example(new_example)
print(dynamic_prompt.format(sentence="Spot can run fast."))
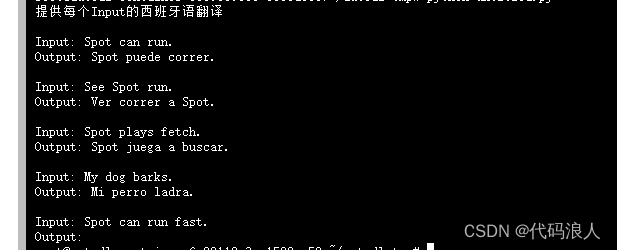
我们可以看到 他确实进行了排序,我们的问题是,Spot跑的飞快
而且第一个是Spot可以跑,第二个看见Spot跑,第三个Spot在玩游戏
第四个:我的狗再叫
第三第四个很明显不符合,所以在最后
1.5.2.2 threshold=0.0,排除具有与输入无ngram重叠的示例
example_selector.threshold=0.0
print(dynamic_prompt.format(sentence="Spot can run fast."))

这里就把第三第四给排除了
1.5.2.3 threshold大于0小于1意味着只有相似度大于 设置值的示例才会被选择
example_selector.threshold=0.09
print(dynamic_prompt.format(sentence="Spot can play fetch."))
1.5.2.4 threshold大于1,不会选择任何
1.0 + 1e-9 的结果是 1.000000001,即在 1.0 的基础上增加了一个非常小的数 1e-9。这种写法通常是为了解决在计算机中浮点数运算可能产生的精度问题。
在这段代码中,将 example_selector.threshold 的值设为 1.0+1e-9,其实就是设置一个非常接近于 1.0,但又比它略大一点点的阈值。这样做可能会使得更多的示例被选择,因为在相似度计算中可能存在一些舍入误差或计算误差,导致某些本来应该被选择的示例未能被选中。
example_selector.threshold=1.0+1e-9
print(dynamic_prompt.format(sentence="Spot can play fetch."))
这里只会显示我们输入的,不会选择任何示例
1.6 相似度
最大边际相关性 ExampleSelector 和 相似度 ExampleSelector 都是示例选择器,它们的区别在于选择示例的方法不同。
相似度 ExampleSelector 则使用文本相似度度量来选择最相关的示例。它不仅考虑了输入和示例之间的相关性,还考虑了它们之间的相似度。具体而言,它计算输入和示例之间的相似度,然后选择与输入最相似的示例作为回答。这种方法适用于输入和示例之间没有直接的相关性,但它们在语义或形式上非常相似的情况,例如聊天机器人对话中的语句。
最大边际相关性 ExampleSelector:
- 基于输入与示例之间的边际相关性来选择示例。
- 计算每个示例与输入之间的相关性,并选择具有最高相关性的示例作为回答。
- 适用于输入和示例之间有明显相关性的情况,例如问答系统中的问题和答案。
相似度 ExampleSelector:
- 使用文本相似度度量来选择最相关的示例。
- 不仅考虑输入和示例之间的相关性,还考虑它们之间的相似度。
- 计算输入和示例之间的相似度,然后选择与输入最相似的示例作为回答。
- 适用于输入和示例之间没有直接的相关性,但在语义或形式上非常相似的情况,例如聊天机器人对话中的语句。
总结:
最大边际相关性 ExampleSelector 关注输入与示例之间的相关性,而相似度 ExampleSelector 则重点考虑它们之间的相似度。两种选择器在选择示例时的侧重点不同,适用于不同的应用场景和数据特征。
说白了就是通过找到嵌入与输入具有最大余弦相似度的示例,然后迭代地添加它们,同时筛选它们与已选择示例的接近程度来实现这一目的。
其实这里《LangChain学习一:模型-实战》中文本嵌入有介绍,这里我们在复习一下
就是说从很多的示例集中,我们通过向量的方式去找到示例里和我们提的问题语义相近的内容作为示例,然后在给大模型,这里就不啰嗦介绍了,那一节里介绍的比较全
学习内容二:输出解析器
未完成待续,明晚继续,睡觉
相关文章:
LangChain学习二:提示-实战(下半部分)
文章目录 上一节内容:LangChain学习二:提示-实战(上半部分)学习目标:提示词中的示例选择器和输出解释器学习内容一:示例选择器1.1 LangChain自定义示例选择器1.2 实现自定义示例选择器1.2.1实战:…...

Network 灰鸽宝典【目录】
目前已有文章 21 篇 Network 灰鸽宝典专栏主要关注服务器的配置,前后端开发环境的配置,编辑器的配置,网络服务的配置,网络命令的应用与配置,windows常见问题的解决等。 文章目录 服务配置环境部署GitNPM 浏览器编辑器系…...
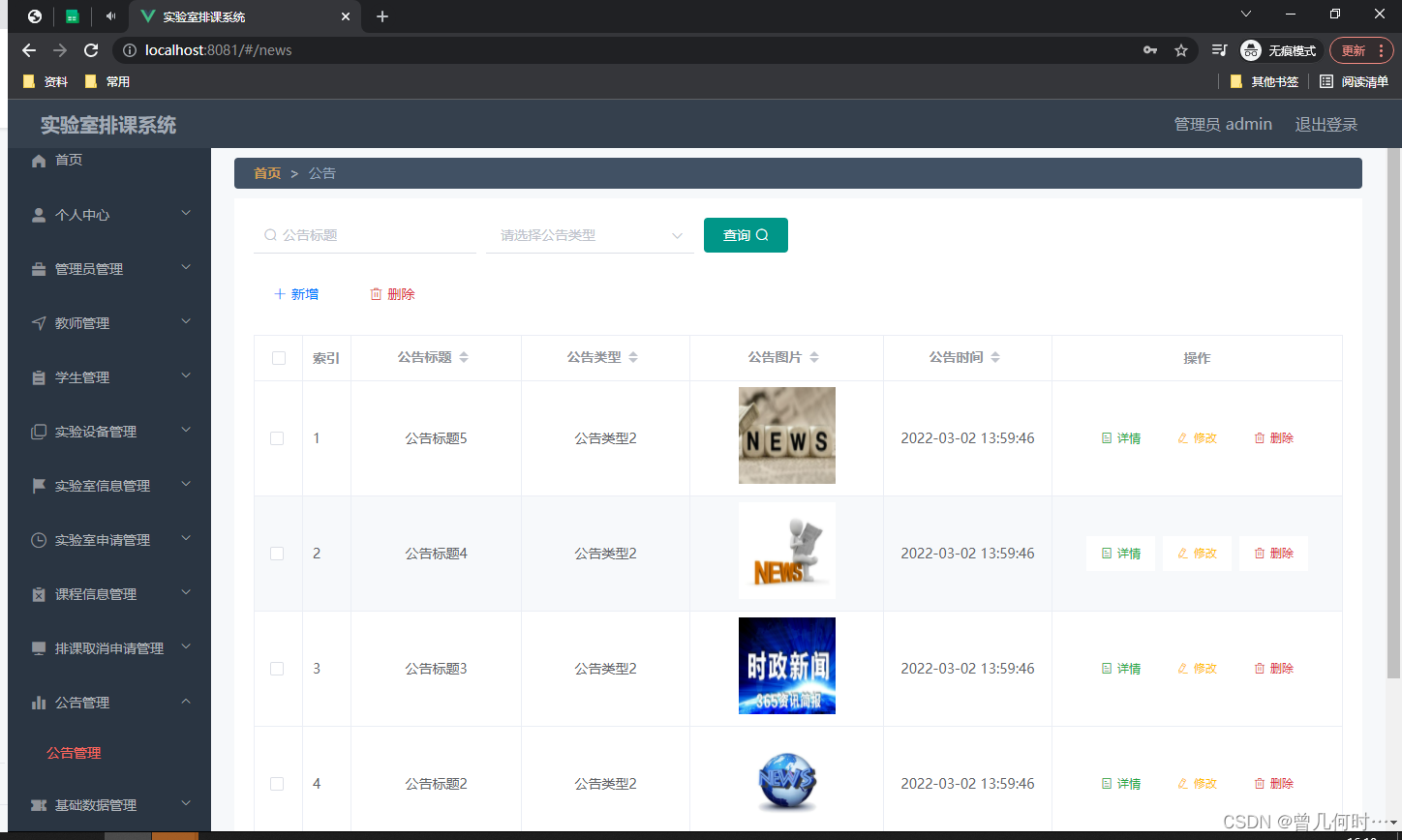
基于SSM的实验室排课系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
Docker部署wordpress和Jenkins
准备机器: 192.168.58.151 (关闭防火墙和selinux) 安装好docker服务 (详细参照:http://t.csdnimg.cn/usG0s 中的国内源安装docker) 部署wordpress: 创建目录: [rootdocker ~]# mkdi…...

C语言—每日选择题—Day45
第一题 1. 以下选项中,对基本类型相同的指针变量不能进行运算的运算符是() A: B:- C: D: 答案及解析 A A:错误,指针不可以相加,因为指针相加可能发生越界&…...
音乐制作软件Studio One mac软件特点
Studio One mac是一款专业的音乐制作软件,由美国PreSonus公司开发。该软件提供了全面的音频编辑和混音功能,包括录制、编曲、合成、采样等多种工具,可用于制作各种类型的音乐,如流行音乐、电子音乐、摇滚乐等。 Studio One mac软件…...
)
华为OD机试 - 会议室占用时间(Java JS Python C)
题目描述 现有若干个会议,所有会议共享一个会议室,用数组表示各个会议的开始时间和结束时间,格式为: [[会议1开始时间, 会议1结束时间], [会议2开始时间, 会议2结束时间]] 请计算会议室占用时间段。 输入描述 第一行输入一个整数 n,表示会议数量 之后输入n行,每行两个…...
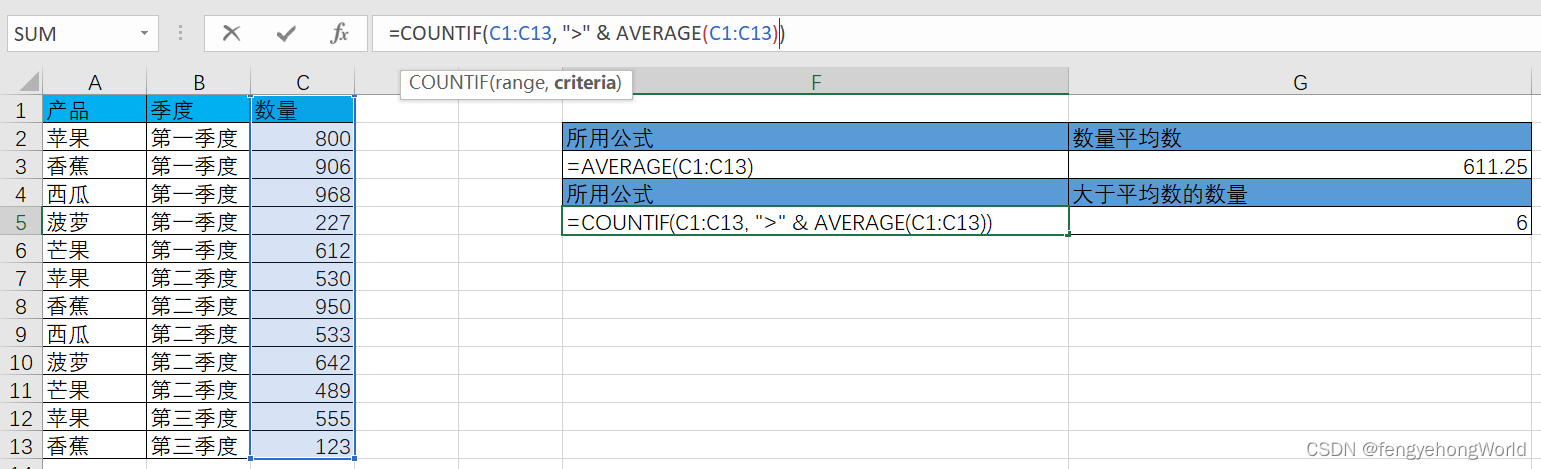
Excel COUNT类函数使用
目录 一. COUNT二. COUNTA三. COUNTBLANK四. COUNTIF五. COUNTIFS 一. COUNT ⏹用于计算指定范围内包含数字的单元格数量。 基本语法 COUNT(value1, [value2], ...)✅统计A2到A7所有数字单元格的数量 ✅统计A2到A7,B2到B7的所有数字单元格的数量 二. COUNTA ⏹计…...

刷题学习记录(文件上传)
[GXYCTF 2019]BabyUpload 知识点:文件上传.htaccessMIME绕过 题目直接给题目标签提示文件上传的类型 思路:先上传.htaccess文件,在上传木马文件,最后蚁剑连接 上传.htaccess文件 再上传一个没有<?的shell 但是要把image/pn…...
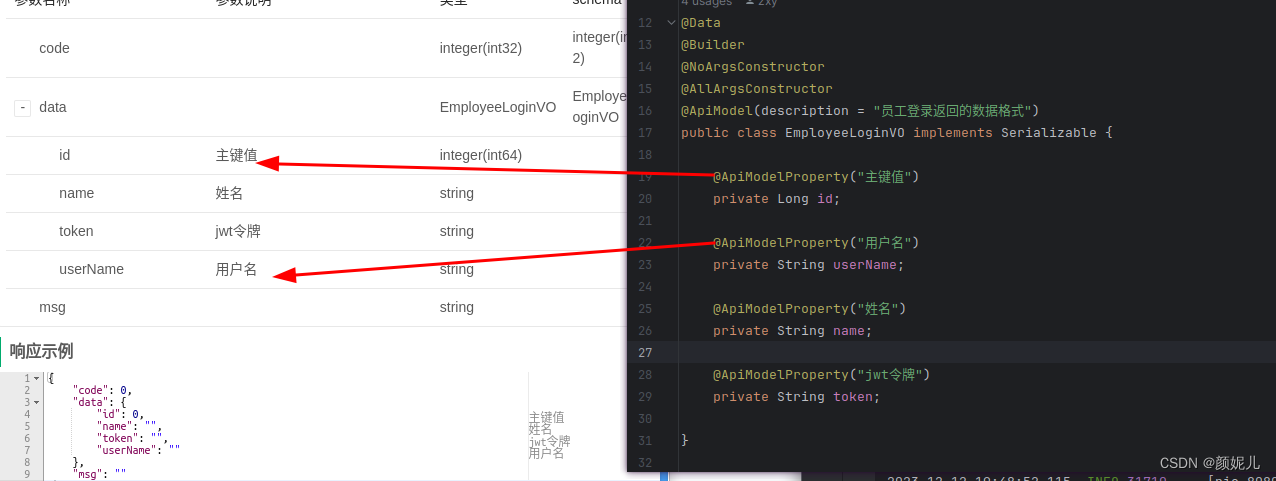
接口管理——Swagger
Swagger是一个用于设计、构建和文档化API的工具集。它包括一系列工具,如Swagger Editor(用于编辑Swagger规范)、Swagger UI(用于可视化API文档)和Swagger Codegen(用于根据API定义生成客户端库、server stu…...

基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建1)定义模型结构2)优化损失函数 3. 模型训练及保存1)模型训练2)模型保存3)映射保存 相关其它博客工程源代码下载其它资料下载…...
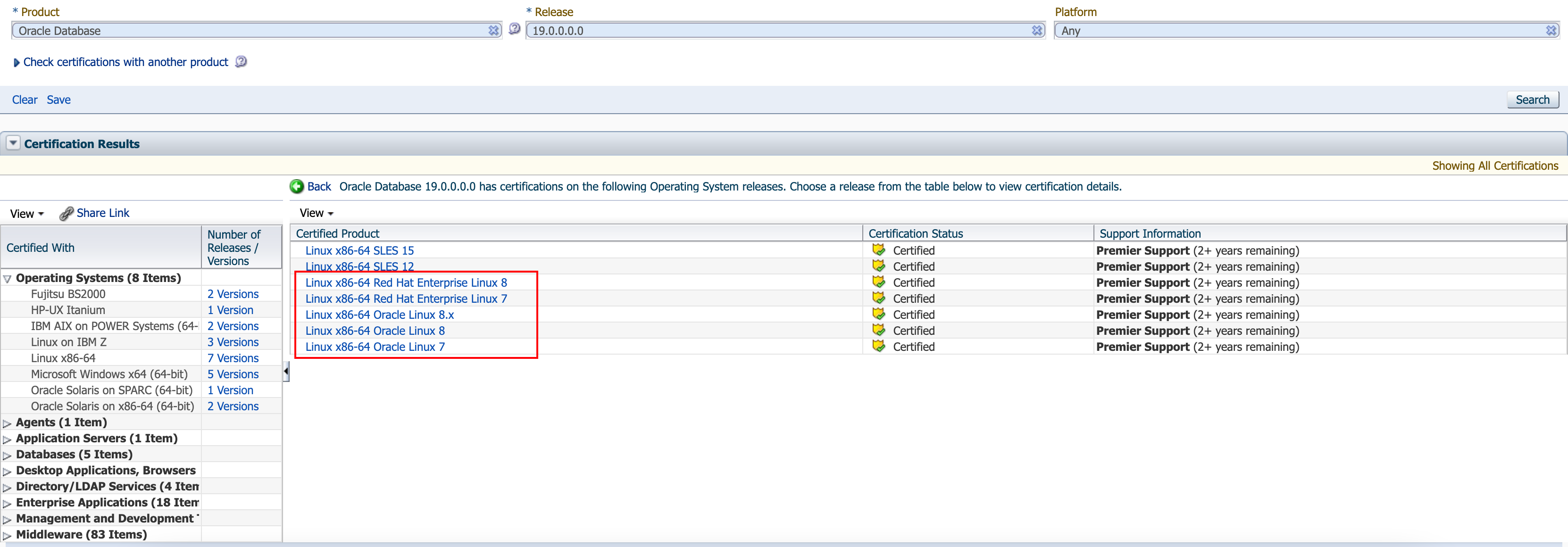
(第5天)进阶 RHEL 7 安装单机 Oracle 19C NON-CDB 数据库
进阶 RHEL 7 安装单机 Oracle 19C NON-CDB 数据库(第5天) 真快,实战第 5 天了,我们来讲讲 19C 的数据库安装吧!19C 是未来几年 Oracle 数据库的大趋势,同样的作为长期稳定版,11GR2 在 2020 年 10 月份官方就宣布停止 Support 了,19C 将成为新的长期稳定版,并持续支持…...
AI自动生成代码工具
AI自动生成代码工具是一种利用人工智能技术来辅助或自动化软件开发过程中的编码任务的工具。这些工具使用机器学习和自然语言处理等技术,根据开发者的需求生成相应的源代码。以下是一些常见的AI自动生成代码工具,希望对大家有所帮助。北京木奇移动技术有…...

jmeter和postman的对比
1.创建接口用例集(没区别) Postman是Collections,Jmeter是线程组,没什么区别。 2.步骤的实现(有区别) Postman和jmeter都是创建http请求 区别1:postman请求的请求URL是一个整体,j…...

深度学习在人体动作识别领域的应用:开源工具、数据集资源及趋动云GPU算力不可或缺
人体动作识别检测是一种通过使用计算机视觉和深度学习技术,对人体姿态和动作进行实时监测和分析的技术。该技术旨在从图像或视频中提取有关人体姿态、动作和行为的信息,以便更深入地识别和理解人的活动。 人体动作识别检测的基本步骤包括: 数…...
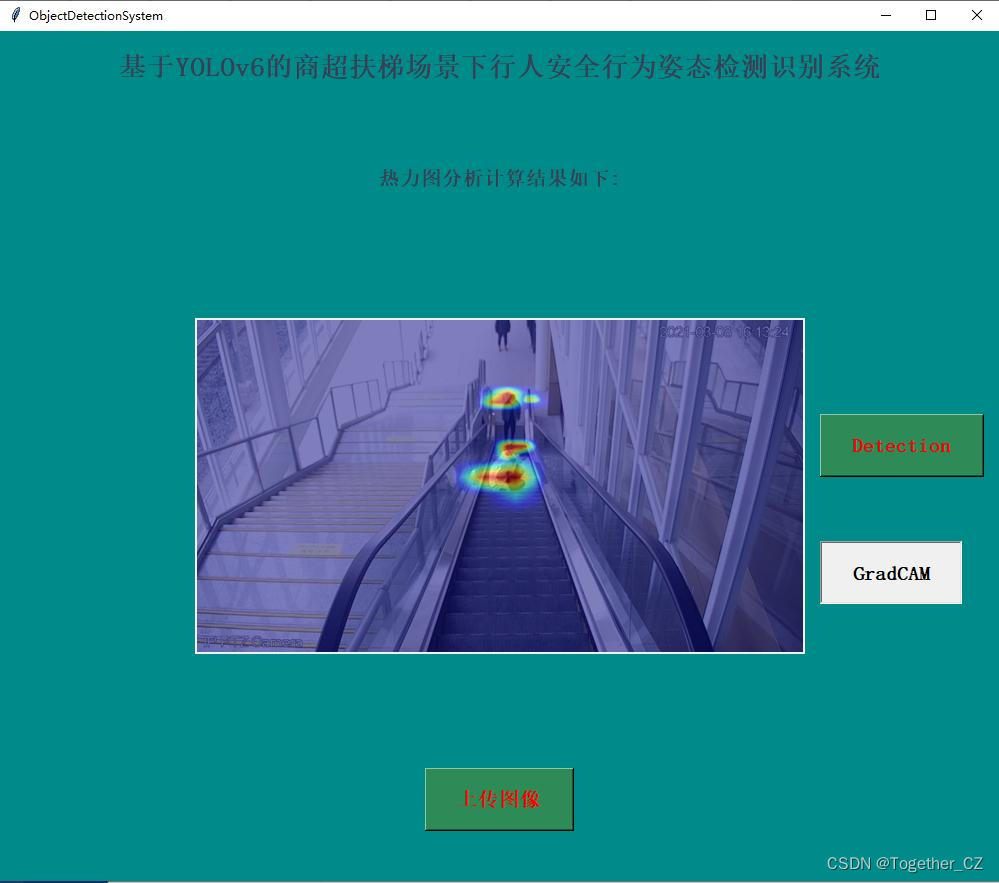
科技提升安全,基于YOLOv6开发构建商超扶梯场景下行人安全行为姿态检测识别系统
在商超等人流量较为密集的场景下经常会报道出现一些行人在扶梯上摔倒、受伤等问题,随着AI技术的快速发展与不断普及,越来越多的商超、地铁等场景开始加装专用的安全检测预警系统,核心工作原理即使AI模型与摄像头图像视频流的实时计算…...
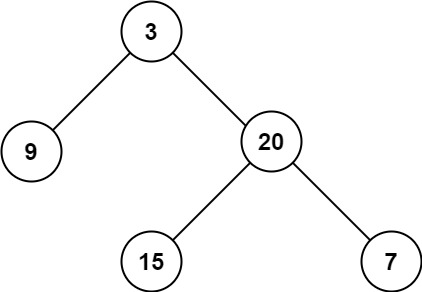
二叉树的最大深度
问题描述: 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3示例 2: 输入࿱…...
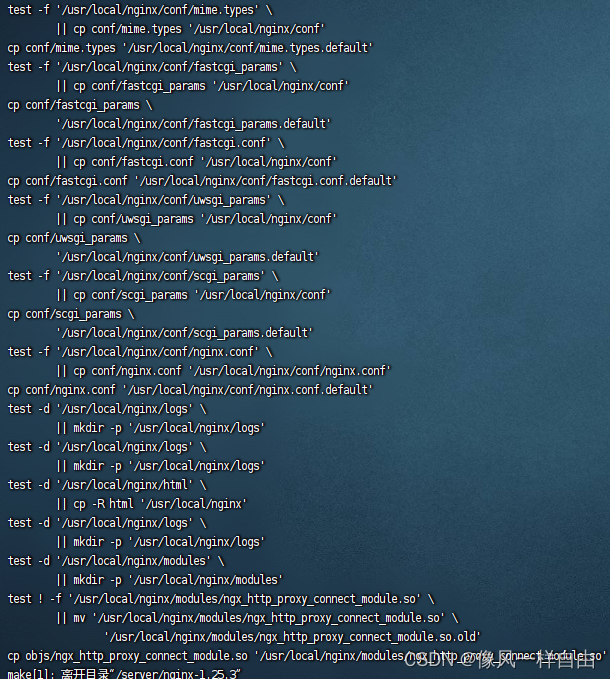
nginx配置正向代理支持https
操作系统版本: Alibaba Cloud Linux 3.2104 LTS 64位 nginx版本: nginx-1.25.3 1. 下载软件 切换目录 cd /server wget http://nginx.org/download/nginx-1.25.3.tar.gz 1.1解压 tar -zxvf nginx-1.25.3.tar.gz 1.2切换到源码所在目录…...

奥比中光 Femto Bolt相机ROS配置
机械臂手眼标定详解 作者: Herman Ye Auromix 测试环境: Ubuntu20.04/22.04 、ROS1 Noetic/ROS2 Humble、X86 PC/Jetson Orin、Kinect DK/Femto Bolt 更新日期: 2023/12/12 注1: Auromix 是一个机器人爱好者开源组织。 注2&#…...

scala表达式
1.8 表达式(重点) # 语句(statement):一段可执行的代码# 表达式(expression):一段可以被求值的代码,在Scala中一切都是表达式 - 表达式一般是一个语句块,可包含一条或者多条语句,多条语句使用“…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...