基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(四)
目录
- 前言
- 引言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 模型构建
- 3. 模型训练及保存
- 4. 模型生成
- 系统测试
- 1. 训练准确率
- 2. 测试效果
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者的反馈中发现许多小伙伴对方言的辨识和分类表现出浓厚兴趣。鉴于此,博主决定专门撰写一篇关于方言分类的博客,以满足读者对这一主题的进一步了解和探索的需求。上篇博客可参考:
《基于Python+WaveNet+CTC+Tensorflow智能语音识别与方言分类—深度学习算法应用(含全部工程源码)》
引言
本项目以科大讯飞提供的数据集为基础,通过特征筛选和提取的过程,选用WaveNet模型进行训练。旨在通过语音的梅尔频率倒谱系数(MFCC)特征,建立方言和相应类别之间的映射关系,解决方言分类问题。
首先,项目从科大讯飞提供的数据集中进行了特征筛选和提取。包括对语音信号的分析,提取出最能代表语音特征的MFCC,为模型训练提供有力支持。
其次,选择了WaveNet模型进行训练。WaveNet模型是一种序列生成器,用于语音建模,在语音合成的声学建模中,可以直接学习采样值序列的映射,通过先前的信号序列预测下一个时刻点值的深度神经网络模型,具有自回归的特点。
在训练过程中,利用语音的MFCC特征,建立了方言和相应类别之间的映射关系。这样,模型能够识别和分类输入语音的方言,并将其划分到相应的类别中。
最终,通过这个项目,实现了方言分类问题的解决方案。这对于语音识别、语音助手等领域具有实际应用的潜力,也有助于保护和传承各地区的语言文化。
总体设计
本部分包括系统整体结构图和系统流程图。
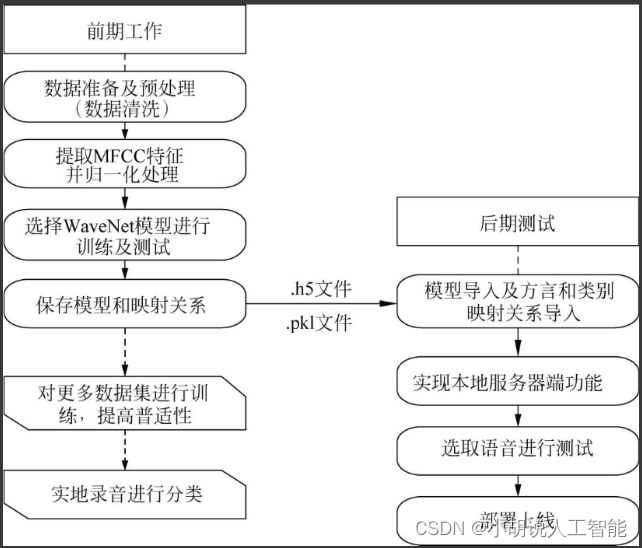
系统整体结构图
系统整体结构如图所示。
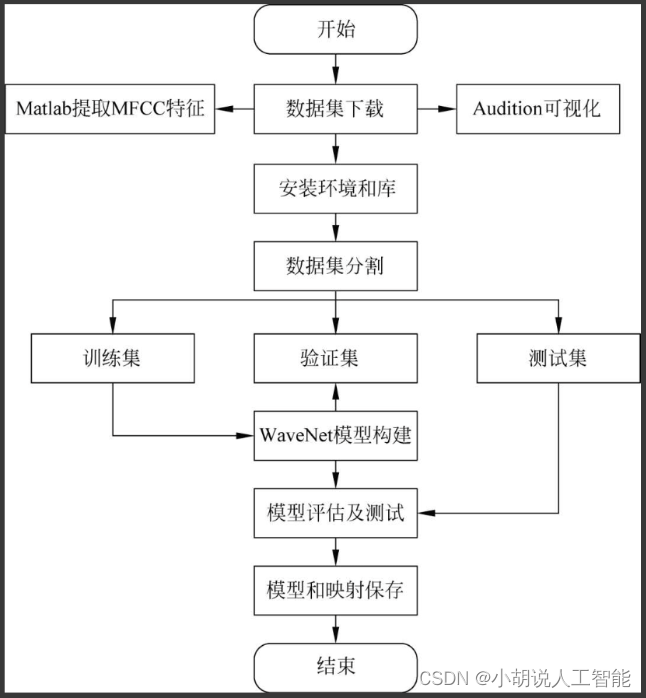
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、JupyterNotebook环境、PyCharm环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本部分包括数据介绍、数据测试和数据处理。
详见博客。
2. 模型构建
数据加载进模型之后,需要定义模型结构并优化损失函数。
详见博客。
3. 模型训练及保存
本部分包括模型训练、模型保存和映射保存。
详见博客。
4. 模型生成
将训练好的.h5模型文件放入总目录下:信息系统设计方言种类识别/fangyan.h5。
相关代码如下:
#打开映射
with open('resources.pkl', 'rb') as fr:[class2id, id2class, mfcc_mean, mfcc_std] = pickle.load(fr)
model = load_model('fangyan.h5')
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/*.pcm')
将保存的方言和种类之间映射关系.pkl文件放到总文件目录下:信息系统设计/方言种类识别/resources.pkl。相关代码如下:
#打开保存的方言和种类之间的映射
with open('resources.pkl', 'rb') as fr:[class2id, id2class, mfcc_mean, mfcc_std] = pickle.load(fr)
在单机上加载训练好的模型,随机选择一条语音进行分类。新建测试主运行文件main.py,加载库之后,调用生成的模型文件获得预测结果。
相关代码如下:
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/*.pcm')
#通过random模块随机提取一条语音数据
path = np.random.choice(paths, 1)[0]
label = path.split('/')[1]
print(label, path)
#本部分的相关代码
# -*- coding:utf-8 -*-
import numpy as np
from keras.models import load_model
from keras.preprocessing.sequence import pad_sequences
import librosa
from python_speech_features import mfcc
import pickle
import wave
import glob
#打开映射
with open('resources.pkl', 'rb') as fr:[class2id, id2class, mfcc_mean, mfcc_std] = pickle.load(fr)
model = load_model('fangyan.h5')
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/*.pcm')
#通过random模块随机提取一条语音数据
path = np.random.choice(paths, 1)[0]
label = path.split('/')[1]
print(label, path)
#语音分片处理
mfcc_dim = 13
sr = 16000
min_length = 1 * sr
slice_length = 3 * sr
#提取语音信号的参数
def load_and_trim(path, sr=16000):audio = np.memmap(path, dtype='h', mode='r')audio = audio[2000:-2000]audio = audio.astype(np.float32)energy = librosa.feature.rmse(audio)frames = np.nonzero(energy >= np.max(energy) / 5)indices = librosa.core.frames_to_samples(frames)[1]audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]slices = []for i in range(0, audio.shape[0], slice_length):s = audio[i: i + slice_length]slices.append(s)return audio, slices
#提取MFCC特征进行测试
audio, slices = load_and_trim(path)
X_data = [mfcc(s, sr, numcep=mfcc_dim) for s in slices]
X_data = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_data]
maxlen = np.max([x.shape[0] for x in X_data])
X_data = pad_sequences(X_data, maxlen, 'float32', padding='post', value=0.0)
print(X_data.shape)
#预测方言种类并输出
prob = model.predict(X_data)
prob = np.mean(prob, axis=0)
pred = np.argmax(prob)
prob = prob[pred]
pred = id2class[pred]
print('True:', label)
print('Pred:', pred, 'Confidence:', prob)
系统测试
本部分包括训练准确率及测试效果。
1. 训练准确率
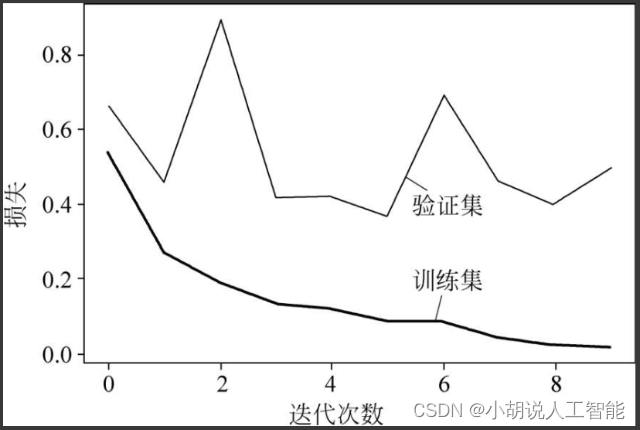
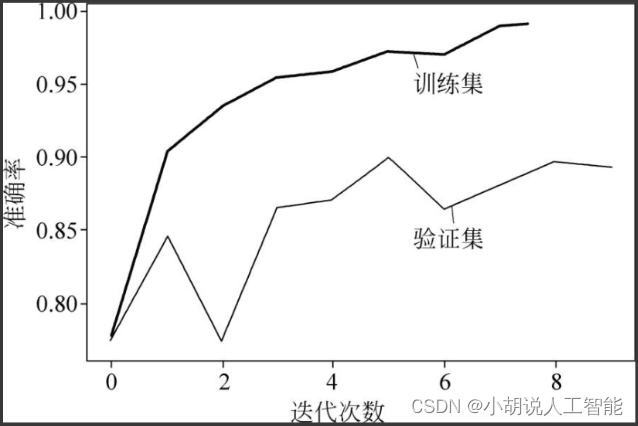
绘制损失函数曲线和准确率曲线,经过10轮训练后,准确率将近100%,验证集准确率在89%左右。相关代码如下:
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
plt.plot(train_loss,label='训练集')
plt.plot(valid_loss,label='验证集')
plt.legend(loc='upperright')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.show()
#训练损失
#验证损失
#绘图
train acc = history.history['acc']
valid_acc = history.history['val_acc']
plt.plot(train_acc,label='训练集')
plt.plot(valid acc,label='验证集')
plt.legend(loc='upper right')
plt.xlabel('迭代次数')
plt.ylabel('准确率')
plt.show()
随着训练次数的增多,模型在训练数据、测试数据上的损失和准确率逐渐收敛,最终趋于稳定,如图3和图4所示。
2. 测试效果
在本地服务器端进行测试,使用PyCharm调用保存的模型和映射。设置PyCharm运行环境,找到本地Python环境并导入,如图所示。
从本地随机抽取一段语音进行测试,相关代码如下:
#glob()提取路径参数
paths = glob.glob('data/*/dev/*/*/* / .pcm')
#通过 random模块随机提取一条语音数据
path = np.random.choice(paths, 1)[0]
label=path.split('/')[1]
print(label,path)
paths=glob.glob('D:/课堂导读/信息系统设计/方言种类分类/data/*/dev/*/*.pcm')
#预测方言种类并输出
prob=model.predict(X_data)
prob = np.mean(prob,axis=0)
pred = np.argmax(prob)
prob = prob[pred]
pred = id2class[pred]
print('True:',label)
print('Pred:', pred, 'Confidence:', prob)
在PyCharm上编辑运行,得到的分类结果与语音片段一致,如图所示。

相关其它博客
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(一)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(二)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
相关文章:
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(四)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建3. 模型训练及保存4. 模型生成 系统测试1. 训练准确率2. 测试效果 相关其它博客工程源代码下载其它资料下载 前言 博主前段时间发布了一篇有关方言识别和分类模型训练的博客ÿ…...
文件操作及函数
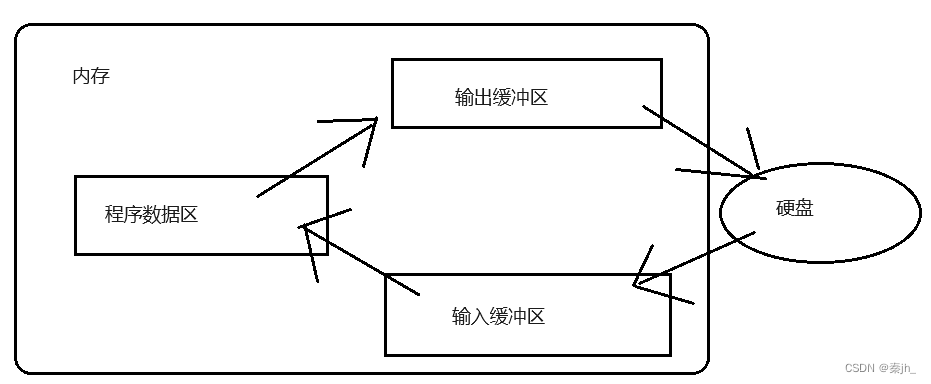
什么是文件? 在程序设计中,文件有两种:程序文件和数据文件。 程序文件 包括源程序文件(.c),目标文件(.obj),可执行程序(.exe)。 数据文件 文件的内容不一定是程序&…...
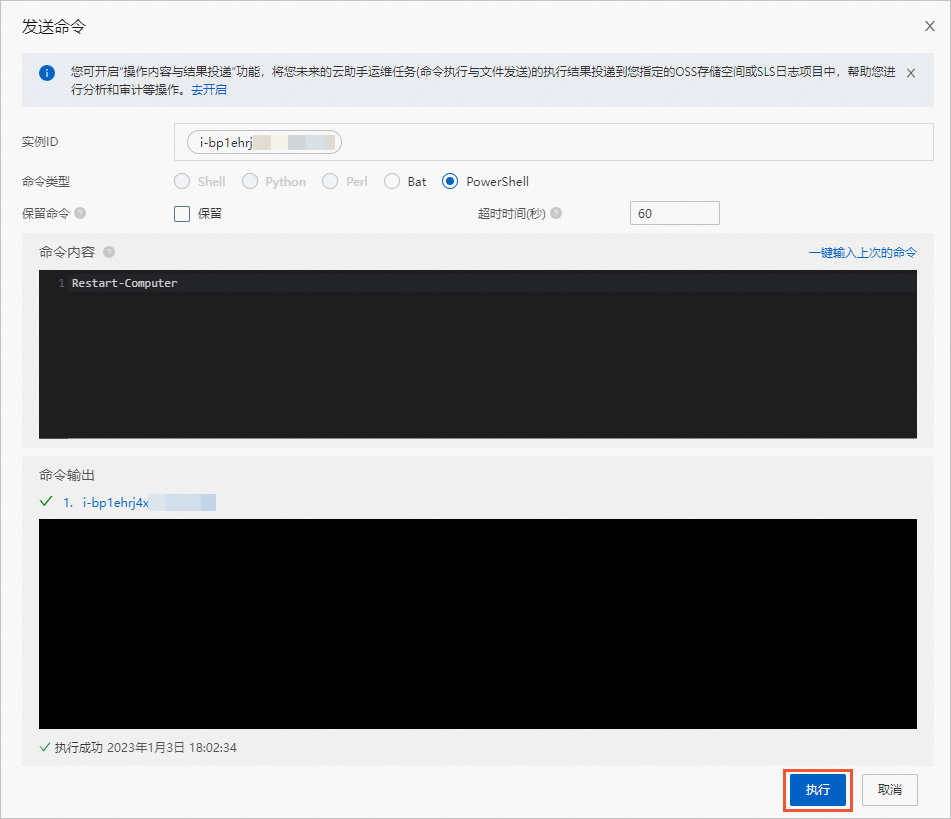
阿里云国际版无法远程连接Windows服务器的排查方法
如果您遇到紧急情况,需要尽快登录Windows实例,请参见以下操作步骤,先检查ECS实例的状态,然后通过云助手向Windows实例发送命令或通过VNC登录实例,具体步骤如下: 步骤一:检查ECS实例状态 无论何…...
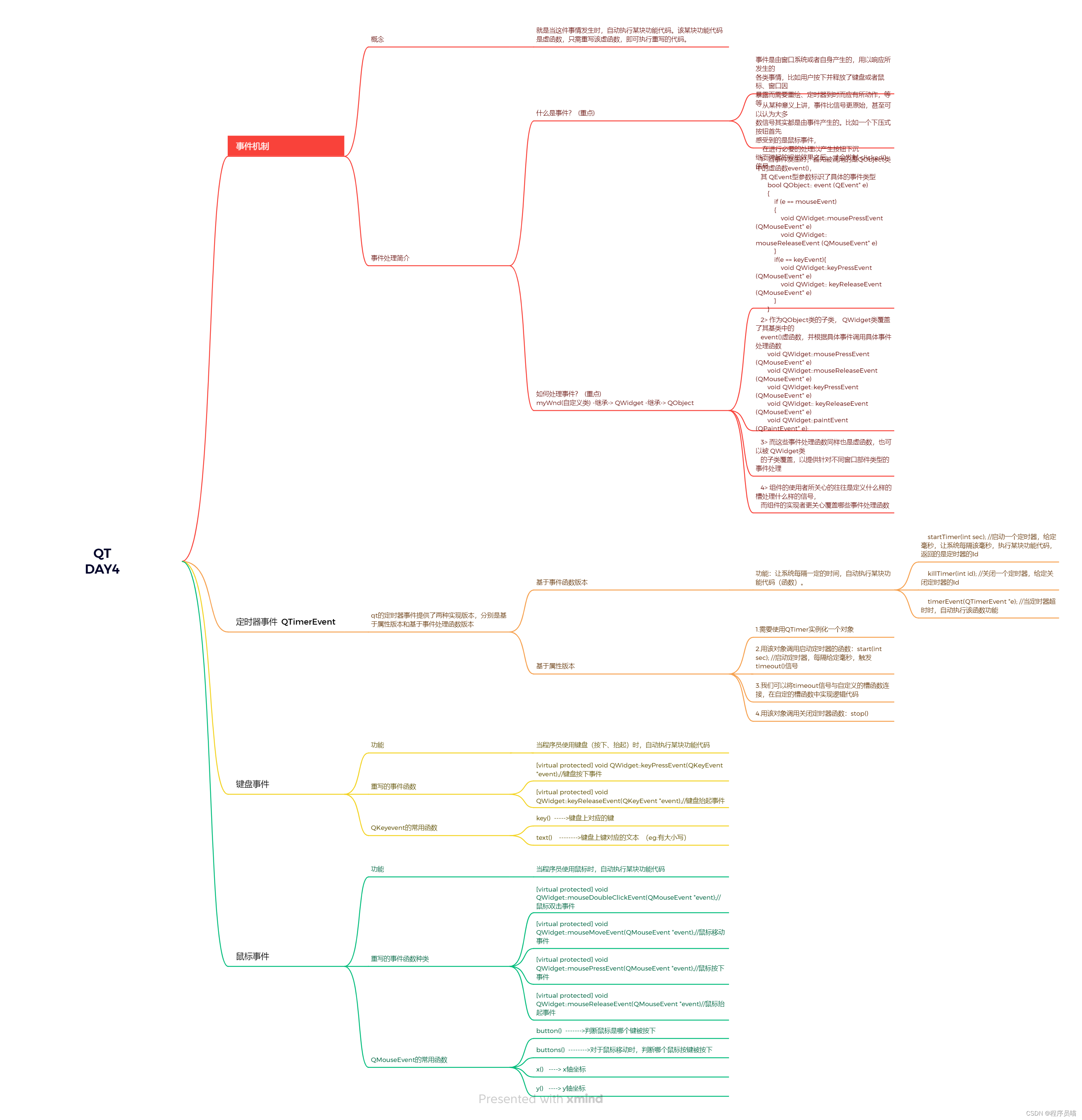
华清远见嵌入式学习——QT——作业4
作业要求: 代码运行效果图: 代码: 头文件: #ifndef ALARMCLOCK_H #define ALARMCLOCK_H#include <QWidget> #include <QTimerEvent> #include <QTimer> #include <QTime> #include <QTextToSpeech&g…...

Visuial Studio 打开 Unity 脚本时,脚本继承MonoBehaviour暂时失效为白色的解决方法
问题描述: u3d2020.3.47f1c1 vs2019 之前C#脚本A好好的,今天改了一行代码,在储存,就出现这个问题了,变白之后,新增的一行代码不生效,之前的代码照常运行。 如下办法都不能解决我的问题&…...

CentOS使用kkFileView实现在线预览word excel pdf等
一、环境安装 1、安装LibreOffice wget https://downloadarchive.documentfoundation.org/libreoffice/old/7.5.3.2/rpm/x86_64/LibreOffice_7.5.3.2_Linux_x86-64_rpm.tar.gz # 解压缩 tar -zxf LibreOffice_7.5.3.2_Linux_x86-64_rpm.tar cd LibreOffice_7.5.3.2_Linux_x86…...

黑豹程序员-EasyExcel实现导出
需求 将业务数据导出到excel中,老牌的可以选择POI,也有个新的选择EasyExcel。 有个小坑,客户要求样式比较美观,数字列要求千位符,保留2位小数。 可以用代码实现但非常繁琐,用模板就特别方便,模…...

【项目小结】优点分析
一、 个人博客系统 一)限制强制登录 问题:限制用户登录后才能进行相关操作解决: 1)前端: ① 写一个函数用于判断登录状态,如果返回的状态码是200就不进行任何操作,否则Ajax实现页面的跳转操作…...

已经写完的论文怎么降低查重率 papergpt
大家好,今天来聊聊已经写完的论文怎么降低查重率,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧: 已经写完的论文怎么降低查重率 背景介绍 在学术界,论文的查重率是评价论文质量的…...
科研论文中PPT图片格式选择与转换:EPS、SVG 和 PDF 的比较
当涉及论文中的图片格式时,导师可能要求使用 EPS 格式的图片。EPS(Encapsulated PostScript)是一种矢量图格式,它以 PostScript 语言描述图像,能够无损地缩放并保持图像清晰度。与像素图像格式(如 PNG 和 J…...

mybatis xml 热部署
平时我们在项目中多多少少会根据不同的情况等等原因去调试sql,在数据库测试完后也需要在代码里面运行测试,但是每次修改就需要重启服务就显得太繁琐,所以如果mybatis的xml也可以热部署当然是最好的了,那我来试试如何可以将mybatis…...
MySQL的事务以及springboot中如何使用事务
事务的四大特性: 概念: 事务 是一组操作的集合,它是不可分割的工作单元。事务会把所有操作作为一个整体,一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 注意: 默认MySQ…...

docker二 redis单机安装
创建文件夹 mkdir -p /usr/local/redis/data /usr/local/redis/logs /usr/local/redis/conf chmod -R 777 /usr/local/redis/data* chmod -R 777 /usr/local/redis/logs*另一种风格 # 创建 redis 配置存放目录 mkdir -p /home/docker/redis/conf && chmod 777 /home/…...
【解决】Vue elementUI table表格 列错位/滑动后切换每页显示数后错位/表格使用fixed后错位...
table表格右侧列固定后,在切换页面之后,就会出现列错误的现象 <el-tablev-adaptive"{ bottomOffset: 85 }"height"100px"v-loading"loading":data"dataList"> 解决方法 方法一 1、给表格添加ref &…...

uniapp实战 —— 分类导航【详解】
效果预览 组件封装 src\pages\index\components\CategoryPanel.vue <script setup lang"ts"> import type { CategoryItem } from /types/index defineProps<{list: CategoryItem[] }>() </script><template><view class"category&…...

LangChain学习二:提示-实战(下半部分)
文章目录 上一节内容:LangChain学习二:提示-实战(上半部分)学习目标:提示词中的示例选择器和输出解释器学习内容一:示例选择器1.1 LangChain自定义示例选择器1.2 实现自定义示例选择器1.2.1实战:…...

Network 灰鸽宝典【目录】
目前已有文章 21 篇 Network 灰鸽宝典专栏主要关注服务器的配置,前后端开发环境的配置,编辑器的配置,网络服务的配置,网络命令的应用与配置,windows常见问题的解决等。 文章目录 服务配置环境部署GitNPM 浏览器编辑器系…...
基于SSM的实验室排课系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
Docker部署wordpress和Jenkins
准备机器: 192.168.58.151 (关闭防火墙和selinux) 安装好docker服务 (详细参照:http://t.csdnimg.cn/usG0s 中的国内源安装docker) 部署wordpress: 创建目录: [rootdocker ~]# mkdi…...

C语言—每日选择题—Day45
第一题 1. 以下选项中,对基本类型相同的指针变量不能进行运算的运算符是() A: B:- C: D: 答案及解析 A A:错误,指针不可以相加,因为指针相加可能发生越界&…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...

门静脉高压——表现
一、门静脉高压表现 00:01 1. 门静脉构成 00:13 组成结构:由肠系膜上静脉和脾静脉汇合构成,是肝脏血液供应的主要来源。淤血后果:门静脉淤血会同时导致脾静脉和肠系膜上静脉淤血,引发后续系列症状。 2. 脾大和脾功能亢进 00:46 …...