网络资源面经2
文章目录
- Kafka 原理,数据怎么平分到消费者
- 生产者分区
- 消费者分区
- Flume HDFS Sink 小文件处理
- Flink 与 Spark Streaming 的差异,具体效果
- Spark 背压机制具体实现原理
- Yarn 调度策略
- Spark Streaming消费方式及区别
- Zookeeper 怎么避免脑裂,什么是脑裂
- 讲一讲什么是 CAP 法则?Zookeeper 符合了这个法则的哪两个?
Kafka 原理,数据怎么平分到消费者
这里主要考的是kafka的分区分配策略
生产者分区
若指定分区号,则直接发给对应分区;若没有分区号,则通过key的hashcode对分区数取模;若也没有key则采取Sticky策略,会随机选择一分区,尽可能使用该分区,待该分区batch已满或者已提交,再随机选择一个分区,与当前分区不同。
消费者分区
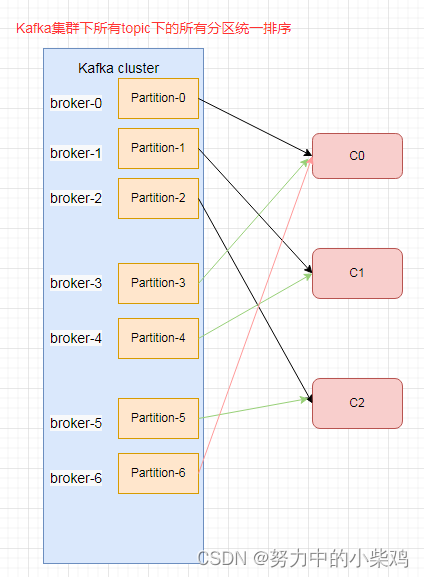
Kafka的分区分配策略
-
RoundRobin
针对所有topic的partition的。把消费者组订阅的所有topic的所有partition组成一个topicAndPartition列表,按照topicAndPartition的hashcode排序,对消费者组的所有消费者线程按照字母顺序排序,然后通过轮询将topicAndPartition列表中的每一个分区发给每一个消费者消费。
-
Range
是kafka默认分区分配策略。针对每一个topic而言的。首先将分区按分区号排序,然后将消费者按字母顺序排序,单个topic内partition数除以消费者组内的消费者线程数,决定每个消费者线程消费几个分区。如果除不尽前几个消费者会多消费一个分区。

-
Sticky
基础分配方式与RoundRobin一致,但是在重分配时,Sticky会尽可能保证与原分区策略一致。例如三个消费者中的一个挂了,如果是RoundRobin会对所有存活的消费者消费的分区进行重分配,如果是Sticky,则只将宕机节点分配的分区重分配给存活的消费者。

Flume HDFS Sink 小文件处理
源码中如果滚动中的文件如果被监测到正在进行HDFS的副本复制,就会自动产生一个文件,不会等到设置的条件触发再产生文件。源码的判断机制是当前正在复制的块序号是否小于配置文件中读取的最小副本数numBlocks < desiredBlocks。所以要想将这个触发条件关闭,需要使这个不等式恒不成立,我们不能修改hadoop的副本数,而Flume给我们提供了一个参数minBlockReplicas=1,我们只需要将这个参数设为1,就可以实现需求。
Flink 与 Spark Streaming 的差异,具体效果
- 流和微批
- 时间语义
Spark 背压机制具体实现原理
spark1.5之前,如果用户要限制Receiver的接受速率,只能通过配置参数spark.streaming.receiver.maxRate实现,虽然这样可以控制接受速率,防止OOM,但也会引入其他问题,当数据量小的时候,处理速率高于maxRate,这样就会导致资源利用率下降。所以从1.5开始,spark实现了一个新功能,可以通过动态控制接收速率来适配处理速率,即背压机制(spark.streaming.backpressure.enabled,默认false):根据JobSchedule反馈的执行信息来动态调整Receiver的接收速率。如果数据量稳定或数据量较小,则无需开启背压,因为背压机制也需要消耗计算资源。
Yarn 调度策略
-
FIFO调度器
单队列,任务会被放入队列中,先被获取先执行。 -
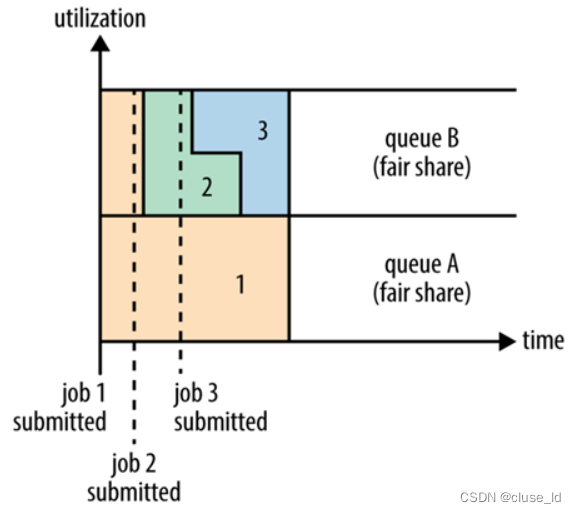
公平调度器
见面分一半。多队列,不会预分资源。当单任务提交时,若无其他任务运行,则独享所有资源。其他队列有任务时,与其他队列平分资源。当本队列有任务时,与本队列任务平分本队列资源。队列内部也可以设置调度策略公平(默认)或者FIFO
-
容量调度器
对资源进行预分,设置A队列执行大任务,B队列执行小任务。大任务一般占用资源较多,A分配80%资源,B分配20%资源。各队列使用FIFO调度。要点:预分队列,预分资源。
Spark Streaming消费方式及区别
- Receiver方式
这种方式使用的是Kafka的高阶API被动的接收Kafka的数据。Spark会启动Executor专门负责接收kafka的数据,并将接收的数据保存在Executor的内存中(当数据量激增时,可能会导致Executor节点的OOM,从而丢失数据)等待计算任务的拉取。这种情况下,如果Spark出错,很可能导致数据丢失,所以Receiver会开启WAL机制,在Receiver接收Kafka的数据时会同时将数据写入hdfs的预写日志中。 - Direct方式
这种方式是Executor主动拉取kafka中的数据。通过周期性访问kafka来获取每个topic+partitoin的最小offset。处理数据的job启动后,就会直接从kafka中获取对应offset范围的数据。
区别:Receiver是使用Kafka高阶API被动的接收Kafka的数据,offset由Kafka维护,采用WAL实现可靠性;Direct是使用Kafka简单API主动拉取由自己维护的offset范围的数据,由Kafka实现可靠性,性能更高。另外设置多个Receiver只能增加获取kafka数据的线程,对处理RDD的线程没有影响,只能通过多个stream进行unio实现。而Direct只需要创建有多个
Zookeeper 怎么避免脑裂,什么是脑裂
脑裂是master-slaves结构中,某个时刻有两个master对外提供服务。例如有俩个机房,一个机房3个zk节点,另一个机房2个zk节点,集群中只有一个master对外提供读写服务。某个时刻两个机房间的连接断开了,每一个机房都选举产生了一个master分别对外提供读写。当两个机房间的连接恢复后,集群又合并到一起去,此时数据该如何合并,数据冲突如何解决等问题出现。这就是脑裂。
zk中避免脑裂的方式是过半选举机制。集群从配置文件中读取到集群总节点数,若选举投票时某个节点的票数大于集群总结点数的一半时,成功选举了,反之继续选举流程。
讲一讲什么是 CAP 法则?Zookeeper 符合了这个法则的哪两个?
CAP原则,又称CAP定理,指的是一个分布式系统中,一致性,可用性,分区容错性三者不可兼得。
一致性(consistency):在分布式系统中的所有数据备份,在同一时刻是否同样的值。
可用性(Available):对任何非失败节点都应该在有限的时间内给出请求的回应。返回结果必须在合理的时间以内,这个合理的时间是根据业务来定的,如果超过业务规定的返回时间这个系统也就不满足可用性
分区容错性(Partition Tolerance):分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
当有数据写入一个多节点集群中时,如果在节点同步时连接断开,那么必然会有节点未同步成功。而此时如果要保证可用性,那么各节点间的数据会不一致,不满足一致性。而如果满足一致性,即停止对外提供服务直到数据同步完成,那么就不满足可用性了。所以一致性和可用性通常是不能同时满足的。
事实上作为分布式系统,分区容错性是必须的,而一致性和可用性是处于对立面的,所以分布式系统一般是采用CP或者AP组合。zookeeper采用的是CP,主要表现在leader选举时不对外提供服务。
相关文章:
网络资源面经2
文章目录Kafka 原理,数据怎么平分到消费者生产者分区消费者分区Flume HDFS Sink 小文件处理Flink 与 Spark Streaming 的差异,具体效果Spark 背压机制具体实现原理Yarn 调度策略Spark Streaming消费方式及区别Zookeeper 怎么避免脑裂,什么是脑…...
4年经验来面试20K的测试岗,一问三不知,我还真不如去招应届生。
公司前段缺人,也面了不少测试,结果竟然没有一个合适的。一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但平均水平很让人失望。看简历很多都是4年工作经验,但面试…...

K8S搭建NACOS集群踩坑问题
一、NACOS容器启动成功无法访问现象描述:通过K8S的statefulset启动,通过NodePort暴露不能在外网访问,只能在MASTER主节点访问。yaml配置:apiVersion: apps/v1 kind: StatefulSet metadata:name: nacos-${parameters.nameSpace}-dm…...

怎么避免计算机SCI论文的重复率过高? - 易智编译EaseEditing
论文成稿前 在撰写阶段就避免重复:在撰写阶段就避免文章中的重复内容,可以减少后期修改的工作量。 在写作前,可以制定良好的计划和大纲,规划好文章的结构和内容,从而减少重复内容。 加强对相关文献的阅读 为了避免自己…...

uni-app路由拦截
新建一个auth.js /** * description 权限存储函数 */ const authorizationKey Authorization export function getAuthorization() { return uni.getStorageSync(authorizationKey) } export function setAuthorization(authorization) { return uni.setStorageSync(aut…...
如何使用固态继电器实现更高可靠性的隔离和更小的解决方案尺寸
自晶体管发明之前,继电器就已被用作开关。从低压信号安全控制高压系统的能力,如隔离电阻监控,对于许多汽车系统的开发是必要的。虽然机电继电器和接触器的技术多年来有所改进,但设计人员要实现其终身可靠性和快速开关速度以及低噪…...

【YOLOv8/YOLOv7/YOLOv5系列算法改进NO.56】引入Contextual Transformer模块(sci期刊创新点之一)
文章目录前言一、解决问题二、基本原理三、添加方法四、总结前言 作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列…...

深圳大学计软《面向对象的程序设计》实验3 指针2
A. 月份查询(指针数组) 题目描述 已知每个月份的英文单词如下,要求创建一个指针数组,数组中的每个指针指向一个月份的英文字符串,要求根据输入的月份数字输出相应的英文单词 1月 January 2月 February 3月 March …...

【基于机器学习的推荐系统项目实战-2】项目介绍与技术选型
本节目录一、项目介绍1.1 采用的数据源1.2 Concrec架构技术选型1.3 Sprak介绍1.4 Flink1.5 TensorFlow一、项目介绍 1.1 采用的数据源 Kaggle Anime Recommendations Dataset。 其中的动漫数据源自myanimelist.net。 1.2 Concrec架构技术选型 数据预处理模块:汇总…...

对称锥规划:锥与对称锥
文章目录对称锥规划:锥与对称锥锥的几何形状常用的指向锥Nonnegative Orthant二阶锥半定锥对称锥对称锥的平方操作对称锥的谱分解对称锥的自身对偶性二阶锥规划SOCP参考文献对称锥规划:锥与对称锥 本文主要讲锥与对称锥的一些基本概念。 基础预备&…...

4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取
情感分析任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等 2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等…...
算法拾遗二十五之暴力递归到动态规划五
算法拾遗二十七之暴力递归到动态规划七题目一【数组累加和最小的】题目二什么暴力递归可以继续优化暴力递归和动态规划的关系面试题和动态规划的关系如何找到某个问题的动态规划方式面试中设计暴力递归的原则知道了暴力递归的原则 然后设计常见的四种尝试模型如何分析有没有重复…...

Linux进程的创建结束类系统调用总结
tags: Linux OS Syscall C 写在前面 总结一下Linux系统的进程创建/终止/等待等系统调用, 参考: Linux/Unix系统编程手册. 下面主要给出例子, 关于函数原型可以参考书中或者man 2 syscall(例如man 2 fork). 测试环境: Ubuntu 20.04 x86_64 gcc-9 进程创建: fork() 用于创建…...

Git分支的合并策略有哪些?Merge和Rebase有什么区别?关于Merge和Rebase的使用建议
Git分支的合并策略有哪些?Merge和Rebase有什么区别?关于Merge和Rebase的使用建议1. 关于Git的一些基本原理1.1 Git的工作流程原理2. Git的分支合并方式浅析2.1 分支是什么2.2 分支的合并策略2.2.1 Three-way-merge(三向合并原理)2…...
2022-2-23作业
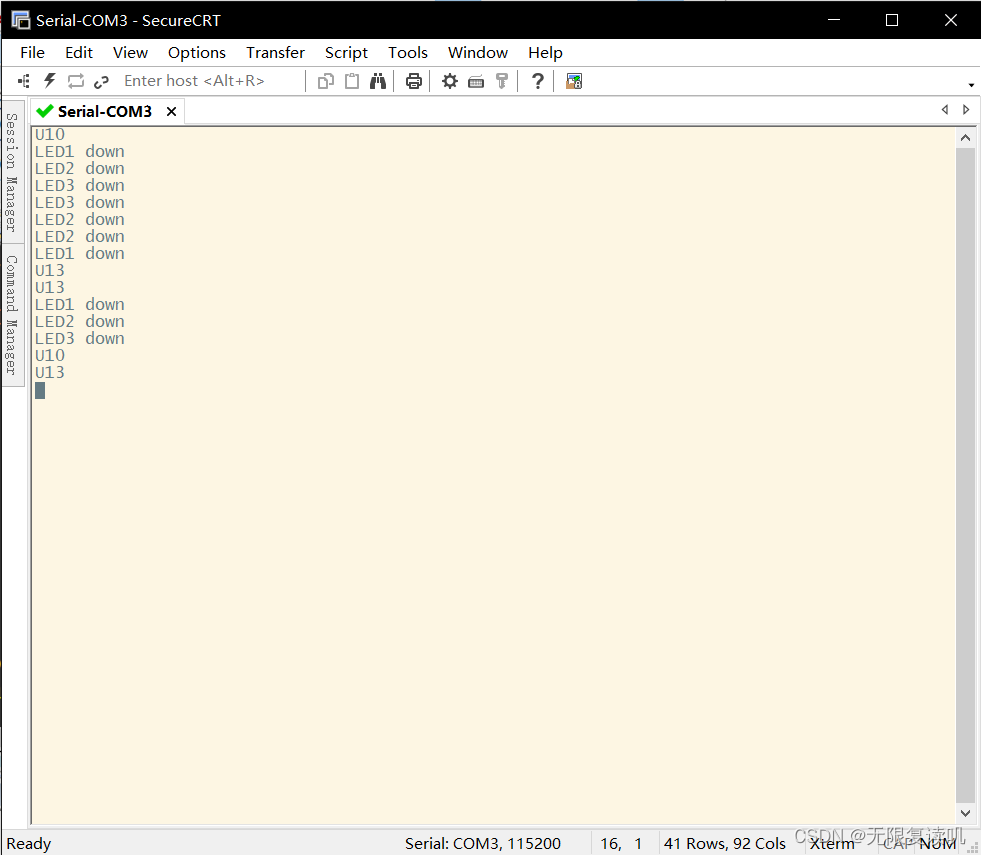
一、通过操作Cortex-A7核,串口输入相应的命令,控制LED灯进行工作 1.例如在串口输入led1on,开饭led1灯点亮 2.例如在串口输入led1off,开饭led1灯熄灭 3.例如在串口输入led2on,开饭led2灯点亮 4.例如在串口输入led2off,开饭led2灯熄灭 5.例如在串口输…...
1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等
文本抽取任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等 2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等…...

“高退货率”标签引热议,亚马逊跨境电商是好是坏?
在多数卖家不知情的情况下,亚马逊“高退货率”标签上线,该消息已被官方证实,目的是为了践行以客户为中心的理念和推动卖家提升服务。 官方确认上线“高退货率”标签 近期,有亚马逊卖家发现产品详情页出现了“高退货率”标签&…...

Pinia2
一、入门案例 1、安装 npm i pinia -S 2、注册插件 //main.ts import { createPinia } from pinia app.use(createPinia()) 3、创建store/countStore.ts import { defineStore } from "pinia"; const useCounterStore defineStore(counterStore,{ state(){ return{…...
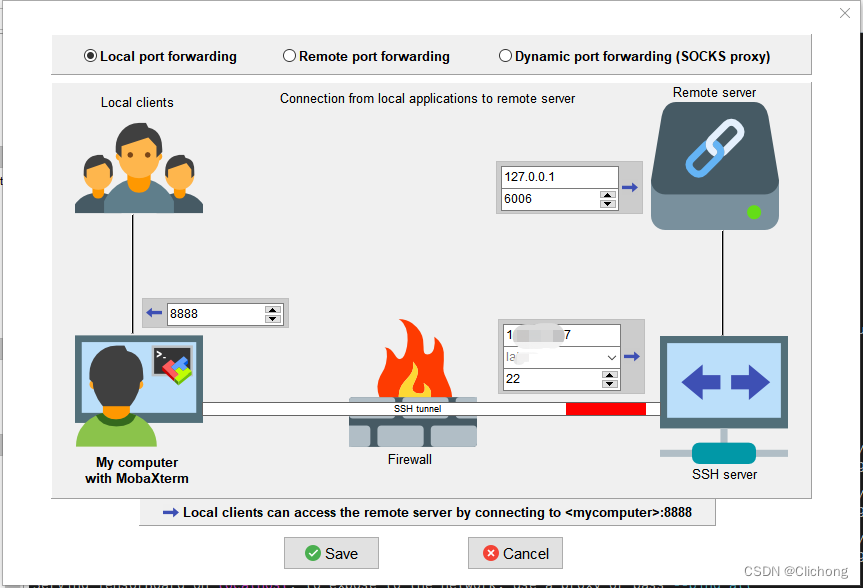
服务器配置 | 在Windows本地打开服务器端Tensorboard结果
文章目录方法1:直接cmd使用ssh登录远程服务器方法2:利用Xshell设置本地端口进行监听方法3:利用MobaXterm设置本地端口监听这里介绍三个方法,在在Windows本地打开服务器端Tensorboard结果 方法1:直接cmd使用ssh登录远程…...
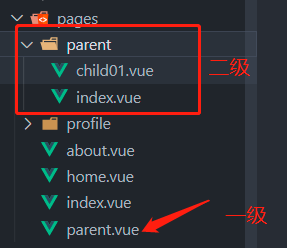
13 nuxt3学习(新建页面 内置组件 assets 路由)
新建页面 Nuxt项目中的页面是在 pages目录 下创建的 在pages目录创建的页面,Nuxt会根据该页面的目录结构和其文件名来自动生成对应的路由。页面路由也称为文件系统路由器(file system router),路由是Nuxt的核心功能之一 方式一…...

Synopsys AXI VIP 从环境搭建到首个验证场景运行
1. 环境准备与VIP安装 第一次接触Synopsys AXI VIP时,我也被那一堆.run文件和环境变量搞得晕头转向。不过别担心,跟着我的步骤走,保证你能在半小时内搞定基础环境搭建。VIP(Verification IP)就像是验证工程师的瑞士军刀…...

Fish-Speech-1.5应用案例:快速生成多语言语音的实际体验
Fish-Speech-1.5应用案例:快速生成多语言语音的实际体验 1. 引言:为什么选择Fish-Speech-1.5 想象一下,你需要为国际客户制作多语言产品演示视频,或者为在线课程添加不同语言的配音。传统方式需要雇佣多位母语配音员,…...

从零开始:Youtu-VL-4B-Instruct-GGUF模型C语言调用接口开发
从零开始:Youtu-VL-4B-Instruct-GGUF模型C语言调用接口开发 在追求极致性能和资源控制的场景里,比如嵌入式设备、高性能计算服务器或者对启动延迟有严苛要求的应用中,Python运行时和框架的额外开销有时会成为瓶颈。这时,直接使用…...

TFT-LCD残影现象的解决方法-激光修复机
一、引言TFT-LCD凭借高画质、低功耗特性,广泛应用于各类显示终端。残影是其常见显示缺陷,表现为屏幕长时间显示固定画面后,切换图像时残留前一画面的痕迹,按持续时间可分为暂时性残影与永久性残影。暂时性残影多可通过静置消除&am…...

目标检测中的特征融合之道:从FPN原理到EFPN改进的深度复盘
在近期深入准备研究生复试及毕业设计的过程中,我对目标检测中的多尺度特征融合技术进行了系统性梳理。本文详细拆解了FPN(Feature Pyramid Networks)的核心架构,并进一步探讨了其改进版本EFPN的设计思路与实现细节。希望通过这篇笔…...

GTE-Base-ZH模型服务监控与告警体系搭建实战
GTE-Base-ZH模型服务监控与告警体系搭建实战 你费了老大劲,终于把GTE-Base-ZH模型服务部署上线了,接口能正常返回向量,心里一块石头落了地。但没过两天,业务方突然跑过来问:“昨晚服务是不是挂了?我们调用…...

Youtu-VL-4B-Instruct多模态推理实战:数学题图解析+逻辑推理+常识问答全流程
Youtu-VL-4B-Instruct多模态推理实战:数学题图解析逻辑推理常识问答全流程 你是不是也遇到过这样的场景?看到一张复杂的图表,想快速理解里面的数据趋势;或者拿到一张手写的数学题照片,希望AI能直接帮你解答࿱…...

新手福音,在快马平台用mlp项目轻松入门深度学习核心原理
对于刚接触机器学习的新手来说,多层感知机(MLP)就像是一把打开深度学习大门的钥匙。它结构清晰,原理直观,是理解神经网络如何“学习”的绝佳起点。然而,很多新手在第一步——写代码实现时,就被各…...

企业考勤系统场景适配能力深度解析:2号人事部的考勤适配多场景吗?
企业考勤系统场景适配能力深度解析:2号人事部如何覆盖全链路用工需求?对于处于购买决策最后阶段的企业HR而言,选择考勤系统的核心诉求早已从“能打卡”升级为“能解决具体场景的痛点”。当远程办公、多班次倒班、跨区域连锁、灵活用工等场景成…...

java毕业设计基于Java的线上一流课程教学辅助系统
前言 基于Spring BootJava的线上一流课程教学辅助系统是一种功能全面、易于使用且高效的教学工具。它能够帮助教师更好地开展教学活动,提升教学质量;同时,也能为学生提供更加便捷、高效的学习方式。一、项目 介绍 开发语言:Java 框…...