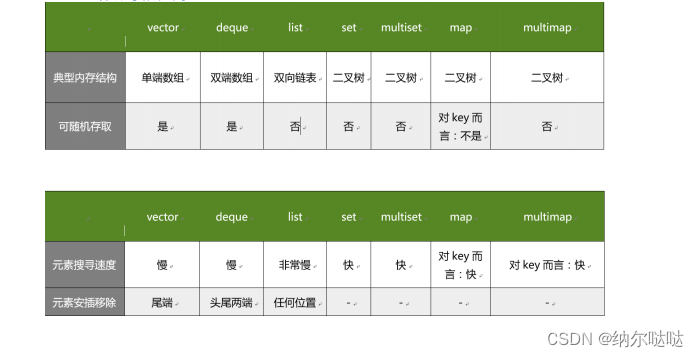
C++STL库的 deque、stack、queue、list、set/multiset、map/multimap
deque 容器

deque 容器实现原理

deque 构造函数
deque 赋值操作
deque 大小操作
deque 双端插入和删除操作
deque 数据存取
deque 插入操作
deque 删除操作
stack 容器
容器基本概念

stack 没有迭代器
stack 构造函数
stack 赋值操作
stack 数据存取操作
stack 大小操作
queue 容器

queue 构造函数
queue 存取、插入和删除操作
queue 赋值操作
queue 大小操作
list 容器
list 容器基本概念

list 构造函数
list 数据元素插入和删除操作
list 大小操作
list 赋值操作
list 反转排序
set/multiset 容器
set/multiset 容器基本概念



set 构造函数
set 赋值操作
set 大小操作
set 插入和删除操作
set 查找操作
set 的返回值 指定 set 排序规则:
对组(pair)
map/multimap 容器
map/multimap 基本概念
map 构造函数
map 赋值操作
map 大小操作
map 插入数据元素操作
map 删除操作
map 查找操作
multimap 案例
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <map>
#include <string>
#include <vector>
using namespace std;
// multimap 案例
// 公司今天招聘了 5 个员工,5 名员工进入公司之后,需要指派员工在那个部门工作
// 人员信息有: 姓名 年龄 电话 工资等组成
// 通过 Multimap 进行信息的插入 保存 显示
// 分部门显示员工信息 显示全部员工信息
#define SALE_DEPATMENT 1 // 销售部门
#define DEVELOP_DEPATMENT 2 // 研发部门
#define FINACIAL_DEPATMENT 3 // 财务部门
#define ALL_DEPATMENT 4 // 所有部门
// 员工类
class person
{
public:string name; // 员工姓名int age; // 员工年龄double salary; // 员工工资string tele; // 员工电话
};
// 创建 5 个员工
void CreatePerson(vector<person> &vlist)
{string seed = "ABCDE";for (int i = 0; i < 5; i++){person p;p.name = "员工";p.name += seed[i];p.age = rand() % 30 + 20;p.salary = rand() % 20000 + 10000;p.tele = "010-8888888";vlist.push_back(p);}
}
// 5 名员工分配到不同的部门
void PersonByGroup(vector<person> &vlist, multimap<int, person> &plist)
{int operate = -1; // 用户的操作for (vector<person>::iterator it = vlist.begin(); it != vlist.end(); it++){cout << "当前员工信息:" << endl;
cout << "姓名:" << it->name << " 年龄:" << it->age << " 工
资:" << it->salary << " 电话:" << it->tele << endl;
cout << "请对该员工进行部门分配(1 销售部门, 2 研发部门, 3 财务
部门):" << endl;
scanf("%d", &operate);
while (true)
{if (operate == SALE_DEPATMENT){ // 将该员工加入到销售部门plist.insert(make_pair(SALE_DEPATMENT, *it));break;}else if (operate == DEVELOP_DEPATMENT){plist.insert(make_pair(DEVELOP_DEPATMENT, *it));break;}else if (operate == FINACIAL_DEPATMENT){plist.insert(make_pair(FINACIAL_DEPATMENT, *it));break;}else{
cout << "您的输入有误,请重新输入(1 销售部门, 2 研
发部门, 3 财务部门):" << endl;
scanf("%d", &operate);}
}}cout << "员工部门分配完毕!" << endl;cout << "********************************************************* **" << endl;
}
// 打印员工信息
void printList(multimap<int, person> &plist, int myoperate)
{if (myoperate == ALL_DEPATMENT){for (multimap<int, person>::iterator it = plist.begin(); it != plist.end(); it++){cout << "姓名:" << it->second.name << " 年龄:" << it->second.age << " 工资:" << it->second.salary << " 电话:" << it->second.t ele << endl;}return;}multimap<int, person>::iterator it = plist.find(myoperate);int depatCount = plist.count(myoperate);int num = 0;if (it != plist.end()){while (it != plist.end() && num < depatCount){cout << "姓名:" << it->second.name << " 年龄:" << it->second.age << " 工资:" << it->second.salary << " 电话:" << it->second.t ele << endl;it++;num++;}}
}
// 根据用户操作显示不同部门的人员列表
void ShowPersonList(multimap<int, person> &plist, int myoperate)
{switch (myoperate){case SALE_DEPATMENT:printList(plist, SALE_DEPATMENT);break;case DEVELOP_DEPATMENT:printList(plist, DEVELOP_DEPATMENT);break;case FINACIAL_DEPATMENT:printList(plist, FINACIAL_DEPATMENT);break;case ALL_DEPATMENT:printList(plist, ALL_DEPATMENT);break;}
}
// 用户操作菜单
void PersonMenue(multimap<int, person> &plist)
{int flag = -1;int isexit = 0;while (true){
cout << "请输入您的操作((1 销售部门, 2 研发部门, 3 财务部门, 4
所有部门, 0 退出):" << endl;
scanf("%d", &flag);
switch (flag)
{
case SALE_DEPATMENT:ShowPersonList(plist, SALE_DEPATMENT);break;
case DEVELOP_DEPATMENT:ShowPersonList(plist, DEVELOP_DEPATMENT);break;
case FINACIAL_DEPATMENT:ShowPersonList(plist, FINACIAL_DEPATMENT);break;
case ALL_DEPATMENT:ShowPersonList(plist, ALL_DEPATMENT);break;
case 0:isexit = 1;break;
default:cout << "您的输入有误,请重新输入!" << endl;break;
}
if (isexit == 1)
{break;
}}
}
int main()
{vector<person> vlist; // 创建的 5 个员工 未分组multimap<int, person> plist; // 保存分组后员工信息// 创建 5 个员工CreatePerson(vlist);// 5 名员工分配到不同的部门PersonByGroup(vlist, plist);// 根据用户输入显示不同部门员工信息列表 或者 显示全部员工的信息列表PersonMenue(plist);system("pause");return EXIT_SUCCESS;
}STL 容器使用时机
相关文章:
C++STL库的 deque、stack、queue、list、set/multiset、map/multimap
deque 容器 Vector 容器是单向开口的连续内存空间, deque 则是一种双向开口的连续线性空 间。所谓的双向开口,意思是可以在头尾两端分别做元素的插入和删除操作,当然, vector 容器也可以在头尾两端插入元素,但是在其…...

Vuex快速上手
一、Vuex 概述 目标:明确Vuex是什么,应用场景以及优势 1.是什么 Vuex 是一个 Vue 的 状态管理工具,状态就是数据。 大白话:Vuex 是一个插件,可以帮我们管理 Vue 通用的数据 (多组件共享的数据)。例如:购…...

计网 - LVS 是如何直接基于 IP 层进行负载平衡调度
文章目录 模型LVS的工作机制初探LVS的负载均衡机制初探 模型 大致来说,可以这么理解(只是帮助我们理解,实际上肯定会有点出入),对于我们的 PC 机来说,物理层可以看成网卡,数据链路层可以看成网卡…...

GEE机器学习——利用支持向量机SVM进行土地分类和精度评定
支持向量机方法 支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,主要用于分类和回归问题。SVM的目标是找到一个最优的超平面,将不同类别的样本点分隔开来,使得两个类别的间隔最大化。具体来说,SVM通过寻找支持向量(即距离超平面最近的样本点),确定…...

【ARM Trace32(劳特巴赫) 使用介绍 13 -- Trace32 断点 Break 命令篇】
文章目录 1. Break.Set1.1 TRACE32 Break1.1.1 Break命令控制CPU的暂停1.2 Break.Set 设置断点1.2.1 Trace32 程序断点1.2.2 读写断点1.2.2.1 变量被改写为特定值触发halt1.2.2.2 设定非值触发halt1.2.2.4 变量被特定函数改写触发halt1.2.3 使用C/C++语法设置断点条件1.2.4 使用…...
【JVM入门到实战】(三) 查看字节码文件的工具
一、 javap -v命令 javap是JDK自带的反编译工具,可以通过控制台查看字节码文件的内容。适合在服务器上查看字节码文件内容。直接输入javap查看所有参数。输入javap -v 字节码文件名称 查看具体的字节码信息。(如果jar包需要先使用 jar –xvf 命令解压&a…...
9:00面试,9:05就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到12月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40…...
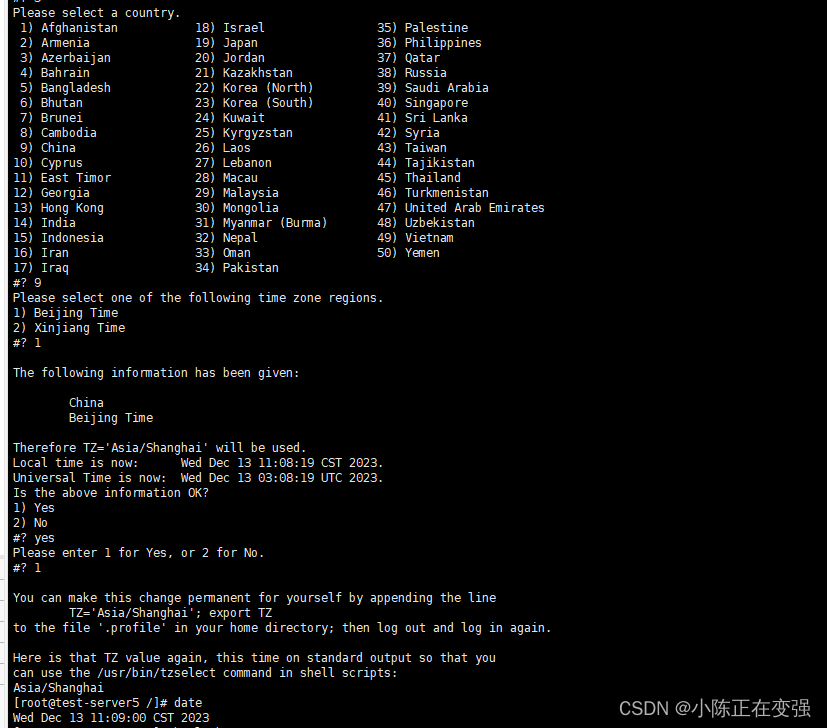
无需重启,修改Linux服务器时区
Linux修改服务器时区(无需重启) 1、复制命令:2、使用tzselect命令:3、使用date查看是否修改正确 1、复制命令: cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime2、使用tzselect命令: tzselect按照要…...

【Android嵌入式开发及实训课程实验】【项目1】 图形界面——计算器项目
【项目1】 图形界面——计算器项目 需求分析界面设计实施1、创建项目2、 界面实现实现代码1.activity_main.xml2.Java代码 - MainActivity.java 3、运行测试 注意点结束~ 需求分析 开发一个简单的计算器项目,该程序只能进行加减乘除运算。要求界面美观,…...
利用SPSS进行神经网络分析过程及结果解读
模拟人类实际神经网络的数学方法问世以来,人们已慢慢习惯了把这种人工神经网络直接称为 神经网络。 神经网络在系统辨识、模式识别、智能控制等领域有着广泛而吸引人的前景,特别在智能控制中,人们对神经网络的自学习功能尤其感兴趣࿰…...

聚观早报 |东方甄选将上架文旅产品;IBM首台模块化量子计算机
【聚观365】12月6日消息 东方甄选将上架文旅产品 IBM首台模块化量子计算机 新思科技携手三星上新兴领域 英伟达与软银推动人工智能研发 苹果对Vision Pro供应商做出调整 东方甄选将上架文旅产品 东方甄选宣布12月10日将在东方甄选APP上线文旅产品,受这一消息影…...
web服务器之——www服务器的基本配置
目录 一、www简介 1、什么是www 2、www所用的协议 3、WEB服务器 4、主要数据 5、浏览器 二、 网址及HTTP简介 1、HTTP协议请求的工作流程 三、www服务器的类型(静态网站(HTML), 动态网站(jsp python,php,perl)) 1、 仅提供…...

微信小程序 -- ios 底部小黑条样式问题
问题: 如图,ios有的机型底部伪home键会显示在按钮之上,导致点击按钮的时候误触 解决: App.vue <script>export default {wx.getSystemInfo({success: res > {let bottomHeight res.screenHeight - res.safeArea.bott…...

白盒测试:探索软件内部结构的有效方法
引言: 在软件开发过程中,测试是确保软件质量的关键环节。传统的黑盒测试方法主要关注软件的功能和外部行为,而忽略了软件的内部结构和实现细节。然而,随着软件复杂性的增加,仅仅依靠黑盒测试已经无法满足项目的需求。因…...
图论-并查集
并查集(Union-find Sets)是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有求连通子图,求最小生成树Kruskal算法和最近公共祖先(LCA)等. 并查集的基本操作主要有: .1.初始化 2.查询find 3.合并union 一般我们都会采用路径压缩 这样…...
redis-学习笔记(Jedis 通用命令)
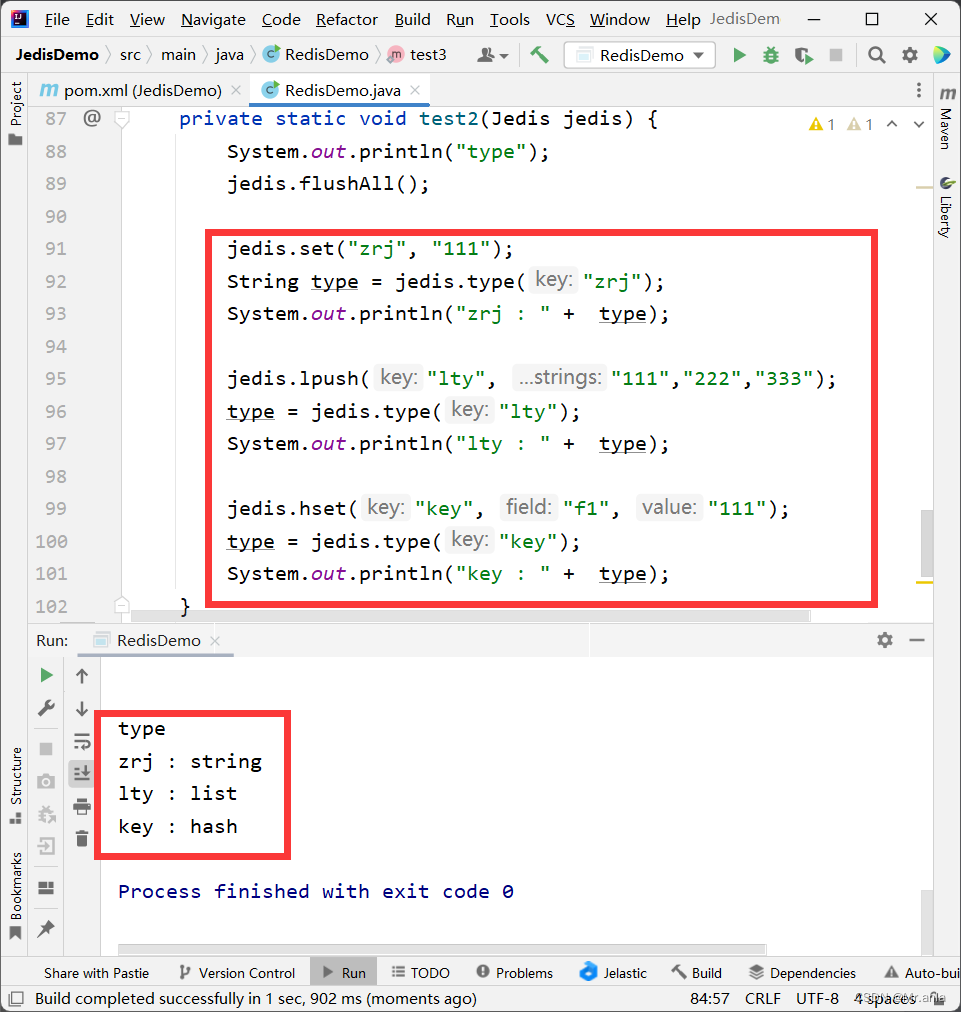
flushAll 清空全部的数据库数据 jedis.flushAll();set & get set 命令 get 命令 运行结果展示 exists 判断该 key 值是否存在 当 redis 中存在该键值对时, 返回 true 如果键值对不存在, 返回 false keys 获取所有的 key 值 参数是模式匹配 *代表匹配任意个字符 _代表匹配一…...
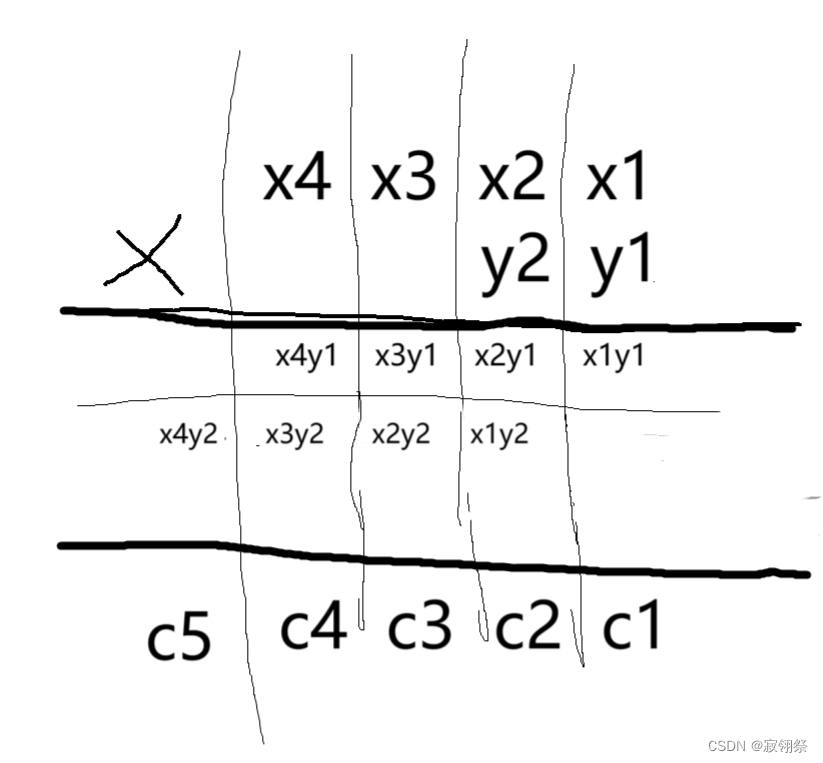
C语言:高精度乘法
P1303 A*B Problem - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 第一次画图,略显简陋。 由图可以看出c的小标与x,y下标的关系为x的下标加上y的下标再减一。 由此得到: c [ i j - 1 ] x [ i ] * y [ j ]x #include<stdio.h> #include<st…...

UE4 Niagara学习笔记
需要在其他发射器的同一个粒子位置发射其他粒子就用Spawn Particles from other Emitter 把发射器名字填上去即可 这里Move to Nearest Distance Field Subface GPU,可以将生成的Niagara附着到最近的物体上 使用场景就是做的火苗附着到物体上...

多维时序 | Matlab实现GA-LSTM-Attention遗传算法优化长短期记忆神经网络融合注意力机制多变量时间序列预测
多维时序 | MATLAB实现BWO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现BWO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | Matlab实…...

LeetCode205. Isomorphic Strings
文章目录 一、题目二、题解 一、题目 Given two strings s and t, determine if they are isomorphic. Two strings s and t are isomorphic if the characters in s can be replaced to get t. All occurrences of a character must be replaced with another character wh…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...
ZYNQ学习记录FPGA(一)ZYNQ简介
一、知识准备 1.一些术语,缩写和概念: 1)ZYNQ全称:ZYNQ7000 All Pgrammable SoC 2)SoC:system on chips(片上系统),对比集成电路的SoB(system on board) 3)ARM:处理器…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

门静脉高压——表现
一、门静脉高压表现 00:01 1. 门静脉构成 00:13 组成结构:由肠系膜上静脉和脾静脉汇合构成,是肝脏血液供应的主要来源。淤血后果:门静脉淤血会同时导致脾静脉和肠系膜上静脉淤血,引发后续系列症状。 2. 脾大和脾功能亢进 00:46 …...

【java】【服务器】线程上下文丢失 是指什么
目录 ■前言 ■正文开始 线程上下文的核心组成部分 为什么会出现上下文丢失? 直观示例说明 为什么上下文如此重要? 解决上下文丢失的关键 总结 ■如果我想在servlet中使用线程,代码应该如何实现 推荐方案:使用 ManagedE…...