Python 之 Pandas 处理字符串和apply() 函数、applymap() 函数、map() 函数详解
文章目录
- 一、处理字符串
- 1. 向量化字符串操作简介
- 2. str 方法的简介
- 二、apply() 函数详解
- 三、applymap() 函数详解
- 四、map() 函数详解
一、处理字符串
- 当我们遇到一个超级大的 DataFrame,里面有一列类型为字符串,要将每一行的字符串都用同一方式进行处理, 一般会想到遍历整合 DataFrame。
- 但是如果直接这样做的话将会耗费很长时间,有时几个小时都处理不完。 因此我们将学习 pandas 快速处理字符串方法。
1. 向量化字符串操作简介
- 量化操作简化了纯数值的数组操作语法,我们不需要再担心数组的长度或维度,只需要把中心放在操作上面。
- 而对字符串的向量化需要工具包的支持,如 Numpy 就没办法直接对字符串进行向量化操作,只能通过繁琐的循环来实现。 Pandas 则可以很好的处理这类问题。
2. str 方法的简介
- Python 会处理字符串起来会很容易,作为工具包的 Pandas 同样可以简单快速的处理字符串,几乎把 Python 内置的字符串方法都给复制过来了,这种方法就是 Pandas 内置的 str 方法。
- 通俗来说就可以将 series 和 index 对象中包含字符串的部分简单看作单个字符串处理,达到批量简单快速处理的目的,str 方法有如下函数可供我们使用。
| 函数 | 含义 |
|---|---|
| lower() | 将的字符串转换为小写 |
| upper() | 将的字符串转换为大写 |
| len() | 得出字符串的长度 |
| strip() | 去除字符串两边的空格(包含换行符) |
| split() | 用指定的分割符分割字符串 |
| cat(sep=“”) | 用给定的分隔符连接字符串元素 |
| contains(pattern) | 如果子字符串包含在元素中,则为每个元素返回一个布尔值 True,否则为 False |
| replace(a,b) | 将值 a 替换为值 b |
| count(pattern) | 返回每个字符串元素出现的次数 |
| startswith(pattern) | 如果 Series 中的元素以指定的字符串开头,则返回 True |
| endswith(pattern) | 如果 Series 中的元素以指定的字符串结尾,则返回 True |
| findall(pattern) | 以列表的形式返出现的字符串 |
| find(pattern) | 返回字符串第一次出现的索引位置 |
- 这里需要注意的是,上述所有字符串函数全部适用于 DataFrame 对象,同时也可以与 Python 内置的字符串函数一起使用,这些函数在处理 Series/DataFrame 对象的时候会自动忽略缺失值数据(NaN)。
- 首先,我们导入需要的 numpy 和 pandas 库。
import pandas as pd
import numpy as np
- (1) lower() 函数可以将的字符串转换为小写。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
s.str.lower()
0 c
1 python
2 java
3 go
4 NaN
5 1125
6 javascript
dtype: object
- (2) upper() 将的字符串转换为大写。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
s.str.upper()
#0 C
#1 PYTHON
#2 JAVA
#3 GO
#4 NaN
#5 1125
#6 JAVASCRIPT
#dtype: object
- (3) len() 得出字符串的长度。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
s.str.len()
#0 1.0
#1 6.0
#2 4.0
#3 2.0
#4 NaN
#5 4.0
#6 10.0
#dtype: float64
- (4) strip() 去除字符串两边的空格(包含换行符)。
s = pd.Series(['C ', ' Python\t \n', ' java ', 'go\t', np.nan, '\t1125 ','\tjavascript'])
s_strip = s.str.strip(" ")
s_strip
#0 C
#1 Python\t \n
#2 java
#3 go\t
#4 NaN
#5 \t1125
#6 \tjavascript
#dtype: object
- (5) split() 用指定的分割符分割字符串。
s = pd.Series(['Zhang hua',' Py thon\n',' java ','go','11 25 ','javascript'])
print(s.str.split(" "))
#0 [Zhang, hua]
#1 [, Py, thon\n]
#2 [, , , java, , , ]
#3 [go]
#4 [11, 25, ]
#5 [javascript]
#dtype: object
- 如果不带参数,会先执行 strip(),再默认以空格分割。
print(s.str.split())
#0 [Zhang, hua]
#1 [Py, thon]
#2 [java]
#3 [go]
#4 [11, 25]
#5 [javascript]
#dtype: object
- 我们也可以对 strip() 的参数进行设置。
print(s.str.strip().str.split(" "))
#0 [Zhang, hua]
#1 [Py, thon]
#2 [java]
#3 [go]
#4 [11, 25]
#5 [javascript]
#dtype: object
- (6) cat(sep=“”) 用给定的分隔符连接字符串元素。
- cat(sep=“”) 函数会自动忽略 NaN。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
s_cat = s.str.cat(sep="_")
s_cat
#'C_Python_java_go_1125_javascript'
- (7) contains(pattern) 如果子字符串包含在元素中,则为每个元素返回一个布尔值 True,否则为 False。
- 我们可以取出 s 中包含空格的元素。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
s.str.contains(" ")
#0 True
#1 True
#2 False
#3 False
#4 True
#5 False
#dtype: bool
- 也可以将 True 返回原数据。
s[s.str.contains(" ")]
#0 C
#1 Python
#4 1125
#dtype: object
- (8) replace(a,b) 将值 a 替换为值 b。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
s.str.replace("java","python")
#0 C
#1 Python
#2 python
#3 go
#4 1125
#5 pythonscript
#dtype: object
- (9) count(pattern) 返回每个字符串元素出现的次数。
s = pd.Series(['C ','Python Python','Python','go','1125 ','javascript'])
s.str.count("Python")
#0 0
#1 2
#2 1
#3 0
#4 0
#5 0
#dtype: int64
- (10) startswith(pattern) 如果 Series 中的元素以指定的字符串开头,则返回 True。
- (11) endswith(pattern) 如果 Series 中的元素以指定的字符串结尾,则返回 True。
- 若以指定的 j 开头的字符串,则返回 True。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
print(s.str.startswith("j"))
#0 False
#1 False
#2 True
#3 False
#4 False
#5 True
#dtype: bool
- (12) repeat(value) 以指定的次数重复每个元素。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
print(s.str.repeat(3))
#0 C C C
#1 Python Python Python
#2 javajavajava
#3 gogogo
#4 1125 1125 1125
#5 javascriptjavascriptjavascript
#dtype: object
- (13) find(pattern) 返回字符串第一次出现的索引位置。
- 这里如果返回 -1 表示该字符串中没有出现指定的字符。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
print(s.str.find("a"))
#0 -1
#1 -1
#2 1
#3 -1
#4 -1
#5 1
#dtype: int64
- (14) findall(pattern) 以列表的形式返出现的字符串。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
print(s.str.findall("a"))
#0 []
#1 []
#2 [a, a]
#3 []
#4 []
#5 [a, a]
#dtype: object
二、apply() 函数详解
- 在日常的数据处理中,经常会对一个 DataFrame 进行逐行、逐列和逐元素的操作,对应这些操作,Pandas 中的 map()、apply() 和 applymap() 可以解决绝大部分这样的数据处理需求。
- 三种方法的使用和区别如下:
- apply() 函数应用在 DataFrame 的行或列中。
- applymap() 函数应用在 DataFrame 的每个元素中。
- map() 函数应用在单独一列(Series)的每个元素中。
- 前面也说了 apply() 函数是一般性的“拆分-应用-合并”方法。 apply() 将一个函数作用于 DataFrame 中的每个行或者列,它既可以得到一个经过广播的标量值,也可以得到一个相同大小的结果数组。
- 我们先来看下函数形式:
df.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
- 其参数含义如下:
- func 表示函数应用于每一列或每一行。
- axis 有 0 和 1 或者索引和列两种取值, 0 或“索引”表示将函数应用于每一列;1或“行”表示将函数应用于每一行。
- 我们先生成初始数据,并将列标签设置为 A 和 B。
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
df
A B
0 4 9
1 4 9
2 4 9
- 可以使用 apply() 函数对 A、B 两列进行求和(axis 参数默认为 0)。
df.apply(np.sum)
#A 12
#B 27
#dtype: int64
- 我们将 axis 参数设置为 1,表示对每一行进行求和。
df.apply(np.sum, axis=1)
#0 13
#1 13
#2 13
#dtype: int64
- 或者我们使用 lambda 函数做简单的运算。
df.apply(lambda x: x + 1)
# A B
#0 5 10
#1 5 10
#2 5 10
- 但是这样使用起来非常不方便,每次都要定义 lambda 函数。因此可以通过 def 定义一个函数,然后再调用该函数,在实际处理中都是定义自己所需要的函数完成操作:
def cal_result(df, x, y):df['C'] = (df['A'] + df['B']) * xdf['D'] = (df['A'] + df['B']) * yreturn df
- 我们使用自定义的函数进行计算,并生成 C、D 两列。
df.apply(cal_result, x=3, y=8, axis=1)
# A B C D
#0 4 9 39 104
#1 4 9 39 104
#2 4 9 39 104
- 在这里我们先定义了一个 cal_result 函数,它的作用是计算 A,B 列和的 x 倍和 y 倍添加到 C,D 列中。
- 这里有三种方式可以完成参数的赋值:
- (1) 第一种方式直接通过关键字参数赋值,指定参数的值。
- (2) 第二种方式是使用 args 关键字参数传入一个包含参数的元组。
- (3) 第三种方式传入通过 ** 传入包含参数和值的字典。
- apply() 函数的使用是很灵活的,再举一个例子,配合 loc 方法我们能够在最后一行得到一个总和:
df.loc[2] = df.apply(np.sum)
df
# A B
#0 4 9
#1 4 9
#2 12 27
三、applymap() 函数详解
- applymap() 函数针对 DataFrame中 的元素进行操作,还是使用这个数据:
df.applymap(func)。
df
# A B
#0 4 9
#1 4 9
#2 12 27
- 我们使用 lambda 函数将其变为浮点型。
df.applymap(lambda x: '%.2f'%x)
# A B
#0 4.00 9.00
#1 4.00 9.00
#2 4.00 9.00
- 在这里可以看到 applymap() 函数操作的是其中的元素,并且是对整个 DataFrame 进行了格式化,我们也可以选择行或列中的元素。
- 对行进行选取。
df[['A']]
# A
#0 4
#1 4
#2 4
- 对列进行选取。
df[['A']].applymap(lambda x: '%.2f'%x)
# A
#0 4.00
#1 4.00
#2 4.00
- 需要注意的是这里必须使用 df[[‘A’]] ,表示这是一个 DataFrame,而不是一个 Series,如果使用 df[‘A’] 就会报错。同样从行取元素也要将它先转成 DataFrame。
df['A'].applymap(lambda x: '%.2f'%x) # 异常
#---------------------------------------------------------------------------
#AttributeError Traceback (most recent call last)
#<ipython-input-11-585649caf30e> in <module>()
#----> 1 df['A'].applymap(lambda x: '%.2f'%x) # 异常
#
#E:\Anaconda\lib\site-packages\pandas\core\generic.py in __getattr__(self, name)
# 5139 if self._info_axis._can_hold_identifiers_and_holds_name(name):
# 5140 return self[name]
#-> 5141 return object.__getattribute__(self, name)
# 5142
# 5143 def __setattr__(self, name: str, value) -> None:
#
#AttributeError: 'Series' object has no attribute 'applymap'
- 还需要注意 apply() 函数和 applymap() 函数的区别:
- apply() 函数操作的是行或列的运算,而不是元素的运算,比如在这里使用格式化操作就会报错。
- applymap() 函数操作的是元素,因此没有诸如 axis 这样的参数,它只接受函数传入。
四、map() 函数详解
- 如果对 applymap() 函数搞清楚了,那么map() 函数就很简单,说白了 map() 函数是应用在 Series 中的,还是举上面的例子。
df['A'].map(lambda x: '%.2f'%x)
#0 4.00
#1 4.00
#2 4.00
#Name: A, dtype: object
- 需要注意的是,Series 没有 applymap() 函数。
df[['A']].applymap(lambda x: '%.2f'%x)
#---------------------------------------------------------------------------
#AttributeError Traceback (most recent call last)
#<ipython-input-11-585649caf30e> in <module>()
#----> 1 df[['A']].applymap(lambda x: '%.2f'%x) # 异常
#
#E:\Anaconda\lib\site-packages\pandas\core\generic.py in __getattr__(self, name)
# 5139 if self._info_axis._can_hold_identifiers_and_holds_name(name):
# 5140 return self[name]
#-> 5141 return object.__getattribute__(self, name)
# 5142
# 5143 def __setattr__(self, name: str, value) -> None:
#
#AttributeError: 'Series' object has no attribute 'applymap'
相关文章:
 函数、applymap() 函数、map() 函数详解)
Python 之 Pandas 处理字符串和apply() 函数、applymap() 函数、map() 函数详解
文章目录一、处理字符串1. 向量化字符串操作简介2. str 方法的简介二、apply() 函数详解三、applymap() 函数详解四、map() 函数详解一、处理字符串 当我们遇到一个超级大的 DataFrame,里面有一列类型为字符串,要将每一行的字符串都用同一方式进行处理&…...
汇川AM402和上位机C#ModebusTcp通讯
目录 一、测试任务 二、测试环境 三、PLC工程 1、组态配置 2、ip地址、端口号 3、全局变量定义 四、C#端Winform程序创建 1创建主界面 2、创建子窗口 3、运行生成,界面效果 4、Modebus协议说明 5、Modebus操作说明 六、测试 1、寄存器读测试 2、MW1300寄…...

给你一个电商网站,你如何测试?功能测试及接口测试思路是什么?
功能测试思路 1、注册测试: 测试注册表单是否可以正确提交用户信息; 测试注册表单是否有输入限制,例如密码长度、邮箱格式等; 测试注册后是否可以正常登录。 2、登录测试: 测试登录表单是否可以正确提交用户信息&…...

Spring Boot 3.0系列【5】基础篇之应用配置文件
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot版本3.0.3 源码地址:https://gitee.com/pearl-organization/study-spring-boot3 文章目录 前言应用配置文件文件格式YAML获取配置属性方式1:@Value方式2: @ConfigurationProperties方式3: @PropertySource方式4…...
SQLyog图形化界面工具【超详细讲解】
目录 一、SQLyog 介绍 二、SQLyog 社区版下载 三、SQLyog 安装 1、选择Chinese后点击OK 2、点击“下一步” 3、选择“我接受”后点击“下一步” 4、点击“下一步” 5、修改安装位置(尽量不要安装在C盘),点击“安装” 6、安装后点击“…...
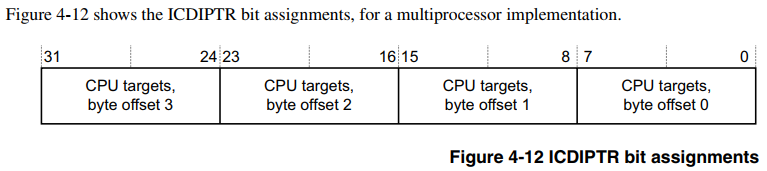
Linux: 中断只被GIC转发到CPU0问题分析
文章目录1. 前言2. 分析背景3. 问题4. 分析4.1 ARM GIC 中断芯片简介4.1.1 中断类型和分布4.1.2 拓扑结构4.2 问题根因4.2.1 设置GIC SPI 中断CPU亲和性4.2.2 GIC初始化:缺省的CPU亲和性4.2.2.1 boot CPU亲和性初始化流程4.2.2.1 其它非 boot CPU亲和性初始化流程5.…...
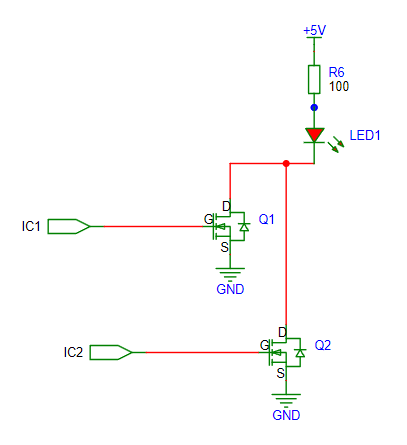
模电学习10. MOS管简单应用电路
模电学习10. MOS管简单使应用电路一、开关和放大器1. 开关电路2. 放大电路二、时序电路中作为反相器使用三、双向电平转换电路1. 原理图2. 工作状态分析(1)分析SDA,信号从左向右(2)分析SDA,信号从右向左四、…...

轻松搞懂Linux中的用户管理
文章目录概念用户账户用户组用户权限用户管理工具概念 用户管理是Linux系统管理员必须掌握的重要技能之一。Linux系统是一个多用户操作系统,可以支持多个用户同时使用,每个用户拥有自己的账户和权限,因此管理员需要了解如何创建、管理和删除…...

力扣-丢失信息的雇员
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:1965. 丢失信息的雇员二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其他…...
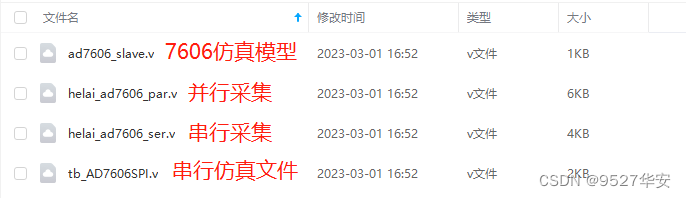
FPGA采集AD7606全网最细讲解 提供串行和并行2套工程源码和技术支持
目录1、前言2、AD7606数据手册解读输入信号采集范围输出模式选择过采样率设置3、AD7606串行输出采集4、AD7606并行输出采集5、vivado仿真6、上板调试验证7、福利:工程代码的获取1、前言 AD7606是一款非常受欢迎的AD芯片,因为他支持8通道同时采集数据&am…...

CSS介绍
文章目录一. CSS介绍二. CSS的引入方式三. CSS选择器一. CSS介绍 定义: 层叠样式表作用: 美化界面: 设置标签文字大小,颜色,字体加粗等样式控制页面布局: 设置浮动,定位等样式 基本语法: 选择器{样式规则 } 样式规则: 属性名1: 属性值1 属性名2: 属性值2 属性名3: 属性值3 ..…...

Auto-encoder 系列
Auto-Encoder (AE)Auto-encoder概念自编码器要做的事:将高维的信息通过encoder压缩到一个低维的code内,然后再使用decoder对其进行重建。“自”不是自动,而是自己训练[1]。PCA要做的事其实与AE一样,只是没有神经网络。对于一个输入…...

【蓝桥杯入门不入土】变幻莫测的链表
文章目录一:链表的类型单链表双链表循环链表二:链表的存储方式三:链表的定义删除节点添加节点四:实战练习1.设计链表2. 移除链表元素最后说一句一:链表的类型 单链表 什么是链表,链表是一种通过指针串联在…...
axios的二次封装
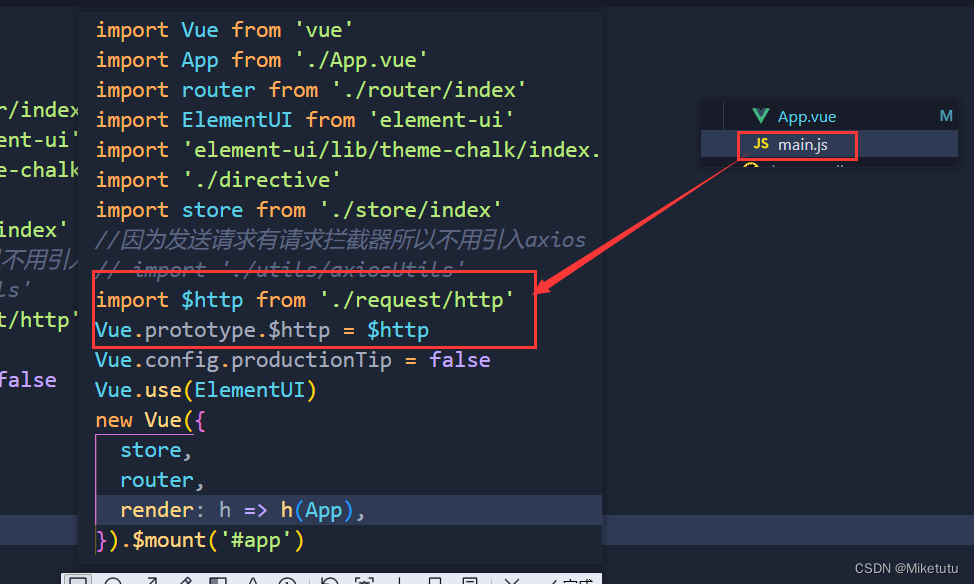
方式一:将axios单独分装到某个配置文件中import axios from axios; const axiosApi axios.create({baseURL:http://127.0.0.1:3000,timeout:3000 }) export default axiosApi在组件中使用:import $http from axios配置文件的地址 $http.get(/student/test).then(re…...
)
GET与POST区别(最详细)
相同点:本质上都是TCP连接。 不同点:由于HTTP规定和服务器/浏览器限制,在应用过程中区别如下: 1.get产生一个TCP数据包,post 产生两个TCP数据包 get请求,浏览器会把http header和data一起发送,…...

精选博客系列|将基于决策树的Ensemble方法用于边缘计算
在即将到来的边缘计算时代,越来越需要边缘设备执行本地快速训练和分类的能力。事实上,无论是手机上的健康应用程序、冰箱上的传感器还是扫地机器人上的摄像头,由于许多原因,例如需要快速响应时间、增强安全性、数据隐私࿰…...
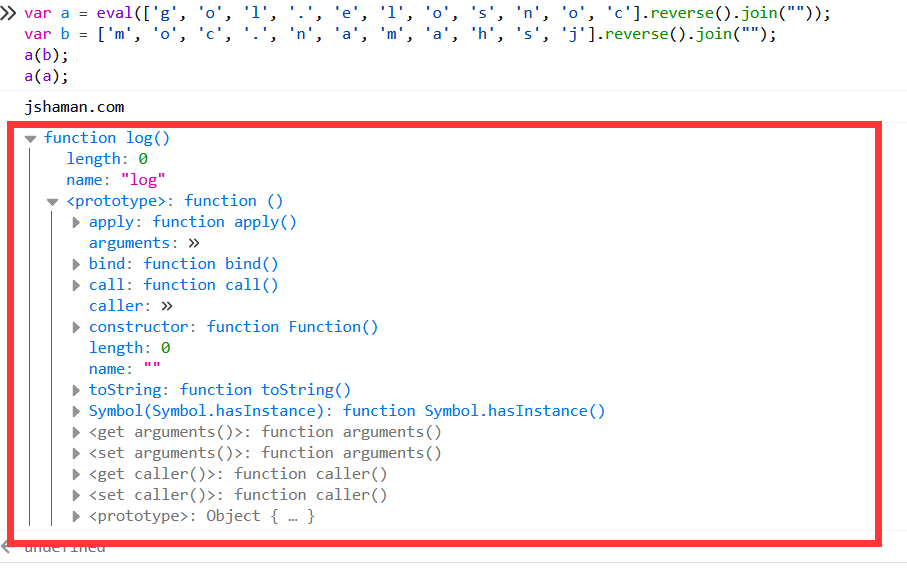
JS混淆加密:Eval的未公开用法
JavaScript奇技淫巧:Eval的未公开用法 作者:http://JShaman.com w2sft,转载请保留此信息很多人都知道,Eval是用来执行JS代码的,可以执行运算、可以输出结果。 但它还有一种未公开的用途,想必很少有人用过。…...
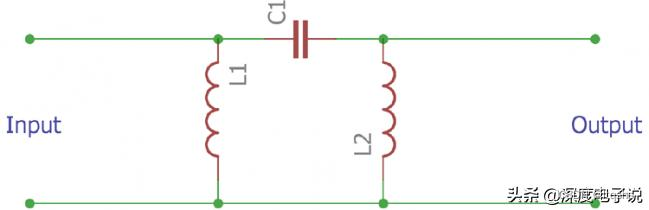
π型滤波器 计算_π型滤波电路
滤波器在功率和音频电子中常用于滤除不必要的频率。而电路设计中,基于不同应用有着许多不同种类的滤波器,但它们的基本理念都是一致的,那就是移除不必要的信号。所有滤波器都可以被分为两类,有源滤波器和无源滤波器。有源滤波器用…...
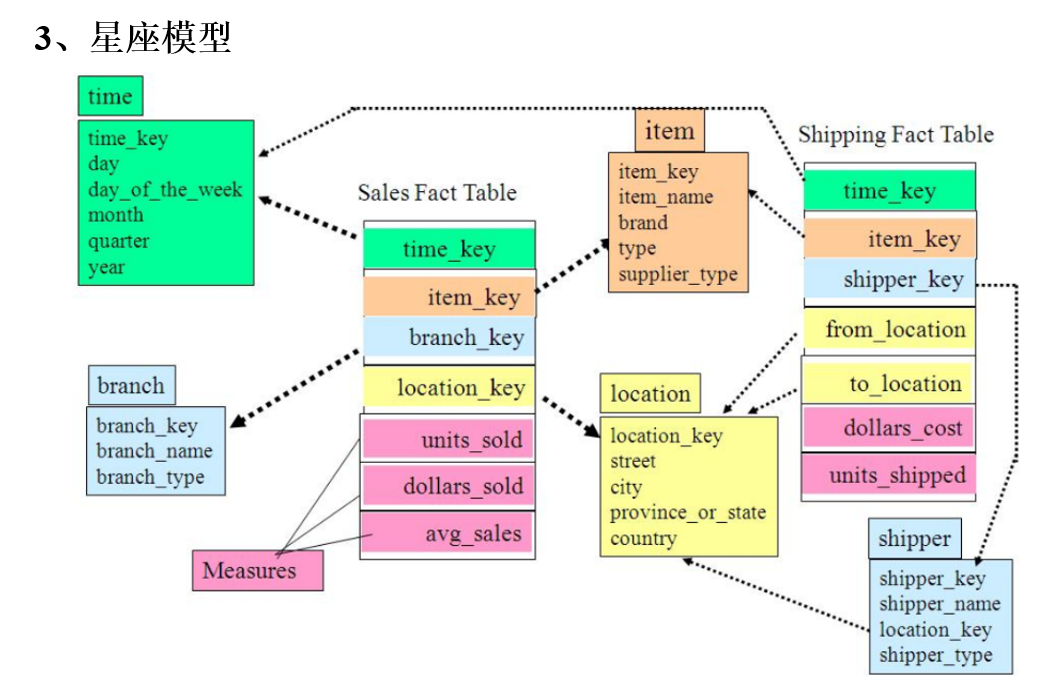
大数据常见术语
大数据常见术语一览 主要内容包含以下(收藏,转发给你身边的朋友) 雪花模型、星型模型和星座模型 事实表 维度表 上钻与下钻 维度退化 数据湖 UV与PV 画像 ETL 机器学习 大数据杀熟 SKU与SPU 即席查询 数据湖 数据中台 ODS,DWD&…...

带你了解“函数递归”
目录 1. 什么是递归? 2. 函数递归的必要条件 2.1 接收一个整型值(无符号),按照顺序打印它的每一位。 代码如下: 2.2 编写一个函数,不用临时变量求字符串长度 代码如下: 2.3 递归与迭代 …...

x86汇编如何使用伪指令实现if,else,while,dowhile,switch-case
x86汇编如何使用伪指令实现if,else,while,dowhile,switch-case 1)汇编伪指令介绍 伪指令是汇编器提供的语法规则,它主要为程序员提供语法糖简化汇编代码的编写。常见的伪指令包括条件汇编类(IF&…...

SpringBoot-基础面试篇
什么是 Spring Boot?Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,使开发者能快速上手。为什么要用Spring…...

降AI率工具8元和3元的,处理80%+有区别吗
“8元一千字太贵了,3元那个不是也能用吗?” 这个问题很合理,特别是对于字数多的毕业论文,价格差距相当可观。 4万字的论文: 8元工具:320元3元工具:约130元 差了190元。那这190元换来的是什么…...

基于SVC和PSS的电力系统暂态稳定性研究:Matlab/Simulink仿真与结果分析
基于SVC和PSS的电力系统暂态稳定性研究 【软件】Matlab/Simulink、Word; 【说明】通过仿真各类短路故障,验证静止无功补偿器(SVC)和电力系统稳定器(PSS)对于提高电力系统暂态稳定性的重要作用; 【文件】包括:Matlab/Simulink仿真模…...

基于模型预测算法的微网双层能量管理模型:考虑储能优化与电池退化成本的全寿命周期仿真
MATLAB代码:基于模型预测算法的含储能微网双层能量管理模型 关键词:储能优化 模型预测控制MPC 微网 优化调度 能量管理 参考文档:《A Two-layer Energy Management System for Microgrids with Hybrid Energy Storage considering Degradat…...

游戏开发中的乒乓缓存实战:Unity双缓冲技术如何提升渲染性能
游戏开发中的乒乓缓存实战:Unity双缓冲技术如何提升渲染性能 在Unity游戏开发中,渲染性能优化一直是开发者关注的焦点。当画面复杂度和特效层级不断提升时,传统的单缓冲机制往往难以满足流畅渲染的需求,这时乒乓缓存(P…...

从智能家居到工业4.0:聊聊STM32和树莓派Pico,谁才是你下一个项目的‘心脏’?
从智能家居到工业4.0:STM32与树莓派Pico的实战选型指南 在嵌入式系统开发领域,选择合适的微控制器往往决定着项目的成败。面对市场上琳琅满目的MCU产品,开发者常常陷入选择困难——是选择传统工业级的STM32系列,还是拥抱新兴的树莓…...

什么是战略解码?
在很多企业的战略会上,我常看到这样一幕: 老板在台上挥斥方遒,讲愿景、讲宏图; 台下高管们埋头苦干,把老板定的10 亿目标, 像切蛋糕一样分给销售、研发和市场部。 大家管这个过程叫“战略解码”。 但是…...

告别复杂配置!Youtu-VL-4B-Instruct开箱即用,快速搭建视觉语言AI助手
告别复杂配置!Youtu-VL-4B-Instruct开箱即用,快速搭建视觉语言AI助手 1. 为什么选择Youtu-VL-4B-Instruct 在当今多模态AI快速发展的时代,视觉语言模型(VLM)正成为企业智能化转型的重要工具。然而,大多数VLM模型要么需要复杂的部…...

AI生成内容版权到底归谁?一文讲透法律边界与避坑方法
AI生成内容的版权归属问题AI生成内容的版权归属目前在全球范围内尚无统一标准,不同国家和地区的法律体系存在差异。核心争议点在于:版权法通常要求作品必须由人类创作,而AI作为工具是否具备“作者”资格。美国版权局2023年明确表示࿰…...