【数据结构】八大经典排序总结
文章目录
- 一、排序的概念及其运用
- 1.排序的概念
- 2.常见排序的分类
- 3.排序的运用
- 二、常见排序算法的实现
- 1.直接插入排序
- 1.1排序思想
- 1.2代码实现
- 1.3复杂度及稳定性
- 1.4特性总结
- 2.希尔排序
- 2.1排序思想
- 2.3复杂度及稳定性
- 2.4特性总结
- 3.直接选择排序
- 3.1排序思想
- 3.2代码实现
- 3.3复杂度及稳定性
- 3.4特性总结
- 4.堆排序
- 4.1排序思想
- 4.2代码实现
- 4.3复杂度及稳定性
- 4.4特性总结
- 5.冒泡排序
- 5.1排序思想
- 5.2代码实现
- 5.3复杂度及稳定性
- 5.4特性总结
- 6.快速排序(重要)
- 6.1排序思想
- 6.2快速排序递归实现
- 6.2.1 hoare法
- 6.2.2 挖坑法
- 6.2.3 前后指针法
- 6.3快速排序递归实现的完整代码
- 6.4快速排序非递归实现
- 6.5复杂度及稳定性
- 6.6特性总结
- 7.归并排序
- 7.1排序思想
- 7.2归并排序递归实现
- 7.3归并排序非递归实现
- 7.4复杂度及稳定性
- 7.5特性总结
- 8.计数排序
- 8.1排序思想
- 8.2代码实现
- 8.3计数排序的缺陷
- 8.4特性总结
- 三、排序总结
一、排序的概念及其运用
1.排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
为什么要关注排序的稳定性
排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。
比如一个班的学生已经按照学号大小排好序了,我现在要求按照年龄从小到大再排个序,如果年龄相同的,必须按照学号从小到大的顺序排列,那么问题来了,你选择的年龄排序方法如果是不稳定的,是不是排序完了后年龄相同的一组学生学号就乱了,你就得把这组年龄相同的学生再按照学号排一遍。如果是稳定的排序算法,我就只需要按照年龄排一遍就好了,这样看来稳定的排序算法是不是节省了时间
所以,在特殊场景下,对排序的稳定性是有要求的;另外,排序的稳定性在校招中也经常被考察
内部排序:数据元素全部放在内存中的排序,比如插入排序,选择排序和交换排序
外部排序:数据元素太多不能同时放在内存中,不能同时放入内存中,而是需要将待排序的数据存储在外存中,待排序时再把数据一部分一部分地调入内存进行排序,在排序的过程中需要多次进行内存和外存之间进行交换,这种排序就称为外部排序,我们的归并排序既可以是内部排序,也可以是外部排序。
**比较排序:**通过比较两个元素的大小来确定元素在内存中的次序,我们常见的选择排序,插入排序,比较排序和归并排序都属于比较排序
**非比较排序:**通过确定每个元素之前,统计相同元素出现次数,根据统计的结果将序列回收到原来的序列中,常见的非比较排序有基数排序,计数排序和桶排序
2.常见排序的分类

3.排序的运用
排序在我们的日常生活中的应用十分广泛,比如我们在网上购物时会对商品的价格,购买数量,评分等等一系列进行排序,又比如我们的成绩也会进行排序,我们的大学也会进行排序等等。


二、常见排序算法的实现
【注意】本篇文章所有的排序都是以升序实现。
1.直接插入排序
1.1排序思想
直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
实际中我们玩扑克牌时,就用了插入排序的思想:

动图演示:
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与
array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移

1.2代码实现
// 直接插入排序
// 最坏时间复杂度O(N^2) -- 逆序
// 最好时间复杂度O(N) -- 顺序有序
void InsertSort(int* a, int n)
{//[0,end]插入end+1 [0,end+1]有序for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];//记录最后一个元素//当目标元素为最小元素,end为-1时退出循环while (end >= 0){//如果大于tmp中的数据,就往后挪,并--endif (tmp < a[end]){a[end + 1] = a[end];end--;}//如果小于tmp中的数据,就跳出循环准备插入else{break;}}//将数据插入到end的后一个位置a[end + 1] = tmp;}
}
【注意】
1.对于单趟排序来说,假设该数组[0,end]有序,我们需要插入end+1位置的数据。使得[0,end+1]有序。
2.我们end的位置一次从0,1,2,3…n-2开始,即end+1从1,2,3…n-1(下标为n-1为数组的最后一个元素)使得[0,1],[0,2]…[0,n-1]有序,我们用变量tmp保存end+1位置的数据,使得在挪动的过程中不会因为覆盖而丢失数据。
3.当tmp保存的元素大小小于数组中任意一个元素的时候,为了避免数组越界,while循环的条件应该是end>=0;d当tmp比第一个元素还小时,end此时为-1,此时tmp里的数据会被放入a[0]位置,逻辑是正确的。
1.3复杂度及稳定性
时间复杂度
最坏情况:当数组的元素为逆序时,第一次插入移动0,第二次插入移动1次…第n次插入移动n-1次,由等差数列求和公式可知,此时的时间复杂度为O(N^2);
最好情况:当数组的元素为顺序时,每次插入都不需要移动数据,遍历一遍数组即可,此时的时间复杂度为O(N);
所以直接插入排序的时间复杂度为O(N^2)
空间复杂度
直接插入排序是在原数组上进行的,没有开辟额外的空间,所以直接插入排序的空间复杂度为O(1)
稳定性
在数组内部前半部为排好序的记录,后半部是未排好序的。 比较时从前半部的后向前比较,所以不会改变相等记录的相对位置。所以直接插入排序是稳定的。
1.4特性总结
1.元素集合越接近有序,直接插入排序算法的时间效率越高
2.时间复杂度:O(N^2)
3.空间复杂度:O(1),它是一种稳定的排序算法
4.稳定性:稳定
2.希尔排序
2.1排序思想
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达gap=1时,所有记录在统一组内排好序。
画图演示

1.一组一组的进行直接插入排序
//希尔排序
// gap > 1 预排序
// gap == 1 直接插入排序//一组一组的进行直接插入排序
void ShellSort1(int* a, int n)
{int gap = n;while (gap > 1){//gap = gap / 2;gap = gap / 3 + 1;for (int i = 0; i < gap; ++i){// [0,end] 插入 end+gap [0, end+gap]有序 -- 间隔为gap的数据for (int j = i; j < n - gap; j += gap){int end = j;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}}
}
2.gap组数据多组依次并排
//gap组数据多组依次并排
void ShellSort2(int* a, int n)
{int gap = n;while (gap > 1){//gap = gap / 2;gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
【注意】
1.关于gap的取值,我们知道,gap越大,大的数据就能越快跳到后面,小的数据就能越快跳到前面,但不是很接近有序;gap越小,大的数据到后面和小的数据到前面的速度就越慢,但更接近有序;所以综合这两种情况,为了提高效率,最初Shell提出取gap=n/2,直到gap==1;后来大佬Knuth提出gap=n/3+1;还有人提出都取奇数好,也有人提出各gap互质为好,我们这里取的是每次缩小3倍
2.对于一组一组的进行直接插入排序,我们每次只排一组数据,当这组数据排完之后再排下一组时候,所以我们需要用两层循环嵌套来保证没=每一组数据都被排序,对于gap组数据多组依次并排,我们每次让i加1,即让所有组数据同时进行排序(第一组插入一个元素后让第二组插入第一个元素,然后第三组插入第一个元素…直到所有组都插入第一个元素之后再插入每一组的第二个元素,…如此循环往复),就像流水线一个,每一个都先做一点,下一组继续做,所以我们只需要使用一个for循环便可以使得所有组数据都可以进行排序。
3.当gap==1时,相当于对数组进行直接插入排序
4.无论gap=n为奇数还是偶数,gap经过不断的除3加1或者不断除2,进行最后一趟排序时gap一定等于1,我们可以带数字进行验证。
2.3复杂度及稳定性
时间复杂度
希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在一些优秀的数据结构书籍中给出的希尔排序的时间复杂度也都不固定:
《数据结构(C语言版)–严蔚敏

《数据结构-用面相对象方法与C++描述》–殷人昆

因为我们的gap是按照Knuth提出的方式取值的,而且Knuth进行了大量的试验统计,我们暂时就按照:O(N1.25)到O(1.6*N1.25)来算,大概为O(N^1.3)
空间复杂度
希尔排序没有额外的内存消耗,空间复杂度为O(1)
稳定性
和插入排序不同,希尔排序是不稳定的,因为在预排序过程中,数值大小的数据可能会被分配到不同的组中,不同的组进行插入排序之后,数值大小相同的数据的相对位置就可能会发生改变,所以希尔排序是不稳定的。
2.4特性总结
希尔排序是对直接插入排序的优化
当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会使得最后一次排序很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比
时间复杂度:O(N^1.3)(不确定)
空间复杂度:O(1)
稳定性:不稳定
3.直接选择排序
3.1排序思想
直接选择排序的基本思想是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。这里我们对其进行一些优化,我们每次从数组中选择最大的和最小的,把最小的放在最前面,最大的放在最后面。
动图演示(优化之前)
在元素集合array[i]–array[n-1]中选择关键码最大(小)的数据元素,若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换,在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重复上述步骤,直到集合剩余1个元素。

3.2代码实现
// 最坏时间复杂度O(N^2)
// 最好时间复杂度O(N^2)//选择排序
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){// 选出最小的放begin位置// 选出最大的放end位置int maxi = begin, mini = begin;for (int i = begin + 1; i < n; ++i){if (a[i] < a[mini]){mini = i;}if (a[i] > a[maxi]){maxi = i;}}Swap(&a[begin], &a[mini]);//修正一下maxiif (maxi == begin){maxi = mini;}Swap(&a[end], &a[maxi]);++begin;--end;}
}
【注意】
我们优化之后程序会出现一个bug,当我们数组的最大元素在数组的最前面(begin==maxi)的时候,我们交换a[begin]和a[mini]之后会使得最大数a[begin]被交换到下标为mini的位置,此时我们需要修正最大数的下标。
3.3复杂度及稳定性
时间复杂度
无论我们的数组是顺序,逆序还是无序,都不会改变排序的效率,因为我们始终是通过遍历数组来找最大和最小值,即使最小值在第一个位置,最大值在最后一个位置,都需要遍历一遍。所以直接选择排序的时间复杂度为O(N^2);
空间复杂度
直接选择排序没有开辟额外的数组,所以空间复杂度为O(1);
稳定性
直接选择排序给我们的直观感受是稳定的,因为他每次选择元素的时候,只有当遇到比自己小的元素时才更新mini,与自己相等的元素并不会更新mini,所以相等元素间的相对位置不会发生改变,但其实它是不稳定的:
我们以 8 9 8 5 5 为例,我们第一次排序发现5为最小元素,所以mini==3,然后交换a[0]和a[mini],第一次排序之后的数组为 5 9 8 8 5 ,我们仔细对比第一次排序前和排序后的数组,我们发现,8和8之间的相对位置发生了改变,所以说直接选择排序其实是不稳定的,我们这里为了方便好理解,我们以未优化的直接选择排序为例。
3.4特性总结
1.直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2.时间复杂度:O(N^2)
3.空间复杂度:O(1)
4.稳定性:不稳定
4.堆排序
4.1排序思想
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是
通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
4.2代码实现
#include <stdio.h>
#include <assert.h>//空间复杂度O(1)
//时间复杂度O(N*logN)typedef int HPDataType;
//交换两个节点
void Swap(HPDataType* p1, HPDataType* p2)
{assert(p1 && p2);HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}//堆的向上调整 --小根堆
void AdjustUp(HPDataType* a, int child)
{assert(a);int parent = (child - 1) / 2; //找到父节点//while (parent >= 0) 当父亲为0时,(0 - 1) / 2 = 0;又会进入循环while (child > 0) //当调整到跟节点的时候不再继续调整{//当子节点小于父节点的时候交换//if (a[child] > a[parent]) 大根堆if (a[child] < a[parent]){Swap(&a[child], &a[parent]);//迭代child = parent;parent = (child - 1) / 2;}//否则跳出循环else{break;}}
}//堆的向下调整 --小根堆
void AdjustDown(HPDataType* a, int n, int parent)
{assert(a);int minchild = parent * 2 + 1;while (minchild < n){//找出那个较小的孩子if (a[minchild] > a[minchild + 1] && minchild + 1 < n){minchild++;}//if (a[minchild] > a[parent]) 大根堆//当子节点小于父节点的时候交换if (a[minchild] < a[parent]){Swap(&a[minchild], &a[parent]);//迭代parent = minchild;minchild = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{/* 建堆 -- 向上调整建堆 - O(N*logN)for (int i = 1; i < n; ++i){AdjustUp(a, i);}*/// 大思路:选择排序,依次选数,从后往前排// 升序 -- 大堆// 降序 -- 小堆//建堆 -- 向下调整建堆 - O(N)for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}int i = 1;while (i < n){Swap(&a[0], &a[n - i]); // 交换堆尾和堆顶的数据AdjustDown(a, n - i, 0); //向下调整++i;}
}int main()
{int a[] = { 15, 1, 19, 25, 8, 34, 65, 4, 27, 7 };HeapSort(a, sizeof(a) / sizeof(int));for (int i = 0; i < sizeof(a) / sizeof(int); i++){printf("%d ", a[i]);}printf("\n");return 0;
}
4.3复杂度及稳定性
时间复杂度
堆排序的建堆的时间复杂度为O(N),选数的时间复杂度为O(N*logN),所以堆排序的时间复杂度为O(N*logN)
空间复杂度
堆排序直接在原数组进行建堆和选数操作,没有额外的内存消耗,所以空间复杂度为O(1)
稳定性
由于堆排序中相同的数据父节点还是孩子节点,做左孩子还是右孩子,这些都没有规定,所以堆排序吧不稳定的
4.4特性总结
1.堆排序使用堆来选数,效率就高了很多。
2.时间复杂度:O(N*logN)
3.空间复杂度:O(1)
4.稳定性:不稳定
5.冒泡排序
5.1排序思想
交换的基本思想:所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
冒泡排序的基本思想:冒泡排序的思想就是利用的比较交换,利用循环将第 i 小或者大的元素归位,归位操作利用的是对 n 个元素中相邻的两个进行比较,如果顺序正确就不交换,如果顺序错误就进行位置的交换。 通过重复的循环访问数组,直到没有可以交换的元素,那么整个排序就已经完成了。
由于冒泡排序本身并不知道排序的数据是否有序了,所以即便目标数据已经有序,它还是会继续比较,直到循环结束,所以为了提高效率,我们可以对冒泡排序进行简单的优化,即增加一个有序的判断标志,使得我们知道排序的数据已经有序的时候能够提前跳出循环,结束排序。
动图演示

5.2代码实现
// 最坏情况:O(N^2)
// 最好情况:O(N)
// 冒泡排序
void BubbleSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int exchange = 0;for (int j = 1; j < n - i; j++){if (a[j - 1] > a[j]){Swap(&a[j - 1], &a[j]);exchange = 1;}}// 如果没有进行交换,则说明已经有序,则直接跳出循环if (exchange == 0){break;}}
}
【注意】
由于冒泡排序本身不知道待排序的数据是否是有序的,所以即便是在后面排序的过程中,数组中的元素都是有序的,它依然会进行进行,所以我们可以进行一个优化:定义一个标志的变量exchange,如果一趟排序完成之后标志仍然没有改变,则说明数组已经有序,则可以直接退出循环,停止后面不必要的排序。
5.3复杂度及稳定性
时间复杂度
最坏的情况:数组如果是逆序的,则第一趟排序需要交换n-1次,第二趟排序需要交换n-2次,…第n-1趟排序需要交换一次,根据等差数列求和可知,此时的时间复杂度为O(N^2)
最好的情况:数组如果是有序或者接近有序,在没有优化之前,数组元素的数据不会影响排序的时间效率,但是在我们进行优化了之后,此时我们遍历很少的次数便会跳出循环,停止排序,时间复杂度最好的情况达到O(N)
所以冒泡排序的时间复杂度为O(N^2)
空间复杂度
冒泡排序没有开辟额外的数组,所以空间复杂度为O(1);
稳定性
冒泡排序每一趟排序时,只有当前一个元素大于后一个元素的时候才会发生交换,我们是可以控制的,在元素相等时不发生交换,所以冒泡排序是稳定的。
5.4特性总结
1.冒泡排序是一种非常容易理解的排序
2.时间复杂度:O(N^2)
3.空间复杂度:O(1)
4.稳定性:稳定
6.快速排序(重要)
6.1排序思想
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
6.2快速排序递归实现
快速排序的过程是这样的,每次单趟排序,先选出一个数作为一个基准值,把比这个小的数放在这个基准值的左边,比这个大的数放在这个基准数的右边,这样经过一次单趟排序之后,这个基准值到了它最终的位置,并且以这个基准数为界,分为了两个左右区间,左边的比它小,右边的比它大,这样我们就可以对左右区间进行同样的操作,每一次单趟排序都会使得一个数到达它最终的位置,当它的左右区间只有一个元素(一个元素本身就可以看做有序)或者是一个不存在的区间时说明排序已经完成。
我们发现,快速排序的过程和二叉树的前序(先序)遍历十分相似,我们每一趟排序确定一个元素的最终位置,我们只需要按照同样的方式排它的左右区间即可,这个就是不断的把问题分为它的子问题去解决,这便是递归的思想。所以说快速排序是一种二叉树结构的交换排序方法。
//快速排序递归实现
void QuickSort(int* a, int left, int right)
{//如果区间只有一个元素或者区间不存在则返回if (right >= left){return;}//单趟排序确定基准值的位置int keyi = PartSort(a, left, right);//递归左区间QuickSort(a, left, keyi - 1);//递归右区间QuickSort(a, keyi + 1, right);
}
关于快速排序的单趟排序,现在主流的有三种方法:hoare法,挖坑法已经前后指针法
【注】:快速排序所有代码中的keyi代表的是数组的下标,key则是代表数组中的元素
6.2.1 hoare法
hoare法的算法思想:我们取最左边的元素做key,然后定义两个指针L和R,L指向区间的第一个元素,R指向区间的最后一个元素,然后让R先走,当R遇到小于或等于key的元素时就停下来,然后让L走,L遇到大于或等于key的数据时停下来,然后交换L和R所对应的值进行交换,然后重复上面的步骤,直到L和R相遇,二者相遇位置所对应的值一定是小于key的,这时候交换key和L/R即可

代码实现
【注意】
1.我们需要保存的是数组元素的下标keyi,而不是数组中元素的大小key,因为在partsort中,key只是一个局部变量,局部变量的改变不会影响数组中的元素
2.在写循环条件的时候,我们需要假上left < right,这是为了避免keyi右边的元素全部大于a[keyi]的时候,R不会停止而造成数组的越界访问,同时也避免L在往右走的过程中不会越过R和不会在相遇点停下来
3.我们判断L和R移动的条件的时候,a[left]或者a[right]等于a[keyi]的时候,我们也让L和R移动,避免出现a[keyi]==a[left]==a[right]这种情况而造成死循环的情况
为什么L和R相遇位置对应的元素一定小于key?
这里的关键在于我们让R先走
我们知道,L和R相遇只有两种情况:L撞R,或者是R撞L
当L撞R的时候,由于R是先走的,所以R停下来的位置下标对应的元素一定是小于key的,所以相遇位置对于的元素是小于key的
当R撞L的时候,这里分为两种情况:1是L一直没有动,此时LR可以,交换后不变,2是L动过,此时L处对于的下标值一定是小于keyi位置的值的,因为在此之前两者一定发生过交换,否则R不会动,所以相遇时对于的下标的值是小于keyi对于的值的
排序优化
我们已经实现了快速排序,我们是选择最左边或者最右边的值做key,但是如果在某些特殊的情况下,比如数组是顺序或者逆序的情况下,快速排序的时间复杂度此时为O(N^2),且有可能会出现栈溢出的情况,这里我们可以对其中的两个逻辑进行优化,一是选key逻辑,二是小区间优化
优化选key逻辑
我们知道,我们当前的算法是选择区间第一个位置的元素作为key,然后通过单趟排序确定该元素的最终最值,那么最好的情况就是我们每次取出的keyi对于的值都为该区间的中位数,这个我们就能不断进行二分,效率就很高

那么最坏的情况是数组有序或者接近有序的时候,在这种情况下我们可以认为keyi处于最左边,这样每次递归左区间的长度为0,右区间的长度为n-1,那么递归的深度为n,即一个会建立n层栈帧,但是我们知道,栈区的空间是非常小的,在Linux下只有8M,那么当我们需要排序的数量达到一定的程度之后,就可能发生栈溢出,导致程序崩溃

针对数组有序或者接近有序造成程序栈溢出的情况,有人对选key的逻辑提出了一下三种优化方法:
1.随机选数,这样使得每次key都为最小或最大的概率变得很小,因为排序的数本来就是随机的,再随机选数就使得选得最小或最大的可能变得更小
2.选中间数做key,这个是专门对有序数组进行的一个优化
3.三数取中-取区间里left,mid,right三个下标对应值的中间值
这里我们选择采用第三种优化方法:
//三数取中
int GetMidIndex(int* a, int left, int right)
{int mid = left + (right - left) / 2;//int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[left] > a[right]){return left;}else{return right;}}else // a[left] >= a[mid]{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]){return left;}else{return right;}}
}
优化后的单趟排序代码
// hoare
int PartSort1(int* a, int left, int right)
{//三数取中int mid = GetMidIndex(a, left, right);Swap(&a[mid], &a[left]);int keyi = left;while (left < right){// 6 6 6 6 6// R找小// left < right,避免left和right错过或者越界// >= 避免死循环while (left < right && a[right] >= a[keyi]){right--;}//L找大while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}// 记录二者相遇的位置使其与key交换int meeti = left;Swap(&a[meeti], &a[keyi]);return meeti;
}
递归小区间优化
我们知道,在完全二叉树中,最后一层的节点数占总节点数的1/2,倒数第二层的节点数占总节点数的1/4,倒数第三场占1/8,也就是说,完全二叉树最后三层的节点数占了总节点数的87.5%
对于快速排序来说,虽然我们递归下来的树并不是一个完全二叉树,因为我们每一层取的key不一定都是中位数,但是总整体上来看,递归下来的二叉树可以认为是一棵完全二叉树,而且对于快速排序来说,最后几层的元素很少(倒数第三层的元素大概为8个,倒数第二层为4个,倒数第一层为2个左右),并且他们都是较为有序的,所以当区间长度小于等于8的时候我们可以使用直接插入排序,为什么不选择其他的排序方式呢,对个冒泡排序来说,循环结束的条件太苛刻了,对于希尔排序,对于大量数据来说效率高,对于数量少的数据在预排阶段就会有很大的消耗,而直接插入排序对于接近有序的数据,那么数据移动的次数就会很少,非常适合这种接近有序的数组的排序,这样我们就不再继续递归分割子区间,从而达到提高效率的目的,我们也可以在长度小于15的时候就使用直接插入排序,这个可以自己选择

优化后的递归函数
//快速排序递归实现-递归优化
// [begin, end]
void QuickSort(int* a, int begin, int end)
{// 如果左右区间相等或者右区间的值小于左区间的值时返回if (begin >= end){return;}// 当递归到元素个数小于8的时候,为了提高效率,直接使用直接插入排序if (end - begin <= 8){InsertSort(a + begin, end - begin + 1);}else{int keyi = PartSort3(a, begin, end);//[begin, keyi-1] keyi [keyi+1, end]// 递归左区间QuickSort(a, begin, keyi - 1);// 递归右区间QuickSort(a, keyi+1, end);}
}
6.2.2 挖坑法
挖坑法的算法思想如下:
首先,我们利用三数取中筛选出合适的数值,然后让其与最左边的数据进行交换,再让key=a[left],其次,定义两个变量L和R,分别指向区间的开始和末尾,与hoare法不同的是,挖坑法会增加一个变量hole,用来记录坑的位置,同时,hoare中使用的是keyi(数组下标),而挖坑法中使用的是key(下标对应的元素)
如下图:坑最开始的位置在最左边,我们让R先走,当R找到比key小的值之后与a[hole]进行交换,并让R的位置作为新的坑,然后让L走,找到比key大的位置,找到后也与坑所在位置的元素进行交换并更新坑,最后重复上述过程,直到L和R相遇,此时直接用key覆盖掉L/R/hole(代表同一个位置)对于的元素即可
动图演示

代码实现
// 挖坑法
int PartSort2(int* a, int left, int right)
{// 三数取中int mid = GetMidIndex(a, left, right);Swap(&a[mid], &a[left]);int key = a[left];int hole = left;while (left < right){// 右边找小,填到左边坑while (a[right] >= key && left < right){--right;}a[hole] = a[right];hole = right;// 左边找大,填到右边坑while (a[left] <= key && left < right){++left;}a[hole] = a[left];hole = left;}a[left] = key;return hole;
}
6.2.3 前后指针法
前后指针的算法思想如下:
首先,最开始的还是和前面两种方法一样,利用三叔取中函数来优化选key逻辑,三种方法不同之处在于一次快速排序的逻辑;对于前后指针法的单趟排序,我们定义第三个变量,keyi=left,prev=left,cur=left+1;其中keyi代表key值所在的下标,而prev和cur就是我们的前后指针,我们让cur先走,当找到小于a[keyi]的时候停下来,然后++prev,再判断cur和prev是否相等,不相等就交换对于的值,重复以上步骤,直到cur>right,最后交换a[keyi]和a[prev]即可

代码实现
//前后指针法
int PartSort3(int* a, int left, int right)
{// 三数取中int mid = GetMidIndex(a, left, right);Swap(&a[mid], &a[left]);int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){// 找小if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}/*while (cur <= right){while (a[cur] < a[keyi] && cur <= right){++prev;Swap(&a[prev], &a[cur]);++cur;}while (a[cur] > a[keyi] && cur <= right){++cur;}}*/Swap(&a[keyi], &a[prev]);return prev;
}
【注意】
1.因为prev是从keyi的位置开始的,而keyi在循环结束时才进行交换,所以我们先让prev++,再观察prev是否等于cur,如果相等就没有必要交换了
2.如果不相等,由于cur比prev先走,并且cur只有遇到小于a[keyi]的值才停下来,++prev,交换prev和cur的值,所以a[prev]一定大于a[cur],二者进行交换
3.当cur>right跳出循环之后,prev并没有进行自增,那么a[prev]一定是小于a[keyi]的,所以直接交换二者即可
6.3快速排序递归实现的完整代码
//交换两个数据
void Swap(int* left, int* right)
{int tmp = *left;*left = *right;*right = tmp;
}
//三数取中
int GetMidIndex(int* a, int left, int right)
{int mid = left + (right - left) / 2;//int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[left] > a[right]){return left;}else{return right;}}else // a[left] >= a[mid]{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]){return left;}else{return right;}}
}// [left, right] -- O(N)
// hoare
int PartSort1(int* a, int left, int right)
{//三数取中int mid = GetMidIndex(a, left, right);//printf("[%d,%d]-%d\n", left, right, mid);Swap(&a[mid], &a[left]);int keyi = left;while (left < right){// 6 6 6 6 6// R找小while (left < right && a[right] >= a[keyi]){right--;}//L找大while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}int meeti = left;Swap(&a[meeti], &a[keyi]);return meeti;
}// 挖坑法
int PartSort2(int* a, int left, int right)
{// 三数取中int mid = GetMidIndex(a, left, right);Swap(&a[mid], &a[left]);int key = a[left];int hole = left;while (left < right){// 右边找小,填到左边坑while (a[right] >= key && left < right){--right;}a[hole] = a[right];hole = right;// 左边找大,填到右边坑while (a[left] <= key && left < right){++left;}a[hole] = a[left];hole = left;}a[left] = key;return hole;
}//前后指针法
int PartSort3(int* a, int left, int right)
{// 三数取中int mid = GetMidIndex(a, left, right);Swap(&a[mid], &a[left]);int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){// 找小if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}/*while (cur <= right){while (a[cur] < a[keyi] && cur <= right){++prev;Swap(&a[prev], &a[cur]);++cur;}while (a[cur] > a[keyi] && cur <= right){++cur;}}*/Swap(&a[keyi], &a[prev]);return prev;
}//快速排序
// [begin, end]
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}if (end - begin <= 8){InsertSort(a + begin, end - begin + 1);}else{int keyi = PartSort3(a, begin, end);//[begin, keyi-1] keyi [keyi+1, end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi+1, end);}
}
6.4快速排序非递归实现
经过上面的学习,我们已经知道如何使用递归的方式来实现快速排序,但是有时候递归的深度太深就会出现栈溢出的问题,对于上面的递归过程来说,其实是一个数组区间变化的过程,先的整个数组,然后被分为左右区间,左右区间又被分为左右区间…而数组的区间我们用left和right边界表示,根据这个思路,我们利用这个就可以得到非递归的思路;
快速排序的非递归我们需要借助一个数据结构–栈,首先我们将数组的左右边界(左闭右闭)入栈,然后取出栈顶的right和left,作为左右区间,取出元素的同时我们需要把这两个元素出栈,此时我们就有了左右区间,之后我们调用单趟排序对此区间进行排序,排序完成之后再将此区间的左右进行入栈操作,重复上述操作,直到栈为空为止
我们会写快速排序的递归方式,为什么还要了解快排的非递归呢?首先,对于未优化的快速排序,当数组中的元素有序或者接近有序的时候,我们使用递归的方式的话,此时递归的深度为N,而递归调用函数的栈帧是在栈上开辟的,而栈很小,在Linux下只有8M左右,所以当我们排序的数据的数量比较大的时候就可能会出现栈溢出,对于优化后的快速排序来说,三数取中只能保证我们每次取出的key值不是最小或者最次小的数,如果我们每次取出的key都是第三,第四小的数的时候,我们依然可能出栈栈溢出的情况,所以对于一些极端的场景,我们使用递归的方式进行排序就可能出现栈溢出的情况,此时非递归就可以避免这种情况
代码实现
//快速排序非递归
void QuickSortNonR(int* a, int begin, int end)
{ST st;StackInit(&st);StackPush(&st, begin);StackPush(&st, end);while (!StackEmpty(&st)){int right = StackTop(&st);StackPop(&st);int left = StackTop(&st);StackPop(&st);int keyi = PartSort3(a, left, right);// [left, keyi-1] keyi [keyi+1,right]if (keyi + 1 < right){StackPush(&st, keyi + 1);StackPush(&st, right);}if (left < keyi - 1){StackPush(&st, left);StackPush(&st, keyi - 1);}}StackDestroy(&st);
}
【注意】
1.我们这里没有提供栈的实现的代码,我们自己写的时候需要加上栈实现的代码,如果我们已经实现过,我们就只需要在当前项目中加上之前我们实现的Stack.h和Stack.c即可
2.由于栈是先进后出的,如果我们的入栈顺序为begin,end,那么我们的出栈顺序就应该为end,begin
3.对于把递归改成非递归,我们通常才用循环,利用数据结构的栈和队列来实现,我们利用栈和队列的时候,通常是模拟递归的过程,我们这里就是模拟递归调用的过程,所以我们在单趟排序之后选择先入右区间,再入左区间,这样就使得左区间就会先出栈,先进行单趟排序,和我们递归方式的顺序一样,当然,我们也可以先入左区间,再入右区间,不会影响最终的结果。
6.5复杂度及稳定性
时间复杂度
递归实现:
快速排序递归的深度大约是logN(假设为此都是二分),每一层的元素个数大约是N,尽管每一层少了之前层数keyi位置的值,但是这个数量对于N来说相差很大,可以忽略,所以数据复杂度为O(N*logN)

非递归实现:
入栈和出栈的时间复杂度为O(logN),然后每次单趟排序的时间复杂度为O(N),,所以时间复杂度为O(N*logN)
空间复杂度
递归实现函数栈帧的创建消耗空间,此时的空间复杂度为O(logN),非递归实现栈的实现有空间的消耗,也为O(logN)
稳定性
由于快速排序选出的key值是不确定的,在交换的过程中可能顺序会发生改变,所以是不稳定的
6.6特性总结
快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
时间复杂度:O(N*logN)
空间复杂度:O(logN)
稳定性:不稳定
7.归并排序
7.1排序思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并
动图演示

7.2归并排序递归实现
如上图所示,如果说快速排序递归实现是相当于二叉树的前序遍历的话,那么归并排序的递归实现就相当于二叉树的后续遍历,因为归并排序思想本质就是将两个有序数组排成一个有序的数组。
归并排序的基本思想:对于两个有序的数组,不断的取小的元素尾插;对于我们真正困难的是如何达到归并排序的条件–被归并的两个区间的元素必须是有序的,这时候我们就需要用到递归的思想了,我们需要不断的将待排序的区间分为左右两个子区间进行递归,直到左右区间元素的个数为1,我们就认为是有序了,然后再进行归并,返回上一层,待上一层的右区间变成有序后,进行归并,归并之后就把有序的拷贝到原数组,然后重复上述的步骤,直到原数组的所有元素都有序为止,就中思想就和二叉树的后续遍历很相似,先访问左子树,再访问右子树,最后再访问根节点。
我们以10 6 7 1 3 9 4 2 为例,先进行不断的缩小子区间,直到左右区间元素的个数为1,然后10 6 ,7 1,3 9,4 2 进行两两归并,返回上一层为6 10 1 7 3 9 2 4 ,再进行两两归并成1 6 7 10 2 3 4 9,最后一次归并为1 2 3 4 6 7 9 10,此时就完成了排序

代码实现
_MergeSort(int* a, int begin, int end, int* tmp)
{if (begin >= end)return;int mid = (begin + end) / 2;// [begin, mid] [mid+1, end]_MergeSort(a, begin, mid, tmp);_MergeSort(a, mid + 1, end, tmp);// 归并 取小的尾插// [begin, mid] [mid+1, end]int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}// 拷贝回原数组 -- 归并哪部分就拷贝哪部分回去memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}//归并排序
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, 0, n - 1, tmp);free(tmp);tmp = NULL;
}
【注意】
我们这里开辟了一个和待排序一样大小的tmp数组,在每一次归并完成之后,需要将tmp数组中归并的结果拷贝到原数组中,这里需要注意的是,我们进行拷贝的区间(数组下标对应),因为tmp中保存的是整个数组区间中一小部分归并的结果,所以我们拷贝的时候也应该拷贝到原数组的对于区间中,否则可能会拷贝一些随机值。
7.3归并排序非递归实现
归并排序递归 和快速排序不同的是,归并排序的左右区间是严格进行二分的,即归并排序递归下来是一棵完全二叉树,那么此时的递归深度为logN,所以归并排序不用担心栈溢出的问题,比如我们需要排序的数据的数量为10亿,此时的递归深度为30,空间是可以重复利用的,左区间递归回来之后函数栈帧销毁继续分配给右区间继续使用,所以我们只需要看深度即可,看次看来,归并排序的非递归的价值不是很大,但是呢,由于归并排序非递归版本会涉及到区间的边界问题,为什么递归不会有这问题呢?这是因为我们子函数里面进行也判断,只有一个元素或者是不存在的区间就直接递归返回上一层,而对于非递归来说,就要考虑区间的边界问题,这个问题又比较的复杂,有的公司可能会拿它来考察我们的编程能力和逻辑思维能力,所以我们还是有必要去学习一下
归并排序的非递归不能使用栈来实现,因为归并排序的非递归类似于二叉树的后续遍历,而同一个区间的left和right可能会被使用多次,而栈出栈之后就找不到原来区间的边界了,所以非常麻烦,我们选择采用循环的方式,就行斐波那契数列一样,通过前面的区间来得到后面的区间

如上图,我们顶一个gap变量,用于指定每次进行排序的一组数据元素的个数,然后不断二倍增长,直到所有的数据都进行归并排序,但是这个对于排序的数组元素的个数有严格的限制,那就是必须的2^N个,否则就可能会发生越界访问

我们仔细分析之后发现,越界的情况一共有三种:
1.第一组越界,第一组越界只可能是right越界,因为如果是第一组的left越界那么就不会进入循环,就不会进行归并排序,此时,第二组全部越界,那么第一组的数据是有序的,右区间么没有需要排序的数据,那么就不需要进行归并,直接break;
2.第二组全部越界,此情况也只有左区间一组数据,也不需要进行归并,直接break;
3.第二组部分越界,即第二组的right越界,此时存在左右两组数据,需要进行归并,那么只能将第二组的right修正为n-1,然后再进行归并
代码实现
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;while (gap < n){// gap个数据 gap个数据归并for (int i = 0; i < n; i += 2 * gap){// 归并 取小的尾插int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;// 第一组越界if (end1 >= n){break;}// 第二组全部越界if (begin2 >= n){break;}// 第二组部分越界if (end2 >= n){// 修正一下end2,继续归并end2 = n - 1;}int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}// 拷贝回原数组 -- 归并哪部分就拷贝哪部分回去memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));}gap *= 2;}free(tmp);tmp = NULL;
}7.4复杂度及稳定性
时间复杂度
对于递归实现的归并排序来说,递归的深度为logN,每层排序的元素个数为N,所以归并排序的时间复杂度为O(N*logN);对于非递归实现来说,gap每次增加2倍,每次gap中待排序的数据等于或小于N,所以非递归实现的归并排序的时间复杂度也为O(N*logN)
空间复杂度
归并排序需要额外的和原数组一样大小的第三方数组,所以空间复杂度为O(N)
稳定性
归并排序的稳定性取决于我们在单次归并过程中取较小的元素尾插,还是取较小或等于的元素尾插,但是排序算法的稳定性只要我们能控制成稳定的,那么该算法就是稳定的,因为任何一个排序算法我们都可以写成不稳定的,所以归并排序是稳定的算法
不稳定写法:
while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}
稳定写法:
while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}
7.5特性总结
1.归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2.时间复杂度:O(N*logN)
3.空间复杂度:O(N)
4.稳定性:稳定
8.计数排序
8.1排序思想
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
1.统计相同元素出现次数
2.根据统计的结果将序列回收到原来的序列中
计数排序就是将数组中对应的数据出现的次数,映射到一个新的初始化为0的新数组的对应的下标中,每出现一次,下标对应的值就+1,其中映射分为绝对映射和相对映射
绝对映射
绝对映射就是Count数组中下标为i的位置记录的是待排序数组中值为i的元素出现的次数,我们先遍历一遍原数组,找出原数组中的最大元素(数组中的元素都大于0),然后我们开辟一个比原数组大于1的空间,然后我们将原数组中的数据映射到新的数组中,最后我们遍历新数组,根据新数组中对应下标的值输出即可,该下标的数组就是下标的出现次数。

相对映射
我们了解绝对映射的原理之后,就会发现绝对映射有以下的缺陷:
1.绝对映射排序的数组中的元素不能的负数,因为数组的下标从0开始,不能为负数
2.当待排序的数组元素值比较大的时候,我们就需要开辟一个很大的空间,此时就会有很大的空间浪费
基于绝对映射的缺陷,我们又设计出了相对映射来对其进行一定程度上的优化,其基本思路为:
我们不再根据数组的最大元素来开辟空间,而是根据数组中的最大元素和最小元素的差值来开辟空间,开辟空间的大小为最大元素-最小元素+1;映射的规则为元素值的大小减去最小元素的大小映射到开辟数组的下标,这样我们数组中的负数也可以进行映射,我们取出元素时,覆盖到原数组的值为下标加上最小值

8.2代码实现
// 时间复杂度:O(N+range)
// 空间复杂度:O(range)
// 适合数据范围集中,也就是range小
// 只适合整数,不适合浮点数、字符串等
//计数排序
void CountSort(int* a, int n)
{int max = a[0], min = a[0];for (int i = 1; i < n; i++){if (a[i] > max){max = a[i];}if (a[i] < min){min = a[i];}}int range = max - min + 1;// 统计次数int* Count = (int*)malloc(sizeof(int) * range);if (Count == NULL){perror("malloc fail");return;}memset(Count, 0, sizeof(int) * range);for (int i = 0; i < n; i++){Count[a[i] - min]++;}// 排序int j = 0;for (int i = 0; i < range; i++){while (Count[i]--){a[j] = i + min;j++;}}
}
8.3计数排序的缺陷
计数排序看起来效率很高,但是它有如下两个缺陷:
1.计数排序只能对整型数据进行排序,对于浮点型,字符型类型等其他类型的数据则不能使用计数排序
2.计数排序适用于数据分布较为集中的情况,当我们分布较分散的时候,空间复杂度就会很大
8.4特性总结
1.计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
2.时间复杂度:O(MAX(N+range))
3.空间复杂度:O(range)
4.稳定性:稳定
三、排序总结
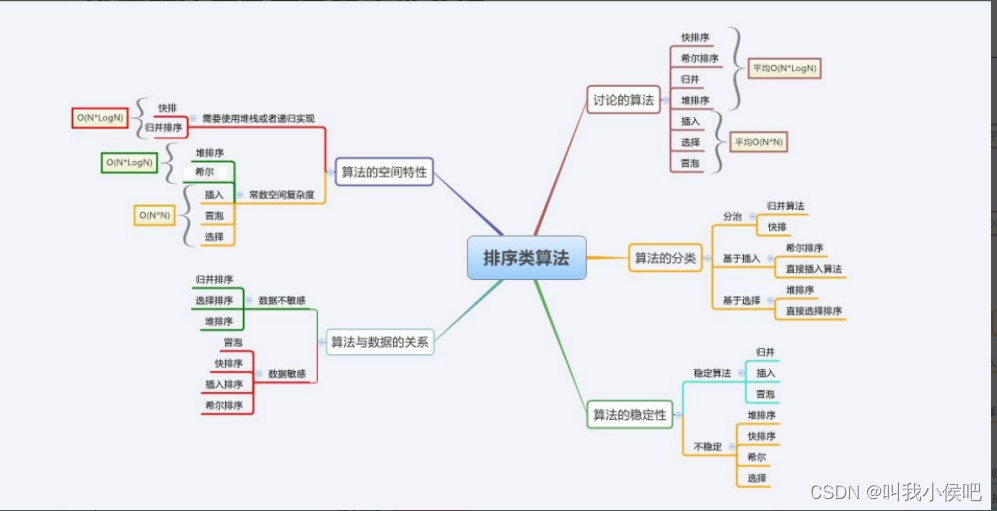
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 直接插入排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 希尔排序 | O(n*logN)~O(N^2) | O(N^1.3) | O(N^2) | O(1) | 不稳定 |
| 直接选择排序 | O(N^2) | O(N^2) | O(N^2) | O(1) | 不稳定 |
| 堆排序 | O(n*logN) | O(n*logN) | O(n*logN) | O(1) | 不稳定 |
| 冒泡排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 快速排序 | O(n*logN) | O(n*logN) | O(N^2) | O(logN)~O(N) | 不稳定 |
| 归并排序 | O(n*logN) | O(n*logN) | O(n^2) | O(N) | 稳定 |
| 计数排序 | O(MAX(N+range)) | O(MAX(N+range)) | O(MAX(N+range)) | O(range) | 稳定 |
相关文章:
【数据结构】八大经典排序总结
文章目录一、排序的概念及其运用1.排序的概念2.常见排序的分类3.排序的运用二、常见排序算法的实现1.直接插入排序1.1排序思想1.2代码实现1.3复杂度及稳定性1.4特性总结2.希尔排序2.1排序思想2.3复杂度及稳定性2.4特性总结3.直接选择排序3.1排序思想3.2代码实现3.3复杂度及稳定…...
BI的能力边界:能解决的企业问题和不擅长的领域
数字化转型本就需要借助信息化相关技术、思想来完成,所以说信息化建设同样是数字化转型过程中非常重要的一环,而这就是商业智能BI和数字化转型的关系 BI 能解决的企业问题 数据是企业的重要资产,也是企业商业智能BI的核心要求。通常&#x…...

金三银四面试必备,“全新”突击真题宝典,阿里腾讯字节都稳了
前言招聘旺季就到了,不知道大家是否准备好了,面对金三银四的招聘旺季,如果没有精心准备那笔者认为那是对自己不负责任;就我们Java程序员来说,多数的公司总体上面试都是以自我介绍项目介绍项目细节/难点提问基础知识点考…...

MYSQL 基础篇 | 02-MYSQL基础应用
文章目录1 MySQL概述2 SQL2.1 SQL通用语法2.2 SQL分类2.3 DDL2.3.1 数据库操作2.3.2 表操作2.4 DML2.4.1 添加数据2.4.2 修改数据2.4.3 删除数据2.5 DQL2.5.1 基础查询2.5.2 条件查询2.5.3 聚合查询2.5.4 分组查询2.5.5 排序查询2.5.6 分页查询2.5.7 综合练习2.6 DCL2.6.1 管理…...

CSS实现checkbox选中动画
前言 👏CSS实现checkbox选中动画,速速来Get吧~ 🥇文末分享源代码。记得点赞关注收藏! 1.实现效果 2.实现步骤 定义css变量,–checked,表示激活选中色值 :root {--checked: orange; }创建父容器…...

工业机器人编程调试怎么学
很多人觉得工业机器人很难学学,实际上机器人涉及的知识远比PLC要少。现简单说明一下初学者学习工业机器人编程调试的流程,以AUBO机器人为例: 首先我们需要知道工业机器人的调试学起来不难,远比编程更简单,示教器上的编…...

Java并发包提供了哪些并发工具类?
第19讲 | Java并发包提供了哪些并发工具类? 通过前面的学习,我们一起回顾了线程、锁等各种并发编程的基本元素,也逐步涉及了 Java 并发包中的部分内容,相信经过前面的热身,我们能够更快地理解 Java 并发包。 今天我要…...
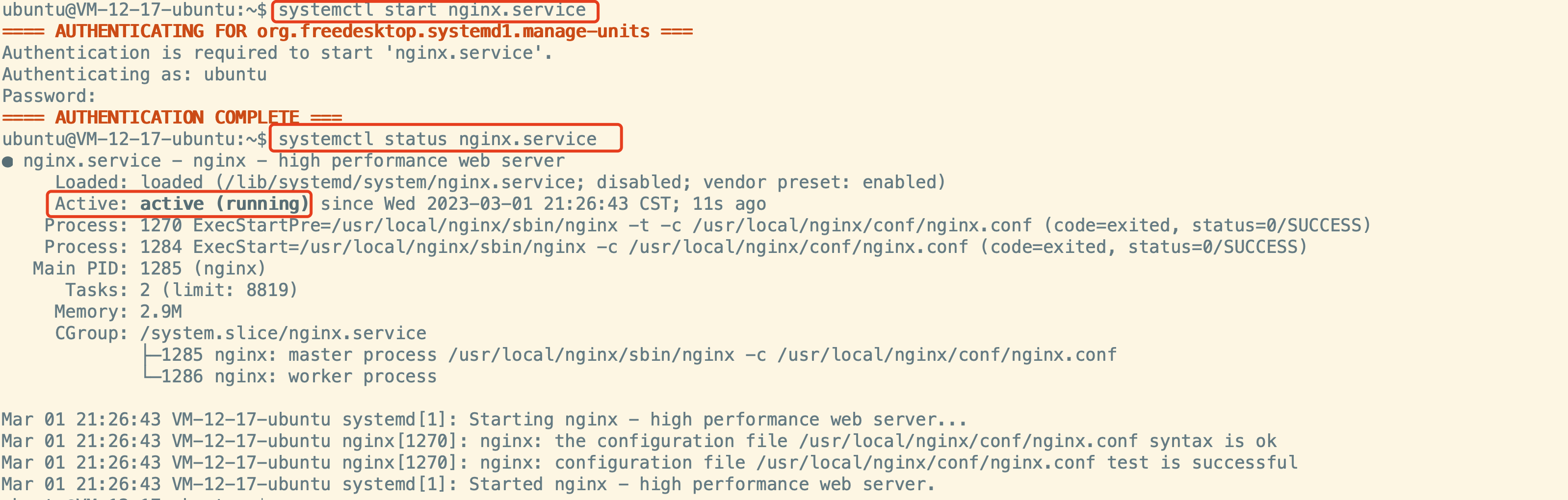
systemctl 启动/停止/重新加载 nginx
systemctl 启动/停止/重新加载 nginx 一、新建nginx.service脚本 sudo vim /usr/lib/systemd/system/nginx.service然后按iii进入编辑模式,粘贴如下内容,其中/usr/local/nginx/是进行make && make install之后的文件夹路径,需要根据…...
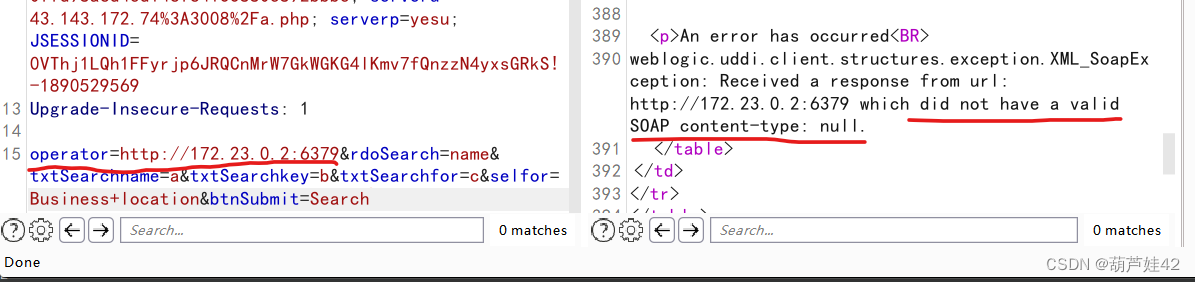
SSRF学习 3
目录 <1> 什么是SSRF? <2> 通常SSRF会发生在哪些位置? <3> 测试流程 <4> Weblogic-ssrf 复现 (1) 漏洞存在点 (2) 注入HTTP头,利用Redis反弹shell (3) 修复方案 <1> 什么是SSRF? SSRF(Serv…...
)
Mysql(数据库基础篇)
👌 棒棒有言:也许我一直照着别人的方向飞,可是这次,我想要用我的方式飞翔一次!人生,既要淡,又要有味。凡事不必太在意,一切随缘,缘深多聚聚,缘浅随它去。凡事…...
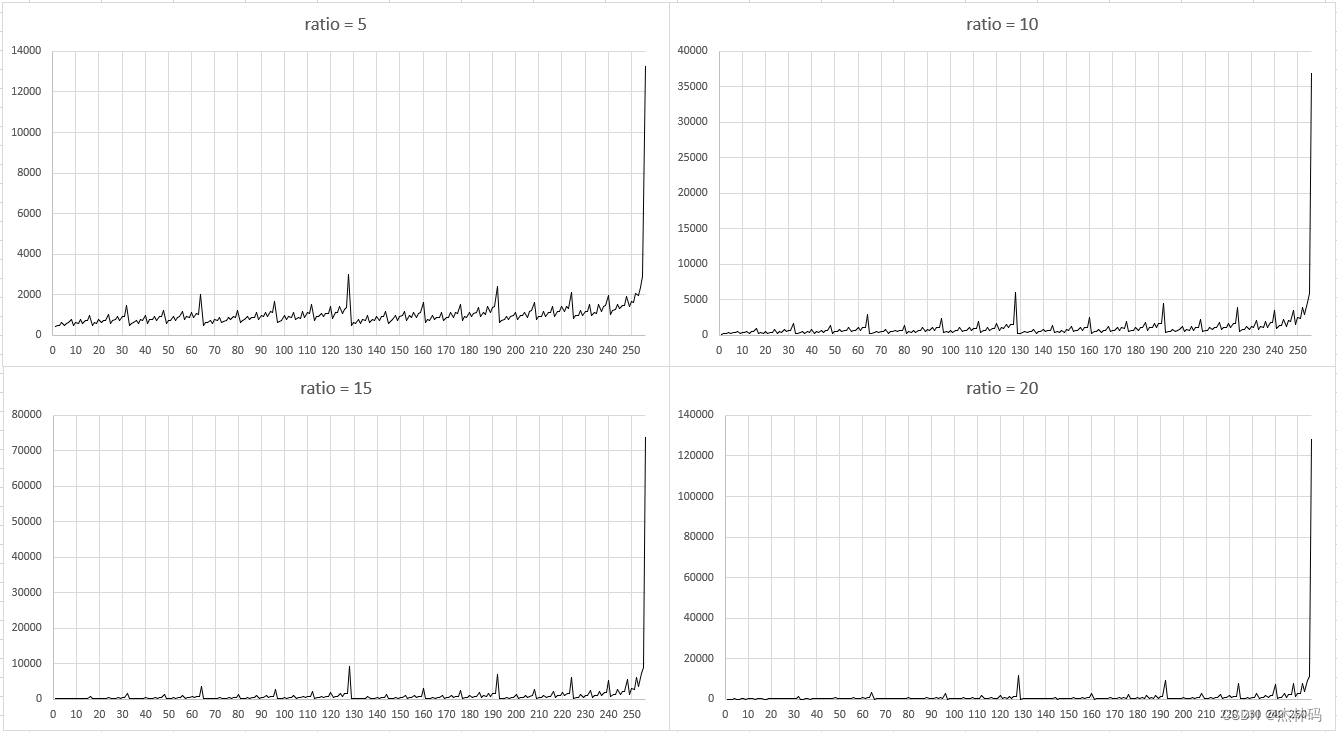
一种全新的图像变换理论的实验(五)——研究目的替代DCT和小波
一、前言 目前在大量的灰度图像测试下,基本确定变换系数ratio取值0-25之间时,逆变化后的图还能基本保障效果,而且越接近0效果越好。本文还是以lenna.bmp灰度图为例,实验不再逆变换,而是把变换后的数据直接输出为bmp的…...
vue3、vite、pinia 快速入门
准备 开发工具及插件IDE:vscode,WebStorm插件:Auto Close Tag、Auto Rename Tag、Live Server通过“!”快速生成html模板正式学习安装vue通过CDN的方式导入vue<script src"" target"_blank">https://unpkg.com/vue3/dist/vue.…...
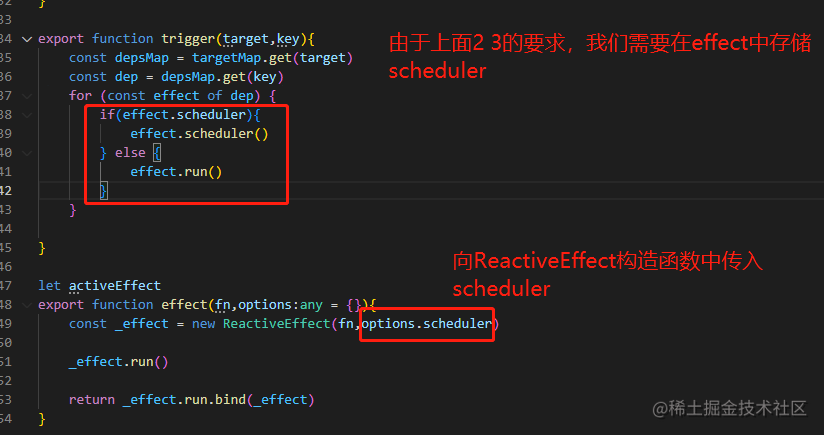
第六章 effect.scheduler功能实现
effect.scheduler功能实现 主要先了解scheduler需要实现什么样的需求,有一下四点: 1 通过 effect 的第二个参数给定一个 scheduler 的 fn 2 effect 第一次执行的时候 还会执行 fn 3 当 响应式对象 set update 不执行fn 而是执行 scheduler 4 如果说…...

软件测试之zentao
禅道 1. 禅道介绍 1.1 禅道项目管理软件是做什么的? 禅道,国产开源项目管理软件。它集产品管理、项目管理、质量管理、文档管理、组织管理和事务管理于一体,是一款专业的研发项目管理软件,完整覆盖了研发项目管理的核心流程。禅…...

美颜sdk动态贴纸的实现流程
随着移动互联网时代的到来,各式各样的 APP层出不穷,从最初的微信、 QQ到如今的抖音、快手等等,再到如今的微博、小红书等等,各式各样的 APP不断涌现。从最开始简单的图片展示到视频聊天,再到现如今丰富多样的各种动态贴…...

Web连接器
分模块编写爬虫(一) 连接器模块基本思路: 输入:url连接输出:url对应的html文本步骤: 定义url和user-agent获取网页的requests对象捕获异常: 403:禁止访问404:页面失效5…...
插上数据的翅膀,开启我升职加薪的梦想之旅
我是麦思思,大学毕业后就进入大厂工作并担任电子消费行业业务部门的数据分析师,对于一个数据分析师而言,Excel是必备技能,函数公式我能随手就来,几十M的文件处理那都是轻轻松松。但是,近几年随着企业业务发…...

来香港饮茶吹水先,免费报名Zabbix Meetup香港站!
Zabbix Meetup 来到香港啦! 春暖花开,Zabbix计划5月来到香港,和你一起饮茶吹水! 时间:5月某日,周几方便? 预计14:00-17:00 形式:线下交流会,免费,线下&…...

李群李代数求导-常用求导公式
参考 A micro Lie theory for state estimation in robotics manif issues 116 常用求导公式 Operation左雅克比右雅克比X−1\mathcal{X}^{-1}X−1JXX−1−I\mathbf{J}_{\mathcal{X}}^{\mathcal{X}^{-1}}\mathbf{-I}JXX−1−IJXX−1−AdX\mathbf{J}_{\mathcal{X}}^{\mathc…...
IIS之web服务器的安装、部署以及使用教程(图文详细版)
WEB服务器的部署 打开虚拟机后查看已经开放的端口,可以看到没有TCP 80、TCP 443,说明HTTP服务端口没有打开 打开我的电脑—双击CD驱动器 选择安装可选的Windows组件 选择应用程序服务器—打开Internet信息服务—选择万维网服务和FTP服务 一路确…...

AdGuard浏览器扩展:企业级隐私保护与广告拦截解决方案
AdGuard浏览器扩展:企业级隐私保护与广告拦截解决方案 【免费下载链接】AdguardBrowserExtension AdGuard browser extension 项目地址: https://gitcode.com/gh_mirrors/ad/AdguardBrowserExtension AdGuard浏览器扩展是一款专注于隐私保护和广告拦截的开源…...

用Arduino玩转GPIO中断:按键消抖+过零检测的5个实战技巧
用Arduino玩转GPIO中断:按键消抖过零检测的5个实战技巧 在智能家居和物联网设备开发中,GPIO中断的高效处理能力往往决定了整个系统的响应速度和稳定性。想象一下,当你按下智能开关却要等待半秒才有反应,或者交流电器在错误的时间点…...

别再手动敲代码了!用通义千问+PHPStudy,30分钟搞定一个带数据库的登录注册系统
零基础30分钟构建登录系统:AIPHPStudy极速开发指南 上周帮学妹调试课程设计时,我发现90%的初学者都在重复造轮子——手动编写那些千篇一律的表单验证和数据库连接代码。其实借助现代开发工具链,完全可以在喝杯咖啡的时间里搭建出完整的登录注…...

基于FreeSWITCH ESL构建高并发智能客服系统的实战指南
在构建智能客服系统时,通信层的稳定与高效是基石。传统的WebSocket或直接SIP处理在高并发场景下,常常面临连接管理复杂、事件处理混乱、资源消耗大等问题。FreeSWITCH作为成熟的软交换平台,其ESL(Event Socket Library)…...

N_m3u8DL-RE:现代流媒体下载的终极解决方案
N_m3u8DL-RE:现代流媒体下载的终极解决方案 【免费下载链接】N_m3u8DL-RE 跨平台、现代且功能强大的流媒体下载器,支持MPD/M3U8/ISM格式。支持英语、简体中文和繁体中文。 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 在当今…...

如何用VarifocalNet提升目标检测性能?从FCOS到VFNet的实战解析
从FCOS到VFNet:实战解析VarifocalNet如何突破目标检测性能瓶颈 目标检测领域近年来涌现出大量创新算法,但性能提升逐渐进入平台期。传统方法如FCOS虽然简洁高效,但在处理密集物体和复杂场景时仍存在明显局限。本文将深入剖析VarifocalNet(VFN…...

利用快马平台快速构建openclawskills技能分享网站原型
最近在构思一个技能分享平台openclawskills,想快速验证这个创意是否可行。传统开发流程需要搭建前后端环境、设计数据库、编写大量基础代码,耗时耗力。后来尝试用InsCode(快马)平台,发现它能大幅缩短原型开发周期,特别适合快速验证…...

为什么你的AI服务OOM频发?Python智能体内存管理5个致命配置错误,今天必须修复
第一章:AI服务OOM频发的底层归因与诊断路径AI服务在高并发推理或大模型微调场景下频繁触发OOM(Out-of-Memory),表面是内存耗尽,实则根植于资源抽象层与运行时协同机制的结构性失配。现代AI框架(如PyTorch、…...

RWKV7-1.5B-g1a参数避坑:top_p=0.9在中文任务中易引发事实性错误实测
RWKV7-1.5B-g1a参数避坑:top_p0.9在中文任务中易引发事实性错误实测 1. 模型简介与测试背景 rwkv7-1.5B-g1a是基于RWKV-7架构的多语言文本生成模型,特别适合中文场景下的基础问答、文案续写和简短总结任务。作为一款轻量级模型,它能在单卡2…...

LaTeX参考文献报错全解析:从\citation到\bibdata的避坑指南
LaTeX参考文献报错全解析:从\citation到\bibdata的避坑指南 当你熬夜赶论文时,突然在编译LaTeX文档时看到一串红色报错:"I found no \bibstyle command"、"I found no \bibdata command"、"I found no \citation co…...