如何正确使用缓存来提升系统性能
文章目录
- 引言
- 什么时候适合加缓存?
- 示例1
- 示例2:
- 示例3:
- 缓存应该怎么配置?
- 数据分布
- **缓存容量大小:**
- 数据淘汰策略
- 缓存的副作用
- 总结
引言
在上一篇文章IO密集型服务提升性能的三种方法中,我们提到了三种优化IO密集型系统的方法,其中添加缓存(cache)的方法是最常用的,而且普适性也是最强的,今天展开讲下如何正确使用缓存。准确说我们需要解决下面三个大问题。
- 什么样的情况下才适合加缓存?
- 缓存应该怎么配置?
- 如何解决或者减少缓存的副作用?
什么时候适合加缓存?
我们先解决第一个问题,什么情况下适合加缓存。 一句话总结就是**如果某个数据获取”成本高“,并且数据是长期有价值,那么这份数据是可以加缓存的。**至于这个”长期“到底有多长,我们会在后文中详细讲解到。 注意 获取成本高 并且 长期有价值, 这两个条件是加缓存的必要条件,必须满足这两个条件才可以添加缓存。成本高和长期有价值这两个词很抽象,怎么判定成本高?什么叫长期有价值?其实这里没有客观的判定标准,只能是通过对比的方式, 我们拿两个具体的示例来说明下。
示例1
你登陆到微信后,你好友的头像需要展示到微信各个页面里(聊天、点赞、评论……),头像是一张图片,图片的获取成本相对于纯文本几十个字节的数据是比较高的,毕竟即便是一张缩略图也有几十KB大小,这里就体现出了图片数据相对的成本高。而微信头像很少会变化,拉取一次长期有效,这里就体现出来了长期有价值的特性。这个场景就很符合可以缓存的数据的特点。事实上微信确实也是这么做的,你换个新头像然后去好友那边观察,那边也不会立即生效的。
示例2:
可能家庭条件好的同学都在双十一买过东西吧,你看中的某个商品库存信息,它是一直在变化的,你现在看到是100但可能下一秒就变成0了。因为这个数据一直是变化的,这个数据对时效性的要求很严格,所以它不满足”长期有价值“这个条件,因此它是无法缓存的。
示例3:
比如我要扫一遍我们系统里所有内容数据,找出其中不合规的内容,对于单条的内容判定是很消耗资源,而且判断结果之后也是一直有效的。这种情况下也没有必要加缓存,因为判定结果我使用一次之后也不会再用了,这里数据不符合长期有价值的特性。 因此这里也是没必要加缓存的。
有些数据单次获取的成本不高,但获取频次非常高,这种总的获取成本非常高其实也算是获取成本高。比如各系统里和人员有个的信息,这种其实一个接口也能快速返回,但架不住调用的次数多,这种情况下也是可以添加缓存来减轻压力的。 我们从获取成本和长期价值两个维度可以将数据请求拆分到4个象限。

通过 获取成本高 并且 长期有价值 这两个维度,你可以想想在你所遇到的所有业务场景中,有哪些是可以通过加缓存来提升性能的?
缓存应该怎么配置?
在解决了什么场景下可以加缓存的时候,就得考虑怎么配置缓存了。这里先来介绍下一个如何评估缓存性能的公式,为了直观点我们以IO密集型场景举例,IO密集型衡量性能的一个关键指标就是访问延迟(latency),在缓存的加持下,整个系统的平均延时计算方式如下:
a v g L a t e n c y = h i t R a t e × c a c h e L a t e n c y + ( 1 − h i t R a t e ) × o r i g i n a l L a t e n c y (1) avgLatency = hitRate \times cacheLatency + (1 - hitRate) \times originalLatency \tag{1} avgLatency=hitRate×cacheLatency+(1−hitRate)×originalLatency(1)
其中 hitRate 代表的是缓存的命中率,cacheLatency是访问一次缓存时的延时,originalLatency 是访问一次原始数据时的延迟。avgLatency就是我们系统最终的延迟,这个值越低越好。 有些同学可能会问,为什么我们不直接把数据全部放到访问最快的存储介质中? 这里就涉及到不同存储介质的特性了,主要是其数据访问速度、价格导致,总之越快的存储介质,单位价格也就越高,这里就不在展开了,大家可以自行查阅下资料。
在我们选定一种缓存介质时,缓存延迟(cacheLatency)也就基本固定下来了,而原始数据的访问延迟(originalLatency)我们肯定是干预不了的。剩下我们能干预的也只有缓存命中率(hitRate)。我们以redis作为缓存为例,然后缓存某个10ms接口的数据,同机房内redis访问延迟是0.1ms的量级 当缓存命中率分别为1% 10% 50% 90% 100%时,我们用上面公式计算出来的结果分别是 9.9ms 9ms 5ms 1ms 0.1ms。可以看出在不同的缓存命中率下最终结果也有着巨大的差异,命中率越高性能越强。
由于成本限制,我们一般是不会将全量的数据导入到缓存介质里的,所以大部分情况下缓存命中率不会是100%,而且还希望缓存空间用的越少越好。如何在有限的缓存介质下,提升系统性能? 从上面的公式就可以看出,提升缓存性能最关键的就是提升缓存的命中率,而缓存的命中率和数据的访问分布、缓存的大小、缓存数据淘汰策略息息相关。
**数据分布:**数据访问是否有规律,是否可以利用这些规律?
**缓存大小:**指缓存最多能存储多少的数据。
**数据淘汰策略:**在缓存已满的情况下,如何剔除缓存中价值最低的数据,腾出空间来给别的数据使用。
数据分布

当我将一份单位时间内访问频次标记在纵坐标轴上,并且按频次从大到小排序。大部分情况下我们会的到以上这张数据访问分布图,可以看出最左侧的一部分数据占掉了总体访问非常大的一部分(头部效应),而且长尾的大量数据被访问的频次很低。这就是大家所熟知的长尾分布。 这种分布下的数据是最时候加缓存的,头部效应越明显加缓存后的性能提升越明显,幸运的是在现实世界中,绝大多数数据的访问分布都是这样的。
当然也有部分数据在单位时间内访问的频次很均匀,这种一般都是程序定时触发的数据访问,这种情况下添加缓存带来的效果提升就很弱,甚至没有提升。 所以你会看到在定时任务里,很少会考虑去加缓存。
缓存容量大小:

在确定了数据分布后,就得考虑缓存容量大小的问题了。从上面的性能计算公式来看,理论上缓存容量越大,缓存对性能提升就越明显,但上文我也提到了越快的存储介质价格越高。在上图中,蓝色框相比红色框在容量增加一倍后,其覆盖的数据访问(曲线下方带背景色面积)远没有增加一倍,后面增加缓存带来的覆盖率增长也会越来越低。
可以看出,缓存容量大小也会显著影响到缓存的命中率,从而影响到性能提升。反过来,我们在知道预期性能目标后,也可以根据上面的公式反向去计算预期缓存命中率,然后计算出缓存的最小合理配置大小。
数据淘汰策略
当缓存已满时,我们就需要考虑如何淘汰出当前缓存下最没有价值的数据,也就是未来最不可能被访问的数据。 没有任何人或者系统拥有准确预知未来的能力,但我们有个简单策略来估算每份数据未来可能被使用的概率,这个策略背后的依据就是局部性,如果某个数据被访问了,那么它未来被访问的概率会高于其他未被访问的数据。已被访问的频次越高,未来再被访问的可能性也就越高。所以这里我们只需要记录下每份数据被访问的频次,然后把缓存中被访问频次最低的一份数据删除掉就行。
说到这里我们已经不小心发明了LFU (Least Frequently Used)缓存淘汰策略,即维护每份数据的访问频次,当缓存空间不足时,淘汰访问频次最少的一份数据。 与之齐名了还有LRU (Least Recently Used),LRU每次淘汰缓存中最长没有被使用过的数据,具体实现的时候按数据被访问的时间由近到远排成一个队列,然后淘汰最尾的一份数据,相对与LFU实现会简单很多。
LFU和LRU在一定程度上都实现了淘汰最低价值数据的功能,但还是有一些差异的。
- LFU (Least Frequently Used): 这种策略会淘汰在一段时间内被访问次数最少的数据。这意味着即使某个数据项最近被访问过,但只要其总的访问次数仍然是最少的,那么就会被淘汰。LFU适合的场景是存在长期热点数据的情况,也就是说有一部分数据的访问频率持续地高于其他数据。
- LRU (Least Recently Used): 这种策略会将最近最少使用的数据项淘汰。也就是说,如果一个数据项在过去被访问的频率较低,那么在需要淘汰数据以腾出空间时,这个数据项会被优先考虑。LRU比较适合在数据访问模式中存在明显的"最近偏好"特性的情况,即最近访问过的数据在未来被再次访问的概率相对较高。
总的来讲,LFU能涵盖的数据时间窗口更大,而LRU只能覆盖缓存大小那么大的时间窗口,所以LFU更适合大时间窗口下头部效应明显的数据,而LRU更适合小时间窗口下头部效应明显的数据。根据我的使用经验,LRU大部分情况下足以。
除了LRU和LFU之外,还有其他的数据淘汰策略,比如FIFO和Random,甚至还有一些LRU和LFU的改进策略,核心都是为了提升缓存的命中率,在具体选择的时候,还是需要根据自己的缓存大小和数据分布,选择合适的数据淘汰策略。
缓存的副作用
缓存最大的副作用就是数据的不一致性,这也是很多人谈缓存色变,甚至成为拒绝使用缓存的理由。确实使用缓存会有数据不一致性的可能,但实际上很多系统是可以接受短暂的数据不一致性的。就像上文中微信头像的问题,实测更换微信头像后,甚至几天后别人看到的还是你的旧头像。不是微信没法解决头像一致性的问题,而是这个问题价值并不大,很多人都能接受。
避免数据一致性的问题分为被动和主动两种方式,被动方式就是给数据设置有效期,像大家在使用redis缓存或者spring-cache时,都是可以设置数据过期时间的。当然数据过期时间的设置也是有讲究的,设大了不仅浪费空间,而且还会增加读到就数据的概率。 命中过期数据的概率可以用以下公式计算:
i n v a l i d H i t R a t e = c a c h e E x p i r e T i m e 2 d a t a U p d a t e I n t e r v a l × c a c h e H i t R a t e (2) invalidHitRate= \frac{\frac{cacheExpireTime}{2}} {dataUpdateInterval} \times cacheHitRate \tag{2} invalidHitRate=dataUpdateInterval2cacheExpireTime×cacheHitRate(2)
其中dataUpdateInterval指的是数据的更新时间间隔,比如某些数据平均3天更新一次,这里就是3天。cacheExpireTime就是你在设置缓存的时候数据的有效期,任意时刻下剩余有效期平均就是原来的1/2。而cacheHitRate就是上文中提到的缓存命中率。 在开接受的错误率下,根据缓存命中率和数据更新的周期,就可以反推出一个合理的缓存数据有效期。 这里需要注意的时,对缓存数据设置过期时间也可能会显著影响缓存的命中率,最终缓存的命中率需要综合缓存大小、数据淘汰策略和缓存过期时间综合去看。
另外一种主动的方式就是在检测到数据发生变化后,主动删除缓存里的数据,或者是主动将变更后的数据写入。相比被动的方式,错误数据的命中率会显著降低。计算错误数据命中率时,将公式2中的cacheExpireTime替换为数据变更处理时间即可,这在实际使用中这部分时间几乎是0。 但主动更新的方式有很高的实现复杂度,首先数据需要有变更事件通知的能力,这在很多系统里都是需要额外开发的。其次还需要实现变更监听和写入的逻辑,又带来了额外的开发量。 所以除非是很重要的数据,一般不会选择主动更新的方式。
总结
在本文中,我们探讨了正确使用缓存以提升系统性能的关键要素。首先,我们通过数据获取成本和长期价值两个维度来确定是否适合添加缓存。然后,我们深入讨论了缓存配置的策略,包括如何根据访问延迟、命中率以及存储成本来评估和优化缓存表现。其中缓存命中率是性能提升的核心,而这与数据访问的分布、缓存的大小和数据的淘汰策略紧密相关。最后,我们讨论了缓存带来的主要副作用:数据一致性问题。我们介绍了两种处理这一问题的方法,一种是被动的设置数据有效期,另一种是主动的数据更新策略,每种方法都有其适用场景和权衡考量。
缓存是一个强大的工具,用好的话还是可以显著提升系统性能的。选择是否以及如何使用缓存需要从数据特性、业务需求和成本收益上综合去考虑。正确的配置和管理可以最大化缓存的优势,同时降低潜在的风险。
相关文章:
如何正确使用缓存来提升系统性能
文章目录 引言什么时候适合加缓存?示例1示例2:示例3: 缓存应该怎么配置?数据分布**缓存容量大小:**数据淘汰策略 缓存的副作用总结 引言 在上一篇文章IO密集型服务提升性能的三种方法中,我们提到了三种优化…...

IDEA中Terminal配置为bash
简介 我们日常命令行都是使用Linux的bash指令,但是我们的开发基本都是基于Windows上的IDEA进行开发的,对此我们可以通过将IDEA将终端Terminal改为git bash自带的bash.exe解决问题。 配置步骤 安装GIT 这步无需多说了,读者可自行到官网下载…...
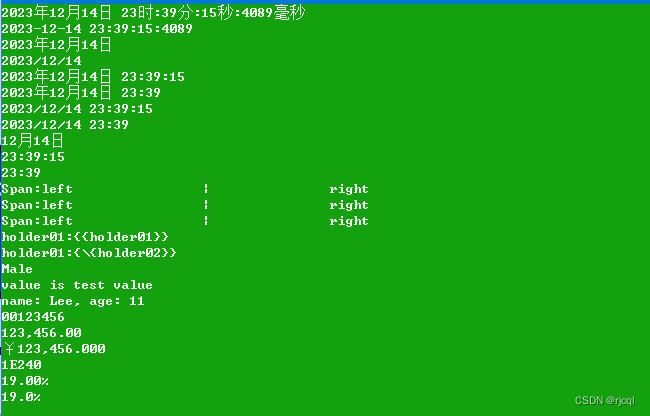
C# 字符串格式化
写在前面 在日常编程中,经常需要对字符串进行格式化操作,以便呈现为不同的格式,满足各种各样的显示需求,C#的字符串格式化参数是非常丰富的,这里做个简单的列举,以供后续参考和延伸。 代码实现 var curr…...
基于亚马逊云科技新功能:Amazon SageMaker Canvas无代码机器学习—以构建货物的交付状态检测模型实战为例深度剖析以突显其特性
授权说明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在亚马逊云科技开发者社区、 知乎、自媒体平台、第三方开发者媒体等亚马逊云科技官方渠道。 目录 🚀一. Amazon SageMaker 🔎1.1 新功能发布:A…...

基于Spring Boot、Mybatis、Redis和Layui的企业电子招投标系统源码实现与立项流程
招投标管理系统是一款适用于招标代理、政府采购、企业采购和工程交易等领域的企业级应用平台。该平台以项目为主线,从项目立项到项目归档,实现了全流程的高效沟通和协作。通过该平台,用户可以实时共享项目数据信息,实现规范化管理…...

electron这样使用更安全
背景: electron大家平时为了方便使用,或是一些网上demo的引导,会让渲染进程的业务界面支持直接使用nodejs,这种开发方式有一定的安全隐患,如果业务界面因为xss之类的漏洞被注入其他代码,危害非常大&#x…...

DPDK多进程之间的通信
文章目录 前言本机DPDK IPC API介绍demo演示 前言 DPDK的主进程和辅助进程之间共享大页内存。关于DPDK多进程的支持文档介绍见:47. 多进程支持。 本文介绍本机DPDK的主进程和辅助进程之间交换短消息的API的使用。 前置要求:DPDK-Hello-World示例应用程…...

Python文本信息解析:从基础到高级实战‘[pp]]‘[
更多Python学习内容:ipengtao.com 大家好,我是彭涛,今天为大家分享 Python文本信息解析:从基础到高级实战,全文3600字,阅读大约10分钟。 文本处理是Python编程中一项不可或缺的技能,覆盖了广泛的…...

c语言多线程队列实现
为了用c语言实现队列进行多线程通信,用于实现一个状态机。 下面是实现过程 1.实现多线程队列入栈和出栈,不加锁 发送线程发送字符1,接收线程接收字符并打印。 多线程没有加锁,会有危险 #include "stdio.h" #include …...

一分钟带你了解电容
电容器中的电容究竟是怎么定义的? 一个电容器,如果带1库的电量时两级间的电势差是1伏,这个电容器的电容就是1法拉,即:CQ/U 。但电容的大小不是由Q(带电量)或U(电压)决定…...

SQLAlchemy 第一篇
安装SQLAlchemy pip install SQLAlchemy查看当前版本 # 查看当前版本import sqlalchemyprint(sqlalchemy.__version__)2.0.23创建数据库连接 此处我们以pymysql为mysql的数据库驱动 安装pymysql pip install pymysqlfrom sqlalchemy import create_engine engine create_…...

Node.js模块化的基本概念和分类及使用方法
1.模块概念 模块:指解决一个复杂问题的时候,自顶向下逐层把系统划分成若干模块的过程。对于整个系统来讲,模块是可以组合、分解和更换的单元。 在编辑领域中的模块,就是遵守固定的规则,把一个大文件拆成独立并且相互…...
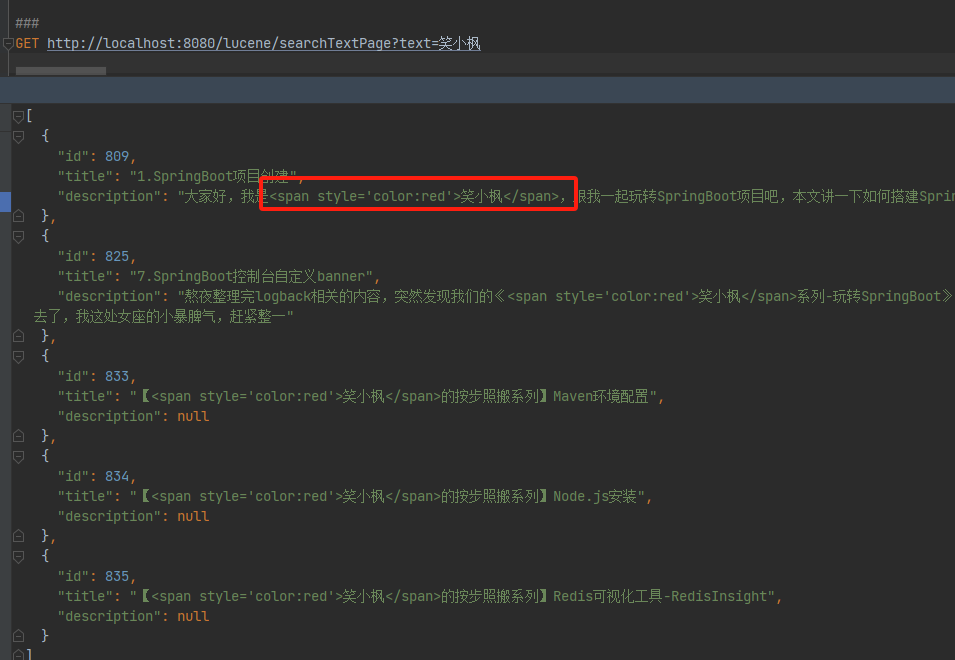
SpringBoot整合Lucene实现全文检索【详细步骤】【附源码】
笑小枫的专属目录 1. 项目背景2. 什么是Lucene3. 引入依赖,配置索引3.1 引入Lucene依赖和分词器依赖3.2 表结构和数据准备3.3 创建索引3.4 修改索引3.5删除索引 4. 数据检索4.1 基础搜索4.2 一个关键词,在多个字段里面搜索4.3 搜索结果高亮显示4.4 分页检…...

基于ssm生活缴费系统及相关安全技术的设计与实现论文
摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对生活缴费信息管理混乱,出错率高,信息安全性差…...
VS的python没有pandas(VS连接mysql数据库)
import pandas as pd from sqlalchemy import create_engine# 初始化数据库连接 engine create_engine(mysqlpymysql://root:556localhost:3306/仓库)sql_chaSELECT * FROM 库房 print(sql_cha) df_read pd.read_sql_query(sql_cha, engine); print(df_read);VS连接mysql如上…...

Java实现pdf文件合并
在maven项目中引入以下依赖包 <dependencies><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-examples</artifactId><version>3.0.1</version></dependency><dependency><groupId>co…...
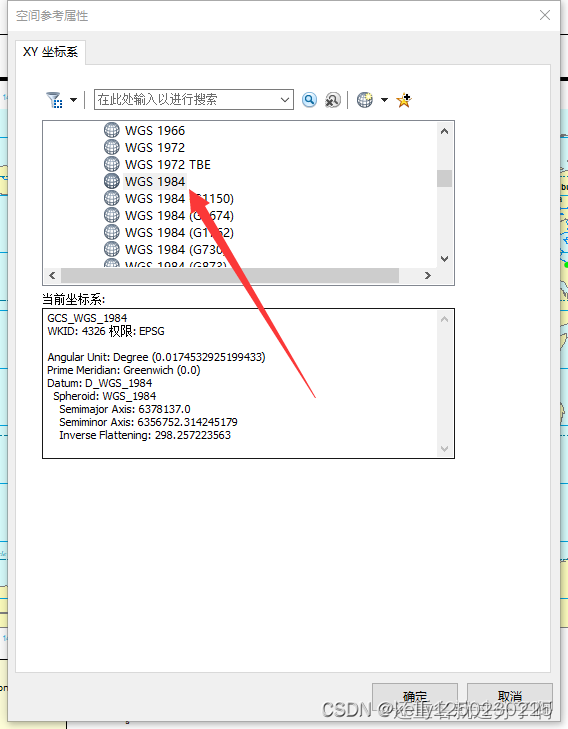
ArcGIS导入excel中的经纬度信息,绘制矢量
1.首先整理坐标信息 2.其次转成2003格式的excel文件 3.导入arcgis,点击右键添加excel数据 4.显示xy数据 5.显示经度和纬度信息 6:点击【地理坐标系】->【World】->【WGS 1984】->【确定】 7.投影带的确定方式: 因为自己一直…...
【Hadoop】
Hadoop是一个开源的分布式离线数据处理框架,底层是用Java语言编写的,包含了HDFS、MapReduce、Yarn三大部分。 组件配置文件启动进程备注Hadoop HDFS需修改需启动 NameNode(NN)作为主节点 DataNode(DN)作为从节点 SecondaryNameNode(SNN)主节点辅助分…...
GitHub帐户管理更改电子邮件
登录到您的 GitHub 帐户: 前往 GitHub 网站并使用您的凭据登录。 访问个人设置: 单击右上角的您的头像,然后选择“Settings”(设置)。 选择电子邮件选项卡: 在左侧边栏中选择“Emails”(电子邮…...

InsCode实践分享
一、背景介绍 随着社交媒体的普及,越来越多的品牌和商家开始关注如何利用社交媒体平台来提高品牌知名度和销售额。其中,Instagram作为一个以图片和视频为主要内容的社交媒体平台,已经成为了很多品牌和商家进行营销的重要渠道。InsCode是Inst…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...