排序算法(二)-冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序
排序算法(二)
前面介绍了排序算法的时间复杂度和空间复杂数据结构与算法—排序算法(一)时间复杂度和空间复杂度介绍-CSDN博客,这次介绍各种排序算法——冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序。
文章目录
- 排序算法(二)
- 1.冒泡排序
- 1.1 基本介绍
- 1.2 冒泡排序应用实例
- 1.3 冒泡排序时间复杂度测试
- 2.选择排序
- 2.1 基本介绍
- 2.2 排序思想
- 2.3 选择排序应用实例
- 2.4 选择排序时间复杂度测试
- 3. 插入排序
- 3.1 基本介绍
- 3.2 排序思想
- 3.3 插入排序应用实例
- 3.4 插入排序时间复杂度测试
- 4. 希尔排序
- 4.1 简单的插入排序存在的问题
- 4.2 希尔排序法介绍
- 4.3 基本思想
- 4.4 希尔排序法应用实例
- 4.4.1 交换法
- 4.4.2 移位法
- 4.5 希尔排序时间复杂度测试
- 4.5.1 交换法
- 4.5.2 移位法
- 5. 快速排序
- 5.1 基本介绍
- 5.2 应用实例
- 5.3 快速排序时间复杂度测试
- 6. 归并排序
- 6.1 基本介绍
- 6.2 基本思想
- 6.3 应用实例
- 6.3.1 归并排序—自顶向下
- 6.3.2 归并排序—自下而上
- 6.3.3 归并排序+插入排序
- 6.4 归并排序时间复杂度测试
- 7 基数排序
- 7.1 基本介绍
- 7.2 基本思想
- 7.3 应用实例
- 7.4 时间复杂度测试
- 8.常用排序算法总结和对比
1.冒泡排序
1.1 基本介绍
**冒泡排序(Bubble Sorting)**的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大
的元素逐渐从前移向后部,就像水底下的气泡一样逐渐向上冒。
因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置
一个标志flag判断元素是否进行过交换。从而减少不必要的比较。(这里说的优化,可以在冒泡排序写好后,再进行)
1.2 冒泡排序应用实例
将五个无序的数:3,9,-1,10,20使用冒泡排序法将其排成一个从小到大的有序数列。

小结:冒泡排序规则
- 一共进行数组大小-1次大循环
- 每一趟排序的次数在逐渐减少
- 如果在某躺排序中,没有发生过一次交换,可以提前结束冒泡排序。这就是优化。
代码如下:
package com.atguigu.sort;/*** @author 小小低头哥* @version 1.0* 冒泡排序*/
public class BubbleSort {public static void main(String[] args) {int arr[] = {3, 9, -1, 10, -2};bubble(arr);System.out.println("排序后的数组");for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}}//将前面的冒泡排序 封装成一个方法public static void bubble(int[] arr){boolean flag = false; //标识变量 表示是否进行过交换for (int i = 0; i < arr.length - 1; i++) {flag = false; //重新置false 看这一轮是否进行过交换for (int j = 0; j < arr.length - i - 1; j++) {if (arr[j + 1] < arr[j]) { //如果后面的小于前面的 则交换flag = true; //表示进行过交换int t = arr[j + 1];arr[j + 1] = arr[j];arr[j] = t;}}if(!flag){ //说明此次排序中 一次交换都没有发生过 说明已经排序完毕break; //结束继续排序}}}
}
1.3 冒泡排序时间复杂度测试
代码如下
public static void main(String[] args) {
// int arr[] = {3, 9, -1, 10, -2};//测试一下冒泡排序的速度O(n^2),给80000个数据进行测试//创建80000个随机的数组//处理80000个数据所花的时间为:9360//处理160000个数据所花的时间为:37083int[] arr = new int[160000];for (int i = 0; i < arr.length; i++) {//Math.random() [0 1)的小数//(Math.random() * 8000000) [0 8000000)小数//(int) (Math.random() * 8000000) [0-8000000)的整数arr[i] = (int) (Math.random() * 8000000);}long start = System.currentTimeMillis();bubble(arr);long end = System.currentTimeMillis();System.out.println("处理" + arr.length + "个数据所花的时间为:" + (end - start));}
结果为:
- 处理80000个数据所花的时间为:9360
- 处理160000个数据所花的时间为:37083
可以看出当数据量翻倍的时候,由冒泡排序时间复杂度 O ( n 2 ) O(n^2) O(n2)知,当变成2n时,时间复杂度为 O ( 4 n 2 ) O(4n^2) O(4n2)。时间复杂度变成了四倍,正好和测试结果对的上,太神奇了!
2.选择排序
2.1 基本介绍
选择排序也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,再依规定交换位置后达到排序的目的。
2.2 排序思想
选择排序(select sorting)也是一种简单的排序方法。它的基本思想是:第一次从arr[o]~arr[n-1]中选取最小值,与arr[0]交换,第二次从arr[1] arr[n-1]中选取最小值,与arr[1]交换,第三次从arr[2]~arr[n-1]中选取最小值, 与arr[2]交换,…,第i次从arr[i-1]~arr[n-1]中选取最小值,与arr[i-1]交换,…,第n-1次从arr[n-2] ~arr[n-1]中选取最小值,与arr[n-2]交换,总共通过n-1次,得到一个按排序码从小到大排列的有序序列。
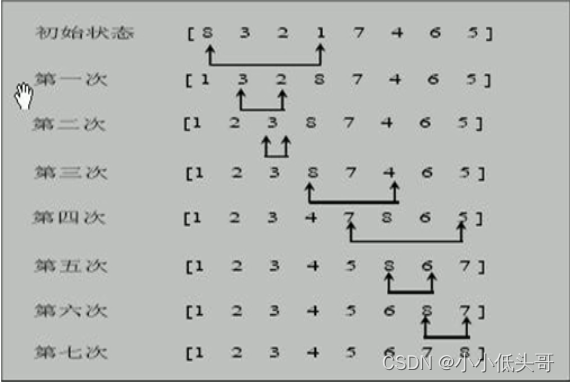
2.3 选择排序应用实例
有一群牛,颜值分别是101,34,119,1请使用选择排序从低到高进行排序[101,34,119,1]。
代码如下
package com.atguigu.sort;/*** @author 小小低头哥* @version 1.0* 选择排序*/
public class SelectSort {public static void main(String[] args) {int[] arr = {101, 34, 119, 1,3,2342,532,5};//选择排序selectSort(arr);System.out.println("排序后的数据为:");for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}}private static void selectSort(int[] arr) {int index; //记录每次大循环中最小数的位置for (int i = 0; i < arr.length; i++) {index = i; //每次大循环初始化为第i个 没被排序的第一个for (int j = i + 1; j < arr.length; j++) {if (arr[j] < arr[index]) {//如果小于指定位置的数//则重新指向更小位置的数index = j;}}//一次大循环结束后 Index就记录下了最小数的位置if(index != i){ //说明最小数确实不是第i个位置的数 index发生了变换//将其与第i个位置的数进行交换int temp = arr[i];arr[i] = arr[index];arr[index] = temp;}}}
}
2.4 选择排序时间复杂度测试
测试代码和1.3中几乎相同,不过是bubble()排序函数换成了selectSort函数。
结果为:
- 处理80000个数据所花的时间为:3350
- 处理160000个数据所花的时间为:13237
可以看出当数据量翻倍的时候,由选择排序时间复杂度 O ( n 2 ) O(n^2) O(n2)知,当变成2n时,时间复杂度为 O ( 4 n 2 ) O(4n^2) O(4n2)。时间复杂度变成了四倍,正好和测试结果对的上。与冒泡排序相同。
**进一步分析:**选择排序法相对于冒泡排序速度更快,主要是减少了交换的次数。冒泡排序每次大循环中符合条件就进行值交换,而选择排序每次大循环中只进行一次。
3. 插入排序
3.1 基本介绍
插入式排序属于内部排序法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,以达到排序的目的。
3.2 排序思想
插入排序 (Insertion Sorting) 的基本思想是:把n个待排序的元素看成一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表

3.3 插入排序应用实例
自己写的如下
package com.atguigu.sort;/*** @author 小小低头哥* @version 1.0* 插入排序*/
public class InsertSort {public static void main(String[] args) {int[] arr1 = {17, 3, 25, 60, 4, 15,34,23,45,53,2}; //无序数组arr1 = insertSort(arr1);System.out.println("插入排序后的数组为:");for (int i = 0; i < arr1.length; i++) {System.out.print(arr1[i] + " ");}}public static int[] insertSort(int[] arr1){int[] arr2 = new int[arr1.length]; //有序数组arr2[0] = arr1[0]; //先将第一个值直接移入有序数组for (int i = 1; i < arr1.length; i++) { //总共比较arr2.length - 1次for (int j = 0; j < i; j++) { //每次比较i次if (arr1[i] < arr2[j]) { //说明可以插入了for (int k = i; k > j; k--) {arr2[k] = arr2[k - 1]; //从第j个元素开始将arr2的元素往后移}arr2[j] = arr1[i]; //将元素插入break; //结束本次小循环}if (j == i - 1) { //如果执行到这一步 则说明arr1[i] 在arr2中最大 直接放在最后arr2[i] = arr1[i];}}}return arr2; //返回新的有序数组}
}
弹幕很多人推荐使用链表的形式,确实会简单,直接插入进去就好了,不需要像数组一样还要后移操作。但是目前只是为了熟悉这个算法,就还是使用的是大家普遍了解的引用数据类型一维数组的形式。没想到后面韩老师使用数组的方法更加方便!
韩老师代码如下
public static void main(String[] args) {int[] arr1 = {17, 3, 25, 60, 4, 15,34,23,45,53,2}; //无序数组insertSort(arr1);System.out.println("插入排序后的数组为:");for (int i = 0; i < arr1.length; i++) {System.out.print(arr1[i] + " ");}
}public static void insertSort(int[] arr){for (int i = 0; i < arr.length; i++) {//定义待插入的数int insertVal = arr[i];int insertIndex = i - 1; //即arr[i]前面这个数的下标//给insertVal找到插入的位置//1. insertIndex >= 0 保证在给insertVal 找插入位置 不越界//2. insertVal < arr[insertIndex] 待插入的数 还没有找到插入位置while (insertIndex >=0 && insertVal < arr[insertIndex]){arr[insertIndex + 1] = arr[insertIndex];insertIndex--;}//退出循环是 说明插入的位置找到了 insertIndex + 1arr[insertIndex + 1] = insertVal;}
}
**太强了!!**韩老师就用一个数组,两个循环就解决了。相比于我写的少用了一个数组和一个循环。
**一个数组:**其实对比无序和有序数组,一个在减,一个在加,无序的头前面一个正好对应有序的尾。两个数组完全可以用一个数组替代。
两个循环:我的代码中是通过从前完后比较大小,然后多的一个循环是k变量的循环,主要是为了后移。但韩老师的代码中是从后往前比较大小,在比较大小的过程中就已经实现后移了,相当于把我代码中两个for循环合并成一个while循环了。如果我要把我代码中两个for循环化成一个for循环,也需要改变一下比较的顺序,从后往前比较。
我改进后的代码
public static void insertSort(int[] arr1) {int j;for (int i = 1; i < arr1.length; i++) { //总共比较arr2.length - 1次int temp = arr1[i]; //取出无序的第1个 并暂时将其作为有序的第i个位置的数据for ( j = i - 1; j >= 0; j--) { //对i个数据的有效序列进行排序 每次比较i次if (temp < arr1[j]) { //说明第i个大于第j个位置的arr1[j + 1] = arr1[j]; //将arr1[j]后移 那么下次arr1[j+1]则是无效位置}else { //说明temp小于第j个位置的数 那么temp直接用temp去填入arr[j+1]的地方arr1[j + 1] = temp; //此时将此无序数据插入成功break; //因为是有序数组 所以后面的无须再比较 本次排序结束}}//这个判断语句一定要写出来 从语法上来说可以写在里面//但是为了让执行时间少一点,不用每次小循环都判断 一定要写出来if(j == 0){ //如果执行到这一步 说明一直在后移 那么则此无序数据最小arr1[0] = temp; //直接将其插入到首位}}}
3.4 插入排序时间复杂度测试
测试代码和1.3中几乎相同,只是将bubble()排序函数换成了InsertSort函数。
我的代码结果为:
- 处理80000个数据所花的时间为:908
- 处理160000个数据所花的时间为:4185
韩老师代码结果为:
- 处理80000个数据所花的时间为:692
- 处理160000个数据所花的时间为:2634
几乎是韩老师代码的三倍,不过其实最坏时间复杂度是相同的。导致相差这个的原因可能是我的代码中的小循环多了点判断语句。
4. 希尔排序
4.1 简单的插入排序存在的问题
简单的插入排序可能存在的问题:
- 数组 arr ={2,3,4, 5,6,1} 这时需要插入的数 1(最小),这样的过程是:
- {2,3,4,5,6,6}
- {2,3,4,5,5,6}
- {2,3,4, 4,5,6}
- {2,3,3,4,5,6}
- {2,2,3,4,5,6}
- {1,2,3,4,5,6}
结论: 当需要插入的数是较小的数时,后移的次数明显增多,对效率有影响。
4.2 希尔排序法介绍
希尔排序是希尔(Donaldshell) 于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为
缩小增量排序。
4.3 基本思想
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止
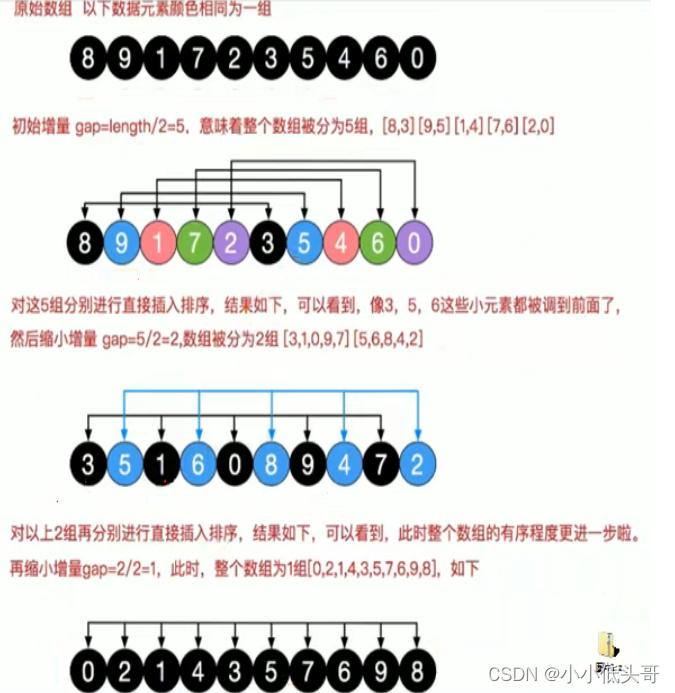
经过上面的“宏观调控”,整个数组的有序化程度成果喜人此时,仅仅需要对以上数列简单微调,无需大量移动操作即可完成整个数组的排序。
==我的理解:==就是将一次很大的插入排序变成了几次小的插入排序。但是这几次小的插入排序的运算量(移动次数)很少,比如最后一组,再使用插入排序时,只要判断前一个元素是否满足条件即可,顶多每次就后移一位。大大减小了后移量。则时间复杂度也减少了。
4.4 希尔排序法应用实例
希尔排序法在对有序序列进行插入时有两种方式:交换法,移动法。
4.4.1 交换法
此方法旨在希尔排序时,对有序序列插入时采用交换法
韩老师代码如下(不过注释都是我按我自己理解写的):
package com.atguigu.sort;/*** @author 小小低头哥* @version 1.0* 希尔排序*/
public class ShellSort {public static void main(String[] args) {int[] arr = {5, 6, 1, 7, 61, 3, 41, 46, 3, 1, 55};shellSort(arr);for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}}private static void shellSort(int[] arr) {int len = arr.length; //就算是奇数也无所谓while (len != 1) { //当len不等于1时可以继续分组进行排序len = len / 2; //分组 相当于每组的步长//之所以从len开始 是从每一组中第二个元素开始与本组中前一个元素进行比较//大循环就是控制每次每组中参与排序的元素的个数//比如i=len+8 那么就是将arr[len+8]所在组进行排序 且只进行排序arr[len+8]及其之前的数据for (int i = len; i < arr.length; i++) {//第二个循环之所以i-len 是用来比较本组前一个元素//j-=len 是确保比较的元素都是本组中的元素 len是步长//类似于进行了一次从后往前遍历的冒泡排序的大循环//但由于除arr[i]个元素外 前面本组的元素都是有序的//所以一次从后往前遍历的冒泡排序大循环对于将arr[i]排好序足矣for (int j = i - len; j >= 0; j -= len) {//此时相当于将arr2[1,2,3,4,5,arr[i]] 进行排序if (arr[j] > arr[j + len]) { //如果此元素比本组中后一个元素要小//交换元素 将大的元素换到后面去int temp = arr[j];arr[j] = arr[j + len];arr[j + len] = temp;} else { //说明此时本元素最大 就该放在后面//而由于前面本组元素都是有序的 所以不需要再进行判断了//本次判断结束break;}}}}}
}
为啥希尔排序法也属于插入法呢,需要从它第一个for循环来理解。每次进行此for循环,其实就是将arr[i]这个无序的数据插入到本组中已经排好序的有序数组中(即arr[i-len],arr[i-2*len]…)。而完成此过程就是第二个for循环来完成的。第二个for循环类似于冒泡排序,不过是从后面开始一个个比较(也想过能不能从前往后比较,其实不行。首先就是本组的头元素不好确定,其次最重要的原因就是:由于交换法逐个比较,类似于冒泡排序,一次冒泡排序的大循环难以把一个从小到大排序的数组(外加最后一个待排序的元素)排好序)。
4.4.2 移位法
理解了交换法,再理解移位法其实挺好理解的
韩老师代码如下
private static void shellSort2(int[] arr) {int len = arr.length; //就算是奇数也无所谓while (len != 1) { //当len不等于1时可以继续分组进行排序len = len / 2;for (int i = len; i < arr.length; i++) { //仍然是从每一组的第二个元素开始进行插入//接下来就是复现简单插入排序法int j = i;int temp = arr[i]; //保存需要插入的数据值while (j >= len && arr[j - len] > arr[j]) { //如果还没比较完最开头的元素以及不满足插入条件arr[j] = arr[j - len]; //则后移j = j - len;}//当退出循环后 则说明找到了插入的位置arr[j] = temp;}}
}
4.5 希尔排序时间复杂度测试
4.5.1 交换法
结果为:
- 处理80000个数据所花的时间为:14
- 处理160000个数据所花的时间为:30
4.5.2 移位法
结果为:
- 处理80000个数据所花的时间为:10
- 处理160000个数据所花的时间为:13
是的!你没有看错!!两种方法都是这么快,太他喵猛了!!!
5. 快速排序
5.1 基本介绍
快速排序 (Quicksort)是对冒泡排序的一种改进:基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
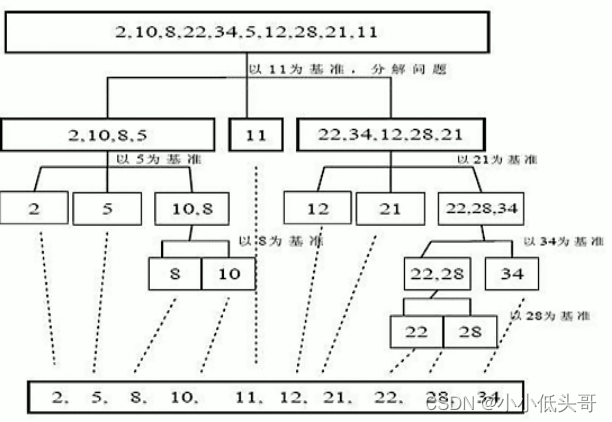
5.2 应用实例
韩老师代码如下
public static void quickSort3(int[] arr, int left, int right) {int l = left; //左指针int r = right; //右指针int pivot = arr[(left + right) / 2];int temp = 0;//while循环的目的是让比pivot 值小的放到左边//比pivot值大的放到右边while (l < r) {//再pivot的左边一直找 找到大于等于pivot值 才退出while (arr[l] < pivot) {l++;}//找出右边小于等于pivot的数while (arr[r] > pivot) { //当右边的数小于等于pivot时才跳出循环r--; //没找到就找下一个}//如果 l >= r 说明pivot的左右两边的值 已经按照左边全部是//小于等于pivot值 右边全部是大于等于pivot值if (l >= r) {break;}//交换位置 将左边找到的大于等于pivot的数放在右边//将右边找到的小于等于pivot的数放在左边temp = arr[r];arr[r] = arr[l];arr[l] = temp;//如果交换完后 发现这个arr[l] == pivot值 r-- 前移if (arr[l] == pivot) {r -= 1;}//如果交换完后 发现arr[r] == pivot值 l++ 后移if (arr[r] == pivot) {l++;}}//如果l == r 必须l++ r-- 否则可能出现栈溢出if (l == r) {l++;r--;}//左递归if (left < r) {quickSort3(arr, left, r);}//右递归if (right > l) {quickSort3(arr, l, right);}}
在尽可能理解老师代码的基础上 自己也写了一份代码 测试过不同种数据 感觉没啥毛病
public static void quickSort(int[] arr, int left, int right) {int l = left; //左指针int r = right; //右指针int pivot = arr[(left + right) / 2];
// System.out.println(pivot);int temp = 0;//一下操作就为了将小于pivot的数放在其左边 大于pivot的数放在其右边while (l < r) { //当l < r的时候才循环//找出左边大于等于pivot的数while (arr[l] < pivot) { //当左边的数大于等于pivot时才跳出循环//没找到就找下一个 最差的情况就是//l此时刚好指向arr[l] = pivot的值//此时说明此位置下的pivot左边的数都小于pivotl++;}//找出右边小于等于pivot的数while (arr[r] > pivot) { //当右边的数小于等于pivot时才跳出循环r--; //没找到就找下一个}//两个循环结束后 l 和 r 都找到了不满足位置条件的数 的位置 对应分别为arr[l] 和 arr[r]的值//不可能出现l > r的情况 因为最后总会有r或l指向privot 顶多出现l和r同时指向privotif (l >= r) { //说明所有数都遍历了 结束了break;}//交换位置 将左边找到的大于等于pivot的数放在右边//将右边找到的小于等于pivot的数放在左边temp = arr[r];arr[r] = arr[l];arr[l] = temp;//此时l左边的数肯定都小于pivot//r右边的数肯定都大于pivot//但是 存在一种情况 就是都刚好等于 pivot//这个时候如果直接继续下一次循环 那么直接死循环了//为了防止这种情况while (arr[l] == arr[r] && arr[r] == pivot) { //如果执行了这个循环 那么已r为基准 arr[r]指向pivot//那么我令左边的arr[l]是排在pivot左边的数l++; //l左边的都是小于pivot的数if (l >= r) {break;}}/*或者while (arr[l] == arr[r] && arr[l] == pivot) {//那么我令arr[r]是排在pivot右边的数r--; //r右边的都是大于pivot的数}*/}if (l != r) {System.out.println("意料之外");}//从上面可以看出 退出循环的条件就是l=r; 且此时指向数组中最后边的等于privot的数的位置
// System.out.println("L=" + l + " r=" + r);//除非左边只有一个数或者没数了才不左递归if (r > left + 1) { //说明左边起码还有两个数quickSort(arr, left, r - 1); //左递归}//除非右边只有一个数或者没数了才不右递归if (l < right - 1) { //说明左边起码还有两个数quickSort(arr, l + 1, right); //左递归}}
5.3 快速排序时间复杂度测试
结果如下:
- 处理80000个数据所花的时间为:19
- 处理160000个数据所花的时间为:38
6. 归并排序
6.1 基本介绍
归并排序(MERGE-SORT 是利用归并的思想实现的排序方法,该算法采用经典的分治 (divide-and-conquer) 策略 (分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案“修补“在起,即分而治之)
6.2 基本思想
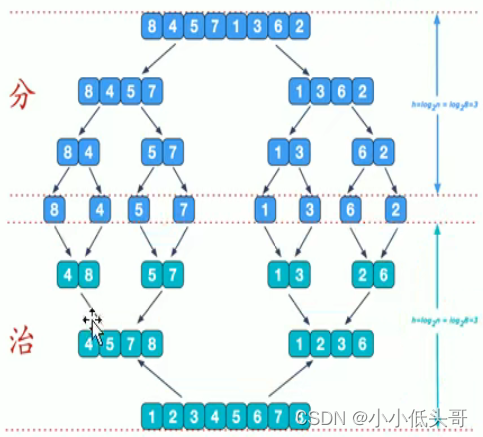
可以看到这种结构很像一棵完全二叉树,本节的归并排序我们采用递归去实现(也可采用迭代的方式去实现)分阶段可以理解为就是递归拆分子序列的过程。
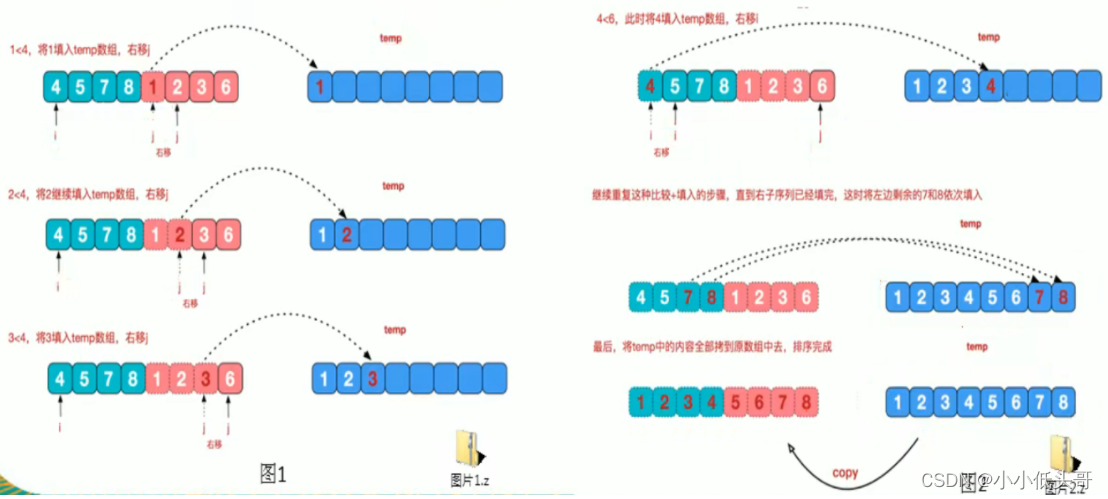
治阶段是将两个有序地子序列合并成一个有序序列。图7是治阶段的最后一次合并,实现步骤如图7所示。
6.3 应用实例
原谅我去看了黑马的数据机构与算法才看懂的
6.3.1 归并排序—自顶向下
由于使用了递归 称之为自顶向下。
黑马程序如下
package com.atguigu.sort;import java.util.Arrays;/*** @author 小小低头哥* @version 1.0* 归并排序*/
public class MergeSort2 {public static void main(String[] args) {int[] a = {9, 3, 7, 2, 8, 5, 1, 4};sort(a);System.out.println(Arrays.toString(a));}public static void sort(int[] a1) {int[] a2 = new int[a1.length];split(a1, 0, a1.length - 1, a2);}public static void split(int[] a1, int left, int right, int[] a2) {int[] array = Arrays.copyOfRange(a1, left, right + 1);
// System.out.print(Arrays.toString(array));//2. 治if (left == right) { //此时只有一个数了return; //递归结束}//1.分//>>> 无符号右移 逻辑右移//>> 算数右移int m = (left + right) >> 1;split(a1, left, m, a2);split(a1, m + 1, right, a2);//左右递归结束//3.合 走到这一步 其实就说明其中有一项左右递归结束了//从后往前 从左往右 按顺序写出来应该是array = [9 3] m = 0 [7 2] m = 0 [9 3 7 2] m = 1// [8 5] m = 0 [1 4] m = 0 [8 5 1 4] m = 1merge(a1, left, m, m + 1, right, a2);System.arraycopy(a2, left, a1, left, right - left + 1);//则返回后a1依次为[3 9 ...] [3 9 2 7...] [2 3 7 9...] [2 3 7 9 5 8...]//[2 3 7 9 5 8 1 4...] [2 3 7 9 1 4 5 8] [1, 2, 3, 4, 5, 7, 8, 9]}/*** 将a1有序的两部分 进行排序后合并* 从小到大按顺序将数放在a2数组的i到(i+jEnd-j+iEnd-i)位置** @param a1 原始数组* @param i 第一个有序数组的开头* @param iEnd 第一个有序数组的结尾* @param j 第二个有序数组的开头* @param jEnd 第二个有序数组的结尾* @param a2 临时数组*/public static void merge(int[] a1, int i, int iEnd, int j, int jEnd, int[] a2) {int k = i;while (i <= iEnd && j <= jEnd) { //每一次循环都将最小数放在a2[k++]位置 直到某一个数组全部放置完毕if (a1[i] < a1[j]) {a2[k] = a1[i];i++;} else {a2[k] = a1[j];j++;}k++;}if (i > iEnd) { //如果第一个有序数组放置完毕 那肯定第二个有序数组没有放置完毕//从a1第j个开始起数jEnd - j + 1个数 将这些数依次放在放在a2第k个数的后面System.arraycopy(a1, j, a2, k, jEnd - j + 1); //因为是顺序的数组 所以直接把剩下的数接在a2的后面}if (j > jEnd) { //如果第二个有序数组放置完毕 那肯定第一个有序数组没有放置完毕System.arraycopy(a1, i, a2, k, iEnd - i + 1);}}
}
6.3.2 归并排序—自下而上
黑马程序如下
public static void sort(int[] a1) {int n = a1.length;int[] a2 = new int[n];//i 代表半个区间的宽度 不同大循环对应的宽度区间不同 每次宽度都会变大两倍for (int i = 1; i < n; i *= 2) {//[left,right] 分别代表待合并区间的左右边界//分别合并宽度为2*i的不同区间中数for (int left = 0; left < n; left += 2 * i) {//如果合并的数据长度不等 比如a1长度为9 当合并最后两个时 左边为8 右边为1 则会出现left + 2 * i - 1 大于 n-1的情况//但是实际此时就是右边界就是n - 1int right = Math.min(left + 2 * i - 1, n - 1);//不可以写成m = (left + right) / 2//如果合并的数据长度不等 比如a1长度为9 当合并最后两个时 左边为8 右边为1//此时left=0 right=8 则m = (left + right) / 2=4//但实际上应该是m=0+8-1=7 即左边界指向第一个有序数组的边界 m+1指向第二有序数组的开头//m在merge中的本质就是第一个有序数组的边界 m+1指向第二有序数组的开头//且m可能会超过数组长度 比如当a1长度为9 i=4 即区间宽度为8时,此时有两个有序数组//一个是左边的八个 一个是右边的一个//如果在判断第二个有序数组m的时候还是这样判断 那么由于此时只有一个数字 且排序好的//此时m = n-1int m = Math.min(left + i - 1, n - 1);
// System.out.printf("宽度为 %d [%d,%d]\n",2*i,left,right);merge(a1, left, m, m + 1, right, a2);System.arraycopy(a2, left, a1, left, right - left + 1);}}}
自下而上方式比如图8中所示,则
- 第一个大循环中,每个区间有2个元素,宽度为2,半区间长为1,共4个区间,将每个区间的前后半空间进行顺序合并
- 第二个大循环中,每个区间有4个元素,宽度为4,半区间长为2,共个2区间[0 3] [4 7],将每个区间的前后半空间进行顺序合并
- 第三个大循环中,每个区间有8个元素,宽度为8,半区间长为4,共1个区间[0 7],将每个区间前后半空间进行顺序合并
6.3.3 归并排序+插入排序
此方法可以在前面两种方法的基础上提高运行速度。经验表明:归并排序适合数据量比较大的排序运算,插入排序适合数据量比较小的排序算法,且越有序越好
黑马程序如下
public static void split(int[] a1, int left, int right, int[] a2) {int[] array = Arrays.copyOfRange(a1, left, right + 1);//2. 治if(right - left <= 32){ //当数据量小于32时就认为分结束了 此时采用插入排序将数据治起来insertion(a1,left,right); //插入排序return;}//1.分//>>> 无符号右移 逻辑右移//>> 算数右移int m = (left + right) >> 1;split(a1, left, m, a2);split(a1, m + 1, right, a2);// [8 5] m = 0 [1 4] m = 0 [8 5 1 4] m = 1merge(a1, left, m, m + 1, right, a2);System.arraycopy(a2, left, a1, left, right - left + 1);}private static void insertion(int[] a1, int left, int right) {for (int low = left + 1; low <= right; low++) {int t = a1[low] ;int i = low - 1;//自右向左插入位置 如果比待插入元素大 则不断右移 空出出入位置while (i >=left && t < a1[i]){a1[i + 1] = a1[i];i--;}//找到插入位置if(i != low -1){a1[i + 1] = t;}}
}
相比于自顶向下的归并排序而言,在治的时候不是到1才返回,而是直接数据量小于32的时候使用插入排序进行排序后再返回。妙哉!
6.4 归并排序时间复杂度测试
三种结果分别如下:
- 自顶向下:
- 处理80000个数据所花的时间为:23
- 处理160000个数据所花的时间为:36
- 自下而上:
- 处理80000个数据所花的时间为:24
- 处理160000个数据所花的时间为:37
- 归并+插入
- 处理80000个数据所花的时间为:15
- 处理160000个数据所花的时间为:32
由结果可知,确实加入插入后速度快了许多
7 基数排序
7.1 基本介绍
- 基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用
- 基数排序法是属于稳定性的排序,基数排序法的是效率高的稳定性排序法
- 基数排序(Radix Sort)是桶排序的扩展
- 基数排序是1887年赫尔曼·何乐礼发明的。它是这样实现的:将整数按位数切割成不同的数字,然后按每个位数分别比较。
7.2 基本思想
- 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序成以后,数列就变成一个有序序列。
- 这样说明,比较难理解,下面我们看一个图文解释,理解基数排序的步骤。
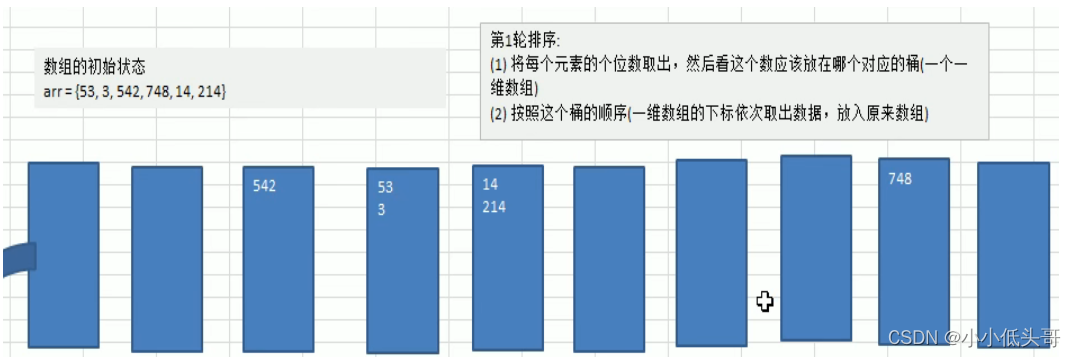
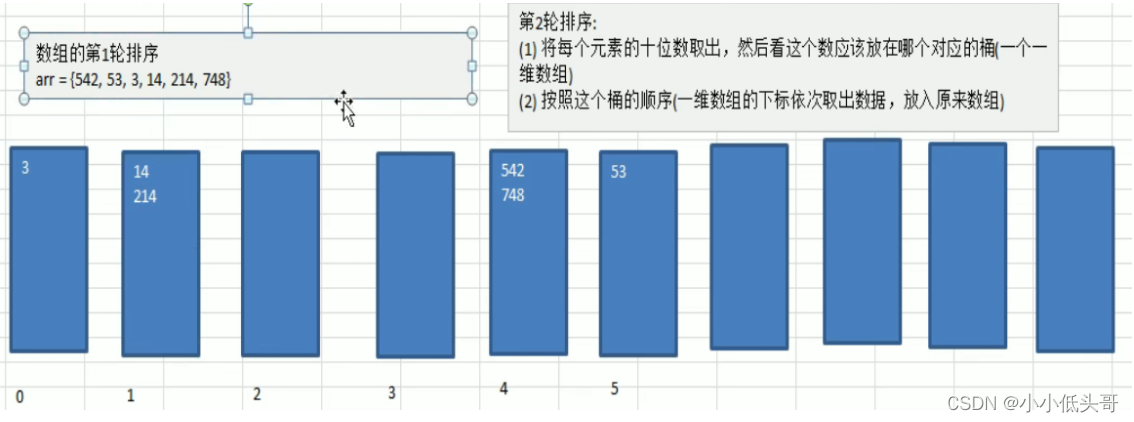
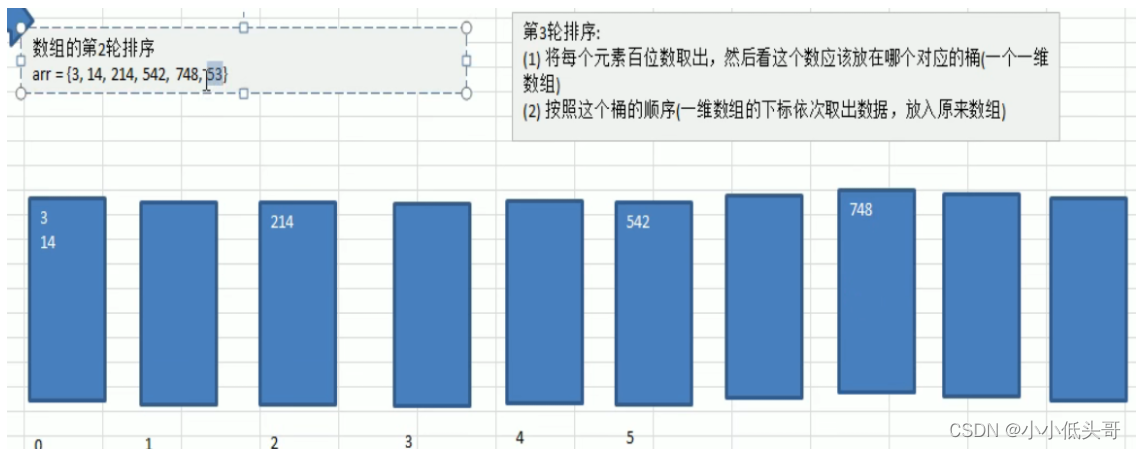
最后第三轮取出来的数据就是顺序排序的
我的理解:
- 其实还挺好理解的。从底位起排序其实就是先将位数底的数先排好序,因为位数相同,数越小的会排在越前面。
- 比如53,14。因为14的十位数小于53的十位数,所以14会放在53的前面。就算把53假设为13,虽然十位相同,但是由于低位早已做过判断,13的3是小于14的4,所以13早已排在14前面。如果十位不比14大,那么就一直在前面,和实际判断相同。注意:此时个位数都会放在第0个桶中,按照个位数排序的顺序再次被出去。并且此时百位数(千位数…)都已经按照十位大小又重新排好序了(之前按个位排好序,现在用十位排序覆盖了。也符合正常判断),等待百位(千位)判断的逆袭。
- 也就是每一次排序(第n次),会把n位数及小于n位数的数都排好序,n+1位数以上的就按照n位数的大小去判断,等待n+1位的逆袭。
至于能不能按照从高位到地位的判断,感觉可行。但是确定最大数的位数有点麻烦,过程也麻烦一点,对于相同高位,但次高位不同的数不友好,需要额外判断,没从小到大方便。
7.3 应用实例
韩老师代码如下
package com.atguigu.sort;import java.util.Arrays;/*** @author 小小低头哥* @version 1.0* 基数排序*/
public class RadixSort {public static void main(String[] args) {int[] arr = {53, 3, 542, 748, 14, 214,46,13,46,1,34,13,46,1,3};radixSort(arr);System.out.println("arr=" + Arrays.toString(arr));}//基数排序方法public static void radixSort(int[] arr) {//1. 得到数组中最大的数的位数int max = arr[0]; //假设第一个数就是最大数for (int i = 1; i < arr.length; i++) {if (max < arr[i]) {max = arr[i];}}//得到最大数是几位数int maxLength = (max + "").length();//定义一个二维数组 表示10个桶 每个桶都是一个一维数组//说明//1. 二维数组包含10个一维数组//2. 为了防止在放入数的时候 数据溢出,则每个一维数组(桶) 大小定为arr.length//3. 明确,基数排序是使用空间换时间的经典算法int[][] bucket = new int[10][arr.length];//为了记录每个桶中 实际存放了多少个数据 定义一个一维数组记录各个桶每次放入的数据个数int[] bucketElementCounts = new int[10];for (int i = 0; i < maxLength; i++) { //从低位循环到最高位//放置元素for (int j = 0; j < arr.length; j++) {int digitOfElement = arr[j] / (int) Math.pow(10, i) % 10; //得到每个为的数//由digitOfElement将arr[j]放入到对应数组位置bucket[digitOfElement][bucketElementCounts[digitOfElement]++] = arr[j];}int index = 0; //索引//按顺序取出函数for (int j = 0; j < 10; j++) {//循环遍历每一个桶//循环遍历每个桶中的元素for (int k = 0; k < bucketElementCounts[j]; k++) {arr[index++] = bucket[j][k];}bucketElementCounts[j] = 0; //取完元素后置零 为下一次循环做准备}}}
}
这份代码不能判断负数,会报错。可以听弹幕的先将所有数加上最小值的模,排完序后再减去最小值的模。
7.4 时间复杂度测试
结果如下:
- 处理80000个数据所花的时间为:49
- 处理160000个数据所花的时间为:80
对比一下,前两次排序,速度还是算慢的,原因是基数排序适合大数据排序。思路和实现确实比较简单。
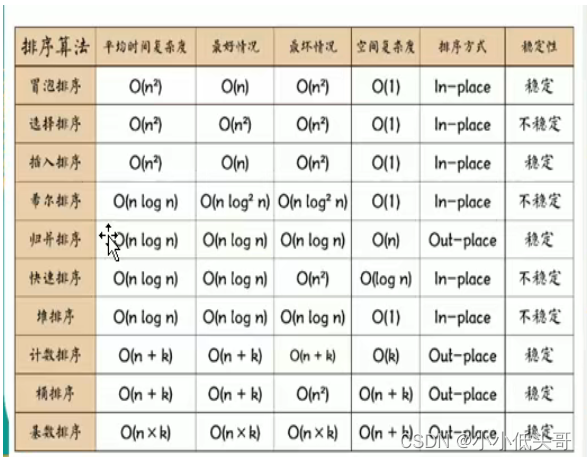
8.常用排序算法总结和对比

相关文章:
排序算法(二)-冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序
排序算法(二) 前面介绍了排序算法的时间复杂度和空间复杂数据结构与算法—排序算法(一)时间复杂度和空间复杂度介绍-CSDN博客,这次介绍各种排序算法——冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序。 文章目录 排…...
智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.探路者算法4.实验参数设定5.算法结果6.参考文…...

高效排队,紧急响应:RabbitMQ Priority Queue全面指南【RabbitMQ 九】
欢迎来到我的博客,代码的世界里,每一行都是一个故事 高效排队,紧急响应:RabbitMQ Priority Queue全面指南 引言前言第一:初识RabbitMQ Priority Queue插件插件的背景和目的:为什么需要消息优先级࿱…...

Java中使用EasyExcel写excel文件
1、公式 package com.web.report.handler;import com.alibaba.excel.context.WriteContext; import com.alibaba.excel.metadata.csv.CsvCellStyle; import com.alibaba.excel.metadata.data.WriteCellData; import com.alibaba.excel.write.handler.CellWriteHandler; import…...
【C语言程序设计】函数程序设计
目录 前言 一、程序阅读 二、程序设计 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 📣如需转载&#…...
GDPU 数据结构 天码行空14
实验十四 查找算法的实现 一、【实验目的】 1、掌握顺序排序,二叉排序树的基本概念 2、掌握顺序排序,二叉排序树的基本算法(查找算法、插入算法、删除算法) 3、理解并掌握二叉排序数查找的平均查找长度。 二、【实验内容】 …...
科技提升安全,基于YOLOv5系列模型【n/s/m/l/x】开发构建商超扶梯场景下行人安全行为姿态检测识别系统
在商超等人流量较为密集的场景下经常会报道出现一些行人在扶梯上摔倒、受伤等问题,随着AI技术的快速发展与不断普及,越来越多的商超、地铁等场景开始加装专用的安全检测预警系统,核心工作原理即使AI模型与摄像头图像视频流的实时计算…...
【网络安全】网络防护之旅 - 对称密码加密算法的实现
🌈个人主页:Sarapines Programmer🔥 系列专栏:《网络安全之道 | 数字征程》⏰墨香寄清辞:千里传信如电光,密码奥妙似仙方。 挑战黑暗剑拔弩张,网络战场誓守长。 目录 😈1. 初识网络安…...

鸿蒙arkTs Toast抽取 及使用
Toast抽取,创建一个Utils import promptAction from ohos.promptAction; import display from ohos.display; export function ToastUtils(msg:string){try {promptAction.showToast({message: msg,duration: 1500,bottom:450});} catch (error) {console.error(sh…...

网络安全渗透测试的相关理论和工具
网络安全 一、引言二、网络安全渗透测试的概念1、黑盒测试2、白盒测试3、灰盒测试 三、网络安全渗透测试的执行标准1、前期与客户的交流阶段1.1 渗透测试的目标网络1.2 进行渗透测试所使用的方法1.3 进行渗透测试所需要的条件1.4 渗透测试过程中的限制条件1.5 渗透测试的工期1.…...

C 语言 xml 库的使用
在C语言中,可以使用多种库来处理XML文件,其中最常用的是libxml2库。libxml2是一个用于解析XML和HTML文档的C语言库,它提供了许多功能,包括解析XML文档、创建XML文档、验证XML文档等等。下面是一个简单的示例,演示读取l…...
群晖(Synology)云备份的方案是什么
群晖云备份方案就是在本地的 NAS 如果出现问题,或者必须需要重做整列的时候,保证数据不丢失。 当然,这些是针对有价值的数据,如果只是电影或者不是自己的拍摄素材文件,其实可以不使用云备份方案,因为毕竟云…...

Flask 中的跨域难题:定义、影响与解决方案深度解析
跨域(Cross-Origin)是指在浏览器中,一个页面的脚本试图访问另一个页面的内容时发生的安全限制。Flask 作为一种 Web 应用框架,也涉及到跨域问题。本文将详细介绍跨域的定义、影响以及解决方案,涵盖如何在 Flask 中处理…...
:V4L2视频)
汽车IVI中控开发入门及进阶(十二):V4L2视频
前言 汽车中控也被称为车机、车载多媒体、车载娱乐等,其中音频视频是非常重要的部分,比如播放各种格式的音乐文件、播放蓝牙接口的音乐、播放U盘或TF卡中的音视频文件,看起来很简单。如果说音频来源于振动,那么图片图像就是光反射的一种表象。模拟信号表示在空间上是连续…...
gitlab下载安装
1.下载 官网rpm包 gitlab/gitlab-ce - Results in gitlab/gitlab-ce 国内镜像 Index of /gitlab-ce/yum/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 2.安装 rpm -ivh gitlab-ce-16.4.3-ce.0.el7.x86_64.rpm 3.配置 vim /etc/gitlab/gitlab.rb 将 externa…...
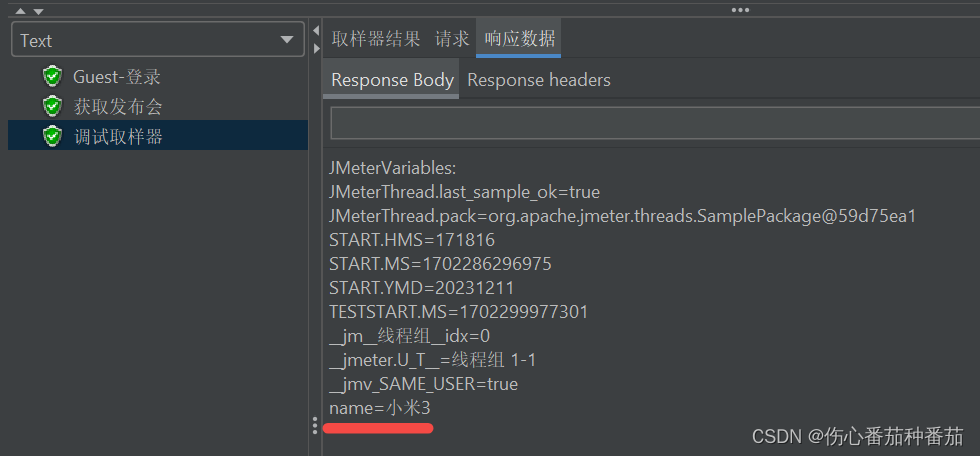
Jmeter,提取响应体中的数据:正则表达式、Json提取器
一、正则表达式 1、线程组--创建线程组; 2、线程组--添加--取样器--HTTP请求; 3、Http请求--添加--后置处理器--正则表达式提取器; 4、线程组--添加--监听器--查看结果树; 5、线程组--添加--取样器--调试取样器。 响应体数据…...

【SpringBoot篇】基于布隆过滤器,缓存空值,解决缓存穿透问题 (商铺查询时可用)
文章目录 🍔什么是缓存穿透🎄解决办法⭐缓存空值处理🎈优点🎈缺点🎍代码实现 ⭐布隆过滤器🎍代码实现 🍔什么是缓存穿透 缓存穿透是指在使用缓存机制时,大量的请求无法从缓存中获取…...
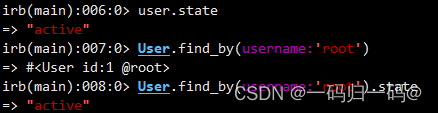
Gitlab基础篇: Gitlab docker 安装部署、Gitlab 设置账号密码
文章目录 1、环境准备2、配置1)、初始化2)、修改gitlab配置文件3)、修改docker配置的gitlab默认端口 gitlab进阶配置gitlab 设置账号密码 1、环境准备 安装docker gitlab前确保docker环境,如果没有搭建docker请查阅“Linux docker 安装文档” docker 下载 gitlab容…...

c++常见函数处理
1、clamp clamp:区间限定函数 int64_t a Clamp(a, MIN_VALUE, MAX_VALUE); #include <iomanip> #include <iostream> #include <sstream>int main() {std::cout << "no setw: [" << 42 << "]\n"<&l…...

MYsql第二次作业
目录 问题 解答 1.显示所有职工的基本信息。 2.查询所有职工所属部门的部门号,不显示重复的部门号。 3.求出所有职工的人数。 4.列出最高工和最低工资。 5.列出职工的平均工资和总工资。 6.创建一个只有职工号、姓名和参加工作的新表,名为工作日…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...