从零构建属于自己的GPT系列5:模型部署1(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在PyCharm中进行
本篇文章配套的代码资源已经上传
从零构建属于自己的GPT系列1:数据预处理
从零构建属于自己的GPT系列2:模型训练1
从零构建属于自己的GPT系列3:模型训练2
从零构建属于自己的GPT系列4:模型训练3
从零构建属于自己的GPT系列5:模型部署1
从零构建属于自己的GPT系列6:模型部署2
1 前端环境安装
安装:
pip install streamlit
测试:
streamlit hello
安装完成后,测试后打印的信息
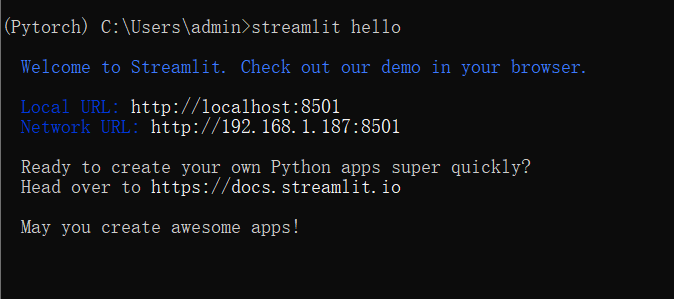
(Pytorch) C:\Users\admin>streamlit hello
Welcome to Streamlit. Check out our demo in your browser.
Local URL: http://localhost:8501 Network URL:
http://192.168.1.187:8501
Ready to create your own Python apps super quickly? Head over to
https://docs.streamlit.io
May you create awesome apps!
接着会自动的弹出一个页面

2 模型加载函数
这个函数把模型加载进来,并且设置成推理模式
def get_model(device, model_path):tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符sep_id = tokenizer.sep_token_idunk_id = tokenizer.unk_token_idmodel = GPT2LMHeadModel.from_pretrained(model_path)model.to(device)model.eval()return tokenizer, model, eod_id, sep_id, unk_id
- 模型加载函数,加载设备cuda,已经训练好的模型的路径
- 加载tokenizer 文件
- 结束特殊字符
- 分隔特殊字符
- 未知词特殊字符
- 加载模型
- 模型进入GPU
- 开启推理模式
- 返回参数
device_ids = 0
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICE"] = str(device_ids)
device = torch.device("cuda" if torch.cuda.is_available() and int(device_ids) >= 0 else "cpu")
tokenizer, model, eod_id, sep_id, unk_id = get_model(device, "model/zuowen_epoch40")
- 指定第一个显卡
- 设置确保 CUDA 设备的编号与 PCI 位置相匹配,使得 CUDA 设备的编号更加一致且可预测
- 通过设置为 str(device_ids)(在这个案例中为 ‘0’),指定了进程只能看到并使用编号为 0 的 GPU
- 有GPU用GPU作为加载设备,否则用CPU
- 调用get_model函数,加载模型
3 文本生成函数
对于给定的上文,生成下一个单词
def generate_next_token(input_ids,args):input_ids = input_ids[:, -200:]outputs = model(input_ids=input_ids)logits = outputs.logitsnext_token_logits = logits[0, -1, :]next_token_logits = next_token_logits / args.temperaturenext_token_logits[unk_id] = -float('Inf')filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=args.top_k, top_p=args.top_p)next_token_id = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)return next_token_id
- 对输入进行一个截断操作,相当于对输入长度进行了限制
- 通过模型得到预测,得到输出,预测的一个词一个词进行预测的
- 得到预测的结果值
- next_token_logits表示最后一个token的hidden_state对应的prediction_scores,也就是模型要预测的下一个token的概率
- 温度表示让结果生成具有多样性
- 设置预测的结果不可以未知字(词)的Token,防止出现异常的东西
- 通过top_k_top_p_filtering()函数对预测结果进行筛选
- 通过预测值转换为概率,得到实际的Token ID
- 返回结果
每次都是通过这种方式预测出下一个词是什么
4 多文本生成函数
到这里就不止是预测下一个词了,要不断的预测
def predict_one_sample(model, tokenizer, device, args, title, context):title_ids = tokenizer.encode(title, add_special_tokens=False)context_ids = tokenizer.encode(context, add_special_tokens=False)input_ids = title_ids + [sep_id] + context_idscur_len = len(input_ids)last_token_id = input_ids[-1] input_ids = torch.tensor([input_ids], dtype=torch.long, device=device)while True:next_token_id = generate_next_token(input_ids,args)input_ids = torch.cat((input_ids, next_token_id.unsqueeze(0)), dim=1)cur_len += 1word = tokenizer.convert_ids_to_tokens(next_token_id.item())if cur_len >= args.generate_max_len and last_token_id == 8 and next_token_id == 3:breakif cur_len >= args.generate_max_len and word in [".", "。", "!", "!", "?", "?", ",", ","]:breakif next_token_id == eod_id:breakresult = tokenizer.decode(input_ids.squeeze(0))content = result.split("<sep>")[1] # 生成的最终内容return content
- 预测一个样本的函数
- 从用户获得输入标题转化为Token ID
- 从用户获得输入正文转化为Token ID
- 标题和正文连接到一起
- 获取输入长度
- 获取已经生成的内容的最后一个元素
- 把输入数据转化为Tensor
- while循环
- 通过生成函数生成下一个词的token id
- 把新生成的token id加到原本的数据中(原本有5个词,预测出第6个词,将第6个词和原来的5个词进行拼接)
- 输入长度增加1
- 将一个 token ID 转换回其对应的文本 token
- 如果超过最大长度并且生成换行符
- 停止生成
- 如果超过最大长度并且生成标点符号
- 停止生成
- 如果生成了结束符
- 停止生成
- 将Token ID转化为文本
- 将生成的文本按照分隔符进行分割
- 返回生成的内容
从零构建属于自己的GPT系列1:数据预处理
从零构建属于自己的GPT系列2:模型训练1
从零构建属于自己的GPT系列3:模型训练2
从零构建属于自己的GPT系列4:模型训练3
从零构建属于自己的GPT系列5:模型部署1
从零构建属于自己的GPT系列6:模型部署2
相关文章:
从零构建属于自己的GPT系列5:模型部署1(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…...

电脑篇——360浏览器打开新标签页自定义,和关闭360导航(强迫症福音)
1.点击“”按钮打开新标签页时会自动打开“资讯聚合”页面,如下图。 如何让我们打开新标签页可以自定义呢(如我这般强迫症必须要新打开的页面干干净净)? 方法:点击号打开新标签页后,在新标签页界面上找到…...

常见的Linux基本指令
目录 什么是Linux? Xshell如何远程控制云服务器 Xshell远程连接云服务器 Linux基本指令 用户管理指令 pwd指令 touch指令 mkdir指令 ls指令 cd指令 rm指令 man命令 cp指令 mv指令 cat指令 head指令 编辑 tail指令 编辑echo指令 find命令 gr…...
ESXI 6.7升级update3
一、适用场景 1、企业已有专业服务器,通过虚拟化环境搭建了vm server; 2、备份整个vm server时,需要使用ovftool工具完成,直接导出ovf模板时报错; 3、升级EXSI6.7的build 8169922版本为update 3版本后,已保…...
bugku--source
dirsearch扫一下 题目提示源代码(source) 也就是源代码泄露,然后发现有.git 猜到是git泄露 拼接后发现有文件 但是点开啥也没有 kali里面下载下来 wegt -r 下载网站的所有内容 ls 查看目录 cd 进入到目录里面 gie reflog 引用日志使用…...

SpringBoot Maven 项目打包的艺术--主清单属性缺失与NoClassDefFoundError的优雅解决方案
Maven项目的Jar包打包问题-没有主清单属性&&ClassNotFoundException 与 NoClassDefFoundError 文章目录 Maven项目的Jar包打包问题-没有主清单属性&&ClassNotFoundException 与 NoClassDefFoundError1、问题出现1.1、Jar包运行:没有主清单属性解决方…...
2023-12-14 二叉树的最大深度和二叉树的最小深度以及完全二叉树的节点个数
二叉树的最大深度和二叉树的最小深度以及完全二叉树的节点个数 104. 二叉树的最大深度 思想:可以使用迭代法或者递归!使用递归更好,帮助理解递归思路!明确递归三部曲–①确定参数以及返回参数 ②递归结束条件 ③单层逻辑是怎么样…...
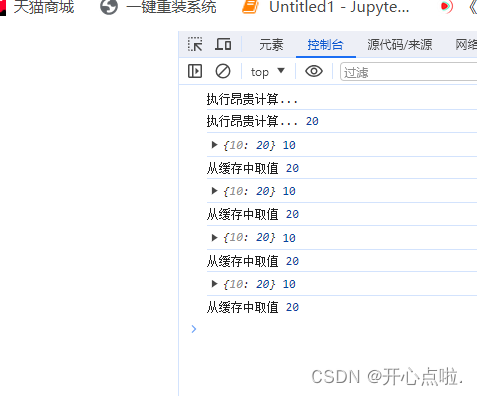
利用闭包与高阶函数实现缓存函数的创建
缓存函数是一种用于存储和重复利用计算结果的机制。其基本思想是,当一个函数被调用并计算出结果时,将该结果存储在某种数据结构中 (通常是一个缓存对象)以备将来使用。当相同的输入参数再次传递给函数时,不再执行实际的计算,而是直…...

P1042 [NOIP2003 普及组] 乒乓球 JAVA 题解
题目背景 国际乒联现在主席沙拉拉自从上任以来就立志于推行一系列改革,以推动乒乓球运动在全球的普及。其中11分制改革引起了很大的争议,有一部分球员因为无法适应新规则只能选择退役。华华就是其中一位,他退役之后走上了乒乓球研究工作&…...

最大公因数,最小公倍数详解
前言 对于初学编程的小伙伴们肯定经常遇见此类问题,而且为之头疼,今天我来给大家分享一下,最大公因数和最小公倍数的求法。让我们开始吧! 文章目录 1,最大公因数法1法2法3 2,最小公倍数3,尾声 …...
无脑利用API实现文心一言AI对话功能?(附代码)
前言:在当今数字化的时代,人工智能(AI)技术正在不断演进,为开发者提供了丰富的工具和资源。其中,API(应用程序接口)成为构建强大AI应用的关键组成部分之一。本文将介绍如何利用API来…...

加速数据采集:用OkHttp和Kotlin构建Amazon图片爬虫
引言 曾想过轻松获取亚马逊上的商品图片用于项目或研究吗?是否曾面对网络速度慢或被网站反爬虫机制拦截而无法完成数据采集任务?如果是,那么本文将为您介绍如何用OkHttp和Kotlin构建一个高效的Amazon图片爬虫解决方案。 背景介绍 亚马逊&a…...
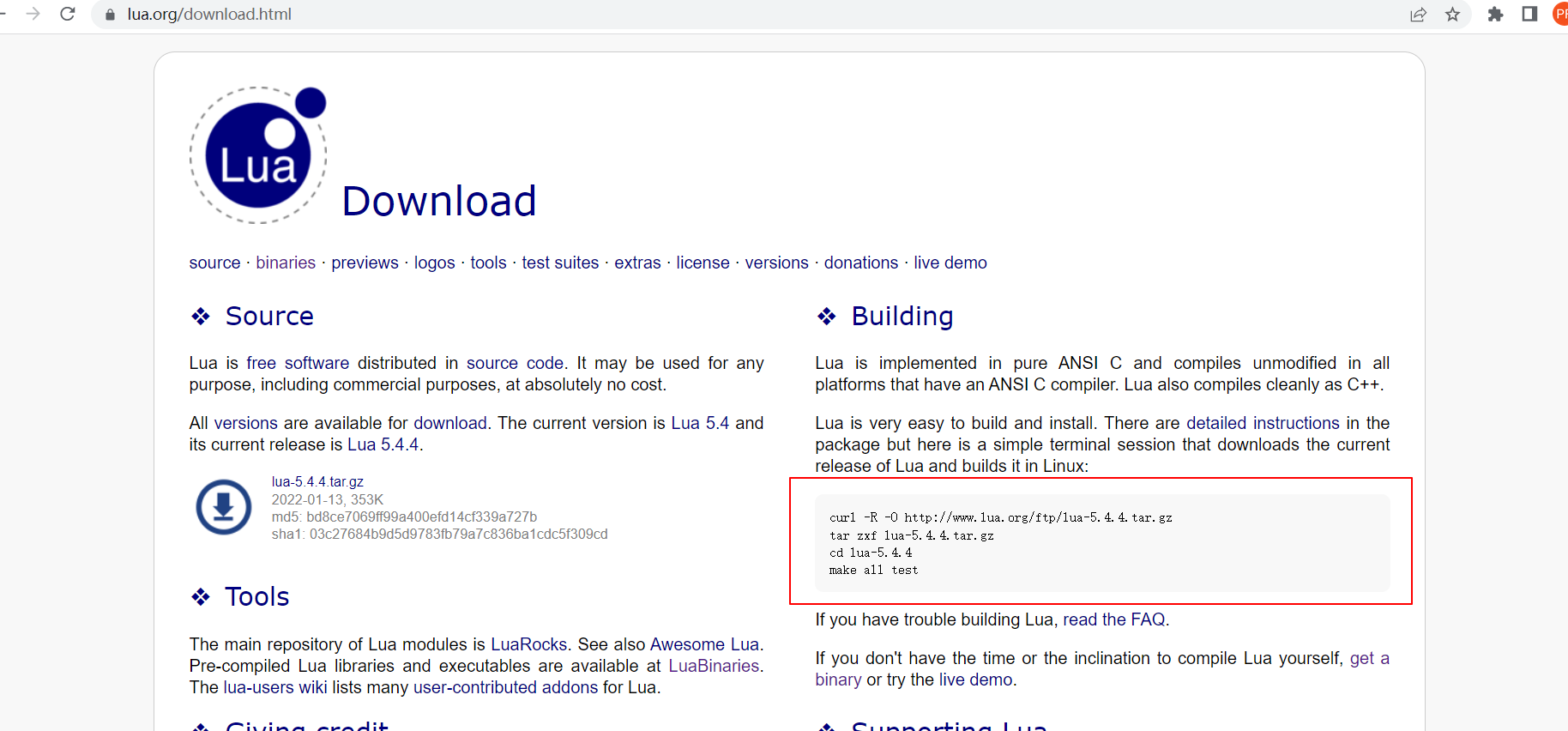
lua安装
lua安装 1.Lua介绍 特点:轻量、小巧。C语言开发。开源。 设计的目的:嵌入到应用程序当中,提供灵活的扩展和定制化的功能。 luanginx,luaredis。 2.windows安装lua windows上安装lua: 检查机器上是否有lua C:\U…...

博士毕业需要发表几篇cssci论文
大家好,今天来聊聊博士毕业需要发表几篇cssci论文,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧: 博士毕业需要发表几篇CSSCI论文 背景介绍 CSSCI即“中文社会科学引文索引”,被…...

UDP报文格式详解
✏️✏️✏️各位看官好,今天给大家分享的是 传输层的另外一个重点协议——UDP。 清风的CSDN博客 🛩️🛩️🛩️希望我的文章能对你有所帮助,有不足的地方还请各位看官多多指教,大家一起学习交流࿰…...
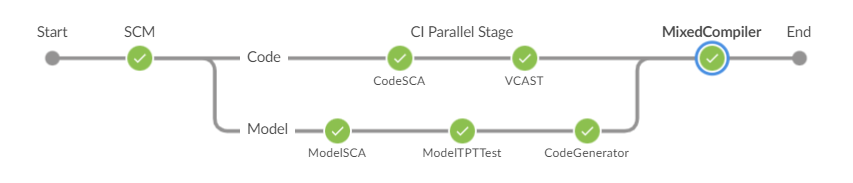
Python自动化测试如何自动生成测试用例?
汽车软件开发自动化测试攻略 随着软件开发在造车行业中占有越来越重要的地位,敏捷开发的思想在造车领域中也逐渐地被重视起来,随之而来的是整车厂对自动化测试需求越来越强烈。本文结合北汇在自动化测试方面的丰富经验,简单介绍一下实施自动…...
)
椋鸟C语言笔记#27:字符串数字提取(atoi、atol、atoll、atof)
萌新的学习笔记,写错了恳请斧正。 目录 atoi 模拟实现 atol与atoll(C99起) atof 合法的浮点值 返回值 使用示例 在stdlib.h中还有几个有意思的字符串函数 它们的功能是将字符串开头的数字提取出来 下面我们具体看一看这几个函数吧 …...

Git 命令使用总结
git init: 在当前目录创建一个新的空Git仓库。git clone [url]: 从远程仓库克隆一个项目到本地。git add [file]: 将文件添加到暂存区。git commit -m “message”: 提交暂存区的文件到本地仓库,并添加一条提交信息。git status: 查看当前工作区的状态(已…...
)
Linux常见面试题30题详细答案解析(二)
1. 如何使用Linux中的包管理器进行软件包依赖管理? Linux中的包管理器如apt、yum等可以自动处理软件包的依赖关系。当安装或升级软件包时,包管理器会自动解决软件包的依赖关系,确保所需的库和工具都已经安装。掌握如何使用包管理器进行依赖管…...
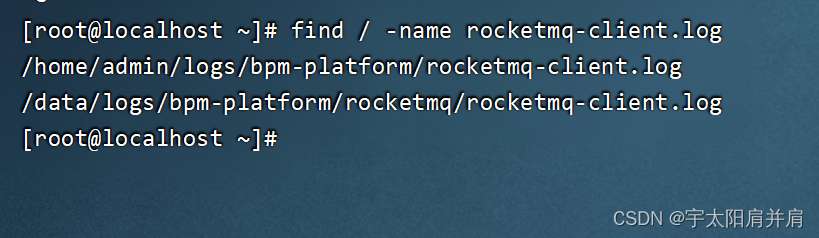
Linux查询指定时间点段日志Linux查询指定文件
Linux服务器高效查询日志查询文件 Ⅰ、常用几种日志查询语法Ⅱ、常用几种查询语法 Ⅰ、常用几种日志查询语法 #查询某日志前xx行日志 head -n 行数 日志文件名 #查询某日志后xx行日志 tail -n 行数 日志文件名 #查询固定时间点日志(前提是这个时间点确实有日志输出…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...