urllib.request --- 用于打开 URL 的可扩展库
源码: Lib/urllib/request.py
urllib.request 模块定义了适用于在各种复杂情况下打开 URL(主要为 HTTP)的函数和类 --- 例如基本认证、摘要认证、重定向、cookies 及其它。
参见
对于更高级别的 HTTP 客户端接口,建议使用 Requests 。
可用性: 非 Emscripten,非 WASI。
此模块在 WebAssembly 平台 wasm32-emscripten 和 wasm32-wasi 上不适用或不可用。 请参阅 WebAssembly 平台 了解详情。
urllib.request 模块定义了以下函数:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
打开 url,它可以是一个包含有效的、被正确编码的 URL 的字符串,或是一个 Request 对象。
data 必须是一个对象,用于给出要发送到服务器的附加数据,若不需要发送数据则为 None。详情请参阅 Request 。
urllib.request 模块采用 HTTP/1.1 协议,并且在其 HTTP 请求中包含 Connection:close 头部信息。
timeout 为可选参数,用于指定阻塞操作(如连接尝试)的超时时间,单位为秒。如未指定,将使用全局默认超时参数)。本参数实际仅对 HTTP、HTTPS 和 FTP 连接有效。
如果给定了 context 参数,则必须是一个 ssl.SSLContext 实例,用于描述各种 SSL 参数。更多详情请参阅 HTTPSConnection 。
cafile 和 capath 为可选参数,用于为 HTTPS 请求指定一组受信 CA 证书。cafile 应指向包含CA 证书的单个文件, capath 则应指向哈希证书文件的目录。更多信息可参阅 ssl.SSLContext.load_verify_locations() 。
参数 cadefault 将被忽略。
本函数总会返回一个对象,该对象可作为 context manager 使用,带有 url、headers 和 status 属性。有关这些属性的更多详细信息,请参阅 urllib.response.addinfourl 。
对于 HTTP 和 HTTPS 的 URL 而言,本函数将返回一个稍经修改的 http.client.HTTPResponse 对象。除了上述 3 个新的方法之外,还有 msg 属性包含了与 reason 属性相同的信息---服务器返回的原因描述文字,而不是 HTTPResponse 的文档所述的响应头部信息。
对于 FTP、文件、数据的URL,以及由传统的 URLopener 和 FancyURLopener 类处理的请求,本函数将返回一个 urllib.response.addinfourl 对象。
协议发生错误时,将会引发 URLError 。
请注意,如果没有处理函数对请求进行处理,则有可能会返回 None 。尽管默认安装的全局 OpenerDirector 会用 UnknownHandler 来确保不会发生这种情况。
此外,如果检测到设置了代理(比如设置了 http_proxy 之类的环境变量),默认会安装 ProxyHandler 并确保通过代理处理请求。
Python 2.6 以下版本中留存的 urllib.urlopen 函数已停止使用了; urllib.request.urlopen() 对应于传统的 urllib2.urlopen 。对代理服务的处理是通过将字典参数传给 urllib.urlopen 来完成的,可以用 ProxyHandler 对象获取到代理处理函数。
默认会触发一条 审计事件 urllib.Request ,参数 fullurl 、 data 、headers 、method 均取自请求对象。
在 3.2 版更改: 增加了 cafile 与 capath。
在 3.2 版更改: 现在将在可能的情况下支持 HTTPS 虚拟主机(也就是说,如果 ssl.HAS_SNI 为真值)。
3.2 新版功能: data 可以是一个可迭代对象。
在 3.3 版更改: 增加了 cadefault。
在 3.4.3 版更改: 增加了 context。
在 3.10 版更改: 当未给出 context 时,HTTPS 连接现在会发送一个带有协议指示器 http/1.1 的 ALPN 扩展。 自定义 context 应当用 set_alpn_protocol() 来设置 ALPN 协议。
3.6 版后已移除: cafile 、 capath 和 cadefault 已废弃,转而推荐使用 context。请改用 ssl.SSLContext.load_cert_chain() 或让 ssl.create_default_context() 选取系统信任的 CA 证书。
urllib.request.install_opener(opener)
安装一个 OpenerDirector 实例,作为默认的全局打开函数。仅当 urlopen 用到该打开函数时才需要安装;否则,只需调用 OpenerDirector.open() 而不是 urlopen()。代码不会检查是否真的属于 OpenerDirector 类,所有具备适当接口的类都能适用。
urllib.request.build_opener([handler, ...])
返回一个 OpenerDirector 实例,以给定顺序把处理函数串联起来。处理函数可以是 BaseHandler 的实例,也可以是 BaseHandler 的子类(这时构造函数必须允许不带任何参数的调用)。以下类的实例将位于 处理函数 之前,除非 处理函数 已包含这些类、其实例或其子类: ProxyHandler (如果检测到代理设置)、UnknownHandler 、HTTPHandler 、HTTPDefaultErrorHandler 、HTTPRedirectHandler 、 FTPHandler 、 FileHandler 、HTTPErrorProcessor 。
若 Python 安装时已带了 SSL 支持(指可以导入 ssl 模块),则还会加入 HTTPSHandler 。
A BaseHandler subclass may also change its handler_order attribute to modify its position in the handlers list.
urllib.request.pathname2url(path)
将路径名 path 从路径本地写法转换为 URL 路径部分所采用的格式。本函数不会生成完整的 URL。返回值将会用 quote() 函数加以编码。
urllib.request.url2pathname(path)
从百分号编码的 URL 中将 path 部分转换为本地路径的写法。本函数不接受完整的 URL,并利用 unquote() 函数对 path 进行解码。
urllib.request.getproxies()
此辅助函数将返回一个将各个方案映射到代理服务器 URL 的字典。 它会先为所有操作系统以大小写不敏感的方式扫描名为 <scheme>_proxy 的环境变量,当无法找到时,则会在 macOS 上从系统配置中而在 Windows 上从 Windows 系统注册表中查找代理信息。 如果同时存在小写和大写形式的环境变量(且内容不一致),则会首先小写形式。
备注
如果存在环境变量 REQUEST_METHOD ,通常表示脚本运行于 CGI 环境中,则环境变量 HTTP_PROXY (大写的 _PROXY)将会被忽略。这是因其可以由客户端用 HTTP 头部信息 “Proxy:”注入。若要在 CGI 环境中使用 HTTP 代理,请显式使用 `ProxyHandler ,或确保变量名称为小写(或至少是 _proxy 后缀)。
提供了以下类:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
URL 请求对象的抽象类。
url 应为一个包含有效的、被正确编码的 URL 的字符串。
data 必须是一个对象,用于给定发往服务器的附加数据,若无需此类数据则为 None 。 目前 唯一用到 data 的只有 HTTP 请求。支持的对象类型包括字节串、类文件对象和可遍历的类字节串对象。如果没有提供 Content-Length 和 Transfer-Encoding 头部字段, HTTPHandler 会根据 data 的类型设置这些头部字段。Content-Length 将用于发送字节对象,而 RFC 7230 第 3.3.1 节中定义的 Transfer-Encoding: chunked 将用于发送文件和其他可遍历对象。
对于 HTTP POST 请求方法而言,data 应该是标准 application/x-www-form-urlencoded 格式的缓冲区。 urllib.parse.urlencode() 函数的参数为映射对象或二元组序列,并返回一个该编码格式的 ASCII 字符串。在用作 data 参数之前,应将其编码为字节串。
headers 应当是一个字典,并将被视同附带了每个键和值作为参数去调用 add_header()。 这通常被用于 "伪装" User-Agent 标头值,浏览器会使用标头值来标识自己 -- 某些 HTTP 服务器只允许来自普通浏览器的请求而不允许来自脚本的请求。 例如,Mozilla Firefox 可能将自己标识为 "Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11",而 urllib 的默认用户代理字符串则是 "Python-urllib/2.6" (在 Python 2.6 中)。 所有发送的标头键都使用驼峰命名法。
如果给出了 data 参数,则应当包含合适的 Content-Type 头部信息。若未提供且 data 不是 None,则会把 Content-Type: application/x-www-form-urlencoded 加入作为默认值。
接下来的两个参数,只对第三方 HTTP cookie 的处理才有用:
origin_req_host 应为发起初始会话的请求主机,定义参见 RFC 2965 。默认指为 http.cookiejar.request_host(self) 。这是用户发起初始请求的主机名或 IP 地址。假设请求是针对 HTML 文档中的图片数据发起的,则本属性应为对包含图像的页面发起请求的主机。
unverifiable 应该标示出请求是否无法验证,定义参见 RFC 2965 。默认值为 False 。所谓无法验证的请求,是指用户没有机会对请求的 URL 做验证。例如,如果请求是针对 HTML 文档中的图像,用户没有机会去许可能自动读取图像,则本参数应为 True。
method 应为字符串,标示要采用的 HTTP 请求方法(例如 'HEAD' )。如果给出本参数,其值会存储在 method 属性中,并由 get_method() 使用。如果 data 为 None 则默认值为 'GET' ,否则为 'POST'。子类可以设置 method 属性来标示不同的默认请求方法。
备注
如果 data 对象无法分多次传递其内容(比如文件或只能生成一次内容的可迭代对象)并且由于 HTTP 重定向或身份验证而发生请求重试行为,则该请求不会正常工作。 data 是紧挨着头部信息发送给 HTTP 服务器的。现有库不支持 HTTP 100-continue 的征询。
在 3.3 版更改: Request 类增加了 Request.method 参数。
在 3.4 版更改: 默认 Request.method 可以在类中标明。
在 3.6 版更改: 如果给出了 Content-Length ,且 data 既不为 None 也不是字节串对象,则不会触发错误。而会退而求其次采用分块传输的编码格式。
class urllib.request.OpenerDirector
OpenerDirector 类通过串接在一起的 BaseHandler 打开 URL,并负责管理 handler 链及从错误中恢复。
class urllib.request.BaseHandler
这是所有已注册 handler 的基类,只做了简单的注册机制。
class urllib.request.HTTPDefaultErrorHandler
为 HTTP 错误响应定义的默认 handler,所有出错响应都会转为 HTTPError 异常。
class urllib.request.HTTPRedirectHandler
一个用于处理重定向的类。
class urllib.request.HTTPCookieProcessor(cookiejar=None)
一个用于处理 HTTP Cookies 的类。
class urllib.request.ProxyHandler(proxies=None)
让请求转往代理服务。 如果给出了 proxies,则它必须是一个将协议名称映射到代理 URL 的字典。 默认是从环境变量 <protocol>_proxy 中读取代理列表。 如果没有设置代理服务的环境变量,则在 Windows 环境下代理设置会从注册表的 Internet Settings 部分获取,而在 macOS 环境下代理信息会从 System Configuration Framework 获取。
若要禁用自动检测出来的代理,请传入空的字典对象。
环境变量 no_proxy 可用于指定不必通过代理访问的主机;应为逗号分隔的主机名后缀列表,可加上 :port ,例如 cern.ch,ncsa.uiuc.edu,some.host:8080 。
备注
如果设置了 REQUEST_METHOD 变量,则会忽略 HTTP_PROXY ;参阅 getproxies() 文档。
class urllib.request.HTTPPasswordMgr
维护 (realm, uri) -> (user, password) 映射数据库。
class urllib.request.HTTPPasswordMgrWithDefaultRealm
维护 (realm, uri) -> (user, password) 映射数据库。realm 为 None 视作全匹配,若没有其他合适的安全区域就会检索它。
class urllib.request.HTTPPasswordMgrWithPriorAuth
HTTPPasswordMgrWithDefaultRealm 的一个变体,也带有 uri -> is_authenticated 映射数据库。可被 BasicAuth 处理函数用于确定立即发送身份认证凭据的时机,而不是先等待 401 响应。
3.5 新版功能.
class urllib.request.AbstractBasicAuthHandler(password_mgr=None)
这是一个帮助完成 HTTP 身份认证的混合类,对远程主机和代理都适用。参数 password_mgr 应与 HTTPPasswordMgr 兼容;关于必须支持哪些接口,请参阅 HTTPPasswordMgr 对象 对象的章节。如果 password_mgr 还提供 is_authenticated 和 update_authenticated 方法(请参阅 HTTPPasswordMgrWithPriorAuth 对象 对象),则 handler 将对给定 URI 用到 is_authenticated 的结果,来确定是否随请求发送身份认证凭据。如果该 URI 的 is_authenticated 返回 True,则发送凭据。如果 is_authenticated 为 False ,则不发送凭据,然后若收到 401 响应,则使用身份认证凭据重新发送请求。如果身份认证成功,则调用 update_authenticated 设置该 URI 的 is_authenticated 为 True,这样后续对该 URI 或其所有父 URI 的请求将自动包含该身份认证凭据。
3.5 新版功能: 增加了对 is_authenticated 的支持。
class urllib.request.HTTPBasicAuthHandler(password_mgr=None)
处理远程主机的身份认证。 password_mgr 应与 HTTPPasswordMgr 兼容;有关哪些接口是必须支持的,请参阅 HTTPPasswordMgr 对象 章节。如果给出错误的身份认证方式, HTTPBasicAuthHandler 将会触发 ValueError 。
class urllib.request.ProxyBasicAuthHandler(password_mgr=None)
处理有代理服务时的身份认证。 password_mgr 应与 HTTPPasswordMgr 兼容;有关哪些接口是必须支持的,请参阅 HTTPPasswordMgr 对象 章节。
class urllib.request.AbstractDigestAuthHandler(password_mgr=None)
这是一个帮助完成 HTTP 身份认证的混合类,对远程主机和代理都适用。参数 password_mgr 应与 HTTPPasswordMgr 兼容;关于必须支持哪些接口,请参阅 HTTPPasswordMgr 对象 的章节。
class urllib.request.HTTPDigestAuthHandler(password_mgr=None)
处理远程主机的身份认证。 password_mgr 应与 HTTPPasswordMgr 兼容;有关哪些接口是必须支持的,请参阅 HTTPPasswordMgr 对象 章节。如果同时添加了 digest 身份认证 handler 和basic 身份认证 handler,则会首先尝试 digest 身份认证。如果 digest 身份认证再返回 40x 响应,会再发送到 basic 身份验证 handler 进行处理。如果给出 Digest 和 Basic 之外的身份认证方式, 本 handler 方法将会触发 ValueError 。
在 3.3 版更改: 碰到不支持的认证方式时,将会触发 ValueError 。
class urllib.request.ProxyDigestAuthHandler(password_mgr=None)
处理有代理服务时的身份认证。 password_mgr 应与 HTTPPasswordMgr 兼容;有关哪些接口是必须支持的,请参阅 HTTPPasswordMgr 对象 章节。
class urllib.request.HTTPHandler
用于打开 HTTP URL 的 handler 类。
class urllib.request.HTTPSHandler(debuglevel=0, context=None, check_hostname=None)
用于打开 HTTPS URL 的 handler 类。context 和 check_hostname 的含义与 http.client.HTTPSConnection 的一样。
在 3.2 版更改: 添加 context 和 check_hostname 参数。
class urllib.request.FileHandler
打开本地文件。
class urllib.request.DataHandler
打开数据 URL。
3.4 新版功能.
class urllib.request.FTPHandler
打开 FTP URL。
class urllib.request.CacheFTPHandler
打开 FTP URL,并将打开的 FTP 连接存入缓存,以便最大程度减少延迟。
class urllib.request.UnknownHandler
处理所有未知类型 URL 的兜底类。
class urllib.request.HTTPErrorProcessor
处理出错的 HTTP 响应。
Request 对象
以下方法介绍了 Request 的公开接口,因此子类可以覆盖所有这些方法。这里还定义了几个公开属性,客户端可以利用这些属性了解经过解析的请求。
Request.full_url
传给构造函数的原始 URL。
在 3.4 版更改.
Request.full_url 是一个带有 setter、getter 和 deleter 的属性。读取 full_url 属性将会返回附带片段(fragment)的初始请求 URL。
Request.type
URI 方式。
Request.host
URI 权限,通常是整个主机,但也有可能带有冒号分隔的端口号。
Request.origin_req_host
请求的原始主机,不含端口。
Request.selector
URI 路径。若 Request 使用代理,selector 将会是传给代理的完整 URL。
Request.data
请求的数据体,未给出则为 None 。
在 3.4 版更改: 现在如果修改 Request.data 的值,则会删除之前设置或计算过的“Content-Length”头部信息。
Request.unverifiable
布尔值,标识本请求是否属于 RFC 2965 中定义的无法验证的情况。
Request.method
要采用的 HTTP 请求方法。默认为 None,表示 get_method() 将对方法进行正常处理。设置本值可以覆盖 get_method() 中的默认处理过程,设置方式可以是在 Request 的子类中给出默认值,也可以通过 method 参数给 Request 构造函数传入一个值。
3.3 新版功能.
在 3.4 版更改: 现在可以在子类中设置默认值;而之前只能通过构造函数的实参进行设置。
Request.get_method()
返回表示 HTTP 请求方法的字符串。如果 Request.method 不为 None ,则返回其值。否则若 Request.data 为 则返回 'GET',不为 None 则返回 'POST' 。只对 HTTP 请求有效。
在 3.3 版更改: 现在 get_method 会兼顾 Request.method 的值。
Request.add_header(key, val)
向请求添加一个标头。 标头目前会被所有处理句柄忽略但只有 HTTP 处理句柄是例外,该处理句柄会将它们加入发给服务器的标头列表中。 请注意同名的标头只能有一个,当 key 发生冲突时后续的调用将会覆盖之前的调用。 目前,这并不会造成 HTTP 功能的损失,因为所有可多次使用而仍有意义的标头都有(特定标头专属的)方式来获得与仅使用一个标头时相同的功能。 请注意使用此方法添加的标头也会被添加到重定向的请求中。
Request.add_unredirected_header(key, header)
添加一项不会被加入重定向请求的头部信息。
Request.has_header(header)
返回本实例是否带有命名头部信息(对常规数据和非重定向数据都会检测)。
Request.remove_header(header)
从本请求实例中移除指定命名的头部信息(对常规数据和非重定向数据都会检测)。
3.4 新版功能.
Request.get_full_url()
返回构造器中给定的 URL。
在 3.4 版更改.
返回 Request.full_url
Request.set_proxy(host, type)
连接代理服务器,为当前请求做准备。 host 和 type 将会取代本实例中的对应值,selector 将会是构造函数中给出的初始 URL。
Request.get_header(header_name, default=None)
返回给定头部信息的数据。如果该头部信息不存在,返回默认值。
Request.header_items()
返回头部信息,形式为(名称, 数据)的元组列表。
在 3.4 版更改: 自 3.3 起已弃用的下列方法已被删除:add_data、has_data、get_data、get_type、get_host、get_selector、get_origin_req_host 和 is_unverifiable 。
OpenerDirector 对象
OpenerDirector 实例有以下方法:
OpenerDirector.add_handler(handler)
handler 应为 BaseHandler 的实例。将检索以下类型的方法,并将其添加到对应的处理链中(注意 HTTP 错误是特殊情况)。请注意,下文中的 protocol 应替换为要处理的实际协议,例如 http_response() 将是 HTTP 协议响应处理函数。并且 type 也应替换为实际的 HTTP 代码,例如 http_error_404() 将处理 HTTP 404 错误。
-
<protocol>_open()— 表明该 handler 知道如何打开 protocol 协议的URL。更多信息请参阅 BaseHandler.<protocol>_open() 。
-
http_error_<type>()— 表明该 handler 知道如何处理代码为 type 的 HTTP 错误。更多信息请参阅 BaseHandler.http_error_<nnn>() 。
-
<protocol>_error()— 表明该 handler 知道如何处理来自协议为 protocol (非http)的错误。 -
<protocol>_request()— 表明该 handler 知道如何预处理协议为 protocol 的请求。更多信息请参阅 BaseHandler.<protocol>_request() 。
-
<protocol>_response()— 表明该 handler 知道如何后处理协议为 protocol 的响应。更多信息请参阅 BaseHandler.<protocol>_response() 。
OpenerDirector.open(url, data=None[, timeout])
打开给定的 url (可以是一个请求对象或一个字符串),可以选择传入给定的 data。 参数、返回值和被引发的异常均与 urlopen() 的相同 (它只是简单地在当前安装的全局 OpenerDirector 上调用 open() 方法)。 可选的 timeout 形参指定了针对阻塞操作例如连接尝试的超时值 (如果未指明,则将使用全局默认的超时设置)。 超时特性仅适用于 HTTP, HTTPS 和 FTP 连接。
OpenerDirector.error(proto, *args)
处理给定协议的错误。将用给定的参数(协议相关)调用已注册的给定协议的错误处理程序。HTTP 协议是特殊情况,采用 HTTP 响应码来确定具体的错误处理程序;请参考 handler 类的 http_error_<type>() 方法。
返回值和异常均与 urlopen() 相同。
OpenerDirector 对象分 3 个阶段打开 URL:
每个阶段中调用这些方法的次序取决于 handler 实例的顺序。
-
每个具有
_request()这类方法的 handler 都会调用本方法对请求进行预处理。 -
调用具有
_open()这类方法的 handler 来处理请求。当 handler 返回非None 值(即响应)或引发异常(通常是 URLError)时,本阶段结束。本阶段能够传播异常。事实上,以上算法首先会尝试名为
default_open()的方法。 如果这些方法全都返回 None,则会对名为<protocol>_open()的方法重复此算法。 如果这些方法也全都返回 None,则会继续对名为unknown_open()的方法重复此算法。请注意,这些方法的代码可能会调用 OpenerDirector 父实例的 open() 和 error() 方法。
-
每个具有
_response()这类方法的 handler 都会调用这些方法,以对响应进行后处理。
BaseHandler 对象
BaseHandler 对象提供了一些直接可用的方法,以及其他一些可供派生类使用的方法。以下是可供直接使用的方法:
BaseHandler.add_parent(director)
将 director 加为父 OpenerDirector。
BaseHandler.close()
移除所有父 OpenerDirector。
以下属性和方法仅供 BaseHandler 的子类使用:
备注
The convention has been adopted that subclasses defining <protocol>_request() or <protocol>_response() methods are named *Processor; all others are named *Handler.
BaseHandler.parent
一个可用的 OpenerDirector,可用于以其他协议打开 URI,或处理错误。
BaseHandler.default_open(req)
本方法在 BaseHandler 中 未 予定义,但其子类若要捕获所有 URL 则应进行定义。
如果实现了本方法,则它将被父类 OpenerDirector 所调用。 它应当返回一个如 OpenerDirector 的 open() 方法的返回值所描述的文件类对象,或是返回 None。 它应当引发 URLError,除非发生真正的异常 (例如,MemoryError 就不应被映射为 URLError)。
本方法将会在所有协议的 open 方法之前被调用。
BaseHandler.<protocol>_open(req)
本方法在 BaseHandler 中 未 予定义,但其子类若要处理给定协议的 URL 则应进行定义。
若定义了本方法,将会被父 OpenerDirector 对象调用。返回值和 default_open() 的一样。
BaseHandler.unknown_open(req)
本方法在 BaseHandler 中 未 予定义,但其子类若要捕获并打开所有未注册 handler 的 URL,则应进行定义。
若实现了本方法,将会被 parent 属性指向的父 OpenerDirector 调用。返回值和 default_open() 的一样。
BaseHandler.http_error_default(req, fp, code, msg, hdrs)
本方法在 BaseHandler 中 未 予定义,但其子类若要为所有未定义 handler 的 HTTP 错误提供一个兜底方法,则应进行重写。OpenerDirector 会自动调用本方法,获取错误信息,而通常在其他时候不应去调用。
req 会是一个 Request 对象,fp 是一个带有 HTTP 错误体的文件类对象,code 是三位数的错误码,msg 是供用户阅读的解释信息,hdrs 则是一个包含出错头部信息的字典对象。
返回值和触发的异常应与 urlopen() 的相同。
BaseHandler.http_error_<nnn>(req, fp, code, msg, hdrs)
nnn 应为三位数的 HTTP 错误码。本方法在 BaseHandler 中也未予定义,但当子类的实例发生代码为 nnn 的 HTTP 错误时,若方法存在则会被调用。
子类应该重写本方法,以便能处理相应的 HTTP 错误。
参数、返回值和触发的异常应与 http_error_default() 相同。
BaseHandler.<protocol>_request(req)
本方法在 BaseHandler 中 未 予定义,但其子类若要对给定协议的请求进行预处理,则应进行定义。
若实现了本方法,将会被父 OpenerDirector 调用。req 将为 Request 对象。返回值应为 Request 对象。
BaseHandler.<protocol>_response(req, response)
本方法在 BaseHandler 中 未 予定义,但其子类若要对给定协议的请求进行后处理,则应进行定义。
若实现了本方法,将会被父 OpenerDirector 调用。req 将为 Request 对象。response 应实现与 urlopen() 返回值相同的接口。返回值应实现与 urlopen() 返回值相同的接口。
HTTPRedirectHandler 对象
备注
某些 HTTP 重定向操作需要本模块的客户端代码提供的功能。这时会触发 HTTPError。有关各种重定向代码的确切含义,请参阅 RFC 2616 。
如果给到 HTTPRedirectHandler 的重定向 URL 不是 HTTP、HTTPS 或 FTP URL,则出于安全考虑将触发 HTTPError 异常。
HTTPRedirectHandler.redirect_request(req, fp, code, msg, hdrs, newurl)
Return a Request or None in response to a redirect. This is called by the default implementations of the http_error_30*() methods when a redirection is received from the server. If a redirection should take place, return a new Request to allow http_error_30*() to perform the redirect to newurl. Otherwise, raise HTTPError if no other handler should try to handle this URL, or return None if you can't but another handler might.
备注
本方法的默认实现代码并未严格遵循 RFC 2616,即 POST 请求的 301 和 302 响应不得在未经用户确认的情况下自动进行重定向。现实情况下,浏览器确实允许自动重定向这些响应,将 POST 更改为 GET ,于是默认实现代码就复现了这种处理方式。
HTTPRedirectHandler.http_error_301(req, fp, code, msg, hdrs)
重定向到 Location: 或 URI: URL。 当得到 HTTP 'moved permanently' 响应时,本方法会被父级 OpenerDirector 调用。
HTTPRedirectHandler.http_error_302(req, fp, code, msg, hdrs)
与 http_error_301() 相同,不过是发生“found”响应时的调用。
HTTPRedirectHandler.http_error_303(req, fp, code, msg, hdrs)
与 http_error_301() 相同,不过是发生“see other”响应时的调用。
HTTPRedirectHandler.http_error_307(req, fp, code, msg, hdrs)
与 http_error_301() 一样,但是针对 '临时重定向' 响应进行调用。 它不允许将请求方法从 POST 改为 GET。
HTTPRedirectHandler.http_error_308(req, fp, code, msg, hdrs)
与 http_error_301() 一样,但是针对 '永久重定向' 响应进行调用。 它不允许将请求方法从 POST 改为 GET。
3.11 新版功能.
HTTPCookieProcessor 对象
HTTPCookieProcessor 的实例具备一个属性:
HTTPCookieProcessor.cookiejar
cookie 存放在 http.cookiejar.CookieJar 中。
ProxyHandler 对象
ProxyHandler.<protocol>_open(request)
ProxyHandler 将为每种 protocol 准备一个 _open() 方法,在构造函数给出的 proxies 字典中包含对应的代理服务器信息。通过调用 request.set_proxy(),本方法将把请求转为通过代理服务器,并会调用 handler 链中的下一个 handler 来完成对应的协议处理。
HTTPPasswordMgr 对象
以下方法 HTTPPasswordMgr 和 HTTPPasswordMgrWithDefaultRealm 对象均有提供。
HTTPPasswordMgr.add_password(realm, uri, user, passwd)
uri 可以是单个 URI,也可以是 URI 列表。realm、user 和 passwd 必须是字符串。这使得在为 realm 和超级 URI 进行身份认证时,(user, passwd) 可用作认证令牌。
HTTPPasswordMgr.find_user_password(realm, authuri)
为给定 realm 和 URI 获取用户名和密码。如果没有匹配的用户名和密码,本方法将会返回 (None, None) 。
对于 HTTPPasswordMgrWithDefaultRealm 对象,如果给定 realm 没有匹配的用户名和密码,将搜索 realm None。
HTTPPasswordMgrWithPriorAuth 对象
这是 HTTPPasswordMgrWithDefaultRealm 的扩展,以便对那些需要一直发送认证凭证的 URI 进行跟踪。
HTTPPasswordMgrWithPriorAuth.add_password(realm, uri, user, passwd, is_authenticated=False)
realm、uri、user、passwd 的含义与 HTTPPasswordMgr.add_password() 的相同。is_authenticated 为给定 URI 或 URI 列表设置 is_authenticated 标志的初始值。如果 is_authenticated 设为 True ,则会忽略 realm。
HTTPPasswordMgrWithPriorAuth.find_user_password(realm, authuri)
与 HTTPPasswordMgrWithDefaultRealm 对象的相同。
HTTPPasswordMgrWithPriorAuth.update_authenticated(self, uri, is_authenticated=False)
更新给定 uri 或 URI 列表的 is_authenticated 标志。
HTTPPasswordMgrWithPriorAuth.is_authenticated(self, authuri)
返回给定 URI is_authenticated 标志的当前状态。
AbstractBasicAuthHandler 对象
AbstractBasicAuthHandler.http_error_auth_reqed(authreq, host, req, headers)
通过获取用户名和密码并重新尝试请求,以处理身份认证请求。 authreq 应该是请求中包含 realm 的头部信息名称,host 指定了需要进行身份认证的 URL 和路径,req 应为 (已失败的) Request 对象 , headers 应该是出错的头部信息。
host 要么是一个认证信息(例如 "python.org" ),要么是一个包含认证信息的 URL(如 "http://python.org/" )。 不论是哪种格式,认证信息中都不能包含用户信息(因此, "python.org" 和 "python.org:80" 没问题,而 "joe:password@python.org" 则不行)。
HTTPBasicAuthHandler 对象
HTTPBasicAuthHandler.http_error_401(req, fp, code, msg, hdrs)
如果可用的话,请用身份认证信息重试请求。
ProxyBasicAuthHandler 对象
ProxyBasicAuthHandler.http_error_407(req, fp, code, msg, hdrs)
如果可用的话,请用身份认证信息重试请求。
AbstractDigestAuthHandler 对象
AbstractDigestAuthHandler.http_error_auth_reqed(authreq, host, req, headers)
authreq 应为请求中有关 realm 的头部信息名称,host 应为需要进行身份认证的主机,req 应为(已失败的) Request 对象, headers 则应为出错的头部信息。
HTTPDigestAuthHandler 对象
HTTPDigestAuthHandler.http_error_401(req, fp, code, msg, hdrs)
如果可用的话,请用身份认证信息重试请求。
ProxyDigestAuthHandler 对象
ProxyDigestAuthHandler.http_error_407(req, fp, code, msg, hdrs)
如果可用的话,请用身份认证信息重试请求。
HTTPHandler 对象
HTTPHandler.http_open(req)
发送 HTTP 请求,根据 req.has_data() 的结果,可能是 GET 或 POST 格式。
HTTPSHandler 对象
HTTPSHandler.https_open(req)
发送 HTTPS 请求,根据 req.has_data() 的结果,可能是 GET 或 POST 格式。
FileHandler 对象
FileHandler.file_open(req)
若无主机名或主机名为 'localhost' ,则打开本地文件。
在 3.2 版更改: 本方法仅适用于本地主机名。如果给出的是远程主机名,将会触发 URLError 。
DataHandler 对象
DataHandler.data_open(req)
读取内含数据的 URL。这种 URL 本身包含了经过编码的数据。 RFC 2397 中给出了数据 URL 的语法定义。目前的代码库将忽略经过 base64 编码的数据 URL 中的空白符,因此 URL 可以放入任何源码文件中。如果数据 URL 的 base64 编码尾部缺少填充,即使某些浏览器不介意,但目前的代码库仍会引发 ValueError。
FTPHandler 对象
FTPHandler.ftp_open(req)
打开由 req 给出的 FTP 文件。登录时的用户名和密码总是为空。
CacheFTPHandler 对象
CacheFTPHandler 对象即为加入以下方法的 FTPHandler 对象:
CacheFTPHandler.setTimeout(t)
设置连接超时为 t 秒。
CacheFTPHandler.setMaxConns(m)
设置已缓存的最大连接数为 m 。
UnknownHandler 对象
UnknownHandler.unknown_open()
触发 URLError 异常。
HTTPErrorProcessor 对象
HTTPErrorProcessor.http_response(request, response)
处理出错的 HTTP 响应。
对于 200 错误码,响应对象应立即返回。
对于 200 以外的错误码,只通过 OpenerDirector.error() 将任务传给 handler 的 http_error_<type>() 方法。如果最终没有 handler 处理错误, HTTPDefaultErrorHandler 将触发 HTTPError。
HTTPErrorProcessor.https_response(request, response)
HTTPS 出错响应的处理。
与 http_response() 方法相同。
例子
如何利用 urllib 包获取网络资源 中给出了更多的示例。
以下示例将读取 python.org 主页并显示前 300 个字节的内容:
>>>
>>> import urllib.request
>>> with urllib.request.urlopen('http://www.python.org/') as f:
... print(f.read(300))
...
b'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\n\n\n<html
xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">\n\n<head>\n
<meta http-equiv="content-type" content="text/html; charset=utf-8" />\n
<title>Python Programming '
请注意,urlopen 将返回字节对象。这是因为 urlopen 无法自动确定由 HTTP 服务器收到的字节流的编码。通常,只要能确定或猜出编码格式,就应将返回的字节对象解码为字符串。
下述 W3C 文档 Character encodings列出了可用于指明(X)HTML 或 XML 文档编码信息的多种方案。
python.org 网站已在 meta 标签中指明,采用的是 utf-8 编码,因此这里将用同样的格式对字节串进行解码。
>>>
>>> with urllib.request.urlopen('http://www.python.org/') as f:
... print(f.read(100).decode('utf-8'))
...
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtm
不用 context manager 方法也能获得同样的结果:
>>>
>>> import urllib.request
>>> f = urllib.request.urlopen('http://www.python.org/')
>>> print(f.read(100).decode('utf-8'))
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtm
以下示例将会把数据流发送给某 CGI 的 stdin,并读取返回数据。请注意,该示例只能工作于 Python 装有 SSL 支持的环境。
>>>
>>> import urllib.request
>>> req = urllib.request.Request(url='https://localhost/cgi-bin/test.cgi',
... data=b'This data is passed to stdin of the CGI')
>>> with urllib.request.urlopen(req) as f:
... print(f.read().decode('utf-8'))
...
Got Data: "This data is passed to stdin of the CGI"
上述示例中的 CGI 代码如下所示:
#!/usr/bin/env python
import sys
data = sys.stdin.read()
print('Content-type: text/plain\n\nGot Data: "%s"' % data)
下面是利用 Request 发送 PUT 请求的示例:
import urllib.request DATA = b'some data' req = urllib.request.Request(url='http://localhost:8080', data=DATA, method='PUT') with urllib.request.urlopen(req) as f:pass print(f.status) print(f.reason)
基本 HTTP 认证示例:
import urllib.request
# Create an OpenerDirector with support for Basic HTTP Authentication...
auth_handler = urllib.request.HTTPBasicAuthHandler()
auth_handler.add_password(realm='PDQ Application',uri='https://mahler:8092/site-updates.py',user='klem',passwd='kadidd!ehopper')
opener = urllib.request.build_opener(auth_handler)
# ...and install it globally so it can be used with urlopen.
urllib.request.install_opener(opener)
urllib.request.urlopen('http://www.example.com/login.html')
build_opener() 默认提供了很多现成的 handler,包括 ProxyHandler。 默认情况下,ProxyHandler 会使用名为 <scheme>_proxy 的环境变量,其中的 <scheme> 是相关的 URL 协议。 例如,可以读取 http_proxy 环境变量来获取 HTTP 代理的 URL。
这个示例将默认的 ProxyHandler 替换为使用以编程方式提供的代理 URL,并通过 ProxyBasicAuthHandler 添加代理认证支持。
proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
# This time, rather than install the OpenerDirector, we use it directly:
opener.open('http://www.example.com/login.html')
添加 HTTP 头部信息:
可利用 Request 构造函数的 headers 参数,或者是:
import urllib.request
req = urllib.request.Request('http://www.example.com/')
req.add_header('Referer', 'http://www.python.org/')
# Customize the default User-Agent header value:
req.add_header('User-Agent', 'urllib-example/0.1 (Contact: . . .)')
r = urllib.request.urlopen(req)
OpenerDirector 自动会在每个 Request 中加入一项 User-Agent 头部信息。若要修改,请参见以下语句:
import urllib.request
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
opener.open('http://www.example.com/')
另请记得,当 Request 传给 urlopen() (或 OpenerDirector.open())时,会加入一些标准的头部信息( Content-Length 、 Content-Type 和 Host)。
以下会话示例用 GET 方法读取包含参数的 URL。
>>>
>>> import urllib.request
>>> import urllib.parse
>>> params = urllib.parse.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
>>> url = "http://www.musi-cal.com/cgi-bin/query?%s" % params
>>> with urllib.request.urlopen(url) as f:
... print(f.read().decode('utf-8'))
...
以下示例换用 POST 方法。请注意 urlencode 输出结果先被编码为字节串 data,再送入 urlopen。
>>>
>>> import urllib.request
>>> import urllib.parse
>>> data = urllib.parse.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
>>> data = data.encode('ascii')
>>> with urllib.request.urlopen("http://requestb.in/xrbl82xr", data) as f:
... print(f.read().decode('utf-8'))
...
以下示例显式指定了 HTTP 代理,以覆盖环境变量中的设置:
>>>
>>> import urllib.request
>>> proxies = {'http': 'http://proxy.example.com:8080/'}
>>> opener = urllib.request.FancyURLopener(proxies)
>>> with opener.open("http://www.python.org") as f:
... f.read().decode('utf-8')
...
以下示例根本不用代理,也覆盖了环境变量中的设置:
>>>
>>> import urllib.request
>>> opener = urllib.request.FancyURLopener({})
>>> with opener.open("http://www.python.org/") as f:
... f.read().decode('utf-8')
...
已停用的接口
以下函数和类是由 Python 2 模块 urllib (相对早于 urllib2 )移植过来的。将来某个时候可能会停用。
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
将 URL 形式的网络对象复制为本地文件。如果 URL 指向本地文件,则必须提供文件名才会执行复制。返回值为元组 (filename, headers) ,其中 filename 是保存网络对象的本地文件名, headers 是由 urlopen() 返回的远程对象 info() 方法的调用结果。可能触发的异常与 urlopen() 相同。
第二个参数指定文件的保存位置(若未给出,则会是名称随机生成的临时文件)。第三个参数是个可调用对象,在建立网络连接时将会调用一次,之后每次读完数据块后会调用一次。该可调用对象将会传入 3 个参数:已传输的块数、块的大小(以字节为单位)和文件总的大小。如果面对的是老旧 FTP 服务器,文件大小参数可能会是 -1 ,这些服务器响应读取请求时不会返回文件大小。
以下例子演示了大部分常用场景:
>>>
>>> import urllib.request
>>> local_filename, headers = urllib.request.urlretrieve('http://python.org/')
>>> html = open(local_filename)
>>> html.close()
如果 url 使用 http: 方式的标识符,则可能给出可选的 data 参数来指定一个 POST 请求 (通常的请求类型为 GET)。 data 参数必须是标准 application/x-www-form-urlencoded 格式的字节串对象;参见 urllib.parse.urlencode() 函数。
urlretrieve() 在检测到可用数据少于预期的大小(即由 Content-Length 标头所报告的大小)时将引发 ContentTooShortError。 例如,这可能会在下载中断时发生。
Content-Length 会被视为大小的下限:如果存在更多的可用数据,urlretrieve 会读取更多的数据,但是如果可用数据少于该值,则会引发异常。
在这种情况下你仍然能够获取已下载的数据,它会存放在异常实例的 content 属性中。
如果未提供 Content-Length 标头,urlretrieve 就无法检查它所下载的数据大小,只是简单地返回它。 在这种情况下你只能假定下载是成功的。
urllib.request.urlcleanup()
清理之前调用 urlretrieve() 时可能留下的临时文件。
class urllib.request.URLopener(proxies=None, **x509)
3.3 版后已移除.
用于打开和读取 URL 的基类。 除非你需要支持使用 http:, ftp: 或 file: 以外的方式来打开对象,那你也许可以使用 FancyURLopener。
在默认情况下,URLopener 类会发送一个内容为 urllib/VVV 的 User-Agent 标头,其中 VVV 是 urllib 的版本号。 应用程序可以通过子类化 URLopener 或 FancyURLopener 并在子类定义中将类属性 version 设为适当的字符串值来定义自己的 User-Agent 标头。
可选的 proxies 形参应当是一个将方式名称映射到代理 URL 的字典,如为空字典则会完全关闭代理。 它的默认值为 None,在这种情况下如果存在环境代理设置则将使用它,正如上文 urlopen() 的定义中所描述的。
一些归属于 x509 的额外关键字形参可在使用 https: 方式时被用于客户端的验证。 支持通过关键字 key_file 和 cert_file 来提供 SSL 密钥和证书;对客户端验证的支持需要提供这两个形参。
如果服务器返回错误代码则 URLopener 对象将引发 OSError 异常。
open(fullurl, data=None)
使用适当的协议打开 fullurl。 此方法会设置缓存和代理信息,然后调用适当的打开方法并附带其输入参数。 如果方式无法被识别,则会调用 open_unknown()。 data 参数的含义与 urlopen() 中的 data 参数相同。
此方法总是会使用 quote() 来对 fullurl 进行转码。
open_unknown(fullurl, data=None)
用于打开未知 URL 类型的可重载接口。
retrieve(url, filename=None, reporthook=None, data=None)
提取 url 的内容并将其存放到 filename 中。 返回值为元组,由一个本地文件名和一个包含响应标头 (对于远程 URL) 的 email.message.Message 对象或者 None (对于本地 URL)。 之后调用方必须打开并读取 filename 的内容。 如果 filename 未给出并且 URL 指向一个本地文件,则会返回输入文件名。 如果 URL 非本地并且 filename 未给出,则文件名为带有与输入 URL 的路径末尾部分后缀相匹配的后缀的 tempfile.mktemp() 的输出。 如果给出了 reporthook,它必须为接受三个数字形参的函数:数据分块编号、读入分块的最大数据量和下载的总数据量 (未知则为 -1)。 它将在开始时和从网络读取每个数据分块之后被调用。 对于本地 URL reporthook 会被忽略。
如果 url 使用 http: 方式的标识符,则可能给出可选的 data 参数来指定一个 POST 请求 (通常的请求类型为 GET)。 data 参数必须为标准的 application/x-www-form-urlencoded 格式 ;参见 urllib.parse.urlencode() 函数。
version
指明打开器对象的用户代理名称的变量。 以便让 urllib 告诉服务器它是某个特定的用户代理,请在子类中将其作为类变量来设置或是在调用基类构造器之前在构造器中设置。
class urllib.request.FancyURLopener(...)
3.3 版后已移除.
FancyURLopener 子类化了 URLopener 以提供对以下 HTTP 响应代码的默认处理: 301, 302, 303, 307 和 401。 对于上述的 30x 响应代码,会使用 Location 标头来获取实际 URL。 对于 401 响应代码 (authentication required),则会执行基本 HTTP 验证。 对于 30x 响应代码,递归层数会受 maxtries 属性值的限制,该值默认为 10。
对于所有其他响应代码,会调用 http_error_default() 方法,你可以在子类中重载此方法来正确地处理错误。
备注
根据 RFC 2616 的说明,对 POST 请求的 301 和 302 响应不可在未经用户确认的情况下自动进行重定向。 在现实情况下,浏览器确实允许自动重定义这些响应,将 POST 更改为 GET,于是 urllib 就会复现这种行为。
传给此构造器的形参与 URLopener 的相同。
备注
当执行基本验证时,FancyURLopener 实例会调用其 prompt_user_passwd() 方法。 默认的实现将向用户询问控制终端所要求的信息。 如有必要子类可以重载此方法来支持更适当的行为。
FancyURLopener 类附带了一个额外方法,它应当被重载以提供适当的行为:
prompt_user_passwd(host, realm)
返回指定的安全体系下在给定的主机上验证用户所需的信息。 返回的值应当是一个元组 (user, password),它可被用于基本验证。
该实现会在终端上提示此信息;应用程序应当重载此方法以使用本地环境下适当的交互模型。
urllib.request 的限制
-
目前,仅支持下列协议: HTTP (0.9 和 1.0 版), FTP, 本地文件, 以及数据 URL。
在 3.4 版更改: 增加了对数据URL 的支持。
-
urlretrieve() 的缓存特性已被禁用,等待有人有时间去正确地解决过期时间标头的处理问题。
-
应当有一个函数来查询特定 URL 是否在缓存中。
-
为了保持向下兼容性,如果某个 URL 看起来是指向本地文件但该文件无法被打开,则该 URL 会使用 FTP 协议来重新解读。 这有时可能会导致令人迷惑的错误消息。
-
urlopen() 和 urlretrieve() 函数在等待网络连接建立时会导致任意长时间的延迟。 这意味着在不使用线程的情况下搭建一个可交互的 Web 客户端是非常困难的。
-
由 urlopen() 或 urlretrieve() 返回的数据就是服务器所返回的原始数据。 这可以是二进制数据(如图片)、纯文本或 HTML 代码等。 HTTP 协议在响应标头中提供了类型信息,这可以通过读取 Content-Type 标头来查看。 如果返回的数据是 HTML,你可以使用 html.parser 模块来解析它。
-
处理 FTP 协议的代码无法区分文件和目录。 这在尝试读取指向不可访问的 URL 时可能导致意外的行为。 如果 URL 以一个
/结束,它会被认为指向一个目录并将作相应的处理。 但是如果读取一个文件的尝试导致了 550 错误(表示 URL 无法找到或不可访问,这常常是由于权限原因),则该路径会被视为一个目录以便处理 URL 是指定一个目录但略去了末尾/的情况。 这在你尝试获取一个因其设置了读取权限因而无法访问的文件时会造成误导性的结果;FTP 代码将尝试读取它,因 550 错误而失败,然后又为这个不可读取的文件执行目录列表操作。 如果需要细粒度的控制,请考虑使用 ftplib 模块,子类化 FancyURLopener,或是修改 _urlopener 来满足你的需求。
urllib.response --- urllib 使用的 Response 类
urllib.response 模块定义了一些函数和提供最小化文件类接口包括 read() 和 readline() 等的类。 此模块定义的函数会由 urllib.request 模块在内部使用。 典型的响应对象是一个 urllib.response.addinfourl 实例:
class urllib.response.addinfourl
url
已读取资源的 URL,通常用于确定是否进行了重定向。
headers
以 EmailMessage 实例的形式返回响应的标头。
status
3.9 新版功能.
由服务器返回的状态码。
geturl()
3.9 版后已移除: 已弃用,建议改用 url。
info()
3.9 版后已移除: 已弃用,建议改用 headers。
code
3.9 版后已移除: 已弃用,建议改用 status。
getcode()
3.9 版后已移除: 已弃用,建议改用 status。
相关文章:

urllib.request --- 用于打开 URL 的可扩展库
源码: Lib/urllib/request.py urllib.request 模块定义了适用于在各种复杂情况下打开 URL(主要为 HTTP)的函数和类 --- 例如基本认证、摘要认证、重定向、cookies 及其它。 参见 对于更高级别的 HTTP 客户端接口,建议使用 Reques…...
【Docker】进阶之路:(十二)Docker Composer
【Docker】进阶之路:(十二)Docker Composer Docker Compose 简介安装 Docker Compose模板文件语法docker-compose.yml 语法说明imagecommandlinksexternal_linksportsexposevolumesvolunes_fromenvironmentenv_fileextendsnetpiddnscap_add,c…...

MES安灯管理:优化生产监控的重要工具
一、MES安灯管理的概念 MES安灯管理是一种基于物理安灯和数字化管理的生产异常管理工具。它通过物理安灯和数字化系统的结合,实现对生产异常的实时监控和及时反馈,从而帮助企业快速响应和解决生产异常,提高生产效率和产品质量。 二、MES系统…...
Unity中URP Shader 的 SRP Batcher
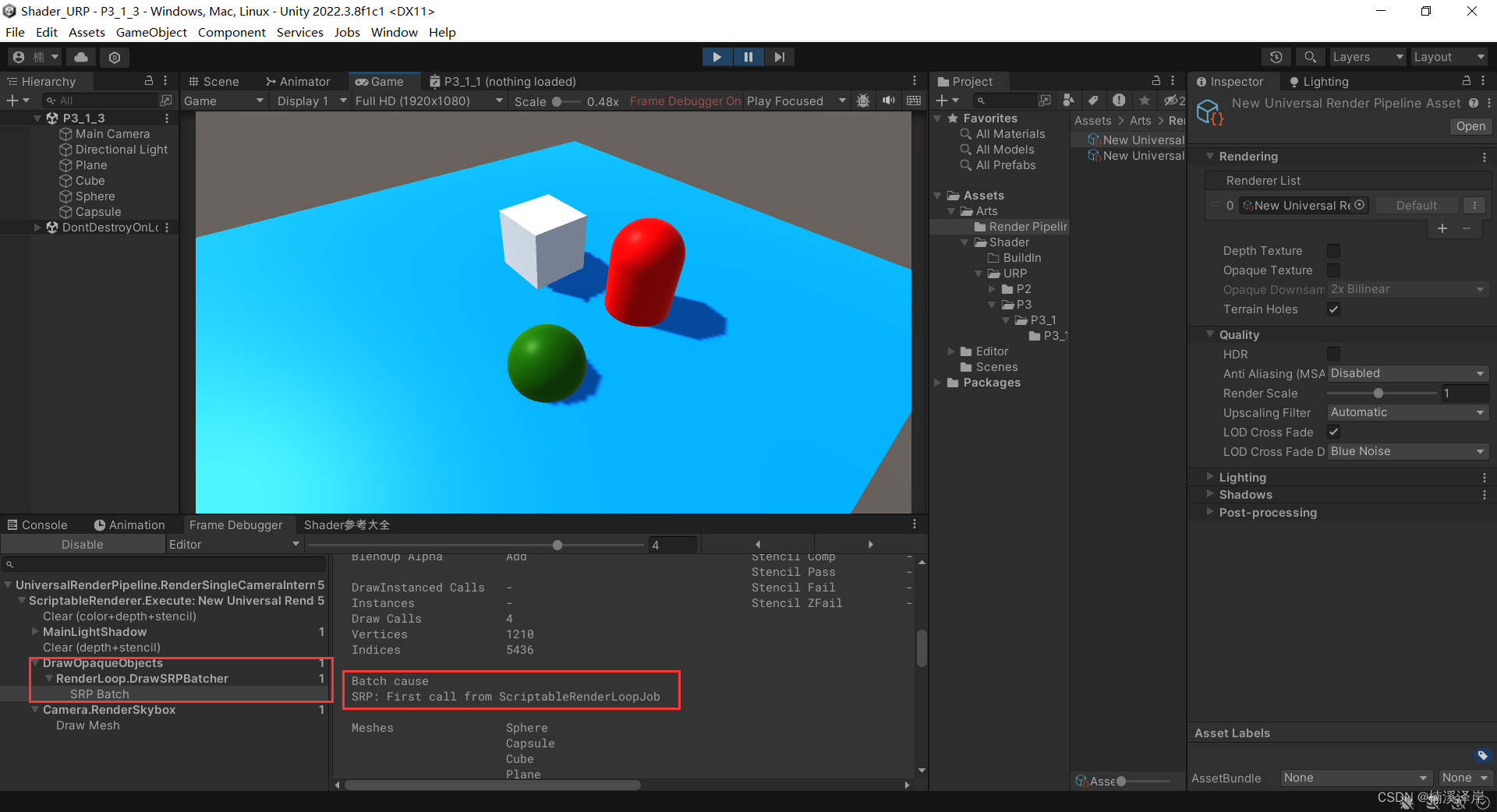
文章目录 前言一、SRP Batcher是什么二、SRP Batcher的使用条件1、可编程渲染管线2、我们用URP作为例子3、URP 设置中 Use SRP Batcher开启4、使 SRP Batcher 代码路径能够渲染对象5、使着色器与 SRP Batcher 兼容: 三、不同合批之间的区别BuildIn Render Pipeline下…...

十四 动手学深度学习v2计算机视觉 ——转置矩阵
文章目录 基本操作填充、步幅和多通道再谈转置卷积不填充,步幅为1填充为p,步幅为1填充为p,步幅为s 基本操作 填充、步幅和多通道 填充: 与常规卷积不同,在转置卷积中,填充被应用于的输出(常规卷…...

Spark-Streaming+Kafka+mysql实战示例
文章目录 前言一、简介1. Spark-Streaming简介2. Kafka简介二、实战演练1. MySQL数据库部分2. 导入依赖3. 编写实体类代码4. 编写kafka主题管理代码5. 编写kafka生产者代码6. 编写Spark-Streaming代码7. 查看数据库8. 代码下载总结前言 本文将介绍一个使用Spark Streaming和Ka…...

C++改写为C
stm使用中,经常能见到CPP的示例,这些是给arduino,esp32用的,stm32 也支持cpp但是你就想用c怎么办呢,比如我在新手的时候:: 这个双冒号就难住了英雄好汉 比如这是个cpp的 如果类不多的情况下 改写…...
抖去推--短视频剪辑、矩阵无人直播saas营销工具一站式开发
抖去推是一款短视频剪辑和矩阵无人直播SAAS营销工具一站式开发平台。它提供了以下功能和特点: 1. 短视频剪辑:抖去推提供了一系列的剪辑工具,包括自动剪辑、特效制作、配音配乐等,可以帮助用户轻松制作出高质量的短视频。 2. 矩阵…...
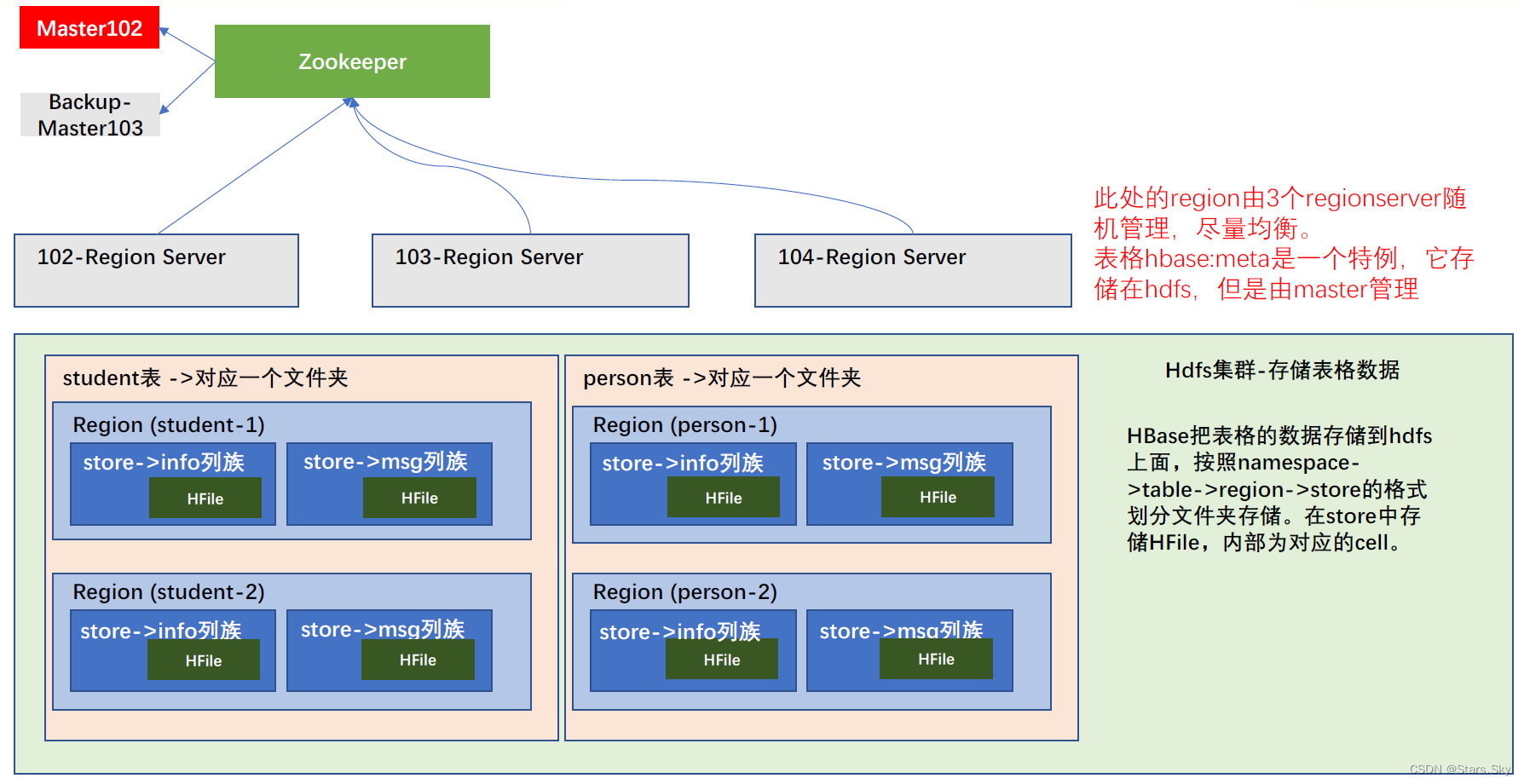
HBase 详细图文介绍
目录 一、HBase 定义 二、HBase 数据模型 2.1 HBase 逻辑结构 2.2 HBase 物理存储结构 2.3 数据模型 2.3.1 Name Space 2.3.2 Table 2.3.3 Row 2.3.4 Column 2.3.5 Time Stamp 2.3.6 Cell 三、HBase 基本架构 架构角色 3.1 Master 3.2 Region Server 3.3 Zo…...

Hanlp自然语言处理如何再Spring Boot中使用
一、HanLP HanLP (Hankcs NLP) 是一个自然语言处理工具包,具有功能强大、性能高效、易于使用的特点。HanLP 主要支持中文文本处理,包括分词、词性标注、命名实体识别、依存句法分析、关键词提取、文本分类、情感分析等多种功能。 HanLP 可以在 Java、Py…...

MySQL 是什么?
MySQL官方网站(http://www.mysql.com/)提供关于MySQL软件的最新信息。 MySQL是一个数据库管理系统。 数据库是一种结构化的数据集合。它可以是从简单的购物清单到图片库,再到企业网络中的大量信息等任何形式。要添加、访问和处理存储在计算…...
)
yarn link使用(npm link)
使用场景 前端开发中,两个项目相互依赖时,使用yarn link(npm link)链接 例如:A项目依赖于本司自己的UI库B,当我们修改了UI库B中的某些代码时,需本地验证后再发布到私服,此时A项目与UI项目B通过yarn link连…...

Docker容器讲解
Docker是一个开源的容器化平台,可以用来在轻量级容器中打包、部署和运行应用程序。Docker的基本概念包括容器、镜像、仓库和服务。 容器是一个独立运行的应用程序包,包括应用程序及其依赖项、运行时环境和配置等。容器相互隔离,可以在不同的…...
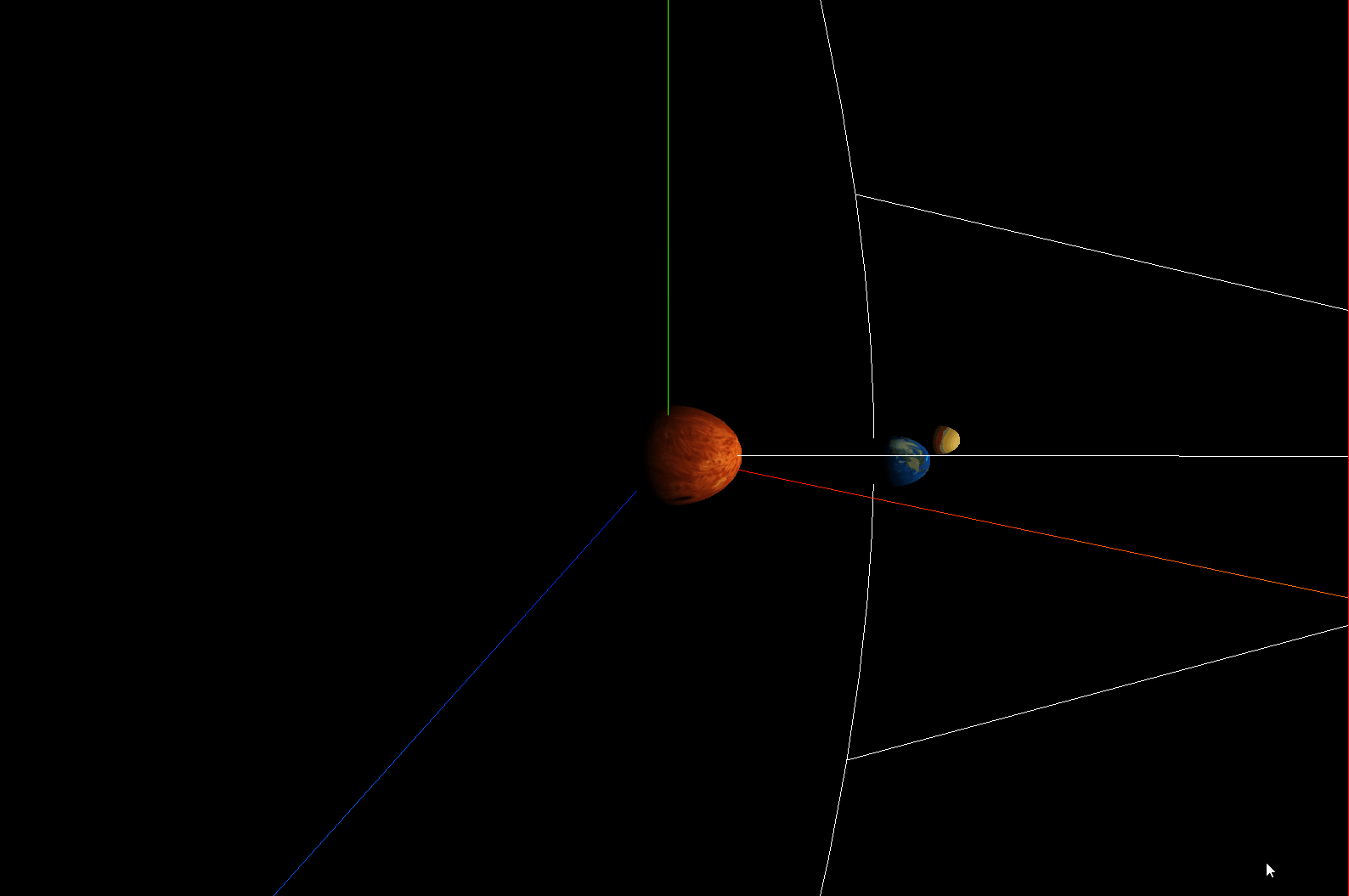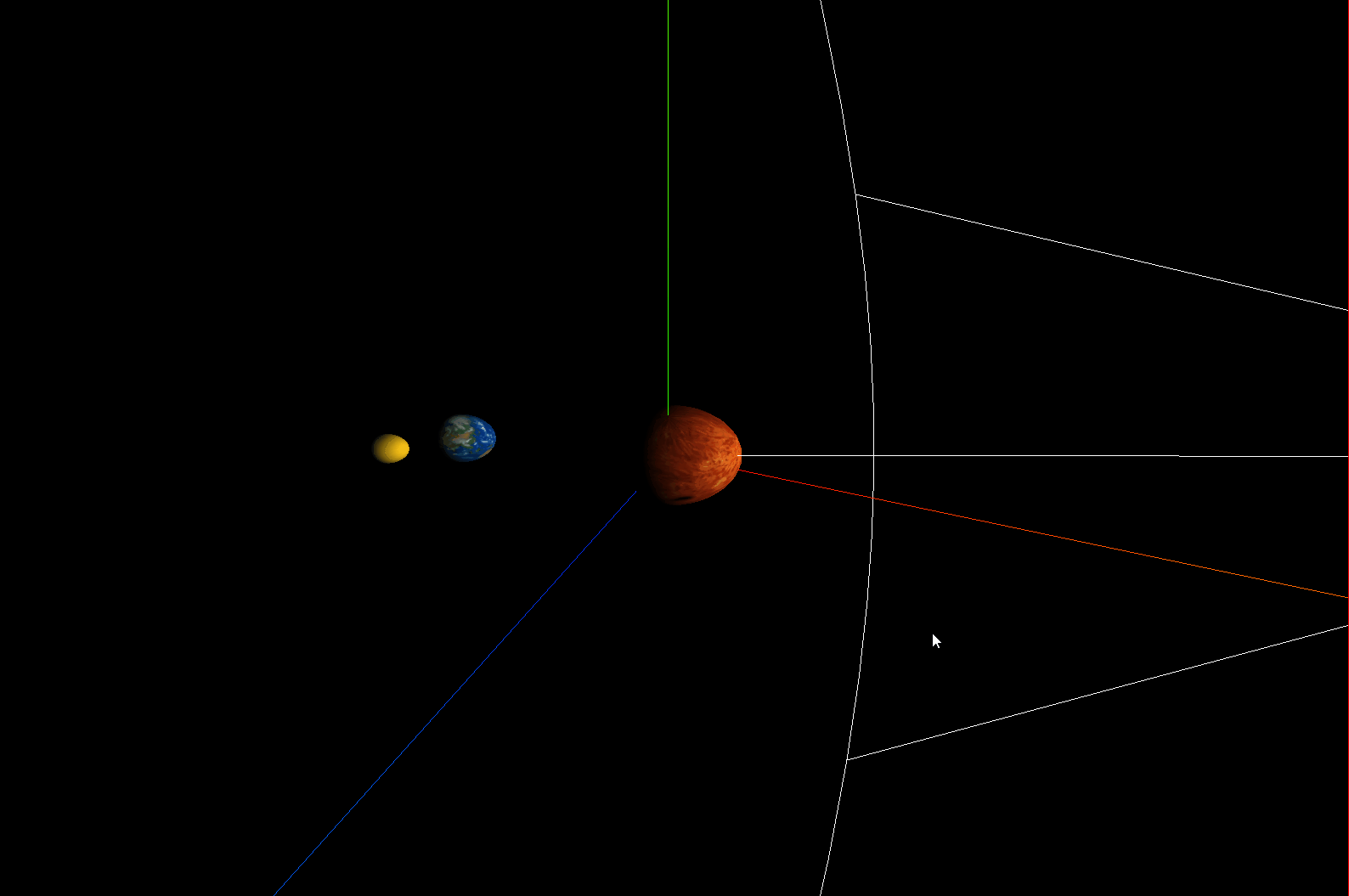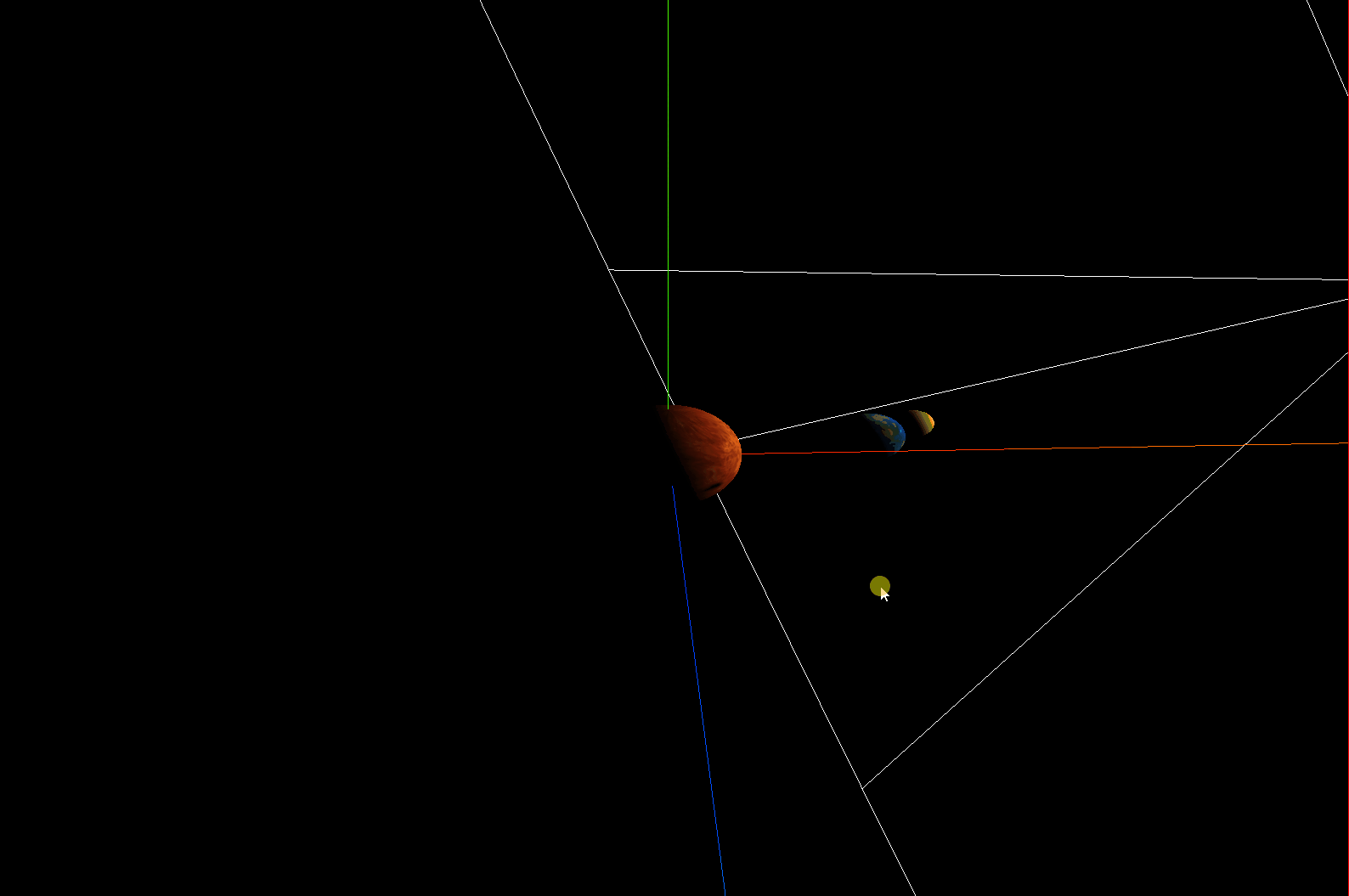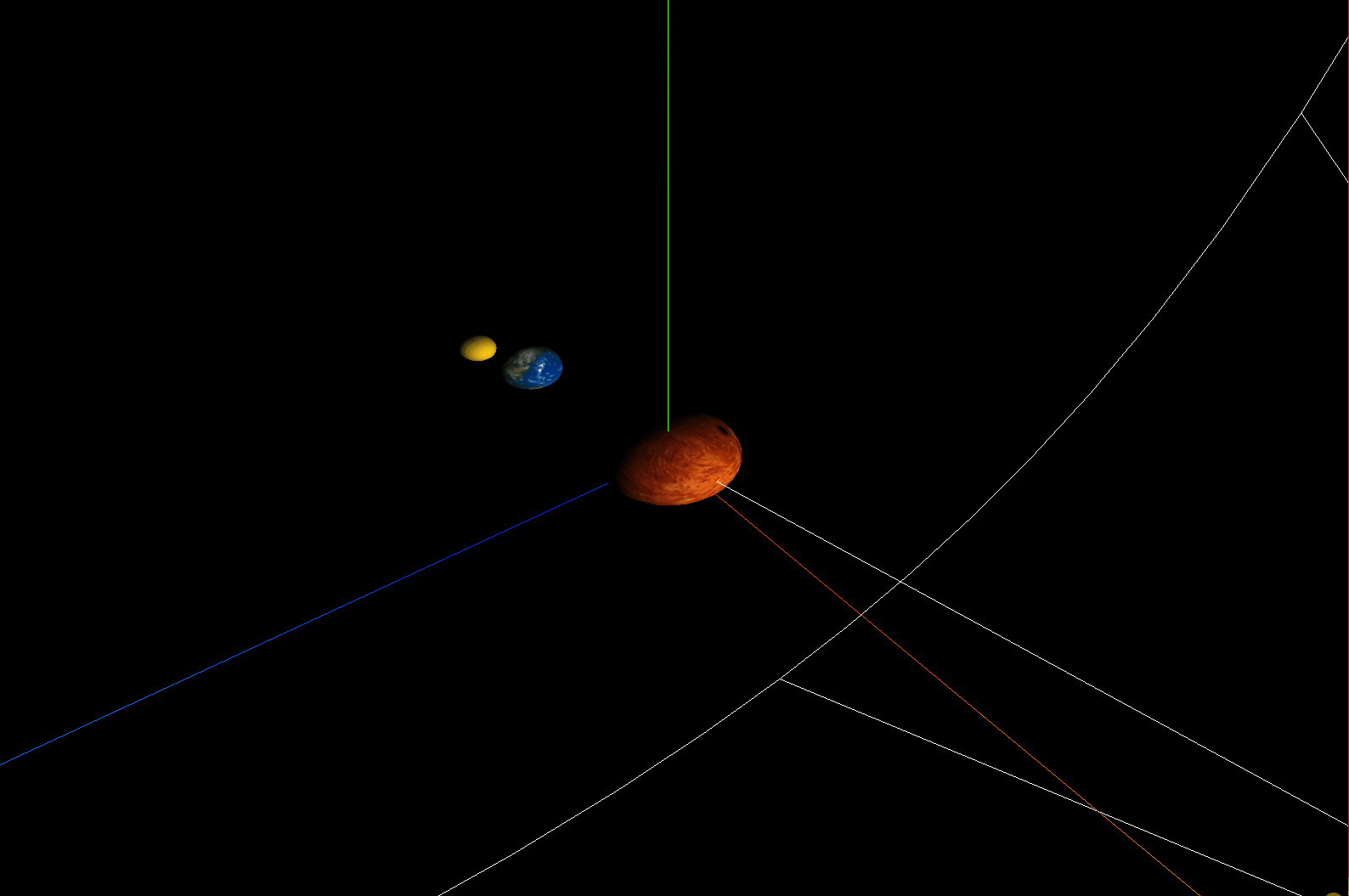
three.js模拟太阳系
地球的旋转轨迹目前设置为了圆形,效果: <template><div><el-container><el-main><div class"box-card-left"><div id"threejs" style"border: 1px solid red"></div><div c…...
WPF仿网易云搭建笔记(1):项目搭建
文章目录 前言项目地址动态样式组合样式批量样式覆盖Prism新建UserControler修改Material Design 笔刷收放列表可以滚动的StackPanel列表点击展开或折叠 实现效果 前言 今天接着继续细化代码,把整体框架写出来 项目地址 WPF仿网易云 Gitee仓库 动态样式 【WPF】C#…...
DDOS 攻击是什么?有哪些常见的DDOS攻击?
DDOS简介 DDOS又称为分布式拒绝服务,全称是Distributed Denial of Service。DDOS本是利用合理的请求造成资源过载,导致服务不可用,从而造成服务器拒绝正常流量服务。就如酒店里的房间是有固定的数量的,比如一个酒店有50个房间&am…...

未来应用从何而来:认知力延伸、边界突破、回归云与产业
文 | 智能相对论 作者 | 沈浪 或许,谁也没想到未来应用来的如此之快,现如今传统应用从开发到体验,已经进入了一个前所未有的颠覆性改革阶段。 不久前,美国人工智能公司OpenAI举办开发者大会。在现场,公司创始人Sam …...

vue零基础
vue 与其他框架的对比 框架设计模式数据绑定灵活度文件模式复杂性学习曲线生态VueMVVM双向灵活单文件小缓完善ReactMVC单向较灵活all in js大陡丰富AngularMVC双向固定多文件较大较陡(Typescript)独立 更多对比细节:vue 官网:ht…...

html中一个div中平均一行分配四个盒子,可展开与收起所有的盒子
html中一个div中平均一行分配四个盒子,可展开与收起所有的盒子 1.截图显示部分 2.代码展示部分 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"wid…...
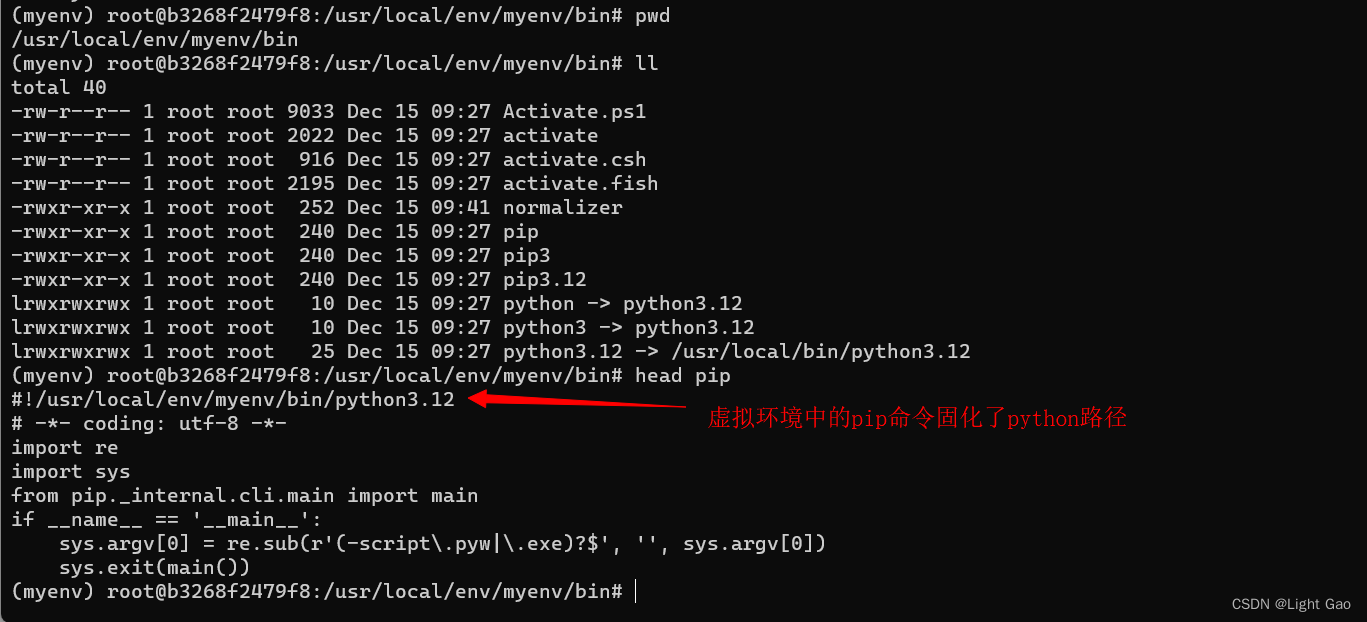
Python虚拟环境指南:告别依赖地狱
一、背景 在SAAS(软件即服务)平台中,用户使用自行定制的Python脚本已经成为司空见惯的做法,然而,由于不同用户对Python三方库的需求各不相同,而底层服务器一般只安装了一个Python版本。举例来说࿰…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...

ArcGIS Pro+ArcGIS给你的地图加上北回归线!
今天来看ArcGIS Pro和ArcGIS中如何给制作的中国地图或者其他大范围地图加上北回归线。 我们将在ArcGIS Pro和ArcGIS中一同介绍。 1 ArcGIS Pro中设置北回归线 1、在ArcGIS Pro中初步设置好经纬格网等,设置经线、纬线都以10间隔显示。 2、需要插入背会归线…...