二百一十五、Flume——Flume拓扑结构之复制和多路复用的开发案例(亲测,附截图)
一、目的
对于Flume的复制和多路复用拓扑结构,进行一个小的开发测试
二、复制和多路复用拓扑结构

(一)结构含义
Flume 支持将事件流向一个或者多个目的地。
(二)结构特征
这种模式可以将相同数据复制到多个channel 中,或者将不同数据分发到不同的 channel 中,sink 可以选择传送到不同的目的地
三、需求案例
(一)案例需求
(二)需求分析

四、前期准备
(一)安装好Hadoop、Hive、Flume等工具
(二)查看Hive的日志在Linux系统中的文件路径
[root@hurys23 conf]# find / -name hive.log
/home/log/hive312/hive.log
(三)在HDFS中创建文件夹flume2,即Hive日志写入的HDFS文件

(四)在/opt/flume目录下创建 flume3 文件夹
[root@hurys23 ~]# cd /opt/flume/
[root@hurys23 flume]# mkdir flume3
[root@hurys23 flume]# ll
总用量 0
drwxr-xr-x 2 root root 6 12月 12 14:41 flume3
drwxr-xr-x 3 root root 102 12月 5 16:08 upload

五、创建flume的任务文件
(一)创建任务文件1 flume-file-flume.conf
配置1个接收日志文件的source和两个channel、两个sink,分别输送给 flume-flume-hdfs 和 flume-flume-dir。
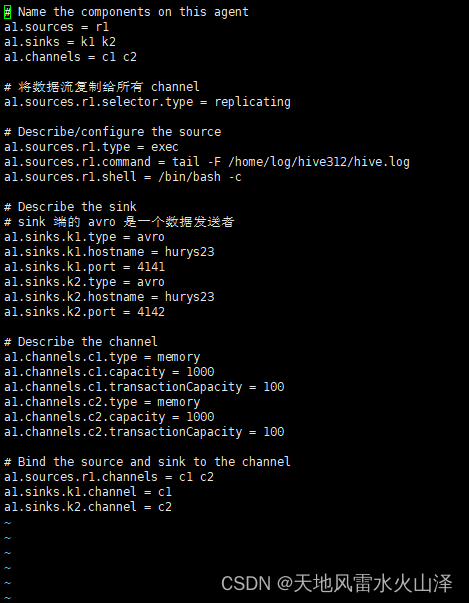
[root@hurys23 conf]# vi flume-file-flume.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有 channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/log/hive312/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
# sink 端的 avro 是一个数据发送者
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hurys23
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hurys23
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
注意:
1、配置文件中的各项参数需要调式,这里只是为了演示,实现目的、打通路径即可!实际在项目中操作时需要调试参数。
2、a1.sources.r1.command = tail -F /home/log/hive312/hive.log 为hive.log在Linux中的路径
3、a1.sinks.k1.hostname = hurys23 hurys23 为服务器名字
(二)创建任务文件2 flume-flume-hdfs.conf
[root@hurys23 conf]# vi flume-flume-hdfs.conf
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
# source 端的 avro 是一个数据接收服务
a2.sources.r1.type = avro
a2.sources.r1.bind = hurys23
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hurys23:8020/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 30
#设置每个文件的滚动大小大概是 128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1

注意:
1、a2.sinks.k1.hdfs.path = hdfs://hurys23:8020/flume2/%Y%m%d/%H 为写入的HDFS文件路径
2、a2.sources.r1.bind = hurys23 hurys23 为服务器名字
(三)创建任务文件3 flume-flume-dir.conf
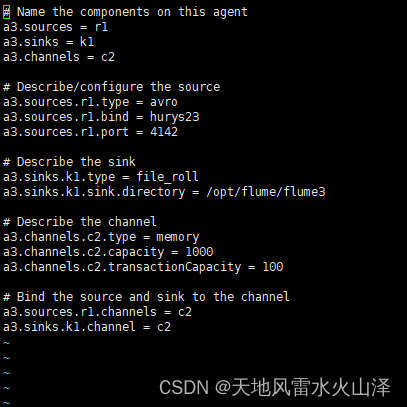
[root@hurys23 conf]# vi flume-flume-dir.conf
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hurys23
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/flume/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
注意:
1、a3.sources.r1.bind = hurys23 hurys23 为服务器名字
2、a3.sinks.k1.sink.directory = /opt/flume/flume3 在Linux中的本地路径
3、/opt/flume/flume3 这个输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会自动创建新的目录
六、分别启动Flume任务文件
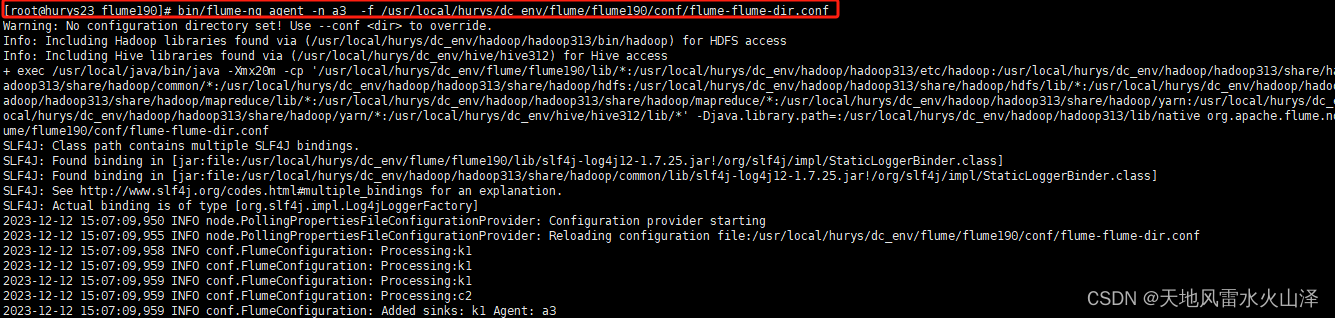
(一)首先启动 a3 flume-flume-dir.conf
[root@hurys23 flume190]# bin/flume-ng agent -n a3 -f /usr/local/hurys/dc_env/flume/flume190/conf/flume-flume-dir.conf
(二)其次启动 a2 flume-flume-hdfs.conf
[root@hurys23 flume190]# bin/flume-ng agent -n a2 -f /usr/local/hurys/dc_env/flume/flume190/conf/flume-flume-hdfs.conf

(三)最后启动 a1 flume-file-flume.conf
[root@hurys23 flume190]# bin/flume-ng agent -n a1 -f /usr/local/hurys/dc_env/flume/flume190/conf/flume-file-flume.conf
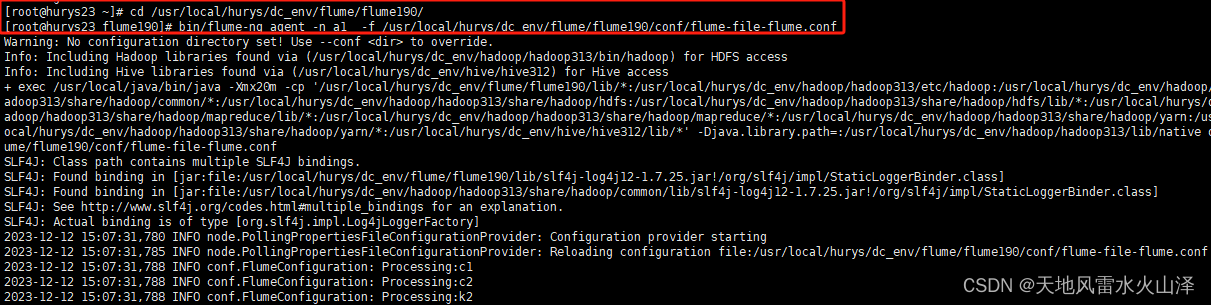
七、Flume任务运行执行状况
(一)a1 a1任务运行截图
采集hive的log日志文件,发送给flume2、flume3
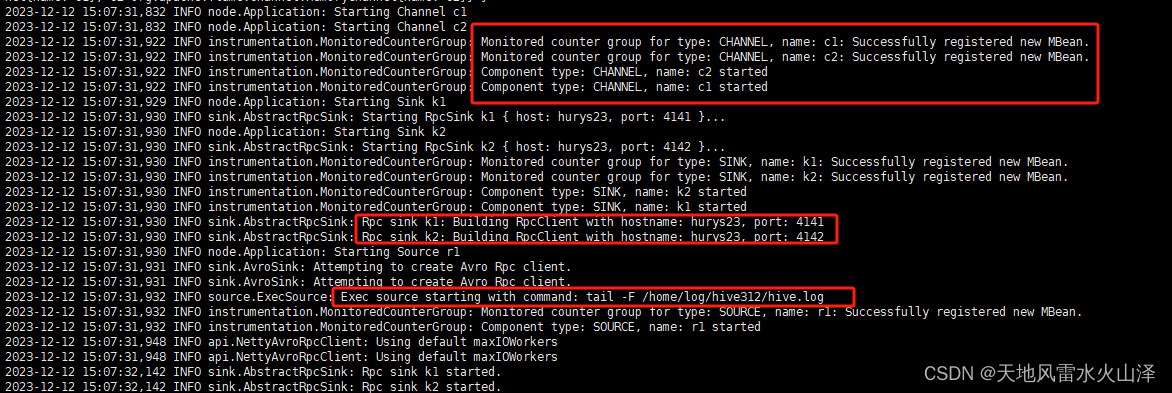
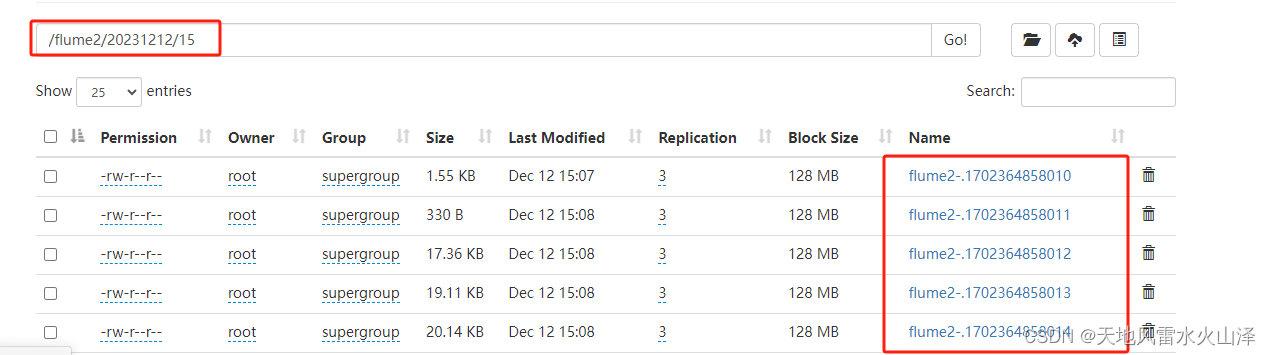
(二)a2 写入的HDFS文件状况
根据时间戳自动生成20231212文件夹、15文件夹及其flume2-文件
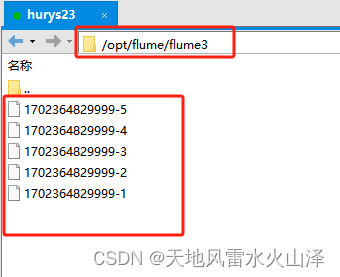
(三)a3 写入的Linux本地文件状况
在Linux的 /opt/flume/flume3目录下自动生成相关文件
[root@hurys23 flume3]# ll
总用量 188
-rw-r--r-- 1 root root 0 12月 12 15:07 1702364829999-1
-rw-r--r-- 1 root root 1922 12月 12 15:07 1702364829999-2
-rw-r--r-- 1 root root 163250 12月 12 15:08 1702364829999-3
-rw-r--r-- 1 root root 23162 12月 12 15:08 1702364829999-4
-rw-r--r-- 1 root root 0 12月 12 15:09 1702364829999-5
Flume复制和多路复用拓扑结构的开发案例测试成功,简单来看,a1是source,a2、a3是sink
这种结构其实也挺常见的,就先到这里,Flume玩法还真挺多的!
相关文章:
二百一十五、Flume——Flume拓扑结构之复制和多路复用的开发案例(亲测,附截图)
一、目的 对于Flume的复制和多路复用拓扑结构,进行一个小的开发测试 二、复制和多路复用拓扑结构 (一)结构含义 Flume 支持将事件流向一个或者多个目的地。 (二)结构特征 这种模式可以将相同数据复制到多个channe…...
Leetcode—2962.统计最大元素出现至少 K 次的子数组【中等】
2023每日刷题(五十六) Leetcode—2962.统计最大元素出现至少 K 次的子数组 滑动窗口算法思想 参考的灵神思路 实现代码 class Solution { public:long long countSubarrays(vector<int>& nums, int k) {int n nums.size();long long ans…...

MapReduce模拟统计每日车流量-解决方案
MapReduce模拟统计每日车流量-解决方案 1.Map阶段:将原始数据分割成若干个小块,每个小块由一个Map任务处理。Map任务将小块中的每个数据项映射成为一个键值对,其中键为时间戳,值为车流量。2.Shuffle阶段:将Map任务输出…...

【深度学习】强化学习(二)马尔可夫决策过程
文章目录 一、强化学习问题1、交互的对象2、强化学习的基本要素3、策略(Policy)4、马尔可夫决策过程1. 基本元素2. 交互过程的表示3. 马尔可夫过程(Markov Process)4. 马尔可夫决策过程(MDP)5. 轨迹的概率计…...

Vue.js 使用基础知识
Vue.js 是一款用于构建用户界面的渐进式框架,它专注于视图层。Vue.js 不同于传统的 JavaScript 框架,它采用了组件化的开发方式,使得开发者可以更加高效和灵活地构建交互式的 Web 应用程序。 目录 什么是 Vue.js安装 Vue.jsVue 实例模板语法插…...

Linux---计划任务
本章主要介绍如何创建计划任务 使用 at 创建计划任务使用 crontab 创建计划任务 有时需要在某个指定的时间执行一个操作,此时就要使用计划任务了。计划任务有两种: 一个是at计划任务,另一个是 crontab计划任务。 下面我们分别来看这两种计划…...

.NET微信网页开发之通过UnionID机制解决多应用用户帐号统一问题
背景 随着公司微信相关业务场景的不断拓展,从最初的一个微信移动应用、然后发展成微信公众号应用、然后又有了微信小程序应用。但是随着应用的拓展,如何保证相同用户的微信用户在不同应用中登录的同一个账号呢?今天的主题就来了.NET微信网页…...
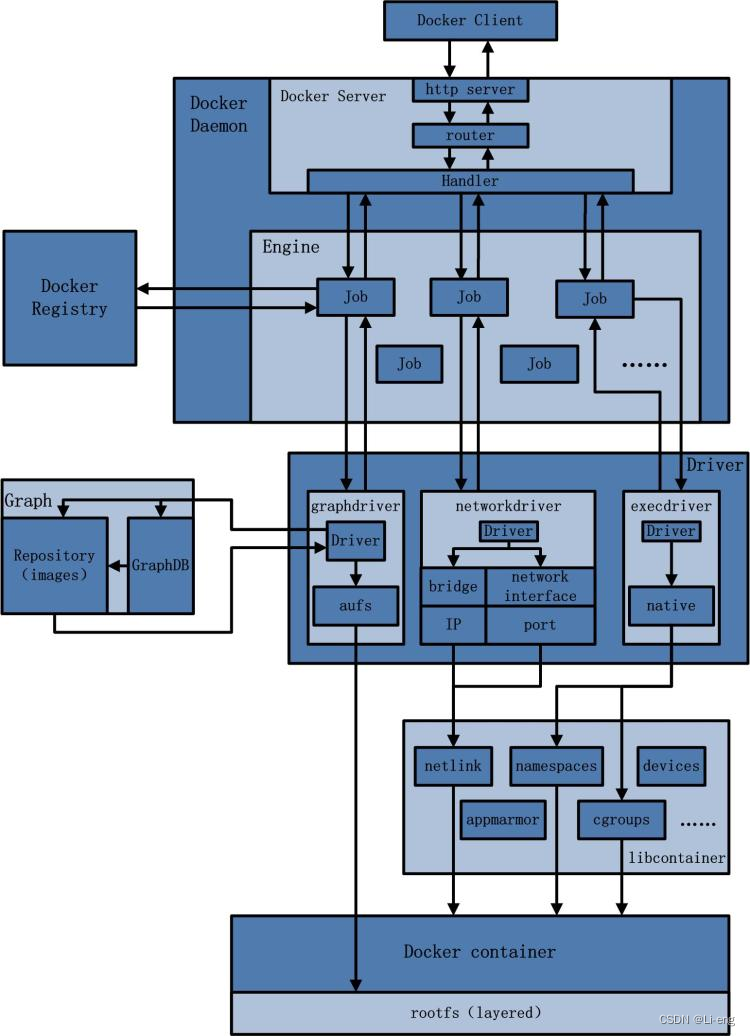
【docker】docker入门与安装
Docker 一、入门 Docker的主要目标是:Build, Ship and Run Any App, Anywhere,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP及其运行环境能做到一次镜像,处处运行。 Docker运行速度快的原因 Docker有比虚拟…...
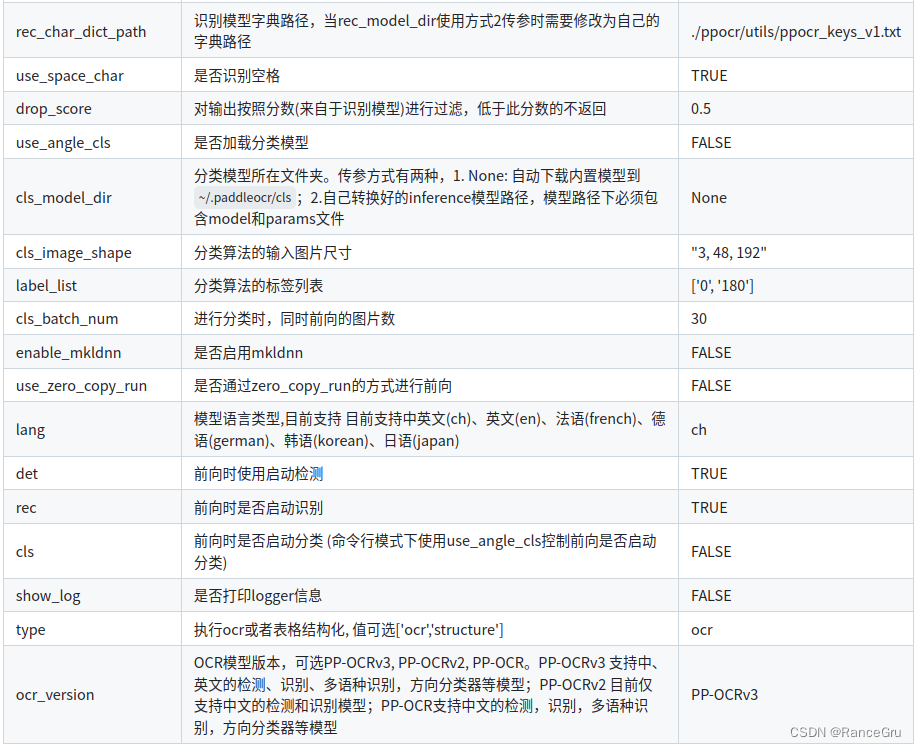
视觉学习笔记12——百度飞浆框架的PaddleOCR 安装、标注、训练以及测试
系列文章目录 虚拟环境部署 参考博客1 参考博客2 参考博客3 参考博客4 文章目录 系列文章目录一、简单介绍1.OCR介绍2.PaddleOCR介绍 二、安装1.anaconda基础环境1)anaconda的基本操作2)搭建飞浆的基础环境 2.安装paddlepaddle-gpu版本1)安装…...

深入分析ClassLocader工作机制
文章目录 一、ClassLoader简介1. 概念2. ClassLoader类结构分析 二、ClassLoader的双亲委派机制三、Class文件的加载流程1. 简介2. 加载字节码到内存3. 验证与解析4. 初始化Class对象 四、常见加载类错误分析1. ClassNotFoundException2. NoClassDefFoundError3. UnsatisfiledL…...
算法通关村第十二关—字符串转换(青铜)
一、转换成小写字母 LeetCode709.给你一个字符串s,将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。 示例1: 输入:s"Hello" 输出:"hello" 示例2: 输入:s&qu…...
)
C#基础与进阶扩展合集-基础篇(持续更新)
目录 本文分两篇,进阶篇点击:C#基础与进阶扩展合集-进阶篇 一、基础入门 Ⅰ 关键字 Ⅱ 特性 Ⅲ 常见异常 Ⅳ 基础扩展 1、哈希表 2、扩展方法 3、自定义集合与索引器 4、迭代器与分部类 5、yield return 6、注册表 7、不安全代码 8、方法…...

ReactJs笔记摘录
文章目录 前言目录结构组件动态组件高阶组件 Hook函数useStateuseEffectuseContextuseReduceruseCallbackuseMemo JSX语法根元素与斜杠使用变量推荐使用className替代class属性写法三元表达式 vs &&antd和tailwindcss 组件通信父传子:props和自定义函数事件…...

2023 re:Invent使用 PartyRock 和 Amazon Bedrock 安全高效构建 AI 应用程序
前言 本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 “Your Data, Your AI, Your Future.(你的数据,你的AI&…...

Mac 打不开github解决方案
序言 github 时有打不开的情况,为此很是烦恼,这里分享一下如何解决这种问题,其实问题的本质是在访问github网页时无法通过github.com的二级域名进行动态域名解析。 解决方案 手动配置静态文件hosts,将该域名和IP的映射关系添加…...

十五 动手学深度学习v2计算机视觉 ——全连接神经网络FCN
文章目录 FCN FCN 全卷积网络先使用卷积神经网络抽取图像特征,然后通过卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。 因此,模型输出与输入图像的高和宽相同,且最终输出通道包含了该空…...
elementUI中的 “this.$confirm“ 基本用法,“this.$confirm“ 调换 “确认“、“取消“ 按钮的位置
文章目录 前言具体操作总结 前言 elementUI中的 "this.$confirm" 基本用法,"this.$confirm" 调换 "确认"、"取消" 按钮的位置 具体操作 基本用法 <script> this.$confirm(这是数据(res.data࿰…...

K8S 常用命令
获取所有的pod资源: kubectl get pod 获取所有的命名空间: kubectl get namespace 获取所有的Deployment资源: kubectl get deployment 删除指定的deploy: kubectl delete deploy nginx 获取所有的服务: kubectl get serv…...

12.使用 Redis 优化登陆模块
目录 1. 使用 Redis 优化登陆模块 1.1 使用 Redis 存储验证码 1.2 使用 Redis 存储登录凭证 1.3 使用 Redis 缓存用户信息 1. 使用 Redis 优化登陆模块 使用 Redis 存储验证码:验证码需要频繁的访问与刷新,对性能要求较高;验证码不需要永…...
Nacos-NacosRule 负载均衡—设置集群使本地服务优先访问
userservice: ribbon: NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则 NacosRule 权重计算方法 目录 一、介绍 二、示例(案例截图) 三、总结 一、介绍 NacosRule是AlibabaNacos自己实现的一个负载均衡策略&…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...