通义千问 Qwen-72B-Chat在PAI-DSW的微调推理实践
01
引言
通义千问-72B(Qwen-72B)是阿里云研发的通义千问大模型系列的720亿参数规模模型。Qwen-72B的预训练数据类型多样、覆盖广泛,包括大量网络文本、专业书籍、代码等。Qwen-72B-Chat是在Qwen-72B的基础上,使用对齐机制打造的基于大语言模型的AI助手。
阿里云人工智能平台PAI是面向开发者和企业的机器学习/深度学习平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务。
本文将以Qwen-72B-Chat为例,介绍如何在PAI平台的交互式建模工具PAI-DSW中微调千问大模型。
02
运行环境要求
GPU推荐使用A800(80GB)
ps:推理需要2卡及以上资源,LoRA微调需要4卡及以上资源
Region:乌兰察布
环境:灵骏集群
镜像:pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/llm-inference:vllm-0.2.1-v6
技术交流
建了技术交流群!想要进交流群、获取如下原版资料的同学,可以直接加微信号:dkl88194。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:dkl88194,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
资料1

资料2

03
准备工作
下载Qwen-72B-Chat
首先,下载模型文件。您可以选择直接执行下面脚本下载,也可以选择从ModelScope下载模型。运行如下代码下载模型。
def aria2(url, filename, d):!aria2c --console-log-level=error -c -x 16 -s 16 {url} -o {filename} -d {d}qwen72b_url = f"http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/qwen72b/Qwen-72B-Chat-sharded.tar"
aria2(qwen72b_url, qwen72b_url.split("/")[-1], "/root/")
! cd /root && tar -xvf Qwen-72B-Chat-sharded.tar
04
LoRA微调
下载示例数据集
! wget -c http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu.aliyuncs.com/qwen72b/sharegpt_zh_1K.json -P /workspace/Qwen
为了快速跑通流程将num_train_epochs设为1,nproc_per_node根据当前示例gpu数量调整
! cd /workspace/Qwen && CUDA_DEVICE_MAX_CONNECTIONS=1 torchrun --nproc_per_node 8 \
--nnodes 1 \
--node_rank 0 \
--master_addr localhost \
--master_port 6001 \
finetune.py \
--model_name_or_path /root/Qwen-72B-Chat-sharded \
--data_path sharegpt_zh_1K.json \
--bf16 True \
--output_dir /root/output_qwen \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 1 \
--learning_rate 3e-4 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 2048 \
--lazy_preprocess True \
--use_lora \
--gradient_checkpointing \
--deepspeed finetune/ds_config_zero3.json
合并Lora权重,如果执行完后,存在GPU显存没有释放问题,可以关闭Kernel,再执行后续代码
from peft import AutoPeftModelForCausalLMmodel = AutoPeftModelForCausalLM.from_pretrained('/root/output_qwen', # path to the output directorydevice_map="auto",trust_remote_code=True
).eval()merged_model = model.merge_and_unload()
# max_shard_size and safe serialization are not necessary.
# They respectively work for sharding checkpoint and save the model to safetensors
merged_model.save_pretrained('/root/qwen72b_sft', max_shard_size="2048MB", safe_serialization=True)
! cp /root/Qwen-72B-Chat-sharded/qwen.tiktoken /root/qwen72b_sft/
! cp /root/Qwen-72B-Chat-sharded/tokenization_qwen.py /root/qwen72b_sft/
! cp /root/Qwen-72B-Chat-sharded/tokenizer_config.json /root/qwen72b_sft/
05
离线推理
tensor_parallel_size参数可以根据dsw示例配置中的GPU数量进行调整
from vllm import LLM
from vllm.sampling_params import SamplingParams
qwen72b = LLM("/root/qwen72b_sft/", tensor_parallel_size=2, trust_remote_code=True, gpu_memory_utilization=0.99)
samplingparams = SamplingParams(temperature=0.0, max_tokens=512, stop=['<|im_end|>'])
prompt = """<|im_start|>system
<|im_end|>
<|im_start|>user
<|im_end|>
Hello! What is your name?<|im_end|>
<|im_start|>assistant
"""
output = qwen72b.generate(prompt, samplingparams)
print(output)
# 通过如下命令释放加载模型del qwen72b
06
试玩模型
WebUI启动方式
我们可以通过如下方式在dsw中启动webui示例:
- 打开terminal1运行如下命令
python -m fastchat.serve.controller
- 打开terminal2运行如下命令
python -m fastchat.serve.vllm_worker --model-path /root/qwen72b_sft --tensor-parallel-size 2 --trust-remote-code --gpu-memory-utilization 0.98
- 在notebook运行如下命令拉起webui,点击生成的local URL跳转到webui界面进行试玩
! python -m fastchat.serve.gradio_web_server_pai --model-list-mode reload
# 通过如下命令杀死所有启动的fastchat服务! kill -s 9 `ps -aux | grep fastchat | awk '{print $2}'`
API启动方式
我们可以通过如下方式在dsw中启动API示例:
- 打开terminal1运行如下命令
python -m fastchat.serve.controller
- 打开terminal2运行如下命令
python -m fastchat.serve.vllm_worker --model-path /root/qwen72b_sft --tensor-parallel-size 2 --trust-remote-code --gpu-memory-utilization 0.98
- 打开terminal3运行如下命令
python -m fastchat.serve.openai_api_server --host localhost --port 8000
- 通过如下方式调用API
import openai
# to get proper authentication, make sure to use a valid key that's listed in
# the --api-keys flag. if no flag value is provided, the `api_key` will be ignored.
openai.api_key = "EMPTY"
openai.api_base = "http://0.0.0.0:8000/v1"
model = "qwen72b_sft"
# create a chat completion
completion = openai.ChatCompletion.create(model=model,temperature=0.0,top_p=0.8,# presence_penalty=2.0,frequency_penalty=0.0,messages=[{"role": "user", "content": "你好"}]
)
# print the completion
print(completion.choices[0].message.content)
# 通过如下命令杀死所有启动的fastchat服务! kill -s 9 `ps -aux | grep fastchat | awk '{print $2}'`
07
PAI SDK 部署eas服务
用户可以通过PAI SDK的方式将模型部署到PAI EAS
安装PAI SDK
! python -m pip install alipai==0.4.4.post0 -i https://pypi.org/simple
初始化配置
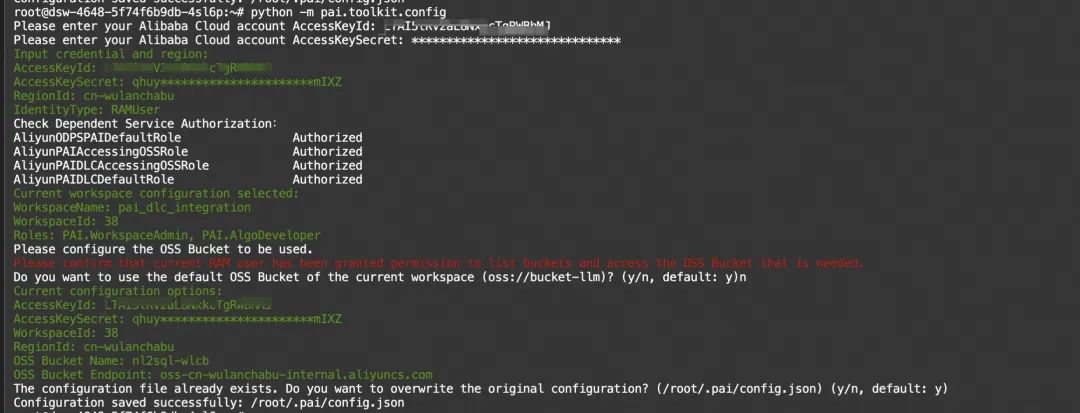
用户首次使用之前需要配置 访问密钥AccessKey (如何创建和获取AccessKey请见文档:创建AccessKey ),使用的 PAI工作空间 ,以及 OSS Bucket 。请在终端上通过以下命令,按照引导逐步完成配置。
请在安装完成后,在命令行终端上执行以下命令,按照引导完成配置
python -m pai.toolkit.config
上传模型至oss
import pai
from pai.session import get_default_sessionprint(pai.__version__)
sess = get_default_session()
from pai.common.oss_utils import upload
# 上传模型
model_uri = upload(source_path='/root/qwen72b_sft', oss_path="qwen72b_sft", bucket=sess.oss_bucket
)
print(model_uri)
使用PAI-BladeLLM部署API服务
配置eas服务config,基于如下的模版进行自定义修改
-
oss.path配置为qwen72b在OSS上的上级目录,如改示例会把oss://example-bucket/挂载至/model
-
metadata.quota_id、metadata.workspace_id根据当前用户的实际情况进行调整,注意确保配置的AK所属用户具备当前工作空间权限
-
blade需要事先对模型进行切分从而节省模型导入时间,若第一次部署服务,切分模型步骤的耗时会较长
config = {"containers": [{"image": "pai-blade-registry.cn-wulanchabu.cr.aliyuncs.com/pai-blade/blade-llm:0.4.0","port": 8081,"script": "[ ! -d \"/model/qwen72b_sft_blade_split_4\" ] && blade_llm_split --world_size 4 --model /model/qwen72b_sft --output_dir /model/qwen72b_sft_blade_split_4;blade_llm_server --model /model/qwen72b_sft_blade_split_4 --attn_cls paged --world_size 4 "}],"metadata": {"cpu": 60,"gpu": 4,"instance": 1,"memory": 256000,"quota_id": "quotaydok5h3tt77","quota_type": "Lingjun","resource_burstable": False,"workspace_id": "38"},"storage": [{"empty_dir": {"medium": "memory","size_limit": 24},"mount_path": "/dev/shm"},{"mount_path": "/model","oss": {"path": "oss://example-bucket/","readOnly": False},"properties": {"resource_type": "model"}}]
}
# service_name可以按需进行修改,同一个region只能存在一个同名服务
from pai.model import Model
m = Model().deploy(service_name = 'qwen72b_sdk_blade_example',options=config)
调用api服务,将Authorization配置为服务token,url填写模型服务路径
import json
import timefrom websockets.sync.client import connectheaders = {"Authorization": "*******"
}
url = 'ws://1612285282502324.cn-wulanchabu.pai-eas.aliyuncs.com/api/predict/qwen72b_sdk_blade_example/generate_stream'prompt = """<|im_start|>system
<|im_end|>
<|im_start|>user
<|im_end|>
Hello! What is your name?<|im_end|>
<|im_start|>assistant
"""
with connect(url, additional_headers=headers) as websocket:websocket.send(json.dumps({"prompt": prompt,"sampling_params": {"temperature": 0.0,"top_p": 0.9,"top_k": 50},"stopping_criterial":{"max_new_tokens": 512,"stop_tokens": [151645, 151644, 151643]}}))tic = time.time()while True:msg = websocket.recv()msg = json.loads(msg)if msg['is_ok']:print(msg['tokens'][0]["text"], end="", flush=True)if msg['is_finished']:breakprint(time.time()-tic)print()print("-" * 40)
在测试完成之后,用户可以在控制台删除服务,也可以通过调用以下命令删除服务.
m.delete_service()
使用fastchat部署webui服务
配置eas服务config,基于如下的模版进行自定义修改
-
oss.path配置为qwen72b在OSS上的目录,如改示例会把oss://example-bucket/qwen72b_sft挂载至/qwen72b
-
metadata.quota_id、metadata.workspace_id根据当前用户的实际情况进行调整,注意确保配置的AK所属用户具备当前工作空间权限
config = {"containers": [{"image": "pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/llm-inference:vllm-0.2.1-v6","port": 7860,"script": "nohup python -m fastchat.serve.controller > tmp1.log 2>&1 & python -m fastchat.serve.gradio_web_server_pai --model-list-mode reload > tmp2.log 2>&1 & python -m fastchat.serve.vllm_worker --model-path /qwen72b --tensor-parallel-size 4 --gpu-memory-utilization 0.98 --trust-remote-code"}],"metadata": {"cpu": 60,"enable_webservice": True,"gpu": 4,"instance": 1,"memory": 256000,"quota_id": "quotaydok5h3tt77","quota_type": "Lingjun","resource_burstable": True,"workspace_id": "38"},"storage": [{"empty_dir": {"medium": "memory","size_limit": 24},"mount_path": "/dev/shm"},{"mount_path": "/qwen72b","oss": {"path": "oss://example-bucket/qwen72b_sft/","readOnly": False},"properties": {"resource_type": "model"}}]
}
# service_name可以按需进行修改,同一个region只能存在一个同名服务
from pai.model import Model
m = Model().deploy(service_name = 'qwen72b_sdk_example',options=config)
在测试完成之后,用户可以在控制台删除服务,也可以通过调用以下命令删除服务.
m.delete_service()
相关文章:
通义千问 Qwen-72B-Chat在PAI-DSW的微调推理实践
01 引言 通义千问-72B(Qwen-72B)是阿里云研发的通义千问大模型系列的720亿参数规模模型。Qwen-72B的预训练数据类型多样、覆盖广泛,包括大量网络文本、专业书籍、代码等。Qwen-72B-Chat是在Qwen-72B的基础上,使用对齐机制打造的…...
web应用体系以及windows网络常见操作应用
本课程目标 1.Dos命令(必须掌握) 2.网络体系(笔试选择填空题) 3.搭建windows测试环境 一、Dos命令 1.DOS窗口启动 启动方式1.进入DOS页面:win+R,键入cmd 启动方式2.开始-运行--输入cmd-回车,此时将出现一个显示命令提示符的窗口,如下图 2、常见的Dos命令: 1、cd…...

FFmpeg 安装配置
FFmpeg 安装配置 依赖包 sudo apt-get install -y autoconf automake bzip2 cmake freetype-devel gcc gcc-c git libtool make mercurial pkgconfig zlib-devel x264-develsudo apt-get install yasm -y安装 wget https://ffmpeg.org/releases/ffmpeg-4.2.3.tar.bz2tar -…...
14:00面试,14:08就出来了,问的问题有点变态。。。。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到5月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...
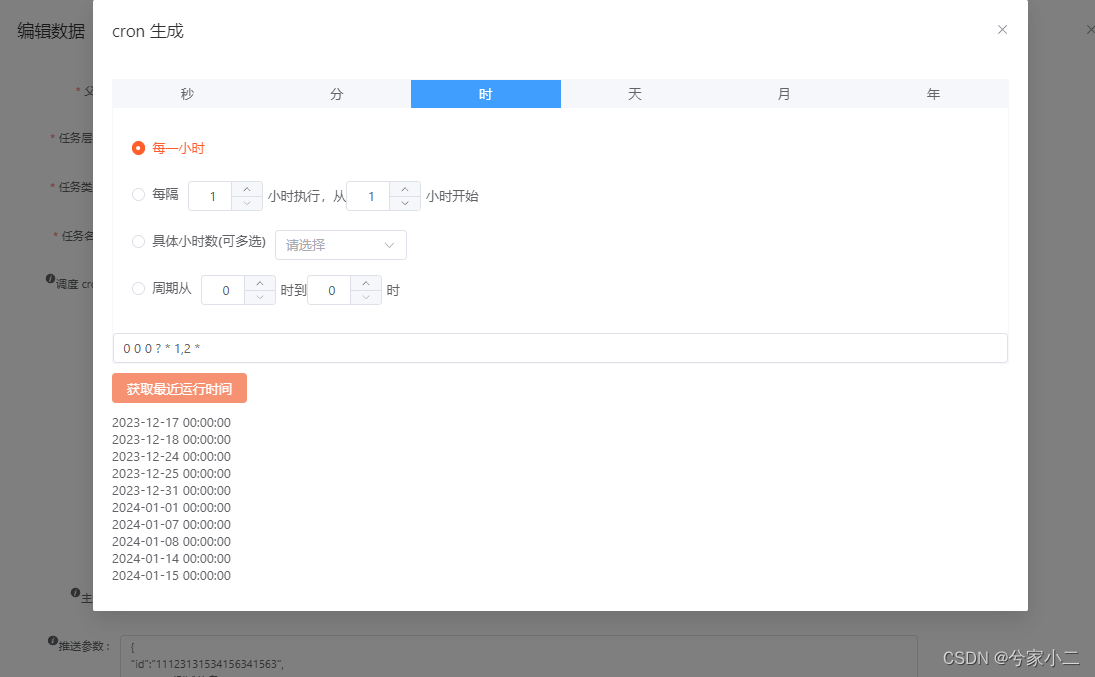
vue3 添加编辑页使用 cron 表达式生成
示例效果图 1、添加组件 <template><div class"v3c"><ul class"v3c-tab"><li class"v3c-tab-item" :class"{ v3c-active: tabActive 1 }" click"onHandleTab(1)">秒</li><li class&qu…...
洛谷P1722 矩阵Ⅱ——卡特兰数
传送门: P1722 矩阵 II - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)https://www.luogu.com.cn/problem/P1722 用不需要除任何数的公式来求。 #define _CRT_SECURE_NO_WARNINGS #include<iostream> #include<cstdio> #include<cmath> #includ…...
Unity | Shader基础知识(第六集:语法<如何加入外部颜色资源>)
目录 一、本节介绍 1 上集回顾 2 本节介绍 二、语法结构 1 复习 2 理论知识 3 Shader里声明的写法 4 Properties和SubShader毕竟不是一家人 三、 片元着色器中使用资源 四、代码实现 五、全部代码 六、下集介绍 相关阅读 Unity - Manual: Writing Surface Shaders…...

使用opencv的Laplacian算子实现图像边缘检测
1 边缘检测介绍 图像边缘检测技术是图像处理和计算机视觉等领域最基本的问题,也是经典的技术难题之一。如何快速、精确地提取图像边缘信息,一直是国内外的研究热点,同时边缘的检测也是图像处理中的一个难题。早期的经典算法包括边缘算子方法…...

5. PyTorch——数据处理模块
1.数据加载 在PyTorch中,数据加载可通过自定义的数据集对象。数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现两个Python魔法方法: __getitem__:返回一条数据,或一个样本。obj[in…...
Android 移动端编译 cityhash动态库
最近做项目, 硬件端 需要 用 cityhash 编译一个 动态库 提供给移动端使用,l 记录一下 编译过程 city .cpp // // Created by Administrator on 2023/12/12. // // Copyright (c) 2011 Google, Inc. // // Permission is hereby granted, free of charg…...
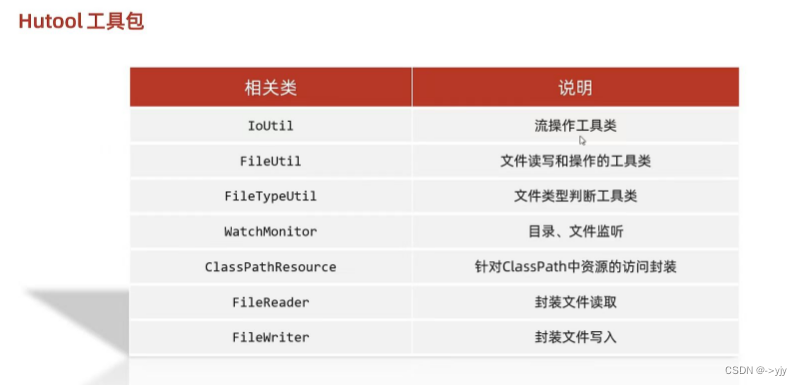
IO流学习
IO流:存储和读取数据的解决方案 import java.io.FileOutputStream; import java.io.IOException;public class Test {public static void main(String[] args) throws IOException {//1.创建对象//写出 输入流 OutputStream//本地文件fileFileOutputStream fos new FileOutputS…...

新手HTML和CSS的常见知识点
目录 1.HTML标题标签(到)用于定义网页中的标题,并按照重要性递减排列。例如: 2.HTML段落标签()用于定义网页中的段落。例如: 3.HTML链接标签()用于创建链接…...

RocketMQ系统性学习-RocketMQ领域模型及Linux下单机安装
MQ 之间的对比 三种常用的 MQ 对比,ActiveMQ、Kafka、RocketMQ 性能方面: 三种 MQ 吞吐量级别为:万,百万,十万消息发送时延:毫秒,毫秒,微秒可用性:主从,分…...
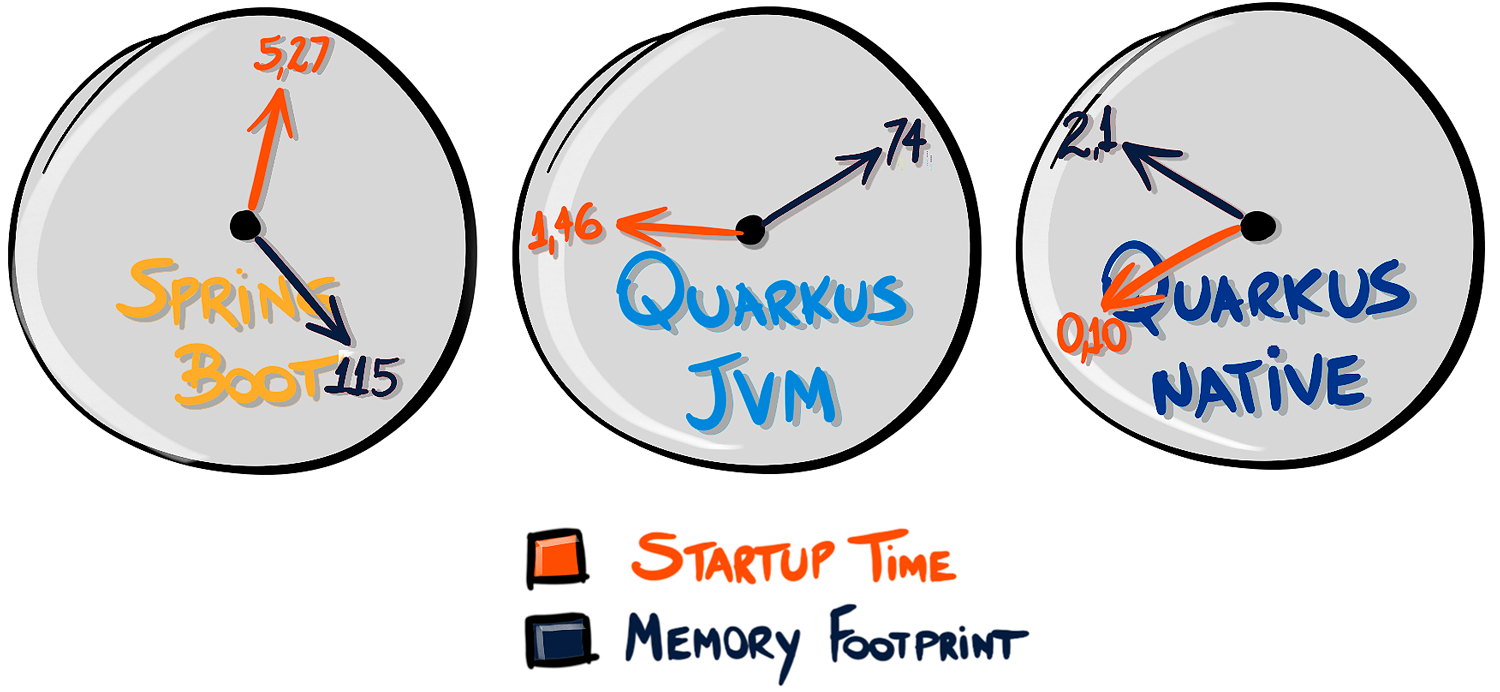
微服务架构之争:Quarkus VS Spring Boot
在容器时代(“Docker时代”),无论如何,Java仍然活着。Java在性能方面一直很有名,主要是因为代码和真实机器之间的抽象层,多平台的成本(一次编写,随处运行——还记得吗?&a…...
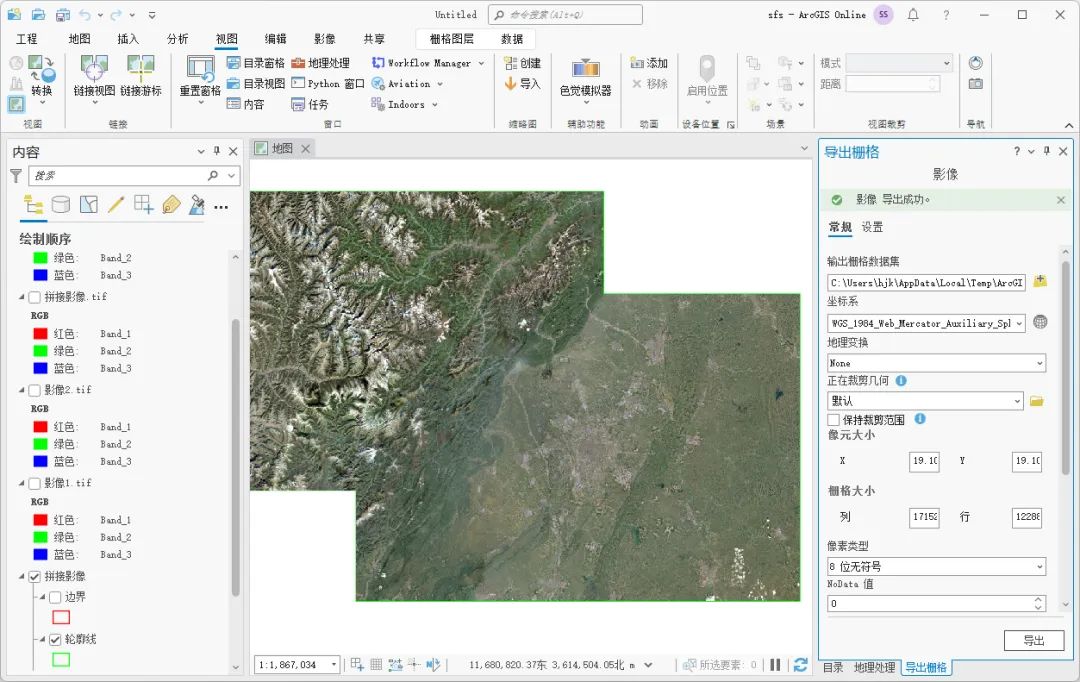
如何使用ArcGIS Pro拼接影像
为了方便数据的存储和传输,我们在网上获取到的影像一般都是分块的,正式使用之前需要对这些影像进行拼接,这里为大家介绍一下ArcGIS Pro中拼接影像的方法,希望能对你有所帮助。 数据来源 本教程所使用的数据是从水经微图中下载的…...
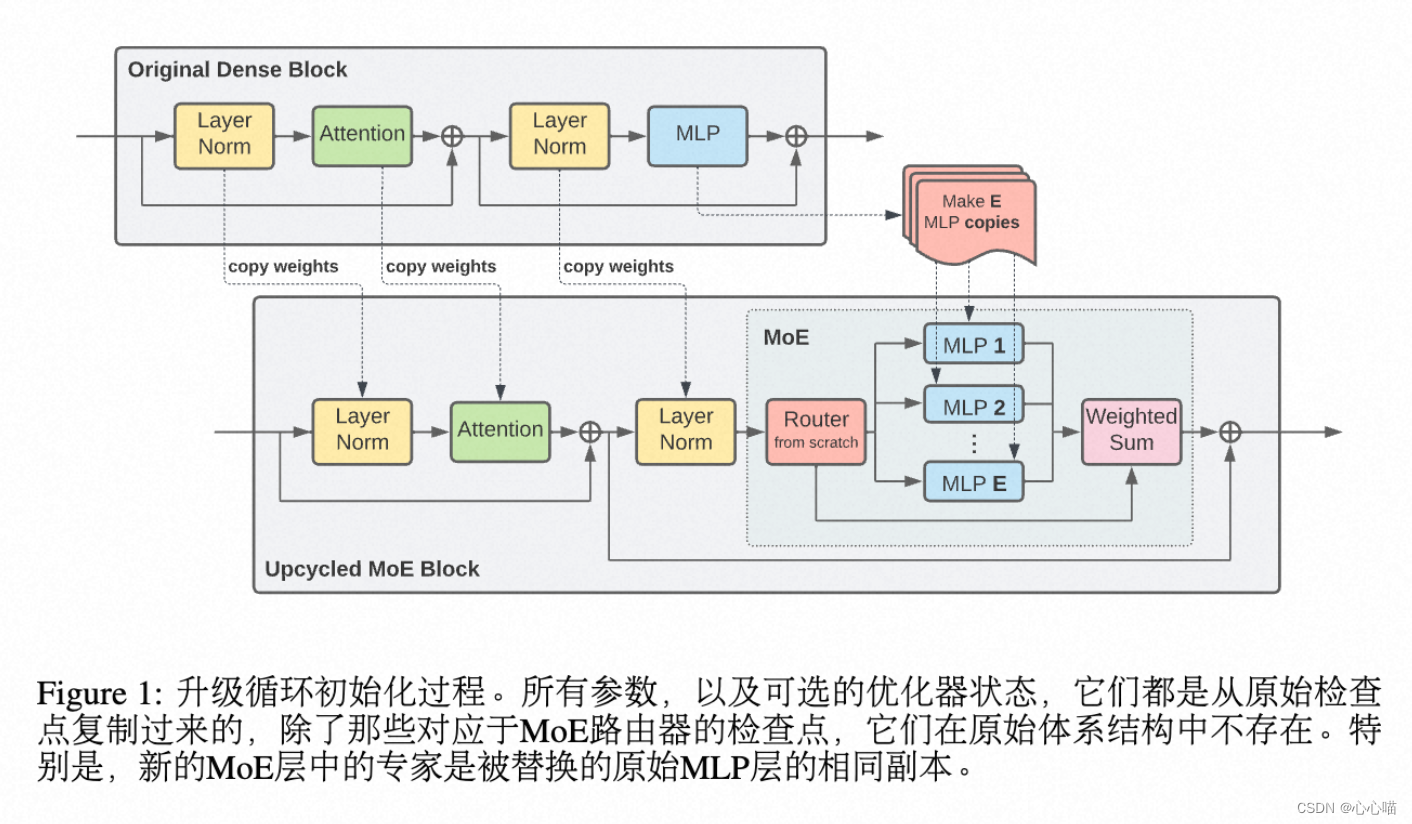
[论文笔记] chatgpt系列 SparseMOE—GPT4的MOE结构
SparseMOE: 稀疏激活的MOE Swtich MOE,所有token要在K个专家网络中,选择一个专家网络。 显存增加。 Experts Choice:路由MOE: 由专家选择token。这样不同的专家都选择到某个token,也可以不选择该token。 由于FFN层的时间复杂度和attention层不同,FFN层的时…...
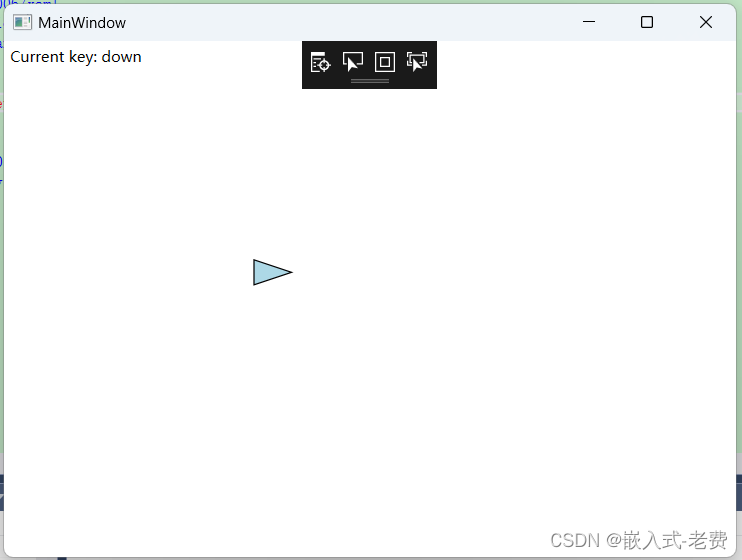
C# WPF上位机开发(键盘绘图控制)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 在软件开发中,如果存在canvas图像的话,一般有几种控制方法。一种是鼠标控制;一种是键盘控制;还有一…...
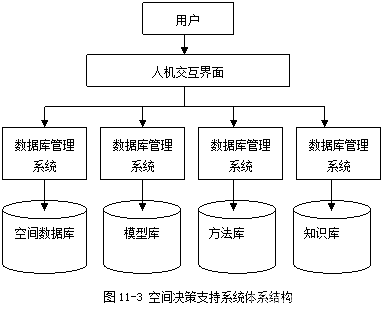
《地理信息系统原理》笔记/期末复习资料(10. 空间数据挖掘与空间决策支持系统)
目录 10. 空间数据挖掘与空间决策支持系统 10.1. 空间数据挖掘 10.1.1. 空间数据挖掘的概念 10.1.2. 空间数据挖掘的方法与过程 10.1.3. 空间数据挖掘的应用 10.2. 空间决策支持系统 10.2.1. 空间决策支持系统的概念 10.2.2. 空间决策支持系统的结构 10.2.3. 空间决策…...
uniapp播放 m3u8格式视频 兼容pc和移动端
支持全自动播放、设置参数 自己摸索出来的,花了一天时间,给点订阅支持下,订阅后,不懂的地方可以私聊我。 代码实现 代码实现 1.安装dplayer组件 npm i dplayer2. static/index.html下引入 hls 引入hls.min.js 可以存放在static项目hls下面<script src="/static…...
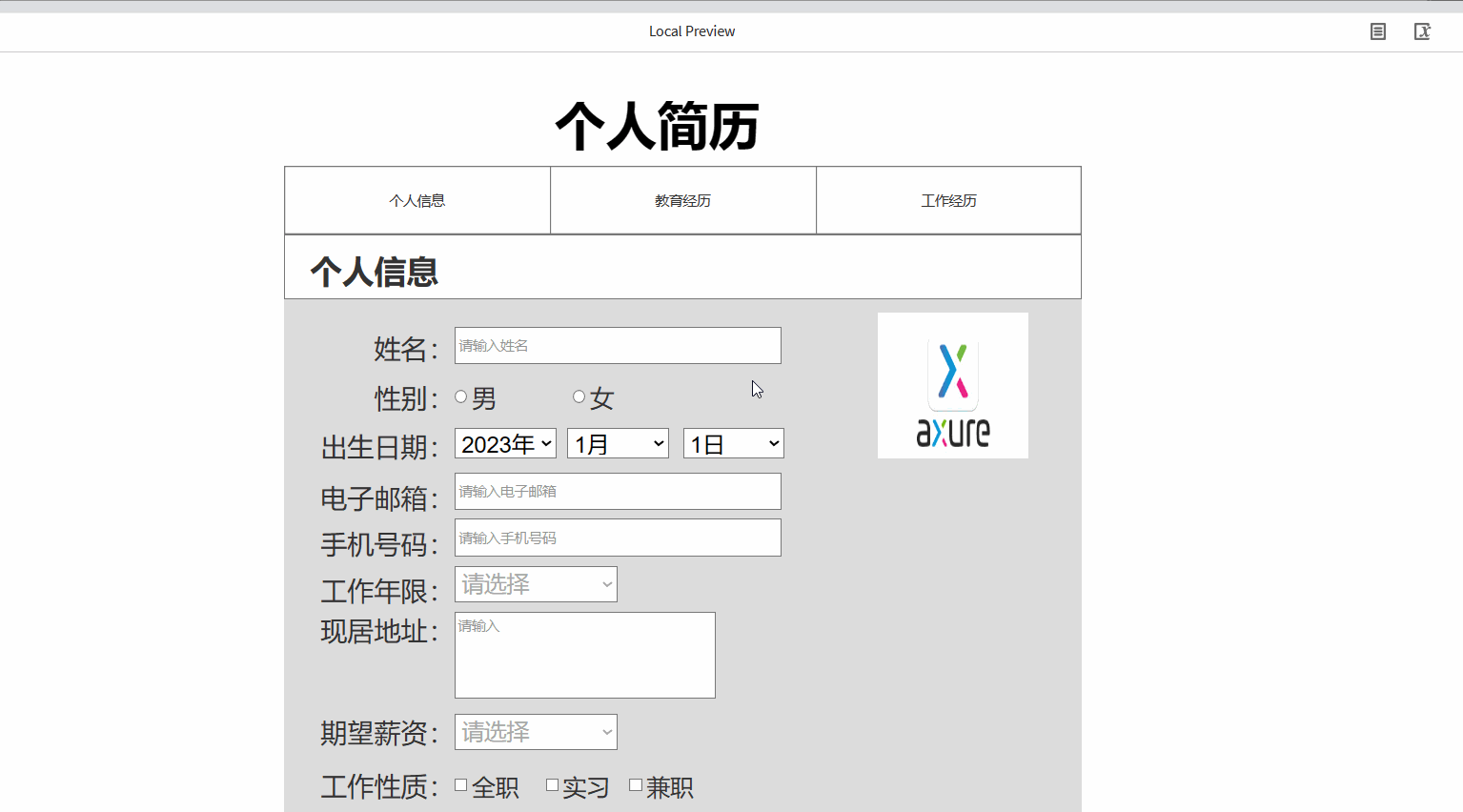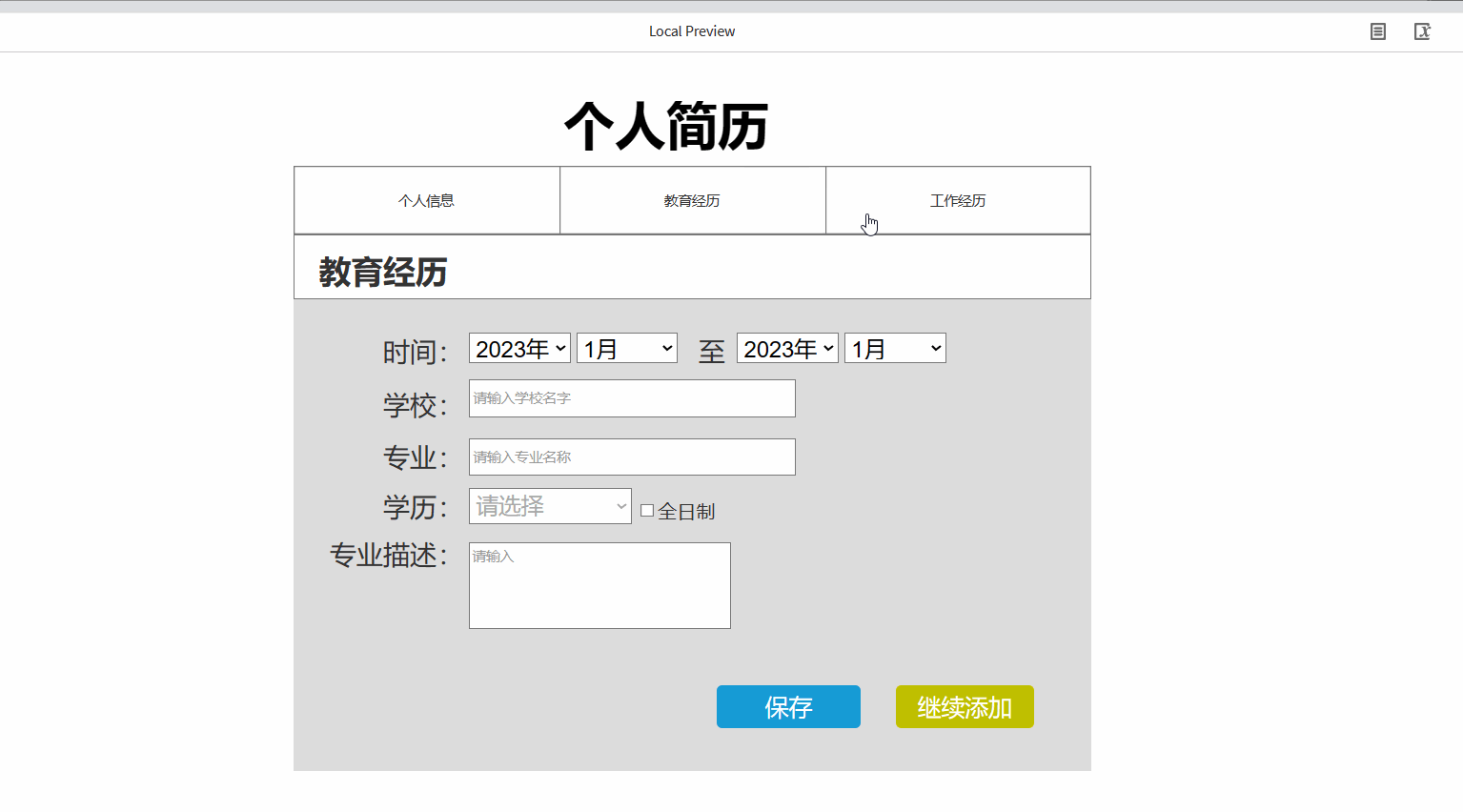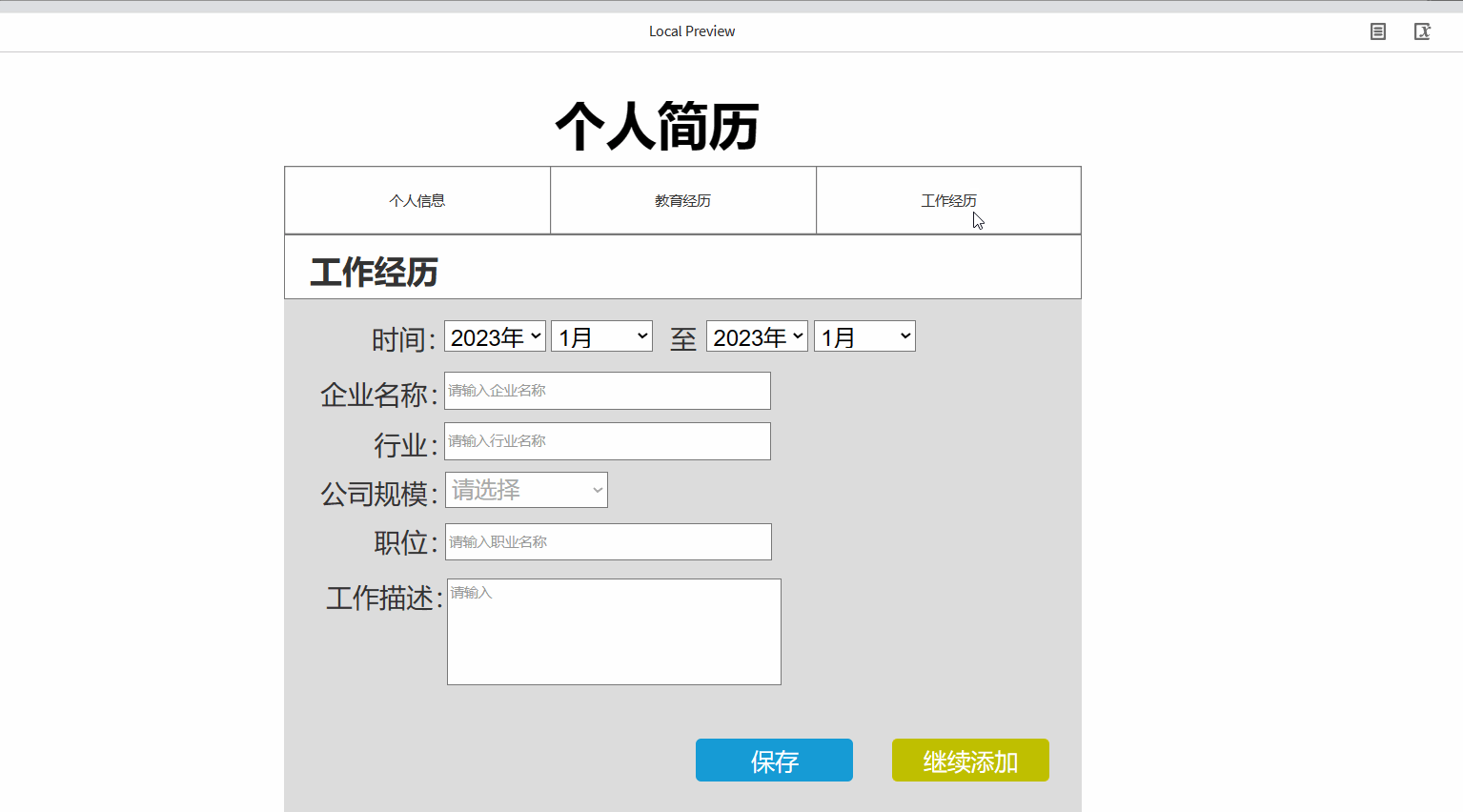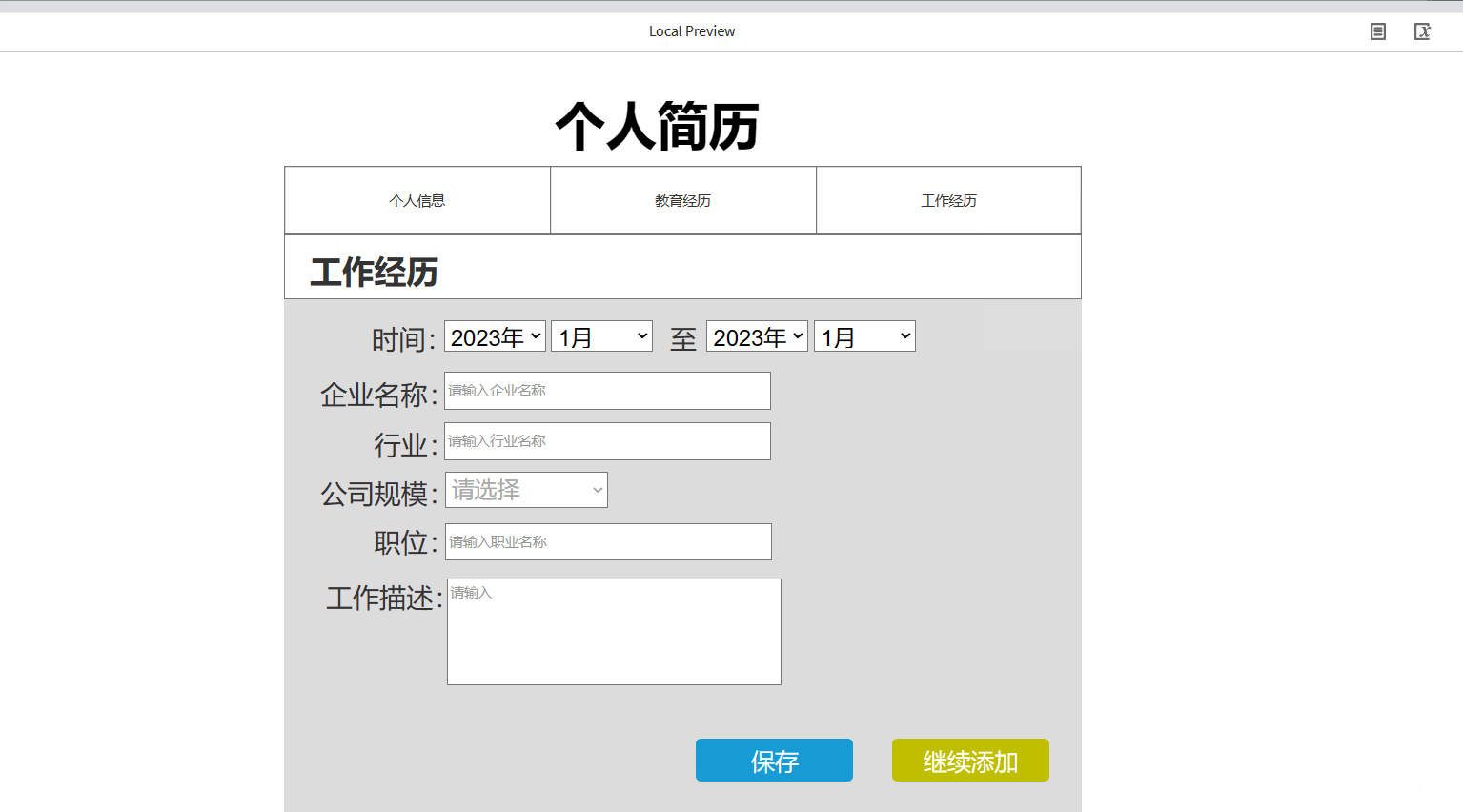
产品经理之Axure的元件库使用详细案例
⭐⭐ 产品经理专栏:产品专栏 ⭐⭐ 个人主页:个人主页 目录 前言 一.Axure的元件库的使用 1.1 元件介绍 1.2 基本元件的使用 1.2.1 矩形、按钮、标题的使用 1.2.2 图片及热区的使用 1.3 表单元件及表格元件的使用 1.3.1表单元件的使用 1.3.…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...
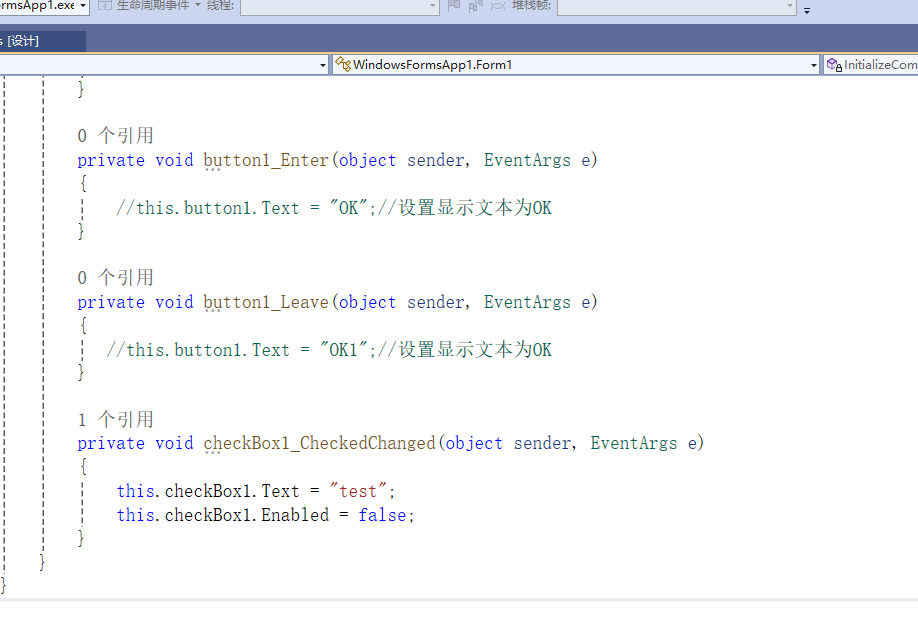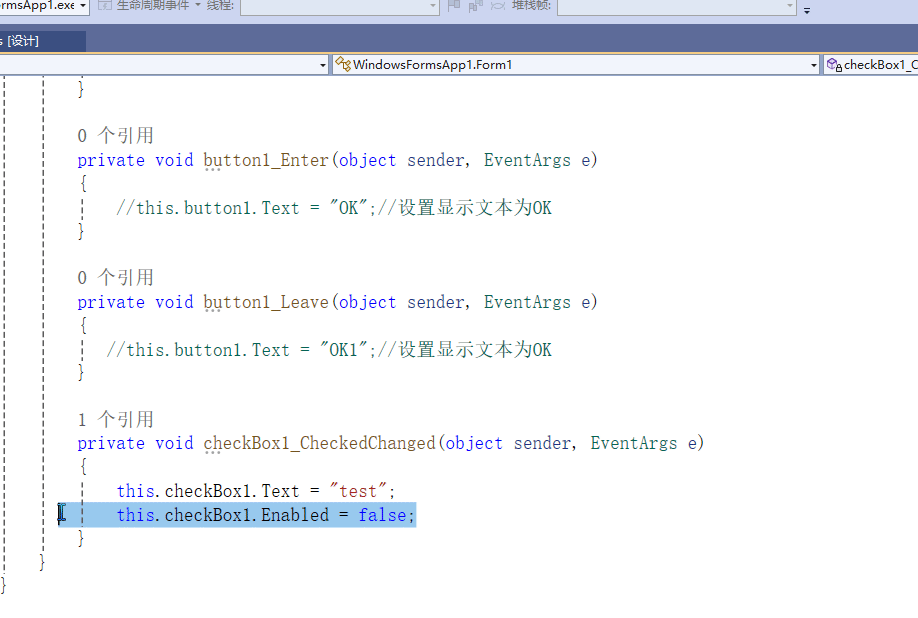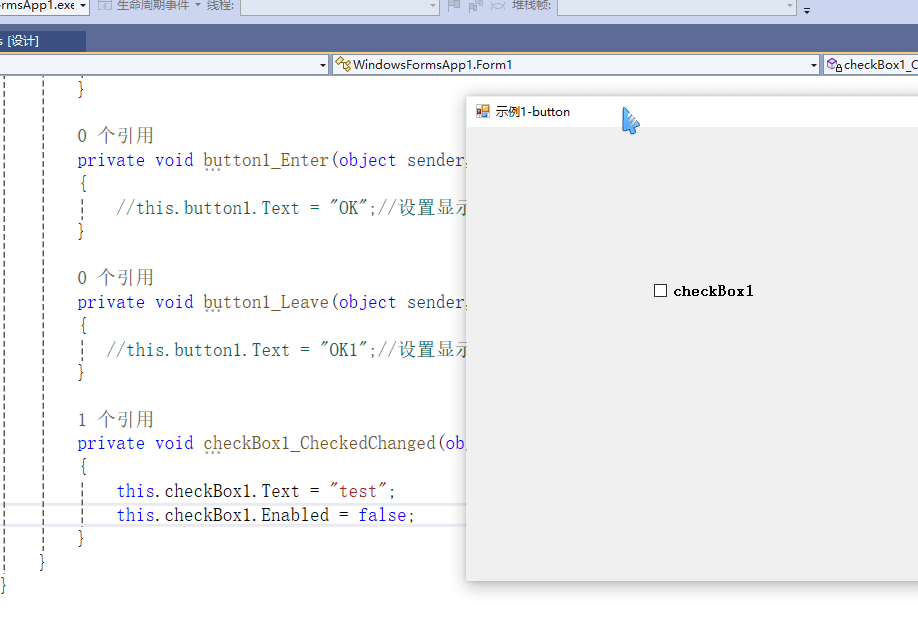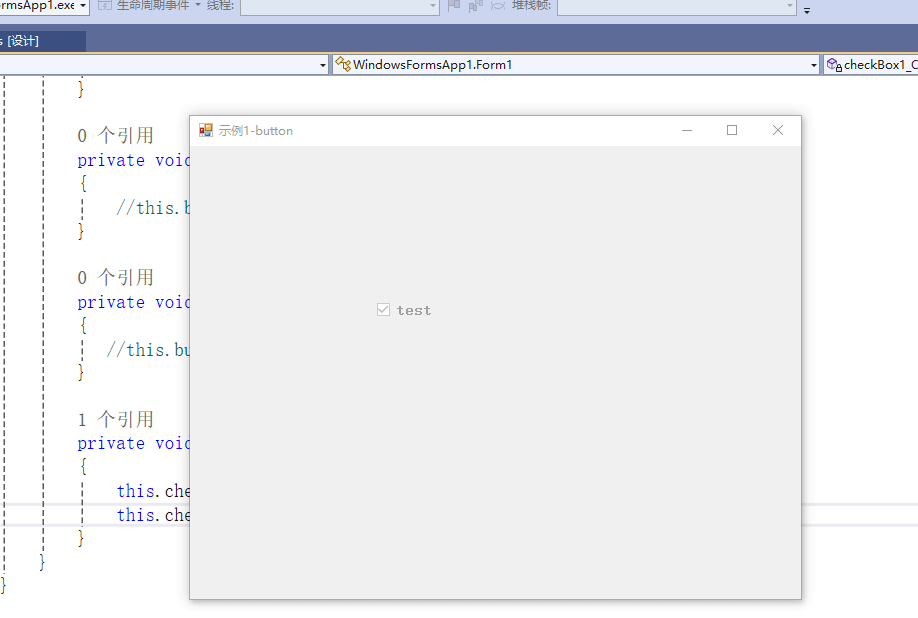
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...
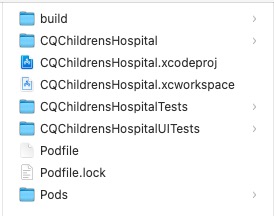
Xcode 16 集成 cocoapods 报错
基于 Xcode 16 新建工程项目,集成 cocoapods 执行 pod init 报错 ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchro…...
:电商转化率优化与网站性能的底层逻辑)
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑 在电子商务领域,转化率与网站性能是决定商业成败的核心指标。今天,我们将深入解析不同类型电商平台的转化率基准,探讨页面加载速度对用户行为的…...
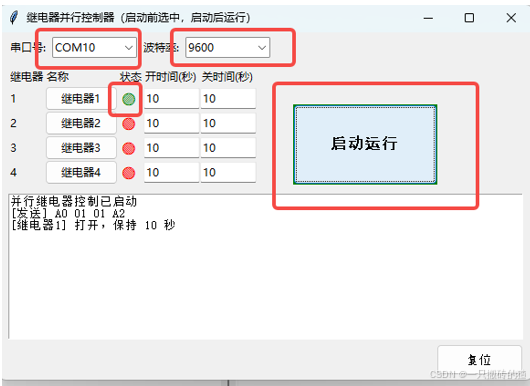
使用ch340继电器完成随机断电测试
前言 如图所示是市面上常见的OTA压测继电器,通过ch340串口模块完成对继电器的分路控制,这里我编写了一个脚本方便对4路继电器的控制,可以设置开启时间,关闭时间,复位等功能 软件界面 在设备管理器查看串口号后&…...