【数据库设计和SQL基础语法】--查询数据--聚合函数
一、聚合函数概述
1.1 定义
聚合函数是一类在数据库中用于对多个行进行计算并返回单个结果的函数。它们能够对数据进行汇总、统计和计算,常用于提取有关数据集的摘要信息。聚合函数在 SQL 查询中广泛应用,包括统计总数、平均值、最大值、最小值等。
1.2 作用
- 对数据集进行汇总和摘要,提供更简洁的信息。
- 支持统计分析,如计算平均值、总和、最大值和最小值等。
- 用于处理大量数据,从而提高查询效率。
1.3 常见聚合函数
常见的聚合函数包括:
- COUNT:计算行数。
- SUM:计算数值列的总和。
- AVG:计算数值列的平均值。
- MIN:找出数值列的最小值。
- MAX:找出数值列的最大值。
二、基本聚合函数
2.1 COUNT
-
基本用法
COUNT 函数用于计算查询结果集中行的数量。以下是 COUNT 函数的基本用法:SELECT COUNT(column_name) AS row_count FROM your_table_name;column_name:指定要计算行数的列名或使用*表示所有列。row_count:作为结果返回的行数。
-
示例
-
计算表中所有行的数量:
SELECT COUNT(*) AS total_rows FROM orders; -
计算特定条件下的行数:
SELECT COUNT(*) AS active_users FROM users WHERE status = 'active'; -
结合其他列进行计数:
SELECT COUNT(DISTINCT department_id) AS unique_departments FROM employees;
-
-
特殊情况
-
使用 COUNT(*) 计算所有行的数量,包括包含 NULL 值的行:
SELECT COUNT(*) AS total_rows FROM your_table_name; -
使用 COUNT(column_name) 计算特定列中非 NULL 值的数量:
SELECT COUNT(email) AS non_null_emails FROM employees;
-
-
注意事项
- COUNT 函数通常与 GROUP BY 子句结合使用,用于进行分组计数。
- COUNT 函数返回的是整数,表示满足条件的行数。
- 注意处理 NULL 值,使用 COUNT(*) 可以包括 NULL 值,而 COUNT(column_name) 会排除 NULL 值。
COUNT 函数是 SQL 中常用的聚合函数之一,用于快速计算行数。在数据统计和分析中具有广泛应用,通过不同的参数和条件组合,可以灵活地满足各种统计需求。
2.2 SUM
-
基本用法
SUM 函数用于计算查询结果集中某列的数值总和。以下是 SUM 函数的基本用法:SELECT SUM(column_name) AS total_sum FROM your_table_name;column_name:指定要计算总和的列名。
-
示例
-
计算订单总金额:
SELECT SUM(total_amount) AS total_order_amount FROM orders; -
计算销售额达到特定条件的产品总和:
SELECT SUM(sales) AS total_sales FROM products WHERE category = 'Electronics'; -
结合其他列进行总和计算:
SELECT department_id, SUM(salary) AS total_salary FROM employees GROUP BY department_id;
-
-
特殊情况
-
使用 SUM(column_name) 计算特定列中数值的总和:
SELECT SUM(quantity) AS total_quantity FROM order_details; -
处理包含 NULL 值的列,使用 IFNULL 或 COALESCE 避免影响总和计算。
-
-
注意事项
- SUM 函数通常与 GROUP BY 子句结合使用,用于对不同组的数据进行总和计算。
- 结果是一个数值,表示满足条件的列值的总和。
SUM 函数是 SQL 中用于计算数值总和的重要聚合函数。通过对指定列应用 SUM 函数,可以快速获取数据列的总和,对于统计和分析数值型数据非常有用。
2.3 AVG
-
基本用法
AVG 函数用于计算查询结果集中某列的数值平均值。以下是 AVG 函数的基本用法:SELECT AVG(column_name) AS average_value FROM your_table_name;column_name:指定要计算平均值的列名。
-
示例
-
计算员工薪水的平均值:
SELECT AVG(salary) AS average_salary FROM employees; -
计算特定产品价格的平均值:
SELECT AVG(price) AS average_price FROM products WHERE category = 'Electronics'; -
结合其他列进行平均值计算:
SELECT department_id, AVG(salary) AS average_salary FROM employees GROUP BY department_id;
- 特殊情况
-
使用 AVG(column_name) 计算特定列中数值的平均值:
SELECT AVG(quantity) AS average_quantity FROM order_details; -
处理包含 NULL 值的列,使用 IFNULL 或 COALESCE 避免影响平均值计算。
-
-
注意事项
- AVG 函数通常与 GROUP BY 子句结合使用,用于对不同组的数据进行平均值计算。
- 结果是一个数值,表示满足条件的列值的平均值。
AVG 函数是 SQL 中用于计算数值平均值的重要聚合函数。通过对指定列应用 AVG 函数,可以轻松获取数据列的平均值,对于统计和分析数值型数据非常有用。
2.4 MIN
-
基本用法
MIN 函数用于计算查询结果集中某列的最小值。以下是 MIN 函数的基本用法:SELECT MIN(column_name) AS min_value FROM your_table_name;column_name:指定要计算最小值的列名。
-
示例
-
计算产品价格的最小值:
SELECT MIN(price) AS min_price FROM products; -
计算不同部门中员工薪水的最小值:
SELECT department_id, MIN(salary) AS min_salary FROM employees GROUP BY department_id;
-
-
特殊情况
-
使用 MIN(column_name) 计算特定列中数值的最小值:
SELECT MIN(quantity) AS min_quantity FROM order_details; -
处理包含 NULL 值的列,使用 IFNULL 或 COALESCE 避免影响最小值计算。
-
-
注意事项
- MIN 函数通常与 GROUP BY 子句结合使用,用于对不同组的数据计算最小值。
- 结果是一个数值,表示满足条件的列值的最小值。
MIN 函数是 SQL 中用于计算最小值的关键聚合函数。通过对指定列应用 MIN 函数,可以轻松获取数据列的最小值,对于数据分析和比较的场景非常有帮助。
2.5 MAX
-
基本用法
MAX 函数用于计算查询结果集中某列的最大值。以下是 MAX 函数的基本用法:SELECT MAX(column_name) AS max_value FROM your_table_name;column_name:指定要计算最大值的列名。
-
示例
-
计算产品价格的最大值:
SELECT MAX(price) AS max_price FROM products; -
计算不同部门中员工薪水的最大值:
SELECT department_id, MAX(salary) AS max_salary FROM employees GROUP BY department_id;
-
-
特殊情况
-
使用 MAX(column_name) 计算特定列中数值的最大值:
SELECT MAX(quantity) AS max_quantity FROM order_details; -
处理包含 NULL 值的列,使用 IFNULL 或 COALESCE 避免影响最大值计算。
-
-
注意事项
- MAX 函数通常与 GROUP BY 子句结合使用,用于对不同组的数据计算最大值。
- 结果是一个数值,表示满足条件的列值的最大值。
MAX 函数是 SQL 中用于计算最大值的关键聚合函数。通过对指定列应用 MAX 函数,可以轻松获取数据列的最大值,对于数据分析和比较的场景非常有帮助。
三、GROUP BY 子句
3.1 分组数据
-
基本概念
GROUP BY 子句用于将查询结果集按照一个或多个列进行分组,以便对每个组应用聚合函数。基本语法如下:SELECT column1, column2, ..., aggregate_function(column) FROM your_table_name GROUP BY column1, column2, ...; -
用法示例
-
按部门分组计算平均工资:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id; -
统计每个产品类别的销售总额:
SELECT category, SUM(total_amount) AS total_sales FROM orders GROUP BY category;
-
-
聚合函数与 GROUP BY
- 在 GROUP BY 子句中使用聚合函数,对每个分组进行计算。
- 常用聚合函数:COUNT、SUM、AVG、MIN、MAX 等。
-
过滤分组
- 使用 HAVING 子句对分组结果进行过滤。
- 例如,筛选出平均工资高于 50000 的部门:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id HAVING AVG(salary) > 50000;
-
注意事项
- GROUP BY 子句中的列通常包括选择列表中的列和聚合函数。
- 聚合函数计算的结果列别名可用于提高结果的可读性。
GROUP BY 子句是 SQL 中用于分组数据并应用聚合函数的关键元素。通过将查询结果分组,可以对每个组进行统计、计算,提供更详细的汇总信息,适用于数据分析和报告生成。
3.2 聚合函数与 GROUP BY 结合使用
在 SQL 中,聚合函数与 GROUP BY 子句结合使用,用于对数据进行分组并对每个分组应用聚合函数,从而得到按组计算的结果。
-
基本语法
SELECT column1, column2, ..., aggregate_function(column) FROM your_table_name GROUP BY column1, column2, ...; -
用法示例
-
计算每个部门的平均工资:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id; -
统计每个产品类别的销售总额:
SELECT category, SUM(total_amount) AS total_sales FROM orders GROUP BY category;
-
-
聚合函数与 GROUP BY 的作用
- COUNT: 统计每个分组中的行数。
- SUM: 计算每个分组中某列的总和。
- AVG: 计算每个分组中某列的平均值。
- MIN: 找出每个分组中某列的最小值。
- MAX: 找出每个分组中某列的最大值。
-
过滤分组
- 使用 HAVING 子句对分组结果进行过滤。
- 例如,筛选出平均工资高于 50000 的部门:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id HAVING AVG(salary) > 50000;
-
注意事项
- GROUP BY 子句中的列通常包括选择列表中的列和聚合函数。
- 聚合函数计算的结果列别名可用于提高结果的可读性。
聚合函数与 GROUP BY 结合使用是 SQL 中强大的数据分析工具,通过分组和计算,可以从大量数据中提取出有价值的统计信息,适用于各种数据分析和报告生成场景。
四、高级聚合函数
4.1 GROUP_CONCAT
GROUP_CONCAT 是一种聚合函数,用于将每个分组中的字符串值合并为一个字符串,并可选地使用分隔符分隔各个值。
-
基本语法
SELECT column1, GROUP_CONCAT(column2 SEPARATOR ',') AS concatenated_values FROM your_table_name GROUP BY column1; -
用法示例
-
合并每个部门的员工名字:
SELECT department_id, GROUP_CONCAT(employee_name SEPARATOR ', ') AS employee_names FROM employees GROUP BY department_id; -
以逗号分隔合并产品类别:
SELECT order_id, GROUP_CONCAT(category SEPARATOR ',') AS categories FROM order_details GROUP BY order_id;
-
-
参数说明
- column2: 要合并的列。
- SEPARATOR: 可选参数,用于指定合并结果中值之间的分隔符,默认为逗号。
-
注意事项
GROUP_CONCAT通常用于合并文本数据,适用于需要将组内多个值合并为一个字符串的情况。
GROUP_CONCAT 函数是 SQL 中用于合并字符串的强大工具,特别适用于需要在分组级别对文本数据进行合并的场景。通过指定适当的分隔符,可以获得清晰可读的合并结果。
4.2 CONCAT_WS
CONCAT_WS 是一种字符串函数,用于将多个字符串连接在一起,并使用指定的分隔符分隔它们。
-
基本语法
SELECT CONCAT_WS(separator, str1, str2, ..., strN) AS concatenated_string; -
用法示例
-
合并姓名并使用空格分隔:
SELECT CONCAT_WS(' ', first_name, last_name) AS full_name FROM employees; -
合并产品名称和价格,并使用逗号分隔:
SELECT CONCAT_WS(', ', product_name, price) AS product_info FROM products;
-
-
参数说明
- separator: 用于分隔各个字符串的分隔符。
- str1, str2, …, strN: 要连接的字符串。
-
注意事项
CONCAT_WS中的第一个参数是分隔符,之后是要连接的字符串,可以是列、常量或表达式。
CONCAT_WS 函数是 SQL 中一个方便的工具,特别适用于需要将多个字符串连接在一起并使用指定分隔符进行分隔的场景。通过灵活使用分隔符,可以生成符合特定格式要求的字符串。
4.3 GROUPING SETS
GROUPING SETS:多组聚合数据
GROUPING SETS 是 SQL 中用于对多个列进行分组的扩展语法,允许同时按照多个列对数据进行聚合。
-
基本语法
SELECT column1, column2, ..., aggregate_function(column) FROM your_table_name GROUP BY GROUPING SETS ((column1, column2, ...), (column1), ()); -
用法示例
-
按照不同列进行分组求和:
SELECT department, city, SUM(sales) AS total_sales FROM sales_data GROUP BY GROUPING SETS ((department, city), (department), ()); -
按照多列进行分组计数:
SELECT country, region, city, COUNT(employee_id) AS employee_count FROM employees GROUP BY GROUPING SETS ((country, region, city), (country, region), (country), ());
-
-
参数说明
- column1, column2, …: 用于分组的列。
- aggregate_function(column): 对分组后的数据进行聚合的函数,如 SUM、COUNT、AVG 等。
- GROUP BY GROUPING SETS: 关键字,指定多组分组的语法。
-
注意事项
GROUPING SETS允许对多个列进行不同层次的分组,可以在一个查询中实现多个不同维度的聚合。
GROUPING SETS 是 SQL 中强大的聚合功能,通过一次查询实现多个不同层次的分组。它提供了更灵活的数据聚合选项,适用于需要在多个维度上进行统计和分析的场景。
4.4 ROLLUP
ROLLUP 是 SQL 中用于实现层次性聚合的语法,它生成分组集的层次结构,逐级递减。
-
基本语法
SELECT column1, column2, ..., aggregate_function(column) FROM your_table_name GROUP BY ROLLUP (column1, column2, ...); -
用法示例
-
按照多列进行层次性聚合求和:
SELECT year, quarter, month, SUM(revenue) AS total_revenue FROM sales_data GROUP BY ROLLUP (year, quarter, month); -
按照不同层次进行计数:
SELECT country, region, city, COUNT(employee_id) AS employee_count FROM employees GROUP BY ROLLUP (country, region, city);
-
-
参数说明
- column1, column2, …: 用于层次性分组的列。
- aggregate_function(column): 对分组后的数据进行聚合的函数,如 SUM、COUNT、AVG 等。
- GROUP BY ROLLUP: 关键字,指定层次性分组的语法。
-
注意事项
ROLLUP生成的结果包含原始列的层次性总计,从最详细的层次逐级递减。
ROLLUP 是 SQL 中用于实现层次性聚合的强大工具,通过一次查询生成多层次的分组总计。它对于需要在不同层次上进行汇总统计的场景非常有用,提供了更高层次的数据摘要。
4.5 CUBE
CUBE: 多维聚合
CUBE 是 SQL 中用于实现多维聚合的语法,它生成所有可能的组合,形成一个多维的汇总。
-
基本语法
SELECT column1, column2, ..., aggregate_function(column) FROM your_table_name GROUP BY CUBE (column1, column2, ...); -
用法示例
-
按照多列进行多维聚合求和:
SELECT year, quarter, month, SUM(revenue) AS total_revenue FROM sales_data GROUP BY CUBE (year, quarter, month); -
按照不同维度进行计数:
SELECT country, region, city, COUNT(employee_id) AS employee_count FROM employees GROUP BY CUBE (country, region, city);
-
-
参数说明
- column1, column2, …: 用于多维分组的列。
- aggregate_function(column): 对分组后的数据进行聚合的函数,如 SUM、COUNT、AVG 等。
- GROUP BY CUBE: 关键字,指定多维分组的语法。
-
注意事项
CUBE生成的结果包含原始列的所有可能组合,形成一个多维的汇总。
CUBE 是 SQL 中用于实现多维聚合的强大工具,通过一次查询生成所有可能的组合,形成一个多维的汇总。它对于需要在不同维度上进行全面统计的场景非常有用,提供了更全面的数据摘要。
五、窗口函数
5.1 OVER 子句
OVER 子句是 SQL 中用于配合窗口函数使用的关键字,它定义了窗口函数执行的窗口范围,允许对查询结果的特定窗口进行计算。
-
基本语法
SELECT column1, column2, ..., window_function(column) OVER (PARTITION BY partition_column ORDER BY order_column ROWS BETWEEN start AND end) FROM your_table_name; -
用法示例
-
计算每个部门的平均工资,并显示每个员工相对于部门的工资排名:
SELECT employee_id, department_id, salary, AVG(salary) OVER (PARTITION BY department_id) AS avg_salary, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS salary_rank FROM employees; -
计算每个月销售额,同时显示累计销售额:
SELECT order_date, sales_amount, SUM(sales_amount) OVER (ORDER BY order_date) AS cumulative_sales FROM sales_data;
-
-
参数说明
- PARTITION BY partition_column: 按照指定列进行分区,窗口函数在每个分区内独立计算。
- ORDER BY order_column: 按照指定列进行排序,定义窗口函数计算的顺序。
- ROWS BETWEEN start AND end: 指定窗口的行范围,可以是 UNBOUNDED PRECEDING、CURRENT ROW、或数字范围。
-
注意事项
OVER子句需要与窗口函数一起使用,常见的窗口函数有SUM()、AVG()、RANK()等。- 可以同时使用
PARTITION BY和ORDER BY进行更精确的窗口范围定义。
OVER 子句是 SQL 中用于配合窗口函数进行灵活计算的关键字,通过指定分区、排序和行范围,可以对查询结果的特定窗口进行精确的聚合和分析。
5.2 ROW_NUMBER()
ROW_NUMBER() 函数
ROW_NUMBER() 是 SQL 中的窗口函数,用于为结果集中的行分配一个唯一的行号。它通常与 OVER 子句结合使用,提供了按指定顺序为每行分配序号的功能。
-
基本语法
SELECT column1, column2, ..., ROW_NUMBER() OVER (PARTITION BY partition_column ORDER BY order_column) AS row_numFROM your_table_name; -
用法示例
-
为每个部门的员工按工资降序分配排名:
SELECT employee_id, department_id, salary, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank_in_department FROM employees; -
为销售数据按日期升序分配序号:
SELECT order_date, sales_amount, ROW_NUMBER() OVER (ORDER BY order_date) AS row_num FROM sales_data;
-
-
参数说明
- PARTITION BY partition_column: 按照指定列进行分区,为每个分区内的行分配行号。
- ORDER BY order_column: 按照指定列进行排序,定义行号的顺序。
-
注意事项
ROW_NUMBER()生成的行号是唯一的、不连续的整数。- 可以使用
PARTITION BY指定分区,行号将在每个分区内独立计算。
ROW_NUMBER() 是一个强大的窗口函数,为查询结果中的行分配唯一的行号,常用于需要为结果集中的行进行排序或排名的场景。
5.3 RANK()
RANK() 是 SQL 中的窗口函数,用于为结果集中的行分配一个排名。它与 ROW_NUMBER() 类似,但具有更强的排名功能,能处理并列情况。
-
基本语法
SELECT column1, column2, ..., RANK() OVER (PARTITION BY partition_column ORDER BY order_column) AS ranking FROM your_table_name; -
用法示例
-
为每个部门的员工按工资降序分配排名:
SELECT employee_id, department_id, salary, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS ranking_in_department FROM employees; -
为销售数据按销售额降序分配排名:
SELECT order_date, sales_amount, RANK() OVER (ORDER BY sales_amount DESC) AS sales_rank FROM sales_data;
-
-
参数说明
- PARTITION BY partition_column: 按照指定列进行分区,为每个分区内的行分配排名。
- ORDER BY order_column: 按照指定列进行排序,定义排名的顺序。
-
注意事项
RANK()生成的排名在并列情况下会跳过重复的排名,下一个排名将按照跳过的数量递增。- 可以使用
PARTITION BY指定分区,排名将在每个分区内独立计算。
RANK() 是一个强大的窗口函数,为查询结果中的行分配排名,特别适用于需要处理并列情况的场景。
5.4 DENSE_RANK()
DENSE_RANK() 函数
DENSE_RANK() 是 SQL 中的窗口函数,类似于 RANK(),用于为结果集中的行分配一个密集排名。与 RANK() 不同,DENSE_RANK() 不会跳过重复的排名,因此在并列情况下排名是连续的。
-
基本语法
SELECT column1, column2, ..., DENSE_RANK() OVER (PARTITION BY partition_column ORDER BY order_column) AS dense_ranking FROM your_table_name; -
用法示例
-
为每个部门的员工按工资降序分配密集排名:
SELECT employee_id, department_id, salary, DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dense_rank_in_department FROM employees; -
为销售数据按销售额降序分配密集排名:
SELECT order_date, sales_amount, DENSE_RANK() OVER (ORDER BY sales_amount DESC) AS dense_sales_rank FROM sales_data;
-
-
参数说明
- PARTITION BY partition_column: 按照指定列进行分区,为每个分区内的行分配密集排名。
- ORDER BY order_column: 按照指定列进行排序,定义密集排名的顺序。
-
注意事项
DENSE_RANK()生成的密集排名在并列情况下是连续的,不会跳过重复的排名。- 可以使用
PARTITION BY指定分区,排名将在每个分区内独立计算。
DENSE_RANK() 是用于为查询结果中的行分配密集排名的窗口函数,适用于需要连续排名的情况,不跳过重复排名。
5.5 LAG() 和 LEAD()
LAG() 和 LEAD() 函数
LAG() 和 LEAD() 是 SQL 中的窗口函数,用于在查询结果中访问行之前或之后的数据。LAG() 获取前一行的值,而 LEAD() 获取后一行的值。
-
基本语法
-- LAG() 语法 LAG(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY order_column) AS lagged_value-- LEAD() 语法 LEAD(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY order_column) AS lead_value -
用法示例
-
获取每个部门的员工工资相对于前一位员工的差值:
SELECT employee_id, department_id, salary, LAG(salary, 1, 0) OVER (PARTITION BY department_id ORDER BY salary) AS lagged_salary FROM employees; -
获取每天销售额相对于后一天的增长率:
SELECT order_date, sales_amount, (LEAD(sales_amount, 1, 0) OVER (ORDER BY order_date) - sales_amount) / sales_amount AS sales_growth_rate FROM sales_data;
-
-
参数说明
- column_name: 要访问的列的名称。
- offset: 要获取的相对行的偏移量(默认为 1,表示前一行或后一行)。
- default_value: 在没有足够行时使用的默认值。
-
注意事项
LAG()和LEAD()主要用于在查询结果中访问相对于当前行的其他行的数据。- 可以使用
PARTITION BY进行分区,以在每个分区内独立计算偏移值。
LAG() 和 LEAD() 是用于访问查询结果中其他行的数据的窗口函数,为分析相对行提供了便利。
六、注意事项和优化建议
7.1 处理 NULL 值
-
NULL 值的特殊处理
- NULL 值比较: 在使用比较运算符(如
=、<>)时,要特别注意 NULL 值的比较。因为与 NULL 值的比较结果是未知的,应使用IS NULL或IS NOT NULL进行检查。 - 使用 COALESCE 或 IFNULL: 使用
COALESCE函数(在多数数据库系统中)或IFNULL函数(在 MySQL 中)来处理 NULL 值。它们可以返回第一个非 NULL 表达式的值。
- NULL 值比较: 在使用比较运算符(如
-
聚合函数和 NULL 值
- COUNT 函数:
COUNT(column_name)不会统计包含 NULL 值的行。如果需要包括 NULL 在内,可以使用COUNT(*)。 - 其他聚合函数: 大多数聚合函数(如
SUM、AVG)在计算时会忽略 NULL 值,确保你的查询逻辑正确处理这一点。
- COUNT 函数:
-
排序和 NULL 值
- ORDER BY 子句: 在排序时,NULL 值的位置可以通过
ORDER BY column_name NULLS FIRST或ORDER BY column_name NULLS LAST进行控制。
- ORDER BY 子句: 在排序时,NULL 值的位置可以通过
-
连接操作和 NULL 值
- 使用 COALESCE 或 IFNULL 连接值: 在连接操作中,如果有可能出现 NULL 值,可以使用
COALESCE或IFNULL将 NULL 转换为其他值。
- 使用 COALESCE 或 IFNULL 连接值: 在连接操作中,如果有可能出现 NULL 值,可以使用
-
优化建议
- 索引和 NULL: 对包含 NULL 值的列进行索引时要小心。在某些数据库系统中,NULL 值可能不会被索引,导致性能问题。
- 避免过多使用 NULL: 尽量设计表结构时避免过多使用 NULL,可以考虑使用默认值或占位符。
- 谨慎使用 OUTER JOIN: 在使用 OUTER JOIN 时,要注意 NULL 值的处理,确保查询逻辑正确。
- 使用 CASE 表达式: 在需要对 NULL 值进行条件判断时,可以使用
CASE表达式明确处理不同情况。
-
测试和验证
- 数据验证: 在实际应用中,对包含 NULL 值的列进行充分的测试和验证,确保查询和操作的结果符合预期。
- 性能测试: 对包含 NULL 值的表进行性能测试,特别是在数据量较大的情况下,以确保查询的效率和性能。
综合考虑上述注意事项和优化建议,可以更好地处理和利用数据库中的 NULL 值,提高查询的准确性和性能。
7.2 性能优化
-
索引优化
- 选择合适的列进行索引: 对于经常用于检索和过滤的列,考虑创建索引以提高查询性能。
- 避免过多索引: 过多的索引可能导致性能下降,因为每次插入、更新或删除操作都需要更新索引。
-
查询优化
- 使用合适的查询方式: 根据查询的目的选择合适的查询方式,如使用 JOIN 时要注意不同类型的 JOIN 对性能的影响。
- *避免 SELECT : 只选择需要的列,而不是使用
SELECT *,以减少数据传输和提高查询效率。
-
表结构设计
- 范式化 vs. 反范式化: 根据实际情况选择合适的范式化级别,有时反范式化可以提高查询性能。
- 垂直分割和水平分割: 将大型表拆分为更小的表,以减少查询的数据量。
-
缓存机制
- 使用缓存: 使用缓存技术,减少对数据库的频繁访问,特别是对于静态或不经常变化的数据。
-
定期维护
- 定期分析查询计划: 定期分析数据库的查询计划,确保索引被充分利用。
- 定期优化数据库统计信息: 更新数据库统计信息,以便数据库优化器能够生成更有效的执行计划。
-
连接池
- 使用连接池: 对于需要频繁连接数据库的应用,使用连接池可以降低连接数据库的开销。
-
数据库引擎选择
- 选择合适的数据库引擎: 不同的数据库引擎在性能方面有差异,根据应用需求选择合适的数据库引擎。
-
分区表
- 使用分区表: 对于大型表,考虑使用分区表来提高查询性能,特别是在处理历史数据时。
-
避免频繁的 COMMIT
- 避免频繁的 COMMIT 操作: 频繁的 COMMIT 操作可能导致性能问题,尽量使用批量提交。
-
监控和日志
- 定期监控数据库性能: 设置监控和日志,及时发现性能问题并进行调优。
- 日志分析: 定期分析数据库的日志,了解数据库的运行状况,及时发现异常和潜在问题。
通过综合考虑上述性能优化策略,可以有效提升数据库系统的性能,确保应用在高负载和大数据量的情况下依然能够稳定运行。
7.3 谨慎使用 DISTINCT
使用 DISTINCT 关键字可以去除结果集中的重复行,但在某些情况下需要谨慎使用,以避免性能问题和不必要的复杂性。
-
性能开销
- 大数据集上的性能问题: 在大数据集上使用
DISTINCT可能导致性能问题,因为数据库需要对整个结果集进行排序和去重操作。 - 考虑替代方案: 考虑是否有其他方法可以达到相同的去重效果,例如使用
GROUP BY子句。
- 大数据集上的性能问题: 在大数据集上使用
-
多列去重
- 多列情况下的复杂性: 在多列情况下,
DISTINCT可能需要比较复杂的排序和比较操作,影响性能。 - 使用 GROUP BY 替代: 如果需要对多列进行去重,考虑使用
GROUP BY子句,并选择合适的聚合函数。
- 多列情况下的复杂性: 在多列情况下,
-
NULL 值处理
- NULL 值的注意事项: 在包含 NULL 值的列上使用
DISTINCT时,可能会遇到 NULL 值的排序和比较问题。 - 使用 IS NOT NULL 过滤: 如果可能,先使用
WHERE子句过滤掉 NULL 值,再使用DISTINCT。
- NULL 值的注意事项: 在包含 NULL 值的列上使用
-
优化查询
- 考虑查询优化: 如果
DISTINCT是为了解决查询结果中的重复数据问题,可以考虑优化查询语句,确保关联条件和过滤条件的准确性。 - 使用窗口函数: 在某些情况下,窗口函数(如
ROW_NUMBER())可能是去重和筛选的更有效手段。
- 考虑查询优化: 如果
-
注意数据模型
- 检查数据模型设计: 如果频繁需要使用
DISTINCT,可能需要重新审视数据模型的设计,看是否可以通过调整模型减少重复数据。
- 检查数据模型设计: 如果频繁需要使用
-
测试性能影响
- 测试和比较性能: 在使用
DISTINCT之前,进行测试并比较性能,确保使用该关键字是必要的。
- 测试和比较性能: 在使用
总体而言,DISTINCT 是一个有用的工具,但在使用时需要谨慎。在大数据环境下,可能需要考虑其他方法来达到相同的目的,以保证查询性能。
八、总结
聚合函数是SQL中重要的工具,用于对数据进行汇总和计算。从COUNT到SUM、AVG,再到强大的窗口函数,深入理解这些函数有助于高效处理和分析数据库中的大量数据。
相关文章:

【数据库设计和SQL基础语法】--查询数据--聚合函数
一、聚合函数概述 1.1 定义 聚合函数是一类在数据库中用于对多个行进行计算并返回单个结果的函数。它们能够对数据进行汇总、统计和计算,常用于提取有关数据集的摘要信息。聚合函数在 SQL 查询中广泛应用,包括统计总数、平均值、最大值、最小值等。 1…...
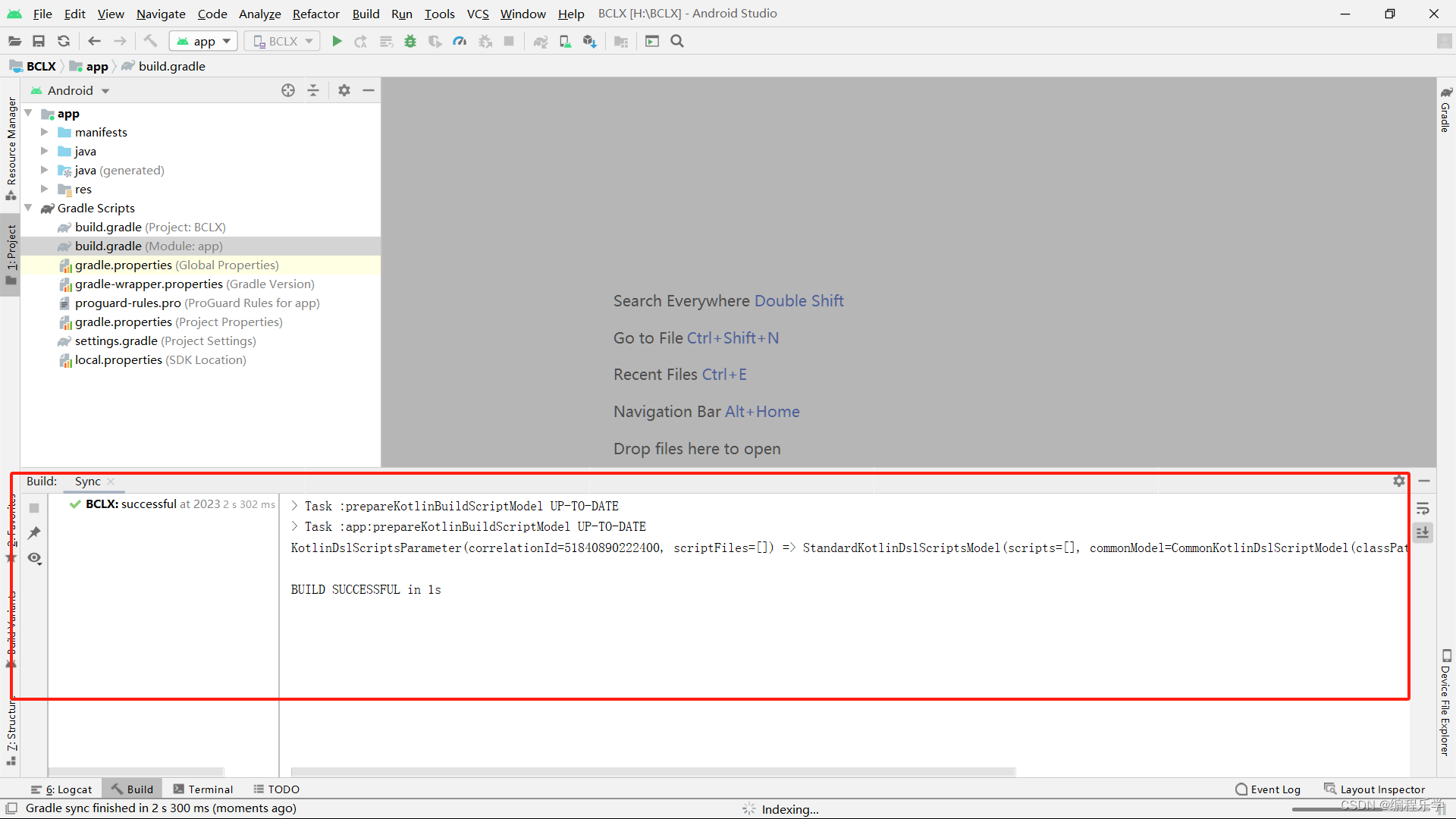
Module ‘app‘: platform ‘android-33‘ not found.
目录 一、报错信息 二、解决方法 一、报错信息 Module app: platform android-33 not found. 检查你的应用程序的build.gradle文件中的targetSdkVersion和compileSdkVersion是否正确设置为已安装的Android SDK版本。 确保你的Android Studio已正确安装并配置了所需的Android …...

MySQL按序批量操作大量数据
MySQL按序批量操作大量数据(Java、springboot、mybatisplus、ElasticSearch) 以同步全量MySQL数据到ElasticSearch为例。 核心代码 业务逻辑: public boolean syncToElasticsearch() {log.info("Starting data synchronization to El…...
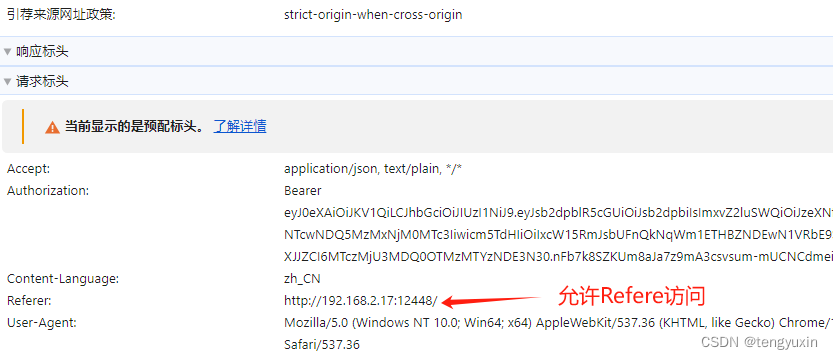
strict-origin-when-cross-origin
严格限制同源策略 (1)允许服务器的同源IP地址访问 (2)允许Referer --- 后端服务器要配置...

【置顶】 本博博文汇总
文章目录 前言音视频ijkplayer源码分析FFmpeg、音视频协议Andriod系统音视频框架C、C Android&Java源码分析、绘制、渲染Dalvik、Art虚拟机Java并发 计算机基础操作系统计算机网络设计模式、数据结构、算法 前言 23年底了,想来也工作十年,也一直在c…...
react.js源码二
三、调度Scheduler scheduling(调度)是fiber reconciliation的一个过程,主要决定应该在何时做什么?在stack reconciler中,reconciliation是“一气呵成”,对于函数来说,这没什么问题,因为我们只想要函数的运行结果,但对于UI来说还需要考虑以下问题: 并不是所有的state更…...

如何学习英语
前言 首先写一些自己的感言吧,其实从大学的时候就在不断地听英语,学英语,但是到毕业十几年后,英语一直没起到什么作用,当然最有作用的时候就是几次英语面试吧。 工作之后有一段学习英语的经历,当时花费了…...

robot测试自动化
一. 安装 黑羽robot 首先确保你电脑上安装好了 Python 3.7 或者 3.8 版本的解释器 hyrobot 使用说明1 | 白月黑羽 安装RF 黑羽robot基于Robot Framework ,所以必须先安装RobotFramework 直接执行如下Pip命令即可: pip install robotframework...
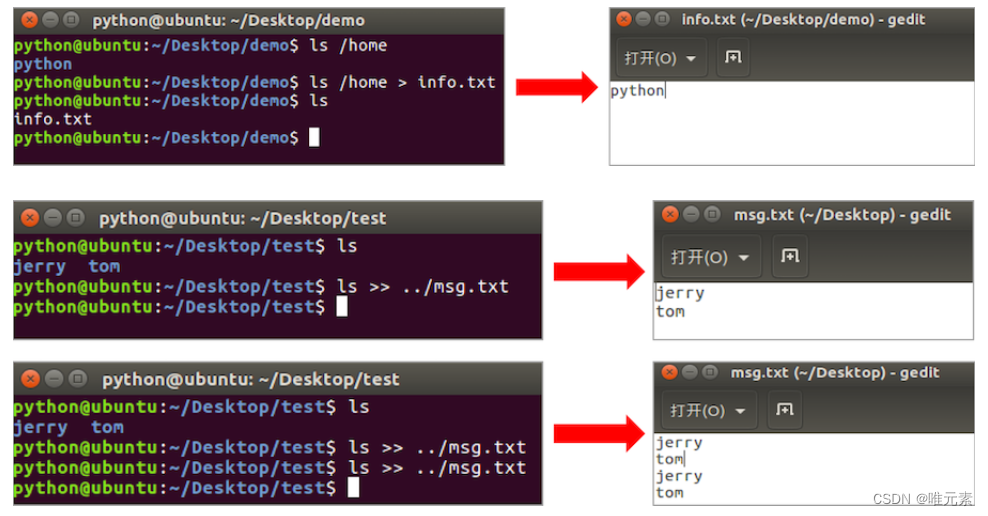
Linux---重定向命令
1. 重定向命令的介绍 重定向也称为输出重定向,把在终端执行命令的结果保存到目标文件。 2. 重定向命令的使用 命令说明>如果文件存在会覆盖原有文件内容,相当于文件操作中的‘w’模式>>如果文件存在会追加写入文件末尾,相当于文件…...

小区生活污水处理需要哪些设备和工艺
在小区生活中,污水处理是一个非常重要的环节,它关乎到环境的保护和居民的生活质量。因此,了解小区生活污水处理所需要的设备和工艺是至关重要的。 首先,在小区生活污水处理中,需要用到的设备包括污水收集系统、初级沉淀…...

【高性能计算】Cpp + Eigen + Intel MKL + 函数写成传引用
CUDA加速原理:CUDA编程学习:自定义Pytorch+cpp/cuda extension 高质量C++进阶[2]:如何让线性代数加速1000倍? 【gcc, cmake, eigen, opencv,ubuntu】三.eigen和mkl安装和使用 Linux下MKL库的安装部署与使用,并利用cmake编译器调用MKL库去提升eigen库的计算速度 Eigen库…...

【教学类-05-02】20231216 (比大小> <=)X-Y之间的比大小88题(补全88格子,有空格分割提示)
作品展示: 背景需求: 1、以前做过一份比大小的题目 【教学类-05-01】20211018 Python VSC 大班 数字比大小(> <)_vsc比较3位数大小-CSDN博客文章浏览阅读674次。【教学类-05-01】20211018 Python VSC 大班…...
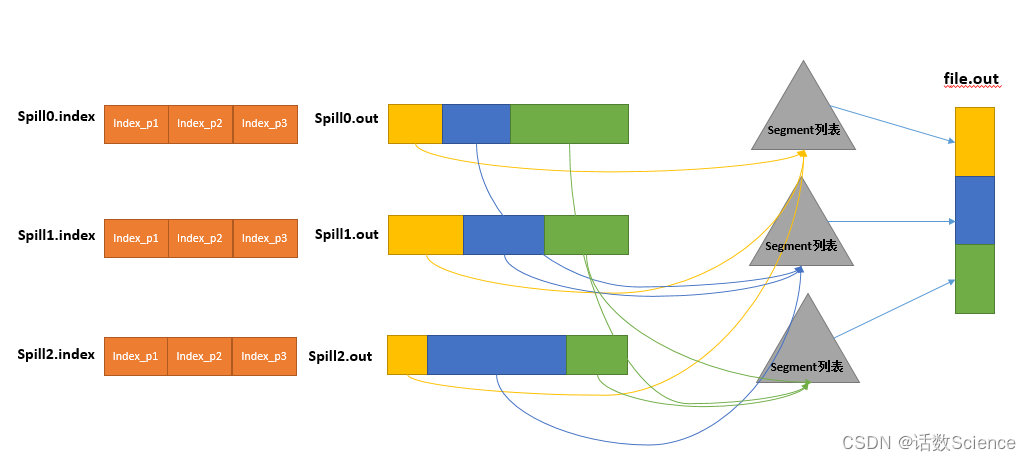
【Spark精讲】Spark与MapReduce对比
目录 对比总结 MapReduce流程 编辑 MapTask流程 ReduceTask流程 MapReduce原理 阶段划分 Map shuffle Partition Collector Sort Spill Merge Reduce shuffle Copy Merge Sort 对比总结 Map端读取文件:都是需要通过split概念来进行逻辑切片&…...
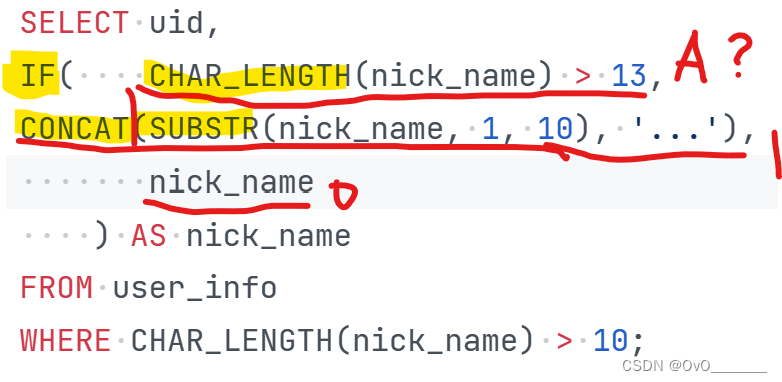
SQL错题集3
1.薪水第二多的员工的emp_no以及其对应的薪水salary limit a,b 其中a表示查询数据的起始位置,b表示返回的数量。 (MySQL数据库中的记录是从0开始的) 注意从0开始 2.员工编号emp_no为10001其自入职以来的薪水salary涨幅值growth 聚合函数不能…...
Elasticsearch:使用 OpenAI 生成嵌入并进行向量搜索 - nodejs
在我之前的文章: Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)(二)(三)(四) 我详细地描述了如何使用…...

[python高级编程]:02-类
此系列主要用于记录Python学习过程中查阅的优秀文章,均为索引方式。其中内容只针对本作者一人,作者熟悉了解的内容不再重复记录。 目录 01-装饰器 overload -- 方法重载 02-多态 多态和鸭子类型 03-设计模式 抽象基类和接口 01-装饰器 overload -- 方…...

java.lang.UnsupportedOperationException异常解决
在执行如下代码时,发现当apps.add("...");代码执行时,会报java.lang.UnsupportedOperationException错误 List<String> apps Arrays.asList("...");apps.add("..."); 问题出现的原因如下: 1、ArrayLi…...
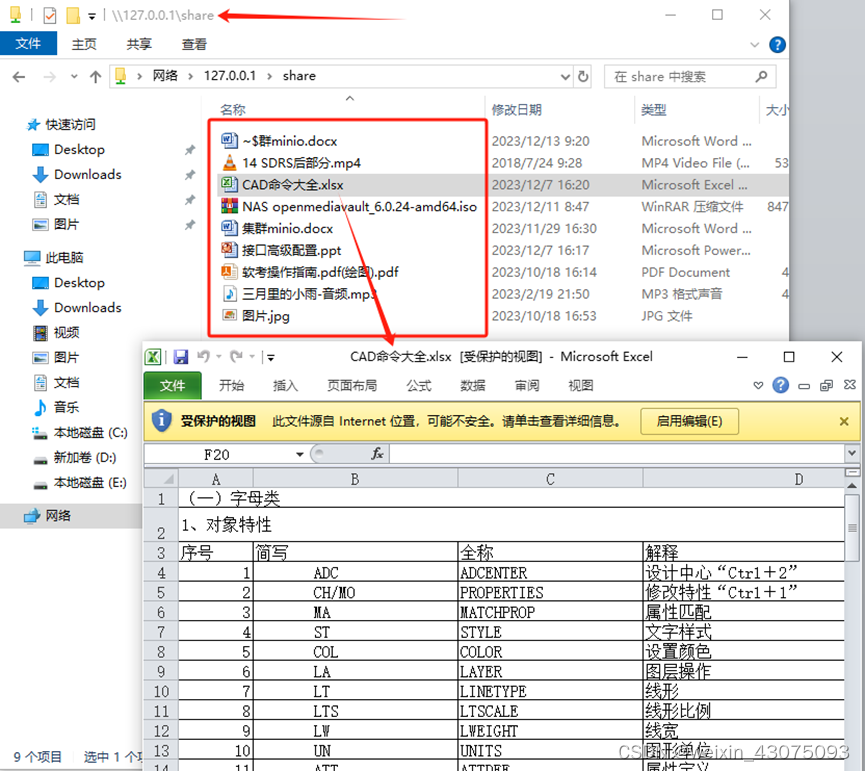
openmediavault debian linux安装配置企业私有网盘(三 )——raid5与btrfs文件系统无损原数据扩容
一、适用环境 1、企业自有物理专业服务器,一些敏感数据不外流时,使用openmediavault自建NAS系统; 2、在虚拟化环境中自建NAS系统,用于内网办公,或出差外网办公时,企业内的文件共享; 3、虚拟化环…...
设计模式)
Two Phase Termination(两阶段)设计模式
Two Phase Termination设计模式是针对任务由两个环节组成,第一个环节是处理业务相关的内容,第二个阶段是处理任务结束时的同步、释放资源等操作。在进行两阶段终结的时候,需要考虑: 第二阶段终止操作必须保证线程安全。 要百分百…...
闲人闲谈PS之四十九——PLM和SAP集成常见的问题
惯例闲话:天气突变,没想到珠三角也骤降了10几度,昨晚还吹风扇模式,早上起来一下子感觉丝丝凉意。闲人还是喜欢冬天,冷,能让人思维清晰,提高工作效率。趁着天气适宜,赶紧加班擦屁股去…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...