ES如何提高准确率之【term-centric】
提高准确率的方法有很多,但是要在提高准确率的同时保证召回率往往比较困难,本文只介绍一种比较常见的情况。
问题场景
我们经常搜索内容,往往不止针对某个字段进行搜索,比如:标题、内容,往往都是一起搜索的。
index结构如下:
{"settings": {"number_of_shards": "1","number_of_replicas": "0"},"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_smart"},"content": {"type": "text","analyzer": "ik_smart"}}}
}
样例数据如下:
{"index":{"_id":1}}
{"title":"我喜欢的一种水果","content":"我喜欢的苹果是红色的,含有铜、碘、锰、锌、钾等元素"}
{"index":{"_id":2}}
{"title":"红色的番茄","content":"番茄是一种红色的水果,含有各种维生素以及糖分"}
{"index":{"_id":3}}
{"title":"樱桃的介绍","content":"樱桃是红色的,含有丰富的糖分、铁、维生素C、蛋白质、维生素E、维生素B族和胡萝卜素"}
{"index":{"_id":4}}
{"title":"不知名介绍","content":"我爱吃红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色的水果"}
现在我要搜索【红色的苹果】,我们人眼看下来,id=1的文档肯定是最佳匹配的。但我们真实搜索结果会怎么样呢?
搜索语句假设如下:
{"query": {"bool": {"should": [{"match": {"title": "红色的苹果"}},{"match": {"content": "红色的苹果"}}]}}
}
上面搜索语句dsl语句看着略微复杂,我们换个写法,效果一样
{"query": {"multi_match": {"query": "红色的苹果","type": "most_fields","fields": ["title","content"]}}
}
结果:
[{"_index":"dong_analyzer_test2","_type":"_doc","_id":"2","_score":1.9675379,"_source":{"title":"红色的番茄","content":"番茄是一种红色的水果,含有各种维生素以及糖分"}},{"_index":"dong_analyzer_test2","_type":"_doc","_id":"1","_score":1.9362588,"_source":{"title":"我喜欢的一种水果","content":"我喜欢的苹果是红色的,含有铜、碘、锰、锌、钾等元素"}},{"_index":"dong_analyzer_test2","_type":"_doc","_id":"3","_score":0.63812846,"_source":{"title":"樱桃的介绍","content":"樱桃是红色的,含有丰富的糖分、铁、维生素C、蛋白质、维生素E、维生素B族和胡萝卜素"}},{"_index":"dong_analyzer_test2","_type":"_doc","_id":"4","_score":0.2719918,"_source":{"title":"不知名介绍","content":"我爱吃红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色的水果"}}
]
很明显和我们人眼评分肯定是不一样的
思考
问题1:为什么id=2的番茄评分最高?
我们先看下切词
{"tokens": [{"token": "红色","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 0},{"token": "的","start_offset": 2,"end_offset": 3,"type": "CN_CHAR","position": 1},{"token": "苹果","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 2}]
}
因为番茄中title中有【红色】【的】,content中有【红色】【的】,title和content同时都命中了,所以匹配到了它。
问题2:id=1的content中不仅有【苹果】还有【红色】【的】为什么评分比id=2的番茄低?
因为id=1的title种没有【红色】【的】,尽管id=1的content的匹配度 大于 id=2的content,但是title匹配度不及id=2
问题3:凭什么title分低一点,content分高一点不能把整体评分拉齐?
一般来说title分低,只要content分高,照样总分可以超过其他文档。那这个样例的问题出在哪了呢?
我们再看下样例:
{"title":"我喜欢的一种水果","content":"我喜欢的苹果是红色的,含有铜、碘、锰、锌、钾等元素"}
{"title":"红色的番茄","content":"番茄是一种红色的水果,含有各种维生素以及糖分"}
{"title":"樱桃的介绍","content":"樱桃是红色的,含有丰富的糖分、铁、维生素C、蛋白质、维生素E、维生素B族和胡萝卜素"}
{"title":"不知名介绍","content":"我爱吃红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色的水果"}
我们发现content中【红色】这个词出现频率非常高。
我们可以想到es的搜索算法中有一个逆向文档频率,它描述的是某个词在所有文档中出现的频率越高,它的权重越低。
回到问题2,content分高一点不能把整体评分拉齐?答案是可以的,但是问题出在了content的分虽然高,但是高的不多,比起title差的远,上面样例中title出现【红色】只有一个而已。
解决方案
方案1 - 调整权重(不建议)
能不能给title权重降低一点?这样就能弥补【红色】权重低的问题了。
- 针对这个样例来说,这样做是可以的。但这仅仅是个样例,现实中我们不能这样去解决问题,因为上面的样例完全可以逆转,让title和content字段互换。难道又要去调整content的权重么?
方案2 - 精确匹配(略微不建议)
上面有个问题就是,id=2的文档中,根本没有【苹果】也被匹配出来了,那么我精确匹配是不是就可以了
{"query": {"multi_match": {"query": "红色的苹果","type": "most_fields","operator": "and","fields": ["title","content"]}}
}
- and代表所有词都必须匹配,当然也可以使用minimum_should_match,但本文的样例必须使用100%
查询结果:
[{"_index":"dong_analyzer_test2","_type":"_doc","_id":"1","_score":1.499949,"_source":{"title":"我喜欢的一种水果","content":"我喜欢的苹果是红色的,含有铜、碘、锰、锌、钾等元素"}}
]
确实我们最希望匹配出来的结果被匹配出来了,并且排在了第一,但是其他不是很相关的文档却没有匹配出来,这降低了召回率。所以这种方案不是特别推荐
备注:这种解决问题的思路是没有问题的,往往这种精确匹配要搭配其他查询条件一起使用,但和本文想讨论的问题不相关,放到其他文章中去介绍。
方案3 - 新建字段(还行)
上面的问题关键在哪呢?
仔细分析可以发现,我们的需求是希望搜索一个query进行多个字段(title、content)的搜索。换句话说,我们其实是希望title和content是一个字段(他们共享TF/IDF),我们并不希望因为某些词在content中出现很频繁,但在title中出现不频繁导致最终评分不符合预期。
根据上面思路,我们是不是可以建一个新字段,把title和content拼接在一起就行了?
{"settings":{"number_of_shards":"1","number_of_replicas":"0"},"mappings":{"properties":{"title":{"type":"text","analyzer":"ik_smart"},"content":{"type":"text","analyzer":"ik_smart"},"title_content":{"type":"text","analyzer":"ik_smart"}}}
}
这样做是可以的,但是有两个弊端
- 业务系统在插入的时候,需要手动把title和content拼接在一起,然后整体写入title_content。
- es存储空间变大,title和content的内容相当于存了双份
方案4 - 新建字段索引(不错)
怎么解决方案3的这个问题呢?
可以利用copy_to
{"settings":{"number_of_shards":"1","number_of_replicas":"0"},"mappings":{"person":{"properties":{"title":{"type":"text","analyzer":"ik_smart","copy_to":"title_content"},"content":{"type":"text","analyzer":"ik_smart","copy_to":"title_content"},"title_content":{"type":"string","analyzer":"ik_smart"}}}}
}
这样es帮我们在插入数据的时候自动把映射的索引copy到了title_content中去。
注意:这里所有的分词器要保持一致
但它同样还有弊端:
- 在创建索引的时候就必须考虑到这种情况,不然还要刷重刷数据
方案5 - term-centric(推荐)
其实解决办法除了重新刷一遍数据以外,还有别的更加优雅的方式,可以不用在建索引的时候把所有情况考虑到位。
利用cross_fields词中心式的方式来解决
{"query": {"multi_match": {"query": "红色的苹果","type": "cross_fields","fields": ["title","content"]}}
}
搜索结果:
[{"_index":"dong_analyzer_test2","_type":"_doc","_id":"1","_score":1.499949,"_source":{"title":"我喜欢的一种水果","content":"我喜欢的苹果是红色的,含有铜、碘、锰、锌、钾等元素"}},{"_index":"dong_analyzer_test2","_type":"_doc","_id":"4","_score":0.30932084,"_source":{"title":"不知名介绍","content":"我爱吃红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色,红色的水果"}},{"_index":"dong_analyzer_test2","_type":"_doc","_id":"2","_score":0.2428131,"_source":{"title":"红色的番茄","content":"番茄是一种红色的水果,含有各种维生素以及糖分"}},{"_index":"dong_analyzer_test2","_type":"_doc","_id":"3","_score":0.23682731,"_source":{"title":"樱桃的介绍","content":"樱桃是红色的,含有丰富的糖分、铁、维生素C、蛋白质、维生素E、维生素B族和胡萝卜素"}}
]
他的原理就是把所有字段当成一个大字段,并在每个字段中查找每个词。
看下es的对cross_fields的分析过程
blended(terms:[title:红色, content:红色])
blended(terms:[title:的, content:的])
blended(terms:[title:苹果, content:苹果])
可以发现es进行三次大搜索,每次大搜索下面有两次小搜索,每次大搜索都是把切词的结果词进行匹配,每次小搜索都是把当前的切词对title和content进行terms匹配,最后把里层和外层搜索评分相加,得到最终结果。
总结
本文探讨了多字段搜索的时候,每个字段的词频和逆向文档频率不同带来的搜索准确率问题。
问题的根本原因在于:搜索的时候大多数都是针对字段进行搜索,但本文中的情况是希望对词进行搜索。
解决思路也是很简单,就是把多个字段的词频和逆向文档频率整合到一起,当然可以在建立索引的时候整合,也可以搜索的时候进行整合查询。
相关文章:

ES如何提高准确率之【term-centric】
提高准确率的方法有很多,但是要在提高准确率的同时保证召回率往往比较困难,本文只介绍一种比较常见的情况。 问题场景 我们经常搜索内容,往往不止针对某个字段进行搜索,比如:标题、内容,往往都是一起搜索…...

DDD落地:爱奇艺打赏服务,如何DDD架构?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 谈谈你的DDD落地经验? 谈谈你对DDD的理解&#x…...

基于JavaWeb+SSM+Vue居住证申报系统小程序的设计和实现
基于JavaWebSSMVue居住证申报系统小程序的设计和实现 源码获取入口KaiTi 报告Lun文目录前言主要技术系统设计功能截图订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码获取入口 KaiTi 报告 1.1题目背景 随着时代的发展,人口流动越来越频繁࿰…...

环境安全之配置管理及配置安全设置指导
一、前言 IT运维过程中,配置的变更和管理是一件非常重要且必要的事,除了一般宏观层面的配置管理,还有应用配置参数的配置优化,本文手机整理常用应用组件配置项配置,尤其安全层面,以提供安全加固指导实践。…...

【C#】Microsoft C# 视频学习总结
一、文档链接 C# 文档 - 入门、教程、参考。| Microsoft Learn 二、基础学习 1、输出语法 Console.WriteLine() using System; namespace HelloWorldApplication {class HelloWorld{static void Main(string[] args){Console.WriteLine("Hello World!");}} }Hel…...
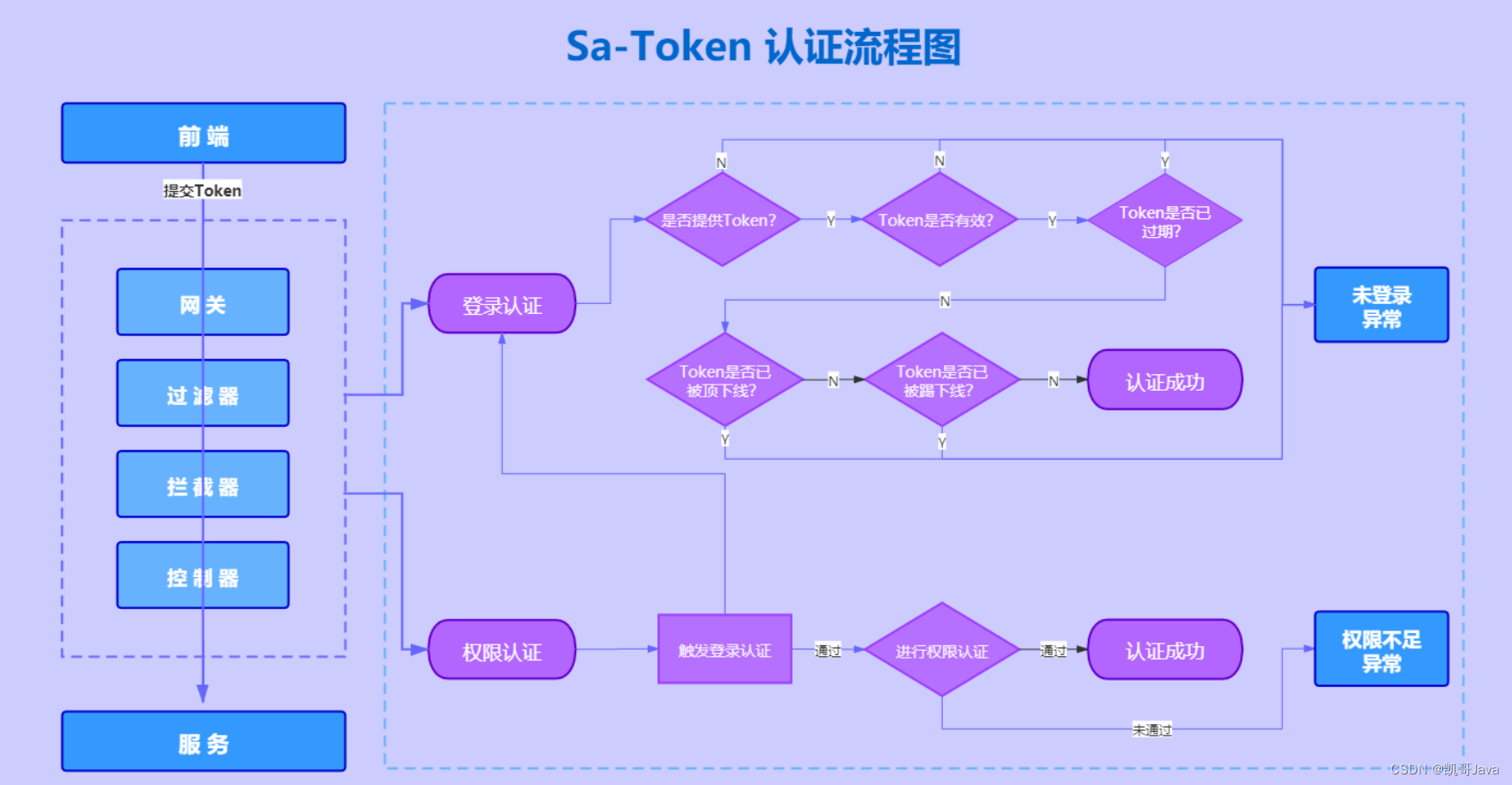
【已解决-实操篇】SaTokenException: 非Web上下文无法获取Request问题解决-实操篇
在上一篇《【理论篇】SaTokenException: 非Web上下文无法获取Request问题解决 -理论篇》中,凯哥(公众号:凯哥Java)介绍了了产生这个问题的源码在哪里,以及怎么解决的方案。没有给出实际操作步骤。 本文,凯哥就通过threadLocal方案…...

论文润色机构哪个好 快码论文
大家好,今天来聊聊论文润色机构哪个好,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧,可以借助此类工具: 标题:论文润色机构哪个好――专业、高效、可靠的学术支持 一…...
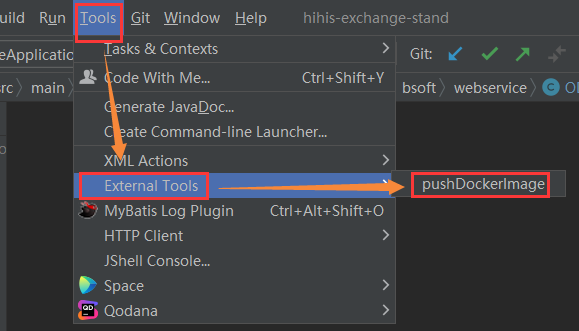
Idea执行bat使用maven打包springboot项目成docker镜像并push到Harbor
如果执行以下命令失败,先把mvn的-q参数去掉,让错误输出到控制台。 《idea配置优化、Maven配置镜像、并行构建加速打包、解决maven打包时偶尔几个文件没权限的问题》下面的使用company-repo私有仓库和阿里云镜像仓库同时使用的配置参考。 bat echo off …...
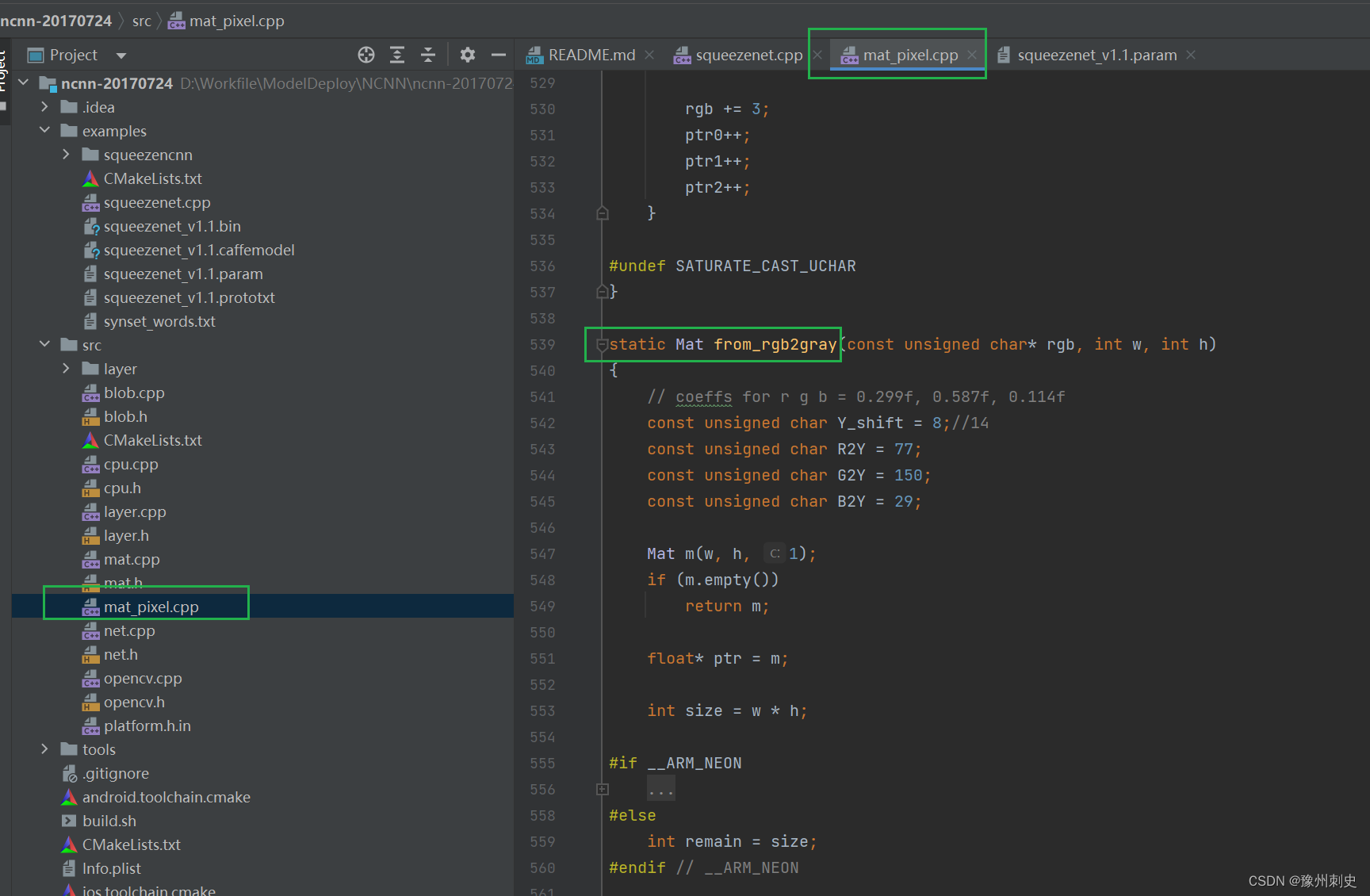
NCNN 源码学习【三】:数据处理
一、Topic:数据处理 这次我们来一段NCNN应用代码中,除了推理外最重要的一部分代码,数据处理: ncnn::Mat in ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR, bgr.cols, bgr.rows, 227, 227);const float mean_v…...
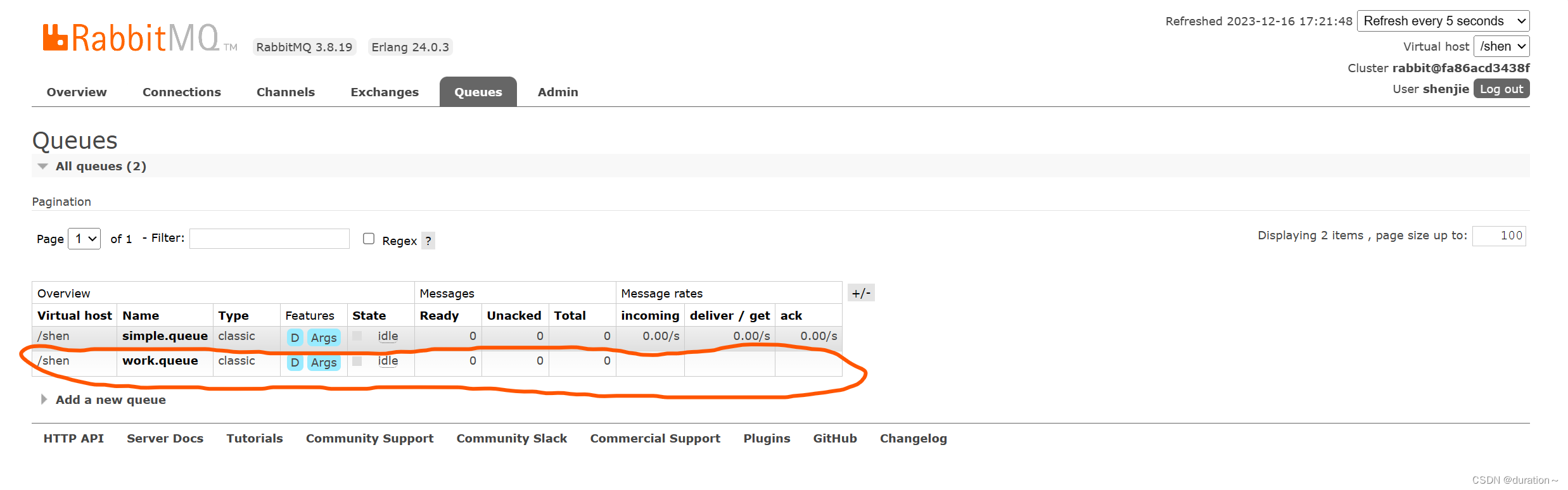
RabbitMq基本使用
目录 SpringAMQP1.准备Demo工程2.快速入门1.1.消息发送1.2.消息接收1.3.测试 3.WorkQueues模型3.1.消息发送3.2.消息接收3.3.测试3.4.能者多劳3.5.总结 SpringAMQP 将来我们开发业务功能的时候,肯定不会在控制台收发消息,而是应该基于编程的方式。由于R…...
windows wsl2 ubuntu上部署 redroid云手机
Redroid WSL2部署文档 下载wsl内核源码 #文档注明 5.15和5.10 版本内核可以部署成功,这里我当前最新的发布版本 #下载wsl 源码 wget --progressbar:force --output-documentlinux-msft-wsl-5.15.133.1.tar.gz https://codeload.github.com/microsoft/WSL2-Linux-Ker…...

创维电视机 | 用当贝播放器解决创维电视机不能播放MKV视频的问题
小故事在下面,感兴趣可以看看,开头我就直接放解决方案 创维电视虽然是基于Android开发的,可以安装apk软件,但是基本不能用,一定要选择适配电视的视频播放器,或者使用本文中提供的创维版当贝播放器。 原软…...
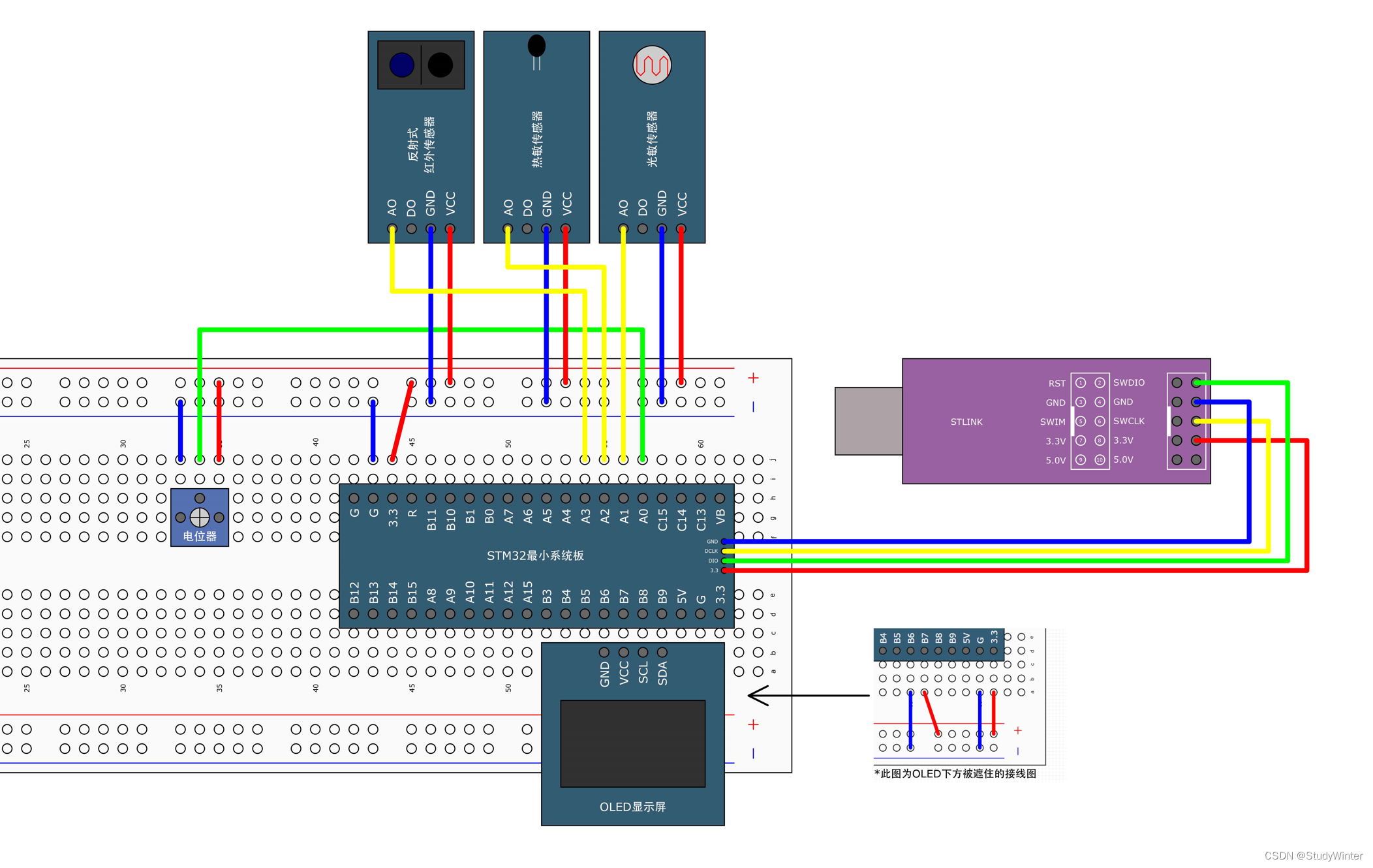
【STM32】DMA直接存储器存取
1 DMA简介 DMA(Direct Memory Access)直接存储器存取 可以直接访问STM32的存储器的,包括运行SRAM、程序存储器Flash和寄存器等等 DMA可以提供外设寄存器和存储器或者存储器和存储器之间的高速数据传输,无须CPU干预,节…...
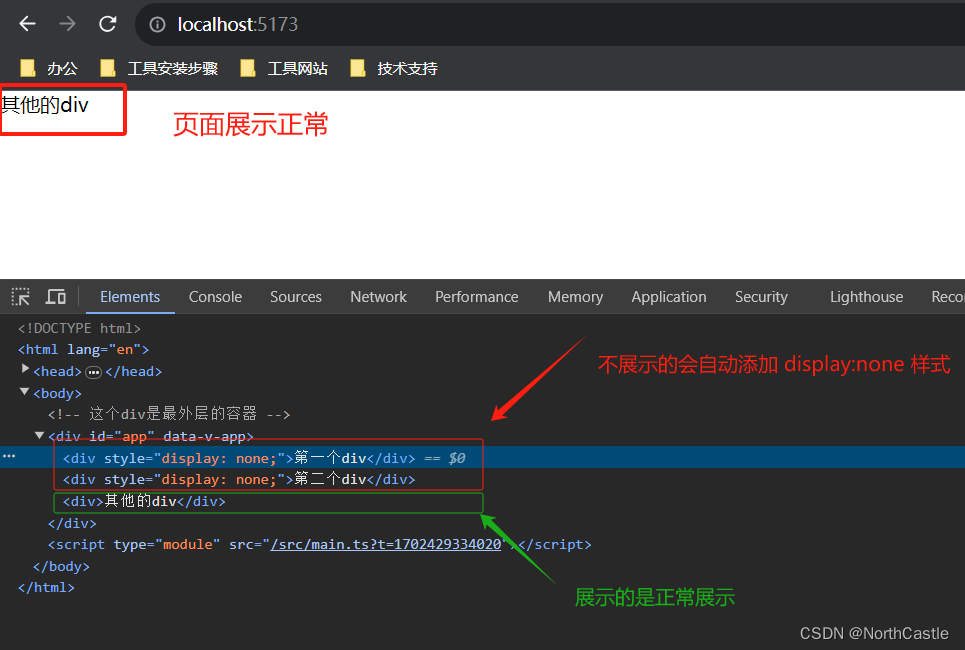
Vue3-09-条件渲染-v-show 的基本使用
v-show 的作用 v-show 可以根据条件表达式的值【展示】或【隐藏】html 元素。v-show 的特点 v-show 的实现方式是 控制 dom 元素的 css的 display的属性, 因此,无论该元素是否展示,该元素都会正常渲染在页面上, 当v-show 的 条件…...
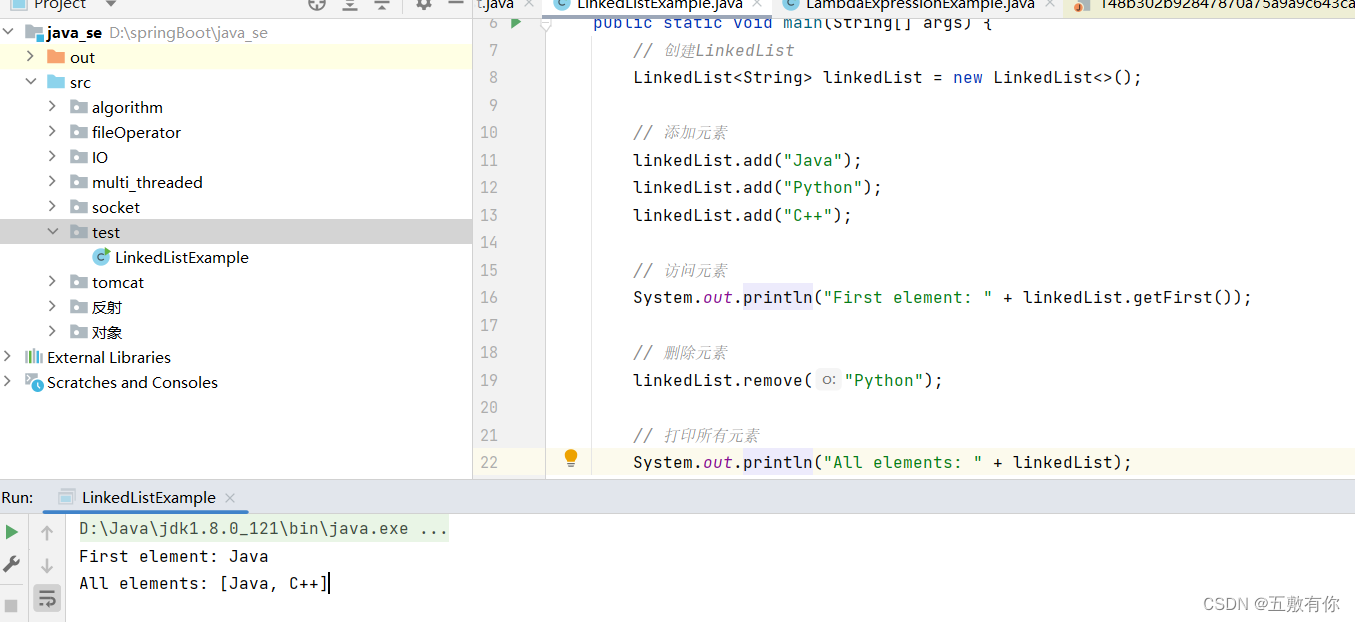
ArrayList与LinkLIst
ArrayList 在Java中,ArrayList是java.util包中的一个类,它实现了List接口,是一个动态数组,可以根据需要自动增长或缩小。下面是ArrayList的一些基本特性以及其底层原理的简要讲解: ArrayList基本特性: 动…...
)
位运算(、|、^、~、>>、<<)
分类 编程技术 1.位运算概述 从现代计算机中所有的数据二进制的形式存储在设备中。即 0、1 两种状态,计算机对二进制数据进行的运算(、-、*、/)都是叫位运算,即将符号位共同参与运算的运算。 口说无凭,举一个简单的例子来看下 CPU 是如何进…...
Centos7部署SVN
文章目录 (1)SVN概述(2)SVN与Samba共享(3)安装SVN(4)SVN搭建实例(5)pc连接svn服务器(6)svn图标所代表含义 (1)…...

Vue中this.$nextTick的执行时机
一、Vue中this.$nextTick的执行时机,整体可分为两种情况: 第一种:下一次 Dom 更新之后执行(即等待DOM更新结束之后,执行nextTick的延迟回调函数); 第二种:页面挂载后 (m…...

Unity中的ShaderToy
文章目录 前言一、ShaderToy网站二、ShaderToy基本框架1、我们可以在ShaderToy网站中,这样看用到的GLSL文档2、void mainImage 是我们的程序入口,类似于片断着色器3、fragColor作为输出变量,为屏幕每一像素的颜色,alpha一般赋值为…...
2 使用postman进行接口测试
上一篇:1 接口测试介绍-CSDN博客 拿到开发提供的接口文档后,结合需求文档开始做接口测试用例设计,下面用最常见也最简单的注册功能介绍整个流程。 说明:以演示接口测试流程为主,不对演示功能做详细的测试,…...

directADC:AVR微控制器高精度低抖动ADC驱动库
1. directADC 库概述:面向 AVR 平台的高级 ADC 控制方案directADC 是一个专为 Atmel AVR 系列微控制器(如 ATmega328P、ATmega2560、ATtiny85 等)设计的轻量级、高精度 ADC 控制库。它并非对标准<avr/io.h>中ADCSRA/ADMUX寄存器操作的简…...

SSD1357驱动RGB OLED 64×64显示库技术解析
1. SparkFun RGB OLED 6464 显示库技术解析1.1 硬件平台与驱动芯片架构SparkFun RGB OLED 6464 显示模块(SKU: SPX-14860)采用 WiseChip UG-6464TDDBG01 型 0.6 英寸全彩 OLED 面板,其核心驱动 IC 为 Solomon Systech SSD1357 —— 一款专为高…...

Nunchaku FLUX.1-dev 构建智能Agent:集成文生图能力的多模态AI助手
Nunchaku FLUX.1-dev 构建智能Agent:集成文生图能力的多模态AI助手 1. 引言:从单一工具到会思考的伙伴 想象一下,你正在和一个AI助手讨论一个创意项目。你说:“我想设计一个未来城市的宣传海报,要有悬浮的交通工具和…...

OpenClaw命令行增强:GLM-4.7-Flash解析自然语言生成Shell脚本
OpenClaw命令行增强:GLM-4.7-Flash解析自然语言生成Shell脚本 1. 为什么需要自然语言转Shell脚本 作为长期与Linux服务器打交道的开发者,我每天都要处理各种文件查找、日志分析和数据统计任务。传统方式需要手动编写Shell脚本,不仅耗时&…...
)
STM32H7 单片机优化实战:DTCMRAM配置与性能提升指南(STM32CubeIDE环境)
1. DTCMRAM基础概念与STM32H7内存架构 在STM32H7系列单片机中,DTCMRAM(Data Tightly Coupled Memory)是一个特殊的高速内存区域。这块内存最大的特点就是零等待周期访问,这意味着CPU可以直接以最高主频访问这块内存,不…...

Step3-VL-10B-Base模型监控:训练过程可视化与分析
Step3-VL-10B-Base模型监控:训练过程可视化与分析 训练大模型就像开长途车,没有仪表盘你永远不知道车况如何。本文将手把手教你用可视化工具监控Step3-VL-10B-Base的训练过程,让模型训练变得透明可控。 1. 为什么需要训练监控? 训…...

轻量模型InternLM2-Chat-1.8B在嵌入式领域的联想:STM32开发日志智能分析
轻量模型InternLM2-Chat-1.8B在嵌入式领域的联想:STM32开发日志智能分析 最近在折腾一个STM32的物联网项目,设备跑起来后,每天产生的日志数据量不小。看着那一行行的时间戳、状态码和调试信息,我就在想,有没有更聪明的…...
Pixel Dimension Fissioner一文详解:16-bit像素UI设计原理与交互逻辑
Pixel Dimension Fissioner一文详解:16-bit像素UI设计原理与交互逻辑 1. 16-bit像素UI设计概述 16-bit像素风格是一种独特的视觉设计语言,它将现代UI设计与复古游戏美学完美融合。Pixel Dimension Fissioner采用这种设计风格,不仅是为了唤起…...

GLM-OCR在办公场景中的应用:快速提取图片文字,提升工作效率
GLM-OCR在办公场景中的应用:快速提取图片文字,提升工作效率 1. 办公场景中的文字识别痛点 在日常办公中,我们经常需要处理各种包含文字的图片文件:会议白板照片、扫描的合同文档、手机拍摄的名片、PDF转存的图片等。传统处理方式…...

AI虚拟房地产架构技术选型:云服务 vs 自建,架构师该怎么选?
AI虚拟房地产架构技术选型:云服务 vs 自建的第一性原理决策框架 元数据框架 标题 AI虚拟房地产架构技术选型:云服务 vs 自建的第一性原理决策框架 关键词 AI虚拟房地产、云服务架构、自建IDC、技术选型、弹性计算、实时渲染、成本优化 摘要 AI虚拟…...