初识大数据应用,一文掌握大数据知识文集(1)
文章目录
- 🏆初识大数据应用知识
- 🔎一、初识大数据应用知识(1)
- 🍁 01、请用Java实现非递归二分查询?
- 🍁 02、是客户端还是Namenode决定输入的分片?
- 🍁 03、mapred.job.tracker命令的作用?
- 🍁 04、请说下MR中Map Task的工作机制?
- 🍁 05、Hive 跟 Hbase的区别?
- 🍁 06、请列出正常工作的hadoop集群中hadoop都需要启动哪些进程,他们的作用分别是什么?
- 🍁 07、KafkaUtils.createDstream 和 KafkaUtils.createDirectstream 区别?
- 🍁 08、Kafka与传统消息队列的区别?
- 🍁 09、Master文件是否提供了多个入口?
- 🍁 10、Spark的数据本地性有哪几种?
- 🍁 11、Spark的shuffle过程是什么?
- 🍁 12、fsimage和edit的区别?
- 🍁 13、List与set的区别?
- 🍁 14、Storm特点有哪些?
- 🍁 15、海量日志数据,提取出某日访问百度次数最多的那个IP,如何实现提取?
🏆初识大数据应用知识

🔎一、初识大数据应用知识(1)
🍁 01、请用Java实现非递归二分查询?
二分查找(Binary Search)又称折半查找(Dichotomy Search),是一种在有序数组中查找某一特定元素的算法。它的基本思想是:通过一趟查找,确定待查找的元素在数组中的哪半部分,然后再在这半部分中查找,直到找到该元素为止。
如果数组中元素很多,那么每次都从头到尾进行顺序查找,效率会很低。二分查找则可以通过折半的方式,使查找次数大大减少。
递归二分查找的算法如下:
- 首先,确定数组的左右边界,即 low 和 high。
- 如果 low > high,说明数组中不存在待查找的元素,返回 -1。
- 计算中间位置 mid = (low + high) / 2。
- 如果待查找的元素等于数组中 mid 位置的元素,则返回 mid。
- 如果待查找的元素小于数组中 mid 位置的元素,则在数组的左半部分 [low, mid - 1] 中继续查找。
- 如果待查找的元素大于数组中 mid 位置的元素,则在数组的右半部分 [mid + 1, high] 中继续查找。
非递归二分查找的算法如下:
- 首先,确定数组的左右边界,即 low 和 high。
- 循环判断:
- 如果 low > high,说明数组中不存在待查找的元素,返回 -1。
- 计算中间位置 mid = (low + high) / 2。
- 如果待查找的元素等于数组中 mid 位置的元素,则返回 mid。
- 如果待查找的元素小于数组中 mid 位置的元素,则将 high 更新为 mid - 1。
- 如果待查找的元素大于数组中 mid 位置的元素,则将 low 更新为 mid + 1。
以下是用 Java 实现的非递归二分查找的代码:
public class BinarySearch {public static int binarySearch(int[] array, int target) {int low = 0;int high = array.length - 1;while (low <= high) {int mid = (low + high) / 2;if (array[mid] == target) {return mid;} else if (array[mid] < target) {low = mid + 1;} else {high = mid - 1;}}return -1;}public static void main(String[] args) {int[] array = {1, 3, 5, 7, 9};int target = 5;int index = binarySearch(array, target);if (index == -1) {System.out.println("元素不存在");} else {System.out.println("元素在数组中的索引为:" + index);}}
}
🍁 02、是客户端还是Namenode决定输入的分片?
在 HDFS 中,客户端负责将文件切片成块,然后将这些块发送到 NameNode。NameNode 负责跟踪文件的块位置,并将这些块存储在不同的 DataNode 上。当客户端需要读取文件时,它会向 NameNode 发送请求,请求读取文件的某个块。NameNode 会将请求转发到存储该块的 DataNode,然后 DataNode 会将该块发送给客户端。
因此,在 HDFS 中,客户端负责决定输入的分片。NameNode 只负责跟踪文件的块位置,并将这些块存储在不同的 DataNode 上。
以下是 HDFS 中文件分片的详细说明:
- 客户端将文件切片成块,每个块的大小为 64 MB。
- 客户端将块发送到 NameNode。
- NameNode 跟踪文件的块位置,并将这些块存储在不同的 DataNode 上。
- 当客户端需要读取文件时,它会向 NameNode 发送请求,请求读取文件的某个块。
- NameNode 会将请求转发到存储该块的 DataNode,然后 DataNode 会将该块发送给客户端。
HDFS 中的文件分片可以提高文件的读写性能。当客户端需要读取文件时,它只需要从一个 DataNode 读取一个块,而不是从多个 DataNode 读取多个块。这样可以减少网络传输的开销,提高文件的读写性能。
HDFS 中的文件分片也可以提高文件的可靠性。如果一个 DataNode 发生故障,那么客户端仍然可以从其他 DataNode 读取文件。这样可以防止数据丢失。
总之,HDFS 中的文件分片可以提高文件的读写性能和可靠性。
🍁 03、mapred.job.tracker命令的作用?
mapred.job.tracker 命令用于设置 MapReduce 作业的跟踪器。跟踪器是 MapReduce 作业的管理器,负责协调作业的执行。
mapred.job.tracker 命令的语法如下:
mapred.job.tracker [-h] [-p port] [-l logdir]
- -h 选项用于显示帮助信息。
- -p 选项用于指定跟踪器的端口号。默认端口号为 50030。
- -l 选项用于指定跟踪器的日志目录。默认日志目录为 $HADOOP_HOME/logs/mapred。
以下是使用 mapred.job.tracker 命令设置 MapReduce 作业的跟踪器的示例:
mapred.job.tracker -p 50031 -l /var/log/mapred
此命令将设置 MapReduce 作业的跟踪器,端口号为 50031,日志目录为 /var/log/mapred。
mapred.job.tracker 命令可以通过以下方式设置 MapReduce 作业的跟踪器:
- 在 Hadoop 配置文件中设置。
- 在启动 MapReduce 作业时使用命令行参数设置。
- 在启动 MapReduce 作业时使用环境变量设置。
在 Hadoop 配置文件中设置 MapReduce 作业的跟踪器,可以通过以下方式进行:
1. 在 $HADOOP_HOME/etc/hadoop/mapred-site.xml 文件中添加以下配置:
<property><name>mapred.job.tracker</name><value>localhost:50031</value>
</property>
2. 重新启动 Hadoop 服务。
在启动 MapReduce 作业时使用命令行参数设置 MapReduce 作业的跟踪器,可以通过以下方式进行:
2.1. 在启动 MapReduce 作业时,使用以下命令:
hadoop jar myjob.jar myjob -D mapred.job.tracker=localhost:50031
2.2. 重新启动 MapReduce 作业。
在启动 MapReduce 作业时使用环境变量设置 MapReduce 作业的跟踪器,可以通过以下方式进行:
2.2.1. 在启动 MapReduce 作业时,设置环境变量 MAPRED_JOB_TRACKER :
export MAPRED_JOB_TRACKER=localhost:50031
2.2.2. 重新启动 MapReduce 作业。
以上就是 mapred.job.tracker 命令的作用和使用方法。
🍁 04、请说下MR中Map Task的工作机制?
Map Task 是 MapReduce 作业中的一个重要组件,负责将输入数据进行分区和映射,并生成中间结果。Map Task 的工作机制如下:
- 从 JobTracker 获取作业配置信息。
- 从 InputFormat 读取输入数据。
- 将输入数据分区。
- 对每个分区调用 Map 函数。
- 将 Map 函数的输出写入到 Reducer 端的输出缓冲区。
- 将 Reducer 端的输出缓冲区提交给 JobTracker。
以下是 Map Task 工作流程的示意图:

Map Task 的工作流程可以分为以下几个阶段:
- 初始化阶段:Map Task 在启动时会从 JobTracker 获取作业配置信息,并初始化 Map 函数和其他相关资源。
- 数据读取阶段:Map Task 会从 InputFormat 读取输入数据,并将数据分区。
- 数据处理阶段:Map Task 会对每个分区调用 Map 函数,并将 Map 函数的输出写入到 Reducer 端的输出缓冲区。
- 数据提交阶段:Map Task 会将 Reducer 端的输出缓冲区提交给 JobTracker。
Map Task 的工作流程是 MapReduce 作业执行过程中的一个重要环节,它负责将输入数据进行分区和映射,并生成中间结果。Map Task 的性能直接影响到 MapReduce 作业的整体性能。
🍁 05、Hive 跟 Hbase的区别?
Hive 和 HBase 都是用于大数据分析的开源软件。它们都提供了 SQL 接口,可以让用户以 SQL 的方式对数据进行查询和分析。但是,它们在设计和实现上有一些不同。
- 数据存储方式不同。Hive 使用 HDFS 作为数据存储系统,而 HBase 使用自己的分布式列存储系统。
- 数据模型不同。Hive 使用关系型数据模型,而 HBase 使用列式数据模型。
- 查询方式不同。Hive 使用 MapReduce 来执行查询,而 HBase 使用自己的查询引擎。
- 适用场景不同。Hive 适合于处理结构化数据,而 HBase 适合于处理半结构化和非结构化数据。
以下是 Hive 和 HBase 的对比表:
| 指标 | Hive | HBase |
|---|---|---|
| 数据存储方式 | HDFS | 自己的分布式列存储系统 |
| 数据模型 | 关系型数据模型 | 列式数据模型 |
| 查询方式 | MapReduce | 自己的查询引擎 |
| 适用场景 | 结构化数据 | 半结构化和非结构化数据 |
总体来说,Hive 和 HBase 都是非常优秀的大数据分析工具。它们各有自己的优势和劣势,用户可以根据自己的实际需求来选择使用哪一个。
🍁 06、请列出正常工作的hadoop集群中hadoop都需要启动哪些进程,他们的作用分别是什么?
在正常工作的 Hadoop 集群中,需要启动以下进程:
- NameNode:NameNode 是 Hadoop 集群的元数据管理器,负责维护文件系统的元数据,包括文件的名称、大小、权限等信息。NameNode 还负责管理文件的块映射,即每个文件的块存储在哪些 DataNode 上。
- DataNode:DataNode 是 Hadoop 集群的存储节点,负责存储文件的块。DataNode 还负责接收来自 NameNode 的命令,并执行这些命令。
- JobTracker:JobTracker 是 MapReduce 作业的管理器,负责协调 MapReduce 作业的执行。JobTracker 会将 MapReduce 作业分解成多个 Map 任务和 Reduce 任务,并将这些任务分配给不同的 TaskTracker 执行。
- TaskTracker:TaskTracker 是 MapReduce 作业的执行节点,负责执行 Map 任务和 Reduce 任务。TaskTracker 会从 JobTracker 接收任务,并执行这些任务。
以下是各个进程的作用:
- NameNode:NameNode 负责维护文件系统的元数据,包括文件的名称、大小、权限等信息。NameNode 还负责管理文件的块映射,即每个文件的块存储在哪些 DataNode 上。
- DataNode:DataNode 负责存储文件的块。DataNode 还负责接收来自 NameNode 的命令,并执行这些命令。
- JobTracker:JobTracker 是 MapReduce 作业的管理器,负责协调 MapReduce 作业的执行。JobTracker 会将 MapReduce 作业分解成多个 Map 任务和 Reduce 任务,并将这些任务分配给不同的 TaskTracker 执行。
- TaskTracker:TaskTracker 是 MapReduce 作业的执行节点,负责执行 Map 任务和 Reduce 任务。TaskTracker 会从 JobTracker 接收任务,并执行这些任务。
以上就是正常工作的 Hadoop 集群中需要启动的进程及其作用。
🍁 07、KafkaUtils.createDstream 和 KafkaUtils.createDirectstream 区别?
KafkaUtils.createDstream 和 KafkaUtils.createDirectstream 是 Spark Streaming 中用于从 Kafka 获取数据流的两个方法。它们的区别如下:
-
createDstream:createDstream 方法使用高级别的 Kafka API,通过 ZooKeeper 来管理 Kafka 的消费者偏移量(consumer offset)。它将消费者偏移量存储在 ZooKeeper 中,并在故障恢复时自动从上次的偏移量位置继续消费。createDstream 方法适用于低延迟的数据处理,但在故障恢复时可能会存在一些数据重复消费的问题。
-
createDirectstream:createDirectstream 方法使用低级别的 Kafka API,绕过 ZooKeeper 直接与 Kafka Broker 通信,手动管理消费者偏移量。它将消费者偏移量存储在外部存储系统(如 HBase、MySQL 等)中,并通过自定义逻辑来控制偏移量的提交和恢复。createDirectstream 方法适用于更精确的消费者偏移量控制和故障恢复,但需要开发者自己实现偏移量的管理逻辑。
综上所述,createDstream 方法使用高级别的 Kafka API,简化了消费者偏移量的管理,适用于低延迟的数据处理场景。而 createDirectstream 方法使用低级别的 Kafka API,需要开发者自己实现消费者偏移量的管理逻辑,适用于更精确的消费者偏移量控制和故障恢复场景。
以下是 KafkaUtils.createDstream 和 KafkaUtils.createDirectstream 的区别:
| 指标 | KafkaUtils.createDstream | KafkaUtils.createDirectstream |
|---|---|---|
| 使用 API | 高级别 Kafka API | 低级别 Kafka API |
| 管理偏移量 | 通过 ZooKeeper | 手动管理 |
| 适用场景 | 低延迟的数据处理 | 更精确的消费者偏移量控制和故障恢复 |
需要注意的是,createDstream 方法在 Spark 1.6 版本中已经被标记为过时(deprecated),推荐使用 createDirectstream 方法。
🍁 08、Kafka与传统消息队列的区别?
Kafka 和传统消息队列有以下几个区别:
- 消息持久化。传统消息队列通常使用内存作为消息存储,而 Kafka 使用磁盘作为消息存储。这使得 Kafka 能够在消息队列崩溃的情况下,仍然保证消息的可靠性。
- 消息分区。传统消息队列通常将消息存储在一个队列中,而 Kafka 将消息存储在多个分区中。这使得 Kafka 能够支持更高的吞吐量和更低的延迟。
- 消息订阅。传统消息队列通常使用轮询的方式来订阅消息,而 Kafka 使用消费者组的方式来订阅消息。这使得 Kafka 能够支持更高的并发性。
- 消息压缩。传统消息队列通常不支持消息压缩,而 Kafka 支持消息压缩。这使得 Kafka 能够节省存储空间和网络带宽。
以下是 Kafka 与传统消息队列的详细区别:
| 指标 | Kafka | 传统消息队列 |
|---|---|---|
| 消息持久化 | 使用磁盘作为消息存储 | 使用内存作为消息存储 |
| 消息分区 | 将消息存储在多个分区中 | 将消息存储在单个队列中 |
| 消息订阅 | 使用消费者组方式订阅消息 | 使用轮询方式订阅消息 |
| 消息压缩 | 支持消息压缩 | 不支持消息压缩 |
| 可靠性 | 提供高可靠性,保证消息不丢失 | 可能存在消息丢失的风险 |
| 吞吐量 | 支持高吞吐量,适合大规模消息处理 | 吞吐量较低,适合低频率消息处理 |
| 延迟 | 提供低延迟处理,适合实时性要求高的场景 | 延迟较高,适合非实时性要求高的场景 |
| 并发性 | 支持高并发处理,适合多个消费者同时消费消息 | 并发性较低,通常只能由一个消费者消费消息 |
需要注意的是,Kafka 相对于传统消息队列来说,更适合于大规模、高吞吐量、实时性要求高以及需要高可靠性的消息处理场景。传统消息队列则更适合于低频率、非实时性要求高的消息处理场景。
🍁 09、Master文件是否提供了多个入口?
Master 文件提供了多个入口,包括:
- Master 主入口:Master 主入口是 Master 的默认入口,用于启动 Master 服务。
- Master 管理入口:Master 管理入口用于管理 Master 服务,包括创建、修改和删除 Master 配置。
- Master 状态入口:Master 状态入口用于查看 Master 的状态,包括 Master 的运行状态、配置信息和日志信息。
- Master 监控入口:Master 监控入口用于监控 Master 的运行状态,包括 Master 的 CPU 使用率、内存使用率和网络使用率。
Master 文件提供了多个入口,可以满足不同用户的需求。例如,如果用户只需要启动 Master 服务,那么可以使用 Master 主入口。如果用户需要管理 Master 服务,那么可以使用 Master 管理入口。如果用户需要查看 Master 的状态,那么可以使用 Master 状态入口。如果用户需要监控 Master 的运行状态,那么可以使用 Master 监控入口。
🍁 10、Spark的数据本地性有哪几种?
Spark 的数据本地性有以下几种:
- 内存本地性:数据在内存中,并且在执行任务的节点上。
- 磁盘本地性:数据在磁盘上,并且在执行任务的节点上。
- 网络本地性:数据在磁盘上,并且在与执行任务的节点相邻的节点上。
Spark 会尽可能地将数据本地化,以提高数据访问的性能。例如,如果 Spark 任务需要访问一个 RDD,那么 Spark 会尝试将这个 RDD 的数据本地化到执行任务的节点上。如果这个 RDD 的数据已经在内存中,那么 Spark 会直接使用内存中的数据。如果这个 RDD 的数据在磁盘上,那么 Spark 会将数据从磁盘读取到内存中。如果这个 RDD 的数据在其他节点的磁盘上,那么 Spark 会将数据从其他节点的磁盘复制到执行任务的节点上。
Spark 的数据本地性可以通过以下方式来提高:
- 使用 Spark 的 cache 操作将数据缓存在内存中。
- 使用 Spark 的 broadcast 操作将数据广播到所有节点的内存中。
- 使用 Spark 的 shuffle 操作将数据从一个节点复制到另一个节点。
Spark 的数据本地性是提高 Spark 性能的重要手段。通过使用 Spark 的数据本地性,可以减少数据访问的延迟,提高 Spark 的性能。
🍁 11、Spark的shuffle过程是什么?
Spark的shuffle过程是指在数据处理过程中,将数据重新分区和排序的过程。它通常发生在数据转换操作(如groupByKey、reduceByKey、join等)之后,用于重新组织数据以满足后续计算的需求。
Spark的shuffle过程包括以下几个步骤:
-
Map阶段:在Map阶段,Spark将输入数据按照指定的键值对进行映射操作,并将数据划分为不同的分区。每个分区内部的数据是按照键进行排序的。
-
Shuffle阶段:在Shuffle阶段,Spark将每个分区的数据根据键进行重新分区,以便将相同键的数据发送到同一个Reducer节点上。这个过程涉及网络传输和数据重组。
-
Sort阶段:在Sort阶段,Spark对每个Reducer节点上的数据进行本地排序,确保相同键的数据在同一个分区内按照指定的排序规则进行排序。
-
Reduce阶段:在Reduce阶段,Spark将相同键的数据进行合并和聚合操作,生成最终的结果。
Shuffle过程是Spark中非常关键和耗时的阶段,它涉及大量的数据传输和数据重组操作,对性能有着重要影响。为了优化Shuffle过程的性能,Spark提供了一些优化策略,如合并排序、局部聚合、数据压缩等。
需要注意的是,Shuffle过程是一个开销较大的操作,因此在Spark应用程序中,尽量减少Shuffle的使用,可以有效提高性能。例如,可以使用更适合局部计算的转换操作(如reduceByKey替代groupByKey),或者使用广播变量来减少Shuffle的数据传输量。
🍁 12、fsimage和edit的区别?
fsimage 和 edit 是 Hadoop HDFS 中的两个重要文件,用于持久化存储文件系统的元数据。它们之间的区别如下:
-
fsimage:fsimage 是 HDFS 的镜像文件,包含了文件系统的完整元数据信息。它记录了文件和目录的层次结构、文件的大小、权限、时间戳等信息。fsimage 文件是只读的,它在 NameNode 启动时加载到内存中,用于快速恢复文件系统的状态。
-
edit:edit 是 HDFS 的编辑日志文件,用于记录文件系统的变更操作。当文件系统发生变更(如创建文件、删除文件、修改文件等)时,这些变更操作会被记录到 edit 文件中。edit 文件是可追加的,新的变更操作会被追加到文件的末尾。edit 文件记录了文件系统的增量变更,可以用于恢复文件系统的最新状态。
fsimage 和 edit 之间的关系如下:
- 当 NameNode 启动时,它会首先加载 fsimage 文件到内存中,将文件系统恢复到最近一次的状态。
- 然后,NameNode 会加载 edit 文件,并将其中的变更操作应用到内存中的文件系统状态上,以更新文件系统的最新状态。
- 在运行时,NameNode 会定期将内存中的变更操作持久化到新的 edit 文件中,以保证文件系统的持久性。
- 当 NameNode 下次启动时,它会先加载 fsimage 文件,然后再加载 edit 文件,以恢复文件系统的最新状态。
总之,fsimage 是文件系统的镜像文件,包含完整的元数据信息,而 edit 是文件系统的编辑日志文件,记录了文件系统的变更操作。fsimage 和 edit 文件一起工作,用于持久化存储和恢复 HDFS 文件系统的状态。
以下是关于fsimage和edit的区别的详细表格说明:
| 特性 | fsimage | edit |
|---|---|---|
| 类型 | 镜像文件 | 编辑日志文件 |
| 内容 | 包含完整的文件系统元数据信息 | 记录文件系统的变更操作 |
| 文件状态 | 只读 | 可追加 |
| 文件加载顺序 | 首先加载到内存中,用于恢复文件系统的状态 | 在fsimage加载后加载,用于更新文件系统的最新状态 |
| 文件恢复 | 用于恢复文件系统到最近一次的状态 | 用于应用变更操作以更新文件系统的最新状态 |
| 持久化 | 不会直接持久化变更操作 | 定期将变更操作持久化到新的edit文件中 |
| 启动过程 | 先加载fsimage,然后加载edit文件 | 先加载fsimage,再加载edit文件,以恢复文件系统的最新状态 |
需要注意的是,fsimage是文件系统的镜像文件,包含完整的元数据信息,用于恢复文件系统的状态。而edit是文件系统的编辑日志文件,记录了文件系统的变更操作,用于更新文件系统的最新状态。fsimage和edit文件一起工作,用于持久化存储和恢复HDFS文件系统的状态。
🍁 13、List与set的区别?
List和Set是Java中常用的集合类,它们在数据存储和操作方式上有以下区别:
-
数据存储方式:List是有序的集合,它可以存储重复的元素,并按照插入顺序维护元素的顺序。Set是无序的集合,它不允许存储重复的元素,并且不维护元素的插入顺序。
-
元素访问:List可以通过索引访问元素,根据元素在列表中的位置来获取或修改元素。Set没有提供索引访问的方式,只能通过迭代器或特定的方法来访问元素。
-
性能:由于List维护元素的顺序,因此在插入和删除元素时可能需要移动其他元素,这会导致性能略低于Set。Set在插入和删除元素时不需要维护顺序,因此性能通常比List更好。
-
重复元素:List允许存储重复的元素,即可以在列表中存在多个相同的元素。Set不允许存储重复的元素,如果尝试将重复元素添加到Set中,只会保留一个副本。
-
常用操作:List提供了按索引访问、添加、删除、修改等常用操作。Set提供了添加、删除、查找等常用操作,还提供了交集、并集、差集等集合运算。
根据具体的需求,选择使用List或Set。如果需要保留元素的插入顺序且允许重复元素,可以选择List。如果不关心元素的顺序且不允许重复元素,可以选择Set。
以下是关于List和Set的详细区别的表格说明:
| 特性 | List | Set |
|---|---|---|
| 数据存储方式 | 有序集合,按照插入顺序维护元素顺序 | 无序集合,不维护元素插入顺序 |
| 元素访问 | 可通过索引访问元素 | 无法通过索引访问元素,需要使用迭代器或特定方法 |
| 元素重复性 | 允许存储重复元素 | 不允许存储重复元素 |
| 性能 | 插入和删除元素时可能需要移动其他元素,性能较低 | 插入和删除元素时不需要维护顺序,性能较高 |
| 常用操作 | 按索引访问、添加、删除、修改等 | 添加、删除、查找等,还提供集合运算 |
| 实现类 | ArrayList、LinkedList等 | HashSet、TreeSet等 |
需要根据具体的需求选择使用List或Set。如果需要保留元素的插入顺序并允许重复元素,可以选择List。如果不关心元素的顺序且不允许重复元素,可以选择Set。具体的实现类可以根据具体需求选择,例如ArrayList和LinkedList是List的常见实现类,HashSet和TreeSet是Set的常见实现类。
🍁 14、Storm特点有哪些?
Storm 是一个分布式实时计算系统,具有以下特点:
-
实时性:Storm 是一个实时计算系统,能够处理实时流数据。它具有低延迟和高吞吐量的特点,能够实时处理大规模数据流。
-
容错性:Storm 具有高度的容错性,能够自动处理节点故障。当节点出现故障时,Storm 会自动重新分配任务,并保证计算的连续性和正确性。
-
可伸缩性:Storm 具有良好的可伸缩性,能够处理大规模的数据流和高并发的计算任务。它支持水平扩展,可以根据需求增加或减少计算节点。
-
灵活性:Storm 提供了灵活的编程模型,可以根据应用需求自定义计算逻辑。它支持多种数据源和数据处理方式,可以适应不同的实时计算场景。
-
可靠性:Storm 具有高度的可靠性,能够确保数据的完整性和一致性。它提供了消息确认机制和事务支持,可以保证数据的可靠传输和处理。
-
多语言支持:Storm 支持多种编程语言,包括Java、Python、Scala等,使开发人员能够使用自己熟悉的语言进行开发。
-
丰富的集成生态系统:Storm 与其他大数据工具和系统(如Hadoop、Kafka、HBase等)可以无缝集成,形成完整的数据处理和分析解决方案。
总之,Storm 是一个实时、可靠、可伸缩的分布式计算系统,具有高度的容错性和灵活性,能够处理大规模的实时数据流。它在实时数据处理、流计算和实时分析等领域具有广泛的应用。
🍁 15、海量日志数据,提取出某日访问百度次数最多的那个IP,如何实现提取?
要提取出某日访问百度次数最多的IP,可以按照以下步骤实现:
-
数据预处理:首先,对海量日志数据进行预处理,将每条日志数据按照日期和IP进行提取和整理。
-
按日期筛选:根据所需提取的日期,筛选出该日期的日志数据。
-
统计IP访问次数:对筛选出的日志数据进行统计,计算每个IP的访问次数。可以使用哈希表或其他数据结构来记录每个IP的访问次数。
-
找出访问次数最多的IP:遍历统计结果,找出访问次数最多的IP。可以使用一个变量来记录当前访问次数最多的IP,逐个比较每个IP的访问次数,更新记录的IP和访问次数。
-
输出结果:输出访问次数最多的IP,即找到了某日访问百度次数最多的IP。
需要注意的是,处理海量日志数据可能需要使用分布式计算框架(如Hadoop、Spark等)或者使用流处理系统(如Storm、Flink等)来处理和分析数据。这些工具提供了并行计算和分布式存储的能力,可以加速数据处理和提取的过程。
以下是一个简单的示例代码,用于从海量日志数据中提取出某日访问百度次数最多的IP:
from collections import defaultdict# 读取日志文件,假设每行日志格式为:日期 IP
def read_logs(log_file):logs = []with open(log_file, 'r') as file:for line in file:date, ip = line.strip().split(' ')logs.append((date, ip))return logs# 统计某日访问次数最多的IP
def find_most_visited_ip(logs, target_date):ip_count = defaultdict(int)for date, ip in logs:if date == target_date:ip_count[ip] += 1most_visited_ip = max(ip_count, key=ip_count.get)return most_visited_ip# 测试
logs = read_logs('logs.txt')
target_date = '2022-01-01'
most_visited_ip = find_most_visited_ip(logs, target_date)
print(f"The most visited IP on {target_date} is: {most_visited_ip}")
在上述示例中,假设日志文件的每行包含日期和IP,使用 read_logs 函数读取日志文件并返回一个包含日期和IP的列表。然后,使用 find_most_visited_ip 函数统计指定日期的IP访问次数,并返回访问次数最多的IP。最后,在测试部分使用示例日志数据和目标日期进行测试,并打印出访问次数最多的IP。
请注意,这只是一个简单的示例,实际处理海量日志数据可能需要使用更高效的算法和分布式计算框架来处理和分析数据。具体的实现方式会根据实际情况和使用的工具而有所不同。

相关文章:
初识大数据应用,一文掌握大数据知识文集(1)
文章目录 🏆初识大数据应用知识🔎一、初识大数据应用知识(1)🍁 01、请用Java实现非递归二分查询?🍁 02、是客户端还是Namenode决定输入的分片?🍁 03、mapred.job.tracker命令的作用?…...
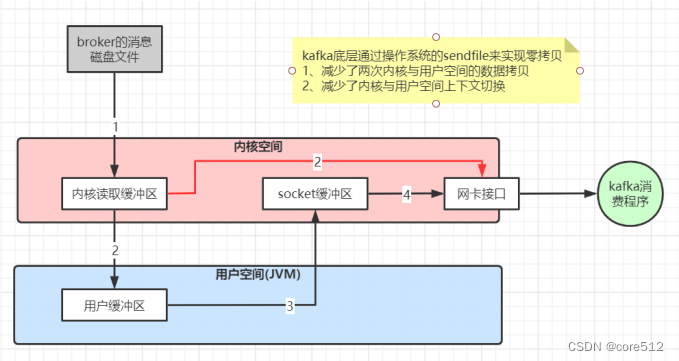
Kafka生产问题总结及性能优化实践
1、消息丢失情况 消息发送端: (1)acks0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。大数据统计报表场景,对性能要求很高&am…...

[MySQL]数据库原理2,Server,DataBase,Connection,latin1、UTF-8,gb2312,Encoding,Default Collation——喵喵期末不挂科
希望你开心,希望你健康,希望你幸福,希望你点赞! 最后的最后,关注喵,关注喵,关注喵,佬佬会看到更多有趣的博客哦!!! 喵喵喵,你对我真的…...

【算法集训】基础数据结构:十、矩阵
矩阵其实就是二维数组,这些题目在9日集训中已经做过,这里做的方法大致相同。 第一题 1351. 统计有序矩阵中的负数 int countNegatives(int** grid, int gridSize, int* gridColSize) {int r gridSize;int c gridColSize[0];int ret 0;for(int i 0;…...

python排序算法 直接插入排序法和折半插入排序法
最近需要使用到一些排序算法,今天主要使针对直接插入排序和折半插入排序进行讲解。 首先是直接插入排序,其排序过程主要是,针对A[a1,a2,a3,a4,a5....an],从排序的序列头部起始位置开始,将其也就是a1视为只有一个元素的…...

【flutter对抗】blutter使用+ACTF习题
最新的能很好反编译flutter程序的项目 1、安装 git clone https://github.com/worawit/blutter --depth1 然后我直接将对应的两个压缩包下载下来(通过浏览器手动下载) 不再通过python的代码来下载,之前一直卡在这个地方。 如果读者可以正…...

OpenHarmony 如何去除系统锁屏应用
前言 OpenHarmony源码版本:4.0release / 3.2 release 开发板:DAYU / rk3568 一、3.2版本去除锁屏应用 在源码根目录下:productdefine/common/inherit/rich.json 中删除screenlock_mgr组件的编译配置,在rich.json文件中搜索th…...

Python - 搭建 Flask 服务实现图像、视频修复需求
目录 一.引言 二.服务构建 1.主函数 upload_gif 2.文件接收 3.专属目录 4.图像修复 5.gif2mp4 6.mp42gif 7.图像返回 三.服务测试 1.服务启动 2.服务调用 四.总结 一.引言 前面我们介绍了如何使用 Real-ESRGAN 进行图像增强并在原始格式 jpeg、jpg、mp4 的基础上…...

C#基础——构造函数、析构函数
C#基础——构造函数、析构函数 1、构造函数 构造函数是一种特殊的方法,用于在创建类的实例时进行初始化操作。构造函数与类同名,并且没有返回类型。 构造函数在对象创建时自动调用,可以用来设置对象的初始状态、分配内存、初始化字段等操作…...

jmeter 如何循环使用接口返回的多值?
有同学在用jmeter做接口测试的时候,经常会遇到这样一种情况: 就是一个接口请求返回了多个值,然后下一个接口想循环使用前一个接口的返回值。 这种要怎么做呢? 有一定基础的人,可能第一反应就是先提取前一个接口返回…...

VLAN 详解一(VLAN 基本原理及 VLAN 划分原则)
VLAN 详解一(VLAN 基本原理及 VLAN 划分原则) 在早期的交换网络中,网络中只有 PC、终端和交换机,当某台主机发送一个广播帧或未知单播帧时,该数据帧会被泛洪,甚至传递到整个广播域。而广播域越大ÿ…...

Android - 分区存储 MediaStore、SAF
官方页面 参考文章 一、概念 分区存储(Scoped Storage)的推出是针对 APP 访问外部存储的行为(乱建乱获取文件和文件夹)进行规范和限制,以减少混乱使得用户能更好的控制自己的文件。 公有目录被分为两大类:…...

Shiro框架权限控制
首先去通过配置类的用户认证,在用户认证完成后,进行用户授权,用户通过授权之后再跳转其他的界面时,会进行一个验证,当前账号是否有权限。 前端权限控制显示的原理 在前端中,通常使用用户的角色或权限信息来…...
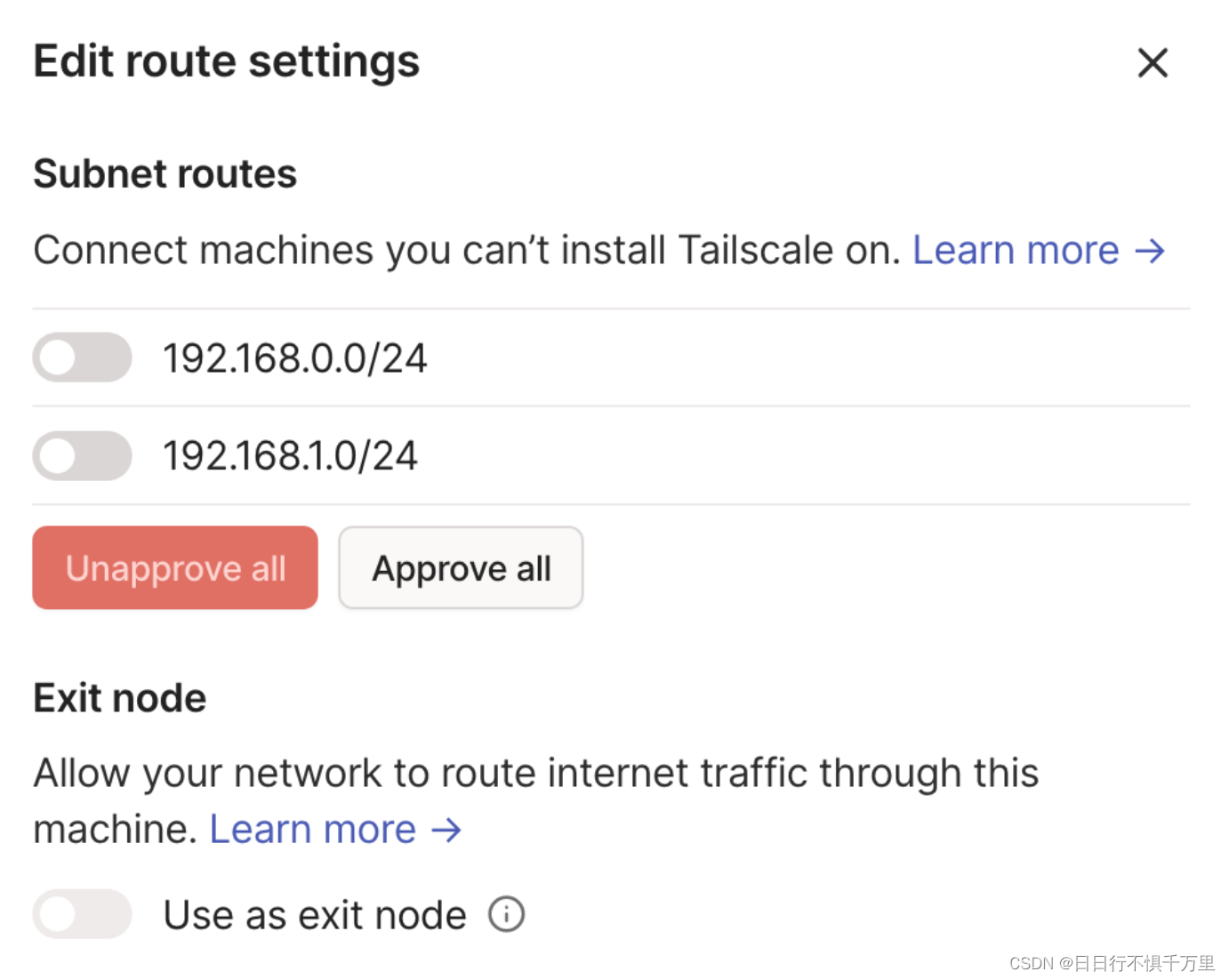
centOS7 安装tailscale并启用子网路由
1、在centOS7上安装Tailscale客户端 #安装命令所在官网位置:https://tailscale.com/download/linux #具体命令为: curl -fsSL https://tailscale.com/install.sh | sh #命令执行后如下图所示2、设置允许IP转发和IP伪装。 安装后,您可以启动…...

spring 项目中如何处理跨越cors问题
1.使用 CrossOrigin 注解 作用于controller 方法上 示例如下 RestController RequestMapping("/account") public class AccountController {CrossOriginGetMapping("/{id}")public Account retrieve(PathVariable Long id) {// ...}DeleteMapping(&quo…...

importlib --- import 的实现
3.1 新版功能. 源代码 Lib/importlib/__init__.py 概述 importlib 包具有三重目标。 一是在 Python 源代码中提供 import 语句的实现(并且因此而扩展 __import__() 函数)。 这提供了一个可移植到任何 Python 解释器的 import 实现。 与使用 Python 以…...

【PyTorch】现代卷积神经网络
文章目录 1. 理论介绍1.1. 深度卷积神经网络(AlexNet)1.1.1. 概述1.1.2. 模型设计 1.2. 使用块的网络(VGG)1.3. 网络中的网络(NiN)1.4. 含并行连结的网络(GoogLeNet)1.5. 批量规范化…...

用python编写九九乘法表
1 问题 我们在学习一门语言的过程中,都会练习到编写九九乘法表这个代码,下面介绍如何编写九九乘法表的流程。 2 方法 (1)打开pycharm集成开发环境,创建一个python文件,并编写第一行代码,主要构建…...
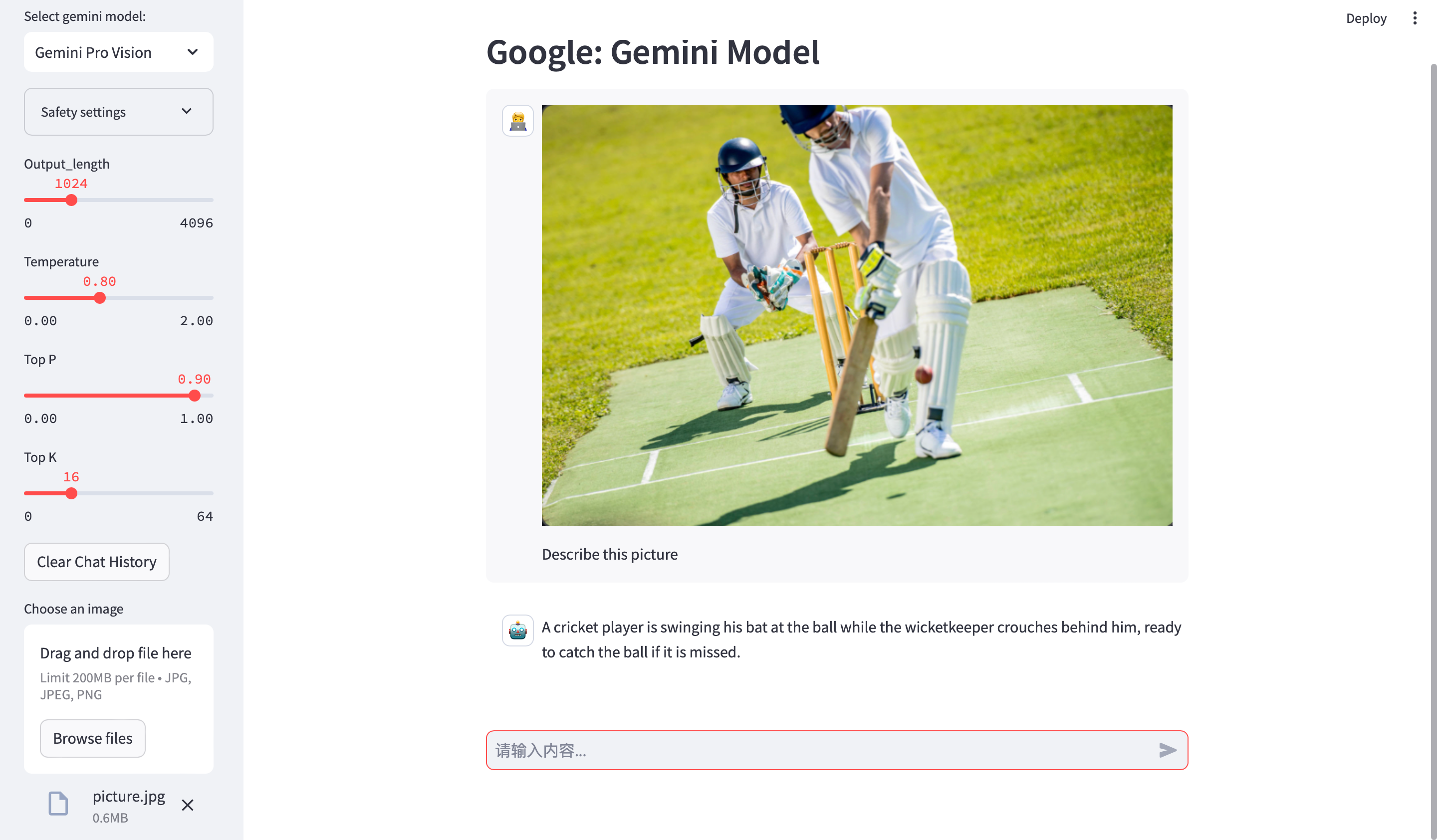
Google Gemini 模型本地可视化
Google近期发布了Gemini模型,而且开放了Gemini Pro API,Gemini Pro 可免费使用! Gemini Pro支持全球180个国家的38种语言,目前接受文本、图片作为输入并生成文本作为输出。 Gemini Pro的表现超越了其他同类模型,当前版…...

数据修复:.BlackBit勒索病毒来袭,安全应对方法解析
导言: 黑色数字罪犯的新玩具——.BlackBit勒索病毒,近来成为网络安全领域的头号威胁。这种恶意软件以其高度隐秘性和毁灭性而引起广泛关注。下面是关于.BlackBit勒索病毒的详细介绍,如不幸感染这个勒索病毒,您可添加我们的技术服…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...
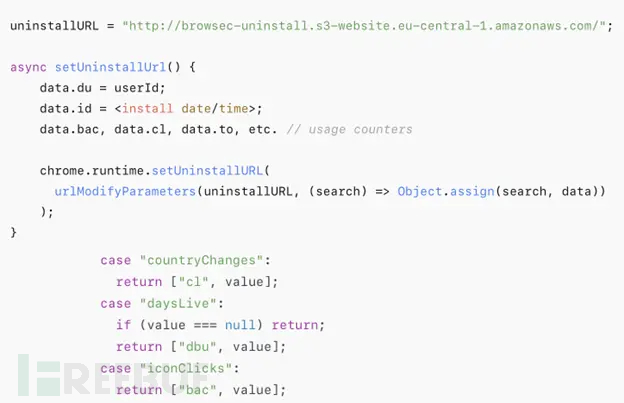
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...

TJCTF 2025
还以为是天津的。这个比较容易,虽然绕了点弯,可还是把CP AK了,不过我会的别人也会,还是没啥名次。记录一下吧。 Crypto bacon-bits with open(flag.txt) as f: flag f.read().strip() with open(text.txt) as t: text t.read…...

Windows 下端口占用排查与释放全攻略
Windows 下端口占用排查与释放全攻略 在开发和运维过程中,经常会遇到端口被占用的问题(如 8080、3306 等常用端口)。本文将详细介绍如何通过命令行和图形化界面快速定位并释放被占用的端口,帮助你高效解决此类问题。 一、准…...