【C++】C++11 新特性
目录
1.列表初始化
1.1. C++98中使用{}初始化的问题
1.2. 内置类型的列表初始化
1.3. 自定义类型的列表初始化
2. 变量类型推导
2.1. 为什么需要类型推导
2.2. decltype类型推导
2.2.1 为什么需要decltype
2.2.2. decltype
3. 对默认成员的控制(default、delete)
3.1. 显式缺省函数
3.2. 删除默认函数
3.3. final和override
4. 右值引用
4.1. 概念
4.2. 右值与左值
4.3. 左值引用与右值引用
4.4. 左值引用的缺陷
4.5. 移动语义
4.6. 移动构造和移动赋值
4.7. 完美转发
5. lambda表达式
5.1. lambda表达式语法
6. 包装器
6.1. 为什么需要包装器
6.2. 包装器的使用
6.3. bind包装器
6.3.1. bind包装器改变参数位置
6.3.2. bind包装器绑定固定参数
7. thread线程库
7.1. thread线程库函数介绍
7.2. 线程函数参数
7.3. lock_guard与unique_lock
7.3.1. Mutex的种类
7.3.2. lock_guard
7.3.3. unique_lock
7.4. 原子性操作库(atomic)
8. 条件变量(condition_variable)
1.列表初始化
1.1. C++98中使用{}初始化的问题
在C++98中,标准允许使用花括号{}对数组元素进行统一的列表初始值设定。比如:
int array1[] = {1,2,3,4,5};
int array2[5] = {0};对于一些自定义的类型,却无法使用这样的初始化。比如:
vector<int> v{1,2,3,4,5};就无法通过编译,导致每次定义vector时,都需要先把vector定义出来,然后使用循环对其赋初始值,非常不方便。C++11为了兼容C语言的这种特性,扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
1.2. 内置类型的列表初始化
int main()
{
// 内置类型变量
int x1 = {10};
int x2{10};
int x3 = 1+2;
int x4 = {1+2};
int x5{1+2};
// 数组
int arr1[5] {1,2,3,4,5};
int arr2[]{1,2,3,4,5};
// 动态数组,在C++98中不支持
int* arr3 = new int[5]{1,2,3,4,5};
// 标准容器
vector<int> v{1,2,3,4,5};
map<int, int> m{{1,1}, {2,2,},{3,3},{4,4},make_pair(5,5)};
return 0;
}注意:列表初始化可以在{}之前使用等号,其效果与不使用=没有什么区别.
1.3. 自定义类型的列表初始化
1.标准库支持单个对象的列表初始化
class Point
{
public:Point(int x = 0, int y = 0): _x(x), _y(y){}
private:int _x;int _y;
};
int main()
{Pointer p{ 1, 2 };return 0;
}2.多个对象的列表初始化
多个对象想要支持列表初始化,需给该类(模板类)添加一个带有initializer_list类型参数的构造函数即可。注意:initializer_list是系统自定义的类模板,该类模板中主要有三个方法:begin()、end()迭代器以及获取区间中元素个数的方法size()。
其底层可以看作是使用数组暂时将需要初始化的数据存储起来。
例如:这里简单实现以下vector底层的初始化列表:
#include <initializer_list>
template<class T>
class Vector {
public:Vector(initializer_list<T> l): _capacity(l.size()), _size(0)
{_array = new T[_capacity];for(auto e : l)_array[_size++] = e;
}
Vector<T>& operator=(initializer_list<T> l) {_array = new T[_capacity];size_t i = 0;for (auto e : l)_array[i++] = e;return *this;
}private:T* _array;size_t _capacity;size_t _size;
};2. 变量类型推导
2.1. 为什么需要类型推导
在定义变量时,必须先给出变量的实际类型,编译器才允许定义,但有些情况下可能不知道需要实际类型怎么给,或者类型写起来特别复杂,比如:
#include <map>
#include <string>
int main()
{short a = 32670;short b = 32670;// c如果给成short,会造成数据丢失,如果能够让编译器根据a+b的结果推导c的实际类型,就不会存在问题short c = a + b;std::map<std::string, std::string> m{{"apple", "苹果"}, {"banana","香蕉"}};// 使用迭代器遍历容器, 迭代器类型太繁琐std::map<std::string, std::string>::iterator it = m.begin();while(it != m.end()){cout<<it->first<<" "<<it->second<<endl;++it;}return 0;
}C++11中,可以使用auto来根据变量初始化表达式类型推导变量的实际类型,可以给程序的书写提供许多方便。将程序中c与it的类型换成auto,程序可以通过编译,而且更加简洁。
#include <map>
#include <string>
int main()
{std::map<std::string, std::string> m{{"apple", "苹果"}, {"banana","香蕉"}};auto it = m.begin();while(it != m.end()){cout<<it->first<<" "<<it->second<<endl;++it;}return 0;
}2.2. decltype类型推导
2.2.1 为什么需要decltype
auto使用的前提是:必须要对auto声明的类型进行初始化,否则编译器无法推导出auto的实际类型。但有时候可能需要根据表达式运行完成之后结果的类型进行推导,因为编译期间,代码不会运行,此时auto也就无能为力。
template<class T1, class T2>
T1 Add(const T1& left, const T2& right)
{return left + right;
}template<class T1, class T2>
auto Add(const T1& left, const T2& right) // 将返回值类型换成auto去自动推导,这里就会出错
{return left + right;
}如果能用加完之后结果的实际类型作为函数的返回值类型就不会出错,但这需要程序运行完才能知道结果的实际类型,即RTTI(Run-Time Type Identification 运行时类型识别)。
C++98中确实已经支持RTTI:typeid只能查看类型不能用其结果类定义类型dynamic_cast只能应用于含有虚函数的继承体系中
运行时类型识别的缺陷是降低程序运行的效率。
2.2.2. decltype
decltype是根据表达式的实际类型推演出定义变量时所用的类型,比如:
1.推演表达式类型作为变量的定义类型
int main()
{int a = 10;int b = 20;// 用decltype推演a+b的实际类型,作为定义c的类型decltype(a+b) c;cout<<typeid(c).name()<<endl; // typeid只能用作打印出对象的类型return 0;
}2. 推演函数返回值的类型
void* func(size_t size)
{return malloc(size);
}
int main()
{// 如果没有带参数,推导函数的类型cout << typeid(decltype(func)).name() << endl;// 如果带参数列表,推导的是函数返回值的类型,注意:此处只是推演,不会执行函数cout << typeid(decltype(func(0))).name() <<endl;return 0;
}
3. 对默认成员的控制(default、delete)
在C++中对于空类编译器会生成一些默认的成员函数,比如:构造函数、拷贝构造函数、运算符重载、析构函数和&和const&的重载、移动构造、移动拷贝构造等函数。如果在类中显式定义了,编译器将不会重新生成默认版本。
有时候这样的规则可能被忘记,最常见的是声明了带参数的构造函数,必要时则需要定义不带参数的版本以实例化无参的对象。而且有时编译器会生成,有时又不生成,容易造成混乱,于是C++11让程序员可以控制是否需要编译器生成。
3.1. 显式缺省函数
在C++11中,可以在默认函数定义或者声明时加上=default,从而显式的指示编译器生成该函数的默认版本,用=default修饰的函数称为显式缺省函数。
比如看以下代码:
#include<iostream>
#include<string>
using namespace std;class person
{
public://person(){}//person() = default;person(const person& p) //这里由于显式的创建拷贝构造,所以编译器不会默认生成构造函数,因为拷贝构造也是特殊的构造函数{_age = p._age;_name = p._name;}
private:int _age;string _name;
};int main()
{person p1; // 由于编译器没有生成默认构造函数,所以这里在定义对象p1时会找不到默认的构造函数导致出错person p2 = p1; return 0;
}
所以这时,如果不想显式的写出构造函数,就可以使用default,这样编译器就会认为并没有默认构造函数,就会自动生成。
person() = default;3.2. 删除默认函数
如果能想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且不给定义,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
例如:不想让一个类对象进行拷贝构造
class person
{
public:person(int age = 10, string name = "edward"):_age(age),_name(name){}person(const person& p) = delete; // C++11做法,使用delete关键字private:int _age;string _name;person(const person& p); // C++98做法:将拷贝构造私有,并且只声明不实现
};int main()
{person p1;return 0;
}3.3. final和override
这两个关键字也是C++11新增的,但是其实我们在学习继承和多态的时候已经见过了,这里不再过多描述。
final:修饰类,使该类不能被继承;修饰虚函数,该虚函数不能被重写。
override:检查派生类虚函数是否重写了基类某个虚函数,如果没有重写编译报错
4. 右值引用
4.1. 概念
C++98中提出了引用的概念,引用即别名,引用变量与其引用实体公共同一块内存空间,而引用的底层是通过指针来实现的,因此使用引用,可以提高程序的可读性。
为了提高程序运行效率,C++11中引入了右值引用,右值引用也是别名,但其只能对右值引用。
int fun(int n)
{return n - 1;
}int main()
{int x = 1, y = 2;int&& a = 10; // 引用常量int&& b = x + y; // 引用表达式int&& c = fun(2); // 引用函数返回值return 0;
}4.2. 右值与左值
左值与右值是C语言中的概念,但C标准并没有给出严格的区分方式,一般认为:可以放在=左边的,或者能够取地址的称为左值,只能放在=右边的,或者不能取地址的称为右值,但是也不一定完全正确。
关于左值与右值的区分不是很好区分,一般认为:
- 普通类型的变量,因为有名字,可以取地址,都认为是左值。
- const修饰的常量,不可修改,只读类型的,理论应该按照右值对待,但因为其可以取地址(如果只是const类型常量的定义,编译器不给其开辟空间,如果对该常量取地址时,编译器才为其开辟空间),C++11认为其是左值。
- 如果表达式的运行结果是一个临时变量或者对象,认为是右值。
- 如果表达式运行结果或单个变量是一个引用则认为是左值。
总结:
- 不能简单地通过能否放在=左侧右侧或者取地址来判断左值或者右值,要根据表达式结果或变量的性质判断,比如上述:c常量
- 能得到引用的表达式一定能够作为引用,否则就用常引用。
C++11对右值进行了严格的区分:
C语言中的纯右值,比如:a+b, 100
将亡值。比如:表达式的中间结果、函数按照值的方式进行返回。
4.3. 左值引用与右值引用
那么这里有一个问题:左值引用能否引用右值,右值引用能否引用左值?
int main()
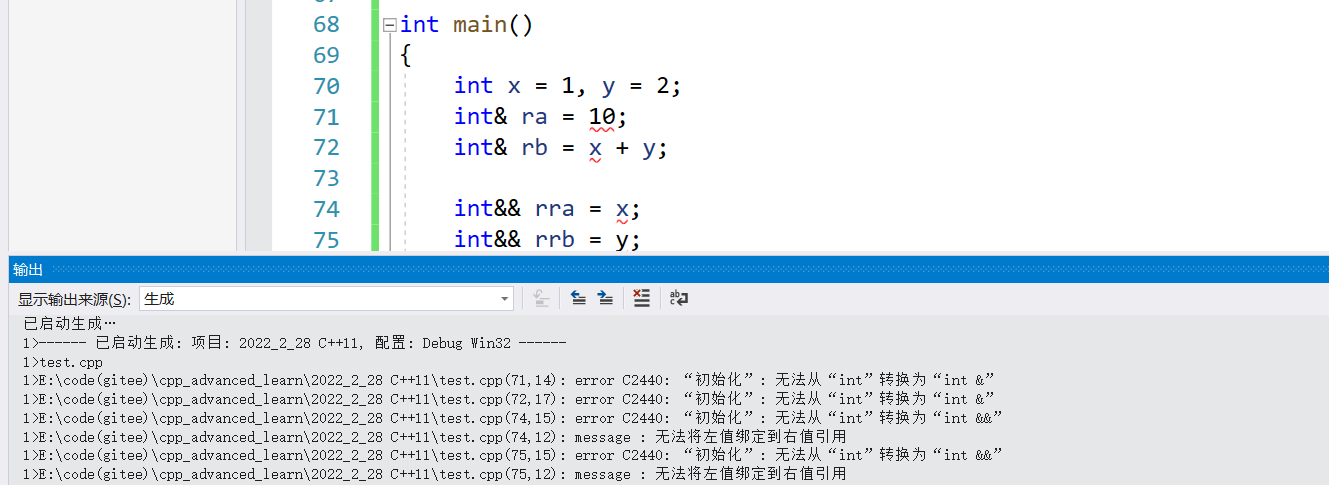
{int x = 1, y = 2;int& ra = 10; // 左值引用引用右值int& rb = x + y;int&& rra = x; // 右值引用引用左指 int&& rrb = y;return 0;
}这里通过编译器可以看到是会报错的:
注意:
普通引用只能引用左值,不能引用右值,const引用既可引用左值,也可引用右值。C++11中右值引用:只能引用右值,一般情况不能直接引用左值,可以通过move将左值变成右值然后引用。
int main()
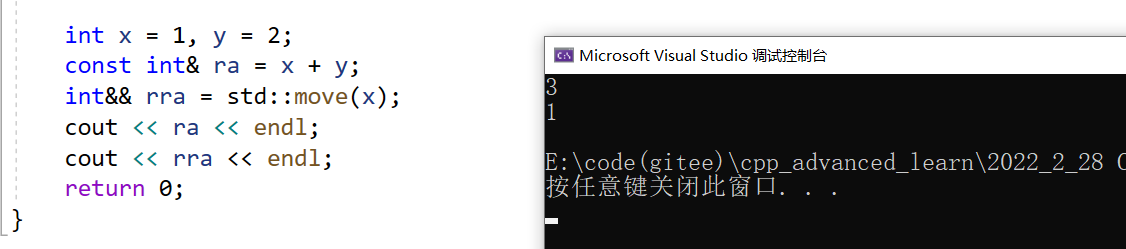
{int x = 1, y = 2;const int& ra = x + y;int&& rra = std::move(x); // move:将x变成右值cout << ra << endl;cout << rra << endl;return 0;
}

4.4. 左值引用的缺陷
当我们在函数中使用引用传传参时几乎是没有任何问题的,但是当函数中的返回值使用引用返回时可能就会出现问题。
比如:我们使用string的实现作为例子
namespace wt
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr), _size(0), _capacity(0){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}~string(){//cout << "~string()" << endl;delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}string operator+(char ch){string tmp(*this);push_back(ch);return tmp;}const char* c_str() const{return _str;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};wt::string to_string(int value){wt::string str;while (value){int val = value % 10;str += ('0' + val);value /= 10;}reverse(str.begin(), str.end());return str;}
}// 场景1
// 左值引用做参数,基本完美的解决所有问题
void func1(wt::string s)
{}void func2(const wt::string& s)
{}// 场景2
// 左值引用做返回值,只能解决部分问题
// wt::string& operator+=(char ch) //解决了
// wt::string operator+(char ch) // 没有解决,不能使用引用返回以前在学习拷贝构造时我们学习过,当上面的operator+这种情况,如果返回值是一个自定义类型,由于返回的是一个右值,所以在处理该函数的作用域之后,该右值会被立即销毁。所以在返回之前,会调用一次拷贝构造将返回值临时保存在调用该函数的栈帧中,然后再将临时值拷贝构造给接收该函数的对象。(这里编译器会优化为一次拷贝构造)
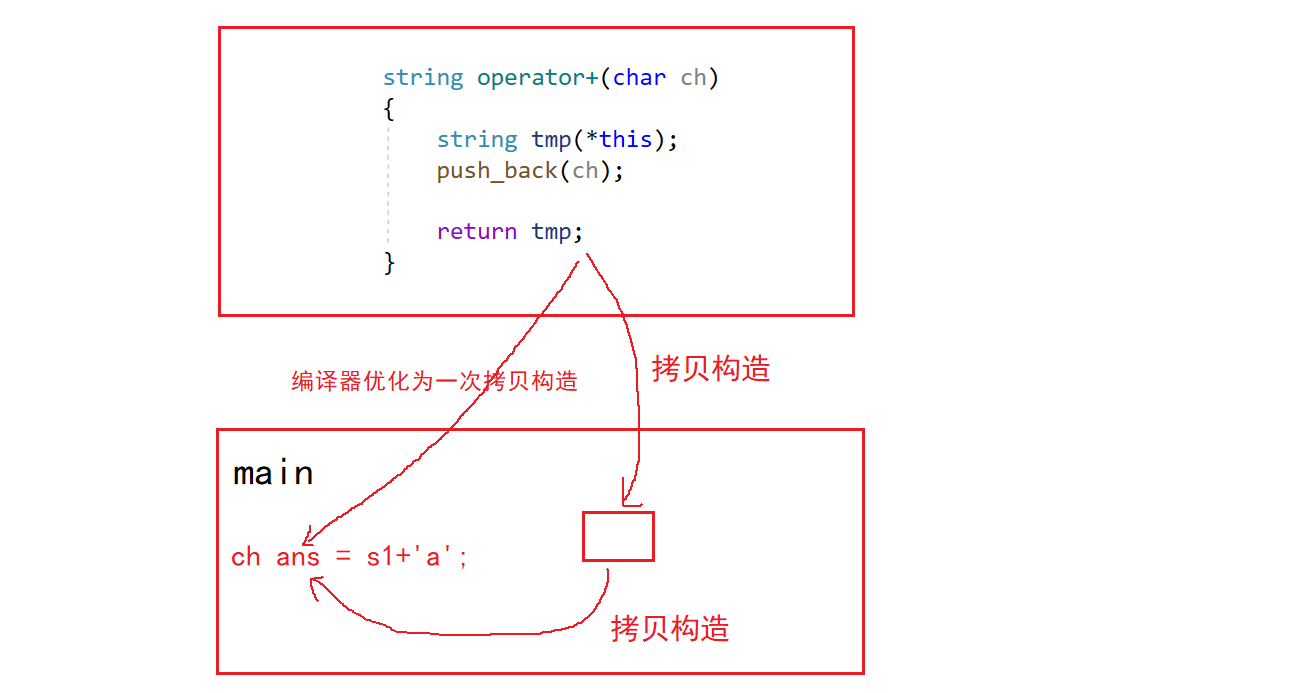
这里会发现:返回值、拷贝构造的临时对象、ans每个对象创建后都有自己的独立的空间,而且每个空间中的内容也完全相同,相当于创建了三个内容完全相同的对象,对于空间是一种浪费,程序的效率也会降低,而且临时对象确实作用不是很大 。
4.5. 移动语义
C++11提出了移动语义概念,即:将一个对象中资源移动到另一个对象中的方式,可以有效缓解该问题。
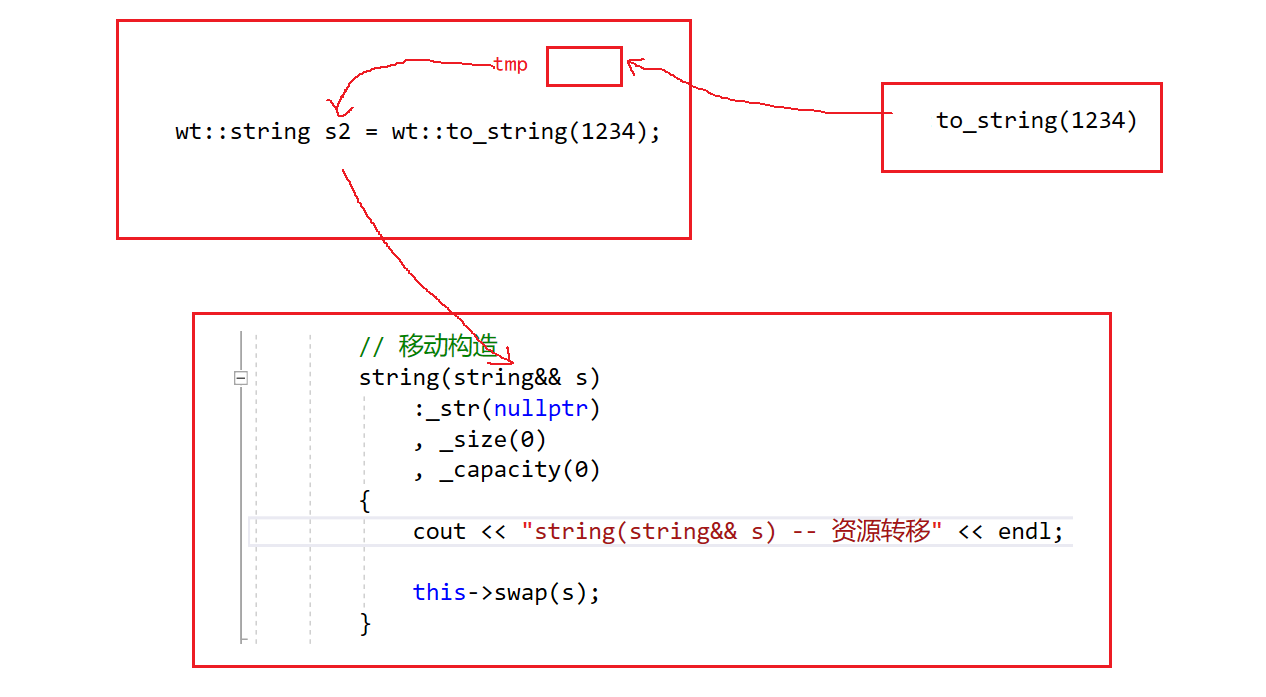
// 移动构造string(string&& s) //创建一个空string对象:_str(nullptr), _size(0), _capacity(0){cout << "string(string&& s) -- 资源转移" << endl;this->swap(s); // 将s内部的资源转移给空对象,由于s是右值后面会被释放,所以这里不会对它造成影响}// 移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 转移资源" << endl;swap(s);return *this;}int main()
{wt::string s1;wt::string s2 = wt::to_string(1234);cout << endl;s1 = wt::to_string(1234);return 0;
}这里我们使用to_string(1234)函数的返回值去初始化s2和赋值给s1,如果没有移动构造和移动赋值,那么肯定是会去深拷贝的:

如果有移动构造和移动赋值则不会:

有了移动语义,应该慎用move,因为如果将一个左值给move了,那么他内部的资源就可能被转移走了,这时再去使用这个左值对象就可能出现问题。
4.6. 移动构造和移动赋值
原来C++类中,有6个默认成员函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
最后重要的是前4个,后两个用处不大。默认成员函数就是我们不写编译器会生成一个默认的。
C++11新增了两个:移动构造函数和移动赋值运算符重载。
针对移动构造函数和移动赋值运算符重载有一些需要注意的点如下:
如果自己没有实现移动构造函数,且没有实现析构函数、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
如果自己没有实现移动赋值重载函数,且没有实现析构函数、拷贝构造、考贝赋值重载中的任意一个,那么编译器会白动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,白定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值
4.7. 完美转发
完美转发是指在函数模板中,完全依照模板的参数的类型,将参数传递给函数模板中调用的另外一个函数。
假如有以下场景:
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t)
{Fun(t);
}int main()
{PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值return 0;
}
根据上面的代码产生的结果我们会发现,为什么给函数中传入的右值,再传入Fun函数后全部匹配到了左值引用的函数?
模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,
但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值,
由于传入的是右值,所以PerfectForward函数在接收他时会创建一块临时的空间保存它,这时这个右值就可以被取地址了,所以它的属性就变成了右值!
我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用我们下面学习的完美转发:
Fun(std::forward<T>(t)); //forward<T> 完美转发:将参数按照传递给转发函数的实际类型转给目标函数,而不产生额外的开销所谓完美:函数模板在向其他函数传递自身形参时,如果相应实参是左值,它就应该被转发为左值;如果相应实参是右值,它就应该被转发为右值。
5. lambda表达式
从C语言的函数指针到C++98的仿函数,在有些时候使用其实很不方便,特别是函数指针,所以C++11中添加了lambda表达式。
5.1. lambda表达式语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
lambda表达式各部分说明
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
注意:
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空。
因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。
int main()
{// 最简单的lambda表达式, 该lambda表达式没有任何意义[]{};// 省略参数列表和返回值类型,返回值类型由编译器推导为intint a = 3, b = 4;[=]{return a + 3; };// 省略了返回值类型,无返回值类型auto fun1 = [&](int c){b = a + c; };fun1(10)cout<< a <<" "<<b<<endl;// 各部分都很完善的lambda函数auto fun2 = [=, &b](int c)->int{return b += a+ c; };cout<<fun2(10)<<endl;// 赋值捕捉xint x = 10;auto add_x = [x](int a) mutable { x *= 2; return a + x; };cout << add_x(10) << endl;return 0;
}通过上述例子可以看出,lambda表达式实际上可以理解为无名函数,该函数无法直接调用,如果想要直接调用,可借助auto将其赋值给一个变量。
捕获列表说明
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
注意:
a. 父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量 [&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。 比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
f. lambda表达式之间不能相互赋值,即使看起来类型相同
实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
6. 包装器
6.1. 为什么需要包装器
function包装器 也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。
- func可能是什么呢?那么func可能是函数名?函数指针?函数对象(仿函数对象)?也有可能
- 是lamber表达式对象?所以这些都是可调用的类型!
- 如此丰富的类型,可能会导致模板的效率低下! 为什么呢?
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}double f(double i)
{return i / 2;
}struct Functor
{double operator()(double d){return d / 3;}
};int main()
{// 函数名cout << useF(f, 22.22) << endl;// 函数对象cout << useF(Functor(), 33.33) << endl; //匿名对象// lamber表达式cout << useF([](double d)->double { return d / 4; }, 44.44) << endl;return 0;
}
-
- 由于函数指针、仿函数、lambda表达式是不同的类型,因此useF函数会被实例化出三份,三次调用useF函数所打印count的地址也是不同的。
- 但实际这里根本没有必要实例化出三份useF函数,因为三次调用useF函数时传入的可调用对象虽然是不同类型的,但这三个可调用对象的返回值和形参类型都是相同的。
使用包装器可以解决这里的问题:
template <class T> function; template <class Ret, class... Args>
class function<Ret(Args...)>;模板参数说明
- Ret :被包装的可调用对象的返回值类型。
- Args... :被包装的可调用对象的形参类型。
6.2. 包装器的使用
function包装器可以对可调用对象进行包装,包括函数指针(函数名)、仿函数(函数对象)、lambda表达式、类的成员函数
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count: " << ++count << endl;cout << "count: " << &count << endl;return f(x);
}double f(double i)
{return i / 2;
}struct Functor
{double operator()(double d){return d / 3;}
};int main()
{//函数名function<double(double)> func1 = f;cout << useF(func1, 22.22) << endl;//函数对象function<double(double)> func2 = Functor();cout << useF(func2, 33.33) << endl;//lambda表达式function<double(double)> func3 = [](double d)->double {return d / 4; };cout << useF(func3, 44.44) << endl;return 0;
}
用包装器分别对着三个可调用对象进行包装,然后再用这三个包装后的可调用对象来调用useF函数,这时就只会实例化出一份useF函数。
根本原因就是因为包装后,这三个可调用对象都是相同的function类型,因此最终只会实例化出一份useF函数,该函数的第一个模板参数的类型就是function类型的。
当包装器包装类的非静态成员函数时需要额外注意:
class Plus
{
public:static int plusi(int a, int b){return a + b;}double plusd(double a, double b){return a + b;}
};
int main()
{function<double(Plus, double, double)> func5 = &Plus::plusd; //&不可省略cout << func5(Plus(), 1.1, 2.2) << endl; // 需要传入类对象去调用类中的非静态成员函数return 0;
}6.3. bind包装器
bind也是一种函数包装器,也叫做适配器。它可以接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
bind函数模板的原型
template <class Fn, class... Args>
bind(Fn&& fn, Args&&... args);template <class Ret, class Fn, class... Args>
bind(Fn&& fn, Args&&... args);- fn : 可调用对象。
- args... :要绑定的参数列表:值或占位符。
6.3.1. bind包装器改变参数位置
int Plus(int a, int b)
{return a - b;
}int main()
{function<int(int, int)> func = bind(Plus, placeholders::_2, placeholders::_1);// 将参数1与参数2交换位置cout << func(1, 2) << endl; //1return 0;
}绑定时第一个参数传入函数指针这个可调用对象,但后续传入的要绑定的参数列表依次是placeholders::2和placeholders::1,表示后续调用新生成的可调用对象时,传入的第一个参数传给placeholders::2,传入的第二个参数传给placeholders::1。
6.3.2. bind包装器绑定固定参数
int Plus(int a, int b)
{return a + b;
}int main()
{//绑定固定参数function<int(int)> func = bind(Plus, placeholders::_1, 10);cout << func(2) << endl; //12return 0;
}- 想把Plus函数的第二个参数固定绑定为10,可以在绑定时将参数列表的placeholders::_2设置为10
- 此时调用绑定后新生成的可调用对象时就只需要传入一个参数,它会将该值与10相加后的结果进行返回
bind包装器的意义:
- 将一个函数的某些参数绑定为固定的值,让我们在调用时可以不用传递某些参数。
- 可以对函数参数的顺序进行灵活调整。
7. thread线程库
7.1. thread线程库函数介绍
在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得代码的可移植性比较差。
C++11中最重要的特性就是对线程进行支持了,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念。
要使用标准库中的线程,必须包含< thread >头文件。
| 函数名 | 功能 |
| thread() | 构造一个线程对象,没有关联任何线程函数,即没有启动任何线程 |
| thread(fn, args1, args2, ...) | 构造一个线程对象,并关联线程函数fn,args1,args2,...为线程函数的参数 |
| get_id() | 获取线程id |
| jionable() | 线程是否还在执行,joinable代表的是一个正在执行中的线程。 |
| jion() | 该函数调用后会阻塞住线程,当该线程结束后,主线程继续执行 |
| detach() | 在创建线程对象后马上调用,用于把被创建线程与线程对象分离开,分离的线程 变为后台线程,创建的线程的"死活"就与主线程无关 |
注意:
- 线程是操作系统中的一个概念,线程对象可以关联一个线程,用来控制线程以及获取线程的状态。
- 当创建一个线程对象后,没有提供线程函数,该对象实际没有对应任何线程 。
例如:
#include<iostream>
#include<thread>
using namespace std;void func(int n)
{cout << this_thread::get_id() << endl; //打印该线程的idfor (int i = 0; i < n; ++i){cout << i << endl;}
}int main()
{thread t1(func, 10); //创建线程//thread(func, 10).detach(); //创建匿名线程 注意:匿名线程必须在创建时将线程分离,因为后面会找不到t1.join(); //线程等待// this_thread::sleep_for(std::chrono::seconds(3)); //使当前线程休眠return 0;
}其实这里线程的创建的方法与前面linux中学习的类似,只是C++11中用对象封装了,使用起来更加方便了。
get_id()的返回值类型为id类型,id类型实际为std::thread命名空间下封装的一个类(因为Windows和Linux下对线程id处理的方式不同,C++中为了方便跨平台的使用所以这样处理),该类中包含了一个结构体:
// vs下查看
typedef struct
{ /* thread identifier for Win32 */void *_Hnd; /* Win32 HANDLE */unsigned int _Id;
} _Thrd_imp_t;当创建一个线程对象后,并且给线程关联线程函数,该线程就被启动,与主线程一起运行。线程函数一般情况下可按照以下三种方式提供:
函数指针
lambda表达式
函数对象
例如:
class add
{
public:int operator()(int x, int y){return x + y;}
};int func(int x, int y)
{return x + y;
}int main()
{int a = 10, b = 20;thread t1(func, a, b); // 函数指针thread t2([=](int, int)->int {return a + b; }, a, b); // lambda表达式function<int<int,int>> A = add();thread t3(A,a,b); // 函数对象t1.join();t2.join();t3.join();return 0;
}thread类是防拷贝的,不允许拷贝构造以及赋值,但是可以移动构造和移动赋值,即将一个线程对象关联线程的状态转移给其他线程对象,转移期间不意向线程的执行。
可以通过jionable()函数判断线程是否是有效的,如果是以下任意情况,则线程无效:
1.采用无参构造函数构造的线程对象
2.线程对象的状态已经转移给其他线程对象
3.线程已经调用jion或者detach结束
面试题:并发与并行的区别?
并发:
当存在多个线程时,若系统仅有一个CPU,则根本不可能真正地同时进行一个以上的线程,系统只能把CPU的运行时间划分为若干个时间段,再将时间段分配给各个线程。在一个线程在其时间段执行时,其余线程处于挂起状。这种方式我们称之为并发。
并行:
若系统拥有一个以上CPU时,则存在多个线程时可并行执行。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行。这种方式我们称之为并行。
区别:
并发和并行是即相似又有区别的两个概念,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。
在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,但在单处理机系统中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。
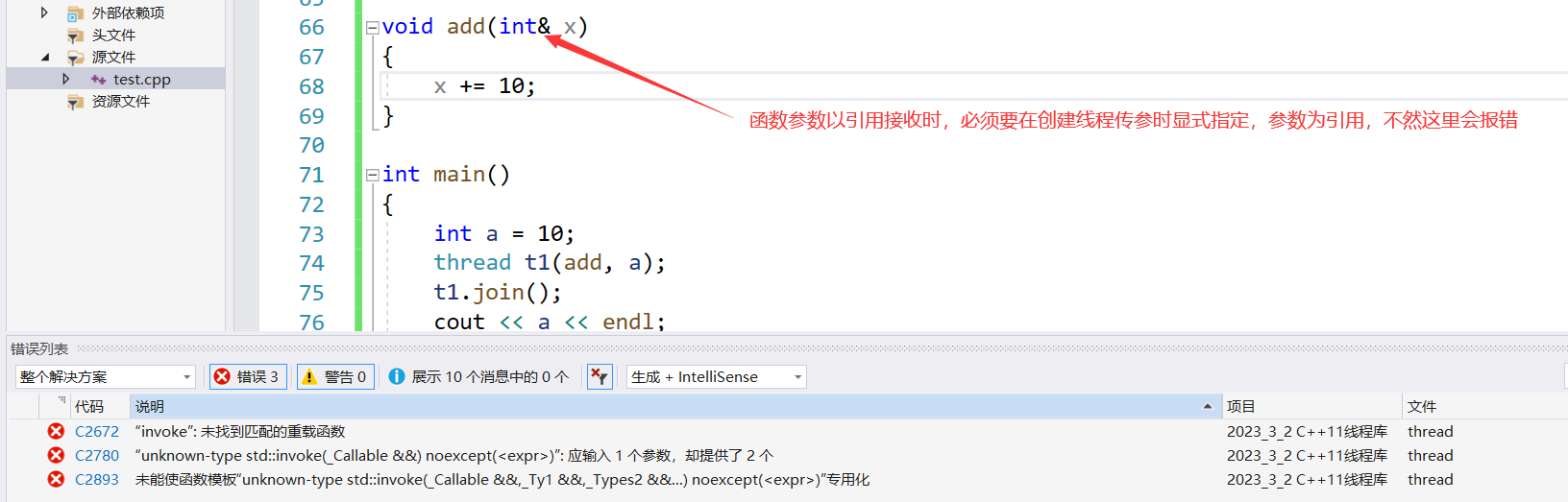
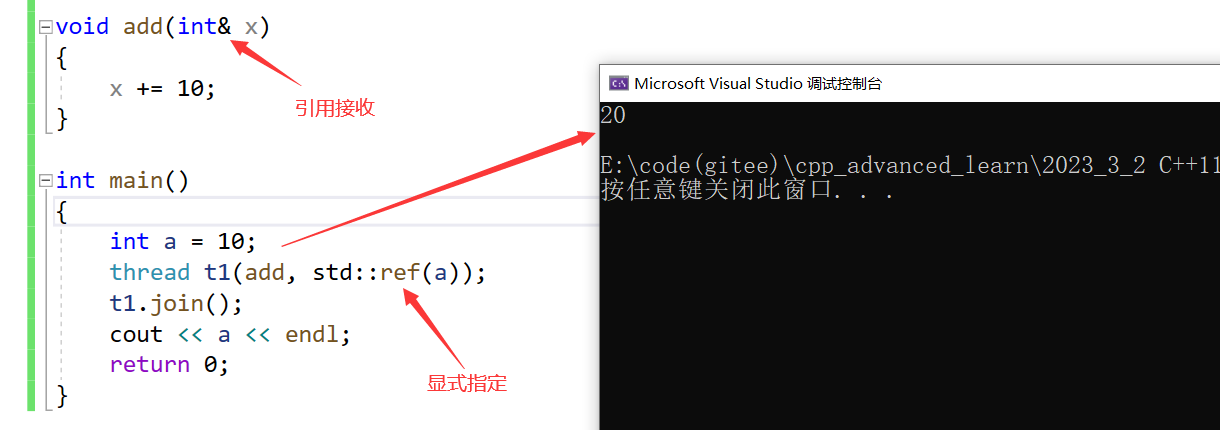
7.2. 线程函数参数
线程函数的参数是以值拷贝的方式拷贝到线程栈空间中的,因此:即使线程参数为引用类型,在线程中修改后也不能修改外部实参,因为其实际引用的是线程栈中的拷贝,而不是外部实参。

当然还有一种方法能够改变参数的值,那就是指针:
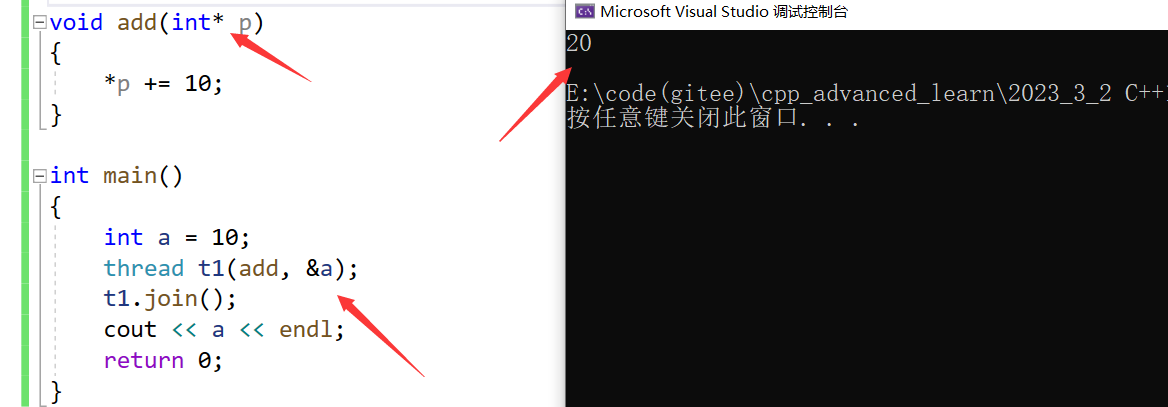
注意:如果是类成员函数作为线程参数时,必须将this作为线程函数参数。
class A
{
public:int add(int x, int y){cout << x + y << endl;return x + y;}
};int main()
{A a;// 传入顺序 线程函数,实例化类指针,函数参数thread t1(&A::add, &a, 10, 20);t1.join();return 0;
}7.3. lock_guard与unique_lock
在多线程环境下,如果想要保证某个变量的安全性,只要将其设置成对应的原子类型即可,即高效又不容易出现死锁问题。但是有些情况下,我们可能需要保证一段代码的安全性,那么就只能通过锁的方式来进行控制。
比如两个线程同时对一个变量进行++操作:
int x = 0;void add(int n)
{for (int i = 0; i < n; ++i){x++;cout << this_thread::get_id() << ":" << x << endl;}
}int main()
{thread t1(add, 10000);thread t2(add, 10000);t1.join();t2.join();return 0;
}上面的代码两个线程各自对x加了10000次,但是从结果中可以发现x最后的值只有1992,所以这其中一定出现了线程安全问题。
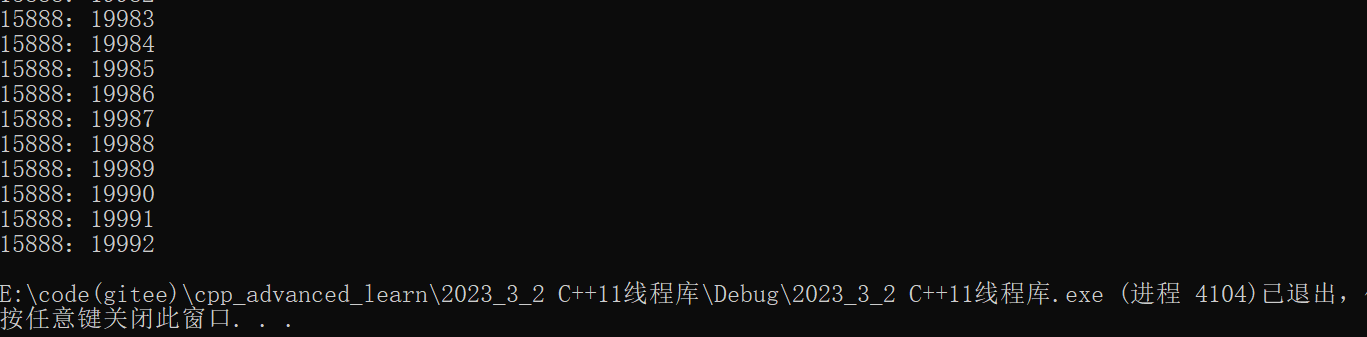
所以这里需要进行加锁操作,C++11中也新增了加锁的库:

那么这里问题来了,这里的加锁应该加载for循环的里面还是外面?
答案是外面。虽然加载外面看起来两个线程就是串行运行了,但是针对这里的实际问题而言++的操作是非常快的,如果锁加在循环里面会导致两个线程频繁的去竞争锁和释放锁,频繁的去切换上下文,导致对资源的消耗非常大。
int x = 0;
mutex mtx;
void add(int n)
{mtx.lock();for (int i = 0; i < n; ++i){//mtx.lock();x++;cout << this_thread::get_id() << ":" << x << endl;//mtx.unlock();}mtx.unlock();
}int main()
{thread t1(add, 10000);thread t2(add, 10000);t1.join();t2.join();return 0;
}7.3.1. Mutex的种类
上述代码的缺陷:锁控制不好时,可能会造成死锁,最常见的比如在锁中间代码返回,或者在锁的范围内抛异常。因此:C++11采用RAII的方式对锁进行了封装,即lock_guard和unique_lock。
在C++11中,Mutex总共包了四个互斥量的种类:
mutex:
C++11提供的最基本的互斥量,该类的对象之间不能拷贝,也不能进行移动。mutex最常用的三个函数:
| 函数名 | 函数功能 |
| lock() | 上锁:锁住互斥量 |
| unlock() | 解锁:释放对互斥量的所有权 |
| try_lock() | 尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞 |
注意,线程函数调用lock()时,可能会发生以下三种情况:
- 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁
- 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住
- 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
线程函数调用try_lock()时,可能会发生以下三种情况:
- 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量
- 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉
- 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
recursive_mutex :
其允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),除此之外,std::recursive_mutex 的特性和std::mutex 大致相同。
timed_mutex :
比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until() 。
try_lock_for()
接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
try_lock_until()
接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
7.3.2. lock_guard
std::lock_gurad 是 C++11 中定义的模板类。定义如下 :
template<class _Mutex>
class lock_guard
{
public:// 在构造lock_gard时,_Mtx还没有被上锁explicit lock_guard(_Mutex& _Mtx): _MyMutex(_Mtx){_MyMutex.lock();}// 在构造lock_gard时,_Mtx已经被上锁,此处不需要再上锁lock_guard(_Mutex& _Mtx, adopt_lock_t): _MyMutex(_Mtx){}~lock_guard() _NOEXCEPT{_MyMutex.unlock();}lock_guard(const lock_guard&) = delete;lock_guard& operator=(const lock_guard&) = delete;
private:_Mutex& _MyMutex;
};lock_guard类模板主要是通过RAII的方式,对其管理的互斥量进行了封装,在需要加锁的地方,只需要用上述介绍的任意互斥体实例化一个lock_guard,调用构造函数成功上锁,出作用域前,lock_guard对象要被销毁,调用析构函数自动解锁,可以有效避免死锁问题。
lock_guard的缺陷:太单一,用户没有办法对该锁进行控制,因此C++11又提供了unique_lock。
7.3.3. unique_lock

与lock_gard类似,unique_lock*类模板也是采用RAII的方式对锁进行了封装,并且也是以独占所有权的方式管理mutex对象的上锁和解锁操作,即其对象之间不能发生拷贝。在构造(或移动(move)赋值)时,unique_lock 对象需要传递一个 Mutex 对象作为它的参数,新创建的 unique_lock 对象负责传入的 Mutex对象的上锁和解锁操作。使用以上类型互斥量实例化unique_lock的对象时,自动调用构造函数上锁,unique_lock对象销毁时自动调用析构函数解锁,可以很方便的防止死锁问题。
与lock_guard不同的是,unique_lock更加的灵活,提供了更多的成员函数:
上锁/解锁操作:lock、try_lock、try_lock_for、try_lock_until和unlock
修改操作:移动赋值、交换(swap:与另一个unique_lock对象互换所管理的互斥量所有权)、释放(release:返回它所管理的互斥量对象的指针,并释放所有权)
获取属性:owns_lock(返回当前对象是否上了锁)、operator bool()(与owns_lock()的功能相同)、mutex(返回当前unique_lock所管理的互斥量的指针)。
7.4. 原子性操作库(atomic)
多线程最主要的问题是共享数据带来的问题(即线程安全)。如果共享数据都是只读的,那么没问题,因为只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。但是,当一个或多个线程要修改共享数据时,就会产生很多潜在的麻烦 。

所谓原子操作:即不可被中断的一个或一系列操作,C++11引入的原子操作类型,使得线程间数据的同步变得非常高效 。
对于上面的问题:两个线程同时对一个变量进行++操作,这里就可以用到原子性操作:
#include<atomic>
atomic<int> x = 0;
void add(int n)
{for (int i = 0; i < n; ++i){x++; // 原子操作cout << this_thread::get_id() << ":" << x << endl;}
}int main()
{thread t1(add, 10000);thread t2(add, 10000);t1.join();t2.join();return 0;
}在C++11中,程序员不需要对原子类型变量进行加锁解锁操作,线程能够对原子类型变量互斥的访问。
更为普遍的,程序员可以使用atomic类模板,定义出需要的任意原子类型。
atmoic<T> t; // 声明一个类型为T的原子类型变量t注意:原子类型通常属于"资源型"数据,多个线程只能访问单个原子类型的拷贝,因此在C++11中,原子类型只能从其模板参数中进行构造,不允许原子类型进行拷贝构造、移动构造以及operator=等,为了防止意外,标准库已经将atmoic模板类中的拷贝构造、移动构造、赋值运算符重载默认删除掉了。
#include <atomic>
int main()
{atomic<int> a1(0);//atomic<int> a2(a1); // 编译失败atomic<int> a2(0);//a2 = a1; // 编译失败return 0;
}8. 条件变量(condition_variable)
在学习Linux时我们学到过条件变量,在C++11中也增加了条件变量。

问题:如果实现一个线程打印偶数,一个线程打印奇数,且两个线程交替打印?
如果我们使用前面学过的加锁来试一试:
int main()
{int end = 100;int i = 0;mutex mtx;thread t1([end, &i, &mtx] {while (i < end){unique_lock<mutex> lock(mtx);this_thread::sleep_for(std::chrono::milliseconds(100));cout << this_thread::get_id() << "->" << i << endl;++i;}});thread t2([end, &i, &mtx] {while (i < end){unique_lock<mutex> lock(mtx);this_thread::sleep_for(std::chrono::milliseconds(100));cout << this_thread::get_id() << "->" << i << endl;++i;}});t1.join();t2.join();return 0;
}
通过结果我们可以看到,上面的方法根本不能实现交替打印奇偶数,甚至一个线程打印了多次。
所以这里可以使用互斥锁+条件变量解决:条件变量可以因为一个条件的不满足而使线程陷入休眠状态,并且释放已经申请到的锁,直到条件满足才会唤醒线程。
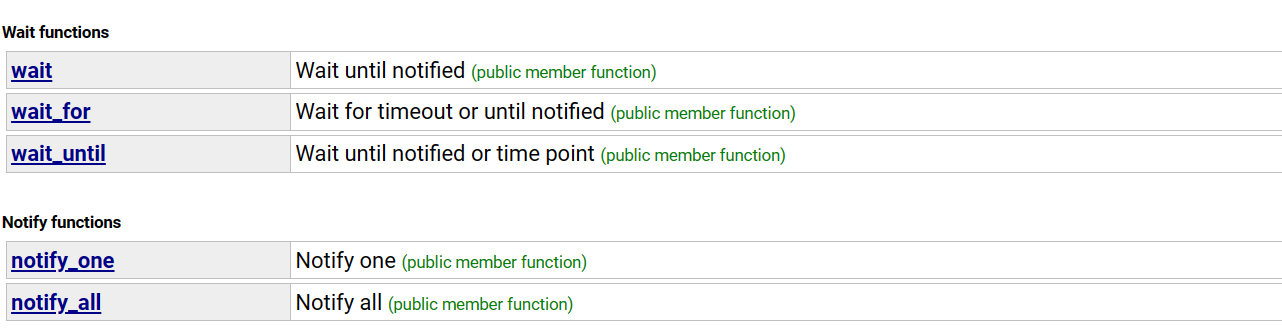

注意:Predicate是一个可调用的对象或函数,他的结果会决定线程是否进入等待,具体实现为下图所示,若while条件成立,会去调用wait函数。

这里条件变量停止等待的条件时pred为真。
#include<condition_variable>
int main()
{int end = 100;int i = 0;mutex mtx;condition_variable cv;bool flag = false;//打印偶数thread t1([end, &i, &mtx,&cv,&flag] {while (i < end){unique_lock<mutex> lock(mtx);// flag=false,返回true,t1不会等待cv.wait(lock, [&flag] {return !flag; });this_thread::sleep_for(std::chrono::milliseconds(100));cout << this_thread::get_id() << "->" << i << endl;++i;flag = true;cv.notify_one();}});//打印奇数thread t2([end, &i, &mtx, &cv, &flag] {while (i < end){unique_lock<mutex> lock(mtx);// flag = false,返回false,t2会等待,如果申请到了锁也会释放cv.wait(lock, [&flag] {return flag; });this_thread::sleep_for(std::chrono::milliseconds(100));cout << this_thread::get_id() << "->" << i << endl;++i;flag = false;cv.notify_one();}});t1.join();t2.join();return 0;
}
相关文章:
【C++】C++11 新特性
目录 1.列表初始化 1.1. C98中使用{}初始化的问题 1.2. 内置类型的列表初始化 1.3. 自定义类型的列表初始化 2. 变量类型推导 2.1. 为什么需要类型推导 2.2. decltype类型推导 2.2.1 为什么需要decltype 2.2.2. decltype 3. 对默认成员的控制(default、delete) 3.1. …...

JPA 相关注解说明
jpa相关注解 JPA(Java Persistence API)是一种Java规范,定义了一套标准的对象关系映射(ORM)API,用于将Java对象映射到关系型数据库中。JPA旨在统一各种ORM框架之间的差异,提供一种标准化的ORM解…...

SAP 生产订单/流程订单中日期的解释
SAP 生产订单/流程订单中日期的解释 基本开始日期:表示订单的开始日期 基本完成日期:表示订单的完成日期 我们在输入基本开始日期和基本完成日期时需要关注 调度 下面的“类型”,其中有向前、向后、当天日期等: 调度类型 为向前…...
Java设计模式笔记——七大设计原则
系列文章目录 第一章 Java 设计模式之七大设计原则 文章目录系列文章目录前言一、单一职责原则1.案例分析2.改进二、开闭原则1.案例分析2.改进三、里氏替换原则1.案例分析2.改进四、依赖倒转原则五、接口隔离原则1.案例分析2.改进六、合成复用原则1.案例分析2.改进七、迪米特原…...
记录第一次接口上线过程
新入职一家公司后,前三天一直在学习公司内部各种制度文化以及考试。 一直到第三天组长突然叫我过去,给了一个需求的思维导图,按照这个需求写这样一个接口, 其实还不错,不用自己去分析需求,按照这上面直接开…...

时序预测 | MATLAB实现Rmsprop算法优化LSTM长短期记忆神经网络时间序列多步预测(滚动预测未来,多指标,含验证Loss曲线)
时序预测 | MATLAB实现Rmsprop算法优化LSTM长短期记忆神经网络时间序列多步预测(滚动预测未来,多指标,含训练和验证Loss曲线) 目录 时序预测 | MATLAB实现Rmsprop算法优化LSTM长短期记忆神经网络时间序列多步预测(滚动预测未来,多指标,含训练和验证Loss曲线)效果一览基本描…...

如何利用Level2行情数据接口追板和交易股票?
十档行情看得更深的A股行情软件,我们在盘口数据中可以看到,买一到买五以及卖一到卖五,共10个价位的挂单情况,但基于上证所的level-2行情软件,视野则扩展到了买一到买十以及卖一到卖十数据,无疑比所有免费软…...

MySQL常用的聚合函数
聚合函数聚合函数对一组值进行运算,并返回单个值。也叫组合函数函数作用COUNT(*|列名) 统计查询结果的⾏数AVG(数值类型列名)求平均值,返回指定列数据的平均值SUM (数值类型列名)求和,返回指定列的总和MAX(列名)查询指定列的最⼤值MIN(列名)查…...
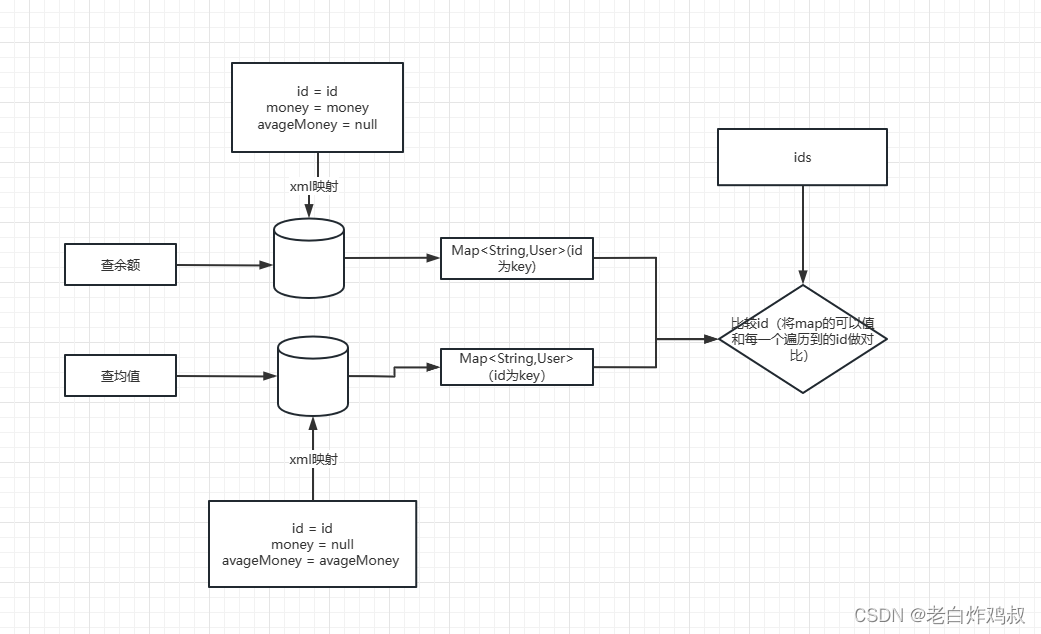
如何评估模糊测试工具-unibench的使用
unibench是一个用来评估模糊测试工具的benchmark。这个benchmark集成了20多个常用的测试程序,以及许多模糊测试工具。 这篇文章(https://zhuanlan.zhihu.com/p/421124258)对unibench进行了简单的介绍,本文就不再赘诉,…...

2023初级会计详细学习计划打卡表!自律逆袭,一次上岸!
2023年初级会计职称考试报名时间:2月7日-28日考试时间:5月13日—17日给大家整理了《经济法基础》和《初级会计实务》两科超实用的学习打卡表重要程度、难易度、易错点、要求掌握内容、章节估分等都全部总结在一起,一目了然!为什么…...

【Python】Python项目打包发布(四)(基于Nuitka打包PySide6项目)
Python项目打包发布汇总 【Python】Python项目打包发布(一)(基于Pyinstaller打包多目录项目) 【Python】Python项目打包发布(二)(基于Pyinstaller打包PyWebIO项目) 【Python】Pytho…...
)
一起Talk Android吧(第五百一十三回:Java中的byte数组与int变量相互转换)
文章目录整体思路示例代码各位看官们大家好,上一回中咱们说的例子是"自定义Dialog",这一回中咱们说的例子是" Java中的byte数组与int变量相互转换"。闲话休提,言归正转, 让我们一起Talk Android吧!在实际项目…...
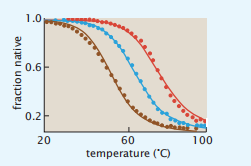
22《Protein Actions Principles and Modeling》-《蛋白质作用原理和建模》中文分享
《Protein Actions Principles and Modeling》-《蛋白质作用原理和建模》 本人能力有限,如果错误欢迎批评指正。 第五章:Folding and Aggregation Are Cooperative Transitions (折叠和聚合是同时进行的) -蛋白质折叠的协同作…...
vue2 @hook 的解析与妙用
目录前言几种用法用法一 将放在多个生命周期的逻辑,统一到一个生命周期中用法二 监听子组件生命周期运行的情况运用场景场景一 许多时候,我们不得不在不同的生命周期中执行某些逻辑,并且这些逻辑会用到一些通用的变量,这些通用变量…...
网络技术|网络地址转换与IPv6|路由设计基础|4
对应讲义——p6 p7NAT例题例1解1例2解2例3解3例4解4一、IPv6地址用二进制格式表示128位的一个IPv6地址,按每16位为一个位段,划分为8个位段。若某个IPv6地址中出现多个连续的二进制0,可以通过压缩某个位段中的前导0来简化IPv6地址的表示。例如…...

MySQL运维知识
1 日志1.1 错误日志1.2 二进制日志查看二进制日志:mysqlbinlog ./binlog.000007purge master logs to binlog.000006reset mastershow variables like %binlog_expire_logs_seconds%默认二进制文件只存放30天,30天后会自动删除。1.3 查询日志1.4 慢查询日…...

易基因-MeRIP-seq揭示衰老和神经变性过程中m6A RNA甲基化修饰的保守下调机制
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。2023年02月22日,《美国国家科学院院刊》(Proc Natl Acad Sci USA)期刊发表了题为“Conserved reduction of m6A RNA modifications during aging and neurodegeneration is lin…...
暑期实习准备——Verilog手撕代码(持续更新中。。。
暑期实习准备——手撕代码牛客刷题笔记Verilog快速入门VL4 移位运算与乘法VL5 位拆分与运算VL6 多功能数据处理器VL8 使用generate…for语句简化代码VL9 使用子模块实现三输入数的大小比较VL11 4位数值比较器电路VL12 4bit超前进位加法器电路VL13 优先编码器电路①VL14 用优先编…...
Qt音视频开发19-vlc内核各种事件通知
一、前言 对于使用第三方的sdk库做开发,除了基本的操作函数接口外,还希望通过事件机制拿到消息通知,比如当前播放进度、音量值变化、静音变化、文件长度、播放结束等,有了这些才是完整的播放功能,在vlc中要拿到各种事…...

Linux基础命令-nice调整进程的优先级
文章目录 Nice 命令介绍 语法格式 常用参数 参考实例 1 调整bash的优先级为-10 2 调整脚本的优先级为6 3 调整指令的优先级 4 默认使用nice命令调整优先级 命令总结 Nice 命令介绍 nice命令的主要功能是用于调整进程的优先级,合理分配系统资源。Linux系…...
的全面排查指南)
2003 - MySQL连接localhost失败(10061错误)的全面排查指南
1. 为什么会出现MySQL连接localhost失败(10061错误)? 当你兴致勃勃地打开数据库客户端准备大干一场时,突然蹦出个"2003 - Cant connect to MySQL server on localhost(10061)"的错误提示,是不是瞬间就懵了&a…...

SMUDebugTool终极指南:快速掌握AMD Ryzen系统调试与优化技巧
SMUDebugTool终极指南:快速掌握AMD Ryzen系统调试与优化技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...

CST中利用SPICE语言自定义复杂lumped element电路的实战指南
1. 突破CST自带元件的限制:为什么需要SPICE语言 刚开始用CST做电路仿真时,我也觉得自带的RLC元件够用了——直到遇到一个带滤波功能的耦合器项目。当时需要模拟一个包含寄生参数的复杂匹配网络,自带的并联RLC元件死活调不出理想的频响曲线。这…...

Cursor试用限制终极解决方案:一篇文章彻底解决你的AI编程困境
Cursor试用限制终极解决方案:一篇文章彻底解决你的AI编程困境 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Youve reached your trial request limit. / Too many free trial accounts used on this machine. Please upgrade to p…...
)
KEITHLEY 6221+2182A组合在霍尔测量中的5个实战技巧(避坑指南)
KEITHLEY 62212182A组合在霍尔测量中的5个实战技巧(避坑指南) 霍尔测量作为材料科学研究中的关键手段,对仪器精度和操作细节的要求近乎苛刻。KEITHLEY 6221电流源与2182A纳伏表的组合,凭借其出色的低噪声性能和微电流处理能力&…...
)
用Python和MATLAB/Simulink复现车辆二自由度模型:从理论公式到仿真验证(附代码)
从理论到实践:Python与MATLAB/Simulink实现车辆二自由度动力学仿真 在自动驾驶和车辆工程领域,理解车辆动力学模型是开发先进控制算法的基础。二自由度模型作为最简单的车辆动力学模型之一,能够有效描述车辆的侧向和横摆运动特性。本文将带您…...

美图靠AI一年收入38亿,不靠免费大模型API,靠的是什么?
财报数据显示,美图2025年全年实现营业收入38.6亿元,同比大幅增长28.8%,整体营收规模再创新高,展现出核心业务的强劲增长韧性。不过公司常规账面净利润为7亿元,同比下降12.7%,看似利润下滑的背后,…...
)
从IPv4到IPv6迁移实战:在eNSP里排查那些容易被忽略的安全配置(避坑指南)
从IPv4到IPv6迁移实战:eNSP环境下的安全配置深度排查指南 当企业网络从IPv4向IPv6过渡时,工程师们常常会陷入一种"配置惯性"——沿用IPv4时代的安全策略直接套用到IPv6环境。这种思维定式往往会导致网络出现各种"隐形漏洞"。本文将通…...

Claude Code 命令行参数实践指南
前言 很多人第一次打开 Claude Code,只会输入 claude,然后开始聊天。这当然可以,但就像开车只会踩油门一样——你根本没用上方向盘和变速箱。 命令行参数(CLI Flags)就是那些被忽视的"方向盘"。掌握它们&a…...

3步解锁B站Hi-Res音频:使用BilibiliDown开源工具轻松获取无损音乐
3步解锁B站Hi-Res音频:使用BilibiliDown开源工具轻松获取无损音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/g…...