【LSM tree 】Log-structured merge-tree 一种分层、有序、面向磁盘的数据结构
文章目录
- 前言
- 基本原理
- 读写流程
- 写流程
- 读流程
- 写放大、读放大和空间放大
- 优化
前言
LSM Tree 全称是Log-structured merge-tree, 是一种分层,有序,面向磁盘的数据结构。其核心原理是磁盘批量顺序写比随机写性能高很多,可以通过围绕这一原理进行设计和优化,让写性能达到最优。相较于传统的B+树,它减少了磁盘随机读取的需求,从而在一定程度上改善了数据库的写能力,当然在一定程度上牺牲了数据库的读能力。LSM tree也是当今流行的各种NoSQL或NewSQL数据库最基础的底层数据结构,广泛使用在包括Hbase,Cassandra,Leveldb, RocksDB, TiDB等项目中。
基本原理
传统的B+树的缺陷就是在访问节点时涉及到了大量的磁盘随机读写,因为你无法保证节点常驻内存,尤其是当B+树管理的索引量很大的时候,这导致数据库读写性能急剧下降。
LSM tree 采取的做法就是通过引入多部件索引来减少磁盘随机读写的需求。在大量插入情况下我们周期性地选取两部分索引进行合并,并且把合并后的有序文件(或内存块)添加到磁盘尾部(或成为新文件),修改节点信息以保证索引树的正确和完善,并且周期性地回收失效索引。因此与其说LSM tree是一种树,不如说它是通过传统索引组织有序文件或内存块的一种方式。
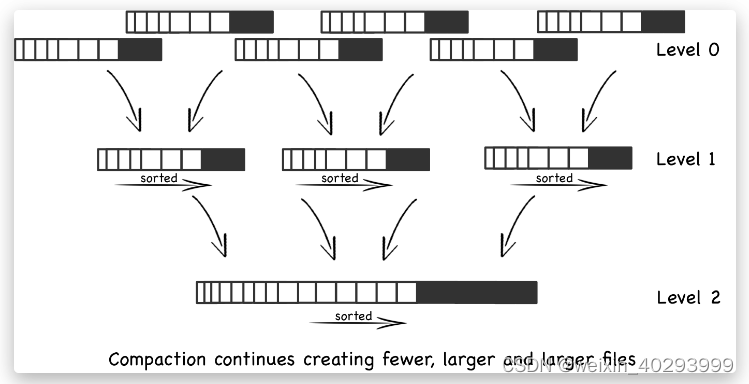
LSM tree的节点可以分为两种:
- MemTable: 保存在内存中的部分,一般可以是红黑树、跳跃表,甚至可以是B树。在HBase中使用的是跳表,在SQLite4中使用的是只能追加写入的红黑树。
- SSTable: 保存在磁盘上的部分,一般由多个内部KeyValue有序的文件组成,它的key和value都是任意的字节数组,并且了提供了按指定key查找和指定范围dekey区间迭代遍历的功能。SSTable内部包含了系列可匹配大小的Block块。关于这些Block块的index存储在SSTable的尾部,用于帮助快速查找。
写操作直接作用于MemTable,因此写入性能接近写内存。每层SSTable文件到达一定条件后,进行合并操作,然后放置到更高层。合并操作在实现上一般的策略驱动、可插件化的。
读写流程
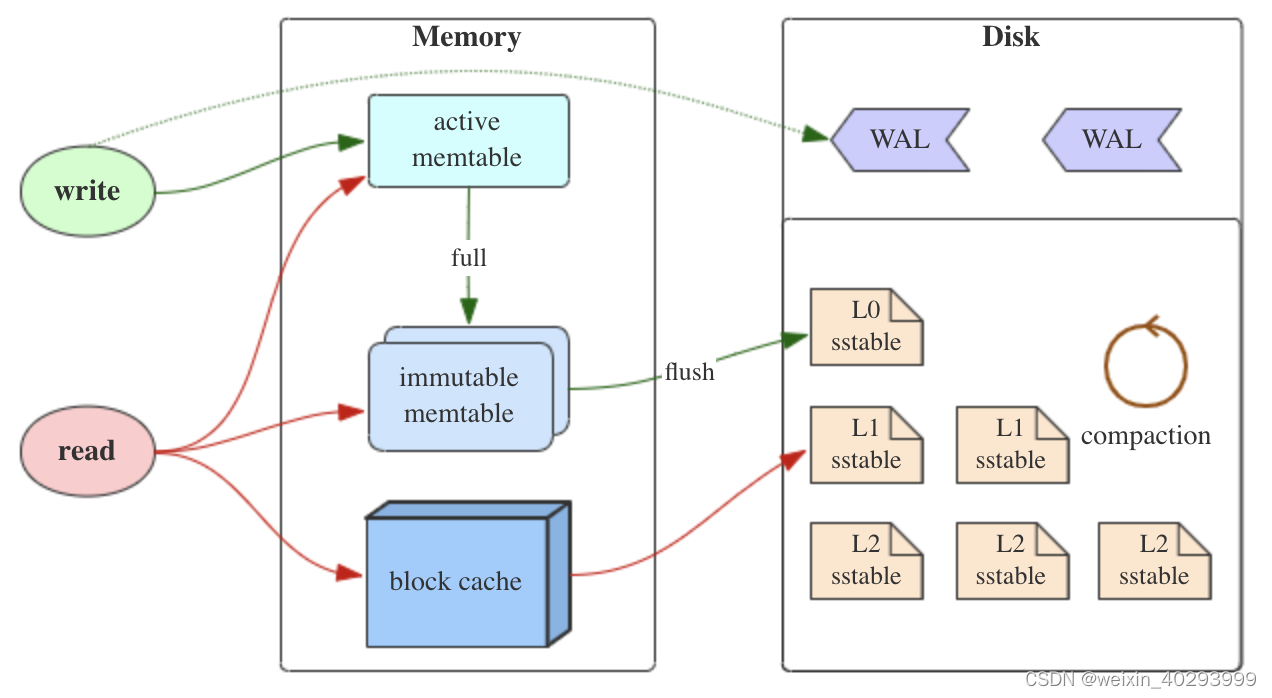
写流程
- 当收到一个写请求时,会先把该条数据记录在 WAL(Write-ahead logging)里面,用作故障恢复。
- 当写完 WAL 后,会把该条数据写入内存的 MemTable 里面(删除操作也通过写入实现,会写入一个删除标记;更新则是写入一条新记录)。
- 当 Memtable 超过一定的大小后,会在内存里面冻结,变成不可变的 Memtable,同时为了不阻塞写操作需要新生成一个 Memtable 继续提供服务。
- 把内存里面不可变的 Memtable 给 flush 到到硬盘上的 SSTable 层中,此步骤也称为 Minor Compaction,这里需要注意在 L0 层的 SSTable 是没有进行合并的,所以这里的 key range 在多个 SSTable 中可能会出现重叠,在层数大于 0 层之后的 SSTable,不存在重叠 key。
- 当每层的磁盘上的 SSTable 的体积超过一定的大小或者个数,也会周期的进行合并。此步骤也称为 Major Compaction。这个阶段会真正的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间,注意由于 SSTable 都是有序的,我们可以直接采用 merge sort 进行高效合并。
读流程
- 当收到一个读请求的时候,会直接先在内存里面查询,如果查询到就返回。
- 内存查询包括服务中的 Memtable 和不可变的 Memtable,也包括对于 SSTable 的缓存 block cache。
- 如果内存中没有查询到就会依次下沉查询 SSTable,直到把所有的层次的 SSTable 查询一遍得到最终结果。
写放大、读放大和空间放大
LSM Tree 将随机写转化为顺序写,而作为代价带来了大量的重复写入。由此会引起写放大、读放大和空间放大。
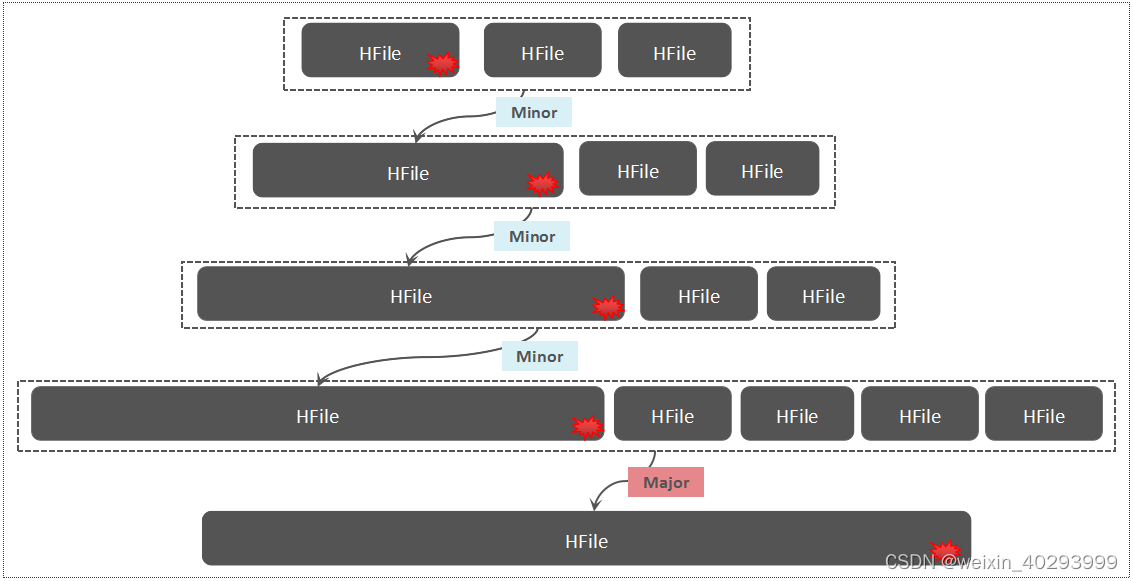
- 写放大(Write Amplification):
平均写入 1 个字节,引擎中在数据的声明周期内实际会写入 n 个字节,其写放大率是 n。如果业务方写入速度是 10MB/s,在引擎端或者操作系统层面能观察到的数据写入速度是 30MB/s,系统的写放大率就是 3。写放大过大会制约系统的实际吞吐。对于 SSD 来说,也会导致 SSD 寿命缩短。
以下是 HBase 中的写放大示意图
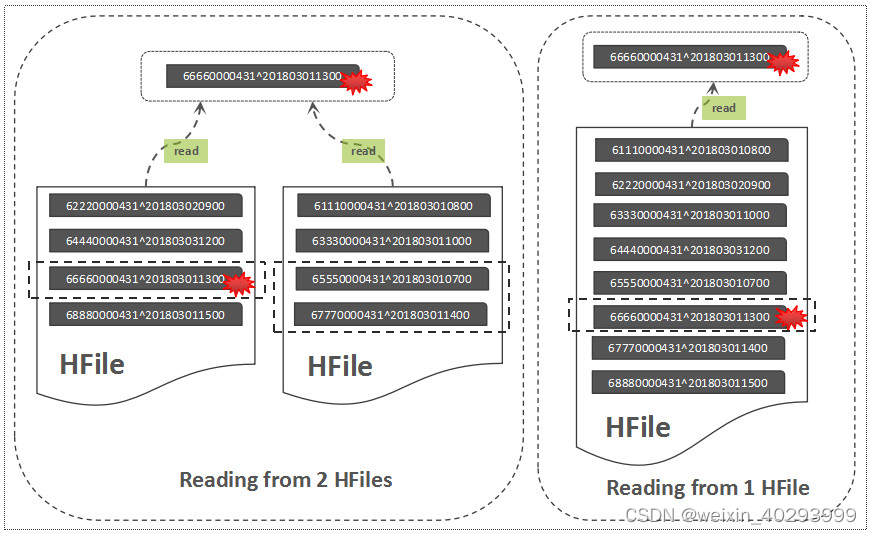
- 读放大(Read Amplification):
一个读请求,系统所需要读 n 个页面来完成查询,其读放大率是 n。逻辑上的读操作可能会命中引擎内部的 cache 或者文件系统 cache,命中不了 cache 就会进行实际的磁盘 IO,命中 cache 的读取操作的代价虽然很低,但是也会消耗 CPU。
以下是 HBase 中的读放大示意图
- 空间放大(Space Amplification):
平均存储 1 个字节的数据,在存储引擎内部所占用的磁盘空间 n 个字节,其空间放大是 n。比如写入 10MB 的数据,磁盘上实际占用了 100MB,这是空间放大率就是 10。空间放大和写放大在调优的时候往往是排斥的,空间放大越大,那么数据可能不需要频繁的 compaction,其写放大就会降低;如果空间放大率设置的小,那么数据就需要频繁的 compaction 来释放存储空间,导致写放大增大
优化
LSM tree 一般从以下几个方面进行优化:
- 压缩
SSTable 是可以启用压缩功能的,并且这种压缩不是将整个 SSTable 一起压缩,而是根据 locality 将数据分组,每个组分别压缩,这样的好处当读取数据的时候,我们不需要解压缩整个文件而是解压缩部分 Group 就可以读取。
- 缓存
因为 SSTable 在写入磁盘后,除了 Compaction 之外,是不会变化的,所以我可以将 Scan 的 Block 进行缓存,从而提高检索的效率。
- Bloom filter
正常情况下,一个读操作是需要读取所有的 SSTable 将结果合并后返回的,但是对于某些 key 而言,有些 SSTable 是根本不包含对应数据的,因此,我们可以对每一个 SSTable 添加 Bloom Filter,因为 Bloom Filter 在判断一个 SSTable 不存在某个 key 的时候,那么就一定不会存在,利用这个特性可以减少不必要的磁盘扫描。
- 合并
通过定期合并瘦身, 可以有效的清除无效数据,缩短读取路径,提高磁盘利用空间。但 Compaction 操作是非常消耗 CPU 和磁盘 IO 的,尤其是在业务高峰期,如果发生了 Major Compaction,则会降低整个系统的吞吐量,这也是在使用一些 NoSQL 数据库时,比如 Hbase,常常会禁用 Major Compaction,并在凌晨业务低峰期进行合并的原因。
ref:https://popesaga.github.io/2020/09/25/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95%EF%BC%9ALSM%20tree/#%E5%86%99%E6%94%BE%E5%A4%A7%E3%80%81%E8%AF%BB%E6%94%BE%E5%A4%A7%E5%92%8C%E7%A9%BA%E9%97%B4%E6%94%BE%E5%A4%A7
相关文章:
【LSM tree 】Log-structured merge-tree 一种分层、有序、面向磁盘的数据结构
文章目录 前言基本原理读写流程写流程读流程 写放大、读放大和空间放大优化 前言 LSM Tree 全称是Log-structured merge-tree, 是一种分层,有序,面向磁盘的数据结构。其核心原理是磁盘批量顺序写比随机写性能高很多,可以通过围绕这一原理进行…...
配置OSPF与BFD联动示例
定义 双向转发检测BFD(Bidirectional Forwarding Detection)是一种用于检测转发引擎之间通信故障的检测机制。 BFD对两个系统间的、同一路径上的同一种数据协议的连通性进行检测,这条路径可以是物理链路或逻辑链路,包括隧道。 …...

01到底应该怎么理解“平均负载”
1、如何了解系统的负载情况? 每次发现系统变慢时, 我们通常做的第⼀件事, 就是执⾏top或者uptime命令, 来了解系统的负载情况。 ⽐如像下⾯这样, 我在命令⾏⾥输⼊了uptime命令, 系统也随即给出了结果。 …...

jmeter,动态参数之随机数、随机日期
通过函数助手,执行以下配置: 执行后的结果树: 数据库中也成功添加了数据,对应字段是随机值:...

uniApp常见知识点-问题答案
1、uniApp中如何进行页面跳转? 答案:可以使用 uni.navigateTo、uni.redirectTo 和 uni.reLaunch 等方法进行页面跳转。其中,uni.navigateTo可以实现页面的普通跳转, uni.redirectTo可以实现页面的重定向跳转, uni.reL…...

云原生基础入门概念
文章目录 发现宝藏云原生的概念云原生的关键技术为何选择云原生?云原生的实际应用好书推荐 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。 云原生的概念 当谈及现…...

一个 tomcat 下如何部署多个项目?附详细步骤
一个tomcat下如何部署多个项目?Linux跟windows系统下的步骤都差不多,以下linux系统下部署为例。windows系统下部署同理。 1 不修改端口,部署多个项目 清楚tomcat目录结构的应该都知道,项目包是放在webapps目录下的,那…...

pycharm强制让terminal停止执行的快捷键
CtrlC即可...
中 MessageBox)
MFC(Microsoft Foundation Classes)中 MessageBox
在MFC(Microsoft Foundation Classes)中,MessageBox是一个常用的对话框类,用于显示消息框并与用户进行交互。MessageBox类提供了多种用法和选项,以下是一些常见的用法和示例说明: 显示简单的消息框&#x…...

如何让.NET应用使用更大的内存
我一直在思考为何Redis这种应用就能独占那么大的内存空间而我开发的应用为何只有4GB大小左右,在此基础上也问了一些大佬,最终还是验证下自己的猜测。 操作系统限制 主要为32位操作系统和64位操作系统。 每个进程自身还分为了用户进程空间和内核进程空…...

【从零开始学习JVM | 第九篇】了解 常见垃圾回收器
前言: 垃圾回收器(Garbage Collector)是现代编程语言中的一项重要技术,它提供了自动内存管理的机制,极大地简化了开发人员对内存分配和释放的繁琐工作。通过垃圾回收器,我们能够更高效地利用计算机的内存资…...
Wordle 游戏实现 - 使用 C++ Qt
标题:Wordle 游戏实现 - 使用 C Qt 摘要: Wordle 是一款文字猜词游戏,玩家需要根据给定的单词猜出正确的答案,并在限定的次数内完成。本文介绍了使用 C 和 Qt 框架实现 Wordle 游戏的基本思路和部分代码示例。 引言:…...

Python 爬虫开发完整环境部署,爬虫核心框架安装
Python 爬虫开发完整环境部署 前言: 关于本篇笔记,参考书籍为 《Python 爬虫开发实战3 》 笔记做出来的一方原因是为了自己对 Python 爬虫加深认知,一方面也想为大家解决在爬虫技术区的一些问题,本篇文章所使用的环境为&#x…...
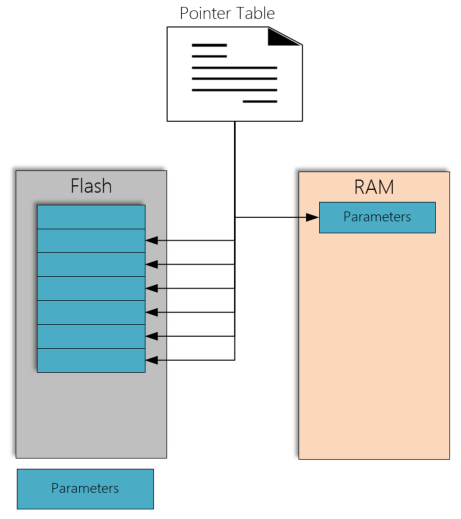
汽车标定技术(十三)--标定概念再详解
目录 1.概述 2.基于Flash的标定 3.基于RAM的标定 4.AUTOSAR基于指针标定概念 5.小结 1.概述 最近有朋友问到是否用overlay标定完数据就直接写在Flash中,其实不然,是需要关闭overlay然后通过XCP Program指令集或者UDS刷进Flash。 从这里看出&#…...
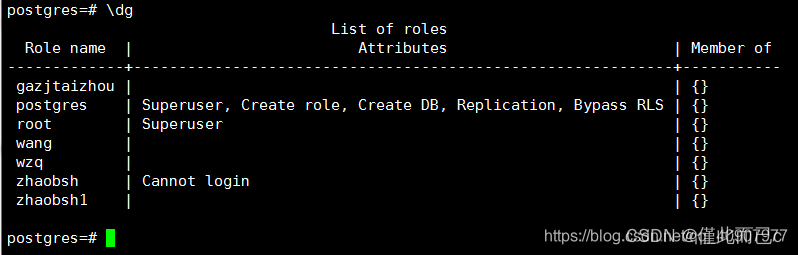
PostgreSQL常用命令
数据库版本 :9.6.6 注意 :PostgreSQL中的不同类型的权限有 SELECT,INSERT,UPDATE,DELETE,TRUNCATE,REFERENCES,TRIGGER,CREATE,CONNECT,TEMPORARY,EXECUTE 和 USAGE。 1. 登录PG数据库 以管理员身份 postgres 登陆,然后通过 #psql -U postgres #sudo -i -u postgres …...

使用python脚本部署k8s集群
1.环境规划: 节点IP地址操作系统配置脚本运行节点192.168.174.5centos7.92G2核server192.168.174.150centos7.92G2核client1192.168.174.151centos7.92G2核client2192.168.174.152centos7.92G2 2.运行准备: yum install -y python python-pip pip in…...

【C语言】操作符详解(四):结构成员访问操作符
目录 结构成员访问操作符 结构体 结构体的声明 结构体变量的定义和初始化 结构成员访问操作符 结构体成员的直接访问 结构体成员的间接访问 结构成员访问操作符 结构体 ⭐C语言已经提供了内置类型,如: char、short、int、long、float、double等,但…...

【算法】二分法
1、二分法 1.1 二分法原理 每次将查找的范围缩小一半,直到最后找到记录或者找不到记录返回。 要求:采用二分法查找时,数据需是排好序的。 1.2二分法思路 判断某个数是否在数组中存在(例:判断3是否在数组中存在&#…...

2023.12.18 JAVA学习day03,while与for循环
目录 0.switch 判断语句 一.for循环 1.简单练习 2.使用for循环计算1-100求和, 以及偶数求和 3.进阶练习,配合键盘录入与判断使用循环 二.while循环 三种格式的区别: 0.switch 判断语句 switch (表达式) { case 1: 语句体1; break; case …...

使用Pytorch从零开始构建StyleGAN2
这篇博文是关于 StyleGAN2 的,来自论文Analyzing and Improving the Image Quality of StyleGAN,我们将使用 PyTorch 对其进行干净、简单且可读的实现,并尝试尽可能地还原原始论文。 如果您没有阅读 StyleGAN2 论文。或者不知道它是如何工作…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...