Note3---初阶二叉树~~

目录
前言🍄
1.树概念及结构☎️
1.1 树的概念🎄
1.2 树的相关概念🦜
1.2.1 部分概念的加深理解🐾
1.2.2 树与非树🪴
1.3 树的表示🎋
1.4 树在实际中的运用(表示文件系统的目录树结构)🥑
2.二叉树概念及结构🧲
2.1概念🫒
2.2 特殊的二叉树🫑
2.2.1 如何求h是多少?h层(高度为h)节点数合计多少?🥝
2.3 二叉树的存储结构🪀
3.二叉树顺序结构及实现💊
3.1 二叉树的顺序结构🧃
3.2 堆的概念及结构🚛
3.2.1 堆的意义🛶
3.3 堆的实现📟
3.3.1 小堆---向下调整💚
3.3.2 大堆---向上调整♻️
3.3.3 建堆时间复杂度🟢
3.3.4 堆的插入🟩
3.3.5 堆的删除🤢
3.4 小堆代码实现📗
3.4.1 Heap.h🔋
3.4.2 Heap.c🔫
4.4.2.1 向上调整的while()结束的判断条件🧑🏻🎤
3.4.3 test.c🧼
4. 堆的应用🍟
4.1 堆排序---升序🧚🏻♀️
4.1.1 建堆的实现🧤
4.1.2 为什么建小堆不实现升序?建大堆实现升序?👒
4.1.3 代码实现🐸
4.1.3.1 Heap.h🐛
4.1.3.2 Heap.c🪖
4.1.3.2 test.c🐢
编辑
4.2 Top-k问题👗
4.2.1 为什么找前k个最大的元素要建小堆?🩴
4.2.2 代码实现🦖
4.2.1 Heap.h🐊
4.2.2 test.c🪲
后语🥊
前言🍄
之前,我们学习了栈和队列的基础知识,有需要的小伙伴可以看小江的上一片篇博客哦~
Note2---栈和队列~~-CSDN博客文章浏览阅读323次,点赞6次,收藏7次。之前,我们学习了顺序表和链表的相关知识,也完成了相应的练习,接下来我们要学习的是栈和队列!本篇将会比较详细的进行讲解栈和队列的相关知识点及如何实现,以及一些)OJ题
https://blog.csdn.net/2301_79184587/article/details/134438809这篇博客,我们一起来了解并学习数据结构中的初阶的二叉树,共同为C++打下牢固的基础!!!
二叉树的知识点和内容比较多,友友们一定要有耐心看完(跳到自己需要的部分也是OK的),下面我们开始今天的学习!!!
1.树概念及结构☎️
1.1 树的概念🎄
树是一种非线性(线性:一字排开)的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
有一个特殊的结点,称为根结点,根节点没有前驱结点
除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
因此,树是递归定义的。
这里我们先引入树的概念,可能会有一些看不懂的,但是没关系,第一部分看懂就行

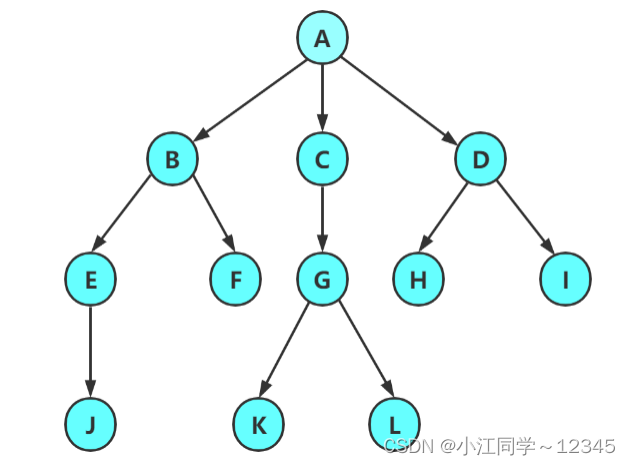
1.2 树的相关概念🦜

注意⚠️
不是所有的概念都是重要的,我会把重要的概念标记出来,其余的我们做个了解就好
节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I...等节点为叶节点
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
思考一下,为什么根定义成1,而不是0?
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
1.2.1 部分概念的加深理解🐾
1. 子节点and父节点
有的节点可能是子节点,也可能同时是父节点---相对性
例如:D是A的子节点,D同时又是H的父节点
2. 节点的层次
说从根开始定义,那是从0还是1?
例如:数组我们从0开始定义下标---数组名是首元素地址(a[i]等价于*(a+i))
但是,我们这里却大多从1开始定义
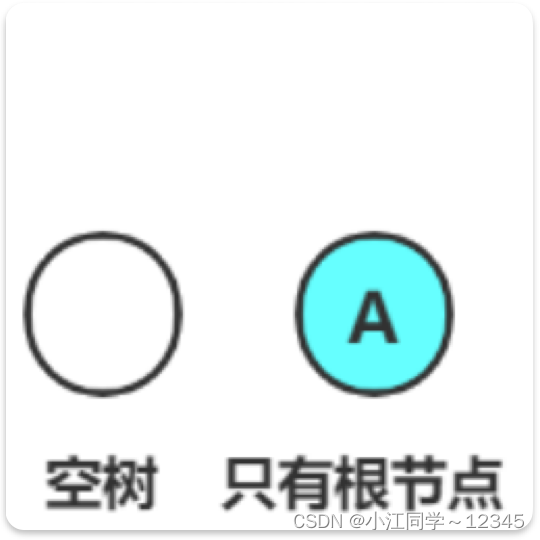
树会有这2种特殊的情况,如果我们从0开始定义:
只有根节点:0
空树:0?or -1?
怎么和只有根节点的情况区分?空树要定义成-1?
是对,定义成-1;注意这样的定义方法也是可以的,但是比较麻烦(后序实现二叉树时,每当需要高度的时候,可能还要思考一下)
如果我们从1开始定义:
只有根节点:1
空树:0
现在就很好区分了
1.2.2 树与非树🪴
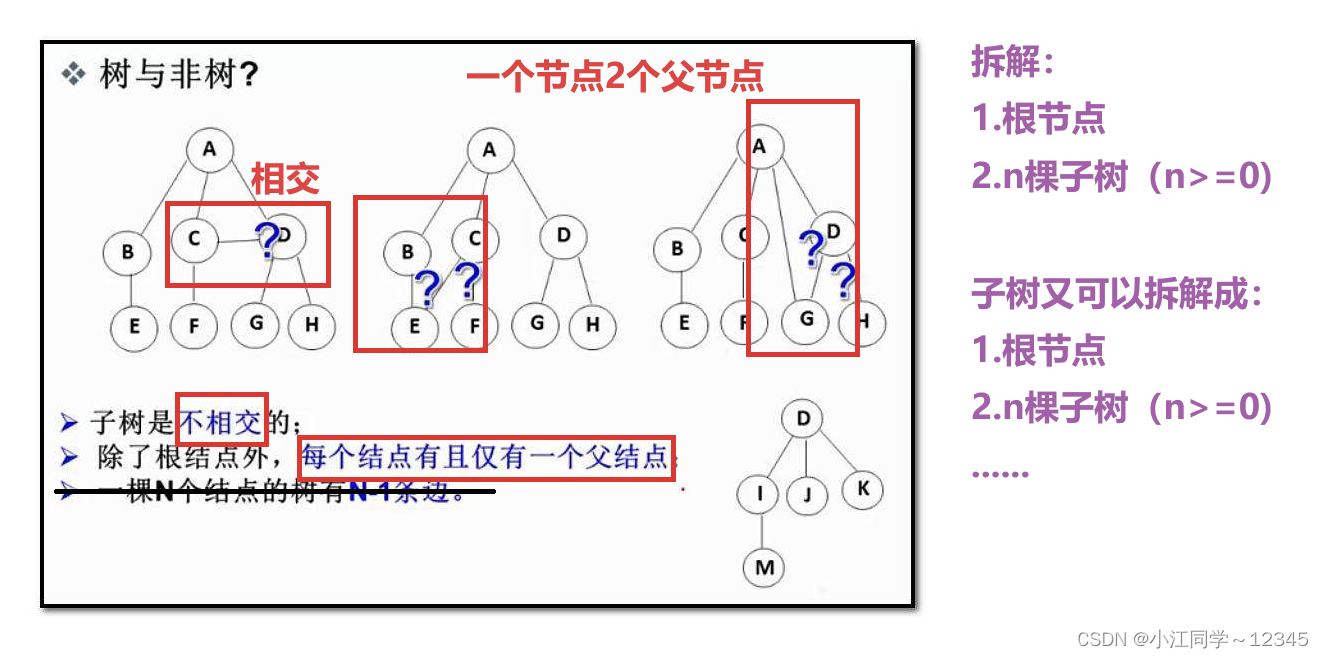
树--->递归--->每次都根+子树---子树(不相交)=0的时候递归结束(即只有叶节点,没有子树了)
---铺垫后面的实现二叉树
1.3 树的表示🎋
要求:保存值域,也要保存结点和结点之间的关系
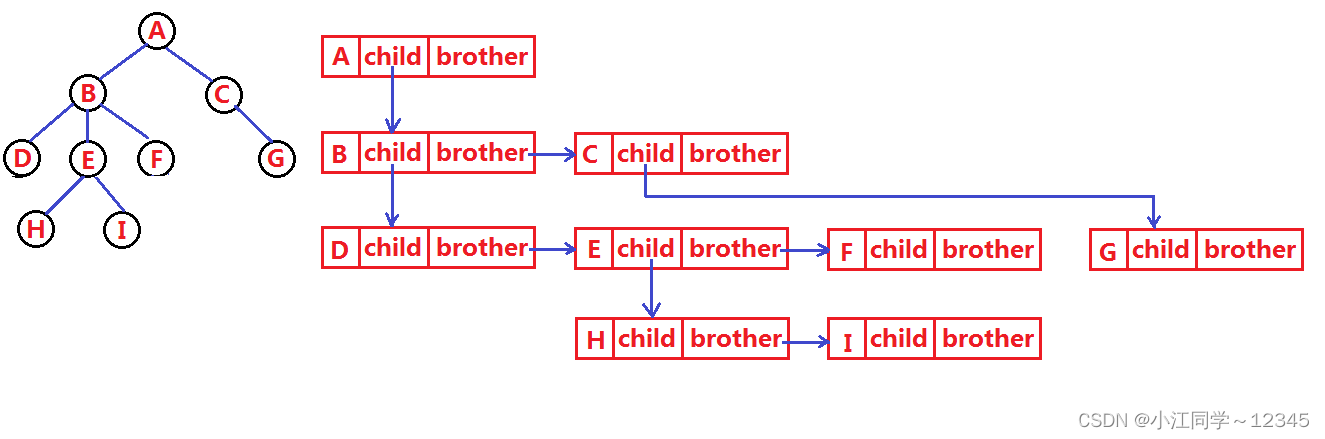
实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法等。我们这里就简单的了解其中最常用的左孩子右兄弟表示法
树的表示复杂在于定义多少个孩子
左孩子右兄弟的思路:
左边第一个为孩子,右边其余的为孩子的兄弟
孩子太多,管不过来--->生老大,让老大管老二,老二管老三......
typedef int DataType;
struct TreeNode
{DataType val;struct TreeNode* leftChild;struct TreeNode* rightBrother;
};
1.4 树在实际中的运用(表示文件系统的目录树结构)🥑
这里的实际运用主要是Linux中的树状目录结构(之后的博客,小江也会带大家学习Linux的基本知识和怎么写代码的)
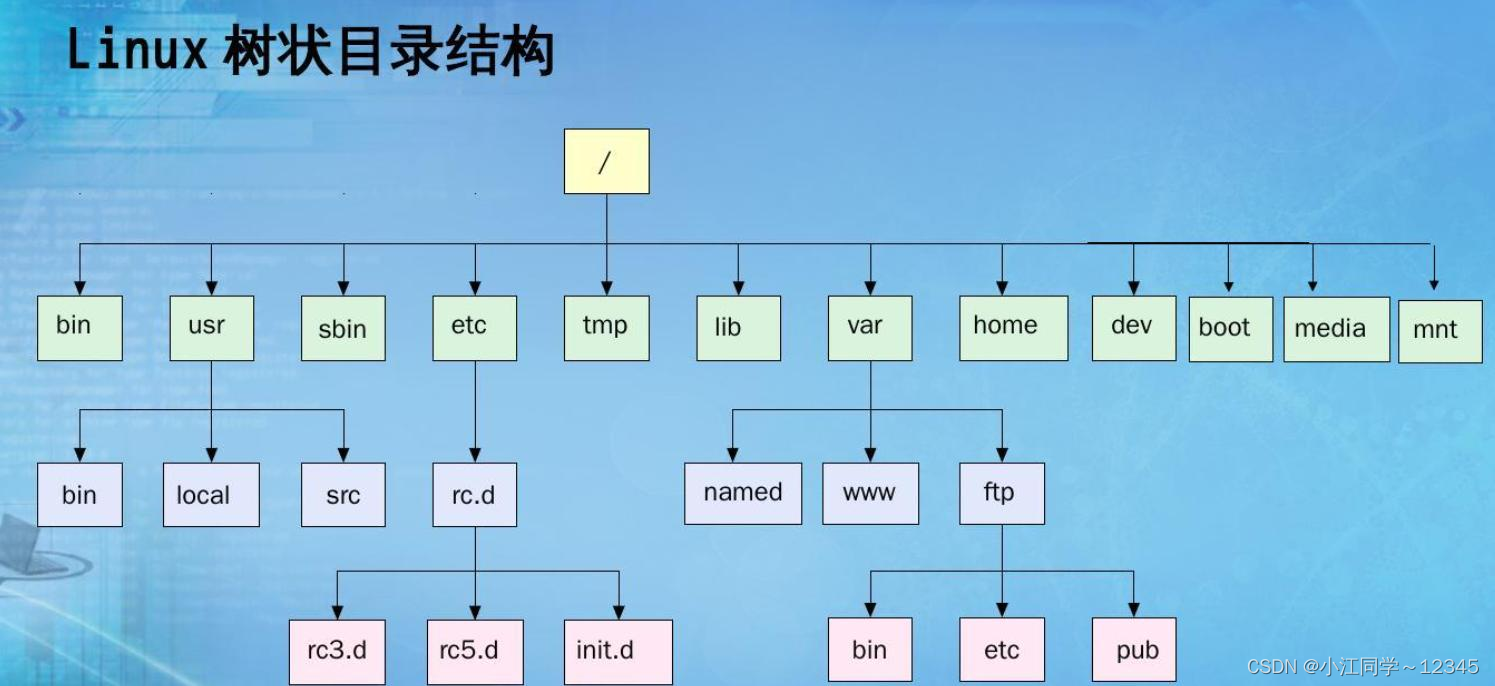
当前目录:/(根目录)
指令:cd user(进入user路径下)
遍历当前目录的下一层树,遍历找到user,然后进入user---指令的本质是程序
2.二叉树概念及结构🧲
2.1概念🫒
一棵二叉树是结点的一个有限集合,该集合:
1. 一个节点只有2个孩子或者为空
2. 由一个根节点加上两棵别称为左子树和右子树的二叉树组成
可以理解为二叉树实行计划生育
可以生1个or不生(0个)or2个(最多2个)

1. 二叉树不存在度大于2的结点
2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
二叉树的左右之分很重要
注意:对于任意的二叉树都是由以下几种情况复合而成的:(之后二叉树的实现会考虑到只有左/右子树,只有根节点,空树的情况)
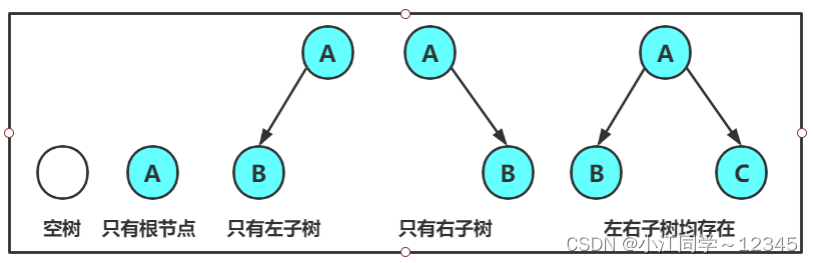
注意⚠️
二叉树不等价于度为2的树
例如:二叉树也可能为空or只有根节点
二者是必要不充分的关系
2.2 特殊的二叉树🫑
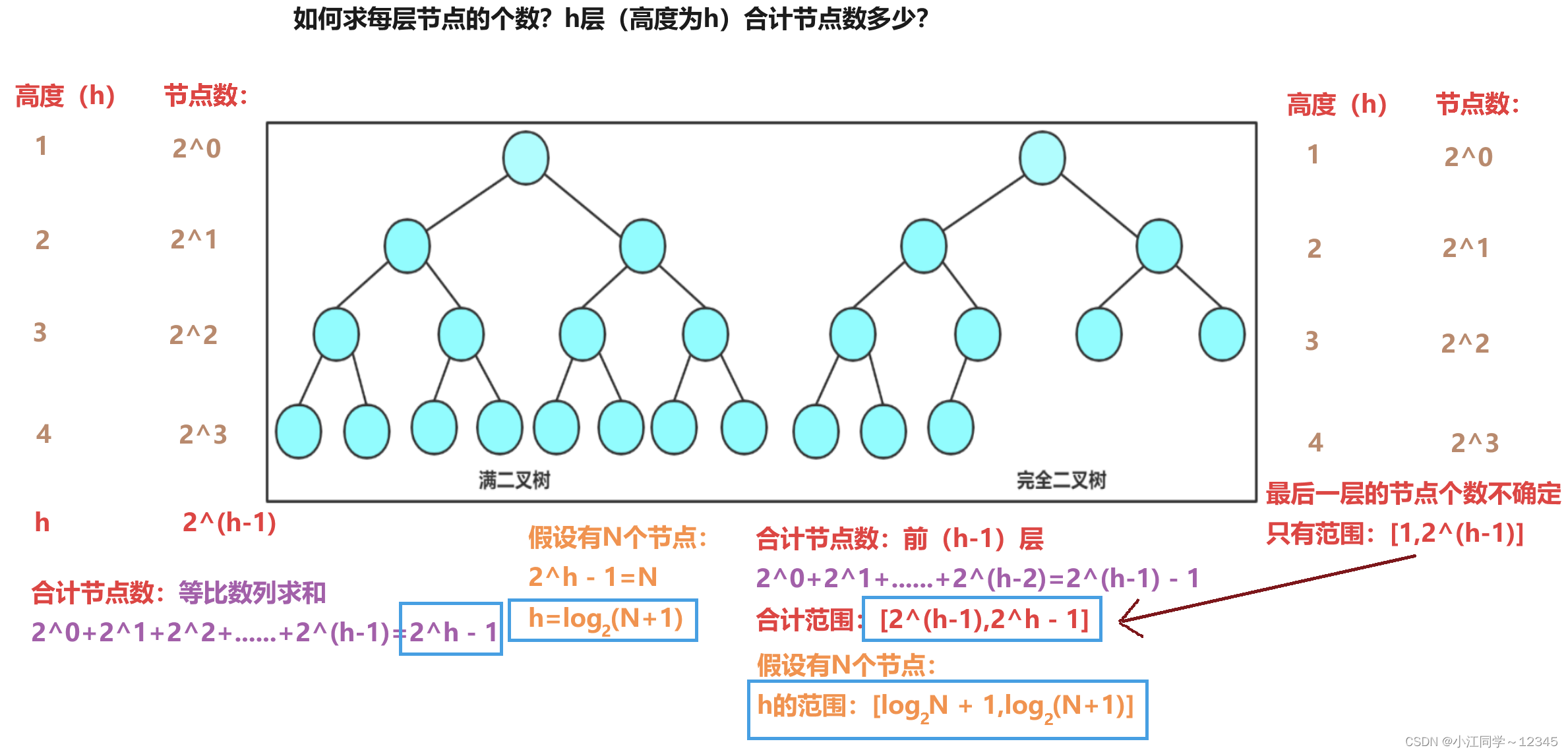
满二叉树:每一层都是满的(每个节点都有2个孩子)
完全二叉树:前(n-1)层都是满的(每个节点都有2个孩子),最后一层不一定是满的,但是从左到右必须是连续的(是否连续的话就要看左子树和右子树了)
满二叉树是特殊的完全二叉树
如图:这就不是连续的了


2.2.1 如何求h是多少?h层(高度为h)节点数合计多少?🥝
2.3 二叉树的存储结构🪀
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
1. 顺序存储---完全二叉树/满二叉树
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储(关于堆我们后面会讲解)。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
2. 链式存储---普通二叉树
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址 。
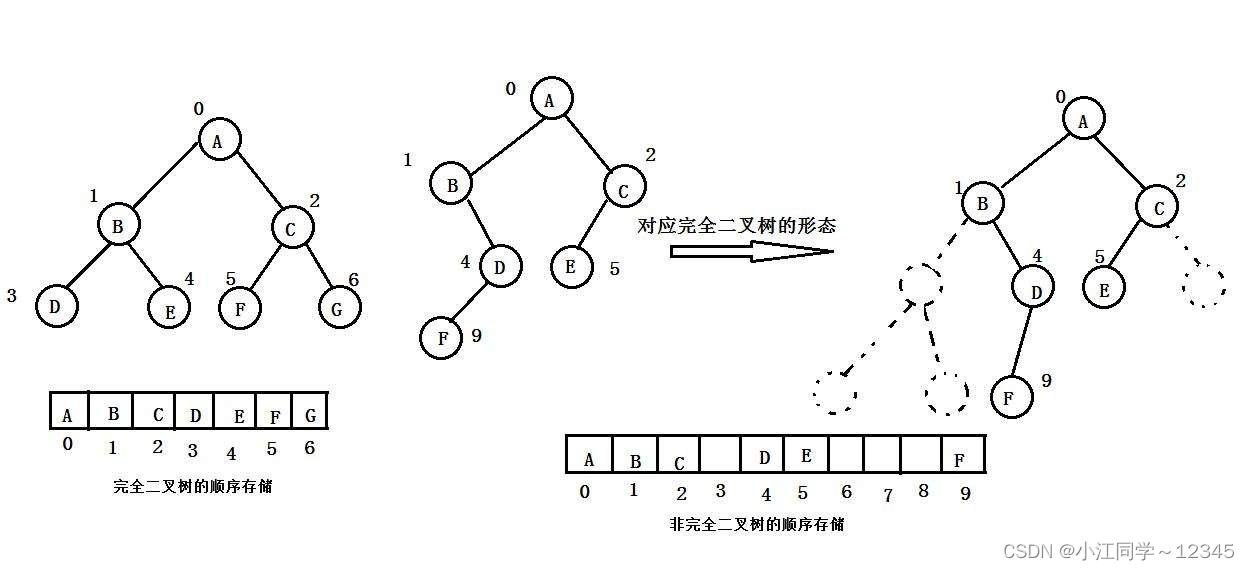
这里说一下子节点和父节点之间的规律:


3.二叉树顺序结构及实现💊
3.1 二叉树的顺序结构🧃
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
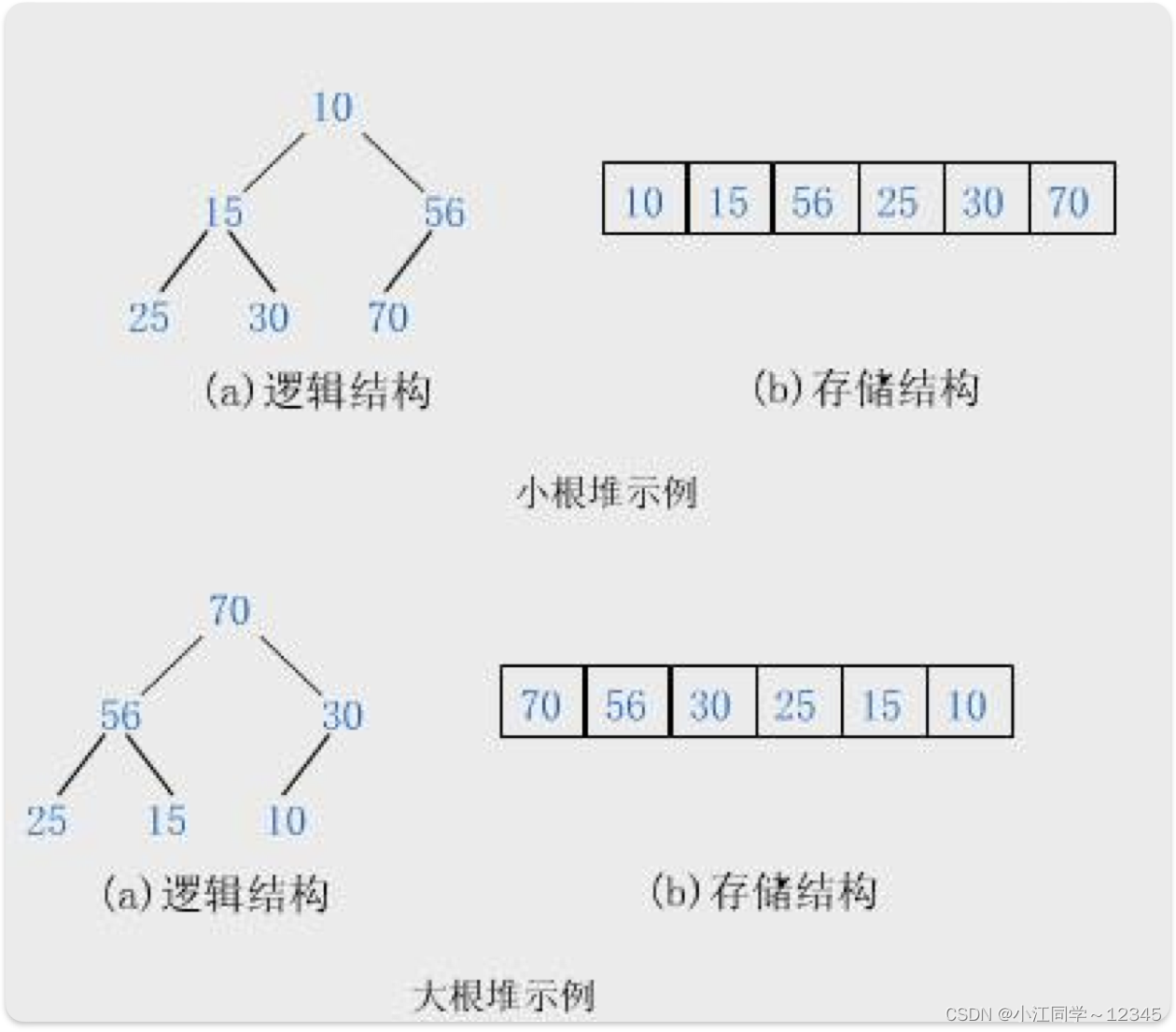
3.2 堆的概念及结构🚛
堆---数据结构(堆总是一棵完全二叉树。)
所有元素按完全二叉树的顺序存储方式存储在一个一维数组中
堆分为:大堆和小堆
大堆:任意一个父亲(data)>=孩子(data)--->根节点是max
小堆:任意一个父亲(data)<=孩子(data)--->根节点是min
3.2.1 堆的意义🛶
1.堆排序
2.解决top k问题
1.堆排序:
大堆不一定有序,但是根是最大的--->调堆(选出max之后取出,找次大的,最多循环h次)
小堆也是同样的道理
时间复杂度:O(N*logN)
上面我们算出了完全二叉树N个节点的高度(h)范围,我们粗略估算大概有logN层,共N个节点,建堆的需要的时间复杂度:N、最多排序h次,故时间复杂度:O(N*logN)
我们大概粗略估算一下:h=logN
N=100万 h=20
最多20次就可以将100万个数据排完了
空间复杂度:O(1)
只要开辟空间给数组存储就行了
2.解决top k问题
例如我们要在100万个数据里面排出前10个最大的数据,利用堆排序的话,不需要排序100万次,只需要循环10次找出前10个最大的
3.3 堆的实现📟
在开始之前,我们先思考一下:之前说堆由顺序结构的数组来存储,那么堆的底层逻辑是顺序表嘛?
并不是,因为堆还要区分大小堆,而顺序表没有大小要求直接插入就行
3.3.1 小堆---向下调整💚
我们先以实现小堆为例,讲解一下向下调整的算法:
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。

3.3.2 大堆---向上调整♻️
我们再以实现大堆为例,讲解一下向上调整的算法:
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算法,把它构建成一个堆。根节点左右子树不是堆,我们怎么调整呢?这里我们从倒数的第一个非叶子节点的子树开始调整,一直调整到根节点的树,就可以调整成堆。

具体的步骤和实现小堆一样,只不过遍历结束的条件是遍历到根节点,还需要递归实现
3.3.3 建堆时间复杂度🟢
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):
向下调整建堆:
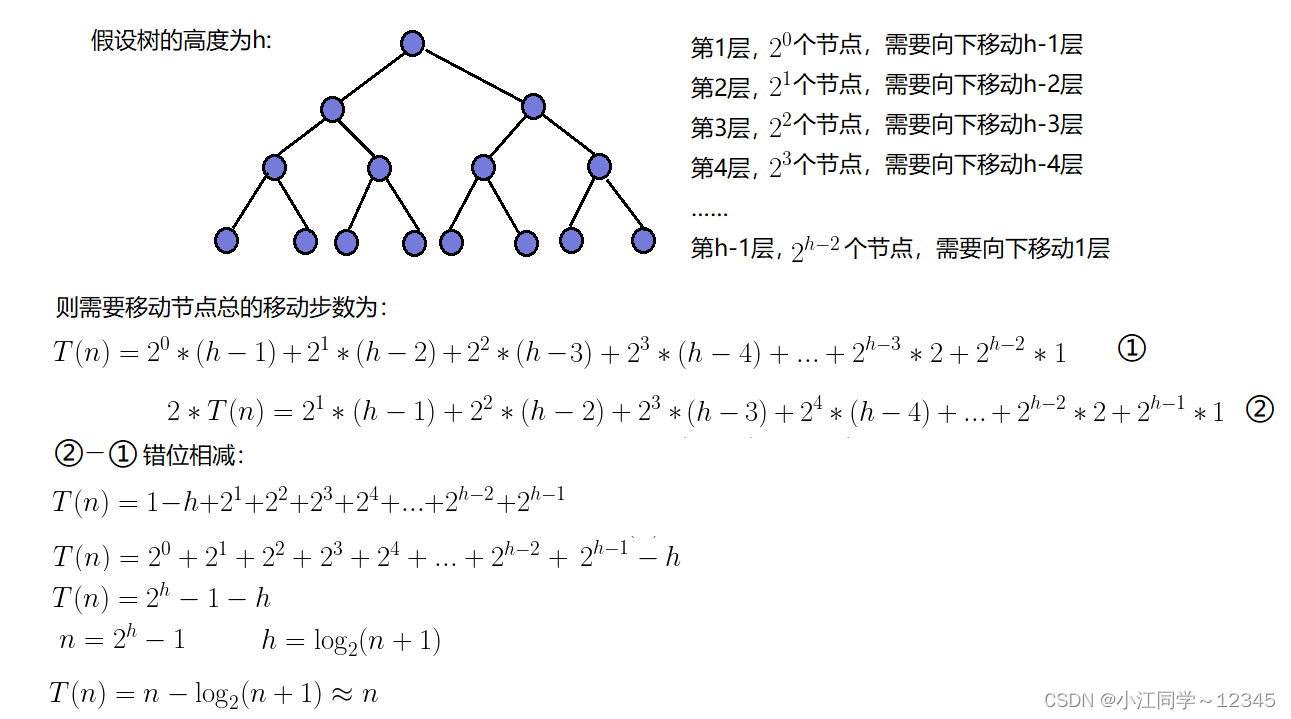
因此:向下调整建堆的时间复杂度为O(N)。
向上调整建堆:
由于证明思路和向下调整差不多,这里我们就不再证明了,而是简单的提一下:
我们向上调整,最后几层的节点个数在整个堆中(看作满二叉树)占比较大,往上移,移动次数又多,时间复杂度肯定高于向下调整
向下调整建堆的时间复杂度大概为O(N*logN)
3.3.4 堆的插入🟩
先插入一个10到数组的尾上,再进行向上调整算法,直到满足堆。

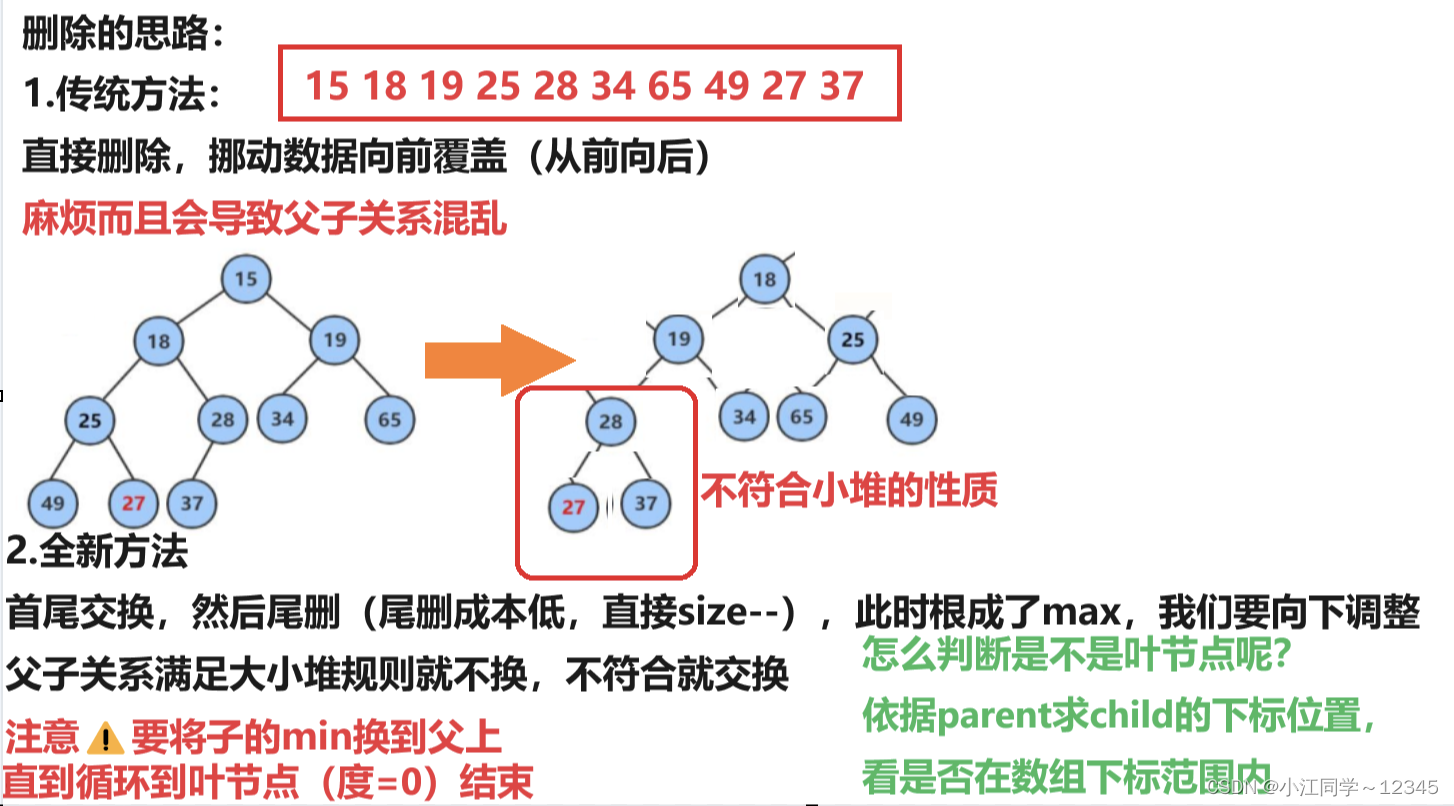
3.3.5 堆的删除🤢
删除堆是删除堆顶的数据
思路:将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。

3.4 小堆代码实现📗
由于大堆和小堆只是调整到时候判断大小的符号不同,我们这里就演示小堆的实现,大堆大家可以自行实现
3.4.1 Heap.h🔋
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int HPDataType;
typedef struct Heap
{HPDataType* _a;//数组存放int _size;//有效存储个数int _capacity;//空间
}Heap;
// 堆的初始化
void HeapInit(Heap* hp);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
bool HeapEmpty(Heap* hp);3.4.2 Heap.c🔫
#include"Heap.h"
// 堆的初始化
void HeapInit(Heap* hp)
{assert(hp);hp->_a = NULL;hp->_capacity = hp->_size = 0;
}
// 堆的销毁
void HeapDestory(Heap* hp)
{assert(hp);free(hp->_a);hp->_a = NULL;hp->_capacity = hp->_size = 0;
}
//交换
void Swap(HPDataType* x, HPDataType* y)
{HPDataType tmp = *x;*x = *y;*y = tmp;
}
//向上调整
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child>0)//到根节点结束{if (a[child] < a[parent]){Swap(&a[child], &a[parent]);//交换位置child = parent;//继续遍历parent = (child - 1) / 2;}else{break;}}
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{assert(hp);//判断空间是否足够if (hp->_capacity == hp->_size){int newcapacity = hp->_capacity == 0 ? 4 : 2 * hp->_capacity;HPDataType* a = (HPDataType*)realloc(hp->_a, sizeof(HPDataType) * newcapacity);if (a == NULL){perror("realloc error!\n");return;}hp->_a = a;hp->_capacity = newcapacity;}//插入数据hp->_a[hp->_size] = x;hp->_size++;//向上调整AdjustUp(hp->_a, hp->_size-1);//之前size++了
}
//向下调整
void AdjustDown(HPDataType* a, int size, int parent)
{//假设法:假设最小的是左孩子,不对的话再修改int child = 2 * parent + 1;while (child<size)//child(左孩子)要在数组范围内{if (a[child + 1] < a[child] && child + 1 < size)//保证右孩子也在范围内{child++;//右孩子小--->和parent交换}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}elsebreak;}
}
// 堆的删除
void HeapPop(Heap* hp)
{assert(hp);assert(hp->_size>0);//首尾交换Swap(&hp->_a[hp->_size - 1], &hp->_a[0]);hp->_size--;//向下调整AdjustDown(hp->_a, hp->_size, 0);//之前size--过了
}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{assert(hp);assert(hp->_size > 0);return hp->_a[0];
}
// 堆的数据个数
int HeapSize(Heap* hp)
{assert(hp);return hp->_size;
}
// 堆的判空
bool HeapEmpty(Heap* hp)
{assert(hp);return hp->_size == 0;
}4.4.2.1 向上调整的while()结束的判断条件🧑🏻🎤
注意⚠️
我们是循环到根节点结束遍历
这里不能是while(parent>=0)
因为最后一次的时候:parent==0--->进入循环--->计算得出parent==0--->还要再次循环
而应该是while(child>0)
因为最后一次的时候:child>0--->进入循环--->计算得出child==0--->结束循环
3.4.3 test.c🧼
#include"Heap.h"
int main()
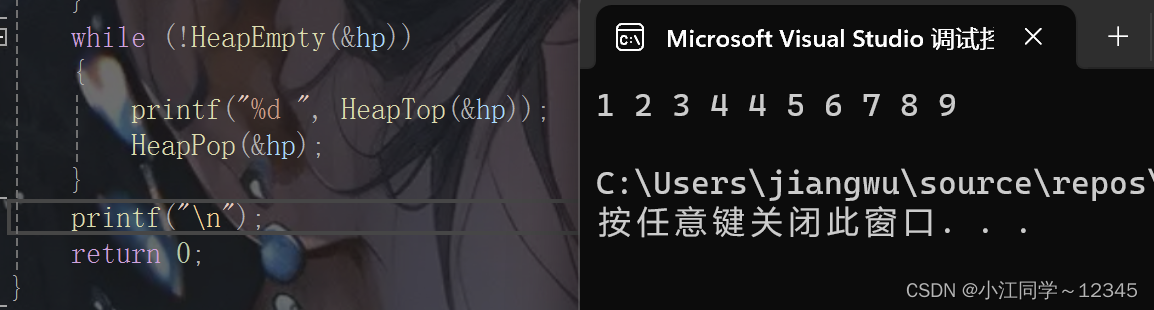
{int a[] = { 4,6,2,1,5,8,4,7,3,9 };Heap hp;HeapInit(&hp);for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){HeapPush(&hp, a[i]);}while (!HeapEmpty(&hp)){printf("%d ", HeapTop(&hp));HeapPop(&hp);}printf("\n");return 0;
}![]()
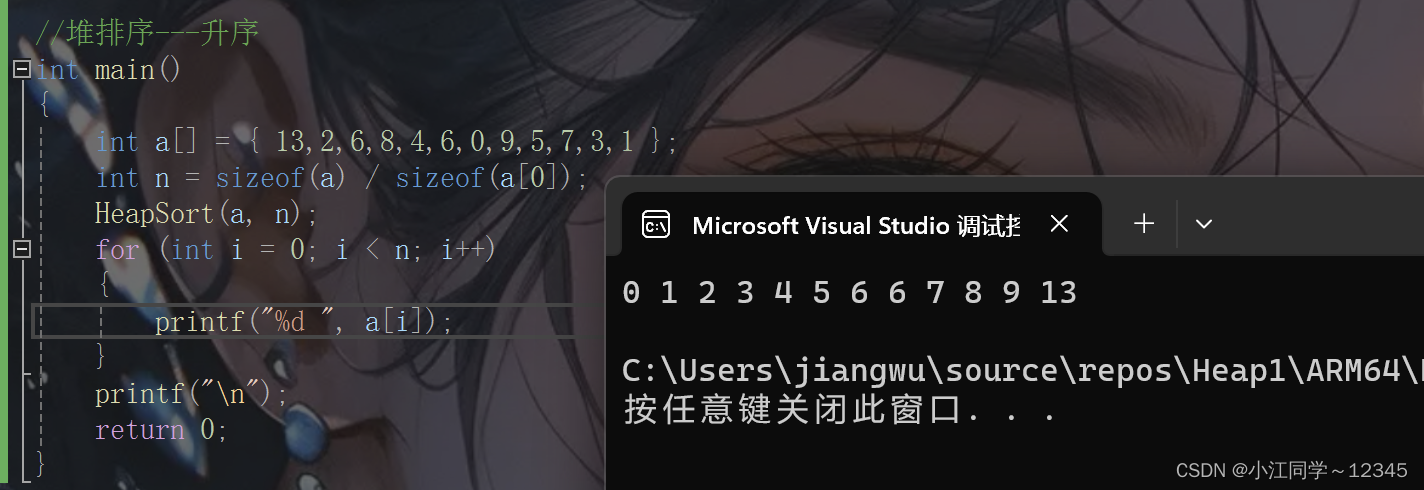
建堆的效果
虽然今天的代码和方法实现排序,但其实不是真正的堆排序
因为:
1.我们是把数组插入到堆里面,相当于在堆里面开了一个数组---一定的消耗
2.时间复杂度:O(N*log N)
空间复杂度:O(N)
3.堆排序是对数组进行排序,但是我们没有更好的方法:直接将数组变成堆--->下面的内容,这也是为什么前面传参,没有把堆的结构体传过去(为堆排序做铺垫),而是传数组
4. 堆的应用🍟
4.1 堆排序---升序🧚🏻♀️
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
1. 建堆
升序:建大堆
降序:建小堆
2. 利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
4.1.1 建堆的实现🧤
由于升序和降序的思路和实现差不多,我们这里就演示实现升序
上面提到建堆可以选择向上调整和向下调整2种方法,我们这里优先选择向下调整,因为时间复杂度低
代码实现是基于之前的堆的实现
本质是模拟堆插入的过程建堆
4.1.2 为什么建小堆不实现升序?建大堆实现升序?👒
按理来说,不应该是小堆实现升序,大堆实现降序嘛?
我们实现升序,分别2个思路对比实现一下:


4.1.3 代码实现🐸
4.1.3.1 Heap.h🐛
//堆排序
void HeapSort(int* a, int n);4.1.3.2 Heap.c🪖
//堆排序--升序
void HeapSort(int* a, int n)
{for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a,n,i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}4.1.3.2 test.c🐢
//堆排序---升序
int main()
{int a[] = { 13,2,6,8,4,6,0,9,5,7,3,1 };int n = sizeof(a) / sizeof(a[0]);HeapSort(a, n);for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n");return 0;
}
4.2 Top-k问题👗
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建堆
不能是前N个元素来建堆,否则占用内存过大
N个数据插入到堆里面,pop K次
时间复杂度:N*logN+K*logN--->O(N*logN) K<<N(忽略不计)
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
时间复杂度:O(N*logK)
4.2.1 为什么找前k个最大的元素要建小堆?🩴
设想一下:
建大堆的话,当最大的数据入堆时,后面的数据就进不来了
建小堆的话,当最大的数据入堆时,沉到堆底,其他数据继续入堆
4.2.2 代码实现🦖
4.2.1 Heap.h🐊
//向下调整
void AdjustDown(HPDataType* a, int size, int parent);4.2.2 test.c🪲
//TOP-K问题
void PrintTopK(int* a,int n,int k)
{//建一个k个数据的小堆int* minheap = (int*)malloc(sizeof(int) * k);if (minheap == NULL){perror("malloc error!\n");return;}//读取前k个,建小堆for(int i = (k - 1 - 1) / 2; i >= 0;i--){AdjustDown(a, k-1, i);}// 将剩余n-k个元素依次与堆顶元素交换,不满则则替换int m = 0;while (m<=n){if (a[m] > minheap[0]){minheap[0] = a[m];AdjustDown(minheap, k, 0);}m++;}for (int i = 0; i < k; i++){printf("%d ", minheap[i]);}printf("\n");
}
int main()
{int n = 10000000;//100万int* a = (int*)malloc(sizeof(int) * n);srand(time(0));for (int i = 0; i < n; ++i){a[i] = (rand()+i) % 10000000;}//自定义k个不在范围内的,好查看方法是否正确a[5] = 10000000 + 1;a[1231] = 10000000 + 2;a[531] = 10000000 + 3;a[5121] = 10000000 + 4;a[115] = 10000000 + 5;a[2335] = 10000000 + 6;a[9999] = 10000000 + 7;a[76] = 10000000 + 8;a[423] = 10000000 + 9;a[3144] = 10000000 + 10;PrintTopK(a, n, 10);return 0;
}
后语🥊
到这里,初阶二叉树的部分就结束了。下篇文章,我们会介绍如何实现二叉树的链式结构和一些二叉树的OJ题和关于二叉树的性质和概念的一些选择题。希望本篇文章对你有帮助!!!
本次的分享到这里就结束了!!!
PS:小江目前只是个新手小白。欢迎大家在评论区讨论哦!有问题也可以讨论的!
如果对你有帮助的话,记得点赞👍+收藏⭐️+关注➕

相关文章:
Note3---初阶二叉树~~
目录 前言🍄 1.树概念及结构☎️ 1.1 树的概念🎄 1.2 树的相关概念🦜 1.2.1 部分概念的加深理解🐾 1.2.2 树与非树🪴 1.3 树的表示🎋 1.4 树在实际中的运用(表示文件系统…...

ElasticSearch学习篇8_Lucene之数据存储(Stored Field、DocValue、BKD Tree)
前言 Lucene全文检索主要分为索引、搜索两个过程,对于索引过程就是将文档磁盘存储然后按照指定格式构建索引文件,其中涉及数据存储一些压缩、数据结构设计还是很巧妙的,下面主要记录学习过程中的StoredField、DocValue以及磁盘BKD Tree的一些…...

ROS机器人入门
http://www.autolabor.com.cn/book/ROSTutorials/ 1、ROS简介 ROS 是一个适用于机器人的开源的元操作系统。其实它并不是一个真正的操作系统,其 底层的任务调度、编译、寻址等任务还是由 Linux 操作系统完成,也就是说 ROS 实际上是运 行在 Linux 上的次级…...

30. 深度学习进阶 - 池化
Hi,你好。我是茶桁。 上一节课,我们详细的学习了卷积的原理,在这个过程中给大家讲了一个比较重要的概念,叫做input channel,和output channel。 当然现在不需要直接去实现, 卷积的原理PyTorch、或者TensorFlow什么的…...

工业应用新典范,飞凌嵌入式FET-D9360-C核心板发布!
来源:飞凌嵌入式官网 当前新一轮科技革命和产业变革突飞猛进,工业领域对高性能、高可靠性、高稳定性的计算需求也在日益增长。为了更好地满足这一需求,飞凌嵌入式与芯驰科技(SemiDrive)强强联合,基于芯驰D9…...
Webrtc 学习交流
花了几周的时间研究了一下webrtc ,并开发了一个小项目,用来点对点私密聊天 交流传输文件等…后续会继续扩展其功能。 体验地址,大狗子的ID,我在线时可以连接测试到我 f3e0d6d0-cfd7-44a4-b333-e82c821cd927 项目特点 除了交换信令与stun 没…...

华为云之轻松搭建 Nginx 静态网站
华为云之轻松搭建 Nginx 静态网站 一、本次实践介绍1. 本次实践目的2. 本次实践环境 二、ECS弹性云服务器介绍三、准备实践环境1. 预置环境2. 查看ECS服务器的账号密码信息3. 登录华为云4. 远程登录ECS服务器 四、安装配置 Nginx1. 安装nginx2. 启动nginx3. 浏览器中访问nginx服…...

【pytorch】图像运行过程中,保证梯度情况下变换
部分操作是危险的,会中断梯度流。 self.patch_transformer(adv_patch, lab_batch, img_size, do_rotateTrue, rand_locFalse)p_img_batch self.patch_applier(img_batch, adv_batch_t) # torch.Size([56, 3, 329, 416])可行危险操作 torch.clamp(adv_batch, 0…...
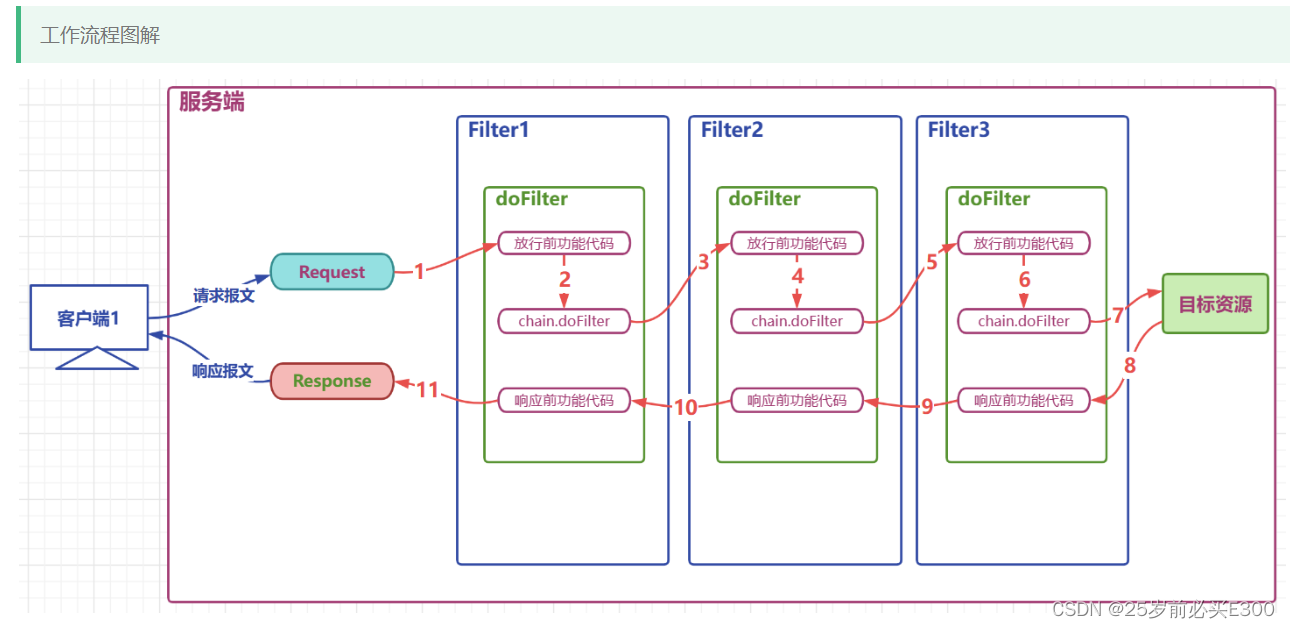
学习Java第70天,过滤器Filter简介
过滤器概述 Filter,即过滤器,是JAVAEE技术规范之一,作用目标资源的请求进行过滤的一套技术规范,是Java Web项目中最为实用的技术之一 Filter接口定义了过滤器的开发规范,所有的过滤器都要实现该接口 Filter的工作位置是项目中所有目标资源之前,容器在创建HttpServletRequest和…...
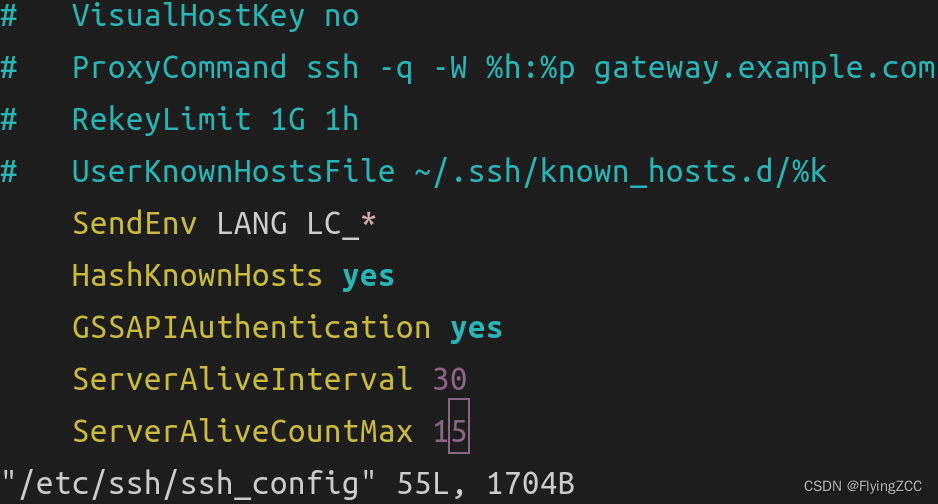
Ubuntu Desktop 22.04 设置 ssh 超时时间
Ubuntu Desktop 22.04 使用 ssh 连接服务器时,发现一段时间不操作就会自动断开连接,解决方法如下: 打开 /etc/ssh/ssh_config 文件: sudo vim /etc/ssh/ssh_config在文件最后添加: # ssh 客户端会每隔 30 秒发送一个…...

【微服务】Spring Aop原理深入解析
目录 一、前言 二、aop概述 2.1 什么是AOP 2.2 AOP中的一些概念 2.2.1 aop通知类型 2.3 AOP实现原理 2.3.1 aop中的代理实现 2.4 静态代理与动态代理 2.4.1 静态代理实现 三、 jdk动态代理与cglib代理 3.1 jdk动态代理 3.1.1 jdk代理示例 3.1.2 jdk动态代理模拟实现…...

Spring Boot JSON中文文档
本文为官方文档直译版本。原文链接 Spring Boot JSON中文文档 引言Jackson自定义序列化器和反序列化器混入 GsonJSON-B 引言 Spring Boot 提供与三个 JSON 映射库的集成: GsonJacksonJSON-B Jackson 是首选的默认库。 Jackson Spring-boot-starter-json 提供了…...
)
Flink系列之:State Time-To-Live (TTL)
Flink系列之:State Time-To-Live TTL 一、TTL二、TTL实现代码三、过期状态的清理 一、TTL Flink的TTL(Time-To-Live)是一种数据过期策略,用于指定数据在流处理中的存活时间。TTL可以应用于Flink中的状态或事件时间窗口࿰…...

数据结构(Chapter Two -01)—线性表及顺序表
2.1 线性表 线性表是具有相同数据类型的n个数据元素的有限序列。第一个元素为表头元素,最后一个元素为表尾元素。除第一个元素,每个元素有且仅有一个直接前驱。除最后一个元素,每个元素都仅有一个直接后继。 其中线性表包括以下(…...

【刷题笔记1】
笔记1 string s;while(cin>>s);cout<<s.length()<<endl;输入为hello nowcoder时,输出为8 (nowcoder的长度) 2.字符串的输入(有空格) string a;getline(cin, a);cout<<a<<endl;输入为ABCabc a 输出为ABCabc a …...

视频数据卡设计方案:120-基于PCIe的视频数据卡
一、产品概述 基于PCIe的一款视频数据收发卡,并通过PCIe传输到存储计算服务器,实现信号的采集、分析、模拟输出,存储。 产品固化FPGA逻辑,实现PCIe的连续采集,单次采集容量2GB,开源的PCIe QT客…...
Windows使用VNC Viewer远程桌面Ubuntu【内网穿透】
文章目录 前言1. ubuntu安装VNC2. 设置vnc开机启动3. windows 安装VNC viewer连接工具4. 内网穿透4.1 安装cpolar【支持使用一键脚本命令安装】4.2 创建隧道映射4.3 测试公网远程访问 5. 配置固定TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址5.3 测试…...
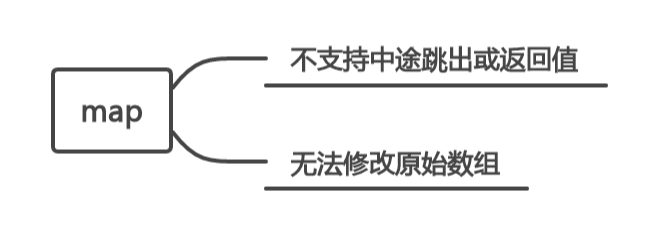
javascript 数组处理的两个利器: `forEach` 和 `map`(上)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
【C语言】SCU安全项目1-FindKeys
目录 前言 命令行参数 16进制转字符串 extract_message1 process_keys12 extract_message2 main process_keys34 前言 因为这个学期基本都在搞CTF的web方向,C语言不免荒废。所幸还会一点指针相关的知识,故第一个安全项目做的挺顺利的,…...

IDA pro软件 如何修改.exe小程序打开对话框显示的文字?
环境: Win10 专业版 IDA pro Version 7.5.201028 .exe小程序 问题描述: IDA pro软件 如何修改.exe小程序打开对话框显示的文字? 解决方案: 一、在IDA Python脚本中编写代码来修改.rdata段中的静态字符串可以使用以下示例代码作为起点(未成功) import idc# 定义要修…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...