【Hive_03】单行函数、聚合函数、窗口函数、自定义函数、炸裂函数
- 1、函数简介
- 2、单行函数
- 2.1 算术运算函数
- 2.2 数值函数
- 2.3 字符串函数
- (1)substring 截取字符串
- (2)replace 替换
- (3)regexp_replace 正则替换
- (4)regexp 正则匹配
- (5)repeat 重复字符串
- (6)split 字符串切割
- (7)nvl 替换null值
- (8)concat 拼接字符串
- (9)concat_ws 以指定分隔符拼接字符串或者字符串数组
- (10)get_json_object 解析json字符串
- 2.4 日期函数
- (1)unix_timestamp 返回当前或指定时间的时间戳
- (2)from_unixtime
- (3)current_date 当前日期
- (4)current_timestamp 当前的日期加时间,并且精确的毫秒
- (5)month:获取日期中的月
- (6)day 获取日期中的日
- (7)hour 获取日期中的小时
- (8)datediff 两个日期相差的天数(结束日期减去开始日期的天数)
- (9)date_add:日期加天数
- (10)date_sub:日期减天数
- (11)date_format:将标准日期解析成指定格式字符串
- 2.5 流程控制函数
- (1)case when:条件判断函数
- (2)if: 条件判断,类似于Java中三元运算符
- 2.6 集合函数
- (1)size 集合中元素的个数
- (2)map 创建map集合
- (3)map_keys 返回map中的key
- (4)map_values 返回map中的value
- (5)array 声明array集合
- (6)array_contains 判断array中是否包含某个元素
- (7)sort_array 将array中的元素排序
- (8)struct 声明struct中的各属性
- (9)named_struct 声明struct的属性和值
- 3、高级聚合函数
- 3.1 collect_list 函数
- 3.2 collect_set 函数
- 4、炸裂函数
- 4.1 expload 函数
- 4.2 posexplode 函数
- 4.3 inline 函数
- 4.4 Lateral View
- 5、窗口函数(开窗函数)
- 5.1 概述
- 5.2 常用窗口函数
- (1)聚合函数
- (2)跨行取值函数
- (3)排名函数
- 6、自定义函数
- 7、自定义UDF函数
- 8、其他
- 8.1 hive当中去重的手段?面试题
- (1)distinct 去重
- (2)group by
- (3)利用窗口函数去重
1、函数简介
Hive会将常用的逻辑封装成函数给用户进行使用,类似于Java中的函数。
好处:避免用户反复写逻辑,可以直接拿来使用。
重点:用户需要知道函数叫什么,能做什么。
Hive提供了大量的内置函数,按照其特点可大致分为如下几类:单行函数、聚合函数、炸裂函数、窗口函数。
以下命令可用于查询所有内置函数的相关信息。
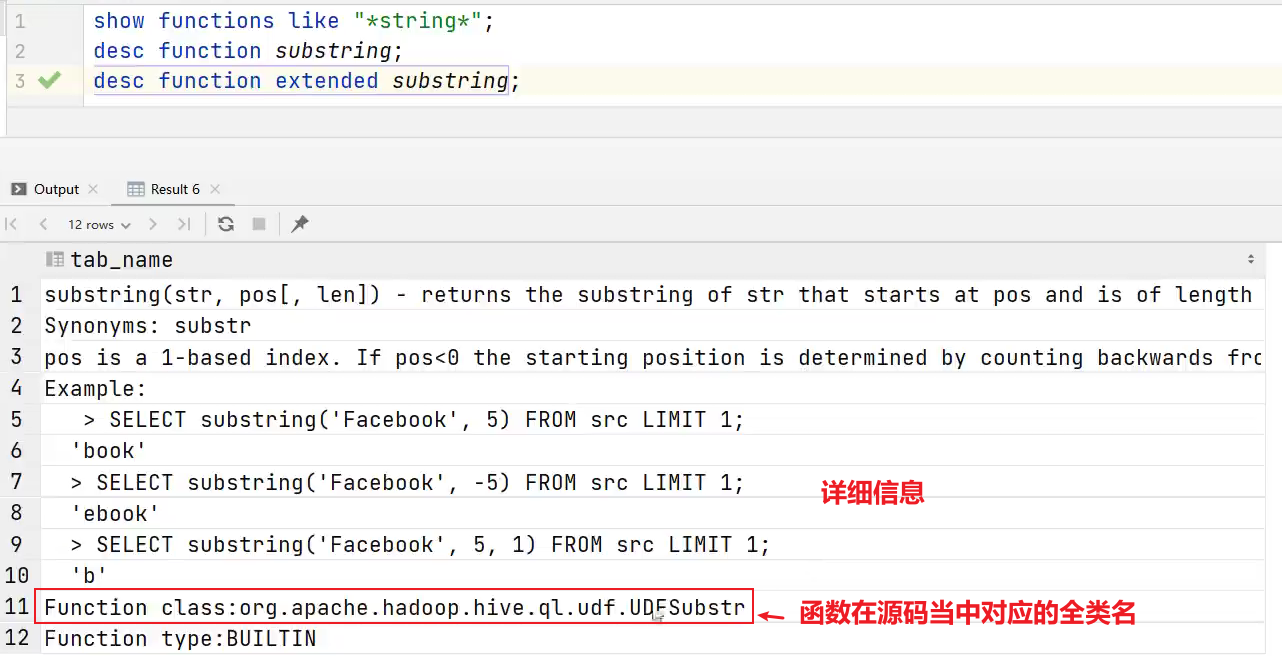
1)查看系统内置函数
hive> show functions;
查看和string有关的函数:
show functions like 'string%';
2)查看内置函数用法
hive> desc function upper; --查看upper函数的用法
3)查看内置函数详细信息
hive> desc function extended substring;
2、单行函数
单行函数的特点是一进一出,即输入一行,输出一行。进:传的参数,出:返回值。
单行函数按照功能可分为如下几类: 日期函数、字符串函数、集合函数、数学函数、流程控制函数等。
2.1 算术运算函数
| 运算符 | 描述 |
|---|---|
| A+B | A和B相加 |
| A-B | A减去B |
| A*B | A和B 相乘 |
| A/B | A除以B |
| A%B | A对B取余 |
| A&B | A和B按位取与 |
| A|B | A和B按位取或 |
| A^B | A和B按位取异或 |
| ~A | A按位取反 |
--算术运算函数
select 1&0; --结果为0
select 3&2; --结果为2。先把3和2转换为2进制,再把处理结果转换为十进制。
查询出所有员工的薪水后加1显示:
hive (default)> select sal + 1 from emp;
2.2 数值函数
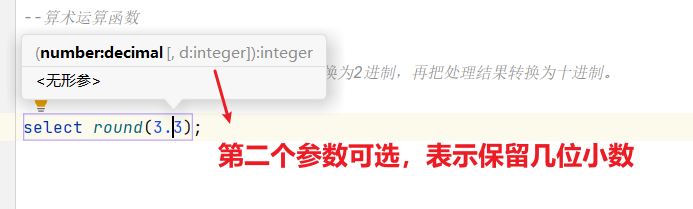
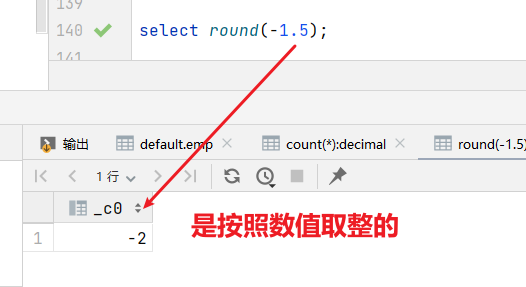
1)round:四舍五入
hive> select round(3.3); 3
2)ceil:向上取整
hive> select ceil(3.1) ; 4
3)floor:向下取整
hive> select floor(4.8); 4
2.3 字符串函数
(1)substring 截取字符串
- 语法一:
substring(string A, int start)
返回值:string
说明:返回字符串A从start位置到结尾的字符串 - 语法二:
substring(string A, int start, int len)
返回值:string
说明:返回字符串A从start位置开始,长度为len的字符串
案例实操:
(1)获取第二个字符以后的所有字符
hive> select substring("wenxin",2);
输出:
enxin
(2)获取倒数第三个字符以后的所有字符
hive> select substring("wenxin",-3);
输出:
xin
(3)从第3个字符开始,向后获取2个字符
hive> select substring("wenxin",3,2);
输出:
nx
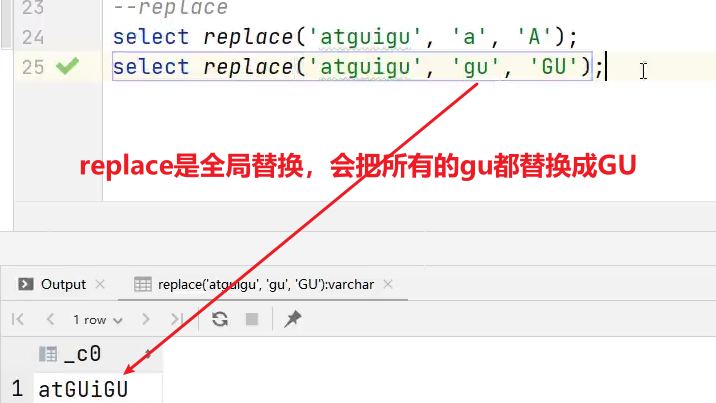
(2)replace 替换
语法:replace(string A, string B, string C)
返回值:string
说明:将字符串A中的子字符串B替换为C。
hive> select replace('wenxinwenxin', 'w', 'W')
输出:
hive> WenxinWenxin
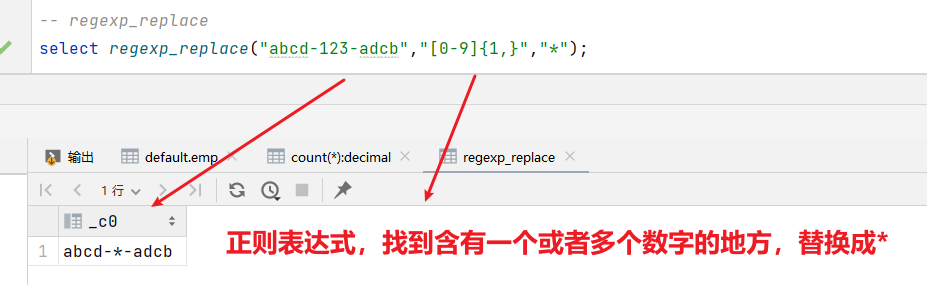
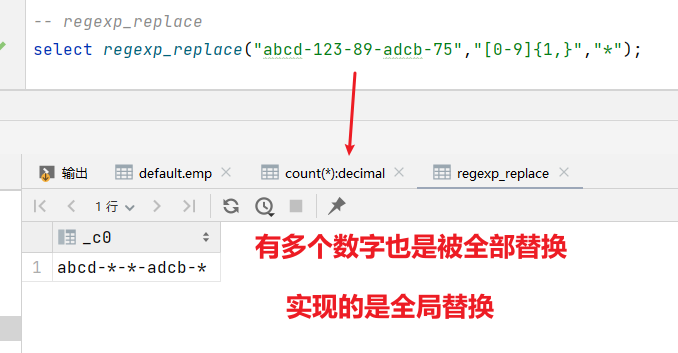
(3)regexp_replace 正则替换
语法:regexp_replace(string A, string B, string C)
返回值:string
说明:将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符。
案例实操:
hive> select regexp_replace('100-200', '(\\d+)', 'num')
上面这个涉及反斜杠转义字符的问题,所有有两个反斜杠
输出:
hive> num-num
正则表达式可视化网址
(4)regexp 正则匹配
语法:字符串 regexp 正则表达式
返回值:boolean
说明:若字符串符合正则表达式,则返回true,否则返回false。
(1)正则匹配成功,输出true
hive> select 'dfsaaaa' regexp 'dfsa+'
输出:
hive> true
(2)正则匹配失败,输出false
hive> select 'dfsaaaa' regexp 'dfsb+';
输出:
hive> false
(5)repeat 重复字符串
语法:repeat(string A, int n)
返回值:string
说明:将字符串A重复n遍。
hive> select repeat('123', 3);
输出:
hive> 123123123
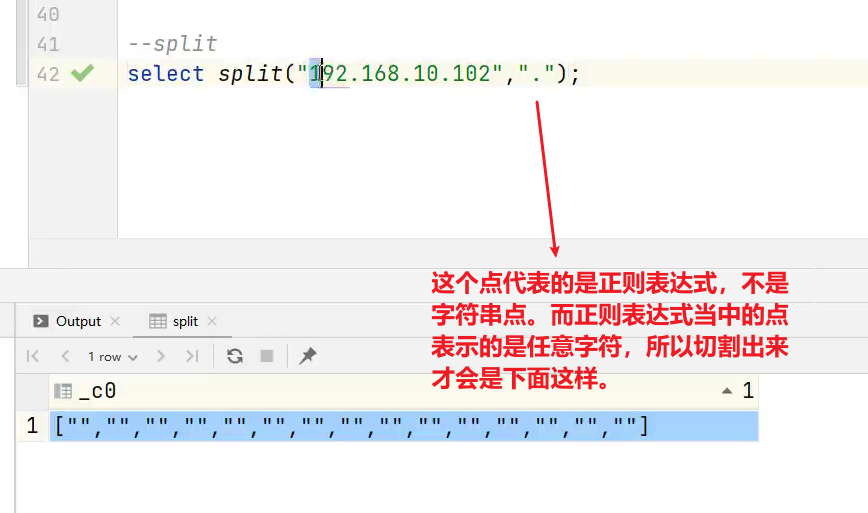
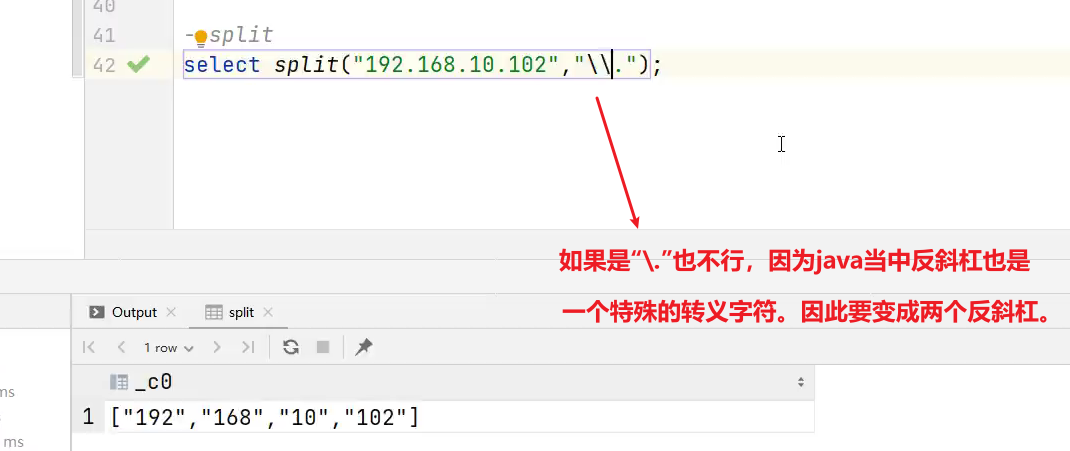
(6)split 字符串切割
语法:split(string str, string pat)
返回值:array
说明:按照正则表达式pat匹配到的内容分割str,分割后的字符串,以数组的形式返回。
hive> select split('a-b-c-d','-');
输出:
hive> ["a","b","c","d"]
(7)nvl 替换null值
语法:nvl(A,B)
说明:若A的值不为null,则返回A,否则返回B。 可以把其理解为给默认值的操作。
hive> select nvl(null,0);
输出:
hive> 0
(8)concat 拼接字符串
语法:concat(string A, string B, string C, ……)
返回:string
说明:将A,B,C……等字符拼接为一个字符串
hive> select concat('beijing','-','shanghai','-','shenzhen');
输出:
hive> beijing-shanghai-shenzhen
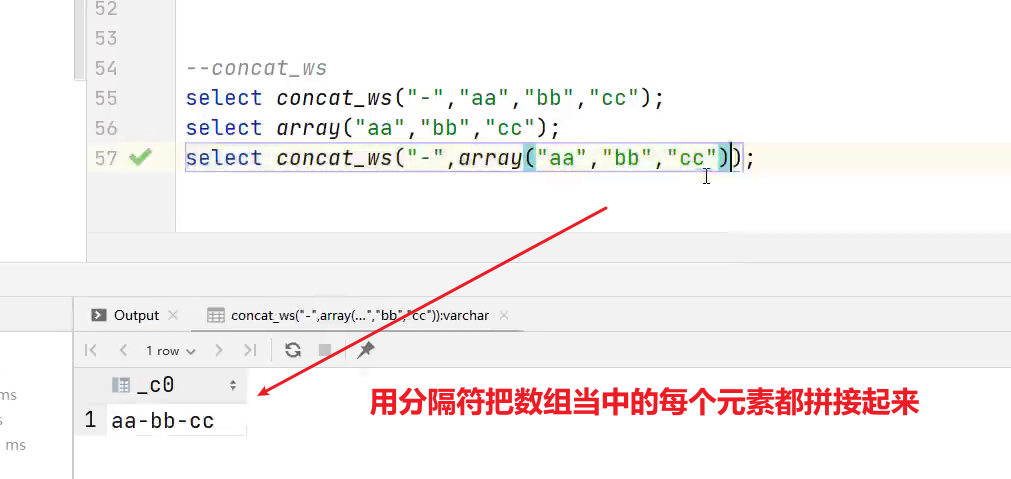
(9)concat_ws 以指定分隔符拼接字符串或者字符串数组
语法:concat_ws(string A, string…| array(string))
返回值:string
说明:使用分隔符A拼接多个字符串,或者一个数组的所有元素。
hive>select concat_ws('-','beijing','shanghai','shenzhen');
输出:
hive> beijing-shanghai-shenzhen
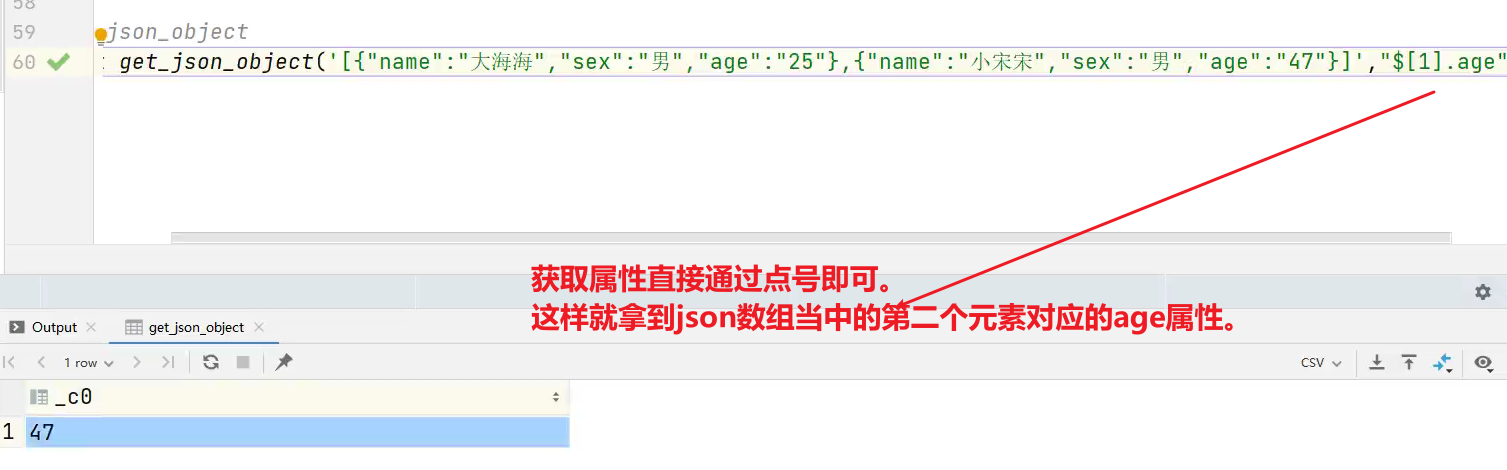
(10)get_json_object 解析json字符串
语法:get_json_object(string json_string, string path)
返回值:string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
案例实操:
(1)获取json数组里面的json具体数据
hive> select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0].name');
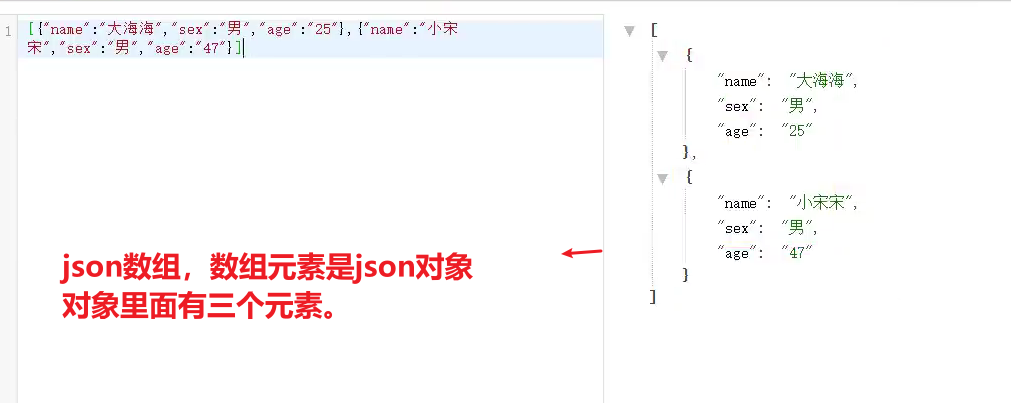
输出:
hive> 大海海
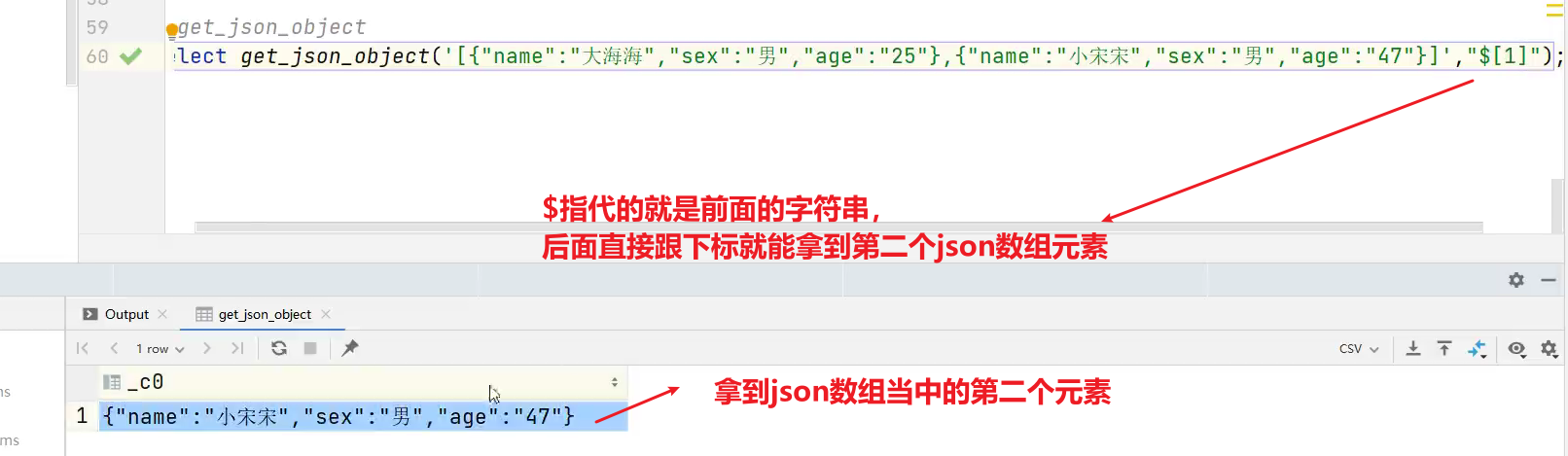
(2)获取json数组里面的数据
hive> select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0]');
输出:
hive> {"name":"大海海","sex":"男","age":"25"}
2.4 日期函数
(1)unix_timestamp 返回当前或指定时间的时间戳
语法:unix_timestamp()
返回值:bigint
案例实操:
hive> select unix_timestamp('2022/08/08 08-08-08','yyyy/MM/dd HH-mm-ss');
输出:
1659946088
说明:-前面是日期后面是指,日期传进来的具体格式

时间戳有10位的和13位的:
- 10位的时间戳单位是秒
- 13位的单位是毫秒
无论是把时间戳转换为时间字符串,还是将时间字符串转换为时间戳,都需要考虑时区的问题。
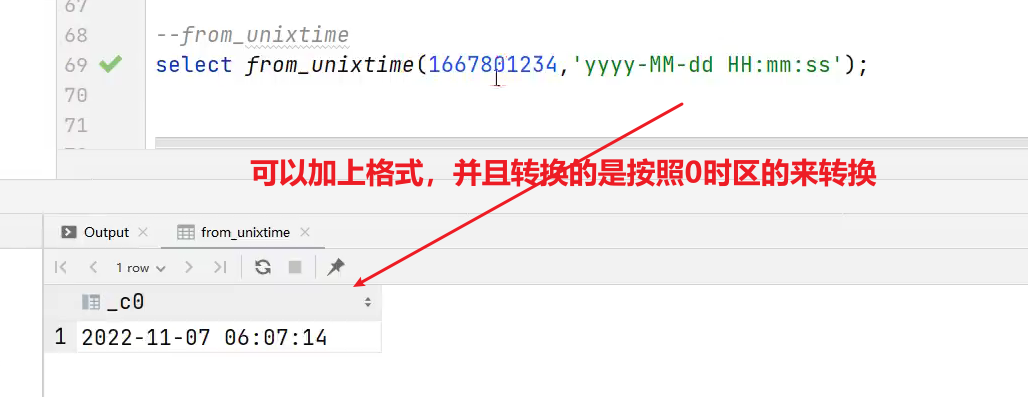
(2)from_unixtime
用法:转化UNIX时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到当前时区的时间格式
语法:from_unixtime(bigint unixtime[, string format])
返回值:string
案例实操:
hive> select from_unixtime(1659946088);
输出:
2022-08-08 08:08:08
(3)current_date 当前日期
hive> select current_date;
输出:
2022-07-11
(4)current_timestamp 当前的日期加时间,并且精确的毫秒
hive> select current_timestamp;
输出:
2022-07-11 15:32:22.402
(5)month:获取日期中的月
语法:month (string date)
返回值:int
案例实操:
hive> select month('2022-08-08 08:08:08');
输出:
8
(6)day 获取日期中的日
语法:day (string date)
返回值:int
案例实操:
hive> select day('2022-08-08 08:08:08')
输出:
8
(7)hour 获取日期中的小时
语法:hour (string date)
返回值:int
案例实操:
hive> select hour('2022-08-08 08:08:08');
输出:
8
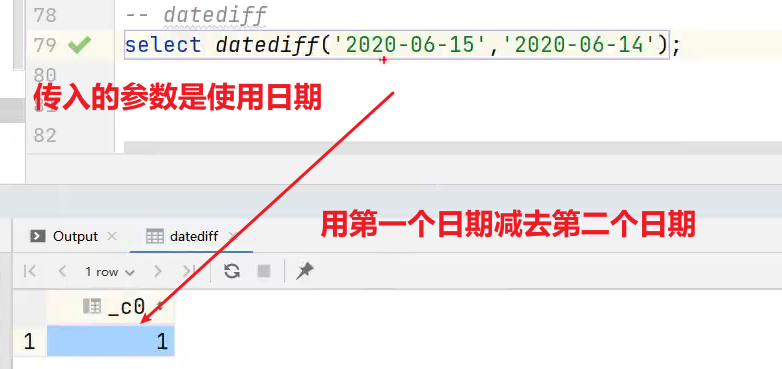
(8)datediff 两个日期相差的天数(结束日期减去开始日期的天数)
语法:datediff(string enddate, string startdate)
返回值:int
案例实操:
hive> select datediff('2021-08-08','2022-10-09');
输出:
-427
(9)date_add:日期加天数
语法:date_add(string startdate, int days)
返回值:string
说明:返回开始日期 startdate 增加 days 天后的日期
案例实操:
hive> select date_add('2022-08-08',2);
输出:
2022-08-10
(10)date_sub:日期减天数
语法:date_sub (string startdate, int days)
返回值:string
说明:返回开始日期startdate减少days天后的日期。
案例实操:
hive> select date_sub('2022-08-08',2);
输出:
2022-08-06
(11)date_format:将标准日期解析成指定格式字符串
hive> select date_format('2022-08-08','yyyy年-MM月-dd日')
输出:
2022年-08月-08日
2.5 流程控制函数
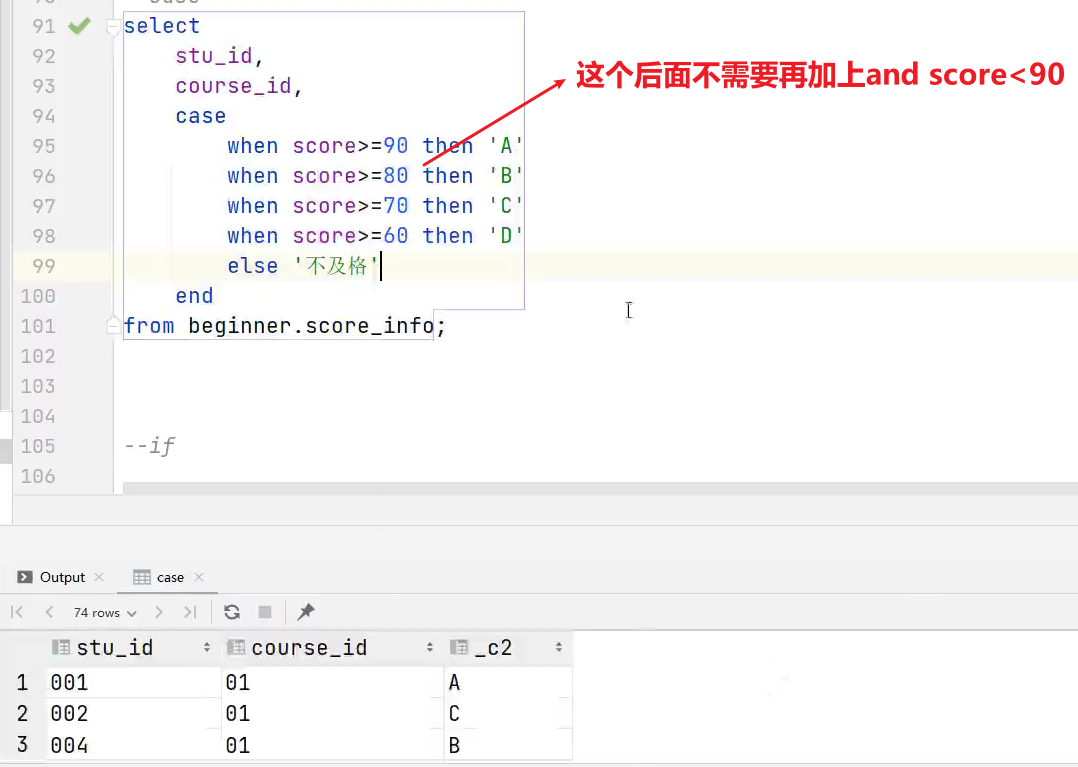
(1)case when:条件判断函数
语法一:case when a then b [when c then d]* [else e] end
返回值:T
说明:如果a为true,则返回b;如果c为true,则返回d;否则返回 e
hive>
select case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end
from tabl eName;
mary
语法二: case a when b then c [when d then e]* [else f] end
返回值: T
说明:如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f
hive>
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end
from t ableName;
mary
- case在执行的时候,是逐个条件去判断的,先判断第一个when,不满足才去判断第二个when。

(2)if: 条件判断,类似于Java中三元运算符
语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值:T
说明:当条件testCondition为true时,返回valueTrue;否则返回valueFalseOrNull
(1)条件满足,输出正确
hive> select if(10 > 5,'正确','错误');
输出:正确
(2)条件满足,输出错误
hive> select if(10 < 5,'正确','错误');
输出:错误
2.6 集合函数
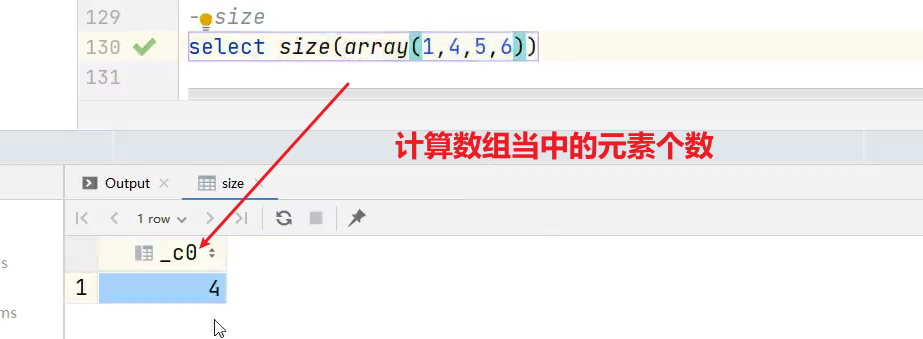
(1)size 集合中元素的个数
hive> select size(friends) from test; --2/2 每一行数据中的friends集合里的个数
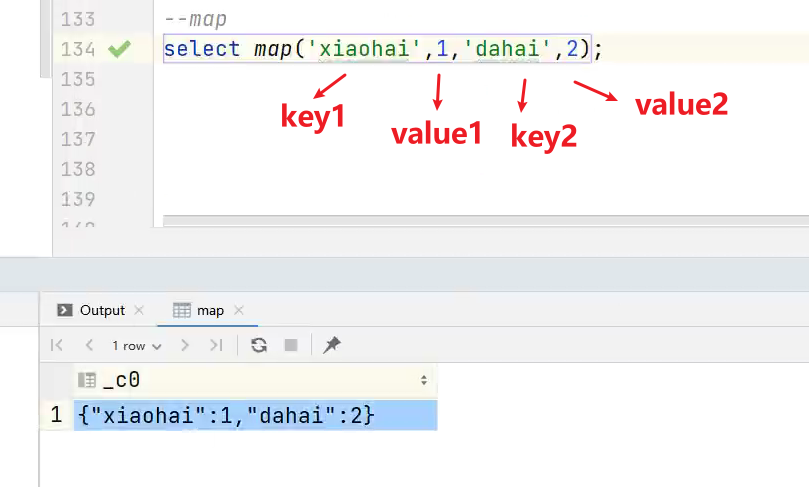
(2)map 创建map集合
语法:map (key1, value1, key2, value2, …)
说明:根据输入的key和value对构建map类型
案例实操:
hive> select map('xiaohai',1,'dahai',2);
输出:
hive> {"xiaohai":1,"dahai":2}
(3)map_keys 返回map中的key
hive> select map_keys(map('xiaohai',1,'dahai',2));
输出:
hive>["xiaohai","dahai"]
(4)map_values 返回map中的value
hive> select map_values(map('xiaohai',1,'dahai',2));
输出:
hive>[1,2]
(5)array 声明array集合
语法:array(val1, val2, …)
说明:根据输入的参数构建数组array类
案例实操:
hive> select array('1','2','3','4');
输出:
hive>["1","2","3","4"]
(6)array_contains 判断array中是否包含某个元素
hive> select array_contains(array('a','b','c','d'),'a');
输出:
hive> true
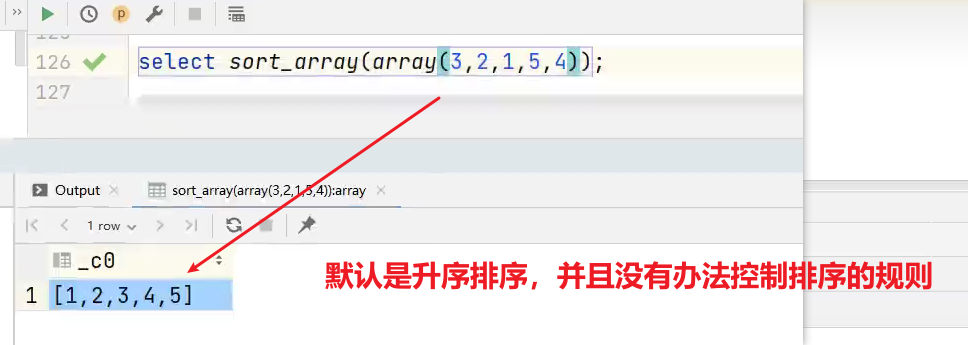
(7)sort_array 将array中的元素排序
hive> select sort_array(array('a','d','c'));
输出:
hive> ["a","c","d"]
(8)struct 声明struct中的各属性
语法:struct(val1, val2, val3, …)
说明:根据输入的参数构建结构体struct类
案例实操:
hive> select struct('name','age','weight');
输出:得到带有字段名的结构体
hive> {"col1":"name","col2":"age","col3":"weight"}
(9)named_struct 声明struct的属性和值
hive> select named_struct('name','xiaosong','age',18,'weight',80);
输出:
hive> {"name":"xiaosong","age":18,"weight":80}
3、高级聚合函数
聚合效果: 多进一出 (多行传入,一个行输出)。
1)普通聚合 count/sum
3.1 collect_list 函数
2)collect_list 收集并形成list集合,结果不去重
hive>
select sex,collect_list(job)
fromemployee
group by sex
结果:
女 ["行政","研发","行政","前台"]
男 ["销售","研发","销售","前台"]
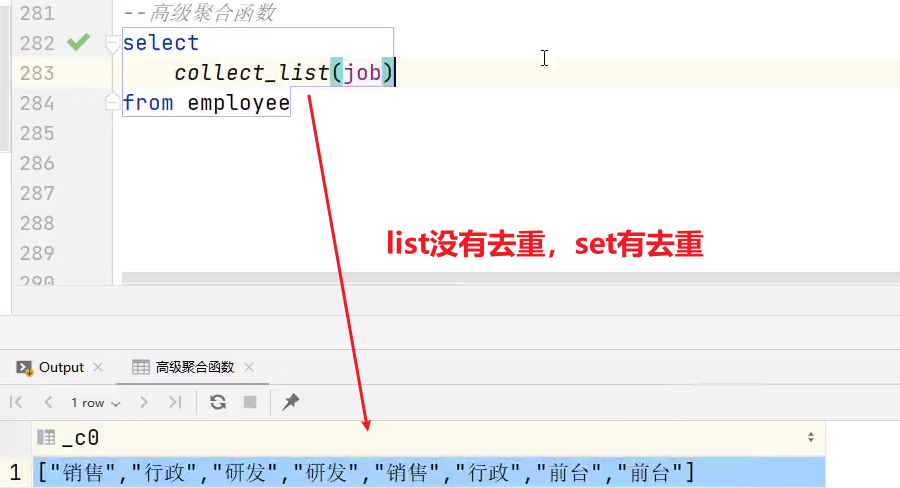
3.2 collect_set 函数
3)collect_set 收集并形成set集合,结果去重
hive>
select sex,collect_set(job)
fromemployee
group by sex
结果:
女 ["行政","研发","前台"]
男 ["销售","研发","前台"]
4、炸裂函数
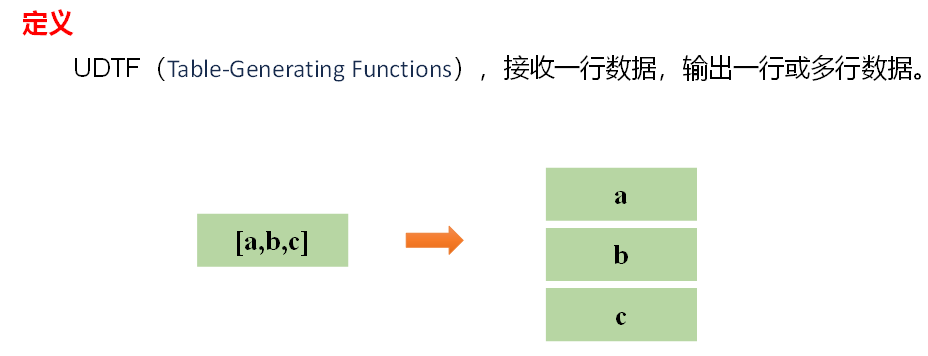
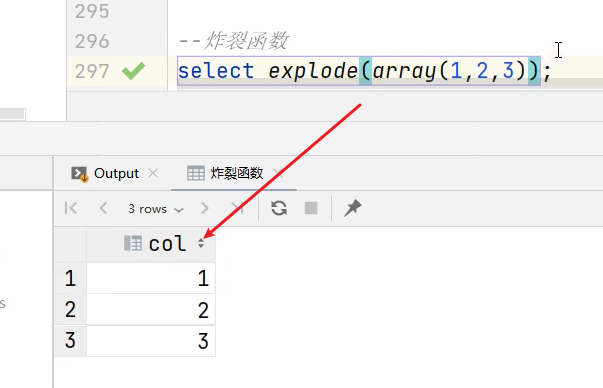
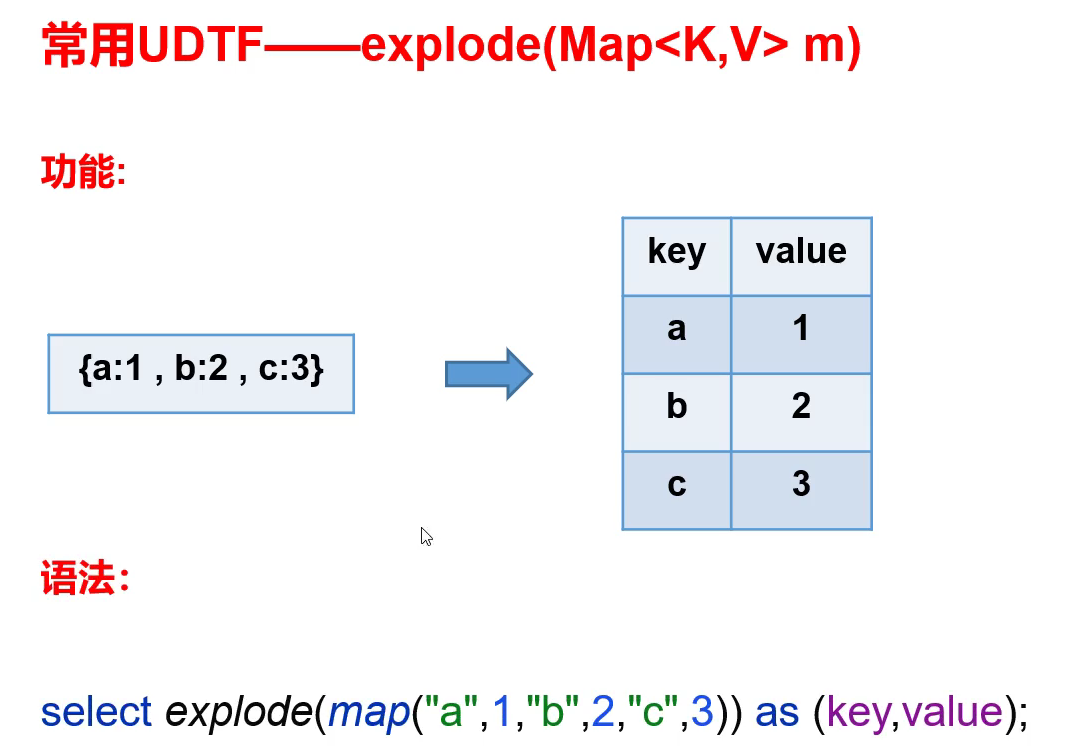
4.1 expload 函数
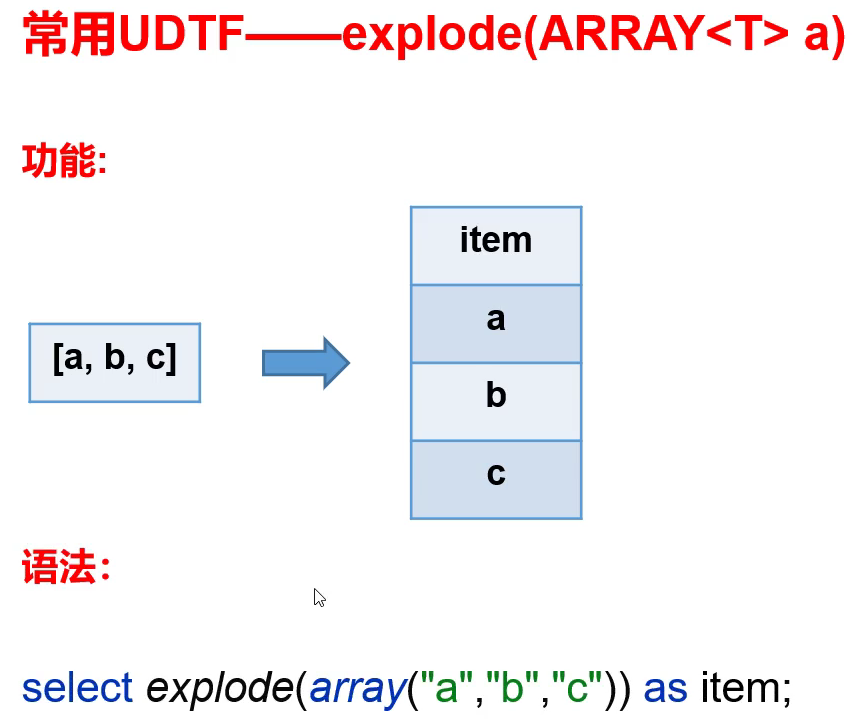
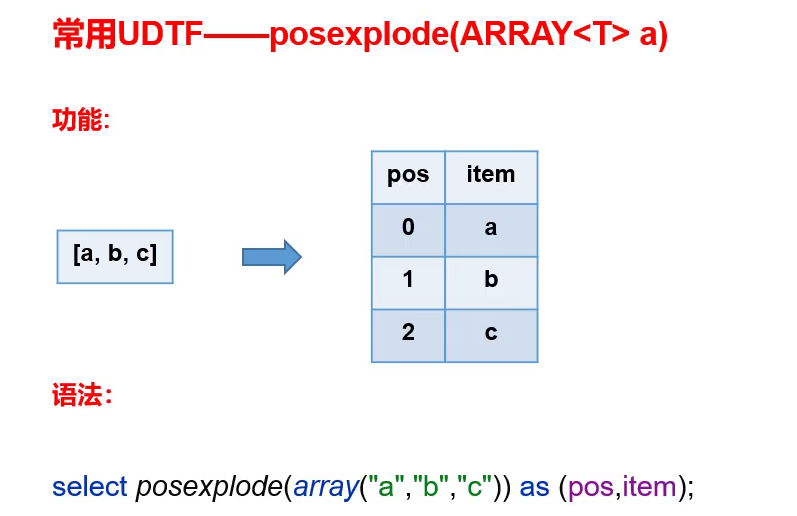
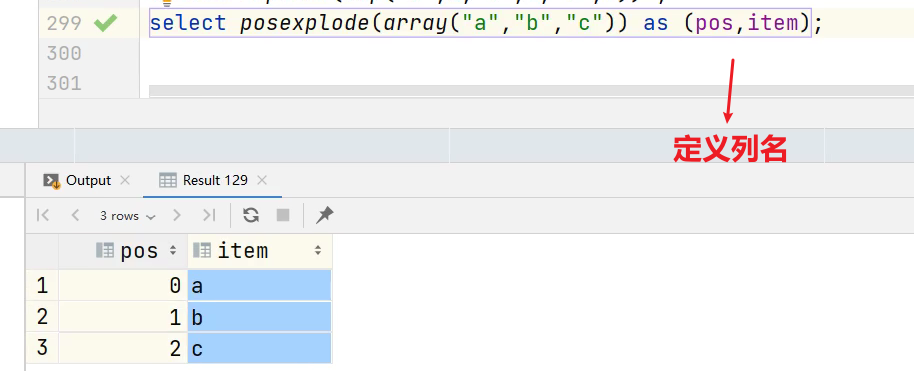
4.2 posexplode 函数
- posexplode相比于explode还会返回索引。
4.3 inline 函数
- inline里面接受的是一个数组,数组里面的元素是结构体

4.4 Lateral View

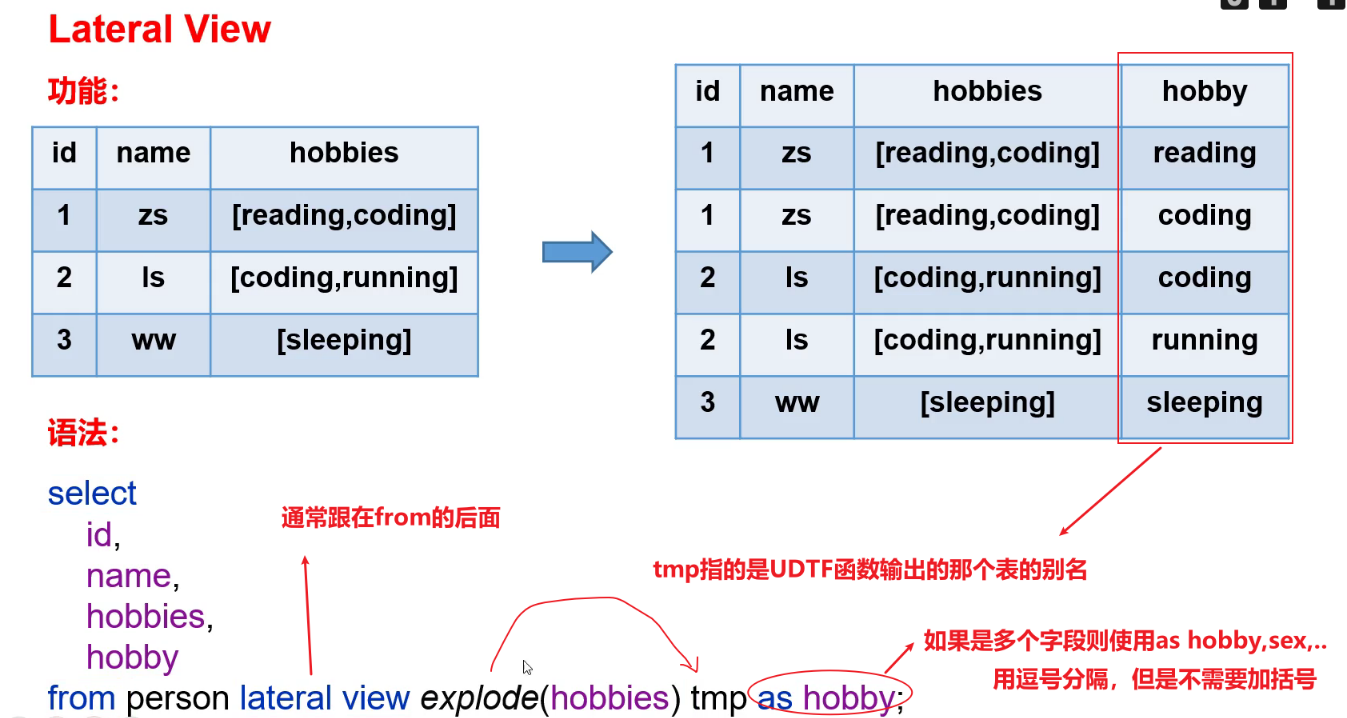
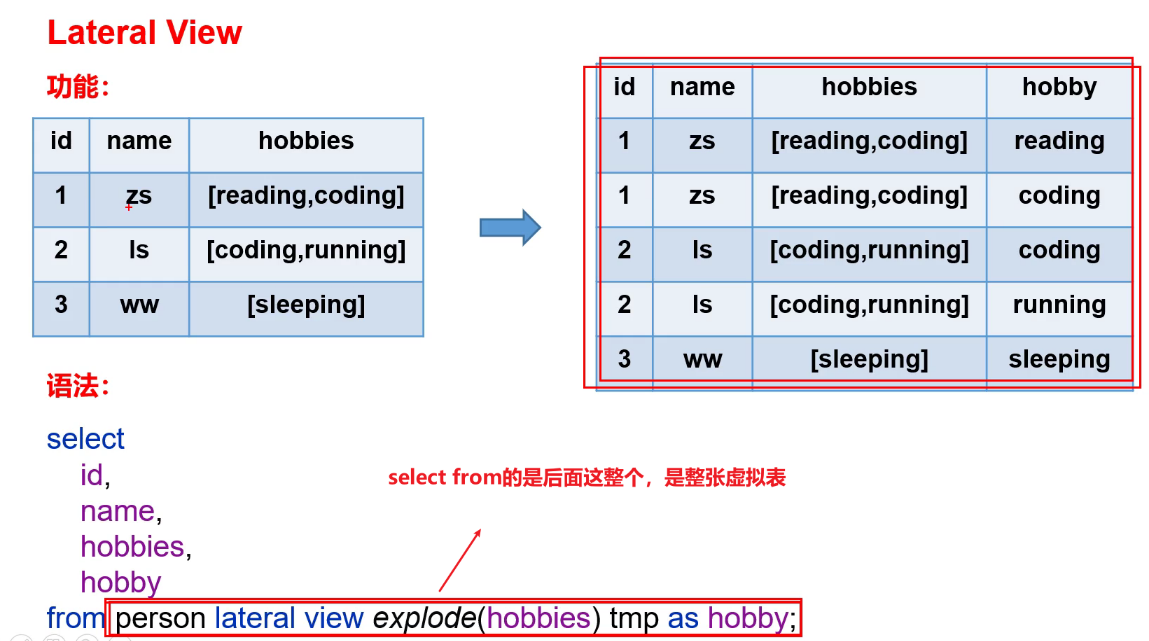
5、窗口函数(开窗函数)
5.1 概述


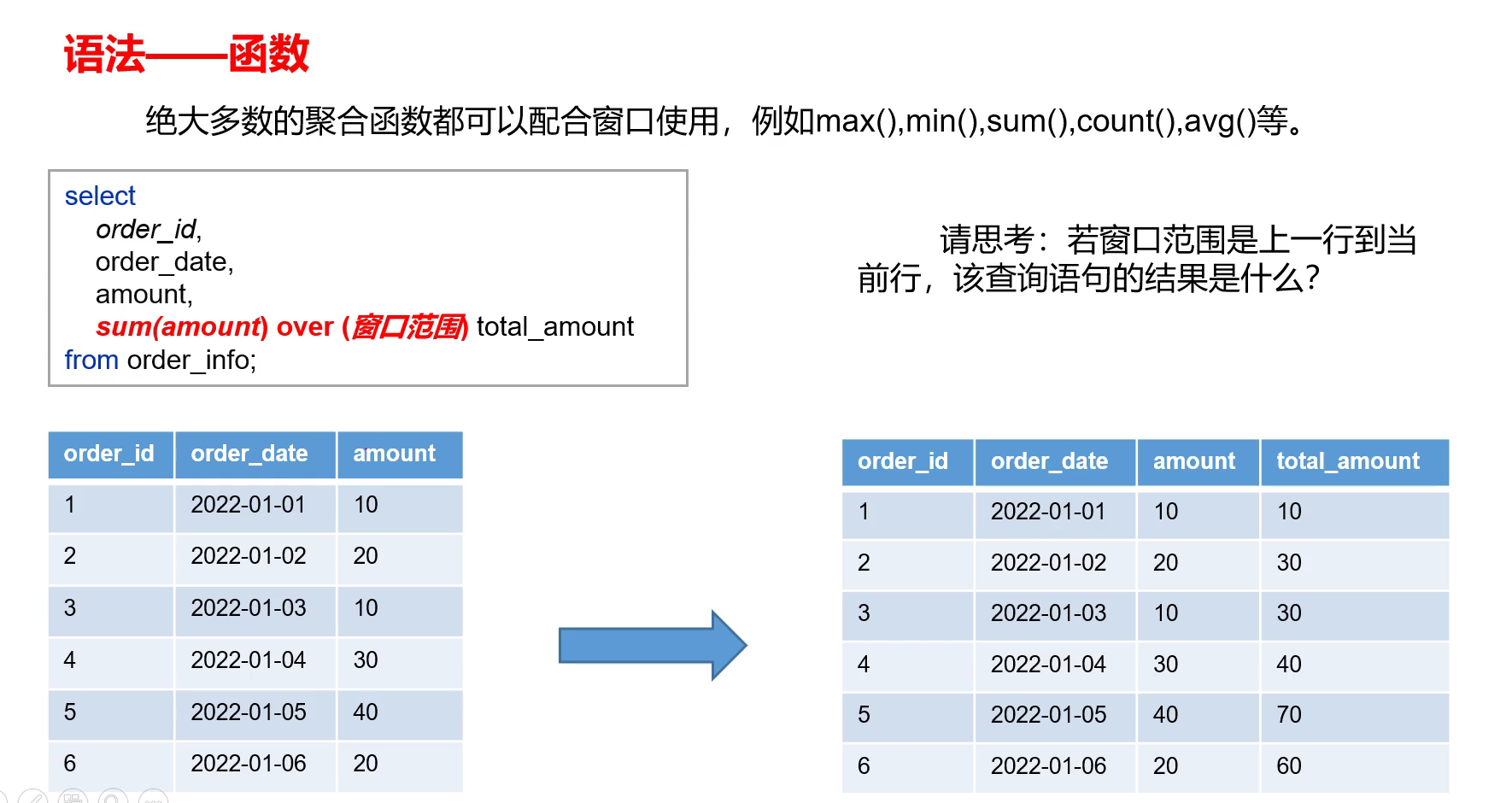

-
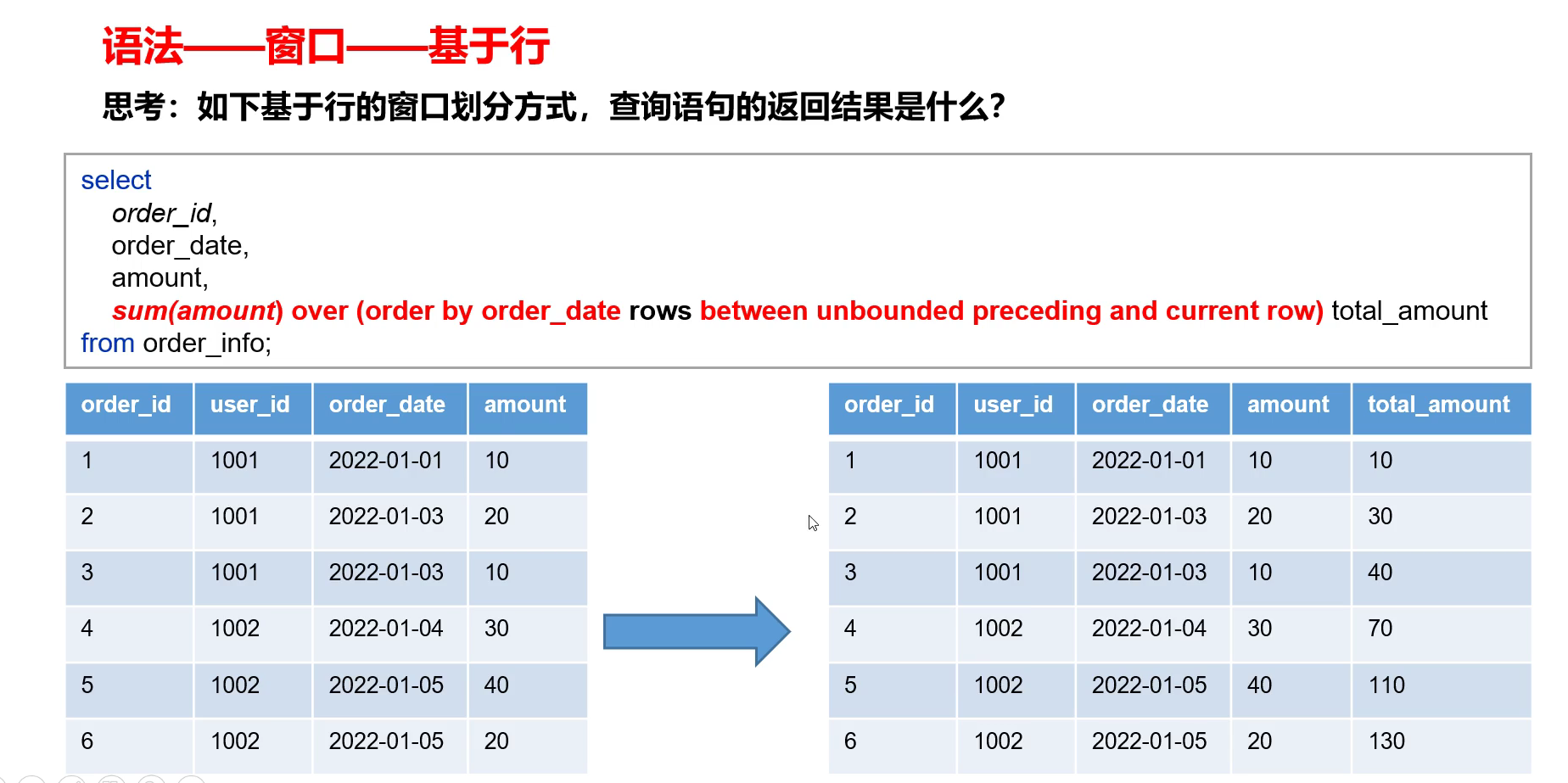
这里窗口范围描述的上一行到当前行指的是:计算当中实际参与的数据的上一行到当前行,而指的不是原表的上一行到当前行。
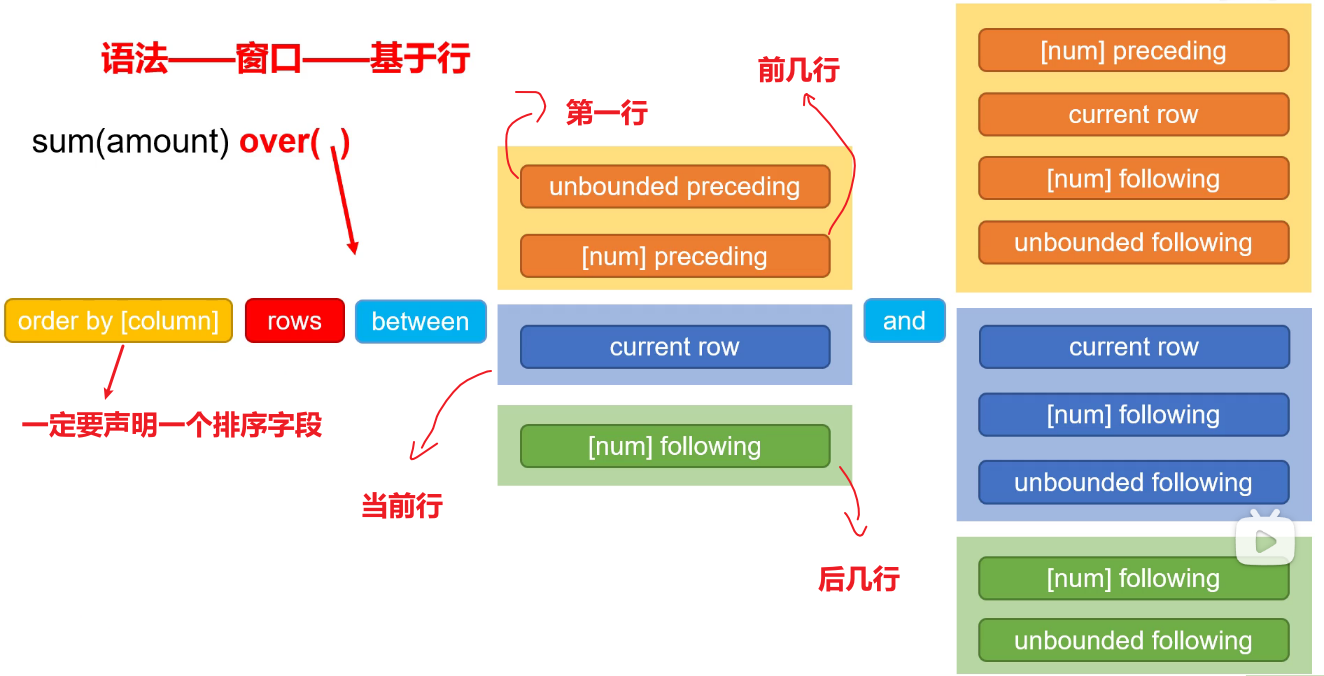
-
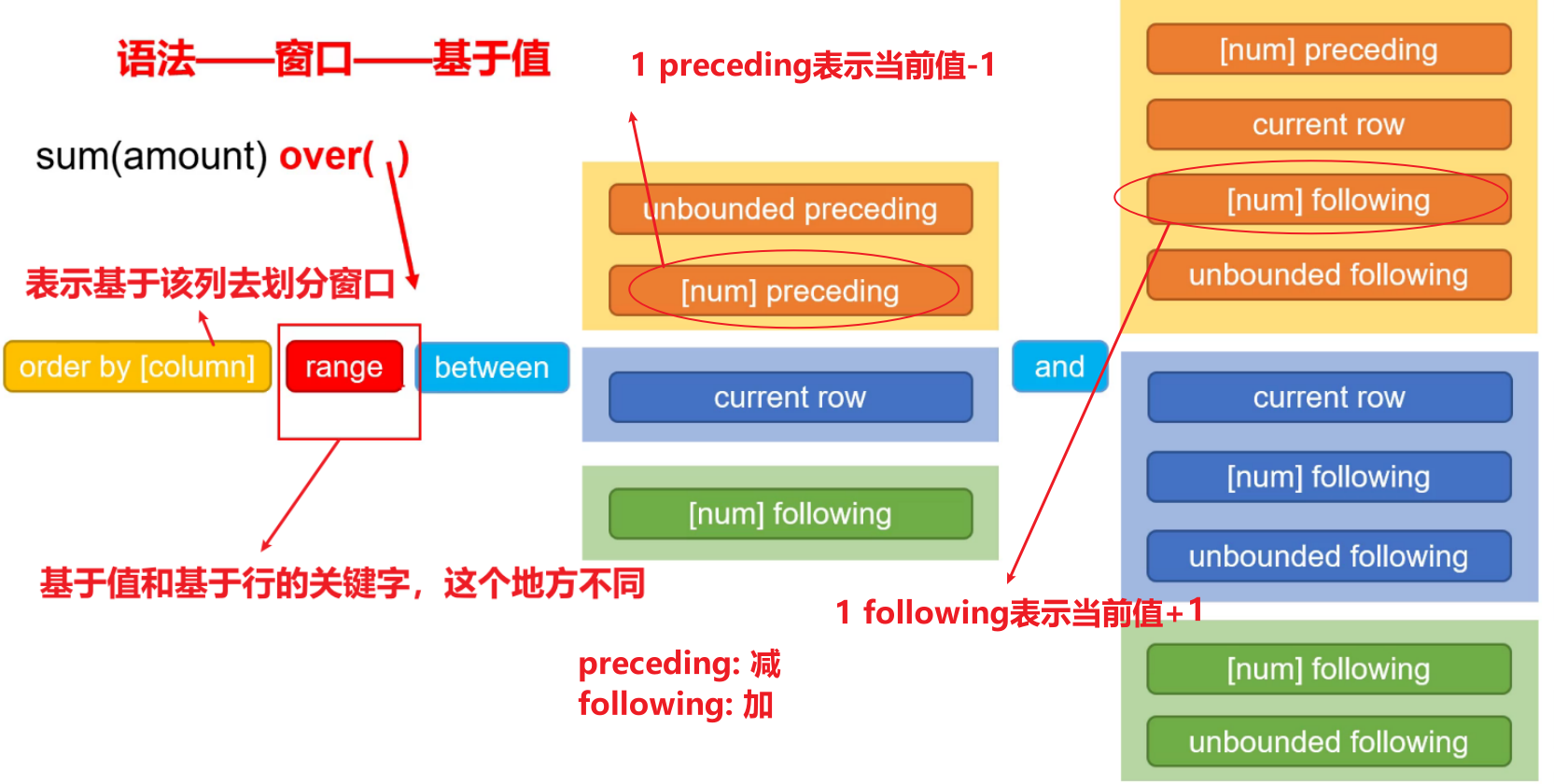
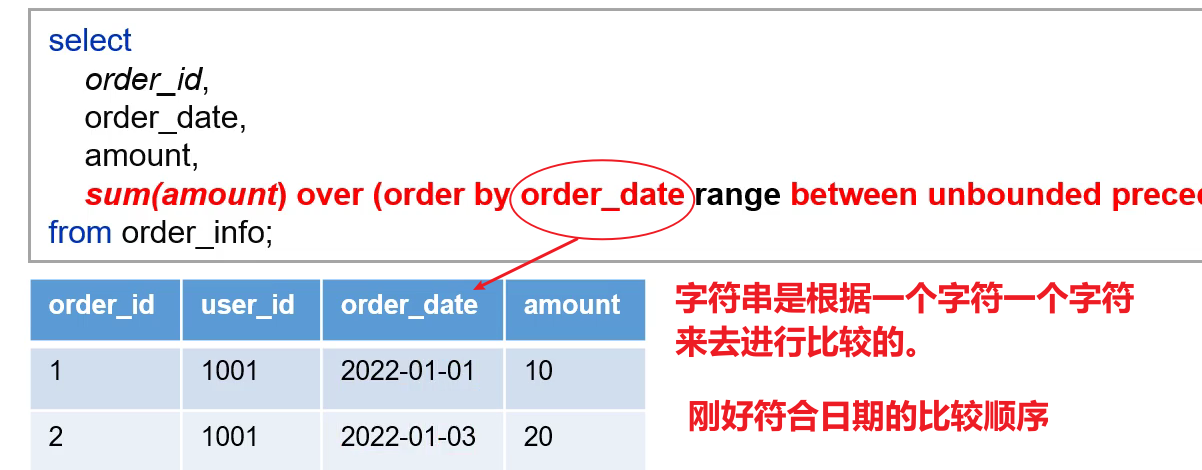
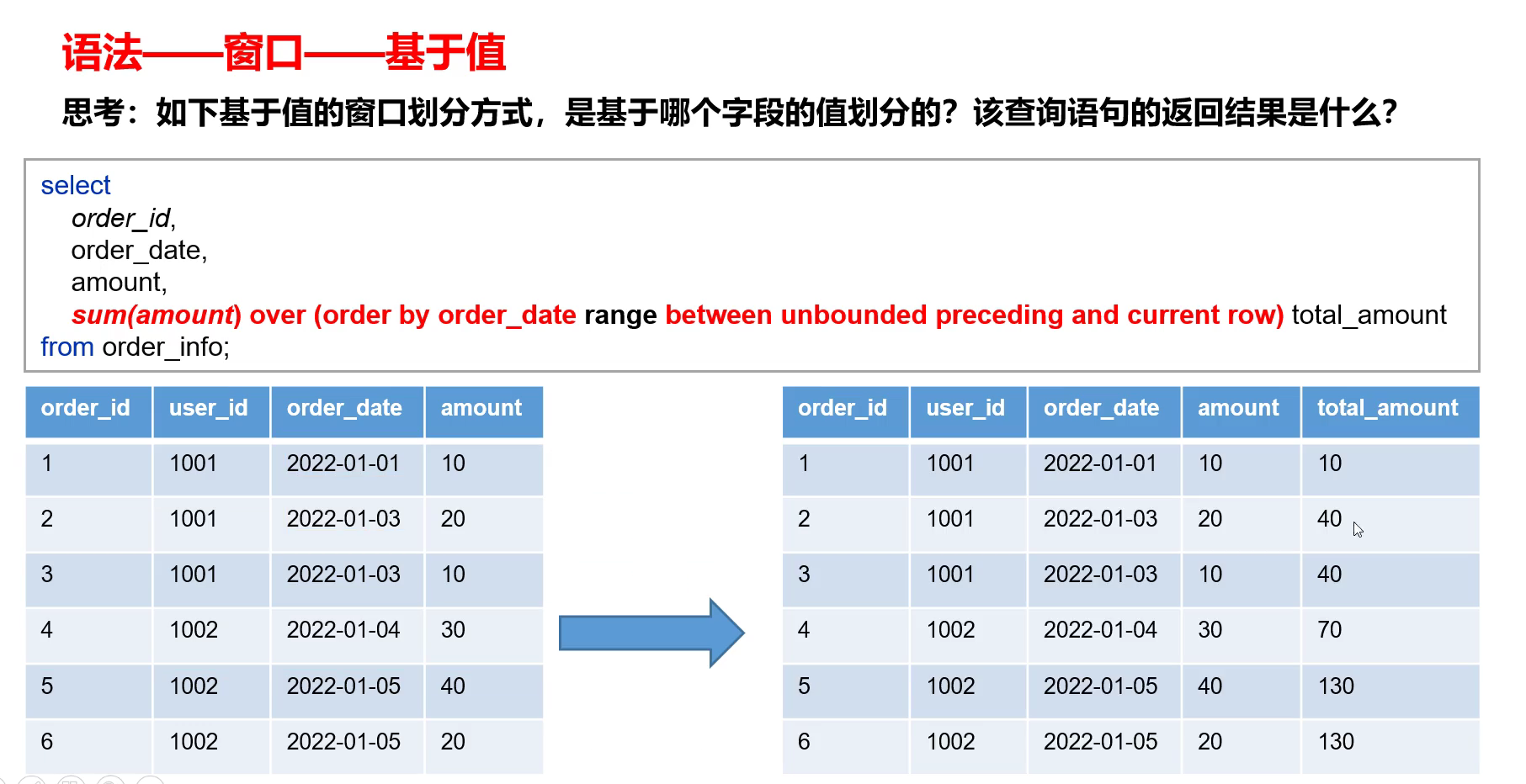
并且对于基于值的窗口函数,只有当between和and当中有包含数值的时候,必须保证order by后面的column是数值型或者字符串的。
-
total_amount:相当于截止到每一个下单日期的总额。

- 由于进行了分区,因此当到达4的时候,和前面的3不在同一个分区,因此只包含其自身。
- 有分区之后的第一行到当前行指的是:该分区当中的第一行到当前行。
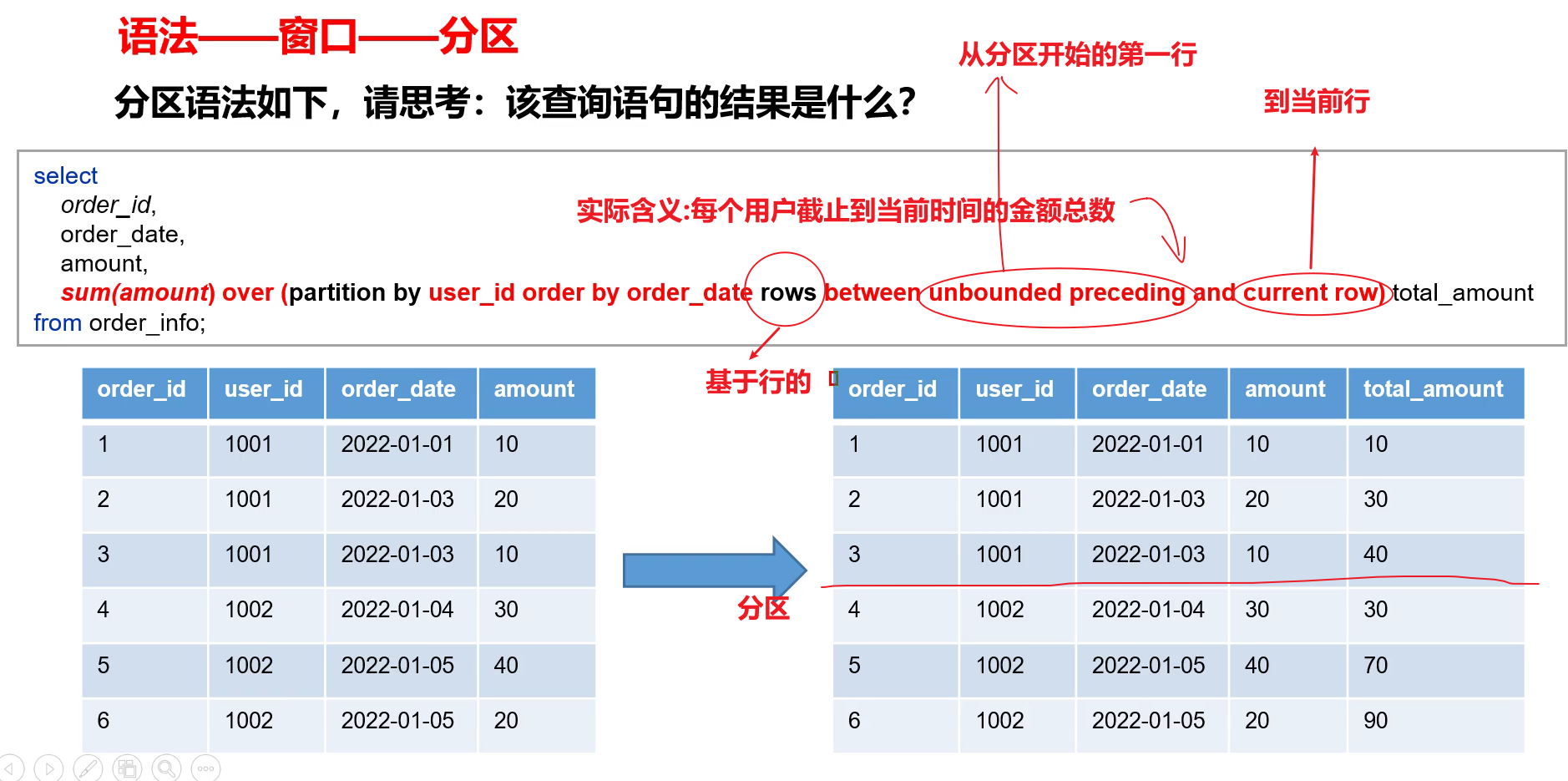

- 对于order by:在基于行和基于值两方面是不同的。在基于行上,如果不写order by,则是随机的,不确定,这样后面写range…between也没有意义【从负无穷到正无穷】。
5.2 常用窗口函数
按照功能,常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数。
(1)聚合函数
max:最大值。
min:最小值。
sum:求和。
avg:平均值。
count:计数。
(2)跨行取值函数
(1)lead和lag
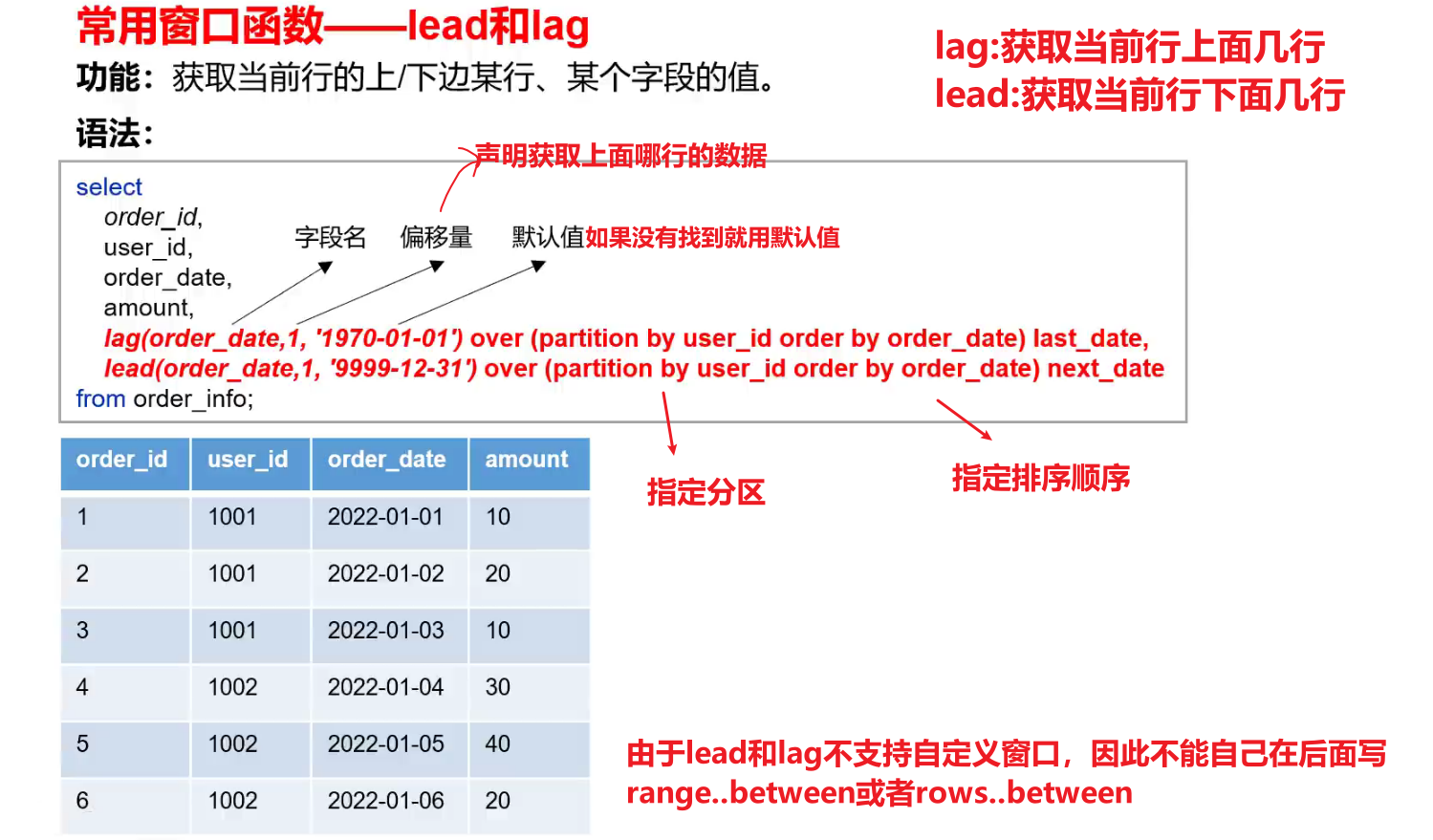
- 注:lag和lead函数不支持自定义窗口。

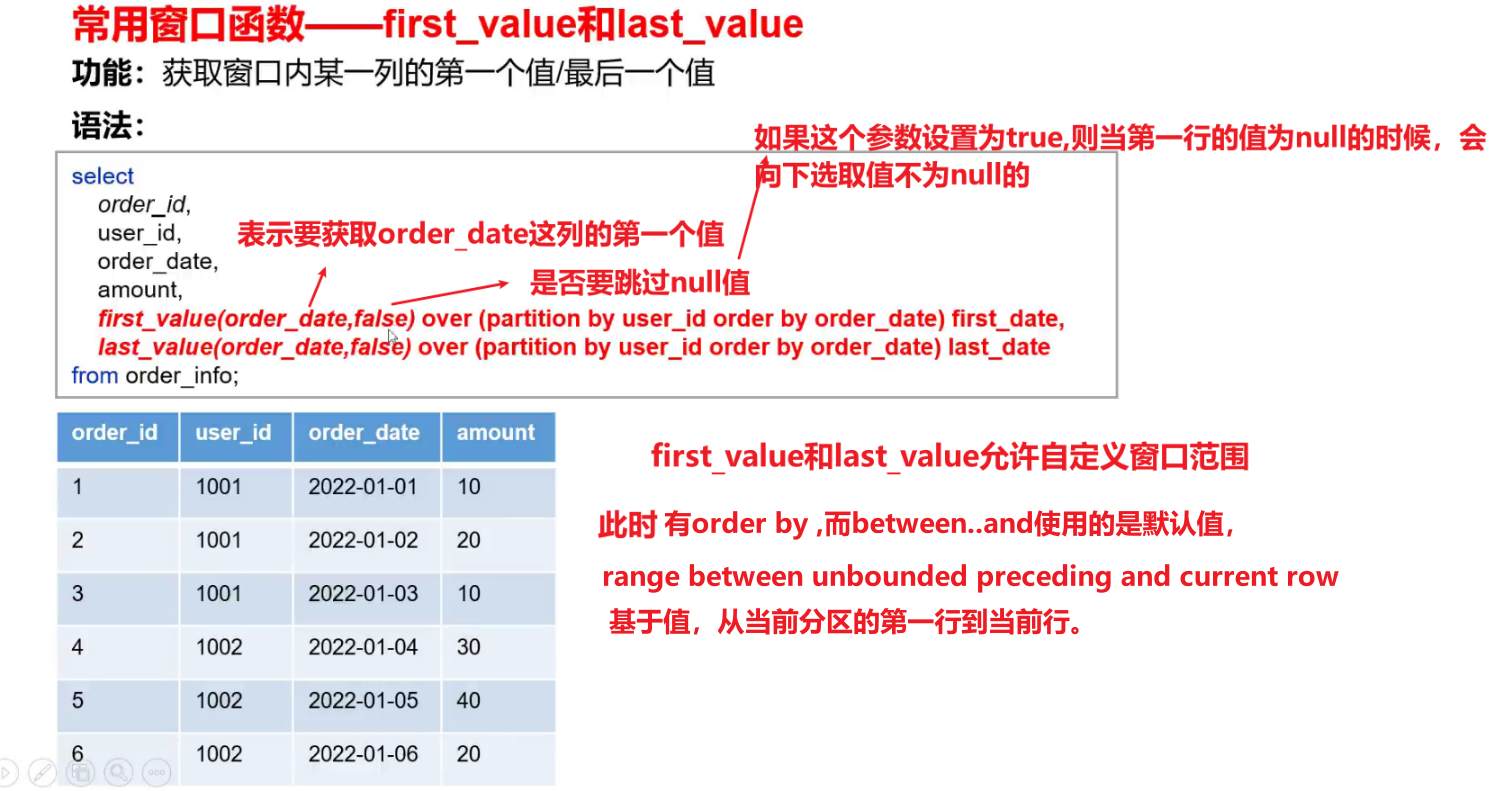
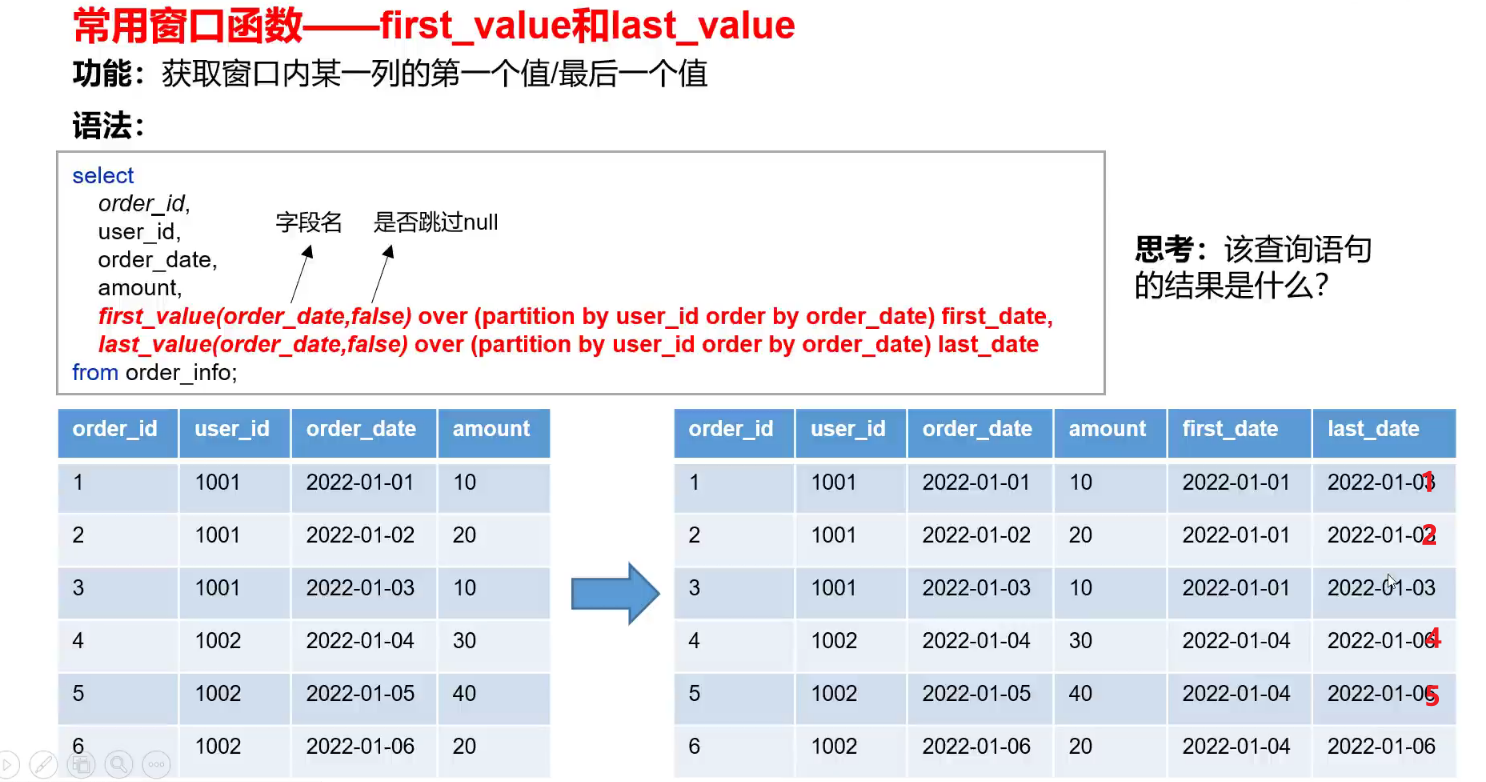
(2)first_value和last_value
(3)排名函数
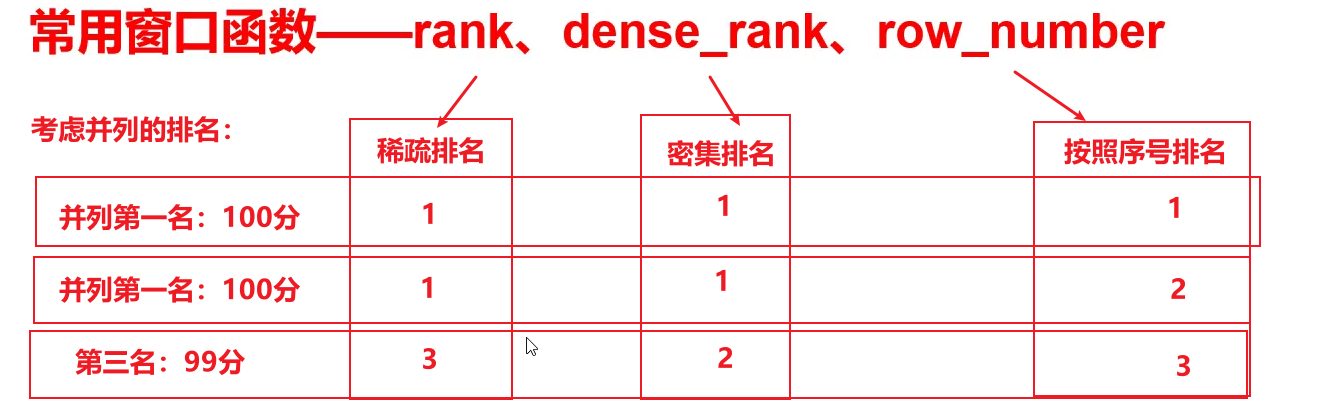
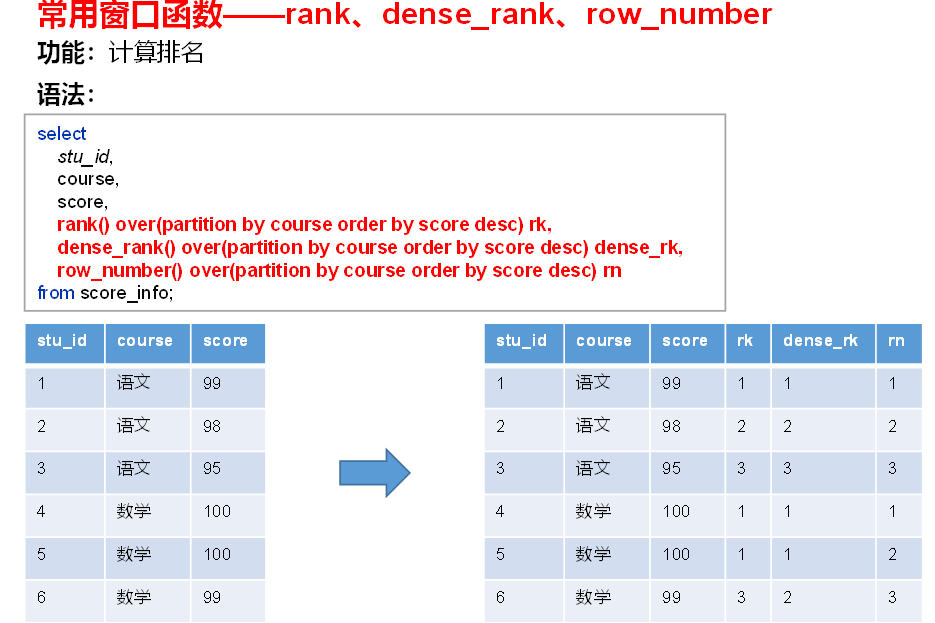
- 注:rank 、dense_rank、row_number不支持自定义窗口。
6、自定义函数
在hive当中有多种函数:比如单行函数、聚合函数、UDTF函数、窗口函数。而这四类函数都可以进行自定义。
- 在具体使用时候,一般较少自定义,如果有也是自定义单行函数。
1)Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2)当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
- UDF(User-Defined-Function): 一进一出。
- UDAF(User-Defined Aggregation Function): 用户自定义聚合函数,多进一出。
类似于:count/max/min - UDTF(User-Defined Table-Generating Functions): 用户自定义表生成函数,一进多出。
如lateral view explode()
4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
5)编程步骤
(1)继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
(2)实现类中的抽象方法
(3)在hive的命令行窗口创建函数
添加jar。
add jar linux_jar_path
创建function。
create [temporary] function [dbname.]function_name AS class_name;
(4)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
7、自定义UDF函数
需求:
自定义一个UDF实现计算给定基本数据类型的长度,例如:
hive(default)> select my_len("abcd");
4
1)创建一个Maven工程Hive
2)导入依赖
<dependencies><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.3</version></dependency>
</dependencies>
3)创建一个类
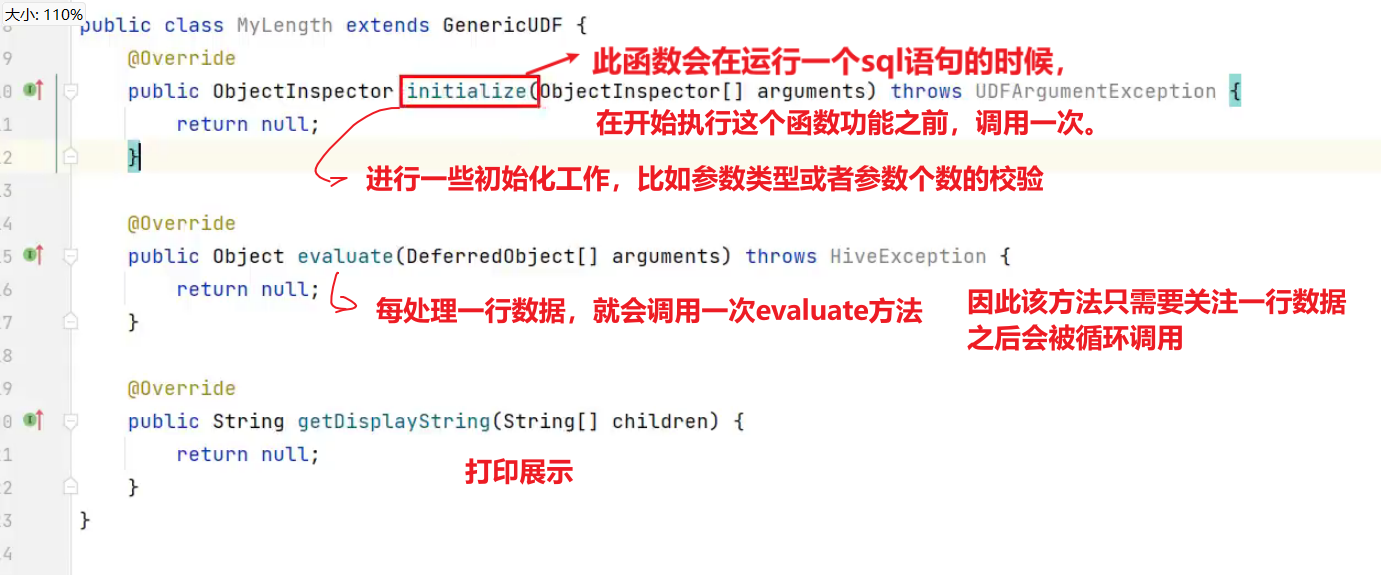
public class MyUDF extends GenericUDF {/*** 判断传进来的参数的类型和长度* 约定返回的数据类型*/@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {if (arguments.length !=1) {throw new UDFArgumentLengthException("please give me only one arg");}if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){throw new UDFArgumentTypeException(1, "i need primitive type arg");}return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}/*** 解决具体逻辑的*/@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {Object o = arguments[0].get();if(o==null){return 0;}return o.toString().length();}@Override// 用于获取解释的字符串public String getDisplayString(String[] children) {return "";}
}4)创建临时函数
(1)打成jar包上传到服务器/opt/module/hive/datas/myudf.jar
(2)将jar包添加到hive的classpath,临时生效
hive (default)> add jar /opt/module/hive/datas/myudf.jar;
(3)创建临时函数与开发好的java class关联
hive (default)>
create temporary function my_len
as "com.wenxin.hive.udf.MyUDF";
(4)即可在hql中使用自定义的临时函数
hive (default)>
select ename,my_len(ename) ename_len
from emp;
(5)删除临时函数
hive (default)> drop temporary function my_len;
注意:临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用。
5)创建永久函数
(1)创建永久函数
注意:因为add jar本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)。
hive (default)>
create function my_len2
as "com.atguigu.hive.udf.MyUDF"
using jar "hdfs://hadoop102:8020/udf/myudf.jar";
(2)即可在hql中使用自定义的永久函数
hive (default)>
select ename,my_len2(ename) ename_len
from emp;
(3)删除永久函数
hive (default)> drop function my_len2;
注意:永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。
永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上,库名.函数名。
8、其他
8.1 hive当中去重的手段?面试题
(1)distinct 去重
select distinctuser_id,create_date
from order_info
distinct后面直接跟多个字段,则会根据多个字段进行去重。
对多个字段进行去重的时候,不需要加括号!
(2)group by
select user_id,create_date
from order_info
group byuser_id,create_date- 按照两个字段去重,则会按照两个字段进行分组,因为group by会把两个字段相同的分到一组。并且一组只会返回一条数据。
(3)利用窗口函数去重
selectuser_id,create_date,row_number() over (partition by user_id,create_date) rn
from order_info
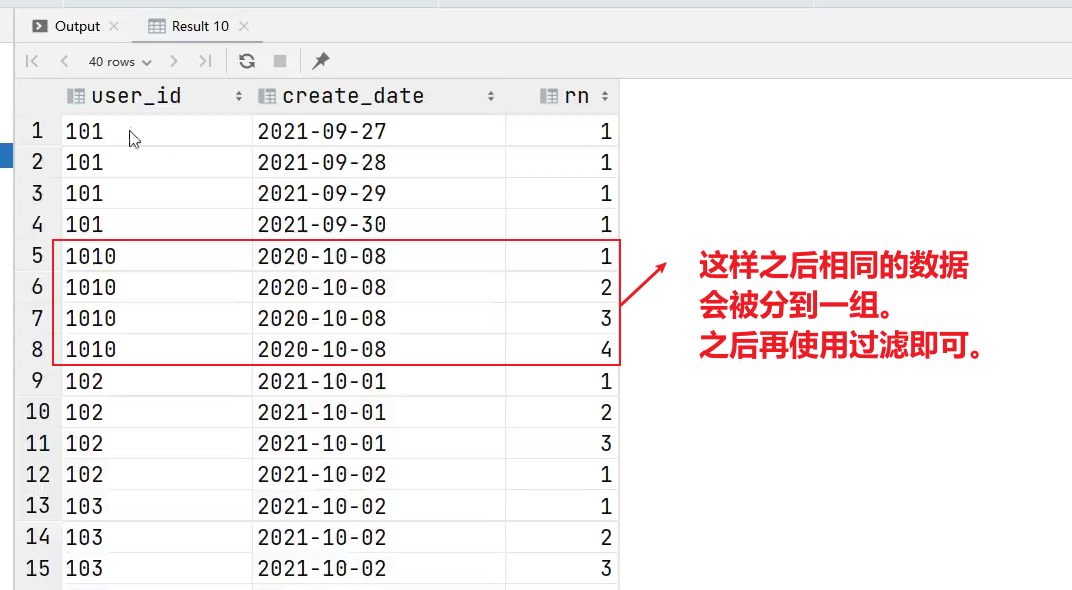
- 将每个分区里面排名为1的取出来即可。
selectuser_id,create_date,
from
(selectuser_id,create_date,row_number() over (partition by user_id,create_date) rnfrom order_info
)t1
where rn=1;
相关文章:
【Hive_03】单行函数、聚合函数、窗口函数、自定义函数、炸裂函数
1、函数简介2、单行函数2.1 算术运算函数2.2 数值函数2.3 字符串函数(1)substring 截取字符串(2)replace 替换(3)regexp_replace 正则替换(4)regexp 正则匹配(5ÿ…...
RabbitMQ手动应答与持久化
1.SleepUtil线程睡眠工具类 package com.hong.utils;/*** Description: 线程睡眠工具类* Author: hong* Date: 2023-12-16 23:10* Version: 1.0**/ public class SleepUtil {public static void sleep(int second) {try {Thread.sleep(1000*second);} catch (InterruptedExcep…...

java使用枚举类型解决if-else大量堆积
调用代码 import com.example.javaone.kk.MyEnum;public class Gst {public static void main(String[] args) {MyEnum eMyEnum.getById(1);System.out.println(e.getGetSize());} }被调用代码 package com.example.javaone.kk; public enum MyEnum {ENUM1(1,2),ENUM2(2,3),E…...

【数据结构】八大排序之直接插入排序算法
🦄个人主页:修修修也 🎏所属专栏:数据结构 ⚙️操作环境:Visual Studio 2022 一.直接插入排序简介及思路 直接插入排序(Straight Insertion Sort)是一种简单直观的插入排序算法. 它的基本操作是: 将一个数据插入到已经排好的有序表中,从而得到一个新的,数…...

网络编程『socket套接字 ‖ 简易UDP网络程序』
🔭个人主页: 北 海 🛜所属专栏: Linux学习之旅、神奇的网络世界 💻操作环境: CentOS 7.6 阿里云远程服务器 文章目录 🌤️前言🌦️正文1.预备知识1.1.IP地址1.2.端口号1.3.端口号与进…...

FreeSWITCH rtp endpoint recvonly
查了下rtp.c的源码,远端端口为0就意味着recvonly,但其实不然,调用switch_rtp_new会马上返回失败 经过反复测试,增加下面几行代码之后终于变成了recvonly: tech_pvt->mode RTP_RECVONLY; rtp_flags[SWITCH_RTP_FLAG_AUTOADJ];…...
Hadoop和Spark的区别
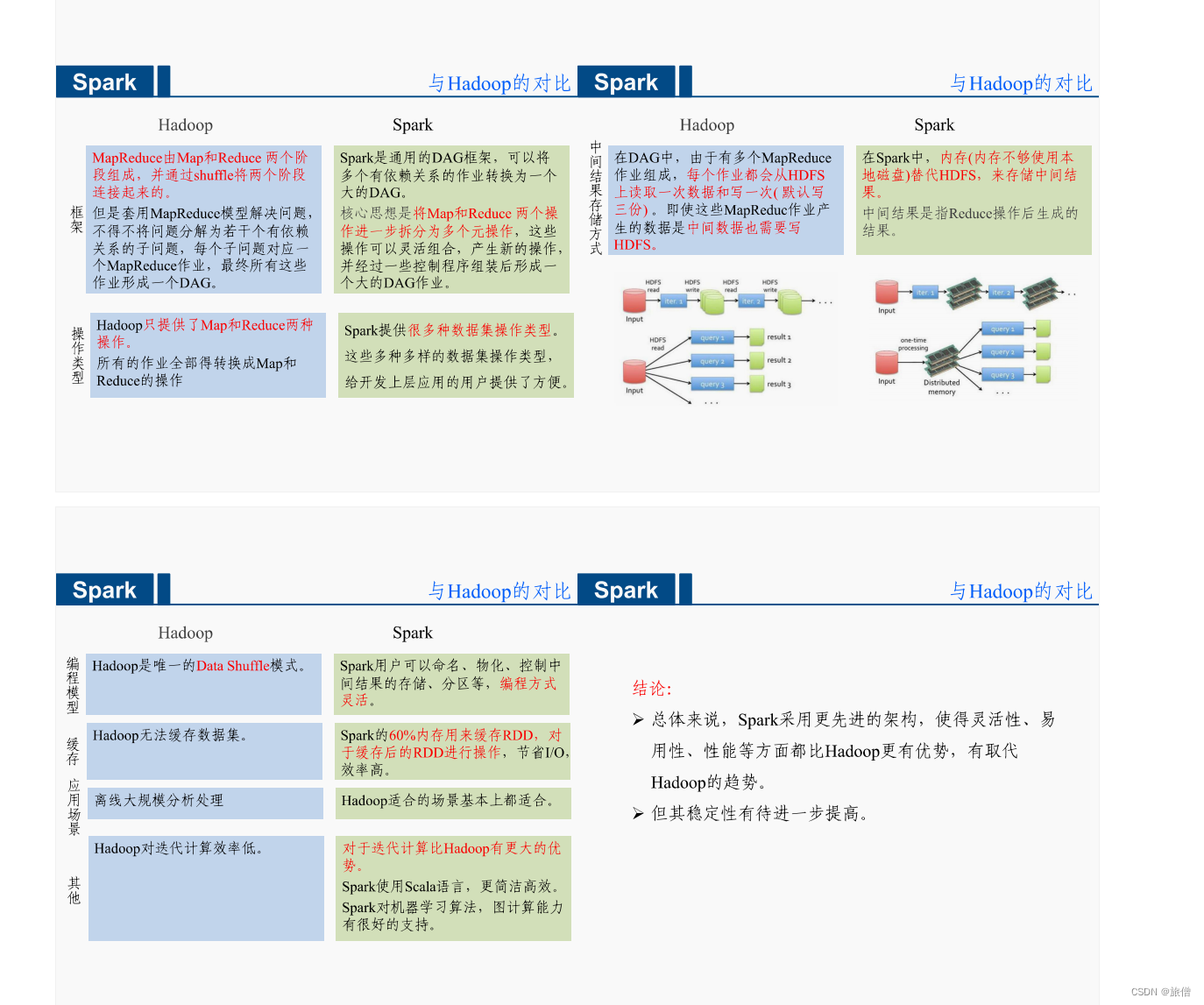
Hadoop 表达能力有限。磁盘IO开销大,延迟度高。任务和任务之间的衔接涉及IO开销。前一个任务完成之前其他任务无法完成,难以胜任复杂、多阶段的计算任务。 Spark Spark模型是对Mapreduce模型的改进,可以说没有HDFS、Mapreduce就没有Spark。…...

英文论文降重修改技巧 papergpt
大家好,今天来聊聊英文论文降重修改技巧,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧,可以借助此类工具: 英文论文降重修改技巧 作为网站编辑,我们经常需要处理大量…...
DevOps搭建(十)-安装Harbor镜像仓库详细步骤
1、下载Harbor 官方地址: https://goharbor.io/ 下载地址: https://github.com/goharbor/harbor/tags 选择文档版本进行下载,这里我们选择v2.7.2版本 2、上传到服务器并解压 上传压缩包到服务器后,解压到/usr/local目录下&a…...
DDA 算法
CAD 算法是计算机辅助设计的算法,几何算法是解决几何问题的算法 CAD 算法是指在计算机辅助设计软件中使用的算法,用于实现各种设计和绘图功能,CAD 广泛应用于建筑、机械、电子等领域,可以大大提高设计效率和精度 绘图算法是 CAD…...
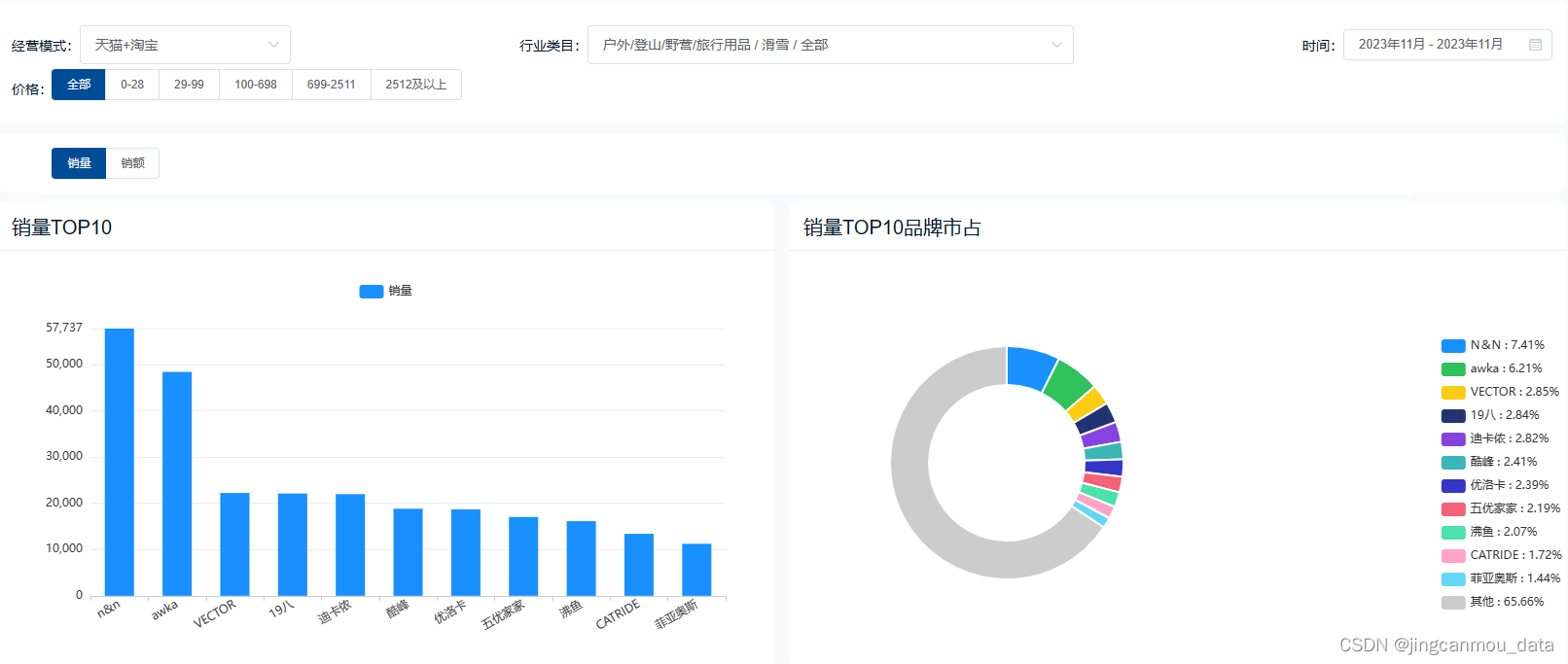
天猫数据平台-淘宝天猫数据-天猫销售数据分析:11月天猫平台滑雪运动装备行业销量翻倍!
随着天气变冷、冬季来临,迎来了疫情后的首个滑雪季,加之自冬奥会结束以来,大众参与冰雪运动的热度持续攀升,因此,冰雪运动的需求正集中释放。 根据相关数据显示,11月以来,全国滑雪场门票预订量较…...

使用OpenCV和PIL库读取图片的区别
OpenCV 和 PIL(Pillow)是两个不同的图像处理库,它们使用不同的数据结构来表示图像。 OpenCV 格式图像: OpenCV 中的图像通常表示为 NumPy 数组。这些数组可以是多维的,例如对于彩色图像,它们是三维数组&am…...
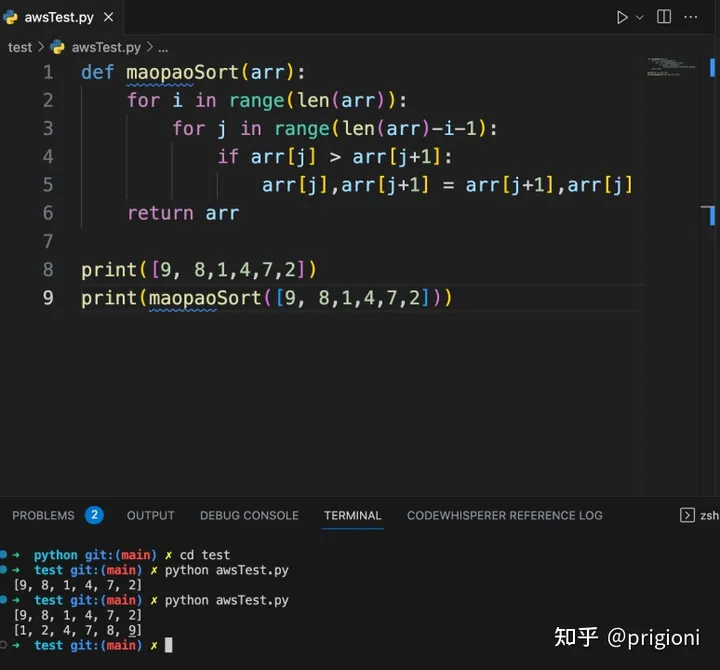
Amazon CodeWhisperer:AI 编程助手
文章作者:prigioni 1. 什么是 Amazon CodeWhisperer? Amazon CodeWhisperer 能够理解以自然语言(英语)编写的注释,并能实时生成多条代码建议,以此提高开发人员生产力。该服务可以直接在集成开发环境&#…...
Linux 使用 Anaconda+Uwsgi 部署 Django项目和前端项目
一、安装Anaconda 使用Anaconda创建python环境的优点: virtualenv只能创建系统原有的python版本,而不能创建创建任意版本的环境 而Anaconda的虚拟环境中,你可以指定任意现存可使用的python环境(包括比原环境版本高的python版本&a…...

分析若依的文件上传处理逻辑
分析若依的文件上传处理逻辑 注:已经从若依框架完成拆分,此处单独分析一下人家精彩的封装,也来理解一下怎么做一个通用的上传接口!如有分析的,理解的不透彻的地方,大家多多包含,欢迎批评指正&am…...

Note3---初阶二叉树~~
目录 前言🍄 1.树概念及结构☎️ 1.1 树的概念🎄 1.2 树的相关概念🦜 1.2.1 部分概念的加深理解🐾 1.2.2 树与非树🪴 1.3 树的表示🎋 1.4 树在实际中的运用(表示文件系统…...

ElasticSearch学习篇8_Lucene之数据存储(Stored Field、DocValue、BKD Tree)
前言 Lucene全文检索主要分为索引、搜索两个过程,对于索引过程就是将文档磁盘存储然后按照指定格式构建索引文件,其中涉及数据存储一些压缩、数据结构设计还是很巧妙的,下面主要记录学习过程中的StoredField、DocValue以及磁盘BKD Tree的一些…...

ROS机器人入门
http://www.autolabor.com.cn/book/ROSTutorials/ 1、ROS简介 ROS 是一个适用于机器人的开源的元操作系统。其实它并不是一个真正的操作系统,其 底层的任务调度、编译、寻址等任务还是由 Linux 操作系统完成,也就是说 ROS 实际上是运 行在 Linux 上的次级…...

30. 深度学习进阶 - 池化
Hi,你好。我是茶桁。 上一节课,我们详细的学习了卷积的原理,在这个过程中给大家讲了一个比较重要的概念,叫做input channel,和output channel。 当然现在不需要直接去实现, 卷积的原理PyTorch、或者TensorFlow什么的…...

工业应用新典范,飞凌嵌入式FET-D9360-C核心板发布!
来源:飞凌嵌入式官网 当前新一轮科技革命和产业变革突飞猛进,工业领域对高性能、高可靠性、高稳定性的计算需求也在日益增长。为了更好地满足这一需求,飞凌嵌入式与芯驰科技(SemiDrive)强强联合,基于芯驰D9…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...