Python轴承故障诊断 (八)基于EMD-CNN-GRU并行模型的故障分类
目录
前言
1 经验模态分解EMD的Python示例
2 轴承故障数据的预处理
2.1 导入数据
2.2 制作数据集和对应标签
2.3 故障数据的EMD分解可视化
2.4 故障数据的EMD分解预处理
3 基于EMD-CNN-GRU并行模型的轴承故障诊断分类
3.1 训练数据、测试数据分组,数据分batch
3.2 定义EMD-CNN-GRU并行分类网络模型
3.3 设置参数,训练模型

往期精彩内容:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理_cwru轴承数据集-CSDN博客
Python轴承故障诊断 (一)短时傅里叶变换STFT-CSDN博客
Python轴承故障诊断 (二)连续小波变换CWT-CSDN博客
Python轴承故障诊断 (三)经验模态分解EMD-CSDN博客
Pytorch-LSTM轴承故障一维信号分类(一)-CSDN博客
Pytorch-CNN轴承故障一维信号分类(二)-CSDN博客
Pytorch-Transformer轴承故障一维信号分类(三)-CSDN博客
Python轴承故障诊断 (四)基于EMD-CNN的故障分类-CSDN博客
Python轴承故障诊断 (五)基于EMD-LSTM的故障分类-CSDN博客
Python轴承故障诊断 (六)基于EMD-Transformer的故障分类-CSDN博客
Python轴承故障诊断 (七)基于EMD-CNN-LSTM的故障分类-CSDN博客
前言
本文基于凯斯西储大学(CWRU)轴承数据,进行经验模态分解EMD的介绍与数据预处理,最后通过Python实现基于EMD的CNN-GRU并行模型对故障数据的分类。凯斯西储大学轴承数据的详细介绍可以参考下文:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理_cwru轴承数据集-CSDN博客
经验模态分解EMD的原理可以参考如下:
Python轴承故障诊断 (三)经验模态分解EMD-CSDN博客
1 经验模态分解EMD的Python示例
第一步,Python 中 EMD包的下载安装:
# 下载
pip install EMD-signal
# 导入
from PyEMD import EMD切记,很多同学安装失败,不是 pip install EMD,也不是pip install PyEMD, 如果 pip list 中 已经有 emd,emd-signal,pyemd包的存在,要先 pip uninstall 移除相关包,然后再进行安装。
第二步,导入相关包
import numpy as np
from PyEMD import EMD
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')第三步,生成一个信号示例
t = np.linspace(0, 1, 1000)
signal = np.sin(11*2*np.pi*t*t) + 6*t*t第四步,创建EMD对象,进行分解
emd = EMD()
# 对信号进行经验模态分解
IMFs = emd(signal)第五步,绘制原始信号和每个本征模态函数(IMF)
plt.figure(figsize=(15,10))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(t, signal, 'r')
plt.title("原始信号")
for num, imf in enumerate(IMFs):plt.subplot(len(IMFs)+1, 1, num+2)plt.plot(t, imf)plt.title("IMF "+str(num+1))
plt.show()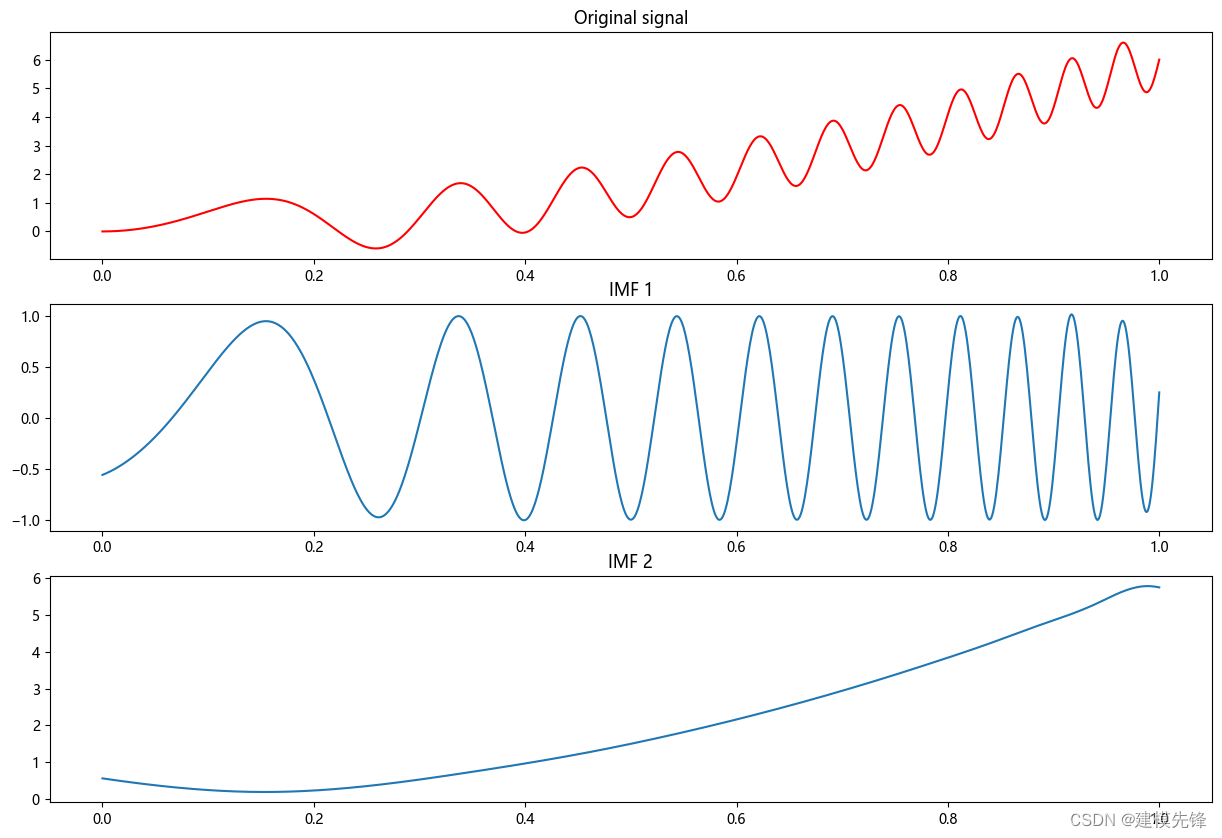
2 轴承故障数据的预处理
2.1 导入数据
参考之前的文章,进行故障10分类的预处理,凯斯西储大学轴承数据10分类数据集:
train_set、val_set、test_set 均为按照7:2:1划分训练集、验证集、测试集,最后保存数据
上图是数据的读取形式以及预处理思路
2.2 制作数据集和对应标签
第一步, 生成数据集

第二步,制作数据集和标签
# 制作数据集和标签
import torch
# 这些转换是为了将数据和标签从Pandas数据结构转换为PyTorch可以处理的张量,
# 以便在神经网络中进行训练和预测。
def make_data_labels(dataframe):'''参数 dataframe: 数据框返回 x_data: 数据集 torch.tensory_label: 对应标签值 torch.tensor'''# 信号值x_data = dataframe.iloc[:,0:-1]# 标签值y_label = dataframe.iloc[:,-1]x_data = torch.tensor(x_data.values).float()y_label = torch.tensor(y_label.values, dtype=torch.int64) # 指定了这些张量的数据类型为64位整数,通常用于分类任务的类别标签return x_data, y_label
# 加载数据
train_set = load('train_set')
val_set = load('val_set')
test_set = load('test_set')
# 制作标签
train_xdata, train_ylabel = make_data_labels(train_set)
val_xdata, val_ylabel = make_data_labels(val_set)
test_xdata, test_ylabel = make_data_labels(test_set)
# 保存数据
dump(train_xdata, 'trainX_1024_10c')
dump(val_xdata, 'valX_1024_10c')
dump(test_xdata, 'testX_1024_10c')
dump(train_ylabel, 'trainY_1024_10c')
dump(val_ylabel, 'valY_1024_10c')
dump(test_ylabel, 'testY_1024_10c')2.3 故障数据的EMD分解可视化
选择正常信号和 0.021英寸内圈、滚珠、外圈故障信号数据来做对比
第一步,导入包,读取数据
import numpy as np
from scipy.io import loadmat
import numpy as np
from scipy.signal import stft
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 读取MAT文件
data1 = loadmat('0_0.mat') # 正常信号
data2 = loadmat('21_1.mat') # 0.021英寸 内圈
data3 = loadmat('21_2.mat') # 0.021英寸 滚珠
data4 = loadmat('21_3.mat') # 0.021英寸 外圈
# 注意,读取出来的data是字典格式,可以通过函数type(data)查看。第二步,数据集中统一读取 驱动端加速度数据,取一个长度为1024的信号进行后续观察和实验
# DE - drive end accelerometer data 驱动端加速度数据
data_list1 = data1['X097_DE_time'].reshape(-1)
data_list2 = data2['X209_DE_time'].reshape(-1)
data_list3 = data3['X222_DE_time'].reshape(-1)
data_list4 = data4['X234_DE_time'].reshape(-1)
# 划窗取值(大多数窗口大小为1024)
time_step= 1024
data_list1 = data_list1[0:time_step]
data_list2 = data_list2[0:time_step]
data_list3 = data_list3[0:time_step]
data_list4 = data_list4[0:time_step]第三步,进行数据可视化
plt.figure(figsize=(20,10))
plt.subplot(2,2,1)
plt.plot(data_list1)
plt.title('正常')
plt.subplot(2,2,2)
plt.plot(data_list2)
plt.title('内圈')
plt.subplot(2,2,3)
plt.plot(data_list3)
plt.title('滚珠')
plt.subplot(2,2,4)
plt.plot(data_list4)
plt.title('外圈')
plt.show()
第四步,首先对正常数据进行EMD分解
import numpy as np
import matplotlib.pyplot as plt
from PyEMD import EMD
t = np.linspace(0, 1, time_step)
data = np.array(data_list1)
# 创建 EMD 对象
emd = EMD()
# 对信号进行经验模态分解
IMFs = emd(data)
# 绘制原始信号和每个本征模态函数(IMF)
plt.figure(figsize=(15,10))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(t, data, 'r')
plt.title("Original signal", fontsize=10)
for num, imf in enumerate(IMFs):plt.subplot(len(IMFs)+1, 1, num+2)plt.plot(t, imf)plt.title("IMF "+str(num+1), fontsize=10)# 增加第一排图和第二排图之间的垂直间距
plt.subplots_adjust(hspace=0.4, wspace=0.2)
plt.show()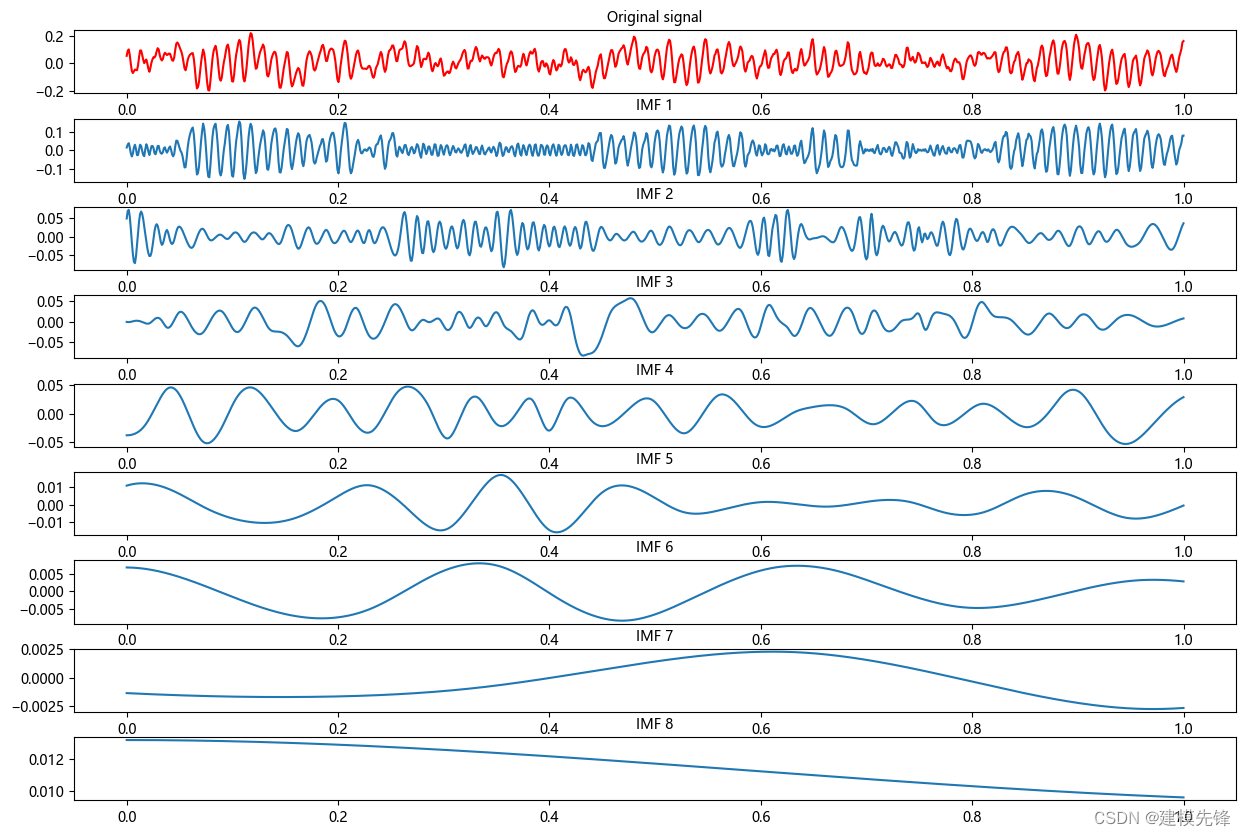
其次,内圈故障EMD分解:
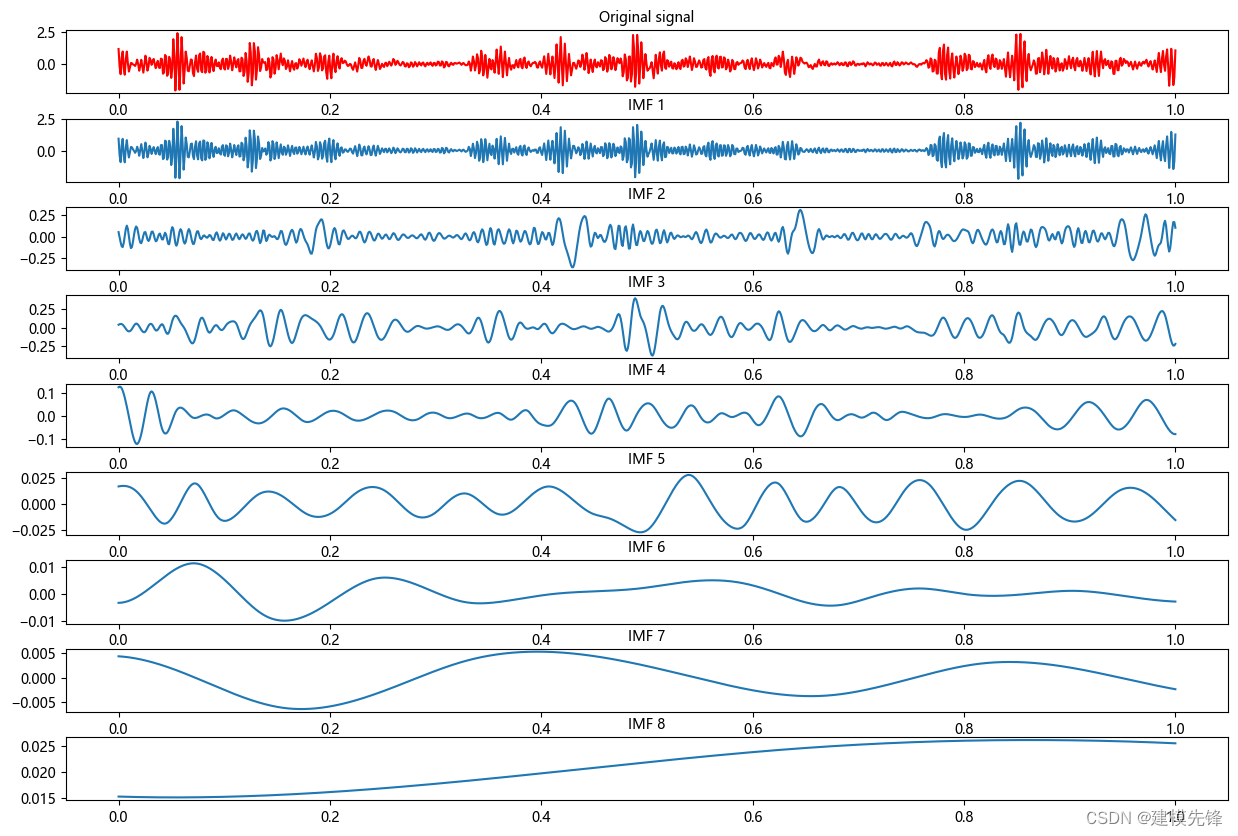
然后,滚珠故障EMD分解:

最后,外圈故障EMD分解:
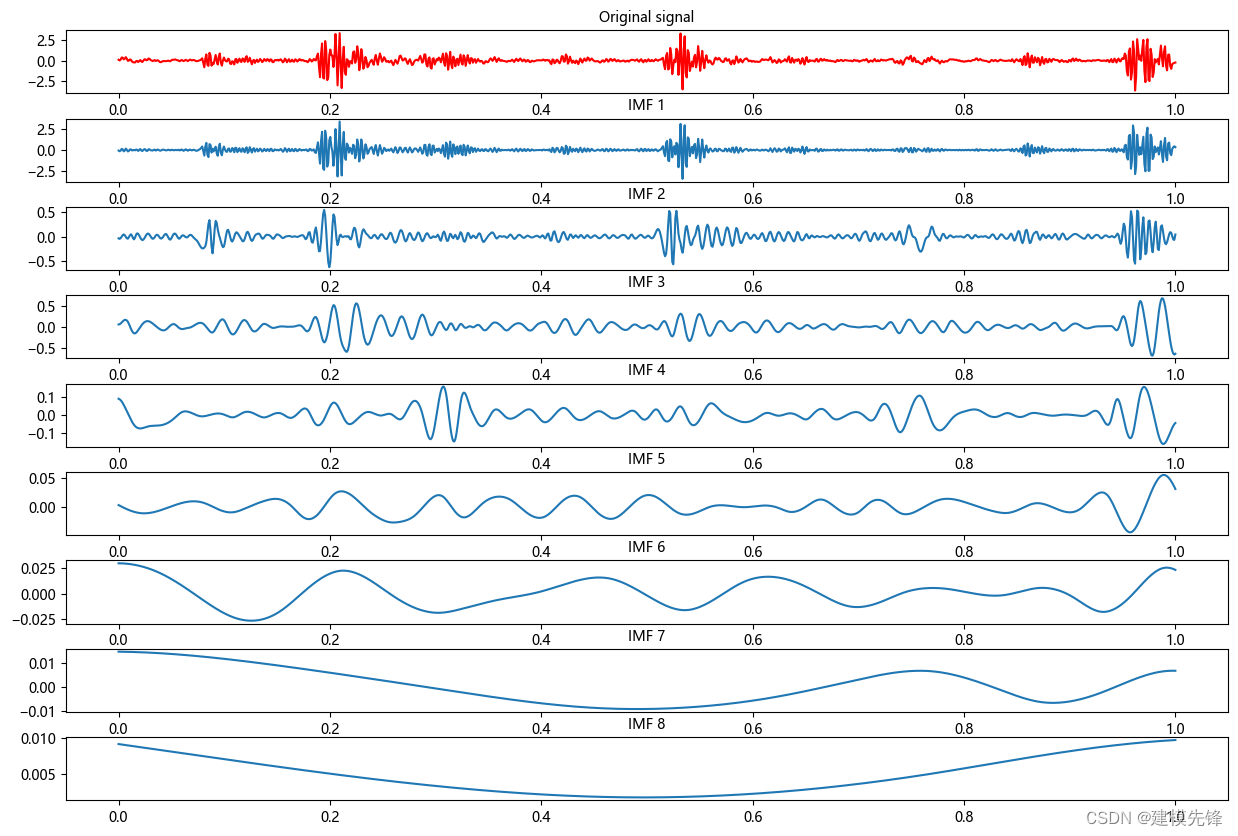
注意,在信号的制作过程中,信号长度的选取比较重要,选择信号长度为1024,既能满足信号在时间维度上的分辨率,也能在后续的EMD分解中分解出数量相近的IMF分量,为进一步做故障模式识别打下基础。
2.4 故障数据的EMD分解预处理
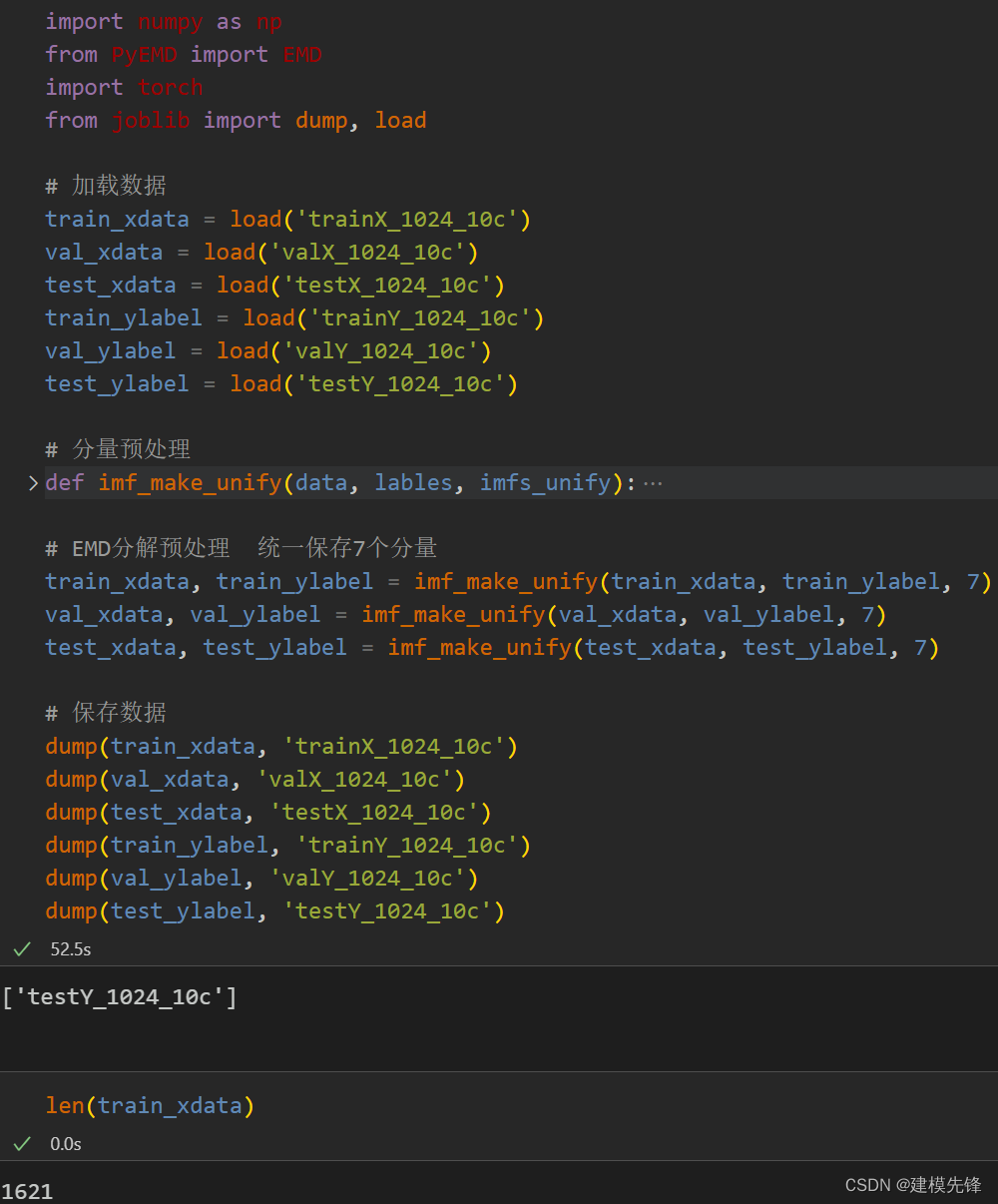
对于EMD分解出的IMF分量个数,并不是所有的样本信号都能分解出8个分量,需要做一下定量分析:
import numpy as np
from PyEMD import EMD
# 加载训练集
train_xdata = load('trainX_1024_10c')
data = np.array(train_xdata)
# 创建 EMD 对象
emd = EMD()
print("测试集:", len(data))
count_min = 0
count_max = 0
count_7 = 0
# 对数据进行EMD分解
for i in range(1631):imfs = emd(data[i], max_imf=8) # max_imf=8if len(imfs) > 8 :count_max += 1elif len(imfs) < 7:count_min += 1elif len(imfs) == 7:count_7 += 1
print("分解结果IMF大于8:", count_max)
print("分解结果IMF小于7:", count_min)
print("分解结果IMF等于7:", count_7)
由结果可以看出,大部分信号样本 都分解出8个分量,将近1/3的信号分解的不是8个分量。EMD设置不了分解出模态分量的数量(函数自适应),为了使一维信号分解,达到相同维度的分量特征,有如下3种处理方式:
-
删除分解分量不统一的样本(少量存在情况可以采用);
-
对于分量个数少的样本采用0值或者其他方法进行特征填充,使其对齐其他样本分量的维度(向多兼容);
-
合并分量数量多的信号(向少兼容);
本文采用第二、三条结合的方式进行预处理,即删除分量小于7的样本,对于分量大于7的样本,把多余的分量进行合并,使所有信号的分量特征保持同样的维度。
3 基于EMD-CNN-GRU并行模型的轴承故障诊断分类
下面基于EMD分解后的轴承故障数据,先通过CNN进行卷积池化操作提取信号的空间特征,同时将信号送入GRU层提取时序特征,最后把空间特征和时序特征进行融合,实现CNN-GRU并行模型的分类方法进行讲解:
3.1 训练数据、测试数据分组,数据分batch
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 有GPU先用GPU训练
# 加载数据集
def dataloader(batch_size, workers=2):# 训练集train_xdata = load('trainX_1024_10c')train_ylabel = load('trainY_1024_10c')# 验证集val_xdata = load('valX_1024_10c')val_ylabel = load('valY_1024_10c')# 测试集test_xdata = load('testX_1024_10c')test_ylabel = load('testY_1024_10c')
# 加载数据train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_xdata, train_ylabel),batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)val_loader = Data.DataLoader(dataset=Data.TensorDataset(val_xdata, val_ylabel),batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_xdata, test_ylabel),batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)return train_loader, val_loader, test_loader
batch_size = 32
# 加载数据
train_loader, val_loader, test_loader = dataloader(batch_size)3.2 定义EMD-CNN-GRU并行分类网络模型
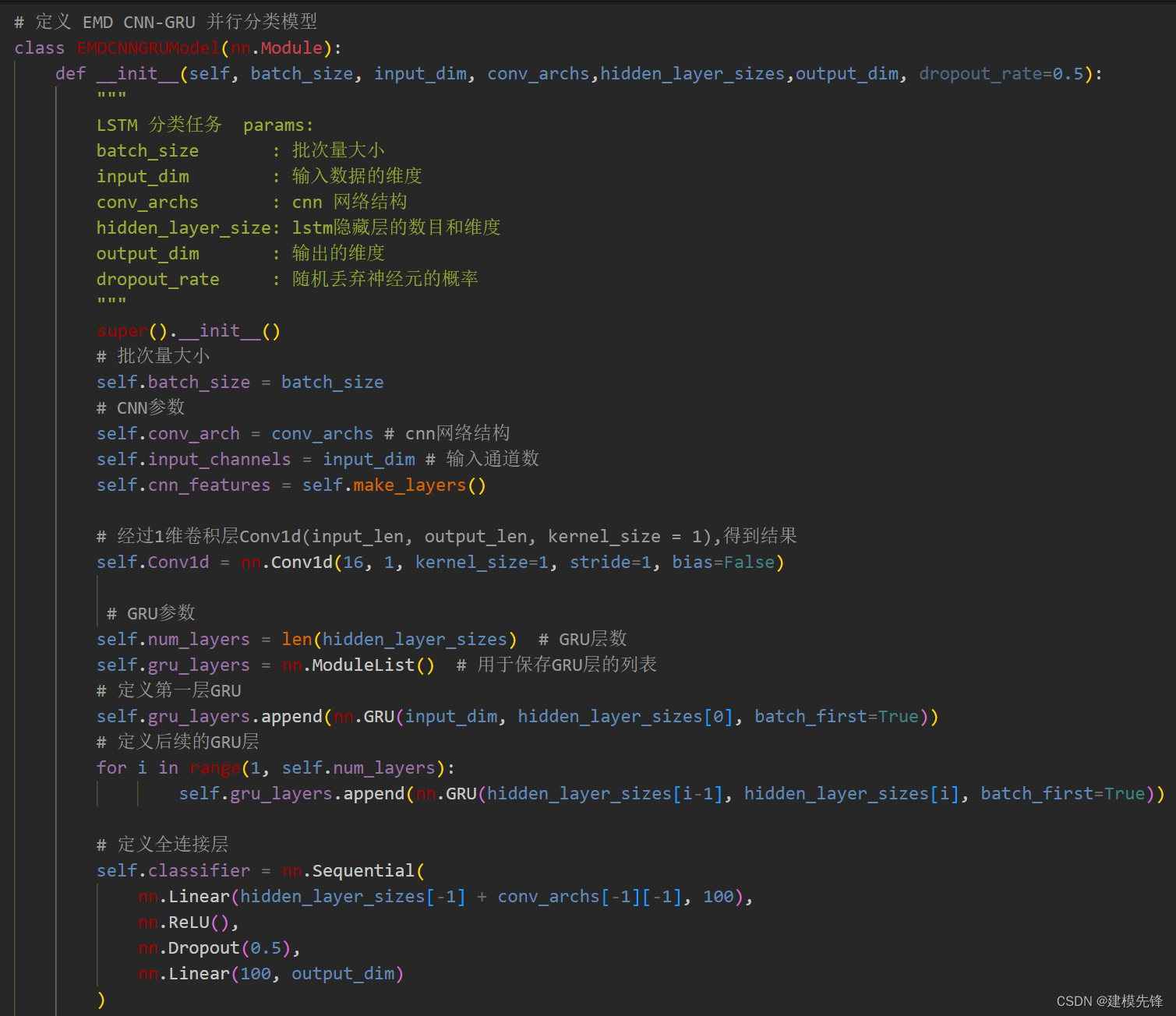
3.3 设置参数,训练模型
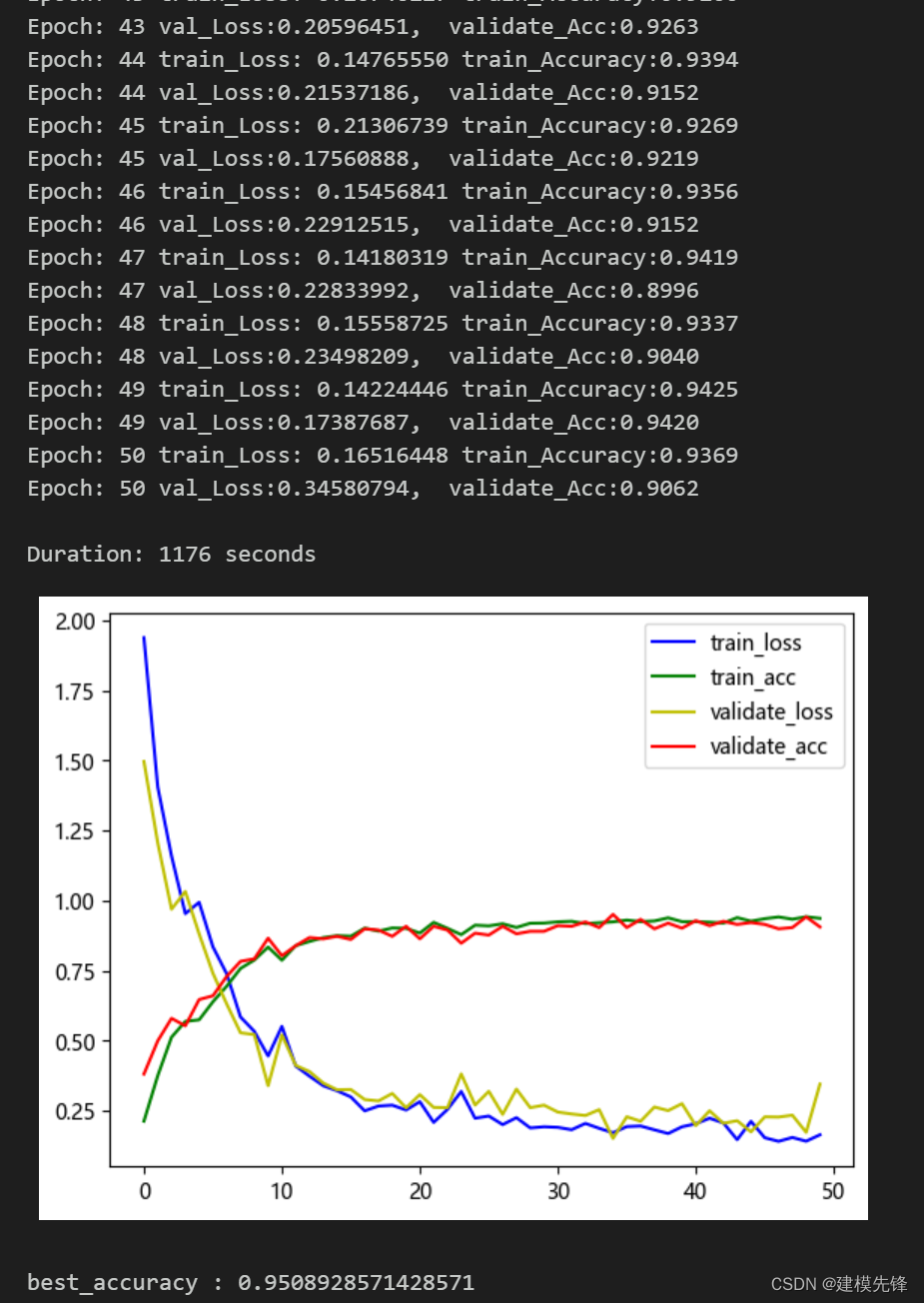
50个epoch,准确率将近95%,用EMD-CNN-GRU并行网络分类效果显著,CNN-GRU并行模型能够充分提取轴承故障信号的空间和时序特征,收敛速度快,性能优越,继续调参可以进一步提高分类准确率。
注意调整参数:
-
可以适当增加CNN层数和隐藏层的维度,微调学习率;
-
调整GRU层数和维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变一维信号堆叠的形状(设置合适的长度和维度)
相关文章:
Python轴承故障诊断 (八)基于EMD-CNN-GRU并行模型的故障分类
目录 前言 1 经验模态分解EMD的Python示例 2 轴承故障数据的预处理 2.1 导入数据 2.2 制作数据集和对应标签 2.3 故障数据的EMD分解可视化 2.4 故障数据的EMD分解预处理 3 基于EMD-CNN-GRU并行模型的轴承故障诊断分类 3.1 训练数据、测试数据分组,数据分ba…...

鸿蒙实现年月日十分选择框,支持年月日、月日、日、年月日时分、时分切换
import DateTimeUtils from ./DateTimeUtils;CustomDialog export default struct RQPickerDialog {controller: CustomDialogControllertitle: string 这是标题TAG: string RQPickerDialog// 0 - 日期类型(年月日) 1 - 时间类型(时分&a…...
IntelliJ IDE 插件开发 | (三)消息通知与事件监听
系列文章 IntelliJ IDE 插件开发 |(一)快速入门IntelliJ IDE 插件开发 |(二)UI 界面与数据持久化IntelliJ IDE 插件开发 |(三)消息通知与事件监听 前言 在前两篇文章中讲解了关于插件开发的基础知识&…...

VUE小知识点
Vue 是一款用于构建用户界面的 JavaScript 框架。它基于标准 HTML、CSS 和 JavaScript 构建,并提供了一套声明式的、组件化的编程模型,帮助你高效地开发用户界面。 Vue 的主要作用是帮助开发者构建现代 Web 应用程序。它允许前端开发人员专注于应用程序…...

深入了解常见的应用层网络协议
目录 1. HTTP协议 1.1. 工作原理 1.2. 应用场景 1.3. 安全性考虑 2. SMTP协议 2.1. 工作原理 2.2. 应用场景 2.3. 安全性考虑 3. FTP协议 3.1. 工作原理 3.2. 应用场景 3.3. 安全性考虑 4. DNS协议 4.1. 工作原理 4.2. 应用场景 4.3. 安全性考虑 5. 安全性考虑…...

网络爬虫 多任务采集
一、JSON文件存储 JSON,全称为 JavaScript 0bject Notation,也就是JavaSript 对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。本节中,我们就来了解如何利用 P…...

真实并发编程问题-1.钉钉面试题
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理、分布式技术原理、数据库技术🔥如果感觉博主的文章还不错的…...
基于vue+element-plus+echarts制作动态绘图页面(柱状图,饼图和折线图)
前言 我们知道echarts是一个非常强大的绘图库,基于这个库,我们可以绘制出精美的图表。对于一张图来说,其实比较重要的就是配置项,填入不同的配置内容就可以呈现出不同的效果。 当然配置项中除了样式之外,最重要的就是…...

2312llvm,02前端
前端 编译器前端,在生成目标相关代码前,把源码变换为编译器的中间表示.因为语言有独特语法和语义,所以一般,前端只处理一个语言或一组类似语言. 比如Clang,处理C,C,objective-C源码. 介绍Clang Clang项目是C,C,Objective-C官方的LLVM前端.Clang的官方网站在此. 实际编译器(…...
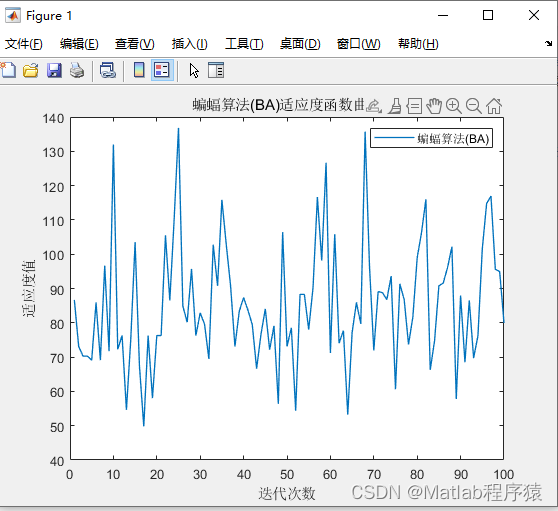
【MATLAB源码-第101期】基于matlab的蝙蝠优化算BA)机器人栅格路径规划,输出做短路径图和适应度曲线。
操作环境: MATLAB 2022a 1、算法描述 蝙蝠算法(BA)是一种基于群体智能的优化算法,灵感来源于蝙蝠捕食时的回声定位行为。这种算法模拟蝙蝠使用回声定位来探测猎物、避开障碍物的能力。在蝙蝠算法中,每只虚拟蝙蝠代表…...
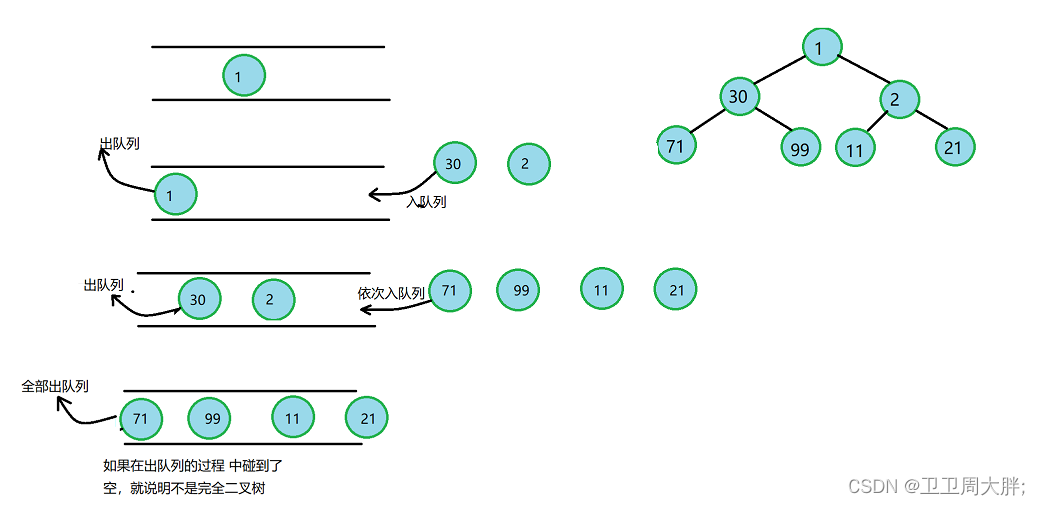
【数据结构】二叉树的模拟实现
前言:前面我们学习了堆的模拟实现,今天我们来进一步学习二叉树,当然了内容肯定是越来越难的,各位我们一起努力! 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:数据结构 👈 &…...
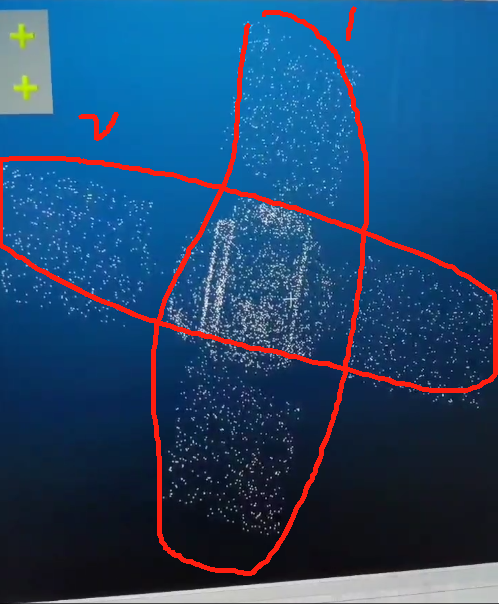
open3d bug:pcd转txt前后位姿发生改变
1、open3d bug:pcd转txt前后位姿发生改变 open3d会对原有结果进行一个微小位姿变换 import open3d as o3d import numpy as np# 读取PCD点云文件 pcd o3d.io.read_point_cloud(/newdisk/darren_pty/zoom_centered_s2.pcd)# 获取点云坐标 points pcd.points# 指定…...

持续集成交付CICD:Jenkins使用GitLab共享库实现基于Ansible的CD流水线部署前后端应用
目录 一、实验 1.部署Ansible自动化运维工具 2.K8S 节点安装nginx 3.Jenkins使用GitLab共享库实现基于Ansible的CD流水线部署前后端应用 二、问题 1.ansible安装报错 2.ansible远程ping失败 3. Jenkins流水线通过ansible命令直接ping多台机器的网络状态报错 一、实验 …...

OpenAI 疑似正在进行 GPT-4.5 灰度测试!
大家好,我是二狗。 今天,有网友爆料OpenAI疑似正在进行GPT-4.5灰度测试! 当网友询问ChatGPT API调用查询模型的确切名称是什么时? ChatGPT的回答竟然是 gpt-4.5-turbo。 也有网友测试之后发现仍然是GPT-4模型。 这是有网友指…...
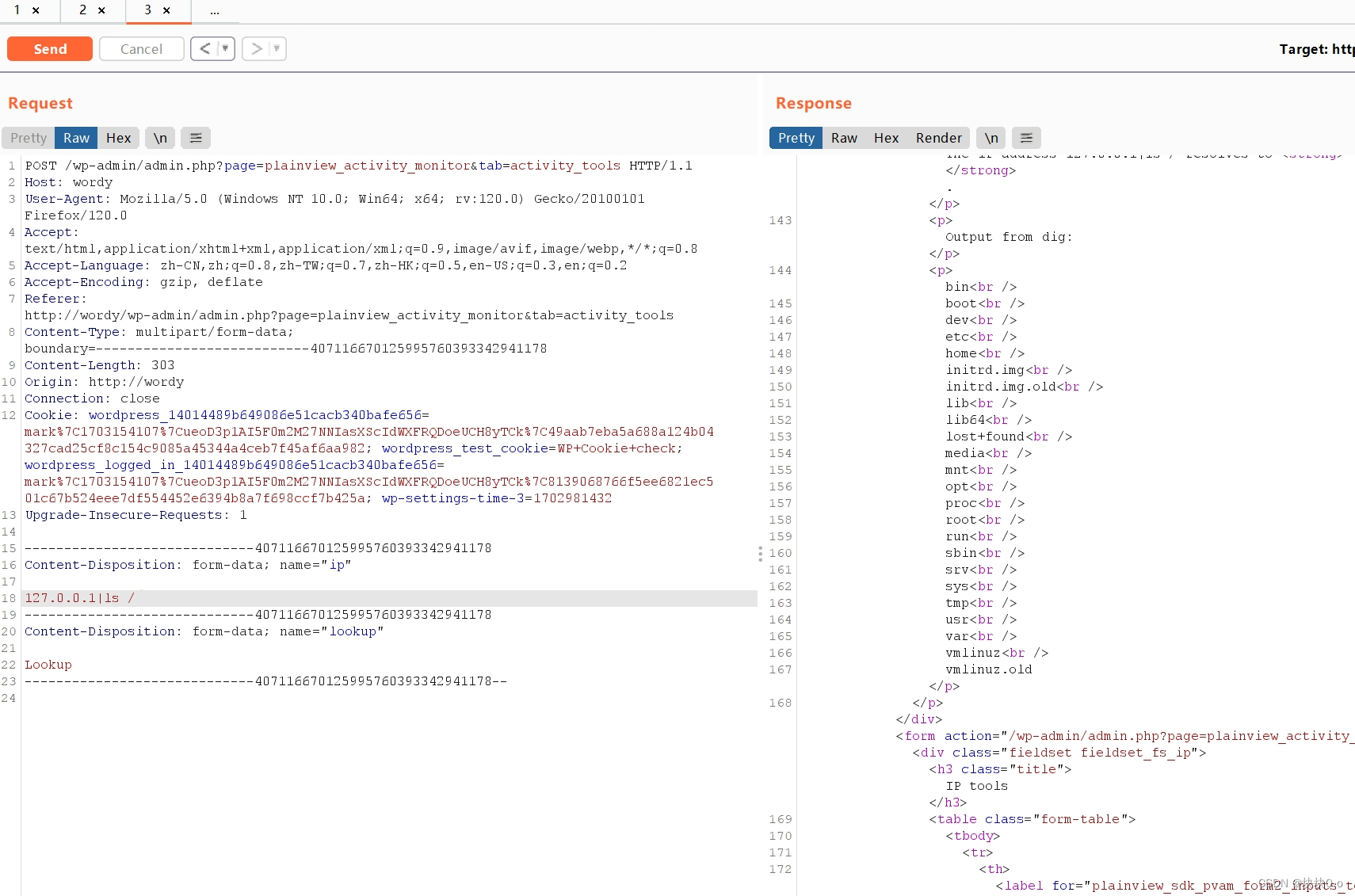
DC-6靶场
DC-6靶场下载: https://www.five86.com/downloads/DC-6.zip 下载后解压会有一个DC-3.ova文件,直接在vm虚拟机点击左上角打开-->文件-->选中这个.ova文件就能创建靶场,kali和靶机都调整至NAT模式,即可开始渗透 首先进行主…...
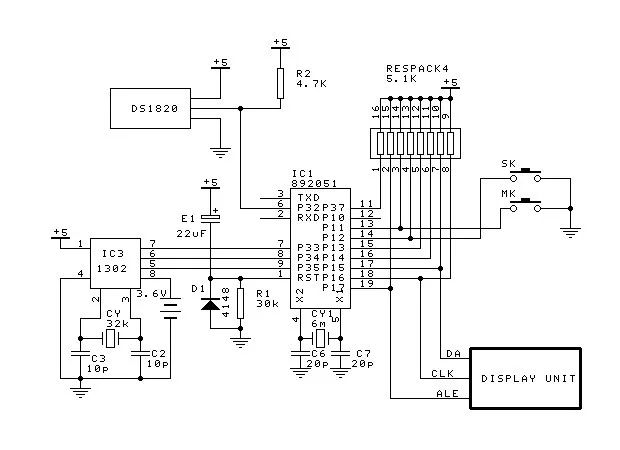
单片机应用实例:LED显示电脑电子钟
本例介绍一种用LED制作的电脑电子钟(电脑万年历)。其制作完成装潢后的照片如下图: 上图中,年、月、日及时间选用的是1.2寸共阳数码管,星期选用的是2.3寸数码管,温度选用的是0.5寸数码管,也可根据…...

会议剪影 | 思腾合力受邀出席首届CCF数字医学学术年会
首届CCF数字医学学术年会(CCF Digital Medicine Symposium,DMS)于2023年12月15日-17日在苏州CCF业务总部召开。这次会议的成功召开,标志着数字医学领域进入了一个新的时代,计算机技术和人工智能在医学领域的应用和发展…...

node.js mongoose中间件(middleware)
目录 简介 定义模型 注册中间件 创建doc实例,并进行增删改查 方法名和注册的中间件名相匹配 执行结果 分析 错误处理中间件 手动抛出错误 注意点 简介 在mongoose中,中间件是一种允许在执行数据库操作前(pre)或后&…...
[Toolschain cpp ros cmakelist python vscode] 记录写每次项目重复的设置和配置 不断更新
写在前面 用以前的设置,快速配置项目,以防长久不用忘记,部分资料在资源文件里还没有整理 outline cmakelist 复用vscode 找到头文件vscode debug现有代码直接关联远端gitros杂记repo 杂记glog杂记 cmakelist 复用 包含了根据系统路径找库…...
【每日OJ—有效的括号(栈)】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 1、有效的括号题目: 1.1方法讲解: 1.2代码实现: 总结 前言 世上有两种耀眼的光芒,一种是正在升起的太阳&#…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...