MySQL——表的增删查改
目录
一.Create(创建)
1.单行数据 + 全列插入
2.多行数据 + 指定列插入
3.插入否则更新
4. 替换
二.Retrieve(读取)
1. select 列 查询
2.where 条件
3.结果排序
4.筛选分页结果
三.Update (修改)
四.Delete(删除)
1.删除数据
2.删除整张表数据
3.截断表
4.去重表数据
五.聚合函数
六.group by子句的使用

一.Create(创建)
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...案例:
创建一张学生表:
mysql> create table students(-> id int unsigned primary key auto_increment,-> name varchar(20) not null,-> qq varchar(20) not null-> );

1.单行数据 + 全列插入
插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增。
指定插入:

全列插入:

2.多行数据 + 指定列插入
插入两条记录,value_list 数量必须和指定列数量及顺序一致:
mysql> insert into students (name,qq) values -> ('孙仲谋','65988135'),-> ('曹孟德','974623215'),-> ('刘玄德','948735415');
3.插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败:
可以选择性的进行同步更新操作 语法:
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...案例:
insert students value (100,'八戒','100100100') on duplicate key update name='项羽(-_-)',qq='110110110';
解释:Query OK, 2 rows affected (0.00 sec)
- -- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
- -- 1 row affected: 表中没有冲突数据,数据被插入
- -- 2 row affected: 表中有冲突数据,并且数据已经被更新
通过 MySQL 函数获取受到影响的数据行数:
SELECT ROW_COUNT();
4. 替换
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入;
replace into students value(100,'八戒','100100100');

-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入
二.Retrieve(读取)
语法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...案例:
-- 创建表结构
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同学姓名',
chinese float DEFAULT 0.0 COMMENT '语文成绩',
math float DEFAULT 0.0 COMMENT '数学成绩',
english float DEFAULT 0.0 COMMENT '英语成绩'
);
-- 插入测试数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0
1. select 列 查询
全列查询:
-- 通常情况下不建议使用 * 进行全列查询:
- 查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用。(索引待后面课程讲解)
select * from exam_result;

指定列查询:
select id,name,english from exam_result;
查询字段为表达式 :

数学成绩统一加十分:
select id ,name,math+10 from exam_result;

计算成绩总分:

为查询结果指定别名
计算成绩总分,并且修改别名为‘总分’:
select id ,name,chinese+math+english 总分 from exam_result;

结果去重 :
select distinct math from exam_result;
2.where 条件
比较运算符:
| 运算符 | 说明 |
| >, >=, | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
案例:
英语不及格的同学即英语成绩 ( < 60 ):
select id,name,english from exam_result where english<60;
语文成绩在 [80, 90] 分的同学及语文成绩:
方法一:
select id,name,chinese from exam_result where chinese>=80 and chinese<=90;
方法二:
select id,name,chinese from exam_result where chinese between 80 and 90;

数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩 :
方法一:
select id,name,math from exam_result where math=58 or math=65 or math=99 or math=98;
方法二:
select id,name,math from exam_result where math in (58,65,99,98);
姓孙的同学 及 孙某同学 :
姓孙的同学,包括孙某某和孙某:
select id,name from exam_result where name like '孙%';
孙某同学,姓名只有两个字:
select id,name from exam_result where name like '孙_';
语文成绩好于英语成绩的同学 :
select id,name,chinese,math from exam_result where chinese>math;
总分在 200 分以下的同学:
注意:WHERE 条件中使用表达式,别名不能用在 WHERE 条件中。
select id,name,chinese+math+english total from exam_result where chinese+math+english <200;

为什么别名不能用在 WHERE 条件中使用?
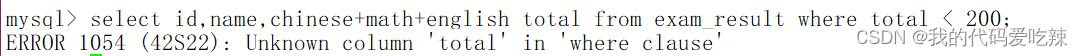
上述SQL语句包括两部分:select和where部分,由于where的语句优先级比select语句优先级高,所以在where中别并并未生效。
语文成绩 > 80 并且不姓孙的同学:
select id,name,chinese from exam_result where chinese>80 and name not like '孙%';
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80:
select name,chinese,math,english,chinese+math+english total from exam_result where name like '孙_' or (chinese+math+english>200 and chinese < math and english > 80);
NULL 的查询
select id,name,qq from exam_result where qq is not null;
select id,name,qq from exam_result where qq is null;

NULL 和 NULL 的比较,= 和 <=> 的区别:


3.结果排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序.
案例:
同学及数学成绩,按数学成绩升序显示:
select id,name,math from exam_result order by math;
select id,name,math from exam_result order by math asc;

同学及数学成绩,按数学成绩降序显示:
select id,name,math from exam_result order by math desc;

同学及 qq 号,按 qq 号排序显示:
select id,name,qq from exam_result order by qq desc;

注意:NULL 视为比任何值都小,降序出现在最下面 。
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示 :
select name,chinese,math,english from exam_result order by math desc , english asc ,chinese asc;

查询同学及总分,由高到低:
order by 中可以使用表达式。
select name,chinese+math+english total from exam_result order by chinese+math+english desc;
select name,chinese+math+english total from exam_result order by total desc;
order by 中可以使用别名的原因是,order SQL语句的优先级小于select的优先级,先筛选出结果在排序。
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示:
select name,math from exam_result where name like '孙%' or name like '曹%' order by math desc;

4.筛选分页结果
语法:
-- 起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。
案例:
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页:
select id,name,chinese,math,english from exam_result order by id limit 3 offset 0;
select id,name,chinese,math,english from exam_result order by id limit 3 offset 3;
select id,name,chinese,math,english from exam_result order by id limit 3 offset 6;
三.Update (修改)
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果进行列值更新。
案例:
将孙悟空同学的数学成绩变更为 80 分:

将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分 :

将总成绩倒数前三的 3 位同学的数学成绩加上 30 分:
update exam_result set math=math+30 order by chinese+math+english limit 3 ;

将所有同学的语文成绩更新为原来的 2 倍:
update exam_result set chinese=chinese*2 ;
四.Delete(删除)
1.删除数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]案例:
删除孙悟空同学的考试成绩:
delete from exam_result where name='孙悟空';
2.删除整张表数据
注意:删除整表操作要慎用!!!!
测试:

删除整张表:

再次插入数据:

我们发现id的,auto_increment,还是会递增。
3.截断表
语法:
TRUNCATE [TABLE] table_name注意:这个操作慎用
- 1. 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 2. 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 3. 会重置 AUTO_INCREMENT 项
案例:

截断表:

再次插入数据:

发现:AUTO_INCREMENT会重新计数。
4.去重表数据
数据准备:

步骤:
- 创建一张和原表一模一样规模的表
- 将原表的数据去重插入到新表中
- 将原表重命名,将新表重命名为原表的名称


五.聚合函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
统计班级共有多少同学:

统计班级同学的 qq 号有多少:
NULL 不会计入结果。

统计本次考试的数学成绩分数个数 :

统计数学成绩总分:

统计平均总分 :

返回英语最高分 :

返回 > 70 分以上的数学最低分 :

六.group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询:
select column1, column2, .. from table group by column;准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
数据库文件 scott_data.sql 文件 提取码wqwq。
这是一个sql数据库备份文件使用souce 直接恢复到mysql。



如何显示每个部门的平均工资和最高工资:
显示每个部门的每种岗位的平均工资和最低工资 :

显示平均工资低于2000的部门和它的平均工资 :
分组查询时使用having进行条件过滤:

--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
相关文章:
MySQL——表的增删查改
目录 一.Create(创建) 1.单行数据 全列插入 2.多行数据 指定列插入 3.插入否则更新 4. 替换 二.Retrieve(读取) 1. select 列 查询 2.where 条件 3.结果排序 4.筛选分页结果 三.Update (修改)…...
javascript_1
3) string ⭐️ js 字符串三种写法 let a "hello"; // 双引号 let b "world"; // 单引号 let c hello; // 反引号 html 代码如下,用 java 和 js 中的字符串如何表示? <a href"1.html">超链接</a> …...
【ranger】CDP环境 更新 ranger 权限策略会发生低概率丢失权限策略的解决方法
一、问题描述: 我们的 kafka 服务在更新(添加) ranger 权限时,会有极低的概率导致 MM2 同步服务报错,报错内容 Not Authorized。但是查看 ranger 权限是赋予的,并且很早配置的权限策略也会报错。 相关组件…...

Python安装及配置
一、前置说明 Python的安装有两种方式:1. 访问Python官方网站下载安装;2. 使用Python的开源发行版进行安装。 Anaconda 是一个用于科学计算、数据分析和机器学习的开源发行版,它包含了许多常用的科学计算和数据分析库。Anaconda 不仅仅是 P…...

Instagram 外贸产品推广技巧
在Instagram上,外贸业务有许多独特的机会来展示其产品并吸引国际买家。成功的外贸产品推广要求细致的策略、引人入胜的创意内容和有针对性的市场洞察。下面的小节将详细解析如何在Instagram上进行外贸产品的有效推广。 1.创意与视觉呈现 Instagram是一个基于图片和…...

5款实用的小工具,让你的日常生活多姿多彩
简单而小巧的工具,经常能在日常中悄然发挥极大的作用。这五款小工具可能成为你生活中不可或缺的一部分。 1.网络浏览器——Brave Brave是一款基于Chromium内核的开源网络浏览器,它可以阻止网站的广告和跟踪程序,保护您的隐私和安全。…...

【改进YOLOv8】磁瓦缺陷分类系统:改进LSKNet骨干网络的YOLOv8
1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 研究背景与意义 近年来,随着智能制造产业的不断发展,基于人工智能与机器视觉的自动化产品缺陷检测技术在各行各业中得到了广泛应用。磁瓦作为永磁电机的主…...
Linux-VRRP
这里写自定义目录标题 一、VRRP简介1.1 什么是VRRP?1.2 keepalived是什么? 二、配置过程2.1 试验模型2.2. Keepalived监控和维护VRRP集群的步骤 一、VRRP简介 1.1 什么是VRRP? VRRP(Virtual Router Redundancy Protocolÿ…...

使用Axure的中继器的交互动作解决增删改查h
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《产品经理如何画泳道图&流程图》 ⛺️ 越努力 ,越幸运 目录 一、中继器的交互 1、什么是中继器的交互 2、Axure中继器的交互 3、如何使用中继器? 二…...
)
华为云Stack 8.X 流量模型分析(一)
一、基础知识 1.tap与tun tap与tun都是操作系统(Linux)内核中的虚拟网络设备,等同于一个以太网设备,可以收发数据报文包。 tap与tun的定义相同,两者仅仅是通过一个Flag来区分。但二者所承担的功能差别较大&am…...
SpringBoot已经禁掉了循环依赖!
还在问循环依赖嘛?SpringBoot已经禁掉了循环依赖! 首发2023-12-18 11:26yuan人生 如果现在面试时还有人问你循环依赖,你就这样怼他:循环依赖是一种代码质量低下的表现,springboot2.6之后的版本已经默认禁用了。 Spr…...
详解(一))
【.NET Core】反射(Reflection)详解(一)
【.NET Core】反射(Reflection)详解(一) 文章目录 【.NET Core】反射(Reflection)详解(一)一、什么是反射二、Assembly类2.1 LoadFile2.2 Load2.3 LoadFrom(String)2.4 GetName()2.5…...
jenkins入门
文章目录 前言一、 jenkins的安装二、新建简单任务总结 前言 本篇文章是 jenkins 的入门级别案例,包括安装、基础概念介绍、新建简单任务 一、 jenkins的安装 下载 jenkins https://www.jenkins.io/download/ 当前案例下载的是 2.426.2 LTS 版本 下载安装jdk11 …...

HarmonyOS --- 首页(新新新手版,高手误入)
一、前言 每一个App都应该有一个首页,在Android中一般由MainActivity Navigation Fragment * N (随便你怎么组合,用别的也一样),鸿蒙呢?瞅瞅吧。阿弥陀佛,苦逼Android学完Java学Dart、学完Da…...
springboot升级到3.2导致mybatis-plus启动报错
在springboot升级到3.2时,服务启动报错 java.lang.IllegalArgumentException: Invalid value type for attribute ‘factoryBeanObjectType’: java.lang.String: java.lang.IllegalArgumentException: Invalid value type for attribute factoryBeanOb…...
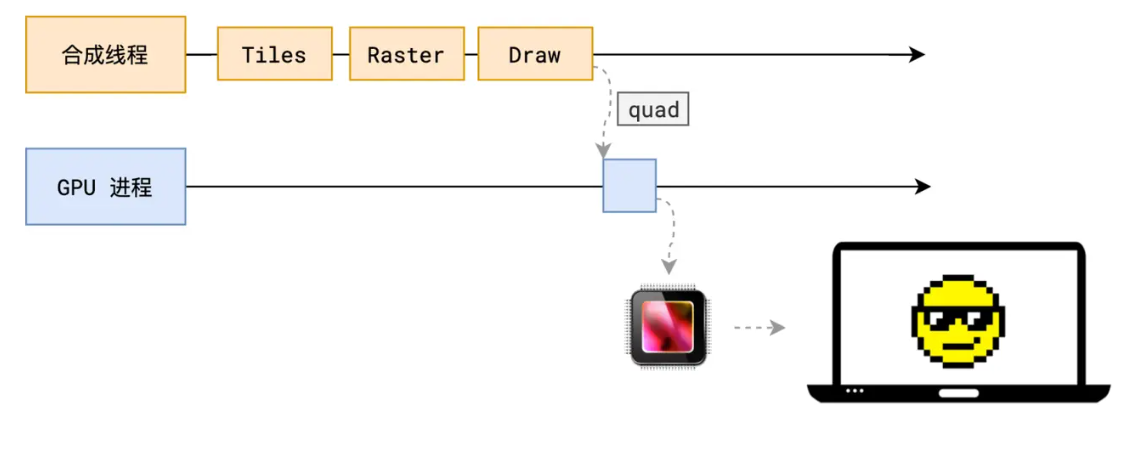
浏览器原理篇—渲染原理
目录导航 为什么要学习浏览器的渲染原理浏览器的渲染流程浏览器的渲染阻塞浏览器的渲染优化 为什么要学习浏览器的渲染原理? 知识深度挖掘: 帮助更好地理解前端性能优化。从而对实现效果进行针对性优化。如:**回流和重绘 **渲染机制。帮助…...

idea安装
mac安装路径 /Users/xxx/Library/Application Support/JetBrains/IntelliJIdeaxxx版本 将路径内文件直接复制到新版本即可, 注意如果为破解版idea.vmoptions配置中的内容是否添加或删除 maven配置如果使用idea, 需要在应用程序IntelliJ IDEA.app中显示包内容, /Applications/I…...

用Flask搭建简单的web模型部署服务
目录结构如下: 分类模型web部署 classification.py import os import cv2 import numpy as np import onnxruntime from flask import Flask, render_template, request, jsonifyapp Flask(__name__)onnx_session onnxruntime.InferenceSession("mobilen…...
lM-ICP)
PCL 点云匹配 3 之 (非线性迭代点云匹配)lM-ICP
一、IM迭代法 PCL IterativeClosestPointNonLinear 非线性L-M迭代法-CSDN博客 Matlab 非线性迭代法(3)阻尼牛顿法 L-M-CSDN博客 MATLAB实现最小二乘法_matlab最小二乘法-CSDN博客...

【C语言】SCU安全项目2-BufBomb
目录 关键代码解读: getxs() getbuf() test() 核心思路 具体操作1 具体操作2 前段时间忙于强网杯、英语4级和一些其他支线,有点摸不清头绪了,特别是qwb只有一个输出,太过坐牢,决定这个安全项目做完后就继续投身…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...