【数据库设计和SQL基础语法】--连接与联接--多表查询与子查询基础(二)
一、子查询基础
1.1 子查询概述
子查询是指在一个查询语句内部嵌套另一个查询语句的过程。子查询可以嵌套在 SELECT、FROM、WHERE 或 HAVING 子句中,用于从数据库中检索数据或执行其他操作。子查询通常返回一个结果集,该结果集可以被包含它的主查询使用。
以下是子查询的一般概述:
- 位置: 子查询可以出现在 SQL 语句的不同部分,包括 SELECT 子句、FROM 子句、WHERE 子句、HAVING 子句等。
- 返回结果: 子查询通常返回一个结果集,这个结果集可以是一个值、一列值、一行值或者多行多列值。
- 用途: 子查询的主要用途之一是在一个查询中使用另一个查询的结果。这样可以在较复杂的查询中进行逻辑判断、过滤数据或进行计算。
- 类型: 子查询可以分为单行子查询和多行子查询。单行子查询返回一行一列的结果,而多行子查询返回多行多列的结果。
- 比较运算符: 子查询通常使用比较运算符(如 =、<、>、IN、EXISTS 等)将其结果与主查询中的数据进行比较。
- 性能考虑: 使用过多的子查询可能会影响查询的性能,因此在编写查询时要注意优化。
以下是一个简单的例子,演示了子查询的基本用法:
SELECT employee_name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
上述查询中,子查询 (SELECT AVG(salary) FROM employees) 返回员工薪水的平均值,然后主查询选择薪水高于平均值的员工信息。
1.2 单行子查询
单行子查询是一种子查询,其结果集只包含单一的行和单一的列。这种类型的子查询通常用于比较操作符(如 =、<、>、<=、>=)的右侧,以便与主查询中的某个值进行比较。单行子查询的结果可以是一个具体的值,也可以是一个表达式。
下面是一个简单的例子,演示了单行子查询的用法:
SELECT employee_name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
在上述例子中,(SELECT AVG(salary) FROM employees) 是一个单行子查询,它返回员工薪水的平均值。主查询选择了那些薪水高于平均值的员工信息。
单行子查询还可以在其他场景中使用,例如在选择默认值或计算中。以下是一个示例:
SELECT product_name, price,(SELECT MAX(price) FROM products) AS max_price
FROM products;
在这个例子中,单行子查询 (SELECT MAX(price) FROM products) 返回产品价格的最大值,然后主查询选择了产品名称、价格和最大价格。
1.3 多行子查询
多行子查询是一种子查询,其结果集可以包含多行和多列。这种类型的子查询通常用于比较操作符(如 IN、ANY、ALL 等),以便与主查询中的一组值进行比较。
以下是一个使用多行子查询的简单示例:
SELECT customer_name
FROM customers
WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= '2023-01-01');
在这个例子中,多行子查询 (SELECT customer_id FROM orders WHERE order_date >= '2023-01-01') 返回了在指定日期之后下过订单的所有客户的ID。主查询选择了那些在子查询结果集中的客户信息。
多行子查询还可以用于 EXISTS 子句,例如:
SELECT employee_name
FROM employees e
WHERE EXISTS (SELECT 1 FROM projects p WHERE p.manager_id = e.employee_id);
在这个例子中,多行子查询 (SELECT 1 FROM projects p WHERE p.manager_id = e.employee_id) 返回了有项目的员工信息。主查询选择了那些在子查询结果集中存在项目的员工信息。
1.4 子查询应用场景
子查询在 SQL 查询中有多种应用场景,它们能够增加查询的灵活性和表达能力。以下是一些常见的子查询应用场景:
- 筛选数据: 使用子查询在 WHERE 子句中进行条件筛选,以过滤出满足特定条件的数据。例如,选择薪水高于平均值的员工或者选择在指定日期之后下过订单的客户。
SELECT employee_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees); - 嵌套查询: 在 SELECT 子句中使用子查询,将子查询的结果作为主查询的一部分进行计算或显示。例如,计算每个员工的平均销售额并显示在查询结果中。
SELECT employee_id, employee_name,(SELECT AVG(sales) FROM sales WHERE sales.employee_id = employees.employee_id) AS avg_sales FROM employees; - IN 子句: 使用子查询在 WHERE 子句中进行多个值的比较,例如选择属于某个特定部门的员工。
SELECT employee_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE department_name = 'Sales'); - EXISTS 子句: 判断子查询是否返回结果,常用于判断某个条件是否满足。例如,选择有项目的员工信息。
SELECT employee_name FROM employees e WHERE EXISTS (SELECT 1 FROM projects p WHERE p.manager_id = e.employee_id); - 子查询与连接: 结合子查询和连接操作,以便在复杂的数据关系中检索所需的信息。
SELECT customer_name FROM customers WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= '2023-01-01');
这些是一些常见的子查询应用场景,但并不局限于此。子查询在 SQL 查询语言中的应用非常灵活,可以根据具体的业务需求和数据结构进行定制。
二、多表查询与子查询的结合运用
2.1 使用子查询进行条件过滤
使用子查询进行条件过滤是一种常见的 SQL 操作,它允许你在 WHERE 子句中使用子查询来过滤主查询的结果。以下是一个例子,演示如何使用子查询进行条件过滤:
假设有两个表:orders 存储订单信息,包括 order_id 和 order_date,以及 products 存储产品信息,包括 product_id 和 product_name。
现在,我们想要获取在某个特定日期之后下过订单的产品信息,可以使用子查询来实现:
SELECT product_id, product_name
FROM products
WHERE product_id IN (SELECT product_idFROM ordersWHERE order_date >= '2023-01-01'
);
在这个例子中,子查询 (SELECT product_id FROM orders WHERE order_date >= '2023-01-01') 返回了在指定日期之后下过订单的产品的 product_id 列表。主查询则使用这个列表来过滤 products 表中的产品信息,最终得到满足条件的产品列表。
Tip:这只是一个简单的例子,实际应用中可以根据具体业务需求进行更复杂的条件过滤。使用子查询进行条件过滤的好处在于,它提供了一种灵活的方式来根据其他查询的结果动态地确定主查询的条件。
2.2 子查询与连接的结合运用
子查询与连接的结合可以帮助在复杂的数据关系中检索所需的信息。以下是一个例子,演示如何使用子查询和连接进行结合运用:
假设有两个表:employees 存储员工信息,包括 employee_id 和 employee_name,以及 projects 存储项目信息,包括 project_id 和 manager_id(表示项目经理的员工ID)。
现在,我们想要获取每个项目的项目名称以及项目经理的姓名。我们可以使用连接操作和子查询来实现:
SELECT project_name, employee_name AS manager_name
FROM projects
JOIN employees ON projects.manager_id = employees.employee_id;
在这个例子中,projects.manager_id 与 employees.employee_id 进行连接,以获取项目经理的姓名。这是一个基本的连接操作。
然而,如果你想要获取每个项目的项目名称以及项目经理的姓名和其它信息,可以使用子查询来获取项目经理的信息:
SELECT project_name,(SELECT employee_name FROM employees WHERE employee_id = projects.manager_id) AS manager_name,(SELECT department_name FROM employees WHERE employee_id = projects.manager_id) AS manager_department
FROM projects;
在这个例子中,子查询 (SELECT employee_name FROM employees WHERE employee_id = projects.manager_id) 用于获取项目经理的姓名,另一个子查询 (SELECT department_name FROM employees WHERE employee_id = projects.manager_id) 用于获取项目经理所在的部门。主查询选择了项目名称以及子查询中获取的项目经理相关信息。
这种结合运用可以根据具体需求,更灵活地检索所需的信息,并充分发挥 SQL 查询的表达能力。
2.3 子查询在多表查询中的嵌套应用
在多表查询中,子查询的嵌套应用可以帮助解决更为复杂的数据检索问题。下面是一个例子,演示了在多表查询中使用子查询的嵌套应用:
假设有三个表:employees 存储员工信息,包括 employee_id 和 employee_name;projects 存储项目信息,包括 project_id 和 project_name;assignments 存储员工分配到项目的信息,包括 employee_id 和 project_id。
现在,我们想要获取每个项目的项目名称以及参与该项目的员工数量。我们可以使用嵌套子查询来实现:
SELECT project_id, project_name,(SELECT COUNT(*) FROM assignments WHERE assignments.project_id = projects.project_id) AS employee_count
FROM projects;
在这个例子中,主查询从 projects 表中选择项目的 project_id 和 project_name,然后嵌套的子查询 (SELECT COUNT(*) FROM assignments WHERE assignments.project_id = projects.project_id) 用于计算每个项目参与的员工数量。子查询中的条件将项目表与分配表关联起来,以获取每个项目的员工数量。
这样的嵌套子查询可以应用于多表查询的各种情况,例如计算聚合函数、获取相关信息等。需要注意的是,过度使用嵌套子查询可能会影响查询性能,因此在实际应用中需要根据具体情况进行优化。
这只是一个简单的示例,实际应用中可能涉及更多的表和更复杂的关系,但通过嵌套子查询,你可以更灵活地处理多表查询的需求。
三、性能优化与最佳实践
3.1 索引的重要性
索引在数据库中起着重要的作用,它是一种数据结构,用于提高数据库查询的性能。以下是索引的一些重要性:
- 加速数据检索: 索引可以帮助数据库引擎快速定位表中的特定行,从而加速数据检索的速度。通过使用索引,数据库可以直接跳转到存储了目标数据的位置,而不必扫描整个表。
- 优化查询性能: 对于经常执行的查询语句,通过在相关列上创建索引,可以显著减少查询的执行时间。这对于大型数据库和复杂查询尤为重要。
- 排序和聚合操作: 索引不仅加速数据检索,还有助于提高排序和聚合操作的性能。对于需要对结果进行排序或进行聚合计算的查询,使用索引可以减少排序和扫描的开销。
- 加速连接操作: 在进行连接操作时,如果连接的列上存在索引,可以减少连接的复杂度,提高连接操作的速度。这对于关联多个表的查询非常重要。
- 唯一性约束: 索引可以用于实现唯一性约束,确保表中某一列的数值是唯一的。这对于防止重复数据的插入非常有用。
- 加速数据修改操作: 尽管索引在数据检索上有很大优势,但在执行插入、更新和删除等修改操作时,可能会稍微降低性能。然而,合理使用索引可以最小化这种影响。
- 支持全文搜索: 对于包含全文搜索的数据库,全文索引可以加速搜索操作,提高搜索的效率。
- 减少磁盘 I/O 操作: 索引可以减少需要读取的数据量,从而减少磁盘 I/O 操作,提高数据库系统的整体性能。
虽然索引对性能有很多好处,但过度创建索引也可能导致一些问题,比如增加写操作的开销、占用更多的磁盘空间等。因此,在设计数据库时,需要根据具体的查询需求和操作模式谨慎选择创建索引的列。综合考虑查询的频率、表的大小和数据修改的频率等因素,可以找到适合应用场景的索引策略。
3.2 适当使用 JOIN 语句
使用 JOIN 语句是在 SQL 查询中关联多个表的一种重要方式。适当使用 JOIN 语句可以帮助你在单个查询中检索到需要的关联数据,提高查询的效率和灵活性。以下是一些建议,以确保 JOIN 语句的适当使用:
- 理解不同类型的 JOIN: SQL 支持不同类型的 JOIN,包括 INNER JOIN、LEFT JOIN、RIGHT JOIN 和 FULL OUTER JOIN。了解这些不同类型的 JOIN 如何工作,以及它们之间的区别是非常重要的。根据实际需求选择适当的 JOIN 类型。
- 选择合适的关联条件: 在使用 JOIN 时,确保选择合适的关联条件,以确保关联的行是相关的。关联条件通常是基于两个表之间的共同列进行的,如员工表的员工ID与项目表的经理ID。
SELECT employee_name, project_name FROM employees INNER JOIN projects ON employees.employee_id = projects.manager_id; - 小心使用多重 JOIN: 当在一个查询中使用多个 JOIN 时,确保了解数据关系,以避免生成过于复杂和难以理解的查询。可以使用表别名来使查询更易读。
SELECT e.employee_name, p.project_name, d.department_name FROM employees e INNER JOIN projects p ON e.employee_id = p.manager_id INNER JOIN departments d ON e.department_id = d.department_id; - 使用索引加速 JOIN: 确保关联列上存在索引,以加速 JOIN 操作。索引可以帮助数据库引擎更快地定位和匹配关联的行。
- 考虑性能影响: JOIN 操作在性能上可能有一些开销,特别是在关联大型表时。在设计查询时,考虑到数据量、索引和表的结构,以最小化性能影响。
- 了解 NULL 值的处理: 在使用 LEFT JOIN 或 RIGHT JOIN 时,要考虑到可能出现的 NULL 值。了解 NULL 值的处理方式,并确保查询的结果符合预期。
SELECT customers.customer_name, orders.order_id FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id;
适当使用 JOIN 语句可以使查询更为灵活,并帮助你获取相关联的数据。但要谨慎使用,确保查询的可读性和性能。根据实际需求选择合适的 JOIN 类型,并注意关联条件的准确性。
3.3 编写高效的子查询
编写高效的子查询对于优化查询性能非常重要。以下是一些建议,可以帮助你编写高效的子查询:
- 选择适当的子查询类型: 子查询可以是标量子查询(返回单一值)、行子查询(返回一行多列)、列子查询(返回单列多行)或表子查询(返回多行多列)。选择适当的子查询类型以满足你的查询需求。
- 避免在循环中使用子查询: 在循环或迭代中执行子查询可能导致性能问题,因为每次迭代都会执行一次子查询。尽量通过连接操作或其他手段来避免在循环中执行子查询。
- 使用 EXISTS 或 NOT EXISTS 替代 IN 或 NOT IN: 在某些情况下,使用 EXISTS 或 NOT EXISTS 可能比使用 IN 或 NOT IN 更有效,尤其是在子查询返回大量数据时。
-- 使用 EXISTS SELECT employee_name FROM employees e WHERE EXISTS (SELECT 1 FROM projects p WHERE p.manager_id = e.employee_id);-- 使用 IN SELECT employee_name FROM employees WHERE employee_id IN (SELECT manager_id FROM projects); - 优化子查询的 WHERE 子句: 在子查询中的 WHERE 子句中使用索引和适当的条件,以提高子查询的性能。
- 使用连接操作代替子查询: 在某些情况下,使用连接操作可能比子查询更有效。尤其是在子查询中涉及多个表时,连接操作通常更为灵活和高效。
- 限制子查询返回的结果集: 在子查询中使用合适的条件,限制返回的结果集大小。这可以减小主查询的处理负担。
- 考虑使用临时表: 在某些情况下,创建临时表并将结果存储在其中,然后在主查询中引用这个临时表可能会提高性能。这对于大型数据集或复杂的计算可能特别有帮助。
- 使用索引加速子查询: 确保子查询涉及的列上有适当的索引,以提高查询性能。
- 避免嵌套过深: 避免嵌套过多的子查询,因为这可能会导致复杂度增加并降低可读性。在可能的情况下,考虑使用连接或其他手段替代嵌套子查询。
- 利用数据库性能工具进行调优: 使用数据库管理系统提供的性能分析工具,了解查询执行计划,以便识别和优化潜在的性能瓶颈。
通过综合考虑这些因素,你可以更有效地编写子查询,提高查询性能并优化数据库操作。
四、示例与演练
4.1 实际 SQL 查询示例
当涉及到实际 SQL 查询时,具体的查询语句会依赖于数据库的结构以及你想要检索或操作的数据。以下是一些实际的 SQL 查询示例,每个例子都展示了一个不同的查询场景:
- 基本查询: 从一个表中选择所有列和所有行。
SELECT * FROM employees; - 条件筛选: 选择符合特定条件的行。
SELECT product_name, price FROM products WHERE price > 100; - 多表连接: 使用 INNER JOIN 连接两个表,检索相关联的数据。
SELECT customers.customer_id, customers.customer_name, orders.order_id FROM customers INNER JOIN orders ON customers.customer_id = orders.customer_id; - 聚合函数: 使用聚合函数计算统计信息。
SELECT department_id, AVG(salary) AS avg_salary, COUNT(*) AS employee_count FROM employees GROUP BY department_id; - 子查询: 使用子查询选择符合条件的子集。
SELECT employee_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees); - 排序和限制: 按特定列的顺序排序结果,并限制返回的行数。
SELECT product_name, price FROM products ORDER BY price DESC LIMIT 10; - 更新操作: 更新表中的数据。
UPDATE employees SET salary = salary * 1.1 WHERE department_id = 2; - 插入操作: 插入新的数据行。
INSERT INTO products (product_name, price) VALUES ('New Product', 50.00); - 删除操作: 删除符合条件的数据行。
DELETE FROM orders WHERE order_date < '2023-01-01';
这些只是一些基本的例子,实际查询语句会根据你的具体需求和数据库结构而变化。在编写实际的 SQL 查询时,确保使用适当的索引、优化查询语句,并通过数据库管理系统提供的工具分析查询性能。
4.2 案例分析与解析
以下是一个简单的案例分析与解析,假设我们有一个包含员工和项目信息的数据库。
案例: 我们想要找出每个部门的平均工资,并列出工资高于部门平均工资的员工信息。
解析: 为了实现这个目标,我们可以使用聚合函数、JOIN 操作和子查询。以下是一个可能的解决方案:
-- 步骤1: 计算每个部门的平均工资
WITH DepartmentAverage AS (SELECT department_id, AVG(salary) AS avg_salaryFROM employeesGROUP BY department_id
)-- 步骤2: 列出工资高于部门平均工资的员工信息
SELECT e.employee_id, e.employee_name, e.salary, e.department_id
FROM employees e
JOIN DepartmentAverage d ON e.department_id = d.department_id
WHERE e.salary > d.avg_salary;
在这个解决方案中,我们使用了 Common Table Expression (CTE) 来计算每个部门的平均工资。然后,我们使用 JOIN 操作将员工表与计算得到的平均工资表关联起来。最后,通过 WHERE 子句过滤出工资高于部门平均工资的员工信息。
这个案例分析涉及到多个 SQL 概念和技术:
- 聚合函数: 使用
AVG()计算平均工资。 - WITH 语句: 使用 CTE 存储中间结果,提高可读性和可维护性。
- JOIN 操作: 通过连接两个表来关联员工和部门平均工资信息。
- 子查询: 在 WHERE 子句中使用子查询来过滤结果。
五、常见问题与解决方案
5.1 多表查询常见错误
在进行多表查询时,有一些常见的错误可能会影响查询的正确性或性能。以下是一些多表查询中常见的错误以及如何避免它们:
-
忽略连接条件: 忘记在 JOIN 操作中指定正确的连接条件,导致不相关的行被错误地关联在一起。
-- 错误的连接,缺少连接条件 SELECT * FROM employees JOIN departments ON employees.department_id = departments.department_id;解决方法: 确保在 JOIN 操作中指定正确的连接条件,以避免不相关的行被关联。
-
忽略 NULL 值: 在使用 LEFT JOIN 或 RIGHT JOIN 时,忽略了 NULL 值,可能导致结果不符合预期。
-- 错误的 LEFT JOIN,没有处理 NULL 值 SELECT customers.customer_id, orders.order_id FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id;解决方法: 在使用 LEFT JOIN 或 RIGHT JOIN 时,要考虑 NULL 值,并根据需要进行适当的处理。
-
使用过多的连接: 连接太多的表可能会导致查询复杂度增加和性能下降。
-- 过多的连接 SELECT * FROM employees JOIN departments ON employees.department_id = departments.department_id JOIN projects ON employees.project_id = projects.project_id;解决方法: 仅连接必要的表,确保查询足够简单且易于理解。
-
未使用索引: 在连接列上缺少索引可能导致连接操作的性能下降。
-- 缺少索引的连接列 SELECT customers.customer_name, orders.order_id FROM customers JOIN orders ON customers.customer_id = orders.customer_id;解决方法: 在连接的列上建立适当的索引,以提高连接操作的性能。
-
未使用 WHERE 子句进行筛选: 没有使用 WHERE 子句限制结果集可能导致返回大量的数据,影响性能。
-- 未使用 WHERE 子句进行筛选 SELECT * FROM employees JOIN departments ON employees.department_id = departments.department_id;解决方法: 使用 WHERE 子句筛选结果集,只检索所需的数据。
-
未考虑性能: 在设计查询时,未考虑查询的性能可能导致较慢的查询速度。
-- 性能不佳的查询 SELECT * FROM large_table1 JOIN large_table2 ON large_table1.column_id = large_table2.column_id;解决方法: 考虑查询的性能,使用合适的索引和优化技术,确保查询效率较高。
在编写多表查询时,仔细检查连接条件、处理 NULL 值、限制结果集大小并考虑性能是避免常见错误的关键。同时,使用数据库系统提供的性能分析工具来检查查询执行计划,帮助发现潜在的性能问题。
5.2 子查询常见问题
在使用子查询时,有一些常见问题可能会影响查询的正确性或性能。以下是一些关于子查询的常见问题及其解决方法:
-
返回多个值的子查询: 如果子查询返回了多个值,但主查询期望得到单一值,会导致错误。
-- 错误的子查询,返回多个值 SELECT employee_name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);解决方法: 确保子查询返回的结果是单一值。可以使用聚合函数、LIMIT 1 或其他方法确保子查询的结果是单一值。
-
处理 NULL 值的子查询: 子查询中的 NULL 值可能影响主查询的结果。例如,使用 IN 或 NOT IN 子查询时,注意 NULL 的处理。
-- 错误的子查询,可能返回 NULL SELECT customer_name FROM customers WHERE customer_id IN (SELECT customer_id FROM orders);解决方法: 使用 EXISTS 或 NOT EXISTS 子查询来处理 NULL 值,或者通过合适的条件确保子查询不返回 NULL。
-
性能问题: 子查询可能导致性能问题,特别是在主查询返回大量数据时。
-- 性能不佳的子查询 SELECT employee_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location = 'New York');解决方法: 考虑是否可以使用连接操作或其他更有效的方法替代子查询,或者确保子查询在关联的列上有索引。
-
嵌套子查询的可读性问题: 嵌套过深的子查询可能会降低查询的可读性,使其难以理解。
-- 嵌套过深的子查询 SELECT employee_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location_id IN (SELECT location_id FROM locations WHERE country_id = 'US'));解决方法: 考虑使用连接操作或其他手段替代嵌套子查询,或者通过使用 WITH 子句创建临时表来提高可读性。
-
过度使用子查询: 使用太多的子查询可能会导致查询复杂度增加,降低性能和可读性。
解决方法: 评估是否可以通过连接操作、临时表或其他手段简化查询,减少子查询的数量。
在使用子查询时,要特别注意处理多个值、NULL 值、性能问题以及可读性问题。仔细考虑查询需求,选择适当的方法,并使用数据库管理系统提供的性能工具来进行调优。
六、总结
SQL查询中,使用JOIN语句关联多表,搭配子查询可提高灵活性。适当选择JOIN类型、索引、连接条件,避免多表连接过度,能优化性能。在子查询中,需处理多个值、NULL值,提升可读性,防止嵌套过深。常规错误包括遗漏连接条件、处理NULL不当、性能问题、嵌套深度过大、过度使用子查询。通过评估需求、优化查询、使用工具进行性能分析,可确保SQL查询高效、准确、可维护。
相关文章:
)
【数据库设计和SQL基础语法】--连接与联接--多表查询与子查询基础(二)
一、子查询基础 1.1 子查询概述 子查询是指在一个查询语句内部嵌套另一个查询语句的过程。子查询可以嵌套在 SELECT、FROM、WHERE 或 HAVING 子句中,用于从数据库中检索数据或执行其他操作。子查询通常返回一个结果集,该结果集可以被包含它的主查询使用…...
Android studio中导入opencv库
具体opencv库的导入流程参考链接:Android Studio开发之路 (五)导入OpenCV以及报错解决 一、出现的错误:NullPointerException: Cannot invoke “java.io.File.toPath()” because “this.mySdkLocation” is null 解决办法&#…...
_基础知识)
Linux(1)_基础知识
第一部分 一、Linux系统概述 创始人:芬兰大学大一的学生写的Linux内核,李纳斯托瓦兹。 Linux时unix的类系统; 特点:多用户 多线程的操作系统; 开源操作系统; 开源项目:操作系统,应用…...

网络相关面试题
简述 TCP 连接的过程(淘系) 参考答案: TCP 协议通过三次握手建立可靠的点对点连接,具体过程是: 首先服务器进入监听状态,然后即可处理连接 第一次握手:建立连接时,客户端发送 syn 包…...

Vue2面试题:说一下对跨域的理解?
http请求分为两大类:普通http请求(如百度请求)和ajax请求(跨域是出现在ajax请求) 同源策略:在浏览器发起ajax请求时,当前的网址和被请求的网址协议、域名、端口号必须完全一致,目的是…...

Axure中如何使用交互样式交互事件交互动作情形
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《产品经理如何画泳道图&流程图》 ⛺️ 越努力 ,越幸运 目录 一、Axure中交互样式 1、什么是交互样式? 2、交互样式的作用? 3、Axure中如何…...
)
1112. 迷宫(DFS之连通性模型)
1112. 迷宫 - AcWing题库 一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由 n∗n 的格点组成,每个格点只有2种状态,.和#,前者表示可以通行后者表示不能通行。 同时当Extense处在某个格点时,他只…...
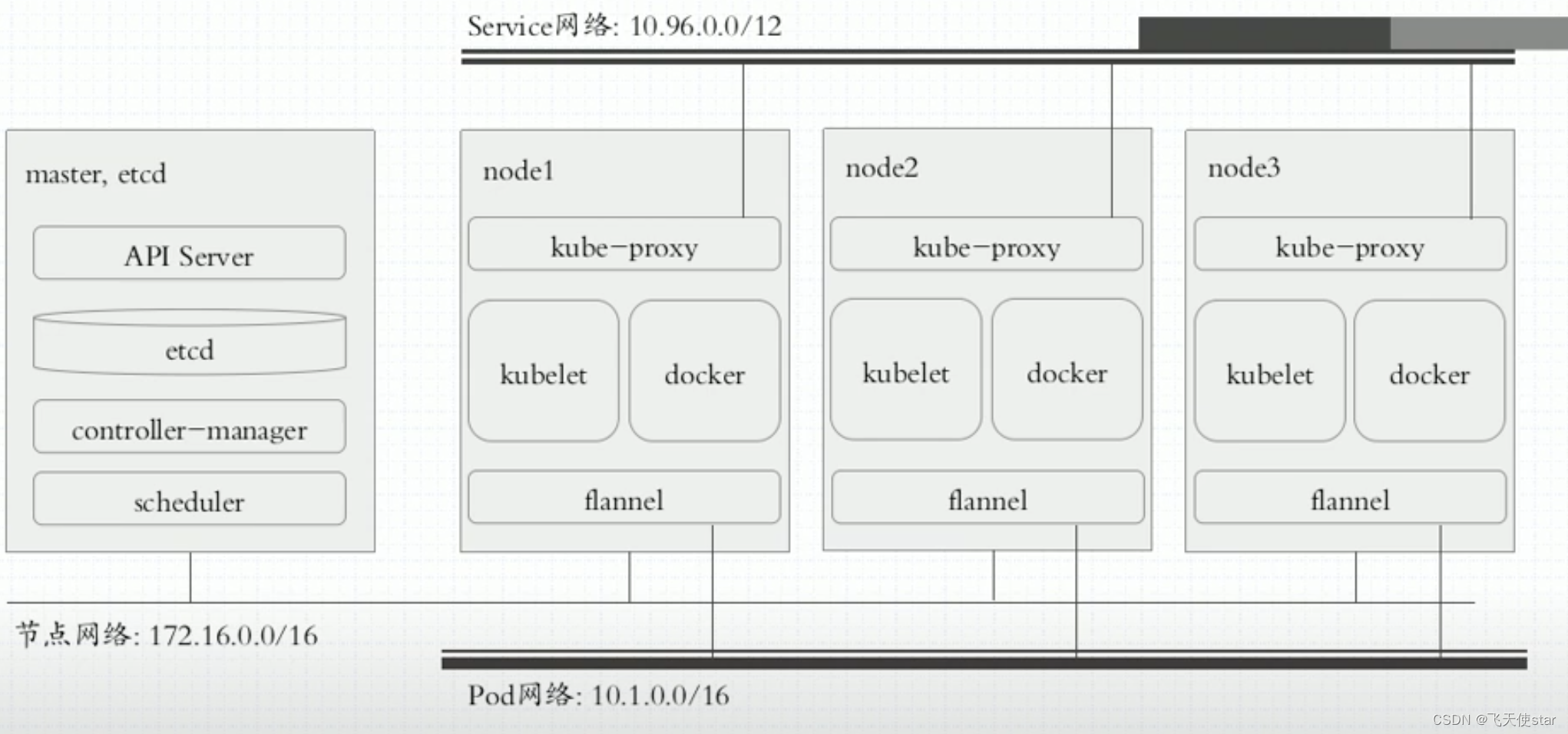
飞天使-k8s知识点1-kubernetes架构简述
文章目录 名词功能要点 k8s核心要素CNCF 云原生框架简介k8s组建介绍 名词 CI 持续集成, 自动化构建和测试:通过使用自动化构建工具和自动化测试套件,持续集成可以帮助开发人员自动构建和测试他们的代码。这样可以快速检测到潜在的问题,并及早…...
linux中deadline调度原理与代码注释
简介 deadline调度是比rt调度更高优先级的调度,它没有依赖于优先级的概念,而是给了每个实时任务一定的调度时间,这样的好处是:使多个实时任务场景的时间分配更合理,不让一些实时任务因为优先级低而饿死。deadline调度…...

jquery、vue、uni-app、小程序的页面传参方式
jQuery、Vue、Uni-app 和小程序(例如微信小程序)都有它们自己的页面传参方式。下面分别介绍这几种方式的页面传参方式: jQuery: 在jQuery中,页面传参通常是通过URL的查询参数来实现的。例如: <a href"page2…...
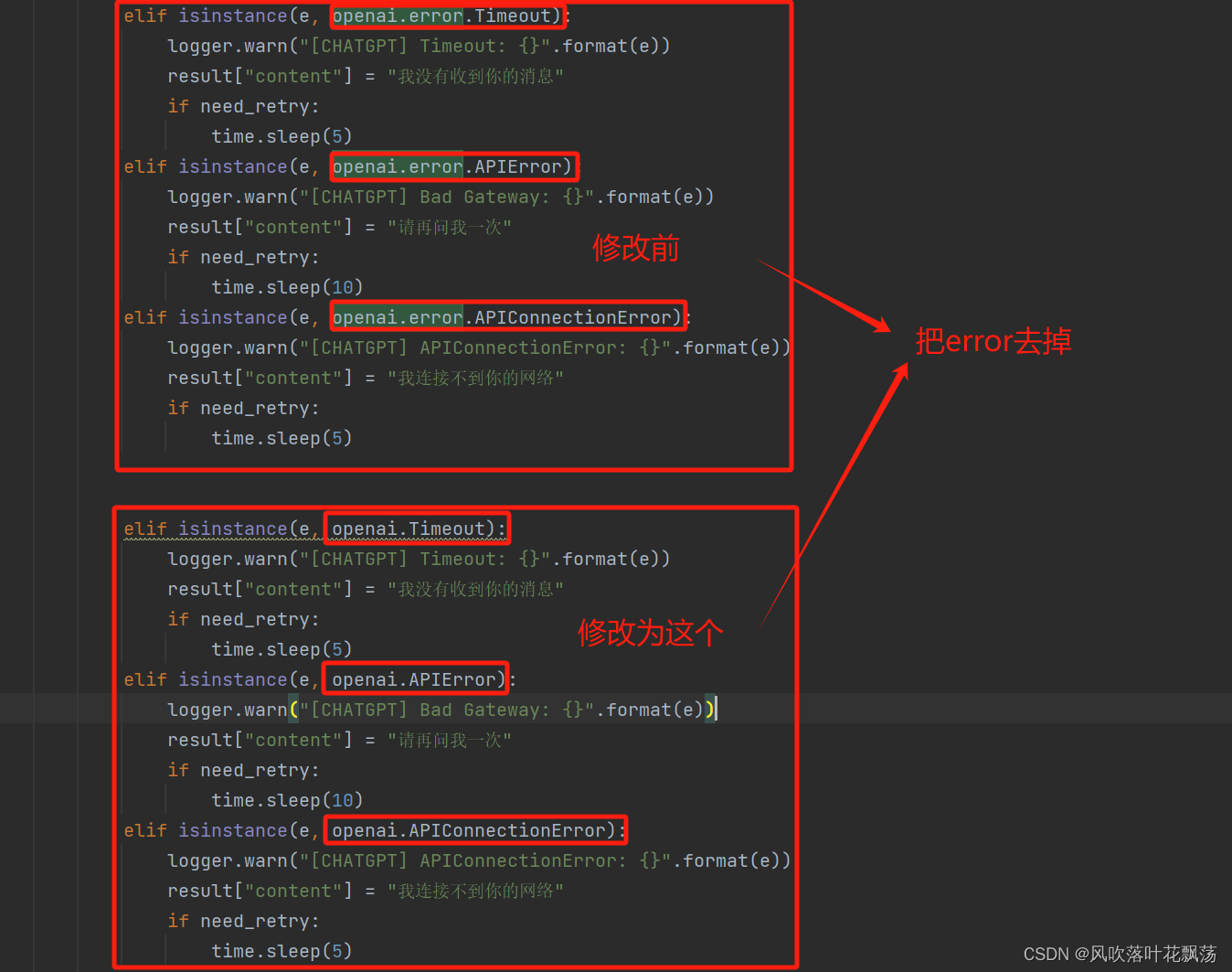
ModuleNotFoundError: No module named ‘openai.error‘
ModuleNotFoundError: No module named ‘openai.error’ result self.fn(*self.args, **self.kwargs) File “H:\chatGPTWeb\chatgpt-on-wechat\channel\chat_channel.py”, line 168, in _handle reply self._generate_reply(context) File “H:\chatGPTWeb\chatgpt-on-wec…...

理解pom.xml中的parent标签
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 循序渐进学SpringBoot ✨特色专栏&…...
element ui el-avatar 源码解析零基础逐行解析
avatar功能介绍 快捷配置头像的样式 avatar 的参数配置 属性说明参数size尺寸type string 类型 (‘large’,‘medium’,‘small’)number类型 validator 校验shape形状circle (原型) square(方形)icon传入的iconsrc传入的图片st…...
Linux下c语言实现动态库的动态调用
在Linux操作系统下,有时候需要在不重新编译程序的情况下,运行时动态地加载库,这时可以通过Linux操作系统提供的API可以实现,涉及到的API主要有dlopen、dlsym和dlclose。使用时,需要加上头文件#include <dlfcn.h>…...
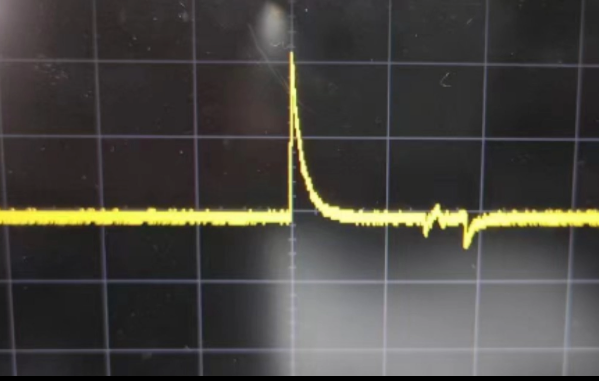
为什么MCU在ADC采样时IO口有毛刺?
大家在使用MCU内部ADC进行信号采样一个静态电压时,可能在IO口上看到这样的波形。这个时候大家一般会认识是信号源有问题,但仔细观察会发现这个毛刺的频率是和ADC触发频率一样的。 那么为什么MCU在ADC采样时IO口会出现毛刺呢?这个毛刺对结果有…...

C# 将 Word 转化分享为电子期刊
目录 需求 方案分析 相关库引入 关键代码 Word 转 Pdf Pdf 转批量 Jpeg Jpeg 转为电子书 实现效果演示 小结 需求 曾经的一个项目,要求实现制作电子期刊定期发送给企业进行阅读,基本的需求如下: 1、由编辑人员使用 Microsoft Word…...

网络世界的黑暗角落:常见漏洞攻防大揭秘
网络世界的黑暗角落:常见漏洞攻防大揭秘 今天带来了网站常见的漏洞总结,大家在自己的服务器上也需要好好进行防护,密码不要过于简单.不然非常容易遭到攻击,最终达到不可挽回的损失.很多黑客想网络乞丐一样将你服务器打宕机,然后要求你进行付费.不知道大家有没有遇到…...

通信领域发展方向
5G网络技术:随着5G网络的建设和商用推广,各家运营商、厂商和研究机构都在探索5G技术的应用场景和解决方案,如网络切片、毫米波通信、多用户MIMO等。 物联网技术:物联网技术已经成为通信行业的重点发展领域,包括传感器…...

21 3GPP中 5G NR高速列车通信标准化
文章目录 信道模型实验——物理层设计相关元素μ(与子载波间隔有关)设计参考信号(DMRS) 本文提出初始接入、移动性管理、线性小区设计等高层技术。描述3GPP采用HST场景的评估参数,阐释了HST应用的物理层技术,包括数字通信和参考信号设计,链路…...

【网络安全】-Linux操作系统—CentOS安装、配置
文章目录 准备工作下载CentOS创建启动盘确保硬件兼容 安装CentOS启动安装程序分区硬盘网络和主机名设置开始安装完成安装 初次登录和配置更新系统安装额外的软件仓库安装网络工具配置防火墙设置SELinux安装文本编辑器配置SSH服务 总结 CentOS是一个基于Red Hat Enterprise Linu…...

Wan2.1-umt5模拟技术面试官:生成Java/Python等岗位的面试题与评价
Wan2.1-umt5模拟技术面试官:打造你的个人AI面试教练 面试准备,尤其是技术面试,对很多开发者来说都是一件既重要又头疼的事情。自己刷题感觉像在盲人摸象,找人模拟面试又需要协调时间,而且很难找到经验丰富的“考官”。…...
)
手把手教你用HuggingFace API调用开源大模型(2025最新版)
手把手教你用HuggingFace API调用开源大模型(2025最新版) 在AI技术快速迭代的今天,开源大模型已成为开发者工具箱中的标配。HuggingFace作为全球最大的开源模型社区,不仅托管了数万个预训练模型,还提供了简单易用的AP…...

30分钟入门:OpenClaw+GLM-4.7-Flash自动化办公初体验
30分钟入门:OpenClawGLM-4.7-Flash自动化办公初体验 1. 为什么选择这个组合? 上周处理月度报表时,我对着上百封邮件和十几个Excel文件发呆——这些重复性工作消耗了太多精力。直到发现OpenClaw这个能操控本地电脑的AI框架,配合o…...

Z-Image-GGUF商业应用:文旅公众号用其日更景点AI绘画吸引粉丝增长
Z-Image-GGUF商业应用:文旅公众号用其日更景点AI绘画吸引粉丝增长 1. 项目背景与机遇 如果你运营着一个地方文旅公众号,每天最头疼的事情是什么?我猜一定是内容创作。今天写哪个景点?明天拍什么照片?后天发什么视频&…...

如何打造跨设备一致的移动开发环境?便携工具让编码效率提升300%
如何打造跨设备一致的移动开发环境?便携工具让编码效率提升300% 【免费下载链接】VSCode-Portable VSCode 便携版 VSCode Portable 项目地址: https://gitcode.com/gh_mirrors/vsc/VSCode-Portable 在多设备协作成为常态的今天,开发者常常面临跨设…...

DeepSeek-OCR-2惊艳效果:91.09%准确率真实测试展示
DeepSeek-OCR-2惊艳效果:91.09%准确率真实测试展示 1. 突破性的OCR识别技术 DeepSeek-OCR-2代表了当前OCR技术的最前沿水平。这款由DeepSeek团队开发的第二代光学字符识别模型,在2026年1月发布后立即引起了广泛关注。它最引人注目的特点是在OmniDocBen…...

从零配置神州路由器IPv6路由:OSPFv3邻居建立失败的7个排查步骤
神州路由器IPv6路由实战:OSPFv3邻居建立深度排错指南 IPv6网络部署已成为企业级基础设施升级的必然选择,而OSPFv3作为IPv6环境下的动态路由协议,在实际配置过程中常会遇到邻居关系无法建立的困扰。本文将针对神州路由器平台,系统梳…...
)
0586-可编程三模式洗衣机-系统设计(51+1602+L298)
功能描述 1、采用51单片机作为主控芯片; 2、采用1602显示倒计时、洗涤模式; 3、采用L298驱动电机,弱洗、强洗、漂洗不同转速; 4、支持三种工作模式: 丝质: 漂洗3分钟 棉质: 弱洗2分钟;强洗5分钟;漂洗3分钟; 化纤: 强洗4分钟;漂洗…...

OpenClaw开源贡献:为ollama-QwQ-32B编写自定义技能指南
OpenClaw开源贡献:为ollama-QwQ-32B编写自定义技能指南 1. 为什么我们需要更多自定义技能 去年冬天,当我第一次尝试用OpenClaw自动整理电脑里散落的论文时,发现现有的技能库无法完美处理PDF批注提取和归类。这个痛点促使我开发了第一个自定…...

华为华三设备CLI分页功能禁用全攻略:从临时关闭到永久配置
华为华三设备CLI分页功能深度优化指南 在设备运维的日常工作中,频繁查看长命令输出是每位工程师的必修课。当display current-configuration这样的命令返回数百行配置时,默认的分页机制反而成了效率的绊脚石——每次都需要手动按空格键继续,既…...