Pytorch的DataLoader输入输出(以文本为例)
本文不做太多原理介绍,直讲使用流畅。想看更多底层实现-〉传送门。
DataLoader简介
torch.utils.data.DataLoader是PyTorch中数据读取的一个重要接口,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口。本文介绍torch.utils.data.DataLoader与torch.utils.data.Dataset结合使用的方法。
torch.utils.data.DataLoader:接收torch.utils.data.Dataset作为输入,得到DataLoader,它是一个迭代器,方便我们去多线程地读取数据,并且可以实现batch以及shuffle的读取等。
torch.utils.data.Dataset:这是一个抽象类,所以我们需要对其进行派生,从而使用其派生类来创建数据集。最主要的两个函数实现为__Len__和__getitem__。
__init__:可以在这里设置加载的data和label。
__Len__:获取数据集大小
__getitem__:根据索引获取一条训练的数据和标签。
dataLoader的基本使用
输入数据格式
在使用torch.utils.data.DataLoader与torch.utils.data.Dataset前,需要对自己的数据读取或者做一些处理,比如我已经将我的文本数据读取到Dict里了,格式如下:(就放了两个例子,list里面存储多个Dict,一个Dict存的数据是我的一条样例)
train_pair =
[{'id': 'bb6b40-en', 'question': 'paddy:rice', 'choices': ['walnut:walnut crisp', 'cotton:cotton seed', 'watermelon:melon seeds', 'peanut:peanut butter'], 'text': ['question: paddy:rice. option: walnut:walnut crisp', 'question: paddy:rice. option: cotton:cotton seed', 'question: paddy:rice. option: watermelon:melon seeds', 'question: paddy:rice. option: peanut:peanut butter'], 'label': 1}, {'id': '1af9fe-en', 'question': 'principal:teacher', 'choices': ['police:thief', 'manager:staff', 'teacher:student', 'doctor:nurse'], 'text': ['question: principal:teacher. option: police:thief', 'question: principal:teacher. option: manager:staff', 'question: principal:teacher. option: teacher:student', 'question: principal:teacher. option: doctor:nurse'], 'label': 1
}]构造DataSet
这里的功能是主要是设置加载的data和label,获取数据集大小并根据索引获取一条训练的数据和标签。是为使用DataLoader作准备。
class MyDataset(Dataset):def __init__(self, data_pairs): super().__init__()self.data = data_pairsdef __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]train_data = MyDataset(train_pair)使用collate_fn在DataLoader基础上自定义自己的输出
这里实现的东西很简单,因为DataLoader会自动把多个Dict中的数据合并。但是,如果我上面的text字段存储了List,List就会被合并成元组,但是我在使用数据的时候希望所有的句子一起输入模型。这样我就可以自己定义一个函数,去控制合并的操作。
def my_collate(batch_line):batch_line = deepcopy(batch_line)text = []label = []for line in batch_line:text.extend(line['text']) #我只使用这两个字段,其他的可以不处理不输出label.append(line["label"])batch = {"text":text,"label":label,}return batchtrain_data_loader = DataLoader(train_data, batch_size=args.batch_size, shuffle=True, collate_fn=my_collate)这是自己控制合并操作的结果:
{'text': ['question: white pollution:biodegradation. option: industrial electricity:solar energy', 'question: white pollution:biodegradation. option: domestic water:reclaimed water recycling', 'question: white pollution:biodegradation. option: chinese herbal prescriptions:medical research','question: stone wall:earth wall. option: legal:illegal', 'question: stone wall:earth wall. option: riverway:waterway', 'question: stone wall:earth wall. option: new house:wedding room', 'question: kiln:ceramics. option: school:student', 'question: kiln:ceramics. option: oven:bread',], 'label': [3, 0]
}如果不自己处理,直接使用:
train_data_loader = DataLoader(train_data, batch_size=args.batch_size, shuffle=True)输出结果就会变成:
{ 'id': ['bb6b40-en','1af9fe-en'], 'question': ['paddy:rice', 'principal:teacher'], 'choices':......(省略)'text': ('question: white pollution:biodegradation. option: industrial electricity:solar energy', 'question: white pollution:biodegradation. option: domestic water:reclaimed water recycling', 'question: white pollution:biodegradation. option: chinese herbal prescriptions:medical research','question: stone wall:earth wall. option: legal:illegal'), ('question: stone wall:earth wall. option: riverway:waterway', 'question: stone wall:earth wall. option: new house:wedding room', 'question: kiln:ceramics. option: school:student', 'question: kiln:ceramics. option: oven:bread'), 'label': [3, 0]
}DataLoader的参数
dataset (Dataset) – 加载数据的数据集。
batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
shuffle (bool, optional) – 设置为True时会在每个epoch重新打乱数据(默认: False).
sampler (Sampler, optional) – 定义从数据集中提取样本的策略,即生成index的方式,可以顺序也可以乱序
num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
collate_fn (callable, optional) –将一个batch的数据和标签进行合并操作。
pin_memory (bool, optional) –设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
drop_last (bool, optional) – 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
timeout,是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。
参考材料
pytorch中的数据导入之DataLoader和Dataset的使用介绍
PyTorch源码解读之torch.utils.data.DataLoader
相关文章:
)
Pytorch的DataLoader输入输出(以文本为例)
本文不做太多原理介绍,直讲使用流畅。想看更多底层实现-〉传送门。DataLoader简介torch.utils.data.DataLoader是PyTorch中数据读取的一个重要接口,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口。本文介绍t…...

代谢组学:Microbiome又一篇!绘制重症先天性心脏病新生儿肠道微生态全景图谱
文章标题:Mapping the early life gut microbiome in neonates with critical congenital heart disease: multiomics insights and implications for host metabolic and immunological health 发表期刊:Microbiome 影响因子:16.837…...

Java基本类型所占字节简述
类型分类所占字节取值范围boolean布尔型1bit0 false、 1 true (1个bit 、1个字节、4个字节)char 字符型(Unicode字符集中的一个元素) 2字节-32768~32767(-2的15次方~2的15次方-1)byte整型1字节-128&a…...

Linux vi常用操作
vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。 这三种模式的作用分别是: 命令模式: 用户刚…...
、ANSI(多字节))
Unicode(宽字节)、ANSI(多字节)
1、什么时候用Unicode(宽字节),什么时候用ANSI(多字节)? 在linux/windows等操作系统中使用的,一般都是Unicode(宽字节)。 下位机PLC/单片机等硬件设备中使用,一般都是ANSI(多字节)。 所以,通讯中(比如VS项目&#x…...

STM32实战之LED循环点亮
接着上一章讲。本章我们来讲一讲LED流水灯,循环点亮LED。 在LED章节有的可能没有讲到,本章会对其进行说明,尽量每个函数说一下作用。也会在最后说一下STM32的寄存器,在编程中寄存器是避免不了的东西,寄存器也是非常好理…...

智慧厕所智能卫生间系统有哪些功能
南宁北站智能厕所主要功能有哪些?1、卫生间环境空气监测男厕、女厕环境空气监测系统包括对厕所内的温度、湿度、氨气、硫化氢、PM2.5、烟雾等气体数据的实时监测。2、卫生间厕位状态监测系统实时监测厕位内目前的使用状态(有人或无人),数据信…...
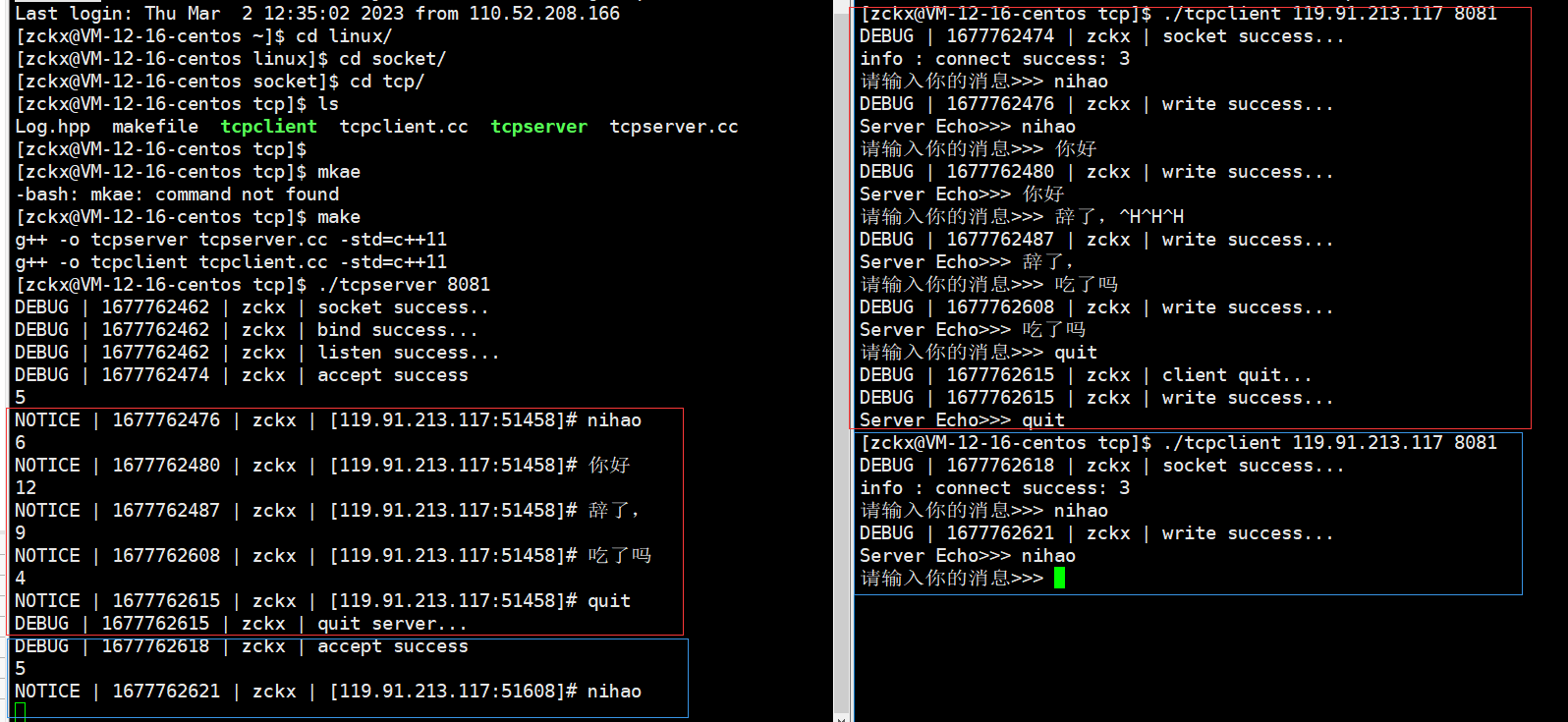
【网络】套接字 -- TCP
🥁作者: 华丞臧. 📕专栏:【网络】 各位读者老爷如果觉得博主写的不错,请诸位多多支持(点赞收藏关注)。如果有错误的地方,欢迎在评论区指出。 推荐一款刷题网站 👉 LeetCode刷题网站 文章…...
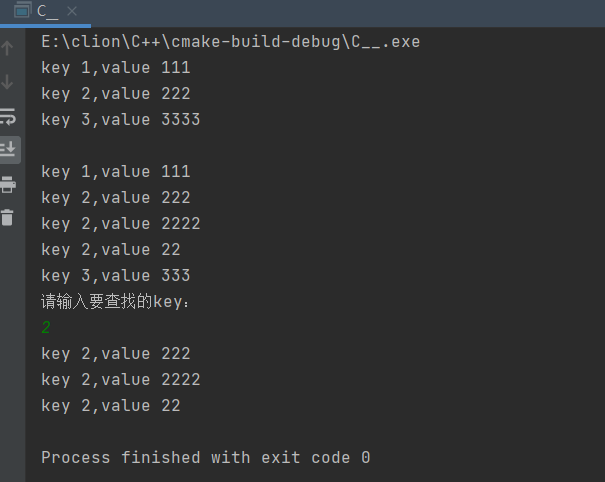
NDK C++ map容器
map容器// TODO map容器 #include <iostream> #include <map>using namespace std;int main() {// TODO map<int, string>按key值排序,同一个key不可以重复插入map<int, string> map1;map1.insert(pair<int, string>(1, "111&qu…...

linux(Centos)安装docker
官网地址:Install Docker Engine on CentOS 首先检查linux系统版本及内核: 安装docker要求系统版本至少为7.x版本,内核至少为3.8以上 cat /etc/redhat-release # 查看系统版本号uname -r #查看linux系统内核 检查系统是否能连上外网&#…...
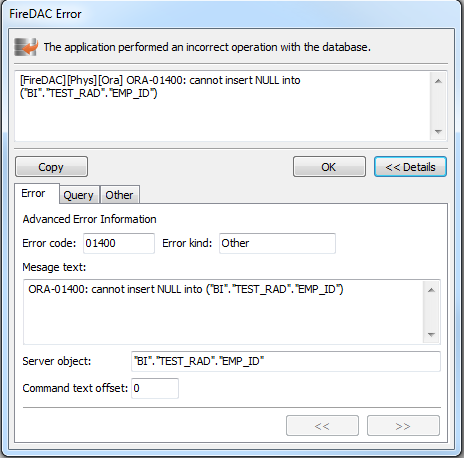
Delphi 中 FireDAC 数据库连接(处理错误)
参见:Delphi 中 FireDAC 数据库连接(总览)本主题描述了如何用FireDAC处理数据库错误。一、概述EFDDBEngineException类是所有DBMS异常的基类。单个异常对象是一个数据库错误的集合,可以通过EFDDBEngineException.Errors[]属性访问…...

算法小抄3-理解使用Python容器之列表
引言 首先说一个概念哈,程序算法数据结构,算法是条件语句与循环语句组成的逻辑结构,而数据结构也就是容器. 算法决定数据该如何处理,而容器则决定如何数据如何存储. 不同的语言对容器有不同的实现方式, 但他们的功能都是相似的, 打好容器基础,你就可以在各式各样的语言中来回横…...
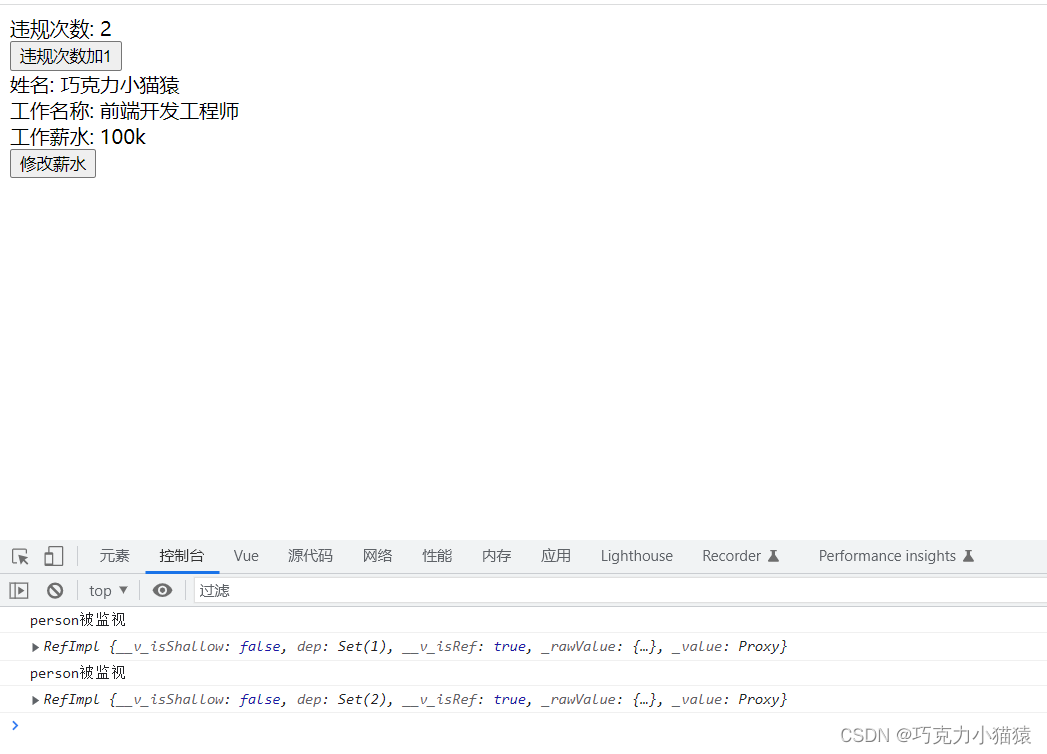
Vue3中watch的value问题
目录前言一,ref和reactive的简单复习1.ref函数1.2 reactive函数1.3 用ref定义对象类型数据不用reactive二,watch的value问题2.1 ref2.1.1 普通类型数据2.1.2 对象类型数据2.1.3 另一种方式2.2 reactive三,总结后记前言 在Vue3中,…...
【线性筛+DP】最大和
看错题了,呃呃,其实就是个简单DP最大和 - 蓝桥云课 (lanqiao.cn)题意:思路:设dp[i]为以1为终点的最大和,然后枚举状态和决策就行了主要是线性筛的应用,它可以预处理出一个数的最小质因子是多少Code…...
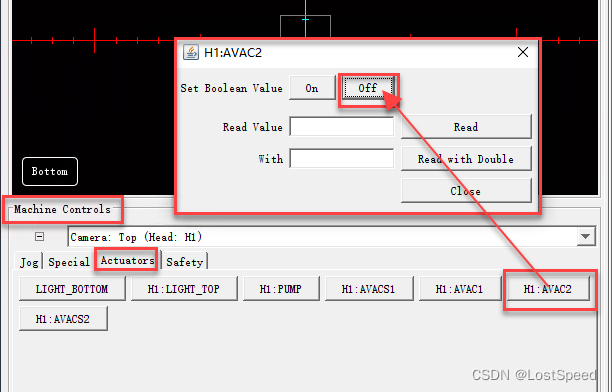
openpnp - configure - 丢弃(Discard)位置的设置
文章目录openpnp - configure - 丢弃(Discard)位置的设置概述笔记设置丢弃位置吸取元件失败后, 吸嘴一直吸气的处理ENDopenpnp - configure - 丢弃(Discard)位置的设置 概述 测试时, 吸取了一个元件, 吸取成功了, 现在想将这个料丢掉. 点击控制面板-Special页中的Discard不好…...
java Object 万字详解 (通俗易懂)
基本介绍构造方法成员方法hashCode()getClass()toString()equals()finalize()JavaBean重写Object类的方法重写toString重写equals一、基本介绍Object类是java类层次最顶层的基类(父类),所有类都是直接或间接继承自Object类,因此&a…...
Java并发简介(什么是并发)
文章目录并发概念并发和并行同步和异步阻塞和非阻塞进程和线程竞态条件和临界区管程并发的特点提升资源利用率程序响应更快并发的问题安全性问题缓存导致的可见性问题线程切换带来的原子性问题编译优化带来的有序性问题保证并发安全的思路互斥同步(阻塞同步…...

团队API管理工具-YAPI
团队API管理工具-YAPI 推荐一款接口管理平台,操作简单、界面友好、功能丰富、支持markdown语法、可使用Postman导入、Swagger同步数据展示、LDAP、权限管理等功能。 YApi是高效、易用、功能强大的api管理平台,旨在为开发、产品、测试人员提供更优雅的接…...

学习记录 --- Pytorch优化器
文章目录参考文献什么是优化器optimizer的定义optimizer的属性defaultsstateparam_groupsoptimizer的方法zero_grad()step()add_param_group()state_dict()、load_state_dict()优化一个网络同时优化多个网络当成一个网络优化当成多个网络优化只优化网络的某些指定的层调整学习率…...

Flink State 状态后端分析
flink状态实现分析 state * State* |* -------------------InternalKvState* | |* MergingState |* | |* …...

YOLOv11检测头架构演进与工程实现剖析
1. YOLOv11检测头架构演进解析 目标检测领域近年来发展迅猛,YOLO系列作为其中的佼佼者,每次迭代都带来显著突破。YOLOv11的检测头设计堪称该系列迄今为止最精妙的架构创新,它彻底重构了传统检测头的任务处理方式。我曾在多个工业项目中尝试过…...
)
别只盯着ChatGPT了!SpringAI工具调用帮你低成本打造专属‘AI员工’(避坑指南)
别只盯着ChatGPT了!SpringAI工具调用帮你低成本打造专属‘AI员工’(避坑指南) 想象一下,你的电商团队每天要处理上百条"库存还有吗?"、"订单能改地址吗?"这样的重复咨询。客服人力成本…...

Verilog任务与函数实战:从APB总线测试到模块化设计避坑指南
Verilog任务与函数实战:从APB总线测试到模块化设计避坑指南 在FPGA和ASIC开发中,Verilog的任务(task)和函数(function)是提高代码复用性和可维护性的关键工具。本文将深入探讨这两者在实际工程中的应用差异…...

ClickHouse配置优化实战:关键参数详解与性能调优指南
1. ClickHouse配置优化的核心逻辑 ClickHouse作为一款高性能的OLAP数据库,其配置优化需要遵循三个黄金法则:资源隔离、瓶颈定位和场景适配。我见过太多团队一上来就盲目调整参数,结果反而导致性能下降。正确的做法应该是先理解系统行为&#…...
)
Asp.Net MVC杂谈之:—步步打造表单验证框架[重排版](1)
在实际使用中,我们可以考虑多种形式来进行这一验证(注:本文目前只研究服务器端验证的情况),最直接的方式莫过于对每个表单值手动用C#代码进行验证了,比如: if(!Int32.TryParse(Request.Form[“age”], out age)){ xxxx… } If(age < xxx || age > xxx){ xxxx… }…...

系统架构设计师-案例分析-数据库系统设计
系统架构设计师-案例分析-数据库系统设计ORM技术数据库类型比较缓存技术RedisMemCache分布式锁规范化反规范化技术并发控制封锁协议分布式数据库数据分片数据仓库ORM技术 ORM(Object-Relational Mapping),它在关系型数据库和对象之间作一个映…...

忍者像素绘卷惊艳效果:宇智波佐助千鸟刃×16-Bit闪电特效像素动效展示
忍者像素绘卷惊艳效果:宇智波佐助千鸟刃16-Bit闪电特效像素动效展示 1. 作品概览 忍者像素绘卷是基于Z-Image-Turbo深度优化的图像生成工作站,它将传统忍者文化与16-Bit复古游戏美学完美融合。这款工具特别适合创作具有强烈视觉冲击力的像素风格动漫角…...

打字侠全面支持三大五笔输入法:初学者快速上手指南
1. 五笔输入法:为什么值得初学者投入时间? 在拼音输入法大行其道的今天,很多初学者可能会疑惑:为什么要花时间学习看起来更复杂的五笔输入法?其实答案很简单——效率。我十年前刚开始接触五笔时也有同样的困惑…...

电源管理入门-4子系统reset
之前的文章电源管理入门-1关机重启详解介绍了整机SoC的重启也可以说是reset,那么子系统的reset,例如某个驱动(网卡、USB等)或者某个子系统(NPU、ISP等运行在独立的M核或者R核上的AI系统),这些零…...

Power BI 网页数据抓取实战:以新浪外汇为例,教你5分钟搞定动态表格导入与清洗
Power BI 网页数据抓取实战:新浪外汇动态表格导入与清洗全流程解析 外汇市场瞬息万变,作为业务分析师,每天手动记录汇率数据既耗时又容易出错。今天我们就以新浪财经外汇数据为例,手把手教你用Power BI实现5分钟自动化抓取清洗的完…...