[CVPR 2023:3D Gaussian Splatting:实时的神经场渲染]
文章目录
- 前言
- 小结
原文地址:https://blog.csdn.net/qq_45752541/article/details/132854115
前言
mesh 和点是最常见的3D场景表示,因为它们是显式的,非常适合于快速的基于GPU/CUDA的栅格化。相比之下,最近的神经辐射场(NeRF)方法建立在连续场景表示的基础上,通常使用体射线行进来优化多层感知器(MLP),以实现捕获场景的新视图合成。类似地,迄今为止最有效的辐射场解决方案建立在连续表示的基础上,通过插值存储的值,例如,体素或哈希[网格或点。虽然这些方法的连续性有助于优化,但渲染所需的随机抽样是昂贵的,并可能导致噪声。我们引入了一种新方法,结合了最好的两个世界:我们的三维高斯表示允许优化与最先进的(SOTA)视觉质量和竞争训练时间,而我们的拼接解决方案确保实时渲染SOTA质量1080p分辨率在几个之前发布的数据集(见下图1)。
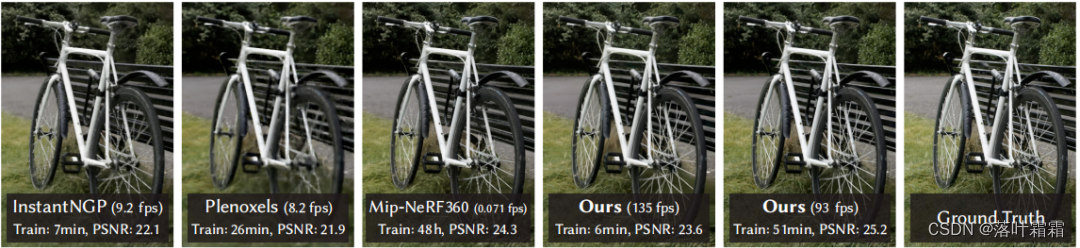
Mip-NeRF360 需要长达48小时的训练时间;快速但质量较低的辐射场方法可以根据场景实现交互式渲染时间(每秒10-15帧),但不能在高分辨率下实现实时渲染。
我们的解决方案有三个主要组件:
首先引入三维高斯分布作为场景表示。与 nerf 方法相同的输入开始,即使用运动结构(SfM)校准的相机,并使用SfM过程中免费产生的稀疏点云初始化三维高斯数集。与大多数需要多视图立体声(MVS)数据的基于点的解决方案相比,仅以SfM点作为输入就获得了高质量的结果。注意,对于nerf合成数据集,我们的方法即使在随机初始化下也能获得高质量。我们证明了三维高斯优点:是可微的体积表示,但它们也可以通过投影到二维,并使用标准𝛼混合,使用等效的图像形成模型作为NeRF。
第二个组成部分是优化三维高斯分布的性质-三维位置,不透明度𝛼,各向异性协方差,和球谐(SH)系数-与自适应密度控制步骤交错,我们在优化过程中添加和偶尔删除三维高斯分布。优化过程产生了一个合理的紧凑、非结构化和精确的场景表示(所有测试场景的100-500万高斯值)。
第三个元素是我们的实时渲染解决方案,它使用快速的GPU排序算法,并受到 tile-based 的栅格化的启发,遵循工作 [Pulsar: Efficient Sphere-Based Neural Rendering CVPR2021]。
首先简要概述了传统的重建,然后讨论了基于点的渲染和辐射场工作,讨论了它们的相似性;辐射场是一个广阔的领域,所以我们只关注直接相关的工作。
2.1 传统的场景重建与渲染
第一种新视图合成方法基于光场,首先密集采样,然后允许非结构化捕获。运动结构(SfM)的出现使一个全新的领域成为可能,其中一组照片可以用来合成新的观点。SfM在相机校准过程中估计了一个稀疏点云,最初用于三维空间的简单可视化。随后的多视图立体声(MVS)多年来产生了令人印象深刻的完整三维重建算法,使几种视图合成算法得以发展。所有这些方法都将输入的图像重新投影并混合到新的视图相机中,并使用几何图形来指导这种重新投影。这些方法在许多情况下产生了极好的结果,但当MVS产生不存在的几何形状时,通常不能从未重建的区域或“过度重建”中完全恢复。最近的神经渲染算法极大地减少了这种伪影,并避免了在GPU上存储所有输入图像的巨大成本,在大多数方面都优于这些方法。
2.2 神经渲染和辐射场
早期采用深度学习技术进行新视图合成[Flynn等人2016;Zhou等人2016];使用CNNs估计混合权重[Hedman等人2018],或使用纹理空间解决方案[里格勒和科尔顿2020;Thies等人2019]。使用基于mvs的几何图形是大多数这些方法的一个主要缺点;此外,使用cnn进行最终渲染经常会导致时间闪烁
新视图合成的体积表示由 Soft3D 发起;随后提出了深度学习技术与体积射线行进的结合基于连续可微密度场来表示几何。由于查询体积需要大量的样本,因此使用体积射线行进进行渲染需要大量的成本。神经辐射场(NeRFs)引入了重要采样和位置编码来提高质量,但使用了一个大的多层感知器,对速度产生负面影响。NeRF的成功导致了解决质量和速度的后续方法的爆炸,通常是通过引入正则化策略;目前用于新视图合成的最先进的图像质量是Mip-NeRF360。虽然渲染质量很优秀,但训练和渲染时间仍然非常高。
加速训练和/或渲染,三种设计选择:使用空间数据结构来存储(神经)特征,随后在体积射线行进过程中进行插值,不同的编码和MLP容量。这些方法包括空间离散化的不同变量、codebook 和编码,允许完全使用较小的MLP或前面的神经网络。典型的 InstantNGP 使用哈希网格和占用网格来加速计算,使用更小的MLP来表示密度和外观;Plenoxels 使用稀疏体素网格来插值连续密度场,并且能够完全放弃神经网络。两者都依赖于球面谐波:前者直接表示方向性效应,后者直接编码其输入到颜色网络。虽然两者都提供了出色的结果,但这些方法仍然难以有效地表示空空间,这部分取决于场景/捕获类型。此外,图像质量在很大程度上受到用于加速的结构化网格的选择的限制,由于需要为给定的光线行进步骤查询许多样本,阻碍了渲染速度。我们使用的非结构化、显式gpu友好的三维高斯算法在没有神经组件的情况下实现更快的渲染速度和更好的质量。
2.3 基于点的渲染和辐射场
基于点的方法(即点云)有效地渲染了断开的和非结构化的几何样本。点采样渲染栅格化具有固定大小的非结构化点集,它可以利用本地支持的点类型的图形api或并行软件栅格化。虽然对于底层数据,点样本呈现存在漏洞,导致混叠,并且是严格不连续的。在高质量的基于点的渲染方面的开创性工作通过“spliting”范围大于像素的点来解决这些问题,例如,圆或椭圆盘、椭球体或表面。
最近人们对可微点渲染技术感兴趣。点已被神经特征增强,并使用CNN渲染导致快速甚至实时视图合成;然而,它们仍然依赖于MVS的初始几何,因此继承其伪影,特别是在困难的情况下过度或欠重建,如无特征/闪亮的区域或薄结构。
基于点的𝛼混合和nerf风格的体积渲染本质上共享相同的图像形成模型。具体来说,颜色𝐶是通过沿着光线的体积渲染来给出的:
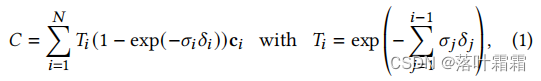
其中密度𝜎、透射率𝑇和颜色c的样品沿射线间隔𝛿𝑖。这可以被重写为
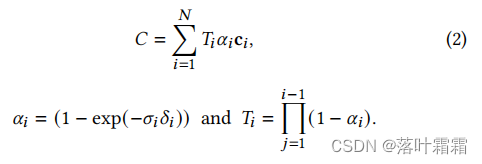
一种典型的基于神经点的方法,通过混合重叠于像素上的N个有序点来计算一个像素的颜色𝐶(其中c𝑖 是每个点的颜色,𝛼𝑖是通过计算协方差Σ的二维高斯分布,乘以学习的每点不透明度给出的):
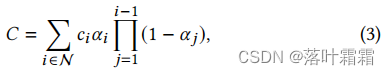
从等式2和3可以看到,splitting和nerf的图像形成模型是相同的。然而,渲染算法是非常不同的。nerf是一种隐式表示空/占用空间的连续表示;需要昂贵的随机抽样来找到等式中的样本2,从而产生噪声和计算消耗。相比之下,点是一种非结构化的、离散的表示方式,它足够灵活,可以允许几何的创造、破坏和位移(类似于nerf)。这是通过优化不透明度和位置来实现的,如之前的工作所示[ Point-Based Neural Rendering with Per-View Optimization],避免了一个完整的体积表示的缺点。
Pulsar 实现了快速的球体栅格化,这启发了我们 基于tile 和排序的渲染。然而,考虑到上面的分析,我们希望在已排序的 splats(翻译为飞溅) 上保持(近似的)传统的𝛼混合,以具有体积表示的优势:我们的栅格化尊重可见性顺序,而不是它们的顺序无关的方法。此外,我们在一个像素的所有splats 上反传梯度,并栅格化各向异性splats 。这些元素都有助于我们的研究结果的高视觉质量。上述方法也使用cnn进行渲染,这导致了时间不稳定性。尽管如此,Pulsar 的渲染速度成为了我们开发快速渲染解决方案的动力。
Gaussian Splatting 使用三维高斯算法来进行更灵活的场景表示,避免了MVS几何的需要,并实现了实时渲染,归功于我们的 tile-based 渲染的投影高斯算法。
最近的一种方法[Xu et al. 2022]基于径向基函数方法,使用点来表示辐射场。他们在优化过程中使用点修剪和致密化技术,但使用体积射线行进,不能实现实时显示率。
3D高斯分布可以被用来表示被捕捉的人体;最近也被用于表示体射线。它们关注的是重建和渲染单个孤立物体(人体或人脸)的具体情况,从而导致深度复杂性较小的场景。相比之下,我们对各向异性协方差的优化,我们的交叉优化/密度控制,以及高效的渲染深度排序,使我们能够处理完整的、复杂的场景,包括背景,包括室内和室外,并具有较大的深度复杂性。
2.4 什么是 Tile-based rasterizer (快速光栅化)
tile-based rasterizer:将三维场景中的mesh面片,分割成小的片段,并将这些片段映射到屏幕上的 tile瓦片(区域而非像素),然后进行光栅化、深度测试和像素着色等操作,最终将三维场景转化为二维图像。这个过程是图形引擎或渲染器中的核心步骤,步骤为:
1)分割三角形:首先,三维场景中的三角形会被分割成小的三角形片段。这个过程通常是由图形引擎或渲染器完成的。分割的目的是为了更好地适应不同的瓦片大小或屏幕分辨率。
2)映射到瓦片:每个小的三角形片段会被映射到屏幕上的相应瓦片中。瓦片是屏幕上的一个小区域,可以是一个像素或者多个像素的集合。这个映射过程会计算片段在屏幕上的位置、深度值等信息。
3)光栅化:映射到瓦片后,tile-based rasterizer会将每个小的三角形片段转化为屏幕上的像素。这个过程被称为光栅化。在光栅化过程中,对于每个片段,会计算其在屏幕上的位置、深度值等信息。
4)深度测试:在光栅化过程中,进行深度测试是非常重要的。深度测试用于确定哪些像素应该被绘制。通过比较片段的深度值与屏幕上对应像素的深度值,可以确定是否绘制该像素。这样可以确保在绘制过程中正确处理遮挡关系,以产生正确的渲染结果。
5)像素着色:光栅化的最后一步是像素着色。在像素着色过程中,根据片段的属性(如颜色、纹理等),为每个像素计算最终的颜色值。这样,三维场景就被转化为了屏幕上的二维图像。
Tile-based rasterizer 能够实现加速,是因为它通过减少内存带宽和光栅化的工作量来提高渲染性能。具体原因:
1)局部性:Tile-based rasterizer利用了渲染过程中的空间局部性。通过将整个屏幕划分为小的瓦片,每次只处理一个瓦片的数据,可以将渲染操作限制在较小的数据集上。这样可以减少内存访问和带宽消耗,提高渲染效率。
2)带宽优化:传统的片段渲染器在每个像素上都会执行光栅化、深度测试和像素着色等操作。而在tile-based rasterizer中,只有在需要绘制的瓦片上才会执行这些操作。这样可以减少对内存带宽的需求,从而提高渲染性能。
3)提前深度测试:在tile-based rasterizer中,深度测试是在光栅化之前进行的。通过在光栅化之前进行深度测试,可以减少不必要的片段处理和像素着色操作,从而节省了处理时间和资源。
4)数据重用:tile-based rasterizer会将每个瓦片的像素数据存储在高速缓存中,并在多个片段之间共享。这样可以避免对相同像素的重复计算,提高渲染效率。
03 OVERVIEW
Gaussian Splatting的输入是一组静态场景的图像,以及由SfM校准的相应摄像机,它产生一个稀疏点云作为衍生物。从稀疏点上,我们创建了一组三维高斯分布,由位置(均值)、协方差矩阵和不透明度𝛼定义,允许一个非常灵活的优化机制。这导致了对三维场景的一个合理紧凑的表示。高度各向异性的体素 splat 可以用来紧凑地表示精细结构。辐射场的方向外观分量(颜色)通过球谐波(SH)表示。该算法通过一系列三维高斯参数的优化,即位置、协方差、𝛼和SH系数与高斯密度的自适应控制操作交织,来创建辐射场表示。效率的关键是 tile-based 的栅格化器允许𝛼混合各向异性斑点,由于快速排序,尊重可见性顺序。输出快速光栅化器还包括一个快速反向传递,通过累积的𝛼值跟踪,没有限制可以接收梯度的高斯数的数量。整体概述如图2所示.

04 可微的三维高斯 Splatting
质量的新视图合成,从一个稀疏的(SfM)点集开始。为了做到这一点,我们需要一个能够继承可微体积表示属性的原型,同时是非结构化和显式的,以允许非常快速的呈现。我们选择了三维高斯分布,这是可微的,可以很容易地投影到二维 Splatting,允许快速的𝛼混合渲染。
我们的表示类似于之前二维点的表示方法[Kopanas等人2021:假设每个点都是一个带有法线的小平面圆]。由于SfM点的极强稀疏性,很难估计法线。从这样的估计中优化带噪声法线将很难。相反,我们将几何模型建模为一组不需要法线的三维高斯函数。我们的高斯分布是由世界空间中定义的全三维协方差矩阵Σ定义的,其中心为点(均值)𝜇:
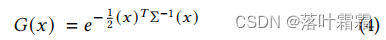
这个高斯分布在混合过程中乘以𝛼。
然而,我们需要将我们的三维高斯投影到二维进行渲染。对图像空间进行投影:给定一个变换矩阵𝑊,摄像机坐标下的协方差矩阵Σ’ 计算如下:

其中𝐽是投影变换的仿射变换的 Jacobian 矩阵。Zwicker等人[2001a]表明,如果我们跳过Σ’ 的第三行和列,我们得到一个具有相同结构和性质的2×2方差矩阵。
一个明显的方法是直接优化协方差矩阵Σ,以获得代表辐射方差场的三维高斯分布。然而,协方差矩阵只有在它们是正的半定的时才具有物理意义。为了优化我们所有的参数,我们使用梯度下降,不能轻易地约束产生这样的有效的矩阵,并且更新步骤和梯度可以很容易地创建无效的协方差矩阵。因此,我们选择了一种更直观、更能表达的表示来进行优化。三维高斯分布的协方差矩阵Σ类似于描述椭球体的构型。给定一个缩放矩阵𝑆和旋转矩阵𝑅,我们可以找到相应的Σ:

为了允许对这两个因素进行独立的优化,我们分别存储它们:一个用于缩放的三维向量𝑠和一个表示旋转的四元数𝑞,来进行组合,以确保规范化𝑞得到一个有效的单位四元数。

三维高斯自适应密度控制的优化
Gaussian Splatting的核心是优化步骤。它创建了一个密集的三维高斯函数集合,精确地表示自由视图合成的场景。优化参数有:位置𝑝、𝛼和协方差Σ外,我们还优化了代表每个高斯分布的颜色𝑐的SH系数,以正确地捕捉场景中与视图相关的外观。
5.1 优化
优化基于连续的渲染迭代:将生成的图像与训练视图进行比较。
由于三维到二维投影的歧义,几何图形可能会被错误地放置。因此,我们的优化需要能够创建几何,也破坏或移动几何(如果定位错误)。
使用随机梯度下降进行优化,利用gpu加速框架。快速栅格对我们的优化效率至关重要,因为它是优化的主要计算瓶颈
使用sigmoid 函数 将 𝛼 约束在[0−1)范围内,得到平滑的梯度。由于类似的原因,对协方差尺度的使用指数激活函数。
协方差矩阵初始化为一个各向同性高斯矩阵,其轴等于到最近的三个点的距离的平均值。我们使用一种类似于 Plenoxels 的标准指数衰减调度技术,但只针对位置。损失函数是L1和D-SSIM项相结合(λ=0.2):

5.2 高斯的自适应控制
从SfM估计的初始稀疏点开始,然后自适应控制高斯分布的数量及其密度(单位体积),允许我们从初始稀疏的高斯集密集,更好地代表场景。warm-up之后,每100次迭代一次,删除透明的高斯分布(α小于阈值 εα) 。
我们对高斯分布的自适应控制需要填充空白区域。它关注缺失几何特征的区域(“欠重建”),但也关注高斯分布覆盖场景中大面积区域的区域(通常对应于“过度重建”)。我们观察到两者都有很大的视空间位置梯度。直观地说,这可能是因为它们对应的是尚未很好地重建的区域,而优化试图移动高斯分布来纠正这一点。
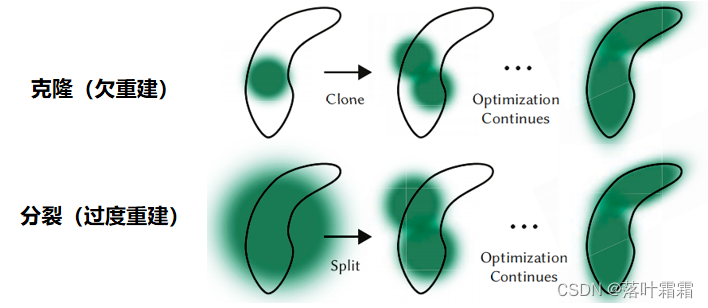
克隆与分裂:
由于这两种情况都是致密化的好候选者,我们用高于阈值┏pos 的视图空间位置梯度的平均大小来描述高斯(测试选择0.0002),过程如图4所示。对于重建不足的区域中的小高斯,通过简单地创建一个相同大小的副本,并将其沿位置梯度的方向移动来克隆高斯。另一方面,高变异区域中的大高斯需要分裂成更小的高斯,用两个新的高斯代替了这些高斯,并用我们实验确定的o=1.6因子除以它们的尺度。
在第一种情况下,我们检测并处理需要同时增加系统的总体积和高斯的数量,而在第二种情况下,我们保留总体积,但增加高斯的数量。与其他体积表示类似,我们的优化可能会被靠近输入摄像机的漂浮物卡住;在我们的例子中,这可能会导致高斯密度的不合理的增加。调节高斯数增加的一种有效方法是:每N= 3000次迭代,将α 设置为接近于零。
优化增加了高斯分布的α,同时允许我们的剔除方法去除 α小于阈值 εα的高斯分布。高斯分布可能会缩小或增长,并与其他分布有相当大的重叠,但我们会周期性地去除在非常大的高斯分布和那些在视图空间中有很大足迹的高斯分布。这种策略可以很好地控制高斯分布的总数。我们模型中的高斯函数在欧几里得空间中始终保持原型;与其他方法不同,我们对遥远或大的高斯分布不需要空间压缩、扭曲或投影策略。
06 高斯分布的快速可微光栅化器(拓展)
我们的目标是拥有快速的整体渲染和快速的排序,以允许近似的 α 混合——包括各向异性的Splatting——并避免对以前工作中存在的可以接收梯度的Splatting 数量的严格限制。
为了实现这些目标,我们为整个图像设计一个 tile-based 光栅器的高斯 Splatting,避免每像素的排序费用阻碍之前 α-mobice解决方案。我们的快速光栅化器允许在任意数量的混合高斯分布上有效地反向传播,而额外的内存消耗较低,每个像素只需要一个恒定的开销。我们的栅格化管道是完全可微的,来投影到2D。
我们的方法首先将屏幕分割成16×16个 tile,然后对视图框和每个tile 选择3D高斯分布。具体来说,我们只保留与视锥相交的置信区间为99%的高斯。此外,我们使用 a guard band来去除极端位置的高斯(即,那些均值接近 near plane 且远离视锥体的高斯),因为其投影的2D协方差是不稳定的。然后,我们根据它们重叠的 tile 数量实例化每个高斯值,并为每个实例分配一个结合视图空间深度和tile ID的键。然后,我们根据这些键快速排序(基于快速 GPU Radix )。而没有额外像素点排序,混合是基于这个初始排序执行的。
因此,我们的 α-混合在某些构型中可以是近似的。然而,当spliting 接近单个像素的大小时,这些近似可以忽略不计。我们发现,这种选择大大提高了训练和渲染性能,而不会在融合场景中产生可见的伪影。
在对高斯排序之后,我们通过识别 splitting 到 tile 的第一个和最后一个深度排序的条目,为每个tile 生成一个列表。对于栅格化,我们为每个 tile 启动一个线程块。每个块首先协作地将高斯数据包加载到共享内存中,然后,对于给定的像素,通过从前到后遍历列表来累积颜色和α 值,从而最大限度地提高数据加载/共享和处理的并行性增益。
栅格化过程中,α 的饱和度是唯一的停止标准。与其他工作相比,我们不限制接收梯度更新的混合原型的数量,以允许我们的方法处理具有任意、不同深度复杂度的场景,并准确地学习它们,而不必诉诸于特定于场景的超参数调优。因此,反向传播必须恢复前向过程中每像素混合点的完整序列。一种解决方案是在全局内存中存储任意长的每像素混合点列表。为了避免隐含的动态内存管理开销,我们选择再次遍历永久列表;我们可以重用从向前传递的高斯和 tile 范围的排序数组。
遍历从影响 tile 中任何像素的最后一个点开始,并再次协作地将点加载到共享内存中。此外,只有当每个像素的深度低于或等于在前向过程中导致其颜色的最后一个点的深度时,每个像素才会开始重叠测试和处理点(代价比较昂贵)。第4节中梯度的计算,要求在原始混合过程中每一步累积的不透明度值。我们可以通过只存储向前传递结束时的总累积不透明来恢复这些中间不透明,而不是横向传递反向传递中逐步缩小的不透明的显式列表。具体来说,每个点在正向过程中存储最终累积的不透明度 α;我们在前后遍历中除以每个点的 α,得到梯度计算所需的系数。
效果:
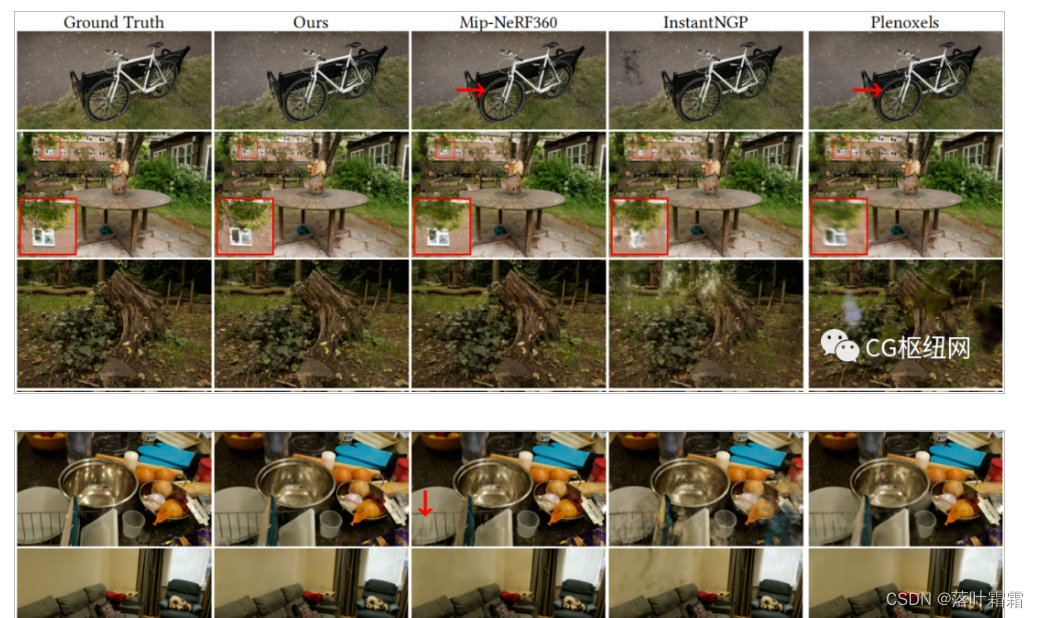

小结
辐射场方法改变了多张照片或视频主导的场景新视角合成。Gaussian Splatting引入了三个关键元素,在保持有竞争力的训练时间的同时实现最先进的视觉质量,重要的是允许在1080p分辨率下实现高质量的实时(≥30 fps)的新视图合成。
首先,从摄像机校准过程中产生的稀疏点开始,我们用三维高斯来表示场景,保持连续体积辐射场的理想特性,同时避免空白空间不必要的计算;
其次,对三维高斯进行交叉优化/密度控制,特别是优化各向异性协方差以实现场景的精确表示;
我们开发了一种快速的可见性感知渲染算法,支持各向异性 splatting,既加速训练,又允许实时渲染。
相关文章:
[CVPR 2023:3D Gaussian Splatting:实时的神经场渲染]
文章目录 前言小结 原文地址:https://blog.csdn.net/qq_45752541/article/details/132854115 前言 mesh 和点是最常见的3D场景表示,因为它们是显式的,非常适合于快速的基于GPU/CUDA的栅格化。相比之下,最近的神经辐射场…...
【SpringBoot快速入门】(4)SpringBoot项目案例代码示例
目录 1 创建工程3 配置文件4 静态资源 之前我们已经学习的Spring、SpringMVC、Mabatis、Maven,详细讲解了Spring、SpringMVC、Mabatis整合SSM的方案和案例,上一节我们学习了SpringBoot的开发步骤、工程构建方法以及工程的快速启动,从这一节开…...
Linux服务器 部署飞书信息发送服务
项目介绍: 飞书信息发送服务是指将飞书信息发送服务部署到一个Linux服务器上。飞书是一款企业级的即时通讯和协作工具,支持发送消息给飞书的功能。通过部署飞书信息发送服务,可以方便内网发送信息给外网飞书。 项目代码结构展示: …...
用C#也能做机器学习?
前言✨ 说到机器学习,大家可能都不陌生,但是用C#来做机器学习,可能很多人还第一次听说。其实在C#中基于ML.NET也是可以做机器学习的,这种方式比较适合.NET程序员在项目中集成机器学习模型,不太适合专门学习机器学习&a…...

Python PDF格式转PPT格式
要将PDF文件转换为PPT,我实在python3.9 环境下转成功的,python3.11不行。 需要 pip install PyMuPDF代码说话 # -*- coding: utf-8 -*-""" author: 赫凯 software: PyCharm file: xxx.py time: 2023/12/21 11:20 """im…...
搭建知识付费平台?明理信息科技为你提供全程解决方案
明理信息科技saas知识付费平台 在当今数字化时代,知识付费已经成为一种趋势,越来越多的人愿意为有价值的知识付费。然而,公共知识付费平台虽然内容丰富,但难以满足个人或企业个性化的需求和品牌打造。同时,开发和维护…...

漫谈UNIX、Linux、UNIX-Like
漫谈UNIX、Linux、UNIX-Like 使用了这么多年Redhat、Ubuntu等Linux、Windows、Solaris操作系统,你是否对UNIX、Unix-Like(类UNIX)还是不太清楚?我以前一直认为Unix-Like就等于Linux。其实,由UNIX派生出来而没有取得UN…...

Netty Review - Netty与Protostuff:打造高效的网络通信
文章目录 概念PrePomServer & ClientProtostuffUtil 解读测试小结 概念 Pre 每日一博 - Protobuf vs. Protostuff:性能、易用性和适用场景分析 Pom <dependency><groupId>com.dyuproject.protostuff</groupId><artifactId>protostuff-…...
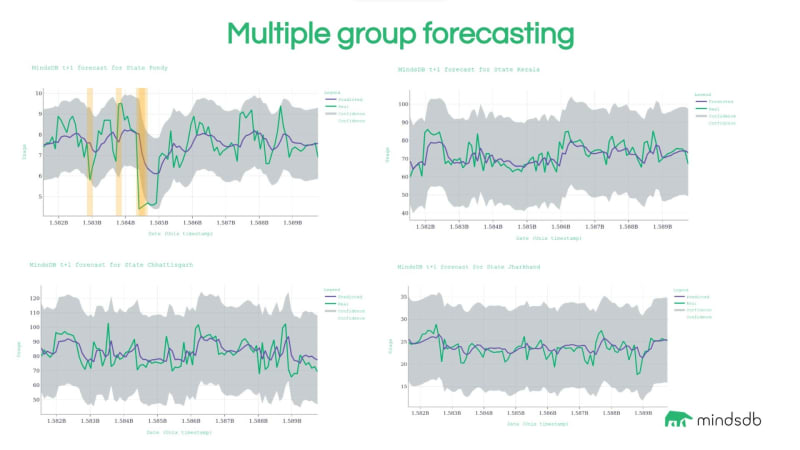
在ClickHouse数据库中启用预测功能
在这篇博文中,我们将介绍如何将机器学习支持的预测功能与 ClickHouse 数据库集成。ClickHouse 是一个快速、开源、面向列的 SQL 数据库,对于数据分析和实时分析非常有用。该项目由 ClickHouse, Inc. 维护和支持。我们将探索它在需要数据准备以…...
)
目标检测YOLO实战应用案例100讲-树上果实识别与跟踪计数(续)
目录 3.2 损失函数优化 3.3 实验过程 3.3.1 果实图像采集 3.3.2 数据扩增...
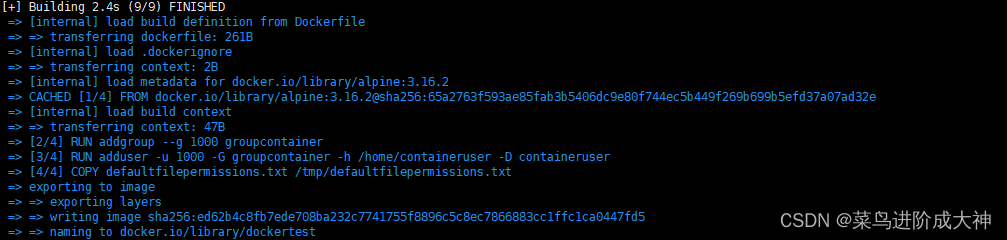
Docker 文件和卷 权限拒绝
一 创作背景 再复制Docker影像文件或访问Docker容器内已安装卷上的文件时我们常常会遇到:“权限被拒绝”的错误,在此,您将了解到为什么会出现“权限被拒绝”的错误以及如何解决这个问题。 二 目的 在深入探讨 Docker 容器中的 Permission De…...
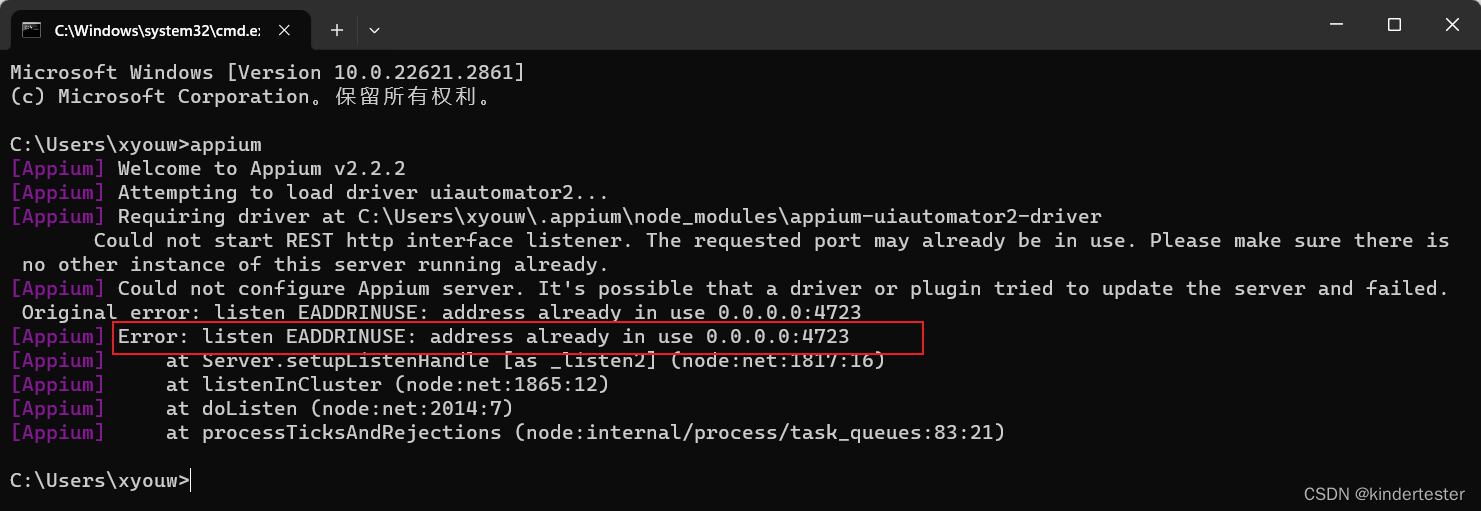
Appium Server 启动失败常见原因及解决办法
Error: listen EADDRINUSE: address already in use 0.0.0.0:4723 如下图: 错误原因:Appium 默认的4723端口被占用 解决办法: 出现该提示,有可能是 Appium Server 已启动,关闭已经启动的 Appium Server 即可。472…...
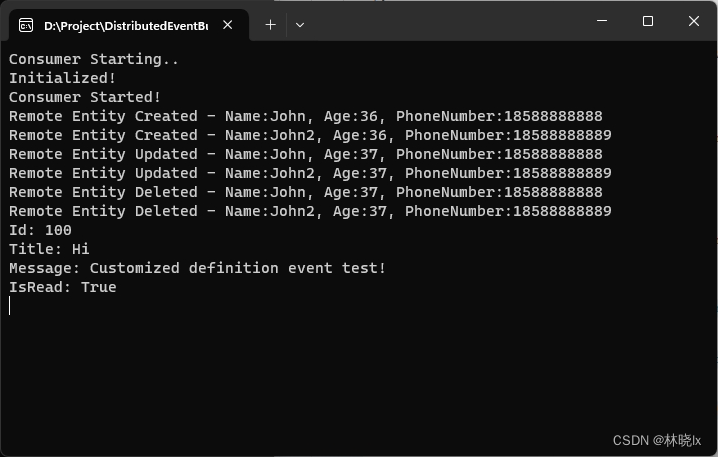
将Abp默认事件总线改造为分布式事件总线
文章目录 原理创建分布式事件总线实现自动订阅和事件转发 使用启动Redis服务配置传递Abp默认事件传递自定义事件 项目地址 原理 本地事件总线是通过Ioc容器来实现的。 IEventBus接口定义了事件总线的基本功能,如注册事件、取消注册事件、触发事件等。 Abp.Events…...
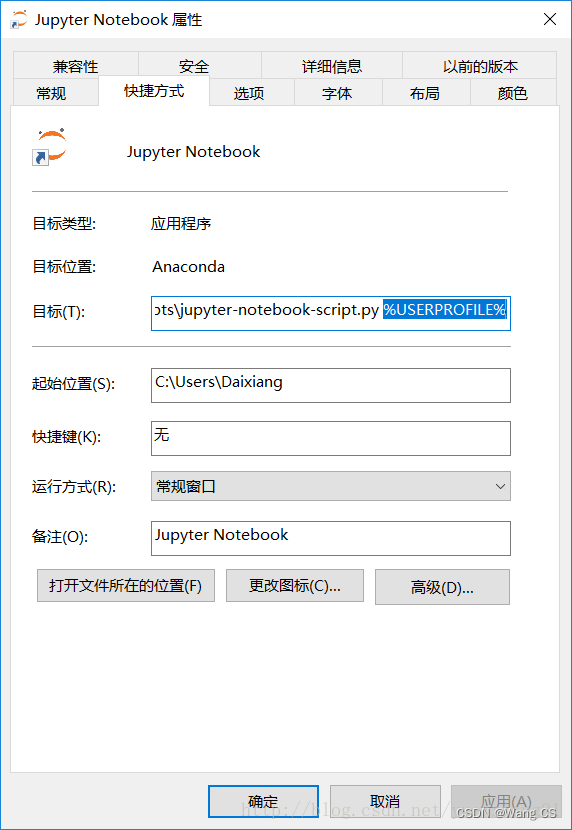
Jupyter Notebook修改默认工作目录
1、参考修改Jupyter Notebook的默认工作目录_jupyter文件路径-CSDN博客修改配置文件 2.在上述博客内容的基础上,这里不是删除【%USERPROFILE%】而是把这个地方替换为所要设置的工作目录路径, 3.【起始位置】也可以更改为所要设置的工作目录路径&#x…...
高校/企业如何去做数据挖掘呢?
随着近年来人工智能及大数据、云计算进入爆发时期,依托三者进行的数据分析、数据挖掘服务已逐渐成为各行业进行产业升级的载体,缓慢渗透进我们的工作和生活,成为新时代升级版的智能“大案牍术”。 那么对于多数企业来说,如何做数据…...

数据仓库-数据治理小厂实践
一、简介 数据治理贯穿数仓中数据的整个生命周期,从数据的产生、加载、清洗、计算,再到数据展示、应用,每个阶段都需要对数据进行治理,像有些比较大的企业都是有自己的数据治理平台或者会开发一些便捷的平台,对于没有平…...
之 线程生命周期管理join() 与 detach())
【C++多线程编程】(五)之 线程生命周期管理join() 与 detach()
在C中,std::thread 类用于创建和管理线程。std::thread 提供了两种主要的方法来控制线程的生命周期:join 和 detach。 detach方式,启动的线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束。join方式&…...

金融信贷场景的风险“要素”与主要“风险点”
目录 要素一:贷款对象 风险点1:为不具备主体资格或主体资格有瑕疵的借款人发放贷款 风险表现: 防控措施: 风险点2:向国家限控行业发放贷款 风险表现: 防控措施: 风险点3:受理不符合准入条件的客户申请 风险表现: 防控措施: 要素二:金额 风险点4:过渡授…...
ubuntu下docker安装,配置python运行环境
参考自: 1.最详细ubuntu安装docker教程 2.使用docker搭建python环境 首先假设已经安装了docker,卸载原来的docker 在命令行中运行: sudo apt-get updatesudo apt-get remove docker docker-engine docker.io containerd runc 安装docker依赖 apt-get…...

在Docker中安装kafka遇到问题记录
命令含义解答: 在docker安装kafka的时候,启动kafka的时候会执行下面语句: docker run -d --log-driver json-file --log-opt max-size100m --log-opt max-file2 --name kafka -p 9092:9092 -e KAFKA_BROKER_ID0 -e KAFKA_ZOOKEEPER_CONNEC…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...