变分自动编码器【03/3】:使用 Docker 和 Bash 脚本进行超参数调整

一、说明
在深入研究第 1 部分中的介绍和实现,并在第 2 部分中探索训练过程之后,我们现在将重点转向在第 3 部分中通过超参数调整来优化模型的性能。要访问本系列的完整代码,请访问我们的 GitHub 存储库在GitHub - asokraju/ImageAutoEncoder: A repository to learn features from Off Road Navigation Vehicles
在任何机器学习模型中,超参数都是我们调整以获得最佳模型性能的旋钮和杠杆。然而,找到正确的设置有点像大海捞针——非常耗时,有时甚至令人困惑!但不用担心,我们将以简单直接的方式引导您完成整个过程。
在本部分中,我们将利用 Docker 和 Bash 脚本对变分自动编码器执行超参数调整。Docker 是一个用于部署应用程序的流行平台,它将帮助我们为实验创建一个隔离的环境,确保我们的结果是可重现的。同时,Bash 脚本将自动执行使用不同超参数运行模型的繁琐任务,从而使该过程更加高效。
那么,您准备好调整您对变分自动编码器的理解并释放模型的全部潜力了吗?让我们一起深入研究“变分自动编码器:使用 Docker 和 Bash 脚本进行超参数调整”!
如果您需要复习或想要重温任何概念,请不要忘记重温第 1 部分和第 2 部分。快乐学习!
二、超参数实验
任何机器学习模型的开发通常都涉及微调一系列超参数。然而,手动测试每种可能的组合将是一项艰巨的任务。这就是master.sh派上worker.sh用场的地方。这两个 bash 脚本自动化了尝试不同超参数并记录结果的过程,为我们节省了大量的时间和精力。
master.sh是我们的控制室,编排我们希望测试的各种超参数组合。它系统地循环遍历我们预定义的一组超参数(在本例中为学习率、潜在维度和批量大小),并且对于每个独特的组合,它调用脚本worker.sh。
剧本worker.sh就是地面上的工人。每次调用它时,它都会从 接收超参数的独特组合master.sh,为该实验设置专用日志目录,然后train.py使用这些特定的超参数运行我们的模型(在本例中)。日志目录根据使用的超参数进行唯一命名,以便我们以后可以轻松识别每个实验的结果。
有了这两个脚本,我们就可以放松下来,让我们的机器完成繁重的工作,使用不同的超参数运行实验并记录结果,以便我们在闲暇时进行分析。
# Contents of master.sh #!/bin/bash -l
for learning_rates in 0.001
dofor latent_dims in 6 8dofor batch_sizes in 128do./scripts/call_experiments.sh $learning_rates $latent_dims $batch_sizesdonedone
done现在让我们仔细看看这些脚本的详细信息。
主脚本:
该master.sh脚本的主要功能是循环遍历我们想要测试模型训练的不同超参数,然后调用脚本worker.sh使用提供的超参数执行每个实验。
我们来分解一下步骤:
#!/bin/bash -l:这一行通常称为 shebang,告诉系统该文件是一个 bash 脚本,应该这样执行。for learning_rates in 0.001:这将开始一个循环,迭代不同的学习率。在本例中,它仅包含一个值 0.001。您可以添加更多由空格分隔的值,例如for learning_rates in 0.001 0.01 0.1。for latent_dims in 6 8和for batch_sizes in 128:这些是其他超参数的附加循环 - 潜在维度和批量大小。./scripts/call_experiments.sh $learning_rates $latent_dims $batch_sizescall_experiments.sh:这是使用当前选择的超参数调用脚本的关键步骤。这些值作为参数传递给worker.sh脚本。done:其中每一个都关闭一个 for 循环。由于存在三个for循环,因此必须有三个done命令。
本质上,该脚本将对指定学习率、潜在维度和批量大小的笛卡尔积执行超参数搜索,并worker.sh为每个组合运行脚本。
工人脚本
该worker.sh脚本旨在接受一组超参数作为输入,为实验设置唯一的日志目录,然后使用这些超参数运行 Python 训练脚本。
# contents of worker.sh#!/bin/bashlearning_rate=$1
latent_dim=$2
batch_size=$3PARENT_DIR="$(dirname $PWD)"
EXEC_DIR=$PWD
log_dir="logs/lr=${learning_rate}_latentdim=${latent_dim}_batchsize=${batch_size}"
mkdir -p $log_dir
echo "Current working directory is: $(pwd)"
python train.py --image-dir='../train_data' --learning-rate=${learning_rate} --latent-dim=${latent_dim} --batch-size=${batch_size} --logs-dir=${log_dir}下面对其步骤进行详细说明:
#!/bin/bash:就像在master.sh脚本中一样,这个 shebang 将文件声明为 bash 脚本。learning_rate=$1、latent_dim=$2、batch_size=$3:这些行捕获 提供的输入参数master.sh并将它们分配给相应的变量。PARENT_DIR="$(dirname $PWD)",EXEC_DIR=$PWD: 在这里,我们将父目录路径和当前目录路径保存到变量中以供将来使用。log_dir="logs/lr=${learning_rate}_latentdim=${latent_dim}_batchsize=${batch_size}",mkdir -p $log_dir:这一对行创建一个唯一的目录来存储当前超参数集的日志。-p命令中的标志确保mkdir它创建整个目录路径(如果不存在)。echo "Current working directory is: $(pwd)":此行只是将当前工作目录打印到终端以进行调试。- 最后一行使用所选的超参数运行 Python 训练脚本,并指定本次运行的日志目录:
python train.py --image-dir='../train_data' --learning-rate=${learning_rate} --latent-dim=${latent_dim} --batch-size=${batch_size} --logs-dir=${log_dir}
总之,该worker.sh脚本使用一组给定的超参数执行单个实验,将实验的输出记录在专用目录中,然后终止。
三、Docker 设置
Dockerfile 和 docker-compose 文件在 Docker 上下文中使用,Docker 是一个允许您将应用程序及其依赖项打包到隔离容器中的平台。
Dockerfile 是一个文本文件,其中包含一组用于构建 Docker 映像的指令。它定义基础映像,设置工作目录,将文件复制到映像中,安装依赖项,并指定启动容器时要运行的命令。
另一方面,docker-compose 文件用于定义和管理多个容器作为单个应用程序的一部分。它允许您定义服务、它们的配置以及它们如何相互交互。
# Contents of Dockerfile
# Use an official Tensorflow runtime as a parent image
FROM tensorflow/tensorflow:latest# Set the working directory to /app
WORKDIR /autoencodersCOPY . .# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
RUN pip install pyyamlRUN chmod +x scripts/master.sh
RUN chmod +x scripts/worker.sh# Run app.py when the container launches
CMD ["python", "train.py"]现在,让我们详细了解 Dockerfile 中的每个步骤:
FROM tensorflow/tensorflow:latest:此行指定要使用的基础映像,这是官方 TensorFlow 运行时映像的最新版本。WORKDIR /autoencoders:将容器内的工作目录设置为/autoencoders. 这是后续命令将被执行的地方。COPY . .:将当前目录(Dockerfile所在目录)中的所有文件复制到/autoencoders容器内的目录中。RUN pip install --no-cache-dir -r requirements.txt:安装文件中指定的Python包requirements.txt。该--no-cache-dir标志用于避免在容器上缓存包索引。RUN pip install pyyaml:pyyaml使用 pip 安装软件包。某些 YAML 相关功能可能需要此包。RUN chmod +x scripts/master.sh和RUN chmod +x scripts/worker.sh:更改 shell 脚本的权限master.sh并使worker.sh它们可执行。CMD ["python", "train.py"]:指定容器启动时运行的默认命令。train.py在本例中,它使用 Python 解释器运行Python 脚本。
# contents of requirements.txt
pandas==1.3.3
numpy==1.21.2
matplotlib==3.4.3
argparse==1.4.0
protobuf==3.20.*
tensorflow==2.7.0
pyyaml现在,让我们继续讨论 docker-compose 文件:
version: '3':指定正在使用的 docker-compose 文件格式的版本。services:定义组成应用程序的服务(容器)。autoencoders:服务的名称。build:指定如何构建该服务的镜像。context: .:将构建上下文设置为当前目录(docker-compose 文件所在的位置)。dockerfile: Dockerfile:指定用于构建映像的 Dockerfile。ports: - "8080:80":将主机上的8080端口映射到容器上的80端口。这允许通过访问容器内运行的服务localhost:8080。volumes: - ./:/autoencoders:将主机上的当前目录挂载到/autoencoders容器内的目录,确保主机上文件的更改反映在容器内。- type: bind source: F:/train_data target: /train_data:将F:/train_data主机上的目录与/train_data容器内的目录绑定,允许从容器内访问训练数据。command: ./scripts/master.sh:指定启动容器时运行的命令。在这种情况下,它运行master.sh位于scripts目录中的脚本。
# Contents of docker-compose.yml
version: '3'
services:autoencoders:build:context: .dockerfile: Dockerfileports:- "8080:80"volumes:- ./:/autoencoders- type: bindsource: F:/train_datatarget: /train_datacommand: ./scripts/master.sh 在您的docker-compose.yml文件中,您指定了两个卷。第一个卷将docker-compose.yml主机上的当前目录(文件所在的位置)映射到/autoencodersDocker 容器中的目录。
第二个卷是绑定挂载,它将主机中的目录或文件绑定到 Docker 容器中的目录或文件。在本例中,您将F:/train_data主机上的目录绑定到/train_dataDocker 容器中的目录。
此行很重要,因为您的训练脚本(在 Docker 容器内运行)期望在 处找到您的训练数据/train_data。但由于 Docker 容器与主机隔离,因此您需要一种方法来向脚本提供训练数据。绑定挂载通过使F:/train_data主机上的目录/train_data在 Docker 容器中可用来实现这一点。
但是,并非每个使用您的脚本的人都会在 处获得训练数据F:/train_data。这就是为什么您需要指示他们根据训练数据所在的位置更改此行。他们可以替换F:/train_data为训练数据的路径。例如,如果他们的训练数据位于C:/Users/user123/data,他们需要将此行更改为:
# Contents of docker-compose.yml
version: '3'
services:autoencoders:build:context: .dockerfile: Dockerfileports:- "8080:80"volumes:- ./:/autoencoders- type: bindsource: C:/Users/user123/datatarget: /train_datacommand: ./scripts/master.sh这些步骤共同定义了用于构建映像并运行关联容器的 Dockerfile 和 docker-compose 文件,从而能够在容器化环境中训练自动编码器。
相关文章:
变分自动编码器【03/3】:使用 Docker 和 Bash 脚本进行超参数调整
一、说明 在深入研究第 1 部分中的介绍和实现,并在第 2 部分中探索训练过程之后,我们现在将重点转向在第 3 部分中通过超参数调整来优化模型的性能。要访问本系列的完整代码,请访问我们的 GitHub 存储库在GitHub - asokraju/ImageAutoEncoder…...
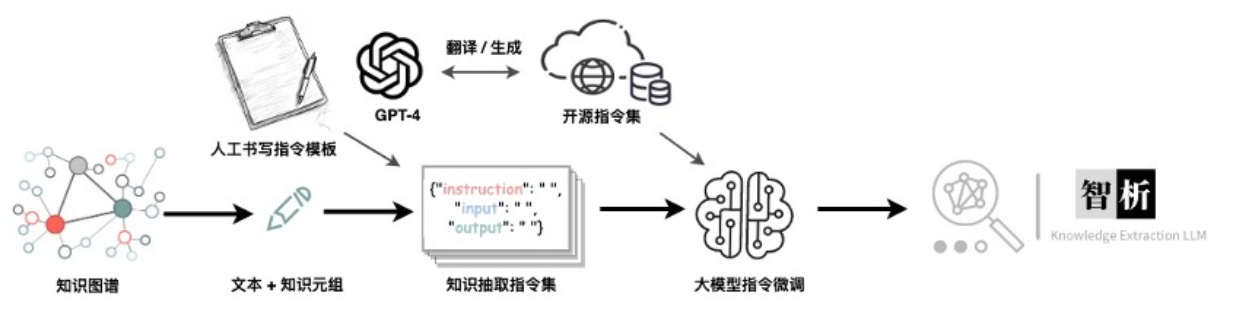
KnowLM知识抽取大模型
文章目录 KnowLM项目介绍KnowLM项目的动机ChatGPT存在的问题 基于LLama的知识抽取的智析大模型数据集构建及训练过程预训练数据集构建预训练训练过程指令微调数据集构建 指令微调训练过程开源的数据集及模型局限性信息抽取Prompt 部署环境配置模型下载预训练模型使用LoRA模型使…...
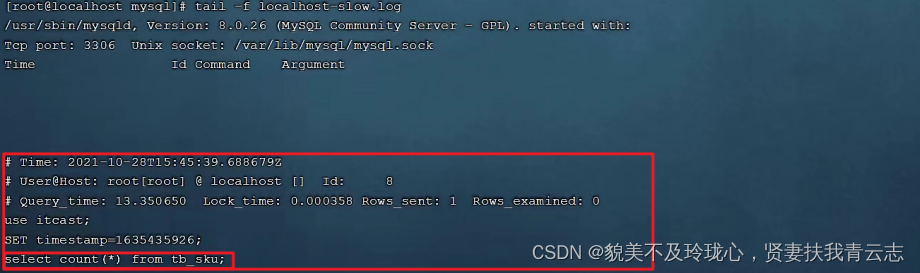
MySQL数据库 索引
目录 索引概述 索引结构 二叉树 B-Tree BTree Hash 索引分类 索引语法 慢查询日志 索引概述 索引 (index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种…...

ES 错误码
2xx状态码(如200)表示请求成功处理,并且不需要重试。 400状态码表示客户端发送了无效的请求,例如请求的语法有误或缺少必需的参数。在这种情况下,重试相同的请求很可能会导致相同的错误。因此,应该先检查并…...

听GPT 讲Rust源代码--src/tools(18)
File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/from_comment.rs 在Rust源代码中的from_comment.rs文件位于Rust分析器(rust-analyzer)工具的ide-ssr库中,它的作用是将注释转换为Rust代码。 具体来说,该文件实现了从注…...

如何实现设备远程控制?
在工业自动化领域,设备远程控制是一项非常重要的技术。它使得设备可以在远离现场的情况下进行远程操作和维护,大大提高了设备的可用性和效率。 设备远程控制的应用场景有哪些? 远程故障排除:当设备出现故障时,工程师…...

百度侯震宇详解:大模型将如何重构云计算?
12月20日,在2023百度云智大会智算大会上,百度集团副总裁侯震宇以“大模型重构云计算”为主题发表演讲。他强调,AI原生时代,面向大模型的基础设施体系需要全面重构,为构建繁荣的AI原生生态筑牢底座。 侯震宇表示&…...

[Java]FileOutputStream的换行/续写/一次性写出一个字符串的方法
1.续写:FileOutputStream这个io流中的write方法默认情况下是覆盖写入的,如果需要追加写入,需要添加一个参数true 2.虽然write只能一个字符一个字符写入 但是我们可以把想输入的字符串放在str 再将str转化成byte数组 import java.io.FileOutp…...

VM进行TCP/IP通信
OK就变成这样 vm充当服务端的话也是差不多的操作 点击连接 这里我把端口号换掉了因为可能被占用报错了,如果有报错可以尝试尝试换个端口号 注: 还有一个点在工作中要是充当服务器,要去网络这边看下他的ip地址 拉到最后面...

剑指Offer 队列栈题目集合
目录 用两个栈实现队列 用两个栈实现队列 刷题链接: https://www.nowcoder.com/practice/54275ddae22f475981afa2244dd448c6 题目描述 思路一: 使用两个栈来实现队列的功能。栈 1 用于存储入队的元素,而栈 2 用于存储出队的元素。 1.push…...

grafana基本使用
一、安装grafana 1.下载 官网下载地址: https://grafana.com/grafana/download官网包的下载地址: yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.2.2-1.x86_64.rpm官网下载速度非常慢,这里选择清华大…...
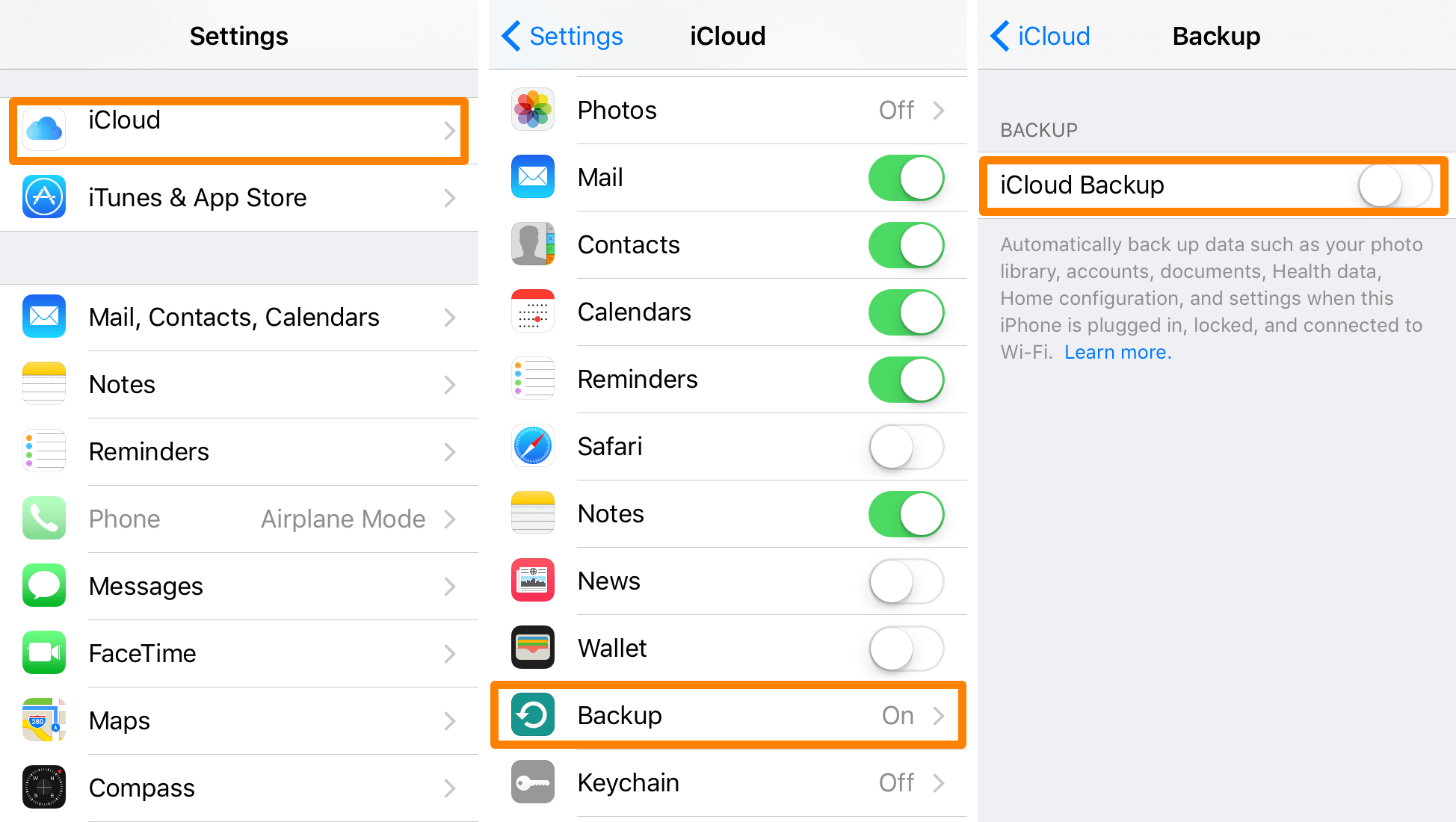
备份至关重要!如何解决iCloud的上次备份无法完成的问题
将iPhone和iPad备份到iCloud对于在设备发生故障或丢失时确保数据安全至关重要。但iOS用户有时会收到一条令人不安的消息,“上次备份无法完成。”下面我们来看看可能导致此问题的原因,如何解决此问题,并使你的iCloud备份再次顺利运行。 这些故…...

【项目问题解决】% sql注入问题
目录 【项目问题解决】% sql注入问题 1.问题描述2.问题原因3.解决思路4.解决方案1.前端限制传入特殊字符2.后端拦截特殊字符-正则表达式3.后端拦截特殊字符-拦截器 5.总结6.参考 文章所属专区 项目问题解决 1.问题描述 在处理接口入参的一些sql注入问题,虽然通过M…...
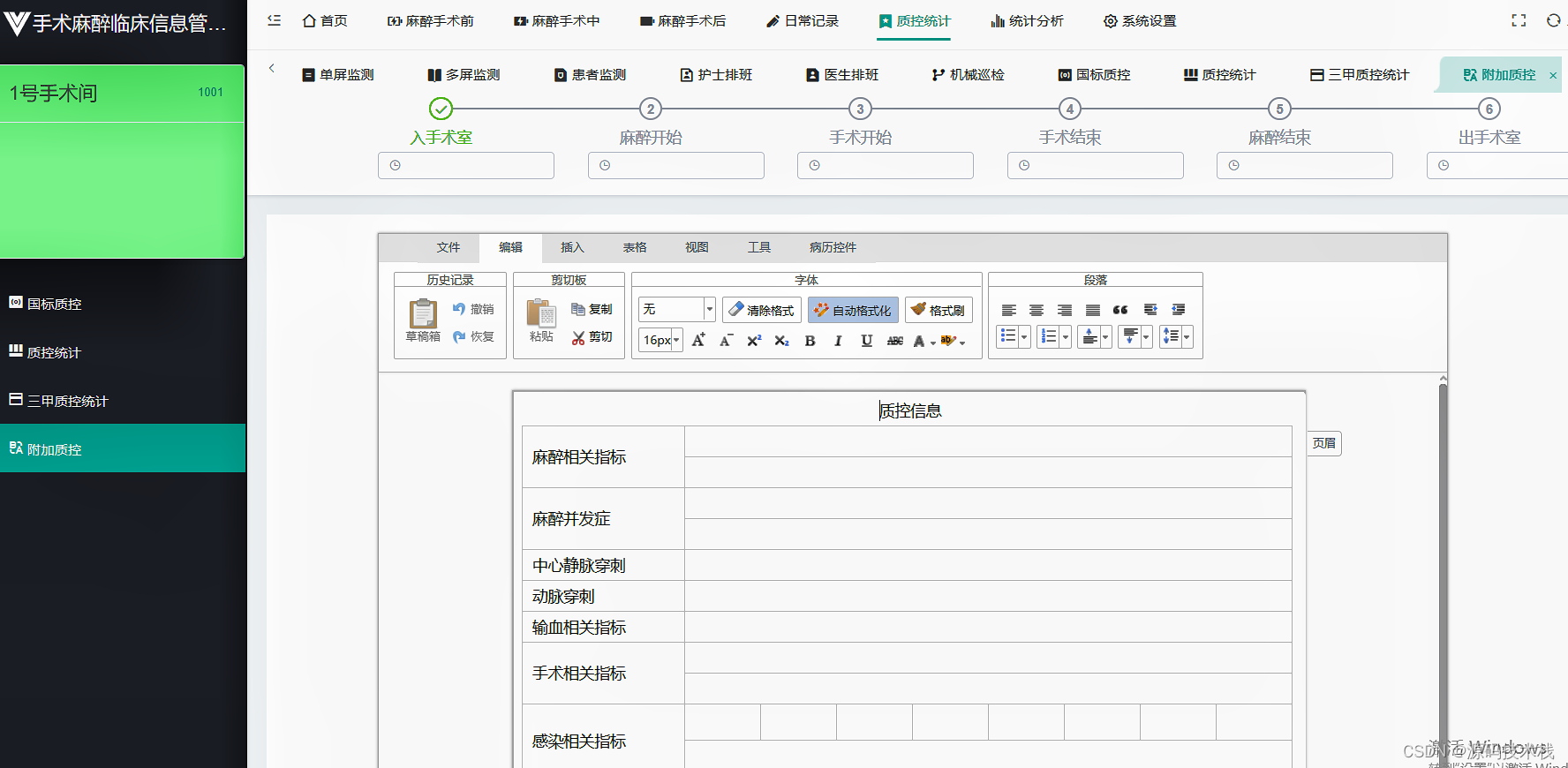
B/S医院手术麻醉临床管理系统源码 手术申请、手术安排
手术麻醉系统概述 手术室是医院各个科室工作交叉汇集的一个重要中心,在时间、空间、设备、药物、材料、人员调配的科学管理、高效运作、安全质控、绩效考核,都十分重要。手术麻醉管理系统(Operation Anesthesia Management System࿰…...

解锁高效工作!5款优秀工时管理软件推荐
工时管理,一直是让许多企业和团队头疼的问题。传统的纸质工时表、复杂的电子表格,不仅操作繁琐,还容易出错。幸好,随着科技的进步,我们迎来了工时管理软件的春天。今天,就让我们一起走进这个新时代…...

ICLR 2024 高分论文 | Step-Back Prompting 使大语言模型通过抽象进行推理
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2024 高分论文:《Step-Back Prompting Enables Reasoning Via Abstraction in Large Language Models》 论文地址:https://openreview.net/forum?id=3bq3jsvcQ1 …...
边缘计算有哪些常用场景?TSINGSEE边缘AI视频分析技术行业解决方案
随着ChatGPT生成式人工智能的爆发,AI技术在业界又掀起一波新浪潮。值得关注的是,边缘AI智能也在AI人工智能技术进步的基础上得到了快速发展。IDC跟踪报告数据显示,2021年我国的边缘计算服务器整体市场规模达到33.1亿美元,预计2020…...

配置BGP的基本示例
目录 BGP简介 BGP定义 配置BGP目的 受益 实验 实验拓扑 编辑 组网需求 配置思路 配置步骤 配置各接口所属的VLAN 配置各Vlanif的ip地址 配置IBGP连接 配置EBGP 查看BGP对等体的连接状态 配置SwitchA发布路由10.1.0.0/16 配置BGP引入直连路由 BGP简介 BGP定义 …...
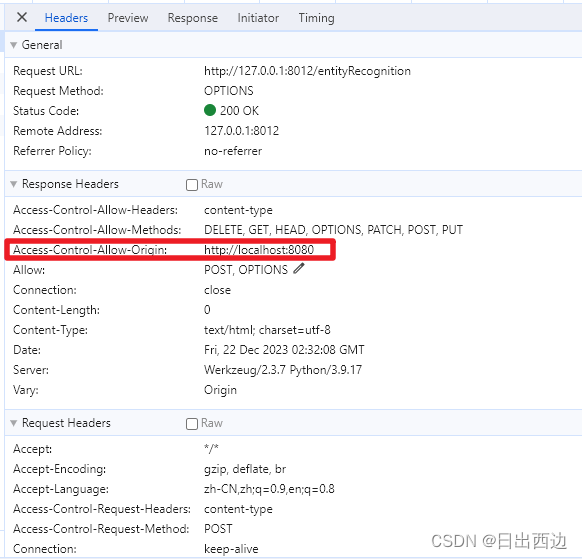
Flask解决接口跨域问题
1、什么是跨域CROS CORS(Cross-Origin Resource Sharing,跨域资源共享)是一种浏览器安全策略,用于控制在一个网页应用中如何让一个域的Web页面能够请求另一个域的资源。在Web开发中,由于同源策略(Same-Ori…...
数据恢复工具推荐!这3款堪称删除文件恢复大师!
“快看看我!经常都会莫名奇妙丢失各种电脑文件,但是又无法通过简单的方法找回重要的数据,有没有什么简单的操作可以帮助我快速恢复数据的呀?非常感谢!” 在我们的日常生活中,无论是工作还是学习,…...

隐私优先方案:OpenClaw+本地化Qwen3-32B处理敏感数据
隐私优先方案:OpenClaw本地化Qwen3-32B处理敏感数据 1. 为什么需要完全离线的数据处理方案 去年我在处理一批法律案件卷宗时,遇到了一个棘手的问题:客户要求所有材料必须在内网环境完成数字化处理,且禁止使用任何云端AI工具。当…...

Qwen2.5-7B-Instruct在Visual Studio中的开发插件实现
Qwen2.5-7B-Instruct在Visual Studio中的开发插件实现 1. 引言 作为一名开发者,你是否曾经在编码过程中遇到过这样的困扰:需要快速生成代码片段、解释复杂算法,或者想要一个智能助手帮你审查代码?现在,借助Qwen2.5-7…...

Spring_couplet_generation 作为教学工具:计算机专业课程设计案例
Spring_couplet_generation 作为教学工具:计算机专业课程设计案例 最近在准备《人工智能导论》的课程设计,想找一个既能体现AI应用全流程,又不会让学生望而却步的实践项目。找来找去,发现用AI写对联这个事儿,其实是个…...

SSD用久了会变慢?手把手教你理解‘写放大’和‘磨损均衡’,以及选购NVMe硬盘时的避坑要点
SSD性能衰减真相:从写放大到磨损均衡的消费级解决方案 当你的高端NVMe SSD用了一年多后突然开始"卡顿",拷贝大文件时速度从3500MB/s暴跌到500MB/s,这很可能不是心理作用。我去年为视频工作站配备的某品牌PCIe 4.0 SSD就遭遇过这种尴…...

Qwen3-0.6B-FP8部署案例:低成本GPU上运行FP8量化大模型的完整链路解析
Qwen3-0.6B-FP8部署案例:低成本GPU上运行FP8量化大模型的完整链路解析 1. 引言:当大模型遇见小显卡 如果你手头只有一张显存不大的显卡,比如8GB甚至更小的,是不是就和大模型无缘了?过去可能是这样,但现在…...

专家观点:图形管线的变革
多年来,图形管线一直依赖于成熟且固定的功能工作负载,如几何处理、光栅化、纹理贴图和着色。这种传统方法为渲染提供了可预测的结构,每个阶段都提供特定且易于理解的功能。然而,这种模式已经悄然发生了深刻转变。现代渲染的特点如…...

军采“拉黑”海澜之家,少帅周立宸手握一张不及格的“合规答卷”
海澜之家,这个曾经以“男人的衣柜”为广告语深入人心的国民级男装品牌,如今却深陷合规泥潭,面临着前所未有的品牌信任危机。其背后的故事,不仅是一段品牌兴衰的记录,更是对企业管理与合规重要性的深刻警示。2026年2月2…...

skill-icons完全指南:从入门到精通,打造专业级GitHub技能展示区
skill-icons完全指南:从入门到精通,打造专业级GitHub技能展示区 【免费下载链接】skill-icons Showcase your skills on your Github readme or resum with ease ✨ 项目地址: https://gitcode.com/gh_mirrors/sk/skill-icons 在竞争激烈的技术领…...

使用OFA图像英文描述模型增强MySQL图像数据库的检索能力
使用OFA图像英文描述模型增强MySQL图像数据库的检索能力 1. 场景痛点与解决方案 你有没有遇到过这样的情况:公司图库里有几万张产品图片,老板让你找"那个红色背景的笔记本电脑海报",你只能一张张翻看,眼睛都快看花了&…...
 Error: A listener indicated an asynchronous response by returning true, but th)
Uncaught (in promise) Error: A listener indicated an asynchronous response by returning true, but th
前端异步通信异常排查:因超时时间设置过短导致消息通道提前关闭 在前端开发中,异步通信(尤其是接口请求)是核心环节,而超时时间的配置看似是小细节,却可能引发难以定位的异常。本文记录一次典型的异步通信异…...