SpringCloud系列知识快速复习 -- part 2(Sentinel微服务保护,Seata分布式事务,Redis分布式缓存和多级缓存)
SpringCloud系列知识快速复习 -- part 2(Sentinel微服务保护,Seata分布式事务,Redis分布式缓存和多级缓存
- Sentinel微服务保护
- 什么是雪崩问题?
- 解决方法
- 服务保护技术对比
- 流量控制
- 簇点链路
- Sentinel流控模式
- 流控效果
- 热点参数限流
- 隔离和降级
- 线程隔离
- 熔断降级
- 授权规则
- 规则持久化
- Seata分布式事务
- CAP定理
- Base理论
- 解决分布式事务的思路
- Seata
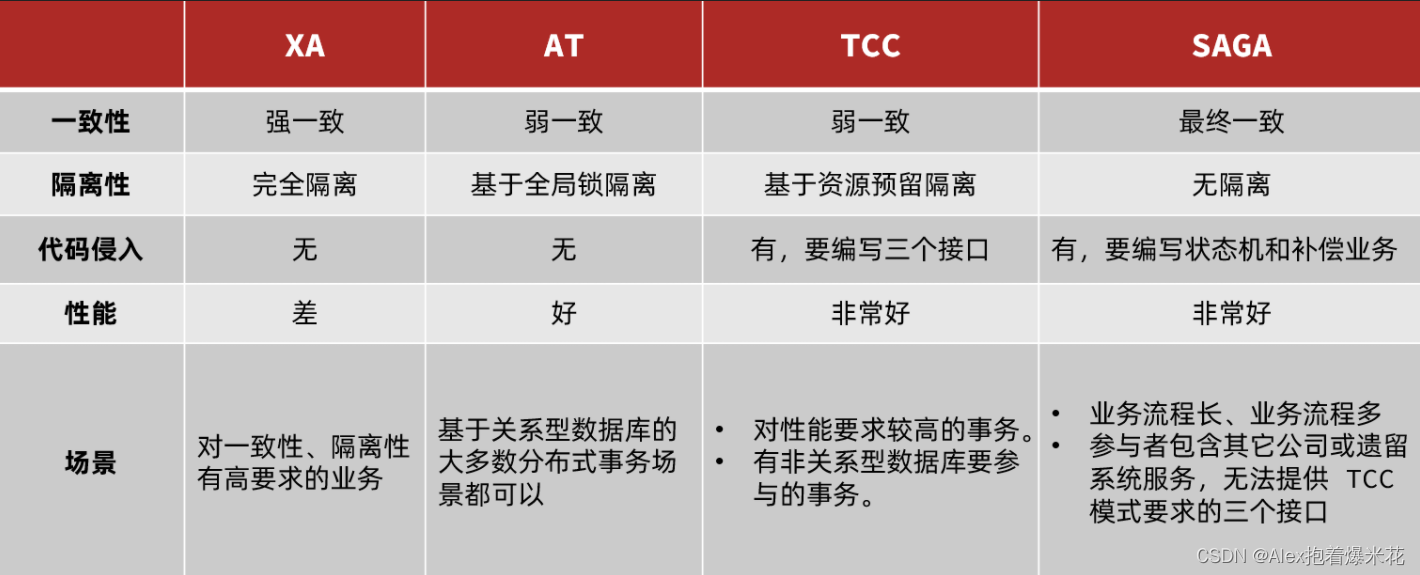
- 四种不同的分布式事务解决方案
- XA模式
- 流程
- 优缺点
- AT模式
- 流程
- 优缺点
- TCC模式
- 流程
- 优缺点
- SAGA模式
- 流程
- 优缺点
- Redis分布式缓存
- Redis缓存预热
- Redis持久化
- RDB原理
- AOF原理
- AOF文件重写
- RDB与AOF对比
- 主从数据同步原理
- 全量同步
- 增量同步
- 主从同步优化
- Redis哨兵
- 集群监控原理
- 集群故障恢复原理
- 故障转移步骤
- RedisTemplate
- 分片集群
- 分片集群特征
- 插槽原理
- 多级缓存
- JVM进程缓存
- Nginx缓存
- OpenResty
- CJSON工具类
- 本地缓存API
- 缓存同步
Sentinel微服务保护
什么是雪崩问题?
微服务之间相互调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况。
解决方法
限流是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。是一种预防措施。
超时处理、线程隔离、降级熔断是在部分服务故障时,将故障控制在一定范围,避免雪崩。是一种补救措施。
服务保护技术对比
- Netfix Hystrix
- Sentinel
- Resilience4J
| Sentinel | Hystrix | |
|---|---|---|
| 隔离策略 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于慢调用比例或异常比例 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持慢启动、匀速排队模式 | 不支持 |
| 系统自适应保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
流量控制
簇点链路
当请求进入微服务时,首先会访问DispatcherServlet,然后进入Controller、Service、Mapper,这样的一个调用链就叫做簇点链路。簇点链路中被监控的每一个接口就是一个资源。
默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint,也就是controller中的方法),因此SpringMVC的每一个端点(Endpoint)就是调用链路中的一个资源。
Sentinel流控模式
流控模式有哪些?
•直接:对当前资源限流
•关联:高优先级资源触发阈值,对低优先级资源限流。
•链路:阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流
满足下面条件可以使用关联模式:
- 两个有竞争关系的资源
- 一个优先级较高,一个优先级较低
流控效果
-
快速失败:QPS超过阈值时,拒绝新的请求
-
warm up: QPS超过阈值时,拒绝新的请求;QPS阈值是逐渐提升的,可以避免冷启动时高并发导致服务宕机。
-
排队等待:请求会进入队列,按照阈值允许的时间间隔依次执行请求;如果请求预期等待时长大于超时时间,直接拒绝
热点参数限流
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计特点参数值的请求,判断是否超过QPS阈值。
隔离和降级
线程隔离:调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽。
熔断降级:是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。
Sentinel支持的雪崩解决方案:
- 线程隔离(仓壁模式)
- 降级熔断
Feign整合Sentinel的步骤:
- 在application.yml中配置:feign.sentienl.enable=true
- 给FeignClient编写FallbackFactory并注册为Bean
- 将FallbackFactory配置到FeignClient
线程隔离
线程隔离有两种方式实现:
-
线程池隔离 给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
-
信号量隔离(Sentinel默认采用) 不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
信号量隔离的特点是?
- 基于计数器模式,简单,开销小
线程池隔离的特点是?
- 基于线程池模式,有额外开销,但隔离控制更强
熔断降级
其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求
状态机包括三个状态:
- closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
- open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
- half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 请求成功:则切换到closed状态
- 请求失败:则切换到open状态
断路器熔断策略有三种:慢调用、异常比例、异常数
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
授权规则
对请求方来源做判断和控制
授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。
-
白名单:来源(origin)在白名单内的调用者允许访问
-
黑名单:来源(origin)在黑名单内的调用者不允许访问
规则持久化
现在,sentinel的所有规则都是内存存储,重启后所有规则都会丢失。在生产环境下,我们必须确保这些规则的持久化,避免丢失。
规则是否能持久化,取决于规则管理模式,sentinel支持三种规则管理模式:
- 原始模式:Sentinel的默认模式,将规则保存在内存,重启服务会丢失。
- pull模式
- push模式
pull模式:控制台将配置的规则推送到Sentinel客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则。
push模式:控制台将配置规则推送到远程配置中心,例如Nacos。Sentinel客户端监听Nacos,获取配置变更的推送消息,完成本地配置更新。
Seata分布式事务
分布式事务,就是指不是在单个服务或单个数据库架构下,产生的事务,例如:
- 跨数据源的分布式事务
- 跨服务的分布式事务
- 综合情况
CAP定理
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性) 因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区,在集群出现分区时,整个系统也要持续对外提供服务
在P一定会出现的情况下,A和C之间只能实现一个
Base理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available (基本可用) 分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态) 在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性) 虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
解决分布式事务的思路
分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论,有两种解决思路:
-
AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
-
CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态
子系统事务,称为分支事务;有关联的各个分支事务在一起称为全局事务
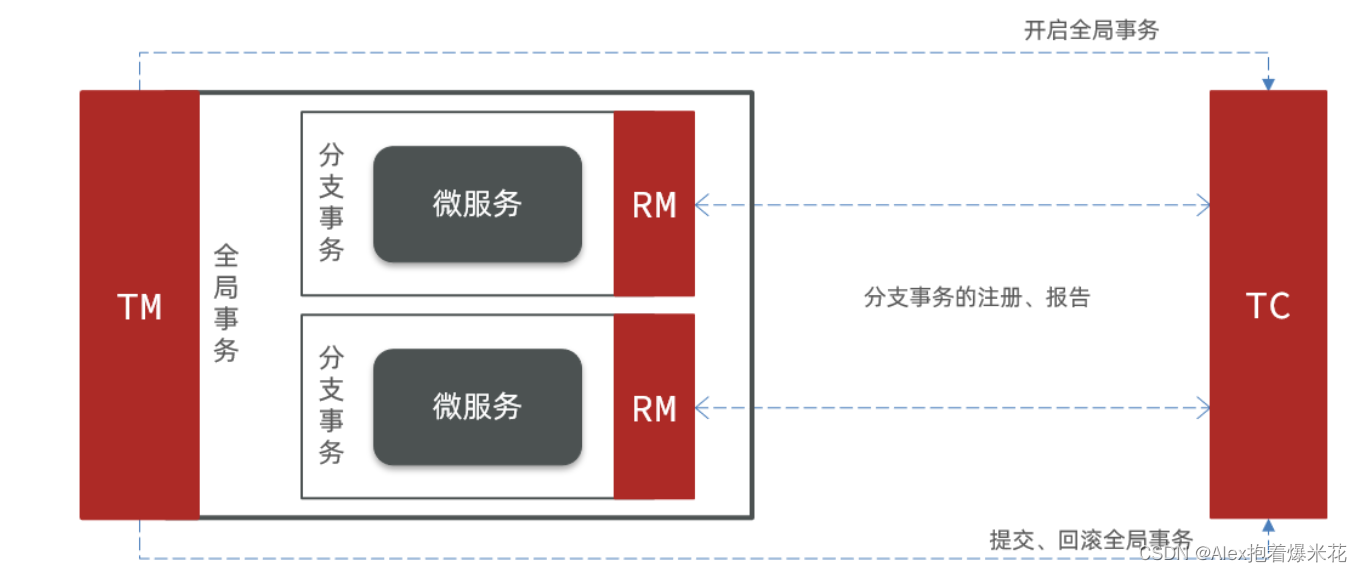
Seata
Seata事务管理中有三个重要的角色:
-
TC (Transaction Coordinator) - 事务协调者 维护全局和分支事务的状态,协调全局事务提交或回滚。
-
TM (Transaction Manager) - 事务管理器 定义全局事务的范围、开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - 资源管理器 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
四种不同的分布式事务解决方案
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,有业务侵入
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式
- SAGA模式:长事务模式,有业务侵入
无论哪种方案,都离不开TC,也就是事务的协调者。
XA模式
基于两阶段提交
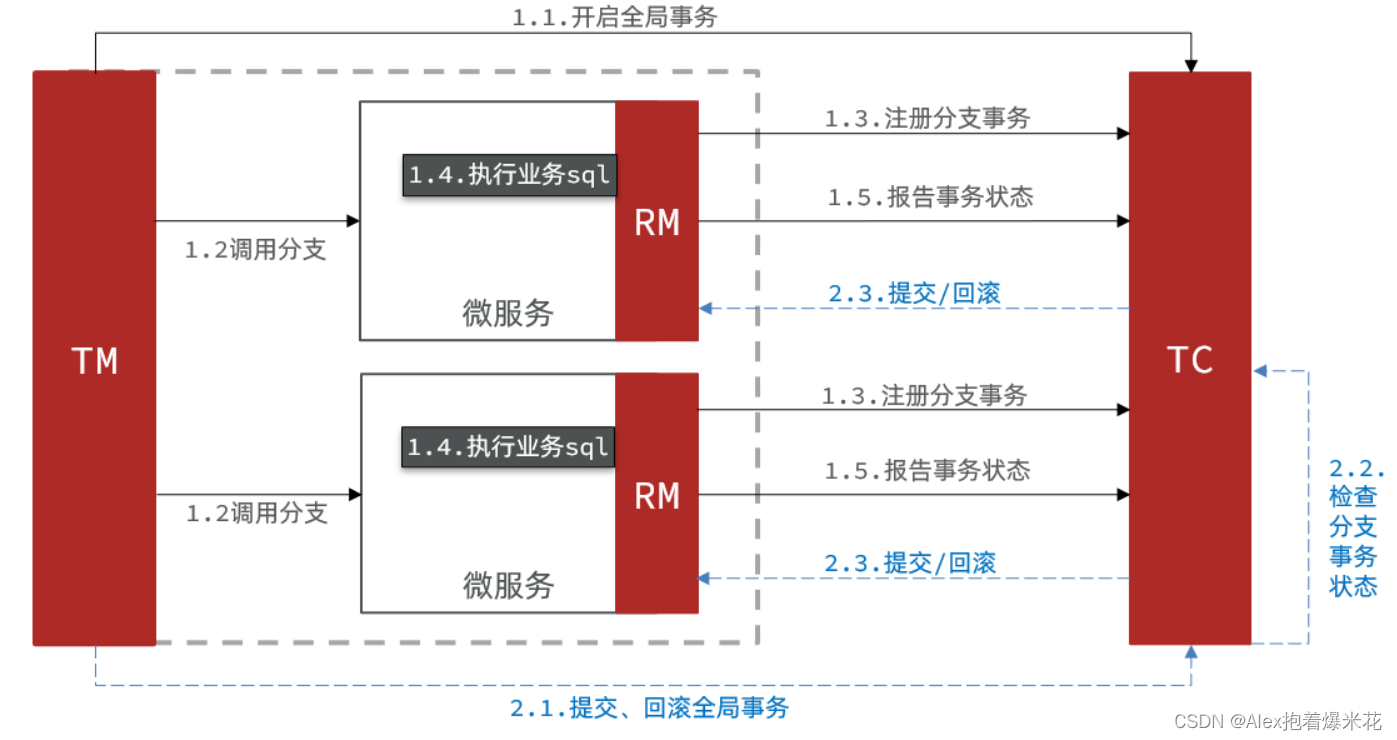
流程
RM一阶段的工作:
- 注册分支事务到TC
- 执行分支业务sql但不提交(继续持有数据库锁)
- 报告执行状态到TC
TC二阶段的工作:
-
TC检测各分支事务执行状态
a. 如果都成功,通知所有RM提交事务
b. 如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
AT模式
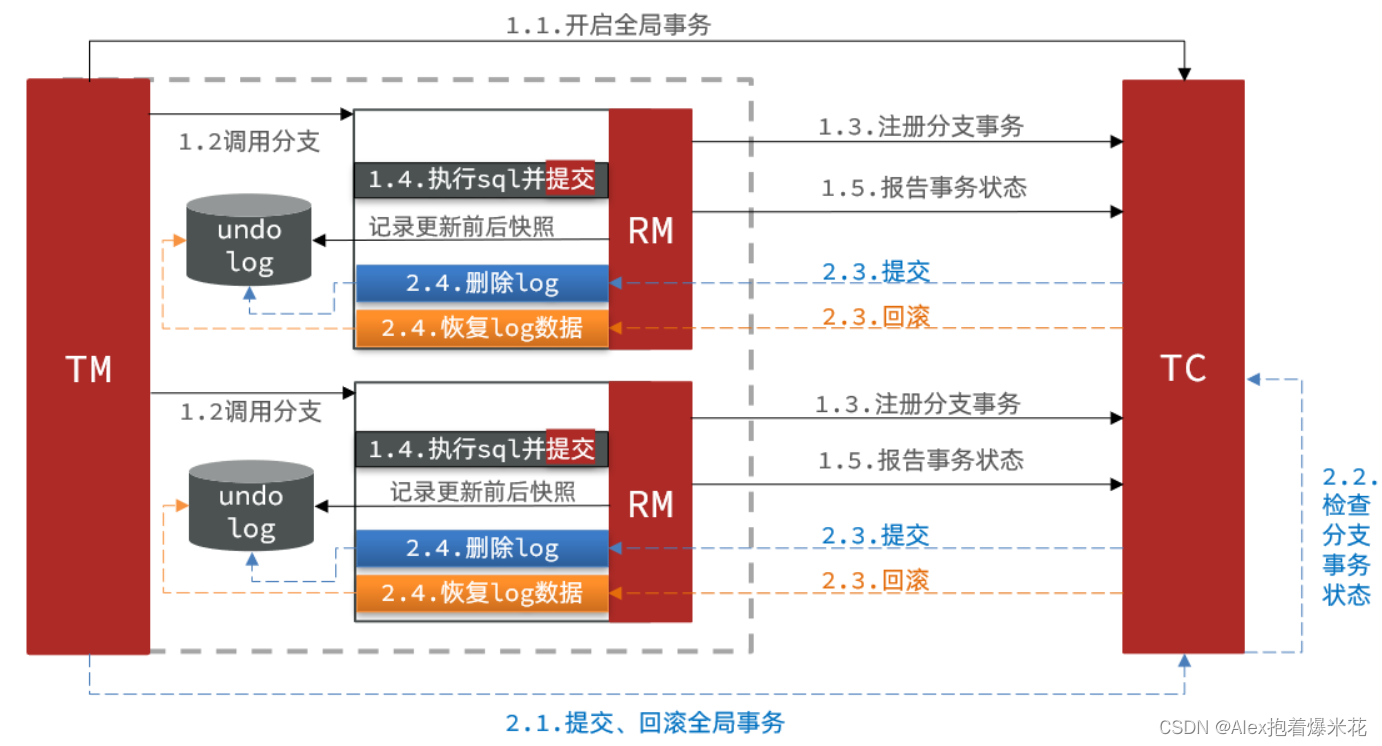
流程
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
缺弥补了XA模型中资源锁定周期过长的缺陷
AT模式与XA模式最大的区别是什么?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
优缺点
AT模式的优点:
- 一阶段完成直接提交事务,释放数据库资源,性能比较好
- 利用
全局锁实现读写隔离 - 没有代码侵入,框架自动完成回滚和提交
AT模式的缺点:
- 两阶段之间属于软状态,属于最终一致
- 框架的快照功能会影响性能,但比XA模式要好很多
- 需要导入数据库表,记录全局锁防止脏写问题
TCC模式
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:
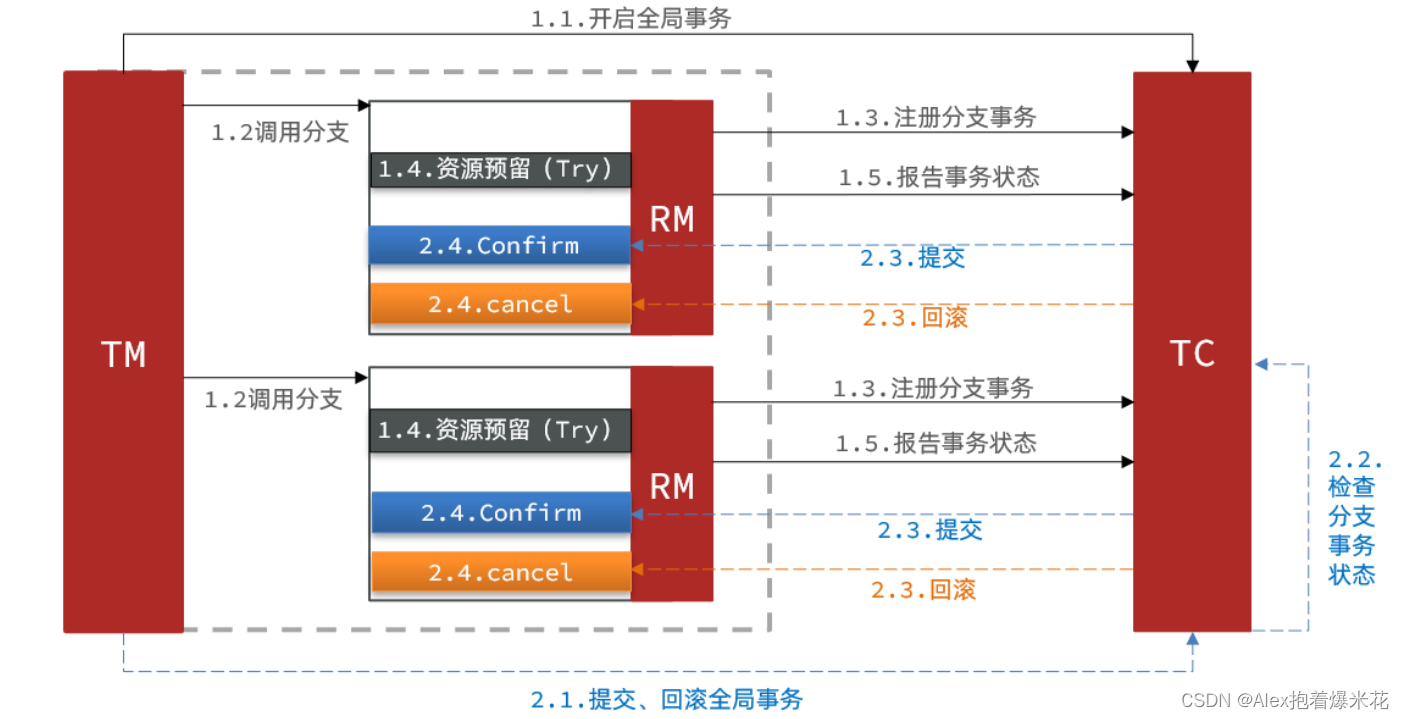
流程
-
Try:资源的检测和预留;
-
Confirm:完成资源操作业务;要求 Try 成功 Confirm 一定要能成功。
-
Cancel:预留资源释放,可以理解为try的反向操作。
优缺点
TCC模式的每个阶段是做什么的?
- Try:资源检查和预留
- Confirm:业务执行和提交
- Cancel:预留资源的释放
TCC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC的缺点是什么?
- 有代码侵入,需要人为编写try、Confirm和Cancel接口,太麻烦
- 软状态,事务是最终一致
- 需要考虑Confirm和Cancel的失败情况,做好
幂等处理,空回滚和事务悬挂
SAGA模式
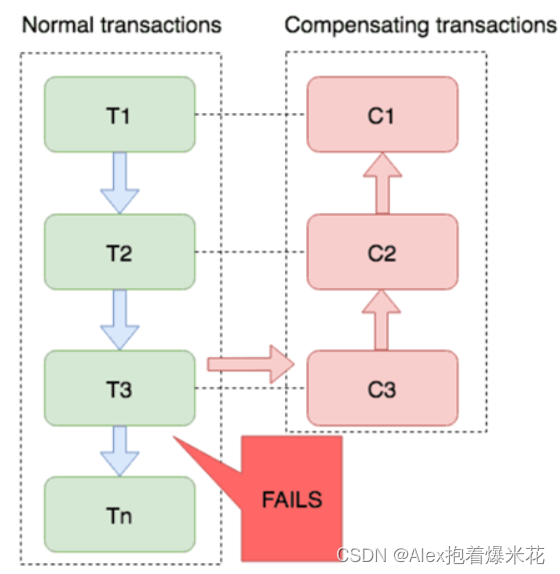
流程
Saga也分为两个阶段:
- 一阶段:直接提交本地事务
- 二阶段:成功则什么都不做;失败则通过编写补偿业务来回滚
优缺点
优点:
- 事务参与者可以基于事件驱动实现异步调用,吞吐高
- 一阶段直接提交事务,无锁,性能好
- 不用编写TCC中的三个阶段,实现简单
缺点:
- 软状态持续时间不确定,时效性差
- 没有锁,没有事务隔离,会有脏写
Redis分布式缓存
Redis缓存预热
Redis缓存会面临冷启动问题:
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
Redis持久化
Redis有两种持久化方案:
- RDB持久化
- AOF持久化
RDB持久化在四种情况下会执行:
- 执行save命令
- 执行bgsave命令
- Redis停机时
- 触发RDB条件时
RDB原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
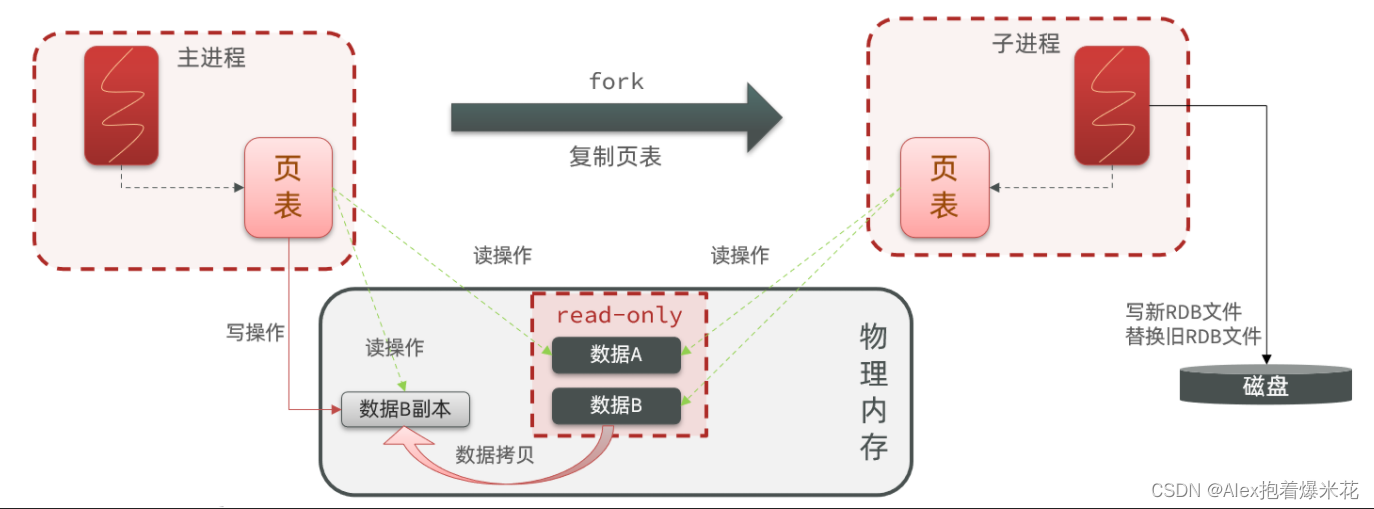
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认是服务停止时
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
AOF原理
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF文件重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
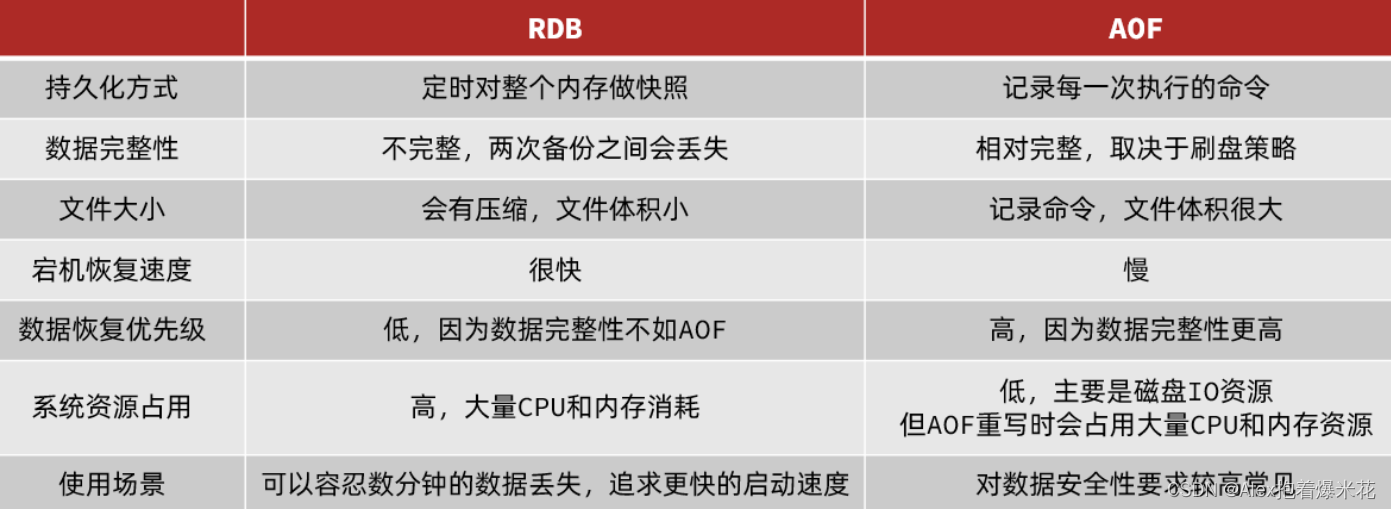
RDB与AOF对比
主从数据同步原理
全量同步

- slave节点请求增量同步
- master节点判断replid,发现不一致,进行全量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点
master如何得知salve是第一次来连接呢
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
- master判断一个节点是否是第一次同步的依据,就是看replid是否一致
增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步
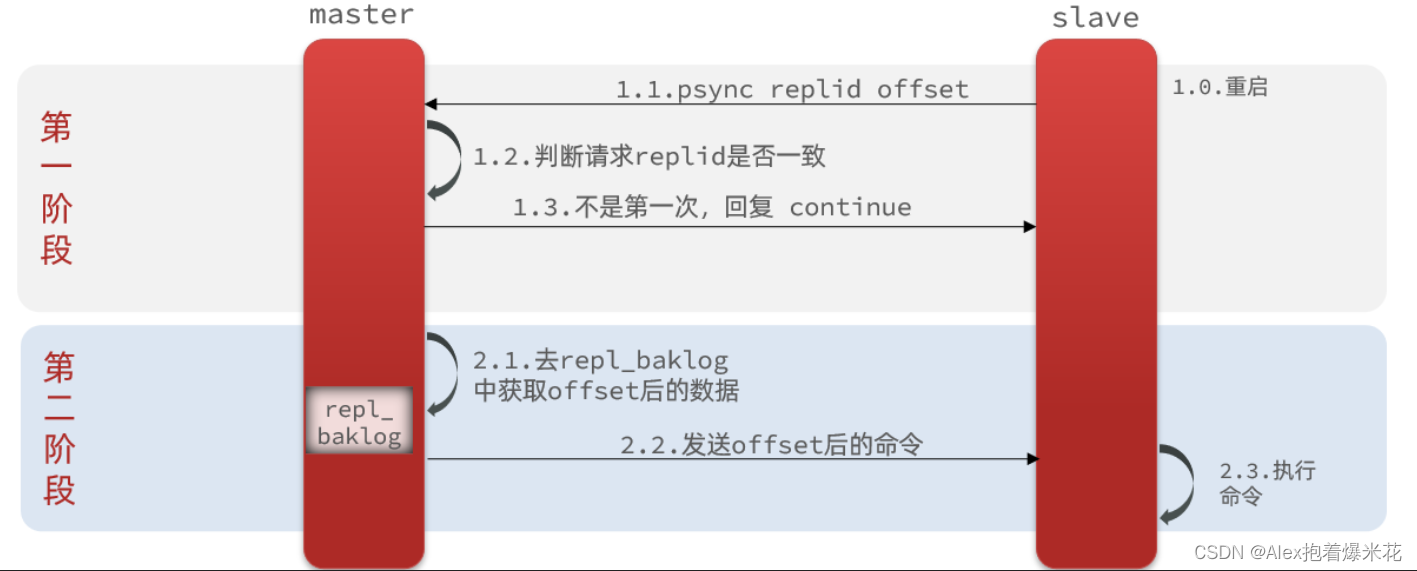
master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步时的repl_baklog文件了。
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
主从同步优化
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
Redis哨兵
哨兵的作用如下:
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
集群监控原理
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
•主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
•客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
集群故障恢复原理
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
故障转移步骤
- sentinel给备选的slave1节点发送slaveof no one命令,让
该节点成为master - sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让
这些slave成为新master的从节点,开始从新的master上同步数据。 - 最后,sentinel
将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
RedisTemplate
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
个bean中配置的有四种读写策略,包括:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
-
海量数据存储问题
-
高并发写的问题
分片集群特征
-
集群中有多个master,每个master保存不同数据
-
每个master都可以有多个slave节点
-
master之间通过ping监测彼此健康状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
插槽原理
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
多级缓存
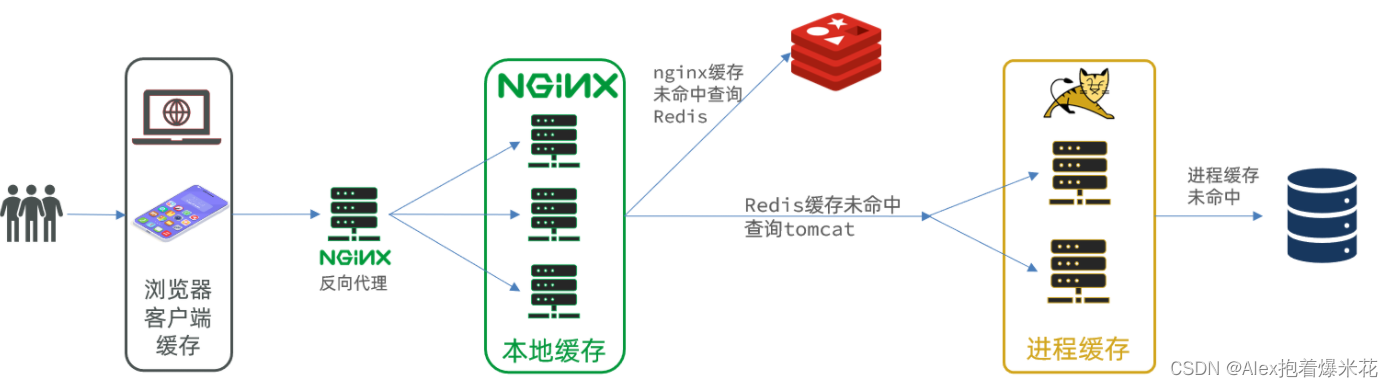
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
JVM进程缓存
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
Caffeine的性能非常好
Nginx缓存
OpenResty
OpenResty 是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
CJSON工具类
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
本地缓存API
OpenResty为Nginx提供了shard dict的功能,可以在nginx的多个worker之间共享数据,实现缓存功能
缓存同步
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写 在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
异步通知 修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
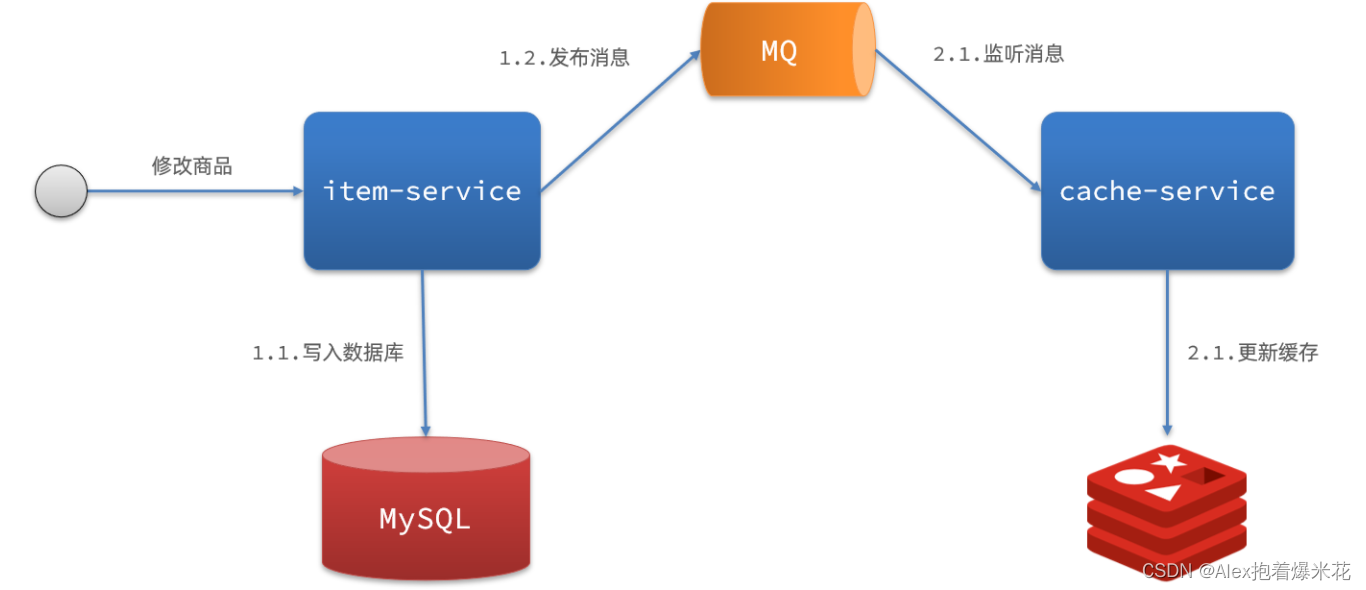
而异步实现又可以基于MQ或者Canal来实现:
-
MQ
-
Canal
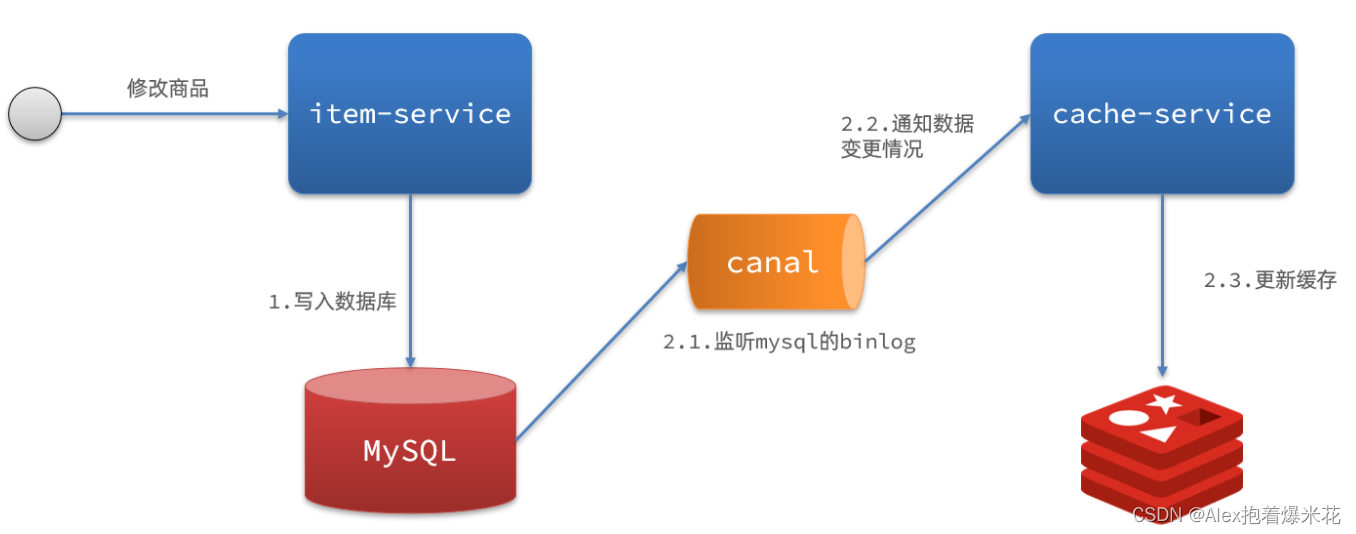
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下: -
1)MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做binary log events
-
2)MySQL slave 将 master 的 binary log events拷贝到它的中继日志(relay log)
-
3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
相关文章:
SpringCloud系列知识快速复习 -- part 2(Sentinel微服务保护,Seata分布式事务,Redis分布式缓存和多级缓存)
SpringCloud系列知识快速复习 -- part 2(Sentinel微服务保护,Seata分布式事务,Redis分布式缓存和多级缓存Sentinel微服务保护什么是雪崩问题?解决方法服务保护技术对比流量控制簇点链路Sentinel流控模式流控效果热点参数限流隔离和…...
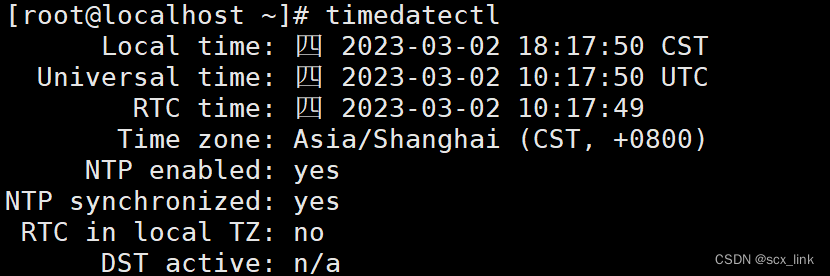
设置CentOS7的时间与网络同步
1.设置时区为北京时间 [rootlocalhost ~]# timedatectl set-timezone Asia/Shanghai 2.查看系统时间 [rootlocalhost ~]# timedatectl Local time: 四 2023-03-02 17:40:41 CST #系统时间 Universal time: 四 2023-03-02 09:40:41 UTC …...

java开发手册之编程规约
文章目录编程规约命名风格常量定义代码格式OOP规约集合处理并发处理控制语句注释规约其它编程规约 命名风格 1.代码中的命名均不能以下划线或者美元符号开始,也不能以下划线或者美元符号结束 例如:_name | name__ | name$ | $name2.代码中的命名严…...
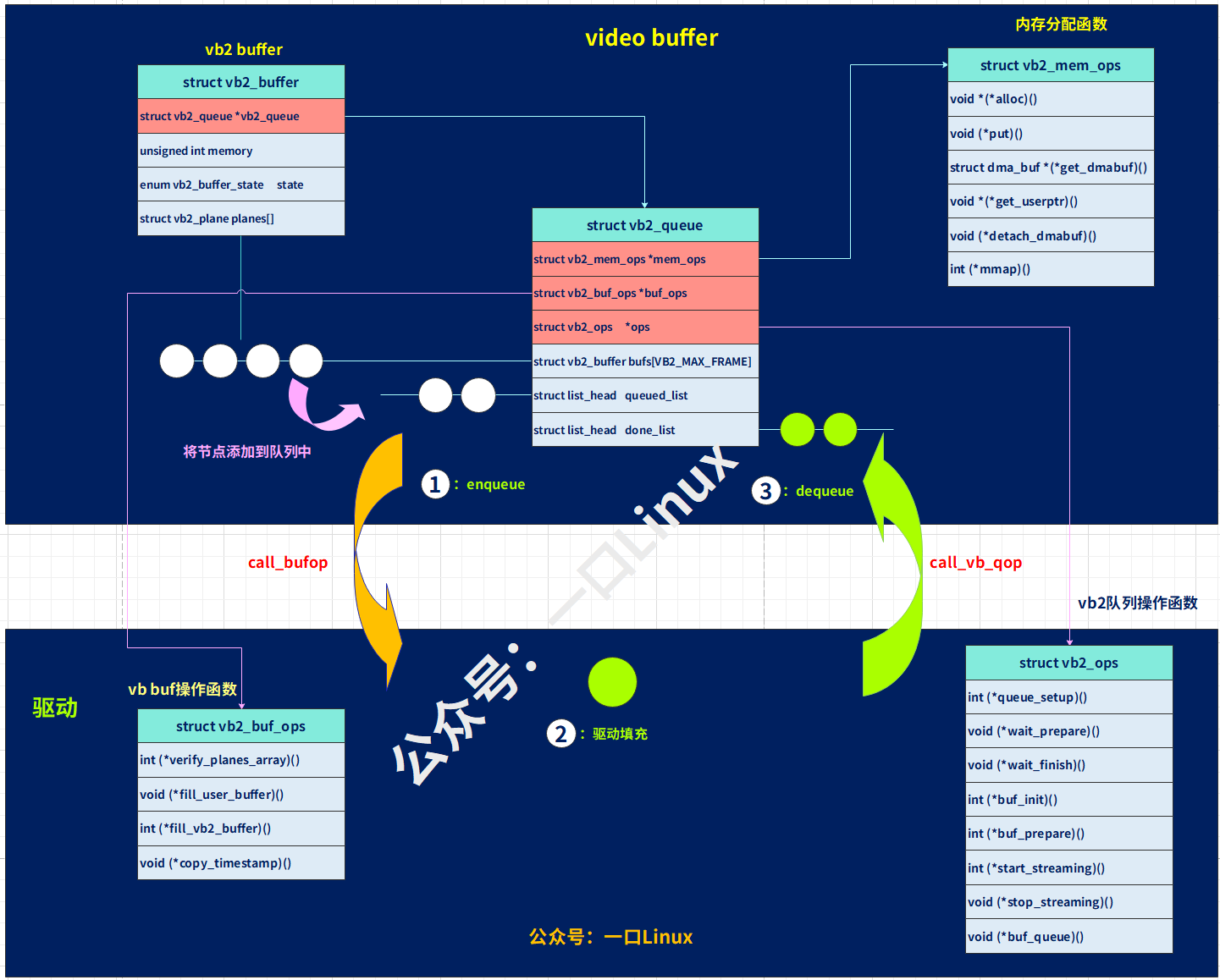
Camera | 5.Linux v4l2架构(基于rk3568)
上一篇我们讲解了如何编写基于V4L2的应用程序编写,本文主要讲解内核中V4L2架构,以及一些最重要的结构体、注册函数。 厂家在实现自己的摄像头控制器驱动时,总体上都遵循这个架构来实现,但是不同厂家、不同型号的SoC,具…...

机房PDU如何挑选?
PDU PDU(Power Distribution Unit,电源分配单元),也就是我们常说的机柜用电源分配插座,PDU是为机柜式安装的电气设备提供电力分配而设计的产品,拥有不同的功能、安装方式和不同插位组合的多种系列规格,能为不同的电源环境提供适合的机架式电源分配解决方案。PDU的应用,…...
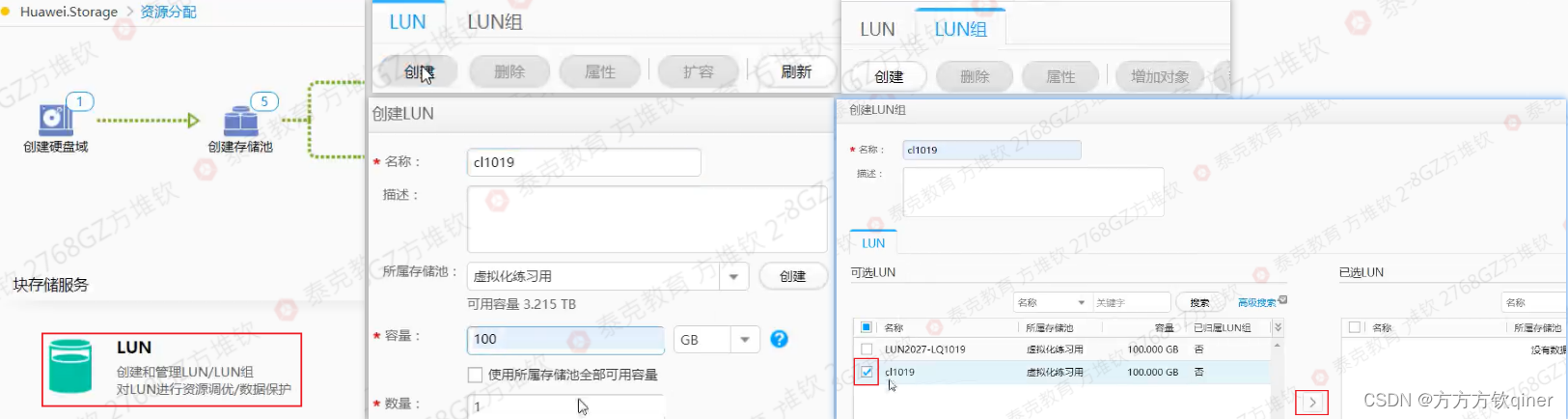
lab备考第二步:HCIE-Cloud-Compute-第一题:FusionCompute
第一题 FusionCompute 一、题目介绍 1.1. 扩容CAN节点与对接共享存储(必选) 题目及【考生提醒关键点】 扩容一台CNA节点,配置管理地址设置为:192.168.100.212。密码设置为:Cloud12#$。【输入之前确认自己的大小写是否…...
)
js-cookie和vue-cookies(Cookie使用教程)
简述:js-cookie和vue-cookies都是vue项目中的插件,下载相关依赖后,可以用来存储、获取、删除Cookie等操作,思路相同,操作时稍有不同,当然也可以用原生js来获取Cookie; ⭐ js-coo…...
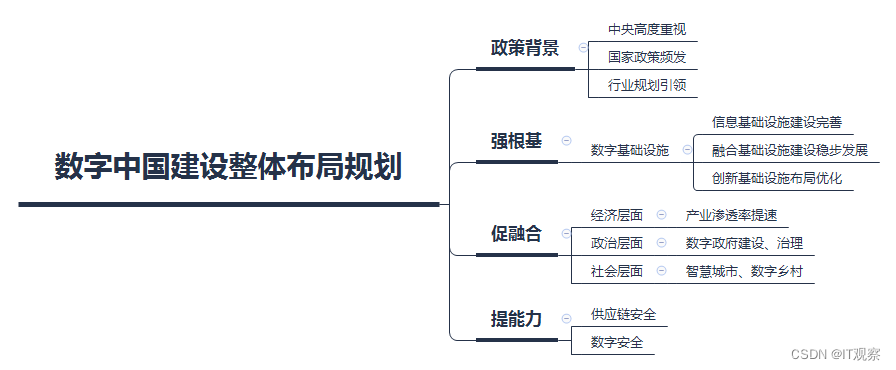
开创高质量发展新局面,优炫数据库助推数字中国建设
最新印发《数字中国建设整体布局规划》,建设数字中国是数字时代推进中国式现代化的重要引擎,是构筑国家竞争新优势的有力支撑。 数字中国建设按照“2522”的整体框架进行布局,即夯实数字基础设施和数据资源体系“两大基础”,推进…...
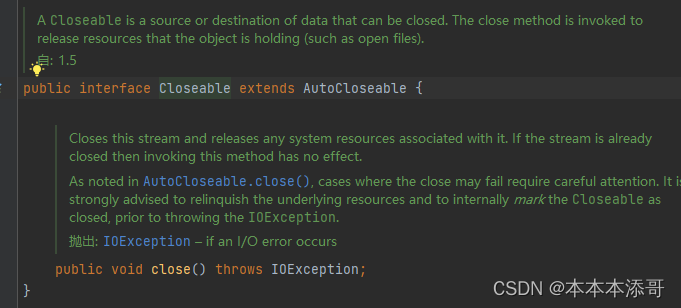
【项目实战】为什么我选择使用CloseableHttpClient,而不是HttpClient,他们俩有什么区别?
一、HttpClient介绍 HttpClient是Commons HttpClient的老版本,已被抛弃,不推荐使用; HttpClient是一个接口,定义了客户端HTTP协议的操作方法。 它可以用于发送HTTP请求和接收HTTP响应。 HttpClient接口提供了很多方法来定制请求…...
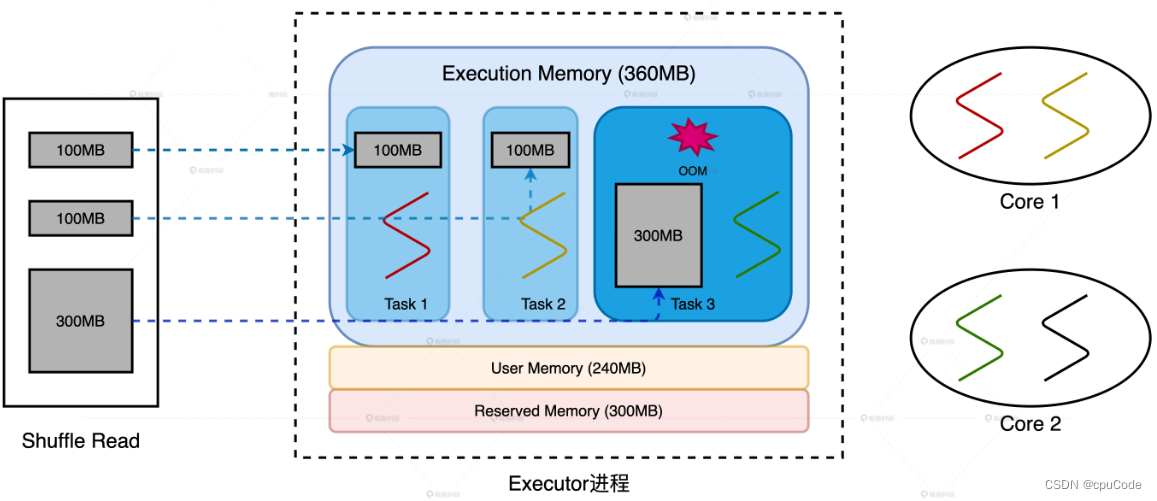
Spark 内存运用
RDD Cache 当同一个 RDD 被引用多次时,就可以考虑进行 Cache,从而提升作业的执行效率 // 用 cache 对 wordCounts 加缓存 wordCounts.cache // cache 后要用 action 才能触发 RDD 内存物化 wordCounts.count// 自定义 Cache 的存储介质、存储形式、副本…...
SpringBoot集成Swagger3.0(入门) 02
文章目录Swagger3常用配置注解接口测试API信息配置Swagger3 Docket开关,过滤,分组Swagger3常用配置注解 ApiImplicitParams,ApiImplicitParam:Swagger3对参数的描述。 参数名参数值name参数名value参数的具体意义,作用。required参…...

网络协议丨ICMP协议
ICMP协议,全称 Internet Control Message Protocol,就是互联网控制报文协议。我们其实对它并不陌生,我们平时经常使用的”ping“一下就是基于这个协议工作的。网络包在异常复杂的网络环境中传输时,常常会遇到各种各样的问题。当遇…...
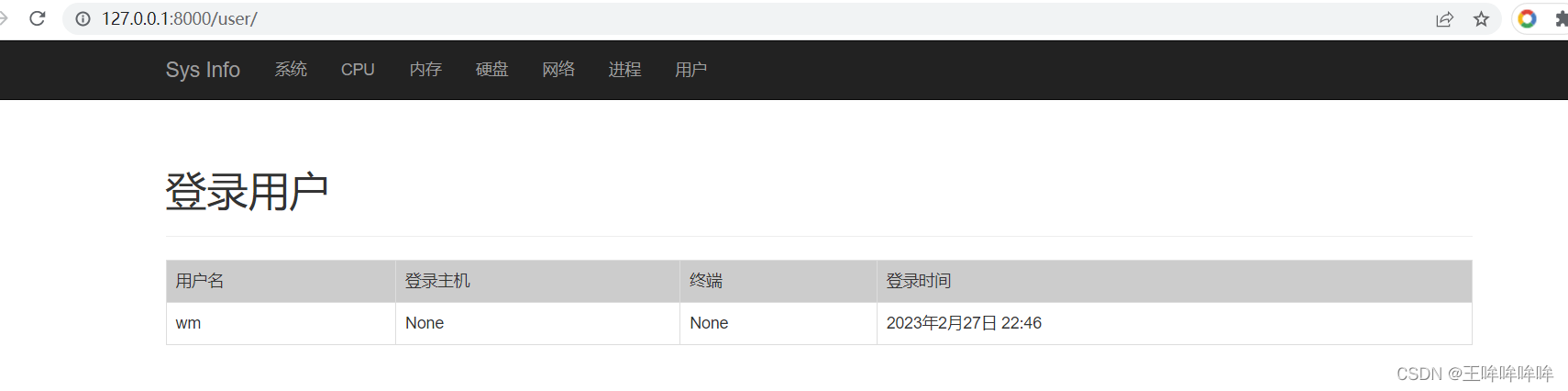
12.1 基于Django的服务器信息查看应用(系统信息、用户信息)
文章目录新建Django项目创建子应用并设置本地化创建数据库表创建超级用户git管理项目(requirements.txt、README.md、.ignore)主机信息监控应用的框架搭建具体功能实现系统信息展示前端界面设计视图函数设计用户信息展示视图函数设计自定义过滤器的实现前…...
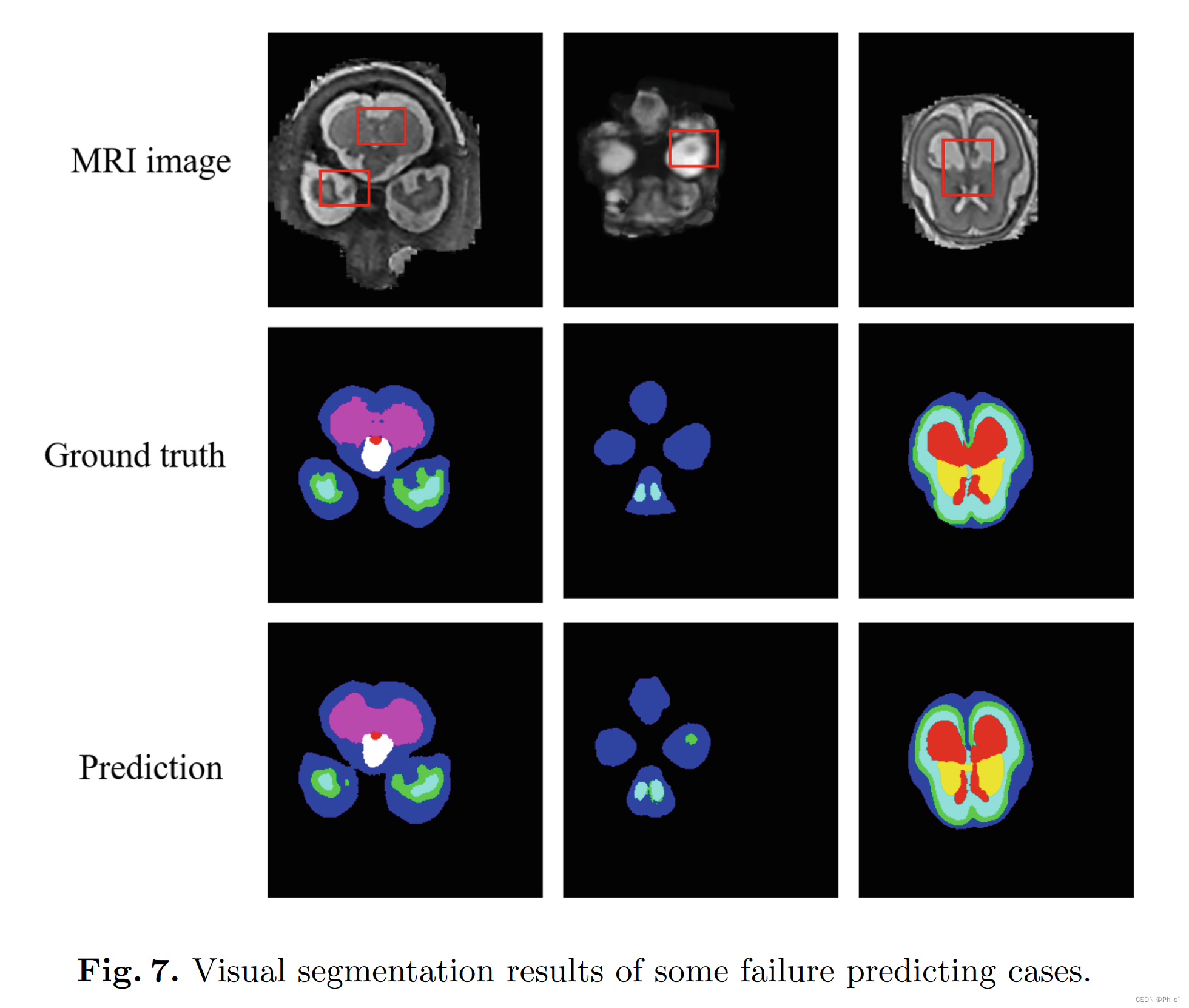
ExSwin-Unet 论文研读
ExSwin-Unet摘要1 引言2 方法2.1 基于窗口的注意力块2.2 外部注意力块2.3 不平衡的 Unet 架构2.4 自适应加权调整2.5 双重损失函数3 实验结果3.1 数据集3.2 实现细节3.3 与 SOTA 方法的比较3.4 消融研究4 讨论和限制5 结论数据集来源: https://feta.grand-challenge…...
置顶!!!主页禁言提示原因:在自己论坛发动态误带敏感词,在自己论坛禁止评论90天
置顶!!!主页禁言提示原因:在自己论坛发动态误带敏感词,在自己论坛禁止评论90天 置顶!!!主页禁言提示原因:在自己论坛发动态误带敏感词,在自己论坛禁止评论90天…...

优思学院|解密六西格玛:探索DMAIC和DMADV之间的区别
六西格玛方法中最为广泛使用的两种方法是DMAIC和DMADV。这两种方法都是为了让企业流程更加高效和有效而设计的。虽然这两种方法有一些重要的共同特点,但它们并不可以互相替代,并且被开发用于不同的企业流程。在更详细地比较这两种方法之前,我…...
)
Pytorch的DataLoader输入输出(以文本为例)
本文不做太多原理介绍,直讲使用流畅。想看更多底层实现-〉传送门。DataLoader简介torch.utils.data.DataLoader是PyTorch中数据读取的一个重要接口,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口。本文介绍t…...

代谢组学:Microbiome又一篇!绘制重症先天性心脏病新生儿肠道微生态全景图谱
文章标题:Mapping the early life gut microbiome in neonates with critical congenital heart disease: multiomics insights and implications for host metabolic and immunological health 发表期刊:Microbiome 影响因子:16.837…...

Java基本类型所占字节简述
类型分类所占字节取值范围boolean布尔型1bit0 false、 1 true (1个bit 、1个字节、4个字节)char 字符型(Unicode字符集中的一个元素) 2字节-32768~32767(-2的15次方~2的15次方-1)byte整型1字节-128&a…...

Linux vi常用操作
vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。 这三种模式的作用分别是: 命令模式: 用户刚…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...