DRF从入门到精通二(Request源码分析、DRF之序列化、反序列化、反序列化校验、序列化器常用字段及参数、source、定制字段、保存数据)
文章目录
- 一、Request对象源码分析
- 区分原生request和新生request
- 新的request还能像原来的reqeust一样使用吗
- 源码片段分析
- 总结:
- 二、DRF之序列化组件
- 序列化介绍
- 序列化步骤
- 序列化组件的基本使用
- 反序列化基本使用
- 反序列化的新增
- 反序列化的新增
- 删除单条
- 反序列化的校验
- 序列化器常用字段和字段参数
- 常用字段类
- 常用字段参数
- 序列化器-source的使用
- source序列化自有字段和关联字段的区别
- 定制字段的两种方式
- 反序列化之保存数据
- 新增
- 修改
- 反序列化之数据校验
- ModelSerializer的使用
- 使用方法
- 总结
一、Request对象源码分析
在上一篇博客中最后分析APIView时,我们分析出继承了APIView的视图,以后request都是新的request了,是DRF提供的Request的对象
区分原生request和新生request
原生request:django.core.handlers.wsgi.WSGIRequest新生request:from rest_framework.request import Request原生request可以在新生request._request中获取
新的request还能像原来的reqeust一样使用吗
用起来屎一样的,新的request只是在原来的request基础上添加了一些功能,并不影响基础功能的使用,其本质就是类似装饰器print(request.method) # getprint(request.path) # /movies/print(request.GET) # 原来的get请求提交的参数print(request.POST) # 原来post请求提交的参数
源码片段分析
'''源码解析之 __init__'''从上面区分原生request和新的request中可以知道,老的request对象其实就是在新的内部,request._request中'我们先看__init__,它是一个初始化方法,类实例化得到对象时,会执行它,然后会往对象中放数据'def __init__(self, request, parsers=None, authenticators=None,negotiator=None, parser_context=None):'''传入的request是老的,django原生的request放到self._request,self是新的request类的对象这里它把传入过来的原request放到这个self._request中,这里的self已经不是视图类了,因为这个Request类没有继承任何一个类,它就是它自己,所以这个self是Request'''self._request = requestself._data = Emptyself._files = Empty.....
在类内部,以 __开头 __结尾的方法, 在某种情况下会自动调用,他们称之为魔法方法。具体有那些,可以自行搜索,因为所有的类都继承了Object类,所以也可以在Object类中看看,但是不全里面
'''源码解析之__getattr__'''类中有个魔法方法:__getattr__,对象.属性,属性不存在会触发它的执行def __getattr__(self, attr): 如果取的属性不存在会去原生的Django的request对象中取出来try:'通过反射,因为这里是self._request所以去Django的request取,能取到就返回,娶不到就执行except代码,如果还取不到则报错'return getattr(self._request, attr)except AttributeError:return self.__getattribute__(attr)'以后用的所有属性或方法,直接用就可以了(通过反射去原来的request中取)'
以后新的request中多了一个属性data,它会把前端post/put提交的请求体中的数据,都放在request.data中,无论何种编码格式,它都是字典
data是一个方法,被property装饰了,变成了数据属性用-以后body中提交的数据,都从这里取(request.POST)-urlencoded,form-data:提交的数据在request.POST中-json格式提交的数据,在request.POST中是没有的,它在request.body中-现在无论那种格式,都可以直接从request.data中取request.query_params:get请求提交的参数,以后从这里取request.FILES:取文件就还是从这个里面取,和之前一样
总结:
1.新的request跟之前的用法一模一样,如果新的request取不到,它使用__getattr__魔法方法去原生request中取。当然原生的也可以直接在新的request中拿到,request._request2.新的request中多了data属性,request.data客户端提交的请求体中的数据,无论是什么编码都在request.data中3.其他的使用和原生的request一模一样request.query_params就是原来的request._request.GET上传的文件从request.FILES'''1.原生Django提交数据(post),只能处理urlencoded和form-data编码,从request.POST中取2.原生Django提交数据(put),处理不了,需要我们从request.body中取出来进行处理分不同编码格式:urlencoded------》例:name=lqz&age=19---》使用字符串切割的方式.splitjson----->{'xxx':'xx','yyy':'yy'}--->需要自己进行json.loads反序列化3.原生Django不能处理json提交的数据(post/put),需要自己做反序列化json----->{'xxx':'xx','yyy':'yy'}--->需要自己进行json.loads反序列化4.新的request解决了所有问题:request.data'''
二、DRF之序列化组件
序列化类(组件)可以做的事情:1.序列化,QuerySet对象,单个对象做序列化给前端2.反序列化数据校验:前端传入数据后校验数据是否合法3.反序列化数据保存:前端传入数据,存到数据库中
序列化介绍
- 在写接口时,需要序列化和反序列化,而且反序列化的过程中要做数据校验,drf直接提供了固定的写法,只需要按照固定写法,只需要按照固定写法使用,就能完成上面的三个需求。
- 提供了两个类
Serializer、ModelSerializer,编写自定义的类,只需要继承drf提供的序列化类,就可以使用其中的某些方法,也能完成上面的三个需求
序列化类的作用:做序列化、反序列化、反序列化校验
序列化步骤
1.写一个py文件,叫serializer.py(命名随意)2.写一个序列化类,继承serializers.Serializer,3.在类中编写需要序列化的字段例:name=serializers.CharField()4.在视图类中使用,导入models文件中的类books,然后实例化得到对象,对查出来的query对象们,对单个对象序列化并传入instance=books参数如果query是复数,一定要串many=True,如果query是单个对象,就无需传入many5.序列化类对象:ser.data---->字典或列表----->通过Response将json格式字符串返回给前端
序列化组件的基本使用
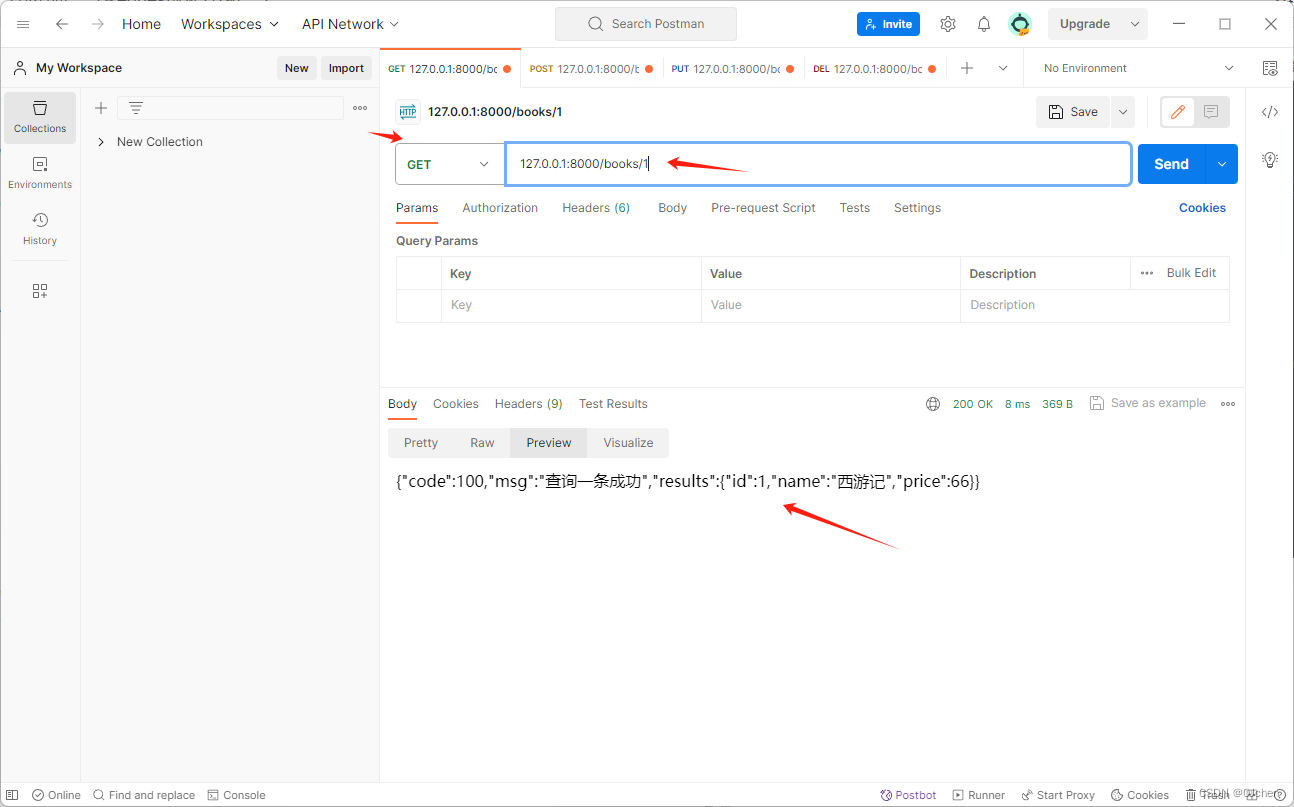
1.创建一个py文件 ----》serializer.pyfrom rest_framework import serializersclass BookSerializer(serializers.Serializer):name = serializers.CharField(max_length=18, min_length=2, required=True)price = serializers.IntegerField(required=True)2.view.py文件中from app01 import modelsfrom rest_framework.views import APIViewfrom rest_framework.response import Responsefrom .serializer import BookSerializerclass BookView(APIView):def get(self, request):book_list = models.Book.objects.all()ser = BookSerializer(instance=book_list, many=True) # 序列化多条需要many=Truereturn Response({'code': 100, 'msg': '查询成功', 'results': ser.data}) # 无论是列表还是字典都可以序列化class BookDetailView(APIView):def get(self, request, pk):book_obj = models.Book.objects.filter(pk=pk).first()ser = BookSerializer(instance=book_obj)if ser.is_valid():return Response({'code': 100, 'msg': '查询一条成功', 'results': ser})else:return Response(ser.errors)3.urls.py文件中urlpatterns = [path('books/', views.BookView.as_view()),path('books/<int:pk>', views.BookDetailView.as_view()),]
反序列化基本使用
反序列化过程:新增、修改
新增:1. 前端传入后端的数据,不论编码格式,都在request.data中,request.data格式是字典前端根据传入的编码格式不一样,从request.data取到的字典形式也是不一样的编码格式 字典urlencoded QueryDictform-data QueryDictjson dict2. 将前端传入的数据request.data进行反序列化,并完成序列化类的反序列化3. 序列化类得到对象并传入参数:data=request.data校验数据保存:ser.save()--->序列化类中重写create方法修改:1. 拿到前端传入的数据,进行反序列化,查出要修改的对象--->序列化类的反序列化2. 序列化类得到对象,传入参数:instance=要修改的对象,data=request.data校验数据 保存:ser.save() --->序列化类中重写update方法
反序列化的新增
序列化类
class BookSerializer(serializers.Serializer):name = serializers.CharField()price = serializers.IntegerField()# 新增一条数据def create(self, validated_data):# 保存的逻辑# validated_data 校验过后的数据 {name,price,publish}# 保存到数据库book = Book.objects.create(**validated_data)# 一定不要忘记返回新增的对象return book
视图类
class BookView(APIView):def get(self, request): # 获取多条数据book_list = models.Book.objects.all()'''instance表示要序列化的数据,many=True表示序列化多条(instance是QuerySet对象)'''ser = BookSerializer(instance=book_list, many=True) # 序列化多条需要many=Truereturn Response({'code': 100, 'msg': '查询成功', 'results': ser.data})def post(self, request):ser = BookSerializer(data=request.data) # 从前端传递数据从request.data中取出来if ser.is_valid(): # is_valid表示校验前端传入的数据,但是我们没有写校验规则# 保存,需要自己写,要在序列化类BookSerializer中重写create方法ser.save() # 调用ser.save,自动触发自定义编辑create方法保存数据'''这个时候发送post请求会发生报错,NotImplementedError: `create()` must be implemented.这个时候点击我们点击save查看源码是调用了Save会触发BaseSerializer的方法判断了 如果instance有值执行update,没有值执行create 看到create没有写 所以我们得重写Create'''return Response({'code': 100, 'msg': '添加成功', 'results': ser.data})else:return Response({'code': 101, 'msg': ser.errors})
反序列化的新增
序列化类
class BookSerializer(serializers.Serializer):name = serializers.CharField()price = serializers.IntegerField()# 修改对象def update(self, instance, validated_data):# instance 要修改的对象# validated_date 校验过后的数据instance.name = validated_data.get('name')instance.price = validated_data.get('price')instance.save() # orm的单个对象,修改了单个对象的属性,只要调用对象.save就可以修改保存到数据库return instance # 记得把修改的对象返回
视图类
class BookDetailView(APIView):def get(self, request, pk): # 获取单条数据book_obj = models.Book.objects.filter(pk=pk).first()ser = BookSerializer(instance=book_obj)return Response({'code': 100, 'msg': '查询一条成功', 'results': ser.data})def put(self, request, pk):book_obj = models.Book.objects.filter(pk=pk).first()ser = BookSerializer(instance=book_obj,data=request.data)if ser.is_valid():ser.save() # 同新增一样,需要重写update方法return Response({'code': 100, 'msg': '修改一条成功', 'results': ser.data})else:return Response({'code': 101, 'msg': ser.errors})
删除单条
class BookDetailView(APIView):def delete(self,request,pk):models.Book.objects.filter(pk=pk).delete()return Response({'code': 100, 'msg': '删除一条成功'})
反序列化的校验
反序列化的数据校验功能类比forms组件
- 局部钩子
- 全局钩子
代码实现
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
from .models import Bookclass BookSerializer(serializers.Serializer):name = serializers.CharField(max_length=18, min_length=2, required=True)price = serializers.IntegerField(required=True)publish = serializers.CharField(min_length=3)# 新增一条数据def create(self, validated_data):# 保存的逻辑# validated_data 校验过后的数据 {name,price,publish}# 保存到数据库book = Book.objects.create(**validated_data)# 一定不要忘记返回新增的对象return book# 修改对象def update(self, instance, validated_data):# instance 要修改的对象# validated_date 校验过后的数据instance.name = validated_data.get('name')instance.price = validated_data.get('price')instance.save() # orm的单个对象,修改了单个对象的属性,只要调用对象.save就可以修改保存到数据库return instance # 记得把修改的对象返回# 局部钩子def validate_price(self,price):if price < 10 or price > 999:raise ValidationError('价格不能高于999或者低于10')return price# 全局钩子def validate(self, attrs):# 校验过后的数据,出版社后三位文字与书名后三位不能一样if attrs.get('publish')[-3] == attrs.get('name')[-3]:raise ValidationError('出版社后三位文字不能与书名后三位一样!')return attrs
序列化器常用字段和字段参数
常用字段类
| 字段名 | 字段构造方式 |
|---|---|
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| FloatField | max_value=None, min_value=None |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format=’hex_verbose’) format: 1)'hex_verbose'如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2)'hex'如 “5ce0e9a55ffa654bcee01238041fb31a” 3)'int' - 如: “123456789012312313134124512351145145114” 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol=’both’, unpack_ipv4=False, **options) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
在序列化器内使用这些字段则是将接收到的字段转换成某个类型的。
如:id字段值为int类型,我们通过id=serializer.CharField()来接收,那么返回到视图里面的则是字符串类型了。
常用字段参数
选项参数:字段不同可使用的参数也不同
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
IntegerField
| 参数名称 | 作用 |
|---|---|
| max_value | 最小值 |
| min_value | 最大值 |
通用参数
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
序列化器-source的使用
提前准备好models.py中的数据
from django.db import models# 创建关联表class Book(models.Model):name = models.CharField(max_length=32)price = models.DecimalField(max_digits=5, decimal_places=2)# 外键 书与出版社 -对多,关联字段写在多的一方,写在Bookpublish=models.ForeignKey(to='Publish',on_delete=models.CASCADE)# 书与作者 多对多 需要建立中间表,django自动生成第三张表authors = models.ManyToManyField(to='Author')class Publish(models.Model):name= models.CharField(max_length=32)city= models.CharField(max_length=32)email = models.EmailField()class Author(models.Model):name = models.CharField(max_length=32)age = models.IntegerField()
source
- 可以定制序列化字段名
- 防止数据被人篡盗,将前端展示的字段名和后端数据的字段名设置成不同的字段名
source序列化自有字段和关联字段的区别
'serializer.py'class BookSerializer(serializers.Serializer):'自有字段,修改字段,映射字段,直接随意写序列化字段名'book_price = serializers.CharField(source='price')name = serializers.CharField(source='name')'关联字段,通过外键获取'一对一、一对多的关联,直接使用外键字段点publish = serializers.CharField(max_length=8,source='publish.name')多对多的关联,source不能用实现定制序列化关联表的字段authors = serializers.CharField(source='authors.all')
代码展示
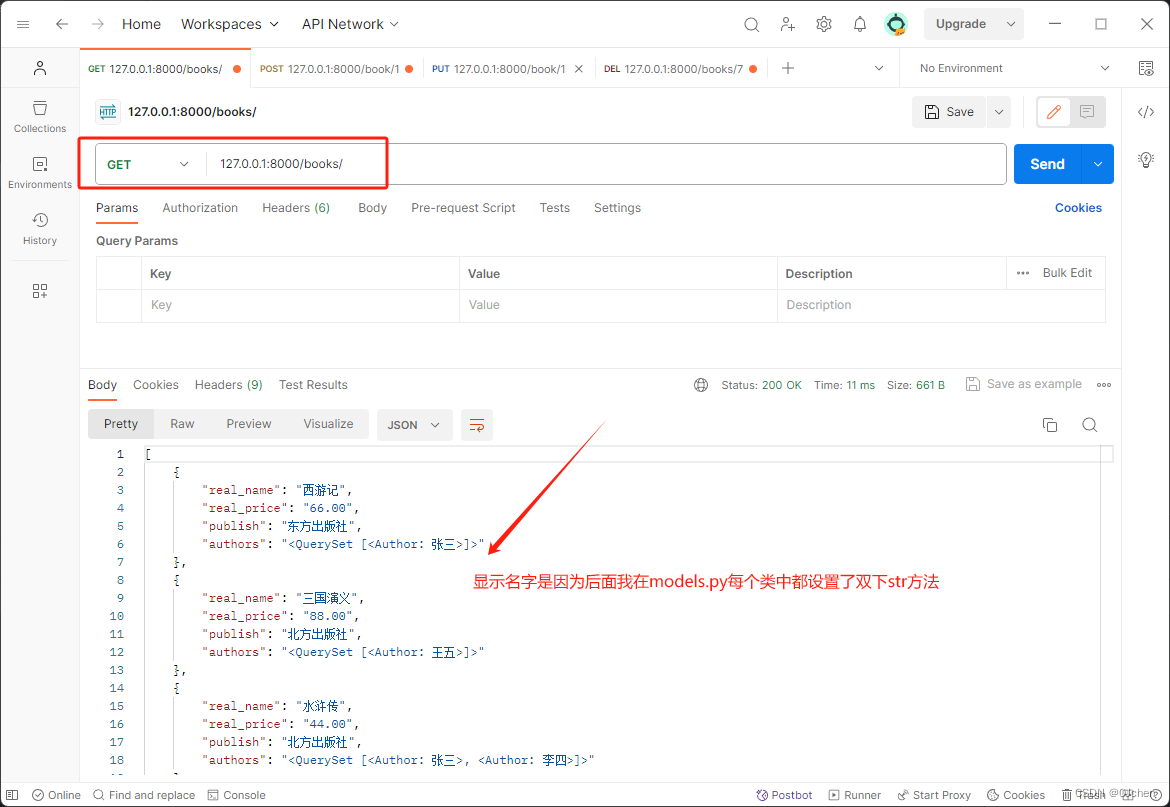
视图类:class BookAPIView(APIView):def get(self,request):books = Book.objects.all()ser = BookSerializer(instance=books,many=True)return Response(ser.data)定制序列化类from rest_framework import serializers# 序列化类class BookSerializer(serializers.Serializer):# 字段参数 都可以通过sourse定制具体的字段名# 自有字段,直接写表字段名real_name = serializers.CharField(max_length=8,source='name')real_price = serializers.CharField(source='price')# 关联字段 一对多 ,直接通过外键点publish=serializers.CharField(source='publish.name')# 多对多,source不能用定制关联表的字段authors = serializers.CharField(source='authors.all')"""1.我们序列化的是book表字段,自有字段名直接通过sourse指定的字段名-->>是Book表的字段名2.sourse定制目标的字段名name(max_length=8)...3.提高了安全性,后端真实的字段名:name、price,序列化给前端字段名:real_name、real_price,"authors": "<QuerySet [<Author: Author object (1)>, <Author: Author object (2)>]>""""
定制字段的两种方式
定制关联字段(publish/authors)的显示形式
- 一对多显示字典:{}
- 多对多显示列表套字典:[{},{},{}]
SerializerMethodField定制
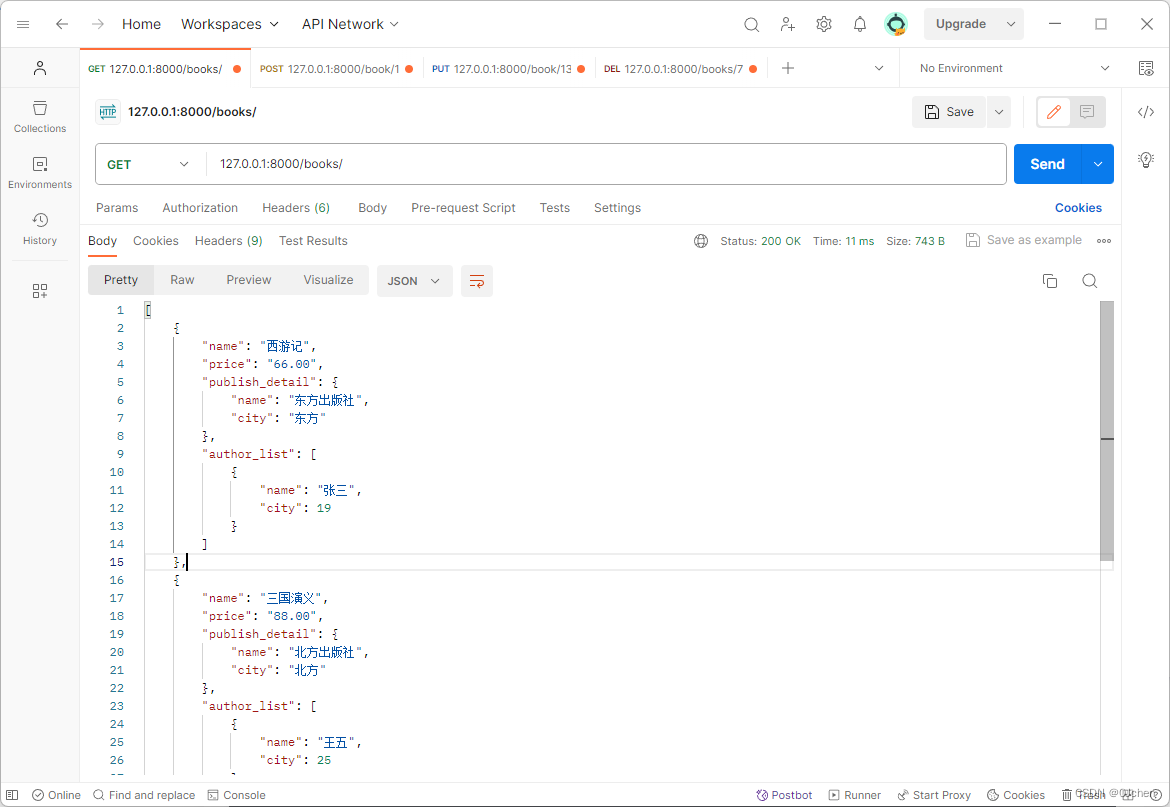
返回给前端的格式
{"name": "西游记","price": "66.00","publish_detail": {"name": "东方出版社","city": "东方"},"author_list": [{"name": "张三","city": 19}]},
高级序列化之SerializerMethodField
class BookSerializer(serializers.Serializer):name = serializers.CharField()price = serializers.CharField()# 定制返回格式----serializerMethodField# 只要写了这个字段类serializerMethodField,必须配合get_字段名publish_detail = serializers.SerializerMethodField()def get_publish_detail(self, obj):print(obj) # 当前序列化到的book对象return {'name': obj.publish.name, 'city': obj.publish.city}author_list = serializers.SerializerMethodField()def get_author_list(self,obj):l = []for author in obj.authors.all():l.append({'name': author.name, 'city': author.age})return l
在表模型中定制
返回给前端格式
{"name": "西游记","price": "66.00","publish_detail": {"name": "东方出版社","city": "东方"},"author_list": [{"name": "张三","age": 19}]},
'models.py'class Book(models.Model):name = models.CharField(max_length=32)price = models.DecimalField(max_digits=5, decimal_places=2)publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)authors = models.ManyToManyField(to='Author')# 定制在模型类中的方法def publish_detail(self):return {'name': self.publish.name, 'city': self.publish.city}def author_list(self):l = []for author in self.authors.all():l.append({'name': author.name, 'age': author.age})return l''class BookSerializer(serializers.Serializer):name = serializers.CharField()price = serializers.CharField()# 定制返回格式----在表模型中写方法,在序列化类中做映射publish_detail = serializers.DictField()author_list = serializers.ListField()
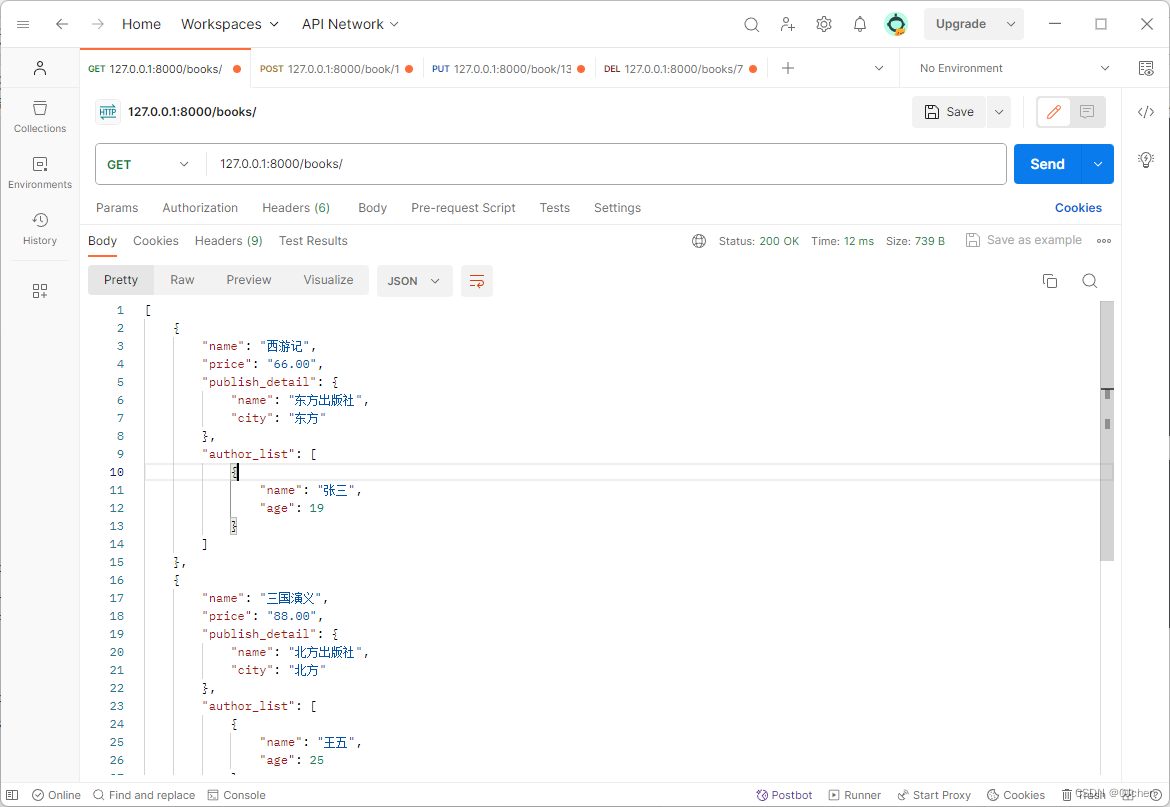
总结:
- 在序列化类中继承
SerializerMethodField,类中编写一个get_字段名(get_publish_detail)方法,该方法返回值=该字段值,该字段只能做序列化字段,反序列化不行 - 在表模型中使用编写:
get_字段名(get_publish_detail)方法,该publish_detail等于方法返回的值,序列化类中需要配合ListField,DictField两个字段类型---->该字段只能做序列化使用,不能实现做反序列化的字段 - 可以将上述的方法可以包装成数据属性—使用伪装@property
反序列化之保存数据
这里我就使用多表关联
'反序列化校验执行流程'1.先执行自有字段的校验(参数控制)-----》最大长度、最小长度、是否为空、是否必填、最小数字2.validators=[方法,] ---->单独给这个字段加校验规则(这个用的少,因为局部钩子就能实现)name=serializers.CharField(validators=[方法,])3.局部钩子校验规则4.全局钩子校验规则
新增
views.py
class BookView(APIView):def get(self, request):books = models.Book.objects.all()ser = BookSerializer(instance=books, many=True)return Response(ser.data)def post(self,request):ser = BookSerializer(data=request.data)if ser.is_valid():ser.save() # 书写序列化类中create方法return Response(ser.data)else:return Response(ser.errors)
序列化类中,使用
read_only和write_only分别定制序列化和反序列化的序列外键字段,并重写新增接口的create方法,read_only和write_only的目的是:需要序列化和反序列化的类,就可以使用这两种方法
read_only:表明该字段仅用于序列化输出,默认是False,序列化过程write_only:表明该字段经用于反序列化输入,默认是False,反序列化过程
serializer.py
class BookSerializer(serializers.Serializer):'''公共的'''name = serializers.CharField()price = serializers.CharField()'''只用来做反序列化'''# publish = serializers.IntegerField(write_only=True)publish_id = serializers.IntegerField(write_only=True)authors = serializers.ListField(write_only=True)'''只用来做序列化'''publish_detail = serializers.SerializerMethodField(read_only=True)author_list = serializers.SerializerMethodField(read_only=True)def get_publish_detail(self, obj):print(obj) # 当前序列化到的book对象return {'name': obj.publish.name, 'city': obj.publish.city}def get_author_list(self,obj):l = []for author in obj.authors.all():l.append({'name': author.name, 'city': author.age})return l'''新增,继承Serializer类必须要重写create方法'''def create(self, validated_date): # validated_date是校验过后的数据authors = validated_date.pop('authors')print(authors)print('------')print(validated_date)'''这里不能用**validated_date打散的方式,因为我们写的是 publish=1这种的它需要放一个对象,而其实存进去是publish_id=1,一个数字,所以无法使用,如果想要使用这个**打散的方式,需要把上面的publish改成publish_id,然后前端发送的也改成publish_id'''# name = validated_date.get('name')# price = validated_date.get('price')# publish_id = validated_date.get('publish')# book = models.Book.objects.create(name=name,price=price,publish_id=publish_id)book = models.Book.objects.create(**validated_date)book.authors.add(*authors)return book
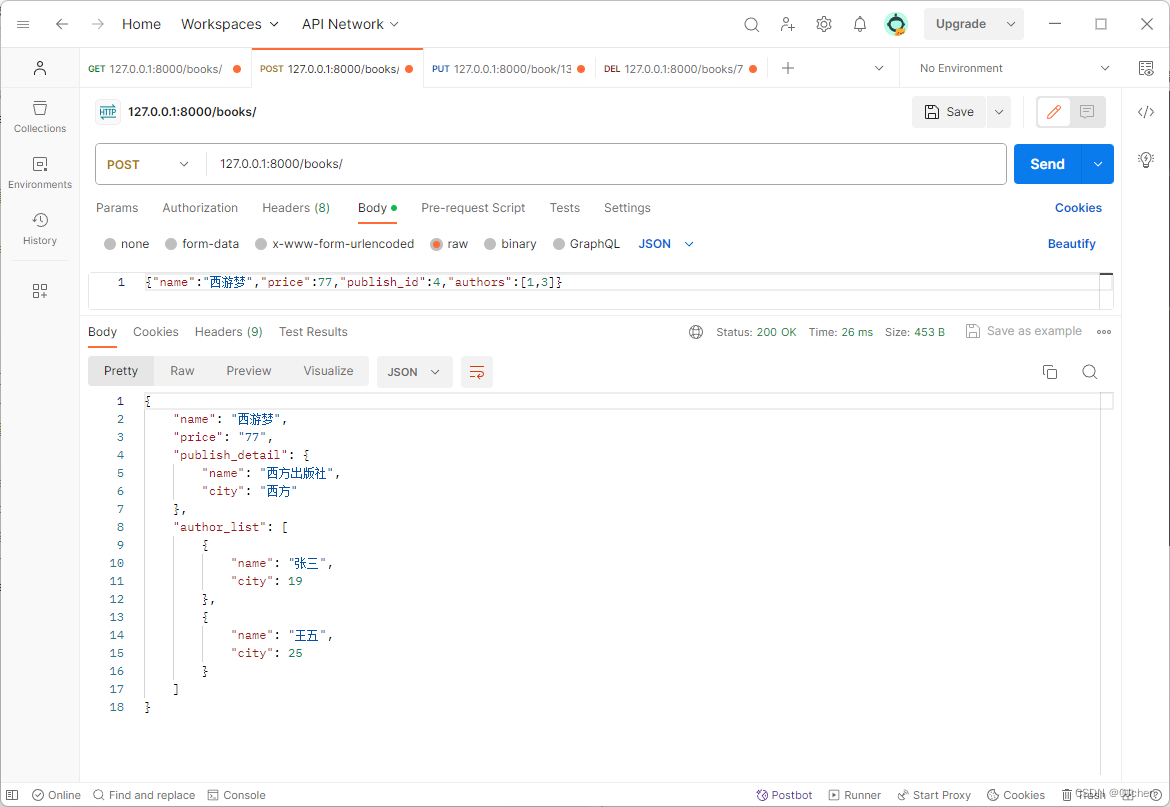
修改
修改跟新增不一样,因为得知道修改那一条,所以接口就得不一样,需要获取到想要修改的一条数据
urls.py
urlpatterns = [path('books/<int:pk>', views.BookDetailView.as_view()),]
views.py
class BookDetailView(APIView):def put(self, request, pk):book = models.Book.objects.get(id=pk)ser = BookSerializer(instance=book, data=request.data)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)
serializer.py
class BookSerializer(serializers.Serializer):'''公共的'''name = serializers.CharField()price = serializers.CharField()'''只用来做反序列化'''# publish = serializers.IntegerField(write_only=True)publish_id = serializers.IntegerField(write_only=True)authors = serializers.ListField(write_only=True)'''只用来做序列化'''publish_detail = serializers.SerializerMethodField(read_only=True)author_list = serializers.SerializerMethodField(read_only=True)def get_publish_detail(self, obj):print(obj) # 当前序列化到的book对象return {'name': obj.publish.name, 'city': obj.publish.city}def get_author_list(self,obj):l = []for author in obj.authors.all():l.append({'name': author.name, 'city': author.age})return l'''修改,继承Serializer类必须要重写update方法'''def update(self, instance,validated_date):# validated_data 校验过后的数据authors = validated_date.pop('authors')'''如果是用的publish的,又想要一次性传入进去,就得自己在定义一个publish_id'''# validated_date['publish_id'] = validated_date.pop('publish')for key in validated_date:setattr(instance, key, validated_date[key])instance.save()'''也可以直接使用set修改,无需清空后再添加'''instance.authors.clear()instance.authors.add(*authors)# instance.authors.set(authors) # 无需打散传入了return instance
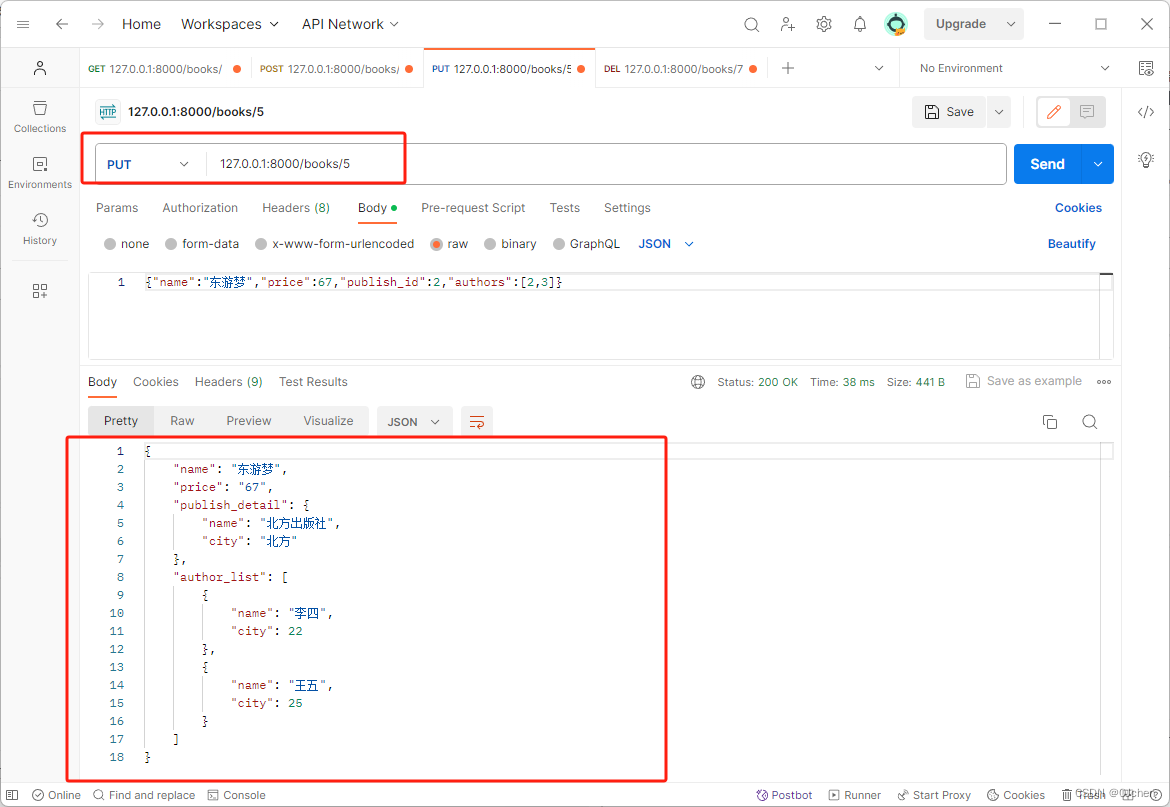
反序列化之数据校验
serializer.py
这里沿用上面案例的数据添加数据校验,数据校验和上面的反序列校验一样,所以这里就不细说了
'校验自有的字段'name = serializers.CharField(max_length=8,error_messages={'max_length:不能超过8位'})'''局部钩子校验'''def validate_name(self,name):l = ['sb', '傻逼','fw']for i in l:if i in name:raise ValidationError('图书命名中不能有敏感词!')return name'''局部钩子校验'''def validate_price(self, price):if int(price) < 10 or int(price) > 999:raise ValidationError('图书价格不能小于2位数或者不能大于4位数!')return price'''全局钩子校验'''def validate(self,attrs):print(attrs)publish_id = attrs.get('publish_id')print(publish_id)publish_obj = models.Publish.objects.filter(pk=publish_id).first()print(publish_obj.name)if attrs.get('name')[-2] == publish_obj.name[-2]:raise ValidationError('图书名后两位不能与出版社后两位相同')return attrs

ModelSerializer的使用
ModelSerializer继承了Serializer,帮我们完成了很多的操作,比如跟表模型强关联,大部分的请求post和put等,几乎不用再序列化的时候重写create和update方法了。
使用方式跟上面的Serializer的基本一样,我这里就还是用上面的案例来操作
serializer.py
'''继承ModelSerializer类做序列化、反序列化以及校验操作'''
class BookModelSerializer(serializers.ModelSerializer):'''其他跟Serializer一样使用,不过无需再重写create和update方法''''''只用来做序列化,这些扩写的字段也需要在field中注册'''publish_detail = serializers.SerializerMethodField(read_only=True)author_list = serializers.SerializerMethodField(read_only=True)def get_publish_detail(self, obj):print(obj) # 当前序列化到的book对象return {'name': obj.publish.name, 'city': obj.publish.city}def get_author_list(self, obj):l = []for author in obj.authors.all():l.append({'name': author.name, 'city': author.age})return lclass Meta:model = models.Book # 这两句是会把表模型中的Book,所有字段映射过来# fields = '__all__'fields = ['name', 'price', 'publish', 'authors', 'publish_detail', 'author_list']'''如果使用表模型定制字段,然后在fields中注册了,可以直接在extra_kwargs中设置字段属性read_only'''extra_kwargs = { # 给某个或某几个字段设置字段属性'name': {'max_length': 18, 'min_length': 2},'price': {'max_digits': 8, 'decimal_places': 3},'publish': {'write_only': True},'authors': {'write_only': True},# 'publish_detail': {'read_only': True},# 'author_list': {'read_only': True},}'''局部钩子'''def validate_name(self,name):l = ['sb', '傻逼','fw']for i in l:if i in name:raise ValidationError('图书命名中不能有敏感词!')return namedef validate_price(self, price):if int(price) < 10 or int(price) > 999:raise ValidationError('图书价格不能小于2位数或者不能大于4位数!')return price# '''全局钩子'''# def validate(self,attrs):# print(attrs)# publish_id = attrs.get('publish')# print(publish_id)# publish_obj = models.Publish.objects.filter(pk=publish_id).first()# print(publish_obj.name)# if attrs.get('name')[-2] == publish_obj.name[-2]:# raise ValidationError('图书名后两位不能与出版社后两位相同')# return attrs
这里为了区分一下,我就更改了接口路由
urlpatterns = [path('books/', views.BookModelView.as_view()),path('books/<int:pk>', views.BookDetailModelView.as_view()),]
views.py,视图类也是为了做一下区分,所以我修改了序列化类名,其他跟serializer那个操作一样
'''继承serializer类的ModelSerializer方式'''class BookModelView(APIView):def get(self,request):book = models.Book.objects.all()ser = BookModelSerializer(instance=book,many=True)return Response(ser.data)def post(self,request):ser = BookModelSerializer(data=request.data)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)class BookDetailModelView(APIView):def put(self, request, pk):book = models.Book.objects.filter(pk=pk).first()ser = BookModelSerializer(instance=book, data=request.data)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)
使用方法
1.定义一个类继承ModelSerializer2.类内部写内部类 Class Meta:(注意区分大小写)3.在内部类中指定model(需要序列化的表)4.在内部类中指定fields(要序列化的字段,写__all__表示所有,不包含方法,也可以写一个个的字段)5.在内部类中指定extra_kwargs,给字段天津爱字段参数6.在序列化类中,可以重写某个字段,优先使用你重写的name = serializers.SerializerMethodField()def get_name(self,obj):return obj.name + '__fw'7.以后几乎不需要重写create和update方法了(除非有需求要用到就得重写)-ModelSerializer写好了,兼容性更好,任意表都可以直接存
总结
ModelSerializer继承自Serializer,我们可以直接查询多条,单条,新增和修改等操作针对fields=['name','email','city']里面的参数要求:1.只要是序列化的字段和反序列化的字段,都要在这注册 如:publish_detail,publish,authors2.序列化的字段,可能不是表模型的字段,是自己写的方法3.序列化的字段,可能是使用SerializerMethodField,也要注册
相关文章:
DRF从入门到精通二(Request源码分析、DRF之序列化、反序列化、反序列化校验、序列化器常用字段及参数、source、定制字段、保存数据)
文章目录 一、Request对象源码分析区分原生request和新生request新的request还能像原来的reqeust一样使用吗源码片段分析总结: 二、DRF之序列化组件序列化介绍序列化步骤序列化组件的基本使用反序列化基本使用反序列化的新增反序列化的新增删除单条 反序列化的校验序…...

Flink系列之:Upsert Kafka SQL 连接器
Flink系列之:Upsert Kafka SQL 连接器 一、Upsert Kafka SQL 连接器二、依赖三、完整示例四、可用元数据五、键和值格式六、主键约束七、一致性保证八、为每个分区生成相应的watermark九、数据类型映射 一、Upsert Kafka SQL 连接器 Scan Source: Unbounded 、Sink…...
)
前端与后端的异步编排(promise、async、await 、CompletableFuture)
前端与后端的异步编排 文章目录 前端与后端的异步编排1、为什么需要异步编排2、前端中的异步2.1 、Promise的使用2.1.1、Promise的基础概念2.1.2、Promise中的两个回调函数2.1.3、工具方法1、Promise.all()2、Promise.race()3、Promise.resolve() 2.2 、async 与 aw…...
python打开opencv图像与QImage图像及其转化
目录 1、Qimage图像 2、opencv图像 3、python打开QImage图像通过Qlabel控件显示 4、python打开QImage图像通过opencv显示 5、python打开opencv图像并显示 6、python打开opencv图像通过Qlabel控件显示 1、Qimage图像 QImage是Qt库中用于存储和处理图像的类。它可以存储多种…...

linux 其他版本RCU
1、不可抢占RCU 如果我们的需求是“不管内核是否编译了可抢占RCU,都要使用不可抢占RCU”,那么应该使用不可抢占RCU的专用编程接口。 读者使用函数rcu_read_lock_sched()标记进入读端临界区,使用函数rcu_read_unlock_ sched()标记退出读端临界…...

【单调栈】LeetCode:2818操作使得分最大
作者推荐 map|动态规划|单调栈|LeetCode975:奇偶跳 涉及知识点 单调栈 题目 给你一个长度为 n 的正整数数组 nums 和一个整数 k 。 一开始,你的分数为 1 。你可以进行以下操作至多 k 次,目标是使你的分数最大: 选择一个之前没有选过的 非…...
uniapp 添加分包页面,配置分包预下载
为什么要分包 ? 分包即将小程序代码分成多个部分打包,可以减少小程序的加载时间,提升用户体验 添加分包页面 比较便捷的方法是使用vscode插件 uni-create-view 新建分包文件夹 以在我的页面,添加分包的设置页面为例,新建文件夹 s…...
成功案例分享:物业管理小程序如何助力打造智慧社区
随着科技的进步和互联网的普及,数字化转型已经渗透到各个行业,包括物业管理。借助小程序这一轻量级应用,物业管理可以实现线上线下服务的无缝对接,提升服务质量,优化用户体验。本文将详细介绍如何通过乔拓云网设计小程…...

Electron执行本地cmd命令
javascript执行本地cmd命令,javascript代码怎么执行_js调用本机cmd-CSDN博客 使用 Node.js 打开本地应用_nodejs启动应用-CSDN博客 笔记:nodejs脚本唤醒本地应用程序或者调用命令-CSDN博客 electron调起本地应用_electron 调用本地程序-CSDN博客 命令行打开vscode 你可以使用…...

YOLOv8改进 | 主干篇 | 利用MobileNetV3替换Backbone(轻量化网络结构)
一、本文介绍 本文给大家带来的改进机制是MobileNetV3,其主要改进思想集中在结合硬件感知的网络架构搜索(NAS)和NetAdapt算法,以优化移动设备CPU上的性能。它采用了新颖的架构设计,包括反转残差结构和线性瓶颈层&…...

MATLAB Mobile - 使用预训练网络对手机拍摄的图像进行分类
系列文章目录 前言 此示例说明如何使用深度学习对移动设备摄像头采集的图像进行分类。 在您的移动设备上安装和设置 MATLAB Mobile™。然后,从 MATLAB Mobile 的“设置”登录 MathWorks Cloud。 在您的设备上启动 MATLAB Mobile。 一、在您的设备上安装 MATLAB M…...

LangChain入门指南:定义、功能和工作原理
LangChain入门指南:定义、功能和工作原理 引言LangChain是什么?LangChain的核心功能LangChain的工作原理LangChain实际应用案例如何开始使用LangChain 引言 在人工智能的浪潮中,语言模型已成为推动技术革新的重要力量。从简单的文本生成到复…...
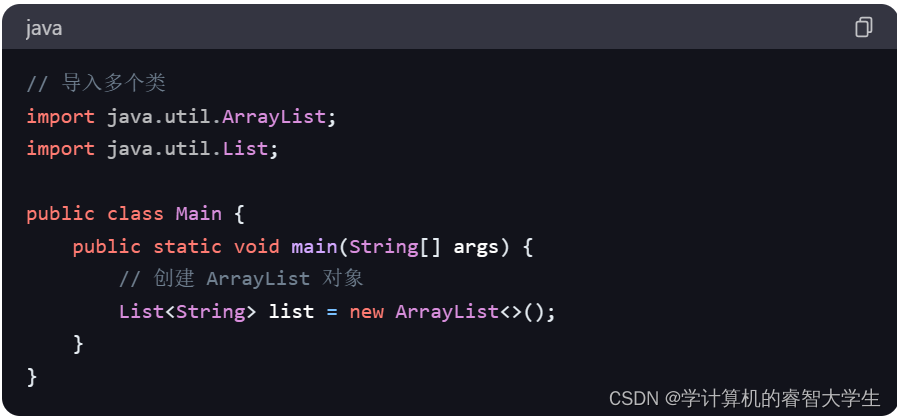
关键字:import关键字
在 Java 中,import关键字用于导入类或接口,使你可以在代码中使用它们而无需完全限定其名称。以下是使用import关键字的示例代码: 在上述示例中,通过使用import关键字导入了java.util.ArrayList类,这样就可以在代码中直…...

【C#】.net core 6.0 通过依赖注入注册和使用上下文服务
给自己一个目标,然后坚持一段时间,总会有收获和感悟! 请求上下文是指在 Web 应用程序中处理请求时,包含有关当前请求的各种信息的对象。这些信息包括请求的头部、身体、查询字符串、路由数据、用户身份验证信息以及其他与请求相关…...
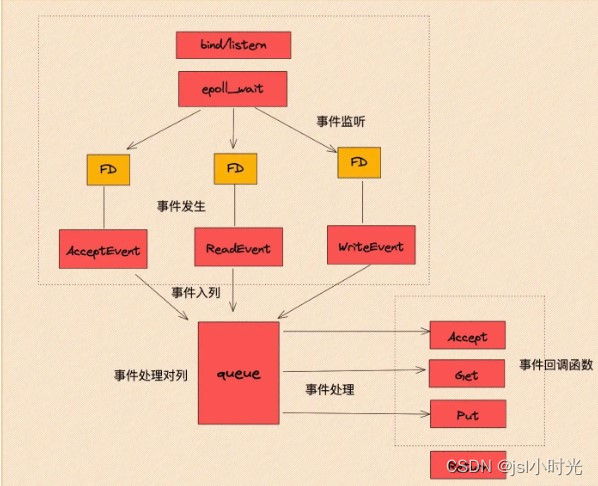
关于redis单线程和IO多路复用的理解
首先,Redis是一个高性能的分布式缓存中间件。其复杂性不言而喻,对于Redis整体而言肯定不是只有一个线程。 我们常说的Redis 是单线程,主要是指 Redis 在网络 IO和键值对读写是采用一个线程来完成的,这也是 Redis 对外提供键值存储…...

第四十一章 XML 映射参数摘要
文章目录 第四十一章 XML 映射参数摘要 第四十一章 XML 映射参数摘要 TopicParameters启用 XML 映射。XMLENABLED 类参数将属性映射到元素或属性。XMLPROJECTION property parameter ("NONE", "ATTRIBUTE", "XMLATTRIBUTE", "CONTENT"…...

redis之五种基本数据类型
一) 字符串(String) 1 使用场景 2 编码 3 编码转换 二) List(列表) 1 使用场景 2 编码 三) Set(无序集合) 1 使用场景 2 编码 3 编码转换 四) ZSet(有序集合) 1 使用场景 2 编码 3 编码转换 五) Hash 1 使用场景 2 编码 3 编码转换 五种基本数据类型 redis…...
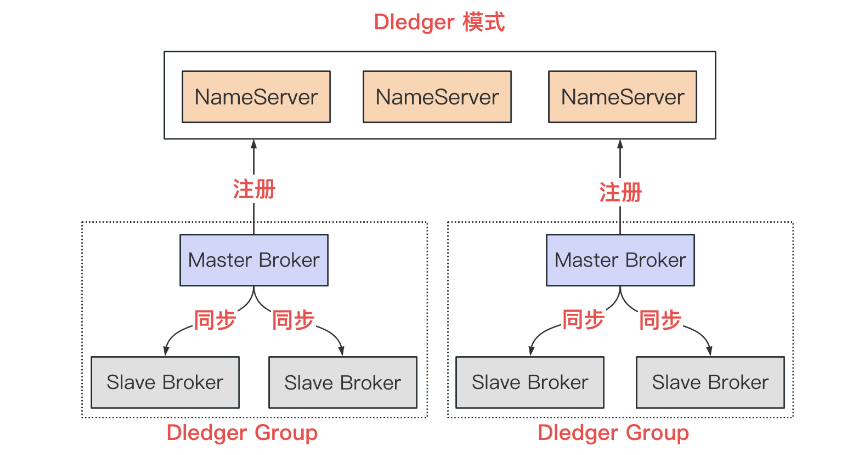
RocketMQ系统性学习-RocketMQ高级特性之消息大量堆积处理、部署架构和高可用机制
🌈🌈🌈🌈🌈🌈🌈🌈 【11来了】文章导读地址:点击查看文章导读! 🍁🍁🍁🍁🍁🍁dz…...
Angular 进阶之五: Signals到底用不用?
Angular 在V16的时候推出了Signals,在17正式作为主打功能之一强烈推荐,看过了各种博主的各种科普文章也没说明白,到底这东西值不值得用?毕竟项目大了,重构代码也不是闹着玩儿的。各种科普文章主要在说两点:…...

构建数字化金融生态系统:云原生的创新方法
内容来自演讲:曾祥龙 | DaoCloud | 解决方案架构师 摘要 本文探讨了金融企业在实施云原生体系时面临的挑战,包括复杂性、安全、数据持久化、服务网格使用和高可用容灾架构等。针对网络管理复杂性,文章提出了Spiderpool开源项目,…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...
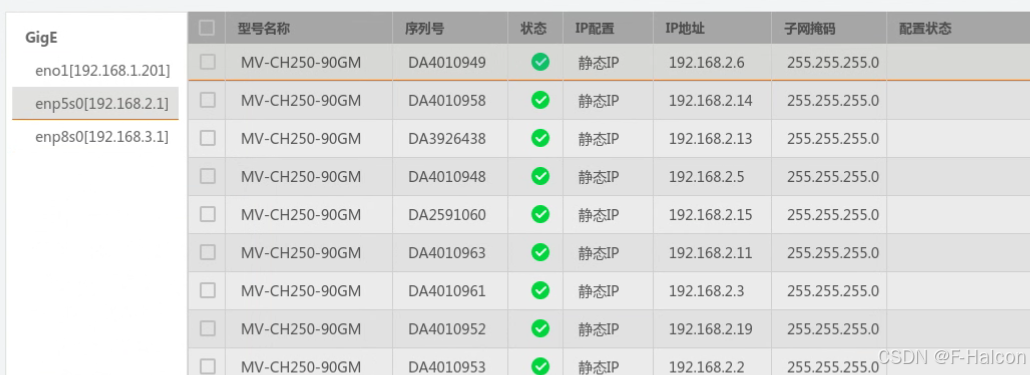
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...