机器学习笔记(二)使用paddlepaddle,再探波士顿房价预测
目标
用paddlepaddle来重写之前那个手写的梯度下降方案,简化内容
流程
实际上就做了几个事:
- 数据准备:将一个批次的数据先转换成nparray格式,再转换成Tensor格式
- 前向计算:将一个批次的样本数据灌入网络中,计算出结果
- 计算损失函数:以前向计算的结果和真是房价作为输入,通过算是函数sqare_error_cost计算出损失函数。
- 反向传播:执行梯度反向传播backward函数,即从后到前逐层计算每一层的梯度,并根据设置的优化算法更新参数(opt.step函数)。
paddlepaddle做了什么?
paddle库替你做了前向计算和损失函数计算,以及反向传播相关的计算函数
数据准备
这部分代码和之前一样,读取数据是独立的
点击查看代码#数据划分函数不依赖库,还是自己读
def load_data():# 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ', dtype=np.float32)# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算train数据集的最大值,最小值maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)# 记录数据的归一化参数,在预测时对数据做归一化global max_valuesglobal min_valuesmax_values = maximumsmin_values = minimums# 对数据进行归一化处理for i in range(feature_num):data[:, i] = (data[:, i] - min_values[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_data定义一个依赖paddle库的类
点击查看代码class Regressor(paddle.nn.Layer):#self代表对象自身def __init__(self):#初始化父类的参数super(Regressor, self).__init__()#定义一层全连接层,输入维度是13,输出维度是1self.fc = Linear(in_features=13, out_features=1)#网络的前向计算函数def forward(self, inputs):x = self.fc(inputs)return x
在上面这个类中,不论是前向计算还是初始化,都是继承了这个paddle.nn.Layer类,用其内部的成员函数执行的
代码
我们定义一个循环来执行这个流程,如下:
点击查看代码EPOCH_NUM = 10 # 设置外层循环次数
BATCH_SIZE = 10 # 设置batch大小# 定义外层循环
for epoch_id in range(EPOCH_NUM):# 在每轮迭代开始之前,将训练数据的顺序随机的打乱np.random.shuffle(training_data)# 将训练数据进行拆分,每个batch包含10条数据mini_batches = [training_data[k:k+BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]# 定义内层循环for iter_id, mini_batch in enumerate(mini_batches):x = np.array(mini_batch[:, :-1]) # 获得当前批次训练数据y = np.array(mini_batch[:, -1:]) # 获得当前批次训练标签(真实房价)# 将numpy数据转为飞桨动态图tensor的格式house_features = paddle.to_tensor(x)prices = paddle.to_tensor(y)# 前向计算predicts = model(house_features)# 计算损失loss = F.square_error_cost(predicts, label=prices)avg_loss = paddle.mean(loss)if iter_id%20==0:print("epoch: {}".format(epoch_id))print("iter: {}".format(str(iter_id)))print("loss is : {}".format(float(avg_loss)))# 反向传播,计算每层参数的梯度值avg_loss.backward()# 更新参数,根据设置好的学习率迭代一步opt.step()# 清空梯度变量,以备下一轮计算opt.clear_grad()
保存模型
在梯度下降得到一个模型了之后,可以把这个神经网络模型保存下来
点击查看代码paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功,模型参数保存在LR_model.pdparams中")
读取模型
在启动模型之前,当然可以读取这样一个模型:
点击查看代码def load_one_example():# 从上边已加载的测试集中,随机选择一条作为测试数据idx = np.random.randint(0, test_data.shape[0])idx = -10one_data, label = test_data[idx, :-1], test_data[idx, -1]# 修改该条数据shape为[1,13]one_data = one_data.reshape([1,-1])return one_data, label # 参数为保存模型参数的文件地址
#读取保存模型
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict) #读取模型文件
model.eval() #转变为预测模式
尝试进行预测
点击查看代码# 参数为数据集的文件地址
one_data, label = load_one_example()
# 将数据转为动态图的variable格式
one_data = paddle.to_tensor(one_data)
#model是定义的模型,这个model(one_data)实际上是对one_Data进行了一次前向传播
predict = model(one_data)# 因为这个predict的值实际上是做了归一化处理的,所以这里需要进行反归一化处理
predict = predict * (max_values[-1] - min_values[-1]) + min_values[-1]
# 对label数据做反归一化处理
label = label * (max_values[-1] - min_values[-1]) + min_values[-1]#模型预测值是22.72234,,实际值是19.700000762939453
print("Inference result is {}, the corresponding label is {}".format(predict.numpy(), label))
相关文章:
使用paddlepaddle,再探波士顿房价预测)
机器学习笔记(二)使用paddlepaddle,再探波士顿房价预测
目标 用paddlepaddle来重写之前那个手写的梯度下降方案,简化内容 流程 实际上就做了几个事: 数据准备:将一个批次的数据先转换成nparray格式,再转换成Tensor格式前向计算:将一个批次的样本数据灌入网络中ÿ…...

【Linux】权限篇(二)
权限目录 1. 前言2. 权限2.1 修改权限2.2 有无权限的对比2.3 另外一个修改权限的方法2.3.1 更改用户角色2.3.2 修改文件权限属性 3. 第一个属性列4. 目录权限5. 默认权限 1. 前言 在之前的一篇博客中分享了关于权限的一些知识,这次紧接上次的进行,有需要…...

reduce累加器的应用
有如下json数据,需要统计Status的值为0和1的数量 const data {"code": "001","results": [{"Status": "0",},{"Status": "0",},{"Status": "1",}] }方法一:用reduce方…...
助力硬件测试工程师之EMC项目测试。
1:更新该系列的目的 接下来的一个月内,将更新硬件测试工程师的其中测试项目--EMC项目,后续将会出安规等项目,助力测试工程师的学习。 2:如何高效率的展现项目的基础以及一些细节知识点 通过思维导图以及标准的规定进行…...
Github 2023-12-23 开源项目日报 Top10
根据Github Trendings的统计,今日(2023-12-23统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Python项目6C项目2C项目1Jupyter Notebook项目1HTML项目1Go项目1非开发语言项目1 免费API集体清单 创建周期…...

Quartz.net 正则表达式触发器
1、创建项目 项目类型控制台应用程序,.Net Framework框架版本 4.7.2 2、引入框架 NuGet\Install-Package Quartz -Version 3.8.0 3、创建Job 自定义Job实现接口IJob,在Execute方法实现定时逻辑, using Quartz; using System; using Sys…...

【已解决】修改了网站的class样式name值,会影响SEO,搜索引擎抓取网站及排名吗?
问题: 修改了网站的class样式name值,会影响搜索引擎抓取网站及排名吗? 解答: 如果你仅仅修改了网站class样式的名称,而没有改变网站的结构和内容,那么搜索引擎通常不会因此而影响它对网站的抓取和排名。但…...

微信小程序开发系列-02注册小程序
上一篇文章,创建了一个最小的小程序,但是,还有3个疑问没有弄清楚,还是基于demo1工程,这篇文章继续探索。 当前的目录结构是否是完备的呢?(虽然小程序可以运行起来)app.js文件内容还…...
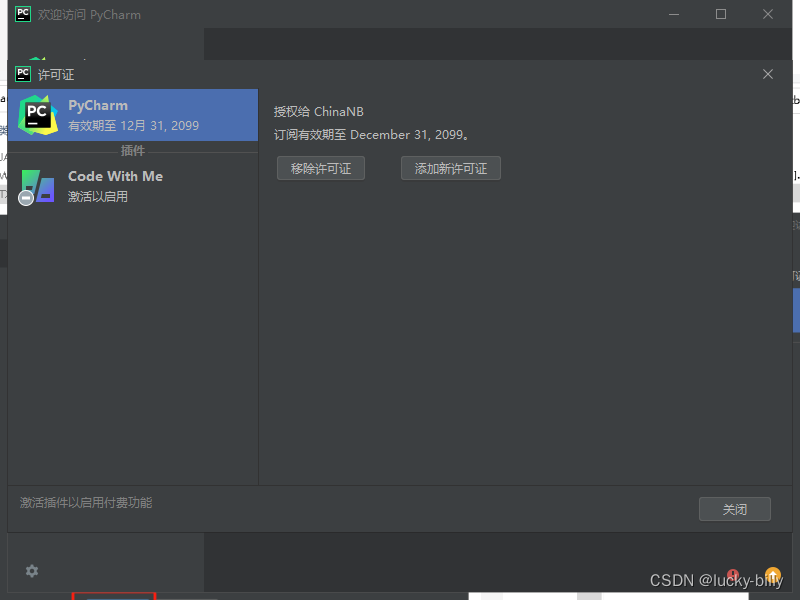
安装 PyCharm 2021.1 保姆级教程
作者:billy 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 前言 目前能下载到的最新版本是 PyCharm 2021.1。 请注意对应 Python 的版本: Python 2: 2.7Python 3: >3.6, <3.11…...
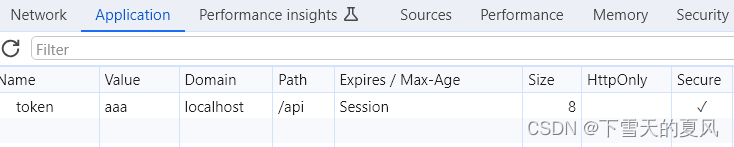
浏览器 cookie 的原理(详)
目录 1,cookie 的出现2,cookie 的组成浏览器自动发送 cookie 的条件 3,设置 cookie3.1,服务端设置3.1,客户端设置3.3,删除 cookie 4,使用流程总结 整理和测试花了很大时间,如果对你有…...

StringBuilder和StringBuffer区别是什么?
想象一下,你在写信,但是你需要不断地添加新的内容或者修改一些词句。在编程中,当你需要这样操作字符串时,就可以用StringBuffer或StringBuilder。 StringBuffer StringBuffer就像是一个多人协作写作的工具。如果你和你的朋友们一…...

【数据分析】数据指标的分类及应用场景
数据分析之数据指标的分类 数据分析离不开对关键指标的分析与跟踪,这些指标通常与具体的业务直接相关。好的指标能够促进业务的健康发展,因为指标与业务目标是一致的,此时指标就能反映业务变化,指标发生变化,行动也发…...
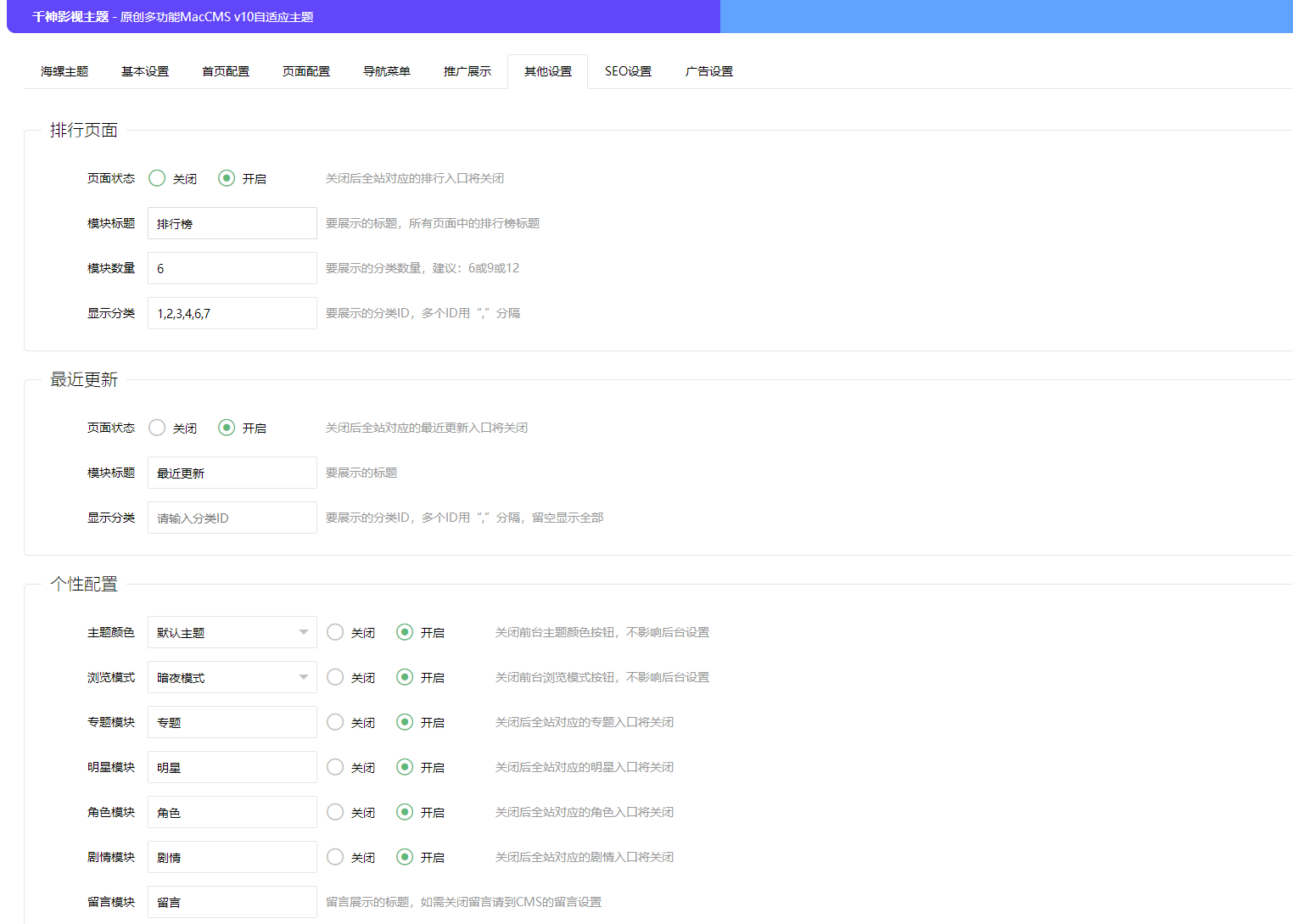
首涂第二十八套_新版海螺M3多功能苹果CMSv10自适应全屏高端模板
首涂第二十八套_新版海螺M3多功能苹果cmsv10自适应全屏高端模板 多功能苹果cmsv10自适应全屏高端模板开源授权版 这是一款带“主题管理系统”的模板。这是一款好模板。 花大价钱收购了海螺这两个模板的版权。官方正品,非盗版。关闭域名授权 后台自定义菜单 请把…...

MatGPT - 访问 OpenAI™ ChatGPT API 的 MATLAB® 应用程序
系列文章目录 前言 MatGPT 是一款 MATLAB 应用程序,可让您轻松访问 OpenAI 的 ChatGPT API。使用该应用程序,您可以加载特定用例的提示列表,并轻松参与对话。如果您是 ChatGPT 和提示工程方面的新手,MatGPT 不失为一个学习的好方…...
Tomcat转SpringBoot、tomcat升级到springboot、springmvc改造springboot
Tomcat转SpringBoot、tomcat升级到springboot、springmvc改造springboot 起因:我接手tomcat-springmvc-hibernate项目,使用tomcat时问题不大。自从信创开始,部分市场使用国产中间件,例如第一次听说的宝兰德、东方通,还…...

浅述无人机技术在地质灾害应急救援场景中的应用
12月18日23时,甘肃临夏州积石山县发生6.2级地震,震源深度10千米,灾区电力、通信受到影响。地震发生后,无人机技术也火速应用在灾区的应急抢险中。目前,根据受灾地区实际情况,翼龙-2H应急救灾型无人机已出动…...

js-cookie的使用以及存储token安全的注意要点
js-cookie的使用以及存储token安全的注意要点 npm 安装 npm i js-cookie -S // https://www.npmjs.com/package/js-cookie引入使用 import Cookies from js-cookie获取 Cookies.get(token); // 读取token Cookies.get() // 读取所有可见的 Cookie > { token: value }设置…...

Android 网络状态判断
1、获取网络信息,首先需要获取权限 <uses-permission android:name"android.permission.INTERNET" /> <uses-permission android:name"android.permission.ACCESS_NETWORK_STATE" /> 2.1我们通过ConnectivityManager可以获取状态…...

管理类联考——数学——真题篇——按知识分类——代数——数列
【等差数列 ⟹ \Longrightarrow ⟹ 通项公式: a n a 1 ( n − 1 ) d a m ( n − m ) d n d a 1 − d A n B a_n a_1(n-1)d a_m(n-m)dnda_1-dAnB ana1(n−1)dam(n−m)dnda1−dAnB ⟹ \Longrightarrow ⟹ A d , B a 1 − d Ad&#x…...
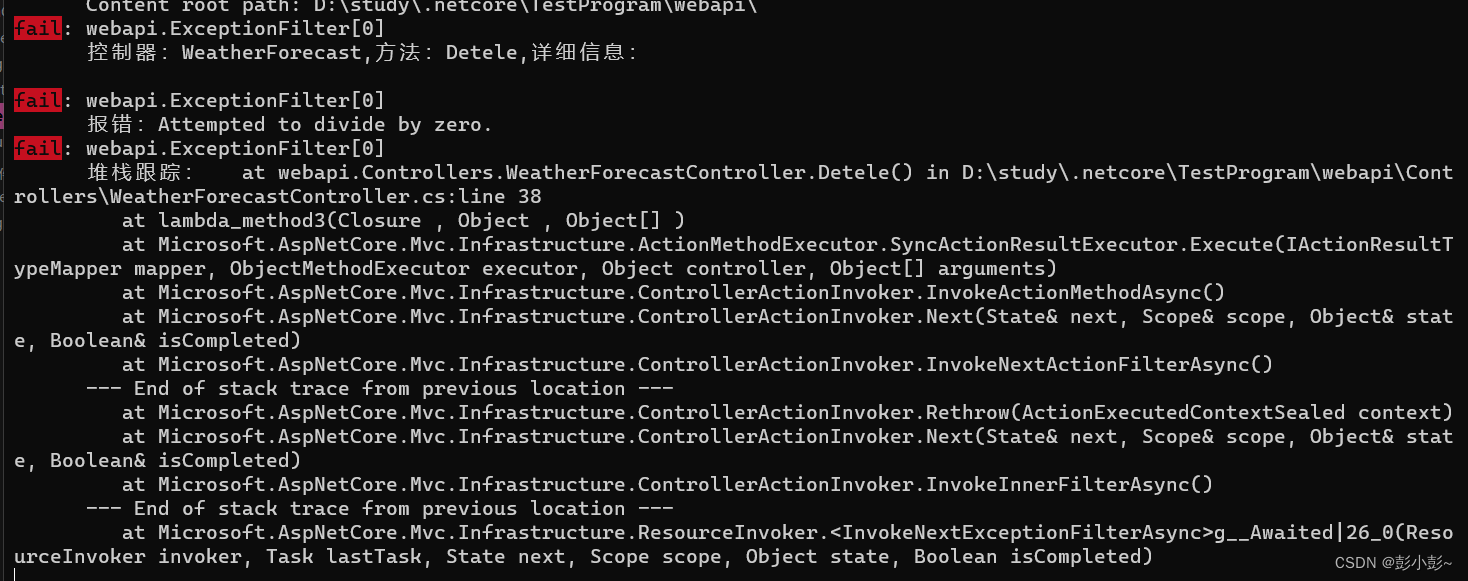
.net core webapi 自定义异常过滤器
1.定义统一返回格式 namespace webapi;/// <summary> /// 统一数据响应格式 /// </summary> public class Results<T> {/// <summary>/// 自定义的响应码,可以和http响应码一致,也可以不一致/// </summary>public int Co…...

SEO 和网站推广有什么区别_如何判断一个网站的 SEO 质量
SEO 和网站推广有什么区别 在数字营销的广阔天地中,SEO(搜索引擎优化)和网站推广是两个常被提及的概念。它们虽然都旨在提升网站的流量和知名度,但实际上,它们之间有着显著的区别。理解这两者的异同,对于有…...

基于合法无代码平台滥用的新型钓鱼攻击机理与防御体系研究
摘要 2026 年 3 月卡巴斯基实验室披露针对 Bubble.io 等正规无代码开发平台的恶意滥用钓鱼攻击,攻击者依托平台高信誉域名、SSL 证书与可视化开发能力,快速生成高仿真钓鱼页面,绕过传统邮件网关与终端检测,实现账号凭证、多因素认…...

手把手教你用FBRT-YOLO在VisDrone数据集上跑出SOTA:从环境配置到模型推理的保姆级教程
手把手教你用FBRT-YOLO在VisDrone数据集上跑出SOTA:从环境配置到模型推理的保姆级教程 航拍图像目标检测一直是计算机视觉领域的难点,尤其是小目标检测问题。无人机拍摄的图像分辨率高、目标密集且尺寸小,传统检测算法往往难以兼顾精度和速度…...

终极Cursor Pro破解教程:告别免费限制,解锁无限AI编程体验
终极Cursor Pro破解教程:告别免费限制,解锁无限AI编程体验 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve r…...
✅)
计算机毕业设计:Python智能二手车数据可视化推荐系统 Flask框架 requests爬虫 协同过滤推荐算法 可视化 汽车之家 机器学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

BiliTools:解决B站资源离线访问难题的跨平台技术方案
BiliTools:解决B站资源离线访问难题的跨平台技术方案 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 在…...

Vue3 + xterm.js 4.x + WebSocket 打造现代化Web终端实战指南
1. 为什么选择Vue3 xterm.js 4.x WebSocket组合? 在构建现代化Web终端时,技术选型直接影响开发效率和最终用户体验。Vue3提供了响应式编程范式和组件化开发优势,xterm.js 4.x是最新版本的浏览器终端模拟器,而WebSocket则实现了…...

ai赋能设计:超越传统ps软件下载,用快马打造你的智能图像创作助手
AI赋能设计:超越传统PS软件下载,用快马打造你的智能图像创作助手 传统PS软件下载后,设计师往往需要花费大量时间在重复性操作上。而现在,通过InsCode(快马)平台结合AI模型,我们可以打造一个全新的智能图像创作助手&am…...

KeymouseGo:让重复操作自动化的效率工具指南
KeymouseGo:让重复操作自动化的效率工具指南 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 在数字化工作环境中…...

MFC界面现代化---自定义标题栏与控件美化实战
1. 为什么需要MFC界面现代化改造 很多老牌企业软件和工业控制系统都基于MFC框架开发,这些系统通常运行了十几年甚至更久。我接手过不少这类项目,最直观的感受就是界面实在太"复古"了——灰底蓝框的窗口、生硬的按钮、像素感明显的图标…...