Hadoop 集群环境搭建
目录
第一部分:系统安装... 3
1:图形化安装... 3
2:选择中文... 3
3:安装选项... 3
4:软件选项... 4
5:安装位置... 4
6:网络配置... 6
7:开始安装... 7
8:创建用户... 7
9:重启系统... 7
10:登录测试... 8
第二部分:初始化设置... 9
1:SSH远程登录... 9
2:yum 源更新... 9
3:安装vim和wget. 11
4:增加test 用户权限... 12
5:修改主机 /tec/hosts 文件... 14
6:配置test 账户免密ssh 登录... 15
7:防火墙设置开机关闭... 17
第三部分:Java jdk 安装配置... 19
1:检查JAVA状态... 19
2:安装JAVA 1.8. 19
3:配置环境变量... 20
第四部分:Hadoop 集群安装... 22
1:下载hadoop. 22
2:修改环境变量... 23
3:节点配置... 24
1:主节点安装(server1)... 24
2:备节点安装(server2 server3)... 28
第五部分:Hadoop 状态检查和常用命令... 31
1:网页状态查看... 31
2:控制台命令... 32
1:常用排查故障命令... 32
2:常用基础命令... 32
3:HDFS命令(Hadoop分布式文件系统)... 32
4:MapReduce作业运行命令... 33
5:YARN(Yet Another Resource Negotiator)命令... 33
6:Hadoop集群管理命令... 33
7:Hadoop配置文件管理命令... 33
第一部分:系统安装
大致过程:软件安装选择-------磁盘分区-------IP地址设置-----用户名密码设置
1:图形化安装
这里选择图形化安装。
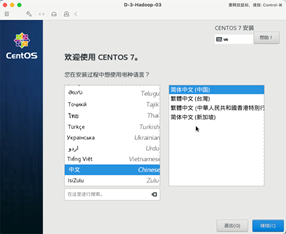
2:选择中文
选择语言为中文。
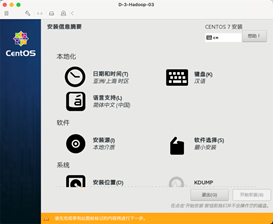
3:安装选项
设置对应的安装选项。
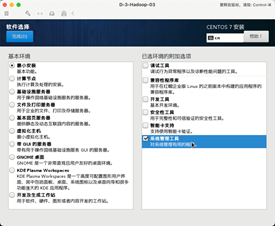
4:软件选项
选择最小安装和系统管理工具。
5:安装位置
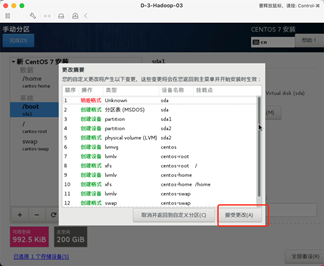
选择对应的磁盘并手动配置磁盘各分区大小。
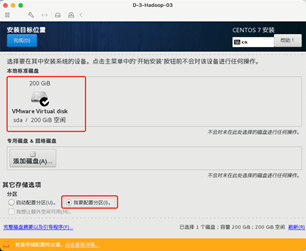
点击自动创建
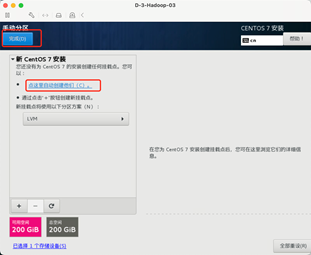
调整 /home 分区和/ 分区的大小,因为Hadoop默认的存储路径是在/目录下,所以/目录需要分配大一点。
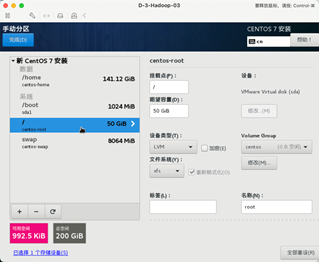
分配后的各部分大小。
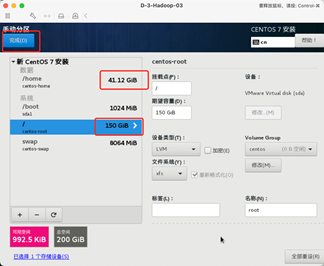
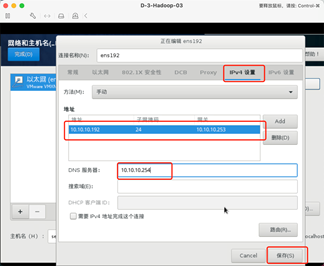
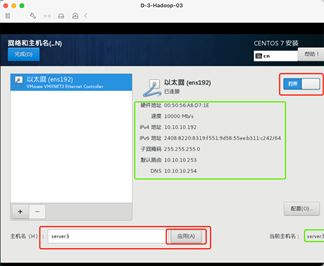
6:网络配置
手动指定IP地址和主机名。
215三台分别是192.168.1.190/191/192
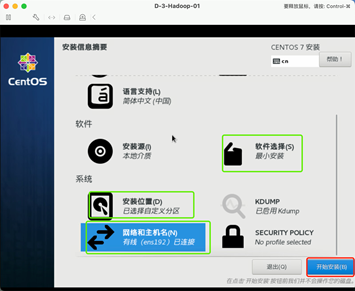
7:开始安装
8:创建用户
创建root密码和用户,简单密码需要保存2次,密码安全测试环境不涉及,
9:重启系统
重启系统后就完成安装了。
10:登录测试
登录系统检测账号密码是否可以登录:
su -l root 切换到root账户
测试网络是否正常:
ping 223.5.5.5(223.5.5.5是阿里的公共DNS服务器地址)
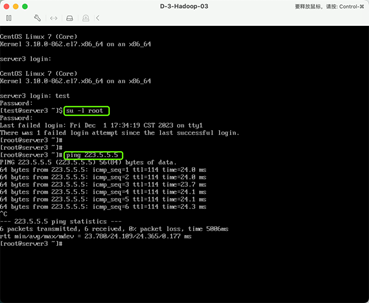
以上完成操作系统的安装。
第二部分:初始化设置
yum update 更新-----vim wget 安装-----sudo 文件增加用户名----/etc/hosts 文件配置3台机器主机名解析---------SSH 免密登录配置------关闭防火墙设置
1:SSH远程登录
使用WindTerm的 窗口水平分割和同步输入进行3台机器同时操作,节省时间。
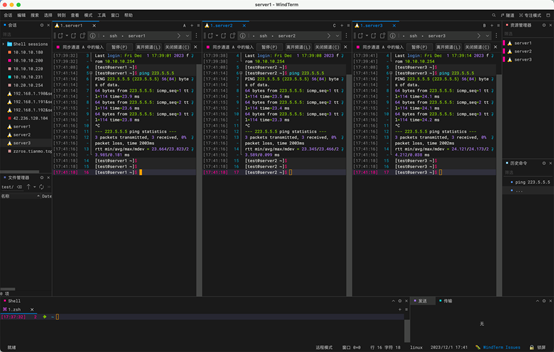
2:yum 源更新
切换到root 账户,使用 yum update, 中间出现确认选项使用 y 确认。
命令:
yum update
更新完成
3:安装vim和wget
vim是文档编辑工具,wget 是下载HTTP的工具。
命令:(root用户模式下)中间出现确认选项使用 y 确认。
yum install vim
yum install wget
4:增加test 用户权限
vi和vim 基础操作。进入后 i和(insert)按键进入插入模式,esc 进入: 模式
:行数 ===去到某一行
:wq ====保存修改
:wq! ====强制保存修改
:q ====退出
:q: ====强制退出
去往第100行。
新增test 用户权限,test 为之前创建的用户。
:wq 进行保存。
5:修改主机 /tec/hosts 文件
命令:
vim /etc/hosts
新增主机名和ip地址对应关系,ip地址根据实际地址(这里是我的内网地址)
修改完成后直接ping 主机名进行测试,通了代表修改成功。
6:配置test 账户免密ssh 登录
Hadoop 默认在非root账户下运行,所以需要返回 test 账户下,使用exit 退出
命令:
cd ~/.ssh/
进入test用户的ssh目录,提示无当前目录,使用ssh 随便远程一台机器即可产生目标目录,使用no 不保存密钥。然后就可以进入~/.ssh/ 目录了
命令:
ssh-keygen -t rsa
生成密钥,会出现一些提示,这里要连续按多次回车,直到它出现一个如下图所示的框框。
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys
加入授权和修改文件权限。
分别使用以下命令拷贝ssh 秘钥,按提示输入 yes 和密码。
命令:
ssh-copy-id test@10.10.10.190
ssh-copy-id test@10.10.10.191
ssh-copy-id test@10.10.10.192
这里是3台机器相互拷贝对方的秘钥,因为我这里使用的是同步输入,每台机器都有自身的秘钥,所以这里有个报错,可以不用管,直接输入密码既可以。(以server3为例server1和server2 需要拷贝server3的密钥,这里提示要是否保存,输入yes 保存,然后输入test 用户密码即可,因为server3不用输入密码,所以这里直接进入了$ 输入模式,这个是正常的,其他2台这里也是一样的)
拷贝完成进行测试,分别使用域名和ip地址测试登录其他机器是否需要输入密码。
命令:
ssh test@server1
ssh test@10.10.10.190
我这里是使用的同步输入,每次都进入相同的服务器,这里可以看到每次都成功了。
7:防火墙设置开机关闭
命令:
sudo systemctl stop firewalld
sudo systemctl disable firewalld

接下来重启下服务器。准备安装java。
第三部分:Java jdk 安装配置
JAVA 安装------环境变量设置-----安装完成后检查
1:检查JAVA状态
切换root账户,输入命令java -version查看当前Java版本。(注意-)我这里显示未安装。
命令:
java -version
2:安装JAVA 1.8
Hadoop在1.7版本或1.8版本都可以,这是是安装的1.8版本的。
命令:
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
安装完成后检查一下
3:配置环境变量
输入vim ~/.bashrc我们在.bashrc中进行环境变量设置。
命令:
vim ~/.bashrc
进入文本后,在 # User specific aliases and functions下面加上如下一行:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
这里的JAVA_HOME的值是当前JDK的安装位置。添加上后就:wq保存退出。
输入source ~/.bashrc让刚才的变量设置生效。
命令:
source ~/.bashrc
完成以上操作后,我们输入如下命令进行检查。
命令:
java -version
$JAVA_HOME/bin/java –version
如下图所示,两个命令的输出结果一样,就没有问题。
以上显示java 安装成功。黄色地方报错的原因是 -version 的 - 不对,修改后就可以了运行了。
以上完成了java 的安装。
第四部分:Hadoop 集群安装
1:下载hadoop
(此处一定要切换回 test 账户,否则hadoop 启动不了)
退出到test 账户下,下载hadoop。
命令:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar -xzvf hadoop-3.3.1.tar.gz
sudo mv hadoop-3.3.1 /usr/local/hadoop
2:修改环境变量
编辑用户的 ~/.bashrc 文件:,在文件末尾添加以下行:
命令:
vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出,然后执行命令:
source ~/.bashrc
3:节点配置
这里主节点和其他节点配置不一样,所以关闭了同步输入
1:主节点安装(server1)
1.1:查询java 的程序位置
命令:
sudo update-alternatives --config java
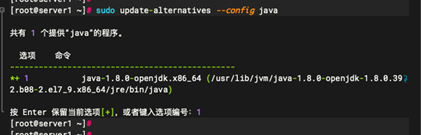
记录当前路径:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-2.el7_9.x86_64/jre
1.2:编辑 Hadoop 环境配置文件:
命令:
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
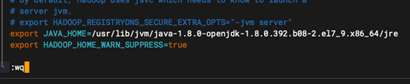
添加以下内容: java 路径替换为上面记录的。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-2.el7_9.x86_64/jre
export HADOOP_HOME_WARN_SUPPRESS=true
1.3:配置 Hadoop 核心文件
命令:
vim /usr/local/hadoop/etc/hadoop/core-site.xml
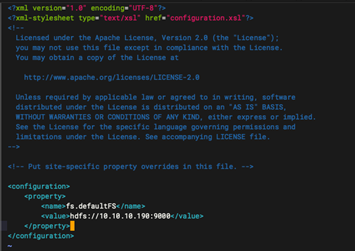
添加以下内容: hdfs://10.10.10.190:9000 替换成对应的地址。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.10.10.190:9000</value>
</property>
</configuration>
1.4:配置 HDFS 文件系统
命令:
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
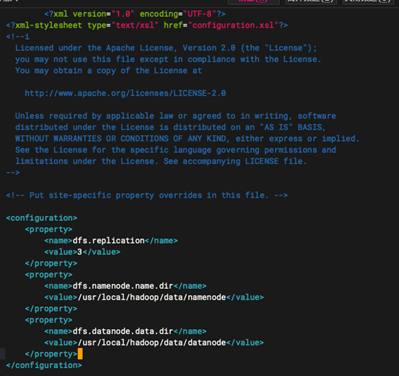
添加以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
</configuration>
1.5:配置 YARN 资源管理器
命令:
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
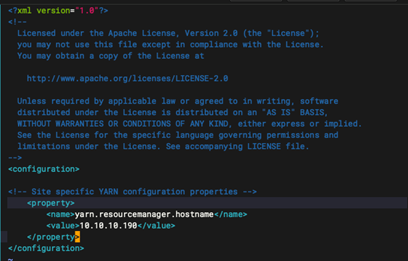
添加以下内容: 10.10.10.190 替换成对应的地址
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.10.10.190</value>
</property>
</configuration>
1.6:创建 HDFS 目录
命令:
hdfs namenode -format
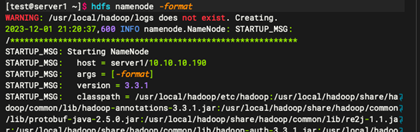
1.7:启动 Hadoop 服务
命令:
start-dfs.sh
start-yarn.sh
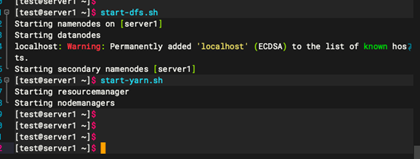
主节点(server1)的hadoop 安装完成。
1.8:查看主节点状态
命名:
hdfs dfsadmin -report
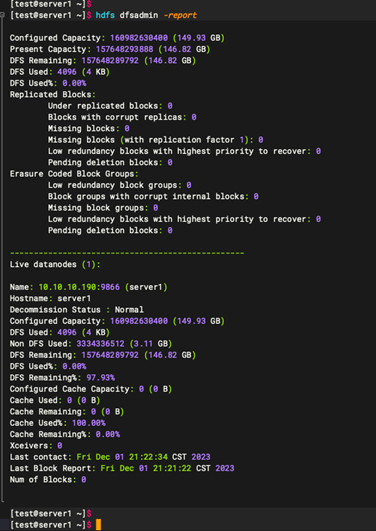
2:备节点安装(server2 server3)
2.1: 从主节点复制 Hadoop 配置到从节点
命令:
scp -r 10.10.10.190:/usr/local/hadoop/etc/hadoop/* /usr/local/hadoop/etc/hadoop/
10.10.10.190修改为对应主节点ip地址
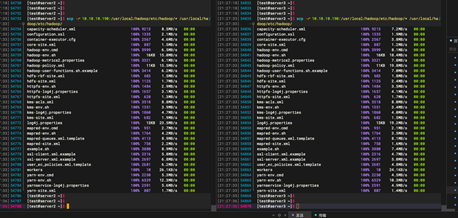
2.2:启动 Hadoop 服务
命令:
start-dfs.sh
start-yarn.sh

2.3:查看主节点状态
命名:
hdfs dfsadmin -report
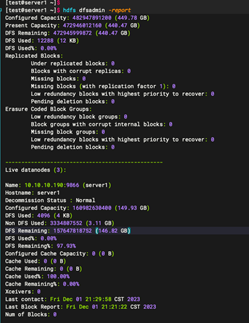
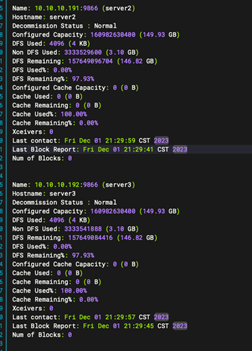
以上就完成hadoop 3台机器集群环境的安装
第五部分:Hadoop 状态检查和常用命令
1:网页状态查看
YARN ResourceManager Web 用户界面 http://10.10.10.190:8088
Hadoop节点信息 http://10.10.10.190:9870


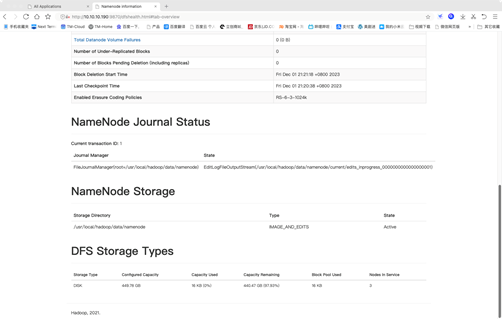
2:控制台命令
1:常用排查故障命令
验证一下集群的状态:hdfs dfsadmin -report
列出 HDFS 上的文件:hdfs dfs -ls
本地文件上传到 HDFS:hdfs dfs -put /path/to/local/file /user/test/
获取节点的主机名或 IP 地址:hdfs dfsadmin -report | grep "Name:"
强制 Hadoop 刷新节点列表: hdfs dfsadmin -refreshNodes
2:常用基础命令
3:HDFS命令(Hadoop分布式文件系统)
上传文件到HDFS:
hdfs dfs -put <local-source> <hdfs-destination>
从HDFS下载文件:
hdfs dfs -get <hdfs-source> <local-destination>
列出HDFS目录内容:
hdfs dfs -ls <hdfs-path>
创建HDFS目录:
hdfs dfs -mkdir <hdfs-directory>
删除HDFS文件或目录:
hdfs dfs -rm <hdfs-path>
复制本地文件到HDFS:
hdfs dfs -copyFromLocal <local-source> <hdfs-destination>
4:MapReduce作业运行命令
提交MapReduce作业:
hadoop jar <jar-file> <main-class> <input-path> <output-path>
查看正在运行的MapReduce作业列表:
yarn application -list
5:YARN(Yet Another Resource Negotiator)命令
查看集群节点资源使用情况:
yarn node -list
查看正在运行的应用程序:
yarn application -list
6:Hadoop集群管理命令
启动Hadoop集群:
start-all.sh
停止Hadoop集群:
stop-all.sh
查看Hadoop集群状态:
hadoop dfsadmin -report
7:Hadoop配置文件管理命令
查看Hadoop配置:
hadoop version
查看Hadoop配置文件内容:
cat $HADOOP_HOME/etc/hadoop/core-site.xml
相关文章:
Hadoop 集群环境搭建
目录 第一部分:系统安装... 3 1:图形化安装... 3 2:选择中文... 3 3:安装选项... 3 4:软件选项... 4 5:安装位置... 4 6:网络配置... 6 7:开始安装... 7 8:创建用户... 7…...

maven完结,你真的学完了吗
书接上文:必学的maven的起步-CSDN博客 分模块开发与设计 分模块开发: 创建模块书写代码模块 模块中需要其他的模块,就将他安装到仓库然后再dep中导入依赖通过maven指令安装模块到本地仓库(install) 聚合与继承 聚合…...
【Xcode】解决Unable to process request - PLA Update available
出现场景 IOS更新app时,使用Xcode上传新版本的包时,提示无法上传。 Unable to process request -PLA update available you currently dont have access to this membership resource. To resolve this issue ,agree to the latest program license a…...

力扣单调栈算法专题训练
目录 1 专题说明2 训练 1 专题说明 本博客用来计算力扣上的单调栈题目、解题思路和代码。 单调栈题目记录: 2232866美丽塔II 2 训练 题目1:2866美丽塔II。 解题思路:先计算出prefix[i],表示0~i满足递增情况下,0~i…...

【NI-RIO入门】理解Windows、Real Time与FPGA之间数据通信的原理
于NI kb摘录 1.概述 对于NI RIO系列设备(CompactRIO、sbRIO、myRIO等)进行编程时,需要注意有三个不同的组件。 人机界面 (HMI) 。有时称为“主机”,为用户提供图形用户界面(GUI),用于监控系统…...

关于游戏性能优化的技巧
关于游戏性能优化的技巧 游戏性能优化对象池Jobs、Burst、多线程间隔处理定时更新全局广播缓存组件缓存常用数据2D残影优化2D骨骼转GPU动画定时器优化DrawCall合批处理优化碰撞层优化粒子特效 游戏性能优化 好久没有在CSDN上面写文章了,今天突然看到鬼谷工作室技术…...
antdesignpro实现滚动加载分页数据
原理解析:每滚动一次相当于翻页,请求后端时给的页码参数要想办法加1,后端才能根据页码给出相应数据 注意后端收到页码参数之后要准确计算出每页的首行数据,关键逻辑代码: # 根据前端传的页码,进行计算下一…...
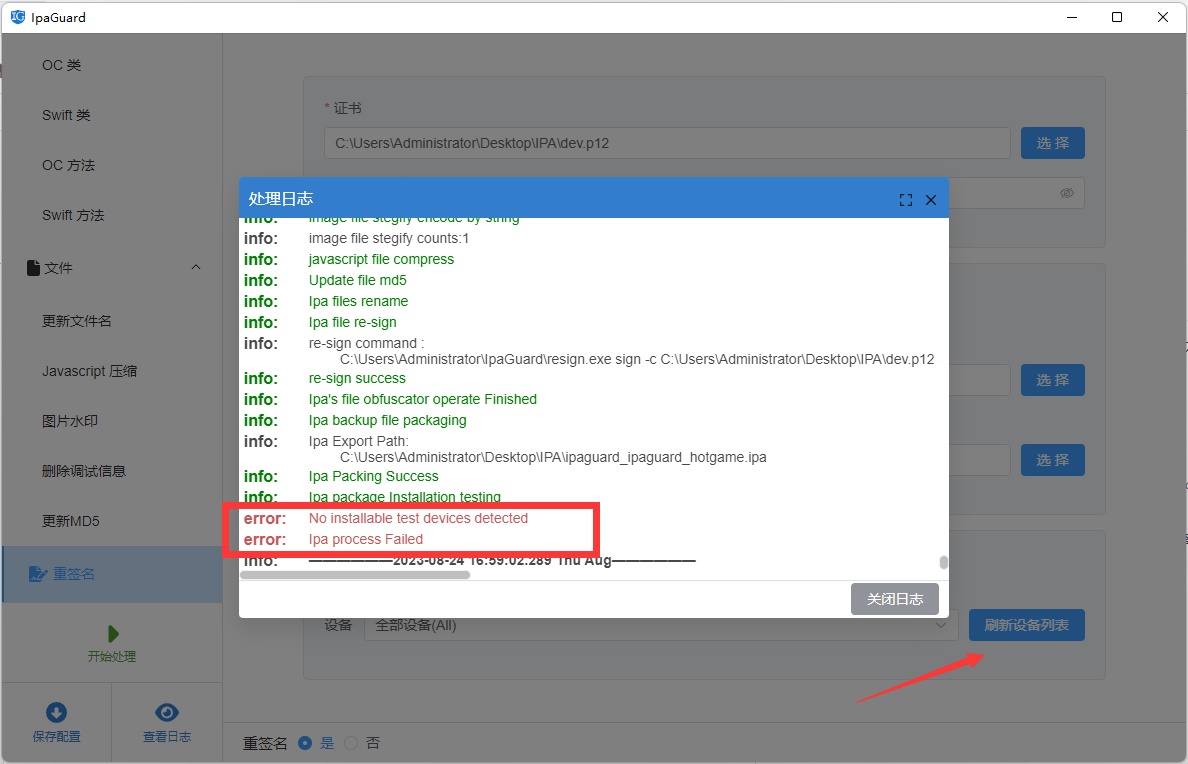
步兵 cocos2dx 加密和混淆
文章目录 摘要引言正文代码加密具体步骤代码加密具体步骤测试和配置阶段IPA 重签名操作步骤 总结参考资料 摘要 本篇博客介绍了针对 iOS 应用中的 Lua 代码进行加密和混淆的相关技术。通过对 Lua 代码进行加密处理,可以确保应用代码的安全性,同时提高性…...

【算法设计与分析】——动态规划算法
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...
WPF组合控件TreeView+DataGrid之DataGrid封装
(关注博主后,在“粉丝专栏”,可免费阅读此文) wpf的功能非常强大,很多控件都是原生的,但是要使用TreeViewDataGrid的组合,就需要我们自己去封装实现。 我们需要的效果如图所示&#x…...

PIL/Pillow
Abstract PIL(Python Imaging Library)是一个用于图像处理的 Python 库。它提供了广泛的功能,包括图像加载、保存、调整大小、裁剪、旋转、滤镜应用等。 由于 PIL 的开发停止在 2009 年,因此推荐使用其后续的维护版本 Pillow。Pillow 是一个兼容 PIL 接…...

ARM 汇编入门
ARM 汇编入门 引言 ARM 汇编语言是 ARM 架构的汇编语言,用于直接控制 ARM 处理器。虽然现代软件开发更多地依赖于高级语言和编译器,但理解 ARM 汇编仍然对于深入了解系统、优化代码和进行低级调试非常重要。本文将为您提供一个简单的 ARM 汇编入门指南…...

SQL进阶:多表查询
在SQL基础部分,我们在讲解的过程中只用到了单表查询。但实际上,常见的业务场景单表查询不能满足,或者拆分查询性能过慢。这个时候我们就需要用到连接查询。即查询多表按一定规则合并后的数据。 注意,合并后的数据也是表ÿ…...
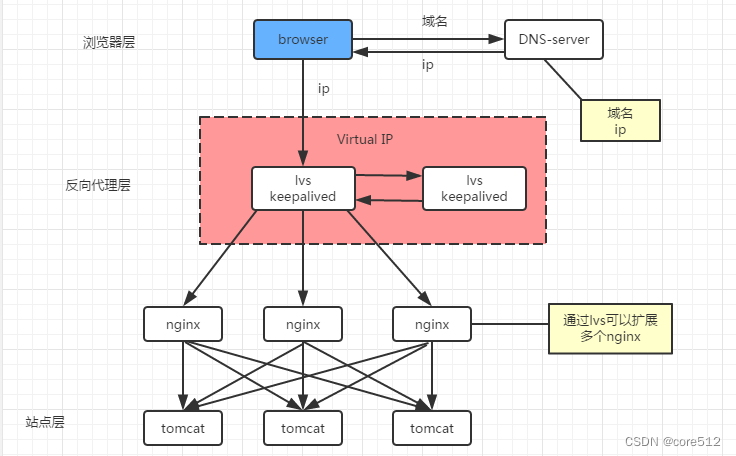
多层负载均衡实现
1、单节点负载均衡 1)站点层与浏览器层之间加入了一个反向代理层,利用高性能的nginx来做反向代理 2)nginx将http请求分发给后端多个web-server 优点: 1)DNS-server不需要动 2)负载均衡:通过ngi…...
Redis取最近10条记录
有时候我们有这样的需求,就是取最近10条数据展示,这些数据不需要存数据库,只用于暂时最近的10条,就没必要在用到Mysql类似的数据库,只需要用redis即可,这样既方便也快! 具体取最近10条的方法&a…...

Mybatis之增删改查
目录 一、引言 二、Mybatis——增 举例:添加用户 三、Mybatis——删 举例:删除用户 四、Mybatis——改 举例:修改用户 五、Mybatis——查 六、注意 END: 一、引言 书接上回,我们在了解完mybatis之后,肯…...

Go 代码检查工具 golangci-lint
一、介绍 golangci-lint 是一个代码检查工具的集合,聚集了多种 Go 代码检查工具,如 golint、go vet 等。 优点: 运行速度快可以集成到 vscode、goland 等开发工具中包含了非常多种代码检查器可以集成到 CI 中这是包含的代码检查器列表&…...

SwiftUI 趣谈之:绝不可能(Never)的 View!
概览 SwiftUI 的出现极大的解放了秃头码农们的生产力。SwiftUI 中众多原生和自定义视图对于我们创建精彩撩人的 App 功不可没! 不过,倘若小伙伴们略微留意过 SwiftUI 框架头文件里的源代码,就会发现里面嵌有一些奇怪 Never 类型,…...

etcd是什么
目录 1.关于etcd2.应用场景 本文主要介绍etcd 概念和基本应用场景。 1.关于etcd etcd是一个开源的、分布式的键值存储系统,用于共享配置和服务发现。它是由CoreOS团队开发的,主要用于实现分布式系统的配置管理和服务发现。 etcd的主要特性包括&#x…...

应用全局的UI状态存储AppStorage
目录 1、概述 2、StorageProp 2.1、观察变化和行为表现 3、StorageLink 3.1、观察变化和行为表现 4、从应用逻辑使用AppStorage和LocalStorage 5、从UI内部使用AppStorage和LocalStorage 6、不建议借助StorageLink的双向同步机制实现事件通知 6.1、推荐的事件通知方式…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...