【数据结构之顺序表】
数据结构学习笔记---002
- 数据结构之顺序表
- 1、介绍线性表
- 1.1、什么是线性表?
- 2、什么是顺序表?
- 2.1、概念及结构
- 2.2、顺序表的分类
- 3、顺序表接口的实现
- 3.1、顺序表动态存储结构的Seqlist.h
- 3.1.1、定义顺序表的动态存储结构
- 3.1.2、声明顺序表各个接口的函数
- 3.2、顺序表动态存储结构的Seqlist.c
- 3.2.1、初始化顺序表
- 3.2.2、销毁顺序表
- 3.2.3、打印顺序表元素
- 3.2.4、顺序表的基本操作
- 3.3、顺序表动态存储结构的main.c
- 3.3.1、TestSL1()
- 3.3.2、TestSL2()
- 3.3.3、TestSL7()
- 4、顺序表巩固练习
- 4.1、顺序表巩固练习题01 --- 去掉重复项
- 4.2、顺序表巩固练习题02 --- 合并两个有序数组
- 5、顺序表总结
数据结构之顺序表
前言:
前篇了解了数据结构和算法,并认识到学好代码,对于数据结构的核心地位,那么这篇就直接开始数据结构的入门学习。
从认识线性表到掌握好最基础的两个存储结构,那么先学习其中顺序存储的顺序表。
/知识点汇总/
1、介绍线性表
1.1、什么是线性表?
线性表是n(n≥0)个具有相同特性的数据元素的有限序列。
线性表是一种在实际中广泛使用的数据结构,常见的线性表、顺序表、链表、栈、队列、字符串…
本质:
在逻辑上是线性结构,也就是连续的一条直线,但是在物理结构上不一定是连续的,在物理上存储通常以数组或链式结构的形式存储。
概念:
线性表是一种数据结构,它包含一组有序的元素,每个元素最多只有一个前驱元素和一个后继元素。
线性表可以用数组或链表来实现:
在数组中,元素在内存中连续存储,可以通过下标直接访问元素。
在链表中,元素在内存中不一定连续存储,每个元素包含数据域和指针域,其中指针域指向下一个元素。
线性表的特点:
元素之间是一对一的关系,可以通过下标访问元素,但是删除或插入元素需要移动其它元素。
线性表是基本的数据结构之一,经常被用于各种算法的实现中。
常见的线性表操作:
包括插入、删除、查找、修改等。
2、什么是顺序表?
2.1、概念及结构
顺序表是一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数据存储。由此在数组上完成数组的增删查改
2.2、顺序表的分类
(1).静态顺序表:使用定长数组存储的元素 ----- 顺序表的静态存储
#define N 7
typedef int SLDataType;
typedef struct Seqlist
{SLDataType array[N];//定长数组size_t size;//有效数据个数
}Seqlist;
静态顺序表的弊端:
在实际应用中,对于数据的长度往往是不确定的,所以静态开辟数组空间时,给太大导致浪费空间资源,太小又无法满足数据的存储,不够用。
(2).动态顺序表:使用动态开辟的数组存储 ----- 顺序表的动态存储
typedef struct Seqlist
{SLDataType* array;//指向动态开辟的数组size_t size;//有效数据的个数size_t capacity;//容量空间的大小
};
动态顺序表的弊端:
需要注意空间使用之后的释放,防止内存泄漏等问题。
3、顺序表接口的实现
在实际应用中,总体还是以动态的分配空间为主,所以主要以动态的顺序表为主。
但是扩容也存在一定的代价,需要注意及时释放等问题。
实现过程建议采用(TestXXX n)函数进行阶段性测试,既方便调试也方便及时解决问题。
3.1、顺序表动态存储结构的Seqlist.h
3.1.1、定义顺序表的动态存储结构
因为是采用的多种类型的数据,所以适用于结构体类型。
//定义顺序表的动态存储
typedef int SLDataType;//这里的重命名主要作用是,不能保证每次使用顺序表都是整型,所以只需要改这里为其它类型更健壮和便利typedef struct SeqList
{SLDataType* a; //有效数据元素 int size; //有效数据个数int capacity; //当前顺序表的容量//考虑扩容的容量是不确定的,需要根据实际的需求而灵活扩容
}SL;
3.1.2、声明顺序表各个接口的函数
//动态顺序表的初始化
void SLInit(SL* ps1);
//顺序表的销毁
void SLDestory(SL* ps1);
//打印顺序表
void SLPrint(SL* ps1);
//检查顺序表当前容量
void SLCheckCapacity(SL* ps1);
//头、尾插入和删除
void SLPushBack(SL* ps1, SLDataType x);//尾插
void SLPushFront(SL* ps1, SLDataType x);//头插
void SLPopBack(SL* ps1);//尾删
void SLPopFront(SL* ps1);//头删
//任意位置的插入和删除
void SLInsert(SL* ps1, int pos, SLDataType x);
void SLErase(SL* ps1, int pos);
//查找元素
//找到后,返回下标
//没找到返回-1
//int SLFind(SL* ps1, int pos, SLDataType x);//从某位开始找
int SLFind(SL* ps1, SLDataType x);
3.2、顺序表动态存储结构的Seqlist.c
主要还是要完成 Seqlist.h 接口对应的 .c 功能函数.
最开始详细的写一下,后面就整体的写了。
3.2.1、初始化顺序表
那么有了基本的动态存储结构,先要产生顺序表,那么就先通过初始化顺序表实现存储空间的开辟。
//动态顺序表的初始化
void SLInit(SL* ps1)
{//暴力检查assert(ps1);//一定不能为空ps1->a = NULL;ps1->size = 0;ps1->capacity = 0;
}
说明:这里的初始化就很简单了,并没有直接使用malloc开辟空间,也并没有写初识的capacity 容量值,是为了在后面的函数中体现一种新颖的写法。
为了方便理解和对比,我会把常规写法也贴出来,如下所示:
#define InitSize 10
typedef int SLDataType;
void InitList(SqList &L)
{L.data = (SLDataType*)malloc(InitSize*sizeof(SLDataType));//用malloc函数申请一片空间L.length = 0; //把顺序表的当前长度设为0L.Maxsize = InitSize; //这是顺序表的最大长度
}
3.2.2、销毁顺序表
为了避免忘记销毁开辟的动态内存空间。所以这里使用动态存储方法,那么通常把初始化和销毁一块就写出来了。
//顺序表的销毁
void SLDestory(SL* ps1)
{//暴力检查assert(ps1);//一定不能为空if (ps1->a != NULL){free(ps1->a);ps1->a = NULL;ps1->size = 0;ps1->capacity = 0;}
}
3.2.3、打印顺序表元素
为了直观的体现数据元素是否成功操作,所以接着写出打印接口函数。
//打印顺序表
void SLPrint(SL* ps1)
{//暴力检查assert(ps1);//一定不能为空for (int i = 0; i < ps1->size; i++){printf("%d ", ps1->a[i]);}printf("\n");
}
3.2.4、顺序表的基本操作
完成了上述函数的功能,那么就可以实现顺序表的基本操作了。插入和删除以及查找(无非就是增删改查)。
头插和头删;尾插和尾删。
其次,我们得有一个意识,比如当一个箱子在放入物品之前,肯定会先检查一下箱子是否已经被放满,同理,也需要检查,被拿物品的箱子是否为空箱子,如果为空就拿不来了。回到顺序表就是需要涉及检查容量和判空的操作,然后因为顺序表的多种操作都涉及到了检查容量,所以独立封装为一个SLCheckCapacity函数,方便调用,具体见如下代码:
//检查顺序表当前容量
void SLCheckCapacity(SL* ps1)
{//暴力检查assert(ps1);//一定不能为空if (ps1->size == ps1->capacity){int newCapacticy = ps1->capacity == 0 ? 4 : ps1->capacity * 2;//因为初始化的时候,初始化为0,所以这里以这样的方式扩容即可,比较巧妙灵活。//使用realloc扩容空间:分为原地扩容和异地扩容。//相较于原地扩容,异地的代价较大,原地的效率高。//判断realloc的返回值判断扩容前后的地址,相同就是原地扩,不同就是异地扩。//另外realloc还有个特点,当对ps1->0为空操作时,就相当于malloc了SLDataType* tmp = (SLDataType*)realloc(ps1->a, sizeof(SLDataType) * newCapacticy);//如果直接realloc操作指针ps1->a的话,会存在一定的问题,如果开辟失败,就会导致ps1->a被更改或者称为野指针等问题。if (tmp == NULL){perror("realloc fail");//exit(0);return;}ps1->a = tmp;ps1->capacity = newCapacticy;}
}
说明:同时这段代码也与前面初始化时的呼应,初始化没有赋予初识空间容量的问题,在这个函数的新颖写法得以体现,巧用了一个三目运算符解决了容量问题(当然扩容的倍数或大小由实际情况决定);其次利用realloc函数解决开辟空间的问题,因为既解决了对空操作的问题,也解决了扩容的问题。(realloc详见注释内容和相关资料)
接着为了体现封装函数的好处,就是解决在多组函数中的反复编写相同代码的好处,所以先写尾插,会发现注释掉的代码直接可以调用SLCheckCapacity函数就能解决了,如下所示:
void SLPushBack(SL* ps1, SLDataType x)//尾插
{//暴力检查assert(ps1);//一定不能为空//if (ps1->size == ps1->capacity)//{// int newCapacticy = ps1->capacity == 0 ? 4 : ps1->capacity * 2;//因为初始化的时候,初始化为0,所以这里以这样的方式扩容即可,比较巧妙灵活。// //使用realloc扩容空间:分为原地扩容和异地扩容。// //相较于原地扩容,异地的代价较大,原地的效率高。// //判断realloc的返回值判断扩容前后的地址,相同就是原地扩,不同就是异地扩。// //另外realloc还有个特点,当对ps1->0为空操作时,就相当于malloc了// SLDataType* tmp = (SLDataType*)realloc(ps1->a, sizeof(SLDataType) * newCapacticy);// //如果直接realloc操作指针ps1->a的话,会存在一定的问题,如果开辟失败,就会导致ps1->a被更改或者称为野指针等问题。// if (tmp == NULL)// {// perror("realloc fail");// //exit(0);// return;// }// ps1->a = tmp;// ps1->capacity = newCapacticy;//}SLCheckCapacity(ps1);ps1->a[ps1->size] = x;ps1->size++;
}
//考虑到扩容在很多操作都需要那么就令其封装一个函数。
头插:
void SLPushFront(SL* ps1, SLDataType x)//头插
{//暴力检查assert(ps1);//一定不能为空SLCheckCapacity(ps1);int end = ps1->size - 1;while (end >= 0){ps1->a[end + 1] = ps1->a[end];--end;}ps1->a[0] = x;ps1->size++;
}
尾删和尾插,判空的操作在顺序表就比较简单了,不必额外写函数,因为直接对ps1->size即可,如下所示:
void SLPopBack(SL* ps1)//尾删
{//暴力检查assert(ps1);//一定不能为空//所以根据调试验证,必须考虑为空,就不再删除了//处理方式一:温柔的检查if (ps1->size == 0){printf("删除失败,为空\n");return;}//处理方式二:暴力的检查//assert(ps1->size > 0);ps1->size--;
}void SLPopFront(SL* ps1)//头删
{//暴力检查assert(ps1);//一定不能为空//暴力检查assert(ps1->size > 0);//数据前挪动int begin = 1;//注意下标的不同,边界就不同while (begin < ps1->size){ps1->a[begin - 1] = ps1->a[begin];++begin;}//有效数据--ps1->size--;
}
任意位置的插入和删除中需要区别一下,pos和size
pos – 定义的是数组下标
size – 定义的是数组元素个数,当作下标需要size-1
补充:
数组下标从0开始是因为,主要是需要与指针形成逻辑自洽
比如:a[i] == *(a+i) a[1] == *(a+1)
还有些原因,是因为数组指针从1开始会式的一些应用场景多一次减法操作,会在一定程度上影响性能。
void SLInsert(SL* ps1, int pos, SLDataType x)//在任意位置插入
{assert(ps1);assert(pos >= 0 && pos <= ps1->size);SLCheckCapacity(ps1);//挪动数据int end = ps1->size - 1;while (end >= pos)//pos = size就是尾插,不会进入循环{ps1->a[end+1] = ps1->a[end];--end;}ps1->a[pos] = x;ps1->size++;
}void SLErase(SL* ps1, int pos)//在任意位置删除
{assert(ps1);assert(pos >= 0 && pos < ps1->size);//删除的边界不能等于size//挪动覆盖int begin = pos + 1;while (begin < ps1->size){ps1->a[begin - 1] = ps1->a[begin];++begin;}ps1->size--;
}
最后一个基本操作查找元素,可按位查找,也可遍历查找。
因为是顺序表,存储元素的地址是连续的所以可以直接满足遍历操作。
//int SLFind(SL* ps1, int pos, SLDataType x);//从某位开始找
int SLFind(SL* ps1, SLDataType x)
{assert(ps1);for (int i = 0; i < ps1->size; i++){if (ps1->a[i] == x){return i;}}return -1;//若返回0,与首元素下标冲突
}
3.3、顺序表动态存储结构的main.c
简单的写几个测试应用,目的是检测各个接口函数是否满足需求,是否存在一些bug。
3.3.1、TestSL1()
主要检测初始化、尾插、头插、打印和销毁,以及参数的传址调用和传值调用。
#include "Seqlist.h"
//测试1:传参,形参是实参的临时拷贝,形参的改变不会姓影响实参,所以传址调用和传值调用
//所以根据需求,通常传地址。
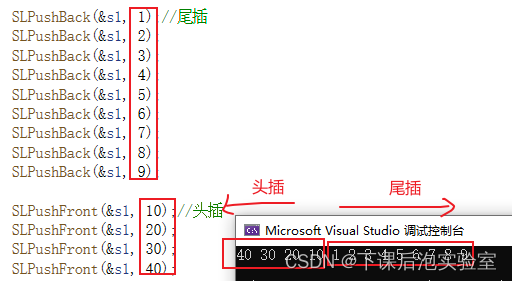
void TestSL1()
{SL s1; //定义结构体变量SLInit(&s1); //传址调用,初始化顺序表SLPushBack(&s1, 1);//尾插SLPushBack(&s1, 2);SLPushBack(&s1, 3);SLPushBack(&s1, 4); SLPushBack(&s1, 5);SLPushBack(&s1, 6);SLPushBack(&s1, 7);SLPushBack(&s1, 8);SLPushBack(&s1, 9);SLPushFront(&s1, 10);//头插SLPushFront(&s1, 20);SLPushFront(&s1, 30);SLPushFront(&s1, 40);SLPrint(&s1);SLDestory(&s1);//顺序表的销毁
}
int main()
{TestSL1();//TestSL2();//TestSL3();//TestSL4();//TestSL5();//TestSL6();//TestSL7();return 0;
}
测试效果展示:
3.3.2、TestSL2()
主要检测尾删直到空,继续删的处理,分析非法访问等情况,思考数据丢失的原因等。
#include "Seqlist.h"
//测试二:
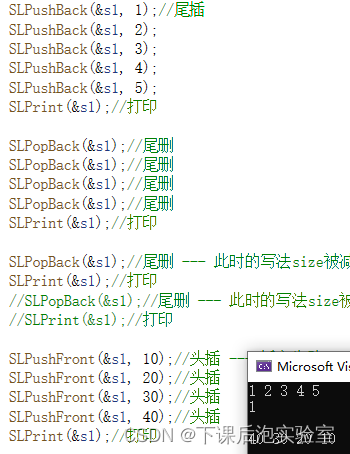
void TestSL2()
{SL s1; //定义结构体变量SLInit(&s1); //传址调用,初始化顺序表SLPushBack(&s1, 1);//尾插SLPushBack(&s1, 2);SLPushBack(&s1, 3);SLPushBack(&s1, 4);SLPushBack(&s1, 5);SLPrint(&s1);//打印SLPopBack(&s1);//尾删SLPopBack(&s1);//尾删SLPopBack(&s1);//尾删SLPopBack(&s1);//尾删SLPrint(&s1);//打印SLPopBack(&s1);//尾删 --- 此时的写法size被减到了0SLPrint(&s1);//打印//SLPopBack(&s1);//尾删 --- 此时的写法size被减到了-1,但是并不会对-1的地址进行访问,所以也不会报错;但是当再进行比如头插操作就会有问题//SLPrint(&s1);//打印SLPushFront(&s1, 10);//头插 --- 插入失败,size为-1,然后end就为size-1=-2,不会进入while循环,就不会非法访问,同时数据也放不进去正确的位置了。SLPushFront(&s1, 20);//头插SLPushFront(&s1, 30);//头插SLPushFront(&s1, 40);//头插SLPrint(&s1);//打印SLDestory(&s1);//顺序表的销毁
}
int main()
{//TestSL1();TestSL2();//TestSL3();//TestSL4();//TestSL5();//TestSL6();//TestSL7();return 0;
}
效果展示:
3.3.3、TestSL7()
主要测试与任意位置的插入和删除函数配合使用的情况
#include "Seqlist.h"
//测试七:与任意位置的插入和删除函数配合使用
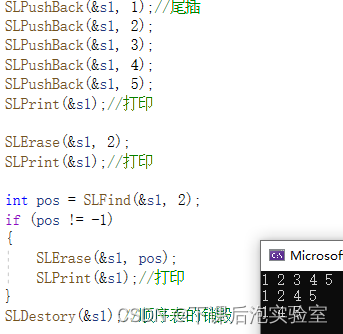
void TestSL7()
{SL s1; //定义结构体变量SLInit(&s1); //传址调用,初始化顺序表SLPushBack(&s1, 1);//尾插SLPushBack(&s1, 2);SLPushBack(&s1, 3);SLPushBack(&s1, 4);SLPushBack(&s1, 5);SLPrint(&s1);//打印SLErase(&s1, 2);SLPrint(&s1);//打印int pos = SLFind(&s1, 2);if (pos != -1){SLErase(&s1, pos);SLPrint(&s1);//打印}SLDestory(&s1);//顺序表的销毁
}
int main()
{//TestSL1();TestSL2();//TestSL3();//TestSL4();//TestSL5();//TestSL6();//TestSL7();return 0;
}
效果展示:
4、顺序表巩固练习
4.1、顺序表巩固练习题01 — 去掉重复项
删除排序数组中的重复项,返回数组中去重后的元素个数。
思路1:去重算法(关键在于排序)
//dest和src相等,则++dest
//dest和src不相等,则++src,a[src] = a[dest],++dest
本质就是dst依次找跟src不相等的元素值,并从前向后依次覆盖
#include <stdio.h>
int removeDuplicates(int* nums, int numsSize)
{int dst = 1;int src = 0;while (dst < numsSize){if (nums[src] != nums[dst])//不相等就覆盖{++src;nums[src] = nums[dst];++dst;//nums[++src] = nums[dst++];}else//否则dst++下一个继续比较{++dst;}}return src + 1;//元素个数加1
}
int main()
{int a[8] = { 0,1,1,2,2,3,3,4 };int ret = removeDuplicates(a, 8);printf("%d\n", ret);return 0;
}
思路2:双指针法
#include <stdio.h>
int removeDuplicates(int* nums, int numsSize)
{int dst = 1;int src = 0;while (dst < numsSize){if (nums[dst-1] != nums[dst])//不相等就覆盖{++src;nums[src] = nums[dst];++dst;//nums[++src] = nums[dst++];}else//否则dst++下一个继续比较{++dst;}}return src + 1;//元素个数加1
}
int main()
{int a[8] = { 0,1,1,2,2,3,3,4 };int ret = removeDuplicates(a, 8);printf("%d\n", ret);return 0;
}
4.2、顺序表巩固练习题02 — 合并两个有序数组
合并两个有序数组,合并后的数组同样按 非递减顺序 排列。
思路1:依次比较,每次取最小的尾插到新数组,这样时间复杂度O(N),空间复杂度O(N)
思路2:依次比较,每次取最大的从后向前覆盖放入,这样时间复杂度O(N),空间复杂度O(1)
#include <stdio.h>
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int i1 = m - 1;int i2 = n - 1;int j = m + n - 1;//while (i1 >= 0 || i2 >= 0)while (i1 >= 0 && i2 >= 0){if (nums2[i2] > nums1[i1]){nums1[j] = nums2[i2];--i2;--j;}else//注意这里并没有处理,nums2,部分元素小于nums1之后剩余的情况{nums1[j] = nums1[i1];--i1;--j;}}//注意处理nums2剩余元素while (i2 >= 0){nums1[j] = nums2[i2];--j;--i2;}
}
int main()
{int a[6] = { 1,2,3,0,0,0 };int b[3] = { -1,-2,6 };merge(a, 6, 3, b, 3, 3);for (int i = 0; i < 6; i++){printf("%d ", a[i]);}return 0;
}
思路3:qsort
#include <stdio.h>
#include <stdlib.h>
int cmp_int(const void* e1, const void* e2)
{return (*(int*)e1) - (*(int*)e2);
}
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{for (int i = 0; i < n; i++){nums1[m + i] = nums2[i];}qsort(nums1, nums1Size, sizeof(int), cmp_int);
}
int main()
{int a[6] = { 1,2,3,0,0,0 };int b[3] = { 2,5,6 };merge(a, 6, 3, b, 3, 3);for (int i = 0; i < 6; i++){printf("%d ", a[i]);}return 0;
}
思路4:归并算法
#include <stdio.h>void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int p1 = 0;int p2 = 0;int nums3[6];int cur = 0;while (p1 < m || p2 < n){if (p1 == m) //如果num1元素放完继续放num2的元素cur = nums2[p2++];else if (p2 == n) //如果num2元素放完继续放num1的元素cur = nums1[p1++];else if (nums1[p1] < nums2[p2]) //如果num1元素小于num2的元素,将小的放入num3cur = nums1[p1++];else //如果num2元素小于num1的元素,将小的放入num3cur = nums2[p2++];nums3[p1 + p2 - 1] = cur; //将cur放入num3 }for (int i = 0; i < m + n; i++) //拷贝{nums1[i] = nums3[i];}
}
int main()
{int a[6] = { 1,2,3,0,0,0 };int b[3] = { -1,-2,6 };merge(a, 6, 3, b, 3, 3);for (int i = 0; i < 6; i++){printf("%d ", a[i]);}return 0;
}
5、顺序表总结
主要有以下两点:
1.尾部插入效率还不错,头部或者中间的插入操作,就需要挪动大量数据,效率低下。
2.在顺序表满了后,只能扩容,而扩容是有一定的消耗代价的;且存在一定的空间浪费;还有这样一个弊端,一次性扩容较多,可能导致浪费较多,而一次性扩容少,就出现频繁的扩容。
所以引出单链表的应用
利用链表的结点之间的关系解决大量挪动数据的问题。
结点之间的地址是随机的不是连续的。
所以通过地址进行管理,利用前一个结点的指针域存储下一个节点的地址,依次找到所有结点。
相关文章:
【数据结构之顺序表】
数据结构学习笔记---002 数据结构之顺序表1、介绍线性表1.1、什么是线性表? 2、什么是顺序表?2.1、概念及结构2.2、顺序表的分类 3、顺序表接口的实现3.1、顺序表动态存储结构的Seqlist.h3.1.1、定义顺序表的动态存储结构3.1.2、声明顺序表各个接口的函数 3.2、顺序表动态存储…...

junit-mock-dubbo
dubbo单元测试分两种情况 Autowired注解是启动上下文环境,使用上下文对象进行测试,适合调试代码 InjectMocks注解是启动上下文环境,使用mock对象替换上下文对象,适合单元测试 BaseTest *** Created by Luohh on 2023/2/10*/ S…...

json解析之fastjson和jackson使用对比
前言 最近项目中需要做埋点分析,首先就需要对埋点日志进行解析处理,刚好这时候体验对比了下fastjson和jackson两者使用的区别,以下分别是针对同一个json串处理,最终的效果都是将json数据解析出来,并统一展示。 一、fa…...

设计模式之-模板方法模式,通俗易懂快速理解,以及模板方法模式的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...
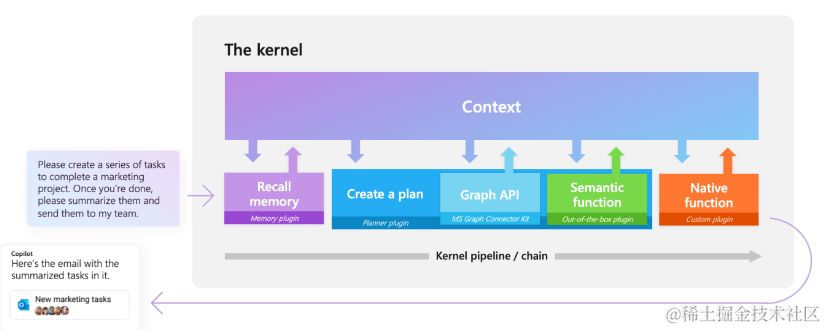
微软官方出品:GPT大模型编排工具,支持C#、Python等多个语言版本
随着ChatGPT的火热,基于大模型开发应用已经成为新的风口。虽然目前的大型模型已经具备相当高的智能水平,但它们仍然无法完全实现业务流程的自动化,从而达到用户的目标。 微软官方开源的Semantic Kernel的AI编排工具,就可以很好的…...

docker安装的php 在cli中使用
1: 修改 ~/.bashrc 中新增 php7 () {ttytty -s && tty--ttydocker run \$tty \--interactive \--rm \--volume /website:/website:rw \--workdir /website/project \--networkdnmp_dnmp \dnmp_php php "$" }–networkdnmp_dnmp 重要, 不然连不上数据库, 可通…...

tcp vegas 为什么好
我吹捧 bbr 时曾论证过它在和 buffer 拧巴的时候表现如何优秀,但这一次说 vegas 时,我说的是从拥塞控制这个问题本身看来,vegas 为什么好,并且正确。 接着昨天 tcp vegas 鉴赏 继续扯。 假设一群共享带宽的流量中有流量退出或有…...

【设计模式】命令模式
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、什么是命令模式? 二、命令模式的优点和应用场景 三、命令模式的要素和实现 3.1 命令 3.2 具体命令 3.3 接受者 …...
Unity头发飘动效果
Unity头发飘动 介绍动作做头发飘动头发骨骼绑定模拟物理组件 UnityChan插件下载UnityChan具体用法确定人物是否绑定好骨骼节点(要做的部位比如头发等)给人物添加SpringManager骨骼管理器给骨骼节点添加SpringBone这里给每个头发骨骼都添加上SpringBone。…...

【MIKE】MIKE河网编辑器操作说明
目录 MIKE河网编辑器说明河网定义河网编辑工具栏河网文件(.nwk11)输入步骤1. 从传统的地图引入底图1.1 底图准备1.2 引入河网底图1.3 输入各河段信息2. 从ARCView .shp文件引入底图MIKE河网编辑器说明 河网编辑器主要功能有两个: ①河网的编辑和参数输人,包括数字化河网及…...

RIPV1配置实验
查看路由器路由表: 删除手工配置的静态路由项: Route1->Config->static Remove删除路由项 删除Route3的路由项,方法同上删除Route2的路由项,方法同上 完成路由器RIP配置: Route1->Config->RIP->Ne…...
快速实现农业机械设备远程监控
农业机械设备远程监控解决方案 一、项目背景 近年来,农业生产事故时有发生,农业安全问题已经成为农业生产中的关键问题,农业监控系统在农业安全生产中发挥着重要作用。农业机械设备以计划维修或定期保养为主,在日常应用的过程中因…...

解决用Fiddler抓包,网页显示你的连接不是专用/私密连接
关键:重置fiddler的证书 在Fiddler重置证书 1、Actions --> Reset All Certificates --> 弹窗一路yes 2、关掉Fiddler,重新打开 3、手机删掉证书,重新下载安装。 (如果还不行,重新试一遍,先把浏览器…...
单片机原理及应用:流水灯的点亮
流水灯是一种简单的单片机控制电路,由许多LED组成,电路工作时LED会按顺序点亮,类似于流水的效果。 下面是运行在keil上的代码,分别使用了数组,移位符和库函数来表示。 //数组法 #include <reg52.h> //头文…...
)
蓝桥杯宝藏排序算法(冒泡、选择、插入)
冒泡排序: def bubble_sort(li): # 函数方式for i in range(len(li)-1):exchangeFalsefor j in range(len(li)-i-1):if li[j]>li[j1]:li[j],li[j1]li[j1],li[j]exchangeTrueif not exchange:return 选择排序: 从左往右找到最小的元素,放在起始位置…...
使用@jiaminghi/data-view实现一个数据大屏
<template><div class"content bg"><!-- 全局容器 --><!-- <dv-full-screen-container> --><!-- 第二行 --><div class"module-box" style"align-items: start; margin-top: 10px"><!-- 左 -->…...
神经网络:池化层知识点
1.CNN中池化的作用 池化层的作用是对感受野内的特征进行选择,提取区域内最具代表性的特征,能够有效地减少输出特征数量,进而减少模型参数量。按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling)&a…...

微服务常见的配置中心简介
微服务架构中,常见的配置中心包括以下几种: Spring Cloud Config: Spring Cloud Config是官方推荐的配置中心解决方案,它支持将配置文件存储在Git、SVN等版本控制系统中。通过提供RESTful API,各个微服务可以远程获取和…...
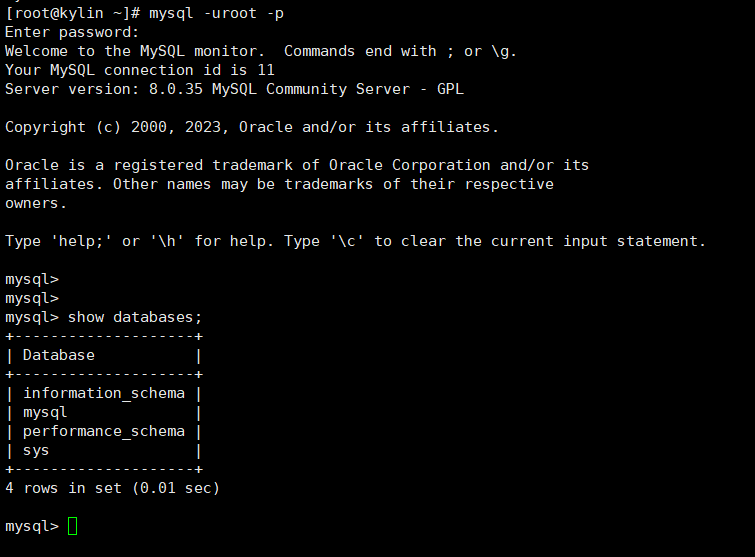
银河麒麟v10 rpm安装包 安装mysql 8.35
银河麒麟v10 rpm安装包 安装mysql 8.35 1、卸载mariadb2、下载Mysql安装包3、安装Mysql 8.353.1、安装Mysql 8.353.3、安装后配置 1、卸载mariadb 由于银河麒麟v10系统默认安装了mariadb 会与Mysql相冲突,因此首先需要卸载系统自带的mariadb 查看系统上默认安装的M…...

一篇文章带你搞定CTFMice基本操作
CTF比赛是在最短时间内拿到最多的flag,mice必须要有人做,或者一支战队必须留出一块时间专门写一些mice,web,pwn最后的一两道基本都会有难度,这时候就看mice的解题速度了! 说实话,这是很大一块&…...

【OpenClaw 全面解析:从零到精通】第 013 篇:OpenClaw 安全机制深度解析——沙盒隔离、权限控制与安全最佳实践
系列说明:本系列共计 20 篇,全面介绍 OpenClaw 开源 AI 智能体框架,从历史背景到核心原理,从安装部署到应用生态。本文为系列第 013 篇,聚焦于 OpenClaw 的安全体系,深入解析其多层安全防护机制。 摘要 Op…...

关于施乐7835开机提示扫描器故障应急解决方法
一、故障现象设备开机后,扫描头无动作扫描头未亮灯自检扫描头未按正常流程移动至初始位置二、故障原因驱动电机脱落(最常见原因)扫描小板与主板连接线松动扫描小板损坏三、维修步骤步骤1:检查扫描头驱动电机操作说明:打…...
Pixel Dimension Fissioner效果展示:逻辑发散度调控前后的文本质量对比
Pixel Dimension Fissioner效果展示:逻辑发散度调控前后的文本质量对比 1. 工具概览 Pixel Dimension Fissioner是一款基于MT5-Zero-Shot-Augment核心引擎构建的创新型文本改写工具。它将传统AI文本处理功能重构为一个充满活力的16-bit像素冒险工坊,让…...

Data-Analysis中的霍洛维兹大数据处理:性能优化技巧
Data-Analysis中的霍洛维兹大数据处理:性能优化技巧 【免费下载链接】Data-Analysis Data Science Using Python 项目地址: https://gitcode.com/gh_mirrors/da/Data-Analysis Data-Analysis是一个基于Python的数据分析项目,提供了丰富的数据科学…...

Clawdbot安全防护指南:网络安全最佳实践与漏洞防范
Clawdbot安全防护指南:网络安全最佳实践与漏洞防范 1. 引言:当AI助手遇上安全挑战 想象一下这样的场景:你的团队正在使用Clawdbot整合Qwen3-32B处理敏感业务数据,突然间发现系统响应变慢,接着有员工报告收到了奇怪的…...

云容笔谈·东方红颜影像生成系统重装系统后快速恢复部署:镜像与数据备份指南
云容笔谈东方红颜影像生成系统重装系统后快速恢复部署:镜像与数据备份指南 重装服务器系统,对很多运维同学来说,就像给电脑重装Windows一样,是件既常规又让人有点紧张的事。常规是因为系统用久了,难免需要清理或升级&…...

图解爱因斯坦求和:从矩阵乘法到注意力机制,一文学会指标标记法
图解爱因斯坦求和:从矩阵乘法到注意力机制,一文学会指标标记法 在深度学习与科学计算的领域中,我们常常需要处理高维张量的复杂运算。想象一下,当你第一次看到Transformer论文中的注意力计算公式时,那些上下标交错的符…...

别再硬编码了!Tkinter的StringVar/IntVar动态绑定技巧:5分钟实现时钟计数器
Tkinter动态绑定实战:用StringVar/IntVar打造流畅GUI界面 在Python GUI开发中,手动更新界面元素是许多开发者常遇到的痛点。想象一下,你正在开发一个实时数据监控系统,每秒需要更新数十个显示数值——如果采用传统的update()方式&…...

帝国CMS后台操作全攻略
帝国CMS后台使用方法如下:一、登录后台在浏览器地址栏输入后台访问路径(默认为/e/admin)输入管理员账号和密码通过验证码验证后进入控制面板二、核心功能操作1. 内容管理文章发布:内容管理 → 信息管理 → 增加新内容编辑流程&…...

如何用ESP32-S3开发板打造你的专属AI语音助手?星智立方开发板深度体验
如何用ESP32-S3开发板打造你的专属AI语音助手?星智立方开发板深度体验 【免费下载链接】xiaozhi-esp32 Build your own AI friend 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaozhi-esp32 想象一下,你只需要对一个小巧的设备说句话&am…...