[node] Node.js 缓冲区Buffer
[node] Node.js 缓冲区Buffer
- 什么是Buffer
- Buffer 与字符编码
- Buffer 的方法概览
- Buffer 的实例
- Buffer 的创建
- 写入缓冲区
- 从 Buffer 区读取数据
- 将 Buffer 转换为 JSON 对象
- Buffer 的合并
- Buffer 的比较
- Buffer 的覆盖
- Buffer 的截取--slice
- Buffer 的长度
- writeUIntLE
- writeUIntBE
什么是Buffer
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。
但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
在v6.0之前创建Buffer对象直接使用new Buffer()构造函数来创建对象实例,但是Buffer对内存的权限操作相比很大,可以直接捕获一些敏感信息,所以在v6.0以后,官方文档里面建议使用 Buffer.from() 接口去创建Buffer对象。
Buffer 与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。
const buf = Buffer.from("test", "ascii");
console.log(buf.toString("hex"));// 输出 74657374
console.log(buf.toString("base64"));// 输出 dGVzdA==
Node.js 目前支持的字符编码包括:
- ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
- utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
- utf16le - 2 或 4 个字节,小字节编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ucs2 - utf16le 的别名。
- base64 - Base64 编码。
- latin1 - 一种把 Buffer 编码成字节编码的字符串的方式。
- binary - latin1 的别名。
- hex - 将每个字节编码为两个十六进制字符。
Buffer 的方法概览
写在前面,下面所有方法中:
- 以LE结尾的API,指定使用endian (Little-Endian)字节序格式读取或写入
- 以BE结尾的API,指定使用endian (Bid-Endian)字节序格式读取或写入
| 方法 | 描述 |
|---|---|
| 分配新的 size 大小单位为8位字节的 buffer。 注意, size 必须小于 kMaxLength,否则,将会抛出异常 RangeError | |
| 拷贝参数 buffer 的数据到 Buffer 实例 | |
| 分配新的 buffer.str 字符串, encoding 编码方式默认为 ‘utf8’ | |
| buf.length | 返回 buf 的 bytes 数。注意这未必是 buf 里面内容的大小。length 是 buffer 对象所分配的内存数,若指定size 它不会随着buf 对象内容的改变而改变,若未指定则会发生变化 |
| buf.toString([encoding[, start[, end]]]) | 根据 encoding (默认 utf8)返回解码过的 string 类型。根据 start (默认 0) ,end (默认 buffer.length)作为取值范围 |
| buf.toJSON() | 将 Buffer 实例转换为 JSON 对象。 |
| buf[index] | 获取或设置指定的字节。返回值代表一个字节,所以返回值的合法范围是十六进制0x00到0xFF 或者十进制0至 255。 |
| buf.equals(otherBuffer) | 比较两个缓冲区是否相等,相等返回 true,否则返回 false |
| buf.compare(otherBuffer) | 比较两个 Buffer 对象,返回数字,表示 buf 在 otherBuffer 之前,之后或相同 |
| buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]]) | 将buf指定区间的内容覆盖targetBuffer指定索引开始的相同长度内容,源和目标可以相同。buf开始位置sourceStart(默认0)和结束位置sourceEnd (默认buf的长度)的区间内容,覆盖targetBuffer从targetStart开始的相同长度的内容 |
| buf.slice([start[, end]]) | 截取 Buffer 对象,从 start(默认是 0 ) 到 end (默认是 buffer.length ) 的区间。 负的索引是从 buffer 尾部开始计算的 |
| buf.fill(value[, offset][, end]) | 使用指定的 value 来填充这个 buffer。如果没有指定 offset (默认是 0) 并且 end (默认是 buffer.length) ,将会填充整个buffer。 |
| buf.write(str[, offset[, length]][, encoding]) | 根据offset 偏移量(默认值是 0)和 encoding 编码方式(默认值是 utf8),将 str 数据写入buffer。 length 是将要写入的字符串的 bytes 大小。 返回 number 类型,表示写入了多少 8 位字节流。如果 buffer 没有足够的空间来放整个 str ,它将只会只写入部分字符串。 length 默认是 buffer.length - offset。 这个方法不会出现写入部分字符。 |
| buf.writeUIntLE(value, offset, byteLength[, noAssert]) | 将 value 写入到 buffer 里, 它由 offset 和 byteLength 决定,最高支持 48 位无符号整数。noAssert(默认 false) 为 true ,不再验证 value 和 offset 的有效性 |
| buf.writeUIntBE(value, offset, byteLength[, noAssert]) | 用法同上。注意:无符号整数 |
| buf.writeIntLE(value, offset, byteLength[, noAssert]) | 用法同上。注意:有符号整数 |
| buf.writeIntBE(value, offset, byteLength[, noAssert]) | 用法同上。注意:有符号整数 |
| buf.readUIntLE(offset, byteLength[, noAssert]) | 根据指定的偏移量,支持读取 48 位以下的无符号数字,指定Endian格式。noAssert (默认 false)为 true 时, 不验证offset是否超过 buffer 的长度 |
| buf.readUIntBE(offset, byteLength[, noAssert]) | 用法同上。注意:无符号整数 |
| buf.readIntLE(offset, byteLength[, noAssert]) | 用法同上。注意:有符号整数 |
| buf.readIntBE(offset, byteLength[, noAssert]) | 用法同上。注意:有符号整数 |
| buf.readUInt8(offset[, noAssert]) | 用法同上。注意:支持读取无符号 8 位整数 |
| buf.readUInt16LE(offset[, noAssert]) | 用法同上。注意:读取一个无符号 16 位整数 |
| buf.readUInt16BE(offset[, noAssert]) | 用法同上。注意:读取一个无符号 16 位整数 |
| buf.readUInt32LE(offset[, noAssert]) | 用法同上。注意:读取一个无符号 32 位整数。 |
| buf.readUInt32BE(offset[, noAssert]) | 用法同上。注意:读取一个无符号 32 位整数。 |
| buf.readInt8(offset[, noAssert]) | 用法同上。注意:读取一个有符号 8 位整数 |
| buf.readInt16LE(offset[, noAssert]) | 用法同上。注意:读取一个 有符号 16 位整数 |
| buf.readInt16BE(offset[, noAssert]) | 用法同上。注意:读取一个 有符号 16 位整数 |
| buf.readInt32LE(offset[, noAssert]) | 用法同上。注意:读取一个有符号 32 位整数。 |
| buf.readInt32BE(offset[, noAssert]) | 用法同上。注意:读取一个有符号 32 位整数。 |
| buf.readFloatLE(offset[, noAssert]) | 用法同上。注意:读取一个 32 位双浮点数。 |
| buf.readFloatBE(offset[, noAssert]) | 用法同上。注意:读取一个 32 位双浮点数。 |
| buf.readDoubleLE(offset[, noAssert]) | 用法同上。注意:读取一个 64 位双精度数。 |
| buf.readDoubleBE(offset[, noAssert]) | 用法同上。注意:读取一个 64 位双精度数。 |
| buf.writeUInt8(value, offset[, noAssert]) | 根据 offset 偏移量和 endian格式将 value 写入 buffer。注意:value 必须是一个合法的无符号 8 位整数。 若noAssert 为 true (默认 false)将不会验证 value 和 offset , 这意味着 value 可能过大,或者 offset 可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用 |
| buf.writeUInt16LE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的无符号 16 位整数 |
| buf.writeUInt16BE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的无符号 16 位整数。 |
| buf.writeUInt32LE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的无符号 32 位整数。 |
| buf.writeUInt32BE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的有符号 32 位整数。 |
| buf.writeInt8(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的 signed 8 位整数。 |
| buf.writeInt16LE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的 signed 16 位整数。 |
| buf.writeInt16BE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的 signed 16 位整数。 |
| buf.writeInt32LE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的 signed 32 位整数。 |
| buf.writeInt32BE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个合法的 signed 32 位整数。 |
| buf.writeFloatLE(value, offset[, noAssert]) | 用法同上。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的。 |
| buf.writeFloatBE(value, offset[, noAssert]) | 用法同上。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的 |
| buf.writeDoubleLE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个有效的 64 位double 类型的值 |
| buf.writeDoubleBE(value, offset[, noAssert]) | 用法同上。注意:value 必须是一个有效的 64 位double 类型的值 |
Buffer 的实例
Buffer 的创建
- Buffer.alloc(size[, fill[, encoding]]): 返回一个size大小的 Buffer 实例,如果没有设置 fill,则默认填满 0
- Buffer.allocUnsafe(size): 返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据
- Buffer.allocUnsafeSlow(size)
- Buffer.from(array): 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖)
- Buffer.from(arrayBuffer[, byteOffset[, length]]): 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。
- Buffer.from(buffer): 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例
- Buffer.from(string[, encoding]): 返回一个被 string 的值初始化的新的 Buffer 实例
// 创建一个长度为 10、且用 0 填充的 Buffer。
const buf1 = Buffer.alloc(10);// 创建一个长度为 10、且用 0x1 填充的 Buffer。
const buf2 = Buffer.alloc(10, 1);// 创建一个长度为 10、且未初始化的 Buffer。
// 这个方法比调用 Buffer.alloc() 更快,
// 但返回的 Buffer 实例可能包含旧数据, 因此需要 fill() 或 write() 重写。
const buf3 = Buffer.allocUnsafe(10);// 创建一个包含 [0x1, 0x2, 0x3] 的 Buffer。
const buf4 = Buffer.from([1, 2, 3]);// 创建一个包含 UTF-8 字节 [0x74, 0xc3, 0xa9, 0x73, 0x74] 的 Buffer。
const buf5 = Buffer.from('test');// 创建一个包含 Latin-1 字节 [0x74, 0xe9, 0x73, 0x74] 的 Buffer。
const buf6 = Buffer.from('test', 'latin1');
写入缓冲区
buf.write(string[, offset[, length]][, encoding])
根据 encoding 的字符编码写入 string 到 buf 中的 offset 位置。 length 参数是写入的字节数。 如果 buf 没有足够的空间写入整个字符串,则只会写入 string 的一部分。 只部分解码的字符不会被写入.该方法返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
- string:写入缓冲区的字符串
- offset:偏移量,缓冲区开始写入的索引值,默认为 0
- length:写入的字节数,默认 buffer.length
- encoding:编码方式,默认utf8
返回实际写入的大小!!!如果 buffer 空间不足, 则只会写入部分字符串
const buf = Buffer.alloc(256);
const len = buf.write("TestDemo1");
console.log(len); // 输出 9
console.log(buf.length); // 输出 256
请注意,上述实例write函数的返回值len是实际的大小,而buf.length则是缓冲区的大小
从 Buffer 区读取数据
buf.toString([encoding[, start[, end]]])
解码缓冲区数据并使用指定的编码返回字符串
- encoding:编码方式,默认utf8
- start:指定开始读取的索引位置,默认为 0
- end: 结束位置,默认为缓冲区的末尾
const buf = Buffer.alloc(256);
const len = buf.write("TestDemo1");
console.log(len); // 输出 9
console.log(buf.length); // 输出 256
const buf1 = Buffer.alloc(3);
buf1.write("TestDemo1");
console.log(buf1.toString()); // 输出 Tes
将 Buffer 转换为 JSON 对象
buf.toJSON()
将 Node Buffer 转换为 JSON 对象,返回 JSON 对象。
const buf = Buffer.alloc(3);
const len = buf.write("3");;
console.log(buf.toJSON()); // 输出 { type: 'Buffer', data: [ 51, 0, 0 ] }
Buffer 的合并
Buffer.concat(list[, totalLength])
Node 缓冲区合并,返回一个多个成员合并的新 Buffer 对象。
- list : 用于合并的 Buffer 对象数组列表
- totalLength : 指定合并后Buffer对象的总长度
var buffer1 = Buffer.from("demo1");
var buffer2 = Buffer.from("test2");
var buffer3 = Buffer.concat([buffer1, buffer2]);
var buffer4 = Buffer.concat([buffer1, buffer2],4);
console.log(buffer3.toString()); //demo1test2
console.log(buffer4.toString()); //demo
Buffer 的比较
buf.compare(otherBuffer);
Node Buffer 比较,返回一个数字,表示 buf 若与 otherBuffer 第一个字符相匹配返回-1;若是完全匹配返回0;其它从中间开始匹配,或者匹配不上返回1
这个方法是按位比较的
- otherBuffer: 与 buf 对象比较的另外一个 Buffer 对象
var buffer2 = Buffer.from("ABCD");var buffer1 = Buffer.from("AB");
var result = buffer1.compare(buffer2);
console.log(result); // 输出 -1var buffer1 = Buffer.from("B");
var result = buffer1.compare(buffer2);
console.log(result); // 输出 1var buffer1 = Buffer.from("E");
var result = buffer1.compare(buffer2);
console.log(result); // 输出 1var buffer1 = Buffer.from("AE");
var result = buffer1.compare(buffer2);
console.log(result); // 输出 1var buffer1 = Buffer.from("ABCD");
var result = buffer1.compare(buffer2);
console.log(result); // 输出 0
Buffer 的覆盖
buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
截取缓冲区 buf指定长度的内容复制到targetBuffer的指定位置,没有返回值
- targetBuffer:要被覆盖的 Buffer 对象
- targetStart:覆盖 Buffer 对象指定开始覆盖的索引位置,默认为 0
- sourceStart: 用于覆盖的Buffer对象的指定开始位置,默认为 0
- sourceEnd: 用于覆盖的Buffer对象的指定结束位置,默认: buffer.length
var buf1 = Buffer.from("abcdefghijkl");
var buf2 = Buffer.from("RUNOOB");//将 buf2 插入到 buf1 指定位置上
buf2.copy(buf1, 2, 0, 2);console.log(buf1.toString());//abRUefghijkl
console.log(buf2.toString());//RUNOOB
Buffer 的截取–slice
buf.slice([start[, end]])
返回指定区间内的缓冲区,它和旧缓冲区指向同一块内存,从索引 start 到 end 的位置区间.被截取缓冲区不变
- start:数字, 可选, 默认 0
- end: 数字, 可选, 默认 buffer.length
var buffer1 = Buffer.from("Test");
// 剪切缓冲区
var buffer2 = buffer1.slice(0, 2);
var buffer3 = Buffer.from("M");
buffer3.copy(buffer1);
console.log(buffer2.toString());//Me
console.log(buffer1.toString());//Mest
Buffer 的长度
const buf = Buffer.from("Test");
console.log(buf.length); // 输出 4
const buf1 = Buffer.from("TestDemo1");
console.log(buf1.length); // 输出 9
writeUIntLE
const buf = Buffer.allocUnsafe(6);
buf.writeUIntLE(0x1234567890ab, 0, 6);
// 输出: <Buffer ab 90 78 56 34 12>
console.log(buf);
writeUIntBE
const buf = Buffer.allocUnsafe(6);
buf.writeUIntBE(0x1234567890ab, 0, 6);
// 输出: <Buffer 12 34 56 78 90 ab>
console.log(buf);
相关文章:

[node] Node.js 缓冲区Buffer
[node] Node.js 缓冲区Buffer 什么是BufferBuffer 与字符编码Buffer 的方法概览Buffer 的实例Buffer 的创建写入缓冲区从 Buffer 区读取数据将 Buffer 转换为 JSON 对象Buffer 的合并Buffer 的比较Buffer 的覆盖Buffer 的截取--sliceBuffer 的长度writeUIntLEwriteUIntBE 什么是…...
【ARM Cortex-M 系列 5 -- RT-Thread renesas/ra4m2-eco 移植编译篇】
文章目录 RT-Thread 移植编译篇编译os.environ 使用示例os.putenv使用示例python from 后指定路径 编译问题_POSIX_C_SOURCE 介绍编译结果 RT-Thread 移植编译篇 本文以瑞萨的ra4m2-eco 为例介绍如何下载rt-thread 及编译的设置。 RT-Thread 代码下载: git clone …...

功能强大的开源数据中台系统 DataCap 1.18.0 发布
推荐一套基于 SpringBoot 开发的简单、易用的开源权限管理平台,建议下载使用: https://github.com/devlive-community/authx 推荐一套为 Java 开发人员提供方便易用的 SDK 来与目前提供服务的的 Open AI 进行交互组件:https://github.com/devlive-commun…...
A Philosophy of Software Design 学习笔记
前言 高耦合,低内聚,降低复杂度:在软件迭代中,不关注软件系统结构,导致软件复杂度累加,软件缺乏系统设计,模块混乱,一旦需求增加、修改或者优化,改变的代价无法评估&…...
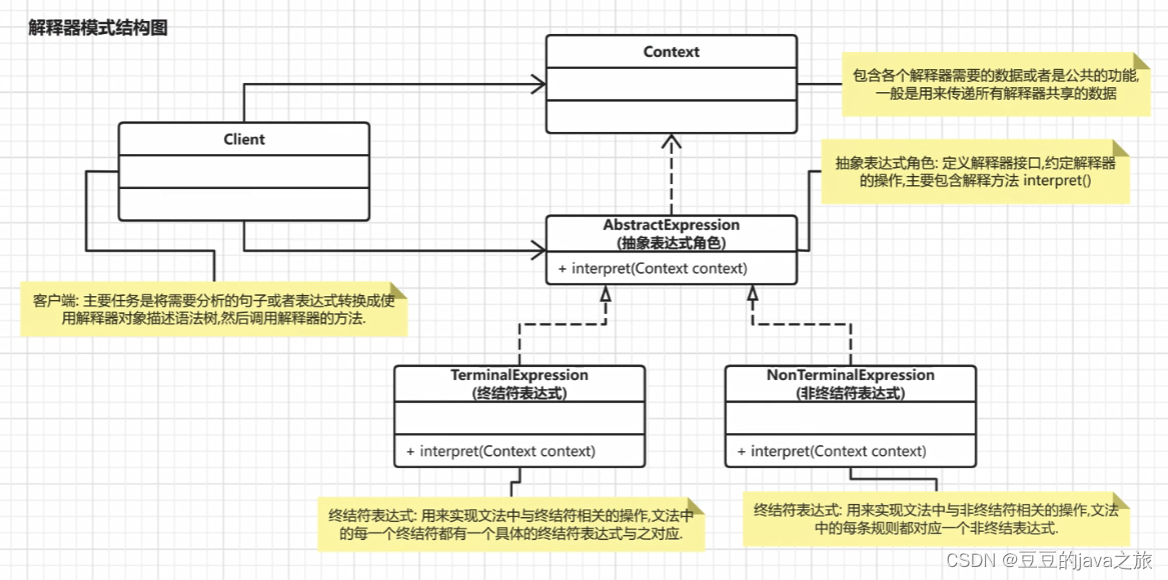
设计模式----解释器模式
一、简介 解释器模式使用频率并不高,通常用来构建一个简单语言的语法解释器,它只在一些非常特定的领域被用到,比如编译器、规则引擎、正则表达式、sql解析等。 解释器模式是行为型设计模式之一,它的原始定义为:用于定义…...
:Conda、RPM、文件权限、apt-get(更新中...)
Linux常用命令(一):Conda、RPM、文件权限、apt-get(更新中...
文章目录 一、Conda二、RPM三、文件权限四、apt-get 一、Conda Conda是一个开源的软件包管理系统和环境管理系统,用于安装和管理软件包及其依赖项。它主要用于Python编程语言,但也可以用于其他语言的项目。Conda可以帮助用户创建不同版本的Python环境&a…...

3 个适用于 Mac 电脑操作的 Android 数据恢复最佳工具 [附步骤]
在当今的数字时代,无论是由于意外删除、系统故障还是其他原因,从 Android 设备中丢失数据不仅会带来不便,而且会造成非常严重的后果。特别是对于Mac用户来说,从Android手机恢复数据是一个很大的麻烦。幸运的是,随着许多…...
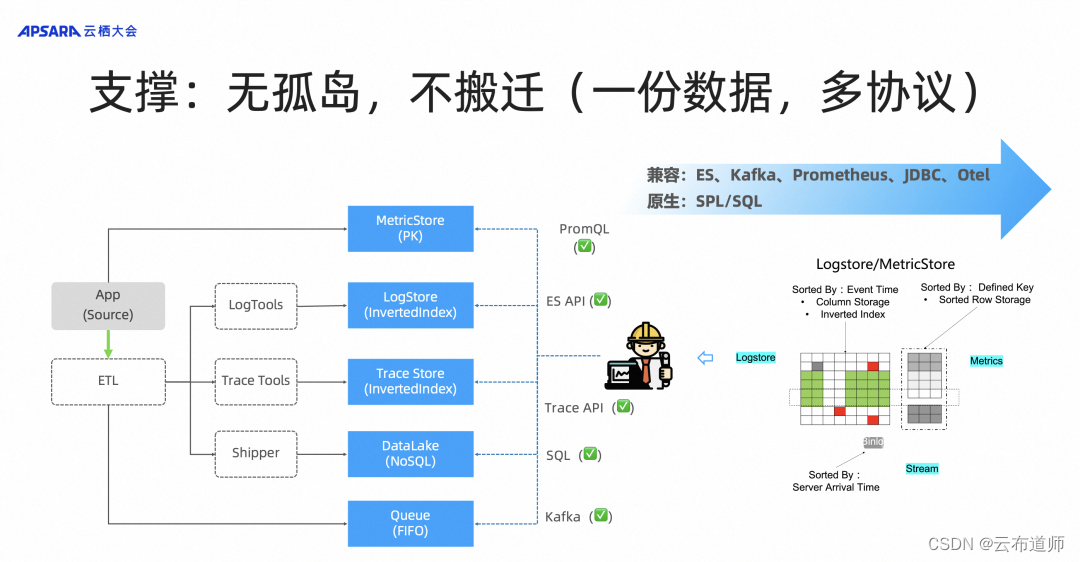
日志服务 SLS 深度解析:拥抱云原生和 AI,基于 SLS 的可观测分析创新
云布道师 10 月 31 日,杭州云栖大会上,日志服务 SLS 研发负责人简志和产品经理孟威等人发表了《日志服务 SLS 深度解析:拥抱云原生和 AI,基于 SLS 的可观测分析创新》的主题演讲,对阿里云日志服务 SLS 产品服务创新以…...

MinIO客户端之rm
MinIO提供了一个命令行程序mc用于协助用户完成日常的维护、管理类工作。 官方资料 mc rm 删除指定的对象。 准备待删除的对象,查看对象,命令如下: ./mc ls local1/bkt2/控制台的输出,如下: [2023-12-16 01:52:54 …...

【Linux笔记】文件和目录操作
🍎个人博客:个人主页 🏆个人专栏:Linux学习 ⛳️ 功不唐捐,玉汝于成 目录 前言 命令 ls (List): pwd (Print Working Directory): cp (Copy): mv (Move): rm (Remove): 结语 我的其他博客 前言 学习Linux命令…...

Vue-router 中hash模式和history模式的区别
Vue-router 中hash模式和history模式的区别 在通过vue-cli创建项目的时候,出现: 于是,去Google一遍。。 vue-router的model有两种模式:hash模式和history模式。 hash模式和history模式的不同 最直观的区别就是在url中 hash 带了一个很丑的…...
Debian在升级过程中报错
当我们在升级的过程中出现如下报错信息 报错信息如下所示: The following signatures couldnt be verified because the public key is not available: NO_PUBKEY ED444FF07D8D0BF6 W: GPG error: http://mirrors.jevincanders.net/kali kali-rolling InRelease: …...

IOS开发问题记录
1. xcode上传app store connect后testflight没有可构建版本的原因 查看你的邮箱, 里面有原因提示 一般为使用了某些权限, 但是plist没有声明 2. xcode 修改display name后名字并没有改变 原因是并没有修改到plist的CFBundleDisplayName的字段 将CFBundleDisplayName的值修改…...
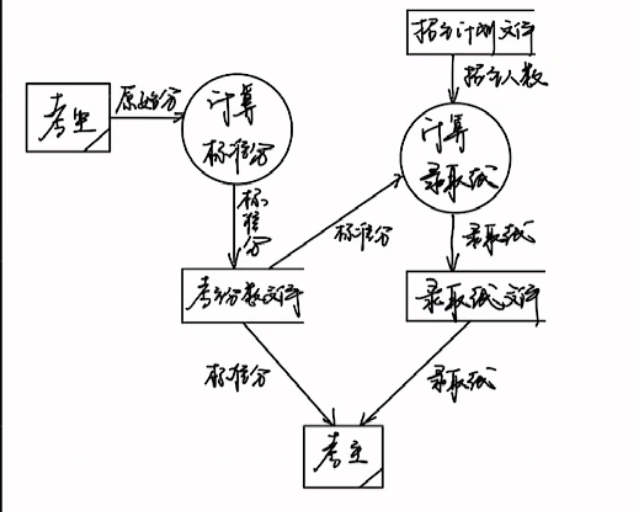
数据流图_DFD图_精简易上手
数据流图(DFD)是一种图形化技术,它描绘信息流和数据从输人移动到输出的过程中所经受的变换。 首先给出一个数据流图样例 基本的四种图形 直角矩形:代表源点或终点,一般来说,是人,如例图的仓库管理员和采购员圆形(也可以画成圆角矩形):是处理,一般来说,是动作,是动词名词的形式…...

使用 Xcode 创建一个新的项目并运行
启动 Xcode: 打开你的 Mac,然后启动 Xcode。你可以在应用程序文件夹中找到它,或者使用 Spotlight 搜索。 创建新项目: 当 Xcode 启动时,选择 “Create a new Xcode project”(创建一个新的 Xcode 项目)。 在项目模板…...

教师未来前景发展
教师是一个光荣而重要的职业,他们承担着培养下一代的责任和使命。随着社会的不断发展和变化,教师的前景也在不断扩大和改变。本文将探讨教师未来的前景发展,并提供一些思考和建议。 首先,教师的就业前景将继续扩大。随着人口的增长…...
-采样过滤)
【华为机试】2023年真题B卷(python)-采样过滤
一、题目 题目描述: 在做物理实验时,为了计算物体移动的速率,通过相机等工具周期性的采样物体移动能离。由于工具故障,采样数据存在误差甚至相误的情况。需要通过一个算法过滤掉不正确的采样值,不同工具的故意模式存在…...

编译opencv和opencv_contrib
1 下载源码 下载opencv源码https://github.com/opencv/opencv 下载opencv源码https://github.com/opencv/opencv_contrib 2 开始编译 构建需要下载ffmpeg的包,cmake构建时会自动下载,但是比较满,这里可以从下面链接直接下载 https://downloa…...
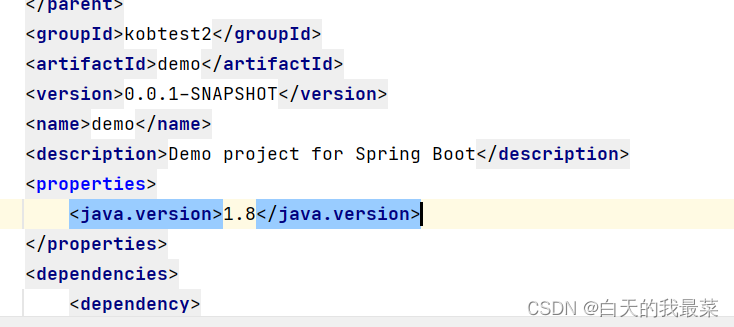
每次maven刷新jdk都要重新设置
pom.xml <java.version>17</java.version> 改为<java.version>1.8</java.version>...

《PySpark大数据分析实战》-18.什么是数据分析
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…...
)
保姆级教程:从下载到配置,手把手搞定CANoe车载测试环境(附CAN盒选购指南)
从零搭建CANoe车载测试环境:避坑指南与实战配置 第一次打开CANoe软件时,那个复杂的界面和密密麻麻的选项让我完全不知所措。作为汽车电子领域最主流的测试工具,CANoe的强大功能背后是陡峭的学习曲线。本文将分享我三年来从零开始搭建测试环境…...
)
半波整流电路DIY实战:从零搭建一个简易电源(附波形实测对比)
半波整流电路DIY实战:从零搭建一个简易电源(附波形实测对比) 在电子制作的世界里,电源电路就像人体的心脏,为各种电子设备提供稳定的能量。而半波整流电路,则是电源设计中最基础也最经典的入门项目。不同于…...

少走弯路:毕业论文全流程降AIGC工具 千笔·专业降AIGC智能体 VS 灵感风暴AI
在人工智能技术迅猛发展的今天,AI工具已经成为许多学生撰写毕业论文的重要辅助手段。然而,随着学术审查标准的不断提高,AI生成内容的痕迹和重复率问题日益凸显,成为众多学生面临的“隐形门槛”。无论是知网、维普还是Turnitin等查…...

STM32CubeMX实战:Fatfs文件系统与SDMMC驱动深度集成
1. 为什么需要Fatfs文件系统? 在嵌入式开发中,SD卡存储是个常见需求。想象一下,你的STM32设备需要记录传感器数据、存储配置文件或者保存日志文件,这时候就需要一个可靠的文件系统来管理这些数据。Fatfs就像是一个"文件管家&…...

SDH网络中的POS接口配置实战——从理论到路由器部署
1. SDH网络与POS接口技术基础 在城域网和广域网的高速数据传输中,SDH(同步数字体系)技术扮演着关键角色。POS(Packet Over SONET/SDH)接口作为SDH网络中的重要组成部分,它巧妙地将IP数据包封装到SDH帧中进行…...
)
Burpsuite Intruder模块实战:5分钟搞定Web登录爆破(附字典配置技巧)
Burpsuite Intruder模块实战:Web登录爆破的精准策略与高效技巧 在网络安全领域,Web应用的安全测试始终是攻防对抗的前沿阵地。作为渗透测试工程师的"瑞士军刀",Burpsuite以其强大的功能和灵活的模块化设计,成为安全从业…...

缓冲区溢出防御实战:从GCC编译选项到现代防护机制全解析
缓冲区溢出防御实战:从GCC编译选项到现代防护机制全解析 1. 缓冲区溢出攻击原理与危害 缓冲区溢出(Buffer Overflow)是计算机安全领域最古老却依然活跃的威胁之一。当程序向固定长度的缓冲区写入超过其容量的数据时,多余的数据会&…...

从零开始用Firecracker构建轻量级安全容器:绕过KVM性能损耗的5个技巧
从零开始用Firecracker构建轻量级安全容器:绕过KVM性能损耗的5个技巧 在边缘计算和物联网领域,资源效率与安全隔离的平衡一直是开发者面临的难题。传统容器技术虽然轻量,但共享内核的设计难以满足高安全需求;而全功能虚拟机虽然隔…...
)
帮你从算法的角度来认识数组------( 二 )
引言紧接上文,我们来讲一下数组对应的leetcode算法题思路和代码485.最大连续1的个数(1)要求给定一个二进制数组 nums , 计算其中最大连续 1 的个数。(2)示例:示例 1: 输入࿱…...

Hunyuan-MT-7B对比实测:与Google翻译等主流工具效果对比
Hunyuan-MT-7B对比实测:与Google翻译等主流工具效果对比 在翻译需求无处不在的今天,我们面临的选择似乎很多:Google翻译、DeepL、百度翻译……这些在线工具触手可及,但当你需要处理专业文档、少数民族语言或长文本时,…...