玩转 Scrapy 框架 (一):Scrapy 框架介绍及使用入门
目录
- 一、Scrapy 框架介绍
- 二、Scrapy 入门
一、Scrapy 框架介绍
简介: Scrapy 是一个基于 Python 开发的爬虫框架,可以说它是当前 Python 爬虫生态中最流行的爬虫框架,该框架提供了非常多爬虫的相关组件,架构清晰,可扩展性强。基于 Scrapy,我们可以灵活高效地完成各种爬虫需求。注意:Scrapy 框架几乎是 Python 爬虫学习和工作过程中必须掌握的框架,需要好好钻研和掌握。 下面是 Scrapy 框架的一些相关资源,包括官网、文档、GitHub 地址,建议不熟悉相关知识的读者在阅读之前浏览一下基本介绍。
Scrapy 官网:https://scrapy.org/
Scrapy 文档:https://docs.scrapy.org/en/latest/
GitHub:https://github.com/scrapy/scrapy/
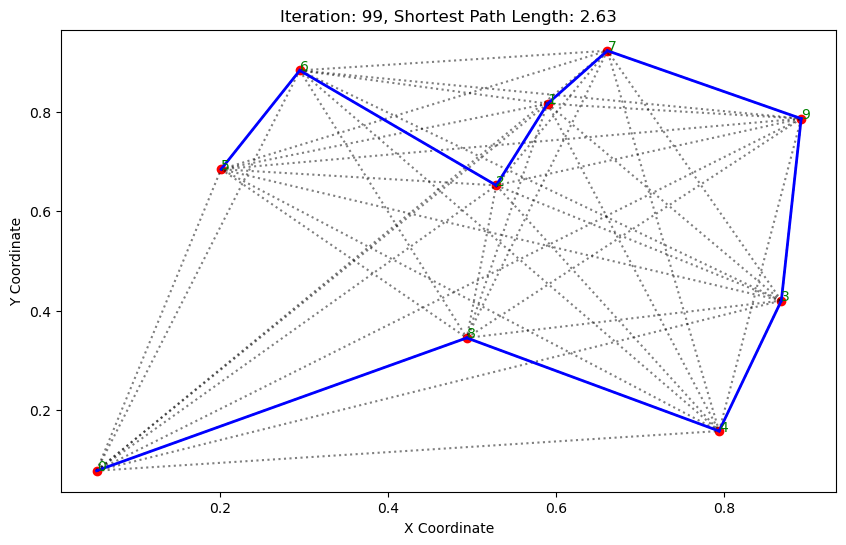
架构: 首先从整体上看一下 Scrapy 框架的架构,如下图所示:

上图来源于 Scrapy 官方文档,初看上去可能比较复杂,下面我们来介绍一下。
Engine: 图中最中间的部分,中文可以称为引擎,用来处理整个系统的数据流和事件,是整个框架的核心,可以理解为整个框架的中央处理器(类似人的大脑),负责数据的流转和逻辑的处理。
Item: 它是一个抽象的数据结构,所以在图中没有体现出来,它定义了爬取结果的数据结构,爬取的数据会被赋值成 Item 对象。每个 Item 就是一个类,类里面定义了爬取结果的数据字段,可以理解为它用来规定爬取数据的存储格式。
Scheduler: 图中下方的部分,中文可以称为调度器,它用来接受 Engine 发过来的 Request 并将其加入队列中,同时也可以将 Request 发回给 Engine 供 Downloader 执行,它主要维护 Request 的调度逻辑,比如先进先出、先进后出、优先级进出等等。
Spiders: 图中上方的部分,中文可以称为蜘蛛,Spiders 是一个复数的统称,其可以对应多个 Spider,每个 Spider 里面定义了站点的爬取逻辑和页面的解析规则,它主要负责解析响应并生成 Item 和新的请求然后发给 Engine 进行处理。
Downloader: 图中右侧部分,中文可以称为下载器,即完成 向服务器发送请求,然后拿到响应 的过程,得到的响应会再发送给 Engine 处理。
Item Pipelines: 图中左侧部分,中文可以称为项目管道,这也是一个复数统称,可以对应多个 Item Pipeline。Item Pipeline 主要负责处理由 Spider 从页面中抽取的 Item,做一些数据清洗、验证和存储等工作,比如将 Item 的某些字段进行规整,将 Item 存储到数据库等操作都可以由 Item Pipeline 来完成。
Downloader Middlewares: 图中 Engine 和 Downloader 之间的方块部分,中文可以称为下载器中间件,同样也是复数统称,其包含多个 Downloader Middleware,它是位于 Engine 和 Downloader 之间的 Hook 框架,负责实现 Downloader 和 Engine 之间的请求和响应的处理过程。
Spider Middlewares: 图中 Engine 和 Spiders 之间的方块部分,中文可以称为蜘蛛中间件,它是位于 Engine 和 Spiders 之间的 Hook 框架,负责实现 Spiders 和 Engine 之间的 Item,请求和响应的处理过程。
以上便是 Scrapy 中所有的核心组件,初看起来可能觉得非常复杂并且难以理解,但上手之后我们会慢慢发现其架构设计之精妙,后面让我们来一点点了解和学习。
数据流: 了解了 Scrapy 的基本组件和功能,通过图和描述我们可以知道,在整个爬虫运行的过程中,Engine 负责了整个数据流的分配和处理,数据流主要包括 Item、Request、Response 这三大部分,那它们又是怎么被 Engine 控制和流转的呢?结合官网的架构图来对数据流做一个简单说明:
- 启动爬虫项目时,Engine 根据要爬取的目标站点找到处理该站点的 Spider,Spider 会生成最初需要爬取的页面对应的一个或多个 Request,然后发给 Engine。
- Engine 从 Spider 中获取这些 Request,然后把它们交给 Scheduler 等待被调度
- Engine 向 Scheduler 索取下一个要处理的 Request,这时候 Scheduler 根据其调度逻辑选择合适的 Request 发送给 Engine
- Engine 将 Scheduler 发来的 Request 转发给 Downloader 进行下载执行,将 Request 发送给 Downloader 的过程会经由许多定义好的 Downloader Middlewares 的处理
- Downloader 将 Request 发送给目标服务器,得到对应的 Response,然后将其返回给 Engine。将 Response 返回 Engine 的过程同样会经由许多定义好的 Downloader Middlewares 的处理。
- Engine 从 Downloader 处接收到的 Response 里包含了爬取的目标站点的内容,Engine 会将此 Response 发送给对应的 Spider 进行处理,将 Response 发送给 Spider 的过程中会经由定义好的 Spider Middlewares 的处理
- Spider 处理 Response,解析 Response 的内容,这时候 Spider 会产生一个或多个爬取结果 Item 或者后续要爬取的目标页面对应的一个或多个 Request,然后再将这些 Item 或 Request 发送给 Engine 进行处理,将 Item 或 Request 发送给 Engine 的过程会经由定义好的 Spider Middlewares 的处理
- Engine 将 Spider 发回的一个或多个 Item 转发给定义好的 Item Pipelines 进行数据处理或存储的一系列操作,将 Spider 发回的一个或多个 Request 转发给 Scheduler 等待下一次被调度。
重复第2步到第8步,直到 Scheduler 中没有更多的 Request,这时候 Engine 会关闭 Spider,整个爬取过程结束。 从整体上来看,各个组件都只专注于一个功能,组件和组件之间的耦合度非常低,也非常容易扩展。再由 Engine 将各个组件组合起来,使得各个组件各司其职,互相配合,共同完成爬取工作。另外加上 Scrapy 对异步处理的支持,Scrapy 还可以最大限度地利用网络带宽,提高数据爬取和处理的效率。
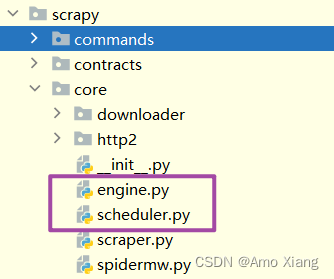
项目结构: 了解了 Scrapy 的基本架构和数据流过程之后,我们再来大致看一下其项目代码的整体架构是怎样的。在这之前我们需要先安装 Scrapy 框架,一般情况下直接使用 pip 直接安装即可,如下:
# windows下可能会安装失败 安装失败请单独下载Wheel文件 然后在使用pip安装
pip/pip3 install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com scrapy
pip/pip3 install scrapy # 不加镜像源# ubuntu 首先要确认以下依赖已经安装
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
# centos 首先要确认以下依赖已经安装
sudo yum groupinstall -y development tools
sudo yum install -y epel-release libxslt-devel libxml2-devel openssl-devel
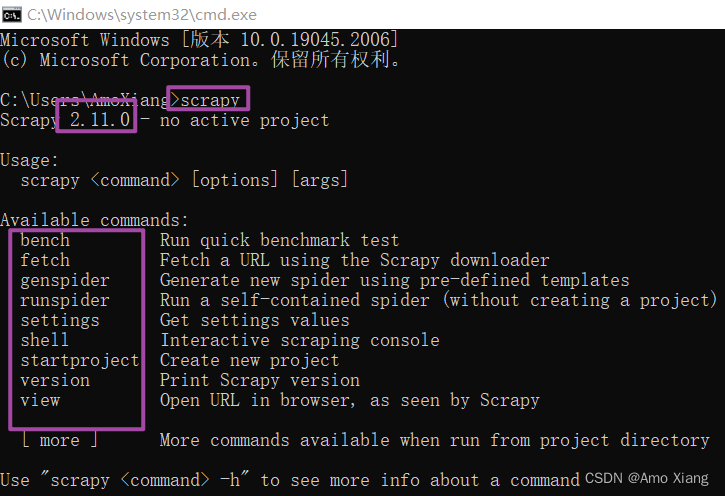
安装成功之后,我们就可以使用 scrapy 命令行了,在命令行输入 scrapy 可以得到下图所示的结果:
Scrapy 可以通过命令行来创建一个爬虫项目,比如我们要创建一个专门用来爬取新闻的项目,取名为 news,那么我们可以执行如下命令:
scrapy startproject news
这里使用 startproject 命令加上项目的名称就创建了一个名为 news 的 Scrapy 爬虫项目。执行完毕之后,当前运行目录下便会出现一个名为 news 的文件夹,该文件夹就对应一个 Scrapy 爬虫项目。接着进入 news 文件夹,我们可以再利用命令行创建一个 Spider 用来专门爬取某个站点的新闻,比如新浪新闻,我们可以使用如下命令创建一个 Spider:
cd .\news\
scrapy genspider sina news.sina.com.cn
# 提示
Created spider 'sina' using template 'basic' in module:news.spiders.sina
这里我们利用 genspider 命令加上 Spider 的名称再加上对应的域名,成功创建了一个 Spider,这个 Spider 会对应一个 Python 文件,出现在项目的 spiders 目录下。现在项目文件的结构如下:
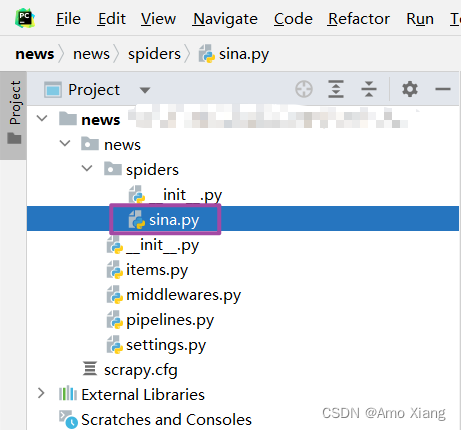
在此将各个文件的功能描述如下:
scrapy.cfg: Scrapy项目的配置文件,其中定义了项目的配置文件路径、部署信息等
items.py: 定义了Item数据结构,所有Item的定义都可以放这里
pipelines.py: 定义了Item Pipeline的实现,所有的Item Pipeline的实现都可以放在这里
settings.py: 定义了项目的全局配置
middlewares.py: 定义了Downloader Middlewares和Spider Middlewares的实现
spiders: 里面包含了一个个 Spider 的实现,每个 Spider 都对应一个 Python 文件
在此我们仅需要对这些文件的结构和用途做初步的了解,后续会对它们进行深入讲解。小结:
本节介绍了 Scrapy 框架的基本架构、数据流过程以及项目结构,如果你之前没有接触过 Scrapy,可能会觉得本节的内容很难理解,属于正常现象。不用担心,后续我会结合实战案例逐节了解 Scrapy 每个组件的用法,在学习的过程中,你会慢慢了解到 Scrapy 的强大和设计精妙之处,到时候再回过头来看看本小节,就会融会贯通了。
二、Scrapy 入门
在上小节我们介绍了 Scrapy 框架的基本架构、数据流过程和项目架构,对 Scrapy 有了初步的认识。接下来我们用 Scrapy 实现一个简单的项目,完成一遍 Scrapy 抓取流程。通过这个过程,我们可以对 Scrapy 的基本用法和原理有大体了解。本节要完成的目标如下:
- 创建一个 Scrapy 项目,熟悉 Scrapy 项目的创建流程。
- 编写一个 Spider 来抓取站点和处理数据,了解 Spider 的基本用法。
- 初步了解 Item Pipeline 的功能,将抓取的内容保存到 MongoDB 数据库。
- 运行 Scrapy 爬虫项目,了解 Scrapy 项目的运行流程。
这里我们以 Scrapy 推荐的官方练习项目为例进行实战演练,抓取的目标站点为:https://quotes.toscrape.com/,页面如下图所示:
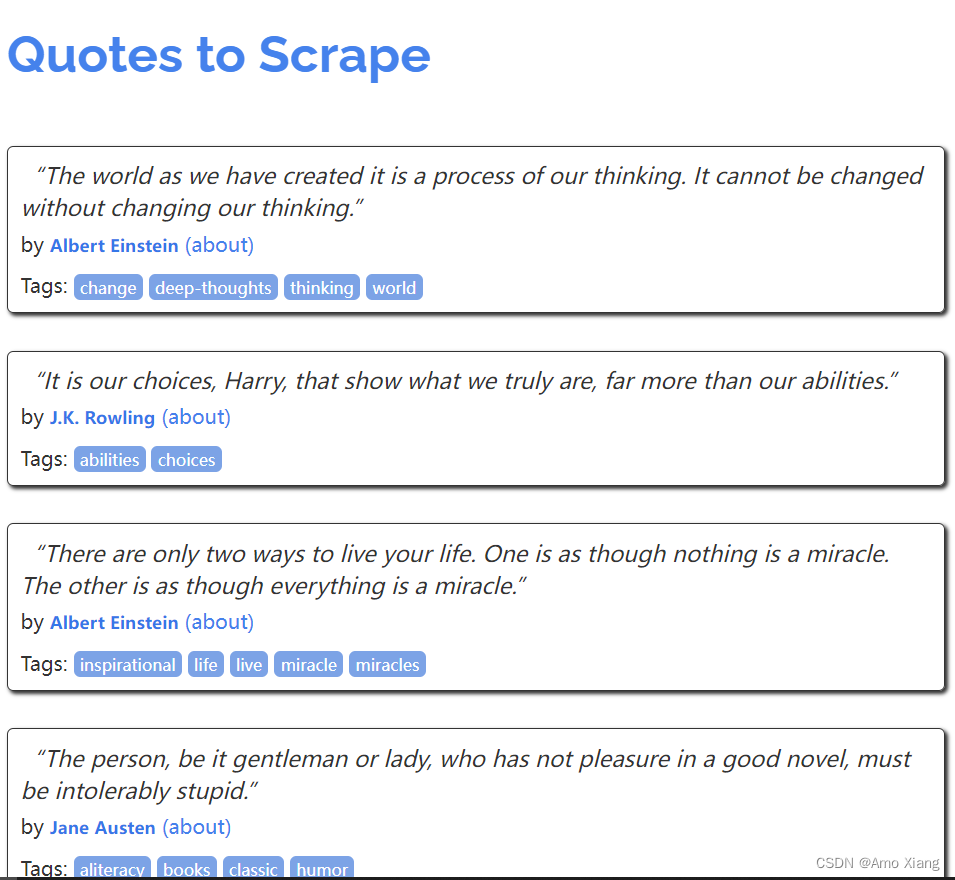
这个站点包含了一系列名人名言、作者和标签,我们需要使用 Scrapy 将其中的内容爬取并保存下来。在开始之前,我们需要安装好 Scrapy 框架、MongoDB 和 PyMongo 库,Scrapy 框架具体的安装可以参考上一小节,MongoDB 和 PyMongo 库可以分别参考笔者文章:https://blog.csdn.net/xw1680/article/details/127626145 与 https://blog.csdn.net/xw1680/article/details/129605416 安装好这三部分之后,我们就可以正常使用 Scrapy 命令了,同时也可以使用 PyMongo 连接 MongoDB 数据库并写入数据了。
① 创建项目: 首先我们需要创建一个 Scrapy 项目,可以直接用命令生成,项目名称可以叫做 ScrapyQuotes,创建命令如下:
运行完毕后,当前文件夹下会生成一个名为 ScrapyQuotes 的文件夹,文件夹结构如下所示:

② 创建 Spider: Spider 是自己定义的类,Scrapy 用它来从网页里抓取内容,并解析抓取结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始 Request,以及怎样处理爬取后的结果的方法。也可以使用命令行创建一个 Spider,比如要生成 Quotes 这个 Spider,可以执行如下命令:

进入刚刚创建的 ScrapyQuotes 文件夹,然后执行 genspider 命令。第一个参数是 Spider 的名称,第二个参数是网站域名。执行完毕后,spiders 文件夹中多了一个 quotes.py,它就是刚刚创建的 Spider,内容如下所示:
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com"]def parse(self, response):pass
这个 QuotesSpider 就是刚才命令行自动创建的 Spider,它继承了 scrapy 的 Spider 类,QuotesSpider 有3个属性,分别为 name、allowed_domains 和 start_urls,还有一个方法 parse。
name: 是每个项目唯一的名字,用来区分不同的 Spider
allowed_domains: 是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉
start_urls: 包含了 Spider 在启动时爬取的 URL 列表,初始请求是由它来定义的
parse: Spider 的一个方法。在默认情况下,start_urls 里面的链接构成的请求完成下载后,parse 方法就会被调用,返回的响应就会作
为唯一的参数传递给 parse 方法。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
补充说明:新的 Scrapy 框架 scrapy.Spider 中的 parse 方法还有一个额外的参数 **kwargs,如下图所示:

而使用 genspider 命令创建的模板中爬虫类重写的 parse 方法是没有这个参数的,故 Pycharm 会进行提示,如下图所示:

为了严谨,这里需要我们手动改写为如下所示的代码:
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com"]def parse(self, response, **kwargs):pass
如果每次都手动进行更改的话,会比较繁琐,我们可以直接更改模板文件:
# 路径: F:\development_tools\Python39\Lib\site-packages\scrapy\templates\spiders\basic.tmpl
import scrapyclass $classname(scrapy.Spider):name = "$name"allowed_domains = ["$domain"]start_urls = ["$url"]# 原始的模板文件是没有**kwargs的def parse(self, response, **kwargs):pass
此时我们手动删除 quotes.py 文件,然后再次使用 genspider 命令创建 Spider 时,会发现 parse 方法中已经自带了 **kwargs 参数。
③ 创建 Item: Item 是保存爬取数据的容器,定义了爬取结果的数据结构。它的使用方法和字典类似。不过相比字典,Item 多了额外的保护机制,可以避免拼写错误或者定义字段错误。创建 Item 需要继承 scrapy 的 Item 类,并且定义类型为 Field 的字段,这个字段就是我们要爬取的字段。观察目标网站,我们可以获取到的内容有下面几项:
text: 文本,即每条名言的内容,是一个字符串
author: 作者,即每条名言的作者,是一个字符串
tags: 标签,即每条名言的标签,是字符串组成的列表
这样的话,每条爬取数据就包含这3个字段,那么我们就可以定义对应的 Item,此时将 items.py 修改如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy# class ScrapyquotesItem(scrapy.Item): 个人习惯,将类名更改如下
class ScrapyQuotesItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()text = scrapy.Field() # 每条名言的内容author = scrapy.Field() # 作者tags = scrapy.Field() # 标签
这里我们声明了 ScrapyQuotesItem,继承了 Item 类,然后使用 Field 定义了3个字段,接下来爬取时我们就会用到这个 Item。
④ 解析 Response: parse 方法的参数 response 是 start_urls 里面的链接爬取后的结果,即页面请求后得到的 Response,Scrapy 将其转化为了一个数据对象,里面包含了页面请求后得到的 Response Status、Body 等内容。这里我梳理一下 Response 可用的属性和方法,以便我们做解析处理使用,如下所示:
# ① url:Request URL
# ② status:Response 状态码,一般情况下请求成功状态码为200
# ③ headers:Response Headers,是一个字典,字段是一一对应的
# ④ body:Response Body,这个通常就是访问页面之后得到的源代码结果了,比如里面包含的是HTML或者JSON字符串,但注意其结果是
# bytes 类型。与requests模块请求后得到的响应属性content类似
# ⑤ request:Response 对应的 Request 对象
# ⑥ certificate:是twisted.internet.ssl.Certifucate类型的对象,通常代表一个SSL证书对象
# ⑦ ip_address:是一个ipaddress.IPv4Address或IPv6Address类型的对象,代表服务器的IP地址
# ⑧ urljoin:是对URL的一个处理方法,可以传入当前页面的相对URL,该方法处理后返回的就是绝对URL
# urljoin 其实使用的就是: from urllib.parse import urljoin 可以去看源码
# ⑨ follow/follow_all:是一个根据URL来生成后续Request的方法,和直接构造Request不同的是,该方法接收的url可以是相对URL,不必
# 一定是绝对URL,因为follow方法中有做url拼接的操作,源码如下:
if isinstance(url, Link):url = url.url
elif url is None:raise ValueError("url can't be None")
url = self.urljoin(url)
另外 Response 还有几个常用的子类,如 TextResponse 和 HtmlResponse, HtmlResponse 又是 TextResponse 的子类,实际上回调方法接收的 response 参数就是一个 HtmlResponse 对象,它还有几个常用的方法或属性。
# ① text: 同body属性,但结果是str类型
# ② encoding: Response的编码,默认是utf-8
# ③ selector: 根据Response的内容构造而成的Selector对象,利用它我们可以进一步调用xpath、css等方法进行结果的提取
# ④ xpath()方法: 传入XPath进行内容提取,等同于调用selector的xpath方法
# ⑤ css()方法: 传入CSS选择器进行内容提取,等同于调用selector的css方法
# ⑥ json()方法: 是Scrapy2.2新增的方法,利用该方法可以直接将text属性转换为JSON对象,本质其实使用的就是json.loads,源码如下:
if self._cached_decoded_json is _NONE:self._cached_decoded_json = json.loads(self.body)
return self._cached_decoded_json
以上便是对 Response 的基本介绍,关于 Response 更详细的解释可以参考官方文档:https://docs.scrapy.org/en/latest/topics/request-response.html#response-objects。所以在 parse 方法中,我们可以直接对 response 变量包含的内容进行解析,比如浏览器请求结果的网页源代码,进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。我们可以看到网页中既有我们想要的结果,又有下一页的链接,这两部分内容我们都需要进行处理。首先看看网页结构,如下图所示:
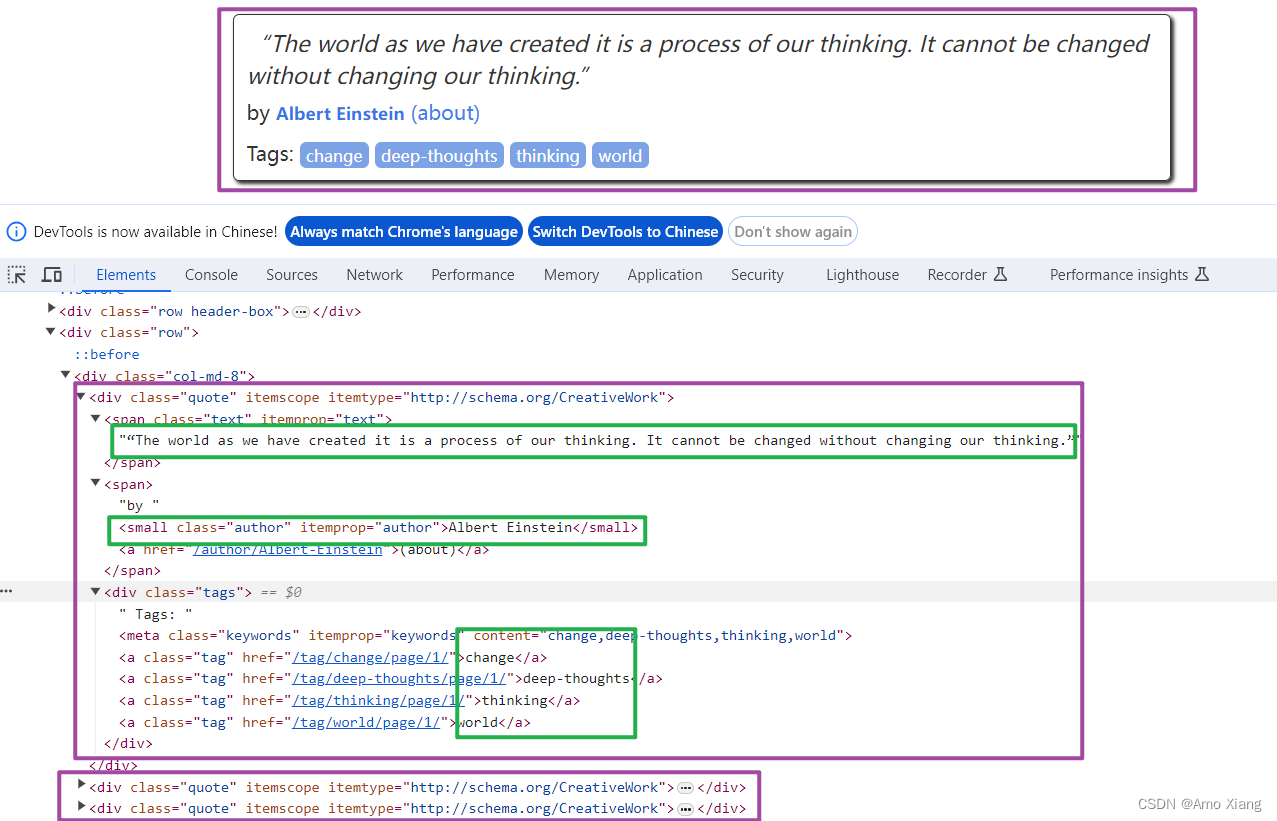
每一页都有多个 class 为 quote 的区块,每个区块内都包含text、author、tags。那么我们先找出所有的 quote,然后提取每个 quote 中的内容。我们可以使用CSS选择器或Xpath选择器进行提取,这个过程我们可以直接借助 response 的 css 或 xpath 方法实现,这都是 Scrapy 给我们封装好的方法,直接调用即可 (CSS选择器和Xpath语法属于爬虫基础内容,笔者这里不再进行赘述), 此处,笔者使用 CSS 选择器进行元素定位与提取,可以将 parse 方法的内容进行如下改写:
def parse(self, response, **kwargs):quotes = response.css("div.quote")for quote in quotes:text = quote.css("span.text::text").extract_first("")author = quote.css("small.author::text").extract_first("")tags = quote.css("div.tags a.tag::text").extract()
这里首先利用 CSS 选择器选取所有的 quote 并将其赋值为 quotes 变量,然后利用 for 循环遍历每个 quote, 解析每个 quote 的内容。ps:单独调用 css 方法我们得到的是 Selector 对象组成的列表;调用 extract 方法会进一步从 Selector 对象里提取其内容,再加上 ::text 则会从 HTML 代码中提取出正文文本。因此对于 text,我们只需要获取结果的第一个元素即可,所以使用 extract_first 方法,得到的就是一个字符串。而对于 tags,我们想要获取所有结果组成的列表,所以使用 extract 方法,得到的就是所有标签字符串组成的列表。
⑤ 使用 Item: 之前已经定义好了 ScrapyQuotesItem,接下来就要使用它了。我们可以把 Item 理解为一个字典,和字典还不太相同,其本质是一个类,所以在使用的时候需要实例化。实例化之后,我们依次用刚才解析的结果赋值 Item 的每一个字段,最后将 Item 返回。QuotesSpider 的改写如下所示:
import scrapy
from ..items import ScrapyQuotesItemclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com"]def parse(self, response, **kwargs):quotes = response.css("div.quote")for quote in quotes:item = ScrapyQuotesItem()item["text"] = quote.css("span.text::text").extract_first("")item["author"] = quote.css("small.author::text").extract_first("")item["tags"] = quote.css("div.tags a.tag::text").extract()yield item
如此一来,首页的所有内容就被解析出来并被赋值成了一个个 ScrapyQuotesItem 了,每个 ScrapyQuotesItem 就代表一条名言,包含名言的内容、作者和标签。
⑥ 后续 Request: 上面的操作实现了从首页抓取内容,如果运行它,我们其实已经可以从首页提取到所有 quote 信息并将其转化为一个个 ScrapyQuotesItem 对象了。我们将页面拉倒最底部,如下图所示:

这里发现有一个 Next 按钮,查看一下源代码,可以看到它的链接是 /page/2/,实际上全链接是 https://quotes.toscrape.com/page/2/,通过这个链接我们就可以构造下一个 Request 了。构造 Request 时需要用到 scrapy 的 Request 类,Request 对象实际上指的就是 scrapy.http.Request 类的一个实例,它包含了 HTTP 请求的基本信息,用这个 Request 类我们可以构造 Request 对象发送 HTTP 请求,它会被 Engine 交给 Downloader 进行处理执行,返回一个 Response 对象。Request 的构造参数梳理如下:
- url: Request 的页面链接,即 Request URL。
- callback:Request 的回调方法,通常这个方法需要定义在 Spider 类里面,并且需要对应一个 response 参数,代表 Request 执行请求后得到的 Response 对象。如果这个 callback 参数不指定,默认会使用 Spider 类里面的 parse 方法。
- method:Request 的方法,默认是 GET,还可以设置为 POST、PUT、DELETE 等。
- meta:Request 请求携带的额外参数,利用 meta,我们可以指定任意处理参数,特定的参数经由 Scrapy 各个组件的处理,可以得到不同的效果。另外,meta 还可以用来向回调方法传递信息。
- body:Request 的内容,即 Request Body,往往 Request Body 对应的是 POST 请求,我们可以使用 FormRequest 或 JsonRequest 更方便地实现 POST 请求。
- headers:Request Headers,是字典形式。
- cookies:Request 携带的 Cookies,可以是字典或列表形式。
- encoding:Request 的编码,默认是 utf-8。
- prority:Request 优先级,默认是0,这个优先级是给 Scheduler 做 Request 调度使用的,数值越大,就越被优先调度并执行。
- dont_filter:Request 不去重,Scrapy 默认会根据 Request 的信息进行去重,使得在爬取过程中不会出现重复的请求,设置为 True 代表这个 Request 会被忽略去重操作,默认是 False。
- errback:错误处理方法,如果在请求过程中出现了错误,这个方法就会被调用。
- flags:请求的标志,可以用于记录类似的处理。
- cb_kwargs:回调方法的额外参数,可以作为字典传递。
值得注意的是,meta 参数是一个十分有用而且易扩展的参数,它可以以字典的形式传递,包含的信息不受限制,所以很多 Scrapy 的插件会基于 meta 参数做一些特殊处理。在默认情况下,Scrapy 就预留了一些特殊的 key 作为特殊处理。比如 request.meta['proxy'] 可以用来设置请求时使用的代理,request.meta['max_retry_times'] 可以设置用来设置请求的最大重试次数等。更多具体的内容可以参见:https://docs.scrapy.org/en/latest/topics/request-response.html
另外,Scrapy 还专门为 POST 请求提供了两个类 ------ FormRequest 和 JsonRequest,它们都是 Request 类的子类,我们可以利用 FormRequest 的 formdata 参数传递表单内容,利用 JsonRequest 的 json 参数传递 JSON 内容,其他的参数和 Request 基本是一致的。二者的详细介绍可以参考官方文档:
JsonRequest:https://docs.scrapy.org/en/latest/topics/request-response.html#jsonrequest
FormRequest:https://docs.scrapy.org/en/latest/topics/request-response.html#formrequest-objects
示例代码如下:
import scrapyclass TestSpider(scrapy.Spider):name = 'test'allowed_domains = ['www.httpbin.org']# start_urls = ['https://www.httpbin.org/post']start_url = 'https://www.httpbin.org/post'# 大坑:注意这里的年龄千万不要写18 否则会报错 所有都以字符串的形式来表示# 至于为什么可以自己去看源码data = {"name": "Amo", "age": "18"}def start_requests(self):yield scrapy.http.FormRequest(self.start_url, callback=self.parse_response, formdata=self.data)yield scrapy.http.JsonRequest(self.start_url, callback=self.parse_response,data=self.data)def parse_response(self, response, **kwargs):print("text", response.text)
使用 start_requests() 方法生成了一个 FormRequest 和 JsonRequest,请求的页面链接修改为了 https://www.httpbin.org/post,它可以把 POST 请求的详情返回,另外 data 保持不变。运行结果如下图所示:
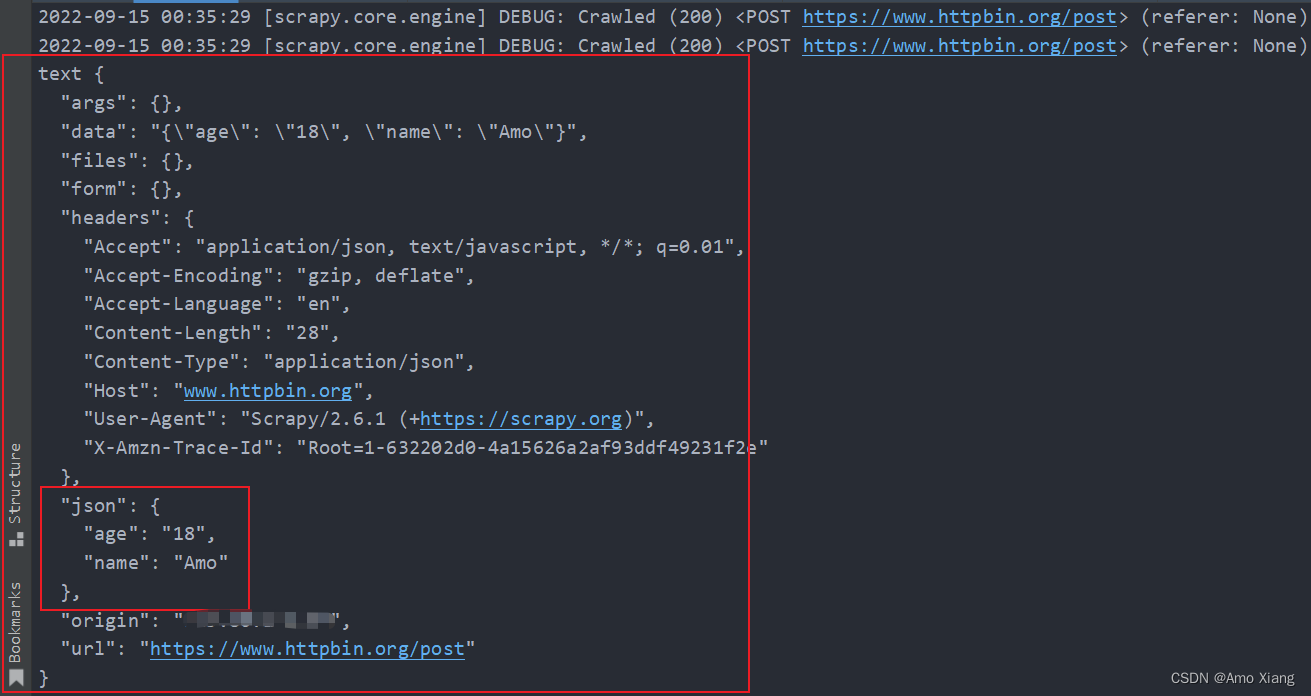
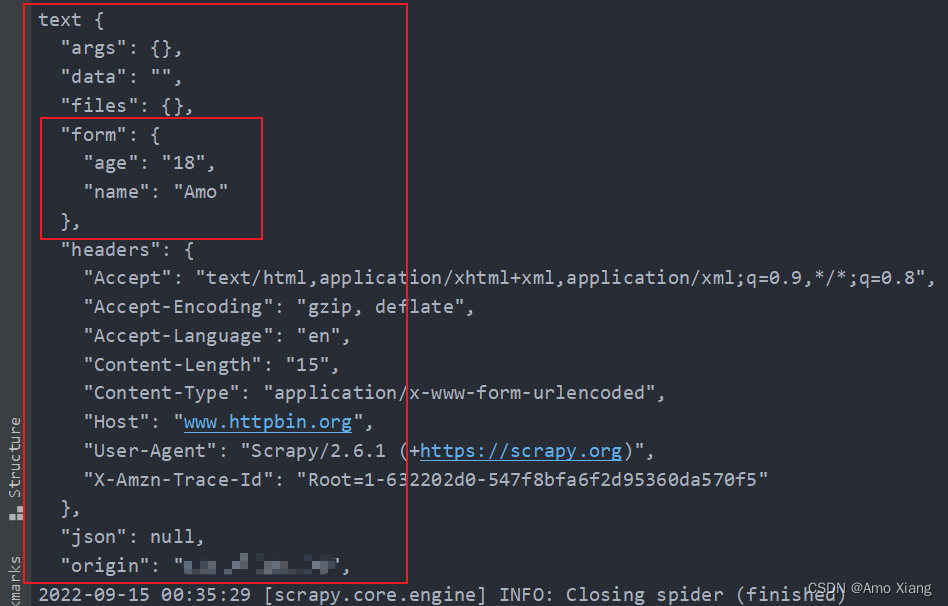
这里我们可以看到两种请求的效果。第一个 JsonRequest,我们可以观察到页面返回结果的 json 字段就是我们所请求时添加的 data 内容,这说明实际上是发送了 Content-Type 为 application/json 的 POST 请求,这种对应的就是发送 JSON 数据。第二个 FormRequest,我们可以观察到页面返回结果的 form 字段就是我们请求时添加的 data 内容,这说明实际上是发送了 Content-Type 为 application/x-www-form-urlencoded 的 POST 请求,这种对应的就是表单提交。这两种 POST 请求的发送方式我们需要区分清楚,并根据服务器的实际需要进行选择。
回到正题, 刚才所定义的 parse 方法就是用来提取名言 text、author、tags 的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们可以再次使用 parse 方法来做页面解析。接下来我们要做的就是利用选择器得到下一页链接并生成请求,在 parse 方法后追加如下的代码:
href = response.css("li.next a::attr(href)").extract_first("")
next_url = response.urljoin(href)
yield scrapy.Request(url=next_url, callback=self.parse)
第一行代码首先通过 CSS 选择器获取下一个页面的链接,即要获取超链接 a 中的 href 属性,这里用到了 ::attr(href) 进行提取,其中 attr 代表提取节点的属性,href 则为要提取的属性名,然后再下一步调用 extract_first 方法获取内容。第二行代码调用了 urljoin 方法,urljoin 方法可以将相对 URL 构造成一个绝对 URL。例如,获取到的下一页地址是 /page/2/,urljoin 方法处理后得到的结果就是:https://quotes.toscrape.com/page/2/。第三行代码通过 url 和 callback 变量构造了一个新的 Request,回调方法 callback 依然使用 parse 方法。这个 Request 执行完成之后,其对应的 Response 会重新经过 parse 方法处理,得到第二页的解析结果,然后以此类推,生成第二页的下一页,也就是第三页的请求。这样爬虫就进入到了一个循环,直到最后一页。通过几行代码,我们就轻松实现了一个抓取循环,将每个页面的结果抓取下来了。现在,改写之后的整个 Spider 类如下所示:
import scrapy
from ..items import ScrapyQuotesItemclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com"]def parse(self, response, **kwargs):quotes = response.css("div.quote")for quote in quotes:item = ScrapyQuotesItem()item["text"] = quote.css("span.text::text").extract_first("")item["author"] = quote.css("small.author::text").extract_first("")item["tags"] = quote.css("div.tags a.tag::text").extract()yield itemhref = response.css("li.next a::attr(href)").extract_first("")next_url = response.urljoin(href)yield scrapy.Request(url=next_url, callback=self.parse)
可以看到整个站点的抓取逻辑就轻松完成了,不需要再去编写怎样发送 Request,不需要去关心异常处理,因为这些工作 Scrapy 都帮我们完成了,我们只需要关注 Spider 本身的抓取和提取逻辑即可。
⑦ 运行: 接下来就是运行项目了,进入项目目录,运行如下命令:
PS D:\Code\dream> cd .\scrapy_study\ScrapyQuotes\
PS D:\Code\dream\scrapy_study\ScrapyQuotes> scrapy crawl quotes# 也可以进入到spiders目录 注意此时quotes.py中导入就不能在使用from ..items了
# 改为: from ScrapyQuotes.items import ScrapyQuotesItem
PS D:\Code\dream\scrapy_study\ScrapyQuotes> cd .\ScrapyQuotes\spiders\
PS D:\Code\dream\scrapy_study\ScrapyQuotes\ScrapyQuotes\spiders> scrapy runspider quotes.py
上面两种方式在 Pycharm 中都无法调试源码,故一般我们会采用下面的方式,在项目的根目录创建 main.py 文件,如下图所示:
在 main.py 文件中编写如下代码:
# -*- coding: utf-8 -*-
# @Time : 2023-12-20 1:44
# @Author : AmoXiang
# @File : main.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680
import os.path
import sysfrom scrapy.cmdline import executesys.path.append(os.path.dirname(os.path.abspath(__file__)))# execute(["scrapy", "crawl", "quotes"])
execute("scrapy crawl quotes".split(" "))
然后我们直接在 Pycharm 中右键运行 main.py 文件即可,运行之后,Scrapy 会先输出当前的版本号以及正在启动的项目名称。然后输出当前 settings.py 中一些重写后的配置。接着会输出当前所应用的 Middlewares 和 Item Pipelines。Middlewares 和 Item Pipelines 都沿用了 Scrapy 的默认配置,我们可以在 settings.py 中配置它们的开启和关闭,后续文章会对它们的用法进行讲解。接下来就是输出各个页面的抓取结果了,可以看到爬虫一边解析,一边翻页,直到将所有内容抓取完毕,然后终止。最后,Scrapy 输出了整个抓取过程的统计信息,如请求的字节数、请求次数、响应次数、完成原因等。整个 Scrapy 程序成功运行,我们通过非常简单的代码就完成了一个站点内容的爬取,所有的名言都被我们抓取下来了。
⑧ 保存到文件: Scrapy 提供的 Feed Exports 可以轻松将抓取结果输出。例如,我们想要将抓取的名言结果保存成 JSON 文件,那么可以执行如下命令:
PS D:\Code\dream\scrapy_study\ScrapyQuotes> scrapy crawl quotes -o quotes.json
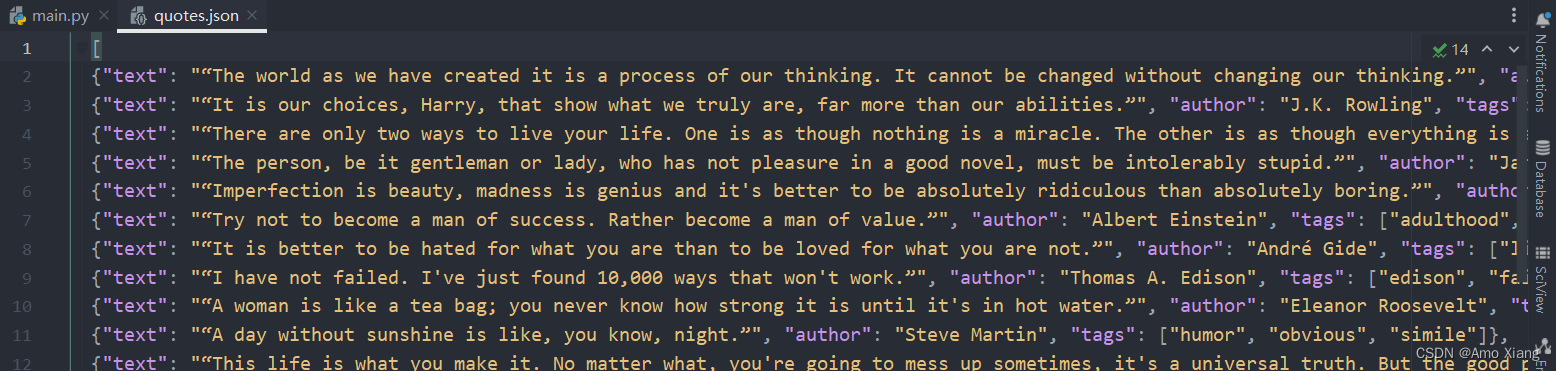
命令运行之后,项目内多了一个 quotes.json 文件,文件包含了刚才抓取的所有内容,内容是 JSON 格式,如下图所示:
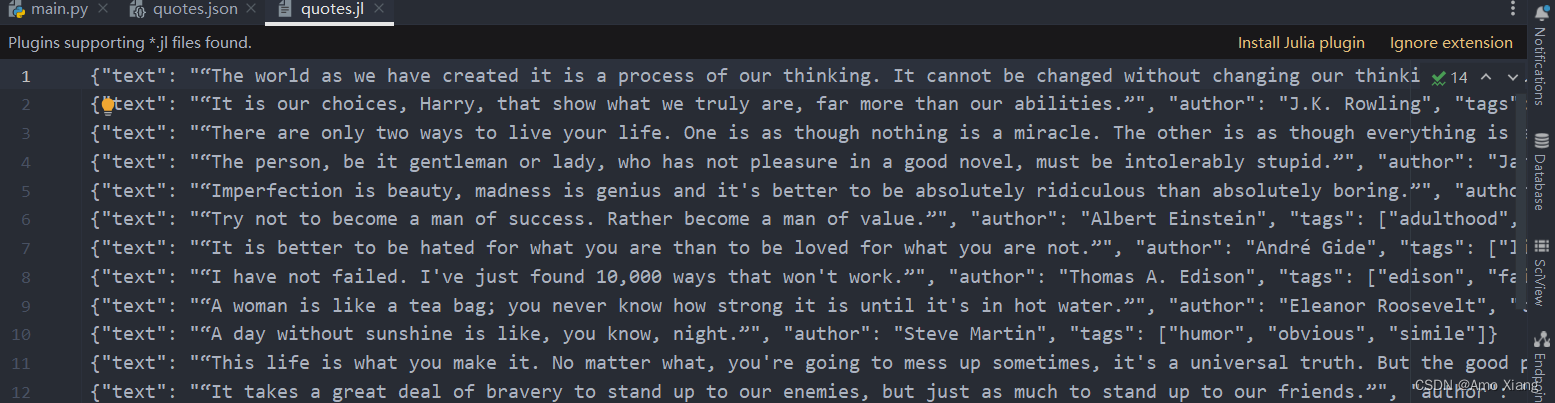
另外我们还可以让每一个 Item 输出一行 JSON,输出后缀为 jl,为 jsonline 的缩写,命令如下:
PS D:\Code\dream\scrapy_study\ScrapyQuotes> scrapy crawl quotes -o quotes.jl
PS D:\Code\dream\scrapy_study\ScrapyQuotes> scrapy crawl quotes -o quotes.jsonlines
如下图所示:
Feed Exports 支持输出的格式还有很多,例如 csv、xml、pickle、marshal 等,同时它支持 ftp、s3 等远程输出,另外还可以通过自定义 ItemExporter 来实现其他的输出。例如,下面命令对应的输出分别为 csv、xml、pickle、marshal 格式以及 ftp 远程输出:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv
其中,ftp 输出需要正确配置用户名、密码、地址、输出路径,否则会报错。通过 Scrapy 提供的 Feed Exports,我们可以轻松地将抓取结果输出到文件中,对于一些小型项目来说,这应该足够了。如果想要更复杂的输出,如输出到数据库等,我们可以使用 Item Pipeline 来完成。
⑨ 使用 Item Pipeline: 如果想进行更复杂的操作,如将结果保存到 MongoDB 数据库中或者筛选某些有用的 Item,那么我们可以定义 Item Pipeline 来实现。Item Pipeline 为项目管道,当 Item 生成后,它会自动发送到 Item Pipeline 处进行处理,我们可以用 Item Pipeline 来做如下操作:
清洗 HTML 数据
验证爬取数据,检查爬取字段
查重并丢弃重复内容
将爬取结果存储到数据库
要实现 Item Pipeline 很简单,只需要定义一个类并实现 process_item 方法即可。启用 Item Pipeline 后,Item Pipeline 会自动调用这个方法,process_item 方法必须返回包含数据的字典或 Item 对象,或者抛出 DropItem 异常。process_item 方法有两个参数。一个参数是 item,每次 Spider 生成的 Item 都会作为参数传递过来,另一个参数是 spider,就是 Spider 的实例。接下来我们实现一个 Item Pipeline,筛掉 text 长度大于 50 的 Item,并将结果保存到 MongoDB。修改项目里的 pipelines.py 文件,之前用命令行自动生成的文件内容可以删掉,增加一个 TextPipeline,内容如下所示:
class TextPipeline(object):def __init__(self):self.limit = 50def process_item(self, item, spider):if item["text"]:if len(item["text"]) > self.limit:item["text"] = item["text"][:self.limit].rstrip() + "..."return itemelse:return DropItem("Missing Text")
这段代码在构造方法里定义了限制长度为 50,实现了 process_item 方法,其参数是 item 和 spider。首先该方法判断 item 的 text 属性是否存在,如果不存在,则抛出 DropItem 异常。如果存在,再判断长度是否大于50,如果大于,那就截断然后拼接省略号,再将 Item 返回。接下来,我们将处理后的 item 存入 MongoDB,定义另外一个 Pipeline。同样在 pipelines.py 中,我们实现另一个类 MongoPipeline,内容如下所示:
class MongoPipeline(object):def __init__(self, connection_string, database):self.connection_string = connection_stringself.database = database@classmethoddef from_crawler(cls, crawler):return cls(connection_string=crawler.settings.get('MONGODB_CONNECTION_STRING'),database=crawler.settings.get('MONGODB_DATABASE'))def open_spider(self, spider):self.client = pymongo.MongoClient(self.connection_string)self.db = self.client[self.database]def process_item(self, item, spider):name = item.__class__.__name__self.db[name].insert_one(dict(item))return itemdef close_spider(self, spider):self.client.close()
MongoPipeline 类实现了另外几个 API 定义的方法。
- from_crawler:一个类方法,用
@classmethod标识,这个方法是以依赖注入的方式实现的,方法的参数就是 crawler。通过 crawler,我们能拿到全局配置的每个配置信息,在全局配置 settings.py 中,可以通过定义 MONGO_URI 和 MONGO_DB 来指定 MongoDB 连接需要的地址以及数据库名称,拿到配置信息之后返回类对象即可。所以这个方法的定义主要是用来获取 settings.py 中的配置的。 - open_spider:当 Spider 被开启时,这个方法被调用,主要进行了一些初始化操作。
- close_spider:当 Spider 被关闭时,这个方法被调用,将数据库连接关闭。
最主要的 process_item 方法则执行了数据插入操作,这里直接调用 insert 方法传入 item 对象即可将数据存储到 MongoDB。定义好 TextPipeline 和 MongoPipeline 这两个类后,我们需要再 settings.py 中使用它们。MongoDB 的连接信息还需要定义。我们在 settings.py 中加入如下内容:
USER_AGENT = ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"" Chrome/120.0.0.0 Safari/537.36")ROBOTSTXT_OBEY = False # 修改为False
ITEM_PIPELINES = {"ScrapyQuotes.pipelines.TextPipeline": 2,"ScrapyQuotes.pipelines.MongoPipeline": 3,
}
MONGODB_CONNECTION_STRING = "localhost"
MONGODB_DATABASE = "ScrapyQuotes"
这里我们声明了 ITEM_PIPELINES 字典,键名是 Pipeline 的类名称,键值是调用优先级,是一个数字,数字越小则对应的 Pipeline 越先被调用,另外我们声明了 MongoDB 的连接字符串和存储的数据库名称。在 Pycharm 中运行 main.py 文件,爬取结束后,我们可以看到 MongoDB 中创建了一个 ScrapyQuotes 的数据库和 ScrapyQuotesItem 的集合,内容如下图所示:
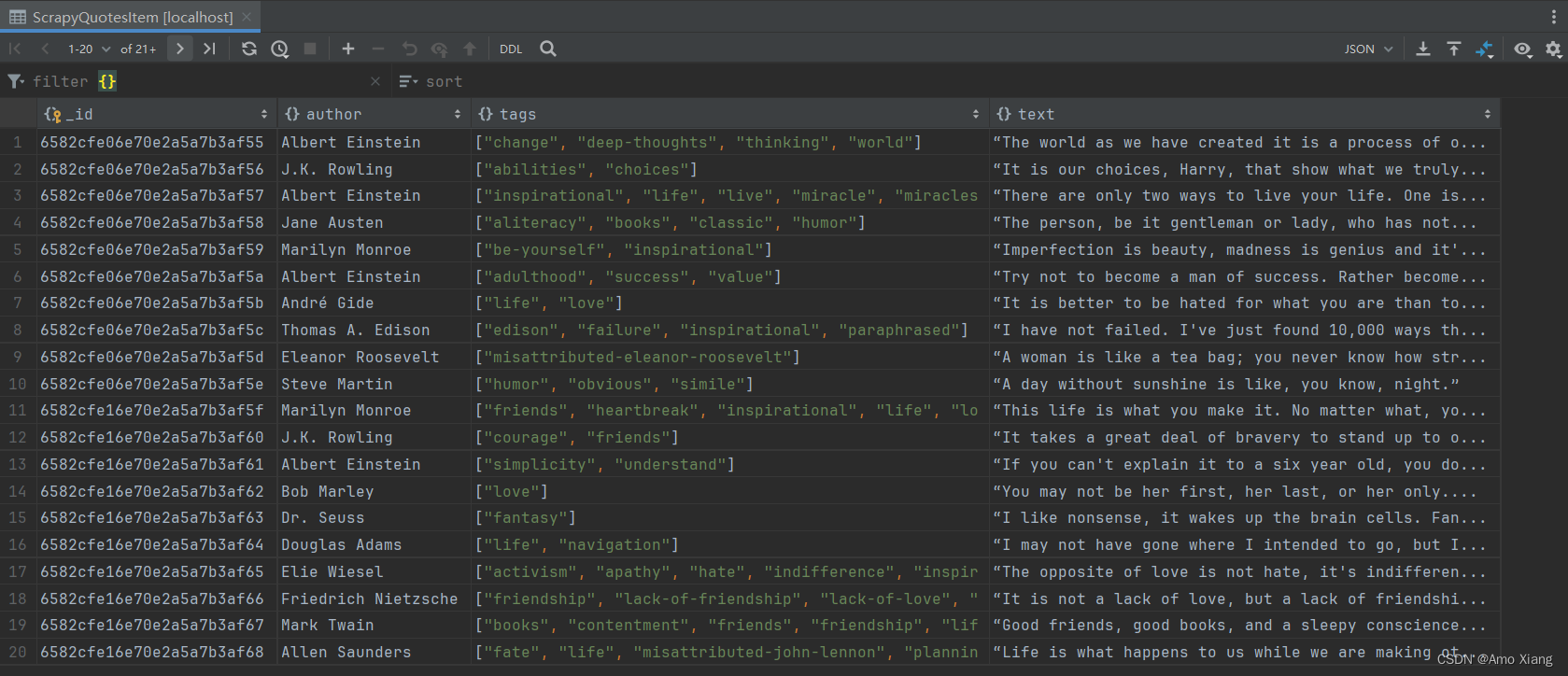
长的 text 已经被处理并追加了省略号,短的 text 保持不变,author 和 tags 也都相应保存到了数据库的集合中。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习Scrapy框架的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
相关文章:
玩转 Scrapy 框架 (一):Scrapy 框架介绍及使用入门
目录 一、Scrapy 框架介绍二、Scrapy 入门 一、Scrapy 框架介绍 简介: Scrapy 是一个基于 Python 开发的爬虫框架,可以说它是当前 Python 爬虫生态中最流行的爬虫框架,该框架提供了非常多爬虫的相关组件,架构清晰,可扩…...
node.js mongoose index(索引)
目录 简介 索引类型 单索引 复合索引 文本索引 简介 在 Mongoose 中,索引(Index)是一种用于提高查询性能的数据结构,它可以加速对数据库中文档的检索操作 索引类型 单索引、复合索引、文本索引、多键索引、哈希索引、地理…...

谷歌推大语言模型VideoPoet:文本图片皆可生成视频和音频
Google Research最近发布了一款名为VideoPoet的大型语言模型(LLM),旨在解决当前视频生成领域的挑战。该领域近年来涌现出许多视频生成模型,但在生成连贯的大运动时仍存在瓶颈。现有领先模型要么生成较小的运动,要么在生…...

ES-mapping
类似数据库中的表结构定义,主要作用如下 定义Index下的字段名( Field Name) 定义字段的类型,比如数值型、字符串型、布尔型等定义倒排索引相关的配置,比如是否索引、记录 position 等 index_options 用于控制倒排索记录的内容,有如…...

Centos 7.9安装Oracle19c步骤亲测可用有视频
视频介绍了在虚拟机安装centos 7.9并安装数据库软件的全过程 视频链接:https://www.zhihu.com/zvideo/1721267375351996416 下面的文字描述是安装数据库的部分介绍 一.安装环境准备 链接:https://pan.baidu.com/s/1Ogn47UZQ2w7iiHAiVdWDSQ 提取码&am…...
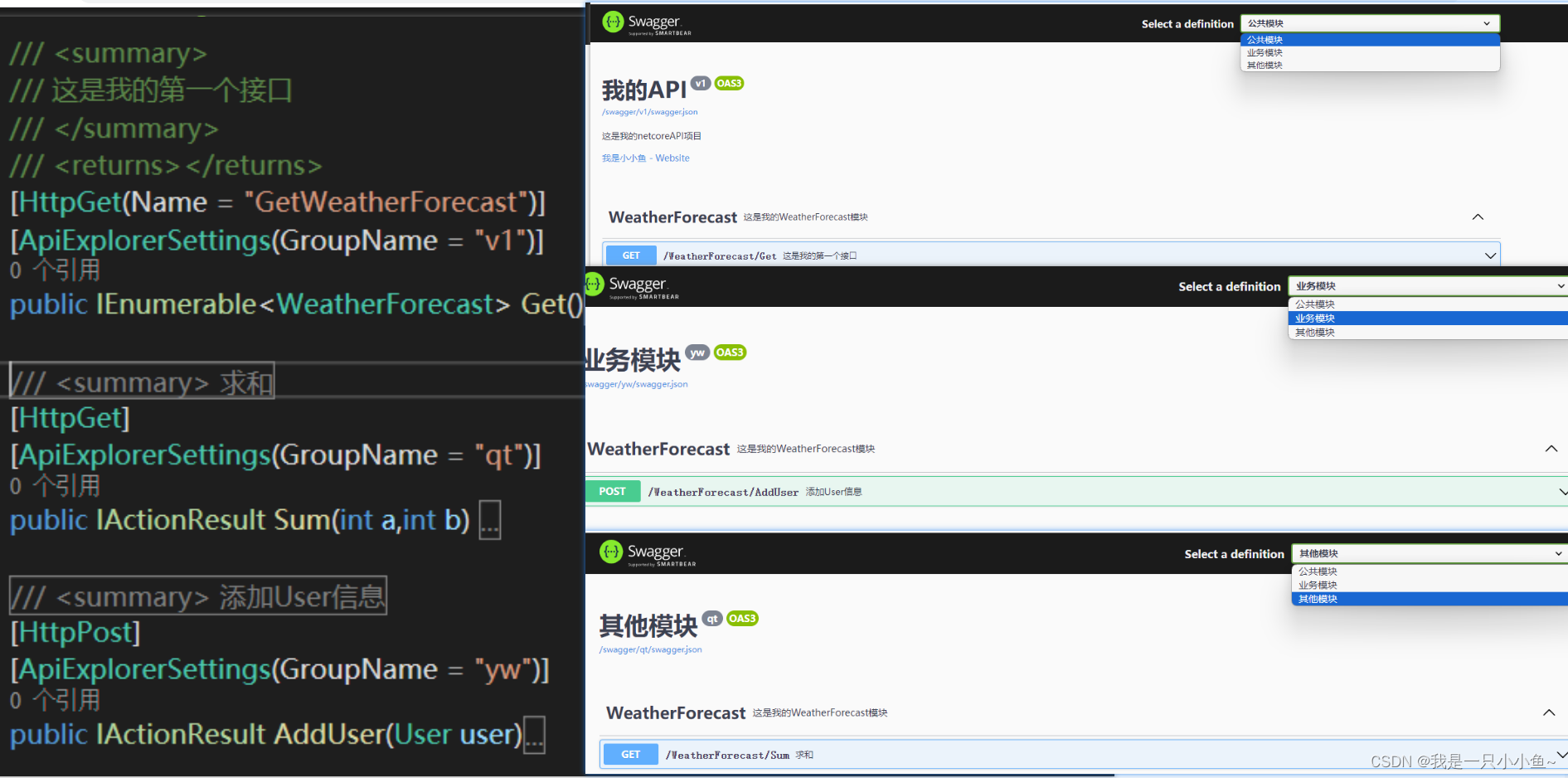
.NET中的Swagger使用
目录 前言 一、Swagger是什么? 二、如何Swagger文档说明的信息 1.在AddSwaggerGen方法中写入文档信息 2.运行效果 二、文档UI界面标题、路由设置 1.在中间件UseSwaggerUI方法中配置 三、文档UI界面添加接口注释 1.在 .csproj中配置 2.在AddSwaggerGen方法中配置Incl…...

结构屈曲分析
结构屈曲分析主要用于判定结构受载后是否有失稳风险,作为工程应用,一般分为线性屈曲分析和非线性屈曲分析。 线性屈曲分析需要具备较多的前提条件,如载荷无偏心、材料无缺陷等,在实际工程应用中结构制作过程和加载方式很难达到线性…...
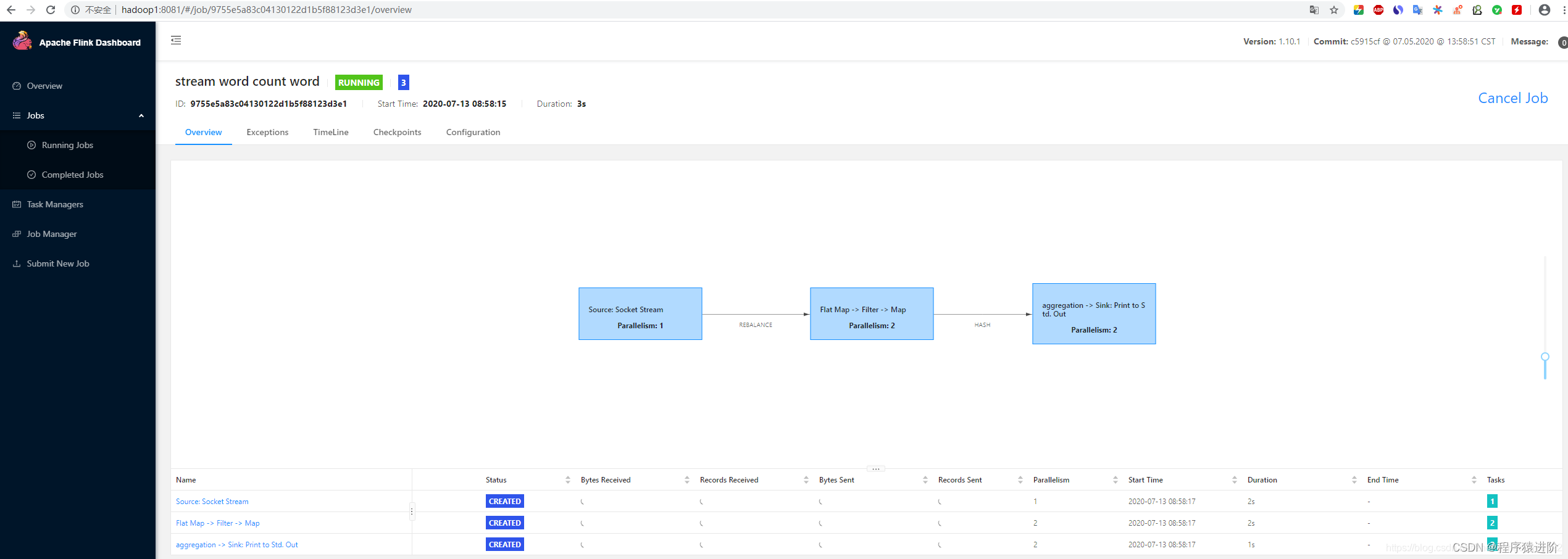
Flink 客户端操作命令及可视化工具
Flink提供了丰富的客户端操作来提交任务和与任务进行交互。下面主要从Flink命令行、Scala Shell、SQL Client、Restful API和 Web五个方面进行整理。 在Flink安装目录的bin目录下可以看到flink,start-scala-shell.sh和sql-client.sh等文件,这些都是客户…...

csrf自动化检测调研
https://github.com/pillarjs/understanding-csrf/blob/master/README_zh.md CSRF 攻击者在钓鱼站点,可以通过创建一个AJAX按钮或者表单来针对你的网站创建一个请求: <form action"https://my.site.com/me/something-destructive" metho…...

记录一个Python鼠标自动模块用法和selenium加载网页插件的设置
写爬虫,或者网页自动化,让程序自动完成一些重复性的枯燥的网页操作,是最常见的需求。能够解放双手,空出时间看看手机,或者学习别的东西,甚至还能帮朋友亲戚减轻工作量。 然而,网页自动化代码编写…...

【数据库系统概论】第3章-关系数据库标准语言SQL(1)
文章目录 3.1 SQL概述3.2 学生-课程数据库3.3 数据定义3.3.1 数据库定义3.3.2 模式的定义3.3.3 基本表的定义3.3.4 索引的建立与删除3.3.5 数据字典 3.1 SQL概述 动词 分类 三级模式 3.2 学生-课程数据库 3.3 数据定义 3.3.1 数据库定义 创建数据库 tips:[ ]表…...

【Python】基于flaskMVT架构与session实现博客前台登录登出功能
目录 一、MVT说明 1.Model层 2.View层 3.Template层 二、功能说明 三、代码框架展示 四、具体代码实现 models.py 登录界面前端代码 博客界面前端代码(profile.html) main.py 一、MVT说明 MVT架构是Model-View-Template的缩写,是…...
为什么有的开关电源需要加自举电容?
一、什么是自举电路? 1.1 自举的概念 首先,自举电路也叫升压电路,是利用自举升压二极管,自举升压电容等电子元件,使电容放电电压和电源电压叠加,从而使电压升高。有的电路升高的电压能达到数倍电源电压。…...
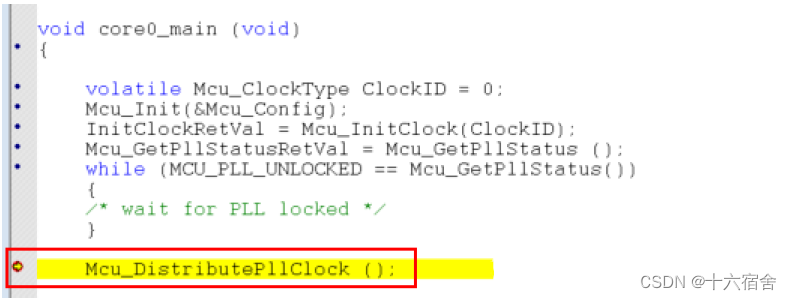
【MCAL】TC397+EB-treso之MCU配置实战 - 芯片时钟
本篇文章介绍了在TC397平台使用EB-treso对MCU驱动模块进行配置的实战过程,主要介绍了后续基本每个外设模块都要涉及的芯片时钟部分,帮助读者了解TC397芯片的时钟树结构,在后续计算配置不同外设模块诸如通信速率,定时器周期等&…...
高级人工智能之群体智能:蚁群算法
群体智能 鸟群: 鱼群: 1.基本介绍 蚁群算法(Ant Colony Optimization, ACO)是一种模拟自然界蚂蚁觅食行为的优化算法。它通常用于解决路径优化问题,如旅行商问题(TSP)。 蚁群算法的基本步骤…...

【SpringBoot应用篇】【AOP+注解】SpringBoot+SpEL表达式基于注解实现权限控制
【SpringBoot应用篇】【AOP注解】SpringBootSpEL表达式基于注解实现权限控制 Spring SpEL基本表达式类相关表达式表达式模板 SpEL表达式实现权限控制PreAuthAuthFunPreAuthAspectUserControllerSpelParserUtils Spring SpEL Spring 表达式语言 SpEL 是一种非常强大的表达式语言…...
Java研学-HTTP 协议
一 概述 1 概念和作用 概念:HTTP 是 HyperText Transfer Protocol (超文本传输协议)的简写,它是 TCP/IP 协议之上的一个应用层协议。简单理解就是 HTTP 协议底层是对 TCP/IP 协议的封装。 作用:用于规定浏览器和服务器之间数据传输的格式…...

差生文具多之(二): perf
栈回溯和符号解析是使用 perf 的两大阻力,本文以应用程序 fio 的观测为例子,提供一些处理它们的经验法则,希望帮助大家无痛使用 perf。 前言 系统级性能优化通常包括两个阶段:性能剖析和代码优化: 性能剖析的目标是寻…...

【SPI和API有什么区别】
✅什么是SPI,和API有什么区别 ✅典型解析🟢拓展知识仓🟢如何定义一个SPI🟢SPI的实现原理 ✅SPI的应用场景SpringDubbo ✅典型解析 Java 中区分 API和 SPI,通俗的进: API和 SPI 都是相对的概念,他们的差别只…...
Day67力扣打卡
打卡记录 美丽塔 II(前缀和 单调栈) 链接 class Solution:def maximumSumOfHeights(self, maxHeights: List[int]) -> int:n len(maxHeights)stack collections.deque()pre, suf [0] * n, [0] * nfor i in range(n):while stack and maxHeights…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...